FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-based CNN Architecture
|
|
|
- Robyn Watson
- 6 years ago
- Views:
Transcription
1 FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-based CNN Architecture Caner Hazirbas, Lingni Ma, Csaba Domoos, and Daniel Cremers Technical University of Munich, Germany Abstract. In this paper we address the problem of semantic labeling of indoor scenes on RGB-D data. With the availability of RGB-D cameras, it is expected that additional depth measurement will improve the accuracy. Here we investigate a solution how to incorporate complementary depth information into a semantic segmentation framewor by maing use of convolutional neural networs (CNNs). Recently encoder-decoder type fully convolutional CNN architectures have achieved a great success in the field of semantic segmentation. Motivated by this observation we propose an encoder-decoder type networ, where the encoder part is composed of two branches of networs that simultaneously extract features from RGB and depth images and fuse depth features into the RGB feature maps as the networ goes deeper. Comprehensive experimental evaluations demonstrate that the proposed fusion-based architecture achieves competitive results with the state-of-the-art methods on the challenging SUN RGB-D benchmar obtaining 76.27% global accuracy, 48.30% average class accuracy and 37.29% average intersectionover-union score. 1 Introduction Visual scene understanding in a glance is one of the most amazing capability of the human brain. In order to model this ability, semantic segmentation aims at giving a class label for each pixel on the image according to its semantic meaning. This problem is one of the most challenging tass in computer vision, and has received a lot of attention from the computer vision community [1,2,3,4,5,6,7]. Convolutional neural networs (CNNs) have recently attained a breathrough in various classification tass such as semantic segmentation. CNNs have been shown to be powerful visual models that yields hierarchies of features. The ey success of this model mainly lies in its general modeling ability for complex visual scenes. Currently CNN-based approaches [3,8,4] provide the state-of-the-art performance in several semantic segmentation benchmars. In contrast to CNN models, by applying hand-crafted features one can generally achieve rather limited accuracy. Utilizing depth additional to the appearance information (i.e. RGB) could potentially improve the performance of semantic segmentation, since the depth These authors contributed equally.



2 2 Caner Hazirbas, Lingni Ma, Csaba Domoos, Daniel Cremers Fig. 1: An exemplar output of FuseNet. From left to right: input RGB and depth images, the predicted semantic labeling and the probability of the corresponding labels, where white and blue denote high and low probability, respectively. channel has complementary information to RGB channels, and encodes structural information of the scene. The depth channel can be easily captured with low cost RGB-D sensors. In general object classes can be recognized based on their color and texture attributes. However, the auxiliary depth may reduce the uncertainty of the segmentation of objects having similar appearance information. Couprie et al. [9] observed that the segmentation of classes having similar depth, appearance and location is improved by maing use of the depth information too, but it is better to use only RGB information to recognize object classes containing high variability of their depth values. Therefore, the optimal way to fuse RGB and depth information has been left an open question. In this paper we address the problem of indoor scene understanding assuming that both RGB and depth information simultaneously available (see Figure 1). This problem is rather crucial in many perceptual applications including robotics. We remar that although indoor scenes have rich semantic information, they are generally more challenging than outdoor scenes due to more severe occlusions of objects and cluttered bacground. For example, indoor object classes, such as chair, dining table and curtain are much harder to recognize than outdoor classes, such as car, road, building and sy. The contribution of the paper can be summarized as follows: We investigate a solution how to incorporate complementary depth information into a semantic segmentation framewor. For this sae we propose an encoder-decoder type networ, referred to as FuseNet, where the encoder part is composed of two branches of networs that simultaneously extract features from RGB and depth images and fuse depth features into the RGB feature maps as the networ goes deeper (see Figure 2). We propose and examine two different ways for fusion of the RGB and depth channels. We also analyze the proposed networ architectures, referred to as dense and sparse fusion (see Figure 3), in terms of the level of fusion. We experimentally show that our proposed method is successfully able to fuse RGB and depth information for semantic segmentation also on cluttered indoor scenes. Moreover, our method achieves competitive results with state-of-the-art methods in terms of segmentation accuracy evaluated on the challenging SUN RGB-D dataset [10].
3 2 Related Wor FuseNet: Incorporating Depth into Semantic Segmentation 3 A fully convolutional networ (FCN) architecture has been introduced in [3] that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations by applying end-to-end training. Noh et al. [6] have proposed a novel networ architecture for semantic segmentation, referred to as DeconvNet, which alleviates the limitations of fully convolutional models (e.g., very limited resolution of labeling). DeconvNet is composed of deconvolution and unpooling layers on top of the VGG 16-layer net [11]. To retrieve semantic labeling on the full image size, Zeiler et al. [12] have introduced a networ composed of deconvolution and unpooling layers. Concurrently, a very similar networ architecture has been presented [13] based on the VGG 16-layer net [11], referred to as SegNet. In contrast to DeconvNet, SegNet consists of smoothed unpooled feature maps with convolution instead of deconvolution. Kendall et al. [14] further improved the segmentation accuracy of SegNet by applying dropout [15] during test time [16]. Some recent semantic segmentation algorithms combine the strengths of CNN and conditional random field (CRF) models. It has been shown that the poor pixel classification accuracy, due to the invariance properties that mae CNNs good for high level tass, can be overcome by combining the responses of the CNN at the final layer with a fully connected CRF model [8]. CNN and CRF models have also been combined in [4]. More precisely, the method proposed in [4] applies mean field approximation as the inference for a CRF model with Gaussian pairwise potentials, where the mean field approximation is modeled as a recurrent neural networ, and the defined networ is trained end-to-end refining the weights of the CNN model. Recently, Lin et al. [7] have also combined CNN and CRF models for learning patch-patch context between image regions, and have achieved the current state-of-the-art performance in semantic segmentation. One of the main ideas in [7] is to define CNN-based pairwise potential functions to capture semantic correlations between neighboring patches. Moreover, efficient piecewise training is applied for the CRF model in order to avoid repeated expensive CRF inference during the course of bac-propagation. In [2] a feed-forward neural networ has been proposed for scene labeling. The long range (pixel) label dependencies can be taen into account by capturing sufficiently large input context patch, around each pixel to be labeled. The method [2] relies on a recurrent convolutional neural networs (RCNN), i.e. a sequential series of networs sharing the same set of parameters. Each instance taes as input both an RGB image and the predictions of the previous instance of the networ. RCNN-based approaches are nown to be difficult to train, in particular, with large data, since long-term dependencies are vanished while the information is accumulated by the recurrence [5]. Byeon et al. [5] have presented long short term memory (LSTM) recurrent neural networs for natural scene images taing into account the complex spatial dependencies of labels. LSTM networs have been commonly used for sequence classification. These networs include recurrently connected layers to learn the dependencies between two frames, and then transfer the probabilistic inference
4 4 Caner Hazirbas, Lingni Ma, Csaba Domoos, Daniel Cremers to the next frame. This allows to easily memorize the context information for long periods of time in sequence data. It has been shown [5] that LSTM networs can be generalized well to any vision-based tas and efficiently capture local and global contextual information with a low computational complexity. State-of-the-art CNNs have the ability to perform segmentation on different inds of input sources such as RGB or even RGB-D. Therefore a trivial way to incorporate depth information would be to stac it to the RGB channels and train the networ on RGB-D data assuming a four-channel input. However, it would not fully exploit the structure of the scene encoded by the depth channel. This will be also shown experimentally in Section 4. By maing use of deeper and wider networ architecture one can expect the increase of the robustness and the accuracy. Hence, one may define a networ architecture with more layers. Nevertheless, this approach would require huge dataset in order to learn all the parameter maing the training infeasible even in the case when the parameters are initialized with a pre-trained networ. 2.1 The State of the Arts on RGB-D Data A new representation of the depth information has been presented by Gupta et al. [1]. This representation, referred to as HHA, consists of three channels: disparity, height of the pixels and the angle between of normals and the gravity vector based on the estimated ground floor, respectively. By maing use of the HHA representation, a superficial improvement was achieved in terms of segmentation accuracy [1]. On the other hand, the information retrieved only from the RGB channels still dominates the HHA representation. As we shall see in Section 4, the HHA representation does not hold more information than the depth itself. Furthermore, computing HHA representation requires high computational cost. In this paper we investigate a better way of exploiting depth information with less computational burden. Li et al. [17] have introduced a novel LSTM Fusion (LSTM-F) model that captures and fuses contextual information from photometric and depth channels by stacing several convolutional layers and an LSTM layer. The memory layer encodes both short- and long-range spatial dependencies in an image along vertical direction. Moreover, another LSTM-F layer integrates the contexts from different channels and performs bi-directional propagation of the fused vertical contexts. In general, these inds of architectures are rather complicated and hence more difficult to train. In contrast to recurrent networs, we propose a simpler networ architecture. 3 FuseNet: Unified CNN Framewor for Fusing RGB and Depth Channels We aim to solve the semantic segmentation problem on RGB-D images. We define the label set as L = {1, 2,..., K}. We assume that we are given a training set {(X i, Y i ) X i R H W 4, Y i L H W for all i = 1,..., M} consisting of
 Fusion Dropout Pooling Unpooling Score Fig. 2: The architecture of the proposed FuseNet. Colors indicate the layer type.")


5 FuseNet: Incorporating Depth into Semantic Segmentation 5 RGB encoder RGB-D decoder RGB branch... Depth encoder Depth branch... fusion zoomed in Conv+BN+ReLU (CBR) Fusion Dropout Pooling Unpooling Score Fig. 2: The architecture of the proposed FuseNet. Colors indicate the layer type. The networ contains two branches to extract features from RGB and depth images, and the feature maps from depth is constantly fused into the RGB branch, denoted with the red arrows. In our architecture, the fusion layer is implemented as an element-wise summation, demonstrated in the dashed box. M four-channel RGB-D images (X i ), having the same size H W, along with the ground-truth labeling (Y i ). Moreover, we assume that the pixels are drawn as i.i.d. samples following a categorical distribution. Based on this assumption, we may define a CNN model to perform multinomial logistic regression. The networ extracts features from the input layer and through filtering provides classification score for each label as an output at each pixel. We model the networ as a composition of functions corresponding to L layers with parameters denoted by W = [w (1), w (2),..., w (L) ], that is f(x; W) = g (L) (g (L 1) ( g (2) (g (1) (x; w (1) ); w (2) ) ; w (L 1) ); w (L) ). (1) The classification score of a pixel x for a given class c is obtained from the function f c (x; W), which is the cth component of f(x; W). Using the softmax function, we can map this score to a probability distribution exp ( f c (x; W) ) p(c x, W) = K =1 exp ( f (x; W ) ). (2) For the training of the networ, i.e. learning the optimal parameters W, the cross-entropy loss is used, which minimizes the KL-divergence between the predicted and the true class distribution: W = arg min W 1 2 W 2 λ MHW M HW i=1 j=1 log p(y ij x ij, W),
