Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
|
|
|
- Neil Gaines
- 6 years ago
- Views:
Transcription

1 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/24/09 1

2 Take a look at high performance computing What s driving HPC Future Trends 2
 Do")
 Perform experiments or build")





 Use high performance")
3 Traditional scientific and engineering paradigm: 1) Do theory or paper design. 2) Perform experiments or build system. Limitations:! Too expensive -- build a throw-away passenger jet.! Too slow -- wait for climate or galactic evolution.! Too difficult -- build large wind tunnels.! Too dangerous -- weapons, drug design, climate experimentation. Computational science paradigm: 3) Use high performance computer systems to simulate the phenomenon Base on known physical laws and efficient numerical methods. 3
4 4
5 Strategic importance of supercomputing! Essential for scientific discovery! Critical for national security! Fundamental contributor to the economy and competitiveness through use in engineering and manufacturing Supercomputers are the tool for solving the most challenging problems through simulations 5
6 TPP performance Rate Size 6
7 100 Pflop/s Pflop/s Pflop/s Tflop/s Tflop/s /% 890% 4$#25%3'()*+,% 0#$2%3'()*+,% 4.#.%1'()*+,% 1 Tflop/s #0$%1'()*+,% 6-8 years 100 Gflop/s Gflop/s 10 1 Gflop/s Mflop/s !..%!"#$%&'()*+,% My Laptop -..%/'()*+,%




8 Looking at the Gordon Bell Prize (Recognize outstanding achievement in high-performance computing applications and encourage development of parallel processing ) " 1 GFlop/s; 1988; Cray Y-MP; 8 Processors! Static finite element analysis " 1 TFlop/s; 1998; Cray T3E; 1024 Processors! Modeling of metallic magnet atoms, using a variation of the locally self-consistent multiple scattering method. " 1 PFlop/s; 2008; Cray XT5; 1.5x10 5 Processors! Superconductive materials " 1 EFlop/s; ~2018;?; 1x10 7 Processors (10 9 threads)


9 Performance Development in Top500 1E+11 1E+10 1 Eflop/s 1E Pflop/s 10 Pflop/s 67/% Pflop/s Tflop/s Tflop/s 890% Gordon Bell Winners Tflop/s Gflop/s 89!..% Gflop/s 1 1 Gflop/s 100 Mflop/s
10 10
\"# )\"#")






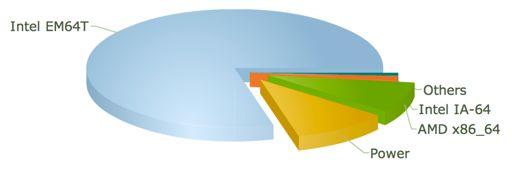
11 =6B,.9-/3#J#1<3./7#1>29/# )"# )"# )"# )"# ("# ("# ("# '"# &"# %"# %"# $"# *"#!!"# 55% 9% 6% 6% 4% 3% 2% 2% 2% 1% 1% 1% 1% 7% +,-./0#1.2./3# +,-./0#4-,5067# 892,:/# ;/972,<# =2,202# AB3.9-2# C/D#E/2F2,0# 1D/0/,# GB33-2# H.2F<# I.>/93#
KK# K#")
$$%# )$$*# )$$L# )$$$# (KKK# (KK)#")

12 =B3.67/9#1/57/,.3#!KK# 6:,;<=,% &KK# 'KK# (KK# )KK# K# )$$'# )$$&# )$$!# )$$%# )$$*# )$$L# )$$$# (KKK# (KK)# (KK(# (KK'# (KK&# (KK!# (KK%# (KK*# (KKL# (KK$# I.>/93# ;6M/9,7/,.# N/,069# =F233-O/0# A:20/7-:# G/3/29:># H,0B3.9<#






13 Of the 500 Fastest Supercomputer Worldwide, Industrial Use is > 60% # # # # # # # # # # # # # # # # # # # # # # # # # # 13 #
14 Rank Site Computer Country Procs Rmax [Pflops] % of Peak Power [MW] Flops/ Watt 1 DOE / OS Oak Ridge Nat Lab Jaguar / Cray Cray XT5 sixcore 2.6 GHz USA 224, DOE / NNSA Los Alamos Nat Lab Roadrunner / IBM BladeCenter QS22/LS21 USA 122, NSF / NICS / U of Tennessee Jaguar / Cray Cray XT5 sixcore 2.6 GHz USA 98, Forschungszentrum Juelich (FZJ) Jugene / IBM Blue Gene/P Solution Germany 294, National SC Center in Tianjin / NUDT Tianhe-1 / NUDT TH-1 / IntelQC + AMD ATI Radeon 4870 China 71, NASA / Ames Research Center/NAS Pleiades / SGI SGI Altix ICE 8200EX USA 56, DOE / NNSA Lawrence Livermore NL BlueGene/L IBM eserver Blue Gene Solution USA 212, DOE / OS Argonne Nat Lab Intrepid / IBM Blue Gene/P Solution USA 163, NSF TACC/U. of Texas Ranger / Sun SunBlade x6420 USA 62, DOE / NNSA Sandia Nat Lab Sun / SunBlade 6275 USA 41,
15 Rank Site Computer Country Procs Rmax [Pflops] % of Peak Power [MW] MFlops /Watt 1 DOE / OS Oak Ridge Nat Lab Jaguar / Cray Cray XT5 sixcore 2.6 GHz USA 224, DOE / NNSA Los Alamos Nat Lab Roadrunner / IBM BladeCenter QS22/LS21 USA 122, NSF / NICS / U of Tennessee Jaguar / Cray Cray XT5 sixcore 2.6 GHz USA 98, Forschungszentrum Juelich (FZJ) Jugene / IBM Blue Gene/P Solution Germany 294, National SC Center in Tianjin / NUDT Tianhe-1 / NUDT TH-1 / IntelQC + AMD ATI Radeon 4870 China 71, NASA / Ames Research Center/NAS Pleiades / SGI SGI Altix ICE 8200EX USA 56, DOE / NNSA Lawrence Livermore NL BlueGene/L IBM eserver Blue Gene Solution USA 212, DOE / OS Argonne Nat Lab Intrepid / IBM Blue Gene/P Solution USA 163, NSF TACC/U. of Texas Ranger / Sun SunBlade x6420 USA 62, DOE / NNSA Sandia Nat Lab Sun / SunBlade 6275 USA 41,




