Trends in Scientific Discovery Engines
|
|
|
- Anna Carpenter
- 5 years ago
- Views:
Transcription
1 Trends in Scientific Discovery Engines Mark Stalzer Center for Advanced Computing Research California Institute of Technology AstroInformatics, September 2012 Redmond WA

2 This is an informal talk about trends in the engines that make scientific discovery happen faster... and things are happening much faster than expected and much slower than we think... Source: Computer History Museum, Mt. View, CA

3 Some Truths about Computing It must be COTS (cheaply manufacturable IP) Cray-1 was COTS: 6 dual in-out ECL gates per chip Drivers: missile guidance and virtual missile guidance Advanced computing systems are all about power and packaging Batteries and 100 MW power plants are expensive Apple ipad and Cray-1 Advanced computers are hard to program But they can be easy to use It only takes a few good abstractions
4 Trends in Simulation Engines: Exascale or Bust (or computing without data)


5 Source: top500.org 6/2012 Top 10 Supercomputers
 0.375 1.6 4.")
6 Socket Parallelism: Top vs Optimized for dot products: complex s = 0; for (complex* lp = xp + n; s += *xp++ * *yp++; xp < lp) ; ASCI White #2 Sequoia #1 GAIN Rmax (Tflops) ,325 2,260x Processor IBM Power 3 IBM BQC 16C Clock (Ghz) x #Sockets 8,192 98,304 12x Socket Parallelism x (3,280) Half of parallelism increase is on-socket, and getting worse... Source: top500.org 6/2002 & 6/2012

7 Intel Many Integrated Core (MIC) 50+ IA64 cores (Pentium-like) 8 (double) SIMD 200+ hardware threads Tflops per socket Will scale to O(1,000) threads ~2 yrs Cache coherent in socket ASCI White performance! Qualitatively different programming model MPI between sockets Massive general threading in a socket: must rewrite codes Example: Image processing parallelism Socket Archipelago
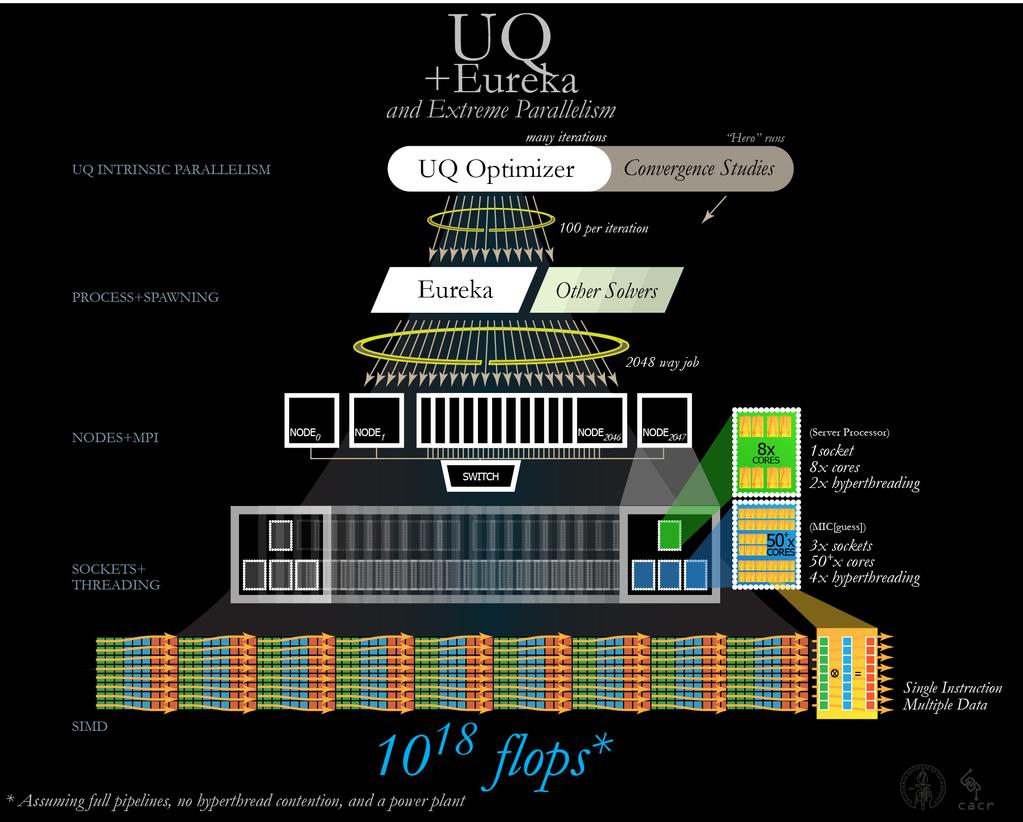
8

9 Follow the Power In 2015, a flop will be ~10 pj: It takes ~50x energy just to move the bits! Source: Peter Kogge, Notre Dame, 8/2011
10 Trends in Data to Discovery Engines

11 Latency Gap Several efforts at closing the latency gap using flash memories... Source: Allan Snavely, UCSD/SDSC

12 Gordon Supernode Architecture Full machine is 32 supernodes interconnected by dual-rail QDR IB in 3D torus. Source: Allan Snavely, UCSD/SDSC
.")
13 Gordon BFS Performance 6.5x Improvement - Available now through XSEDE ( Source: Shawn Strande & Allan Snavely, UCSD/SDSC
: A bit of seq.")
 Mbytes / MIPS ~ 1 (Memory ratio) One")
 Simulation codes may have an Amdahl # of")
:")
14 Amdahl-Balanced Blades Gene Amdahl s Laws for I/O & memory (1965, 2007): A bit of seq. I/O per sec. per instruction per sec. (Amdahl #) Mbytes / MIPS ~ 1 (Memory ratio) One I/O operations per 50,000 instructions (IOPS ratio) Simulation codes may have an Amdahl # of 10-5 ; data intensive apps may need ~1 Szalay, Bell, Huang, Terzis, White (Hotpower-09): Source: Alex Szalay, JHU
 35 TB of spinning disk Blazing I/O performance: 18 GB/s Amdahl # = 1 for under $30 K")
15 Cyberbricks 36-node Amdahl cluster at 1,200 W total! N330 dual core Atom, 16 GPU cores, 4 GB Aggregate disk space of ~43 TB About 1 SSD 120 GB per core (~8 TB) 35 TB of spinning disk Blazing I/O performance: 18 GB/s Amdahl # = 1 for under $30 K Using the GPUs for data mining: 6.4 B multidimensional regressions in 5 min over 1.2 TB Ported RF module from R to C#/CUDA Source: Alex Szalay, JHU

16 Calxeda/HP Moonshot The EnergyCore is a single chip with a Cortex-A9 ARM processor running between 1.1GHz and 1.4GHz. The chip includes 4MB of cache, an 80-Gigabit fabric switch and a management engine for power optimization. Servers with the chip, 4GB of memory and a large-capacity solid-state drive [SATA] draw 5 watts of power. Besides using a low-power ARM processor, Calxeda has cut down chip power consumption by integrating key server components. - Agam Shah, Computerworld, Nov 11, 2011
17 Gordon and Cyberbricks are real (and 6-10x is great but still constrained by I/O architecture) What if we do make believe computer architecture?








18 Power Miser Devices: Apple A5 to C1 A5 SoC/PoP ARM/GPU/USB 2.0/Flash cntrl. 512 MB 10 Gflops? at 1W? 64 GB NAND Flash Sources: Apple, Wikipedia, Micron, Toshiba C1 Proc./Accel./Link/Flash engine 1 GB LDDR2 (64 bit wide) PoP 64 Gflops at 6 W + 2 W (1 Ghz) 128 GB NAND Flash RAID All existing IP; need <1 year
19 A More Extreme Approach: Switch fabric IB FlashBlades Links Accelerator/Storage C1/ 128F 1 GB GB 96 GB CPU x16 PCIe QPI... 64x Basic blade X1 C1/ 1 GB 128F GB X1 is an FPGA switch for C1 array & QPI to CPU & PCIe to IB The CPU orchestrates abstractions; to the CPU the array looks like: A ~6 TB, 25 GB/s (burst), 50 us, disk (file system, triple stores) A ~4 TFlops accelerator (OpenCL with embedded triple stores) This all fits on a standard blade (2 sides) and uses commodity IP Draws about 600 W and is 100x faster on disk operations
, June")
20 FlashBlade Packaging - Stalzer, FlashBlades: System Architecture and Applications, Workshop on Architectures and Systems for Big Data (ASBD), June 2012, Portland OR
21 Implications for Data to Discovery HUGE data processing capability: a single server can read (and process ) its entire contents in about 10 minutes (200 MB/s) A same size disk array would take 100x to read (2 TB disks) 100x faster at random access (50 us vs. 5 ms) Balanced I/O and computation This is qualitatively new, what could we do with it? Want applications with #reads >> #writes One rack (0.5 PB) could handle LSST processing for a year? Good for LHC/CMS data analysis (comparing data to Monte- Carlo simulations of the standard model) Analytics, search, intelligence, video processing, tomography,... Metadata server for massive archival disk arrays
22 Triple Stores (a Storage Metric?) Triple stores (object, attribute, value) Graphs: (a, f, b) Query: select (?, f, b) and (b,?, c) Implementation Hash tables for partial triples (x, y,?) Performance order dependent; need working memory Use distributed hash tables across C1 array Flash byte random access mode latency: ~1 us vs. 5,000 us 1,000x Inferencing performance and mutation rate?? f b? c
23 Another Big Data Implementation Technology

24 It Only Takes Ops (?) Source: R. Kurzweil, The Law of Accelerating Returns, 3/2001, The Singularity is Near, pg. 124, 2005
25 A Flops Engine Quantity: Need about 200 servers (14 blades at 7U each) Big IB switch fabric too (168 IB ports/rack) Volume (need lots of air): 2,000 ft 3 Flash memory: ~17 PB SDSC runs 18 PB of tape storage (1,000 s of scientific data sets) Constraint: no more than 1,000-2,000 writes/chip/day? Data ingestion and reflective analysis by engine Checkpoints in <10 s About 10 Pflops at ~2 MW (does not include cooling) Cost unknown due to rapidly dropping flash costs, new packaging, and other economies of scale
 Bandwidth: 1 PB/s? (0.5x - 12x - 30x) Packaging: 0.")

