arxiv: v1 [cs.cv] 21 Jun 2017
|
|
|
- Phebe Edwards
- 5 years ago
- Views:
Transcription
1 Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction arxiv: v1 [cs.cv] 21 Jun 2017 Chen-Hsuan Lin, Chen Kong, Simon Lucey The Robotics Institute Carnegie Mellon University Abstract Conventional methods of 3D object generative modeling learn volumetric predictions using deep networks with 3D convolutional operations, which are direct analogies to classical 2D ones. However, these methods are computationally wasteful in attempt to predict 3D shapes, where information is rich only on the surfaces. In this paper, we propose a novel 3D generative modeling framework to efficiently generate object shapes in the form of dense point clouds. We use 2D convolutional operations to predict the 3D structure from multiple viewpoints and jointly apply geometric reasoning with 2D projection optimization. We introduce the pseudorenderer, a differentiable module to approximate the true rendering operation, to synthesize novel depth maps for optimization. Experimental results for singleimage 3D object reconstruction tasks show that we outperforms state-of-the-art methods in terms of shape similarity and prediction density. 1 Introduction Generative models using convolutional neural networks (ConvNets) have achieved state of the art in image/object generation problems. Notable works of the class include variational autoencoders [14] and generative adversarial networks [7], both of which have drawn large success in various applications [11, 20, 35, 27, 30]. With the recent introduction of large publicly available 3D model repositories [29, 1], the study of generative modeling on 3D data using similar frameworks has also become of increasing interest. In computer vision and graphics, 3D object models can take on various forms of representations. Of such, triangular meshes and point clouds are popular for their vectorized (and thus scalable) data representations as well as their compact encoding of shape information, optionally embedded with texture. However, this efficient representation comes with an inherent drawback as the dimensionality per 3D shape sample can vary, making the application of learning methods problematic. Furthermore, such data representations do not elegantly fit within conventional ConvNets as Euclidean convolutional operations cannot be directly applied. Hitherto, most existing works on 3D model generation resort to volumetric representations, allowing 3D Euclidean convolution to operate on regular discretized voxel grids. 3D ConvNets (as opposed to the classical 2D form) have been applied successfully to 3D volumetric representations for both discriminative [29, 18, 9] and generative [6, 2, 31, 28] problems. Despite their recent success, 3D ConvNets suffer from an inherent drawback when modeling shapes with volumetric representations. Unlike 2D images, where every pixel contains meaningful spatial and texture information, volumetric representations are information-sparse. More specifically, a 3D object is expressed as a voxel-wise occupancy grid, where voxels outside the object (set to off) and inside the object (set to on) are unimportant and fundamentally not of particular interest. In other words, the richest information of shape representations lies on the surface of the 3D object, which makes up only a slight fraction of all voxels in an occupancy grid. Consequently, 3D ConvNets are extremely wasteful in both computation and memory in trying to predict much unuseful data with
2 high-complexity 3D convolutions, severely limiting the granularity of the 3D volumetric shapes that can be modeled even on high-end GPU-nodes commonly used in deep learning research. In this paper, we propose an efficient framework to represent and generate 3D object shapes with dense point clouds. We achieve this by learning to predict the 3D structures from multiple viewpoints, which is jointly optimized through 3D geometric reasoning. In contrast to prior art that adopts 3D ConvNets to operate on volumetric data, we leverage 2D convolutional operations to predict points clouds that shape the surface of the 3D objects. Our experimental results show that we generate much denser and more accurate shapes than state-of-the-art 3D prediction methods. Our contributions are summarized as follows: We advocate that 2D ConvNets are capable of generating dense point clouds that shapes the surface of 3D objects in an undiscretized 3D space. We introduce a pseudo-rendering pipeline to serve as a differentiable approximation of true rendering. We further utilize the pseudo-rendered depth images for 2D projection optimization for learning dense 3D shapes. We demonstrate the efficacy of our method on single-image 3D reconstruction problems, which significantly outperforms state-of-the-art methods. 2 Related Work 3D shape generation. As 2D ConvNets have demonstrated huge success on a myriad of image generation problems, most works on 3D shape generation follow the analogue using 3D ConvNets to generate volumetric shapes. Prior works include using 3D autoencoders [6] and recurrent networks [2] to learn a latent representation for volumetric data generation. Similar applications include the use of an additional encoded pose embedding to learn shape deformations [33] and using adversarial training to learn more realistic shape generation [28, 5]. Learning volumetric predictions from 2D projected observations has also been explored [31, 22, 5], which use 3D differentiable sampling on voxel grids for spatial transformations [12]. Constraining the ray consistency of 2D observations have also been suggested very recently [26]. Most of the above approaches utilize 3D convolutional operations, which is computationally expensive and allows only coarse 3D voxel resolution. The lack of granularity from such volumetric generation has been an open problem following these works. Riegler et al. [23] proposed to tackle the problem by using adaptive hierarchical octary trees on voxel grids to encourage encoding more informative parts of 3D shapes. Concurrent works follow to use similar concepts [8, 25] to predict 3D volumetric data with higher granularity. Recently, Fan et al. [4] also sought to generate unordered point clouds by using variants of multi-layer perceptrons to predict multiple 3D coordinates. However, the required learnable parameters linearly proportional to the number of 3D point predictions and does not scale well; in addition, using 3D distance metrics as optimization criteria is intractable for large number of points. In contrast, we leverage convolutional operations with a joint 2D project criterion to capture the correlation between generated point clouds and optimize in a more computationally tractable fashion. 3D view synthesis. Research has also been done in learning to synthesize novel 3D views of 2D objects in images. Most approaches using ConvNets follow the convention of an encoder-decoder framework. This has been explored by mixing 3D pose information into the latent embedding vector for the synthesis decoder [24, 34, 19]. A portion of these works also discussed the problem of disentangling the 3D pose representation from object identity information [16, 32, 21], allowing further control on the identity representation space. The drawback of these approaches is their inefficiency in representing 3D geometry as we later show in the experiments, one should explicitly factorize the underlying 3D geometry instead of implicitly encoding it into mixed representations. Resolving the geometry has been proven more efficient than tolerating in several works (e.g. Spatial Transformer Networks [12, 17]). 2
, which is based on 2D convolutional operations, to predict the 3D structure at N viewpoints.")

3 Figure 1: Network architecture. From an encoded latent representation, we propose to use a structure generator (Sec 3.1), which is based on 2D convolutional operations, to predict the 3D structure at N viewpoints. The point clouds are fused by transforming the 3D structure at each viewpoint to the canonical coordinates. The pseudo-renderer (Sec. 3.2) synthesizes depth images from novel viewpoints, which are further used for joint 2D projection optimization. This contains no learnable parameters and reasons based purely on 3D geometry. 3 Approach Our goal is to generate 3D predictions that compactly shape the surface geometry with dense point clouds. The overall pipeline is illustrated in Fig. 1. We start with an encoder that maps the input data to a latent representation space. The encoder may take on various forms of data depending on the application; in our experiments, we focus on encoding RGB images for single-image 3D reconstruction tasks. From the latent representation, we propose to generate the dense point clouds using a structure generator based on 2D convolutions with a joint 2D projection criterion, described in detail as follows. 3.1 Structure Generator The structure generator predicts the 3D structure of the object at N different viewpoints (along with their binary masks), i.e. the 3D coordinates ˆx i = [ˆx i ŷ i ẑ i ] at each pixel location. Pixel values in natural images can be synthesized through convolutional generative models mainly due to their exhibition of strong local spatial dependencies; similar phenomenons can be observed for point clouds when treating them as (x, y, z) multi-channel images on a 2D grid. Based on this insight, the structure generator is mainly based on 2D convolutional operations to predict the (x, y, z) images representing the 3D surface geometry. This approach circumvents the need of time-consuming and memory-expensive 3D convolutional operations for volumetric predictions. The evidence of such validity is verified in our experimental results. Assuming the 3D rigid transformation matrices of the N viewpoints (R 1, t 1 )...(R N, t N ) are given a priori, each 3D point ˆx i at viewpoint n can be transformed to the canonical 3D coordinates as ˆp i via ˆp i = R 1 ( ) n K 1ˆx i t n i, (1) where K is the predefined camera intrinsic matrix. This defines the relationship between the predicted 3D points and the fused collection of point clouds in the canonical 3D coordinates, which is the outcome of our network. 3.2 Joint 2D Projection Optimization To learn point cloud generation using the provided 3D CAD models as supervision, the standard approach would be to optimize over a 3D-based metric that defines the distance between the point cloud and the ground-truth CAD model (e.g. Chamfer distance [4]). Such metric usually involves computing surface projections for every generated point, which can be computationally expensive for very dense predictions, making it intractable. 3
 Collision could easily occur if (ˆx i, ŷ i ) were directly discretized.")

