DOMAIN ADAPTATION FOR STRUCTURED OUTPUT VIA DISENTANGLED PATCH REPRESENTATIONS
|
|
|
- Marcus Hall
- 5 years ago
- Views:
Transcription
1 DOMAIN ADAPTATION FOR STRUCTURED OUTPUT VIA DISENTANGLED PATCH REPRESENTATIONS Anonymous authors Paper under double-blind review ABSTRACT Predicting structured outputs such as semantic segmentation relies on expensive per-pixel annotations to learn strong supervised models like convolutional neural networks. However, these models trained on one data domain may not generalize well to other domains unequipped with annotations for model finetuning. To avoid the labor-intensive process of annotation, we develop a domain adaptation method to adapt the source data to the unlabeled target domain. To this end, we propose to learn discriminative feature representations of patches based on label histograms in the source domain, through the construction of a disentangled space. With such representations as guidance, we then use an adversarial learning scheme to push the feature representations in target patches to the closer distributions in source ones. In addition, we show that our framework can integrate a global alignment process with the proposed patch-level alignment and achieve state-of-the-art performance on semantic segmentation. Extensive ablation studies and experiments are conducted on numerous benchmark datasets with various settings, such as synthetic-to-real and cross-city scenarios. 1 INTRODUCTION Recent deep learning-based methods have made significant progress on vision tasks, such as object recognition (Krizhevsky et al., 2012) and semantic segmentation (Long et al., 2015a), relying on large-scale annotations to supervise the learning process. However, for a test domain different from the annotated training data, learned models usually do not generalize well. In such cases, domain adaptation methods have been developed to close the gap between a source domain with annotations and a target domain without labels. Along this line of research, numerous methods have been developed for image classification (Saenko et al., 2010; Ganin & Lempitsky, 2015), but despite recent works on domain adaptation for pixel-level prediction tasks such as semantic segmentation (Hoffman et al., 2016), there still remains significant room for improvement. Yet domain adaptation is a crucial need for pixel-level predictions, as the cost to annotate ground truth is prohibitively expensive. For instance, road-scene images in different cities may have various appearance distributions, while conditions even within the same city may vary significantly over time or weather. Existing state-of-the-art methods use feature-level (Hoffman et al., 2016) or output space adaptation (Tsai et al., 2018) to align the distributions between the source and target domains using adversarial learning (Goodfellow et al., 2014; Zhu et al., 2017). These approaches usually exploit the global distribution alignment, such as spatial layout, but such global statistics may already differ significantly between two domains due to differences in camera pose or field of view. Figure 1 illustrates one example, where two images share a similar layout, but the corresponding grids do not match well. Such misalignment may introduce an incorrect bias during adaptation. Instead, we consider to match patches that are more likely to be shared across domains regardless of where they are located. One way to utilize patch-level information is to align their distributions through adversarial learning. However, this is not straightforward since patches may have high variation among each other and there is no guidance for the model to know which patch distributions are close. Motivated by recent advances in learning disentangled representations (Kulkarni et al., 2015; Odena et al., 2017), we adopt a similar approach by considering label histograms of patches as a factor and learn discriminative 1
 and push a target representation (unfilled symbol) close to the distribution of source ones, regardless of where these")

2 Figure 1: Illustration of the proposed patch-level alignment against the global alignment that considers the spatial relationship between grids. We first learn discriminative representations for source patches (solid symbols) and push a target representation (unfilled symbol) close to the distribution of source ones, regardless of where these patches are located in the image. representations for patches to relax the high-variation problem among them. Then, we use the learned representations as a bridge to better align patches between source and target domains. Specifically, we utilize two adversarial modules to align both the global and patch-level distributions between two domains, where the global one is based on the output space adaptation (Tsai et al., 2018), and the patch-based one is achieved through the proposed alignment by learning discriminative representations. To guide the learning process, we first use the pixel-level annotations provided in the source domain and extract the label histogram as a patch-level representation. We then apply K-means clustering to group extracted patch representations into K clusters, whose cluster assignments are then used as the ground truth to train a classifier shared across two domains for transferring a learned discriminative representation of patches from the source to the target domain. Ideally, given the patches in the target domain, they would be classified into one of K categories. However, since there is a domain gap, we further use an adversarial loss to push the feature representations of target patches close to the distribution of the source patches in this clustered space (see Figure 1). Note that our representation learning can be viewed as a kind of disentanglement guided by the label histogram, but is different from existing methods that use pre-defined factors such as object pose (Kulkarni et al., 2015). In experiments, we follow the domain adaptation setting in (Hoffman et al., 2016) and perform pixellevel road-scene image segmentation. We conduct experiments under various settings, including the synthetic-to-real, i.e., GTA5 (Richter et al., 2016)/SYNTHIA (Ros et al., 2016) to Cityscapes (Cordts et al., 2016) and cross-city, i.e., Cityscapes to Oxford RobotCar (Maddern et al., 2017) scenarios. In addition, we provide extensive ablation studies to validate each component in the proposed framework. By combining global and patch-level alignments, we show that our approach performs favorably against state-of-the-art methods in terms of accuracy and visual quality. We note that the proposed framework is general and could be applicable to other forms of structured outputs such as depth, which will be studied in our future work. The contributions of this work are as follows. First, we propose a domain adaptation framework for structured output prediction by utilizing global and patch-level adversarial learning modules. Second, we develop a method to learn discriminative representations guided by the label histogram of patches via clustering and show that these representations help the patch-level alignment. Third, we demonstrate that the proposed adaptation method performs favorably against various baselines and state-of-the-art methods on semantic segmentation. 2 RELATED WORK Within the context of this work, we discuss the domain adaptation methods, including image classification and pixel-level prediction tasks. In addition, algorithms that are relevant to learning disentangled representations are discussed in this section. Domain Adaptation. Domain adaptation approaches have been developed for the image classification task via aligning the feature distributions between the source and target domains. Conventional methods use hand-crafted features (Gong et al., 2012; Fernando et al., 2013) to minimize the discrep- 2
3 ancy across domains, while recent algorithms utilize deep architectures (Ganin & Lempitsky, 2015; Tzeng et al., 2015) to learn domain-invariant features. One common practice is to adopt the adversarial learning scheme (Ganin et al., 2016) and minimize the Maximum Mean Discrepancy (Long et al., 2015b). A number of variants have been developed via designing different classifiers (Long et al., 2016) and loss functions (Tzeng et al., 2017; 2015). In addition, other recent work aims to enhance feature representations by pixel-level transfer (Bousmalis et al., 2017) and domain separation (Bousmalis et al., 2016). Compared to the image classification task, domain adaptation for structured pixel-level predictions has not been widely studied. Hoffman et al. (2016) first introduce to tackle the domain adaptation problem on semantic segmentation for road-scene images, e.g., synthetic-to-real images. Similar to the image classification case, they propose to use adversarial networks and align global feature representations across two domains. In addition, a category-specific prior is extracted from the source domain and is transferred to the target distribution as a constraint. However, these priors, e.g., object size and class distribution, may be already inconsistent between two domains. Instead of designing such constraints, the CDA method (Zhang et al., 2017) applies the SVM classifier to capture label distributions on superpixels as the property to train the adapted model on the target domain. Similarly, as proposed in (Chen et al., 2017), a class-wise domain adversarial alignment is performed by assigning pseudo labels to the target data. Moreover, an object prior is extracted from Google Street View to help alignment for static objects. The above-mentioned domain adaptation methods on structured output all use a global distribution alignment and some class-specific priors to match statistics between two domains. However, such class-level alignment does not preserve the structured information like the patches. In contrast, we propose to learn discriminative representations for patches and use these learned representations to help patch-level alignment. Moreover, our framework does not require additional priors/annotations and the entire network can be trained in an end-to-end fashion. Compared to the recently proposed output space adaptation method (Tsai et al., 2018) that also enables end-to-end training, our algorithm focuses on learning patch-level representations that aid the alignment process. Learning Disentangled Representation. Learning a latent disentangled space has led to a better understanding for numerous tasks such as facial recognition (Reed et al., 2014), image generation (Chen et al., 2016b; Odena et al., 2017), and view synthesis (Kulkarni et al., 2015; Yang et al., 2015). These approaches use pre-defined factors to learn interpretable representations of the image. Kulkarni et al. (2015) propose to learn graphic codes that are disentangled with respect to various image transformations, e.g., pose and lighting, for rendering 3D images. Similarly, Yang et al. (2015) synthesize 3D objects from a single image via an encoder-decoder architecture that learns latent representations based on the rotation factor. Recently, AC-GAN (Odena et al., 2017) develops a generative adversarial network (GAN) with an auxiliary classifier conditioned on the given factors such as image labels and attributes. Although these methods present promising results on using the specified factors and learning a disentangled space to help the target task, they focus on handling the data in a single domain. Motivated by this line of research, we propose to learn discriminative representations for patches to help the domain adaptation task. To this end, we take advantages of the available label distributions and naturally utilize them as a disentangled factor, in which our framework does not require to pre-define any factors like conventional methods. 3 DOMAIN ADAPTATION FOR STRUCTURED OUTPUT In this section, we describe our proposed domain adaptation framework for predicting structured outputs, our adversarial learning scheme to align distributions across domains, and the use of discriminative representations for patches to help the alignment. 3.1 ALGORITHMIC OVERVIEW Given the source and target images I s, I t R H W 3 and the source labels Y s, our goal is to align the predicted output distribution O t of the target data with the source distribution O s. As shown in Figure 2(a), we use a loss function for supervised learning on the source data to predict the structured output, and an adversarial loss is adopted to align the global distribution. Based on this 3
. (b) Our algorithm combines global and patch-level alignments in a general framework that better preserves local structure.")