26 Comparison to a Natural Big Data Engine Operations: 10 Pops (1x) Memory: 1 PB (0.06x & forgets) Bandwidth: 1 PB/s? (0.5x - 12x - 30x) Packaging: 0.25 ft 3 (8,000x) Power: 25 W (80,000x)! Where s the algorithm? Sources: Brain picture: Wikipedia; Memory: R. Kurzweil, pg 127; Bandwidth: author
 is essentially island level parallelism Threads are tribe level parallelism and much much faster What if all threads")
27 Socket Archipelago (2017) Cluster Socket Parallelism 100,000 10,000 Rel. Latency ~1,000 1 Parallelism is becoming dramatically bimodal MPI (or process) is essentially island level parallelism Threads are tribe level parallelism and much much faster What if all threads want to talk with another island at once? Must have very large L2 cache on socket Non-volatile storage must be integrated too (stacking) Analogy: cortical columns
28 Engine Software Architecture Applications LAPACK, SQL, PETSc, Root, etc., Data to Discovery? Domain Abstractions & Orchestration Numeric & Storage Kernels MPI & Threads Distributed Substrate Algorithms Convergence & Complexity? Communicating Accelerated Processes Semantics & Tuning? FlashBlades? Integrated Compute & Storage Networked Data Resources Balance
29 Concluding Remarks We are not stuck with clusters : COTS is also IP not just Fry s. What is the Top500-like benchmark for data? Metrics drive development Massively threaded programming is the future, but can be partially hidden by libraries (kernels). Think in terms of what can be done with a shrinking ops system
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
A New NSF TeraGrid Resource for Data-Intensive Science
 A New NSF TeraGrid Resource for Data-Intensive Science Michael L. Norman Principal Investigator Director, SDSC Allan Snavely Co-Principal Investigator Project Scientist Slide 1 Coping with the data deluge
A New NSF TeraGrid Resource for Data-Intensive Science Michael L. Norman Principal Investigator Director, SDSC Allan Snavely Co-Principal Investigator Project Scientist Slide 1 Coping with the data deluge
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
HPC Storage Use Cases & Future Trends
 Oct, 2014 HPC Storage Use Cases & Future Trends Massively-Scalable Platforms and Solutions Engineered for the Big Data and Cloud Era Atul Vidwansa Email: atul@ DDN About Us DDN is a Leader in Massively
Oct, 2014 HPC Storage Use Cases & Future Trends Massively-Scalable Platforms and Solutions Engineered for the Big Data and Cloud Era Atul Vidwansa Email: atul@ DDN About Us DDN is a Leader in Massively
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Building supercomputers from embedded technologies
 http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
ACCELERATE YOUR ANALYTICS GAME WITH ORACLE SOLUTIONS ON PURE STORAGE
 ACCELERATE YOUR ANALYTICS GAME WITH ORACLE SOLUTIONS ON PURE STORAGE An innovative storage solution from Pure Storage can help you get the most business value from all of your data THE SINGLE MOST IMPORTANT
ACCELERATE YOUR ANALYTICS GAME WITH ORACLE SOLUTIONS ON PURE STORAGE An innovative storage solution from Pure Storage can help you get the most business value from all of your data THE SINGLE MOST IMPORTANT
Real Parallel Computers
 Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
The Road from Peta to ExaFlop
 The Road from Peta to ExaFlop Andreas Bechtolsheim June 23, 2009 HPC Driving the Computer Business Server Unit Mix (IDC 2008) Enterprise HPC Web 100 75 50 25 0 2003 2008 2013 HPC grew from 13% of units
The Road from Peta to ExaFlop Andreas Bechtolsheim June 23, 2009 HPC Driving the Computer Business Server Unit Mix (IDC 2008) Enterprise HPC Web 100 75 50 25 0 2003 2008 2013 HPC grew from 13% of units
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
HPC and the AppleTV-Cluster
 HPC and the AppleTV-Cluster Dieter Kranzlmüller, Karl Fürlinger, Christof Klausecker Munich Network Management Team Ludwig-Maximilians-Universität München (LMU) & Leibniz Supercomputing Centre (LRZ) Outline
HPC and the AppleTV-Cluster Dieter Kranzlmüller, Karl Fürlinger, Christof Klausecker Munich Network Management Team Ludwig-Maximilians-Universität München (LMU) & Leibniz Supercomputing Centre (LRZ) Outline
PSAM, NEC PCIe SSD Appliance for Microsoft SQL Server (Reference Architecture) September 4 th, 2014 NEC Corporation