16 Recently upgraded to a 2.3 Pflop/s system with more than 224K processor cores using AMD s 6 Core chip. Peak performance System memory Disk space Disk bandwidth Interconnect bandwidth 2.3 PF 300 TB 10 PB 240+ GB/s 374 TB/s


17


18 ! University of Tennessee s National Institute for Computational Sciences! Housed at ORNL, operated for the NSF, named Kraken! Number 3 on the Top500 Just upgraded to 1 Pflop/s peak 99,072 cores, AMD 2.6 GHz 6 core chip, w/129 TB memory
 I/O Nodes: 600 Networks: Three-dimensonal torus (compute nodes) Power Consumption:!")
19 IBM BG/P - 72 Racks with 32 nodecards x 32 compute nodes (total 73,728)! Compute node: 4-way SMP processor! Processor type: 32-bit PowerPC 450 core 850 MHz Processors: 294,912! Overall peak performance: 1 Pflop/s! Linpack: Tflop/s! Main memory: 2 Gbytes per node (aggregate 144 TB) I/O Nodes: 600 Networks: Three-dimensonal torus (compute nodes) Power Consumption:! max. 35 kw per rack 19

!")
20 Tianhe-1 Hybrid system, commodity + GPUs Theoretical peak 1.21 Pflop/s Linpack Benchmark at Tflop/s 2560 nodes, each node: 2 Intel Quadcore Xeon ,120 AMD ATI 4780 GPUs (each 10 cores)! 71,680 cores! Infiniband connected

21 Performance of Top20 Over 10 Years Pflop/s
22 Blue Waters NCSA/Illinois 10 Pflop/s peak; 1 Pflop/s sustained per second in 2010 Kraken NICS/U of Tennessee 1 Pflop/s peak per second Ranger TACC/U of Texas 504 Tflop/s peak per second Campuses across the U.S. Several sites Tflop/s peak per second
23 0..>...% 0.>...% 0>...% 0..% 0.% 0%.%
24 0..>...% 0.>...% 0>...% 0..% 0.% 0%.%
25 0..>...% 0.>...% 0>...% 0..% 0.% 0%.%
26 Rank Site Manufac turer Computer Cores 5 National SuperComputer; Tianjin NUDT NUDT TH-1 Cluster, Xeon ATI Radeon HD 4870! Shanghai Supercomputer Center Dawning Dawning 5000A, QC Opteron 1.9 Ghz, Windows Computer Network Information, CAS Lenovo DeepComp 7000, HS21/x3950 Cluster, Xeon Network Company IBM BladeCenter HS22 Cluster, Xeon Network Company IBM BladeCenter HS22 Cluster, Xeon Network Company IBM BladeCenter HS22 Cluster, Xeon Telecommunication Company HP Cluster Platform 3000 BL480c, Xeon Nanjing University IBM BladeCenter HS22 Cluster, Xeon Network Company IBM BladeCenter HS22 Cluster, Xeon Network Company IBM BladeCenter HS22 Cluster, Xeon Network Company IBM BladeCenter HS22 Cluster, Xeon Network Company IBM BladeCenter HS22 Cluster, Xeon Logistic Services HP Cluster Platform 3000 BL460c G1, Xeon Network Company IBM BladeCenter HS22 Cluster, Xeon Telecommunication Company HP Cluster Platform 3000 BL460c CNPC Sichuan Geophysical IBM BladeCenter HS21 Cluster, Xeon Telecommunication Company HP Cluster Platform 3000 BL460c G Telecommunication Company HP Cluster Platform 3000 BL460c G6, Xeon Institute of Engineering Mechanics HP Cluster Platform 3000 BL460c G1, Xeon Petroleum Company IBM BladeCenter HS21 Cluster, Xeon China Petroleum University IBM BladeCenter LS22, Opteron 3072
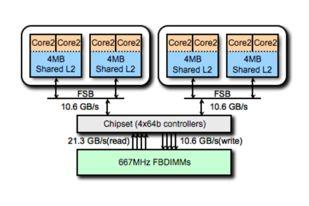

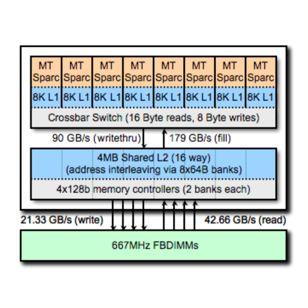
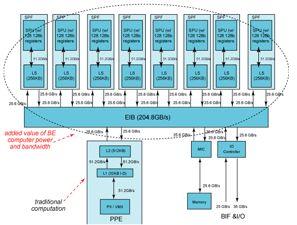
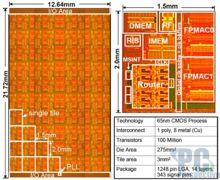