6 6 Caner Hazirbas, Lingni Ma, Csaba Domoos, Daniel Cremers depth CBR2 2 depth CBR3 3 depth CBR2 1 depth CBR3 1 depth CBR3 3 depth CBR2 2 depth CBR CBR2 1 CBR2 2 fuse2 pool2 CBR3 1 CBR3 2 CBR3 3 fuse3 pool3 (a) Sparse fusion (SF) CBR2 1 fuse2 1 CBR2 2 fuse2 2 pool2 CBR3 1 fuse3 1 CBR3 2 fuse3 2 CBR3 3 fuse3 3 pool3 (b) Dense fusion (DF) Fig. 3: Illustration of different fusion strategies at the second (CBR2) and third (CBR3) convolution blocs of VGG 16-layer net. (a) The fusion layer is only inserted before each pooling layer. (b) The fusion layer is inserted after each CBR bloc.... where x ij R 4 stands for the jth pixel of the ith training image and y ij L is its ground-truth label. The hyper-parameter λ > 0 is chosen to apply weighting for the regularization of the parameters (i.e. L 2 -norm of W). At inference, a probability distribution is predicted for each pixel via softmax normalization, defined in (2), and the labeling is calculated based on the highest class probability. 3.1 FuseNet Architecture We propose an encoder-decoder type networ architecture as shown in Figure 2. The proposed networ has two major parts: 1) the encoder part extracts features and 2) the decoder part upsamples the feature maps bac to the original input resolution. This encoder-decoder style has been already introduced in several previous wors such as DeconvNet [6] and SegNet [13] and has achieved good segmentation performance. Although our proposed networ is based on this type of architecture, we further consider to have two encoder branches. These two branches extract features from RGB and depth images. We note that the depth image is normalized to have the same value range as color images, i.e. into the interval of [0,255]. In order to combine information from both input modules, we fuse the feature maps from the depth branch into the feature maps of the RGB branch. We refer to this architecture as FuseNet (see Figure 2). The encoder part of FuseNet resembles the 16-layer VGG net [11], except of the fully connected layers fc6, fc7 and fc8, since the fully connected layers reduce the resolution with a factor of 49, which increases the difficulty of the upsampling part. In our networ, we always use batch normalization (BN) after convolution (Conv) and before rectified linear unit 1 (ReLU) to reduce the internal covariate shift [18]. We refer to the combination of convolution, batch normalization and ReLU as CBR bloc, respectively. The BN layer first normalizes the feature maps to have zero-mean and unit-variance, and then scales and shifts 1 The rectified linear unit is defined as σ(x) = max(0, x).
7 FuseNet: Incorporating Depth into Semantic Segmentation 7 them afterwards. In particular, the scale and shift parameters are learned during training. As a result, color features are not overwritten by depth features, but the networ learns how to combine them in an optimal way. The decoder part is a counterpart of the encoder part, where memorized unpooling is applied to upsample the feature maps. In the decoder part, we again use the CBR blocs. We also did experiments with deconvolution instead of convolution, and observed very similar performance. As proposed in [14], we also apply dropout in both the encoder and the decoder parts to further boost the performance. However, we do not use dropout during test time. The ey ingredient of the FuseNet architecture is the fusion bloc, which combines the feature maps of the depth branch and the RGB branch. The fusion layer is implemented as element-wise summation. In FuseNet, we always insert the fusion layer after the CBR bloc. By maing use of fusion the discontinuities of the features maps computed on the depth image are added into the RGB branch in order to enhance the RGB feature maps. As it can be observed in many cases, the features in the color domain and in the geometric domain complement each other. Based on this observation, we propose two fusion strategies: a) dense fusion (DF), where the fusion layer is added after each CBR bloc of the RGB branch. b) sparse fusion (SF), where the fusion layer is only inserted before each pooling. These two strategies are illustrated in Figure Fusion of Feature Maps In this section, we reason the fusion of the feature maps between the RGB and the depth branches. To utilize depth information a simple way would be just stacing the RGB and depth images into a four-channel input. However, we argue that by fusing RGB and depth information the feature maps are usually more discriminant than the ones obtained from the staced input. As we introduced before in Equation (1), each layer is modeled as a function g that maps a set of input x to a set of output a with parameter w. We denote the th feature map in the lth layer by g (l). Suppose that the given layer operation consists of convolution and ReLU, therefore x (l+1) = g (l) (x(l) ; w (l) ) = σ( w(l), x(l) + b (l) ). If the input is a four-channel RGB-D image, then the feature maps can be decomposed as x = [a T b T ] T, where a R d 1, b R d 2 with d 1 + d 2 = d := dim(x) are features learned from the color channels and from the depth channel, respectively. According to this observation, we may write that x (l+1) = σ( w (l), x(l) + b (l) ) = σ( u(l), a(l) + c (l) + v(l), b(l) + d (l) ) = max ( 0, u (l), a(l) + c (l) + v(l), b(l) + d (l) )) max(0, u (l), a(l) + c (l) ) + max(0, v(l), b(l) + d (l) ) (3) = σ( u (l), a(l) + c (l) ) + σ( v(l), b(l) + d (l) ),

 = [u(l)t v (l)t ]T and b (l) = c(l) + d(l). Based on the inequality in (3), we show that the fusion of activations of the color and the depth branches (i.e. their element-wise summation) produces a stronger signal than the activation on the fused features.")


.")
8 8 Caner Hazirbas, Lingni Ma, Csaba Domoos, Daniel Cremers Input RGB-D RGB branch Depth branch Sum before ReLU Proposed Fig. 4: Comparison of two out of 64 feature maps produced at the CBR1 1 layer. The features from RGB and depth mostly compensate each other, where the textureless region usually have rich structure features and structureless regions usually present texture features. This visually illustrates that the proposed fusion strategy better preserves the informative features from color and depth than applying element-wise summation followed by ReLU. where we applied the decomposition of w (l) = [u(l)t v (l)t ]T and b (l) = c(l) + d(l). Based on the inequality in (3), we show that the fusion of activations of the color and the depth branches (i.e. their element-wise summation) produces a stronger signal than the activation on the fused features. Nevertheless, the stronger activation does not necessarily lead to a better accuracy. However, with fusion, we do not only increase the neuron-wise activation values, but also preserve activations at different neuron locations. The intuition behind this can be seen by considering low-level features (e.g., edges). Namely, due to the fact that the edges extracted in RGB and depth images are usually complementary to each other. One may combine the edges from both inputs to obtain more information. Consequently, these low-level features help the networ to extract better high-level features, and thus enhance the ultimate accuracy. To demonstrate the advantage of the proposed fusion, we visualize the feature maps produced by CBR1 1 in Figure 4, which corresponds to low-level feature extraction (e.g., edges). As it can be seen the low-level features in RGB and depth are usually complementary to each other. For example, the textureless region can be distinguished by its structure, such as the lap against the wall, whereas the structureless region can be distinguished by the color, such as the painting on the wall. While combining the feature maps before the ReLU layer fail to preserve activations, however, the proposed fusion strategy, applied after the ReLU layer, preserves well all the useful information from both branches. Since low-level features help the networ to extract better high-level ones, the proposed fusion thus enhances the ultimate accuracy.
9 FuseNet: Incorporating Depth into Semantic Segmentation 9 4 Experimental Evaluation In this section, we evaluate the proposed networ through extensive experiments. For this purpose, we use the publicly available SUN RGB-D scene understanding benchmar [10]. This dataset contains synchronized RGB-D pairs, where pixel-wise annotation is available. The standard trainval-test split consists of 5050 images for testing and 5285 images for training/validation. This benchmar is a collection of images captured with different types of RGB-D cameras. The dataset also contains in-painted depth images, obtained by maing use of multiview fusion technique. In the experiments we used the standard training and test split with in-painted depth images. However, we excluded 587 training images that are originally obtained with RealSense RGB-D camera. This is due to the fact that raw depth images from the aforementioned camera consist of many invalid measurements, therefore in-painted depth images have many false values. We remar that the SUN RGB-D dataset is highly unbalanced in terms of class instances, where 16 out of 37 classes rarely present. To prevent the networ from over-fitting towards unbalanced class distribution, we weighted the loss for each class with the median frequency class balancing according to [19]. In particular, the class floormat and shower-curtain have the least frequencies and they are the most challenging ones in the segmentation tas. Moreover, approximately 0.25% pixels are not annotated and do not belong to any of the 37 target classes. Training We trained the all networs end-to-end. Therefore images were resized to the resolution of To this end we applied bilinear interpolation on the RGB images and nearest-neighbor interpolation on the depth images and the ground-truth labeling. The networs were implemented with the Caffe framewor [20] and were trained with stochastic gradient descent (SGD) solver [21] using a batch size of 4. The input data was randomly shuffled after each epoch. The learning rate was initialized to and was multiplied by 0.9 in every 50,000 iterations. We used a momentum of 0.9 and set weight decay to We trained the networs until convergence, when no further decrease in the loss was observed. The parameters in the encoder part of the networ were fine-tuned from the VGG 16-layer model [11] pre-trained on the ImageNet dataset [22]. The original VGGNet requires a three-channel color image. Therefore, for different input dimensions we processed the weights of first layer (i.e. conv1 1) as follows: i) averaged the weights along the channel for a single-channel depth input; ii) staced the weights with their average for a four-channel RGB-D input; iii) duplicated the weights for a six-channel RGB-HHA input. Testing We evaluated the results on the original 5050 test images. For quantitative evaluation, we used three criteria. Let TP, FP, FN denote the total number of true positive, false positive, false negative, respectively, and N denotes the total number of annotated pixels. We define the following three criteria:
10 10 Caner Hazirbas, Lingni Ma, Csaba Domoos, Daniel Cremers Table 1: Segmentation results on the SUN RGB-D benchmar [10] in comparison to the state of the art. Our methods DF1 and SF5 outperforms most of the existing methods, except of the Context-CRF [7]. Global Mean IoU FCN-32s [3] FCN-16s [3] Bayesian SegNet [14] (RGB) LSTM [17] Context-CRF [7] (RGB) FuseNet-SF FuseNet-DF i) Global accuracy, referred to as global, is the percentage of the correctly classified pixels, defined as Global = 1 TP c, c {1...K}. N c ii) Mean accuracy, referred to as mean, is the average of classwise accuracy, defined as Mean = 1 TP c. K TP c + FP c iii) Intersection-over-union (IoU) is average value of the intersection of the prediction and ground truth regions over the union of them, defined as IoU = 1 K c c TP c TP c + FP c + FN c. Among these three measures, the global accuracy is relatively less informative due to the unbalanced class distribution. In general, the frequent classes receive a high score and hence dominate the less frequent ones. Therefore we also measured the average class accuracy and IoU score to provide a better evaluation of our method. 4.1 Quantitative Results In the first experiment, we compared our FuseNet to the state-of-the-art methods. The results are presented in Table 1. We denote the SparseFusion and DenseFusion by SF, DF, respectively, following by the number of fusion layers used in the networ (e.g., SF5). The results shows that our FuseNet outperforms most of the existing methods with a significant margin. FuseNet is not as competitive in comparison to the Context-CRF [7]. However, it is also worth noting that the Context-CRF trains the networ with a different loss function that corresponds to piecewise CRF training. It also requires mean-field approximation at
11 FuseNet: Incorporating Depth into Semantic Segmentation 11 Table 2: Segmentation results of FuseNet in comparison to the networs trained with RGB, depth, HHA and their combinations. The second part of the table provides the results of variations of FuseNet. We show that FuseNet obtained significant improvements by extracting more informative features from depth. Input Global Mean IoU Depth HHA RGB RGB-D RGB-HHA FusetNet-SF FusetNet-SF FusetNet-SF FusetNet-SF FusetNet-SF FusetNet-DF FusetNet-DF FusetNet-DF FusetNet-DF FusetNet-DF the inference stage, followed by a dense fully connected CRF refinement to produce the final prediction. Applying the similar loss function and post-processing, FuseNet is liely to produce on-par or better results. In the second experiment, we compare the FuseNet to networ trained with different representation of depth, in order to further evaluate the effectiveness of depth fusion and different fusion variations. The results are presented in Table 2. It can be seen that stacing depth and HHA into color gives slight improvements over networ trained with only color, depth or HHA. In contrast, with the depth fusion of FuseNet, we improve over a significant margin, in particular with respect to the IoU scores. We remar that the depth fusion is in particular useful as a replacement for HHA. Instead of preprocessing a single channel depth images to obtain hand crafted three-channel HHA representation, FuseNet learns high dimensional features from depth end-to-end, which is more informative as shown by experiments. In Table 2, we also analyzed the performance of different variations of FuseNet. Since the original VGG 16-layer networ has 5 levels of pooling, we increase the number of fusion layers as the networ gets deeper. The experiments show that segmentation accuracy gets improved from SF1 to SF5, however the increase appears saturated up to the fusion after the 4th pooling, i.e., SF4. The possible reason behind the accuracy saturation is that depth already provides very distinguished features at low-level to compensate textureless regions in RGB, and we consistently fuse features extracted from depth into the RGB-branch. The same trend can be observed with DF. In the third experiment, we further compare FuseNet-SF5, FuseNet-DF1 to the networ trained with RGB-D input. In Table 3 and 4, we report the classwise accuracy and IoU scores of 37 classes, respectively. For class accuracy, all
12 12 Caner Hazirbas, Lingni Ma, Csaba Domoos, Daniel Cremers Table 3: Classwise segmentation accuracy of 37 classes. We compare FuseNet- SF5, FuseNet-DF1 to the networ trained with staced RGB-D input. wall floor cabin bed chair sofa table door wdw bslf pic cnter blinds RGB-D SF DF des shelf ctn drssr pillow mirror mat clthes ceil boos fridge tv paper RGB-D SF DF towel shwr box board person stand toilet sin lamp btub bag mean RGB-D SF DF Table 4: Classwise IoU scores of 37 classes. We compare FuseNet-SF5, FuseNet- DF1 to the networ trained with staced RGB-D input. wall floor cabin bed chair sofa table door wdw bslf pic cnter blinds RGB-D SF DF des shelf ctn drssr pillow mirror mat clths ceil boos fridge tv paper RGB-D SF DF towel shwr box board person stand toilet sin lamp btub bag mean RGB-D SF DF the three networ architectures give very comparable results. However, for IoU scores, SF5 outperforms in 30 out of 37 classes in comparison to other two networs. Since the classwise IoU is a better measurement over global and mean accuracy, FuseNet obtains significant improvements over the networ trained with staced RGB-D, showing that depth fusion is a better approach to extract informative features from depth and to combine them with color features. In Figure 5, we demonstrate some visual comparison of the FuseNet. 5 Conclusions In this paper, we have presented a fusion-based CNN networ for semantic labeling on RGB-D data. More precisely, we have proposed a solution to fuse depth information with RGB data by maing use of a CNN. The proposed networ has an encoder-decoder type architecture, where the encoder part is composed of two branches of networs that simultaneously extract features from RGB and depth channels. These features are then fused into the RGB feature maps as the networ goes deeper.









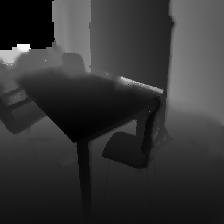














13 FuseNet: Incorporating Depth into Semantic Segmentation 13 RGB Depth Depth only RGB Staced RGB-D Groundtruth FuseNet- DF1 FuseNet- SF5 wall floor cabin bed chair sofa table door wdw bslf pic cnter blinds des shelf ctn drssr pillow mirror mat clthes ceil boos fridge tv paper towel shwr box board person stand toilet sin lamp btub bag Fig. 5: Qualitative segmentation results for different architectures. The first three rows contain RGB and depth images along with the ground-truth, respectively, followed by the segmentation results. Last two rows contain the results obtained by our DF1 and SF5 approaches.
14 14 Caner Hazirbas, Lingni Ma, Csaba Domoos, Daniel Cremers By conducting a comprehensive evaluation, we may conclude that the our approach is a competitive solution for semantic segmentation on RGB-D data. The proposed FuseNet outperforms the current CNN-based networs on the challenging SUN RGB-D benchmar [10]. We have also investigated two possible fusion approaches, i.e. dense fusion and sparse fusion. By applying the latter one with a single fusion operation we have obtained a slightly better performance. Nevertheless we may conclude that both fusion approaches provide similar results. Interestingly, we can also claim that HHA representation itself provides a superficial improvement to the depth information. We also remar that a straight-forward extension of the proposed approach can be applied for other classification tass such as image or scene classification. Acnowledgement. This wor was partially supported by the Alexander von Humboldt Foundation. References 1. Gupta, S., Girshic, R., Arbelaez, P., Mali, J.: Learning rich features from RGB- D images for object detection and segmentation. In Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., eds.: Proceedings of European Conference on Computer Vision. Volume 8695 of Lecture Notes in Computer Science., Zurich, Switzerland, Springer (2014) Pinheiro, P.O., Collobert, R.: Recurrent convolutional neural networs for scene labeling. In: Proceedings of International Conference on Machine Learning, Beijing, China (2014) 3. Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networs for semantic segmentation. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, IEEE (2015) Zheng, S., Jayasumana, S., Romera-Paredes, B., Vineet, V., Su, Z., Du, D., Huang, C., Torr, P.: Conditional random fields as recurrent neural networs. In: Proceedings of IEEE International Conference on Computer Vision, Santiago, Chile, IEEE (2015) Byeon, W., Breuel, T.M., Raue, F., Liwici, M.: Scene labeling with LSTM recurrent neural networs. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, IEEE (2015) Noh, H., Hong, S., Han, B.: Learning deconvolution networ for semantic segmentation. Proceedings of IEEE International Conference on Computer Vision (2015) 7. Lin, G., Shen, C., van den Hengel, A., Reid, I.: Exploring context with deep structured models for semantic segmentation. arxiv preprint arxiv: (2016) 8. Chen, L.C., Papandreou, G., Koinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation with deep convolutional nets and fully connected CRFs. In: Proceedings of International Conference on Learning Representations, San Diego, CA, USA (2015) 9. Couprie, C., Farabet, C., Najman, L., LeCun, Y.: Indoor semantic segmentation using depth information. In: Proceedings of International Conference on Learning Representations. (2013)
15 FuseNet: Incorporating Depth into Semantic Segmentation Song, S., Lichtenberg, S.P., Xiao, J.: Sun rgb-d: A rgb-d scene understanding benchmar suite. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. (2015) Simonyan, K., Zisserman, A.: Very deep convolutional networs for large-scale image recognition. Proceedings of International Conference on Learning Representations (2015) 12. Zeiler, M.D., Fergus, R.: Visualizing and understanding convolutional networs. In Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., eds.: Proceedings of European Conference on Computer Vision. Volume 8689 of Lecture Notes in Computer Science., Zurich, Switzerland, Springer (2014) Badrinarayanan, V., Handa, A., Cipolla, R.: SegNet: A deep convolutional encoderdecoder architecture for robust semantic pixel-wise labelling. arxiv preprint arxiv: (2015) 14. Kendall, A., Badrinarayanan, V., Cipolla, R.: Bayesian SegNet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding. arxiv preprint arxiv: (2015) 15. Srivastava, N., Hinton, G., Krizhevsy, A., Sutsever, I., Salahutdinov, R.: Dropout: A simple way to prevent neural networs from overfitting. Journal of Machine Learning Research 15 (2014) Gal, Y., Ghahramani, Z.: Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. Computing Research Repository (2015) 17. Li, L.Z., Yuang, G., Xiaodan, L., Yizhou, Y., Hui, C., Liang, L.: RGB-D Scene labeling with long short-term memorized fusion model. arxiv preprint arxiv: v2 (2016) 18. Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep networ training by reducing internal covariate shift. In Bach, F.R., Blei, D.M., eds.: Proceedings of International Conference on Machine Learning. Volume 37 of JMLR Proceedings., JMLR.org (2015) Eigen, D., Fergus, R.: Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In: Proceedings of IEEE International Conference on Computer Vision. (2015) Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshic, R., Guadarrama, S., Darrell, T.: Caffe: Convolutional architecture for fast feature embedding. arxiv preprint arxiv: (2014) 21. Bottou, L.: Stochastic gradient descent trics. In: Neural Networs: Trics of the Trade. Springer (2012) Russaovsy, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision 115 (2015)
A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION
 A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION Wenkai Zhang a, b, Hai Huang c, *, Matthias Schmitz c, Xian Sun a, Hongqi Wang a, Helmut Mayer c a Key Laboratory
A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION Wenkai Zhang a, b, Hai Huang c, *, Matthias Schmitz c, Xian Sun a, Hongqi Wang a, Helmut Mayer c a Key Laboratory
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation
 RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation Seong-Jin Park POSTECH Ki-Sang Hong POSTECH {windray,hongks,leesy}@postech.ac.kr Seungyong Lee POSTECH Abstract In multi-class
RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation Seong-Jin Park POSTECH Ki-Sang Hong POSTECH {windray,hongks,leesy}@postech.ac.kr Seungyong Lee POSTECH Abstract In multi-class
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Presentation Outline. Semantic Segmentation. Overview. Presentation Outline CNN. Learning Deconvolution Network for Semantic Segmentation 6/6/16
 6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Fully Convolutional Network for Depth Estimation and Semantic Segmentation
 Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Pedestrian and Part Position Detection using a Regression-based Multiple Task Deep Convolutional Neural Network
 Pedestrian and Part Position Detection using a Regression-based Multiple Tas Deep Convolutional Neural Networ Taayoshi Yamashita Computer Science Department yamashita@cs.chubu.ac.jp Hiroshi Fuui Computer
Pedestrian and Part Position Detection using a Regression-based Multiple Tas Deep Convolutional Neural Networ Taayoshi Yamashita Computer Science Department yamashita@cs.chubu.ac.jp Hiroshi Fuui Computer
Conditional Random Fields as Recurrent Neural Networks
 BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
BIL722 - Deep Learning for Computer Vision Conditional Random Fields as Recurrent Neural Networks S. Zheng, S. Jayasumana, B. Romera-Paredes V. Vineet, Z. Su, D. Du, C. Huang, P.H.S. Torr Introduction
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Learning Deep Structured Models for Semantic Segmentation. Guosheng Lin
 Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
3D Densely Convolutional Networks for Volumetric Segmentation. Toan Duc Bui, Jitae Shin, and Taesup Moon
 3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Dense Image Labeling Using Deep Convolutional Neural Networks
 Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
Convolution Neural Networks for Chinese Handwriting Recognition
 Convolution Neural Networks for Chinese Handwriting Recognition Xu Chen Stanford University 450 Serra Mall, Stanford, CA 94305 xchen91@stanford.edu Abstract Convolutional neural networks have been proven
Convolution Neural Networks for Chinese Handwriting Recognition Xu Chen Stanford University 450 Serra Mall, Stanford, CA 94305 xchen91@stanford.edu Abstract Convolutional neural networks have been proven
Semantic Segmentation
 Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
RGBd Image Semantic Labelling for Urban Driving Scenes via a DCNN
 RGBd Image Semantic Labelling for Urban Driving Scenes via a DCNN Jason Bolito, Research School of Computer Science, ANU Supervisors: Yiran Zhong & Hongdong Li 2 Outline 1. Motivation and Background 2.
RGBd Image Semantic Labelling for Urban Driving Scenes via a DCNN Jason Bolito, Research School of Computer Science, ANU Supervisors: Yiran Zhong & Hongdong Li 2 Outline 1. Motivation and Background 2.
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Gradient of the lower bound
 Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Weakly Supervised with Latent PhD advisor: Dr. Ambedkar Dukkipati Department of Computer Science and Automation gaurav.pandey@csa.iisc.ernet.in Objective Given a training set that comprises image and image-level
Deep Learning. Visualizing and Understanding Convolutional Networks. Christopher Funk. Pennsylvania State University.
 Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Real-Time Depth Estimation from 2D Images
 Real-Time Depth Estimation from 2D Images Jack Zhu Ralph Ma jackzhu@stanford.edu ralphma@stanford.edu. Abstract ages. We explore the differences in training on an untrained network, and on a network pre-trained
Real-Time Depth Estimation from 2D Images Jack Zhu Ralph Ma jackzhu@stanford.edu ralphma@stanford.edu. Abstract ages. We explore the differences in training on an untrained network, and on a network pre-trained
Convolutional Networks in Scene Labelling
 Convolutional Networks in Scene Labelling Ashwin Paranjape Stanford ashwinpp@stanford.edu Ayesha Mudassir Stanford aysh@stanford.edu Abstract This project tries to address a well known problem of multi-class
Convolutional Networks in Scene Labelling Ashwin Paranjape Stanford ashwinpp@stanford.edu Ayesha Mudassir Stanford aysh@stanford.edu Abstract This project tries to address a well known problem of multi-class
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Elastic Neural Networks for Classification
 Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
Recurrent Convolutional Neural Networks for Scene Labeling
 Recurrent Convolutional Neural Networks for Scene Labeling Pedro O. Pinheiro, Ronan Collobert Reviewed by Yizhe Zhang August 14, 2015 Scene labeling task Scene labeling: assign a class label to each pixel
Recurrent Convolutional Neural Networks for Scene Labeling Pedro O. Pinheiro, Ronan Collobert Reviewed by Yizhe Zhang August 14, 2015 Scene labeling task Scene labeling: assign a class label to each pixel
HENet: A Highly Efficient Convolutional Neural. Networks Optimized for Accuracy, Speed and Storage
 HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Ryerson University CP8208. Soft Computing and Machine Intelligence. Naive Road-Detection using CNNS. Authors: Sarah Asiri - Domenic Curro
 Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Deep Learning Cook Book
 Deep Learning Cook Book Robert Haschke (CITEC) Overview Input Representation Output Layer + Cost Function Hidden Layer Units Initialization Regularization Input representation Choose an input representation
Deep Learning Cook Book Robert Haschke (CITEC) Overview Input Representation Output Layer + Cost Function Hidden Layer Units Initialization Regularization Input representation Choose an input representation
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
 : Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1 Anton Milan 2 Chunhua Shen 2,3 Ian Reid 2,3 1 Nanyang Technological University 2 University of Adelaide 3 Australian
: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1 Anton Milan 2 Chunhua Shen 2,3 Ian Reid 2,3 1 Nanyang Technological University 2 University of Adelaide 3 Australian
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018
 Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
arxiv: v1 [cs.cv] 24 May 2016
![arxiv: v1 [cs.cv] 24 May 2016](/thumbs/80/80473828.jpg "arxiv: v1 [cs.cv] 24 May 2016") Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Deep Learning and Its Applications
 Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
Contextual Dropout. Sam Fok. Abstract. 1. Introduction. 2. Background and Related Work
 Contextual Dropout Finding subnets for subtasks Sam Fok samfok@stanford.edu Abstract The feedforward networks widely used in classification are static and have no means for leveraging information about
Contextual Dropout Finding subnets for subtasks Sam Fok samfok@stanford.edu Abstract The feedforward networks widely used in classification are static and have no means for leveraging information about
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Learning Fully Dense Neural Networks for Image Semantic Segmentation
 Learning Fully Dense Neural Networks for Image Semantic Segmentation Mingmin Zhen 1, Jinglu Wang 2, Lei Zhou 1, Tian Fang 3, Long Quan 1 1 Hong Kong University of Science and Technology, 2 Microsoft Research
Learning Fully Dense Neural Networks for Image Semantic Segmentation Mingmin Zhen 1, Jinglu Wang 2, Lei Zhou 1, Tian Fang 3, Long Quan 1 1 Hong Kong University of Science and Technology, 2 Microsoft Research
Depth Estimation from a Single Image Using a Deep Neural Network Milestone Report
 Figure 1: The architecture of the convolutional network. Input: a single view image; Output: a depth map. 3 Related Work In [4] they used depth maps of indoor scenes produced by a Microsoft Kinect to successfully
Figure 1: The architecture of the convolutional network. Input: a single view image; Output: a depth map. 3 Related Work In [4] they used depth maps of indoor scenes produced by a Microsoft Kinect to successfully
LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation
 LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation Abhishek Chaurasia School of Electrical and Computer Engineering Purdue University West Lafayette, USA Email: aabhish@purdue.edu
LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation Abhishek Chaurasia School of Electrical and Computer Engineering Purdue University West Lafayette, USA Email: aabhish@purdue.edu
COMP9444 Neural Networks and Deep Learning 7. Image Processing. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
Supplementary material for Analyzing Filters Toward Efficient ConvNet
 Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation
 Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation Md Atiqur Rahman and Yang Wang Department of Computer Science, University of Manitoba, Canada {atique, ywang}@cs.umanitoba.ca
Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation Md Atiqur Rahman and Yang Wang Department of Computer Science, University of Manitoba, Canada {atique, ywang}@cs.umanitoba.ca
arxiv: v4 [cs.cv] 6 Jul 2016
![arxiv: v4 [cs.cv] 6 Jul 2016](/thumbs/93/112985717.jpg "arxiv: v4 [cs.cv] 6 Jul 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Hand-Object Interaction Detection with Fully Convolutional Networks
 Hand-Object Interaction Detection with Fully Convolutional Networks Matthias Schröder Helge Ritter Neuroinformatics Group, Bielefeld University {maschroe,helge}@techfak.uni-bielefeld.de Abstract Detecting
Hand-Object Interaction Detection with Fully Convolutional Networks Matthias Schröder Helge Ritter Neuroinformatics Group, Bielefeld University {maschroe,helge}@techfak.uni-bielefeld.de Abstract Detecting
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
 : Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1,2, Anton Milan 1, Chunhua Shen 1,2, Ian Reid 1,2 1 The University of Adelaide, 2 Australian Centre for Robotic
: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1,2, Anton Milan 1, Chunhua Shen 1,2, Ian Reid 1,2 1 The University of Adelaide, 2 Australian Centre for Robotic
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS. Mustafa Ozan Tezcan
 MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
In Defense of Fully Connected Layers in Visual Representation Transfer
 In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task
 Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Fine-tuning Pre-trained Large Scaled ImageNet model on smaller dataset for Detection task Kyunghee Kim Stanford University 353 Serra Mall Stanford, CA 94305 kyunghee.kim@stanford.edu Abstract We use a
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
Learning with Side Information through Modality Hallucination
 Master Seminar Report for Recent Trends in 3D Computer Vision Learning with Side Information through Modality Hallucination Judy Hoffman, Saurabh Gupta, Trevor Darrell. CVPR 2016 Nan Yang Supervisor: Benjamin
Master Seminar Report for Recent Trends in 3D Computer Vision Learning with Side Information through Modality Hallucination Judy Hoffman, Saurabh Gupta, Trevor Darrell. CVPR 2016 Nan Yang Supervisor: Benjamin
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Introduction to Neural Networks
 Introduction to Neural Networks Jakob Verbeek 2017-2018 Biological motivation Neuron is basic computational unit of the brain about 10^11 neurons in human brain Simplified neuron model as linear threshold
Introduction to Neural Networks Jakob Verbeek 2017-2018 Biological motivation Neuron is basic computational unit of the brain about 10^11 neurons in human brain Simplified neuron model as linear threshold
Multi-View 3D Object Detection Network for Autonomous Driving
 Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Advanced Video Analysis & Imaging
 Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
A Novel Multi-Frame Color Images Super-Resolution Framework based on Deep Convolutional Neural Network. Zhe Li, Shu Li, Jianmin Wang and Hongyang Wang
 5th International Conference on Measurement, Instrumentation and Automation (ICMIA 2016) A Novel Multi-Frame Color Images Super-Resolution Framewor based on Deep Convolutional Neural Networ Zhe Li, Shu
5th International Conference on Measurement, Instrumentation and Automation (ICMIA 2016) A Novel Multi-Frame Color Images Super-Resolution Framewor based on Deep Convolutional Neural Networ Zhe Li, Shu
SEMANTIC COMPUTING. Lecture 8: Introduction to Deep Learning. TU Dresden, 7 December Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
SEMANTIC COMPUTING Lecture 8: Introduction to Deep Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 7 December 2018 Overview Introduction Deep Learning General Neural Networks
A Deep Learning Approach to Vehicle Speed Estimation
 A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
Tiny ImageNet Visual Recognition Challenge
 Tiny ImageNet Visual Recognition Challenge Ya Le Department of Statistics Stanford University yle@stanford.edu Xuan Yang Department of Electrical Engineering Stanford University xuany@stanford.edu Abstract
Tiny ImageNet Visual Recognition Challenge Ya Le Department of Statistics Stanford University yle@stanford.edu Xuan Yang Department of Electrical Engineering Stanford University xuany@stanford.edu Abstract
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Classification of objects from Video Data (Group 30)
") Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Tunnel Effect in CNNs: Image Reconstruction From Max-Switch Locations
 Downloaded from orbit.dtu.dk on: Nov 01, 2018 Tunnel Effect in CNNs: Image Reconstruction From Max-Switch Locations de La Roche Saint Andre, Matthieu ; Rieger, Laura ; Hannemose, Morten; Kim, Junmo Published
Downloaded from orbit.dtu.dk on: Nov 01, 2018 Tunnel Effect in CNNs: Image Reconstruction From Max-Switch Locations de La Roche Saint Andre, Matthieu ; Rieger, Laura ; Hannemose, Morten; Kim, Junmo Published
Convolution Neural Network for Traditional Chinese Calligraphy Recognition
 Convolution Neural Network for Traditional Chinese Calligraphy Recognition Boqi Li Mechanical Engineering Stanford University boqili@stanford.edu Abstract script. Fig. 1 shows examples of the same TCC
Convolution Neural Network for Traditional Chinese Calligraphy Recognition Boqi Li Mechanical Engineering Stanford University boqili@stanford.edu Abstract script. Fig. 1 shows examples of the same TCC
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
SUMMARY. they need large amounts of computational resources to train
 Learning to Label Seismic Structures with Deconvolution Networks and Weak Labels Yazeed Alaudah, Shan Gao, and Ghassan AlRegib {alaudah,gaoshan427,alregib}@gatech.edu Center for Energy and Geo Processing
Learning to Label Seismic Structures with Deconvolution Networks and Weak Labels Yazeed Alaudah, Shan Gao, and Ghassan AlRegib {alaudah,gaoshan427,alregib}@gatech.edu Center for Energy and Geo Processing
Using Machine Learning for Classification of Cancer Cells
 Using Machine Learning for Classification of Cancer Cells Camille Biscarrat University of California, Berkeley I Introduction Cell screening is a commonly used technique in the development of new drugs.
Using Machine Learning for Classification of Cancer Cells Camille Biscarrat University of California, Berkeley I Introduction Cell screening is a commonly used technique in the development of new drugs.
Inception Network Overview. David White CS793
 Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials
 Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University