 September 4 th, 2014 NEC Corporation") PSAM, NEC PCIe SSD Appliance for Microsoft SQL Server (Reference Architecture) September 4 th, 2014 NEC Corporation 1. Overview of NEC PCIe SSD Appliance for Microsoft SQL Server Page 2 NEC Corporation
PSAM, NEC PCIe SSD Appliance for Microsoft SQL Server (Reference Architecture) September 4 th, 2014 NEC Corporation 1. Overview of NEC PCIe SSD Appliance for Microsoft SQL Server Page 2 NEC Corporation
Accelerating Real-Time Big Data. Breaking the limitations of captive NVMe storage
 Accelerating Real-Time Big Data Breaking the limitations of captive NVMe storage 18M IOPs in 2u Agenda Everything related to storage is changing! The 3rd Platform NVM Express architected for solid state
Accelerating Real-Time Big Data Breaking the limitations of captive NVMe storage 18M IOPs in 2u Agenda Everything related to storage is changing! The 3rd Platform NVM Express architected for solid state
Future of Enzo. Michael L. Norman James Bordner LCA/SDSC/UCSD
 Future of Enzo Michael L. Norman James Bordner LCA/SDSC/UCSD SDSC Resources Data to Discovery Host SDNAP San Diego network access point for multiple 10 Gbs WANs ESNet, NSF TeraGrid, CENIC, Internet2, StarTap
Future of Enzo Michael L. Norman James Bordner LCA/SDSC/UCSD SDSC Resources Data to Discovery Host SDNAP San Diego network access point for multiple 10 Gbs WANs ESNet, NSF TeraGrid, CENIC, Internet2, StarTap
HOW TO BUILD A MODERN AI
 HOW TO BUILD A MODERN AI FOR THE UNKNOWN IN MODERN DATA 1 2016 PURE STORAGE INC. 2 Official Languages Act (1969/1988) 3 Translation Bureau 4 5 DAWN OF 4 TH INDUSTRIAL REVOLUTION BIG DATA, AI DRIVING CHANGE
HOW TO BUILD A MODERN AI FOR THE UNKNOWN IN MODERN DATA 1 2016 PURE STORAGE INC. 2 Official Languages Act (1969/1988) 3 Translation Bureau 4 5 DAWN OF 4 TH INDUSTRIAL REVOLUTION BIG DATA, AI DRIVING CHANGE
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC?
 Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Composite Metrics for System Throughput in HPC
 Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
Blue Gene/Q. Hardware Overview Michael Stephan. Mitglied der Helmholtz-Gemeinschaft
 Blue Gene/Q Hardware Overview 02.02.2015 Michael Stephan Blue Gene/Q: Design goals System-on-Chip (SoC) design Processor comprises both processing cores and network Optimal performance / watt ratio Small
Blue Gene/Q Hardware Overview 02.02.2015 Michael Stephan Blue Gene/Q: Design goals System-on-Chip (SoC) design Processor comprises both processing cores and network Optimal performance / watt ratio Small
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
8/28/12. CSE 820 Graduate Computer Architecture. Richard Enbody. Dr. Enbody. 1 st Day 2
 CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
New Approach to Unstructured Data
 Innovations in All-Flash Storage Deliver a New Approach to Unstructured Data Table of Contents Developing a new approach to unstructured data...2 Designing a new storage architecture...2 Understanding
Innovations in All-Flash Storage Deliver a New Approach to Unstructured Data Table of Contents Developing a new approach to unstructured data...2 Designing a new storage architecture...2 Understanding
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries
 Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
(software agnostic) Computational Considerations
 Computational Considerations") (software agnostic) Computational Considerations The Issues CPU GPU Emerging - FPGA, Phi, Nervana Storage Networking CPU 2 Threads core core Processor/Chip Processor/Chip Computer CPU Threads vs. Cores
(software agnostic) Computational Considerations The Issues CPU GPU Emerging - FPGA, Phi, Nervana Storage Networking CPU 2 Threads core core Processor/Chip Processor/Chip Computer CPU Threads vs. Cores
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
A Better Storage Solution
 A Better Storage Solution Presented by: Richard Goss Presentation to The Problem with Hard Disks Processors have increased in speed by orders of magnitude over the years. But spinning hard disk drives
A Better Storage Solution Presented by: Richard Goss Presentation to The Problem with Hard Disks Processors have increased in speed by orders of magnitude over the years. But spinning hard disk drives
Scaling to Petaflop. Ola Torudbakken Distinguished Engineer. Sun Microsystems, Inc
 Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Performance Modeling and Analysis of Flash based Storage Devices