4 Figure 2: Concept of pseudo-rendering. Multiple transformed 3D points may correspond to projection on the same pixels in the image space. (a) Collision could easily occur if (ˆx i, ŷ i ) were directly discretized. (b) Upsampling the target image increases the precision of the projection locations and thus alleviates the collision effect. A max-pooling operation on the inverse depth values follows as to obtain the original resolution while maintaining the effective depth value at each pixel. (c) Examples of pseudo-rendered depth images with various upsampling factors U (only valid depth values without collision are shown). Pseudo-rendering achieves closer performance to true rendering with a higher value of U. We overcome this issue by alternatively optimizing over the joint 2D projection error of novel viewpoints. Instead of using only projected binary masks as supervision [31, 5, 22], we conjecture that a well-generated 3D shape should also have the ability to render reasonable depth images from any viewpoint. To realize this concept, we introduce the pseudo-renderer, a differentiable module to approximate true rendering, to synthesize novel depth images from dense point clouds. Pseudo-rendering. Given the 3D rigid transformation matrix of a novel viewpoint (R k, t k ), each canonical 3D point ˆp i can be further transformed to ˆx i back in the image coordinates via ˆx i = K (R k ˆp i + t k ) i. (2) This is the inverse operation of Eq. (1) with different transformation matrices and can be combined with Eq. (1) together, composing a single effective transformation. By such, we obtain the (ˆx i, ŷ i ) location as well as the new depth value ẑ i at viewpoint k. To produce a pixelated depth image, one would also need to discretize all (ˆx i, ŷ i ) coordinates, resulting in possibly multiple transformed points projecting and colliding onto the same pixel (Fig. 2). We resolve this issue with the pseudo-renderer f PR ( ), which increases the projection resolution to alleviate such collision effect. Specifically, ˆx i is projected onto a target image upsampled by a factor of U, reducing the quantization error of (ˆx i, ŷ i ) as well as the probability of collision occurrence. A max-pooling operation on the inverse depth values with kernel size U follows to downsample back to the original resolution while maintaining the minimum depth value at each pixel location. We use such approximation of the rendering operation to maintain differentiability and parallelizability within the backpropagation framework. Optimization. We use the pseudo-rendered depth images Ẑ = f PR({ˆx i }) and the resulting masks ˆM at novel viewpoints for optimization. The loss function consists of the mask loss L mask and the depth loss L depth, respectively defined as K L mask = M k log ˆM k (1 M k ) log (1 ˆM ) K 1 k and L depth = Ẑk Z k, (3) k=1 where we simultaneously optimize over K novel viewpoints at a time. M k and Z k are the groundtruth mask and depth images at the kth novel viewpoint. We use element-wise L 1 loss for the depth (posing it as a pixel-wise binary classification problem) and cross-entropy loss for the mask. The overall loss function is defined as L = L mask + λ L depth, where λ is the weighting factor. Optimizing the structure generator over novel projections enforces joint 3D geometric reasoning between the predicted point clouds from the N viewpoints. It also allows the optimization error to evenly distribute across novel viewpoints instead of focusing on the fixed N viewpoints. k=1 4
5 Sec. Input Latent Number of filters size vector image encoder structure generator D conv: 96, 128, 192, 256 linear: 1024, 2048, 4096 linear: 2048, 1024, 512 deconv: 192, 128, 96, 64, D conv: 128, 192, 256, 384, 512 linear: 2048, 4096, linear: 4096, 2048, 1024 deconv: 384, 256, 192, 128, 96 Table 1: Architectural details of our proposed method for each experiment. 4 Experiments We evaluate our proposed method by analyzing its performance in the application of single-image 3D reconstruction and comparing against state-of-the-art methods. Data preparation. We train and evaluate all networks using the ShapeNet database [1], which contains a large collection of categorized 3D CAD models. For each CAD model, we pre-render 100 depth/mask image pairs of size at random novel viewpoints as the ground truth of the loss function. We consider the entire space of possible 3D rotations (including in-plane rotation) for the viewpoints and assume identity translation for simplicity. The input images are objects pre-rendered from a fixed elevation and 24 different azimuth angles. Architectural details. The structure generator follows the structure of conventional deep generative models, consisting of linear layers followed by 2D convolution layers (with kernel size 3 3). The dimensions of all feature maps are halved after each encoder convolution and doubled after each generator convolution. Details of network dimensions are listed in Table 1. At the end of the decoder, we add an extra convolution layer with filters of size 1 1 to encourage individuality of the generated pixels. Batch normalization [10] and ReLU activations are added between all layers. The generator predicts N = 8 images of size with 4 channels (x, y, z and the binary mask), where the fixed viewpoints are chosen from the 8 corners of a centered cube. Orthographic projection is assumed in the transformation in (1) and (2). We use U = 5 for the upsampling factor of the pseudo-renderer in our experiments. Training details. All networks are optimized using the Adam optimizer [13]. We take a two-stage training procedure: the structure generator is first pretrained to predict the depth images from the N viewpoints (with a constant learning rate of 1e-2), and then the entire network is fine-tuned with joint 2D projection optimization (with a constant learning rate of 1e-4). For the training parameters, we set λ = 1.0 and K = 5. Quantitative metrics. We measure using the average point-wise 3D Euclidean distance between two 3D models: for each point ˆp i in the source model, the distance to the target model S is defined as E i = min pj S ˆp i p j 2. This metric is defined bidirectionally as the distance from the predicted point cloud to the ground-truth CAD model and vice versa. It is necessary to report both metrics for they represent different aspects of quality the former measures 3D shape similarity and the latter measures surface coverage [15]. We represent the ground-truth CAD models as collections of uniformly densified 3D points on the surfaces (100K densified points in our settings). 4.1 Single Object Category We start by evaluating the efficacy of our dense point cloud representation on 3D reconstruction for a single object category. We use the chair category from ShapeNet, which consists of 6,778 CAD models. We compare against (a) Tatarchenko et al. [24], which learns implicit 3D representations through a mixed embedding, and (b) Perspective Transformer Networks (PTN) [31], which learns to predict volumetric data by minimizing the projection error. We include two variants of PTN as well as a baseline 3D ConvNet from Yan et al. [31]. We use the same 80%-20% training/test split provided by Yan et al. [31]. We pretrain our network for 200K iterations and fine-tune end-to-end for 100K iterations. For the method of Tatarchenko et al. [24], we evaluate by predicting depth images from our same N 5

![only) [31] 1.827 2.660 PTN (proj.](/docs-images/82/85530580/images/6-1.jpg "only) [31] 2.181 2.170 PTN (vol.")
![& proj.) [31] 1.840 2.](/docs-images/82/85530580/images/6-2.jpg "585 Tatarchenko et al. [24] 2.381 3.")




 input image ground-truth CAD")
 PTN (vol. & proj.")



























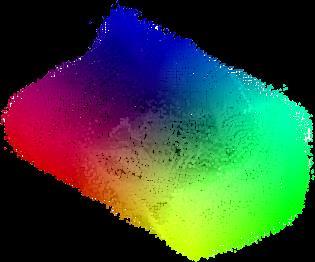
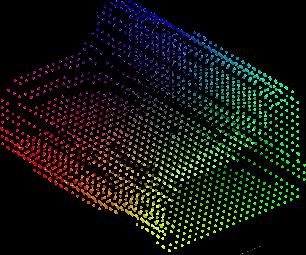
6 Method 3D error metric pred. GT GT pred. 3D ConvNet (vol. only) [31] PTN (proj. only) [31] PTN (vol. & proj.) [31] Tatarchenko et al. [24] Proposed method Table 2: Average 3D test error of the single-category experiment. Our method outperforms all baselines in both metrics, indicating the superiority in fine-grained shape similarity and point cloud coverage on the surface. (All numbers are scaled by 0.01) input image ground-truth CAD model 3D ConvNet PTN (proj. only) PTN (vol. & proj.) Tatarchenko et al. ours 2184 pts pts pts pts pts pts pts pts pts pts pts pts pts pts pts. Figure 3: Qualitative results from the single-category experiment. Our method generates denser predictions compared to the volumetric baselines and more accurate shapes than Tatarchenko et al. [24], which learns 3D synthesis implicitly. The RGB values of the point cloud represents the 3D coordinate values. Best viewed in color. viewpoints and transform the resulting point clouds to the canonical coordinates. This shares the same network architecture to ours, but with 3D pose information additionally encoded using 3 linear layers (with 64 filters) and concatenated with the latent vector. We use the novel depth/mask pairs as direct supervision for the decoder output and train this network for 300K iterations with a constant learning rate of 1e-2. For PTN [31], we extract the surface voxels (by subtracting the prediction by its eroded version) and rescale them such that the tightest 3D bounding boxes of the prediction and the ground-truth CAD models have the same volume. We use the pretrained models readily provided by the authors. The quantitative results on the test split are reported in Table 2. We achieve a lower average 3D distance than all baselines in both metrics, even though our approach is optimized with joint 2D projections instead of these 3D error metrics. This demonstrates that we are capable of predicting more accurate shapes with higher density and finer granularity. This highlights the efficiency of our approach using 2D ConvNets to generate 3D shapes compared to 3D ConvNet methods such as PTN [31] as they attempt to predict all voxel occupancies inside a 3D grid space. Compared to Tatarchenko et al. [24], an important takeaway is that 3D geometry should explicitly factorized when possible instead of being implicitly learned by the network parameters. It is much more efficient to focus on predicting the geometry from a sufficient number of viewpoints and combining them with known geometric transformations. 6
7 Category 3D-R2N2 [2] Fan et al. [4] Proposed 1 view 3 views 5 views (1 view) (1 view) airplane / / / / / bench / / / / / cabinet / / / / / car / / / / / chair / / / / / display / / / / / lamp / / / / / loudspeaker / / / / / rifle / / / / / sofa / / / / / table / / / / / telephone / / / / / watercraft / / / / / mean / / / / / Table 3: Average 3D test error of the multi-category experiment, where the numbers are shown as [ prediction GT / GT prediction ]. The mean is computed across categories. For the single-view case, we outperform all baselines in 8 and 10 out of 13 categories for the two 3D error metrics. (All numbers are scaled by 0.01) We visualize the generated 3D shapes in Fig. 3. Compared to the baselines, we predict more accurate object structures with a much higher point cloud density (around 10 higher than 32 3 volumetric methods). This further highlights the desirability of our approach we are able to efficiently use 2D convolutional operations and utilize high-resolution supervision given similar memory budgets. 4.2 General Object Categories We also evaluate our network on the single-image 3D reconstruction task trained with multiple object categories. We compare against (a) 3D-R2N2 [2], which learns volumeric predictions through recurrent networks, and (b) Fan et al. [4], which predicts an unordered set of D points. We use 13 categories of ShapeNet for evaluation (listed in Table 3), where the 80%-20% training/test split is provided by Choy et al. [2]. We evaluate 3D-R2N2 by its surface voxels using the same procedure as described in Sec We pretrain our network for 300K iterations and fine-tune end-to-end for 100K iterations; for the baselines, we use the pretrained models readily provided by the authors. We list the quantitative results in Table 3, where the metrics are reported per-category. Our method achieves an overall lower error in both metrics. We outperform the volumetric baselines (3D-R2N2) by a large margin and has better prediction performance than Fan et al.in most cases. We also visualize the predictions in Fig. 4; again we see that our method predicts more accurate shapes with higher point density. We find that our method can be more problematic when objects contain very thin structures (e.g. lamps); adding hybrid linear layers [4] may help improve performance. 4.3 Generative Representation Analysis We analyze the learned generative representations by observing the 3D predictions from manipulation in the latent space. Previous works have demonstrated that deep generative networks can generate meaningful pixel/voxel predictions by performing linear operations in the latent space [20, 3, 28]; here, we explore the possibility of such manipulation for dense point clouds in an undiscretized space. We show in Fig. 5 the resulting dense shapes generated from the embedding vector interpolated in the latent space. The morphing transition is smooth with plausible interpolated shapes, which suggests that our structure generator can generate meaningful 3D predictions from convex combinations of encoded latent vectors. The structure generator is also capable of generating reasonable novel shapes from arithmetic results in the latent space from Fig. 6) we observe semantic feature replacement of table height/shape as well as chair arms/backs. These results suggest that the high-level semantic information encoded in the latent vectors are manipulable and interpretable of the resulting dense point clouds through the structure generator. 7













")







































8 category airplane bench car 7454 pts pts pts. 269 pts. 627 pts. display lamp sofa table watercraft pts pts pts pts pts pts pts. 422 pts pts pts. 729 pts. input image groundtruth CAD model ours Fan et al. 3D-R2N2 (1 view) Figure 4: Qualitative results from the multi-category experiment. Our method generates denser and more certain predictions compared to the baselines. input image prediction shape interpolation prediction input image Figure 5: Dense shapes generated from interpolated latent embeddings of two input images (leftmost and rightmost). The interpolated shapes maintain reasonable structures of chairs. Figure 6: Dense shapes generated from arithmetic operations in the latent space (left: tables, right: chairs), where the input images are shown in the top row. 5 Conclusion In this paper, we introduced a framework for generating 3D shapes in the form of dense point clouds. Compared to conventional volumetric prediction methods using 3D ConvNets, it is more efficient to utilize 2D convolutional operations to predict surface information of 3D shapes. We showed that by introducing a pseudo-renderer, we are able to synthesize approximate depth images from novel viewpoints to optimize the 2D projection error within a backpropagation framework. Experimental results for single-image 3D reconstruction tasks showed that we generate more accurate and much denser 3D shapes than state-of-the-art 3D reconstruction methods. 8
