CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
|
|
|
- Lauren Bradley
- 6 years ago
- Views:
Transcription
1 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar
2 CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary
3 INTRODUCTION The Cray XK6 supercomputer is a trifecta of scalar, network and many-core innovation. Hybrid supercomputer Combination of: Cray s Gemini interconnect, AMD's leading multi-core scalar processors and NVIDIA s powerful many-core GPU processors Enhanced version of XE6 Uses Blade architecture as in Cray XE6 Capable of scaling to 500,000 scalar processors and 50 petaflops of hybrid peak performance

4 HISTORY In 1988, Cray Research introduced Cray Y-MP, the world's first supercomputer Sustained over 1 gigaflop on many applications Fujitsu's Numerical Wind Tunnel supercomputer used 166 vector processors to gain the top spot in 1994 with a peak speed of 1.7 gigaflops per processor. The Hitachi SR2201: peak performance of 600 gigaflops in 1996 by using 2048 The Intel Paragon had 1000 to 4000 Intel i860 processors, was ranked the fastest in the world in 1993
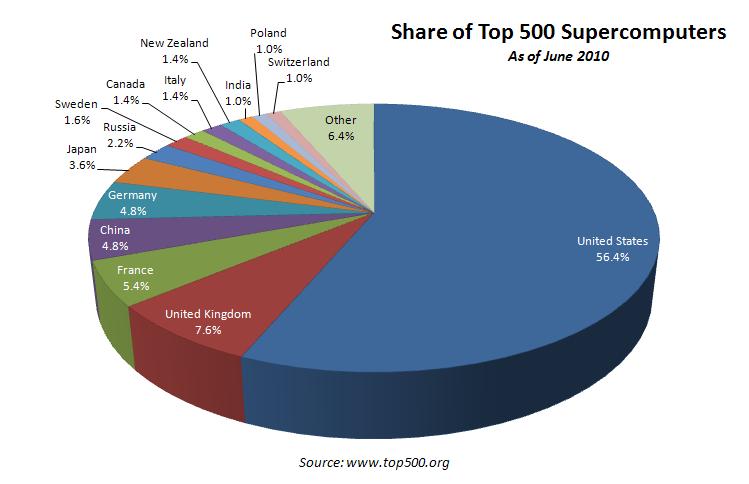
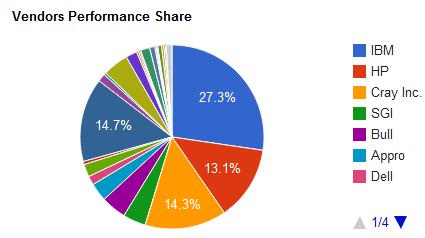
5 SUPER-COMPUTER STATISTICS

6 COMPARISON WITH THE PRESENT CRAY SUPERCOMPUTERS
7 CRAY XK6- ARCHITECTURE Four nodes per blade Adaptive hybrid computing Scalable compute nodes, I/Os Gemini Mezzanine Plug compatible with Cray XE6 blade Configurable processor, memory and SXM GPU AMD Opteron 6200 Series processor: Highly associative on-chip data cache supports aggressive out-of-order execution Integrated memory controller Significant performance advantage to algorithms The NVIDIA Tesla 20-series: Based on the next generation CUDA GPU architecture codenamed Fermi
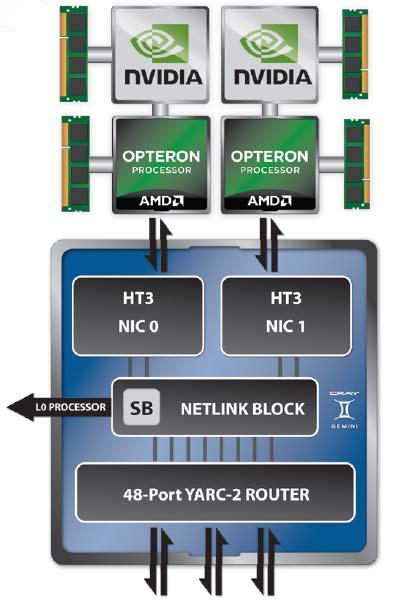
8 NODE- ARCHITECTURE
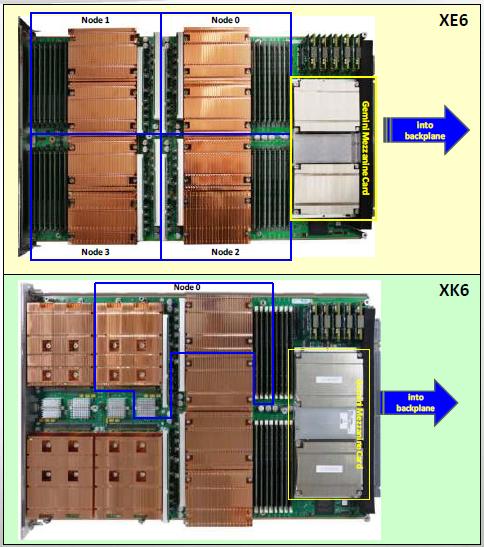
9 XK6 ACCELERATOR BLADE
10 GEMINI INTERCONNECTION NETWORK
11 GEMINI INTERCONNECTION NETWORKS Each node acts as 2 nodes on a 3D Torus Each Node provided with a High Radix YARC router to support up to 168 Gbps. Parallel electrical and optical paths High Bandwidth and lower latency for both long and short messages Low cost of integration Gemini Mezzanine card to avoid memory ICN bottlenecks.
12 NVIDIA TESLA X2090 Special Embedded version of Tesla M2090. Provides High Performance Computing for highly parallel applications. 448 cores with 6 GB GDDR5 Memory. Can support up to 600+ GFLOPs High Bandwidth to host Quick Master-Slave Communication. CUDA capable for easy programmability.
 With 1536 cores, can give 70+ TFLOPs")
13 CRAY XK6 CABINETS Each cabinet has up to 96 processors Two processors wrapped in the form of a blade (XE6 compatible) With 1536 cores, can give 70+ TFLOPs performance
14 SPECIFICATIONS
15 SPECIFICATIONS

16 PERFORMANCE- LUDWIG 10 cabinets of Cray XK6 936 GPUs (nodes) Only 4% deviation from perfect scaling between 8 and 936 GPUs Application sustaining 40+ Tflop/s and still scaling... Strong scaling also very good, but physicists want to simulate larger systems
17 PERFORMANCE - HIMENO Parallel 3D Poisson equation solver benchmark iterative loop evaluating 19-point stencil Co-Array Fortran version of code Fully ported to accelerators using 27 directive pairs Strong scaling Use asynchronous GPU data transfers and kernel launches to help avoid this

18 INDUSTRIAL ACCEPTANCE Oak Ridge National Laboratory Jaguar/TITAN High computation capacity for Scientific research 200 cabinets with > nodes. Estimated PFLOPs Currently upgrading from XT5 based Jaguar system to XK6 based Titan system with increased performance.

19 INDUSTRIAL ACCEPTANCE

20 INDUSTRIAL ACCEPTANCE CSCS- Swiss National Super Computing Centre Cray XE6 402 Tflops 1496 nodes Gemini Interconnects Cray XK6 176 nodes with one AMD and one GPU element each
21 SUMMARY Higher Supercomputing potential with GPU Accelerated computing Better Inter node communication with the Gemini Optical interconnects Backward compatible with XE6 cabinets and can be merged with XE6 systems. Highly suited to Scientific Research computations requiring high computational power of the order of 100s TFLOPs
22 REFERENCES CrayXK6Brochure.pdf Applications on Cray XK6, Roberto Ansaloni
Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Presentations: Jack Dongarra, University of Tennessee & ORNL. The HPL Benchmark: Past, Present & Future. Mike Heroux, Sandia National Laboratories
 HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Waiting for Moore s Law to save your serial code start getting bleak in 2004 Source: published SPECInt data Moore s Law is not at all
Supercomputers. Alex Reid & James O'Donoghue
 Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
John Levesque Nov 16, 2001
 1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
1 We see that the GPU is the best device available for us today to be able to get to the performance we want and meet our users requirements for a very high performance node with very high memory bandwidth.
Steve Scott, Tesla CTO SC 11 November 15, 2011
 Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
Steve Scott, Tesla CTO SC 11 November 15, 2011 What goal do these products have in common? Performance / W Exaflop Expectations First Exaflop Computer K Computer ~10 MW CM5 ~200 KW Not constant size, cost
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Computational Challenges and Opportunities for Nuclear Astrophysics
 Computational Challenges and Opportunities for Nuclear Astrophysics Bronson Messer Acting Group Leader Scientific Computing Group National Center for Computational Sciences Theoretical Astrophysics Group
Computational Challenges and Opportunities for Nuclear Astrophysics Bronson Messer Acting Group Leader Scientific Computing Group National Center for Computational Sciences Theoretical Astrophysics Group
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
It s a Multicore World. John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist
 It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
It s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Waiting for Moore s Law to save your serial code started getting bleak in 2004 Source: published SPECInt
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers
 Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
Overlapping Computation and Communication for Advection on Hybrid Parallel Computers James B White III (Trey) trey@ucar.edu National Center for Atmospheric Research Jack Dongarra dongarra@eecs.utk.edu
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
HPC Technology Update Challenges or Chances?
 HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
HPC Saudi Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences. Presented to: March 14, 2017
 Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Parallel Computer Architecture II
 Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
The next generation supercomputer. Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency
 The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
The next generation supercomputer and NWP system of JMA Masami NARITA, Keiichi KATAYAMA Numerical Prediction Division, Japan Meteorological Agency Contents JMA supercomputer systems Current system (Mar
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Automatic Tuning of the High Performance Linpack Benchmark
 Automatic Tuning of the High Performance Linpack Benchmark Ruowei Chen Supervisor: Dr. Peter Strazdins The Australian National University What is the HPL Benchmark? World s Top 500 Supercomputers http://www.top500.org
Automatic Tuning of the High Performance Linpack Benchmark Ruowei Chen Supervisor: Dr. Peter Strazdins The Australian National University What is the HPL Benchmark? World s Top 500 Supercomputers http://www.top500.org
Top500
 Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
Top500 www.top500.org Salvatore Orlando (from a presentation by J. Dongarra, and top500 website) 1 2 MPPs Performance on massively parallel machines Larger problem sizes, i.e. sizes that make sense Performance
Update on Cray Activities in the Earth Sciences
 Update on Cray Activities in the Earth Sciences Presented to the 13 th ECMWF Workshop on the Use of HPC in Meteorology 3-7 November 2008 Per Nyberg nyberg@cray.com Director, Marketing and Business Development
Update on Cray Activities in the Earth Sciences Presented to the 13 th ECMWF Workshop on the Use of HPC in Meteorology 3-7 November 2008 Per Nyberg nyberg@cray.com Director, Marketing and Business Development
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Early Experiences Writing Performance Portable OpenMP 4 Codes
 Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Using the Cray Programming Environment to Convert an all MPI code to a Hybrid-Multi-core Ready Application
 Using the Cray Programming Environment to Convert an all MPI code to a Hybrid-Multi-core Ready Application John Levesque Cray s Supercomputing Center of Excellence The Target ORNL s Titan System Upgrade
Using the Cray Programming Environment to Convert an all MPI code to a Hybrid-Multi-core Ready Application John Levesque Cray s Supercomputing Center of Excellence The Target ORNL s Titan System Upgrade
J. Blair Perot. Ali Khajeh-Saeed. Software Engineer CD-adapco. Mechanical Engineering UMASS, Amherst
 Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Exascale Challenges and Applications Initiatives for Earth System Modeling
 Exascale Challenges and Applications Initiatives for Earth System Modeling Workshop on Weather and Climate Prediction on Next Generation Supercomputers 22-25 October 2012 Tom Edwards tedwards@cray.com
Exascale Challenges and Applications Initiatives for Earth System Modeling Workshop on Weather and Climate Prediction on Next Generation Supercomputers 22-25 October 2012 Tom Edwards tedwards@cray.com
HPC Issues for DFT Calculations. Adrian Jackson EPCC
 HC Issues for DFT Calculations Adrian Jackson ECC Scientific Simulation Simulation fast becoming 4 th pillar of science Observation, Theory, Experimentation, Simulation Explore universe through simulation
HC Issues for DFT Calculations Adrian Jackson ECC Scientific Simulation Simulation fast becoming 4 th pillar of science Observation, Theory, Experimentation, Simulation Explore universe through simulation
Introduction to Parallel Computing
 Introduction to Parallel Computing Iain Miller Iain.miller@ecmwf.int Slides adapted from those of George Mozdzynski ECMWF January 22, 2016 Outline Parallel computing? Types of computer Parallel Computers
Introduction to Parallel Computing Iain Miller Iain.miller@ecmwf.int Slides adapted from those of George Mozdzynski ECMWF January 22, 2016 Outline Parallel computing? Types of computer Parallel Computers
Wednesday : Basic Overview. Thursday : Optimization
 Cray Inc. Wednesday : Basic Overview XT Architecture XT Programming Environment XT MPT : CRAY MPI Cray Scientific Libraries CRAYPAT : Basic HOWTO Handons Thursday : Optimization Where and How to Optimize
Cray Inc. Wednesday : Basic Overview XT Architecture XT Programming Environment XT MPT : CRAY MPI Cray Scientific Libraries CRAYPAT : Basic HOWTO Handons Thursday : Optimization Where and How to Optimize
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
A PCIe Congestion-Aware Performance Model for Densely Populated Accelerator Servers
 A PCIe Congestion-Aware Performance Model for Densely Populated Accelerator Servers Maxime Martinasso, Grzegorz Kwasniewski, Sadaf R. Alam, Thomas C. Schulthess, Torsten Hoefler Swiss National Supercomputing
A PCIe Congestion-Aware Performance Model for Densely Populated Accelerator Servers Maxime Martinasso, Grzegorz Kwasniewski, Sadaf R. Alam, Thomas C. Schulthess, Torsten Hoefler Swiss National Supercomputing
High-Performance Computing & Simulations in Quantum Many-Body Systems PART I. Thomas Schulthess
 High-Performance Computing & Simulations in Quantum Many-Body Systems PART I Thomas Schulthess schulthess@phys.ethz.ch What exactly is high-performance computing? 1E10 1E9 1E8 1E7 relative performance
High-Performance Computing & Simulations in Quantum Many-Body Systems PART I Thomas Schulthess schulthess@phys.ethz.ch What exactly is high-performance computing? 1E10 1E9 1E8 1E7 relative performance
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
Confessions of an Accidental Benchmarker
 Confessions of an Accidental Benchmarker http://bit.ly/hpcg-benchmark 1 Appendix B of the Linpack Users Guide Designed to help users extrapolate execution Linpack software package First benchmark report
Confessions of an Accidental Benchmarker http://bit.ly/hpcg-benchmark 1 Appendix B of the Linpack Users Guide Designed to help users extrapolate execution Linpack software package First benchmark report
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015
 AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
Distributed Dense Linear Algebra on Heterogeneous Architectures. George Bosilca
 Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
Distributed Dense Linear Algebra on Heterogeneous Architectures George Bosilca bosilca@eecs.utk.edu Centraro, Italy June 2010 Factors that Necessitate to Redesign of Our Software» Steepness of the ascent
The Titan Tools Experience
 The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
Hybrid Architectures Why Should I Bother?
 Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Hybrid Architectures Why Should I Bother? CSCS-FoMICS-USI Summer School on Computer Simulations in Science and Engineering Michael Bader July 8 19, 2013 Computer Simulations in Science and Engineering,
Trends of Network Topology on Supercomputers. Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27
 Trends of Network Topology on Supercomputers Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27 From Graph Golf to Real Interconnection Networks Case 1: On-chip Networks Case 2: Supercomputer
Trends of Network Topology on Supercomputers Michihiro Koibuchi National Institute of Informatics, Japan 2018/11/27 From Graph Golf to Real Interconnection Networks Case 1: On-chip Networks Case 2: Supercomputer
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
HIGH-PERFORMANCE COMPUTING
 HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Timothy Lanfear, NVIDIA WHY GPU COMPUTING? Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of
HIGH-PERFORMANCE COMPUTING WITH NVIDIA TESLA GPUS Timothy Lanfear, NVIDIA WHY GPU COMPUTING? Science is Desperate for Throughput Gigaflops 1,000,000,000 1 Exaflop 1,000,000 1 Petaflop Bacteria 100s of
High-Performance Computing - and why Learn about it?
 High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
High-Performance Computing - and why Learn about it? Tarek El-Ghazawi The George Washington University Washington D.C., USA Outline What is High-Performance Computing? Why is High-Performance Computing
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
Accelerating HPL on Heterogeneous GPU Clusters
 Accelerating HPL on Heterogeneous GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline
Accelerating HPL on Heterogeneous GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline
HOKUSAI System. Figure 0-1 System diagram
 HOKUSAI System October 11, 2017 Information Systems Division, RIKEN 1.1 System Overview The HOKUSAI system consists of the following key components: - Massively Parallel Computer(GWMPC,BWMPC) - Application
HOKUSAI System October 11, 2017 Information Systems Division, RIKEN 1.1 System Overview The HOKUSAI system consists of the following key components: - Massively Parallel Computer(GWMPC,BWMPC) - Application
Recent Advances in Heterogeneous Computing using Charm++
 Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs
 Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs O. Fuhrer, T. Gysi, X. Lapillonne, C. Osuna, T. Dimanti, T. Schultess and the HP2C team Eidgenössisches
Adapting Numerical Weather Prediction codes to heterogeneous architectures: porting the COSMO model to GPUs O. Fuhrer, T. Gysi, X. Lapillonne, C. Osuna, T. Dimanti, T. Schultess and the HP2C team Eidgenössisches
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Report on the Sunway TaihuLight System. Jack Dongarra. University of Tennessee. Oak Ridge National Laboratory
 Report on the Sunway TaihuLight System Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 24, 2016 University of Tennessee Department of Electrical Engineering and Computer Science
Report on the Sunway TaihuLight System Jack Dongarra University of Tennessee Oak Ridge National Laboratory June 24, 2016 University of Tennessee Department of Electrical Engineering and Computer Science
Turbostream: A CFD solver for manycore
 Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
PLAN-E Workshop Switzerland. Welcome! September 8, 2016
 PLAN-E Workshop Switzerland Welcome! September 8, 2016 The Swiss National Supercomputing Centre Driving innovation in computational research in Switzerland Michele De Lorenzi (CSCS) PLAN-E September 8,
PLAN-E Workshop Switzerland Welcome! September 8, 2016 The Swiss National Supercomputing Centre Driving innovation in computational research in Switzerland Michele De Lorenzi (CSCS) PLAN-E September 8,
The Cray Rainier System: Integrated Scalar/Vector Computing
 THE SUPERCOMPUTER COMPANY The Cray Rainier System: Integrated Scalar/Vector Computing Per Nyberg 11 th ECMWF Workshop on HPC in Meteorology Topics Current Product Overview Cray Technology Strengths Rainier
THE SUPERCOMPUTER COMPANY The Cray Rainier System: Integrated Scalar/Vector Computing Per Nyberg 11 th ECMWF Workshop on HPC in Meteorology Topics Current Product Overview Cray Technology Strengths Rainier
It s not my fault! Finding errors in parallel codes 找並行程序的錯誤
 It s not my fault! Finding errors in parallel codes 找並行程序的錯誤 David Abramson Minh Dinh (UQ) Chao Jin (UQ) Research Computing Centre, University of Queensland, Brisbane Australia Luiz DeRose (Cray) Bob Moench
It s not my fault! Finding errors in parallel codes 找並行程序的錯誤 David Abramson Minh Dinh (UQ) Chao Jin (UQ) Research Computing Centre, University of Queensland, Brisbane Australia Luiz DeRose (Cray) Bob Moench
CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters
 CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters Ching-Hsiang Chu, Khaled Hamidouche, Akshay Venkatesh, Ammar Ahmad Awan and Dhabaleswar K. (DK) Panda Speaker: Sourav Chakraborty
CUDA Kernel based Collective Reduction Operations on Large-scale GPU Clusters Ching-Hsiang Chu, Khaled Hamidouche, Akshay Venkatesh, Ammar Ahmad Awan and Dhabaleswar K. (DK) Panda Speaker: Sourav Chakraborty
Lecture 20: Distributed Memory Parallelism. William Gropp
 Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
CINECA and the European HPC Ecosystem
 CINECA and the European HPC Ecosystem Giovanni Erbacci Supercomputing, Applications and Innovation Department, CINECA g.erbacci@cineca.it Enabling Applications on Intel MIC based Parallel Architectures
CINECA and the European HPC Ecosystem Giovanni Erbacci Supercomputing, Applications and Innovation Department, CINECA g.erbacci@cineca.it Enabling Applications on Intel MIC based Parallel Architectures
ADVANCED COMPUTER ARCHITECTURES
 088949 ADVANCED COMPUTER ARCHITECTURES AA 2016/2017 Website: http://home.deib.polimi.it/silvano/aca-como.htm Prof. Cristina Silvano email: cristina.silvano@polimi.it Dipartimento di Elettronica, Informazione
088949 ADVANCED COMPUTER ARCHITECTURES AA 2016/2017 Website: http://home.deib.polimi.it/silvano/aca-como.htm Prof. Cristina Silvano email: cristina.silvano@polimi.it Dipartimento di Elettronica, Informazione
Cray XT3 for Science
 HPCx Annual Seminar 2006 Cray XT3 for Science David Tanqueray Cray UK Limited dt@cray.com Topics Cray Introduction The Cray XT3 Cray Roadmap Some XT3 Applications Page 2 Supercomputing is all we do Sustained
HPCx Annual Seminar 2006 Cray XT3 for Science David Tanqueray Cray UK Limited dt@cray.com Topics Cray Introduction The Cray XT3 Cray Roadmap Some XT3 Applications Page 2 Supercomputing is all we do Sustained
Introducing the next generation of affordable and productive massively parallel processing (MPP) computing the Cray XE6m supercomputer.
 computing the Cray XE6m supercomputer.") Introducing the next generation of affordable and productive massively parallel processing (MPP) computing the Cray XE6m supercomputer. Building on the reliability and scalability of the Cray XE6 supercomputer
Introducing the next generation of affordable and productive massively parallel processing (MPP) computing the Cray XE6m supercomputer. Building on the reliability and scalability of the Cray XE6 supercomputer
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Practical Scientific Computing
 Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Accelerating GPU computation through mixed-precision methods. Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University
 Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Parallel Computer Architecture - Basics -
 Parallel Computer Architecture - Basics - Christian Terboven 19.03.2012 / Aachen, Germany Stand: 15.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda Processor
Parallel Computer Architecture - Basics - Christian Terboven 19.03.2012 / Aachen, Germany Stand: 15.03.2012 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda Processor
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Breakthrough Science via Extreme Scalability. Greg Clifford Segment Manager, Cray Inc.
 Breakthrough Science via Extreme Scalability Greg Clifford Segment Manager, Cray Inc. clifford@cray.com Cray s focus The requirement for highly scalable systems Cray XE6 technology The path to Exascale
Breakthrough Science via Extreme Scalability Greg Clifford Segment Manager, Cray Inc. clifford@cray.com Cray s focus The requirement for highly scalable systems Cray XE6 technology The path to Exascale
Radiation Modeling Using the Uintah Heterogeneous CPU/GPU Runtime System
 Radiation Modeling Using the Uintah Heterogeneous CPU/GPU Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins, Todd Harman Scientific Computing and Imaging Institute & University of Utah I. Uintah
Radiation Modeling Using the Uintah Heterogeneous CPU/GPU Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins, Todd Harman Scientific Computing and Imaging Institute & University of Utah I. Uintah
The way toward peta-flops
 The way toward peta-flops ISC-2011 Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Where things started from DESIGN CONCEPTS 2 New challenges and requirements! Optimal sustained flops
The way toward peta-flops ISC-2011 Dr. Pierre Lagier Chief Technology Officer Fujitsu Systems Europe Where things started from DESIGN CONCEPTS 2 New challenges and requirements! Optimal sustained flops
Tri-Hybrid Computational Fluid Dynamics on DOE s Cray XK7, Titan.
