Lecture 09. Spark for batch and streaming processing FREDERICK AYALA-GÓMEZ. CS-E4610 Modern Database Systems
|
|
|
- Alexander Caldwell
- 5 years ago
- Views:
Transcription
1 CS-E4610 Modern Database Systems Lecture 09 Spark for batch and streaming processing FREDERICK AYALA-GÓMEZ PHD STUDENT I N COMPUTER SCIENCE, ELT E UNIVERSITY VISITING R ESEA RCHER, A A LTO UNIVERSITY 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 1
2 Agenda Why not MapReduce? Spark at a glance How to use Spark? Iterative Algorithms Interactive Analytics Scala at a glance Distributed Data Parallelism Fault Tolerance Programming Model Spark Runtime RDD Transformations (Lazy) Actions (Eager) Reduction Operations Pair RDDs Join Shuffling and Partitioning 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 2
3 User Program Why not map reduce? (1) fork (2) assign map (1) fork Master (1) fork (2) assign reduce MapReduce flows are acyclic split 0 split 1 split 2 split 3 split 4 (3) read worker worker (4) local write (5) remote read worker worker (6) write output file 0 output file 1 Not efficient for some applications Input files worker Map phase Intermediate files (on local disks) Reduce phase Output files Figure 1: Execution overview 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 3
4 Why not map reduce? Zaharia, Matei, et al. "Spark: Cluster computing with working sets." HotCloud (2010): 95. Iterative algorithms Many common machine learning algorithms repeatedly apply the same function on the same dataset (e.g., gradient descent) MapReduce repeatedly reloads (reads & writes) data which is costly 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 4
5 Why not map reduce? Zaharia, Matei, et al. "Spark: Cluster computing with working sets." HotCloud (2010): 95. Interactive analytics Load data in memory and query repeatedly MapReduce would re-read data 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 5

6 Lightning-fast cluster computing Spark at a Glance. 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 6
 Prof.")

7 Before we talk about Spark Let s talk about Scala Java Generics Scala Lightbend (Typesafe) Prof. Martin Odersky Coursera: Functional Programming in Scala, École Polytechnique Fédérale de Lausanne 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 7

8 From Fast Single Cores to Multicores Data from Kunle Olukotun, Lance Hammond, Herb Sutter, Burton Smith, Chris Batten and Krste Asanovic Martin Odersky, "Working Hard to Keep It Simple. OSCON Java /16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 8


9 Typical Bare Metal Servers 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 9
10 High Performance Computing (15/11) RANK SITE CORES 1 National Super Computer Center in Guangzhou China 3,120,000 2 DOE/SC/Oak Ridge National Laboratory United States 560,640 3 DOE/NNSA/LLNL United States 1,572,864 4 RIKEN Advanced Institute for Computational Science (AICS) Japan 705,024 5 DOE/SC/Argonne National Laboratory United States 786,432 6 DOE/NNSA/LANL/SNL United States 301,056 7 Swiss National Supercomputing Centre (CSCS) Switzerland 115,984 8 HLRS - Höchstleistungsrechenzentrum Stuttgart Germany 185,088 9 King Abdullah University of Science and Technology Saudi Arabia 196, Texas Advanced Computing Center/Univ. of Texas United States 462, /16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 10
11 Concurrency and Parallelism Manage concurrent execution threads Execute programs faster using the multi-cores 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 11
12 What can go wrong? Concurrent Threads Shared Mutable State var x = 0 async { x = x + 1} async { x = x * 2} // x could be 0, 1, 2 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 12

13 Threads in Java Manage concurrent & parellel executions Threads Executors ForkJoin Parallel Streams Completable Futures 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 13
14 Scala at a Glance Static Typing Scala Functional - High Order Functions - Immutable over mutable - Avoid Shared Mutable States - Efficient Immutable Data Structures Lightweight Syntax Object Oriented 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 14