27 27
 is a family of general-purpose MIPS-compatible CPUs developed at the Institute of Computing Technology, Chinese Academy of Sciences.")
28 Loongson (Chinese: ;!academic name: Godson, also known as Dragon chip) is a family of general-purpose MIPS-compatible CPUs developed at the Institute of Computing Technology, Chinese Academy of Sciences. The chief architect is Professor Weiwu Hu. The 65!nm Loongson 3 (Godson-3) is able to run at a clock speed between 1.0 to 1.2 GHz, with 4 CPU cores (10W) first and 8 cores later (20W), and it is expected to debut in Will use this chip as basis for Petascale system in
 Today accelerators are attached Next generation")

29 Most likely be a hybrid design Think standard multicore chips and accelerator (GPUs) Today accelerators are attached Next generation more integrated Intel s Larrabee?! 8,16,32,or 64 x86 cores AMD s Fusion in 2011! Multicore with embedded graphics ATI Nvidia s plans? 29





30 + 3D Stacked Memory Many Floating- Point Cores Different Classes of Chips Home Games / Graphics Business Scientific
31 Moore s Law is Alive and Well 1.E+07 1.E+06 1.E+05 Transistors (in Thousands) 1.E+04 1.E+03 1.E+02 1.E+01 1.E+00 1.E
32 But Clock Frequency Scaling Replaced by Scaling Cores / Chip 1.E+07 1.E+06 1.E+05 Transistors (in Thousands) Frequency (MHz) Cores 1.E+04 1.E+03 1.E+02 1.E+01 1.E+00 1.E

 Cores 1.E+03 1.E+02 1.E+01 1.E+00 1.")
33 Performance Has Also Slowed, Along with Power 1.E+07 1.E+06 1.E+05 1.E+04 Transistors (in Thousands) Frequency (MHz) Power (W) Cores 1.E+03 1.E+02 1.E+01 1.E+00 1.E
34 Frequency 34
35 Frequency 35
36 Number of cores per chip doubles every 2 year, while clock speed decreases (not increases). Need to deal with systems with millions of concurrent threads Future generation will have billions of threads! Need to be able to easily replace inter-chip parallelism with intro-chip parallelism Number of threads of execution doubles every 2 year 100,000 90,000 80,000 70,000 60,000 50,000 40,000 30,000 20,000 10,000 0 Average Number of Cores Per Supercomputer
37 Must rethink the design of our software! Another disruptive technology Similar to what happened with cluster computing and message passing! Rethink and rewrite the applications, algorithms, and software 37

! Fusion Energy (3/09)! Nuclear Energy (5/09)! Biology (8/09)!")

38 " DOE Exascale Steering Committee! ANL, LANL, LBNL, LLNL, SNL, ORNL + PNL, BNL! Charter: Decadal plan to provide exascale applications and technologies for DOE mission needs " ~100 People! Climate Science (11/08)! High Energy Physics (12/08)! Nuclear physics (1/09)! Fusion Energy (3/09)! Nuclear Energy (5/09)! Biology (8/09)! Basic Energy Science (8/09)! Joint National Security (10/09)! Computer Science! Mathematics! Computer Architecture Strong science case for the continued escalation of high-end computing.
 with chips perhaps as")



39 Exascale systems are likely feasible by 2017± Million processing elements (cores or mini-cores) with chips perhaps as dense as 1,000 cores per socket, clock rates will grow more slowly 3D packaging likely Large-scale optics based interconnects PB of aggregate memory Hardware and software based fault management Heterogeneous cores Performance per watt stretch goal 100 GF/watt of sustained performance >> MW Exascale system! Power, area and capital costs will be significantly higher than for today s fastest systems 39
40 Steepness of the ascent from terascale to petascale to exascale Extreme parallelism and hybrid design! Preparing for million/billion way parallelism Tightening memory/bandwidth bottleneck! Limits on power/clock speed implication on multicore! Reducing communication will become much more intense! Memory per core changes, byte-to-flop ratio will change Necessary Fault Tolerance! MTTF will drop! Checkpoint/restart has limitations Software infrastructure does not exist today

41 For the last decade or more, the research investment strategy has been overwhelmingly biased in favor of hardware. This strategy needs to be rebalanced - barriers to progress are increasingly on the software side. Moreover, the return on investment is more favorable to software.! Hardware has a half-life measured in years, while software has a half-life measured in decades. High Performance Ecosystem out of balance! Hardware, OS, Compilers, Software, Algorithms, Applications No Moore s Law for software, algorithms and applications



42 Top500 Hans Meuer, Prometeus Erich Strohmaier, LBNL/NERSC Horst Simon, LBNL/NERSC
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/3/09 1 ! Take a look at high performance computing! What s driving HPC! Issues with power consumption! Future
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 12/3/09 1 ! Take a look at high performance computing! What s driving HPC! Issues with power consumption! Future
Jack Dongarra University of Tennessee Oak Ridge National Laboratory
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory 3/9/11 1 TPP performance Rate Size 2 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 100 Tflop/s 100000 10 Tflop/s 10000
Jack Dongarra University of Tennessee Oak Ridge National Laboratory 3/9/11 1 TPP performance Rate Size 2 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 100 Tflop/s 100000 10 Tflop/s 10000
Jack Dongarra INNOVATIVE COMP ING LABORATORY. University i of Tennessee Oak Ridge National Laboratory
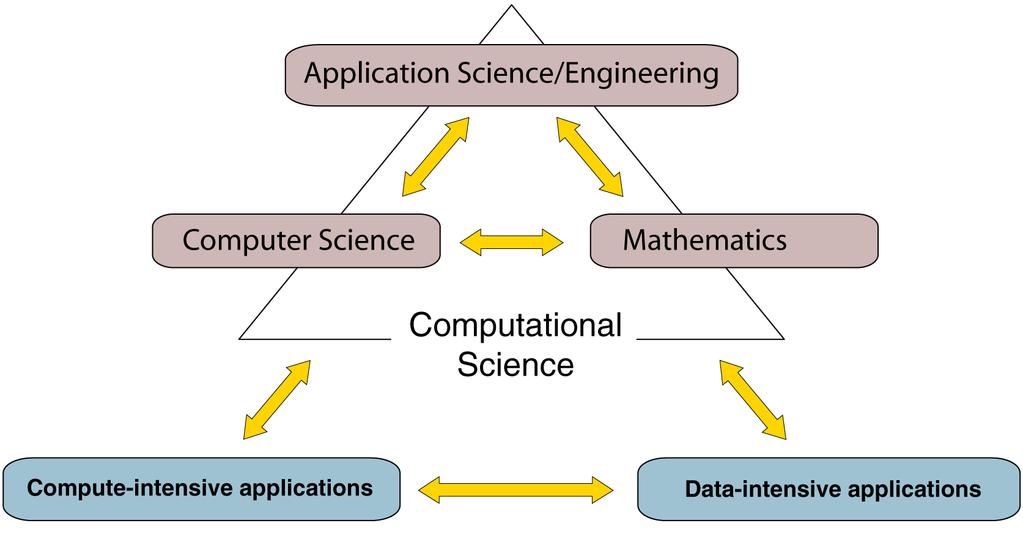
 Computational Science, High Performance Computing, and the IGMCS Program Jack Dongarra INNOVATIVE COMP ING LABORATORY University i of Tennessee Oak Ridge National Laboratory 1 The Third Pillar of 21st
Computational Science, High Performance Computing, and the IGMCS Program Jack Dongarra INNOVATIVE COMP ING LABORATORY University i of Tennessee Oak Ridge National Laboratory 1 The Third Pillar of 21st
An Overview of High Performance Computing and Challenges for the Future
 An Overview of High Performance Computing and Challenges for the Future Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 6/15/2009 1 H. Meuer, H. Simon, E. Strohmaier,
An Overview of High Performance Computing and Challenges for the Future Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 6/15/2009 1 H. Meuer, H. Simon, E. Strohmaier,
Presentations: Jack Dongarra, University of Tennessee & ORNL. The HPL Benchmark: Past, Present & Future. Mike Heroux, Sandia National Laboratories
 HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
An Overview of High Performance Computing and Future Requirements
 An Overview of High Performance Computing and Future Requirements Jack Dongarra University of Tennessee Oak Ridge National Laboratory 1 H. Meuer, H. Simon, E. Strohmaier, & JD - Listing of the 500 most
An Overview of High Performance Computing and Future Requirements Jack Dongarra University of Tennessee Oak Ridge National Laboratory 1 H. Meuer, H. Simon, E. Strohmaier, & JD - Listing of the 500 most
High Performance Computing in Europe and USA: A Comparison
 High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology
 TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
Emerging Heterogeneous Technologies for High Performance Computing
 MURPA (Monash Undergraduate Research Projects Abroad) Emerging Heterogeneous Technologies for High Performance Computing Jack Dongarra University of Tennessee Oak Ridge National Lab University of Manchester
MURPA (Monash Undergraduate Research Projects Abroad) Emerging Heterogeneous Technologies for High Performance Computing Jack Dongarra University of Tennessee Oak Ridge National Lab University of Manchester
CSE5351: Parallel Procesisng. Part 1B. UTA Copyright (c) Slide No 1
 Slide No 1") Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
Slide No 1 CSE5351: Parallel Procesisng Part 1B Slide No 2 State of the Art In Supercomputing Several of the next slides (or modified) are the courtesy of Dr. Jack Dongarra, a distinguished professor of
Top500
 Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
A Linear Algebra Library for Multicore/Accelerators: the PLASMA/MAGMA Collection
 A Linear Algebra Library for Multicore/Accelerators: the PLASMA/MAGMA Collection Jack Dongarra University of Tennessee Oak Ridge National Laboratory 11/24/2009 1 Gflop/s LAPACK LU - Intel64-16 cores DGETRF
A Linear Algebra Library for Multicore/Accelerators: the PLASMA/MAGMA Collection Jack Dongarra University of Tennessee Oak Ridge National Laboratory 11/24/2009 1 Gflop/s LAPACK LU - Intel64-16 cores DGETRF
Chapter 1. Introduction
 Chapter 1 Introduction Why High Performance Computing? Quote: It is hard to understand an ocean because it is too big. It is hard to understand a molecule because it is too small. It is hard to understand
Chapter 1 Introduction Why High Performance Computing? Quote: It is hard to understand an ocean because it is too big. It is hard to understand a molecule because it is too small. It is hard to understand
High Performance Computing in Europe and USA: A Comparison
 High Performance Computing in Europe and USA: A Comparison Erich Strohmaier 1 and Hans W. Meuer 2 1 NERSC, Lawrence Berkeley National Laboratory, USA 2 University of Mannheim, Germany 1 Introduction In
High Performance Computing in Europe and USA: A Comparison Erich Strohmaier 1 and Hans W. Meuer 2 1 NERSC, Lawrence Berkeley National Laboratory, USA 2 University of Mannheim, Germany 1 Introduction In
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Presentation of the 16th List
 Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Roadmapping of HPC interconnects
 Roadmapping of HPC interconnects MIT Microphotonics Center, Fall Meeting Nov. 21, 2008 Alan Benner, bennera@us.ibm.com Outline Top500 Systems, Nov. 2008 - Review of most recent list & implications on interconnect
Roadmapping of HPC interconnects MIT Microphotonics Center, Fall Meeting Nov. 21, 2008 Alan Benner, bennera@us.ibm.com Outline Top500 Systems, Nov. 2008 - Review of most recent list & implications on interconnect
Making a Case for a Green500 List
 Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
Distributed Dense Linear Algebra on Heterogeneous Architectures. George Bosilca
 Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Supercomputers. Alex Reid & James O'Donoghue
 Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
An Overview of High Performance Computing
 IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
What have we learned from the TOP500 lists?
 What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Real Parallel Computers
 Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Aggregation of Real-Time System Monitoring Data for Analyzing Large-Scale Parallel and Distributed Computing Environments
 Aggregation of Real-Time System Monitoring Data for Analyzing Large-Scale Parallel and Distributed Computing Environments Swen Böhm 1,2, Christian Engelmann 2, and Stephen L. Scott 2 1 Department of Computer
Aggregation of Real-Time System Monitoring Data for Analyzing Large-Scale Parallel and Distributed Computing Environments Swen Böhm 1,2, Christian Engelmann 2, and Stephen L. Scott 2 1 Department of Computer
TOP500 Listen und industrielle/kommerzielle Anwendungen
 TOP500 Listen und industrielle/kommerzielle Anwendungen Hans Werner Meuer Universität Mannheim Gesprächsrunde Nichtnumerische Anwendungen im Bereich des Höchstleistungsrechnens des BMBF Berlin, 16./ 17.
TOP500 Listen und industrielle/kommerzielle Anwendungen Hans Werner Meuer Universität Mannheim Gesprächsrunde Nichtnumerische Anwendungen im Bereich des Höchstleistungsrechnens des BMBF Berlin, 16./ 17.
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Introduction to FREE National Resources for Scientific Computing. Dana Brunson. Jeff Pummill
 Introduction to FREE National Resources for Scientific Computing Dana Brunson Oklahoma State University High Performance Computing Center Jeff Pummill University of Arkansas High Peformance Computing Center
Introduction to FREE National Resources for Scientific Computing Dana Brunson Oklahoma State University High Performance Computing Center Jeff Pummill University of Arkansas High Peformance Computing Center
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice
 InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
InfiniBand Strengthens Leadership as The High-Speed Interconnect Of Choice Providing the Best Return on Investment by Delivering the Highest System Efficiency and Utilization Top500 Supercomputers June
The TOP500 list. Hans-Werner Meuer University of Mannheim. SPEC Workshop, University of Wuppertal, Germany September 13, 1999
 The TOP500 list Hans-Werner Meuer University of Mannheim SPEC Workshop, University of Wuppertal, Germany September 13, 1999 Outline TOP500 Approach HPC-Market as of 6/99 Market Trends, Architecture Trends,
The TOP500 list Hans-Werner Meuer University of Mannheim SPEC Workshop, University of Wuppertal, Germany September 13, 1999 Outline TOP500 Approach HPC-Market as of 6/99 Market Trends, Architecture Trends,
Introduction to Computational Science (aka Scientific Computing)
") (aka Scientific Computing) Xianyi Zeng xzeng@utep.edu Department of Mathematical Sciences The University of Texas at El Paso. August 23, 2016. Acknowledgement Dr. Shirley Moore for setting up a high standard
(aka Scientific Computing) Xianyi Zeng xzeng@utep.edu Department of Mathematical Sciences The University of Texas at El Paso. August 23, 2016. Acknowledgement Dr. Shirley Moore for setting up a high standard
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
INSPUR and HPC Innovation
 INSPUR and HPC Innovation Dong Qi (Forrest) Product manager Inspur dongqi@inspur.com Contents 1 2 3 4 5 Inspur introduction HPC Challenge and Inspur HPC strategy HPC cases Inspur contribution to HPC community
INSPUR and HPC Innovation Dong Qi (Forrest) Product manager Inspur dongqi@inspur.com Contents 1 2 3 4 5 Inspur introduction HPC Challenge and Inspur HPC strategy HPC cases Inspur contribution to HPC community
Overview. High Performance Computing - History of the Supercomputer. Modern Definitions (II)
") Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
Overview High Performance Computing - History of the Supercomputer Dr M. Probert Autumn Term 2017 Early systems with proprietary components, operating systems and tools Development of vector computing
HPC as a Driver for Computing Technology and Education
 HPC as a Driver for Computing Technology and Education Tarek El-Ghazawi The George Washington University Washington D.C., USA NOW- July 2015: The TOP 10 Systems Rank Site Computer Cores Rmax [Pflops] %
HPC as a Driver for Computing Technology and Education Tarek El-Ghazawi The George Washington University Washington D.C., USA NOW- July 2015: The TOP 10 Systems Rank Site Computer Cores Rmax [Pflops] %
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
The TOP500 Project of the Universities Mannheim and Tennessee
 The TOP500 Project of the Universities Mannheim and Tennessee Hans Werner Meuer University of Mannheim EURO-PAR 2000 29. August - 01. September 2000 Munich/Germany Outline TOP500 Approach HPC-Market as
The TOP500 Project of the Universities Mannheim and Tennessee Hans Werner Meuer University of Mannheim EURO-PAR 2000 29. August - 01. September 2000 Munich/Germany Outline TOP500 Approach HPC-Market as
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
INSPUR and HPC Innovation. Dong Qi (Forrest) Oversea PM