 Performance Modeling and Analysis of Flash based Storage Devices H. Howie Huang, Shan Li George Washington University Alex Szalay, Andreas Terzis Johns Hopkins University MSST 11 May 26, 2011 NAND Flash
Performance Modeling and Analysis of Flash based Storage Devices H. Howie Huang, Shan Li George Washington University Alex Szalay, Andreas Terzis Johns Hopkins University MSST 11 May 26, 2011 NAND Flash
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
Developing Low Latency NVMe Systems for HyperscaleData Centers. Prepared by Engling Yeo Santa Clara, CA Date: 08/04/2017
 Developing Low Latency NVMe Systems for HyperscaleData Centers Prepared by Engling Yeo Santa Clara, CA 95054 Date: 08/04/2017 Quality of Service IOPS, Throughput, Latency Short predictable read latencies
Developing Low Latency NVMe Systems for HyperscaleData Centers Prepared by Engling Yeo Santa Clara, CA 95054 Date: 08/04/2017 Quality of Service IOPS, Throughput, Latency Short predictable read latencies
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Deep Learning Performance and Cost Evaluation
 Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Don Wang, Rene Meyer, Ph.D. info@ AMAX Corporation Publish date: October 25,
Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Don Wang, Rene Meyer, Ph.D. info@ AMAX Corporation Publish date: October 25,
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
Mellanox Technologies Maximize Cluster Performance and Productivity. Gilad Shainer, October, 2007
 Mellanox Technologies Maximize Cluster Performance and Productivity Gilad Shainer, shainer@mellanox.com October, 27 Mellanox Technologies Hardware OEMs Servers And Blades Applications End-Users Enterprise
Mellanox Technologies Maximize Cluster Performance and Productivity Gilad Shainer, shainer@mellanox.com October, 27 Mellanox Technologies Hardware OEMs Servers And Blades Applications End-Users Enterprise
Workload Optimized Systems: The Wheel of Reincarnation. Michael Sporer, Netezza Appliance Hardware Architect 21 April 2013
 Workload Optimized Systems: The Wheel of Reincarnation Michael Sporer, Netezza Appliance Hardware Architect 21 April 2013 Outline Definition Technology Minicomputers Prime Workstations Apollo Graphics
Workload Optimized Systems: The Wheel of Reincarnation Michael Sporer, Netezza Appliance Hardware Architect 21 April 2013 Outline Definition Technology Minicomputers Prime Workstations Apollo Graphics
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering. Computer Architecture ECE 568
 UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 6 Input/Output Israel Koren ECE568/Koren Part.6. CPU performance keeps increasing 26 72-core Xeon
UNIVERSITY OF MASSACHUSETTS Dept. of Electrical & Computer Engineering Computer Architecture ECE 568 Part 6 Input/Output Israel Koren ECE568/Koren Part.6. CPU performance keeps increasing 26 72-core Xeon
19. prosince 2018 CIIRC Praha. Milan Král, IBM Radek Špimr
 19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
19. prosince 2018 CIIRC Praha Milan Král, IBM Radek Špimr CORAL CORAL 2 CORAL Installation at ORNL CORAL Installation at LLNL Order of Magnitude Leap in Computational Power Real, Accelerated Science ACME
Trends in the Infrastructure of Computing
 Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Trends in the Infrastructure of Computing CSCE 9: Computing in the Modern World Dr. Jason D. Bakos My Questions How do computer processors work? Why do computer processors get faster over time? How much
Altera SDK for OpenCL
 Altera SDK for OpenCL A novel SDK that opens up the world of FPGAs to today s developers Altera Technology Roadshow 2013 Today s News Altera today announces its SDK for OpenCL Altera Joins Khronos Group
Altera SDK for OpenCL A novel SDK that opens up the world of FPGAs to today s developers Altera Technology Roadshow 2013 Today s News Altera today announces its SDK for OpenCL Altera Joins Khronos Group
Intel Solid State Drive Data Center Family for PCIe* in Baidu s Data Center Environment
 Intel Solid State Drive Data Center Family for PCIe* in Baidu s Data Center Environment Case Study Order Number: 334534-002US Ordering Information Contact your local Intel sales representative for ordering
Intel Solid State Drive Data Center Family for PCIe* in Baidu s Data Center Environment Case Study Order Number: 334534-002US Ordering Information Contact your local Intel sales representative for ordering
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
European energy efficient supercomputer project
 http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
ALCF Argonne Leadership Computing Facility
 ALCF Argonne Leadership Computing Facility ALCF Data Analytics and Visualization Resources William (Bill) Allcock Leadership Computing Facility Argonne Leadership Computing Facility Established 2006. Dedicated
ALCF Argonne Leadership Computing Facility ALCF Data Analytics and Visualization Resources William (Bill) Allcock Leadership Computing Facility Argonne Leadership Computing Facility Established 2006. Dedicated
The Mont-Blanc Project
 http://www.montblanc-project.eu The Mont-Blanc Project Daniele Tafani Leibniz Supercomputing Centre 1 Ter@tec Forum 26 th June 2013 This project and the research leading to these results has received funding
http://www.montblanc-project.eu The Mont-Blanc Project Daniele Tafani Leibniz Supercomputing Centre 1 Ter@tec Forum 26 th June 2013 This project and the research leading to these results has received funding
Barcelona Supercomputing Center
 www.bsc.es Barcelona Supercomputing Center Centro Nacional de Supercomputación EMIT 2016. Barcelona June 2 nd, 2016 Barcelona Supercomputing Center Centro Nacional de Supercomputación BSC-CNS objectives:
www.bsc.es Barcelona Supercomputing Center Centro Nacional de Supercomputación EMIT 2016. Barcelona June 2 nd, 2016 Barcelona Supercomputing Center Centro Nacional de Supercomputación BSC-CNS objectives:
Performance of computer systems
 Performance of computer systems Many different factors among which: Technology Raw speed of the circuits (clock, switching time) Process technology (how many transistors on a chip) Organization What type
Performance of computer systems Many different factors among which: Technology Raw speed of the circuits (clock, switching time) Process technology (how many transistors on a chip) Organization What type
Computer Architecture. Fall Dongkun Shin, SKKU
 Computer Architecture Fall 2018 1 Syllabus Instructors: Dongkun Shin Office : Room 85470 E-mail : dongkun@skku.edu Office Hours: Wed. 15:00-17:30 or by appointment Lecture notes nyx.skku.ac.kr Courses
Computer Architecture Fall 2018 1 Syllabus Instructors: Dongkun Shin Office : Room 85470 E-mail : dongkun@skku.edu Office Hours: Wed. 15:00-17:30 or by appointment Lecture notes nyx.skku.ac.kr Courses
Welcome. Altera Technology Roadshow 2013
 Welcome Altera Technology Roadshow 2013 Altera at a Glance Founded in Silicon Valley, California in 1983 Industry s first reprogrammable logic semiconductors $1.78 billion in 2012 sales Over 2,900 employees
Welcome Altera Technology Roadshow 2013 Altera at a Glance Founded in Silicon Valley, California in 1983 Industry s first reprogrammable logic semiconductors $1.78 billion in 2012 sales Over 2,900 employees
ENERGY-EFFICIENT VISUALIZATION PIPELINES A CASE STUDY IN CLIMATE SIMULATION
 ENERGY-EFFICIENT VISUALIZATION PIPELINES A CASE STUDY IN CLIMATE SIMULATION Vignesh Adhinarayanan Ph.D. (CS) Student Synergy Lab, Virginia Tech INTRODUCTION Supercomputers are constrained by power Power
ENERGY-EFFICIENT VISUALIZATION PIPELINES A CASE STUDY IN CLIMATE SIMULATION Vignesh Adhinarayanan Ph.D. (CS) Student Synergy Lab, Virginia Tech INTRODUCTION Supercomputers are constrained by power Power
Feedback on BeeGFS. A Parallel File System for High Performance Computing
 Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Innovations in Non-Volatile Memory 3D NAND and its Implications May 2016 Rob Peglar, VP Advanced Storage,
 Innovations in Non-Volatile Memory 3D NAND and its Implications May 2016 Rob Peglar, VP Advanced Storage, Micron @peglarr 2015 Micron Technology, Inc All rights reserved Products are warranted only to
Innovations in Non-Volatile Memory 3D NAND and its Implications May 2016 Rob Peglar, VP Advanced Storage, Micron @peglarr 2015 Micron Technology, Inc All rights reserved Products are warranted only to
Isilon Performance. Name
 1 Isilon Performance Name 2 Agenda Architecture Overview Next Generation Hardware Performance Caching Performance Streaming Reads Performance Tuning OneFS Architecture Overview Copyright 2014 EMC Corporation.
1 Isilon Performance Name 2 Agenda Architecture Overview Next Generation Hardware Performance Caching Performance Streaming Reads Performance Tuning OneFS Architecture Overview Copyright 2014 EMC Corporation.
Building supercomputers from commodity embedded chips
 http://www.montblanc-project.eu Building supercomputers from commodity embedded chips Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from commodity embedded chips Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
Evaluation Report: Improving SQL Server Database Performance with Dot Hill AssuredSAN 4824 Flash Upgrades
 Evaluation Report: Improving SQL Server Database Performance with Dot Hill AssuredSAN 4824 Flash Upgrades Evaluation report prepared under contract with Dot Hill August 2015 Executive Summary Solid state
Evaluation Report: Improving SQL Server Database Performance with Dot Hill AssuredSAN 4824 Flash Upgrades Evaluation report prepared under contract with Dot Hill August 2015 Executive Summary Solid state
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Data Intensive Computing SUBTITLE WITH TWO LINES OF TEXT IF NECESSARY PASIG June, 2009
 Data Intensive Computing SUBTITLE WITH TWO LINES OF TEXT IF NECESSARY PASIG June, 2009 Presenter s Name Simon CW See Title & and Division HPC Cloud Computing Sun Microsystems Technology Center Sun Microsystems,
Data Intensive Computing SUBTITLE WITH TWO LINES OF TEXT IF NECESSARY PASIG June, 2009 Presenter s Name Simon CW See Title & and Division HPC Cloud Computing Sun Microsystems Technology Center Sun Microsystems,
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
BlueGene/L. Computer Science, University of Warwick. Source: IBM
 BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
SAP HANA. Jake Klein/ SVP SAP HANA June, 2013
 SAP HANA Jake Klein/ SVP SAP HANA June, 2013 SAP 3 YEARS AGO Middleware BI / Analytics Core ERP + Suite 2013 WHERE ARE WE NOW? Cloud Mobile Applications SAP HANA Analytics D&T Changed Reality Disruptive
SAP HANA Jake Klein/ SVP SAP HANA June, 2013 SAP 3 YEARS AGO Middleware BI / Analytics Core ERP + Suite 2013 WHERE ARE WE NOW? Cloud Mobile Applications SAP HANA Analytics D&T Changed Reality Disruptive
Philippe Thierry Sr Staff Engineer Intel Corp.
 HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
Deep Learning Performance and Cost Evaluation
 Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Rene Meyer, Ph.D. AMAX Corporation Publish date: October 25, 2018 Abstract Introduction
Micron 5210 ION Quad-Level Cell (QLC) SSDs vs 7200 RPM HDDs in Centralized NAS Storage Repositories A Technical White Paper Rene Meyer, Ph.D. AMAX Corporation Publish date: October 25, 2018 Abstract Introduction
The Impact of SSD Selection on SQL Server Performance. Solution Brief. Understanding the differences in NVMe and SATA SSD throughput
 Solution Brief The Impact of SSD Selection on SQL Server Performance Understanding the differences in NVMe and SATA SSD throughput 2018, Cloud Evolutions Data gathered by Cloud Evolutions. All product
Solution Brief The Impact of SSD Selection on SQL Server Performance Understanding the differences in NVMe and SATA SSD throughput 2018, Cloud Evolutions Data gathered by Cloud Evolutions. All product
Moneta: A High-Performance Storage Architecture for Next-generation, Non-volatile Memories
 Moneta: A High-Performance Storage Architecture for Next-generation, Non-volatile Memories Adrian M. Caulfield Arup De, Joel Coburn, Todor I. Mollov, Rajesh K. Gupta, Steven Swanson Non-Volatile Systems
Moneta: A High-Performance Storage Architecture for Next-generation, Non-volatile Memories Adrian M. Caulfield Arup De, Joel Coburn, Todor I. Mollov, Rajesh K. Gupta, Steven Swanson Non-Volatile Systems
Computer Science 61C Spring Friedland and Weaver. Input/Output
 Input/Output 1 A Computer is Useless without I/O I/O handles persistent storage Disks, SSD memory, etc I/O handles user interfaces Keyboard/mouse/display I/O handles network 2 Basic I/O: Devices are Memory
Input/Output 1 A Computer is Useless without I/O I/O handles persistent storage Disks, SSD memory, etc I/O handles user interfaces Keyboard/mouse/display I/O handles network 2 Basic I/O: Devices are Memory
Cold Storage: The Road to Enterprise Ilya Kuznetsov YADRO
 Cold Storage: The Road to Enterprise Ilya Kuznetsov YADRO Agenda Technical challenge Custom product Growth of aspirations Enterprise requirements Making an enterprise cold storage product 2 Technical Challenge
Cold Storage: The Road to Enterprise Ilya Kuznetsov YADRO Agenda Technical challenge Custom product Growth of aspirations Enterprise requirements Making an enterprise cold storage product 2 Technical Challenge
Gen-Z Memory-Driven Computing
 Gen-Z Memory-Driven Computing Our vision for the future of computing Patrick Demichel Distinguished Technologist Explosive growth of data More Data Need answers FAST! Value of Analyzed Data 2005 0.1ZB
Gen-Z Memory-Driven Computing Our vision for the future of computing Patrick Demichel Distinguished Technologist Explosive growth of data More Data Need answers FAST! Value of Analyzed Data 2005 0.1ZB