15 Scala Collections Help to Organize Data Immutable collections never change. Collections are Sequential or Parallel 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 15
16 Shared Memory Data Parallelism (Scala Parallel collections) result = ratings.map( ) CPU Thread 0 Split data CPU Thread 1 Threads run independently CPU Thread 2 Combine Results 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 16
 Split data among nodes Nodes run independently Node 3 Node 4 Combine Results Network latency is a problem")
17 Distributed Data Parallelism Node 1 Node 2 result = ratings.map( ) Split data among nodes Nodes run independently Node 3 Node 4 Combine Results Network latency is a problem 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 17
18 Distribution: Failure and Latency Task Latency Humanized (Latency * 1 Billion) L1 cache reference 0.5 ns 0.5 s One heart beat (0.5 s) Branch mispredict 5 ns 5 s Yawn L2 cache reference 7 ns 7 s Long yawn Mutex lock/unlock 25 ns 25 s Making a coffee Main memory reference 100 ns 100 s Brushing your teeth Compress 1K bytes with Zippy 3,000 ns = 3 µs 50 min One episode of a TV show (including ad breaks) Send 2K bytes over 1 Gbps network 20,000 ns = 20 µs 5.5 hr From lunch to end of work day SSD random read 150,000 ns = 150 µs 1.7 days A normal weekend Read 1 MB sequentially from 250,000 ns = 250 µs 2.9 days A long weekend memory Round trip within same datacenter 500,000 ns = 0.5 ms 5.8 days A medium vacation Read 1 MB sequentially from SSD* 1,000,000 ns = 1 ms 11.6 days Waiting for almost 2 weeks for a delivery Disk seek 10,000,000 ns = 10 ms 16.5 weeks A semester in university Read 1 MB sequentially from disk 20,000,000 ns = 20 ms 7.8 months Almost producing a new human being Send packet CA->Netherlands->CA 150,000,000 ns = 150 ms 4.8 years Average time it takes to get a bachelor s degree Memory Disk Network Fast >Slow /16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 18
19 Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation. USENIX Association, /16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 19
20 Spark Resilient Distributed Datasets (RDD) Immutable collection of objects (Read-only) Partitioned across machines Once defined, programmer treats it as available (System re-builds it if lost / leaves memory) Users can explicitly cache RDDs in memory Re-use across MapReduce-like parallel operations 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 20
21 Main Challenge: Efficient fault-tolerance Should be easy to re-build if part of data (e.g., a partition) is lost. Achieved through coarse-grained transformations and lineage 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 21
22 Fault-tolerance Coarse transformations e.g., map applies the same function to the data items. Lineage: Series of transformations that led to a dataset. If a partition is lost, there is enough information to reapply the transformations and re-compute it 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 22
23 Programming Model Developers write a drive program high-level control flow Think of RDDs as objects that represent datasets that you distribute among several workers, and transform and apply actions in parallel. Can also use restricted types of shared variables 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 23
24 Spark runtime Driver tasks results RAM Worker Input Data Worker Input Data RAM RAM Worker Input Data 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 24 tion Sca thes nod save the var of a R para
25 RDD Immutable (read-only) collection of objects partitioned across a set of machines, that can be re-built if a partition is lost. Constructed in the following ways: From a file in a shared file system (e.g., HDFS) Parallelizing a collection (e.g., an array) divide into partitions and send to multiple nodes Transforming an existing RDD (applying a map operation) 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 25

26 Hadoop Distributed FS (HDFS) architecture Different than Spark 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 26
27 RDD It does not exist at all time. Instead, there is enough information to compute the RDD when needed. RDDs are lazily-created and ephemeral Lazy: Materialized only when information is extracted from them (through actions!) Ephemeral: Might be discarded after use 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 27
28 Transformations (Lazy) Lazy operations. The results are not immediately computed Create a new RDD 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 28
29 Actions (Eager) RDDs are computed every time you run an action. Return a value to the program or output the results (e.g., HDFS) 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 29
. l00x more performant than MapReduce (Hadoop), and more productive!")
30 Why Spark? Zaharia, Matei, et al. "Spark: Cluster computing with working sets." HotCloud (2010): 95. MapReduce: Spark: Simple API (map, reduce) Fault-tolerant Simple and rich API. Fault-tolerant Reduces latency using ideas from functional programming (immutability, in-memory). l00x more performant than MapReduce (Hadoop), and more productive! Logistic regression in Hadoop and Spark 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 30
 Driver Transformation Action Out[]: There are 20 movies about zombies... scary.")
31 How does a Spark program looks like? (PySpark) Driver Transformation Action Out[]: There are 20 movies about zombies... scary. RDD 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 31
![How does a Spark program looks like? (PySpark) Driver RDD Transformation Action Out[]: There are 20 movies about zombies... scary!](/docs-images/92/109593880/images/32-2.jpg "Out[]: There are 524 movies about romance <3 Let s think about what happened 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING")
32 How does a Spark program looks like? (PySpark) Driver RDD Transformation Action Out[]: There are 20 movies about zombies... scary! Out[]: There are 524 movies about romance <3 Let s think about what happened 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 32
33 Caching and Persistence To prevent re-computing the RDDs, we can persist the data. cache: Memory only storage persist: Persistence can be customized at different levels (e.g., memory, disk) The default persistence is at memory level 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 33
 Driver Persist RDD Action Out[]: There")


34 How does a Spark program looks like? (PySpark) Driver Persist RDD Action Out[]: There are 20 movies about zombies... scary! Out[]: There are 524 movies about romance <3 Transformation In the second time, the lines RDD was loaded from memory 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 34
 Driver Program Cluster Manager (YARN/Mesos) Run")
 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING")
35 Cluster Topology Contains the main Creates RDDs Coordinates the execution (transformations and actions) Driver Program Cluster Manager (YARN/Mesos) Run tasks Return Results Persist RDDs Worker Node (Executor) Worker Node (Executor) Worker Node (Executor) 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 35
36 YARN-cluster mode 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 36
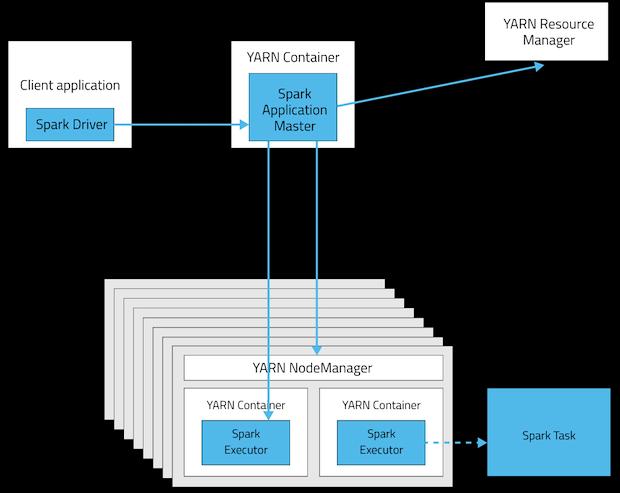

37 YARN-client mode 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 37

38 Difference between running modes 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 38
![Cluster Topology - Evaluation Out[]: There are 20 movies about zombies... scary.](/docs-images/92/109593880/images/39-2.jpg "Action Where are the zombie movies printed?")
39 Cluster Topology - Evaluation Out[]: There are 20 movies about zombies... scary. Action Where are the zombie movies printed? 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 39
40 Cluster Topology - Evaluation Actions usually communicate between workers nodes and the driver s node. It is important to think about where the tasks are going to be executed. Large RDDs may cause out of memory errors in the driver node for some actions (e.g., collect). In that case, it s a good idea to output directly from the worker. 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 40
41 Reduction Operations Traverse a collection and combine elements to produce a single combined result. reduce(op) Reduces the elements of this RDD using the specified associative and cumulative operator. fold(zerovalue, op) Aggregate the elements of each partition, and then the results for all the partitions, using a given associative function and a neutral "zero value." Requires the same type of data in the return. aggregate(zerovalue, seqop, combop) Aggregate the elements of each partition, and then the results for all the partitions, using a given combine functions and a neutral "zero value." Possible to change the return type. 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 41
 Useful because it improves how we handle the RDD Pair RDDs have special methods for working with the data associated to the keys.")
42 Pair RDD Dean, Jeffrey, and Sanjay Ghemawat. "MapReduce: simplified data processing on large clusters." Communications of the ACM 51.1 (2008): Usually, we have large datasets that we can organize by a key (e.g., movie_id, user_id) Useful because it improves how we handle the RDD Pair RDDs have special methods for working with the data associated to the keys. 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 42

43 GroupByKey example 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 43
44 ReduceByKey example 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 44
45 Word Count example Out[]: ('the', 20711) ('and', 15343) ('a', 10785) ('of', 9892) ('film', 9206) ('by', 8377) ('in', 7646) ('The', 7362) ('is', 6290) ('was', 5728) 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 45
46 Join You can combine Pair RDDs using a join. The combination can be by: Inner joins (join) Key that appear in both Pair RDDs Outer joins (left0uterjoin/right0uterjoin) Guarantees that on the RDD all they keys (left or right) will be present Keys that do not appear on the other RDD have a None value. 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 46
47 Shuffling and Partitioning Partitioning Partitioning Shuffle Shuffle and partitioning is expensive! As it they have to send data in the network 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 47


48 Spark Streaming Motivation Big Data never stops Data is being produced all the time Spark provides a DStream to handle sources that send data constantly 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 48

49 DStream Discretized Stream represents a continuous stream of data Input data stream is received from source, or the processed data stream generated by transforming the input stream. Internally DStream is a continuous series of RDDs Each RDD in a DStream contains data from a certain interval Similarly, we can apply transformations and actions to Dstreams. 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 49
50 As a summary Spark is a distributed big data processing framework. Distribution brings new concerns: Node failure and latency Uses Resilient Distributed Datasets (RDD) to distribute and parallelize the data. RDDs are lazily-created and ephemeral Caching and persistence is used to preserve a RDD in memory, disk, or both RDDs are fault tolerant Able to recover the state of an RDD using coarse-grained transformations and lineage. Transformations are lazy (e.g., map, filter, groupby, sortby, reducebykey) Actions are eager (e.g., take, collect, reduce, first, foreach) The topology of the cluster matters Working with RDDs implies shuffling and partitioning Impact on performance due to latency Spark provides Big Data Streaming processing via DStreams 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 50
51 That s all for now! Tutorial: Batch and streaming processing with PySpark Monday, 19 March, 14:15» 16:00, T2 / C105 (T2), Tietotekniikka, Konemiehentie 2 Thanks! Questions? Frederick Ayala-Gómez frederick.ayala@aalto.fi 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 51
52 Credits and References Slides from Michael Mathioudakis from previous Aalto s Modern Database Systems Course. Big Data Analysis with Scala and Spark, Dr. Heather Miller, École Polytechnique Fédérale de Lausanne. Zaharia, Matei, et al. "Spark: Cluster Computing with Working Sets." HotCloud 10 (2010): Zaharia, Matei, et al. "Resilient distributed datasets: A fault-tolerant abstraction for inmemory cluster computing." Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation. Learning Spark: Lightning-Fast Big Data Analysis, by Holden Karau, Andy Konwinski, Patrick Wendell, Matei Zaharia 03/16/2018 LECTURE 09 SPARK FOR BATCH AND STREAMING PROCESSING 52
L3: Spark & RDD. CDS Department of Computational and Data Sciences. Department of Computational and Data Sciences
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
CSC 261/461 Database Systems Lecture 24. Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101
 CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
CSC 261/461 Database Systems Lecture 24 Spring 2017 MW 3:25 pm 4:40 pm January 18 May 3 Dewey 1101 Announcements Term Paper due on April 20 April 23 Project 1 Milestone 4 is out Due on 05/03 But I would
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Introduction to Spark
 Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
Big Data Analytics with Apache Spark. Nastaran Fatemi
 Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Spark: A Brief History. https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf
 Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/85/91873103.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Frequently asked questions from the previous class survey 48-bit bookending in Bzip2: does the number have to be special? Spark seems to have too many
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Frequently asked questions from the previous class survey 48-bit bookending in Bzip2: does the number have to be special? Spark seems to have too many
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK STREAMING] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Can Spark repartition
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK STREAMING] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Can Spark repartition
Introduction to Apache Spark
 Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/22/2018 Week 10-A Sangmi Lee Pallickara. FAQs.
 10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/83/87457683.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Return type for collect()? Can
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Return type for collect()? Can
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
CS Spark. Slides from Matei Zaharia and Databricks
 CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
MapReduce & Resilient Distributed Datasets. Yiqing Hua, Mengqi(Mandy) Xia
 Xia") MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
MapReduce & Resilient Distributed Datasets Yiqing Hua, Mengqi(Mandy) Xia Outline - MapReduce: - - Resilient Distributed Datasets (RDD) - - Motivation Examples The Design and How it Works Performance Motivation
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
a Spark in the cloud iterative and interactive cluster computing
 a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
a Spark in the cloud iterative and interactive cluster computing Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Data processing in Apache Spark Pelle Jakovits 5 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Frameworks
Spark. In- Memory Cluster Computing for Iterative and Interactive Applications
 Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Spark In- Memory Cluster Computing for Iterative and Interactive Applications Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker,
Bringing code to the data: from MySQL to RocksDB for high volume searches
 Bringing code to the data: from MySQL to RocksDB for high volume searches Percona Live 2016 Santa Clara, CA Ivan Kruglov Senior Developer ivan.kruglov@booking.com Agenda Problem domain Evolution of search
Bringing code to the data: from MySQL to RocksDB for high volume searches Percona Live 2016 Santa Clara, CA Ivan Kruglov Senior Developer ivan.kruglov@booking.com Agenda Problem domain Evolution of search
We consider the general additive objective function that we saw in previous lectures: n F (w; x i, y i ) i=1
 i=1") CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
CSE 544 Principles of Database Management Systems. Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 10 Parallel Programming Models: Map Reduce and Spark Announcements HW2 due this Thursday AWS accounts Any success? Feel
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Reactive App using Actor model & Apache Spark. Rahul Kumar Software
 Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/83/87457744.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey If an RDD is read once, transformed will Spark
CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey If an RDD is read once, transformed will Spark
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
1. HPC & I/O 2. BioPerl
 1. HPC & I/O 2. BioPerl A simplified picture of the system User machines Login server(s) jhpce01.jhsph.edu jhpce02.jhsph.edu 72 nodes ~3000 cores compute farm direct attached storage Research network
1. HPC & I/O 2. BioPerl A simplified picture of the system User machines Login server(s) jhpce01.jhsph.edu jhpce02.jhsph.edu 72 nodes ~3000 cores compute farm direct attached storage Research network
Structured Streaming. Big Data Analysis with Scala and Spark Heather Miller
 Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
COSC-589 Web Search and Sense-making Information Retrieval In the Big Data Era. Spring Instructor: Grace Hui Yang
 COSC-589 Web Search and Sense-making Information Retrieval In the Big Data Era Spring 2016 Instructor: Grace Hui Yang The Web provides abundant information which allows us to live more conveniently and
COSC-589 Web Search and Sense-making Information Retrieval In the Big Data Era Spring 2016 Instructor: Grace Hui Yang The Web provides abundant information which allows us to live more conveniently and
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Big Data Analytics with Apache Spark (Part 2) Nastaran Fatemi
 Nastaran Fatemi") Big Data Analytics with Apache Spark (Part 2) Nastaran Fatemi What we ve seen so far Spark s Programming Model We saw that, at a glance, Spark looks like Scala collections However, internally, Spark behaves
Big Data Analytics with Apache Spark (Part 2) Nastaran Fatemi What we ve seen so far Spark s Programming Model We saw that, at a glance, Spark looks like Scala collections However, internally, Spark behaves
Discretized Streams. An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters
 Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Introduction to Apache Spark. Patrick Wendell - Databricks
 Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
SparkStreaming. Large scale near- realtime stream processing. Tathagata Das (TD) UC Berkeley UC BERKELEY
 UC Berkeley UC BERKELEY") SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
SparkStreaming Large scale near- realtime stream processing Tathagata Das (TD) UC Berkeley UC BERKELEY Motivation Many important applications must process large data streams at second- scale latencies
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
COMP Parallel Computing. Lecture 22 November 29, Datacenters and Large Scale Data Processing
 - Parallel Computing Lecture 22 November 29, 2018 Datacenters and Large Scale Data Processing Topics Parallel memory hierarchy extend to include disk storage Google web search Large parallel application
- Parallel Computing Lecture 22 November 29, 2018 Datacenters and Large Scale Data Processing Topics Parallel memory hierarchy extend to include disk storage Google web search Large parallel application
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big Data Analytics. C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark. Lars Schmidt-Thieme
 Big Data Analytics C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer
Big Data Analytics C. Distributed Computing Environments / C.2. Resilient Distributed Datasets: Apache Spark Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute of Computer
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Concepts and Technologies for Distributed Systems and Big Data Processing Futures, Async, and Actors
 Concepts and Technologies for Distributed Systems and Big Data Processing Futures, Async, and Actors KTH Royal Institute of Technology Stockholm, Sweden TU Darmstadt, Germany, 19 May and 26 May 2017 About
Concepts and Technologies for Distributed Systems and Big Data Processing Futures, Async, and Actors KTH Royal Institute of Technology Stockholm, Sweden TU Darmstadt, Germany, 19 May and 26 May 2017 About
IoT Platform using Geode and ActiveMQ
 IoT Platform using Geode and ActiveMQ Scalable IoT Platform Swapnil Bawaskar @sbawaskar sbawaskar@apache.org Agenda Introduction IoT MQTT Apache ActiveMQ Artemis Apache Geode Real world use case Q&A 2
IoT Platform using Geode and ActiveMQ Scalable IoT Platform Swapnil Bawaskar @sbawaskar sbawaskar@apache.org Agenda Introduction IoT MQTT Apache ActiveMQ Artemis Apache Geode Real world use case Q&A 2
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics
 Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
Clash of the Titans: MapReduce vs. Spark for Large Scale Data Analytics Presented by: Dishant Mittal Authors: Juwei Shi, Yunjie Qiu, Umar Firooq Minhas, Lemei Jiao, Chen Wang, Berthold Reinwald and Fatma
15.1 Data flow vs. traditional network programming
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 15, 5/22/2017. Scribed by D. Penner, A. Shoemaker, and
Distributed Computing with Spark and MapReduce
 Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Distributed Computing with Spark and MapReduce Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Traditional Network Programming Message-passing between nodes (e.g. MPI) Very difficult to do at scale:» How
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
A Parallel R Framework
 A Parallel R Framework for Processing Large Dataset on Distributed Systems Nov. 17, 2013 This work is initiated and supported by Huawei Technologies Rise of Data-Intensive Analytics Data Sources Personal
A Parallel R Framework for Processing Large Dataset on Distributed Systems Nov. 17, 2013 This work is initiated and supported by Huawei Technologies Rise of Data-Intensive Analytics Data Sources Personal
Applied Spark. From Concepts to Bitcoin Analytics. Andrew F.
 Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Spark Streaming. Guido Salvaneschi
 Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Data processing in Apache Spark Pelle Jakovits 8 October, 2014, Tartu Outline Introduction to Spark Resilient Distributed Data (RDD) Available data operations Examples Advantages and Disadvantages Frameworks
Data processing in Apache Spark
 Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Data processing in Apache Spark Pelle Jakovits 21 October, 2015, Tartu Outline Introduction to Spark Resilient Distributed Datasets (RDD) Data operations RDD transformations Examples Fault tolerance Streaming
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Memory-Based Cloud Architectures
 Memory-Based Cloud Architectures ( Or: Technical Challenges for OnDemand Business Software) Jan Schaffner Enterprise Platform and Integration Concepts Group Example: Enterprise Benchmarking -) *%'+,#$)
Memory-Based Cloud Architectures ( Or: Technical Challenges for OnDemand Business Software) Jan Schaffner Enterprise Platform and Integration Concepts Group Example: Enterprise Benchmarking -) *%'+,#$)
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
Integration of Machine Learning Library in Apache Apex
 Integration of Machine Learning Library in Apache Apex Anurag Wagh, Krushika Tapedia, Harsh Pathak Vishwakarma Institute of Information Technology, Pune, India Abstract- Machine Learning is a type of artificial
Integration of Machine Learning Library in Apache Apex Anurag Wagh, Krushika Tapedia, Harsh Pathak Vishwakarma Institute of Information Technology, Pune, India Abstract- Machine Learning is a type of artificial
CS535 Big Data Fall 2017 Colorado State University 9/19/2017 Sangmi Lee Pallickara Week 5- A.
 http://wwwcscolostateedu/~cs535 9/19/2016 CS535 Big Data - Fall 2017 Week 5-A-1 CS535 BIG DATA FAQs PART 1 BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 3 IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
http://wwwcscolostateedu/~cs535 9/19/2016 CS535 Big Data - Fall 2017 Week 5-A-1 CS535 BIG DATA FAQs PART 1 BATCH COMPUTING MODEL FOR BIG DATA ANALYTICS 3 IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
Introduction to Apache Spark
 1 Introduction to Apache Spark Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of this lectures is inspired by: The lecture notes of Yann Vernaz. The lecture notes of Vincent
1 Introduction to Apache Spark Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of this lectures is inspired by: The lecture notes of Yann Vernaz. The lecture notes of Vincent
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci, Charles Zheng.
 CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Databricks and Stanford. Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci,
CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Databricks and Stanford. Lecture 4, 04/08/2015. Scribed by Eric Lax, Andreas Santucci,
A (quick) retrospect. COMPSCI210 Recitation 22th Apr 2013 Vamsi Thummala
 retrospect. COMPSCI210 Recitation 22th Apr 2013 Vamsi Thummala") A (quick) retrospect COMPSCI210 Recitation 22th Apr 2013 Vamsi Thummala Latency Comparison L1 cache reference 0.5 ns Branch mispredict 5 ns L2 cache reference 7 ns 14x L1 cache Mutex lock/unlock 25 ns
A (quick) retrospect COMPSCI210 Recitation 22th Apr 2013 Vamsi Thummala Latency Comparison L1 cache reference 0.5 ns Branch mispredict 5 ns L2 cache reference 7 ns 14x L1 cache Mutex lock/unlock 25 ns
Introduction to MapReduce Algorithms and Analysis
 Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Introduction to MapReduce Algorithms and Analysis Jeff M. Phillips October 25, 2013 Trade-Offs Massive parallelism that is very easy to program. Cheaper than HPC style (uses top of the line everything)
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/24/2018 Week 10-B Sangmi Lee Pallickara
 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
Survey on Incremental MapReduce for Data Mining
 Survey on Incremental MapReduce for Data Mining Trupti M. Shinde 1, Prof.S.V.Chobe 2 1 Research Scholar, Computer Engineering Dept., Dr. D. Y. Patil Institute of Engineering &Technology, 2 Associate Professor,
Survey on Incremental MapReduce for Data Mining Trupti M. Shinde 1, Prof.S.V.Chobe 2 1 Research Scholar, Computer Engineering Dept., Dr. D. Y. Patil Institute of Engineering &Technology, 2 Associate Professor,
Shuffling, Partitioning, and Closures. Parallel Programming and Data Analysis Heather Miller
 Shuffling, Partitioning, and Closures Parallel Programming and Data Analysis Heather Miller What we ve learned so far We extended data parallel programming to the distributed case. We saw that Apache Spark
Shuffling, Partitioning, and Closures Parallel Programming and Data Analysis Heather Miller What we ve learned so far We extended data parallel programming to the distributed case. We saw that Apache Spark
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark