Accelerator-centric operating systems
|
|
|
- Rosanna Marcia Thornton
- 6 years ago
- Views:
Transcription
1 Accelerator-centric operating systems Rethinking the role of s in modern computers Mark Silberstein EE, Technion
2 System design challenge: Programmability and Performance 2
3 System design challenge: Programmability and Performance Hardware architectures Systems Developers Systems Software 3




4 Computer hardware: circa ~2000 Network Adapter Graphical Processing Units (GPUs) Storage controller Size = transistor count 4
5 Systems software stack circa ~2000 Applications OS I/O devices 5




6 Computer hardware: circa ~2015 Network I/O accelerator GPU parallel accelerator Storage I/O accelerator Accelerators for encryption, media, signal processing... 6
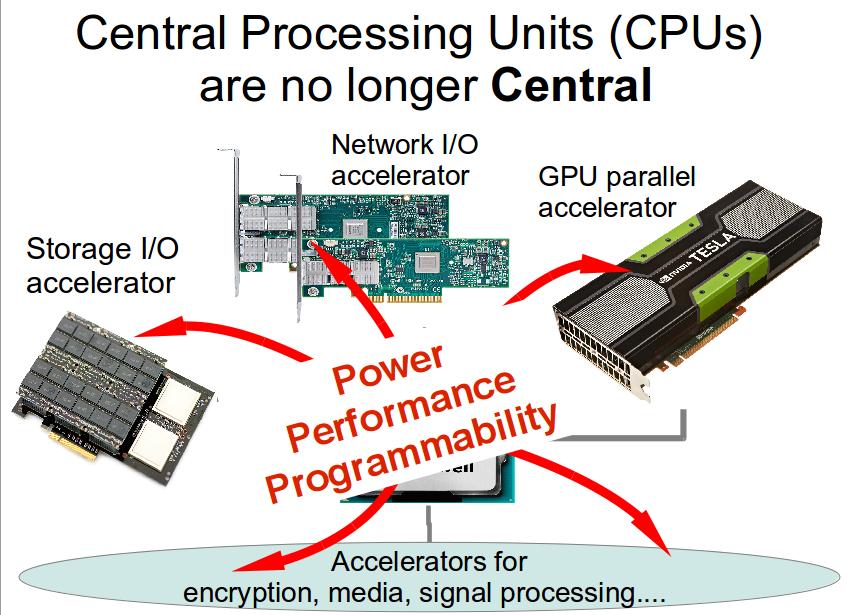
7 Central Processing Units (s) are no longer Central Network I/O accelerator GPU parallel accelerator Storage I/O accelerator r e Pow ance m r y t o i f l i r b a Pe m m a r g o r P Accelerators for encryption, media, signal processing... 7
8 Systems software stack circa 2015 Accelerated applications OS I/O I/O Manycore processors accelerators FPGA FPGAs Hybrid DSPs -GPU GPUs GPUs 8
9 Software-hardware gap is widening Accelerated applications Inadequate abstractions and management mechanisms OS I/O I/O Manycore processors accelerators FPGA FPGAs DSPs GPUs GPUs 9

10 THE problem: - centric software architecture Network Storage GPU 10
11 Breaking the -centric system design OS Services GPU OS Services Operating system OS Services Network Storage Hardware is here We need OS support 11
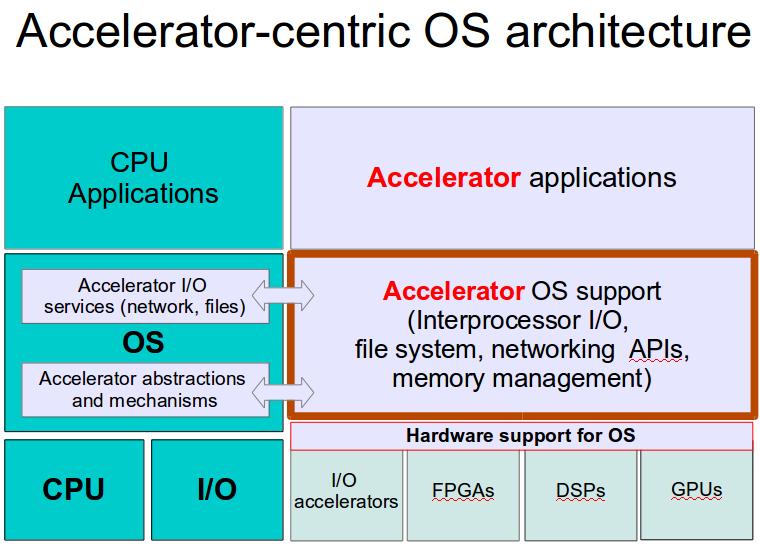
12 Accelerator-centric OS architecture Applications Accelerator I/O services (network, files) OS Accelerator abstractions and mechanisms Accelerator applications Accelerator OS support (Interprocessor I/O, file system, networking APIs, memory management) Hardware support for OS I/O Manycore I/O accelerators processors FPGAs FPGA DSPs GPUs 12
13 This talk Applications Accelerator I/O services (network, files) OS Accelerator abstractions and mechanisms Accelerator applications Accelerator OS support (Interprocessor I/O, file system, networking APIs ) OSDI14, CACM14 ASPLOS13, TOCS14, Hardware support for OS Storage Network Manycore I/O accelerators processors FPGA DSPs GPUs GPUs 13
14 GPU 101 and motivation GPUnet: Network Stack for GPUs GPUfs: File access support for GPUs Recap: Accelerator-centric OS architecture 14
15 Hybrid GPU- 101 Architecture GPU 15
16 Co-processor model GPU Computation 16
17 Co-processor model GPU Computation tation 17
18 Co-processor model GPU kernel Computation tation GPU t a t i o n 18
19 Co-processor model GPU Computation 19
20 GPUs make a difference... Top 10 fastest supercomputers use GPUs GPUs enable order-of-magnitude speedups in... Physics Vision HCI Meteorology Graph Algorithms Deep Nets Bioinformatics Linear Algebra Finance 20
21 GPUs make a difference, but why only in HPC? Top 10 fastest supercomputers use GPUs GPUs enable order-of-magnitude speedups in... Physics Vision HCI Meteorology Graph Algorithms Deep Nets Bioinformatics Linear Algebra Finance... Web servers, Network services Antivirus File search???? 21
22 Programming complexity exposed Example: GPU-accelerated server 22
23 server NIC recv() compute() send() 23
24 Inside a GPU-accelerated server NIC GPU PCIe bus Theory recv() GPU_compute() send() 24
25 Inside a GPU-accelerated server recv(); NIC GPU recv(); batch(); Theory recv() GPU_compute() send() 25
26 Inside a GPU-accelerated server transfer(); NIC GPU recv(); Theory recv() GPU_compute() send() batch(); optimize(); transfer(); 26
27 Inside a GPU-accelerated server invoke(); NIC recv(); Theory recv() GPU_compute() send() batch(); optimize(); transfer(); balance(); GPU_compute(); GPU_compute() 27
28 Inside a GPU-accelerated server transfer(); NIC GPU recv(); Theory recv() GPU_compute() send() batch(); optimize(); transfer(); balance(); GPU_compute(); GPU_compute() transfer(); cleanup(); 28
29 Inside a GPU-accelerated server send(); NIC GPU recv(); Theory recv() GPU_compute() send() batch(); optimize(); transfer(); balance(); GPU_compute() transfer(); cleanup(); dispatch(); send(); 29
30 Aggressive pipelining Inside a GPU-accelerated server Buffering, asynchrony, multithreading NIC recv (); recv (); recv batch(); recv(); (); batch(); recv() GPU_compute() send() batch(); optimize(); batch(); optimize(); optimize(); transfer(); optimize(); transfer(); transfer(); balance(); transfer(); balance(); balance(); GPU_compute(); balance(); GPU_compute(); GPU_compute(); transfer(); GPU_compute(); GPU_compute() transfer(); transfer(); cleanup(); transfer(); cleanup(); cleanup(); dispatch(); cleanup(); dispatch(); dispatch(); send(); dispatch(); send(); send(); send(); 30
31 y r a s s e c e n un This code is for a to manage a GPU recv (); recv (); recv (); batch(); batch(); batch(); batch(); optimize(); optimize(); optimize(); optimize(); transfer(); transfer(); transfer(); transfer(); balance(); balance(); balance(); GPU_compute(); balance(); GPU_compute(); GPU_compute(); transfer(); GPU_compute() transfer(); transfer(); cleanup(); cleanup(); transfer(); cleanup(); dispatch(); dispatch(); dispatch(); cleanup(); send(); send(); send(); dispatch(); 31
32 GPUs are not co-processors GPUs are peer-processors They need I/O abstractions 32
33 GPUnet: socket API for GPUs Application view node0.technion.ac.il GPU native server socket(af_inet,sock_stream); listen(:2340) GPUnet Network GPU native client client socket(af_inet,sock_stream); connect( node0:2340 ) socket(af_inet,sock_stream); connect( node0:2340 ); GPUnet 33
34 GPU-accelerated server with GPUnet not involved NIC GPU PCIe bus recv() GPU_compute() send() 34
35 GPU-accelerated server with GPUnet GPU NIC PCIe bus recv() GPU_compute() send() 35
36 GPU-accelerated server with GPUnet No request batching send() recv() NIC recv() recv() recv() GPU_compute() GPU_compute() GPU_compute() send() send() send() Transparent pipelining 36
37 GPU-accelerated server with GPUnet send() recv() NIC recv() recv() recv() GPU_compute() GPU_compute() GPU_compute() send() send() send() Seamless buffer management 37
38 GPUnet design Simplicity GPU Socket API Reliable in-order streaming GPU Reliable channel RDMA Transports Non-RDMA Transports Infiniband UNIX Domain Sockets, TCP/IP NIC Performance 38
39 GPUfs: file access for GPUs Application view ) ile GPU3 m m ap () le ) d_fi hare n( s ope f d_ re ha ( s en op System-wide shared namespace GPU2 GPU1 write () s POSIX ()-like API GPUfs Host File System Persistent storage 39



")
 send()")
40 Face verification server client (unmodified) via rsocket GPU server (GPUnet) memcached (unmodified) via rsocket Infiniband? = recv() features() GPU_features() query_db() compare() GPU_compare() send() 40
41 Latency (μsec) Face verification: Different implementations GPU (no GPUnet) cores 1.9x throughput 1/3x latency (500usec) ½ LOC GPU GPUnet Throughput (KReq/sec) 41
42 Recap: Accelerator-centric OS design 42
43 Why OS layer on accelerators? To abstract away... Hardware interaction overhead Programming model gap I/O and memory performance gap I/O topology 43
44 Challenges Hardware Systems software consistency, NUMA, limitations No OS hardware support, physical device sharing, state sharing Applications Data layout reorganization, resource management 44
45 45
46 46


47 47
48 Coming up next... Distributed accelerator applications High concurrency servers Multi-accelerator OS support Interprocessor I/O, file system, networking APIs, VM, memory consistency, isolation, security Manycore I/O accelerators processors FPGAs FPGA DSPs GPUs 48
49 Team Accelerated systems group, Technion Amir Wated, Sagi Shachar, Feras Daud, Pavel Lifshitz Collaborators Operating System Architecture group, UT Austin Sangman Kim, Yige Hu, Emmett Witchel 49

50 Accelerator-centric OS design GPUfs GPU GPUnet GPU Looking for a graduate degree in systems? We're hiring! mark@ee.technion.ac.il 50
GPUnet: networking abstractions for GPU programs
 net: networking abstractions for programs Mark Silberstein Technion Israel Institute of Technology Sangman Kim, Seonggu Huh, Xinya Zhang Yige Hu, Emmett Witchel University of Texas at Austin Amir Wated
net: networking abstractions for programs Mark Silberstein Technion Israel Institute of Technology Sangman Kim, Seonggu Huh, Xinya Zhang Yige Hu, Emmett Witchel University of Texas at Austin Amir Wated
GPUfs: Integrating a file system with GPUs
 ASPLOS 2013 GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Traditional System Architecture Applications
ASPLOS 2013 GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Traditional System Architecture Applications
GPUfs: Integrating a file system with GPUs
 GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Traditional System Architecture Applications OS CPU
GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Traditional System Architecture Applications OS CPU
GPUnet: Networking Abstractions for GPU Programs. Author: Andrzej Jackowski
 Author: Andrzej Jackowski 1 Author: Andrzej Jackowski 2 GPU programming problem 3 GPU distributed application flow 1. recv req Network 4. send repl 2. exec on GPU CPU & Memory 3. get results GPU & Memory
Author: Andrzej Jackowski 1 Author: Andrzej Jackowski 2 GPU programming problem 3 GPU distributed application flow 1. recv req Network 4. send repl 2. exec on GPU CPU & Memory 3. get results GPU & Memory
GPUfs: Integrating a file system with GPUs
 GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Building systems with GPUs is hard. Why? 2 Goal of
GPUfs: Integrating a file system with GPUs Mark Silberstein (UT Austin/Technion) Bryan Ford (Yale), Idit Keidar (Technion) Emmett Witchel (UT Austin) 1 Building systems with GPUs is hard. Why? 2 Goal of
Eleos: Exit-Less OS Services for SGX Enclaves
 Eleos: Exit-Less OS Services for SGX Enclaves Meni Orenbach Marina Minkin Pavel Lifshits Mark Silberstein Accelerated Computing Systems Lab Haifa, Israel What do we do? Improve performance: I/O intensive
Eleos: Exit-Less OS Services for SGX Enclaves Meni Orenbach Marina Minkin Pavel Lifshits Mark Silberstein Accelerated Computing Systems Lab Haifa, Israel What do we do? Improve performance: I/O intensive
Parallel Stochastic Gradient Descent: The case for native GPU-side GPI
 Parallel Stochastic Gradient Descent: The case for native GPU-side GPI J. Keuper Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Mark Silberstein Accelerated Computer
Parallel Stochastic Gradient Descent: The case for native GPU-side GPI J. Keuper Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Mark Silberstein Accelerated Computer
Solros: A Data-Centric Operating System Architecture for Heterogeneous Computing
 Solros: A Data-Centric Operating System Architecture for Heterogeneous Computing Changwoo Min, Woonhak Kang, Mohan Kumar, Sanidhya Kashyap, Steffen Maass, Heeseung Jo, Taesoo Kim Virginia Tech, ebay, Georgia
Solros: A Data-Centric Operating System Architecture for Heterogeneous Computing Changwoo Min, Woonhak Kang, Mohan Kumar, Sanidhya Kashyap, Steffen Maass, Heeseung Jo, Taesoo Kim Virginia Tech, ebay, Georgia
2017 Storage Developer Conference. Mellanox Technologies. All Rights Reserved.
 Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
Ethernet Storage Fabrics Using RDMA with Fast NVMe-oF Storage to Reduce Latency and Improve Efficiency Kevin Deierling & Idan Burstein Mellanox Technologies 1 Storage Media Technology Storage Media Access
Paving the Road to Exascale
 Paving the Road to Exascale Gilad Shainer August 2015, MVAPICH User Group (MUG) Meeting The Ever Growing Demand for Performance Performance Terascale Petascale Exascale 1 st Roadrunner 2000 2005 2010 2015
Paving the Road to Exascale Gilad Shainer August 2015, MVAPICH User Group (MUG) Meeting The Ever Growing Demand for Performance Performance Terascale Petascale Exascale 1 st Roadrunner 2000 2005 2010 2015
Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation
 Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation Yiying Zhang Datacenter 3 Monolithic Computer OS / Hypervisor 4 Can monolithic Application Hardware
Farewell to Servers: Hardware, Software, and Network Approaches towards Datacenter Resource Disaggregation Yiying Zhang Datacenter 3 Monolithic Computer OS / Hypervisor 4 Can monolithic Application Hardware
IX: A Protected Dataplane Operating System for High Throughput and Low Latency
 IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
IX: A Protected Dataplane Operating System for High Throughput and Low Latency Adam Belay et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Presented by Han Zhang & Zaina Hamid Challenges
Memory Management Strategies for Data Serving with RDMA
 Memory Management Strategies for Data Serving with RDMA Dennis Dalessandro and Pete Wyckoff (presenting) Ohio Supercomputer Center {dennis,pw}@osc.edu HotI'07 23 August 2007 Motivation Increasing demands
Memory Management Strategies for Data Serving with RDMA Dennis Dalessandro and Pete Wyckoff (presenting) Ohio Supercomputer Center {dennis,pw}@osc.edu HotI'07 23 August 2007 Motivation Increasing demands
Messaging Overview. Introduction. Gen-Z Messaging
 Page 1 of 6 Messaging Overview Introduction Gen-Z is a new data access technology that not only enhances memory and data storage solutions, but also provides a framework for both optimized and traditional
Page 1 of 6 Messaging Overview Introduction Gen-Z is a new data access technology that not only enhances memory and data storage solutions, but also provides a framework for both optimized and traditional
Interconnect Your Future
 Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Empower Diverse Open Transport Layer Protocols in Cloud Networking GEORGE ZHAO DIRECTOR OSS & ECOSYSTEM, HUAWEI
 Empower Diverse Open Transport Layer Protocols in Cloud Networking GEORGE ZHAO DIRECTOR OSS & ECOSYSTEM, HUAWEI Agenda FD.io Introduction Challenges in Container & Cloud Native Apps Proposed Solutions
Empower Diverse Open Transport Layer Protocols in Cloud Networking GEORGE ZHAO DIRECTOR OSS & ECOSYSTEM, HUAWEI Agenda FD.io Introduction Challenges in Container & Cloud Native Apps Proposed Solutions
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
FaRM: Fast Remote Memory
 FaRM: Fast Remote Memory Problem Context DRAM prices have decreased significantly Cost effective to build commodity servers w/hundreds of GBs E.g. - cluster with 100 machines can hold tens of TBs of main
FaRM: Fast Remote Memory Problem Context DRAM prices have decreased significantly Cost effective to build commodity servers w/hundreds of GBs E.g. - cluster with 100 machines can hold tens of TBs of main
Speeding up Linux TCP/IP with a Fast Packet I/O Framework
 Speeding up Linux TCP/IP with a Fast Packet I/O Framework Michio Honda Advanced Technology Group, NetApp michio@netapp.com With acknowledge to Kenichi Yasukata, Douglas Santry and Lars Eggert 1 Motivation
Speeding up Linux TCP/IP with a Fast Packet I/O Framework Michio Honda Advanced Technology Group, NetApp michio@netapp.com With acknowledge to Kenichi Yasukata, Douglas Santry and Lars Eggert 1 Motivation
EXTENDING AN ASYNCHRONOUS MESSAGING LIBRARY USING AN RDMA-ENABLED INTERCONNECT. Konstantinos Alexopoulos ECE NTUA CSLab
 EXTENDING AN ASYNCHRONOUS MESSAGING LIBRARY USING AN RDMA-ENABLED INTERCONNECT Konstantinos Alexopoulos ECE NTUA CSLab MOTIVATION HPC, Multi-node & Heterogeneous Systems Communication with low latency
EXTENDING AN ASYNCHRONOUS MESSAGING LIBRARY USING AN RDMA-ENABLED INTERCONNECT Konstantinos Alexopoulos ECE NTUA CSLab MOTIVATION HPC, Multi-node & Heterogeneous Systems Communication with low latency
IsoStack Highly Efficient Network Processing on Dedicated Cores
 IsoStack Highly Efficient Network Processing on Dedicated Cores Leah Shalev Eran Borovik, Julian Satran, Muli Ben-Yehuda Outline Motivation IsoStack architecture Prototype TCP/IP over 10GE on a single
IsoStack Highly Efficient Network Processing on Dedicated Cores Leah Shalev Eran Borovik, Julian Satran, Muli Ben-Yehuda Outline Motivation IsoStack architecture Prototype TCP/IP over 10GE on a single
NTRDMA v0.1. An Open Source Driver for PCIe NTB and DMA. Allen Hubbe at Linux Piter 2015 NTRDMA. Messaging App. IB Verbs. dmaengine.h ntb.
 Messaging App IB Verbs NTRDMA dmaengine.h ntb.h DMA DMA DMA NTRDMA v0.1 An Open Source Driver for PCIe and DMA Allen Hubbe at Linux Piter 2015 1 INTRODUCTION Allen Hubbe Senior Software Engineer EMC Corporation
Messaging App IB Verbs NTRDMA dmaengine.h ntb.h DMA DMA DMA NTRDMA v0.1 An Open Source Driver for PCIe and DMA Allen Hubbe at Linux Piter 2015 1 INTRODUCTION Allen Hubbe Senior Software Engineer EMC Corporation
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Advanced Computer Networks. End Host Optimization
 Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
OpenOnload. Dave Parry VP of Engineering Steve Pope CTO Dave Riddoch Chief Software Architect
 OpenOnload Dave Parry VP of Engineering Steve Pope CTO Dave Riddoch Chief Software Architect Copyright 2012 Solarflare Communications, Inc. All Rights Reserved. OpenOnload Acceleration Software Accelerated
OpenOnload Dave Parry VP of Engineering Steve Pope CTO Dave Riddoch Chief Software Architect Copyright 2012 Solarflare Communications, Inc. All Rights Reserved. OpenOnload Acceleration Software Accelerated
The Common Communication Interface (CCI)
") The Common Communication Interface (CCI) Presented by: Galen Shipman Technology Integration Lead Oak Ridge National Laboratory Collaborators: Scott Atchley, George Bosilca, Peter Braam, David Dillow, Patrick
The Common Communication Interface (CCI) Presented by: Galen Shipman Technology Integration Lead Oak Ridge National Laboratory Collaborators: Scott Atchley, George Bosilca, Peter Braam, David Dillow, Patrick
Networking at the Speed of Light
 Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
Networking at the Speed of Light Dror Goldenberg VP Software Architecture MaRS Workshop April 2017 Cloud The Software Defined Data Center Resource virtualization Efficient services VM, Containers uservices
The Power of Batching in the Click Modular Router
 The Power of Batching in the Click Modular Router Joongi Kim, Seonggu Huh, Keon Jang, * KyoungSoo Park, Sue Moon Computer Science Dept., KAIST Microsoft Research Cambridge, UK * Electrical Engineering
The Power of Batching in the Click Modular Router Joongi Kim, Seonggu Huh, Keon Jang, * KyoungSoo Park, Sue Moon Computer Science Dept., KAIST Microsoft Research Cambridge, UK * Electrical Engineering
Graph Streaming Processor
 Graph Streaming Processor A Next-Generation Computing Architecture Val G. Cook Chief Software Architect Satyaki Koneru Chief Technology Officer Ke Yin Chief Scientist Dinakar Munagala Chief Executive Officer
Graph Streaming Processor A Next-Generation Computing Architecture Val G. Cook Chief Software Architect Satyaki Koneru Chief Technology Officer Ke Yin Chief Scientist Dinakar Munagala Chief Executive Officer
Application Acceleration Beyond Flash Storage
 Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
2008 International ANSYS Conference
 2008 International ANSYS Conference Maximizing Productivity With InfiniBand-Based Clusters Gilad Shainer Director of Technical Marketing Mellanox Technologies 2008 ANSYS, Inc. All rights reserved. 1 ANSYS,
2008 International ANSYS Conference Maximizing Productivity With InfiniBand-Based Clusters Gilad Shainer Director of Technical Marketing Mellanox Technologies 2008 ANSYS, Inc. All rights reserved. 1 ANSYS,
Last Class: OS and Computer Architecture. Last Class: OS and Computer Architecture
 Last Class: OS and Computer Architecture System bus Network card CPU, memory, I/O devices, network card, system bus Lecture 4, page 1 Last Class: OS and Computer Architecture OS Service Protection Interrupts
Last Class: OS and Computer Architecture System bus Network card CPU, memory, I/O devices, network card, system bus Lecture 4, page 1 Last Class: OS and Computer Architecture OS Service Protection Interrupts
TxFS: Leveraging File-System Crash Consistency to Provide ACID Transactions
 TxFS: Leveraging File-System Crash Consistency to Provide ACID Transactions Yige Hu, Zhiting Zhu, Ian Neal, Youngjin Kwon, Tianyu Chen, Vijay Chidambaram, Emmett Witchel The University of Texas at Austin
TxFS: Leveraging File-System Crash Consistency to Provide ACID Transactions Yige Hu, Zhiting Zhu, Ian Neal, Youngjin Kwon, Tianyu Chen, Vijay Chidambaram, Emmett Witchel The University of Texas at Austin
DDN. DDN Updates. Data DirectNeworks Japan, Inc Shuichi Ihara. DDN Storage 2017 DDN Storage
 DDN DDN Updates Data DirectNeworks Japan, Inc Shuichi Ihara DDN A Broad Range of Technologies to Best Address Your Needs Protection Security Data Distribution and Lifecycle Management Open Monitoring Your
DDN DDN Updates Data DirectNeworks Japan, Inc Shuichi Ihara DDN A Broad Range of Technologies to Best Address Your Needs Protection Security Data Distribution and Lifecycle Management Open Monitoring Your
Strata: A Cross Media File System. Youngjin Kwon, Henrique Fingler, Tyler Hunt, Simon Peter, Emmett Witchel, Thomas Anderson
 A Cross Media File System Youngjin Kwon, Henrique Fingler, Tyler Hunt, Simon Peter, Emmett Witchel, Thomas Anderson 1 Let s build a fast server NoSQL store, Database, File server, Mail server Requirements
A Cross Media File System Youngjin Kwon, Henrique Fingler, Tyler Hunt, Simon Peter, Emmett Witchel, Thomas Anderson 1 Let s build a fast server NoSQL store, Database, File server, Mail server Requirements
Maximum Performance. How to get it and how to avoid pitfalls. Christoph Lameter, PhD
 Maximum Performance How to get it and how to avoid pitfalls Christoph Lameter, PhD cl@linux.com Performance Just push a button? Systems are optimized by default for good general performance in all areas.
Maximum Performance How to get it and how to avoid pitfalls Christoph Lameter, PhD cl@linux.com Performance Just push a button? Systems are optimized by default for good general performance in all areas.
How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC
 How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC Three Consortia Formed in Oct 2016 Gen-Z Open CAPI CCIX complex to rack scale memory fabric Cache coherent accelerator
How Might Recently Formed System Interconnect Consortia Affect PM? Doug Voigt, SNIA TC Three Consortia Formed in Oct 2016 Gen-Z Open CAPI CCIX complex to rack scale memory fabric Cache coherent accelerator
LITE Kernel RDMA. Support for Datacenter Applications. Shin-Yeh Tsai, Yiying Zhang
 LITE Kernel RDMA Support for Datacenter Applications Shin-Yeh Tsai, Yiying Zhang Time 2 Berkeley Socket Userspace Kernel Hardware Time 1983 2 Berkeley Socket TCP Offload engine Arrakis & mtcp IX Userspace
LITE Kernel RDMA Support for Datacenter Applications Shin-Yeh Tsai, Yiying Zhang Time 2 Berkeley Socket Userspace Kernel Hardware Time 1983 2 Berkeley Socket TCP Offload engine Arrakis & mtcp IX Userspace
PARAVIRTUAL RDMA DEVICE
 12th ANNUAL WORKSHOP 2016 PARAVIRTUAL RDMA DEVICE Aditya Sarwade, Adit Ranadive, Jorgen Hansen, Bhavesh Davda, George Zhang, Shelley Gong VMware, Inc. [ April 5th, 2016 ] MOTIVATION User Kernel Socket
12th ANNUAL WORKSHOP 2016 PARAVIRTUAL RDMA DEVICE Aditya Sarwade, Adit Ranadive, Jorgen Hansen, Bhavesh Davda, George Zhang, Shelley Gong VMware, Inc. [ April 5th, 2016 ] MOTIVATION User Kernel Socket
In-Network Computing. Sebastian Kalcher, Senior System Engineer HPC. May 2017
 In-Network Computing Sebastian Kalcher, Senior System Engineer HPC May 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait
In-Network Computing Sebastian Kalcher, Senior System Engineer HPC May 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait
HMM: GUP NO MORE! XDC Jérôme Glisse
 HMM: GUP NO MORE! XDC 2018 Jérôme Glisse HETEROGENEOUS COMPUTING CPU is dead, long live the CPU Heterogeneous computing is back, one device for each workload: GPUs for massively parallel workload Accelerators
HMM: GUP NO MORE! XDC 2018 Jérôme Glisse HETEROGENEOUS COMPUTING CPU is dead, long live the CPU Heterogeneous computing is back, one device for each workload: GPUs for massively parallel workload Accelerators
Using (Suricata over) PF_RING for NIC-Independent Acceleration
 PF_RING for NIC-Independent Acceleration") Using (Suricata over) PF_RING for NIC-Independent Acceleration Luca Deri Alfredo Cardigliano Outlook About ntop. Introduction to PF_RING. Integrating PF_RING with
Using (Suricata over) PF_RING for NIC-Independent Acceleration Luca Deri Alfredo Cardigliano Outlook About ntop. Introduction to PF_RING. Integrating PF_RING with
FPGA Augmented ASICs: The Time Has Come
 FPGA Augmented ASICs: The Time Has Come David Riddoch Steve Pope Copyright 2012 Solarflare Communications, Inc. All Rights Reserved. Hardware acceleration is Niche (With the obvious exception of graphics
FPGA Augmented ASICs: The Time Has Come David Riddoch Steve Pope Copyright 2012 Solarflare Communications, Inc. All Rights Reserved. Hardware acceleration is Niche (With the obvious exception of graphics
打造 Linux 下的高性能网络 北京酷锐达信息技术有限公司技术总监史应生.
 打造 Linux 下的高性能网络 北京酷锐达信息技术有限公司技术总监史应生 shiys@solutionware.com.cn BY DEFAULT, LINUX NETWORKING NOT TUNED FOR MAX PERFORMANCE, MORE FOR RELIABILITY Trade-off :Low Latency, throughput, determinism Performance
打造 Linux 下的高性能网络 北京酷锐达信息技术有限公司技术总监史应生 shiys@solutionware.com.cn BY DEFAULT, LINUX NETWORKING NOT TUNED FOR MAX PERFORMANCE, MORE FOR RELIABILITY Trade-off :Low Latency, throughput, determinism Performance
Designing Next-Generation Data- Centers with Advanced Communication Protocols and Systems Services. Presented by: Jitong Chen
 Designing Next-Generation Data- Centers with Advanced Communication Protocols and Systems Services Presented by: Jitong Chen Outline Architecture of Web-based Data Center Three-Stage framework to benefit
Designing Next-Generation Data- Centers with Advanced Communication Protocols and Systems Services Presented by: Jitong Chen Outline Architecture of Web-based Data Center Three-Stage framework to benefit
Birds of a Feather Presentation
 Mellanox InfiniBand QDR 4Gb/s The Fabric of Choice for High Performance Computing Gilad Shainer, shainer@mellanox.com June 28 Birds of a Feather Presentation InfiniBand Technology Leadership Industry Standard
Mellanox InfiniBand QDR 4Gb/s The Fabric of Choice for High Performance Computing Gilad Shainer, shainer@mellanox.com June 28 Birds of a Feather Presentation InfiniBand Technology Leadership Industry Standard
Virtualization, Xen and Denali
 Virtualization, Xen and Denali Susmit Shannigrahi November 9, 2011 Susmit Shannigrahi () Virtualization, Xen and Denali November 9, 2011 1 / 70 Introduction Virtualization is the technology to allow two
Virtualization, Xen and Denali Susmit Shannigrahi November 9, 2011 Susmit Shannigrahi () Virtualization, Xen and Denali November 9, 2011 1 / 70 Introduction Virtualization is the technology to allow two
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
WORKLOAD CHARACTERIZATION OF INTERACTIVE CLOUD SERVICES BIG AND SMALL SERVER PLATFORMS
 WORKLOAD CHARACTERIZATION OF INTERACTIVE CLOUD SERVICES ON BIG AND SMALL SERVER PLATFORMS Shuang Chen*, Shay Galon**, Christina Delimitrou*, Srilatha Manne**, and José Martínez* *Cornell University **Cavium
WORKLOAD CHARACTERIZATION OF INTERACTIVE CLOUD SERVICES ON BIG AND SMALL SERVER PLATFORMS Shuang Chen*, Shay Galon**, Christina Delimitrou*, Srilatha Manne**, and José Martínez* *Cornell University **Cavium
Remote Persistent Memory SNIA Nonvolatile Memory Programming TWG
 Remote Persistent Memory SNIA Nonvolatile Memory Programming TWG Tom Talpey Microsoft 2018 Storage Developer Conference. SNIA. All Rights Reserved. 1 Outline SNIA NVMP TWG activities Remote Access for
