Practical Scientific Computing
|
|
|
- Norah Hodge
- 5 years ago
- Views:
Transcription
1 Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, Dipl.-Ing. Ioan Lucian Muntean, MSc. Csaba A. Vigh,
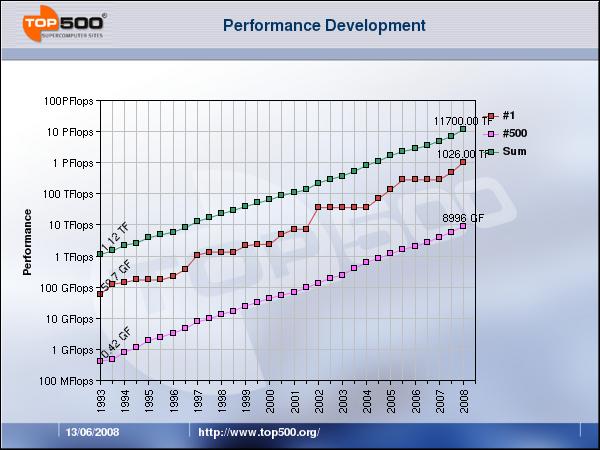
2 Motivation
 based on NEC SX-6 architecture developed by three governmental agencies highly parallel vector supercomputer consists of 640 nodes (plus 2 control & 128 data switching) 8 vector")
3 Motivation The Earth Simulator world s #1 from installed in 2002 in Yokohama, Japan ES-building (approx. 50m 65m 17m) based on NEC SX-6 architecture developed by three governmental agencies highly parallel vector supercomputer consists of 640 nodes (plus 2 control & 128 data switching) 8 vector processors (8 GFlops each) 16 GB shared memory 5120 processors (40.96 TFlops peak performance) and 10 TB memory; TFlops sustained performance (Linpack) nodes connected by single stage crossbar (83,200 cables with a total extension of 2400km; 8 TBps total bandwidth) further 700 TB disc space and 1.6 PB mass storage

 2.")
4 Motivation Roadrunner world s #1 since 2008 installed in 2008 at Los Alamos National Lab, New Mexico, USA cooperation of DoE, LANL, IBM massive parallel supercomputer consists of 122,400 cores 12,240 PowerXCell chips at 3.2 GHz 6,562 dual-core of AMD Opteron chips at 1.8 GHz 98 TB Memory PFlops peak performance; PFlops sustained performance (Linpack) 2.35 MWatt power consumption Efficiency: 437 million calculations per Watt OS: open source Linux from Red Hat
 one of Germany s 3 supercomputers SGI Altix 4700 consists of 19 nodes (SGI NUMA link 2D torus) 256 blades (ccnuma link with partition fat tree) Intel Itanium2")
5 Motivation HLRB II (world s #10 for 07/2007) installed in 2006 at LRZ, Garching installation costs 38 M monthly costs approx. 400,000 upgrade in 2007 (finished) one of Germany s 3 supercomputers SGI Altix 4700 consists of 19 nodes (SGI NUMA link 2D torus) 256 blades (ccnuma link with partition fat tree) Intel Itanium2 Montecito Dual Core (12.8 GFlops) 4 GB memory per core 9728 processor cores (62.3 TFlops peak performance) and 39 TB memory; 56.5 TFlops sustained performance (Linpack) footprint 24m 12m; total weight 103 metric tons
6 Motivation why parallel programming and HPC? complex problems (especially the so called grand challenges ) demand for more computing power climate or geophysics simulation (tsunami, e. g.) structure or flow simulation (crash test, e. g.) development systems (CAD, e. g.) large data analysis (Large Hadron Collider at CERN, e. g.) military applications (crypto analysis, e. g.) performance increase due to faster hardware, more memory ( work harder ) more efficient algorithms, optimisation ( work smarter ) parallel computing ( get some help )
7 Motivation why parallel programming and HPC? complex problems (especially the so called grand challenges ) demand for more computing power climate or geophysics simulation (tsunami, e. g.) structure or flow simulation (crash test, e. g.) development systems (CAD, e. g.) large data analysis (Large Hadron Collider at CERN, e. g.) military applications (crypto analysis, e. g.) performance increase due to faster hardware, more memory ( work harder ) more efficient algorithms, optimisation ( work smarter ) parallel computing ( get some help )
8 Motivation objectives (in case all resources would be available N-times) throughput: compute N problems simultaneously running N instances of a sequential program with different data sets ( embarrassing parallelism ); SETI@home, e. g. drawback: limited resources of single nodes response time: compute one problem at a fraction (1/N) of time running one instance (i. e. N processes) of a parallel program for jointly solving a problem; finding prime numbers, e. g. drawback: writing a parallel program; communication problem size: compute one problem with N-times larger data running one instance (i. e. N processes) of a parallel program, using the sum of all local memories for computing larger problem sizes; iterative solution of SLE, e. g. drawback: writing a parallel program; communication
9 Content memory access, cache-efficiency performance analysis of programs dependency analysis / vectorisation SSE options of Intel processor shared-memory programming (OpenMP) distributed-memory programming (MPI) combination SM/DM (hybrid approach)
10 Realisation 5 exercise sheets (fortnightly) 3 weeks processing time (groups of two persons) projects 5 weeks processing time (groups of 3 / 4 persons) A1 B1 A2 B2 A3 B3 A4 B4 A5 B5 P PZ PA