4 (a) Global alignment (baseline model) (b) Our framework with patch-level alignment Figure 2: Overview of the proposed framework. (a) A baseline model that utilizes global alignment in (Tsai et al., 2018). (b) Our algorithm combines global and patch-level alignments in a general framework that better preserves local structure. Note that O s, O t (0, 1) H W C are distributions and the figures used here are only for illustration purposes. baseline model, we further incorporate a classification loss in a clustered space to learn patch-level discriminative representations F s from the source output distribution O s, shown in Figure 2(b). For target data, we employ another adversarial loss to align the patch-level distributions between F s and F t, where the goal is to push F t to be closer to the distribution of F s. Objective Function. As described in Figure 2(b), we formulate the adaptation task as composed of the following loss functions: L total (I s, I t, Y s, Γ(Y s )) = L s + λ d L d + λ g adv Lg adv + λl advl l adv, (1) where L s and L d are supervised loss functions for learning the structured prediction and the discriminative representation on source data, respectively, while Γ denotes the clustering process on the ground truth label distribution. To align the target distribution, we utilize global and patch-level adversarial loss functions, which are denoted as L g adv and Ll adv, respectively. Here, λ s are the weights for different loss functions. The following sections describe details of the baseline model and the proposed framework. Figure 3 shows the main components and loss functions of our method. 3.2 GLOBAL ALIGNMENT WITH ADVERSARIAL LEARNING We first adopt a baseline model that consists of a supervised cross-entropy loss L s and an output space adaptation module using L g adv for global alignment as shown in Figure 2(a). The loss L s can be optimized by a fully-convolutional network G that predicts the structured output with the loss summed over the spatial map indexed with h, w and the number of categories C: L s (I s, Y s ; G) = h,w c C Y s (h,w,c) log(o s (h,w,c) ), (2) where O s = G(I s ) (0, 1) is the predicted output distribution through the softmax function and is up-sampled to the size of the input image. Here, we will use the same h and w as the index for all the formulations. For the adversarial loss L g adv, we follow the practice of GAN training by optimizing G and a discriminator D g that performs the binary classification to distinguish whether the output prediction is from the source image or the target one. L g adv (I s, I t ; G, D g ) = h,w E[log D g (O s ) (h,w,1) ] + E[log(1 D g (O t ) (h,w,1) )]. (3) Then we optimize the following min-max problem for G and D g, with inputs to the functions dropped for simplicity: min max L s (G) + λ g G D adv Lg adv (G, D g). (4) g 3.3 PATCH-LEVEL ALIGNMENT WITH DISCRIMINATIVE REPRESENTATIONS Figure 1 shows that we may find transferable structured output representations shared across source and target images from smaller patches rather than from the entire image or larger grids. Based on this observation, we propose to perform a patch-level domain alignment. Specifically, rather than naively aligning the distributions of all patches between two domains, we first perform clustering 4

5 Figure 3: The proposed network architecture that consists of a generator G and a categorization module H for learning discriminative patch representations. In the clustered space, solid symbols denote source representations and unfilled ones are target representations pulled to the source distribution. on patches from the source-domain examples using ground truth segmentation labels to construct a set of prototypical patch patterns. Then, we let patches from the target domain adapt to this disentangled (clustered) space of source patch representations by guiding them to select the closest cluster regardless of the spatial location via adversarial objective. In the following, we describe details of the proposed patch-level alignment. Learning Discriminative Representations. In order to learn a disentangled space, class labels (Salimans et al., 2016) or pre-defined factors (Odena et al., 2017) are usually provided as supervisory signals. However, it is non-trivial to assign some sort of class membership to individual patches of an image. One may apply unsupervised clustering of image patches using pixel representations, but it is unclear whether the constructed clustering would separate patches in a semantically meaningful way. In this work, we take advantage of already available per-pixel annotations in the source domain to construct semantically disentangled space of patch representations. To achieve this, we use label histograms for patches as the disentangled factor. We first randomly sample patches from source images, use a 2-by-2 grid on patches to extract spatial label histograms, and concatenate them into a vector, where each histogram is a 2 2 C dimensional vector. Second, we apply K-means clustering on these histograms, whereby the label for any patch can be assigned as the cluster center with the closest distance on the histogram. To incorporate this clustered space during training the network G on source data, we add a classification module H after the predicted output O s, to simulate the procedure of constructing the label histogram and learn a discriminative representation. We denote the learned representation as F s = H(G(I s )) (0, 1) U V K through the softmax function, where K is the number of clusters. Here, each data point on the spatial map F s corresponds to a patch of the input image, and we obtain the group label Γ(Y s ) for each patch accordingly. Then the learning process to construct the clustered space can be formulated as a cross-entropy loss: L d (I s, Γ(Y s ); G, H) = u,v k K Γ(Y s ) (u,v,k) log(f (u,v,k) s ). (5) Patch-level Adversarial Alignment. The ensuing task is to align the representations of target patches to the clustered space constructed in the source domain. To this end, we utilize another adversarial loss between F s and F t, where F t is generated in the same way as described above. Our goal is to align patches regardless of where they are located in the image, that is, without the spatial and neighborhood supports. Thus, we reshape F by concatenating the K-dimensional vectors along the spatial map, which results in U V independent data points. We note that a similar effect can be achieved by using a convolution layer with a proper stride and kernel size. We denote this reshaped data as ˆF and formulate the adversarial objective: L l adv(i s, I t ; G, H, D l ) = u,v E[log D l ( ˆF s ) (u,v,1) ] + E[log(1 D l ( ˆF t ) (u,v,1) )], (6) 5
6 where D l is the discriminator to classify whether the feature representation ˆF is from the source or the target domain. Finally, we integrate (5) and (6) into the min-max problem in (4): min G,H max D g,d l L s (G) + λ d L d (G, H) + λ g adv Lg adv (G, D g) + λ l advl l adv(g, H, D l ). (7) 3.4 NETWORK OPTIMIZATION Following the standard procedure for training a GAN (Goodfellow et al., 2014), we alternate the optimization between three steps: 1) update the discriminator D g, 2) update the discriminator D l, and 3) update the network G and H while fixing the discriminators. Update the Discriminator D g. We train the discriminator D g to distinguish between the source output distribution (labeled as 1) and the target distribution (labeled as 0). The maximization problem on D g in (7) is equivalent to minimizing the binary cross-entropy loss: L g D (O s, O t ; D g ) = h,w log(d g (O s ) (h,w,1) ) + log(1 D g (O t ) (h,w,1) ). (8) Update the Discriminator D l. Similarly, we train the discriminator D l to classify whether the feature representation ˆF is from the source or the target domain: L l D( ˆF s, ˆF t ; D l ) = u,v log(d l ( ˆF s ) (u,v,1) ) + log(1 D l ( ˆF t ) (u,v,1) ). (9) Update the Network G and H. The goal of this step is to push the target distribution closer to the source distribution using the optimized D g and D l, while maintaining good performance on the main tasks using G and H. As a result, the minimization problem in (7) is the combination of two supervised loss functions, namely, (2) and (5), with two adversarial loss functions, where the adversarial ones can be expressed as binary cross-entropy loss functions that assign the source label to the target distribution: L total = L s + λ d L d λ g adv log(d g (O t ) (h,w,1) ) λ l adv log(d l ( ˆF t ) (u,v,1) ). (10) h,w We note that