9 References [1] A. X. Chang, T. Funkhouser, L. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, et al. Shapenet: An information-rich 3d model repository. arxiv preprint arxiv: , [2] C. B. Choy, D. Xu, J. Gwak, K. Chen, and S. Savarese. 3d-r2n2: A unified approach for single and multiview 3d object reconstruction. In European Conference on Computer Vision, pages Springer, [3] A. Dosovitskiy, J. Tobias Springenberg, and T. Brox. Learning to generate chairs with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [4] H. Fan, H. Su, and L. Guibas. A point set generation network for 3d object reconstruction from a single image. arxiv preprint arxiv: , [5] M. Gadelha, S. Maji, and R. Wang. 3d shape induction from 2d views of multiple objects. arxiv preprint arxiv: , [6] R. Girdhar, D. F. Fouhey, M. Rodriguez, and A. Gupta. Learning a predictable and generative vector representation for objects. In European Conference on Computer Vision, pages Springer, [7] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages , [8] C. Häne, S. Tulsiani, and J. Malik. Hierarchical surface prediction for 3d object reconstruction. arxiv preprint arxiv: , [9] V. Hegde and R. Zadeh. Fusionnet: 3d object classification using multiple data representations. arxiv preprint arxiv: , [10] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. pages , [11] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. arxiv preprint arxiv: , [12] M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In Advances in Neural Information Processing Systems, pages , [13] D. Kingma and J. Ba. Adam: A method for stochastic optimization [14] D. P. Kingma and M. Welling. Auto-encoding variational bayes [15] C. Kong, C.-H. Lin, and S. Lucey. Using locally corresponding cad models for dense 3d reconstructions from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, [16] T. D. Kulkarni, W. F. Whitney, P. Kohli, and J. Tenenbaum. Deep convolutional inverse graphics network. In Advances in Neural Information Processing Systems, pages , [17] C.-H. Lin and S. Lucey. Inverse compositional spatial transformer networks. arxiv preprint arxiv: , [18] D. Maturana and S. Scherer. Voxnet: A 3d convolutional neural network for real-time object recognition. In Intelligent Robots and Systems (IROS), 2015 IEEE/RSJ International Conference on, pages IEEE, [19] E. Park, J. Yang, E. Yumer, D. Ceylan, and A. C. Berg. Transformation-grounded image generation network for novel 3d view synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, [20] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arxiv preprint arxiv: , [21] S. E. Reed, Y. Zhang, Y. Zhang, and H. Lee. Deep visual analogy-making. In Advances in Neural Information Processing Systems, pages , [22] D. J. Rezende, S. A. Eslami, S. Mohamed, P. Battaglia, M. Jaderberg, and N. Heess. Unsupervised learning of 3d structure from images. In Advances In Neural Information Processing Systems, pages , [23] G. Riegler, A. O. Ulusoys, and A. Geiger. Octnet: Learning deep 3d representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, [24] M. Tatarchenko, A. Dosovitskiy, and T. Brox. Multi-view 3d models from single images with a convolutional network. In European Conference on Computer Vision, pages Springer, [25] M. Tatarchenko, A. Dosovitskiy, and T. Brox. Octree generating networks: Efficient convolutional architectures for high-resolution 3d outputs. arxiv preprint arxiv: , [26] S. Tulsiani, T. Zhou, A. A. Efros, and J. Malik. Multi-view supervision for single-view reconstruction via differentiable ray consistency. arxiv preprint arxiv: , [27] X. Wang and A. Gupta. Generative image modeling using style and structure adversarial networks. In European Conference on Computer Vision, pages Springer,
10 [28] J. Wu, C. Zhang, T. Xue, B. Freeman, and J. Tenenbaum. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In Advances in Neural Information Processing Systems, pages 82 90, [29] Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages , [30] X. Yan, J. Yang, K. Sohn, and H. Lee. Attribute2image: Conditional image generation from visual attributes. In European Conference on Computer Vision, pages Springer, [31] X. Yan, J. Yang, E. Yumer, Y. Guo, and H. Lee. Perspective transformer nets: Learning single-view 3d object reconstruction without 3d supervision. In Advances in Neural Information Processing Systems, pages , [32] J. Yang, S. E. Reed, M.-H. Yang, and H. Lee. Weakly-supervised disentangling with recurrent transformations for 3d view synthesis. In Advances in Neural Information Processing Systems, pages , [33] M. E. Yumer and N. J. Mitra. Learning semantic deformation flows with 3d convolutional networks. In European Conference on Computer Vision, pages Springer, [34] T. Zhou, S. Tulsiani, W. Sun, J. Malik, and A. A. Efros. View synthesis by appearance flow. In European Conference on Computer Vision, pages Springer, [35] J.-Y. Zhu, P. Krähenbühl, E. Shechtman, and A. A. Efros. Generative visual manipulation on the natural image manifold. In European Conference on Computer Vision, pages Springer,
Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction
 Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction Chen-Hsuan Lin Chen Kong Simon Lucey The Robotics Institute Carnegie Mellon University chlin@cmu.edu, {chenk,slucey}@cs.cmu.edu
Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction Chen-Hsuan Lin Chen Kong Simon Lucey The Robotics Institute Carnegie Mellon University chlin@cmu.edu, {chenk,slucey}@cs.cmu.edu
CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision
 CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision Navaneet K L *, Priyanka Mandikal * and R. Venkatesh Babu Video Analytics Lab, IISc, Bangalore, India
CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision Navaneet K L *, Priyanka Mandikal * and R. Venkatesh Babu Video Analytics Lab, IISc, Bangalore, India
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks
 An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
An Empirical Study of Generative Adversarial Networks for Computer Vision Tasks Report for Undergraduate Project - CS396A Vinayak Tantia (Roll No: 14805) Guide: Prof Gaurav Sharma CSE, IIT Kanpur, India
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision
 CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision Navaneet K L *, Priyanka Mandikal *, Mayank Agarwal, and R. Venkatesh Babu Video Analytics Lab, CDS, Indian
CAPNet: Continuous Approximation Projection For 3D Point Cloud Reconstruction Using 2D Supervision Navaneet K L *, Priyanka Mandikal *, Mayank Agarwal, and R. Venkatesh Babu Video Analytics Lab, CDS, Indian
3D Deep Learning on Geometric Forms. Hao Su
 3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
Learning Adversarial 3D Model Generation with 2D Image Enhancer
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) Learning Adversarial 3D Model Generation with 2D Image Enhancer Jing Zhu, Jin Xie, Yi Fang NYU Multimedia and Visual Computing Lab
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) Learning Adversarial 3D Model Generation with 2D Image Enhancer Jing Zhu, Jin Xie, Yi Fang NYU Multimedia and Visual Computing Lab
arxiv: v1 [cs.cv] 10 Sep 2018
![arxiv: v1 [cs.cv] 10 Sep 2018](/thumbs/93/117973766.jpg "arxiv: v1 [cs.cv] 10 Sep 2018") Deep Single-View 3D Object Reconstruction with Visual Hull Embedding Hanqing Wang 1 Jiaolong Yang 2 Wei Liang 1 Xin Tong 2 1 Beijing Institute of Technology 2 Microsoft Research {hanqingwang,liangwei}@bit.edu.cn
Deep Single-View 3D Object Reconstruction with Visual Hull Embedding Hanqing Wang 1 Jiaolong Yang 2 Wei Liang 1 Xin Tong 2 1 Beijing Institute of Technology 2 Microsoft Research {hanqingwang,liangwei}@bit.edu.cn
GAL: Geometric Adversarial Loss for Single-View 3D-Object Reconstruction
 GAL: Geometric Adversarial Loss for Single-View 3D-Object Reconstruction Li Jiang 1, Shaoshuai Shi 1, Xiaojuan Qi 1, and Jiaya Jia 1,2 1 The Chinese University of Hong Kong 2 Tencent YouTu Lab {lijiang,
GAL: Geometric Adversarial Loss for Single-View 3D-Object Reconstruction Li Jiang 1, Shaoshuai Shi 1, Xiaojuan Qi 1, and Jiaya Jia 1,2 1 The Chinese University of Hong Kong 2 Tencent YouTu Lab {lijiang,
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
arxiv: v1 [cs.cv] 5 Jul 2017
![arxiv: v1 [cs.cv] 5 Jul 2017](/thumbs/95/123923253.jpg "arxiv: v1 [cs.cv] 5 Jul 2017") AlignGAN: Learning to Align Cross- Images with Conditional Generative Adversarial Networks Xudong Mao Department of Computer Science City University of Hong Kong xudonmao@gmail.com Qing Li Department of
AlignGAN: Learning to Align Cross- Images with Conditional Generative Adversarial Networks Xudong Mao Department of Computer Science City University of Hong Kong xudonmao@gmail.com Qing Li Department of
Pixels, voxels, and views: A study of shape representations for single view 3D object shape prediction
 Pixels, voxels, and views: A study of shape representations for single view 3D object shape prediction Daeyun Shin 1 Charless C. Fowlkes 1 Derek Hoiem 2 1 University of California, Irvine 2 University
Pixels, voxels, and views: A study of shape representations for single view 3D object shape prediction Daeyun Shin 1 Charless C. Fowlkes 1 Derek Hoiem 2 1 University of California, Irvine 2 University
arxiv: v1 [cs.cv] 30 Sep 2018
![arxiv: v1 [cs.cv] 30 Sep 2018](/thumbs/89/99613806.jpg "arxiv: v1 [cs.cv] 30 Sep 2018") 3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
3D-PSRNet: Part Segmented 3D Point Cloud Reconstruction From a Single Image Priyanka Mandikal, Navaneet K L, and R. Venkatesh Babu arxiv:1810.00461v1 [cs.cv] 30 Sep 2018 Indian Institute of Science, Bangalore,
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Seeing the unseen. Data-driven 3D Understanding from Single Images. Hao Su
 Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Seeing the unseen Data-driven 3D Understanding from Single Images Hao Su Image world Shape world 3D perception from a single image Monocular vision a typical prey a typical predator Cited from https://en.wikipedia.org/wiki/binocular_vision
Learning to generate 3D shapes
 Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Learning to generate 3D shapes Subhransu Maji College of Information and Computer Sciences University of Massachusetts, Amherst http://people.cs.umass.edu/smaji August 10, 2018 @ Caltech Creating 3D shapes
Multi-view 3D Models from Single Images with a Convolutional Network
 Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko University of Freiburg Skoltech - 2nd Christmas Colloquium on Computer Vision Humans have prior knowledge about 3D
Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko University of Freiburg Skoltech - 2nd Christmas Colloquium on Computer Vision Humans have prior knowledge about 3D
Point Cloud Completion of Foot Shape from a Single Depth Map for Fit Matching using Deep Learning View Synthesis
 Point Cloud Completion of Foot Shape from a Single Depth Map for Fit Matching using Deep Learning View Synthesis Nolan Lunscher University of Waterloo 200 University Ave W. nlunscher@uwaterloo.ca John
Point Cloud Completion of Foot Shape from a Single Depth Map for Fit Matching using Deep Learning View Synthesis Nolan Lunscher University of Waterloo 200 University Ave W. nlunscher@uwaterloo.ca John
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
arxiv: v1 [cs.cv] 17 Nov 2016
![arxiv: v1 [cs.cv] 17 Nov 2016](/thumbs/86/93859848.jpg "arxiv: v1 [cs.cv] 17 Nov 2016") Inverting The Generator Of A Generative Adversarial Network arxiv:1611.05644v1 [cs.cv] 17 Nov 2016 Antonia Creswell BICV Group Bioengineering Imperial College London ac2211@ic.ac.uk Abstract Anil Anthony
Inverting The Generator Of A Generative Adversarial Network arxiv:1611.05644v1 [cs.cv] 17 Nov 2016 Antonia Creswell BICV Group Bioengineering Imperial College London ac2211@ic.ac.uk Abstract Anil Anthony
CS468: 3D Deep Learning on Point Cloud Data. class label part label. Hao Su. image. May 10, 2017
 CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
CS468: 3D Deep Learning on Point Cloud Data class label part label Hao Su image. May 10, 2017 Agenda Point cloud generation Point cloud analysis CVPR 17, Point Set Generation Pipeline render CVPR 17, Point
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Matryoshka Networks: Predicting 3D Geometry via Nested Shape Layers
 Matryoshka Networks: Predicting 3D Geometry via Nested Shape Layers Stephan R. Richter 1,2 Stefan Roth 1 1 TU Darmstadt 2 Intel Labs Figure 1. Exemplary shape reconstructions from a single by our Matryoshka
Matryoshka Networks: Predicting 3D Geometry via Nested Shape Layers Stephan R. Richter 1,2 Stefan Roth 1 1 TU Darmstadt 2 Intel Labs Figure 1. Exemplary shape reconstructions from a single by our Matryoshka
arxiv: v3 [cs.cv] 30 Oct 2017
![arxiv: v3 [cs.cv] 30 Oct 2017](/thumbs/82/85101201.jpg "arxiv: v3 [cs.cv] 30 Oct 2017") Improved Adversarial Systems for 3D Object Generation and Reconstruction Edward J. Smith Department of Computer Science McGill University Canada edward.smith@mail.mcgill.ca David Meger Department of Computer
Improved Adversarial Systems for 3D Object Generation and Reconstruction Edward J. Smith Department of Computer Science McGill University Canada edward.smith@mail.mcgill.ca David Meger Department of Computer
arxiv: v1 [cs.cv] 16 Jul 2017
![arxiv: v1 [cs.cv] 16 Jul 2017](/thumbs/85/91311140.jpg "arxiv: v1 [cs.cv] 16 Jul 2017") enerative adversarial network based on resnet for conditional image restoration Paper: jc*-**-**-****: enerative Adversarial Network based on Resnet for Conditional Image Restoration Meng Wang, Huafeng
enerative adversarial network based on resnet for conditional image restoration Paper: jc*-**-**-****: enerative Adversarial Network based on Resnet for Conditional Image Restoration Meng Wang, Huafeng
arxiv: v1 [cs.cv] 7 Mar 2018
![arxiv: v1 [cs.cv] 7 Mar 2018](/thumbs/95/125565711.jpg "arxiv: v1 [cs.cv] 7 Mar 2018") Accepted as a conference paper at the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN) 2018 Inferencing Based on Unsupervised Learning of Disentangled
Accepted as a conference paper at the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN) 2018 Inferencing Based on Unsupervised Learning of Disentangled
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY
 MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
MULTI-LEVEL 3D CONVOLUTIONAL NEURAL NETWORK FOR OBJECT RECOGNITION SAMBIT GHADAI XIAN LEE ADITYA BALU SOUMIK SARKAR ADARSH KRISHNAMURTHY Outline Object Recognition Multi-Level Volumetric Representations
arxiv: v1 [cs.gr] 22 Sep 2017
![arxiv: v1 [cs.gr] 22 Sep 2017](/thumbs/75/72203215.jpg "arxiv: v1 [cs.gr] 22 Sep 2017") Hierarchical Detail Enhancing Mesh-Based Shape Generation with 3D Generative Adversarial Network arxiv:1709.07581v1 [cs.gr] 22 Sep 2017 Chiyu Max Jiang University of California Berkeley, CA 94720 chiyu.jiang@berkeley.edu
Hierarchical Detail Enhancing Mesh-Based Shape Generation with 3D Generative Adversarial Network arxiv:1709.07581v1 [cs.gr] 22 Sep 2017 Chiyu Max Jiang University of California Berkeley, CA 94720 chiyu.jiang@berkeley.edu
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material
 Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material Peak memory usage, GB 10 1 0.1 0.01 OGN Quadratic Dense Cubic Iteration time, s 10
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Supplementary Material Peak memory usage, GB 10 1 0.1 0.01 OGN Quadratic Dense Cubic Iteration time, s 10
DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION
 2017 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 25 28, 2017, TOKYO, JAPAN DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1,
2017 IEEE INTERNATIONAL WORKSHOP ON MACHINE LEARNING FOR SIGNAL PROCESSING, SEPT. 25 28, 2017, TOKYO, JAPAN DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1,
DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION
 DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1, Wei-Chen Chiu 2, Sheng-De Wang 1, and Yu-Chiang Frank Wang 1 1 Graduate Institute of Electrical Engineering,
DOMAIN-ADAPTIVE GENERATIVE ADVERSARIAL NETWORKS FOR SKETCH-TO-PHOTO INVERSION Yen-Cheng Liu 1, Wei-Chen Chiu 2, Sheng-De Wang 1, and Yu-Chiang Frank Wang 1 1 Graduate Institute of Electrical Engineering,
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Introduction In this supplementary material, Section 2 details the 3D annotation for CAD models and real
Paired 3D Model Generation with Conditional Generative Adversarial Networks
 Accepted to 3D Reconstruction in the Wild Workshop European Conference on Computer Vision (ECCV) 2018 Paired 3D Model Generation with Conditional Generative Adversarial Networks Cihan Öngün Alptekin Temizel
Accepted to 3D Reconstruction in the Wild Workshop European Conference on Computer Vision (ECCV) 2018 Paired 3D Model Generation with Conditional Generative Adversarial Networks Cihan Öngün Alptekin Temizel
Supplementary A. Overview. C. Time and Space Complexity. B. Shape Retrieval. D. Permutation Invariant SOM. B.1. Dataset
 Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Cross-domain Deep Encoding for 3D Voxels and 2D Images
 Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
Cross-domain Deep Encoding for 3D Voxels and 2D Images Jingwei Ji Stanford University jingweij@stanford.edu Danyang Wang Stanford University danyangw@stanford.edu 1. Introduction 3D reconstruction is one
Multiresolution Tree Networks for 3D Point Cloud Processing
 Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha, Rui Wang and Subhransu Maji College of Information and Computer Sciences, University of Massachusetts - Amherst {mgadelha, ruiwang,
Multiresolution Tree Networks for 3D Point Cloud Processing Matheus Gadelha, Rui Wang and Subhransu Maji College of Information and Computer Sciences, University of Massachusetts - Amherst {mgadelha, ruiwang,
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos
 Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Hierarchical Surface Prediction for 3D Object Reconstruction
 Hierarchical Surface Prediction for 3D Object Reconstruction Christian Häne, Shubham Tulsiani, Jitendra Malik University of California, Berkeley {chaene, shubhtuls, malik}@eecs.berkeley.edu Abstract Recently,
Hierarchical Surface Prediction for 3D Object Reconstruction Christian Häne, Shubham Tulsiani, Jitendra Malik University of California, Berkeley {chaene, shubhtuls, malik}@eecs.berkeley.edu Abstract Recently,
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image. Supplementary Material
 Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
arxiv: v1 [cs.cv] 6 Sep 2018
![arxiv: v1 [cs.cv] 6 Sep 2018](/thumbs/85/92251412.jpg "arxiv: v1 [cs.cv] 6 Sep 2018") arxiv:1809.01890v1 [cs.cv] 6 Sep 2018 Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks Koichi Hamada, Kentaro Tachibana, Tianqi Li, Hiroto
arxiv:1809.01890v1 [cs.cv] 6 Sep 2018 Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks Koichi Hamada, Kentaro Tachibana, Tianqi Li, Hiroto
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
arxiv: v3 [cs.cv] 7 Aug 2017
![arxiv: v3 [cs.cv] 7 Aug 2017](/thumbs/89/99392312.jpg "arxiv: v3 [cs.cv] 7 Aug 2017") Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Maxim Tatarchenko1 tatarchm@cs.uni-freiburg.de arxiv:1703.09438v3 [cs.cv] 7 Aug 2017 1 Alexey Dosovitskiy1,2
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Maxim Tatarchenko1 tatarchm@cs.uni-freiburg.de arxiv:1703.09438v3 [cs.cv] 7 Aug 2017 1 Alexey Dosovitskiy1,2
COMP 551 Applied Machine Learning Lecture 16: Deep Learning
 COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
COMP 551 Applied Machine Learning Lecture 16: Deep Learning Instructor: Ryan Lowe (ryan.lowe@cs.mcgill.ca) Slides mostly by: Class web page: www.cs.mcgill.ca/~hvanho2/comp551 Unless otherwise noted, all
arxiv: v1 [cs.cv] 28 Nov 2018
![arxiv: v1 [cs.cv] 28 Nov 2018](/thumbs/91/104803963.jpg "arxiv: v1 [cs.cv] 28 Nov 2018") MeshNet: Mesh Neural Network for 3D Shape Representation Yutong Feng, 1 Yifan Feng, 2 Haoxuan You, 1 Xibin Zhao 1, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University, China. 2 School of
MeshNet: Mesh Neural Network for 3D Shape Representation Yutong Feng, 1 Yifan Feng, 2 Haoxuan You, 1 Xibin Zhao 1, Yue Gao 1 1 BNRist, KLISS, School of Software, Tsinghua University, China. 2 School of
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS
 LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
LEARNING TO GENERATE CHAIRS WITH CONVOLUTIONAL NEURAL NETWORKS Alexey Dosovitskiy, Jost Tobias Springenberg and Thomas Brox University of Freiburg Presented by: Shreyansh Daftry Visual Learning and Recognition
Deep Convolutional Inverse Graphics Network
 Deep Convolutional Inverse Graphics Network Tejas D. Kulkarni* 1, William F. Whitney* 2, Pushmeet Kohli 3, Joshua B. Tenenbaum 4 1,2,4 Massachusetts Institute of Technology, Cambridge, USA 3 Microsoft
Deep Convolutional Inverse Graphics Network Tejas D. Kulkarni* 1, William F. Whitney* 2, Pushmeet Kohli 3, Joshua B. Tenenbaum 4 1,2,4 Massachusetts Institute of Technology, Cambridge, USA 3 Microsoft
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
arxiv: v2 [cs.cv] 24 Apr 2018
![arxiv: v2 [cs.cv] 24 Apr 2018](/thumbs/96/127548925.jpg "arxiv: v2 [cs.cv] 24 Apr 2018") Multi-view Consistency as Supervisory Signal for Learning Shape and Pose Prediction Shubham Tulsiani, Alexei A. Efros, Jitendra Malik University of California, Berkeley {shubhtuls, efros, malik}@eecs.berkeley.edu
Multi-view Consistency as Supervisory Signal for Learning Shape and Pose Prediction Shubham Tulsiani, Alexei A. Efros, Jitendra Malik University of California, Berkeley {shubhtuls, efros, malik}@eecs.berkeley.edu
arxiv: v1 [cs.cv] 4 Nov 2017
![arxiv: v1 [cs.cv] 4 Nov 2017](/thumbs/88/114981783.jpg "arxiv: v1 [cs.cv] 4 Nov 2017") Object-Centric Photometric Bundle Adjustment with Deep Shape Prior Rui Zhu, Chaoyang Wang, Chen-Hsuan Lin, Ziyan Wang, Simon Lucey The Robotics Institute, Carnegie Mellon University {rz1, chaoyanw, chenhsul,
Object-Centric Photometric Bundle Adjustment with Deep Shape Prior Rui Zhu, Chaoyang Wang, Chen-Hsuan Lin, Ziyan Wang, Simon Lucey The Robotics Institute, Carnegie Mellon University {rz1, chaoyanw, chenhsul,
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs
 Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Maxim Tatarchenko 1 Alexey Dosovitskiy 1,2 Thomas Brox 1 tatarchm@cs.uni-freiburg.de adosovitskiy@gmail.com
Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs Maxim Tatarchenko 1 Alexey Dosovitskiy 1,2 Thomas Brox 1 tatarchm@cs.uni-freiburg.de adosovitskiy@gmail.com
arxiv: v1 [cs.cv] 16 Nov 2015
![arxiv: v1 [cs.cv] 16 Nov 2015](/thumbs/85/92600288.jpg "arxiv: v1 [cs.cv] 16 Nov 2015") Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression Zhiao Huang hza@megvii.com Erjin Zhou zej@megvii.com Zhimin Cao czm@megvii.com arxiv:1511.04901v1 [cs.cv] 16 Nov 2015 Abstract Facial
arxiv: v1 [cs.cv] 17 Jan 2017
![arxiv: v1 [cs.cv] 17 Jan 2017](/thumbs/74/71448557.jpg "arxiv: v1 [cs.cv] 17 Jan 2017") 3D Reconstruction of Simple Objects from A Single View Silhouette Image arxiv:1701.04752v1 [cs.cv] 17 Jan 2017 Abstract Xinhan Di Trinity College Ireland dixi@tcd.ie Pengqian Yu National University of
3D Reconstruction of Simple Objects from A Single View Silhouette Image arxiv:1701.04752v1 [cs.cv] 17 Jan 2017 Abstract Xinhan Di Trinity College Ireland dixi@tcd.ie Pengqian Yu National University of