11 Realization total of 40 points 6 points per exercise sheet (4 + 2) 10 points per project ( ) hand over 2 days before discussion prerequisite: programs must compile and execute in SCCS pool discussion presentation of results (+ questions) diploma students 32 points necessary (min. 3 per exercise and min. 5 per project) master student practical: 10 points registration necessary withdrawal before discussion of first exercise sheet
12 Exercise sheets Preliminary topics sheet 1: memory access and performance analysis sheet 2: dependencies and vectorisation sheet 3: shared-memory programming sheet 4: programming with MPI sheet 5: hybrid programming and grid computing
13 Projects possible projects traffic simulation statics simulation (FEM) simulation game (navel battle, e. g.) grid computing
14 questions?
Practical Scientific Computing
 Practical Scientific Computing Performance-optimised Programming Preliminary discussion, 17.7.2007 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de Dipl.-Geophys.
Practical Scientific Computing Performance-optimised Programming Preliminary discussion, 17.7.2007 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de Dipl.-Geophys.
Introduction to Parallel Programming
 Introduction to Parallel Programming ATHENS Course on Parallel Numerical Simulation Munich, March 19 23, 2007 Dr. Ralf-Peter Mundani Scientific Computing in Computer Science Technische Universität München
Introduction to Parallel Programming ATHENS Course on Parallel Numerical Simulation Munich, March 19 23, 2007 Dr. Ralf-Peter Mundani Scientific Computing in Computer Science Technische Universität München
High Performance Computing Programming Paradigms and Scalability Part 1: Introduction
 High Performance Computing Programming Paradigms and Scalability Part 1: Introduction PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering (CiE) Scientific Computing (SCCS) Summer Term
High Performance Computing Programming Paradigms and Scalability Part 1: Introduction PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering (CiE) Scientific Computing (SCCS) Summer Term
General Remarks. Overview. General Remarks. High Performance Computing Programming Paradigms and Scalability Part 1: Introduction
 High erformance Computing rogramming aradigms and Scalability art 1: Introduction D Dr. rer. nat. habil. Ralf-eter Mundani Computation in Engineering (CiE) Scientific Computing (SCCS) Summer Term 2015
High erformance Computing rogramming aradigms and Scalability art 1: Introduction D Dr. rer. nat. habil. Ralf-eter Mundani Computation in Engineering (CiE) Scientific Computing (SCCS) Summer Term 2015
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Network Products
 Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Cluster Network Products Cluster interconnects include, among others: Gigabit Ethernet Myrinet Quadrics InfiniBand 1 Interconnects in Top500 list 11/2009 2 Interconnects in Top500 list 11/2008 3 Cluster
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
CCS HPC. Interconnection Network. PC MPP (Massively Parallel Processor) MPP IBM
 MPP IBM") CCS HC taisuke@cs.tsukuba.ac.jp 1 2 CU memoryi/o 2 2 4single chipmulti-core CU 10 C CM (Massively arallel rocessor) M IBM BlueGene/L 65536 Interconnection Network 3 4 (distributed memory system) (shared
CCS HC taisuke@cs.tsukuba.ac.jp 1 2 CU memoryi/o 2 2 4single chipmulti-core CU 10 C CM (Massively arallel rocessor) M IBM BlueGene/L 65536 Interconnection Network 3 4 (distributed memory system) (shared
BlueGene/L. Computer Science, University of Warwick. Source: IBM
 BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
Brand-New Vector Supercomputer
 Brand-New Vector Supercomputer NEC Corporation IT Platform Division Shintaro MOMOSE SC13 1 New Product NEC Released A Brand-New Vector Supercomputer, SX-ACE Just Now. Vector Supercomputer for Memory Bandwidth
Brand-New Vector Supercomputer NEC Corporation IT Platform Division Shintaro MOMOSE SC13 1 New Product NEC Released A Brand-New Vector Supercomputer, SX-ACE Just Now. Vector Supercomputer for Memory Bandwidth
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Outline. Execution Environments for Parallel Applications. Supercomputers. Supercomputers
 Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
Parallel Computing. PD Dr. rer. nat. habil. Ralf-Peter Mundani. Computation in Engineering / BGU Scientific Computing in Computer Science / INF