updating H would also update G through back-propagation, and thus the feature representations are enhanced in G. In addition, we only require G during the testing phase, so that runtime is unaffected compared to the baseline approach. u,v 3.5 NETWORK ARCHITECTURE AND IMPLEMENTATION DETAILS Discriminator. For the discriminator D g using a spatial map O as the input, we adopt an architecture similar to (Radford et al., 2016) but use fully-convolutional layers. It contains 5 convolution layers with kernel size 4 4, stride 2 and channel numbers {64, 128, 256, 512, 1}. In addition, a leaky ReLU activation (Maas et al., 2013) is added after each convolution layer, except the last layer. For the discriminator D l, input data is a K-dimensional vector and we utilize 3 fully-connected layers similar to (Tzeng et al., 2017), with leaky ReLU activation and channel numbers {256, 512, 1}. Generator. The generator consists of the network G with a categorization module H. For a fair comparison, we follow the framework used in (Tsai et al., 2018) that adopts DeepLab-v2 (Chen et al., 2016a) with the ResNet-101 architecture (He et al., 2016) pre-trained on ImageNet (Deng et al., 2009) as our baseline network G. To add the module H on the output prediction O, we first use an adaptive average pooling layer to generate a spatial map, where each data point on the map has a desired receptive field corresponding to the size of extracted patches. Then this pooled map is fed into two convolution layers and a feature map F is produced with the channel number K. Figure 3 illustrates the main components of the proposed architecture. Implementation Details. We implement the proposed framework using the PyTorch toolbox on a single Titan X GPU with 12 GB memory. To train the discriminators, we use the Adam optimizer (Kingma & Ba, 2015) with initial learning rate of 10 4 and momentums set as 0.9 and For learning the generator, we use the Stochastic Gradient Descent (SGD) solver where the momentum is 0.9, the weight decay is and the initial learning rate is For all 6
7 Table 1: Ablation study on GTA5-to-Cityscapes using the ResNet-101 network. We also show the corresponding loss functions used in each setting. GTA5 Cityscapes Without Adaptation Disentanglement Global Alignment Patch-level Alignment L s L s + L d L s + L g adv L s + L d + L l adv miou Without L d Without L l adv Without Reshaped ˆF Ours (final) L s + L g adv + Ll adv L s + L d + L g adv L s + L d + L g adv + Ll adv L s + L d + L g adv + Ll adv miou the networks, we decrease the learning rates using the polynomial decay with a power of 0.9, as described in (Chen et al., 2016a). During training, we use λ d = 0.01, λ g adv = λl adv = and K = 50 for all the experiments. Note that we first train the model only using the loss L s for 10K iterations to avoid initially noisy predictions and then train the network using all the loss functions for 100K iterations. More details of the hyper-parameters such as image and patch sizes are provided in the appendix. 4 EXPERIMENTAL RESULTS We evaluate the proposed framework for domain adaptation on semantic segmentation. We first conduct an extensive ablation study to validate each component in the algorithm on the GTA5-to- Cityscapes (synthetic-to-real) scenario. Second, we show that our method performs favorably against state-of-the-art approaches on numerous benchmark datasets and settings. 4.1 EVALUATED DATASETS AND METRIC We evaluate our domain adaptation method on semantic segmentation under various settings, including synthetic-to-real and cross-city scenarios. First, we adapt the synthetic GTA5 (Richter et al., 2016) dataset to the Cityscapes (Cordts et al., 2016) dataset that contains real road-scene images. Similarly, we use the SYNTHIA (Ros et al., 2016) dataset with a larger domain gap compared to Cityscapes images. For the above experiments, we follow (Hoffman et al., 2016) to split the training and test sets. To overcome the realistic case when two domains are in different cities under various weather conditions, we adapt Cityscapes with sunny images to the Oxford RobotCar (Maddern et al., 2017) dataset that contains rainy scenes. We manually select 10 sequences in the Oxford RobotCar dataset annotated with the rainy tag, in which we randomly split them into 7 sequences for training and 3 for testing. We sequentially sample 895 images as training images and annotate 271 images with per-pixel semantic segmentation ground truth as the test set for evaluation. The annotated ground truth will be made publicly available. For all the experiments, intersection-over-union (IoU) ratio is used as the metric to evaluate different methods. 4.2 ABLATION STUDY In Table 1, we conduct an ablation study on the GTA5-to-Cityscapes scenario to understand the impact of different loss functions and design choices in the proposed framework. Loss Functions. In the first row of Table 1, we show different steps of the proposed method, including disentanglement, global alignment, and patch-level alignment. Interestingly, we find that adding disentanglement without any alignments (L s + L d ) also improves the performance (from 36.6% to 38.8%), which demonstrates that the learned feature representation enhances the discrimination and generalization ability. Finally, as shown in the last result of the second row, our method that combines both the global and patch-level alignments achieve the highest IoU as 43.2%. Impact on L d and L l adv. In the first two results of the second row, we conduct experiments to validate the effectiveness of our patch-level alignment. We show that both losses, L d and L l adv, are necessary to assist this alignment process. Removing either of them will result in performance loss, i.e., 1.9% and 1.5% lower than our final result. The reason behind this is that, L d is to construct a clustered space so that L l adv can then effectively perform patch-level alignment in this space. 7

8 Our Method Without Patch Adaptation Figure 4: Visualization of patch-level feature representations via t-sne. In each figure, two thousand patches are sampled from each source and target domain. Table 2: Results of adapting GTA5 to Cityscapes. In the first and second groups, VGG-16 and ResNet-101 base networks are adopted, respectively. Method road sidewalk building wall fence pole light sign GTA5 Cityscapes Hoffman et al. (2016) Zhang et al. (2017) Hoffman et al. (2018) Tsai et al. (2018) Ours (VGG-16) Without Adaptation Tsai et al. (2018) (Feature) Tsai et al. (2018) (Output) Ours (ResNet-101) veg terrain sky person rider car truck bus train mbike bike miou Without Reshaped ˆF. In the module H that transforms the output distribution to the clustered space, the features are reshaped as independent data points ˆF to remove the spatial relationship and are then used as the input to the discriminator D l. To validate the usefulness, we show that without the reshaping process, the performance drops 2.4% in IoU. This result matches our assumption that patches with similar representations should be aligned regardless of their locations. Visualization of Feature Representations. In Figure 4, we show the t-sne visualization (van der Maaten & Hinton, 2008) of the patch-level features in the clustered space of our method and compare with the one without patch-level adaptation. The result shows that with adaptation in the clustered space, the features are embedded into groups and the source/target representations overlap to each other well. Example patch visualizations are provided in the appendix. 4.3 COMPARISONS WITH STATE-OF-THE-ART METHODS In this section, we compare the proposed method with state-of-the-art algorithms under various scenarios, including synthetic-to-real and cross-city cases. Synthetic-to-real Case. We first present experimental results for adapting GTA5 to Cityscapes in Table 2. The methods in the upper group adopt the VGG-16 architecture as the base network and we show that our approach performs favorably against state-of-the-art adaptations via feature (Hoffman et al., 2016; Zhang et al., 2017), pixel-level (Hoffman et al., 2018), and output space (Tsai et al., 2018) alignments. In the bottom group, we further utilize the stronger ResNet-101 base network and compare our result with (Tsai et al., 2018) under two settings, i.e., feature and output space adaptations. We show that the proposed method improves the IoU with a gain of 1.8% and achieves the best IoU on 14 out of the 19 categories. In Table 3, we show results for adapting SYNTHIA to Cityscapes and similar improvements are observed comparing with state-of-the-art methods. In addition, we shows visual comparisons in Figure 5 and more results are presented in the appendix. Cross-city Case. Adapting between real images across different cities and conditions is an important scenario for practical applications. We choose a challenge case where the weather condition is different (i.e., sunny v.s rainy) in two cities by adapting Cityscapes to Oxford RobotCar. The proposed 8
9 Target Image Ground Truth Before Adaptation Global Alignment Ours Figure 5: Example results for GTA5-to-Cityscapes. Our method often generates the segmentation with more details (e.g., sidewalk and pole) while producing less noisy regions. Table 3: Results of adapting SYNTHIA to Cityscapes. In the first and second groups, VGG-16 and ResNet-101 base networks are adopted, respectively. Method road sidewalk building light sign veg SYNTHIA Cityscapes Hoffman et al. (2016) Zhang et al. (2017) Chen et al. (2017) Tsai et al. (2018) Ours (VGG-16) Without Adaptation Tsai et al. (2018) (Feature) Tsai et al. (2018) (Output) Ours (ResNet-101) sky person rider car bus mbike bike miou framework achieves a mean IoU of 65.0% averaged on 10 categories, significantly improving the model without adaptation by 8.8%. To compare with the state-of-the-art method (Tsai et al., 2018), we run the authors released code and obtain a mean IoU of 63.6%, which is 1.4% lower than the proposed method. Further results and comparisons are provided in the appendix. 5 CONCLUSIONS In this paper, we present a domain adaptation method for structured output via a general framework that combines global and patch-level alignments. The global alignment is achieved by the output space adaptation, while the patch-level one is performed via learning discriminative representations of patches across domains. To learn such patch-level representations, we propose to construct a clustered space of the source patches and adopt an adversarial learning scheme to push the target patch distributions closer to the source ones. We conduct extensive ablation study and experiments to validate the effectiveness of the proposed method under numerous challenges on semantic segmentation, including synthetic-to-real and cross-city scenarios, and show that our approach performs favorably against existing algorithms. REFERENCES K. Bousmalis, G. Trigeorgis, N. Silberman, D. Krishnan, and D. Erhan. Domain separation networks. In NIPS, K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, and D. Krishnan. Unsupervised pixel-level domain adaptation with generative adversarial networks. In CVPR, Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. CoRR, abs/ , 2016a. X. Chen, Y. Duan, R. Houthooft, J. Schulman, I. Sutskever, and P. Abbeel. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In NIPS, 2016b. 9
10 Y.-H. Chen, W.-Y. Chen, Y.-T. Chen, B.-C. Tsai, Y.-C. F. Wang, and M. Sun. No more discrimination: Cross city adaptation of road scene segmenters. In ICCV, M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR, Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, B. Fernando, A. Habrard, M. Sebban, and T. Tuytelaars. Unsupervised visual domain adaptation using subspace alignment. In ICCV, Yaroslav Ganin and Victor Lempitsky. Unsupervised domain adaptation by backpropagation. In ICML, Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks. In JMLR, Boqing Gong, Yuan Shi, Fei Sha, and Kristen Grauman. Geodesic flow kernel for unsupervised domain adaptation. In CVPR, I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In NIPS, Y. Grandvalet and Y. Bengio. Semi-supervised learning by entropy minimization. In NIPS, K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, J. Hoffman, D. Wang, F. Yu, and T. Darrell. Fcns in the wild: Pixel-level adversarial and constraintbased adaptation. CoRR, abs/ , J. Hoffman, E. Tzeng, T. Park, J.-Y. Zhu, P. Isola, K. Saenko, A. A. Efros, and T. Darrell. Cycada: Cycle-consistent adversarial domain adaptation. In ICML, D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR, A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, T. D. Kulkarni, W. F. Whitney, P. Kohli, and J. Tenenbaum. Deep convolutional inverse graphics network. In NIPS, J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015a. Mingsheng Long, Yue Cao, Jianmin Wang, and Michael Jordan. Learning transferable features with deep adaptation networks. In ICML, 2015b. Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I Jordan. Unsupervised domain adaptation with residual transfer networks. In NIPS, Andrew L Maas, Awni Y Hannun, and Andrew Y Ng. Rectifier nonlinearities improve neural network acoustic models. In ICML, W. Maddern, G. Pascoe, C. Linegar, and P. Newman. 1 year, 1000km: The oxford robotcar dataset. The International Journal of Robotics Research (IJRR), 36(1), A. Odena, C. Olah, and J. Shlens. Conditional image synthesis with auxiliary classifier gans. In ICML, A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, S. Reed, K. Sohn, Y. Zhang, and H. Lee. Learning to disentangle factors of variation with manifold interaction. In ICML,
11 S. R. Richter, V. Vineet, S. Roth, and V. Koltun. Playing for data: Ground truth from computer games. In ECCV, G. Ros, L. Sellart, J. Materzynska, D. Vazquez, and A. Lopez. The SYNTHIA Dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In CVPR, Kate Saenko, Brian Kulis, Mario Fritz, and Trevor Darrell. Adapting visual category models to new domains. In ECCV, Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In NIPS, Y.-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang, and M. Chandraker. Learning to adapt structured output space for semantic segmentation. In CVPR, Eric Tzeng, Judy Hoffman, Trevor Darrell, and Kate Saenko. Simultaneous deep transfer across domains and tasks. In ICCV, Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In CVPR, L. J. P van der Maaten and G. E. Hinton. Visualizing high-dimensional data using t-sne. Journal of Machine Learning Research, 9: , J. Yang, S. E. Reed, M.-H. Yang, and H. Lee. Weakly-supervised disentangling with recurrent transformations for 3d view synthesis. In NIPS, Y. Zhang, P. David, and B. Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In ICCV, Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. ICCV,

12 A TRAINING DETAILS To train the model in an end-to-end manner, we randomly sample one image from each of the source and target domain (i.e., batch size as 1) in a training iteration. Then we follow the optimization strategy as described in Section 3.4 of the paper. Table 4 shows the image and patch sizes during training and testing. Note that, the aspect ratio of the image is always maintained (i.e., no cropping) and then the image is down-sampled to the size as in the table. Table 4: Image and patch sizes for training and testing. Dataset Cityscapes GTA5 SYNTHIA Oxford RobotCar Patch size for training Image size for training Image size for testing B RELATION TO ENTROPY MINIMIZATION Entropy minimization (Grandvalet & Bengio, 2004) can be used as a loss in our model to push the target feature representation F t to one of the source clusters. To add this regularization, we replace the adversarial loss on the patch level with an entropy loss as in (Long et al., 2016), i.e., k H(σ( ˆF t /τ)) (u,v,k), H is the information entropy L s + L d + L g adv + Ll en, where L l en = u,v function, σ is the softmax function, and τ is the temperature of the softmax. The model with adding this entropy regularization achieves the IoU as 41.9%, that is lower than the proposed patchlevel adversarial alignment as 43.2%. The reason is that, different from the entropy minimization approach that does not use the source distribution as the guidance, our model learns discriminative representations for the target patches by pushing them closer to the source distribution in the clustered space guided by the label histogram. C VISUALIZATION OF PATCH-LEVEL REPRESENTATIONS In Figure 6, we show example patches from the source and target domains corresponding to the t-sne visualization. For each group in the clustered space via t-sne, we show that source and target patches share high similarity between each other, which demonstrates the effectiveness of the proposed patch-level alignment. Figure 6: Visualization of patch-level representations. We first show feature representations via t-sne of our method and compare with the one without the proposed patch-level alignment. In addition, we show patch examples in the clustered space. In each group, patches are similar in appearance between the source and target domains. 12
13 D RESULT OF ADAPTING CITYSCAPES TO OXFORD ROBOTCAR In Table 5, we present the complete result for adapting Cityscapes (sunny condition) to Oxford RobotCar (rainy scene). We compare the proposed method with the model without adaptation and the output space adaptation approach (Tsai et al., 2018). More qualitative results are provided in Figure 7 and 8. Table 5: Results of adapting Cityscapes to Oxford RobotCar. Cityscapes Oxford RobotCar Method road sidewalk building light sign veg sky person automobile two-wheel miou Without Adaptation Tsai et al. (2018) Ours E QUALITATIVE COMPARISONS We provide more visual comparisons for GTA5-to-Cityscapes and SYNTHIA-to-Cityscapes scenarios from Figure 9 to Figure 11. In each row, we present the results of the model without adaptation, output space adaptation (Tsai et al., 2018), and the proposed method. We show that our approach often yields better segmentation outputs with more details and produces less noisy regions. 13





































14 Under review as a conference paper at ICLR 2019 Figure 7: Example results of adapted segmentation for the Cityscapes-to-OxfordRobotCar setting. We sequentially show images in a video and their adapted segmentations generated by our method. Figure 8: Example results of adapted segmentation for the Cityscapes-to-OxfordRobotCar setting. We sequentially show images in a video and their adapted segmentations generated by our method. 14





























15 Under review as a conference paper at ICLR 2019 Target Image Ground Truth Before Adaptation Global Alignment Ours Figure 9: Example results of adapted segmentation for the GTA5-to-Cityscapes setting. For each target image, we show results before adaptation, output space adaptation Tsai et al. (2018), and the proposed method. 15


























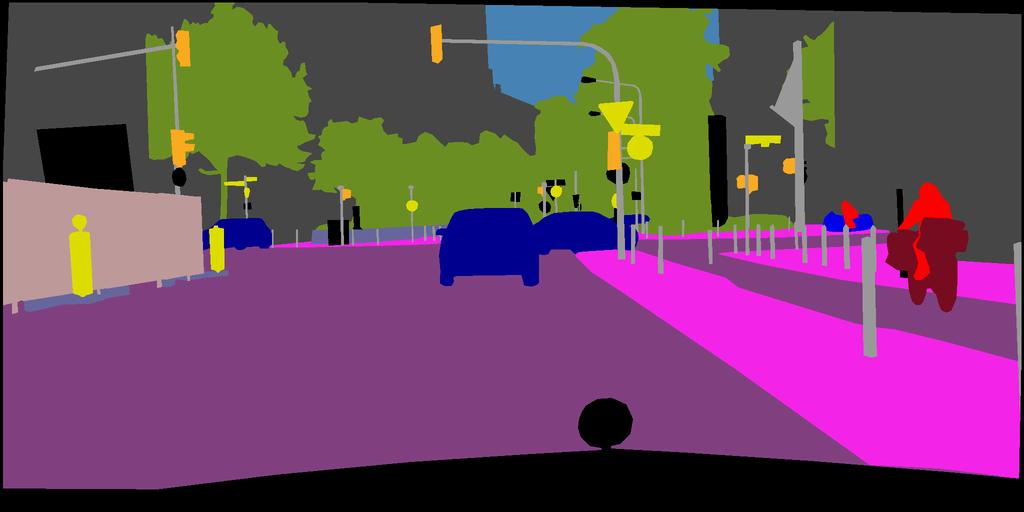














16 Under review as a conference paper at ICLR 2019 Target Image Ground Truth Before Adaptation Global Alignment Ours Figure 10: Example results of adapted segmentation for the GTA5-to-Cityscapes setting. For each target image, we show results before adaptation, output space adaptation Tsai et al. (2018), and the proposed method. 16


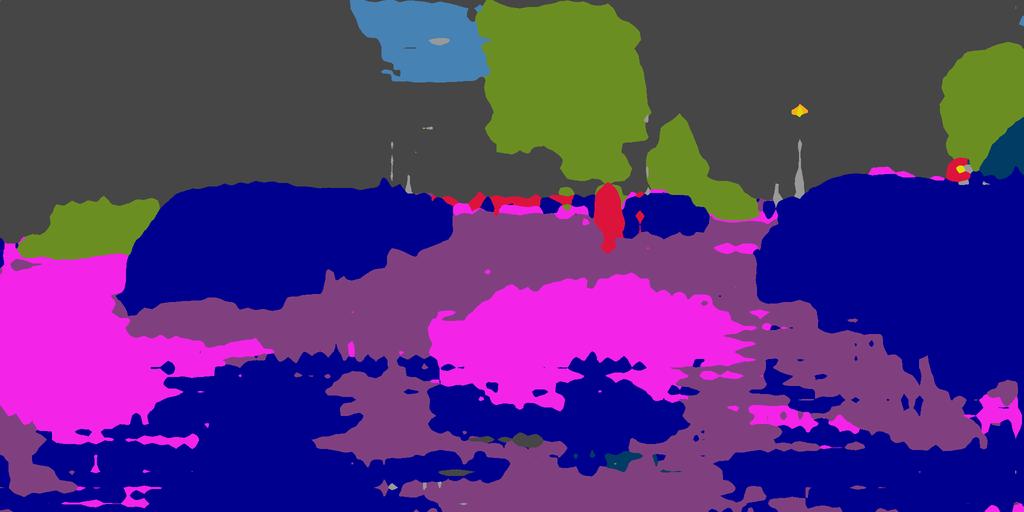



























17 Under review as a conference paper at ICLR 2019 Target Image Ground Truth Before Adaptation Global Alignment Ours Figure 11: Example results of adapted segmentation for the SYNTHIA-to-Cityscapes setting. For each target image, we show results before adaptation, output space adaptation Tsai et al. (2018), and the proposed method. 17
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
Progress on Generative Adversarial Networks
 Progress on Generative Adversarial Networks Wangmeng Zuo Vision Perception and Cognition Centre Harbin Institute of Technology Content Image generation: problem formulation Three issues about GAN Discriminate
Progress on Generative Adversarial Networks Wangmeng Zuo Vision Perception and Cognition Centre Harbin Institute of Technology Content Image generation: problem formulation Three issues about GAN Discriminate
Deep Model Adaptation using Domain Adversarial Training
 Deep Model Adaptation using Domain Adversarial Training Victor Lempitsky, joint work with Yaroslav Ganin Skolkovo Institute of Science and Technology ( Skoltech ) Moscow region, Russia Deep supervised
Deep Model Adaptation using Domain Adversarial Training Victor Lempitsky, joint work with Yaroslav Ganin Skolkovo Institute of Science and Technology ( Skoltech ) Moscow region, Russia Deep supervised
arxiv: v1 [cs.cv] 1 Dec 2017
![arxiv: v1 [cs.cv] 1 Dec 2017](/thumbs/86/93359750.jpg "arxiv: v1 [cs.cv] 1 Dec 2017") Image to Image Translation for Domain Adaptation Zak Murez 1,2 Soheil Kolouri 2 David Kriegman 1 Ravi Ramamoorthi 1 Kyungnam Kim 2 1 University of California, San Diego; 2 HRL Laboratories, LLC; {zmurez,kriegman,ravir}@cs.ucsd.edu,
Image to Image Translation for Domain Adaptation Zak Murez 1,2 Soheil Kolouri 2 David Kriegman 1 Ravi Ramamoorthi 1 Kyungnam Kim 2 1 University of California, San Diego; 2 HRL Laboratories, LLC; {zmurez,kriegman,ravir}@cs.ucsd.edu,
arxiv: v2 [cs.cv] 1 Apr 2018
![arxiv: v2 [cs.cv] 1 Apr 2018](/thumbs/94/118088355.jpg "arxiv: v2 [cs.cv] 1 Apr 2018") Proposed Approach Extreme Domain Shift Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation Swami Sankaranarayanan 1 Yogesh Balaji 1 Arpit Jain 2 Ser Nam Lim 2,3 Rama Chellappa
Proposed Approach Extreme Domain Shift Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation Swami Sankaranarayanan 1 Yogesh Balaji 1 Arpit Jain 2 Ser Nam Lim 2,3 Rama Chellappa
arxiv: v1 [cs.cv] 7 Mar 2018
![arxiv: v1 [cs.cv] 7 Mar 2018](/thumbs/95/125565711.jpg "arxiv: v1 [cs.cv] 7 Mar 2018") Accepted as a conference paper at the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN) 2018 Inferencing Based on Unsupervised Learning of Disentangled
Accepted as a conference paper at the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN) 2018 Inferencing Based on Unsupervised Learning of Disentangled
arxiv: v1 [cs.cv] 10 Nov 2017
![arxiv: v1 [cs.cv] 10 Nov 2017](/thumbs/74/70631687.jpg "arxiv: v1 [cs.cv] 10 Nov 2017") A FULLY CONVOLUTIONAL TRI-BRANCH NETWORK (FCTN) FOR DOMAIN ADAPTATION Junting Zhang, Chen Liang and C.-C. Jay Kuo University of Southern California, Los Angeles, CA 90089, USA arxiv:1711.03694v1 [cs.cv]
A FULLY CONVOLUTIONAL TRI-BRANCH NETWORK (FCTN) FOR DOMAIN ADAPTATION Junting Zhang, Chen Liang and C.-C. Jay Kuo University of Southern California, Los Angeles, CA 90089, USA arxiv:1711.03694v1 [cs.cv]
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet.
 Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Synscapes A photorealistic syntehtic dataset for street scene parsing Jonas Unger Department of Science and Technology Linköpings Universitet 7D Labs VINNOVA https://7dlabs.com Photo-realistic image synthesis
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos
 Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
GENERATIVE ADVERSARIAL NETWORK-BASED VIR-
 GENERATIVE ADVERSARIAL NETWORK-BASED VIR- TUAL TRY-ON WITH CLOTHING REGION Shizuma Kubo, Yusuke Iwasawa, and Yutaka Matsuo The University of Tokyo Bunkyo-ku, Japan {kubo, iwasawa, matsuo}@weblab.t.u-tokyo.ac.jp
GENERATIVE ADVERSARIAL NETWORK-BASED VIR- TUAL TRY-ON WITH CLOTHING REGION Shizuma Kubo, Yusuke Iwasawa, and Yutaka Matsuo The University of Tokyo Bunkyo-ku, Japan {kubo, iwasawa, matsuo}@weblab.t.u-tokyo.ac.jp
Introduction to Generative Adversarial Networks
 Introduction to Generative Adversarial Networks Luke de Oliveira Vai Technologies Lawrence Berkeley National Laboratory @lukede0 @lukedeo lukedeo@vaitech.io https://ldo.io 1 Outline Why Generative Modeling?
Introduction to Generative Adversarial Networks Luke de Oliveira Vai Technologies Lawrence Berkeley National Laboratory @lukede0 @lukedeo lukedeo@vaitech.io https://ldo.io 1 Outline Why Generative Modeling?
arxiv: v1 [cs.cv] 5 Jul 2017
![arxiv: v1 [cs.cv] 5 Jul 2017](/thumbs/95/123923253.jpg "arxiv: v1 [cs.cv] 5 Jul 2017") AlignGAN: Learning to Align Cross- Images with Conditional Generative Adversarial Networks Xudong Mao Department of Computer Science City University of Hong Kong xudonmao@gmail.com Qing Li Department of
AlignGAN: Learning to Align Cross- Images with Conditional Generative Adversarial Networks Xudong Mao Department of Computer Science City University of Hong Kong xudonmao@gmail.com Qing Li Department of
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
A Unified Feature Disentangler for Multi-Domain Image Translation and Manipulation
 A Unified Feature Disentangler for Multi-Domain Image Translation and Manipulation Alexander H. Liu 1 Yen-Cheng Liu 2 Yu-Ying Yeh 3 Yu-Chiang Frank Wang 1,4 1 National Taiwan University, Taiwan 2 Georgia
A Unified Feature Disentangler for Multi-Domain Image Translation and Manipulation Alexander H. Liu 1 Yen-Cheng Liu 2 Yu-Ying Yeh 3 Yu-Chiang Frank Wang 1,4 1 National Taiwan University, Taiwan 2 Georgia
Unsupervised Learning
 Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Deep Learning for Graphics Unsupervised Learning Niloy Mitra Iasonas Kokkinos Paul Guerrero Vladimir Kim Kostas Rematas Tobias Ritschel UCL UCL/Facebook UCL Adobe Research U Washington UCL Timetable Niloy
Image to Image Translation for Domain Adaptation
 Image to Image Translation for Domain Adaptation Zak Murez 1,2 Soheil Kolouri 2 David Kriegman 1 Ravi Ramamoorthi 1 Kyungnam Kim 2 1 University of California, San Diego; 2 HRL Laboratories, LLC; {zmurez,kriegman,ravir}@cs.ucsd.edu,
Image to Image Translation for Domain Adaptation Zak Murez 1,2 Soheil Kolouri 2 David Kriegman 1 Ravi Ramamoorthi 1 Kyungnam Kim 2 1 University of California, San Diego; 2 HRL Laboratories, LLC; {zmurez,kriegman,ravir}@cs.ucsd.edu,
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
DOMAIN ADAPTATION FOR BIOMEDICAL IMAGE SEGMENTATION USING ADVERSARIAL TRAINING. Mehran Javanmardi, Tolga Tasdizen
 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018) April 4-7, 2018, Washington, D.C., USA DOMAIN ADAPTATION FOR BIOMEDICAL IMAGE SEGMENTATION USING ADVERSARIAL TRAINING Mehran Javanmardi,
2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018) April 4-7, 2018, Washington, D.C., USA DOMAIN ADAPTATION FOR BIOMEDICAL IMAGE SEGMENTATION USING ADVERSARIAL TRAINING Mehran Javanmardi,
arxiv: v1 [cs.cv] 1 Nov 2018
![arxiv: v1 [cs.cv] 1 Nov 2018](/thumbs/89/100791471.jpg "arxiv: v1 [cs.cv] 1 Nov 2018") Examining Performance of Sketch-to-Image Translation Models with Multiclass Automatically Generated Paired Training Data Dichao Hu College of Computing, Georgia Institute of Technology, 801 Atlantic Dr
Examining Performance of Sketch-to-Image Translation Models with Multiclass Automatically Generated Paired Training Data Dichao Hu College of Computing, Georgia Institute of Technology, 801 Atlantic Dr
Unsupervised domain adaptation of deep object detectors
 Unsupervised domain adaptation of deep object detectors Debjeet Majumdar 1 and Vinay P. Namboodiri2 Indian Institute of Technology, Kanpur - Computer Science and Engineering Kalyanpur, Kanpur, Uttar Pradesh
Unsupervised domain adaptation of deep object detectors Debjeet Majumdar 1 and Vinay P. Namboodiri2 Indian Institute of Technology, Kanpur - Computer Science and Engineering Kalyanpur, Kanpur, Uttar Pradesh
Alternatives to Direct Supervision
 CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
CreativeAI: Deep Learning for Graphics Alternatives to Direct Supervision Niloy Mitra Iasonas Kokkinos Paul Guerrero Nils Thuerey Tobias Ritschel UCL UCL UCL TUM UCL Timetable Theory and Basics State of
Conditional Generative Adversarial Network for Structured Domain Adaptation
 Conditional Generative Adversarial Network for Structured Domain Adaptation Weixiang Hong Nanyang Technological University weixiang.hong@outlook.com Ming Yang Horizon Robotics, Inc. ming.yang@horizon-robotics.com
Conditional Generative Adversarial Network for Structured Domain Adaptation Weixiang Hong Nanyang Technological University weixiang.hong@outlook.com Ming Yang Horizon Robotics, Inc. ming.yang@horizon-robotics.com
arxiv: v2 [cs.cv] 28 Mar 2018
![arxiv: v2 [cs.cv] 28 Mar 2018](/thumbs/93/111152445.jpg "arxiv: v2 [cs.cv] 28 Mar 2018") Importance Weighted Adversarial Nets for Partial Domain Adaptation Jing Zhang, Zewei Ding, Wanqing Li, Philip Ogunbona Advanced Multimedia Research Lab, University of Wollongong, Australia jz60@uowmail.edu.au,
Importance Weighted Adversarial Nets for Partial Domain Adaptation Jing Zhang, Zewei Ding, Wanqing Li, Philip Ogunbona Advanced Multimedia Research Lab, University of Wollongong, Australia jz60@uowmail.edu.au,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION
 2017 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 25 28, 2017, TOKYO, JAPAN DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1,
2017 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 25 28, 2017, TOKYO, JAPAN DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1,
DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION
 DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1, Wei-Chen Chiu 2, Sheng-De Wang 1, and Yu-Chiang Frank Wang 1 1 Graduate Institute of Electrical Engineering,
DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1, Wei-Chen Chiu 2, Sheng-De Wang 1, and Yu-Chiang Frank Wang 1 1 Graduate Institute of Electrical Engineering,
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
CyCADA: Cycle-Consistent Adversarial Domain Adaptation
 Judy Hoffman 1 Eric Tzeng 1 Taesung Park 1 Jun-Yan Zhu 1 Phillip Isola 12 Kate Saenko 3 Alexei A. Efros 1 Trevor Darrell 1 Abstract Domain adaptation is critical for success in new, unseen environments.
Judy Hoffman 1 Eric Tzeng 1 Taesung Park 1 Jun-Yan Zhu 1 Phillip Isola 12 Kate Saenko 3 Alexei A. Efros 1 Trevor Darrell 1 Abstract Domain adaptation is critical for success in new, unseen environments.
arxiv: v1 [cs.cv] 3 Dec 2018
![arxiv: v1 [cs.cv] 3 Dec 2018](/thumbs/91/106616262.jpg "arxiv: v1 [cs.cv] 3 Dec 2018") SPLAT: Semantic Pixel-Level Adaptation Transforms for Detection arxiv:1812.00929v1 [cs.cv] 3 Dec 2018 Eric Tzeng UC Berkeley etzeng@eecs.berkeley.edu Abstract Domain adaptation of visual detectors is a
SPLAT: Semantic Pixel-Level Adaptation Transforms for Detection arxiv:1812.00929v1 [cs.cv] 3 Dec 2018 Eric Tzeng UC Berkeley etzeng@eecs.berkeley.edu Abstract Domain adaptation of visual detectors is a
arxiv: v1 [cs.cv] 8 Nov 2017
![arxiv: v1 [cs.cv] 8 Nov 2017](/thumbs/95/125130268.jpg "arxiv: v1 [cs.cv] 8 Nov 2017") CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu BAIR, UC Berkeley {jhoffman,etzeng,taesung_park,junyanz}@eecs.berkeley arxiv:1711.03213v1 [cs.cv]
CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu BAIR, UC Berkeley {jhoffman,etzeng,taesung_park,junyanz}@eecs.berkeley arxiv:1711.03213v1 [cs.cv]
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
arxiv: v1 [cs.cv] 27 Apr 2017
![arxiv: v1 [cs.cv] 27 Apr 2017](/thumbs/79/79134921.jpg "arxiv: v1 [cs.cv] 27 Apr 2017") No More Discrimination: Cross City Adaptation of Road Scene Segmenters Yi-Hsin Chen 1, Wei-Yu Chen 3,4, Yu-Ting Chen 1, Bo-Cheng Tsai 2, Yu-Chiang Frank Wang 4, Min Sun 1 arxiv:1704.08509v1 [cs.cv] 27
No More Discrimination: Cross City Adaptation of Road Scene Segmenters Yi-Hsin Chen 1, Wei-Yu Chen 3,4, Yu-Ting Chen 1, Bo-Cheng Tsai 2, Yu-Chiang Frank Wang 4, Min Sun 1 arxiv:1704.08509v1 [cs.cv] 27
arxiv: v1 [cs.cv] 17 Nov 2016
![arxiv: v1 [cs.cv] 17 Nov 2016](/thumbs/86/93859848.jpg "arxiv: v1 [cs.cv] 17 Nov 2016") Inverting The Generator Of A Generative Adversarial Network arxiv:1611.05644v1 [cs.cv] 17 Nov 2016 Antonia Creswell BICV Group Bioengineering Imperial College London ac2211@ic.ac.uk Abstract Anil Anthony
Inverting The Generator Of A Generative Adversarial Network arxiv:1611.05644v1 [cs.cv] 17 Nov 2016 Antonia Creswell BICV Group Bioengineering Imperial College London ac2211@ic.ac.uk Abstract Anil Anthony
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Thinking Outside the Box: Spatial Anticipation of Semantic Categories
 GARBADE, GALL: SPATIAL ANTICIPATION OF SEMANTIC CATEGORIES 1 Thinking Outside the Box: Spatial Anticipation of Semantic Categories Martin Garbade garbade@iai.uni-bonn.de Juergen Gall gall@iai.uni-bonn.de
GARBADE, GALL: SPATIAL ANTICIPATION OF SEMANTIC CATEGORIES 1 Thinking Outside the Box: Spatial Anticipation of Semantic Categories Martin Garbade garbade@iai.uni-bonn.de Juergen Gall gall@iai.uni-bonn.de
IMPROVING THE ROBUSTNESS OF CONVOLUTIONAL NETWORKS TO APPEARANCE VARIABILITY IN BIOMEDICAL IMAGES
 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018) April 4-7, 2018, Washington, D.C., USA IMPROVING THE ROBUSTNESS OF CONVOLUTIONAL NETWORKS TO APPEARANCE VARIABILITY IN BIOMEDICAL
2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018) April 4-7, 2018, Washington, D.C., USA IMPROVING THE ROBUSTNESS OF CONVOLUTIONAL NETWORKS TO APPEARANCE VARIABILITY IN BIOMEDICAL
Learning Transferable Features with Deep Adaptation Networks
 Learning Transferable Features with Deep Adaptation Networks Mingsheng Long, Yue Cao, Jianmin Wang, Michael I. Jordan Presented by Changyou Chen October 30, 2015 1 Changyou Chen Learning Transferable Features
Learning Transferable Features with Deep Adaptation Networks Mingsheng Long, Yue Cao, Jianmin Wang, Michael I. Jordan Presented by Changyou Chen October 30, 2015 1 Changyou Chen Learning Transferable Features
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
SYNTHESIS OF IMAGES BY TWO-STAGE GENERATIVE ADVERSARIAL NETWORKS. Qiang Huang, Philip J.B. Jackson, Mark D. Plumbley, Wenwu Wang
 SYNTHESIS OF IMAGES BY TWO-STAGE GENERATIVE ADVERSARIAL NETWORKS Qiang Huang, Philip J.B. Jackson, Mark D. Plumbley, Wenwu Wang Centre for Vision, Speech and Signal Processing University of Surrey, Guildford,
SYNTHESIS OF IMAGES BY TWO-STAGE GENERATIVE ADVERSARIAL NETWORKS Qiang Huang, Philip J.B. Jackson, Mark D. Plumbley, Wenwu Wang Centre for Vision, Speech and Signal Processing University of Surrey, Guildford,
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models
 One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
arxiv: v4 [cs.cv] 3 Apr 2018
![arxiv: v4 [cs.cv] 3 Apr 2018](/thumbs/82/84970736.jpg "arxiv: v4 [cs.cv] 3 Apr 2018") Maximum Classifier Discrepancy for Unsupervised Domain Adaptation Kuniaki Saito 1, Kohei Watanabe 1, Yoshitaka Ushiku 1, and Tatsuya Harada 1,2 1 The University of Tokyo, 2 RIKEN {k-saito,watanabe,ushiku,harada}@mi.t.u-tokyo.ac.jp
Maximum Classifier Discrepancy for Unsupervised Domain Adaptation Kuniaki Saito 1, Kohei Watanabe 1, Yoshitaka Ushiku 1, and Tatsuya Harada 1,2 1 The University of Tokyo, 2 RIKEN {k-saito,watanabe,ushiku,harada}@mi.t.u-tokyo.ac.jp
Team G-RMI: Google Research & Machine Intelligence
 Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
arxiv: v1 [cs.cv] 28 Sep 2018
![arxiv: v1 [cs.cv] 28 Sep 2018](/thumbs/87/96663405.jpg "arxiv: v1 [cs.cv] 28 Sep 2018") Domain Generalization with Domain-Specific Aggregation Modules Antonio D Innocente 1,2 and Barbara Caputo 2 arxiv:1809.10966v1 [cs.cv] 28 Sep 2018 1 Sapienza University of Rome Rome, Italy dinnocente@diag.unroma1.it
Domain Generalization with Domain-Specific Aggregation Modules Antonio D Innocente 1,2 and Barbara Caputo 2 arxiv:1809.10966v1 [cs.cv] 28 Sep 2018 1 Sapienza University of Rome Rome, Italy dinnocente@diag.unroma1.it
VisDA: A Synthetic-to-Real Benchmark for Visual Domain Adaptation
 VisDA: A Synthetic-to-Real Benchmark for Visual Domain Adaptation Xingchao Peng 1, Ben Usman 1, Neela Kaushik 1, Dequan Wang 2, Judy Hoffman 2, and Kate Saenko 1 xpeng,usmn,nkaushik,saenko@bu.edu, jhoffman,dqwang@eecs.berkeley.edu
VisDA: A Synthetic-to-Real Benchmark for Visual Domain Adaptation Xingchao Peng 1, Ben Usman 1, Neela Kaushik 1, Dequan Wang 2, Judy Hoffman 2, and Kate Saenko 1 xpeng,usmn,nkaushik,saenko@bu.edu, jhoffman,dqwang@eecs.berkeley.edu
arxiv: v1 [cs.cv] 6 Sep 2018
![arxiv: v1 [cs.cv] 6 Sep 2018](/thumbs/85/92251412.jpg "arxiv: v1 [cs.cv] 6 Sep 2018") arxiv:1809.01890v1 [cs.cv] 6 Sep 2018 Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks Koichi Hamada, Kentaro Tachibana, Tianqi Li, Hiroto
arxiv:1809.01890v1 [cs.cv] 6 Sep 2018 Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks Koichi Hamada, Kentaro Tachibana, Tianqi Li, Hiroto
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
arxiv: v1 [eess.sp] 23 Oct 2018
![arxiv: v1 [eess.sp] 23 Oct 2018](/thumbs/94/119614192.jpg "arxiv: v1 [eess.sp] 23 Oct 2018") Reproducing AmbientGAN: Generative models from lossy measurements arxiv:1810.10108v1 [eess.sp] 23 Oct 2018 Mehdi Ahmadi Polytechnique Montreal mehdi.ahmadi@polymtl.ca Mostafa Abdelnaim University de Montreal
Reproducing AmbientGAN: Generative models from lossy measurements arxiv:1810.10108v1 [eess.sp] 23 Oct 2018 Mehdi Ahmadi Polytechnique Montreal mehdi.ahmadi@polymtl.ca Mostafa Abdelnaim University de Montreal
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Unsupervised Image-to-Image Translation Networks
 Unsupervised Image-to-Image Translation Networks Ming-Yu Liu, Thomas Breuel, Jan Kautz NVIDIA {mingyul,tbreuel,jkautz}@nvidia.com Abstract Unsupervised image-to-image translation aims at learning a joint
Unsupervised Image-to-Image Translation Networks Ming-Yu Liu, Thomas Breuel, Jan Kautz NVIDIA {mingyul,tbreuel,jkautz}@nvidia.com Abstract Unsupervised image-to-image translation aims at learning a joint
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
arxiv: v3 [cs.cv] 29 Dec 2017
![arxiv: v3 [cs.cv] 29 Dec 2017](/thumbs/74/70503284.jpg "arxiv: v3 [cs.cv] 29 Dec 2017") CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu BAIR, UC Berkeley {jhoffman,etzeng,taesung_park,junyanz}@eecs.berkeley arxiv:1711.03213v3 [cs.cv]
CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu BAIR, UC Berkeley {jhoffman,etzeng,taesung_park,junyanz}@eecs.berkeley arxiv:1711.03213v3 [cs.cv]
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Inverting The Generator Of A Generative Adversarial Network
 1 Inverting The Generator Of A Generative Adversarial Network Antonia Creswell and Anil A Bharath, Imperial College London arxiv:1802.05701v1 [cs.cv] 15 Feb 2018 Abstract Generative adversarial networks
1 Inverting The Generator Of A Generative Adversarial Network Antonia Creswell and Anil A Bharath, Imperial College London arxiv:1802.05701v1 [cs.cv] 15 Feb 2018 Abstract Generative adversarial networks
Advanced Video Analysis & Imaging
 Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
An Adversarial Regularisation for Semi-Supervised Training of Structured Output Neural Networks
 An Adversarial Regularisation for Semi-Supervised Training of Structured Output Neural Networks Mateusz Koziński 2 Loïc Simon Frédéric Jurie Groupe de recherche en Informatique, Image, Automatique et Instrumentation
An Adversarial Regularisation for Semi-Supervised Training of Structured Output Neural Networks Mateusz Koziński 2 Loïc Simon Frédéric Jurie Groupe de recherche en Informatique, Image, Automatique et Instrumentation
Exploiting Images for Video Recognition with Hierarchical Generative Adversarial Networks
 Exploiting Images for Video Recognition with Hierarchical Generative Adversarial Networks Feiwu Yu 1, Xinxiao Wu 1, Yuchao Sun 1, Lixin Duan 2 1 Beijing Laboratory of Intelligent Information Technology,
Exploiting Images for Video Recognition with Hierarchical Generative Adversarial Networks Feiwu Yu 1, Xinxiao Wu 1, Yuchao Sun 1, Lixin Duan 2 1 Beijing Laboratory of Intelligent Information Technology,
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Deep Neural Networks:
 Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION
 CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION Anonymous authors Paper under double-blind review ABSTRACT Domain adaptation is critical for success in new, unseen environments. Adversarial adaptation
CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION Anonymous authors Paper under double-blind review ABSTRACT Domain adaptation is critical for success in new, unseen environments. Adversarial adaptation
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform. Xintao Wang Ke Yu Chao Dong Chen Change Loy
 Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Xintao Wang Ke Yu Chao Dong Chen Change Loy Problem enlarge 4 times Low-resolution image High-resolution image Previous
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Xintao Wang Ke Yu Chao Dong Chen Change Loy Problem enlarge 4 times Low-resolution image High-resolution image Previous
Lightweight Unsupervised Domain Adaptation by Convolutional Filter Reconstruction
 Lightweight Unsupervised Domain Adaptation by Convolutional Filter Reconstruction Rahaf Aljundi, Tinne Tuytelaars KU Leuven, ESAT-PSI - iminds, Belgium Abstract. Recently proposed domain adaptation methods
Lightweight Unsupervised Domain Adaptation by Convolutional Filter Reconstruction Rahaf Aljundi, Tinne Tuytelaars KU Leuven, ESAT-PSI - iminds, Belgium Abstract. Recently proposed domain adaptation methods
arxiv: v1 [cs.mm] 12 Jan 2016
![arxiv: v1 [cs.mm] 12 Jan 2016](/thumbs/73/69424856.jpg "arxiv: v1 [cs.mm] 12 Jan 2016") Learning Subclass Representations for Visually-varied Image Classification Xinchao Li, Peng Xu, Yue Shi, Martha Larson, Alan Hanjalic Multimedia Information Retrieval Lab, Delft University of Technology
Learning Subclass Representations for Visually-varied Image Classification Xinchao Li, Peng Xu, Yue Shi, Martha Larson, Alan Hanjalic Multimedia Information Retrieval Lab, Delft University of Technology
Semantic Segmentation with Scarce Data
 Semantic Segmentation with Scarce Data Isay Katsman * 1 Rohun Tripathi * 1 Andreas Veit 1 Serge Belongie 1 Abstract Semantic segmentation is a challenging vision problem that usually necessitates the collection
Semantic Segmentation with Scarce Data Isay Katsman * 1 Rohun Tripathi * 1 Andreas Veit 1 Serge Belongie 1 Abstract Semantic segmentation is a challenging vision problem that usually necessitates the collection
Ryerson University CP8208. Soft Computing and Machine Intelligence. Naive Road-Detection using CNNS. Authors: Sarah Asiri - Domenic Curro
 Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
arxiv: v1 [cs.ne] 11 Jun 2018
![arxiv: v1 [cs.ne] 11 Jun 2018](/thumbs/80/80526645.jpg "arxiv: v1 [cs.ne] 11 Jun 2018") Generative Adversarial Network Architectures For Image Synthesis Using Capsule Networks arxiv:1806.03796v1 [cs.ne] 11 Jun 2018 Yash Upadhyay University of Minnesota, Twin Cities Minneapolis, MN, 55414
Generative Adversarial Network Architectures For Image Synthesis Using Capsule Networks arxiv:1806.03796v1 [cs.ne] 11 Jun 2018 Yash Upadhyay University of Minnesota, Twin Cities Minneapolis, MN, 55414
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
Stacked Denoising Autoencoders for Face Pose Normalization
 Stacked Denoising Autoencoders for Face Pose Normalization Yoonseop Kang 1, Kang-Tae Lee 2,JihyunEun 2, Sung Eun Park 2 and Seungjin Choi 1 1 Department of Computer Science and Engineering Pohang University
Stacked Denoising Autoencoders for Face Pose Normalization Yoonseop Kang 1, Kang-Tae Lee 2,JihyunEun 2, Sung Eun Park 2 and Seungjin Choi 1 1 Department of Computer Science and Engineering Pohang University
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs
 In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
Semi Supervised Semantic Segmentation Using Generative Adversarial Network
 Semi Supervised Semantic Segmentation Using Generative Adversarial Network Nasim Souly Concetto Spampinato Mubarak Shah nsouly@eecs.ucf.edu cspampin@dieei.unict.it shah@crcv.ucf.edu Abstract Unlabeled
Semi Supervised Semantic Segmentation Using Generative Adversarial Network Nasim Souly Concetto Spampinato Mubarak Shah nsouly@eecs.ucf.edu cspampin@dieei.unict.it shah@crcv.ucf.edu Abstract Unlabeled
arxiv: v4 [cs.cv] 7 Jul 2018
![arxiv: v4 [cs.cv] 7 Jul 2018](/thumbs/92/109397378.jpg "arxiv: v4 [cs.cv] 7 Jul 2018") Domain Adaptation Meets Disentangled Representation Learning and Style Transfer Hoang Tran Vu and Ching-Chun Huang Department of Electrical Engineering, National Chung Cheng University, Taiwan arxiv:1712.09025v4
Domain Adaptation Meets Disentangled Representation Learning and Style Transfer Hoang Tran Vu and Ching-Chun Huang Department of Electrical Engineering, National Chung Cheng University, Taiwan arxiv:1712.09025v4
Geodesic Flow Kernel for Unsupervised Domain Adaptation
 Geodesic Flow Kernel for Unsupervised Domain Adaptation Boqing Gong University of Southern California Joint work with Yuan Shi, Fei Sha, and Kristen Grauman 1 Motivation TRAIN TEST Mismatch between different
Geodesic Flow Kernel for Unsupervised Domain Adaptation Boqing Gong University of Southern California Joint work with Yuan Shi, Fei Sha, and Kristen Grauman 1 Motivation TRAIN TEST Mismatch between different
Generalizing A Person Retrieval Model Hetero- and Homogeneously
 Generalizing A Person Retrieval Model Hetero- and Homogeneously Zhun Zhong 1,2, Liang Zheng 2,3, Shaozi Li 1( ),Yi Yang 2 1 Cognitive Science Department, Xiamen University, China 2 Centre for Artificial
Generalizing A Person Retrieval Model Hetero- and Homogeneously Zhun Zhong 1,2, Liang Zheng 2,3, Shaozi Li 1( ),Yi Yang 2 1 Cognitive Science Department, Xiamen University, China 2 Centre for Artificial
Generative Networks. James Hays Computer Vision
 Generative Networks James Hays Computer Vision Interesting Illusion: Ames Window https://www.youtube.com/watch?v=ahjqe8eukhc https://en.wikipedia.org/wiki/ames_trapezoid Recap Unsupervised Learning Style
Generative Networks James Hays Computer Vision Interesting Illusion: Ames Window https://www.youtube.com/watch?v=ahjqe8eukhc https://en.wikipedia.org/wiki/ames_trapezoid Recap Unsupervised Learning Style
Generalizing A Person Retrieval Model Hetero- and Homogeneously
 Generalizing A Person Retrieval Model Hetero- and Homogeneously Zhun Zhong 1,2, Liang Zheng 2,3, Shaozi Li 1( ),Yi Yang 2 1 Cognitive Science Department, Xiamen University, China 2 Centre for Artificial
Generalizing A Person Retrieval Model Hetero- and Homogeneously Zhun Zhong 1,2, Liang Zheng 2,3, Shaozi Li 1( ),Yi Yang 2 1 Cognitive Science Department, Xiamen University, China 2 Centre for Artificial
Generative Models II. Phillip Isola, MIT, OpenAI DLSS 7/27/18
 Generative Models II Phillip Isola, MIT, OpenAI DLSS 7/27/18 What s a generative model? For this talk: models that output high-dimensional data (Or, anything involving a GAN, VAE, PixelCNN, etc) Useful
Generative Models II Phillip Isola, MIT, OpenAI DLSS 7/27/18 What s a generative model? For this talk: models that output high-dimensional data (Or, anything involving a GAN, VAE, PixelCNN, etc) Useful
Fully Convolutional Adaptation Networks for Semantic Segmentation
 Fully Convolutional Adaptation Networks for Semantic Segmentation Yiheng Zhang, Zhaofan Qiu, Ting Yao, Dong Liu, and Tao Mei University of Science and Technology of China, Hefei, China Microsoft Research,
Fully Convolutional Adaptation Networks for Semantic Segmentation Yiheng Zhang, Zhaofan Qiu, Ting Yao, Dong Liu, and Tao Mei University of Science and Technology of China, Hefei, China Microsoft Research,
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
GAN Related Works. CVPR 2018 & Selective Works in ICML and NIPS. Zhifei Zhang
 GAN Related Works CVPR 2018 & Selective Works in ICML and NIPS Zhifei Zhang Generative Adversarial Networks (GANs) 9/12/2018 2 Generative Adversarial Networks (GANs) Feedforward Backpropagation Real? z
GAN Related Works CVPR 2018 & Selective Works in ICML and NIPS Zhifei Zhang Generative Adversarial Networks (GANs) 9/12/2018 2 Generative Adversarial Networks (GANs) Feedforward Backpropagation Real? z
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Tiny ImageNet Visual Recognition Challenge
 Tiny ImageNet Visual Recognition Challenge Ya Le Department of Statistics Stanford University yle@stanford.edu Xuan Yang Department of Electrical Engineering Stanford University xuany@stanford.edu Abstract
Tiny ImageNet Visual Recognition Challenge Ya Le Department of Statistics Stanford University yle@stanford.edu Xuan Yang Department of Electrical Engineering Stanford University xuany@stanford.edu Abstract
Generative Adversarial Network
 Generative Adversarial Network Many slides from NIPS 2014 Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio Generative adversarial
Generative Adversarial Network Many slides from NIPS 2014 Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio Generative adversarial
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning for Visual Manipulation and Synthesis
 Deep Learning for Visual Manipulation and Synthesis Jun-Yan Zhu 朱俊彦 UC Berkeley 2017/01/11 @ VALSE What is visual manipulation? Image Editing Program input photo User Input result Desired output: stay
Deep Learning for Visual Manipulation and Synthesis Jun-Yan Zhu 朱俊彦 UC Berkeley 2017/01/11 @ VALSE What is visual manipulation? Image Editing Program input photo User Input result Desired output: stay
arxiv: v3 [cs.cv] 21 Aug 2018
![arxiv: v3 [cs.cv] 21 Aug 2018](/thumbs/84/91200697.jpg "arxiv: v3 [cs.cv] 21 Aug 2018") Adaptive Affinity Fields for Semantic Segmentation Tsung-Wei Ke*, Jyh-Jing Hwang*, Ziwei Liu, and Stella X. Yu UC Berkeley / ICSI {twke,jyh,zwliu,stellayu}@berkeley.edu arxiv:1803.10335v3 [cs.cv] 21 Aug
Adaptive Affinity Fields for Semantic Segmentation Tsung-Wei Ke*, Jyh-Jing Hwang*, Ziwei Liu, and Stella X. Yu UC Berkeley / ICSI {twke,jyh,zwliu,stellayu}@berkeley.edu arxiv:1803.10335v3 [cs.cv] 21 Aug
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Visual Recommender System with Adversarial Generator-Encoder Networks
 Visual Recommender System with Adversarial Generator-Encoder Networks Bowen Yao Stanford University 450 Serra Mall, Stanford, CA 94305 boweny@stanford.edu Yilin Chen Stanford University 450 Serra Mall
Visual Recommender System with Adversarial Generator-Encoder Networks Bowen Yao Stanford University 450 Serra Mall, Stanford, CA 94305 boweny@stanford.edu Yilin Chen Stanford University 450 Serra Mall
Paired 3D Model Generation with Conditional Generative Adversarial Networks
 Accepted to 3D Reconstruction in the Wild Workshop European Conference on Computer Vision (ECCV) 2018 Paired 3D Model Generation with Conditional Generative Adversarial Networks Cihan Öngün Alptekin Temizel
Accepted to 3D Reconstruction in the Wild Workshop European Conference on Computer Vision (ECCV) 2018 Paired 3D Model Generation with Conditional Generative Adversarial Networks Cihan Öngün Alptekin Temizel
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Facial Expression Classification with Random Filters Feature Extraction
 Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
 Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Learning visual odometry with a convolutional network
 Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com
Learning visual odometry with a convolutional network Kishore Konda 1, Roland Memisevic 2 1 Goethe University Frankfurt 2 University of Montreal konda.kishorereddy@gmail.com, roland.memisevic@gmail.com