CSCI-GA Database Systems Lecture 8: Physical Schema: Storage
 CSCI-GA.2433-001 Database Systems Lecture 8: Physical Schema: Storage Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com View 1 View 2 View 3 Conceptual Schema Physical Schema 1. Create a
CSCI-GA.2433-001 Database Systems Lecture 8: Physical Schema: Storage Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com View 1 View 2 View 3 Conceptual Schema Physical Schema 1. Create a
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive. Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center
 Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
Exploiting the OpenPOWER Platform for Big Data Analytics and Cognitive Rajesh Bordawekar and Ruchir Puri IBM T. J. Watson Research Center 3/17/2015 2014 IBM Corporation Outline IBM OpenPower Platform Accelerating
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance
 Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
LQCD Facilities at Jefferson Lab. Chip Watson May 6, 2011
 LQCD Facilities at Jefferson Lab Chip Watson May 6, 2011 Page 1 Outline Overview of hardware at Jefferson Lab GPU evolution since last year GPU R&D activities Operations Summary Page 2 CPU + Infiniband
LQCD Facilities at Jefferson Lab Chip Watson May 6, 2011 Page 1 Outline Overview of hardware at Jefferson Lab GPU evolution since last year GPU R&D activities Operations Summary Page 2 CPU + Infiniband
Oracle Performance on M5000 with F20 Flash Cache. Benchmark Report September 2011
 Oracle Performance on M5000 with F20 Flash Cache Benchmark Report September 2011 Contents 1 About Benchware 2 Flash Cache Technology 3 Storage Performance Tests 4 Conclusion copyright 2011 by benchware.ch
Oracle Performance on M5000 with F20 Flash Cache Benchmark Report September 2011 Contents 1 About Benchware 2 Flash Cache Technology 3 Storage Performance Tests 4 Conclusion copyright 2011 by benchware.ch
Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright. lbl.gov
 Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright njwright @ lbl.gov NERSC- National Energy Research Scientific Computing Center Mission: Accelerate the pace of scientific discovery
Tuning I/O Performance for Data Intensive Computing. Nicholas J. Wright njwright @ lbl.gov NERSC- National Energy Research Scientific Computing Center Mission: Accelerate the pace of scientific discovery
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM
 IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
IMPROVING ENERGY EFFICIENCY THROUGH PARALLELIZATION AND VECTORIZATION ON INTEL R CORE TM I5 AND I7 PROCESSORS Juan M. Cebrián 1 Lasse Natvig 1 Jan Christian Meyer 2 1 Depart. of Computer and Information
CSE 451: Operating Systems Spring Module 12 Secondary Storage. Steve Gribble
 CSE 451: Operating Systems Spring 2009 Module 12 Secondary Storage Steve Gribble Secondary storage Secondary storage typically: is anything that is outside of primary memory does not permit direct execution
CSE 451: Operating Systems Spring 2009 Module 12 Secondary Storage Steve Gribble Secondary storage Secondary storage typically: is anything that is outside of primary memory does not permit direct execution
Outline. Execution Environments for Parallel Applications. Supercomputers. Supercomputers
 Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Key Points. Rotational delay vs seek delay Disks are slow. Techniques for making disks faster. Flash and SSDs
 IO 1 Today IO 2 Key Points CPU interface and interaction with IO IO devices The basic structure of the IO system (north bridge, south bridge, etc.) The key advantages of high speed serial lines. The benefits
IO 1 Today IO 2 Key Points CPU interface and interaction with IO IO devices The basic structure of the IO system (north bridge, south bridge, etc.) The key advantages of high speed serial lines. The benefits
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
Achieve Optimal Network Throughput on the Cisco UCS S3260 Storage Server
 White Paper Achieve Optimal Network Throughput on the Cisco UCS S3260 Storage Server Executive Summary This document describes the network I/O performance characteristics of the Cisco UCS S3260 Storage
White Paper Achieve Optimal Network Throughput on the Cisco UCS S3260 Storage Server Executive Summary This document describes the network I/O performance characteristics of the Cisco UCS S3260 Storage
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Warehouse- Scale Computing and the BDAS Stack
 Warehouse- Scale Computing and the BDAS Stack Ion Stoica UC Berkeley UC BERKELEY Overview Workloads Hardware trends and implications in modern datacenters BDAS stack What is Big Data used For? Reports,
Warehouse- Scale Computing and the BDAS Stack Ion Stoica UC Berkeley UC BERKELEY Overview Workloads Hardware trends and implications in modern datacenters BDAS stack What is Big Data used For? Reports,