 Oversea PM") INSPUR and HPC Innovation Dong Qi (Forrest) Oversea PM dongqi@inspur.com Contents 1 2 3 4 5 Inspur introduction HPC Challenge and Inspur HPC strategy HPC cases Inspur contribution to HPC community Inspur
INSPUR and HPC Innovation Dong Qi (Forrest) Oversea PM dongqi@inspur.com Contents 1 2 3 4 5 Inspur introduction HPC Challenge and Inspur HPC strategy HPC cases Inspur contribution to HPC community Inspur
IBM HPC DIRECTIONS. Dr Don Grice. ECMWF Workshop November, IBM Corporation
 IBM HPC DIRECTIONS Dr Don Grice ECMWF Workshop November, 2008 IBM HPC Directions Agenda What Technology Trends Mean to Applications Critical Issues for getting beyond a PF Overview of the Roadrunner Project
IBM HPC DIRECTIONS Dr Don Grice ECMWF Workshop November, 2008 IBM HPC Directions Agenda What Technology Trends Mean to Applications Critical Issues for getting beyond a PF Overview of the Roadrunner Project
Godson Processor and its Application in High Performance Computers
 Godson Processor and its Application in High Performance Computers Weiwu Hu Institute of Computing Technology, Chinese Academy of Sciences Loongson Technologies Corporation Limited hww@ict.ac.cn 1 Contents
Godson Processor and its Application in High Performance Computers Weiwu Hu Institute of Computing Technology, Chinese Academy of Sciences Loongson Technologies Corporation Limited hww@ict.ac.cn 1 Contents
Parallel Computing: From Inexpensive Servers to Supercomputers
 Parallel Computing: From Inexpensive Servers to Supercomputers Lyle N. Long The Pennsylvania State University & The California Institute of Technology Seminar to the Koch Lab http://www.personal.psu.edu/lnl
Parallel Computing: From Inexpensive Servers to Supercomputers Lyle N. Long The Pennsylvania State University & The California Institute of Technology Seminar to the Koch Lab http://www.personal.psu.edu/lnl
Confessions of an Accidental Benchmarker
 Confessions of an Accidental Benchmarker http://bit.ly/hpcg-benchmark 1 Appendix B of the Linpack Users Guide Designed to help users extrapolate execution Linpack software package First benchmark report
Confessions of an Accidental Benchmarker http://bit.ly/hpcg-benchmark 1 Appendix B of the Linpack Users Guide Designed to help users extrapolate execution Linpack software package First benchmark report
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Practical Scientific Computing
 Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
High-Performance Computing & Simulations in Quantum Many-Body Systems PART I. Thomas Schulthess
 High-Performance Computing & Simulations in Quantum Many-Body Systems PART I Thomas Schulthess schulthess@phys.ethz.ch What exactly is high-performance computing? 1E10 1E9 1E8 1E7 relative performance
High-Performance Computing & Simulations in Quantum Many-Body Systems PART I Thomas Schulthess schulthess@phys.ethz.ch What exactly is high-performance computing? 1E10 1E9 1E8 1E7 relative performance
High-Performance Scientific Computing
 High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
High-Performance Scientific Computing Instructor: Randy LeVeque TA: Grady Lemoine Applied Mathematics 483/583, Spring 2011 http://www.amath.washington.edu/~rjl/am583 World s fastest computers http://top500.org
CS4961 Parallel Programming. Lecture 1: Introduction 08/25/2009. Course Details. Mary Hall August 25, Today s Lecture.
 Parallel Programming Lecture 1: Introduction Mary Hall August 25, 2009 Course Details Time and Location: TuTh, 9:10-10:30 AM, WEB L112 Course Website - http://www.eng.utah.edu/~cs4961/ Instructor: Mary
Parallel Programming Lecture 1: Introduction Mary Hall August 25, 2009 Course Details Time and Location: TuTh, 9:10-10:30 AM, WEB L112 Course Website - http://www.eng.utah.edu/~cs4961/ Instructor: Mary
From Majorca with love
 From Majorca with love IEEE Photonics Society - Winter Topicals 2010 Photonics for Routing and Interconnects January 11, 2010 Organizers: H. Dorren (Technical University of Eindhoven) L. Kimerling (MIT)
From Majorca with love IEEE Photonics Society - Winter Topicals 2010 Photonics for Routing and Interconnects January 11, 2010 Organizers: H. Dorren (Technical University of Eindhoven) L. Kimerling (MIT)
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Using Graphics Chips for General Purpose Computation
 White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 11/20/13 1 Rank Site Computer Country Cores Rmax [Pflops] % of Peak Power [MW] MFlops /Watt 1 2 3 4 National
Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 11/20/13 1 Rank Site Computer Country Cores Rmax [Pflops] % of Peak Power [MW] MFlops /Watt 1 2 3 4 National
PART I - Fundamentals of Parallel Computing
 PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
PART I - Fundamentals of Parallel Computing Objectives What is scientific computing? The need for more computing power The need for parallel computing and parallel programs 1 What is scientific computing?
ALCF Argonne Leadership Computing Facility
 ALCF Argonne Leadership Computing Facility ALCF Data Analytics and Visualization Resources William (Bill) Allcock Leadership Computing Facility Argonne Leadership Computing Facility Established 2006. Dedicated
ALCF Argonne Leadership Computing Facility ALCF Data Analytics and Visualization Resources William (Bill) Allcock Leadership Computing Facility Argonne Leadership Computing Facility Established 2006. Dedicated
Fra superdatamaskiner til grafikkprosessorer og
 Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
Fra superdatamaskiner til grafikkprosessorer og Brødtekst maskinlæring Prof. Anne C. Elster IDI HPC/Lab Parallel Computing: Personal perspective 1980 s: Concurrent and Parallel Pascal 1986: Intel ipsc
