Part Discovery from Partial Correspondence
|
|
|
- Rebecca Owens
- 6 years ago
- Views:
Transcription



1 Part Discovery from Partial Correspondence Subhransu Maji Gregory Shakhnarovich Toyota Technological Institute at Chicago, IL, USA Abstract We study the problem of part discovery when partial correspondence between instances of a category are available. For visual categories that exhibit high diversity in structure such as buildings, our approach can be used to discover parts that are hard to name, but can be easily expressed as a correspondence between pairs of images. Parts naturally emerge from point-wise landmark matches across many instances within a category. We propose a learning framework for automatic discovery of parts in such weakly supervised settings, and show the utility of the rich part library learned in this way for three tasks: object detection, category-specific saliency estimation, and fine-grained image parsing. 1. Introduction Many visual categories have inherent structure: body parts of animals, itectural elements in a building, components of mechanical devices, etc. Discovery of such structure may be highly useful in design of recognition algorithms applicable on a large scale. Prior work in computer vision has addressed this task as either unsupervised, or highly supervised, with painstakingly annotated image sets. In this paper, we study the problem of discovering such structure with only a weak form of supervision: partial correspondence between pairs of instances within an object category. Notion of parts is important to computer vision because much of recent work on visual recognition relies on the idea of representing a category as a composition of smaller fragments (or parts) arranged in variety of layouts. The parts act as diagnostic elements for the category; their presence and arrangement provides rich information regarding the presence and location of the object, its pose, size and finegrained properties, e.g., itectural style of a building or type of a car. Structure discovery may be especially important for categories of man-made objects, such as buildings, furniture, boats or aeroplanes. Examples of such categories are shown in Figure 1. Presence or absence of parts, or the number Figure 1. Objects and their diagnostic parts. of their appearances, varies across instances; e.g., a church building may or may not have a spire, an airplane may have four, two or no visible engines. Furthermore, instances of these parts could differ drastically in their appearance, e.g., shape of s for buildings, form of armrests for chairs. Still, despite this structural flexibility and appearance variability, humans can reliably recognize corresponding points across instances, even when the observer does not have a name for the part and does not precisely know its function. We leverage this ability through a recently introduced annotation paradigm that relies on people marking such correspondences, and propose a novel approach to construction of a library of parts driven by such annotations. Such annotations can enable discovery of parts that are aligned to human-semantics for categories that are otherwise hard to annotate using traditional methods of named keypoints, and part bounding boxes. We show the utility of the rich part library learned in this way for three tasks: object detection, category-specific saliency estimation, and fine-grained image parsing Prior Work Most modern object detection methods rely on the notion of parts. These approaches differ on two important axes: 1
, which are much more semantic in nature than matches obtained using SIFT descriptors (right).")


![More recent work has exploited the idea of pictorial structures [9] and deformable part models [8].](/docs-images/80/81757716/images/2-4.jpg "In such models parts are learned as a byproduct of optimizing the discriminative objective, involving reasoning about part appearance as well as their joint location relative to the object.")


![The idea of using pairwise correspondences as source of learning parts was introduced in [15], along with an intuitive interface for collecting such correspondences.](/docs-images/80/81757716/images/2-7.jpg "However, in [15] parts were learned in a rather naïve fashion, and no framework for selecting the parts was proposed, nor was the utility of the learned parts demonstrated on any task.")

2 Semantic correspondence SIFT correspondence Figure 2. Example annotations collected on Amazon s Mechanical Turk (left), which are much more semantic in nature than matches obtained using SIFT descriptors (right). complexity of part library, and the level of supervision in part construction or discovery. Poselet models [1, 2] rely on highly supervised annotations in which a set of 1 to 2 keypoints per category, defined by the designer of the annotation task, are marked. A large library of parts (poselets) is then formed by finding repeatable and detectable configurations of these keypoints. In contrast, in many models the parts are learned automatically. This idea goes back to constellation models [22, 21] where the parts were learned via clustering of patches. More recent work has exploited the idea of pictorial structures [9] and deformable part models [8]. In such models parts are learned as a byproduct of optimizing the discriminative objective, involving reasoning about part appearance as well as their joint location relative to the object. Such approaches are usually limited to a handful of parts per model; in contrast we learn much larger libraries of parts. A very different approach is taken in [19, 4], where parts are learned and selected in an iterative framework, with the objective to optimize specificity/sensitivity tradeoff. Our work differs in its use of the correspondence annotations, used very efficiently via semantic graph defined in the next section. This is a much more efficient strategy for constraining the se space. The idea of using pairwise correspondences as source of learning parts was introduced in [15], along with an intuitive interface for collecting such correspondences. However, in [15] parts were learned in a rather naïve fashion, and no framework for selecting the parts was proposed, nor was the utility of the learned parts demonstrated on any task. In this paper we show how we can leverage the pairwise correspondence data to multiple fundamental tasks. One can contrast this approach to using correspondences between detected interest points. Methods that rely on such interest points use them as a kind of parts, and compare them with either universal descriptors like SIFT, or descriptors learned for the task. Examples of such approach include [17, 14, 2]. The latter work describes learning correspondence between patches that described the same element (part) of an urban scene. In contrast to our work, the points are detected using interest point operator, and the training relies on 3D correspondences obtained from structure from motion. As we show in Section 5, using generic interest point operators is inferior to using category-specific parts learned using our proposed approach. Finally, a relevant body of work [5, 18, 7] addresses learning a good set of parts or attributes which are often parts in disguise. The focus there is usually either on unsupervised learning, or on learning nameable parts; our work, in contrast, occupies the middle ground in which we rely on semantic meaning of parts perceived by humans without forcing a potentially contrived nameable nomenclature. In the sections below we describe the procedure for learning a basic library of parts for a category using pairwise correspondences, and then proceed with a description of applying the part library to three tasks: object detection, landmark prediction and fine-grained image parsing. 2. From partial correspondence to parts In this section we describe the framework for learning a library of parts using the correspondence annotations. We describe the annotation framework which was used to collect annotations in Section 2.1; how these can be used to define a semantic graph between images that enables part discovery in Section 2.2; the discriminative learning framework to learn part appearance models in Section Obtaining correspondence annotations Following [15] we obtain correspondence annotations by presenting subjects with pairs of images, and asking them to click on pairs of matching points in the two instances of the category. People were recruited to annotate images on Amazon Mechanical Turk. They were given concise instructions, asking them to annotate landmarks, defined as any interesting feature of a church building. They were given a few visual examples, along with an emphatic clarification that these are not exhaustive; no further instructions were provided. Then, each person was presented with a sequence of image pairs, each containing a prominent church building. They can click on any number of landmark pairs that they deem corresponding between the two images.
, include a variety of semantic matches: identical structural elements of buildings (s, spires, corners, and gables), and vaguely")
. 2.2. Semantic graph of correspondence Figure 3 illustrates how landmark correspondences between instances can be used to estimate the corresponding bounding boxes of parts in the two images.")
.")
![The correspondence can be propagated beyond explicitly clicked landmark pairs using the semantic graph [15].](/docs-images/80/81757716/images/3-4.jpg "In this graph, there is an edge connecting every pair of landmarks identified as matching in the annotation.")
3 Using this interface, we have collected annotations for 1 pairs among 288 images of church buildings downloaded from Flickr. Landmark pairs, a few examples of which are shown in Figure 2 (left), include a variety of semantic matches: identical structural elements of buildings (s, spires, corners, and gables), and vaguely defined yet consistent matches, the likes of the mid-point of roof slope. Compare these to matches obtained using SIFT features as seen in Figure 2 (right) Semantic graph of correspondence Figure 3 illustrates how landmark correspondences between instances can be used to estimate the corresponding bounding boxes of parts in the two images. We estimate the similarity transform (translation and scaling) that maps the landmarks within the box from one image to another. If there are less than two landmarks within the box we set the scale as the relative scale of the two objects (determined by the bounding box of the entire set of landmarks in each image). The correspondence can be propagated beyond explicitly clicked landmark pairs using the semantic graph [15]. In this graph, there is an edge connecting every pair of landmarks identified as matching in the annotation. In this way, we can trace a part along a path in semantic graph from an image in left column to an image in the right column, even though we do not have explicit annotation for that pair of images. Figure 4 shows various parts found from the source image by propagating the correspondence in the semantic graph in a breadth first manner. There are multiple ways to reach the same image by traversing different intermediate images and landmark pairs and we maintain a set of nonoverlapping s for each image. Doing so enables us to find multiple occurrences of a part in an object Learning a library of parts The main idea of our algorithm for learning parts is to start with a possible single example of a part sampled from the data, augment it by examples harvested over the semantic graph, and construct a robust appearance model for the part that can explain sufficient fraction of these examples. Sampling seed s. We sample parts around the clicked landmarks in each image. The landmarks represent parts of the whole that are partially matched across instances. However the scale of the part around each landmark is unknown. We sample a large number of seed s centered at each landmark, uniformly at random. The uniform sampling respects the underlying frequency of each part, i.e., parts that are matched frequently across each image are likely to be sampled frequently. It is useful to contrast this method to alternative methods for sampling seeds. Sampling uniformly over image pix- Figure 3. Correspondence propagation in the semantic graph from the image on the left to the image on the right in each row. els would clearly be wasteful. Sampling using responses of a generic interest point operator such as Harris corner or DoG operator [14] might seem like a plausible alternative. However, as we show in Section 5, it is inferior to the landmark-driven saliency. Learning an appearance model. We use HOG features [3] to model part appearance. Given a sampled seed, we initialize the model by training the HOG filter w () to separate the seed patch from a set of background patches; this step resembles the exemplar-svm of [16]. Next, we propagate the correspondence from the seed using breadth-first se in the semantic graph as shown in Figure 4. This provides a set of hypothesized locations for the part in other images. We denote them x(i i,l () i,s () i ), for i =1,...,k, where x(i,l,s) is the patch extracted from image I at location L and with scale s; these locations and scales are estimated as explained in Section 2.2 and shown in Figure 3. We would like to use these additional likely examples of the part to retrain the model. Since the correspondence is sparse, the estimated location and scale of these initial hypothesized matches is likely noisy. Furthermore, some of these matches may belong to a different visual sub-type of the part, e.g., a different kind of or door. Therefore we treat the unknown location and scale of the matches as latent variables, and train the model using the following iterative algorithm. In iteration t, we find for each hypothesized match the


 w(t 1), x(ii, L, s) (1) Where, N (L, s) denotes all the locations and")
 greater than τ =.5 with the rectangle at (L, s).")

.")

.")

 method of [11] to learn w.")















4 Figure 4. Breadth-first correspondence propagation in the semantic graph. The source part in shown in red in the leftmost figure. Parts found at depth one and two are shown in green and blue respectively. location and scale near the initial estimate obtained using the semantic graph that maximize the response of w(t 1) : (t) (t) (Li, si ) = argmax () () L,s N (Li,si ) w(t 1), x(ii, L, s) (1) Where, N (L, s) denotes all the locations and scales for which the corresponding rectangles have an overlap (defined as the intersection over union of areas) greater than τ =.5 with the rectangle at (L, s). Then, we retrain w(t) (t) (t) using the updated list of matches x(ii, Li, si ) as positive examples, and continue to next iteration until convergence. To make the process robust under visual diversity, we only retain w(t) using the k matches with the highest score under w(t 1). In practice the process converges in a few iterations. This procedure is illustrated in Figure 5. For each of three parts shown, the top row contains the initial hypothesized matches found using semantic graph (ordered by depth at which they were found). The bottom row shows the refined matches after the training converges, with location and scale at which the response to the filter w is maximized. The ordering now reflects the response in (1). We use the Linear Discriminant Analysis (LDA) method of [11] to learn w. The method replaces the entire negative set by a single Gaussian distribution estimated from a large number of images. This significantly speeds up the learning procedure as it avoids the hard-negative mining step commonly during training. However, we still have to perform the latent updates described in Equation 1 during training. 3. Experimental setup Datasets for training and testing. For our experiments we divided the set of 288 annotated images as described in Section 2.1 into a training set of 216 images, and a test set of 72 images. We call this dataset church-corr. During training we only use the semantic graph edges entirely contained in the training set (church-corr-train), resulting in 617 correspondence pairs, each labelled with an average of five landmarks. The test set (church-corr-test) is used to evaluate the utility of parts for predicting the location of the human-clicked landmarks, a semantic saliency prediction task described in Section 5. Since the church-corr dataset contains church buildings that occupy most of the image, we collected an additional set of 127 images where the church building occupies a small portion of the image to test the utility of parts for localizing them (Section 4). The chance performance of detection in these images is small. For these images we also obtained bounding box annotations and the set if further divided into a training set of 64 images and a test set of 63 images. We call this dataset church-loc. Methods for training parts. We compare various methods of learning parts: (1) Exemplar LDA (random seeds): randomly sampled seeds w/o graph (2) Exemplar LDA (landmark seeds): seeds sampled on landmarks w/o graph (3) Latent LDA: seeds sampled on landmarks w/ graph (4) Discriminative patches [19]. The first ignores the annotations completely and can be thought of as a simplified version of [19]. It lacks the careful cross-validation and multiple rounds of training with kmeans like clustering in between iterations. The second simply uses the landmarks to bias the seed sampling step, hopefully resulting in fewer wasted seeds. The third (our proposed method) additionally uses the correspondence annotations to find similar patches in the training set using the procedure described in Section 2.3. In comparison to [19], this step is computationally much more efficient since the se for similar patches is restricted to a small fraction s in the entire set using the semantic graph. We trained a set of 2 parts for various methods on the church-corr-train subset. For our graph-based learning we restricted the maximum depth of our breadth-first se to two. For [19] we used publicly available code provided by the authors which takes as input the number of desired
 Learned HOG filter")

 and the latent se")
 described in Section 2.3.")















![based detector [13] for](/docs-images/80/81757716/images/5-21.jpg "combining multiple parts.")































5 filter similar s Figure 5. (Left) Learned HOG filter along with the top 1 locations of each part found using the semantic graph (top row for each part) and the latent se procedure (bottom row for each part) described in Section 2.3. patches. During training however some of these are dropped resulting in a fewer number of trained patches, hence we trained a larger number of discriminative patches and selected a random subset of 2 for a fair comparison. 4. Detecting church buildings The parts learned in the previous step can be utilized for localizing objects. On the training data we can estimate the spatial distribution of the object relative to the part and use this to predict the location of the object. Specifically, we use the top 1 detections on the church-loc-train set to estimate the mean offsets in scale and location of the object bounding box relative to the part bounding box. Figure 7 shows some parts, their estimated offsets, and top few detections. We use a simple Hough voting based detector [13] for combining multiple parts. Votes from multiple part detections are combined in a greedy manner. For each image, part detections are sorted by their detection score (after normalizing to [, 1] using the sigmoid function) and considered one by one to find clusters of parts that belong together (based on the overlap of their predicted bounding boxes being greater than τ =.5). We stop after n=5 part detections are considered. Each cluster represents a detection, from which we predict the overall bounding box as the weighted average of the predictions of each member and score as the sum of their detection scores. This is similar to the detection strategy using poselets [1]. Other baselines. In addition we trained the following deformable part models [8] using voc-release5 of the code [1]: (1) Single root only model without parts, (2) Mixture of three root only models, (3) Single root + part model, and (4) Mixture of three root + part models. These were trained on the same subset of images (churchcorr-train) used for training our parts. As a reference the last model is nearly the state-of-the-art on the PASCAL VOC object detection challenge [6] Results We adopt the PASCAL VOC setup for evaluating detections. Bounding box predictions that overlap the ground truth bounding box (defined by the intersection over union) greater than τ are considered correct detections, while multiple detections of the same object are considered false positives. We refer the readers to [6] for details. We compare various methods for training parts individually and as a combination for localizing church buildings on the churchloc-test set. From our experiments we make the following observations: Landmark seeds are better than random seeds. This can be seen in Figure 6 (left) which plots the performance of various parts sorted by the detection AP. The performance of the exemplar LDA method using landmark seeds is significantly better than using random seeds, as can be seen by the difference between the red curve and the dashed black curve in 6 (left).
6 Using the semantic graph leads to further improvements. This can be seen as the difference between the solid black curve and the dashed black curve in Figure 6 (left). Moreover, the performance is better than the parts obtained using [19]. We used the same seeds for the exemplar LDA and latent LDA parts during training, hence we can compare the performance of each part individually for both these methods. This can be seen in Figure 6 (middle) which plots the performance of the 2 parts individually. Latent LDA improves performance 63.5% of the time. Our part-based detectors compare favorably to state-ofthe-art. We combine the predictions of the top 3 parts using the method described in Section 3 and evaluate it on church-loc-test. Figure 6 (right) plots the detection AP of various methods as a function of overlap threshold (τ) used for evaluation. Typically, τ=.5 is used in a variety of object detection benchmarks (e.g. PASCAL VOC), but one can obtain a better insight about the performance by looking at the entire AP vs. overlap tradeoff curve. At τ=.5, the latent LDA obtains an AP=39.9%, outperforming the DPM detector which obtains an AP=34.75%. The performance of discriminative patches is also quite good at AP=38.34%, while that of random patches (AP=16.67%) and exemplar LDA (AP=19.95%) is not very competitive. Out of the various DPM detectors we found that the single root only detector performed the best, hinting that a simple tree model of the parts is inadequate for capturing the variety in part layouts. The difference between the various part-based methods and the DPM detector is more stark at a looser overlap threshold of τ=.4, where there is a 15% gap between the latent LDA part-based detector and the DPM detector. This shows that many of the detections are near misses at τ=.5. We believe that a better modeling of the part layouts can help with the bounding box prediction task. Figure 8 shows high scoring detections on the churchloc-test set along with the locations of parts shown in different colors. The part activations reflect the variety in the layouts of different buildings. In addition to using the parts as a building block for a detector, we are interested in exploring their role in other scene parsing tasks. We describe two such experiments next. 5. Landmark saliency prediction A landmark saliency map is a function s(x, y) [, 1], x,y s(x, y) = 1, which is a likelihood that a location of the image is a landmark. We can evaluate the likelihood of a given set of ground truth landmark locations under the saliency map as a measure of its predictive quality. Assume a set of n images are all scaled to contain the same number of pixels m. Let S k,k =1,...,n, denote the set of landmarks in the k th image. The Mean Average Likelihood (MAL) is defined as: MAL = 1 n n ms(x, y) (2) S k (x,y) S k k=1 According to this definition, the uniform saliency map has MAL =1since s(x, y) =1/m, x, y. Our saliency detector uses the top 3 parts sorted according to their part detection accuracy on the training set. Given an image, the highest scoring detections above the threshold, up to a maximum of 5 detections, are found for each part. Each detection contributes saliency proportional to the detection score to the center of the detection. The contributions are accumulated across all detections to obtain the initial saliency map. This is then smoothed with a Gaussian with σ =.1d, where d is the length of the image diagonal, and normalized to sum to one, to obtain the final saliency map. We set the number of pixels m = 1 6. Our approach can be seen as category-specific interest points, and we compare this approach to a baseline that uses standard unsupervised scale-space interest point detectors based on Differences of Gaussians (DoG) and the Itti and Koch saliency model [12]. Table 1 shows the MAL scores for various approaches on the church-corr-test subset of our dataset. According to our saliency maps, the landmarks are 6.4 more likely than the DoG saliency, and 4.2 more likely than the Itti and Koch saliency. The latent LDA parts outperform both the exemplar LDA parts and discriminative patches [19] based saliency. Figure 9 shows example saliency maps for a few images for a variety of methods. As one might expect, our part-based saliency tends to be sharply localized near doors, s, and s. Method MAL Difference of Gaussian 1.23 Itti and Koch 1.86 Discriminative patches 6.14 Exemplar LDA (Landmark seeds) 5.79 Latent LDA on the graph 7.84 Table 1. Mean Average Likelihood (MAL) of landmarks according to various saliency maps. 6. Fine-grained image parsing Beyond the standard classification and detection tasks, the rich library of correspondence-driven parts allows us to reason about fine-grained structure of visual categories. For instance, we can attach semantic meaning to a set of parts at almost no cost by simply showing a human a few high-scoring detections. If the parts appear to correspond to a coherent visual concept with a name, say, or, the name for the concept is recorded. Figure 1 (top row) shows such labels assigned to various such
 Exemplar LDA")

 (63 winner) 2.")

 Exemplar LDA (Random seeds) Discriminative patches")

 Detection performance of the 2 parts individually.")



![quit] (Right) Example part detections on test images. Figure 7.](/docs-images/80/81757716/images/7-11.jpg "(Left) Learned part filters.")



![Figure 1 (bottom row) shows example images from the SUNS dataset [23],](/docs-images/80/81757716/images/7-15.jpg "where we have visualized each image with labels positioned at the center")



7 Comparision of various parts 1.2 Latent LDA on the graph Exemplar LDA (Landmark seeds) Exemplar LDA (Random seeds) Discriminative patches.18 AP AP Latent LDA on the graph (137 winner) Exemplar LDA (Landmark seeds) (63 winner) Number of parts Latent LDA on graph Exemplar LDA (Landmark seeds) Exemplar LDA (Random seeds) Discriminative patches DPM detector.5.8 AAP 34.61, AAP 29.68, AAP 26.76, AAP 31.97, AAP 31.68,.9 AP.2 Detection results Exemplar LDA vs. Latent LDA Part index Overlap threshold Figure 6. (Left) Detection performance of the 2 parts individually. (Middle) Comparison of parts using latent LDA and exemplar LDA using the same seeds. (Right) Detection performance of the combination of parts, and other baselines; AAP stands for average AP over thresholds. Part filter Relative position Top detections on the test set Showing detections 1 8/12937 [Press ESCeach key to part. quit] (Right) Example part detections on test images. Figure 7. (Left) Learned part filters. (Middle) The vote associated with Showing detections 1 8/7236 [Press ESC key to quit] Figure 8. Example church detections. The corresponding parts in each detection are shown in different colors. parts. These semantic labels can be visualized on new images by pooling the part detections across models that correspond to the same label. Figure 1 (bottom row) shows example images from the SUNS dataset [23], where we have visualized each image with labels positioned at the center of the detection. Such parsing may be used for se and retrieval of images based on attributes such as churches with s on s, churches with two s, etc. 7. Conclusions and discussion We have described a method for semi-supervised discovery of semantically meaningful parts from pairwise correspondence annotations: pairs of landmark in images that are deemed matching. A library of parts can be discovered from such annotations by a discriminative algorithm that learns an appearance model for each part. On a category of church buildings, these parts are useful in a variety of ways: as building blocks for a part-based object detector, as category-specific interest point operators, and as a tool for fine-grained visual parsing for applications such as retrieval by attributes. To exploit the rich part library discovered with the proposed framework for detection and segmentation, one likely needs an appropriate layout model connecting many parts into a coherent category model, beyond the simplistic stargraph model used in our experiments. Such a layout model is the subject of our future work on this topic. 1







![activations. In ECCV, 21. 2, 5 [2] L. Bourdev and J.](/docs-images/80/81757716/images/8-7.jpg "Malik.")


![In CVPR, 25. 3 [4] C. Doersch, S. Singh, A. Gupta, J.](/docs-images/80/81757716/images/8-10.jpg "Sivic, and A. A. Efros.")


![recognition. In CVPR, 212. 2 [6] M. Everingham, L.](/docs-images/80/81757716/images/8-13.jpg "Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman.")
, jun. 21. 5 [7] A. Farhadi, I.")

![generalization. In CVPR, 21. 2 [8] P. Felzenszwalb, R.](/docs-images/80/81757716/images/8-16.jpg "Girshick, D. McAllester, and D. Ramanan.")
, 21. 2, 5 [9] P. F.")

![IJCV, 61, January 25. 2 [1] R. B. Girshick, P. F.](/docs-images/80/81757716/images/8-19.jpg "Felzenszwalb, and D. McAllester.")





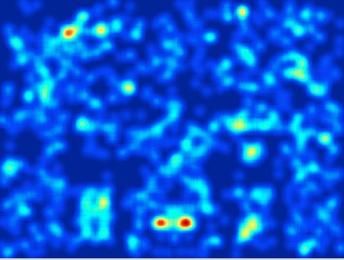





8 left right on right left on left right on right left right right left left on left left on left left on lefton on left on Figure 1. Fine-grained parsing of images. On the top row are labels assigned to parts by humans and on the bottom row are localized labels obtained by pooling the corresponding part detections on images. Image Parts DoG Itti & Koch Figure 9. From left to right images shown with the landmarks; saliency maps from our parts, Difference of Gaussian (DoG) interest point operator, and the Itti and Koch model. References [1] L. Bourdev, S. Maji, T. Brox, and J. Malik. Detecting people using mutually consistent poselet activations. In ECCV, 21. 2, 5 [2] L. Bourdev and J. Malik. Poselets:body part detectors trained using 3D human pose annotations. In ICCV, [3] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR, [4] C. Doersch, S. Singh, A. Gupta, J. Sivic, and A. A. Efros. What makes Paris look like Paris? In ACM SIGGRAPH, [5] K. Duan, I. Bloomington, D. Parikh, and K. Grauman. Discovering localized attributes for fine-grained recognition. In CVPR, [6] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman. The Pascal Visual Object Classes (VOC) challenge. IJCV, 88(2), jun [7] A. Farhadi, I. Endres, and D. Hoiem. Attribute-centric recognition for cross-category generalization. In CVPR, [8] P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained partbased models. IEEE TPAMI, 32(9), 21. 2, 5 [9] P. F. Felzenszwalb and D. P. Huttenlocher. Pictorial structures for object recognition. IJCV, 61, January [1] R. B. Girshick, P. F. Felzenszwalb, and D. McAllester. Discriminatively trained deformable part models, release 5. rbg/latent-release5/. 5 [11] B. Hariharan, J. Malik, and D. Ramanan. Discriminative decorrelation for clustering and classification. In ECCV, [12] L. Itti and C. Koch. Computational modelling of visual attention. Nature reviews neuroscience, 2(3), [13] B. Leibe, A. Leonardis, and B. Schiele. Robust object detection with interleaved categorization and segmentation. IJCV, 77(1), [14] D. Lowe. Distinctive image features from scale-invariant keypoints. IJCV, 6(2), 24. 2, 3 [15] S. Maji and G. Shakhnarovich. Part annotations via pairwise correspondence. In Workshop on Human Computation, AAAI, , 3 [16] T. Malisiewicz, A. Gupta, and A. A. Efros. Ensemble of exemplar-svms for object detection and beyond. In ICCV, [17] J. Mutch and D. G. Lowe. Multiclass object recognition with sparse, localized features. In CVPR, [18] D. Parikh and K. Grauman. Interactive discovery of taskspecic nameable attributes. In Workshop on Fine-Grained Visual Categorization, CVPR, [19] S. Singh, A. Gupta, and A. Efros. Unsupervised discovery of mid-level discriminative patches. In ECCV, , 4, 6 [2] C. Strecha, A. Bronstein, M. Bronstein, and P. Fua. LDAHash: Improved matching with smaller descriptors. IEEE PAMI, 34(1), [21] M. Weber, M. Welling, and P. Perona. Towards automatic discovery of object categories. In CVPR, 2. 2 [22] M. Weber, M. Welling, and P. Perona. Unsupervised learning of models for recognition. In ECCV, 2. 2 [23] J. Xiao, J. Hays, K. Ehinger, A. Oliva, and A. Torralba. SUN database: Large-scale scene recognition from abbey to zoo. In CVPR, 21. 7
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model
 Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Object Detection with Partial Occlusion Based on a Deformable Parts-Based Model Johnson Hsieh (johnsonhsieh@gmail.com), Alexander Chia (alexchia@stanford.edu) Abstract -- Object occlusion presents a major
Part based models for recognition. Kristen Grauman
 Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Category-level localization
 Category-level localization Cordelia Schmid Recognition Classification Object present/absent in an image Often presence of a significant amount of background clutter Localization / Detection Localize object
Category-level localization Cordelia Schmid Recognition Classification Object present/absent in an image Often presence of a significant amount of background clutter Localization / Detection Localize object
Using the Deformable Part Model with Autoencoded Feature Descriptors for Object Detection
 Using the Deformable Part Model with Autoencoded Feature Descriptors for Object Detection Hyunghoon Cho and David Wu December 10, 2010 1 Introduction Given its performance in recent years' PASCAL Visual
Using the Deformable Part Model with Autoencoded Feature Descriptors for Object Detection Hyunghoon Cho and David Wu December 10, 2010 1 Introduction Given its performance in recent years' PASCAL Visual
Learning Collections of Part Models for Object Recognition
 Learning Collections of Part Models for Object Recognition Ian Endres, Kevin J. Shih, Johnston Jiaa, Derek Hoiem University of Illinois at Urbana-Champaign {iendres2,kjshih2,jiaa1,dhoiem}@illinois.edu
Learning Collections of Part Models for Object Recognition Ian Endres, Kevin J. Shih, Johnston Jiaa, Derek Hoiem University of Illinois at Urbana-Champaign {iendres2,kjshih2,jiaa1,dhoiem}@illinois.edu
Part-based models. Lecture 10
 Part-based models Lecture 10 Overview Representation Location Appearance Generative interpretation Learning Distance transforms Other approaches using parts Felzenszwalb, Girshick, McAllester, Ramanan
Part-based models Lecture 10 Overview Representation Location Appearance Generative interpretation Learning Distance transforms Other approaches using parts Felzenszwalb, Girshick, McAllester, Ramanan
Detection III: Analyzing and Debugging Detection Methods
 CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
CS 1699: Intro to Computer Vision Detection III: Analyzing and Debugging Detection Methods Prof. Adriana Kovashka University of Pittsburgh November 17, 2015 Today Review: Deformable part models How can
Learning and Recognizing Visual Object Categories Without First Detecting Features
 Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Part-based and local feature models for generic object recognition
 Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models
 Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models Mathieu Aubry (INRIA) Daniel Maturana (CMU) Alexei Efros (UC Berkeley) Bryan Russell (Intel) Josef Sivic (INRIA)
Seeing 3D chairs: Exemplar part-based 2D-3D alignment using a large dataset of CAD models Mathieu Aubry (INRIA) Daniel Maturana (CMU) Alexei Efros (UC Berkeley) Bryan Russell (Intel) Josef Sivic (INRIA)
Object Detection by 3D Aspectlets and Occlusion Reasoning
 Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Object Detection by 3D Aspectlets and Occlusion Reasoning Yu Xiang University of Michigan Silvio Savarese Stanford University In the 4th International IEEE Workshop on 3D Representation and Recognition
Selective Search for Object Recognition
 Selective Search for Object Recognition Uijlings et al. Schuyler Smith Overview Introduction Object Recognition Selective Search Similarity Metrics Results Object Recognition Kitten Goal: Problem: Where
Selective Search for Object Recognition Uijlings et al. Schuyler Smith Overview Introduction Object Recognition Selective Search Similarity Metrics Results Object Recognition Kitten Goal: Problem: Where
Object Category Detection. Slides mostly from Derek Hoiem
 Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
Beyond bags of features: Adding spatial information. Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
 Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
CS229: Action Recognition in Tennis
 CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
Discriminative classifiers for image recognition
 Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Object Recognition. Computer Vision. Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce
 Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Modeling 3D viewpoint for part-based object recognition of rigid objects
 Modeling 3D viewpoint for part-based object recognition of rigid objects Joshua Schwartz Department of Computer Science Cornell University jdvs@cs.cornell.edu Abstract Part-based object models based on
Modeling 3D viewpoint for part-based object recognition of rigid objects Joshua Schwartz Department of Computer Science Cornell University jdvs@cs.cornell.edu Abstract Part-based object models based on
DPM Configurations for Human Interaction Detection
 DPM Configurations for Human Interaction Detection Coert van Gemeren Ronald Poppe Remco C. Veltkamp Interaction Technology Group, Department of Information and Computing Sciences, Utrecht University, The
DPM Configurations for Human Interaction Detection Coert van Gemeren Ronald Poppe Remco C. Veltkamp Interaction Technology Group, Department of Information and Computing Sciences, Utrecht University, The
Segmenting Objects in Weakly Labeled Videos
 Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Detecting Objects using Deformation Dictionaries
 Detecting Objects using Deformation Dictionaries Bharath Hariharan UC Berkeley bharath2@eecs.berkeley.edu C. Lawrence Zitnick Microsoft Research larryz@microsoft.com Piotr Dollár Microsoft Research pdollar@microsoft.com
Detecting Objects using Deformation Dictionaries Bharath Hariharan UC Berkeley bharath2@eecs.berkeley.edu C. Lawrence Zitnick Microsoft Research larryz@microsoft.com Piotr Dollár Microsoft Research pdollar@microsoft.com
Selection of Scale-Invariant Parts for Object Class Recognition
 Selection of Scale-Invariant Parts for Object Class Recognition Gy. Dorkó and C. Schmid INRIA Rhône-Alpes, GRAVIR-CNRS 655, av. de l Europe, 3833 Montbonnot, France fdorko,schmidg@inrialpes.fr Abstract
Selection of Scale-Invariant Parts for Object Class Recognition Gy. Dorkó and C. Schmid INRIA Rhône-Alpes, GRAVIR-CNRS 655, av. de l Europe, 3833 Montbonnot, France fdorko,schmidg@inrialpes.fr Abstract
High Level Computer Vision
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de http://www.d2.mpi-inf.mpg.de/cv Please Note No
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de http://www.d2.mpi-inf.mpg.de/cv Please Note No
The Caltech-UCSD Birds Dataset
 The Caltech-UCSD Birds-200-2011 Dataset Catherine Wah 1, Steve Branson 1, Peter Welinder 2, Pietro Perona 2, Serge Belongie 1 1 University of California, San Diego 2 California Institute of Technology
The Caltech-UCSD Birds-200-2011 Dataset Catherine Wah 1, Steve Branson 1, Peter Welinder 2, Pietro Perona 2, Serge Belongie 1 1 University of California, San Diego 2 California Institute of Technology
Classifying Images with Visual/Textual Cues. By Steven Kappes and Yan Cao
 Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Part-Based Models for Object Class Recognition Part 3
 High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
High Level Computer Vision! Part-Based Models for Object Class Recognition Part 3 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de! http://www.d2.mpi-inf.mpg.de/cv ! State-of-the-Art
Modern Object Detection. Most slides from Ali Farhadi
 Modern Object Detection Most slides from Ali Farhadi Comparison of Classifiers assuming x in {0 1} Learning Objective Training Inference Naïve Bayes maximize j i logp + logp ( x y ; θ ) ( y ; θ ) i ij
Modern Object Detection Most slides from Ali Farhadi Comparison of Classifiers assuming x in {0 1} Learning Objective Training Inference Naïve Bayes maximize j i logp + logp ( x y ; θ ) ( y ; θ ) i ij
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Development in Object Detection. Junyuan Lin May 4th
 Development in Object Detection Junyuan Lin May 4th Line of Research [1] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection, CVPR 2005. HOG Feature template [2] P. Felzenszwalb,
Development in Object Detection Junyuan Lin May 4th Line of Research [1] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection, CVPR 2005. HOG Feature template [2] P. Felzenszwalb,
CRF Based Point Cloud Segmentation Jonathan Nation
 CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
Using k-poselets for detecting people and localizing their keypoints
 Using k-poselets for detecting people and localizing their keypoints Georgia Gkioxari, Bharath Hariharan, Ross Girshick and itendra Malik University of California, Berkeley - Berkeley, CA 94720 {gkioxari,bharath2,rbg,malik}@berkeley.edu
Using k-poselets for detecting people and localizing their keypoints Georgia Gkioxari, Bharath Hariharan, Ross Girshick and itendra Malik University of California, Berkeley - Berkeley, CA 94720 {gkioxari,bharath2,rbg,malik}@berkeley.edu
Recap Image Classification with Bags of Local Features
 Recap Image Classification with Bags of Local Features Bag of Feature models were the state of the art for image classification for a decade BoF may still be the state of the art for instance retrieval
Recap Image Classification with Bags of Local Features Bag of Feature models were the state of the art for image classification for a decade BoF may still be the state of the art for instance retrieval
Category-level Localization
 Category-level Localization Andrew Zisserman Visual Geometry Group University of Oxford http://www.robots.ox.ac.uk/~vgg Includes slides from: Ondra Chum, Alyosha Efros, Mark Everingham, Pedro Felzenszwalb,
Category-level Localization Andrew Zisserman Visual Geometry Group University of Oxford http://www.robots.ox.ac.uk/~vgg Includes slides from: Ondra Chum, Alyosha Efros, Mark Everingham, Pedro Felzenszwalb,
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
ImageCLEF 2011
 SZTAKI @ ImageCLEF 2011 Bálint Daróczy joint work with András Benczúr, Róbert Pethes Data Mining and Web Search Group Computer and Automation Research Institute Hungarian Academy of Sciences Training/test
SZTAKI @ ImageCLEF 2011 Bálint Daróczy joint work with András Benczúr, Róbert Pethes Data Mining and Web Search Group Computer and Automation Research Institute Hungarian Academy of Sciences Training/test
Beyond Bags of features Spatial information & Shape models
 Beyond Bags of features Spatial information & Shape models Jana Kosecka Many slides adapted from S. Lazebnik, FeiFei Li, Rob Fergus, and Antonio Torralba Detection, recognition (so far )! Bags of features
Beyond Bags of features Spatial information & Shape models Jana Kosecka Many slides adapted from S. Lazebnik, FeiFei Li, Rob Fergus, and Antonio Torralba Detection, recognition (so far )! Bags of features
2/15/2009. Part-Based Models. Andrew Harp. Part Based Models. Detect object from physical arrangement of individual features
 Part-Based Models Andrew Harp Part Based Models Detect object from physical arrangement of individual features 1 Implementation Based on the Simple Parts and Structure Object Detector by R. Fergus Allows
Part-Based Models Andrew Harp Part Based Models Detect object from physical arrangement of individual features 1 Implementation Based on the Simple Parts and Structure Object Detector by R. Fergus Allows
Patch-based Object Recognition. Basic Idea
 Patch-based Object Recognition 1! Basic Idea Determine interest points in image Determine local image properties around interest points Use local image properties for object classification Example: Interest
Patch-based Object Recognition 1! Basic Idea Determine interest points in image Determine local image properties around interest points Use local image properties for object classification Example: Interest
Action recognition in videos
 Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014
 Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014 Problem Definition Viewpoint estimation: Given an image, predicting viewpoint for object of
Is 2D Information Enough For Viewpoint Estimation? Amir Ghodrati, Marco Pedersoli, Tinne Tuytelaars BMVC 2014 Problem Definition Viewpoint estimation: Given an image, predicting viewpoint for object of
ECS 289H: Visual Recognition Fall Yong Jae Lee Department of Computer Science
 ECS 289H: Visual Recognition Fall 2014 Yong Jae Lee Department of Computer Science Plan for today Questions? Research overview Standard supervised visual learning building Category models Annotators tree
ECS 289H: Visual Recognition Fall 2014 Yong Jae Lee Department of Computer Science Plan for today Questions? Research overview Standard supervised visual learning building Category models Annotators tree
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Automatic Learning and Extraction of Multi-Local Features
 Automatic Learning and Extraction of Multi-Local Features Oscar Danielsson, Stefan Carlsson and Josephine Sullivan School of Computer Science and Communications Royal Inst. of Technology, Stockholm, Sweden
Automatic Learning and Extraction of Multi-Local Features Oscar Danielsson, Stefan Carlsson and Josephine Sullivan School of Computer Science and Communications Royal Inst. of Technology, Stockholm, Sweden
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Structured Models in. Dan Huttenlocher. June 2010
 Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
Find that! Visual Object Detection Primer
 Find that! Visual Object Detection Primer SkTech/MIT Innovation Workshop August 16, 2012 Dr. Tomasz Malisiewicz tomasz@csail.mit.edu Find that! Your Goals...imagine one such system that drives information
Find that! Visual Object Detection Primer SkTech/MIT Innovation Workshop August 16, 2012 Dr. Tomasz Malisiewicz tomasz@csail.mit.edu Find that! Your Goals...imagine one such system that drives information
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Feature Matching and Robust Fitting
 Feature Matching and Robust Fitting Computer Vision CS 143, Brown Read Szeliski 4.1 James Hays Acknowledgment: Many slides from Derek Hoiem and Grauman&Leibe 2008 AAAI Tutorial Project 2 questions? This
Feature Matching and Robust Fitting Computer Vision CS 143, Brown Read Szeliski 4.1 James Hays Acknowledgment: Many slides from Derek Hoiem and Grauman&Leibe 2008 AAAI Tutorial Project 2 questions? This
Window based detectors
 Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
Window based detectors CS 554 Computer Vision Pinar Duygulu Bilkent University (Source: James Hays, Brown) Today Window-based generic object detection basic pipeline boosting classifiers face detection
String distance for automatic image classification
 String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
c 2011 by Pedro Moises Crisostomo Romero. All rights reserved.
 c 2011 by Pedro Moises Crisostomo Romero. All rights reserved. HAND DETECTION ON IMAGES BASED ON DEFORMABLE PART MODELS AND ADDITIONAL FEATURES BY PEDRO MOISES CRISOSTOMO ROMERO THESIS Submitted in partial
c 2011 by Pedro Moises Crisostomo Romero. All rights reserved. HAND DETECTION ON IMAGES BASED ON DEFORMABLE PART MODELS AND ADDITIONAL FEATURES BY PEDRO MOISES CRISOSTOMO ROMERO THESIS Submitted in partial
Loose Shape Model for Discriminative Learning of Object Categories
 Loose Shape Model for Discriminative Learning of Object Categories Margarita Osadchy and Elran Morash Computer Science Department University of Haifa Mount Carmel, Haifa 31905, Israel rita@cs.haifa.ac.il
Loose Shape Model for Discriminative Learning of Object Categories Margarita Osadchy and Elran Morash Computer Science Department University of Haifa Mount Carmel, Haifa 31905, Israel rita@cs.haifa.ac.il
Gradient of the lower bound
 Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Supervised learning. y = f(x) function
 function") Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Linear combinations of simple classifiers for the PASCAL challenge
 Linear combinations of simple classifiers for the PASCAL challenge Nik A. Melchior and David Lee 16 721 Advanced Perception The Robotics Institute Carnegie Mellon University Email: melchior@cmu.edu, dlee1@andrew.cmu.edu
Linear combinations of simple classifiers for the PASCAL challenge Nik A. Melchior and David Lee 16 721 Advanced Perception The Robotics Institute Carnegie Mellon University Email: melchior@cmu.edu, dlee1@andrew.cmu.edu
Virtual Training for Multi-View Object Class Recognition
 Virtual Training for Multi-View Object Class Recognition Han-Pang Chiu Leslie Pack Kaelbling Tomás Lozano-Pérez MIT Computer Science and Artificial Intelligence Laboratory Cambridge, MA 02139, USA {chiu,lpk,tlp}@csail.mit.edu
Virtual Training for Multi-View Object Class Recognition Han-Pang Chiu Leslie Pack Kaelbling Tomás Lozano-Pérez MIT Computer Science and Artificial Intelligence Laboratory Cambridge, MA 02139, USA {chiu,lpk,tlp}@csail.mit.edu
Object Detection with Discriminatively Trained Part Based Models
 Object Detection with Discriminatively Trained Part Based Models Pedro F. Felzenszwelb, Ross B. Girshick, David McAllester and Deva Ramanan Presented by Fabricio Santolin da Silva Kaustav Basu Some slides
Object Detection with Discriminatively Trained Part Based Models Pedro F. Felzenszwelb, Ross B. Girshick, David McAllester and Deva Ramanan Presented by Fabricio Santolin da Silva Kaustav Basu Some slides
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Joint Inference in Image Databases via Dense Correspondence. Michael Rubinstein MIT CSAIL (while interning at Microsoft Research)
") Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Joint Inference in Image Databases via Dense Correspondence Michael Rubinstein MIT CSAIL (while interning at Microsoft Research) My work Throughout the year (and my PhD thesis): Temporal Video Analysis
Occlusion Patterns for Object Class Detection
 Occlusion Patterns for Object Class Detection Bojan Pepik1 Michael Stark1,2 Peter Gehler3 Bernt Schiele1 Max Planck Institute for Informatics, 2Stanford University, 3Max Planck Institute for Intelligent
Occlusion Patterns for Object Class Detection Bojan Pepik1 Michael Stark1,2 Peter Gehler3 Bernt Schiele1 Max Planck Institute for Informatics, 2Stanford University, 3Max Planck Institute for Intelligent
Improving Recognition through Object Sub-categorization
 Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
A Discriminatively Trained, Multiscale, Deformable Part Model
 A Discriminatively Trained, Multiscale, Deformable Part Model by Pedro Felzenszwalb, David McAllester, and Deva Ramanan CS381V Visual Recognition - Paper Presentation Slide credit: Duan Tran Slide credit:
A Discriminatively Trained, Multiscale, Deformable Part Model by Pedro Felzenszwalb, David McAllester, and Deva Ramanan CS381V Visual Recognition - Paper Presentation Slide credit: Duan Tran Slide credit:
Rich feature hierarchies for accurate object detection and semantic segmentation
 Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
Rich feature hierarchies for accurate object detection and semantic segmentation BY; ROSS GIRSHICK, JEFF DONAHUE, TREVOR DARRELL AND JITENDRA MALIK PRESENTER; MUHAMMAD OSAMA Object detection vs. classification
Tri-modal Human Body Segmentation
 Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Lecture 16: Object recognition: Part-based generative models
 Lecture 16: Object recognition: Part-based generative models Professor Stanford Vision Lab 1 What we will learn today? Introduction Constellation model Weakly supervised training One-shot learning (Problem
Lecture 16: Object recognition: Part-based generative models Professor Stanford Vision Lab 1 What we will learn today? Introduction Constellation model Weakly supervised training One-shot learning (Problem
Segmentation as Selective Search for Object Recognition in ILSVRC2011
 Segmentation as Selective Search for Object Recognition in ILSVRC2011 Koen van de Sande Jasper Uijlings Arnold Smeulders Theo Gevers Nicu Sebe Cees Snoek University of Amsterdam, University of Trento ILSVRC2011
Segmentation as Selective Search for Object Recognition in ILSVRC2011 Koen van de Sande Jasper Uijlings Arnold Smeulders Theo Gevers Nicu Sebe Cees Snoek University of Amsterdam, University of Trento ILSVRC2011
CS 231A Computer Vision (Fall 2011) Problem Set 4
 Problem Set 4") CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based
CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based
Combining ROI-base and Superpixel Segmentation for Pedestrian Detection Ji Ma1,2, a, Jingjiao Li1, Zhenni Li1 and Li Ma2
 6th International Conference on Machinery, Materials, Environment, Biotechnology and Computer (MMEBC 2016) Combining ROI-base and Superpixel Segmentation for Pedestrian Detection Ji Ma1,2, a, Jingjiao
6th International Conference on Machinery, Materials, Environment, Biotechnology and Computer (MMEBC 2016) Combining ROI-base and Superpixel Segmentation for Pedestrian Detection Ji Ma1,2, a, Jingjiao
A Study of Vehicle Detector Generalization on U.S. Highway
 26 IEEE 9th International Conference on Intelligent Transportation Systems (ITSC) Windsor Oceanico Hotel, Rio de Janeiro, Brazil, November -4, 26 A Study of Vehicle Generalization on U.S. Highway Rakesh
26 IEEE 9th International Conference on Intelligent Transportation Systems (ITSC) Windsor Oceanico Hotel, Rio de Janeiro, Brazil, November -4, 26 A Study of Vehicle Generalization on U.S. Highway Rakesh
Object Recognition II
 Object Recognition II Linda Shapiro EE/CSE 576 with CNN slides from Ross Girshick 1 Outline Object detection the task, evaluation, datasets Convolutional Neural Networks (CNNs) overview and history Region-based
Object Recognition II Linda Shapiro EE/CSE 576 with CNN slides from Ross Girshick 1 Outline Object detection the task, evaluation, datasets Convolutional Neural Networks (CNNs) overview and history Region-based
Learning Compact Visual Attributes for Large-scale Image Classification
 Learning Compact Visual Attributes for Large-scale Image Classification Yu Su and Frédéric Jurie GREYC CNRS UMR 6072, University of Caen Basse-Normandie, Caen, France {yu.su,frederic.jurie}@unicaen.fr
Learning Compact Visual Attributes for Large-scale Image Classification Yu Su and Frédéric Jurie GREYC CNRS UMR 6072, University of Caen Basse-Normandie, Caen, France {yu.su,frederic.jurie}@unicaen.fr
Object Category Detection: Sliding Windows
 04/10/12 Object Category Detection: Sliding Windows Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical
04/10/12 Object Category Detection: Sliding Windows Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical
An Efficient Divide-and-Conquer Cascade for Nonlinear Object Detection
 An Efficient Divide-and-Conquer Cascade for Nonlinear Object Detection Christoph H. Lampert Max Planck Institute for Biological Cybernetics, Tübingen, Germany chl@tuebingen.mpg.de Abstract We introduce
An Efficient Divide-and-Conquer Cascade for Nonlinear Object Detection Christoph H. Lampert Max Planck Institute for Biological Cybernetics, Tübingen, Germany chl@tuebingen.mpg.de Abstract We introduce
Detecting Multiple Symmetries with Extended SIFT
 1 Detecting Multiple Symmetries with Extended SIFT 2 3 Anonymous ACCV submission Paper ID 388 4 5 6 7 8 9 10 11 12 13 14 15 16 Abstract. This paper describes an effective method for detecting multiple
1 Detecting Multiple Symmetries with Extended SIFT 2 3 Anonymous ACCV submission Paper ID 388 4 5 6 7 8 9 10 11 12 13 14 15 16 Abstract. This paper describes an effective method for detecting multiple
Bird Part Localization Using Exemplar-Based Models with Enforced Pose and Subcategory Consistency
 Bird Part Localization Using Exemplar-Based Models with Enforced Pose and Subcategory Consistency Jiongxin Liu and Peter N. Belhumeur Columbia University {liujx09, belhumeur}@cs.columbia.edu Abstract In
Bird Part Localization Using Exemplar-Based Models with Enforced Pose and Subcategory Consistency Jiongxin Liu and Peter N. Belhumeur Columbia University {liujx09, belhumeur}@cs.columbia.edu Abstract In
Detecting Object Instances Without Discriminative Features
 Detecting Object Instances Without Discriminative Features Edward Hsiao June 19, 2013 Thesis Committee: Martial Hebert, Chair Alexei Efros Takeo Kanade Andrew Zisserman, University of Oxford 1 Object Instance
Detecting Object Instances Without Discriminative Features Edward Hsiao June 19, 2013 Thesis Committee: Martial Hebert, Chair Alexei Efros Takeo Kanade Andrew Zisserman, University of Oxford 1 Object Instance
Building Part-based Object Detectors via 3D Geometry
 Building Part-based Object Detectors via 3D Geometry Abhinav Shrivastava Abhinav Gupta The Robotics Institute, Carnegie Mellon University http://graphics.cs.cmu.edu/projects/gdpm Abstract This paper proposes
Building Part-based Object Detectors via 3D Geometry Abhinav Shrivastava Abhinav Gupta The Robotics Institute, Carnegie Mellon University http://graphics.cs.cmu.edu/projects/gdpm Abstract This paper proposes
Object Recognition with Deformable Models
 Object Recognition with Deformable Models Pedro F. Felzenszwalb Department of Computer Science University of Chicago Joint work with: Dan Huttenlocher, Joshua Schwartz, David McAllester, Deva Ramanan.
Object Recognition with Deformable Models Pedro F. Felzenszwalb Department of Computer Science University of Chicago Joint work with: Dan Huttenlocher, Joshua Schwartz, David McAllester, Deva Ramanan.
Video understanding using part based object detection models
 Video understanding using part based object detection models Vignesh Ramanathan Stanford University Stanford, CA-94305 vigneshr@stanford.edu Kevin Tang (mentor) Stanford University Stanford, CA-94305 kdtang@cs.stanford.edu
Video understanding using part based object detection models Vignesh Ramanathan Stanford University Stanford, CA-94305 vigneshr@stanford.edu Kevin Tang (mentor) Stanford University Stanford, CA-94305 kdtang@cs.stanford.edu
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Bias-Variance Trade-off (cont d) + Image Representations
 + Image Representations") CS 275: Machine Learning Bias-Variance Trade-off (cont d) + Image Representations Prof. Adriana Kovashka University of Pittsburgh January 2, 26 Announcement Homework now due Feb. Generalization Training
CS 275: Machine Learning Bias-Variance Trade-off (cont d) + Image Representations Prof. Adriana Kovashka University of Pittsburgh January 2, 26 Announcement Homework now due Feb. Generalization Training
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS
 LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
Lecture 15: Detecting Objects by Parts
 Lecture 15: Detecting Objects by Parts David R. Morales, Austin O. Narcomey, Minh-An Quinn, Guilherme Reis, Omar Solis Department of Computer Science Stanford University Stanford, CA 94305 {mrlsdvd, aon2,
Lecture 15: Detecting Objects by Parts David R. Morales, Austin O. Narcomey, Minh-An Quinn, Guilherme Reis, Omar Solis Department of Computer Science Stanford University Stanford, CA 94305 {mrlsdvd, aon2,
Multi-Component Models for Object Detection
 Multi-Component Models for Object Detection Chunhui Gu 1, Pablo Arbeláez 2, Yuanqing Lin 3, Kai Yu 4, and Jitendra Malik 2 1 Google Inc., Mountain View, CA, USA, chunhui@google.com 2 UC Berkeley, Berkeley,
Multi-Component Models for Object Detection Chunhui Gu 1, Pablo Arbeláez 2, Yuanqing Lin 3, Kai Yu 4, and Jitendra Malik 2 1 Google Inc., Mountain View, CA, USA, chunhui@google.com 2 UC Berkeley, Berkeley,
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
Category vs. instance recognition
 Category vs. instance recognition Category: Find all the people Find all the buildings Often within a single image Often sliding window Instance: Is this face James? Find this specific famous building
Category vs. instance recognition Category: Find all the people Find all the buildings Often within a single image Often sliding window Instance: Is this face James? Find this specific famous building
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Predicting Functional Regions of Objects
 Predicting Functional Regions of Objects Chaitanya Desai University of California, Irvine desaic@uci.edu Deva Ramanan University of California, Irvine dramanan@ics.uci.edu Abstract We revisit the notion
Predicting Functional Regions of Objects Chaitanya Desai University of California, Irvine desaic@uci.edu Deva Ramanan University of California, Irvine dramanan@ics.uci.edu Abstract We revisit the notion
Painting-to-3D Model Alignment Via Discriminative Visual Elements. Mathieu Aubry (INRIA) Bryan Russell (Intel) Josef Sivic (INRIA)
 Bryan Russell (Intel) Josef Sivic (INRIA)") Painting-to-3D Model Alignment Via Discriminative Visual Elements Mathieu Aubry (INRIA) Bryan Russell (Intel) Josef Sivic (INRIA) This work Browsing across time 1699 1740 1750 1800 1800 1699 1740 1750
Painting-to-3D Model Alignment Via Discriminative Visual Elements Mathieu Aubry (INRIA) Bryan Russell (Intel) Josef Sivic (INRIA) This work Browsing across time 1699 1740 1750 1800 1800 1699 1740 1750
Deformable Part Models Revisited: A Performance Evaluation for Object Category Pose Estimation
 Deformable Part Models Revisited: A Performance Evaluation for Object Category Pose Estimation Roberto J. Lo pez-sastre Tinne Tuytelaars2 Silvio Savarese3 GRAM, Dept. Signal Theory and Communications,
Deformable Part Models Revisited: A Performance Evaluation for Object Category Pose Estimation Roberto J. Lo pez-sastre Tinne Tuytelaars2 Silvio Savarese3 GRAM, Dept. Signal Theory and Communications,
Local features and image matching. Prof. Xin Yang HUST
 Local features and image matching Prof. Xin Yang HUST Last time RANSAC for robust geometric transformation estimation Translation, Affine, Homography Image warping Given a 2D transformation T and a source
Local features and image matching Prof. Xin Yang HUST Last time RANSAC for robust geometric transformation estimation Translation, Affine, Homography Image warping Given a 2D transformation T and a source
Apprenticeship Learning: Transfer of Knowledge via Dataset Augmentation
 Apprenticeship Learning: Transfer of Knowledge via Dataset Augmentation Miroslav Kobetski and Josephine Sullivan Computer Vision and Active Perception, KTH, 114 28 Stockholm kobetski@kth.se, sullivan@nada.kth.se
Apprenticeship Learning: Transfer of Knowledge via Dataset Augmentation Miroslav Kobetski and Josephine Sullivan Computer Vision and Active Perception, KTH, 114 28 Stockholm kobetski@kth.se, sullivan@nada.kth.se
Actions and Attributes from Wholes and Parts
 Actions and Attributes from Wholes and Parts Georgia Gkioxari UC Berkeley gkioxari@berkeley.edu Ross Girshick Microsoft Research rbg@microsoft.com Jitendra Malik UC Berkeley malik@berkeley.edu Abstract
Actions and Attributes from Wholes and Parts Georgia Gkioxari UC Berkeley gkioxari@berkeley.edu Ross Girshick Microsoft Research rbg@microsoft.com Jitendra Malik UC Berkeley malik@berkeley.edu Abstract