CLASSIFICATION Experiments
|
|
|
- Edward Ryan
- 5 years ago
- Views:
Transcription
1 CLASSIFICATION Experiments January 27,2015 CS3710: Visual Recognition Bhavin Modi





2 Bag of features Object Bag of words



3 1. Extract features 2. Learn visual vocabulary Bag of features: outline 3. Quantize features using visual vocabulary 4. Represent images by frequencies of visual words Slide Credits: Li Fei-Fei
4 Bag of features Summary

5 What about Spatial Information Slide Credits:Cordelia Schmid

6 Beyond Bag of features Slide Credits: Li Fei-Fei
7 Spatial Pyramid Matching

8 Image Representation Slide Credits: Li Fei-Fei
9 Kernel Function Histogram Intersection Function: Pyramid Match Kernel: Final Kernel is the sum of the separate channels:
10 Spatial Pyramid Vector Dimensions

11 Weakness of the model
12 Experiments Conducted #3 Datasets Used: 15 Scene, Caltech-101, and Graz. Strong Features: SIFT descriptors of 16x16 pixel patches computed over a grid with spacing of 8 pixels. Weak Features: Oriented Edge Points,i.e., points whose gradient magnitude in a given direction exceeds a minimum threshold. Dictionary Size and Levels are tested for different values, M=200,400 and L=0,1,2,3 (not in all cases)

13 15 Scene One of the most complete scene categories at the time. Each Category has 200 to 400 images. Conclusions made: Using all levels together confers a statistically significant benefit. For strong features single level performance drops as we go from L=2 to L=3, while weak features improve. Performance at L=2 and L=3 is almost equivalent, moving from M=200 to M=400 has a very small performance increase. Performs Better with 13 classes (74.7%) than 15 classes(72.2%) at L=0.


14 Caltech-101 Has geometric stability and lack of clutter. Contains 31 to 800 images per category. Slide Credits: Cordelia Schmid

15 Caltech-101 Conclusions: Prone to intra-class variations. Results shown for M=200, M=400 shows no significant improvement. Best performance 64.6% with L=2, M=200 with strong features. Best Classification Rate for 15 scene was 72.2% and it is 64.6% for Caltech-101.
16 Graz Dataset Has 2 object categories Bikes and People with heavy clutter and pose changes. M=200, L=0 and L=2 for strong features. Conclusions: Improvement for L=0 to L=2 is relatively small since it is difficult to find useful global features. Performance at 86.3% is higher than 15 Scene and Caltech-101.
17 New Experiments Conducted 1.Used the Caltech-256 dataset (256 Categories) to check if performance decreases on increasing the number of classes. 2. Vary the size of dictionary, M, to see the effects on accuracy. Values used M=10,50, and 200. (200 is said to be the optimal) Control Parameters present (Default Shown): Image size=1000 Grid spacing=8 Patch size=16 Dictionary Size=200 Number of Texton Images=50 Pyramid Levels=3
18 Why Caltech-256? CALTECH-101 Weaknesses: The dataset is too clean: images are very uniform in presentation, aligned from left to right, and usually not occluded. Limited number of categories. Some categories contain few images: certain categories are not represented as well as others, containing as few as 31 images. For example binocular (33), wild cat (34) Caltech-256 is another image dataset created at the California Institute of technology in 2007, a successor to Caltech-101. It is intended to address some of the weaknesses inherent to Caltech-101.
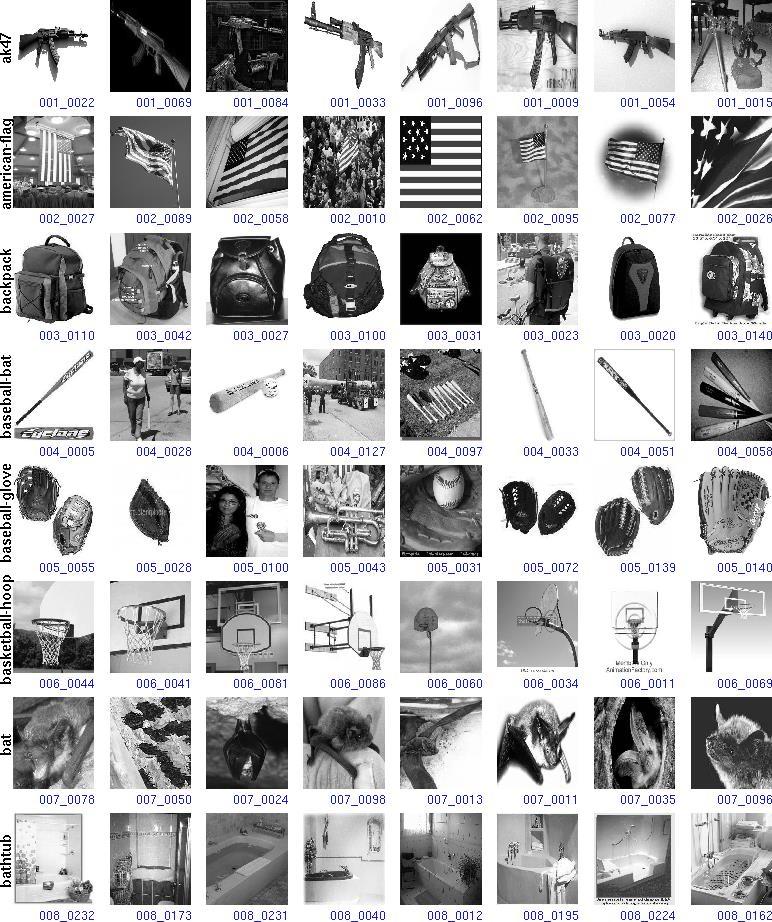
19
20 Slide Credits: Vision.Caltech.edu
21 Results Experiment 1: Dataset Caltech-256, multiple categories considered Training images=30 per category Test Images=50 per category L=3 (0,1,2) M=200. Experiment 2: Same as above but categories considered= M=10 2. M=50 3. M=200
22 14 12 Category: 10 Accuracy: Accuracy % Category: 50 Accuracy: Category: 100 Accuracy: 1.64 Category: 160 Accuracy: Category: 256 Accuracy: Number of Categories
23 1.1 M: 200 Accuracy: Accuracy % M: 50 Accuracy: M: 10 Accuracy: M (Dictionary Size)
24 Problems As we can see the accuracy% is very low. Which leads to believe that there is some error in implementation, so we try to figure out the reason by performing three debugging steps: All debugging is done on the Catech-256 dataset, for 100 Categories, M=200, L=3, No. of training images=30 per category, No. of testing images=50 per category. Accuracy on Test Set=1.64% (82/5000) Accuracy on Train Set= % (2615/3000) 1. Compute the Big Kernel 2. Using the inbuilt Linear Kernel and RBF Kernel 3. Calculating Kernel Means Values
25 1. Calculating the Big Kernel Accuracy=1.64%, No Change Debugging Results 2. Using a Linear or RBF Kernel on the test data and doing a Sanity Check on the training data. Train Set Test Set Linear Kernel 8.4% 0.92% RBF Kernel 8.267% 1% 3. Calculating the ratio of the *mean* K(sample, other samples from same class) values and the *mean* K(sample, samples from different classes ratio) values, for both the train and test kernels. Train Set Test Set Mean K Same Class Mean K Diff. Class








26 Debugging II We check the predicted Labels on the test set to see the which category was assigned to majority of the images. We see category that 6-Basketball Hoops and 59-Drinking Straw have more than 1000 images assigned to these two categories.
27 Evaluation on Other Datasets Slide Credits:Cordelia Schmid
28 Summary Discussion Spatial pyramid representation: appearance of local image patches + coarse global position information Substantial improvement over bag of features Depends on the similarity of image layout
29 Future Work Done Packing More Information in the Pyramid: 1.Bosch et al. (2007), Used descriptors PHOW and PHOG. 2. Germett et al. (2008), Kernel Codebook uses a Gaussian kernel over every centroid w, every bin gets 1 if descriptor ri is assigned(nearest) to its centroid w, every descriptor contributes some information to every bin(depending on σ). 3.Shengye Yan et al. (2012), Beyond Spatial Pyramid uses a two level feature extraction method using encoding and pooling procedures on the window-based features to acquire new image features.
30 References 1. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories-Svetlana Lazebnik, Cordelia Schmid, Jean Ponce. 2.Part 1: Bag-of-words models ppt by Li Fei-Fei (Princeton). 3. Recent Advancements on the Bag of Visual Words Model for image classification and concept detection- Costantino Grana and Giuseppe Serra. 4. Bag-of-features for category classification-cordelia Schmid, INRIA. 5. Chih-Chung Chang and Chih-Jen Lin, LIBSVM : a library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2:27:1--27:27, Caltech-256 Dataset-
31 Thank You
Beyond bags of Features
 Beyond bags of Features Spatial Pyramid Matching for Recognizing Natural Scene Categories Camille Schreck, Romain Vavassori Ensimag December 14, 2012 Schreck, Vavassori (Ensimag) Beyond bags of Features
Beyond bags of Features Spatial Pyramid Matching for Recognizing Natural Scene Categories Camille Schreck, Romain Vavassori Ensimag December 14, 2012 Schreck, Vavassori (Ensimag) Beyond bags of Features
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Beyond Bags of Features
 : for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
: for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
Local Features and Bag of Words Models
 10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
Supervised learning. y = f(x) function
 function") Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Part-based and local feature models for generic object recognition
 Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Bag-of-features. Cordelia Schmid
 Bag-of-features for category classification Cordelia Schmid Visual search Particular objects and scenes, large databases Category recognition Image classification: assigning a class label to the image
Bag-of-features for category classification Cordelia Schmid Visual search Particular objects and scenes, large databases Category recognition Image classification: assigning a class label to the image
Object Recognition. Computer Vision. Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce
 Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Object Recognition Computer Vision Slides from Lana Lazebnik, Fei-Fei Li, Rob Fergus, Antonio Torralba, and Jean Ponce How many visual object categories are there? Biederman 1987 ANIMALS PLANTS OBJECTS
Patch Descriptors. CSE 455 Linda Shapiro
 Patch Descriptors CSE 455 Linda Shapiro How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Patch Descriptors CSE 455 Linda Shapiro How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Bag of Words Models. CS4670 / 5670: Computer Vision Noah Snavely. Bag-of-words models 11/26/2013
 CS4670 / 5670: Computer Vision Noah Snavely Bag-of-words models Object Bag of words Bag of Words Models Adapted from slides by Rob Fergus and Svetlana Lazebnik 1 Object Bag of words Origin 1: Texture Recognition
CS4670 / 5670: Computer Vision Noah Snavely Bag-of-words models Object Bag of words Bag of Words Models Adapted from slides by Rob Fergus and Svetlana Lazebnik 1 Object Bag of words Origin 1: Texture Recognition
Introduction to object recognition. Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others
 Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
Introduction to object recognition Slides adapted from Fei-Fei Li, Rob Fergus, Antonio Torralba, and others Overview Basic recognition tasks A statistical learning approach Traditional or shallow recognition
Beyond bags of features: Adding spatial information. Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba
 Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
Beyond bags of features: Adding spatial information Many slides adapted from Fei-Fei Li, Rob Fergus, and Antonio Torralba Adding spatial information Forming vocabularies from pairs of nearby features doublets
String distance for automatic image classification
 String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
TA Section: Problem Set 4
 TA Section: Problem Set 4 Outline Discriminative vs. Generative Classifiers Image representation and recognition models Bag of Words Model Part-based Model Constellation Model Pictorial Structures Model
TA Section: Problem Set 4 Outline Discriminative vs. Generative Classifiers Image representation and recognition models Bag of Words Model Part-based Model Constellation Model Pictorial Structures Model
ImageCLEF 2011
 SZTAKI @ ImageCLEF 2011 Bálint Daróczy joint work with András Benczúr, Róbert Pethes Data Mining and Web Search Group Computer and Automation Research Institute Hungarian Academy of Sciences Training/test
SZTAKI @ ImageCLEF 2011 Bálint Daróczy joint work with András Benczúr, Róbert Pethes Data Mining and Web Search Group Computer and Automation Research Institute Hungarian Academy of Sciences Training/test
Local Features and Kernels for Classifcation of Texture and Object Categories: A Comprehensive Study
 Local Features and Kernels for Classifcation of Texture and Object Categories: A Comprehensive Study J. Zhang 1 M. Marszałek 1 S. Lazebnik 2 C. Schmid 1 1 INRIA Rhône-Alpes, LEAR - GRAVIR Montbonnot, France
Local Features and Kernels for Classifcation of Texture and Object Categories: A Comprehensive Study J. Zhang 1 M. Marszałek 1 S. Lazebnik 2 C. Schmid 1 1 INRIA Rhône-Alpes, LEAR - GRAVIR Montbonnot, France
CS6670: Computer Vision
 CS6670: Computer Vision Noah Snavely Lecture 16: Bag-of-words models Object Bag of words Announcements Project 3: Eigenfaces due Wednesday, November 11 at 11:59pm solo project Final project presentations:
CS6670: Computer Vision Noah Snavely Lecture 16: Bag-of-words models Object Bag of words Announcements Project 3: Eigenfaces due Wednesday, November 11 at 11:59pm solo project Final project presentations:
Sparse coding for image classification
 Sparse coding for image classification Columbia University Electrical Engineering: Kun Rong(kr2496@columbia.edu) Yongzhou Xiang(yx2211@columbia.edu) Yin Cui(yc2776@columbia.edu) Outline Background Introduction
Sparse coding for image classification Columbia University Electrical Engineering: Kun Rong(kr2496@columbia.edu) Yongzhou Xiang(yx2211@columbia.edu) Yin Cui(yc2776@columbia.edu) Outline Background Introduction
Developing Open Source code for Pyramidal Histogram Feature Sets
 Developing Open Source code for Pyramidal Histogram Feature Sets BTech Project Report by Subodh Misra subodhm@iitk.ac.in Y648 Guide: Prof. Amitabha Mukerjee Dept of Computer Science and Engineering IIT
Developing Open Source code for Pyramidal Histogram Feature Sets BTech Project Report by Subodh Misra subodhm@iitk.ac.in Y648 Guide: Prof. Amitabha Mukerjee Dept of Computer Science and Engineering IIT
Part based models for recognition. Kristen Grauman
 Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Bias-Variance Trade-off + Other Models and Problems
 CS 1699: Intro to Computer Vision Bias-Variance Trade-off + Other Models and Problems Prof. Adriana Kovashka University of Pittsburgh November 3, 2015 Outline Support Vector Machines (review + other uses)
CS 1699: Intro to Computer Vision Bias-Variance Trade-off + Other Models and Problems Prof. Adriana Kovashka University of Pittsburgh November 3, 2015 Outline Support Vector Machines (review + other uses)
Preliminary Local Feature Selection by Support Vector Machine for Bag of Features
 Preliminary Local Feature Selection by Support Vector Machine for Bag of Features Tetsu Matsukawa Koji Suzuki Takio Kurita :University of Tsukuba :National Institute of Advanced Industrial Science and
Preliminary Local Feature Selection by Support Vector Machine for Bag of Features Tetsu Matsukawa Koji Suzuki Takio Kurita :University of Tsukuba :National Institute of Advanced Industrial Science and
arxiv: v3 [cs.cv] 3 Oct 2012
![arxiv: v3 [cs.cv] 3 Oct 2012](/thumbs/96/128756091.jpg "arxiv: v3 [cs.cv] 3 Oct 2012") Combined Descriptors in Spatial Pyramid Domain for Image Classification Junlin Hu and Ping Guo arxiv:1210.0386v3 [cs.cv] 3 Oct 2012 Image Processing and Pattern Recognition Laboratory Beijing Normal University,
Combined Descriptors in Spatial Pyramid Domain for Image Classification Junlin Hu and Ping Guo arxiv:1210.0386v3 [cs.cv] 3 Oct 2012 Image Processing and Pattern Recognition Laboratory Beijing Normal University,
Classifying Images with Visual/Textual Cues. By Steven Kappes and Yan Cao
 Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Classifying Images with Visual/Textual Cues By Steven Kappes and Yan Cao Motivation Image search Building large sets of classified images Robotics Background Object recognition is unsolved Deformable shaped
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials
 Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
Category-level localization
 Category-level localization Cordelia Schmid Recognition Classification Object present/absent in an image Often presence of a significant amount of background clutter Localization / Detection Localize object
Category-level localization Cordelia Schmid Recognition Classification Object present/absent in an image Often presence of a significant amount of background clutter Localization / Detection Localize object
Object recognition. Methods for classification and image representation
 Object recognition Methods for classification and image representation Credits Slides by Pete Barnum Slides by FeiFei Li Paul Viola, Michael Jones, Robust Realtime Object Detection, IJCV 04 Navneet Dalal
Object recognition Methods for classification and image representation Credits Slides by Pete Barnum Slides by FeiFei Li Paul Viola, Michael Jones, Robust Realtime Object Detection, IJCV 04 Navneet Dalal
Evaluation of GIST descriptors for web scale image search
 Evaluation of GIST descriptors for web scale image search Matthijs Douze Hervé Jégou, Harsimrat Sandhawalia, Laurent Amsaleg and Cordelia Schmid INRIA Grenoble, France July 9, 2009 Evaluation of GIST for
Evaluation of GIST descriptors for web scale image search Matthijs Douze Hervé Jégou, Harsimrat Sandhawalia, Laurent Amsaleg and Cordelia Schmid INRIA Grenoble, France July 9, 2009 Evaluation of GIST for
Patch Descriptors. EE/CSE 576 Linda Shapiro
 Patch Descriptors EE/CSE 576 Linda Shapiro 1 How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Patch Descriptors EE/CSE 576 Linda Shapiro 1 How can we find corresponding points? How can we find correspondences? How do we describe an image patch? How do we describe an image patch? Patches with similar
Exploring Bag of Words Architectures in the Facial Expression Domain
 Exploring Bag of Words Architectures in the Facial Expression Domain Karan Sikka, Tingfan Wu, Josh Susskind, and Marian Bartlett Machine Perception Laboratory, University of California San Diego {ksikka,ting,josh,marni}@mplab.ucsd.edu
Exploring Bag of Words Architectures in the Facial Expression Domain Karan Sikka, Tingfan Wu, Josh Susskind, and Marian Bartlett Machine Perception Laboratory, University of California San Diego {ksikka,ting,josh,marni}@mplab.ucsd.edu
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Recognition of Animal Skin Texture Attributes in the Wild. Amey Dharwadker (aap2174) Kai Zhang (kz2213)
 Kai Zhang (kz2213)") Recognition of Animal Skin Texture Attributes in the Wild Amey Dharwadker (aap2174) Kai Zhang (kz2213) Motivation Patterns and textures are have an important role in object description and understanding
Recognition of Animal Skin Texture Attributes in the Wild Amey Dharwadker (aap2174) Kai Zhang (kz2213) Motivation Patterns and textures are have an important role in object description and understanding
Learning Representations for Visual Object Class Recognition
 Learning Representations for Visual Object Class Recognition Marcin Marszałek Cordelia Schmid Hedi Harzallah Joost van de Weijer LEAR, INRIA Grenoble, Rhône-Alpes, France October 15th, 2007 Bag-of-Features
Learning Representations for Visual Object Class Recognition Marcin Marszałek Cordelia Schmid Hedi Harzallah Joost van de Weijer LEAR, INRIA Grenoble, Rhône-Alpes, France October 15th, 2007 Bag-of-Features
Object Classification Problem
 HIERARCHICAL OBJECT CATEGORIZATION" Gregory Griffin and Pietro Perona. Learning and Using Taxonomies For Fast Visual Categorization. CVPR 2008 Marcin Marszalek and Cordelia Schmid. Constructing Category
HIERARCHICAL OBJECT CATEGORIZATION" Gregory Griffin and Pietro Perona. Learning and Using Taxonomies For Fast Visual Categorization. CVPR 2008 Marcin Marszalek and Cordelia Schmid. Constructing Category
IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES
 IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES Pin-Syuan Huang, Jing-Yi Tsai, Yu-Fang Wang, and Chun-Yi Tsai Department of Computer Science and Information Engineering, National Taitung University,
IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES Pin-Syuan Huang, Jing-Yi Tsai, Yu-Fang Wang, and Chun-Yi Tsai Department of Computer Science and Information Engineering, National Taitung University,
Improved Spatial Pyramid Matching for Image Classification
 Improved Spatial Pyramid Matching for Image Classification Mohammad Shahiduzzaman, Dengsheng Zhang, and Guojun Lu Gippsland School of IT, Monash University, Australia {Shahid.Zaman,Dengsheng.Zhang,Guojun.Lu}@monash.edu
Improved Spatial Pyramid Matching for Image Classification Mohammad Shahiduzzaman, Dengsheng Zhang, and Guojun Lu Gippsland School of IT, Monash University, Australia {Shahid.Zaman,Dengsheng.Zhang,Guojun.Lu}@monash.edu
Mixtures of Gaussians and Advanced Feature Encoding
 Mixtures of Gaussians and Advanced Feature Encoding Computer Vision Ali Borji UWM Many slides from James Hayes, Derek Hoiem, Florent Perronnin, and Hervé Why do good recognition systems go bad? E.g. Why
Mixtures of Gaussians and Advanced Feature Encoding Computer Vision Ali Borji UWM Many slides from James Hayes, Derek Hoiem, Florent Perronnin, and Hervé Why do good recognition systems go bad? E.g. Why
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Action recognition in videos
 Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
P-CNN: Pose-based CNN Features for Action Recognition. Iman Rezazadeh
 P-CNN: Pose-based CNN Features for Action Recognition Iman Rezazadeh Introduction automatic understanding of dynamic scenes strong variations of people and scenes in motion and appearance Fine-grained
P-CNN: Pose-based CNN Features for Action Recognition Iman Rezazadeh Introduction automatic understanding of dynamic scenes strong variations of people and scenes in motion and appearance Fine-grained
Scene Recognition using Bag-of-Words
 Scene Recognition using Bag-of-Words Sarthak Ahuja B.Tech Computer Science Indraprastha Institute of Information Technology Okhla, Delhi 110020 Email: sarthak12088@iiitd.ac.in Anchita Goel B.Tech Computer
Scene Recognition using Bag-of-Words Sarthak Ahuja B.Tech Computer Science Indraprastha Institute of Information Technology Okhla, Delhi 110020 Email: sarthak12088@iiitd.ac.in Anchita Goel B.Tech Computer
 5*4%),-
5*4%),- Visual Object Recognition
 Perceptual and Sensory Augmented Computing Visual Object Recognition Tutorial Visual Object Recognition Bastian Leibe Computer Vision Laboratory ETH Zurich Chicago, 14.07.2008 & Kristen Grauman Department
Perceptual and Sensory Augmented Computing Visual Object Recognition Tutorial Visual Object Recognition Bastian Leibe Computer Vision Laboratory ETH Zurich Chicago, 14.07.2008 & Kristen Grauman Department
By Suren Manvelyan,
 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan, http://www.surenmanvelyan.com/gallery/7116 By Suren Manvelyan,
CS 231A Computer Vision (Fall 2011) Problem Set 4
 Problem Set 4") CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based
CS 231A Computer Vision (Fall 2011) Problem Set 4 Due: Nov. 30 th, 2011 (9:30am) 1 Part-based models for Object Recognition (50 points) One approach to object recognition is to use a deformable part-based
Beyond Bags of features Spatial information & Shape models
 Beyond Bags of features Spatial information & Shape models Jana Kosecka Many slides adapted from S. Lazebnik, FeiFei Li, Rob Fergus, and Antonio Torralba Detection, recognition (so far )! Bags of features
Beyond Bags of features Spatial information & Shape models Jana Kosecka Many slides adapted from S. Lazebnik, FeiFei Li, Rob Fergus, and Antonio Torralba Detection, recognition (so far )! Bags of features
Object Category Detection. Slides mostly from Derek Hoiem
 Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
Object Category Detection Slides mostly from Derek Hoiem Today s class: Object Category Detection Overview of object category detection Statistical template matching with sliding window Part-based Models
arxiv: v1 [cs.lg] 20 Dec 2013
![arxiv: v1 [cs.lg] 20 Dec 2013](/thumbs/89/99594013.jpg "arxiv: v1 [cs.lg] 20 Dec 2013") Unsupervised Feature Learning by Deep Sparse Coding Yunlong He Koray Kavukcuoglu Yun Wang Arthur Szlam Yanjun Qi arxiv:1312.5783v1 [cs.lg] 20 Dec 2013 Abstract In this paper, we propose a new unsupervised
Unsupervised Feature Learning by Deep Sparse Coding Yunlong He Koray Kavukcuoglu Yun Wang Arthur Szlam Yanjun Qi arxiv:1312.5783v1 [cs.lg] 20 Dec 2013 Abstract In this paper, we propose a new unsupervised
Recognition with Bag-ofWords. (Borrowing heavily from Tutorial Slides by Li Fei-fei)
") Recognition with Bag-ofWords (Borrowing heavily from Tutorial Slides by Li Fei-fei) Recognition So far, we ve worked on recognizing edges Now, we ll work on recognizing objects We will use a bag-of-words
Recognition with Bag-ofWords (Borrowing heavily from Tutorial Slides by Li Fei-fei) Recognition So far, we ve worked on recognizing edges Now, we ll work on recognizing objects We will use a bag-of-words
CEE598 - Visual Sensing for Civil Infrastructure Eng. & Mgmt.
 CEE598 - Visual Sensing for Civil Infrastructure Eng. & Mgmt. Section 10 - Detectors part II Descriptors Mani Golparvar-Fard Department of Civil and Environmental Engineering 3129D, Newmark Civil Engineering
CEE598 - Visual Sensing for Civil Infrastructure Eng. & Mgmt. Section 10 - Detectors part II Descriptors Mani Golparvar-Fard Department of Civil and Environmental Engineering 3129D, Newmark Civil Engineering
Supervised learning. y = f(x) function
 function") Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Supervised learning y = f(x) output prediction function Image feature Training: given a training set of labeled examples {(x 1,y 1 ),, (x N,y N )}, estimate the prediction function f by minimizing the
Visual words. Map high-dimensional descriptors to tokens/words by quantizing the feature space.
 Visual words Map high-dimensional descriptors to tokens/words by quantizing the feature space. Quantize via clustering; cluster centers are the visual words Word #2 Descriptor feature space Assign word
Visual words Map high-dimensional descriptors to tokens/words by quantizing the feature space. Quantize via clustering; cluster centers are the visual words Word #2 Descriptor feature space Assign word
CS 4495 Computer Vision A. Bobick. CS 4495 Computer Vision. Features 2 SIFT descriptor. Aaron Bobick School of Interactive Computing
 CS 4495 Computer Vision Features 2 SIFT descriptor Aaron Bobick School of Interactive Computing Administrivia PS 3: Out due Oct 6 th. Features recap: Goal is to find corresponding locations in two images.
CS 4495 Computer Vision Features 2 SIFT descriptor Aaron Bobick School of Interactive Computing Administrivia PS 3: Out due Oct 6 th. Features recap: Goal is to find corresponding locations in two images.
The SIFT (Scale Invariant Feature
 The SIFT (Scale Invariant Feature Transform) Detector and Descriptor developed by David Lowe University of British Columbia Initial paper ICCV 1999 Newer journal paper IJCV 2004 Review: Matt Brown s Canonical
The SIFT (Scale Invariant Feature Transform) Detector and Descriptor developed by David Lowe University of British Columbia Initial paper ICCV 1999 Newer journal paper IJCV 2004 Review: Matt Brown s Canonical
Announcements. Recognition. Recognition. Recognition. Recognition. Homework 3 is due May 18, 11:59 PM Reading: Computer Vision I CSE 152 Lecture 14
 Announcements Computer Vision I CSE 152 Lecture 14 Homework 3 is due May 18, 11:59 PM Reading: Chapter 15: Learning to Classify Chapter 16: Classifying Images Chapter 17: Detecting Objects in Images Given
Announcements Computer Vision I CSE 152 Lecture 14 Homework 3 is due May 18, 11:59 PM Reading: Chapter 15: Learning to Classify Chapter 16: Classifying Images Chapter 17: Detecting Objects in Images Given
Object Detection Using Segmented Images
 Object Detection Using Segmented Images Naran Bayanbat Stanford University Palo Alto, CA naranb@stanford.edu Jason Chen Stanford University Palo Alto, CA jasonch@stanford.edu Abstract Object detection
Object Detection Using Segmented Images Naran Bayanbat Stanford University Palo Alto, CA naranb@stanford.edu Jason Chen Stanford University Palo Alto, CA jasonch@stanford.edu Abstract Object detection
Efficient Kernels for Identifying Unbounded-Order Spatial Features
 Efficient Kernels for Identifying Unbounded-Order Spatial Features Yimeng Zhang Carnegie Mellon University yimengz@andrew.cmu.edu Tsuhan Chen Cornell University tsuhan@ece.cornell.edu Abstract Higher order
Efficient Kernels for Identifying Unbounded-Order Spatial Features Yimeng Zhang Carnegie Mellon University yimengz@andrew.cmu.edu Tsuhan Chen Cornell University tsuhan@ece.cornell.edu Abstract Higher order
Learning Object Representations for Visual Object Class Recognition
 Learning Object Representations for Visual Object Class Recognition Marcin Marszalek, Cordelia Schmid, Hedi Harzallah, Joost Van de Weijer To cite this version: Marcin Marszalek, Cordelia Schmid, Hedi
Learning Object Representations for Visual Object Class Recognition Marcin Marszalek, Cordelia Schmid, Hedi Harzallah, Joost Van de Weijer To cite this version: Marcin Marszalek, Cordelia Schmid, Hedi
Features Points. Andrea Torsello DAIS Università Ca Foscari via Torino 155, Mestre (VE)
") Features Points Andrea Torsello DAIS Università Ca Foscari via Torino 155, 30172 Mestre (VE) Finding Corners Edge detectors perform poorly at corners. Corners provide repeatable points for matching, so
Features Points Andrea Torsello DAIS Università Ca Foscari via Torino 155, 30172 Mestre (VE) Finding Corners Edge detectors perform poorly at corners. Corners provide repeatable points for matching, so
Multiple Kernel Learning for Emotion Recognition in the Wild
 Multiple Kernel Learning for Emotion Recognition in the Wild Karan Sikka, Karmen Dykstra, Suchitra Sathyanarayana, Gwen Littlewort and Marian S. Bartlett Machine Perception Laboratory UCSD EmotiW Challenge,
Multiple Kernel Learning for Emotion Recognition in the Wild Karan Sikka, Karmen Dykstra, Suchitra Sathyanarayana, Gwen Littlewort and Marian S. Bartlett Machine Perception Laboratory UCSD EmotiW Challenge,
Using Geometric Blur for Point Correspondence
 1 Using Geometric Blur for Point Correspondence Nisarg Vyas Electrical and Computer Engineering Department, Carnegie Mellon University, Pittsburgh, PA Abstract In computer vision applications, point correspondence
1 Using Geometric Blur for Point Correspondence Nisarg Vyas Electrical and Computer Engineering Department, Carnegie Mellon University, Pittsburgh, PA Abstract In computer vision applications, point correspondence
EECS150 - Digital Design Lecture 14 FIFO 2 and SIFT. Recap and Outline
 EECS150 - Digital Design Lecture 14 FIFO 2 and SIFT Oct. 15, 2013 Prof. Ronald Fearing Electrical Engineering and Computer Sciences University of California, Berkeley (slides courtesy of Prof. John Wawrzynek)
EECS150 - Digital Design Lecture 14 FIFO 2 and SIFT Oct. 15, 2013 Prof. Ronald Fearing Electrical Engineering and Computer Sciences University of California, Berkeley (slides courtesy of Prof. John Wawrzynek)
ROBUST SCENE CLASSIFICATION BY GIST WITH ANGULAR RADIAL PARTITIONING. Wei Liu, Serkan Kiranyaz and Moncef Gabbouj
 Proceedings of the 5th International Symposium on Communications, Control and Signal Processing, ISCCSP 2012, Rome, Italy, 2-4 May 2012 ROBUST SCENE CLASSIFICATION BY GIST WITH ANGULAR RADIAL PARTITIONING
Proceedings of the 5th International Symposium on Communications, Control and Signal Processing, ISCCSP 2012, Rome, Italy, 2-4 May 2012 ROBUST SCENE CLASSIFICATION BY GIST WITH ANGULAR RADIAL PARTITIONING
CS229: Action Recognition in Tennis
 CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction
 Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
Learning Realistic Human Actions from Movies
 Learning Realistic Human Actions from Movies Ivan Laptev*, Marcin Marszałek**, Cordelia Schmid**, Benjamin Rozenfeld*** INRIA Rennes, France ** INRIA Grenoble, France *** Bar-Ilan University, Israel Presented
Learning Realistic Human Actions from Movies Ivan Laptev*, Marcin Marszałek**, Cordelia Schmid**, Benjamin Rozenfeld*** INRIA Rennes, France ** INRIA Grenoble, France *** Bar-Ilan University, Israel Presented
Artistic ideation based on computer vision methods
 Journal of Theoretical and Applied Computer Science Vol. 6, No. 2, 2012, pp. 72 78 ISSN 2299-2634 http://www.jtacs.org Artistic ideation based on computer vision methods Ferran Reverter, Pilar Rosado,
Journal of Theoretical and Applied Computer Science Vol. 6, No. 2, 2012, pp. 72 78 ISSN 2299-2634 http://www.jtacs.org Artistic ideation based on computer vision methods Ferran Reverter, Pilar Rosado,
Feature Descriptors. CS 510 Lecture #21 April 29 th, 2013
 Feature Descriptors CS 510 Lecture #21 April 29 th, 2013 Programming Assignment #4 Due two weeks from today Any questions? How is it going? Where are we? We have two umbrella schemes for object recognition
Feature Descriptors CS 510 Lecture #21 April 29 th, 2013 Programming Assignment #4 Due two weeks from today Any questions? How is it going? Where are we? We have two umbrella schemes for object recognition
Previous Lecture - Coded aperture photography
 Previous Lecture - Coded aperture photography Depth from a single image based on the amount of blur Estimate the amount of blur using and recover a sharp image by deconvolution with a sparse gradient prior.
Previous Lecture - Coded aperture photography Depth from a single image based on the amount of blur Estimate the amount of blur using and recover a sharp image by deconvolution with a sparse gradient prior.
Local Feature Detectors
 Local Feature Detectors Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr Slides adapted from Cordelia Schmid and David Lowe, CVPR 2003 Tutorial, Matthew Brown,
Local Feature Detectors Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr Slides adapted from Cordelia Schmid and David Lowe, CVPR 2003 Tutorial, Matthew Brown,
Novelty Detection Using Sparse Online Gaussian Processes for Visual Object Recognition
 Proceedings of the Twenty-Sixth International Florida Artificial Intelligence Research Society Conference Novelty Detection Using Sparse Online Gaussian Processes for Visual Object Recognition Ruben Ramirez-Padron
Proceedings of the Twenty-Sixth International Florida Artificial Intelligence Research Society Conference Novelty Detection Using Sparse Online Gaussian Processes for Visual Object Recognition Ruben Ramirez-Padron
Computer Vision Course Lecture 04. Template Matching Image Pyramids. Ceyhun Burak Akgül, PhD cba-research.com. Spring 2015 Last updated 11/03/2015
 Computer Vision Course Lecture 04 Template Matching Image Pyramids Ceyhun Burak Akgül, PhD cba-research.com Spring 2015 Last updated 11/03/2015 Photo credit: Olivier Teboul vision.mas.ecp.fr/personnel/teboul
Computer Vision Course Lecture 04 Template Matching Image Pyramids Ceyhun Burak Akgül, PhD cba-research.com Spring 2015 Last updated 11/03/2015 Photo credit: Olivier Teboul vision.mas.ecp.fr/personnel/teboul
Recap Image Classification with Bags of Local Features
 Recap Image Classification with Bags of Local Features Bag of Feature models were the state of the art for image classification for a decade BoF may still be the state of the art for instance retrieval
Recap Image Classification with Bags of Local Features Bag of Feature models were the state of the art for image classification for a decade BoF may still be the state of the art for instance retrieval
Spatial Pyramids and Two-layer Stacking SVM Classifiers for Image Categorization: A Comparative Study
 Spatial Pyramids and Two-layer Stacking SVM Classifiers for Image Categorization: A Comparative Study Azizi Abdullah, Remco C. Veltkamp and Marco A. Wiering Abstract Recent research in image recognition
Spatial Pyramids and Two-layer Stacking SVM Classifiers for Image Categorization: A Comparative Study Azizi Abdullah, Remco C. Veltkamp and Marco A. Wiering Abstract Recent research in image recognition
Computer Vision. Exercise Session 10 Image Categorization
 Computer Vision Exercise Session 10 Image Categorization Object Categorization Task Description Given a small number of training images of a category, recognize a-priori unknown instances of that category
Computer Vision Exercise Session 10 Image Categorization Object Categorization Task Description Given a small number of training images of a category, recognize a-priori unknown instances of that category
Summarization of Egocentric Moving Videos for Generating Walking Route Guidance
 Summarization of Egocentric Moving Videos for Generating Walking Route Guidance Masaya Okamoto and Keiji Yanai Department of Informatics, The University of Electro-Communications 1-5-1 Chofugaoka, Chofu-shi,
Summarization of Egocentric Moving Videos for Generating Walking Route Guidance Masaya Okamoto and Keiji Yanai Department of Informatics, The University of Electro-Communications 1-5-1 Chofugaoka, Chofu-shi,
Semantic Pooling for Image Categorization using Multiple Kernel Learning
 Semantic Pooling for Image Categorization using Multiple Kernel Learning Thibaut Durand (1,2), Nicolas Thome (1), Matthieu Cord (1), David Picard (2) (1) Sorbonne Universités, UPMC Univ Paris 06, UMR 7606,
Semantic Pooling for Image Categorization using Multiple Kernel Learning Thibaut Durand (1,2), Nicolas Thome (1), Matthieu Cord (1), David Picard (2) (1) Sorbonne Universités, UPMC Univ Paris 06, UMR 7606,
Computer Vision. Recap: Smoothing with a Gaussian. Recap: Effect of σ on derivatives. Computer Science Tripos Part II. Dr Christopher Town
 Recap: Smoothing with a Gaussian Computer Vision Computer Science Tripos Part II Dr Christopher Town Recall: parameter σ is the scale / width / spread of the Gaussian kernel, and controls the amount of
Recap: Smoothing with a Gaussian Computer Vision Computer Science Tripos Part II Dr Christopher Town Recall: parameter σ is the scale / width / spread of the Gaussian kernel, and controls the amount of
Local features: detection and description. Local invariant features
 Local features: detection and description Local invariant features Detection of interest points Harris corner detection Scale invariant blob detection: LoG Description of local patches SIFT : Histograms
Local features: detection and description Local invariant features Detection of interest points Harris corner detection Scale invariant blob detection: LoG Description of local patches SIFT : Histograms
I2R ImageCLEF Photo Annotation 2009 Working Notes
 I2R ImageCLEF Photo Annotation 2009 Working Notes Jiquan Ngiam and Hanlin Goh Institute for Infocomm Research, Singapore, 1 Fusionopolis Way, Singapore 138632 {jqngiam, hlgoh}@i2r.a-star.edu.sg Abstract
I2R ImageCLEF Photo Annotation 2009 Working Notes Jiquan Ngiam and Hanlin Goh Institute for Infocomm Research, Singapore, 1 Fusionopolis Way, Singapore 138632 {jqngiam, hlgoh}@i2r.a-star.edu.sg Abstract
Large-scale Video Classification with Convolutional Neural Networks
 Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
Image Matching. AKA: Image registration, the correspondence problem, Tracking,
 Image Matching AKA: Image registration, the correspondence problem, Tracking, What Corresponds to What? Daisy? Daisy From: www.amphian.com Relevant for Analysis of Image Pairs (or more) Also Relevant for
Image Matching AKA: Image registration, the correspondence problem, Tracking, What Corresponds to What? Daisy? Daisy From: www.amphian.com Relevant for Analysis of Image Pairs (or more) Also Relevant for
TEXTURE CLASSIFICATION METHODS: A REVIEW
 TEXTURE CLASSIFICATION METHODS: A REVIEW Ms. Sonal B. Bhandare Prof. Dr. S. M. Kamalapur M.E. Student Associate Professor Deparment of Computer Engineering, Deparment of Computer Engineering, K. K. Wagh
TEXTURE CLASSIFICATION METHODS: A REVIEW Ms. Sonal B. Bhandare Prof. Dr. S. M. Kamalapur M.E. Student Associate Professor Deparment of Computer Engineering, Deparment of Computer Engineering, K. K. Wagh
Bus Detection and recognition for visually impaired people
 Bus Detection and recognition for visually impaired people Hangrong Pan, Chucai Yi, and Yingli Tian The City College of New York The Graduate Center The City University of New York MAP4VIP Outline Motivation
Bus Detection and recognition for visually impaired people Hangrong Pan, Chucai Yi, and Yingli Tian The City College of New York The Graduate Center The City University of New York MAP4VIP Outline Motivation
Geometric VLAD for Large Scale Image Search. Zixuan Wang 1, Wei Di 2, Anurag Bhardwaj 2, Vignesh Jagadesh 2, Robinson Piramuthu 2
 Geometric VLAD for Large Scale Image Search Zixuan Wang 1, Wei Di 2, Anurag Bhardwaj 2, Vignesh Jagadesh 2, Robinson Piramuthu 2 1 2 Our Goal 1) Robust to various imaging conditions 2) Small memory footprint
Geometric VLAD for Large Scale Image Search Zixuan Wang 1, Wei Di 2, Anurag Bhardwaj 2, Vignesh Jagadesh 2, Robinson Piramuthu 2 1 2 Our Goal 1) Robust to various imaging conditions 2) Small memory footprint
CS 221: Object Recognition and Tracking
 CS 221: Object Recognition and Tracking Sandeep Sripada(ssandeep), Venu Gopal Kasturi(venuk) & Gautam Kumar Parai(gkparai) 1 Introduction In this project, we implemented an object recognition and tracking
CS 221: Object Recognition and Tracking Sandeep Sripada(ssandeep), Venu Gopal Kasturi(venuk) & Gautam Kumar Parai(gkparai) 1 Introduction In this project, we implemented an object recognition and tracking
Efficient Object Localization with Gaussianized Vector Representation
 Efficient Object Localization with Gaussianized Vector Representation ABSTRACT Xiaodan Zhuang xzhuang2@uiuc.edu Mark A. Hasegawa-Johnson jhasegaw@uiuc.edu Recently, the Gaussianized vector representation
Efficient Object Localization with Gaussianized Vector Representation ABSTRACT Xiaodan Zhuang xzhuang2@uiuc.edu Mark A. Hasegawa-Johnson jhasegaw@uiuc.edu Recently, the Gaussianized vector representation
CS6716 Pattern Recognition
 CS6716 Pattern Recognition Aaron Bobick School of Interactive Computing Administrivia PS3 is out now, due April 8. Today chapter 12 of the Hastie book. Slides (and entertainment) from Moataz Al-Haj Three
CS6716 Pattern Recognition Aaron Bobick School of Interactive Computing Administrivia PS3 is out now, due April 8. Today chapter 12 of the Hastie book. Slides (and entertainment) from Moataz Al-Haj Three
Local features: detection and description May 12 th, 2015
 Local features: detection and description May 12 th, 2015 Yong Jae Lee UC Davis Announcements PS1 grades up on SmartSite PS1 stats: Mean: 83.26 Standard Dev: 28.51 PS2 deadline extended to Saturday, 11:59
Local features: detection and description May 12 th, 2015 Yong Jae Lee UC Davis Announcements PS1 grades up on SmartSite PS1 stats: Mean: 83.26 Standard Dev: 28.51 PS2 deadline extended to Saturday, 11:59
Learning Visual Semantics: Models, Massive Computation, and Innovative Applications
 Learning Visual Semantics: Models, Massive Computation, and Innovative Applications Part II: Visual Features and Representations Liangliang Cao, IBM Watson Research Center Evolvement of Visual Features
Learning Visual Semantics: Models, Massive Computation, and Innovative Applications Part II: Visual Features and Representations Liangliang Cao, IBM Watson Research Center Evolvement of Visual Features
Object Recognition in Images and Video: Advanced Bag-of-Words 27 April / 61
 Object Recognition in Images and Video: Advanced Bag-of-Words http://www.micc.unifi.it/bagdanov/obrec Prof. Andrew D. Bagdanov Dipartimento di Ingegneria dell Informazione Università degli Studi di Firenze
Object Recognition in Images and Video: Advanced Bag-of-Words http://www.micc.unifi.it/bagdanov/obrec Prof. Andrew D. Bagdanov Dipartimento di Ingegneria dell Informazione Università degli Studi di Firenze
CV as making bank. Intel buys Mobileye! $15 billion. Mobileye:
 CV as making bank Intel buys Mobileye! $15 billion Mobileye: Spin-off from Hebrew University, Israel 450 engineers 15 million cars installed 313 car models June 2016 - Tesla left Mobileye Fatal crash car
CV as making bank Intel buys Mobileye! $15 billion Mobileye: Spin-off from Hebrew University, Israel 450 engineers 15 million cars installed 313 car models June 2016 - Tesla left Mobileye Fatal crash car
Classification of Subject Motion for Improved Reconstruction of Dynamic Magnetic Resonance Imaging
 1 CS 9 Final Project Classification of Subject Motion for Improved Reconstruction of Dynamic Magnetic Resonance Imaging Feiyu Chen Department of Electrical Engineering ABSTRACT Subject motion is a significant
1 CS 9 Final Project Classification of Subject Motion for Improved Reconstruction of Dynamic Magnetic Resonance Imaging Feiyu Chen Department of Electrical Engineering ABSTRACT Subject motion is a significant
Visual Object Recognition
 Visual Object Recognition -67777 Instructor: Daphna Weinshall, daphna@cs.huji.ac.il Office: Ross 211 Office hours: Sunday 12:00-13:00 1 Sources Recognizing and Learning Object Categories ICCV 2005 short
Visual Object Recognition -67777 Instructor: Daphna Weinshall, daphna@cs.huji.ac.il Office: Ross 211 Office hours: Sunday 12:00-13:00 1 Sources Recognizing and Learning Object Categories ICCV 2005 short
Recognizing human actions in still images: a study of bag-of-features and part-based representations
 DELAITRE, LAPTEV, SIVIC: RECOGNIZING HUMAN ACTIONS IN STILL IMAGES. 1 Recognizing human actions in still images: a study of bag-of-features and part-based representations Vincent Delaitre 1 vincent.delaitre@ens-lyon.org
DELAITRE, LAPTEV, SIVIC: RECOGNIZING HUMAN ACTIONS IN STILL IMAGES. 1 Recognizing human actions in still images: a study of bag-of-features and part-based representations Vincent Delaitre 1 vincent.delaitre@ens-lyon.org
OBJECT CATEGORIZATION
 OBJECT CATEGORIZATION Ing. Lorenzo Seidenari e-mail: seidenari@dsi.unifi.it Slides: Ing. Lamberto Ballan November 18th, 2009 What is an Object? Merriam-Webster Definition: Something material that may be
OBJECT CATEGORIZATION Ing. Lorenzo Seidenari e-mail: seidenari@dsi.unifi.it Slides: Ing. Lamberto Ballan November 18th, 2009 What is an Object? Merriam-Webster Definition: Something material that may be
Evaluation and comparison of interest points/regions
 Introduction Evaluation and comparison of interest points/regions Quantitative evaluation of interest point/region detectors points / regions at the same relative location and area Repeatability rate :
Introduction Evaluation and comparison of interest points/regions Quantitative evaluation of interest point/region detectors points / regions at the same relative location and area Repeatability rate :
Outline 7/2/201011/6/
 Outline Pattern recognition in computer vision Background on the development of SIFT SIFT algorithm and some of its variations Computational considerations (SURF) Potential improvement Summary 01 2 Pattern
Outline Pattern recognition in computer vision Background on the development of SIFT SIFT algorithm and some of its variations Computational considerations (SURF) Potential improvement Summary 01 2 Pattern
Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition
 Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition Bangpeng Yao 1, Juan Carlos Niebles 2,3, Li Fei-Fei 1 1 Department of Computer Science, Princeton University, NJ 08540, USA
Mining Discriminative Adjectives and Prepositions for Natural Scene Recognition Bangpeng Yao 1, Juan Carlos Niebles 2,3, Li Fei-Fei 1 1 Department of Computer Science, Princeton University, NJ 08540, USA
Midterm Wed. Local features: detection and description. Today. Last time. Local features: main components. Goal: interest operator repeatability
 Midterm Wed. Local features: detection and description Monday March 7 Prof. UT Austin Covers material up until 3/1 Solutions to practice eam handed out today Bring a 8.5 11 sheet of notes if you want Review
Midterm Wed. Local features: detection and description Monday March 7 Prof. UT Austin Covers material up until 3/1 Solutions to practice eam handed out today Bring a 8.5 11 sheet of notes if you want Review