 Parallel Computing PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2018/19 General Remarks Ralf-Peter Mundani email
Parallel Computing PD Dr. rer. nat. habil. Ralf-Peter Mundani Computation in Engineering / BGU Scientific Computing in Computer Science / INF Winter Term 2018/19 General Remarks Ralf-Peter Mundani email
High Performance Computing: Blue-Gene and Road Runner. Ravi Patel
 High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
High Performance Computing: Blue-Gene and Road Runner Ravi Patel 1 HPC General Information 2 HPC Considerations Criterion Performance Speed Power Scalability Number of nodes Latency bottlenecks Reliability
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice
 InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
Three Generations of Linux Dr. Alexander Dunaevskiy
 Three Generations of Linux Server Systems as TSM-Platform at 17.08.2007 Dr. Alexander Dunaevskiy dunaevskiy@lrz.de d LRZ in Words LRZ is the biggest supercomputing centre in Germany LRZ provides a wide
Three Generations of Linux Server Systems as TSM-Platform at 17.08.2007 Dr. Alexander Dunaevskiy dunaevskiy@lrz.de d LRZ in Words LRZ is the biggest supercomputing centre in Germany LRZ provides a wide
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
Benchmark Results. 2006/10/03
 Benchmark Results cychou@nchc.org.tw 2006/10/03 Outline Motivation HPC Challenge Benchmark Suite Software Installation guide Fine Tune Results Analysis Summary 2 Motivation Evaluate, Compare, Characterize
Benchmark Results cychou@nchc.org.tw 2006/10/03 Outline Motivation HPC Challenge Benchmark Suite Software Installation guide Fine Tune Results Analysis Summary 2 Motivation Evaluate, Compare, Characterize
Current Status of the Next- Generation Supercomputer in Japan. YOKOKAWA, Mitsuo Next-Generation Supercomputer R&D Center RIKEN
 Current Status of the Next- Generation Supercomputer in Japan YOKOKAWA, Mitsuo Next-Generation Supercomputer R&D Center RIKEN International Workshop on Peta-Scale Computing Programming Environment, Languages
Current Status of the Next- Generation Supercomputer in Japan YOKOKAWA, Mitsuo Next-Generation Supercomputer R&D Center RIKEN International Workshop on Peta-Scale Computing Programming Environment, Languages
SMP and ccnuma Multiprocessor Systems. Sharing of Resources in Parallel and Distributed Computing Systems
 Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
The next generation supercomputer. Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency
 The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
Making a Case for a Green500 List
 Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
What does Heterogeneity bring?
 What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
What does Heterogeneity bring? Ken Koch Scientific Advisor, CCS-DO, LANL LACSI 2006 Conference October 18, 2006 Some Terminology Homogeneous Of the same or similar nature or kind Uniform in structure or
Overview. High Performance Computing - History of the Supercomputer. Modern Definitions (II)
") Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Programming Techniques for Supercomputers
 Programming Techniques for Supercomputers Prof. Dr. G. Wellein (a,b) Dr. G. Hager (a) Dr.-Ing. M. Wittmann (a) (a) HPC Services Regionales Rechenzentrum Erlangen (b) Department für Informatik University
Programming Techniques for Supercomputers Prof. Dr. G. Wellein (a,b) Dr. G. Hager (a) Dr.-Ing. M. Wittmann (a) (a) HPC Services Regionales Rechenzentrum Erlangen (b) Department für Informatik University
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 "
 CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16/!!! Outline Overview of parallel machines (~hardware) and programming models
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16/!!! Outline Overview of parallel machines (~hardware) and programming models
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
The Center for Computational Research
 The Center for Computational Research Russ Miller Director, Center for Computational Research UB Distinguished Professor, Computer Science & Engineering Senior Research Scientist, Hauptman-Woodward Medical
The Center for Computational Research Russ Miller Director, Center for Computational Research UB Distinguished Professor, Computer Science & Engineering Senior Research Scientist, Hauptman-Woodward Medical
Tianhe-2, the world s fastest supercomputer. Shaohua Wu Senior HPC application development engineer
 Tianhe-2, the world s fastest supercomputer Shaohua Wu Senior HPC application development engineer Inspur Inspur revenue 5.8 2010-2013 6.4 2011 2012 Unit: billion$ 8.8 2013 21% Staff: 14, 000+ 12% 10%
Tianhe-2, the world s fastest supercomputer Shaohua Wu Senior HPC application development engineer Inspur Inspur revenue 5.8 2010-2013 6.4 2011 2012 Unit: billion$ 8.8 2013 21% Staff: 14, 000+ 12% 10%
Inauguration Cartesius June 14, 2013
 Inauguration Cartesius June 14, 2013 Hardware is Easy...but what about software/applications/implementation/? Dr. Peter Michielse Deputy Director 1 Agenda History Cartesius Hardware path to exascale: the
Inauguration Cartesius June 14, 2013 Hardware is Easy...but what about software/applications/implementation/? Dr. Peter Michielse Deputy Director 1 Agenda History Cartesius Hardware path to exascale: the
Stockholm Brain Institute Blue Gene/L
 Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
The IBM Blue Gene/Q: Application performance, scalability and optimisation
 The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
Building supercomputers from commodity embedded chips
 http://www.montblanc-project.eu Building supercomputers from commodity embedded chips Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from commodity embedded chips Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
CS 267: Introduction to Parallel Machines and Programming Models Lecture 3 "
 CS 267: Introduction to Parallel Machines and Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr15/!!! Outline Overview of parallel machines (~hardware) and programming models (~software) Shared
CS 267: Introduction to Parallel Machines and Lecture 3 " James Demmel www.cs.berkeley.edu/~demmel/cs267_spr15/!!! Outline Overview of parallel machines (~hardware) and programming models (~software) Shared
The Earth Simulator System
 Architecture and Hardware for HPC Special Issue on High Performance Computing The Earth Simulator System - - - & - - - & - By Shinichi HABATA,* Mitsuo YOKOKAWA and Shigemune KITAWAKI The Earth Simulator,
Architecture and Hardware for HPC Special Issue on High Performance Computing The Earth Simulator System - - - & - - - & - By Shinichi HABATA,* Mitsuo YOKOKAWA and Shigemune KITAWAKI The Earth Simulator,
: A new version of Supercomputing or life after the end of the Moore s Law
 : A new version of Supercomputing or life after the end of the Moore s Law Dr.-Ing. Alexey Cheptsov SEMAPRO 2015 :: 21.07.2015 :: Dr. Alexey Cheptsov OUTLINE About us Convergence of Supercomputing into
: A new version of Supercomputing or life after the end of the Moore s Law Dr.-Ing. Alexey Cheptsov SEMAPRO 2015 :: 21.07.2015 :: Dr. Alexey Cheptsov OUTLINE About us Convergence of Supercomputing into
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Scaling to Petaflop. Ola Torudbakken Distinguished Engineer. Sun Microsystems, Inc
 Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
High Performance Computing - Parallel Computers and Networks. Prof Matt Probert
 High Performance Computing - Parallel Computers and Networks Prof Matt Probert http://www-users.york.ac.uk/~mijp1 Overview Parallel on a chip? Shared vs. distributed memory Latency & bandwidth Topology
High Performance Computing - Parallel Computers and Networks Prof Matt Probert http://www-users.york.ac.uk/~mijp1 Overview Parallel on a chip? Shared vs. distributed memory Latency & bandwidth Topology
Managing Hardware Power Saving Modes for High Performance Computing
 Managing Hardware Power Saving Modes for High Performance Computing Second International Green Computing Conference 2011, Orlando Timo Minartz, Michael Knobloch, Thomas Ludwig, Bernd Mohr timo.minartz@informatik.uni-hamburg.de
Managing Hardware Power Saving Modes for High Performance Computing Second International Green Computing Conference 2011, Orlando Timo Minartz, Michael Knobloch, Thomas Ludwig, Bernd Mohr timo.minartz@informatik.uni-hamburg.de
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Roadmapping of HPC interconnects
 Roadmapping of HPC interconnects MIT Microphotonics Center, Fall Meeting Nov. 21, 2008 Alan Benner, bennera@us.ibm.com Outline Top500 Systems, Nov. 2008 - Review of most recent list & implications on interconnect
Roadmapping of HPC interconnects MIT Microphotonics Center, Fall Meeting Nov. 21, 2008 Alan Benner, bennera@us.ibm.com Outline Top500 Systems, Nov. 2008 - Review of most recent list & implications on interconnect
Parallel Programming with MPI
 Parallel Programming with MPI Science and Technology Support Ohio Supercomputer Center 1224 Kinnear Road. Columbus, OH 43212 (614) 292-1800 oschelp@osc.edu http://www.osc.edu/supercomputing/ Functions
Parallel Programming with MPI Science and Technology Support Ohio Supercomputer Center 1224 Kinnear Road. Columbus, OH 43212 (614) 292-1800 oschelp@osc.edu http://www.osc.edu/supercomputing/ Functions
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
Introduction to High-Performance Computing Dr. Axel Kohlmeyer Associate Dean for Scientific Computing, CST Associate Director, Institute for Computational Science Assistant Vice President for High-Performance
COSC 6374 Parallel Computation. Parallel Computer Architectures
 OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Spring 2010 Flynn s Taxonomy SISD:
OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Spring 2010 Flynn s Taxonomy SISD:
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
An Overview of High Performance Computing
 IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology
 TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
Experiences of the Development of the Supercomputers
 Experiences of the Development of the Supercomputers - Earth Simulator and K Computer YOKOKAWA, Mitsuo Kobe University/RIKEN AICS Application Oriented Systems Developed in Japan No.1 systems in TOP500
Experiences of the Development of the Supercomputers - Earth Simulator and K Computer YOKOKAWA, Mitsuo Kobe University/RIKEN AICS Application Oriented Systems Developed in Japan No.1 systems in TOP500
Presentations: Jack Dongarra, University of Tennessee & ORNL. The HPL Benchmark: Past, Present & Future. Mike Heroux, Sandia National Laboratories
 HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/24/09 1 Take a look at high performance computing What s driving HPC Future Trends 2 Traditional scientific
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/24/09 1 Take a look at high performance computing What s driving HPC Future Trends 2 Traditional scientific
COSC 6374 Parallel Computation. Parallel Computer Architectures
 OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Edgar Gabriel Fall 2015 Flynn s Taxonomy
OS 6374 Parallel omputation Parallel omputer Architectures Some slides on network topologies based on a similar presentation by Michael Resch, University of Stuttgart Edgar Gabriel Fall 2015 Flynn s Taxonomy
IBM HPC DIRECTIONS. Dr Don Grice. ECMWF Workshop November, IBM Corporation
 IBM HPC DIRECTIONS Dr Don Grice ECMWF Workshop November, 2008 IBM HPC Directions Agenda What Technology Trends Mean to Applications Critical Issues for getting beyond a PF Overview of the Roadrunner Project
IBM HPC DIRECTIONS Dr Don Grice ECMWF Workshop November, 2008 IBM HPC Directions Agenda What Technology Trends Mean to Applications Critical Issues for getting beyond a PF Overview of the Roadrunner Project
Experts in Application Acceleration Synective Labs AB
 Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
The way toward peta-flops
 The way toward peta-flops ISC-2011 Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Where things started from DESIGN CONCEPTS 2 New challenges and requirements! Optimal sustained flops
The way toward peta-flops ISC-2011 Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Where things started from DESIGN CONCEPTS 2 New challenges and requirements! Optimal sustained flops
HOKUSAI System. Figure 0-1 System diagram
 HOKUSAI System October 11, 2017 Information Systems Division, RIKEN 1.1 System Overview The HOKUSAI system consists of the following key components: - Massively Parallel Computer(GWMPC,BWMPC) - Application
HOKUSAI System October 11, 2017 Information Systems Division, RIKEN 1.1 System Overview The HOKUSAI system consists of the following key components: - Massively Parallel Computer(GWMPC,BWMPC) - Application
SC2002, Baltimore (http://www.sc-conference.org/sc2002) From the Earth Simulator to PC Clusters
 From the Earth Simulator to PC Clusters") SC2002, Baltimore (http://www.sc-conference.org/sc2002) From the Earth Simulator to PC Clusters Structure of SC2002 Top500 List Dinosaurs Department Earth simulator US -answers (Cray SX1, ASCI purple),
SC2002, Baltimore (http://www.sc-conference.org/sc2002) From the Earth Simulator to PC Clusters Structure of SC2002 Top500 List Dinosaurs Department Earth simulator US -answers (Cray SX1, ASCI purple),
The AMD64 Technology for Server and Workstation. Dr. Ulrich Knechtel Enterprise Program Manager EMEA
 The AMD64 Technology for Server and Workstation Dr. Ulrich Knechtel Enterprise Program Manager EMEA Agenda Direct Connect Architecture AMD Opteron TM Processor Roadmap Competition OEM support The AMD64
The AMD64 Technology for Server and Workstation Dr. Ulrich Knechtel Enterprise Program Manager EMEA Agenda Direct Connect Architecture AMD Opteron TM Processor Roadmap Competition OEM support The AMD64
HECToR. UK National Supercomputing Service. Andy Turner & Chris Johnson
 HECToR UK National Supercomputing Service Andy Turner & Chris Johnson Outline EPCC HECToR Introduction HECToR Phase 3 Introduction to AMD Bulldozer Architecture Performance Application placement the hardware
HECToR UK National Supercomputing Service Andy Turner & Chris Johnson Outline EPCC HECToR Introduction HECToR Phase 3 Introduction to AMD Bulldozer Architecture Performance Application placement the hardware
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
The Architecture and the Application Performance of the Earth Simulator
 The Architecture and the Application Performance of the Earth Simulator Ken ichi Itakura (JAMSTEC) http://www.jamstec.go.jp 15 Dec., 2011 ICTS-TIFR Discussion Meeting-2011 1 Location of Earth Simulator
The Architecture and the Application Performance of the Earth Simulator Ken ichi Itakura (JAMSTEC) http://www.jamstec.go.jp 15 Dec., 2011 ICTS-TIFR Discussion Meeting-2011 1 Location of Earth Simulator
Affordable and power efficient computing for high energy physics: CPU and FFT benchmarks of ARM processors
 Affordable and power efficient computing for high energy physics: CPU and FFT benchmarks of ARM processors Mitchell A Cox, Robert Reed and Bruce Mellado School of Physics, University of the Witwatersrand.
Affordable and power efficient computing for high energy physics: CPU and FFT benchmarks of ARM processors Mitchell A Cox, Robert Reed and Bruce Mellado School of Physics, University of the Witwatersrand.
Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks
 Center for Information Services and High Performance Computing (ZIH) Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks EnA-HPC, Sept 16 th 2010, Robert Schöne, Daniel Molka,
Center for Information Services and High Performance Computing (ZIH) Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks EnA-HPC, Sept 16 th 2010, Robert Schöne, Daniel Molka,
Integrating GPUs as fast co-processors into the existing parallel FE package FEAST
 Integrating GPUs as fast co-processors into the existing parallel FE package FEAST Dipl.-Inform. Dominik Göddeke (dominik.goeddeke@math.uni-dortmund.de) Mathematics III: Applied Mathematics and Numerics
Integrating GPUs as fast co-processors into the existing parallel FE package FEAST Dipl.-Inform. Dominik Göddeke (dominik.goeddeke@math.uni-dortmund.de) Mathematics III: Applied Mathematics and Numerics
Jülich Supercomputing Centre
 Mitglied der Helmholtz-Gemeinschaft Jülich Supercomputing Centre Norbert Attig Jülich Supercomputing Centre (JSC) Forschungszentrum Jülich (FZJ) Aug 26, 2009 DOAG Regionaltreffen NRW 2 Supercomputing at
Mitglied der Helmholtz-Gemeinschaft Jülich Supercomputing Centre Norbert Attig Jülich Supercomputing Centre (JSC) Forschungszentrum Jülich (FZJ) Aug 26, 2009 DOAG Regionaltreffen NRW 2 Supercomputing at
Update on LRZ Leibniz Supercomputing Centre of the Bavarian Academy of Sciences and Humanities. 2 Oct 2018 Prof. Dr. Dieter Kranzlmüller
 Update on LRZ Leibniz Supercomputing Centre of the Bavarian Academy of Sciences and Humanities 2 Oct 2018 Prof. Dr. Dieter Kranzlmüller 1 Leibniz Supercomputing Centre Bavarian Academy of Sciences and
Update on LRZ Leibniz Supercomputing Centre of the Bavarian Academy of Sciences and Humanities 2 Oct 2018 Prof. Dr. Dieter Kranzlmüller 1 Leibniz Supercomputing Centre Bavarian Academy of Sciences and
A New NSF TeraGrid Resource for Data-Intensive Science
 A New NSF TeraGrid Resource for Data-Intensive Science Michael L. Norman Principal Investigator Director, SDSC Allan Snavely Co-Principal Investigator Project Scientist Slide 1 Coping with the data deluge
A New NSF TeraGrid Resource for Data-Intensive Science Michael L. Norman Principal Investigator Director, SDSC Allan Snavely Co-Principal Investigator Project Scientist Slide 1 Coping with the data deluge
Godson Processor and its Application in High Performance Computers
 Godson Processor and its Application in High Performance Computers Weiwu Hu Institute of Computing Technology, Chinese Academy of Sciences Loongson Technologies Corporation Limited hww@ict.ac.cn 1 Contents
Godson Processor and its Application in High Performance Computers Weiwu Hu Institute of Computing Technology, Chinese Academy of Sciences Loongson Technologies Corporation Limited hww@ict.ac.cn 1 Contents
John Hengeveld Director of Marketing, HPC Evangelist
 MIC, Intel and Rearchitecting for Exascale John Hengeveld Director of Marketing, HPC Evangelist Intel Data Center Group Dr. Jean-Laurent Philippe, PhD Technical Sales Manager & Exascale Technical Lead
MIC, Intel and Rearchitecting for Exascale John Hengeveld Director of Marketing, HPC Evangelist Intel Data Center Group Dr. Jean-Laurent Philippe, PhD Technical Sales Manager & Exascale Technical Lead
for Supercomputers Prof. Dr. G. Wellein (a,b), Dr. G. Hager (a), J. Habich (a) HPC Services Regionales Rechenzentrum Erlangen (b)
, Dr. G. Hager (a), J. Habich (a) HPC Services Regionales Rechenzentrum Erlangen (b)") Programming Techniques for Supercomputers Prof. Dr. G. Wellein (a,b), Dr. G. Hager (a), J. Habich (a) (a) HPC Services Regionales Rechenzentrum Erlangen (b) Department für Informatik University Erlangen-Nürnberg
Programming Techniques for Supercomputers Prof. Dr. G. Wellein (a,b), Dr. G. Hager (a), J. Habich (a) (a) HPC Services Regionales Rechenzentrum Erlangen (b) Department für Informatik University Erlangen-Nürnberg
Customer Success Story Los Alamos National Laboratory
 Customer Success Story Los Alamos National Laboratory Panasas High Performance Storage Powers the First Petaflop Supercomputer at Los Alamos National Laboratory Case Study June 2010 Highlights First Petaflop
Customer Success Story Los Alamos National Laboratory Panasas High Performance Storage Powers the First Petaflop Supercomputer at Los Alamos National Laboratory Case Study June 2010 Highlights First Petaflop
Dheeraj Bhardwaj May 12, 2003
 HPC Systems and Models Dheeraj Bhardwaj Department of Computer Science & Engineering Indian Institute of Technology, Delhi 110 016 India http://www.cse.iitd.ac.in/~dheerajb 1 Sequential Computers Traditional
HPC Systems and Models Dheeraj Bhardwaj Department of Computer Science & Engineering Indian Institute of Technology, Delhi 110 016 India http://www.cse.iitd.ac.in/~dheerajb 1 Sequential Computers Traditional
Commodity Cluster Computing
 Commodity Cluster Computing Ralf Gruber, EPFL-SIC/CAPA/Swiss-Tx, Lausanne http://capawww.epfl.ch Commodity Cluster Computing 1. Introduction 2. Characterisation of nodes, parallel machines,applications
Commodity Cluster Computing Ralf Gruber, EPFL-SIC/CAPA/Swiss-Tx, Lausanne http://capawww.epfl.ch Commodity Cluster Computing 1. Introduction 2. Characterisation of nodes, parallel machines,applications
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
Power your planet. Optimizing the Enterprise Data Center POWER7 Powers a Smarter Infrastructure
 Power your planet. Optimizing the Enterprise Data Center POWER7 Powers a Smarter Infrastructure Enoch Lau Field Technical Sales Specialist, Power Systems Systems & Technology Group Power your planet. Smarter
Power your planet. Optimizing the Enterprise Data Center POWER7 Powers a Smarter Infrastructure Enoch Lau Field Technical Sales Specialist, Power Systems Systems & Technology Group Power your planet. Smarter
Habanero Operating Committee. January
 Habanero Operating Committee January 25 2017 Habanero Overview 1. Execute Nodes 2. Head Nodes 3. Storage 4. Network Execute Nodes Type Quantity Standard 176 High Memory 32 GPU* 14 Total 222 Execute Nodes
Habanero Operating Committee January 25 2017 Habanero Overview 1. Execute Nodes 2. Head Nodes 3. Storage 4. Network Execute Nodes Type Quantity Standard 176 High Memory 32 GPU* 14 Total 222 Execute Nodes
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Overview. Idea: Reduce CPU clock frequency This idea is well suited specifically for visualization
 Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan & Matt Larsen (University of Oregon), Hank Childs (Lawrence Berkeley National Laboratory) 26
Exploring Tradeoffs Between Power and Performance for a Scientific Visualization Algorithm Stephanie Labasan & Matt Larsen (University of Oregon), Hank Childs (Lawrence Berkeley National Laboratory) 26
High Performance Computing for PDE Towards Petascale Computing
 High Performance Computing for PDE Towards Petascale Computing S. Turek, D. Göddeke with support by: Chr. Becker, S. Buijssen, M. Grajewski, H. Wobker Institut für Angewandte Mathematik, Univ. Dortmund
High Performance Computing for PDE Towards Petascale Computing S. Turek, D. Göddeke with support by: Chr. Becker, S. Buijssen, M. Grajewski, H. Wobker Institut für Angewandte Mathematik, Univ. Dortmund
Introducing OTF / Vampir / VampirTrace
 Center for Information Services and High Performance Computing (ZIH) Introducing OTF / Vampir / VampirTrace Zellescher Weg 12 Willers-Bau A115 Tel. +49 351-463 - 34049 (Robert.Henschel@zih.tu-dresden.de)
Center for Information Services and High Performance Computing (ZIH) Introducing OTF / Vampir / VampirTrace Zellescher Weg 12 Willers-Bau A115 Tel. +49 351-463 - 34049 (Robert.Henschel@zih.tu-dresden.de)
Improving Linear Algebra Computation on NUMA platforms through auto-tuned tuned nested parallelism
 Improving Linear Algebra Computation on NUMA platforms through auto-tuned tuned nested parallelism Javier Cuenca, Luis P. García, Domingo Giménez Parallel Computing Group University of Murcia, SPAIN parallelum
Improving Linear Algebra Computation on NUMA platforms through auto-tuned tuned nested parallelism Javier Cuenca, Luis P. García, Domingo Giménez Parallel Computing Group University of Murcia, SPAIN parallelum
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC?
 Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
High Performance Computing in C and C++
 High Performance Computing in C and C++ Rita Borgo Computer Science Department, Swansea University WELCOME BACK Course Administration Contact Details Dr. Rita Borgo Home page: http://cs.swan.ac.uk/~csrb/
High Performance Computing in C and C++ Rita Borgo Computer Science Department, Swansea University WELCOME BACK Course Administration Contact Details Dr. Rita Borgo Home page: http://cs.swan.ac.uk/~csrb/
Supercomputers. Alex Reid & James O'Donoghue
 Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Parallel Programming Concepts. Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04. Parallel Background. Why Bother?
 Parallel Programming Concepts Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04 Parallel Background Why Bother? 1 What is Parallel Programming? Simultaneous use of multiple
Parallel Programming Concepts Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04 Parallel Background Why Bother? 1 What is Parallel Programming? Simultaneous use of multiple
Design and Evaluation of a 2048 Core Cluster System
 Design and Evaluation of a 2048 Core Cluster System, Torsten Höfler, Torsten Mehlan and Wolfgang Rehm Computer Architecture Group Department of Computer Science Chemnitz University of Technology December
Design and Evaluation of a 2048 Core Cluster System, Torsten Höfler, Torsten Mehlan and Wolfgang Rehm Computer Architecture Group Department of Computer Science Chemnitz University of Technology December
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
MIMD Overview. Intel Paragon XP/S Overview. XP/S Usage. XP/S Nodes and Interconnection. ! Distributed-memory MIMD multicomputer
 MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
MIMD Overview Intel Paragon XP/S Overview! MIMDs in the 1980s and 1990s! Distributed-memory multicomputers! Intel Paragon XP/S! Thinking Machines CM-5! IBM SP2! Distributed-memory multicomputers with hardware
HPC Architectures evolution: the case of Marconi, the new CINECA flagship system. Piero Lanucara
 HPC Architectures evolution: the case of Marconi, the new CINECA flagship system Piero Lanucara Many advantages as a supercomputing resource: Low energy consumption. Limited floor space requirements Fast
HPC Architectures evolution: the case of Marconi, the new CINECA flagship system Piero Lanucara Many advantages as a supercomputing resource: Low energy consumption. Limited floor space requirements Fast
Comparing Linux Clusters for the Community Climate System Model
 Comparing Linux Clusters for the Community Climate System Model Matthew Woitaszek, Michael Oberg, and Henry M. Tufo Department of Computer Science University of Colorado, Boulder {matthew.woitaszek, michael.oberg}@colorado.edu,
Comparing Linux Clusters for the Community Climate System Model Matthew Woitaszek, Michael Oberg, and Henry M. Tufo Department of Computer Science University of Colorado, Boulder {matthew.woitaszek, michael.oberg}@colorado.edu,