The DEEP-ER take on I/O
|
|
|
- Arline Warren
- 5 years ago
- Views:
Transcription
1 Wolfgang Frings Jülich Supercomputing Centre Workshop Exascale I/O: Challenges, Innovations and Solutions SC16, Salt Lake City 18 November 2016 The research leading to these results has received funding from the European Community's Seventh Framework Programme (FP7/ ) under Grant Agreement n and n


2 DEEP and DEEP-ER EU-Exascale projects 20 partners Total budget: 28,3 M EU-funding: 14,5 M Nov 2011 Mar


3 I/O Hardware Innovation On- NVM Network attached memory 3

 High temperature")

 Geoscience")
 Oil exploration")


4 Driven by Applications Pilot applications: Space weather simulation (KULeuven) High temperature superconductivity (CINECA) Human exposure to electromagnetic fields (Inria) Geoscience (BADW-LRZ) Radio astronomy (ASTRON) Oil exploration (BSC) Lattice QCD (UREG) Goals: Analyse I/O and resiliency requirements of HPC codes Evaluate DEEP-ER I/O and resiliency concept and its programmability 4



5 Scalable I/O Improve I/O scalability on all usage-levels Used also for checkpointing 5



6 BeeGFS and Caching Two instances: Global FS on HDD server Cache FS on NVM at node API for cache domain handling Synchronous version Asynchronous version 6
7 Architecture of the asynchronous cache API User application DEEP-ER cache daemon Application workflow I/0 subsystem DEEP-ER cache API 1. Wait() Messaging facility 2.a Check list Lookup list of requests in processing DEEP-ER cache library Messaging facility 1. Asynchronous API call 2.b Check list FIFO with new requests Lookup list 2. Add request to FIFO 3.a Worker take request from FIFO 3.b Add request to list Worker threads 5. remove request from list Workflow synchronous API call Workflow asynchronous API call Workflow wait call Synchronous API call (executed by the thread of the caller process) 4. Process work Cache file system Global file system 7

 0 1 2 3 4 5 ROMIO Lustre Driver MPI MPI-IO ADIO")

8 New MPI-IO Hints e10_cache e10_cache_path e10_cache_flush_flag e10_cache_discard_flag e10_cache_threads DEEP-ER Cache Integration in ROMIO Processes Buffers Tested in DEEP cluster Global Sync Group (MPI_COMM_WORLD) ROMIO Lustre Driver MPI MPI-IO ADIO (Abstract Device IO) GPFS Driver UFS Driver DEEP-ER Cache Parallel File System BeeGFS Driver Collective Buffers Collective I/O DEEP-ER Cache Independent I/O Parallel File System 8
: time to write S(k) to the cache Ts(k): time to sync S(k) with the parallel file system C(k): compute time at phase k")
9 Workflows Using DEEP-ER Cache cache enabled cache disabled S(k): amount of written to the file at phase k (here constant) Tc(k): time to write S(k) to the cache Ts(k): time to sync S(k) with the parallel file system C(k): compute time at phase k 9
10 MPIWRAP Support Library MPI-IO hints are defined in a config file and injected by libmpiwrap into the middleware Provides deeper and more flexible control of MPI-IO functionalities to the users Provides transparent integration of E10 functionalities into applications Works with any high level library (e.g. phdf5) MPI_{Init,Finalize} MPI_File_{open,close} ROMIO Lustre Driver MPI MPI-IO ADIO (Abstract Device IO) GPFS Driver MPIWRAP UFS Driver Parallel File System BeeGFS Driver 10
./checkpoint/file.0001./checkpoint/file.nnnn Parallel file system")
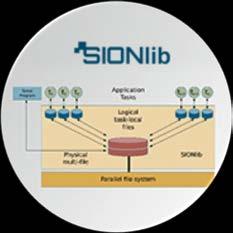
11 : Shared Files for Task- Data Parallel Application HDF5 NETCDF MPI-I/O POSIX I/O Parallel file system t 1 t 2 t n-1 t n #files: O(10000)./checkpoint/file.0001./checkpoint/file.nnnn Parallel file system
12 : Shared Files for Task- Data Parallel Application HDF5 NETCDF MPI-I/O POSIX I/O Serial program Application t 1 t 2 t 3 Tasks t n-2 t n-1 t n Parallel file system #files: O(10) Physical multi-file Logical task- files Parallel file system
13 : Strategy for Local Storage Tasks t 1 t n/2 t n/2+1 t n file container multi-file approach metablock 1 metablock 2 mapping metablock 1 metablock 2 Shared file 1 Shared file n I/Onode I/Onode I/Onode I/Onode Staging I/Onode I/Onode I/Onode I/Onode node group with storage Local Storage node group with storage Transparent access from application to container Global Storage
14 : Local checkpointing MPI/OpenMP tt t tt t tt t tt t tt t ttt Global File System Mapping: task writes to storage, using one physical file of file container Transparent access to from application Transparent access to when files migrated to global storage Re-distribution of task- in layer possible (Buddy-CP)
15 : Buddy-CP Logical mapping MPI/OpenMP tt t ttt ttt t t t t t t t tt Global File System buddy buddy buddy buddy buddy buddy Mapping: 1:1 task writes to storage and storage of buddy node 1:m task writes to storage and storage of m buddy nodes Data exchange to buddy node is done via MPI/OpenMP layer Collective checkpoint calls required Open: sid=sion_paropen_mpi(, bw,buddy=m,mpi_comm_world, ) Write: sion_coll_write_mpi(,size,elements,sid) Close: sion_parclose(sid)
16 Restore checkpoint after failure MPI/OpenMP tt t t t t t t t t t t t t t t tt Global File System buddy buddy buddy buddy buddy buddy Automatic analysis of availability on storage On missing : falls back to buddy if first open fails Open: sid=sion_paropen_mpi(, br,buddy=m,mpi_comm_world, ) Read: sion_coll_read_mpi(,size,elements,sid) Close: sion_parclose(sid)
17 and SCR interoperability SCR_Start_checkpt() SCR_Route_file(fn, fn_scr) fn = check1 fn_scr= /abspath/check1 sid=sion_paropen_mpi(fn_scr, wb,buddy...) info=sion_get_io_info(sid) sion_parclose_mpi(sid) SCR_Complete_checkpt() (node0) /abspath/check1 (node1) /abspath/check (node0) /abspath/check1_buddy_ (node1) /abspath/check1_buddy_ List of filename opened on this task - Bytes written SCR_update_filename(nfiles, info.names,info.sizes, info.roles)
18 Preliminary results MAXW-DGTD: Human exposure to electromagnetic fields (Inria) reduces number of files less filesystem overhead Data write time [s] P1 P1 with P3 P3 with # of tasks # of tasks P1 P1 with P3 P3 with output times on DEEP
19 Preliminary results NVMe Oil exploration (BSC) sdv-work NVMe Backward Forward 28, Impact of NVMe Propagation time [s] Backward Forward sdv-work NVMe Human exposure to electromagnetic fields (Inria) sdv-work NVMe P P P P I/O performance of MAXW-DGTD Writing time [s] P1 P2 P3 P4 sdv-work NVMe 19
20 Summary DEEP-ER explores future directions of I/O On POSIX optimization level On filesystem level BeeGFS On MPI-IO level E10 Aims to be able to test and combine the approaches Exploration and validations of new hardware NVMe NAM More information on 20
The DEEP (and DEEP-ER) projects
 projects") The DEEP (and DEEP-ER) projects Estela Suarez - Jülich Supercomputing Centre BDEC for Europe Workshop Barcelona, 28.01.2015 The research leading to these results has received funding from the European
The DEEP (and DEEP-ER) projects Estela Suarez - Jülich Supercomputing Centre BDEC for Europe Workshop Barcelona, 28.01.2015 The research leading to these results has received funding from the European
I/O and Scheduling aspects in DEEP-EST
 I/O and Scheduling aspects in DEEP-EST Norbert Eicker Jülich Supercomputing Centre & University of Wuppertal The research leading to these results has received funding from the European Community's Seventh
I/O and Scheduling aspects in DEEP-EST Norbert Eicker Jülich Supercomputing Centre & University of Wuppertal The research leading to these results has received funding from the European Community's Seventh
I/O Monitoring at JSC, SIONlib & Resiliency
 Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
Mitglied der Helmholtz-Gemeinschaft I/O Monitoring at JSC, SIONlib & Resiliency Update: I/O Infrastructure @ JSC Update: Monitoring with LLview (I/O, Memory, Load) I/O Workloads on Jureca SIONlib: Task-Local
Parallel I/O on JUQUEEN
 Parallel I/O on JUQUEEN 4. Februar 2014, JUQUEEN Porting and Tuning Workshop Mitglied der Helmholtz-Gemeinschaft Wolfgang Frings w.frings@fz-juelich.de Jülich Supercomputing Centre Overview Parallel I/O
Parallel I/O on JUQUEEN 4. Februar 2014, JUQUEEN Porting and Tuning Workshop Mitglied der Helmholtz-Gemeinschaft Wolfgang Frings w.frings@fz-juelich.de Jülich Supercomputing Centre Overview Parallel I/O
I/O at JSC. I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O. Wolfgang Frings
 Mitglied der Helmholtz-Gemeinschaft I/O at JSC I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O Wolfgang Frings W.Frings@fz-juelich.de Jülich Supercomputing
Mitglied der Helmholtz-Gemeinschaft I/O at JSC I/O Infrastructure Workloads, Use Case I/O System Usage and Performance SIONlib: Task-Local I/O Wolfgang Frings W.Frings@fz-juelich.de Jülich Supercomputing
Analyzing the High Performance Parallel I/O on LRZ HPC systems. Sandra Méndez. HPC Group, LRZ. June 23, 2016
 Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Approaches to I/O Scalability Challenges in the ECMWF Forecasting System
 Approaches to I/O Scalability Challenges in the ECMWF Forecasting System PASC 16, June 9 2016 Florian Rathgeber, Simon Smart, Tiago Quintino, Baudouin Raoult, Stephan Siemen, Peter Bauer Development Section,
Approaches to I/O Scalability Challenges in the ECMWF Forecasting System PASC 16, June 9 2016 Florian Rathgeber, Simon Smart, Tiago Quintino, Baudouin Raoult, Stephan Siemen, Peter Bauer Development Section,
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Dynamical Exascale Entry Platform
 DEEP Dynamical Exascale Entry Platform 2 nd IS-ENES Workshop on High performance computing for climate models 30.01.2013, Toulouse, France Estela Suarez The research leading to these results has received
DEEP Dynamical Exascale Entry Platform 2 nd IS-ENES Workshop on High performance computing for climate models 30.01.2013, Toulouse, France Estela Suarez The research leading to these results has received
ECMWF s Next Generation IO for the IFS Model
 ECMWF s Next Generation IO for the Model Part of ECMWF s Scalability Programme Tiago Quintino, B. Raoult, P. Bauer ECMWF tiago.quintino@ecmwf.int ECMWF January 14, 2016 ECMWF s HPC Targets What do we do?
ECMWF s Next Generation IO for the Model Part of ECMWF s Scalability Programme Tiago Quintino, B. Raoult, P. Bauer ECMWF tiago.quintino@ecmwf.int ECMWF January 14, 2016 ECMWF s HPC Targets What do we do?
Index LEVERAGING THE POWER OF HETEROGENEITY FOR NEXT GENERATION SUPERCOMPUTERS
 LEVERAGING THE POWER OF HETEROGENEITY FOR NEXT GENERATION SUPERCOMPUTERS 3 The Power of Heterogeneity 4 A DEEP-ER Look 5 DEEP-ER Hardware Architecture 9 DEEP-ER Co-Design 11 DEEP-ER Software Stack 15 DEEP-ER
LEVERAGING THE POWER OF HETEROGENEITY FOR NEXT GENERATION SUPERCOMPUTERS 3 The Power of Heterogeneity 4 A DEEP-ER Look 5 DEEP-ER Hardware Architecture 9 DEEP-ER Co-Design 11 DEEP-ER Software Stack 15 DEEP-ER
ECMWF's Next Generation IO for the IFS Model and Product Generation
 ECMWF's Next Generation IO for the IFS Model and Product Generation Future workflow adaptations Tiago Quintino, B. Raoult, S. Smart, A. Bonanni, F. Rathgeber, P. Bauer ECMWF tiago.quintino@ecmwf.int ECMWF
ECMWF's Next Generation IO for the IFS Model and Product Generation Future workflow adaptations Tiago Quintino, B. Raoult, S. Smart, A. Bonanni, F. Rathgeber, P. Bauer ECMWF tiago.quintino@ecmwf.int ECMWF
HPC projects. Grischa Bolls
 HPC projects Grischa Bolls Outline Why projects? 7th Framework Programme Infrastructure stack IDataCool, CoolMuc Mont-Blanc Poject Deep Project Exa2Green Project 2 Why projects? Pave the way for exascale
HPC projects Grischa Bolls Outline Why projects? 7th Framework Programme Infrastructure stack IDataCool, CoolMuc Mont-Blanc Poject Deep Project Exa2Green Project 2 Why projects? Pave the way for exascale
Improved Solutions for I/O Provisioning and Application Acceleration
 1 Improved Solutions for I/O Provisioning and Application Acceleration August 11, 2015 Jeff Sisilli Sr. Director Product Marketing jsisilli@ddn.com 2 Why Burst Buffer? The Supercomputing Tug-of-War A supercomputer
1 Improved Solutions for I/O Provisioning and Application Acceleration August 11, 2015 Jeff Sisilli Sr. Director Product Marketing jsisilli@ddn.com 2 Why Burst Buffer? The Supercomputing Tug-of-War A supercomputer
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning
 Extreme Application Acceleration & Highly Efficient I/O Provisioning") IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
IME (Infinite Memory Engine) Extreme Application Acceleration & Highly Efficient I/O Provisioning September 22 nd 2015 Tommaso Cecchi 2 What is IME? This breakthrough, software defined storage application
pnfs, POSIX, and MPI-IO: A Tale of Three Semantics
 Dean Hildebrand Research Staff Member PDSW 2009 pnfs, POSIX, and MPI-IO: A Tale of Three Semantics Dean Hildebrand, Roger Haskin Arifa Nisar IBM Almaden Northwestern University Agenda Motivation pnfs HPC
Dean Hildebrand Research Staff Member PDSW 2009 pnfs, POSIX, and MPI-IO: A Tale of Three Semantics Dean Hildebrand, Roger Haskin Arifa Nisar IBM Almaden Northwestern University Agenda Motivation pnfs HPC
A Breakthrough in Non-Volatile Memory Technology FUJITSU LIMITED
 A Breakthrough in Non-Volatile Memory Technology & 0 2018 FUJITSU LIMITED IT needs to accelerate time-to-market Situation: End users and applications need instant access to data to progress faster and
A Breakthrough in Non-Volatile Memory Technology & 0 2018 FUJITSU LIMITED IT needs to accelerate time-to-market Situation: End users and applications need instant access to data to progress faster and
Employing HPC DEEP-EST for HEP Data Analysis. Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN)
, Maria Girone (CERN)") Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Application Performance on IME
 Application Performance on IME Toine Beckers, DDN Marco Grossi, ICHEC Burst Buffer Designs Introduce fast buffer layer Layer between memory and persistent storage Pre-stage application data Buffer writes
Application Performance on IME Toine Beckers, DDN Marco Grossi, ICHEC Burst Buffer Designs Introduce fast buffer layer Layer between memory and persistent storage Pre-stage application data Buffer writes
I/O Profiling Towards the Exascale
 I/O Profiling Towards the Exascale holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden NEXTGenIO & SAGE: Working towards Exascale I/O Barcelona, NEXTGenIO facts Project Research & Innovation
I/O Profiling Towards the Exascale holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden NEXTGenIO & SAGE: Working towards Exascale I/O Barcelona, NEXTGenIO facts Project Research & Innovation
POP CoE: Understanding applications and how to prepare for exascale
 POP CoE: Understanding applications and how to prepare for exascale Jesus Labarta (BSC) EU H2020 Center of Excellence (CoE) Lecce, May 17 th 2018 5 th ENES HPC workshop POP objective Promote methodologies
POP CoE: Understanding applications and how to prepare for exascale Jesus Labarta (BSC) EU H2020 Center of Excellence (CoE) Lecce, May 17 th 2018 5 th ENES HPC workshop POP objective Promote methodologies
Techniques to improve the scalability of Checkpoint-Restart
 Techniques to improve the scalability of Checkpoint-Restart Bogdan Nicolae Exascale Systems Group IBM Research Ireland 1 Outline A few words about the lab and team Challenges of Exascale A case for Checkpoint-Restart
Techniques to improve the scalability of Checkpoint-Restart Bogdan Nicolae Exascale Systems Group IBM Research Ireland 1 Outline A few words about the lab and team Challenges of Exascale A case for Checkpoint-Restart
Integrating Analysis and Computation with Trios Services
 October 31, 2012 Integrating Analysis and Computation with Trios Services Approved for Public Release: SAND2012-9323P Ron A. Oldfield Scalable System Software Sandia National Laboratories Albuquerque,
October 31, 2012 Integrating Analysis and Computation with Trios Services Approved for Public Release: SAND2012-9323P Ron A. Oldfield Scalable System Software Sandia National Laboratories Albuquerque,
EIOW Exa-scale I/O workgroup (exascale10)
") EIOW Exa-scale I/O workgroup (exascale10) Meghan McClelland Peter Braam Lug 2013 Large scale data management is fundamentally broken but functions somewhat successfully as an awkward patchwork Current
EIOW Exa-scale I/O workgroup (exascale10) Meghan McClelland Peter Braam Lug 2013 Large scale data management is fundamentally broken but functions somewhat successfully as an awkward patchwork Current
Parallel I/O and Portable Data Formats I/O strategies
 Parallel I/O and Portable Data Formats I/O strategies Sebastian Lührs s.luehrs@fz-juelich.de Jülich Supercomputing Centre Forschungszentrum Jülich GmbH Jülich, March 13 th, 2017 Outline Common I/O strategies
Parallel I/O and Portable Data Formats I/O strategies Sebastian Lührs s.luehrs@fz-juelich.de Jülich Supercomputing Centre Forschungszentrum Jülich GmbH Jülich, March 13 th, 2017 Outline Common I/O strategies
Structuring PLFS for Extensibility
 Structuring PLFS for Extensibility Chuck Cranor, Milo Polte, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University What is PLFS? Parallel Log Structured File System Interposed filesystem b/w
Structuring PLFS for Extensibility Chuck Cranor, Milo Polte, Garth Gibson PARALLEL DATA LABORATORY Carnegie Mellon University What is PLFS? Parallel Log Structured File System Interposed filesystem b/w
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete
 Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
Store Process Analyze Collaborate Archive Cloud The HPC Storage Leader Invent Discover Compete 1 DDN Who We Are 2 We Design, Deploy and Optimize Storage Systems Which Solve HPC, Big Data and Cloud Business
Infinite Memory Engine Freedom from Filesystem Foibles
 1 Infinite Memory Engine Freedom from Filesystem Foibles James Coomer 25 th Sept 2017 2 Bad stuff can happen to filesystems Malaligned High Concurrency Random Shared File COMPUTE NODES FILESYSTEM 3 And
1 Infinite Memory Engine Freedom from Filesystem Foibles James Coomer 25 th Sept 2017 2 Bad stuff can happen to filesystems Malaligned High Concurrency Random Shared File COMPUTE NODES FILESYSTEM 3 And
I/O: State of the art and Future developments
 I/O: State of the art and Future developments Giorgio Amati SCAI Dept. Rome, 18/19 May 2016 Some questions Just to know each other: Why are you here? Which is the typical I/O size you work with? GB? TB?
I/O: State of the art and Future developments Giorgio Amati SCAI Dept. Rome, 18/19 May 2016 Some questions Just to know each other: Why are you here? Which is the typical I/O size you work with? GB? TB?
RAIDIX Data Storage Solution. Clustered Data Storage Based on the RAIDIX Software and GPFS File System
 RAIDIX Data Storage Solution Clustered Data Storage Based on the RAIDIX Software and GPFS File System 2017 Contents Synopsis... 2 Introduction... 3 Challenges and the Solution... 4 Solution Architecture...
RAIDIX Data Storage Solution Clustered Data Storage Based on the RAIDIX Software and GPFS File System 2017 Contents Synopsis... 2 Introduction... 3 Challenges and the Solution... 4 Solution Architecture...
NEXTGenIO Performance Tools for In-Memory I/O
 NEXTGenIO Performance Tools for In- I/O holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden 22 nd -23 rd March 2017 Credits Intro slides by Adrian Jackson (EPCC) A new hierarchy New non-volatile
NEXTGenIO Performance Tools for In- I/O holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden 22 nd -23 rd March 2017 Credits Intro slides by Adrian Jackson (EPCC) A new hierarchy New non-volatile
Data Movement & Tiering with DMF 7
 Data Movement & Tiering with DMF 7 Kirill Malkin Director of Engineering April 2019 Why Move or Tier Data? We wish we could keep everything in DRAM, but It s volatile It s expensive Data in Memory 2 Why
Data Movement & Tiering with DMF 7 Kirill Malkin Director of Engineering April 2019 Why Move or Tier Data? We wish we could keep everything in DRAM, but It s volatile It s expensive Data in Memory 2 Why
Analyzing I/O Performance on a NEXTGenIO Class System
 Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
HDF5 I/O Performance. HDF and HDF-EOS Workshop VI December 5, 2002
 HDF5 I/O Performance HDF and HDF-EOS Workshop VI December 5, 2002 1 Goal of this talk Give an overview of the HDF5 Library tuning knobs for sequential and parallel performance 2 Challenging task HDF5 Library
HDF5 I/O Performance HDF and HDF-EOS Workshop VI December 5, 2002 1 Goal of this talk Give an overview of the HDF5 Library tuning knobs for sequential and parallel performance 2 Challenging task HDF5 Library
Advanced Data Placement via Ad-hoc File Systems at Extreme Scales (ADA-FS)
") Advanced Data Placement via Ad-hoc File Systems at Extreme Scales (ADA-FS) Understanding I/O Performance Behavior (UIOP) 2017 Sebastian Oeste, Mehmet Soysal, Marc-André Vef, Michael Kluge, Wolfgang E.
Advanced Data Placement via Ad-hoc File Systems at Extreme Scales (ADA-FS) Understanding I/O Performance Behavior (UIOP) 2017 Sebastian Oeste, Mehmet Soysal, Marc-André Vef, Michael Kluge, Wolfgang E.
Large-scale Ultrasound Simulations Using the Hybrid OpenMP/MPI Decomposition
 Large-scale Ultrasound Simulations Using the Hybrid OpenMP/MPI Decomposition Jiri Jaros*, Vojtech Nikl*, Bradley E. Treeby *Department of Compute Systems, Brno University of Technology Department of Medical
Large-scale Ultrasound Simulations Using the Hybrid OpenMP/MPI Decomposition Jiri Jaros*, Vojtech Nikl*, Bradley E. Treeby *Department of Compute Systems, Brno University of Technology Department of Medical
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files
 System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
System that permanently stores data Usually layered on top of a lower-level physical storage medium Divided into logical units called files Addressable by a filename ( foo.txt ) Usually supports hierarchical
IBM Spectrum NAS, IBM Spectrum Scale and IBM Cloud Object Storage
 IBM Spectrum NAS, IBM Spectrum Scale and IBM Cloud Object Storage Silverton Consulting, Inc. StorInt Briefing 2017 SILVERTON CONSULTING, INC. ALL RIGHTS RESERVED Page 2 Introduction Unstructured data has
IBM Spectrum NAS, IBM Spectrum Scale and IBM Cloud Object Storage Silverton Consulting, Inc. StorInt Briefing 2017 SILVERTON CONSULTING, INC. ALL RIGHTS RESERVED Page 2 Introduction Unstructured data has
DELL EMC ISILON F800 AND H600 I/O PERFORMANCE
 DELL EMC ISILON F800 AND H600 I/O PERFORMANCE ABSTRACT This white paper provides F800 and H600 performance data. It is intended for performance-minded administrators of large compute clusters that access
DELL EMC ISILON F800 AND H600 I/O PERFORMANCE ABSTRACT This white paper provides F800 and H600 performance data. It is intended for performance-minded administrators of large compute clusters that access
UK LUG 10 th July Lustre at Exascale. Eric Barton. CTO Whamcloud, Inc Whamcloud, Inc.
 UK LUG 10 th July 2012 Lustre at Exascale Eric Barton CTO Whamcloud, Inc. eeb@whamcloud.com Agenda Exascale I/O requirements Exascale I/O model 3 Lustre at Exascale - UK LUG 10th July 2012 Exascale I/O
UK LUG 10 th July 2012 Lustre at Exascale Eric Barton CTO Whamcloud, Inc. eeb@whamcloud.com Agenda Exascale I/O requirements Exascale I/O model 3 Lustre at Exascale - UK LUG 10th July 2012 Exascale I/O
Co-existence: Can Big Data and Big Computation Co-exist on the Same Systems?
 Co-existence: Can Big Data and Big Computation Co-exist on the Same Systems? Dr. William Kramer National Center for Supercomputing Applications, University of Illinois Where these views come from Large
Co-existence: Can Big Data and Big Computation Co-exist on the Same Systems? Dr. William Kramer National Center for Supercomputing Applications, University of Illinois Where these views come from Large
Stream Processing for Remote Collaborative Data Analysis
 Stream Processing for Remote Collaborative Data Analysis Scott Klasky 146, C. S. Chang 2, Jong Choi 1, Michael Churchill 2, Tahsin Kurc 51, Manish Parashar 3, Alex Sim 7, Matthew Wolf 14, John Wu 7 1 ORNL,
Stream Processing for Remote Collaborative Data Analysis Scott Klasky 146, C. S. Chang 2, Jong Choi 1, Michael Churchill 2, Tahsin Kurc 51, Manish Parashar 3, Alex Sim 7, Matthew Wolf 14, John Wu 7 1 ORNL,
Parallel NetCDF. Rob Latham Mathematics and Computer Science Division Argonne National Laboratory
 Parallel NetCDF Rob Latham Mathematics and Computer Science Division Argonne National Laboratory robl@mcs.anl.gov I/O for Computational Science Application Application Parallel File System I/O Hardware
Parallel NetCDF Rob Latham Mathematics and Computer Science Division Argonne National Laboratory robl@mcs.anl.gov I/O for Computational Science Application Application Parallel File System I/O Hardware
Parallel I/O Libraries and Techniques
 Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
Parallel I/O Libraries and Techniques Mark Howison User Services & Support I/O for scientifc data I/O is commonly used by scientific applications to: Store numerical output from simulations Load initial
Next-Generation NVMe-Native Parallel Filesystem for Accelerating HPC Workloads
 Next-Generation NVMe-Native Parallel Filesystem for Accelerating HPC Workloads Liran Zvibel CEO, Co-founder WekaIO @liranzvibel 1 WekaIO Matrix: Full-featured and Flexible Public or Private S3 Compatible
Next-Generation NVMe-Native Parallel Filesystem for Accelerating HPC Workloads Liran Zvibel CEO, Co-founder WekaIO @liranzvibel 1 WekaIO Matrix: Full-featured and Flexible Public or Private S3 Compatible
AllScale Pilots Applications AmDaDos Adaptive Meshing and Data Assimilation for the Deepwater Horizon Oil Spill
 This project has received funding from the European Union s Horizon 2020 research and innovation programme under grant agreement No. 671603 An Exascale Programming, Multi-objective Optimisation and Resilience
This project has received funding from the European Union s Horizon 2020 research and innovation programme under grant agreement No. 671603 An Exascale Programming, Multi-objective Optimisation and Resilience
Application Example Running on Top of GPI-Space Integrating D/C
 Application Example Running on Top of GPI-Space Integrating D/C Tiberiu Rotaru Fraunhofer ITWM This project is funded from the European Union s Horizon 2020 Research and Innovation programme under Grant
Application Example Running on Top of GPI-Space Integrating D/C Tiberiu Rotaru Fraunhofer ITWM This project is funded from the European Union s Horizon 2020 Research and Innovation programme under Grant
Task-based distributed processing for radio-interferometric imaging with CASA
 H2020-Astronomy ESFRI and Research Infrastructure Cluster (Grant Agreement number: 653477). Task-based distributed processing for radio-interferometric imaging with CASA BOJAN NIKOLIC 2 nd ASTERICS-OBELICS
H2020-Astronomy ESFRI and Research Infrastructure Cluster (Grant Agreement number: 653477). Task-based distributed processing for radio-interferometric imaging with CASA BOJAN NIKOLIC 2 nd ASTERICS-OBELICS
JÜLICH SUPERCOMPUTING CENTRE Site Introduction Michael Stephan Forschungszentrum Jülich
 JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
JÜLICH SUPERCOMPUTING CENTRE Site Introduction 09.04.2018 Michael Stephan JSC @ Forschungszentrum Jülich FORSCHUNGSZENTRUM JÜLICH Research Centre Jülich One of the 15 Helmholtz Research Centers in Germany
The Fusion Distributed File System
 Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Slide 1 / 44 The Fusion Distributed File System Dongfang Zhao February 2015 Slide 2 / 44 Outline Introduction FusionFS System Architecture Metadata Management Data Movement Implementation Details Unique
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
THOUGHTS ABOUT THE FUTURE OF I/O
 THOUGHTS ABOUT THE FUTURE OF I/O Dagstuhl Seminar Challenges and Opportunities of User-Level File Systems for HPC Franz-Josef Pfreundt, May 2017 Deep Learning I/O Challenges Memory Centric Computing :
THOUGHTS ABOUT THE FUTURE OF I/O Dagstuhl Seminar Challenges and Opportunities of User-Level File Systems for HPC Franz-Josef Pfreundt, May 2017 Deep Learning I/O Challenges Memory Centric Computing :
Emerging Technologies for HPC Storage
 Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
An Exploration into Object Storage for Exascale Supercomputers. Raghu Chandrasekar
 An Exploration into Object Storage for Exascale Supercomputers Raghu Chandrasekar Agenda Introduction Trends and Challenges Design and Implementation of SAROJA Preliminary evaluations Summary and Conclusion
An Exploration into Object Storage for Exascale Supercomputers Raghu Chandrasekar Agenda Introduction Trends and Challenges Design and Implementation of SAROJA Preliminary evaluations Summary and Conclusion
MULTITHERMAN: Out-of-band High-Resolution HPC Power and Performance Monitoring Support for Big-Data Analysis
 MULTITHERMAN: Out-of-band High-Resolution HPC Power and Performance Monitoring Support for Big-Data Analysis EU H2020 FETHPC project ANTAREX (g.a. 671623) EU FP7 ERC Project MULTITHERMAN (g.a.291125) EETHPC,
MULTITHERMAN: Out-of-band High-Resolution HPC Power and Performance Monitoring Support for Big-Data Analysis EU H2020 FETHPC project ANTAREX (g.a. 671623) EU FP7 ERC Project MULTITHERMAN (g.a.291125) EETHPC,
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Workshop: Innovation Procurement in Horizon 2020 PCP Contractors wanted
 Workshop: Innovation Procurement in Horizon 2020 PCP Contractors wanted Supercomputing Centre Institute for Advanced Simulation / FZJ 1 www.prace-ri.eu Challenges: Aging Society Energy Food How we can
Workshop: Innovation Procurement in Horizon 2020 PCP Contractors wanted Supercomputing Centre Institute for Advanced Simulation / FZJ 1 www.prace-ri.eu Challenges: Aging Society Energy Food How we can
Storage for HPC, HPDA and Machine Learning (ML)
") for HPC, HPDA and Machine Learning (ML) Frank Kraemer, IBM Systems Architect mailto:kraemerf@de.ibm.com IBM Data Management for Autonomous Driving (AD) significantly increase development efficiency by
for HPC, HPDA and Machine Learning (ML) Frank Kraemer, IBM Systems Architect mailto:kraemerf@de.ibm.com IBM Data Management for Autonomous Driving (AD) significantly increase development efficiency by
Introduction to HPC Parallel I/O
 Introduction to HPC Parallel I/O Feiyi Wang (Ph.D.) and Sarp Oral (Ph.D.) Technology Integration Group Oak Ridge Leadership Computing ORNL is managed by UT-Battelle for the US Department of Energy Outline
Introduction to HPC Parallel I/O Feiyi Wang (Ph.D.) and Sarp Oral (Ph.D.) Technology Integration Group Oak Ridge Leadership Computing ORNL is managed by UT-Battelle for the US Department of Energy Outline
HPC state of play. HPC Ecosystem. HPC system supply. HPC use 24% EU 4,3% EU. Application software & tools. Academia 23% Bio-sciences 22% CAE 21%
 Only half of US GDP spending HPC state of play HPC Ecosystem HPC system supply 4,3% EU EU market: 630 M/yr (EU lost 10% capacity from 2007 to 2009) 24% EU HPC use Academia 23% Bio-sciences 22% CAE 21%
Only half of US GDP spending HPC state of play HPC Ecosystem HPC system supply 4,3% EU EU market: 630 M/yr (EU lost 10% capacity from 2007 to 2009) 24% EU HPC use Academia 23% Bio-sciences 22% CAE 21%
Application level asynchronous check-pointing / restart: first experiences with GPI
 ERLANGEN REGIONAL COMPUTING CENTER Application level asynchronous check-pointing / restart: first experiences with GPI Faisal Shahzad and Gerhard Wellein Dagstuhl Seminar Resilience in Exascale Computing
ERLANGEN REGIONAL COMPUTING CENTER Application level asynchronous check-pointing / restart: first experiences with GPI Faisal Shahzad and Gerhard Wellein Dagstuhl Seminar Resilience in Exascale Computing
CSD3 The Cambridge Service for Data Driven Discovery. A New National HPC Service for Data Intensive science
 CSD3 The Cambridge Service for Data Driven Discovery A New National HPC Service for Data Intensive science Dr Paul Calleja Director of Research Computing University of Cambridge Problem statement Today
CSD3 The Cambridge Service for Data Driven Discovery A New National HPC Service for Data Intensive science Dr Paul Calleja Director of Research Computing University of Cambridge Problem statement Today
Parallel I/O and Portable Data Formats
 Parallel I/O and Portable Data Formats Sebastian Lührs s.luehrs@fz-juelich.de Jülich Supercomputing Centre Forschungszentrum Jülich GmbH Reykjavík, August 25 th, 2017 Overview I/O can be the main bottleneck
Parallel I/O and Portable Data Formats Sebastian Lührs s.luehrs@fz-juelich.de Jülich Supercomputing Centre Forschungszentrum Jülich GmbH Reykjavík, August 25 th, 2017 Overview I/O can be the main bottleneck
Storage-Based Convergence Between HPC and Big Data
 Storage-Based Convergence Between HPC and Big Data Pierre Matri*, Alexandru Costan, Gabriel Antoniu, Jesús Montes*, María S. Pérez* * Universidad Politécnica de Madrid, Madrid, Spain INSA Rennes / IRISA,
Storage-Based Convergence Between HPC and Big Data Pierre Matri*, Alexandru Costan, Gabriel Antoniu, Jesús Montes*, María S. Pérez* * Universidad Politécnica de Madrid, Madrid, Spain INSA Rennes / IRISA,
Fast Forward I/O & Storage
 Fast Forward I/O & Storage Eric Barton Lead Architect 1 Department of Energy - Fast Forward Challenge FastForward RFP provided US Government funding for exascale research and development Sponsored by 7
Fast Forward I/O & Storage Eric Barton Lead Architect 1 Department of Energy - Fast Forward Challenge FastForward RFP provided US Government funding for exascale research and development Sponsored by 7
FVM - How to program the Multi-Core FVM instead of MPI
 FVM - How to program the Multi-Core FVM instead of MPI DLR, 15. October 2009 Dr. Mirko Rahn Competence Center High Performance Computing and Visualization Fraunhofer Institut for Industrial Mathematics
FVM - How to program the Multi-Core FVM instead of MPI DLR, 15. October 2009 Dr. Mirko Rahn Competence Center High Performance Computing and Visualization Fraunhofer Institut for Industrial Mathematics
Building supercomputers from embedded technologies
 http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
http://www.montblanc-project.eu Building supercomputers from embedded technologies Alex Ramirez Barcelona Supercomputing Center Technical Coordinator This project and the research leading to these results
Extreme I/O Scaling with HDF5
 Extreme I/O Scaling with HDF5 Quincey Koziol Director of Core Software Development and HPC The HDF Group koziol@hdfgroup.org July 15, 2012 XSEDE 12 - Extreme Scaling Workshop 1 Outline Brief overview of
Extreme I/O Scaling with HDF5 Quincey Koziol Director of Core Software Development and HPC The HDF Group koziol@hdfgroup.org July 15, 2012 XSEDE 12 - Extreme Scaling Workshop 1 Outline Brief overview of
Developing Integrated Data Services for Cray Systems with a Gemini Interconnect
 Developing Integrated Data Services for Cray Systems with a Gemini Interconnect Ron A. Oldfield Scalable System So4ware Sandia Na9onal Laboratories Albuquerque, NM, USA raoldfi@sandia.gov Cray User Group
Developing Integrated Data Services for Cray Systems with a Gemini Interconnect Ron A. Oldfield Scalable System So4ware Sandia Na9onal Laboratories Albuquerque, NM, USA raoldfi@sandia.gov Cray User Group
Energy Efficiency Tuning: READEX. Madhura Kumaraswamy Technische Universität München
 Energy Efficiency Tuning: READEX Madhura Kumaraswamy Technische Universität München Project Overview READEX Starting date: 1. September 2015 Duration: 3 years Runtime Exploitation of Application Dynamism
Energy Efficiency Tuning: READEX Madhura Kumaraswamy Technische Universität München Project Overview READEX Starting date: 1. September 2015 Duration: 3 years Runtime Exploitation of Application Dynamism
Data Analytics and Storage System (DASS) Mixing POSIX and Hadoop Architectures. 13 November 2016
 Mixing POSIX and Hadoop Architectures. 13 November 2016") National Aeronautics and Space Administration Data Analytics and Storage System (DASS) Mixing POSIX and Hadoop Architectures 13 November 2016 Carrie Spear (carrie.e.spear@nasa.gov) HPC Architect/Contractor
National Aeronautics and Space Administration Data Analytics and Storage System (DASS) Mixing POSIX and Hadoop Architectures 13 November 2016 Carrie Spear (carrie.e.spear@nasa.gov) HPC Architect/Contractor
Coordinating Parallel HSM in Object-based Cluster Filesystems
 Coordinating Parallel HSM in Object-based Cluster Filesystems Dingshan He, Xianbo Zhang, David Du University of Minnesota Gary Grider Los Alamos National Lab Agenda Motivations Parallel archiving/retrieving
Coordinating Parallel HSM in Object-based Cluster Filesystems Dingshan He, Xianbo Zhang, David Du University of Minnesota Gary Grider Los Alamos National Lab Agenda Motivations Parallel archiving/retrieving
Data Movement & Storage Using the Data Capacitor Filesystem
 Data Movement & Storage Using the Data Capacitor Filesystem Justin Miller jupmille@indiana.edu http://pti.iu.edu/dc Big Data for Science Workshop July 2010 Challenges for DISC Keynote by Alex Szalay identified
Data Movement & Storage Using the Data Capacitor Filesystem Justin Miller jupmille@indiana.edu http://pti.iu.edu/dc Big Data for Science Workshop July 2010 Challenges for DISC Keynote by Alex Szalay identified
The Digitising European Industry strategy & H2020 calls related to Cyber-Physical Systems
 The Digitising European Industry strategy & H2020 calls related to Cyber-Physical Systems #DigitiseEU Dr. Werner Steinhögl European Commission - DG CONNECT Technologies and Systems for Digitising Industry
The Digitising European Industry strategy & H2020 calls related to Cyber-Physical Systems #DigitiseEU Dr. Werner Steinhögl European Commission - DG CONNECT Technologies and Systems for Digitising Industry
Welcome to the. Jülich Supercomputing Centre. D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich
, Forschungszentrum Jülich") Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Thursday, Nov 26 13:00-13:30
Mitglied der Helmholtz-Gemeinschaft Welcome to the Jülich Supercomputing Centre D. Rohe and N. Attig Jülich Supercomputing Centre (JSC), Forschungszentrum Jülich Schedule: Thursday, Nov 26 13:00-13:30
2014 LENOVO INTERNAL. ALL RIGHTS RESERVED.
 2014 LENOVO INTERNAL. ALL RIGHTS RESERVED. Who is Lenovo? A $39 billion, Fortune 500 technology company - Publicly listed/traded on the Hong Kong Stock Exchange - 54,000 employees serving clients in 160+
2014 LENOVO INTERNAL. ALL RIGHTS RESERVED. Who is Lenovo? A $39 billion, Fortune 500 technology company - Publicly listed/traded on the Hong Kong Stock Exchange - 54,000 employees serving clients in 160+
Introduction to High Performance Parallel I/O
 Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
Introduction to High Performance Parallel I/O Richard Gerber Deputy Group Lead NERSC User Services August 30, 2013-1- Some slides from Katie Antypas I/O Needs Getting Bigger All the Time I/O needs growing
PARALLEL I/O FOR SHARED MEMORY APPLICATIONS USING OPENMP
 PARALLEL I/O FOR SHARED MEMORY APPLICATIONS USING OPENMP A Dissertation Presented to the Faculty of the Department of Computer Science University of Houston In Partial Fulfillment of the Requirements for
PARALLEL I/O FOR SHARED MEMORY APPLICATIONS USING OPENMP A Dissertation Presented to the Faculty of the Department of Computer Science University of Houston In Partial Fulfillment of the Requirements for
Scalable In-memory Checkpoint with Automatic Restart on Failures
 Scalable In-memory Checkpoint with Automatic Restart on Failures Xiang Ni, Esteban Meneses, Laxmikant V. Kalé Parallel Programming Laboratory University of Illinois at Urbana-Champaign November, 2012 8th
Scalable In-memory Checkpoint with Automatic Restart on Failures Xiang Ni, Esteban Meneses, Laxmikant V. Kalé Parallel Programming Laboratory University of Illinois at Urbana-Champaign November, 2012 8th
Challenges in HPC I/O
 Challenges in HPC I/O Universität Basel Julian M. Kunkel German Climate Computing Center / Universität Hamburg 10. October 2014 Outline 1 High-Performance Computing 2 Parallel File Systems and Challenges
Challenges in HPC I/O Universität Basel Julian M. Kunkel German Climate Computing Center / Universität Hamburg 10. October 2014 Outline 1 High-Performance Computing 2 Parallel File Systems and Challenges
MPI RUNTIMES AT JSC, NOW AND IN THE FUTURE
 , NOW AND IN THE FUTURE Which, why and how do they compare in our systems? 08.07.2018 I MUG 18, COLUMBUS (OH) I DAMIAN ALVAREZ Outline FZJ mission JSC s role JSC s vision for Exascale-era computing JSC
, NOW AND IN THE FUTURE Which, why and how do they compare in our systems? 08.07.2018 I MUG 18, COLUMBUS (OH) I DAMIAN ALVAREZ Outline FZJ mission JSC s role JSC s vision for Exascale-era computing JSC
Data Management. Parallel Filesystems. Dr David Henty HPC Training and Support
 Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
Data Management Dr David Henty HPC Training and Support d.henty@epcc.ed.ac.uk +44 131 650 5960 Overview Lecture will cover Why is IO difficult Why is parallel IO even worse Lustre GPFS Performance on ARCHER
LUG 2012 From Lustre 2.1 to Lustre HSM IFERC (Rokkasho, Japan)
") LUG 2012 From Lustre 2.1 to Lustre HSM Lustre @ IFERC (Rokkasho, Japan) Diego.Moreno@bull.net From Lustre-2.1 to Lustre-HSM - Outline About Bull HELIOS @ IFERC (Rokkasho, Japan) Lustre-HSM - Basis of Lustre-HSM
LUG 2012 From Lustre 2.1 to Lustre HSM Lustre @ IFERC (Rokkasho, Japan) Diego.Moreno@bull.net From Lustre-2.1 to Lustre-HSM - Outline About Bull HELIOS @ IFERC (Rokkasho, Japan) Lustre-HSM - Basis of Lustre-HSM
PRACE Project Access Technical Guidelines - 19 th Call for Proposals
 PRACE Project Access Technical Guidelines - 19 th Call for Proposals Peer-Review Office Version 5 06/03/2019 The contributing sites and the corresponding computer systems for this call are: System Architecture
PRACE Project Access Technical Guidelines - 19 th Call for Proposals Peer-Review Office Version 5 06/03/2019 The contributing sites and the corresponding computer systems for this call are: System Architecture
PoS(eIeS2013)008. From Large Scale to Cloud Computing. Speaker. Pooyan Dadvand 1. Sònia Sagristà. Eugenio Oñate
008. From Large Scale to Cloud Computing. Speaker. Pooyan Dadvand 1. Sònia Sagristà. Eugenio Oñate") 1 International Center for Numerical Methods in Engineering (CIMNE) Edificio C1, Campus Norte UPC, Gran Capitán s/n, 08034 Barcelona, Spain E-mail: pooyan@cimne.upc.edu Sònia Sagristà International Center
1 International Center for Numerical Methods in Engineering (CIMNE) Edificio C1, Campus Norte UPC, Gran Capitán s/n, 08034 Barcelona, Spain E-mail: pooyan@cimne.upc.edu Sònia Sagristà International Center
libhio: Optimizing IO on Cray XC Systems With DataWarp
 libhio: Optimizing IO on Cray XC Systems With DataWarp May 9, 2017 Nathan Hjelm Cray Users Group May 9, 2017 Los Alamos National Laboratory LA-UR-17-23841 5/8/2017 1 Outline Background HIO Design Functionality
libhio: Optimizing IO on Cray XC Systems With DataWarp May 9, 2017 Nathan Hjelm Cray Users Group May 9, 2017 Los Alamos National Laboratory LA-UR-17-23841 5/8/2017 1 Outline Background HIO Design Functionality
Leveraging Parallelware in MAESTRO and EPEEC
 Leveraging Parallelware in MAESTRO and EPEEC and Enhancements to Parallelware Manuel Arenaz manuel.arenaz@appentra.com PRACE booth #2033 Thursday, 15 November 2018 Dallas, US http://www.prace-ri.eu/praceatsc18/
Leveraging Parallelware in MAESTRO and EPEEC and Enhancements to Parallelware Manuel Arenaz manuel.arenaz@appentra.com PRACE booth #2033 Thursday, 15 November 2018 Dallas, US http://www.prace-ri.eu/praceatsc18/
Systems Architectures towards Exascale
 Systems Architectures towards Exascale D. Pleiter German-Indian Workshop on HPC Architectures and Applications Pune 29 November 2016 Outline Introduction Exascale computing Technology trends Architectures
Systems Architectures towards Exascale D. Pleiter German-Indian Workshop on HPC Architectures and Applications Pune 29 November 2016 Outline Introduction Exascale computing Technology trends Architectures
SUSE. High Performance Computing. Eduardo Diaz. Alberto Esteban. PreSales SUSE Linux Enterprise
 SUSE High Performance Computing Eduardo Diaz PreSales SUSE Linux Enterprise ediaz@suse.com Alberto Esteban Territory Manager North-East SUSE Linux Enterprise aesteban@suse.com HPC Overview SUSE High Performance
SUSE High Performance Computing Eduardo Diaz PreSales SUSE Linux Enterprise ediaz@suse.com Alberto Esteban Territory Manager North-East SUSE Linux Enterprise aesteban@suse.com HPC Overview SUSE High Performance
CERN openlab & IBM Research Workshop Trip Report
 CERN openlab & IBM Research Workshop Trip Report Jakob Blomer, Javier Cervantes, Pere Mato, Radu Popescu 2018-12-03 Workshop Organization 1 full day at IBM Research Zürich ~25 participants from CERN ~10
CERN openlab & IBM Research Workshop Trip Report Jakob Blomer, Javier Cervantes, Pere Mato, Radu Popescu 2018-12-03 Workshop Organization 1 full day at IBM Research Zürich ~25 participants from CERN ~10
XtreemFS a case for object-based storage in Grid data management. Jan Stender, Zuse Institute Berlin
 XtreemFS a case for object-based storage in Grid data management Jan Stender, Zuse Institute Berlin In this talk... Traditional Grid Data Management Object-based file systems XtreemFS Grid use cases for
XtreemFS a case for object-based storage in Grid data management Jan Stender, Zuse Institute Berlin In this talk... Traditional Grid Data Management Object-based file systems XtreemFS Grid use cases for
Storage Challenges at Los Alamos National Lab
 John Bent john.bent@emc.com Storage Challenges at Los Alamos National Lab Meghan McClelland meghan@lanl.gov Gary Grider ggrider@lanl.gov Aaron Torres agtorre@lanl.gov Brett Kettering brettk@lanl.gov Adam
John Bent john.bent@emc.com Storage Challenges at Los Alamos National Lab Meghan McClelland meghan@lanl.gov Gary Grider ggrider@lanl.gov Aaron Torres agtorre@lanl.gov Brett Kettering brettk@lanl.gov Adam
Brent Gorda. General Manager, High Performance Data Division
 Brent Gorda General Manager, High Performance Data Division Legal Disclaimer Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the
Brent Gorda General Manager, High Performance Data Division Legal Disclaimer Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the
Utilizing Unused Resources To Improve Checkpoint Performance
 Utilizing Unused Resources To Improve Checkpoint Performance Ross Miller Oak Ridge Leadership Computing Facility Oak Ridge National Laboratory Oak Ridge, Tennessee Email: rgmiller@ornl.gov Scott Atchley
Utilizing Unused Resources To Improve Checkpoint Performance Ross Miller Oak Ridge Leadership Computing Facility Oak Ridge National Laboratory Oak Ridge, Tennessee Email: rgmiller@ornl.gov Scott Atchley
MULTITHERMAN: Out-of-band High-Resolution HPC Power and Performance Monitoring Support for Big-Data Analysis
 MULTITHERMAN: Out-of-band High-Resolution HPC Power and Performance Monitoring Support for Big-Data Analysis EU H2020 FETHPC project ANTAREX (g.a. 671623) EU FP7 ERC Project MULTITHERMAN (g.a.291125) HPC
MULTITHERMAN: Out-of-band High-Resolution HPC Power and Performance Monitoring Support for Big-Data Analysis EU H2020 FETHPC project ANTAREX (g.a. 671623) EU FP7 ERC Project MULTITHERMAN (g.a.291125) HPC
SEVENTH FRAMEWORK PROGRAMME
 SEVENTH FRAMEWORK PROGRAMME FP7-ICT-2013-10 DEEP-ER DEEP Extended Reach Grant Agreement Number: 610476 D7.1 Report on performance extrapolation based on design decisions Approved Version: 2.0 Author(s):
SEVENTH FRAMEWORK PROGRAMME FP7-ICT-2013-10 DEEP-ER DEEP Extended Reach Grant Agreement Number: 610476 D7.1 Report on performance extrapolation based on design decisions Approved Version: 2.0 Author(s):
EMPRESS Extensible Metadata PRovider for Extreme-scale Scientific Simulations
 EMPRESS Extensible Metadata PRovider for Extreme-scale Scientific Simulations Photos placed in horizontal position with even amount of white space between photos and header Margaret Lawson, Jay Lofstead,
EMPRESS Extensible Metadata PRovider for Extreme-scale Scientific Simulations Photos placed in horizontal position with even amount of white space between photos and header Margaret Lawson, Jay Lofstead,
The Google File System
 The Google File System Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung ACM SIGOPS 2003 {Google Research} Vaibhav Bajpai NDS Seminar 2011 Looking Back time Classics Sun NFS (1985) CMU Andrew FS (1988) Fault
The Google File System Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung ACM SIGOPS 2003 {Google Research} Vaibhav Bajpai NDS Seminar 2011 Looking Back time Classics Sun NFS (1985) CMU Andrew FS (1988) Fault
Optimization of non-contiguous MPI-I/O operations
 Optimization of non-contiguous MPI-I/O operations Enno Zickler Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg
Optimization of non-contiguous MPI-I/O operations Enno Zickler Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg