Guiding Model Search Using Segmentation
|
|
|
- Gabriel Melton
- 5 years ago
- Views:
Transcription

1 Guiding Model Search Using Segmentation Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada V5A S6 Abstract In this paper we show how a segmentation as preprocessing paradigm can be used to improve the efficiency and accuracy of model search in an image. We operationalize this idea using an over-segmentation of an image into superpixels. The problem domain we explore is human body pose estimation from still images. The superpixels prove useful in two ways. First, we restrict the joint positions in our human body model to lie at centers of superpixels, which reduces the size of the model search space. In addition, accurate support masks for computing features on half-limbs of the body model are obtained by using agglomerations of superpixels as half-limb segments. We present results on a challenging dataset of people in sports news images.. Introduction In this paper we show how a segmentation as preprocessing paradigm can be used to improve the efficiency and accuracy of model search in an image. We use the superpixels of Ren and Malik [] to operationalize this idea, and test it in the problem domain of human body pose estimation from still images. Consider the image in Figure (a). Given the task of localizing the joint positions of the human figure in this image, a naive search based on a particular body model would require examining every pixel as a putative left wrist location, left elbow location, and so forth. If the body model has a complicated structure (the model we use has O(N 8 ) complexity, with N pixels in the image), the search procedure is computationally prohibitive. Instead, we use segmentation as a pre-processing step to limit the size of the state space which we must search over for each joint. Figure (b) shows an example over-segmentation into superpixels. In our approach we examine every superpixel center, rather than every pixel, as a putative joint position. The images we consider in our experiments are large, N = 5 5K pixels, This work is supported by grants from NSERC (RGPIN-3223) and the SFU President s Research Fund. (a) Figure : (a) Input image of 6K pixels. (b) An oversegmentation of 933 superpixels. We approximate the position of each joint of the human figure as a superpixel center, and each half-limb as being composed of superpixels. so the reduction to N sp superpixels provides a clear computational improvement. In addition to reducing the state space of search, the superpixels can provide accuracy improvements by defining support masks on which to compute features. For the problem we are interested in, human body pose estimation, model-based approaches typically define a particular shape (such as rectangle in 2D) of half-limb on which to compute image features. Instead we use the image boundaries given by the superpixels to define support masks for half-limbs. These more accurate support masks that adhere closely to image boundaries result in features that include less background clutter. The structure of this paper is as follows. We start by reviewing previous work in Section 2. Section 3 describes our human body model based on the superpixel representation. Section 4 describes our inference procedure. Results are presented in Section 5, and we conclude in Section Related Work Some of the earliest research related to the problem of human body pose estimation is the pedestrian tracking work (b)
2 of Hogg [3]. A vast quantity of work continued in this vein, using high degree-of-freedom 3D models of people, rendering them in the image plane, and comparing them with image data. Gavrila [2] provides a survey of this work. These approaches typically require a hand-initialized first frame, and the large number of parameters in their models lead to difficult tracking problems in high dimensional spaces. The complexities in 3D model-based tracking have led researchers to pose the problem as one of matching to stored 2D exemplars. Toyama and Blake [9] used exemplars for tracking people as 2D edge maps. Mori and Malik [6], and Sullivan and Carlsson [7] directly address the problem of pose estimation. They stored sets of 2D exemplars upon which joint locations have been marked. Joint locations are transferred to novel images using shape matching. Shakhnarovich et al. [2] address variation in pose and appearance in exemplar matching through brute force, using a variation of locality sensitive hashing for speed to match upper body configurations of standing, front facing people in background subtracted video sequences. Another family of approaches use a 2D model to find or track people. The approach we describe in this paper falls into this category. Felzenswalb and Huttenlocher [] score rectangles using either a fixed clothing model or silhouettes from background subtraction of video sequences and then quickly find an optimal configuration using the distance transform to perform dynamic programming on the canonical tree model. Morris and Rehg [8] use a 2D Scaled Prismatic Model to track people and avoid the singularities associated with some 3d models. A subset of these 2D approaches apply a simple low-level detector to produce a set of candidate parts, and then a top-down procedure makes inferences about the parts and finds the best assembly. Song et al. [5] detect corner features in video sequences and model their joint statistics using tree-structured models. Ioffe and Forsyth [4] use a simple rectangle detector to find candidates and assemble them by sampling based on kinematic constraints. Ramanan and Forsyth [9] describe a self-starting tracker that builds an appearance model for people given salient rectangular primitives extracted from video sequences. One difficulty with the tree-based body models that are often used to reduce the complexity of search is that there is no direct mechanism for preventing the reuse of image pixels. An arm with a good low-level score could be labeled as both the right and left arm. Felzenswalb and Huttenlocher [] address this by sampling from the tree-based distribution over body poses, which is computed extremely efficiently using the distance transform, and then evaluating these samples using a more complicated model. In this work, we instead use a model that incorporates occlusion reasoning directly and use superpixels to reduce the computational difficulties in model search. A few recent works are of particular relevance to this paper. The inference algorithm we will use to sample the distribution over human body poses is a Markov Chain Monte Carlo (MCMC) algorithm. Lee and Cohen [5] presented impressive results on pose estimation using proposal maps, based on face and skin detection, to guide a MCMC sampler to promising regions of the image. Tu et al. [2] perform object recognition and segmentation simultaneously, combining face and letter detectors with segmentation in a DD-MCMC framework. Sigal et al. [4] and Sudderth et al. [6] track people and hands respectively, using looselimbed models, models consisting in a collection of loosely connected geometric primitives, and use non-parametric belief propagation to perform inference. Sudderth et al. build occlusion reasoning into their hand model. Sigal et al. use shouters to focus the attention of the inference procedure. The idea of using an over-segmentation as support masks on which to compute features has been developed previously by Tao et al. [8] who used colour segmentation as pre-processing for stereo matching. The superpixels we use in this paper are obtained via the Normalized Cuts algorithm [3], and at this scale ( superpixels) provide better support masks than colour segmentation, particularly in the presence of texture. 3. Body Model We use a 2D human body model that consists in 8 half-limbs (upper and lower arms and legs), a torso, and two occlusion variables describing relative depth orderings of the arms, legs and torso. This model is similar in spirit to the commonly used cardboard person models (e.g.[, 9]) in which the torso and each half-limb is represented by a pre-defined 2D primitive (typically a rectangle), and the kinematics of the body are modelled as a collection of 2D angles formed at links between these primitives. There are two differences between our model and these others. First, the half-limbs are restricted to respect the spatial constraints imposed by the reduction of the original image to a collection of superpixels. The endpoints of the halflimbs (i.e. the positions of the joints: elbows, shoulders, etc.) are restricted to lie in the center of one of the N sp superpixels. This restriction drastically reduces the search space of possible half-limbs (N = 5K 3K pixels as endpoints to N sp ) while yielding only a minimal amount of lost precision in spatial location of the half-limbs. Further, each half-limb is formed as an agglomeration of superpixels. In addition to forming more complex shapes than would be possible with any particular 2D primitive, this allows for efficient computation of features for half-limbs by combining features computed on a per superpixel basis. The second difference is the addition of the two occlusion variables, one representing the depth ordering of
3 the left and right arms with respect to each other and the torso, and one the depth ordering of the left and right legs. These occlusion variables allow half-limbs to claim exclusive ownership over regions of the image, avoiding the double counting of image evidence that often occurs in models that lack such information (such as tree-structured models). Further, they allow us to predict appearance of partially occluded limbs. Given the locations of the half-limbs, and the depth ordering in the occlusion variables, we render the upper body and, separately, lower body in a back-to-front ordering to determine which superpixels are claimed by each half-limb. More precisely, a model state X is defined as follows: X = (X lua, X lla, X rua, X rla, X lul, X lll, X rul, X rll, h u, h l ) where X lua represents the left upper arm, X rll the right lower leg, and so forth. Each X i takes a value which is an index into the set of all possible half-limbs, X i {, 2,..., S}. The number of possible half-limbs S Nsp, 2 where N sp is the number of superpixels. The details of constructing the set of all possible half-limbs are presented below (Section 3.); essentially half-limbs of a few widths are placed between all pairs of superpixels within some bounded distance of each other. Note that the torso is defined implicitly in this representation, based on the shoulder and hip locations of the upper limbs. The variables h u and h l represent the upper body (arms and torso) and lower body (legs) occlusion states respectively. h u can take values representing one of four depth orderings: left-arm/right-arm/torso, left-arm/torso/right-arm, right-arm/left-arm/torso, rightarm/torso/left-arm (both arms may not be behind torso, and an upper arm cannot occlude its adjacent lower arm). h l can take two values, representing left-leg/right-leg and rightleg/left-leg depth orderings. We will denote by U the upper body variables, U = {X lua, X lla, X rua, X rla, h u }, and L the lower body variables L = {X lul, X lll, X rul, X rll, h l }. A particular model configuration is deemed plausible if:. The half-limbs form a kinematically valid human body. 2. Each individual half-limb chosen looks like a halflimb itself. 3. There is symmetry in appearance of corresponding left and right half-limbs. 4. Adjacent half-limbs and corresponding left and right half-limbs have similar widths. As such, we define a distribution over model states X as a product of four distributions: p(x) = p k (X) p l (X) p a (X) p w (X) () Kinematic constraints forcing the half-limbs that comprise the body to be connected are represented in p k (X): p k (X) ψ k (X lua, X lla ) ψ k (X rua, X rla ) ψ k (X lul, X lll ) ψ k (X rul, X rll ) ψ kt (X) (2) where { if Xi, X ψ k (X i, X j ) = j adjacent otherwise A pair of half-limbs are defined to be adjacent if they share an elbow/knee superpixel. ψ kt (X) {, } enforces constraints on the size and shape of the torso induced by the upper limbs of state X. The other distributions, p l (X), p a (X), and p w (X), are defined in the following subsections. 3.. Half-limb Model In building our set of S half-limbs, we would like to consider elongated segments, composed of superpixels, of various widths around a bone-line connecting every nearby pair of superpixels. We model a half-limb as a connected region bounded by a pair of polylines and the line segments connecting their endpoints. This modelling assumption is motivated by the available spatial structure of the superpixel segmentation, as described below. The cues which we use when considering half-limbs in isolation, without any global assembly constraints, are () amount of edge energy on, and (2) overall shape of the boundary of the half-limb. We desire a representation for these constraints which can be efficiently computed given cues defined based on superpixels. As these cues are defined on the boundaries of segments, we construct a superpixel dual graph on which to compute these cues. The superpixel dual graph, shown in Figure 2(b) is constructed by taking a polygonal approximation to the original superpixel boundaries (Figure 2(a)) and creating a vertex where 3 or more superpixels meet, and an edge between vertices which are endpoints of a side of a superpixel. Image edge energy and graph edge orientation are associated with each graph edge in this dual graph. Given a half-limb X i bounded by a pair of polyline paths in this dual graph, we define a limb-ness potential for the halflimb based on the average amount of edge energy ē i, average amount of orientation variation ō i, and total length of these bounding paths l i : ψ l (X i ) = e e 2 (ē i µ e) 2 e l 2 (3) (l i µ l ) 2 e o 2 (ō i µ o) 2 (4) Considering half-limbs bounded by all possible paths through the dual graph would be a daunting and unnecessary task. Instead, between a pair of dual graph vertices we restrict ourselves to the path which is shortest, using straight line distance edge costs. For a particular pair of superpixels
 Given two superpixels, shown with thick blue line between their centers, shortest paths between dual graph vertices near each superpixel are considered.")
4 (a) (b) (c) (d) Figure 2: Finding half-limbs. (a) Superpixel centers and boundaries. (b) Superpixel dual graph, red dot denote vertices, black lines edges. (c) Given two superpixels, shown with thick blue line between their centers, shortest paths between dual graph vertices near each superpixel are considered. (d) A chosen half-limb is shown outlined in gray. A small collection of half-limbs at various widths is kept for each pair of superpixels. used as the endpoints of the bone-line we only consider dual graph vertices within a small range of allowable widths near these superpixels as start and end points of the polylines forming the half-limb boundaries. These shortest paths are precomputed using Dijkstra s algorithm. We also precompute edge energy, orientation, and length counts along edges in the dual graph, and hence can efficiently evaluate the potential ψ l ( ) for any half-limb. Figures 2(c) and (d) illustrate this process. We keep the best half-limbs, those with the highest half-limb potential, between a pair of superpixels, at a few different widths. Note that we have not yet taken into account occlusion reasoning. When evaluating the limb-ness potential for a half-limb, we discount edges that are occluded by another half-limb and replace their edge energy and orientation variation counts by outlier costs D e and D o. If ω i is the fraction of half-limb X i occluded by other half-limbs in the upper or lower body, the limb potential is computed using: ē i = ( ω i ) ê i + ω i D e (5) ō i = ( ω i ) ô i + ω i D o (6) where ê i and ô i are the average energy and orientation deviation on the unoccluded portions of the limb respectively. The distribution p l (X) is defined as the product of these individual limb potentials, in addition to a similar potential for the torso ψ t (X): p l (X) ψ t (X) ψ l (X i ) (7) i Half limbs 3.2. Appearance Consistency We assume that the human figures in our images wear clothing that is symmetric in appearance. For example, the colour of the left upper arm should be the same as that of the right upper arm. The appearance consistency potential for corresponding left and right body parts is defined based on this assumption. We measure the appearance similarity between a pair of half-limbs by comparing the colour histograms of the two half-limbs. We precompute a vector quantization of the colours of superpixels so that these histograms can be efficiently computed for any half-limb. Each superpixel in an input image is given the mean colour, represented in LAB colour space, of the pixels inside it. We then run kmeans on the mean superpixel colours. The appearance of a superpixel i is represented by its vector quantization label c i, keeping the size (number of pixels) s i of each superpixel. The occlusion reasoning described above is used to obtain S i, the set of superpixels comprising half-limb X i. A colour histogram C i is then efficiently computed using the precomputed superpixel colour labels and sizes. The j th bin of C i is: C i (j) = s k (8) k S i,c k =j We compare the colour histograms of the two segments using the earth mover s distance (EMD), with the implementation provided by Rubner et al. []. The appearance consistency potential on a pair of limbs is a function of the EMD between the colour histograms of the limbs, along with an outlier cost D c for the occluded portion of the limbs. ψ a (C i, C j ) = e c 2 (( ω ij) EMD(C i,c j)+ω ijd c) 2 (9) Following the notation above, ω ij = max(ω i, ω j ) is the larger of the fractions of the two segments lost under occlusion. This same ψ a ( ) is applied to upper and lower arms and legs to form the appearance distribution p a (X): ψ u a(u) = ψ a (C lua, C rua ) ψ a (C lla, C rla ) () ψ l a (L) = ψ a(c lul, C rul ) ψ a (C lll, C rll ) () p a (X) ψa u (U) ψl a (L) (2)
5 3.3. Width Consistency We also assume that the widths of adjacent and left/right pairs of limbs are similar. A potential that measures the similarity in width of the adjacent ends of upper and lower arms and legs (width at elbow or knee), as well as widths of corresponding left/right half-limbs is also included. This potential ψ w ( ), and the distribution p w (X), take a similar form to those previously described. 4. Inference Even with the reduction in state space achieved by means of the superpixels, the final inference task using our model is still a difficult one. Exact inference in this model would still require O(N 8 sp ) time. Even though N sp << N, the number of pixels in the image, this is still intractable. Instead, we employ Gibbs sampling, a Markov Chain Monte Carlo algorithm, to obtain samples from the distribution p(x). An important detail is that the Gibbs sampling procedure operates on joint positions rather than the half-limb labels (X i ), since the kinematic constraints p k are brittle and assign probability to any disconnected body pose. We initialize our model to a neutral standing pose in the center of the image. At each step of the algorithm we choose a particular joint J k or occlusion label (h u or h l ) at random. We then set the value of the occlusion label or limb(s) X k adjacent to the joint J k by sampling from the conditional distribution p(h i Xˆk) or p(x k Xˆk), where Xˆk denotes the remaining variables with those adjacent to joint J k, or the relevant occlusion variable, removed. Computing this conditional distribution in our model is relatively simple, and involves setting the position of J k to be any of N sp locations, and re-evaluating upper or lower body potentials for the half-limbs that are adjacent at that superpixel. Our MATLAB implementation takes about second per iteration of Gibbs sampling on a 2GHz AMD Opteron 246. Note that the ideas of shouters [4] or proposal maps [5] could be used in conjunction with the superpixel representation for improved performance. 5. Results The dataset we use is a collection of sports news photographs of baseball players. This dataset is very challenging, with dramatic variations in pose and clothing, and significant background clutter. Four images from our dataset were used to set the free parameters in our body model, and 53 images were used for testing. For each input image, we compute superpixels and colour, edge energy, orientation, and length cues upon them in a pre-processing step. The Gibbs sampling algorithm is then run times, with 2 sampling iterations per run. Modes from the distribution Sample MATLAB code for computing the superpixels is available at: mori/research/superpixels p(x) are obtained by running kmeans on the set of 2d joint positions of the set of samples. Figure 3 shows quantitative results, histograms of pixel error in joint positions. The scale of the people in the test images is quite large - the average height is approximately 4 pixels. Figures 3(a-c) show results using the entire test set. There are a few very large errors in these histograms. However, we are able to detect when such difficulties have occurred. Figures 3(d-f) show results using only the top 5 images from our test set, as sorted by unnormalized p(x) values. Further, joint localization errors are broken down into upper and lower body errors. Lower body joints (hips, knees, ankles) are reasonably well localized, while upper body joints (shoulders, elbows, wrists) prove extremely difficult to find. These quantitative results, while by no means accurate, are compare favourably to the state of the art on this extremely difficult problem. In Figure 4 we show qualitative results on images from our test set. The top row of each set shows input images overlayed with superpixel boundaries, followed by recovered human body poses, and segmentation masks corresponding to the half-limbs. The first five input images (top row) are the top five matches from our test set chosen in a principled fashion (sorted p(x) values), while the remaining examples are of the usual judiciously chosen variety. In order to shed more light on the quantitative results, average joint errors in the top five images are 42.4, 27.7, 57.3, 37.4, 25.4, significant error measurements for qualitatively reasonable results. 6. Discussion In this paper we have shown how segmentation can be used as a preprocessing step to improve the efficiency and accuracy of model search in an image. We have demonstrated two advantages of this approach reducing the state space of model search and defining accurate support masks on which to compute features. Using these ideas, we have shown promising results on the difficult task of human body pose estimation in still images. The results presented in this paper are comparable in quality to those in our previous work [7]. In our previous method, an initial coarse segmentation followed by a classifier was used to provide candidate half-limbs. An adhoc assembly method that required solving a constraint satisfaction problem was then used to assemble these candidate half-limbs. However, this CSP step was brittle, requiring that at least 3 half-limbs were found by the initial segmentation-classification stage, and caused unrecoverable errors. In contrast, the method presented in this paper performs inference over superpixel locations using a body model. This idea seems generally useful, and we believe it could be applied to other object recognition problems.
6 .9.8 Errors for lower body joints Hips Knees Ankles.9.8 Errors for upper body joints Shoulders Elbows Wrists.9.8 Average error over all joints Top Top 5 Top (a) (b) (c).9.8 Errors for lower body joints Hips Knees Ankles.9.8 Errors for upper body joints Shoulders Elbows Wrists.9.8 Average error over all joints Top Top 5 Top (d) (e) (f) Figure 3: Histograms over pixel error in joint positions. (a-c) Histograms computed using all images in our test set. (d-f) Histograms using best 5 matching images in dataset (highest unnormalized p(x)). (a,d)/(b,e) Error in lower/upper body joint positions for overall best configuration out of top modes of p(x). (c,f) Average error over all joints. References [] P. F. Felzenszwalb and D. P. Huttenlocher. Pictorial structures for object recognition. Int. Journal of Computer Vision, 6():55 79, 25. [2] D. M. Gavrila. The visual analysis of human movement: A survey. Computer Vision and Image Understanding: CVIU, 73():82 98, 999. [3] D. Hogg. Model-based vision: A program to see a walking person. Image and Vision Computing, ():5 2, 983. [4] S. Ioffe and D. Forsyth. Probabilistic methods for finding people. Int. Journal of Computer Vision, 43():45 68, 2. [5] M. W. Lee and I. Cohen. Proposal maps driven mcmc for estimating human body pose in static images. In Proc. IEEE Comput. Soc. Conf. Comput. Vision and Pattern Recogn., volume 2, pages , 24. [6] G. Mori and J. Malik. Estimating human body configurations using shape context matching. In ECCV LNCS 2352, volume 3, pages , 22. [7] G. Mori, X. Ren, A. Efros, and J. Malik. Recovering human body configurations: Combining segmentation and recognition. In Proc. IEEE CVPR, volume 2, pages , 24. [8] D. Morris and J. Rehg. Singularity analysis for articulated object tracking. In Proc. IEEE Comput. Soc. Conf. Comput. Vision and Pattern Recogn., pages , 998. [9] D. Ramanan and D. A. Forsyth. Finding and tracking people from the bottom up. In Proc. IEEE Comput. Soc. Conf. Comput. Vision and Pattern Recogn., 23. [] X. Ren and J. Malik. Learning a classification model for segmentation. In Proc. 9th Int. Conf. Computer Vision, volume, pages 7, 23. [] Y. Rubner, C. Tomasi, and L. J. Guibas. The earth mover s distance as a metric for image retrieval. Int. Journal of Computer Vision, 4(2):99 2, 2. [2] G. Shakhnarovich, P. Viola, and T. Darrell. Fast pose estimation with parameter sensitive hashing. In Proc. 9th Int. Conf. Computer Vision, volume 2, pages , 23. [3] J. Shi and J. Malik. Normalized cuts and image segmentation. IEEE Trans. PAMI, 22(8):888 95, 2. [4] L. Sigal, S. Bhatia, S. Roth, M. J. Black, and M. Isard. Tracking loose-limbed people. In Proc. IEEE Comput. Soc. Conf. Comput. Vision and Pattern Recogn., 24. [5] Y. Song, L. Goncalves, and P. Perona. Unsupervised learning of human motion. IEEE Trans. PAMI, 25(7):84 827, 23. [6] E. Sudderth, M. Mandel, W. Freeman, and A. Willsky. Distributed occlusion reasoning for tracking with nonparametric belief propagation. In NIPS, 24. [7] J. Sullivan and S. Carlsson. Recognizing and tracking human action. In European Conference on Computer Vision LNCS 2352, volume, pages , 22. [8] H. Tao, H. Sawhney, and R. Kumar. A global matching framework for stereo computation. In Proc. 8th Int. Conf. Computer Vision, 2. [9] K. Toyama and A. Blake. Probabilistic exemplar-based tracking in a metric space. In Proc. ICCV, volume 2, pages 5 57, 2. [2] Z. Tu, X. Chen, A. Yuille, and S. Zhu. Image parsing: segmentation, detection, and recognition. In Proc. 9th Int. Conf. Computer Vision, pages 8 25, 23.





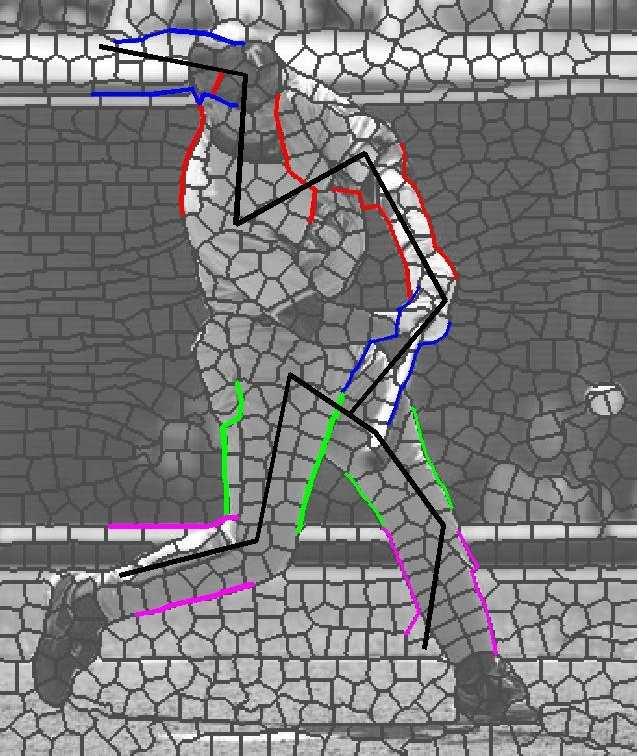
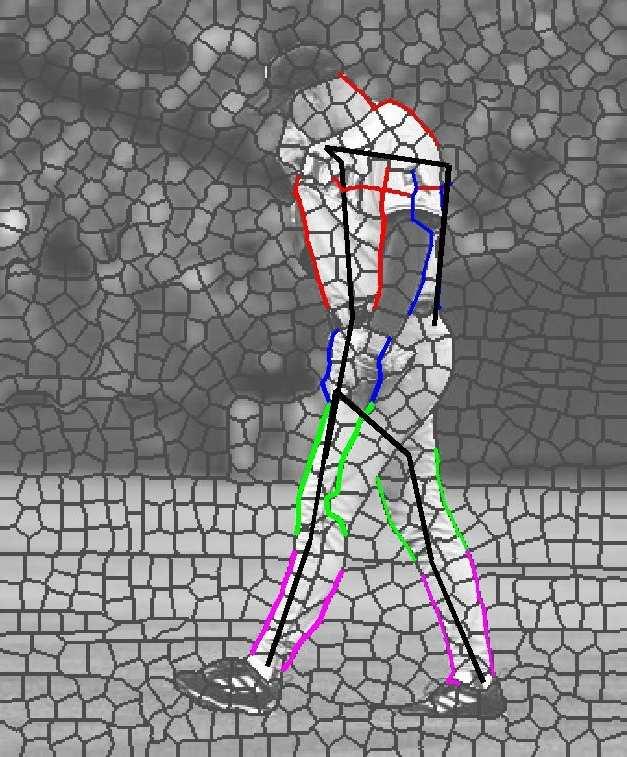
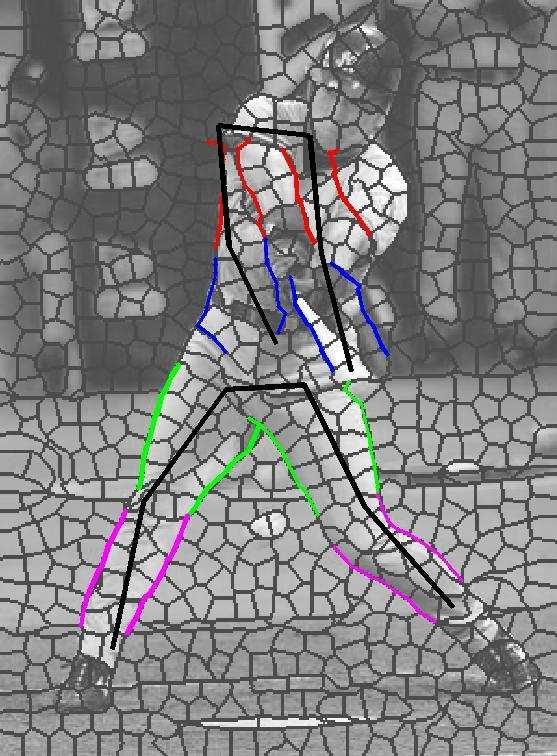









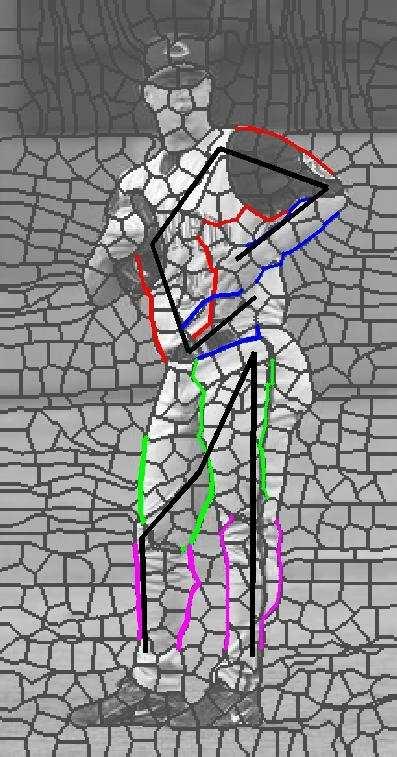
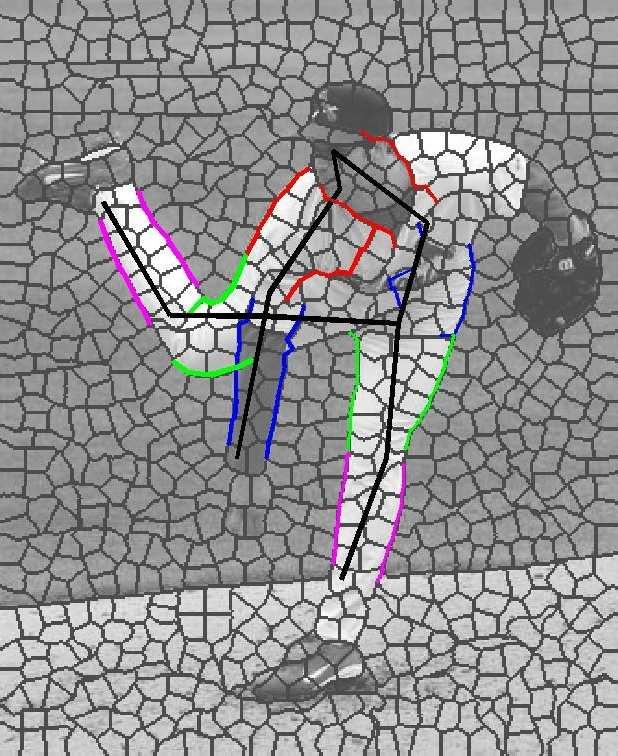

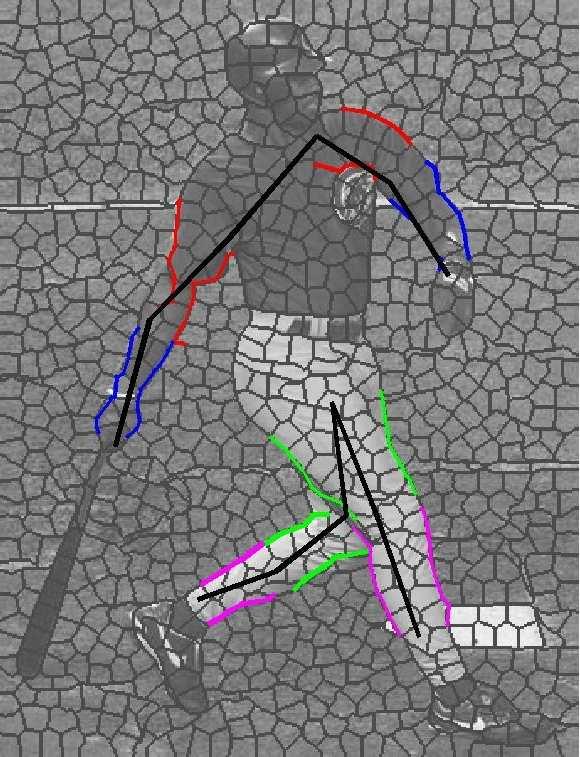





7 Figure 4: Two sets of sample results. In each set, top row shows input image with overlayed superpixel boundaries, followed by recovered pose (upper arms in red, lower in blue, upper legs in green, lower in purple), and segmentation associated with each half-limb.
Recovering Human Body Configurations: Combining Segmentation and Recognition
 Recovering Human Body Configurations: Combining Segmentation and Recognition Greg Mori, Xiaofeng Ren, Alexei A. Efros and Jitendra Malik Computer Science Division Robotics Research Group UC Berkeley University
Recovering Human Body Configurations: Combining Segmentation and Recognition Greg Mori, Xiaofeng Ren, Alexei A. Efros and Jitendra Malik Computer Science Division Robotics Research Group UC Berkeley University
Human Upper Body Pose Estimation in Static Images
 1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
Boosted Multiple Deformable Trees for Parsing Human Poses
 Boosted Multiple Deformable Trees for Parsing Human Poses Yang Wang and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {ywang12,mori}@cs.sfu.ca Abstract. Tree-structured
Boosted Multiple Deformable Trees for Parsing Human Poses Yang Wang and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {ywang12,mori}@cs.sfu.ca Abstract. Tree-structured
Human Pose Estimation with Rotated Geometric Blur
 Human Pose Estimation with Rotated Geometric Blur Bo Chen, Nhan Nguyen, and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, CANADA {bca11,tnn}@sfu.ca, mori@cs.sfu.ca Abstract
Human Pose Estimation with Rotated Geometric Blur Bo Chen, Nhan Nguyen, and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, CANADA {bca11,tnn}@sfu.ca, mori@cs.sfu.ca Abstract
Learning to Estimate Human Pose with Data Driven Belief Propagation
 Learning to Estimate Human Pose with Data Driven Belief Propagation Gang Hua Ming-Hsuan Yang Ying Wu ECE Department, Northwestern University Honda Research Institute Evanston, IL 60208, U.S.A. Mountain
Learning to Estimate Human Pose with Data Driven Belief Propagation Gang Hua Ming-Hsuan Yang Ying Wu ECE Department, Northwestern University Honda Research Institute Evanston, IL 60208, U.S.A. Mountain
Detecting and Parsing of Visual Objects: Humans and Animals. Alan Yuille (UCLA)
") Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Detecting and Parsing of Visual Objects: Humans and Animals Alan Yuille (UCLA) Summary This talk describes recent work on detection and parsing visual objects. The methods represent objects in terms of
Combining PGMs and Discriminative Models for Upper Body Pose Detection
 Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Combining PGMs and Discriminative Models for Upper Body Pose Detection Gedas Bertasius May 30, 2014 1 Introduction In this project, I utilized probabilistic graphical models together with discriminative
Recognition Rate. 90 S 90 W 90 R Segment Length T
 Human Action Recognition By Sequence of Movelet Codewords Xiaolin Feng y Pietro Perona yz y California Institute of Technology, 36-93, Pasadena, CA 925, USA z Universit a dipadova, Italy fxlfeng,peronag@vision.caltech.edu
Human Action Recognition By Sequence of Movelet Codewords Xiaolin Feng y Pietro Perona yz y California Institute of Technology, 36-93, Pasadena, CA 925, USA z Universit a dipadova, Italy fxlfeng,peronag@vision.caltech.edu
A Hierarchical Compositional System for Rapid Object Detection
 A Hierarchical Compositional System for Rapid Object Detection Long Zhu and Alan Yuille Department of Statistics University of California at Los Angeles Los Angeles, CA 90095 {lzhu,yuille}@stat.ucla.edu
A Hierarchical Compositional System for Rapid Object Detection Long Zhu and Alan Yuille Department of Statistics University of California at Los Angeles Los Angeles, CA 90095 {lzhu,yuille}@stat.ucla.edu
Measure Locally, Reason Globally: Occlusion-sensitive Articulated Pose Estimation
 Measure Locally, Reason Globally: Occlusion-sensitive Articulated Pose Estimation Leonid Sigal Michael J. Black Department of Computer Science, Brown University, Providence, RI 02912 {ls,black}@cs.brown.edu
Measure Locally, Reason Globally: Occlusion-sensitive Articulated Pose Estimation Leonid Sigal Michael J. Black Department of Computer Science, Brown University, Providence, RI 02912 {ls,black}@cs.brown.edu
Estimating Human Pose in Images. Navraj Singh December 11, 2009
 Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Estimating Human Pose in Images Navraj Singh December 11, 2009 Introduction This project attempts to improve the performance of an existing method of estimating the pose of humans in still images. Tasks
Finding and Tracking People from the Bottom Up
 Finding and Tracking People from the Bottom Up Deva Ramanan and D. A. Forsyth Computer Science Division University of California, Berkeley Berkeley, CA 9472 ramanan@cs.berkeley.edu, daf@cs.berkeley.edu
Finding and Tracking People from the Bottom Up Deva Ramanan and D. A. Forsyth Computer Science Division University of California, Berkeley Berkeley, CA 9472 ramanan@cs.berkeley.edu, daf@cs.berkeley.edu
People Tracking and Segmentation Using Efficient Shape Sequences Matching
 People Tracking and Segmentation Using Efficient Shape Sequences Matching Junqiu Wang, Yasushi Yagi, and Yasushi Makihara The Institute of Scientific and Industrial Research, Osaka University 8-1 Mihogaoka,
People Tracking and Segmentation Using Efficient Shape Sequences Matching Junqiu Wang, Yasushi Yagi, and Yasushi Makihara The Institute of Scientific and Industrial Research, Osaka University 8-1 Mihogaoka,
Human Pose Estimation Using Consistent Max-Covering
 Human Pose Estimation Using Consistent Max-Covering Hao Jiang Computer Science Department, Boston College Chestnut Hill, MA 2467, USA hjiang@cs.bc.edu Abstract We propose a novel consistent max-covering
Human Pose Estimation Using Consistent Max-Covering Hao Jiang Computer Science Department, Boston College Chestnut Hill, MA 2467, USA hjiang@cs.bc.edu Abstract We propose a novel consistent max-covering
Hierarchical Part-Based Human Body Pose Estimation
 Hierarchical Part-Based Human Body Pose Estimation R. Navaratnam A. Thayananthan P. H. S. Torr R. Cipolla University of Cambridge Oxford Brookes Univeristy Department of Engineering Cambridge, CB2 1PZ,
Hierarchical Part-Based Human Body Pose Estimation R. Navaratnam A. Thayananthan P. H. S. Torr R. Cipolla University of Cambridge Oxford Brookes Univeristy Department of Engineering Cambridge, CB2 1PZ,
Global Pose Estimation Using Non-Tree Models
 Global Pose Estimation Using Non-Tree Models Hao Jiang and David R. Martin Computer Science Department, Boston College Chestnut Hill, MA 02467, USA hjiang@cs.bc.edu, dmartin@cs.bc.edu Abstract We propose
Global Pose Estimation Using Non-Tree Models Hao Jiang and David R. Martin Computer Science Department, Boston College Chestnut Hill, MA 02467, USA hjiang@cs.bc.edu, dmartin@cs.bc.edu Abstract We propose
Predicting 3D People from 2D Pictures
 Predicting 3D People from 2D Pictures Leonid Sigal Michael J. Black Department of Computer Science Brown University http://www.cs.brown.edu/people/ls/ CIAR Summer School August 15-20, 2006 Leonid Sigal
Predicting 3D People from 2D Pictures Leonid Sigal Michael J. Black Department of Computer Science Brown University http://www.cs.brown.edu/people/ls/ CIAR Summer School August 15-20, 2006 Leonid Sigal
Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos
 Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos Yihang Bo Institute of Automation, CAS & Boston College yihang.bo@gmail.com Hao Jiang Computer Science Department, Boston
Scale and Rotation Invariant Approach to Tracking Human Body Part Regions in Videos Yihang Bo Institute of Automation, CAS & Boston College yihang.bo@gmail.com Hao Jiang Computer Science Department, Boston
Nonflat Observation Model and Adaptive Depth Order Estimation for 3D Human Pose Tracking
 Nonflat Observation Model and Adaptive Depth Order Estimation for 3D Human Pose Tracking Nam-Gyu Cho, Alan Yuille and Seong-Whan Lee Department of Brain and Cognitive Engineering, orea University, orea
Nonflat Observation Model and Adaptive Depth Order Estimation for 3D Human Pose Tracking Nam-Gyu Cho, Alan Yuille and Seong-Whan Lee Department of Brain and Cognitive Engineering, orea University, orea
Learning to parse images of articulated bodies
 Learning to parse images of articulated bodies Deva Ramanan Toyota Technological Institute at Chicago Chicago, IL 60637 ramanan@tti-c.org Abstract We consider the machine vision task of pose estimation
Learning to parse images of articulated bodies Deva Ramanan Toyota Technological Institute at Chicago Chicago, IL 60637 ramanan@tti-c.org Abstract We consider the machine vision task of pose estimation
Multiple Pose Context Trees for estimating Human Pose in Object Context
 Multiple Pose Context Trees for estimating Human Pose in Object Context Vivek Kumar Singh Furqan Muhammad Khan Ram Nevatia University of Southern California Los Angeles, CA {viveksin furqankh nevatia}@usc.edu
Multiple Pose Context Trees for estimating Human Pose in Object Context Vivek Kumar Singh Furqan Muhammad Khan Ram Nevatia University of Southern California Los Angeles, CA {viveksin furqankh nevatia}@usc.edu
CS 223B Computer Vision Problem Set 3
 CS 223B Computer Vision Problem Set 3 Due: Feb. 22 nd, 2011 1 Probabilistic Recursion for Tracking In this problem you will derive a method for tracking a point of interest through a sequence of images.
CS 223B Computer Vision Problem Set 3 Due: Feb. 22 nd, 2011 1 Probabilistic Recursion for Tracking In this problem you will derive a method for tracking a point of interest through a sequence of images.
and we can apply the recursive definition of the cost-to-go function to get
 Section 20.2 Parsing People in Images 602 and we can apply the recursive definition of the cost-to-go function to get argmax f X 1,...,X n chain (X 1,...,X n ) = argmax ( ) f X 1 chain (X 1 )+fcost-to-go
Section 20.2 Parsing People in Images 602 and we can apply the recursive definition of the cost-to-go function to get argmax f X 1,...,X n chain (X 1,...,X n ) = argmax ( ) f X 1 chain (X 1 )+fcost-to-go
Finding people in repeated shots of the same scene
 1 Finding people in repeated shots of the same scene Josef Sivic 1 C. Lawrence Zitnick Richard Szeliski 1 University of Oxford Microsoft Research Abstract The goal of this work is to find all occurrences
1 Finding people in repeated shots of the same scene Josef Sivic 1 C. Lawrence Zitnick Richard Szeliski 1 University of Oxford Microsoft Research Abstract The goal of this work is to find all occurrences
Detecting and Segmenting Humans in Crowded Scenes
 Detecting and Segmenting Humans in Crowded Scenes Mikel D. Rodriguez University of Central Florida 4000 Central Florida Blvd Orlando, Florida, 32816 mikel@cs.ucf.edu Mubarak Shah University of Central
Detecting and Segmenting Humans in Crowded Scenes Mikel D. Rodriguez University of Central Florida 4000 Central Florida Blvd Orlando, Florida, 32816 mikel@cs.ucf.edu Mubarak Shah University of Central
Strike a Pose: Tracking People by Finding Stylized Poses
 Strike a Pose: Tracking People by Finding Stylized Poses Deva Ramanan 1 and D. A. Forsyth 1 and Andrew Zisserman 2 1 University of California, Berkeley Berkeley, CA 94720 2 University of Oxford Oxford,
Strike a Pose: Tracking People by Finding Stylized Poses Deva Ramanan 1 and D. A. Forsyth 1 and Andrew Zisserman 2 1 University of California, Berkeley Berkeley, CA 94720 2 University of Oxford Oxford,
Tracking People. Tracking People: Context
 Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
CS 231A Computer Vision (Fall 2012) Problem Set 3
 Problem Set 3") CS 231A Computer Vision (Fall 2012) Problem Set 3 Due: Nov. 13 th, 2012 (2:15pm) 1 Probabilistic Recursion for Tracking (20 points) In this problem you will derive a method for tracking a point of interest
CS 231A Computer Vision (Fall 2012) Problem Set 3 Due: Nov. 13 th, 2012 (2:15pm) 1 Probabilistic Recursion for Tracking (20 points) In this problem you will derive a method for tracking a point of interest
Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation
 JOHNSON, EVERINGHAM: CLUSTERED MODELS FOR HUMAN POSE ESTIMATION 1 Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation Sam Johnson s.a.johnson04@leeds.ac.uk Mark Everingham m.everingham@leeds.ac.uk
JOHNSON, EVERINGHAM: CLUSTERED MODELS FOR HUMAN POSE ESTIMATION 1 Clustered Pose and Nonlinear Appearance Models for Human Pose Estimation Sam Johnson s.a.johnson04@leeds.ac.uk Mark Everingham m.everingham@leeds.ac.uk
Local cues and global constraints in image understanding
 Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
Local cues and global constraints in image understanding Olga Barinova Lomonosov Moscow State University *Many slides adopted from the courses of Anton Konushin Image understanding «To see means to know
Inferring 3D People from 2D Images
 Inferring 3D People from 2D Images Department of Computer Science Brown University http://www.cs.brown.edu/~black Collaborators Hedvig Sidenbladh, Swedish Defense Research Inst. Leon Sigal, Brown University
Inferring 3D People from 2D Images Department of Computer Science Brown University http://www.cs.brown.edu/~black Collaborators Hedvig Sidenbladh, Swedish Defense Research Inst. Leon Sigal, Brown University
Human Limb Delineation and Joint Position Recovery Using Localized Boundary Models
 Human Limb Delineation and Joint Position Recovery Using Localized Boundary Models Chris McIntosh, Ghassan Hamarneh Medical Image Analysis Lab School of Computing Science Simon Fraser University, Burnaby,
Human Limb Delineation and Joint Position Recovery Using Localized Boundary Models Chris McIntosh, Ghassan Hamarneh Medical Image Analysis Lab School of Computing Science Simon Fraser University, Burnaby,
Unsupervised Human Members Tracking Based on an Silhouette Detection and Analysis Scheme
 Unsupervised Human Members Tracking Based on an Silhouette Detection and Analysis Scheme Costas Panagiotakis and Anastasios Doulamis Abstract In this paper, an unsupervised, automatic video human members(human
Unsupervised Human Members Tracking Based on an Silhouette Detection and Analysis Scheme Costas Panagiotakis and Anastasios Doulamis Abstract In this paper, an unsupervised, automatic video human members(human
Action Recognition in Cluttered Dynamic Scenes using Pose-Specific Part Models
 Action Recognition in Cluttered Dynamic Scenes using Pose-Specific Part Models Vivek Kumar Singh University of Southern California Los Angeles, CA, USA viveksin@usc.edu Ram Nevatia University of Southern
Action Recognition in Cluttered Dynamic Scenes using Pose-Specific Part Models Vivek Kumar Singh University of Southern California Los Angeles, CA, USA viveksin@usc.edu Ram Nevatia University of Southern
Visuelle Perzeption für Mensch- Maschine Schnittstellen
 Visuelle Perzeption für Mensch- Maschine Schnittstellen Vorlesung, WS 2009 Prof. Dr. Rainer Stiefelhagen Dr. Edgar Seemann Institut für Anthropomatik Universität Karlsruhe (TH) http://cvhci.ira.uka.de
Visuelle Perzeption für Mensch- Maschine Schnittstellen Vorlesung, WS 2009 Prof. Dr. Rainer Stiefelhagen Dr. Edgar Seemann Institut für Anthropomatik Universität Karlsruhe (TH) http://cvhci.ira.uka.de
Detecting Pedestrians by Learning Shapelet Features
 Detecting Pedestrians by Learning Shapelet Features Payam Sabzmeydani and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {psabzmey,mori}@cs.sfu.ca Abstract In this paper,
Detecting Pedestrians by Learning Shapelet Features Payam Sabzmeydani and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {psabzmey,mori}@cs.sfu.ca Abstract In this paper,
Using the Kolmogorov-Smirnov Test for Image Segmentation
 Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Using the Kolmogorov-Smirnov Test for Image Segmentation Yong Jae Lee CS395T Computational Statistics Final Project Report May 6th, 2009 I. INTRODUCTION Image segmentation is a fundamental task in computer
Combining Discriminative Appearance and Segmentation Cues for Articulated Human Pose Estimation
 Combining Discriminative Appearance and Segmentation Cues for Articulated Human Pose Estimation Sam Johnson and Mark Everingham School of Computing University of Leeds {mat4saj m.everingham}@leeds.ac.uk
Combining Discriminative Appearance and Segmentation Cues for Articulated Human Pose Estimation Sam Johnson and Mark Everingham School of Computing University of Leeds {mat4saj m.everingham}@leeds.ac.uk
Efficient Human Pose Estimation via Parsing a Tree Structure Based Human Model
 Efficient Human Pose Estimation via Parsing a Tree Structure Based Human Model Xiaoqin Zhang 1,Changcheng Li 2, Xiaofeng Tong 3,Weiming Hu 1,Steve Maybank 4,Yimin Zhang 3 1 National Laboratory of Pattern
Efficient Human Pose Estimation via Parsing a Tree Structure Based Human Model Xiaoqin Zhang 1,Changcheng Li 2, Xiaofeng Tong 3,Weiming Hu 1,Steve Maybank 4,Yimin Zhang 3 1 National Laboratory of Pattern
Tri-modal Human Body Segmentation
 Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
On the Sustained Tracking of Human Motion
 On the Sustained Tracking of Human Motion Yaser Ajmal Sheikh Robotics Institute Carnegie Mellon University Pittsburgh, PA 15213 yaser@cs.cmu.edu Ankur Datta Robotics Institute Carnegie Mellon University
On the Sustained Tracking of Human Motion Yaser Ajmal Sheikh Robotics Institute Carnegie Mellon University Pittsburgh, PA 15213 yaser@cs.cmu.edu Ankur Datta Robotics Institute Carnegie Mellon University
Object Pose Detection in Range Scan Data
 Object Pose Detection in Range Scan Data Jim Rodgers, Dragomir Anguelov, Hoi-Cheung Pang, Daphne Koller Computer Science Department Stanford University, CA 94305 {jimkr, drago, hcpang, koller}@cs.stanford.edu
Object Pose Detection in Range Scan Data Jim Rodgers, Dragomir Anguelov, Hoi-Cheung Pang, Daphne Koller Computer Science Department Stanford University, CA 94305 {jimkr, drago, hcpang, koller}@cs.stanford.edu
Key Developments in Human Pose Estimation for Kinect
 Key Developments in Human Pose Estimation for Kinect Pushmeet Kohli and Jamie Shotton Abstract The last few years have seen a surge in the development of natural user interfaces. These interfaces do not
Key Developments in Human Pose Estimation for Kinect Pushmeet Kohli and Jamie Shotton Abstract The last few years have seen a surge in the development of natural user interfaces. These interfaces do not
Shape-based Pedestrian Parsing
 Shape-based Pedestrian Parsing Yihang Bo School of Computer and Information Technology Beijing Jiaotong University, China yihang.bo@gmail.com Charless C. Fowlkes Department of Computer Science University
Shape-based Pedestrian Parsing Yihang Bo School of Computer and Information Technology Beijing Jiaotong University, China yihang.bo@gmail.com Charless C. Fowlkes Department of Computer Science University
Improved Human Parsing with a Full Relational Model
 Improved Human Parsing with a Full Relational Model Duan Tran and David Forsyth University of Illinois at Urbana-Champaign, USA {ddtran2,daf}@illinois.edu Abstract. We show quantitative evidence that a
Improved Human Parsing with a Full Relational Model Duan Tran and David Forsyth University of Illinois at Urbana-Champaign, USA {ddtran2,daf}@illinois.edu Abstract. We show quantitative evidence that a
IMA Preprint Series # 2154
 A GRAPH-BASED FOREGROUND REPRESENTATION AND ITS APPLICATION IN EXAMPLE BASED PEOPLE MATCHING IN VIDEO By Kedar A. Patwardhan Guillermo Sapiro and Vassilios Morellas IMA Preprint Series # 2154 ( January
A GRAPH-BASED FOREGROUND REPRESENTATION AND ITS APPLICATION IN EXAMPLE BASED PEOPLE MATCHING IN VIDEO By Kedar A. Patwardhan Guillermo Sapiro and Vassilios Morellas IMA Preprint Series # 2154 ( January
Visual Motion Analysis and Tracking Part II
 Visual Motion Analysis and Tracking Part II David J Fleet and Allan D Jepson CIAR NCAP Summer School July 12-16, 16, 2005 Outline Optical Flow and Tracking: Optical flow estimation (robust, iterative refinement,
Visual Motion Analysis and Tracking Part II David J Fleet and Allan D Jepson CIAR NCAP Summer School July 12-16, 16, 2005 Outline Optical Flow and Tracking: Optical flow estimation (robust, iterative refinement,
HUMAN PARSING WITH A CASCADE OF HIERARCHICAL POSELET BASED PRUNERS
 HUMAN PARSING WITH A CASCADE OF HIERARCHICAL POSELET BASED PRUNERS Duan Tran Yang Wang David Forsyth University of Illinois at Urbana Champaign University of Manitoba ABSTRACT We address the problem of
HUMAN PARSING WITH A CASCADE OF HIERARCHICAL POSELET BASED PRUNERS Duan Tran Yang Wang David Forsyth University of Illinois at Urbana Champaign University of Manitoba ABSTRACT We address the problem of
CS354 Computer Graphics Character Animation and Skinning
 Slide Credit: Don Fussell CS354 Computer Graphics Character Animation and Skinning Qixing Huang April 9th 2018 Instance Transformation Start with a prototype object (a symbol) Each appearance of the object
Slide Credit: Don Fussell CS354 Computer Graphics Character Animation and Skinning Qixing Huang April 9th 2018 Instance Transformation Start with a prototype object (a symbol) Each appearance of the object
Structured Models in. Dan Huttenlocher. June 2010
 Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
Efficient Mean Shift Belief Propagation for Vision Tracking
 Efficient Mean Shift Belief Propagation for Vision Tracking Minwoo Park, Yanxi Liu * and Robert T. Collins Department of Computer Science and Engineering, *Department of Electrical Engineering The Pennsylvania
Efficient Mean Shift Belief Propagation for Vision Tracking Minwoo Park, Yanxi Liu * and Robert T. Collins Department of Computer Science and Engineering, *Department of Electrical Engineering The Pennsylvania
Tracking of Human Body using Multiple Predictors
 Tracking of Human Body using Multiple Predictors Rui M Jesus 1, Arnaldo J Abrantes 1, and Jorge S Marques 2 1 Instituto Superior de Engenharia de Lisboa, Postfach 351-218317001, Rua Conselheiro Emído Navarro,
Tracking of Human Body using Multiple Predictors Rui M Jesus 1, Arnaldo J Abrantes 1, and Jorge S Marques 2 1 Instituto Superior de Engenharia de Lisboa, Postfach 351-218317001, Rua Conselheiro Emído Navarro,
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
A Layered Deformable Model for Gait Analysis
 A Layered Deformable Model for Gait Analysis Haiping Lu, K.N. Plataniotis and A.N. Venetsanopoulos Bell Canada Multimedia Laboratory The Edward S. Rogers Sr. Department of Electrical and Computer Engineering
A Layered Deformable Model for Gait Analysis Haiping Lu, K.N. Plataniotis and A.N. Venetsanopoulos Bell Canada Multimedia Laboratory The Edward S. Rogers Sr. Department of Electrical and Computer Engineering
Inferring 3D Body Pose from Silhouettes using Activity Manifold Learning
 CVPR 4 Inferring 3D Body Pose from Silhouettes using Activity Manifold Learning Ahmed Elgammal and Chan-Su Lee Department of Computer Science, Rutgers University, New Brunswick, NJ, USA {elgammal,chansu}@cs.rutgers.edu
CVPR 4 Inferring 3D Body Pose from Silhouettes using Activity Manifold Learning Ahmed Elgammal and Chan-Su Lee Department of Computer Science, Rutgers University, New Brunswick, NJ, USA {elgammal,chansu}@cs.rutgers.edu
Bottom-up Recognition and Parsing of the Human Body
 University of Pennsylvania ScholarlyCommons Departmental Papers (CIS) Department of Computer & Information Science 2007 Bottom-up Recognition and Parsing of the Human Body Praveen Srinivasan University
University of Pennsylvania ScholarlyCommons Departmental Papers (CIS) Department of Computer & Information Science 2007 Bottom-up Recognition and Parsing of the Human Body Praveen Srinivasan University
Human pose estimation using Active Shape Models
 Human pose estimation using Active Shape Models Changhyuk Jang and Keechul Jung Abstract Human pose estimation can be executed using Active Shape Models. The existing techniques for applying to human-body
Human pose estimation using Active Shape Models Changhyuk Jang and Keechul Jung Abstract Human pose estimation can be executed using Active Shape Models. The existing techniques for applying to human-body
A Comparison on Different 2D Human Pose Estimation Method
 A Comparison on Different 2D Human Pose Estimation Method Santhanu P.Mohan 1, Athira Sugathan 2, Sumesh Sekharan 3 1 Assistant Professor, IT Department, VJCET, Kerala, India 2 Student, CVIP, ASE, Tamilnadu,
A Comparison on Different 2D Human Pose Estimation Method Santhanu P.Mohan 1, Athira Sugathan 2, Sumesh Sekharan 3 1 Assistant Professor, IT Department, VJCET, Kerala, India 2 Student, CVIP, ASE, Tamilnadu,
Efficient Extraction of Human Motion Volumes by Tracking
 Efficient Extraction of Human Motion Volumes by Tracking Juan Carlos Niebles Princeton University, USA Universidad del Norte, Colombia jniebles@princeton.edu Bohyung Han Electrical and Computer Engineering
Efficient Extraction of Human Motion Volumes by Tracking Juan Carlos Niebles Princeton University, USA Universidad del Norte, Colombia jniebles@princeton.edu Bohyung Han Electrical and Computer Engineering
Segmentation. Bottom up Segmentation Semantic Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Segmentation Bottom up Segmentation Semantic Segmentation Semantic Labeling of Street Scenes Ground Truth Labels 11 classes, almost all occur simultaneously, large changes in viewpoint, scale sky, road,
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
Supervised texture detection in images
 Supervised texture detection in images Branislav Mičušík and Allan Hanbury Pattern Recognition and Image Processing Group, Institute of Computer Aided Automation, Vienna University of Technology Favoritenstraße
Supervised texture detection in images Branislav Mičušík and Allan Hanbury Pattern Recognition and Image Processing Group, Institute of Computer Aided Automation, Vienna University of Technology Favoritenstraße
Color Image Segmentation
 Color Image Segmentation Yining Deng, B. S. Manjunath and Hyundoo Shin* Department of Electrical and Computer Engineering University of California, Santa Barbara, CA 93106-9560 *Samsung Electronics Inc.
Color Image Segmentation Yining Deng, B. S. Manjunath and Hyundoo Shin* Department of Electrical and Computer Engineering University of California, Santa Barbara, CA 93106-9560 *Samsung Electronics Inc.
Online Figure-ground Segmentation with Edge Pixel Classification
 Online Figure-ground Segmentation with Edge Pixel Classification Zhaozheng Yin Robert T. Collins Department of Computer Science and Engineering The Pennsylvania State University, USA {zyin,rcollins}@cse.psu.edu,
Online Figure-ground Segmentation with Edge Pixel Classification Zhaozheng Yin Robert T. Collins Department of Computer Science and Engineering The Pennsylvania State University, USA {zyin,rcollins}@cse.psu.edu,
Automatic Annotation of Everyday Movements
 Automatic Annotation of Everyday Movements Deva Ramanan and D. A. Forsyth Computer Science Division University of California, Berkeley Berkeley, CA 94720 ramanan@cs.berkeley.edu, daf@cs.berkeley.edu Abstract
Automatic Annotation of Everyday Movements Deva Ramanan and D. A. Forsyth Computer Science Division University of California, Berkeley Berkeley, CA 94720 ramanan@cs.berkeley.edu, daf@cs.berkeley.edu Abstract
Segmentation and Grouping April 19 th, 2018
 Segmentation and Grouping April 19 th, 2018 Yong Jae Lee UC Davis Features and filters Transforming and describing images; textures, edges 2 Grouping and fitting [fig from Shi et al] Clustering, segmentation,
Segmentation and Grouping April 19 th, 2018 Yong Jae Lee UC Davis Features and filters Transforming and describing images; textures, edges 2 Grouping and fitting [fig from Shi et al] Clustering, segmentation,
Detection of Multiple, Partially Occluded Humans in a Single Image by Bayesian Combination of Edgelet Part Detectors
 Detection of Multiple, Partially Occluded Humans in a Single Image by Bayesian Combination of Edgelet Part Detectors Bo Wu Ram Nevatia University of Southern California Institute for Robotics and Intelligent
Detection of Multiple, Partially Occluded Humans in a Single Image by Bayesian Combination of Edgelet Part Detectors Bo Wu Ram Nevatia University of Southern California Institute for Robotics and Intelligent
Articulated Pose Estimation with Flexible Mixtures-of-Parts
 Articulated Pose Estimation with Flexible Mixtures-of-Parts PRESENTATION: JESSE DAVIS CS 3710 VISUAL RECOGNITION Outline Modeling Special Cases Inferences Learning Experiments Problem and Relevance Problem:
Articulated Pose Estimation with Flexible Mixtures-of-Parts PRESENTATION: JESSE DAVIS CS 3710 VISUAL RECOGNITION Outline Modeling Special Cases Inferences Learning Experiments Problem and Relevance Problem:
3D Deep Learning on Geometric Forms. Hao Su
 3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
Segmenting Objects in Weakly Labeled Videos
 Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
An Adaptive Appearance Model Approach for Model-based Articulated Object Tracking
 An Adaptive Appearance Model Approach for Model-based Articulated Object Tracking Alexandru O. Bălan Michael J. Black Department of Computer Science - Brown University Providence, RI 02912, USA {alb, black}@cs.brown.edu
An Adaptive Appearance Model Approach for Model-based Articulated Object Tracking Alexandru O. Bălan Michael J. Black Department of Computer Science - Brown University Providence, RI 02912, USA {alb, black}@cs.brown.edu
A Unified Spatio-Temporal Articulated Model for Tracking
 A Unified Spatio-Temporal Articulated Model for Tracking Xiangyang Lan Daniel P. Huttenlocher {xylan,dph}@cs.cornell.edu Cornell University Ithaca NY 14853 Abstract Tracking articulated objects in image
A Unified Spatio-Temporal Articulated Model for Tracking Xiangyang Lan Daniel P. Huttenlocher {xylan,dph}@cs.cornell.edu Cornell University Ithaca NY 14853 Abstract Tracking articulated objects in image
Beyond Bags of features Spatial information & Shape models
 Beyond Bags of features Spatial information & Shape models Jana Kosecka Many slides adapted from S. Lazebnik, FeiFei Li, Rob Fergus, and Antonio Torralba Detection, recognition (so far )! Bags of features
Beyond Bags of features Spatial information & Shape models Jana Kosecka Many slides adapted from S. Lazebnik, FeiFei Li, Rob Fergus, and Antonio Torralba Detection, recognition (so far )! Bags of features
Segmentation & Clustering
 EECS 442 Computer vision Segmentation & Clustering Segmentation in human vision K-mean clustering Mean-shift Graph-cut Reading: Chapters 14 [FP] Some slides of this lectures are courtesy of prof F. Li,
EECS 442 Computer vision Segmentation & Clustering Segmentation in human vision K-mean clustering Mean-shift Graph-cut Reading: Chapters 14 [FP] Some slides of this lectures are courtesy of prof F. Li,
Boundary Fragment Matching and Articulated Pose Under Occlusion. Nicholas R. Howe
 Boundary Fragment Matching and Articulated Pose Under Occlusion Nicholas R. Howe Low-Budget Motion Capture Constraints (informal/archived footage): Single camera No body markers Consequent Challenges:
Boundary Fragment Matching and Articulated Pose Under Occlusion Nicholas R. Howe Low-Budget Motion Capture Constraints (informal/archived footage): Single camera No body markers Consequent Challenges:
Grouping and Segmentation
 03/17/15 Grouping and Segmentation Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class Segmentation and grouping Gestalt cues By clustering (mean-shift) By boundaries (watershed)
03/17/15 Grouping and Segmentation Computer Vision CS 543 / ECE 549 University of Illinois Derek Hoiem Today s class Segmentation and grouping Gestalt cues By clustering (mean-shift) By boundaries (watershed)
Tracking as Repeated Figure/Ground Segmentation
 Tracking as Repeated Figure/Ground Segmentation Xiaofeng Ren Toyota Technological Institute at Chicago 1427 E. 60th Street, Chicago, IL 60637 xren@tti-c.org Jitendra Malik Computer Science Division University
Tracking as Repeated Figure/Ground Segmentation Xiaofeng Ren Toyota Technological Institute at Chicago 1427 E. 60th Street, Chicago, IL 60637 xren@tti-c.org Jitendra Malik Computer Science Division University
Human Body Pose Estimation Using Silhouette Shape Analysis
 Human Body Pose Estimation Using Silhouette Shape Analysis Anurag Mittal Siemens Corporate Research Inc. Princeton, NJ 08540 Liang Zhao, Larry S. Davis Department of Computer Science University of Maryland
Human Body Pose Estimation Using Silhouette Shape Analysis Anurag Mittal Siemens Corporate Research Inc. Princeton, NJ 08540 Liang Zhao, Larry S. Davis Department of Computer Science University of Maryland
Linear combinations of simple classifiers for the PASCAL challenge
 Linear combinations of simple classifiers for the PASCAL challenge Nik A. Melchior and David Lee 16 721 Advanced Perception The Robotics Institute Carnegie Mellon University Email: melchior@cmu.edu, dlee1@andrew.cmu.edu
Linear combinations of simple classifiers for the PASCAL challenge Nik A. Melchior and David Lee 16 721 Advanced Perception The Robotics Institute Carnegie Mellon University Email: melchior@cmu.edu, dlee1@andrew.cmu.edu
A Survey of Light Source Detection Methods
 A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
Unsupervised Discovery of Action Classes
 Unsupervised Discovery of Action Classes Yang Wang, Hao Jiang, Mark S. Drew, Ze-Nian Li and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {ywang12,hjiangb,mark,li,mori}@cs.sfu.ca
Unsupervised Discovery of Action Classes Yang Wang, Hao Jiang, Mark S. Drew, Ze-Nian Li and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {ywang12,hjiangb,mark,li,mori}@cs.sfu.ca
Automatic Gait Recognition. - Karthik Sridharan
 Automatic Gait Recognition - Karthik Sridharan Gait as a Biometric Gait A person s manner of walking Webster Definition It is a non-contact, unobtrusive, perceivable at a distance and hard to disguise
Automatic Gait Recognition - Karthik Sridharan Gait as a Biometric Gait A person s manner of walking Webster Definition It is a non-contact, unobtrusive, perceivable at a distance and hard to disguise
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE. Nan Hu. Stanford University Electrical Engineering
 STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
STRUCTURAL EDGE LEARNING FOR 3-D RECONSTRUCTION FROM A SINGLE STILL IMAGE Nan Hu Stanford University Electrical Engineering nanhu@stanford.edu ABSTRACT Learning 3-D scene structure from a single still
Tracking and Recognizing People in Colour using the Earth Mover s Distance
 Tracking and Recognizing People in Colour using the Earth Mover s Distance DANIEL WOJTASZEK, ROBERT LAGANIÈRE S.I.T.E. University of Ottawa, Ottawa, Ontario, Canada K1N 6N5 danielw@site.uottawa.ca, laganier@site.uottawa.ca
Tracking and Recognizing People in Colour using the Earth Mover s Distance DANIEL WOJTASZEK, ROBERT LAGANIÈRE S.I.T.E. University of Ottawa, Ottawa, Ontario, Canada K1N 6N5 danielw@site.uottawa.ca, laganier@site.uottawa.ca
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Part-Based Models for Object Class Recognition Part 2
 High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
High Level Computer Vision Part-Based Models for Object Class Recognition Part 2 Bernt Schiele - schiele@mpi-inf.mpg.de Mario Fritz - mfritz@mpi-inf.mpg.de https://www.mpi-inf.mpg.de/hlcv Class of Object
Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach
 Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach Vandit Gajjar gajjar.vandit.381@ldce.ac.in Ayesha Gurnani gurnani.ayesha.52@ldce.ac.in Yash Khandhediya khandhediya.yash.364@ldce.ac.in
Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach Vandit Gajjar gajjar.vandit.381@ldce.ac.in Ayesha Gurnani gurnani.ayesha.52@ldce.ac.in Yash Khandhediya khandhediya.yash.364@ldce.ac.in
Object detection using non-redundant local Binary Patterns
 University of Wollongong Research Online Faculty of Informatics - Papers (Archive) Faculty of Engineering and Information Sciences 2010 Object detection using non-redundant local Binary Patterns Duc Thanh
University of Wollongong Research Online Faculty of Informatics - Papers (Archive) Faculty of Engineering and Information Sciences 2010 Object detection using non-redundant local Binary Patterns Duc Thanh
3D Face and Hand Tracking for American Sign Language Recognition
 3D Face and Hand Tracking for American Sign Language Recognition NSF-ITR (2004-2008) D. Metaxas, A. Elgammal, V. Pavlovic (Rutgers Univ.) C. Neidle (Boston Univ.) C. Vogler (Gallaudet) The need for automated
3D Face and Hand Tracking for American Sign Language Recognition NSF-ITR (2004-2008) D. Metaxas, A. Elgammal, V. Pavlovic (Rutgers Univ.) C. Neidle (Boston Univ.) C. Vogler (Gallaudet) The need for automated
Human Motion Detection and Tracking for Video Surveillance
 Human Motion Detection and Tracking for Video Surveillance Prithviraj Banerjee and Somnath Sengupta Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur,
Human Motion Detection and Tracking for Video Surveillance Prithviraj Banerjee and Somnath Sengupta Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur,
Human Detection. A state-of-the-art survey. Mohammad Dorgham. University of Hamburg
 Human Detection A state-of-the-art survey Mohammad Dorgham University of Hamburg Presentation outline Motivation Applications Overview of approaches (categorized) Approaches details References Motivation
Human Detection A state-of-the-art survey Mohammad Dorgham University of Hamburg Presentation outline Motivation Applications Overview of approaches (categorized) Approaches details References Motivation
CS 231A Computer Vision (Winter 2014) Problem Set 3
 Problem Set 3") CS 231A Computer Vision (Winter 2014) Problem Set 3 Due: Feb. 18 th, 2015 (11:59pm) 1 Single Object Recognition Via SIFT (45 points) In his 2004 SIFT paper, David Lowe demonstrates impressive object recognition
CS 231A Computer Vision (Winter 2014) Problem Set 3 Due: Feb. 18 th, 2015 (11:59pm) 1 Single Object Recognition Via SIFT (45 points) In his 2004 SIFT paper, David Lowe demonstrates impressive object recognition
Visual Tracking of Human Body with Deforming Motion and Shape Average
 Visual Tracking of Human Body with Deforming Motion and Shape Average Alessandro Bissacco UCLA Computer Science Los Angeles, CA 90095 bissacco@cs.ucla.edu UCLA CSD-TR # 020046 Abstract In this work we
Visual Tracking of Human Body with Deforming Motion and Shape Average Alessandro Bissacco UCLA Computer Science Los Angeles, CA 90095 bissacco@cs.ucla.edu UCLA CSD-TR # 020046 Abstract In this work we
Part I: HumanEva-I dataset and evaluation metrics
 Part I: HumanEva-I dataset and evaluation metrics Leonid Sigal Michael J. Black Department of Computer Science Brown University http://www.cs.brown.edu/people/ls/ http://vision.cs.brown.edu/humaneva/ Motivation
Part I: HumanEva-I dataset and evaluation metrics Leonid Sigal Michael J. Black Department of Computer Science Brown University http://www.cs.brown.edu/people/ls/ http://vision.cs.brown.edu/humaneva/ Motivation
Parsing Human Motion with Stretchable Models
 Parsing Human Motion with Stretchable Models Benjamin Sapp David Weiss Ben Taskar University of Pennsylvania Philadelphia, PA 19104 {bensapp,djweiss,taskar}@cis.upenn.edu Abstract We address the problem
Parsing Human Motion with Stretchable Models Benjamin Sapp David Weiss Ben Taskar University of Pennsylvania Philadelphia, PA 19104 {bensapp,djweiss,taskar}@cis.upenn.edu Abstract We address the problem
Viewpoint invariant exemplar-based 3D human tracking
 Computer Vision and Image Understanding 104 (2006) 178 189 www.elsevier.com/locate/cviu Viewpoint invariant exemplar-based 3D human tracking Eng-Jon Ong *, Antonio S. Micilotta, Richard Bowden, Adrian
Computer Vision and Image Understanding 104 (2006) 178 189 www.elsevier.com/locate/cviu Viewpoint invariant exemplar-based 3D human tracking Eng-Jon Ong *, Antonio S. Micilotta, Richard Bowden, Adrian
Easy Minimax Estimation with Random Forests for Human Pose Estimation
 Easy Minimax Estimation with Random Forests for Human Pose Estimation P. Daphne Tsatsoulis and David Forsyth Department of Computer Science University of Illinois at Urbana-Champaign {tsatsou2, daf}@illinois.edu
Easy Minimax Estimation with Random Forests for Human Pose Estimation P. Daphne Tsatsoulis and David Forsyth Department of Computer Science University of Illinois at Urbana-Champaign {tsatsou2, daf}@illinois.edu
Texture April 17 th, 2018
 Texture April 17 th, 2018 Yong Jae Lee UC Davis Announcements PS1 out today Due 5/2 nd, 11:59 pm start early! 2 Review: last time Edge detection: Filter for gradient Threshold gradient magnitude, thin
Texture April 17 th, 2018 Yong Jae Lee UC Davis Announcements PS1 out today Due 5/2 nd, 11:59 pm start early! 2 Review: last time Edge detection: Filter for gradient Threshold gradient magnitude, thin
Mobile Human Detection Systems based on Sliding Windows Approach-A Review
 Mobile Human Detection Systems based on Sliding Windows Approach-A Review Seminar: Mobile Human detection systems Njieutcheu Tassi cedrique Rovile Department of Computer Engineering University of Heidelberg
Mobile Human Detection Systems based on Sliding Windows Approach-A Review Seminar: Mobile Human detection systems Njieutcheu Tassi cedrique Rovile Department of Computer Engineering University of Heidelberg
Cardboard People: A Parameterized Model of Articulated Image Motion
 Cardboard People: A Parameterized Model of Articulated Image Motion Shanon X. Ju Michael J. Black y Yaser Yacoob z Department of Computer Science, University of Toronto, Toronto, Ontario M5S A4 Canada
Cardboard People: A Parameterized Model of Articulated Image Motion Shanon X. Ju Michael J. Black y Yaser Yacoob z Department of Computer Science, University of Toronto, Toronto, Ontario M5S A4 Canada