Remote Persistent Memory SNIA Nonvolatile Memory Programming TWG Tom Talpey Microsoft 2018 Storage Developer Conference. SNIA. All Rights Reserved. 1 Outline SNIA NVMP TWG activities Remote Access for
The NE010 iwarp Adapter
 The NE010 iwarp Adapter Gary Montry Senior Scientist +1-512-493-3241 GMontry@NetEffect.com Today s Data Center Users Applications networking adapter LAN Ethernet NAS block storage clustering adapter adapter
The NE010 iwarp Adapter Gary Montry Senior Scientist +1-512-493-3241 GMontry@NetEffect.com Today s Data Center Users Applications networking adapter LAN Ethernet NAS block storage clustering adapter adapter
Containing RDMA and High Performance Computing
 Containing RDMA and High Performance Computing Liran Liss ContainerCon 2015 Agenda High Performance Computing (HPC) networking RDMA 101 Containing RDMA Challenges Solution approach RDMA network namespace
Containing RDMA and High Performance Computing Liran Liss ContainerCon 2015 Agenda High Performance Computing (HPC) networking RDMA 101 Containing RDMA Challenges Solution approach RDMA network namespace
IX: A Protected Dataplane Operating System for High Throughput and Low Latency
 IX: A Protected Dataplane Operating System for High Throughput and Low Latency Belay, A. et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Reviewed by Chun-Yu and Xinghao Li Summary In this
IX: A Protected Dataplane Operating System for High Throughput and Low Latency Belay, A. et al. Proc. of the 11th USENIX Symp. on OSDI, pp. 49-65, 2014. Reviewed by Chun-Yu and Xinghao Li Summary In this
IO virtualization. Michael Kagan Mellanox Technologies
 IO virtualization Michael Kagan Mellanox Technologies IO Virtualization Mission non-stop s to consumers Flexibility assign IO resources to consumer as needed Agility assignment of IO resources to consumer
IO virtualization Michael Kagan Mellanox Technologies IO Virtualization Mission non-stop s to consumers Flexibility assign IO resources to consumer as needed Agility assignment of IO resources to consumer
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Fast packet processing in the cloud. Dániel Géhberger Ericsson Research
 Fast packet processing in the cloud Dániel Géhberger Ericsson Research Outline Motivation Service chains Hardware related topics, acceleration Virtualization basics Software performance and acceleration
Fast packet processing in the cloud Dániel Géhberger Ericsson Research Outline Motivation Service chains Hardware related topics, acceleration Virtualization basics Software performance and acceleration
Advanced Computer Networks. RDMA, Network Virtualization
 Advanced Computer Networks 263 3501 00 RDMA, Network Virtualization Patrick Stuedi Spring Semester 2013 Oriana Riva, Department of Computer Science ETH Zürich Last Week Scaling Layer 2 Portland VL2 TCP
Advanced Computer Networks 263 3501 00 RDMA, Network Virtualization Patrick Stuedi Spring Semester 2013 Oriana Riva, Department of Computer Science ETH Zürich Last Week Scaling Layer 2 Portland VL2 TCP
Baidu s Best Practice with Low Latency Networks
 Baidu s Best Practice with Low Latency Networks Feng Gao IEEE 802 IC NEND Orlando, FL November 2017 Presented by Huawei Low Latency Network Solutions 01 1. Background Introduction 2. Network Latency Analysis
Baidu s Best Practice with Low Latency Networks Feng Gao IEEE 802 IC NEND Orlando, FL November 2017 Presented by Huawei Low Latency Network Solutions 01 1. Background Introduction 2. Network Latency Analysis
Flexible Architecture Research Machine (FARM)
") Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
DCS-ctrl: A Fast and Flexible Device-Control Mechanism for Device-Centric Server Architecture
 DCS-ctrl: A Fast and Flexible ice-control Mechanism for ice-centric Server Architecture Dongup Kwon 1, Jaehyung Ahn 2, Dongju Chae 2, Mohammadamin Ajdari 2, Jaewon Lee 1, Suheon Bae 1, Youngsok Kim 1,
DCS-ctrl: A Fast and Flexible ice-control Mechanism for ice-centric Server Architecture Dongup Kwon 1, Jaehyung Ahn 2, Dongju Chae 2, Mohammadamin Ajdari 2, Jaewon Lee 1, Suheon Bae 1, Youngsok Kim 1,
Next-Generation NVMe-Native Parallel Filesystem for Accelerating HPC Workloads
 Next-Generation NVMe-Native Parallel Filesystem for Accelerating HPC Workloads Liran Zvibel CEO, Co-founder WekaIO @liranzvibel 1 WekaIO Matrix: Full-featured and Flexible Public or Private S3 Compatible
Next-Generation NVMe-Native Parallel Filesystem for Accelerating HPC Workloads Liran Zvibel CEO, Co-founder WekaIO @liranzvibel 1 WekaIO Matrix: Full-featured and Flexible Public or Private S3 Compatible
UCX: An Open Source Framework for HPC Network APIs and Beyond
 UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
UCX: An Open Source Framework for HPC Network APIs and Beyond Presented by: Pavel Shamis / Pasha ORNL is managed by UT-Battelle for the US Department of Energy Co-Design Collaboration The Next Generation
M 3 Microkernel-based System for Heterogeneous Manycores
 M 3 Microkernel-based System for Heterogeneous Manycores Nils Asmussen MKC, 06/29/2017 1 / 48 Overall System Design Prototype Platforms Capabilities OS Services Context Switching Evaluation Heterogeneous
M 3 Microkernel-based System for Heterogeneous Manycores Nils Asmussen MKC, 06/29/2017 1 / 48 Overall System Design Prototype Platforms Capabilities OS Services Context Switching Evaluation Heterogeneous
In-Network Computing. Paving the Road to Exascale. 5th Annual MVAPICH User Group (MUG) Meeting, August 2017
 Meeting, August 2017") In-Network Computing Paving the Road to Exascale 5th Annual MVAPICH User Group (MUG) Meeting, August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric
In-Network Computing Paving the Road to Exascale 5th Annual MVAPICH User Group (MUG) Meeting, August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric
Flavors of Memory supported by Linux, their use and benefit. Christoph Lameter, Ph.D,
 Flavors of Memory supported by Linux, their use and benefit Christoph Lameter, Ph.D, Twitter: @qant Flavors Of Memory The term computer memory is a simple term but there are numerous nuances
Flavors of Memory supported by Linux, their use and benefit Christoph Lameter, Ph.D, Twitter: @qant Flavors Of Memory The term computer memory is a simple term but there are numerous nuances
A 101 Guide to Heterogeneous, Accelerated, Data Centric Computing Architectures
 A 101 Guide to Heterogeneous, Accelerated, Centric Computing Architectures Allan Cantle President & Founder, Nallatech Join the Conversation #OpenPOWERSummit 2016 OpenPOWER Foundation Buzzword & Acronym
A 101 Guide to Heterogeneous, Accelerated, Centric Computing Architectures Allan Cantle President & Founder, Nallatech Join the Conversation #OpenPOWERSummit 2016 OpenPOWER Foundation Buzzword & Acronym
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
DDN. DDN Updates. DataDirect Neworks Japan, Inc Nobu Hashizume. DDN Storage 2018 DDN Storage 1
 1 DDN DDN Updates DataDirect Neworks Japan, Inc Nobu Hashizume DDN Storage 2018 DDN Storage 1 2 DDN A Broad Range of Technologies to Best Address Your Needs Your Use Cases Research Big Data Enterprise
1 DDN DDN Updates DataDirect Neworks Japan, Inc Nobu Hashizume DDN Storage 2018 DDN Storage 1 2 DDN A Broad Range of Technologies to Best Address Your Needs Your Use Cases Research Big Data Enterprise
RDMA programming concepts
 RDMA programming concepts Robert D. Russell InterOperability Laboratory & Computer Science Department University of New Hampshire Durham, New Hampshire 03824, USA 2013 Open Fabrics Alliance,
RDMA programming concepts Robert D. Russell InterOperability Laboratory & Computer Science Department University of New Hampshire Durham, New Hampshire 03824, USA 2013 Open Fabrics Alliance,
Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects?
 Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects? N. S. Islam, X. Lu, M. W. Rahman, and D. K. Panda Network- Based Compu2ng Laboratory Department of Computer
Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects? N. S. Islam, X. Lu, M. W. Rahman, and D. K. Panda Network- Based Compu2ng Laboratory Department of Computer
An NVMe-based Offload Engine for Storage Acceleration Sean Gibb, Eideticom Stephen Bates, Raithlin
 An NVMe-based Offload Engine for Storage Acceleration Sean Gibb, Eideticom Stephen Bates, Raithlin 1 Overview Acceleration for Storage NVMe for Acceleration How are we using (abusing ;-)) NVMe to support
An NVMe-based Offload Engine for Storage Acceleration Sean Gibb, Eideticom Stephen Bates, Raithlin 1 Overview Acceleration for Storage NVMe for Acceleration How are we using (abusing ;-)) NVMe to support
Process Description and Control
 Process Description and Control 1 Process:the concept Process = a program in execution Example processes: OS kernel OS shell Program executing after compilation www-browser Process management by OS : Allocate
Process Description and Control 1 Process:the concept Process = a program in execution Example processes: OS kernel OS shell Program executing after compilation www-browser Process management by OS : Allocate
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Motivation. Threads. Multithreaded Server Architecture. Thread of execution. Chapter 4
 Motivation Threads Chapter 4 Most modern applications are multithreaded Threads run within application Multiple tasks with the application can be implemented by separate Update display Fetch data Spell
Motivation Threads Chapter 4 Most modern applications are multithreaded Threads run within application Multiple tasks with the application can be implemented by separate Update display Fetch data Spell
Research Faculty Summit Systems Fueling future disruptions
 Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
Programmable NICs. Lecture 14, Computer Networks (198:552)
") Programmable NICs Lecture 14, Computer Networks (198:552) Network Interface Cards (NICs) The physical interface between a machine and the wire Life of a transmitted packet Userspace application NIC Transport
Programmable NICs Lecture 14, Computer Networks (198:552) Network Interface Cards (NICs) The physical interface between a machine and the wire Life of a transmitted packet Userspace application NIC Transport
Generic System Calls for GPUs
 Generic System Calls for GPUs Ján Veselý*, Arkaprava Basu, Abhishek Bhattacharjee*, Gabriel H. Loh, Mark Oskin, Steven K. Reinhardt *Rutgers University, Indian Institute of Science, Advanced Micro Devices
Generic System Calls for GPUs Ján Veselý*, Arkaprava Basu, Abhishek Bhattacharjee*, Gabriel H. Loh, Mark Oskin, Steven K. Reinhardt *Rutgers University, Indian Institute of Science, Advanced Micro Devices
Snapify: Capturing Snapshots of Offload Applications on Xeon Phi Manycore Processors
 Snapify: Capturing Snapshots of Offload Applications on Xeon Phi Manycore Processors Arash Rezaei 1, Giuseppe Coviello 2, Cheng-Hong Li 2, Srimat Chakradhar 2, Frank Mueller 1 1 Department of Computer
Snapify: Capturing Snapshots of Offload Applications on Xeon Phi Manycore Processors Arash Rezaei 1, Giuseppe Coviello 2, Cheng-Hong Li 2, Srimat Chakradhar 2, Frank Mueller 1 1 Department of Computer
IO-Lite: A Unified I/O Buffering and Caching System
 IO-Lite: A Unified I/O Buffering and Caching System Vivek S. Pai, Peter Druschel and Willy Zwaenepoel Rice University (Presented by Chuanpeng Li) 2005-4-25 CS458 Presentation 1 IO-Lite Motivation Network
IO-Lite: A Unified I/O Buffering and Caching System Vivek S. Pai, Peter Druschel and Willy Zwaenepoel Rice University (Presented by Chuanpeng Li) 2005-4-25 CS458 Presentation 1 IO-Lite Motivation Network
OPERATING SYSTEM. Chapter 4: Threads
 OPERATING SYSTEM Chapter 4: Threads Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples Objectives To
OPERATING SYSTEM Chapter 4: Threads Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples Objectives To
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.
 Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Martin Dubois, ing. Contents
 Martin Dubois, ing Contents Without OpenNet vs With OpenNet Technical information Possible applications Artificial Intelligence Deep Packet Inspection Image and Video processing Network equipment development
Martin Dubois, ing Contents Without OpenNet vs With OpenNet Technical information Possible applications Artificial Intelligence Deep Packet Inspection Image and Video processing Network equipment development
New Communication Standard Takyon Proposal Overview
 Khronos Group Inc. 2018 - Page 1 Heterogenous Communications Exploratory Group New Communication Standard Takyon Proposal Overview November 2018 Khronos Group Inc. 2018 - Page 2 Khronos Exploratory Group
Khronos Group Inc. 2018 - Page 1 Heterogenous Communications Exploratory Group New Communication Standard Takyon Proposal Overview November 2018 Khronos Group Inc. 2018 - Page 2 Khronos Exploratory Group
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
Solutions for Scalable HPC
 Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
Solutions for Scalable HPC Scot Schultz, Director HPC/Technical Computing HPC Advisory Council Stanford Conference Feb 2014 Leading Supplier of End-to-End Interconnect Solutions Comprehensive End-to-End
Operating System. Chapter 4. Threads. Lynn Choi School of Electrical Engineering
 Operating System Chapter 4. Threads Lynn Choi School of Electrical Engineering Process Characteristics Resource ownership Includes a virtual address space (process image) Ownership of resources including
Operating System Chapter 4. Threads Lynn Choi School of Electrical Engineering Process Characteristics Resource ownership Includes a virtual address space (process image) Ownership of resources including
Containers Do Not Need Network Stacks
 s Do Not Need Network Stacks Ryo Nakamura iijlab seminar 2018/10/16 Based on Ryo Nakamura, Yuji Sekiya, and Hajime Tazaki. 2018. Grafting Sockets for Fast Networking. In ANCS 18: Symposium on Architectures
s Do Not Need Network Stacks Ryo Nakamura iijlab seminar 2018/10/16 Based on Ryo Nakamura, Yuji Sekiya, and Hajime Tazaki. 2018. Grafting Sockets for Fast Networking. In ANCS 18: Symposium on Architectures
Mapping MPI+X Applications to Multi-GPU Architectures
 Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
Mapping MPI+X Applications to Multi-GPU Architectures A Performance-Portable Approach Edgar A. León Computer Scientist San Jose, CA March 28, 2018 GPU Technology Conference This work was performed under
RapidIO.org Update.
 RapidIO.org Update rickoco@rapidio.org June 2015 2015 RapidIO.org 1 Outline RapidIO Overview Benefits Interconnect Comparison Ecosystem System Challenges RapidIO Markets Data Center & HPC Communications
RapidIO.org Update rickoco@rapidio.org June 2015 2015 RapidIO.org 1 Outline RapidIO Overview Benefits Interconnect Comparison Ecosystem System Challenges RapidIO Markets Data Center & HPC Communications
Review: Hardware user/kernel boundary
 Review: Hardware user/kernel boundary applic. applic. applic. user lib lib lib kernel syscall pg fault syscall FS VM sockets disk disk NIC context switch TCP retransmits,... device interrupts Processor
Review: Hardware user/kernel boundary applic. applic. applic. user lib lib lib kernel syscall pg fault syscall FS VM sockets disk disk NIC context switch TCP retransmits,... device interrupts Processor
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Introduction to OpenOnload Building Application Transparency and Protocol Conformance into Application Acceleration Middleware
 White Paper Introduction to OpenOnload Building Application Transparency and Protocol Conformance into Application Acceleration Middleware Steve Pope, PhD Chief Technical Officer Solarflare Communications
White Paper Introduction to OpenOnload Building Application Transparency and Protocol Conformance into Application Acceleration Middleware Steve Pope, PhD Chief Technical Officer Solarflare Communications
Why AI Frameworks Need (not only) RDMA?
 RDMA?") Why AI Frameworks Need (not only) RDMA? With Design and Implementation Experience of Networking Support on TensorFlow GDR, Apache MXNet, WeChat Amber, and Tencent Angel Bairen Yi (byi@connect.ust.hk) Jingrong
Why AI Frameworks Need (not only) RDMA? With Design and Implementation Experience of Networking Support on TensorFlow GDR, Apache MXNet, WeChat Amber, and Tencent Angel Bairen Yi (byi@connect.ust.hk) Jingrong
Accelerating Web Protocols Using RDMA
 Accelerating Web Protocols Using RDMA Dennis Dalessandro Ohio Supercomputer Center NCA 2007 Who's Responsible for this? Dennis Dalessandro Ohio Supercomputer Center - Springfield dennis@osc.edu Pete Wyckoff
Accelerating Web Protocols Using RDMA Dennis Dalessandro Ohio Supercomputer Center NCA 2007 Who's Responsible for this? Dennis Dalessandro Ohio Supercomputer Center - Springfield dennis@osc.edu Pete Wyckoff
RDMA and Hardware Support
 RDMA and Hardware Support SIGCOMM Topic Preview 2018 Yibo Zhu Microsoft Research 1 The (Traditional) Journey of Data How app developers see the network Under the hood This architecture had been working
RDMA and Hardware Support SIGCOMM Topic Preview 2018 Yibo Zhu Microsoft Research 1 The (Traditional) Journey of Data How app developers see the network Under the hood This architecture had been working
Sharing High-Performance Devices Across Multiple Virtual Machines
 Sharing High-Performance Devices Across Multiple Virtual Machines Preamble What does sharing devices across multiple virtual machines in our title mean? How is it different from virtual networking / NSX,
Sharing High-Performance Devices Across Multiple Virtual Machines Preamble What does sharing devices across multiple virtual machines in our title mean? How is it different from virtual networking / NSX,
Mellanox Technologies Maximize Cluster Performance and Productivity. Gilad Shainer, October, 2007
 Mellanox Technologies Maximize Cluster Performance and Productivity Gilad Shainer, shainer@mellanox.com October, 27 Mellanox Technologies Hardware OEMs Servers And Blades Applications End-Users Enterprise
Mellanox Technologies Maximize Cluster Performance and Productivity Gilad Shainer, shainer@mellanox.com October, 27 Mellanox Technologies Hardware OEMs Servers And Blades Applications End-Users Enterprise
Operating-System Structures
 Operating-System Structures Chapter 2 Operating System Services One set provides functions that are helpful to the user: User interface Program execution I/O operations File-system manipulation Communications
Operating-System Structures Chapter 2 Operating System Services One set provides functions that are helpful to the user: User interface Program execution I/O operations File-system manipulation Communications