 Tri-Hybrid Computational Fluid Dynamics on DOE s Cray XK7, Titan. Aaron Vose, Brian Mitchell, and John Levesque. Cray User Group, May 2014. GE Global Research: mitchellb@ge.com Cray Inc.: avose@cray.com,
Tri-Hybrid Computational Fluid Dynamics on DOE s Cray XK7, Titan. Aaron Vose, Brian Mitchell, and John Levesque. Cray User Group, May 2014. GE Global Research: mitchellb@ge.com Cray Inc.: avose@cray.com,
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
NVidia s GPU Microarchitectures. By Stephen Lucas and Gerald Kotas
 NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC
 A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC Hisashi YASHIRO RIKEN Advanced Institute of Computational Science Kobe, Japan My topic The study for Cloud computing My topic
A Simulation of Global Atmosphere Model NICAM on TSUBAME 2.5 Using OpenACC Hisashi YASHIRO RIKEN Advanced Institute of Computational Science Kobe, Japan My topic The study for Cloud computing My topic
GPU Debugging Made Easy. David Lecomber CTO, Allinea Software
 GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
Performance Analysis and Optimization of Gyrokinetic Torodial Code on TH-1A Supercomputer
 Performance Analysis and Optimization of Gyrokinetic Torodial Code on TH-1A Supercomputer Xiaoqian Zhu 1,2, Xin Liu 1, Xiangfei Meng 2, Jinghua Feng 2 1 School of Computer, National University of Defense
Performance Analysis and Optimization of Gyrokinetic Torodial Code on TH-1A Supercomputer Xiaoqian Zhu 1,2, Xin Liu 1, Xiangfei Meng 2, Jinghua Feng 2 1 School of Computer, National University of Defense
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics
 Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017
 OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
Master Educational Program Information technology in applications Mathematical computations with GPUs Introduction Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University How to.. Process terabytes
Performance Study of Popular Computational Chemistry Software Packages on Cray HPC Systems
 Performance Study of Popular Computational Chemistry Software Packages on Cray HPC Systems Junjie Li (lijunj@iu.edu) Shijie Sheng (shengs@iu.edu) Raymond Sheppard (rsheppar@iu.edu) Pervasive Technology
Performance Study of Popular Computational Chemistry Software Packages on Cray HPC Systems Junjie Li (lijunj@iu.edu) Shijie Sheng (shengs@iu.edu) Raymond Sheppard (rsheppar@iu.edu) Pervasive Technology
Thinking Outside of the Tera-Scale Box. Piotr Luszczek
 Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
NVIDIA GPUs in Earth System Modelling Thomas Bradley
 NVIDIA GPUs in Earth System Modelling Thomas Bradley Agenda: GPU Developments for CWO Motivation for GPUs in CWO Parallelisation Considerations GPU Technology Roadmap MOTIVATION FOR GPUS IN CWO NVIDIA
NVIDIA GPUs in Earth System Modelling Thomas Bradley Agenda: GPU Developments for CWO Motivation for GPUs in CWO Parallelisation Considerations GPU Technology Roadmap MOTIVATION FOR GPUS IN CWO NVIDIA
The Impact of Optics on HPC System Interconnects
 The Impact of Optics on HPC System Interconnects Mike Parker and Steve Scott Hot Interconnects 2009 Manhattan, NYC Will cost-effective optics fundamentally change the landscape of networking? Yes. Changes
The Impact of Optics on HPC System Interconnects Mike Parker and Steve Scott Hot Interconnects 2009 Manhattan, NYC Will cost-effective optics fundamentally change the landscape of networking? Yes. Changes