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material
 SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
SurfNet: Generating 3D shape surfaces using deep residual networks-supplementary Material Ayan Sinha MIT Asim Unmesh IIT Kanpur Qixing Huang UT Austin Karthik Ramani Purdue sinhayan@mit.edu a.unmesh@gmail.com
arxiv: v2 [cs.cv] 2 Aug 2016
![arxiv: v2 [cs.cv] 2 Aug 2016](/thumbs/75/71973800.jpg "arxiv: v2 [cs.cv] 2 Aug 2016") arxiv:1511.06702v2 [cs.cv] 2 Aug 2016 Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko, Alexey Dosovitskiy, Thomas Brox Department of Computer Science University of
arxiv:1511.06702v2 [cs.cv] 2 Aug 2016 Multi-view 3D Models from Single Images with a Convolutional Network Maxim Tatarchenko, Alexey Dosovitskiy, Thomas Brox Department of Computer Science University of
arxiv: v1 [cs.cv] 1 Nov 2018
![arxiv: v1 [cs.cv] 1 Nov 2018](/thumbs/89/100791471.jpg "arxiv: v1 [cs.cv] 1 Nov 2018") Examining Performance of Sketch-to-Image Translation Models with Multiclass Automatically Generated Paired Training Data Dichao Hu College of Computing, Georgia Institute of Technology, 801 Atlantic Dr
Examining Performance of Sketch-to-Image Translation Models with Multiclass Automatically Generated Paired Training Data Dichao Hu College of Computing, Georgia Institute of Technology, 801 Atlantic Dr
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Inverting The Generator Of A Generative Adversarial Network
 1 Inverting The Generator Of A Generative Adversarial Network Antonia Creswell and Anil A Bharath, Imperial College London arxiv:1802.05701v1 [cs.cv] 15 Feb 2018 Abstract Generative adversarial networks
1 Inverting The Generator Of A Generative Adversarial Network Antonia Creswell and Anil A Bharath, Imperial College London arxiv:1802.05701v1 [cs.cv] 15 Feb 2018 Abstract Generative adversarial networks
arxiv: v2 [cs.cv] 6 Nov 2017
![arxiv: v2 [cs.cv] 6 Nov 2017](/thumbs/82/85274322.jpg "arxiv: v2 [cs.cv] 6 Nov 2017") Hierarchical Surface Prediction for 3D Object Reconstruction Christian Häne, Shubham Tulsiani, Jitendra Malik University of California, Berkeley {chaene, shubhtuls, malik}@eecs.berkeley.edu arxiv:1704.00710v2
Hierarchical Surface Prediction for 3D Object Reconstruction Christian Häne, Shubham Tulsiani, Jitendra Malik University of California, Berkeley {chaene, shubhtuls, malik}@eecs.berkeley.edu arxiv:1704.00710v2
arxiv: v1 [cs.cv] 29 Mar 2018
![arxiv: v1 [cs.cv] 29 Mar 2018](/thumbs/87/95879394.jpg "arxiv: v1 [cs.cv] 29 Mar 2018") arxiv:1803.10932v1 [cs.cv] 29 Mar 2018 Learning Free-Form Deformations for 3D Object Reconstruction Dominic Jack, Jhony K. Pontes, Sridha Sridharan, Clinton Fookes, Sareh Shirazi, Frederic Maire, Anders
arxiv:1803.10932v1 [cs.cv] 29 Mar 2018 Learning Free-Form Deformations for 3D Object Reconstruction Dominic Jack, Jhony K. Pontes, Sridha Sridharan, Clinton Fookes, Sareh Shirazi, Frederic Maire, Anders
Deep Learning Approaches to 3D Shape Completion
 Deep Learning Approaches to 3D Shape Completion Prafull Sharma Stanford University prafull7@stanford.edu Jarrod Cingel Stanford University jcingel@stanford.edu Abstract This project explores various methods
Deep Learning Approaches to 3D Shape Completion Prafull Sharma Stanford University prafull7@stanford.edu Jarrod Cingel Stanford University jcingel@stanford.edu Abstract This project explores various methods
Supplementary: Cross-modal Deep Variational Hand Pose Estimation
 Supplementary: Cross-modal Deep Variational Hand Pose Estimation Adrian Spurr, Jie Song, Seonwook Park, Otmar Hilliges ETH Zurich {spurra,jsong,spark,otmarh}@inf.ethz.ch Encoder/Decoder Linear(512) Table
Supplementary: Cross-modal Deep Variational Hand Pose Estimation Adrian Spurr, Jie Song, Seonwook Park, Otmar Hilliges ETH Zurich {spurra,jsong,spark,otmarh}@inf.ethz.ch Encoder/Decoder Linear(512) Table
Deep Models for 3D Reconstruction
 Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Deep Models for 3D Reconstruction Andreas Geiger Autonomous Vision Group, MPI for Intelligent Systems, Tübingen Computer Vision and Geometry Group, ETH Zürich October 12, 2017 Max Planck Institute for
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
arxiv: v2 [cs.cv] 4 Oct 2017
![arxiv: v2 [cs.cv] 4 Oct 2017](/thumbs/80/81784543.jpg "arxiv: v2 [cs.cv] 4 Oct 2017") Weakly supervised 3D Reconstruction with Adversarial Constraint JunYoung Gwak Stanford University jgwak@stanford.edu Christopher B. Choy * Stanford University chrischoy@stanford.edu Manmohan Chandraker
Weakly supervised 3D Reconstruction with Adversarial Constraint JunYoung Gwak Stanford University jgwak@stanford.edu Christopher B. Choy * Stanford University chrischoy@stanford.edu Manmohan Chandraker
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
POINT CLOUD DEEP LEARNING
 POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
POINT CLOUD DEEP LEARNING Innfarn Yoo, 3/29/28 / 57 Introduction AGENDA Previous Work Method Result Conclusion 2 / 57 INTRODUCTION 3 / 57 2D OBJECT CLASSIFICATION Deep Learning for 2D Object Classification
arxiv: v4 [cs.cv] 29 Mar 2019
![arxiv: v4 [cs.cv] 29 Mar 2019](/thumbs/96/128038877.jpg "arxiv: v4 [cs.cv] 29 Mar 2019") PartNet: A Recursive Part Decomposition Network for Fine-grained and Hierarchical Shape Segmentation Fenggen Yu 1 Kun Liu 1 * Yan Zhang 1 Chenyang Zhu 2 Kai Xu 2 1 Nanjing University 2 National University
PartNet: A Recursive Part Decomposition Network for Fine-grained and Hierarchical Shape Segmentation Fenggen Yu 1 Kun Liu 1 * Yan Zhang 1 Chenyang Zhu 2 Kai Xu 2 1 Nanjing University 2 National University
arxiv: v3 [cs.cv] 9 Sep 2016
![arxiv: v3 [cs.cv] 9 Sep 2016](/thumbs/79/79085631.jpg "arxiv: v3 [cs.cv] 9 Sep 2016") arxiv:1604.03755v3 [cs.cv] 9 Sep 2016 VConv-DAE: Deep Volumetric Shape Learning Without Object Labels Abhishek Sharma 1, Oliver Grau 2, Mario Fritz 3 1 Intel Visual Computing Institute 2 Intel 3 Max Planck
arxiv:1604.03755v3 [cs.cv] 9 Sep 2016 VConv-DAE: Deep Volumetric Shape Learning Without Object Labels Abhishek Sharma 1, Oliver Grau 2, Mario Fritz 3 1 Intel Visual Computing Institute 2 Intel 3 Max Planck
3D Densely Convolutional Networks for Volumetric Segmentation. Toan Duc Bui, Jitae Shin, and Taesup Moon
 3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
Deep Learning for Visual Manipulation and Synthesis
 Deep Learning for Visual Manipulation and Synthesis Jun-Yan Zhu 朱俊彦 UC Berkeley 2017/01/11 @ VALSE What is visual manipulation? Image Editing Program input photo User Input result Desired output: stay
Deep Learning for Visual Manipulation and Synthesis Jun-Yan Zhu 朱俊彦 UC Berkeley 2017/01/11 @ VALSE What is visual manipulation? Image Editing Program input photo User Input result Desired output: stay
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models
 One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
Photo-realistic Renderings for Machines Seong-heum Kim
 Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
Photo-realistic Renderings for Machines 20105034 Seong-heum Kim CS580 Student Presentations 2016.04.28 Photo-realistic Renderings for Machines Scene radiances Model descriptions (Light, Shape, Material,
arxiv: v1 [cs.cv] 19 Jul 2017
![arxiv: v1 [cs.cv] 19 Jul 2017](/thumbs/81/83678394.jpg "arxiv: v1 [cs.cv] 19 Jul 2017") GADELHA ET AL.: SHAPE GENERATION USING SPATIALLY PARTITIONED POINT CLOUDS1 arxiv:1707.06267v1 [cs.cv] 19 Jul 2017 Shape Generation using Spatially Partitioned Point Clouds Matheus Gadelha mgadelha@cs.umass.edu
GADELHA ET AL.: SHAPE GENERATION USING SPATIALLY PARTITIONED POINT CLOUDS1 arxiv:1707.06267v1 [cs.cv] 19 Jul 2017 Shape Generation using Spatially Partitioned Point Clouds Matheus Gadelha mgadelha@cs.umass.edu
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network
 Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network Xinhai Liu, Zhizhong Han,2, Yu-Shen Liu, Matthias Zwicker 2 School of Software,
Point2Sequence: Learning the Shape Representation of 3D Point Clouds with an Attention-based Sequence to Sequence Network Xinhai Liu, Zhizhong Han,2, Yu-Shen Liu, Matthias Zwicker 2 School of Software,
Progress on Generative Adversarial Networks
 Progress on Generative Adversarial Networks Wangmeng Zuo Vision Perception and Cognition Centre Harbin Institute of Technology Content Image generation: problem formulation Three issues about GAN Discriminate
Progress on Generative Adversarial Networks Wangmeng Zuo Vision Perception and Cognition Centre Harbin Institute of Technology Content Image generation: problem formulation Three issues about GAN Discriminate
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks
 Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
arxiv: v1 [cs.cv] 17 Apr 2018
![arxiv: v1 [cs.cv] 17 Apr 2018](/thumbs/96/126522064.jpg "arxiv: v1 [cs.cv] 17 Apr 2018") Im2Avatar: Colorful 3D Reconstruction from a Single Image Yongbin Sun MIT yb sun@mit.edu Ziwei Liu UC Berkley zwliu@icsi.berkeley.edu Yue Wang MIT yuewang@csail.mit.edu Sanjay E. Sarma MIT sesarma@mit.edu
Im2Avatar: Colorful 3D Reconstruction from a Single Image Yongbin Sun MIT yb sun@mit.edu Ziwei Liu UC Berkley zwliu@icsi.berkeley.edu Yue Wang MIT yuewang@csail.mit.edu Sanjay E. Sarma MIT sesarma@mit.edu
3D-LMNet: Latent Embedding Matching for Accurate and Diverse 3D Point Cloud Reconstruction from a Single Image
 MANDIKAL, K L, AGARWAL, BABU: 3D POINT CLOUD RECONSTRUCTION 1 : Latent Embedding Matching for Accurate and Diverse 3D Point Cloud Reconstruction from a Single Image Priyanka Mandikal priyanka.mandikal@gmail.com
MANDIKAL, K L, AGARWAL, BABU: 3D POINT CLOUD RECONSTRUCTION 1 : Latent Embedding Matching for Accurate and Diverse 3D Point Cloud Reconstruction from a Single Image Priyanka Mandikal priyanka.mandikal@gmail.com
Composable Unpaired Image to Image Translation
 Composable Unpaired Image to Image Translation Laura Graesser New York University lhg256@nyu.edu Anant Gupta New York University ag4508@nyu.edu Abstract There has been remarkable recent work in unpaired
Composable Unpaired Image to Image Translation Laura Graesser New York University lhg256@nyu.edu Anant Gupta New York University ag4508@nyu.edu Abstract There has been remarkable recent work in unpaired
arxiv: v1 [cs.cv] 27 Jan 2019
![arxiv: v1 [cs.cv] 27 Jan 2019](/thumbs/95/122752774.jpg "arxiv: v1 [cs.cv] 27 Jan 2019") : Euclidean Point Cloud Auto-Encoder and Sampler Edoardo Remelli 1 Pierre Baque 1 Pascal Fua 1 Abstract arxiv:1901.09394v1 [cs.cv] 27 Jan 2019 Most algorithms that rely on deep learning-based approaches
: Euclidean Point Cloud Auto-Encoder and Sampler Edoardo Remelli 1 Pierre Baque 1 Pascal Fua 1 Abstract arxiv:1901.09394v1 [cs.cv] 27 Jan 2019 Most algorithms that rely on deep learning-based approaches
Spontaneously Emerging Object Part Segmentation
 Spontaneously Emerging Object Part Segmentation Yijie Wang Machine Learning Department Carnegie Mellon University yijiewang@cmu.edu Katerina Fragkiadaki Machine Learning Department Carnegie Mellon University
Spontaneously Emerging Object Part Segmentation Yijie Wang Machine Learning Department Carnegie Mellon University yijiewang@cmu.edu Katerina Fragkiadaki Machine Learning Department Carnegie Mellon University
arxiv: v1 [stat.ml] 14 Sep 2017
![arxiv: v1 [stat.ml] 14 Sep 2017](/thumbs/78/77167912.jpg "arxiv: v1 [stat.ml] 14 Sep 2017") The Conditional Analogy GAN: Swapping Fashion Articles on People Images Nikolay Jetchev Zalando Research nikolay.jetchev@zalando.de Urs Bergmann Zalando Research urs.bergmann@zalando.de arxiv:1709.04695v1
The Conditional Analogy GAN: Swapping Fashion Articles on People Images Nikolay Jetchev Zalando Research nikolay.jetchev@zalando.de Urs Bergmann Zalando Research urs.bergmann@zalando.de arxiv:1709.04695v1
Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval
 Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval Alexandr Notchenko, Ermek Kapushev, Evgeny Burnaev {avnotchenko,kapushev,burnaevevgeny}@gmail.com Skolkovo Institute of Science and
Sparse 3D Convolutional Neural Networks for Large-Scale Shape Retrieval Alexandr Notchenko, Ermek Kapushev, Evgeny Burnaev {avnotchenko,kapushev,burnaevevgeny}@gmail.com Skolkovo Institute of Science and
Learning Shape Priors for Single-View 3D Completion and Reconstruction
 Learning Shape Priors for Single-View 3D Completion and Reconstruction Jiajun Wu* 1, Chengkai Zhang* 1, Xiuming Zhang 1, Zhoutong Zhang 1, William T. Freeman 1,2, and Joshua B. Tenenbaum 1 1 MIT CSAIL,
Learning Shape Priors for Single-View 3D Completion and Reconstruction Jiajun Wu* 1, Chengkai Zhang* 1, Xiuming Zhang 1, Zhoutong Zhang 1, William T. Freeman 1,2, and Joshua B. Tenenbaum 1 1 MIT CSAIL,
arxiv: v1 [cs.cv] 27 Nov 2018 Abstract
![arxiv: v1 [cs.cv] 27 Nov 2018 Abstract](/thumbs/91/105025156.jpg "arxiv: v1 [cs.cv] 27 Nov 2018 Abstract") Iterative Transformer Network for 3D Point Cloud Wentao Yuan David Held Christoph Mertz Martial Hebert The Robotics Institute Carnegie Mellon University {wyuan1, dheld, cmertz, mhebert}@cs.cmu.edu arxiv:1811.11209v1
Iterative Transformer Network for 3D Point Cloud Wentao Yuan David Held Christoph Mertz Martial Hebert The Robotics Institute Carnegie Mellon University {wyuan1, dheld, cmertz, mhebert}@cs.cmu.edu arxiv:1811.11209v1
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS. Mustafa Ozan Tezcan
 MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
MOTION ESTIMATION USING CONVOLUTIONAL NEURAL NETWORKS Mustafa Ozan Tezcan Boston University Department of Electrical and Computer Engineering 8 Saint Mary s Street Boston, MA 2215 www.bu.edu/ece Dec. 19,
A Papier-Mâché Approach to Learning 3D Surface Generation
 A Papier-Mâché Approach to Learning 3D Surface Generation Thibault Groueix 1, Matthew Fisher 2, Vladimir G. Kim 2, Bryan C. Russell 2, Mathieu Aubry 1 1 LIGM (UMR 8049), École des Ponts, UPE, 2 Adobe Research
A Papier-Mâché Approach to Learning 3D Surface Generation Thibault Groueix 1, Matthew Fisher 2, Vladimir G. Kim 2, Bryan C. Russell 2, Mathieu Aubry 1 1 LIGM (UMR 8049), École des Ponts, UPE, 2 Adobe Research
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material
 Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz Supplemental Material Ayush Tewari 1,2 Michael Zollhöfer 1,2,3 Pablo Garrido 1,2 Florian Bernard 1,2 Hyeongwoo
Deep Learning. Vladimir Golkov Technical University of Munich Computer Vision Group
 Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Deep Learning Vladimir Golkov Technical University of Munich Computer Vision Group 1D Input, 1D Output target input 2 2D Input, 1D Output: Data Distribution Complexity Imagine many dimensions (data occupies
Structure-oriented Networks of Shape Collections
 Structure-oriented Networks of Shape Collections Noa Fish 1 Oliver van Kaick 2 Amit Bermano 3 Daniel Cohen-Or 1 1 Tel Aviv University 2 Carleton University 3 Princeton University 1 pplementary material
Structure-oriented Networks of Shape Collections Noa Fish 1 Oliver van Kaick 2 Amit Bermano 3 Daniel Cohen-Or 1 1 Tel Aviv University 2 Carleton University 3 Princeton University 1 pplementary material
Lab meeting (Paper review session) Stacked Generative Adversarial Networks
 Stacked Generative Adversarial Networks") Lab meeting (Paper review session) Stacked Generative Adversarial Networks 2017. 02. 01. Saehoon Kim (Ph. D. candidate) Machine Learning Group Papers to be covered Stacked Generative Adversarial Networks
Lab meeting (Paper review session) Stacked Generative Adversarial Networks 2017. 02. 01. Saehoon Kim (Ph. D. candidate) Machine Learning Group Papers to be covered Stacked Generative Adversarial Networks