HPC Algorithms and Applications
 HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
HPC Algorithms and Applications Intro Michael Bader Winter 2015/2016 Intro, Winter 2015/2016 1 Part I Scientific Computing and Numerical Simulation Intro, Winter 2015/2016 2 The Simulation Pipeline phenomenon,
Green Supercomputing
 Green Supercomputing On the Energy Consumption of Modern E-Science Prof. Dr. Thomas Ludwig German Climate Computing Centre Hamburg, Germany ludwig@dkrz.de Outline DKRZ 2013 and Climate Science The Exascale
Green Supercomputing On the Energy Consumption of Modern E-Science Prof. Dr. Thomas Ludwig German Climate Computing Centre Hamburg, Germany ludwig@dkrz.de Outline DKRZ 2013 and Climate Science The Exascale
Technology challenges and trends over the next decade (A look through a 2030 crystal ball) Al Gara Intel Fellow & Chief HPC System Architect
 Al Gara Intel Fellow & Chief HPC System Architect") Technology challenges and trends over the next decade (A look through a 2030 crystal ball) Al Gara Intel Fellow & Chief HPC System Architect Today s Focus Areas For Discussion Will look at various technologies
Technology challenges and trends over the next decade (A look through a 2030 crystal ball) Al Gara Intel Fellow & Chief HPC System Architect Today s Focus Areas For Discussion Will look at various technologies
An Overview of High Performance Computing. Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/2005 1
 An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/ 1 Overview Look at fastest computers From the Top5 Some of the changes that face
An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/ 1 Overview Look at fastest computers From the Top5 Some of the changes that face
Scaling to Petaflop. Ola Torudbakken Distinguished Engineer. Sun Microsystems, Inc
 Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Parallel and Distributed Systems. Hardware Trends. Why Parallel or Distributed Computing? What is a parallel computer?
 Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Jack Dongarra. University of Tennessee Oak Ridge National Laboratory University of Manchester 9/8/2010 1
 Impact of Architecture and Technology for Extreme Scale on Software and Algorithm Design Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 9/8/2010 1 H. Meuer,
Impact of Architecture and Technology for Extreme Scale on Software and Algorithm Design Jack Dongarra University of Tennessee Oak Ridge National Laboratory University of Manchester 9/8/2010 1 H. Meuer,
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory
 Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Managing HPC Active Archive Storage with HPSS RAIT at Oak Ridge National Laboratory Quinn Mitchell HPC UNIX/LINUX Storage Systems ORNL is managed by UT-Battelle for the US Department of Energy U.S. Department
Building Self-Healing Mass Storage Arrays. for Large Cluster Systems
 Building Self-Healing Mass Storage Arrays for Large Cluster Systems NSC08, Linköping, 14. October 2008 Toine Beckers tbeckers@datadirectnet.com Agenda Company Overview Balanced I/O Systems MTBF and Availability
Building Self-Healing Mass Storage Arrays for Large Cluster Systems NSC08, Linköping, 14. October 2008 Toine Beckers tbeckers@datadirectnet.com Agenda Company Overview Balanced I/O Systems MTBF and Availability
Exascale: Parallelism gone wild!
 IPDPS TCPP meeting, April 2010 Exascale: Parallelism gone wild! Craig Stunkel, Outline Why are we talking about Exascale? Why will it be fundamentally different? How will we attack the challenges? In particular,
IPDPS TCPP meeting, April 2010 Exascale: Parallelism gone wild! Craig Stunkel, Outline Why are we talking about Exascale? Why will it be fundamentally different? How will we attack the challenges? In particular,
20 Jahre TOP500 mit einem Ausblick auf neuere Entwicklungen
 20 Jahre TOP500 mit einem Ausblick auf neuere Entwicklungen Hans Meuer Prometeus GmbH & Universität Mannheim hans@meuer.de ZKI Herbsttagung in Leipzig 11. - 12. September 2012 page 1 Outline Mannheim Supercomputer
20 Jahre TOP500 mit einem Ausblick auf neuere Entwicklungen Hans Meuer Prometeus GmbH & Universität Mannheim hans@meuer.de ZKI Herbsttagung in Leipzig 11. - 12. September 2012 page 1 Outline Mannheim Supercomputer
Aim High. Intel Technical Update Teratec 07 Symposium. June 20, Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group
 Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
Aim High Intel Technical Update Teratec 07 Symposium June 20, 2007 Stephen R. Wheat, Ph.D. Director, HPC Digital Enterprise Group Risk Factors Today s s presentations contain forward-looking statements.
HPC Technology Trends
 HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
HPC Technology Trends High Performance Embedded Computing Conference September 18, 2007 David S Scott, Ph.D. Petascale Product Line Architect Digital Enterprise Group Risk Factors Today s s presentations
Customer Success Story Los Alamos National Laboratory
 Customer Success Story Los Alamos National Laboratory Panasas High Performance Storage Powers the First Petaflop Supercomputer at Los Alamos National Laboratory Case Study June 2010 Highlights First Petaflop
Customer Success Story Los Alamos National Laboratory Panasas High Performance Storage Powers the First Petaflop Supercomputer at Los Alamos National Laboratory Case Study June 2010 Highlights First Petaflop
Complexity and Advanced Algorithms. Introduction to Parallel Algorithms
 Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Complexity and Advanced Algorithms Introduction to Parallel Algorithms Why Parallel Computing? Save time, resources, memory,... Who is using it? Academia Industry Government Individuals? Two practical
Technology Trends Presentation For Power Symposium
 Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
Technology Trends Presentation For Power Symposium 2006 8-23-06 Darryl Solie, Distinguished Engineer, Chief System Architect IBM Systems & Technology Group From Ingenuity to Impact Copyright IBM Corporation
Hybrid Architectures Why Should I Bother?
 Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Exascale: challenges and opportunities in a power constrained world
 Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
Exascale: challenges and opportunities in a power constrained world Carlo Cavazzoni c.cavazzoni@cineca.it SuperComputing Applications and Innovation Department CINECA CINECA non profit Consortium, made
The Future of High- Performance Computing
 Lecture 26: The Future of High- Performance Computing Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Comparing Two Large-Scale Systems Oakridge Titan Google Data Center Monolithic
Lecture 26: The Future of High- Performance Computing Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2017 Comparing Two Large-Scale Systems Oakridge Titan Google Data Center Monolithic
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Stockholm Brain Institute Blue Gene/L
 Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
HPCS HPCchallenge Benchmark Suite
 HPCS HPCchallenge Benchmark Suite David Koester, Ph.D. () Jack Dongarra (UTK) Piotr Luszczek () 28 September 2004 Slide-1 Outline Brief DARPA HPCS Overview Architecture/Application Characterization Preliminary
HPCS HPCchallenge Benchmark Suite David Koester, Ph.D. () Jack Dongarra (UTK) Piotr Luszczek () 28 September 2004 Slide-1 Outline Brief DARPA HPCS Overview Architecture/Application Characterization Preliminary
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future
 Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future November 16 th, 2011 Motoi Okuda Technical Computing Solution Unit Fujitsu Limited Agenda Achievements
Fujitsu s Technologies Leading to Practical Petascale Computing: K computer, PRIMEHPC FX10 and the Future November 16 th, 2011 Motoi Okuda Technical Computing Solution Unit Fujitsu Limited Agenda Achievements
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Digital Signal Processor Supercomputing
 Digital Signal Processor Supercomputing ENCM 515: Individual Report Prepared by Steven Rahn Submitted: November 29, 2013 Abstract: Analyzing the history of supercomputers: how the industry arrived to where
Digital Signal Processor Supercomputing ENCM 515: Individual Report Prepared by Steven Rahn Submitted: November 29, 2013 Abstract: Analyzing the history of supercomputers: how the industry arrived to where
Parallel Programming
 Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
Parallel Programming Introduction Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 Acknowledgements Prof. Felix Wolf, TU Darmstadt Prof. Matthias
HPC Saudi Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences. Presented to: March 14, 2017
 Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Power Profiling of Cholesky and QR Factorizations on Distributed Memory Systems
 International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
International Conference on Energy-Aware High Performance Computing Hamburg, Germany Bosilca, Ltaief, Dongarra (KAUST, UTK) Power Sept Profiling, DLA Algorithms ENAHPC / 6 Power Profiling of Cholesky and
Los Alamos National Laboratory Modeling & Simulation
 Los Alamos National Laboratory Modeling & Simulation Lawrence J. Cox, Ph.D. Deputy Division Leader Computer, Computational and Statistical Sciences February 2, 2009 LA-UR 09-00573 Modeling and Simulation
Los Alamos National Laboratory Modeling & Simulation Lawrence J. Cox, Ph.D. Deputy Division Leader Computer, Computational and Statistical Sciences February 2, 2009 LA-UR 09-00573 Modeling and Simulation
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
IBM Spectrum Scale IO performance
 IBM Spectrum Scale 5.0.0 IO performance Silverton Consulting, Inc. StorInt Briefing 2 Introduction High-performance computing (HPC) and scientific computing are in a constant state of transition. Artificial
IBM Spectrum Scale 5.0.0 IO performance Silverton Consulting, Inc. StorInt Briefing 2 Introduction High-performance computing (HPC) and scientific computing are in a constant state of transition. Artificial
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics
 CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
CS 5803 Introduction to High Performance Computer Architecture: Performance Metrics A.R. Hurson 323 Computer Science Building, Missouri S&T hurson@mst.edu 1 Instructor: Ali R. Hurson 323 CS Building hurson@mst.edu
What is Good Performance. Benchmark at Home and Office. Benchmark at Home and Office. Program with 2 threads Home program.
 Performance COMP375 Computer Architecture and dorganization What is Good Performance Which is the best performing jet? Airplane Passengers Range (mi) Speed (mph) Boeing 737-100 101 630 598 Boeing 747 470
Performance COMP375 Computer Architecture and dorganization What is Good Performance Which is the best performing jet? Airplane Passengers Range (mi) Speed (mph) Boeing 737-100 101 630 598 Boeing 747 470
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique