GPU, GP-GPU, GPU computing. Luca Benini
|
|
|
- Lambert Colin Lindsey
- 5 years ago
- Views:
Transcription

1 GPU, GP-GPU, GPU computing Luca Benini


2 (GP-) GPU Today 601mm 2 From TU/e 5kk73 Zhenyu Ye Henk Corporaal 2013 (update 2015 Benini)

3 A Typical GPU Card
")
4 GPU Is In Your Pocket Too Adreno 430 (onboard the Snapdragon 810)




5 Maxwell 2 Architecture: GM204 (GTX980) 1.2GHZ CLK, 1.2v Vdd 2048Cuda Cores


6 Maxwell 2 Architecture SMM has four warp schedulers, All core SMM functional units are assigned to a particular scheduler, with no shared units. Each warp scheduler has the flexibility to dual-issue (such as issuing a math operation to a CUDA Core in the same cycle as a memory operation to a load/store unit) SMM 64k 32-bit registers and 64 warps max. Maximum number of registers per thread (255). Maximum number of active thread blocks per multiprocessor has been doubled over SMX to 32 - occupancy improvement for kernels that use small thread blocks of 64 or fewer threads 64KB of dedicated shared memory per SM Ref. ANANDTECH 14
7 GPU Architecture evolution From Nvidia GTC2015

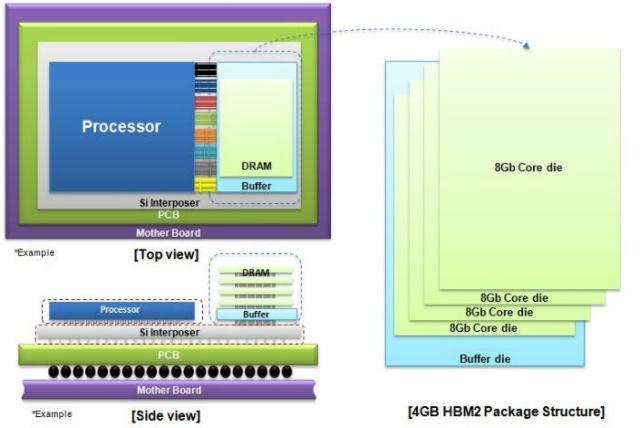
8 Pascal Architecture




9 Nvidia DGX-1
10 Why GPUs? Graphics workloads are embarrassingly parallel Data-parallel Pipeline-parallel CPU and GPU execute in parallel Hardware: texture filtering, rasterization, etc.

11 Data Parallel Beyond Graphics Cloth simulation Particle system Matrix multiply Image from:

12

13

14

15
16
17

18

19

20

21
22

23

24

25

26

27
28

29

30

31
32
33
34

35
36

37

38

39

40

41

42
43

44
45
46 GP-GPU More in depth!
47 Let's Start with Examples Don't worry, we will start from C and RISC!
![Let's Start with C and RISC int A[2][4];](/docs-images/89/100569905/images/48-0.jpg "for(i=0;i<2;i++){ for(j=0;j<4;j++){ A[i][j]++;")
 Programmer's view")
48 Let's Start with C and RISC int A[2][4]; for(i=0;i<2;i++){ for(j=0;j<4;j++){ A[i][j]++; } } Assembly code of inner-loop lw r0, 4(r1) addi r0, r0, 1 sw r0, 4(r1) Programmer's view of RISC
49 Most CPUs Have Vector SIMD Units Programmer's view of a vector SIMD
50 Let's Program the Vector SIMD Unroll inner-loop to vector operation. int A[2][4]; int A[2][4]; for(i=0;i<2;i++){ for(i=0;i<2;i++){ for(j=0;j<4;j++){ movups xmm0, [ &A[i][0] ] // load A[i][j]++; } addps xmm0, xmm1 // add 1 } movups [ &A[i][0] ], xmm0 // store } int A[2][4]; for(i=0;i<2;i++){ for(j=0;j<4;j++){ A[i][j]++; } } Assembly code of inner-loop Looks like the previous example, but instructions execute on 4 ALUs. lw r0, 4(r1) addi r0, r0, 1 sw r0, 4(r1)
51 How Do Vector Programs Run? int A[2][4]; for(i=0;i<2;i++){ movups xmm0, [ &A[i][0] ] // load addps xmm0, xmm1 // add 1 movups [ &A[i][0] ], xmm0 // store }

52 CUDA Programmer's View of GPUs A GPU contains multiple SIMD Units.
53 CUDA Programmer's View of GPUs A GPU contains multiple SIMD Units. All of them can access global memory.

54 What Are the Differences? SSE GPU Let's start with two important differences: 1. GPUs use threads instead of vectors 2. GPUs have the "Shared Memory" spaces

55 Thread Hierarchy in CUDA Grid contains Thread Blocks Thread Block contains Threads
56 Let's Start Again from C int A[2][4]; for(i=0;i<2;i++){ } for(j=0;j<4;j++){ } A[i][j]++; convert into CUDA int A[2][4]; kernelf<<<(2,1),(4,1)>>>(a); // define threads device kernelf(a){ // all threads run same kernel i = blockidx.x; // each thread block has its id j = threadidx.x; // each thread has its id A[i][j]++; // each thread has a different i and j }
57 What Is the Thread Hierarchy? thread 3 of block 1 operates on element A[1][3] int A[2][4]; kernelf<<<(2,1),(4,1)>>>(a); // define threads device kernelf(a){ // all threads run same kernel i = blockidx.x; // each thread block has its id j = threadidx.x; // each thread has its id A[i][j]++; // each thread has a different i and j }

58 How Are Threads Scheduled?



59 Blocks Are Dynamically Scheduled
60 How Are Threads Executed? int A[2][4]; kernelf<<<(2,1),(4,1)>>>(a); device kernelf(a){ i = blockidx.x; j = threadidx.x; A[i][j]++; } mv.u32 %r0, %ctaid.x mv.u32 %r1, %ntid.x mv.u32 %r2, %tid.x mad.u32 %r3, %r2, %r1, %r0 ld.global.s32 %r4, [%r3] add.s32 %r4, %r4, 1 st.global.s32 [%r3], %r4 // r0 = i = blockidx.x // r1 = "threads-per-block" // r2 = j = threadidx.x // r3 = i * "threads-per-block" + j // r4 = A[i][j] // r4 = r4 + 1 // A[i][j] = r4
61 Utilizing Memory Hierarchy
62 Example: Average Filters Average over a 3x3 window for a 16x16 array kernelf<<<(1,1),(16,16)>>>(a); device kernelf(a){ i = threadidx.y; j = threadidx.x; tmp = (A[i-1][j-1] + A[i-1][j]... + A[i+1][i+1] ) / 9; A[i][j] = tmp; }
63 Utilizing the Shared Memory Average over a 3x3 window for a 16x16 array kernelf<<<(1,1),(16,16)>>>(a); device kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.x; smem[i][j] = A[i][j]; // load to smem A[i][j] = ( smem[i-1][j-1] + smem[i-1][j]... + smem[i+1][i+1] ) / 9; }
64 Utilizing the Shared Memory kernelf<<<(1,1),(16,16)>>>(a); device kernelf(a){ shared smem[16][16]; i = threadidx.y; allocate shared j = threadidx.x; mem smem[i][j] = A[i][j]; // load to smem A[i][j] = ( smem[i-1][j-1] + smem[i-1][j]... + smem[i+1][i+1] ) / 9; }
65 However, the Program Is Incorrect kernelf<<<(1,1),(16,16)>>>(a); device kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.x; smem[i][j] = A[i][j]; // load to smem A[i][j] = ( smem[i-1][j-1] + smem[i-1][j]... + smem[i+1][i+1] ) / 9; }
,(16,16)>>>(a); device kernelf(a){ shared smem[16][16]; i =")

66 Let's See What's Wrong Assume 256 threads are scheduled on 8 PEs. kernelf<<<(1,1),(16,16)>>>(a); device kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.x; Before load instruction smem[i][j] = A[i][j]; // load to smem A[i][j] = ( smem[i-1][j-1] + smem[i-1][j]... + smem[i+1][i+1] ) / 9; }
67 Let's See What's Wrong Assume 256 threads are scheduled on 8 PEs. kernelf<<<(1,1),(16,16)>>>(a); device } kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.x; smem[i][j] = A[i][j]; // load to smem A[i][j] = ( smem[i-1][j-1] + smem[i-1][j]... Some threads finish the load earlier than others. + smem[i+1][i+1] ) / 9; Threads starts window operation as soon as it loads it own data element.
68 Let's See What's Wrong Assume 256 threads are scheduled on 8 PEs. Some elements in the window are not yet loaded by other threads. Error! kernelf<<<(1,1),(16,16)>>>(a); device } kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.x; smem[i][j] = A[i][j]; // load to smem A[i][j] = ( smem[i-1][j-1] + smem[i-1][j]... Some threads finish the load earlier than others. + smem[i+1][i+1] ) / 9; Threads starts window operation as soon as it loads it own data element.
69 How To Solve It? Assume 256 threads are scheduled on 8 PEs. kernelf<<<(1,1),(16,16)>>>(a); device } kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.x; smem[i][j] = A[i][j]; // load to smem A[i][j] = ( smem[i-1][j-1] + smem[i-1][j]... Some threads finish the load earlier than others. + smem[i+1][i+1] ) / 9;
70 Use a "SYNC" barrier! Assume 256 threads are scheduled on 8 PEs. kernelf<<<(1,1),(16,16)>>>(a); device } kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.x; smem[i][j] = A[i][j]; // load to smem sync(); // threads wait at barrier A[i][j] = ( smem[i-1][j-1] + smem[i-1][j]... Some threads finish the load earlier than others. + smem[i+1][i+1] ) / 9;
71 Use a "SYNC" barrier! Assume 256 threads are scheduled on 8 PEs. kernelf<<<(1,1),(16,16)>>>(a); device } kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.x; smem[i][j] = A[i][j]; // load to smem sync(); // threads wait at barrier A[i][j] = ( smem[i-1][j-1] + smem[i-1][j]... Some threads finish the load earlier than others. Wait until all threads hit barrier. + smem[i+1][i+1] ) / 9;
,(16,16)>>>(a); device } kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.")
72 Use a "SYNC" barrier! Assume 256 threads are scheduled on 8 PEs. All elements in the window are loaded when each thread starts averaging. kernelf<<<(1,1),(16,16)>>>(a); device } kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.x; smem[i][j] = A[i][j]; // load to smem sync(); // threads wait at barrier A[i][j] = ( smem[i-1][j-1] + smem[i-1][j]... + smem[i+1][i+1] ) / 9;
73 Review What We Have Learned 1. Single Instruction Multiple Thread (SIMT) 2. Shared memory Q: What are the pros and cons of explicitly managed memory? Q: What are the fundamental difference between SIMT and vector SIMD programming model?
74 Take the Same Example Again Average over a 3x3 window for a 16x16 array Assume vector SIMD and SIMT both have shared memory. What is the difference?
75 Vector SIMD v.s. SIMT int A[16][16]; // global memory shared int B[16][16]; // shared mem for(i=0;i<16;i++){ for(j=0;i<4;j+=4){ movups xmm0, [ &A[i][j] ] movups [ &B[i][j] ], xmm0 }} for(i=0;i<16;i++){ for(j=0;i<4;j+=4){ addps xmm1, [ &B[i-1][j-1] ] addps xmm1, [ &B[i-1][j] ]... divps xmm1, 9 }} for(i=0;i<16;i++){ for(j=0;i<4;j+=4){ addps [ &A[i][j] ], xmm1 }} kernelf<<<(1,1),(16,16)>>>(a); device kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.x; smem[i][j] = A[i][j]; // load to smem sync(); // threads wait at barrier A[i][j] = ( smem[i-1][j-1] + smem[i-1][j]... + smem[i+1][i+1] ) / 9; }
76 Vector SIMD v.s. SIMT int A[16][16]; shared int B[16][16]; for(i=0;i<16;i++){ for(j=0;i<4;j+=4){ movups xmm0, [ &A[i][j] ] movups [ &B[i][j] ], xmm0 }} for(i=0;i<16;i++){ Each inst. is executed by for(j=0;i<4;j+=4){ all PEs in locked step. addps xmm1, [ &B[i-1][j-1] ] addps xmm1, [ &B[i-1][j] ]... divps xmm1, 9 }} for(i=0;i<16;i++){ for(j=0;i<4;j+=4){ addps [ &A[i][j] ], xmm1 }} Programmers need to know there are 4 PEs. kernelf<<<(1,1),(16,16)>>>(a); device } kernelf(a){ shared smem[16][16]; i = threadidx.y; j = threadidx.x; smem[i][j] = A[i][j]; # of PEs in HW is transparent to programmers. sync(); // threads wait at barrier A[i][j] = ( smem[i-1][j-1] Programmers + smem[i-1][j] give up exec.... ordering to HW. + smem[i+1][i+1] ) / 9;
 into thread level parallelism")
77 Review What We Have Learned Programmers convert data level parallelism (DLP) into thread level parallelism (TLP).

78 HW Groups Threads Into Warps Example: 32 threads per warp
79 Why Make Things Complicated? Remember the hazards in MIPS? Structural hazards Data hazards Control hazards
80 More About GPUs Work Let's start with an example.

81 Example of Implementation Note: NVIDIA may use a more complicated implementation.


82 Example of Register Allocation Assumption: register file has 32 lanes each warp has 32 threads each thread uses 8 registers

83 Example Program Address: Inst 0x0004: add r0, r1, r2 0x0008: sub r3, r4, r5 Assume warp 0 and warp 1 are scheduled for execution.
84 Read Src Op Program Address: Inst 0x0004: add r0, r1, r2 0x0008: sub r3, r4, r5 Read source operands: r1 for warp 0 r4 for warp 1
85 Buffer Src Op Program Address: Inst 0x0004: add r0, r1, r2 0x0008: sub r3, r4, r5 Push ops to op collector: r1 for warp 0 r4 for warp 1
86 Read Src Op Program Address: Inst 0x0004: add r0, r1, r2 0x0008: sub r3, r4, r5 Read source operands: r2 for warp 0 r5 for warp 1
87 Buffer Src Op Program Address: Inst 0x0004: add r0, r1, r2 0x0008: sub r3, r4, r5 Push ops to op collector: r2 for warp 0 r5 for warp 1
88 Execute Program Address: Inst 0x0004: add r0, r1, r2 0x0008: sub r3, r4, r5 Compute the first 16 threads in the warp.
89 Execute Program Address: Inst 0x0004: add r0, r1, r2 0x0008: sub r3, r4, r5 Compute the last 16 threads in the warp.
90 Write back Program Address: Inst 0x0004: add r0, r1, r2 0x0008: sub r3, r4, r5 Write back: r0 for warp 0 r3 for warp 1
91 What Are the Possible Hazards? Three types of hazards we have learned earlier: Structural hazards Data hazards Control hazards


92 Structural Hazards In practice, structural hazards need to be handled dynamically.

93 Data Hazards In practice, we have much longer pipeline!

94 Control Hazards We cannot travel back in time, what should we do?
95 How Do GPUs Solve Hazards? However, GPUs (and SIMDs in general) have additional challenges: the branch!

96 Let's Start Again from a CPU Let's start from a MIPS.

97 A Naive SIMD Processor


98 Handling Branch In GPU Threads within a warp are free to branch. if( $r17 > $r19 ){ $r16 = $r20 + $r31 } else{ $r16 = $r21 - $r32 } $r18 = $r15 + $r16 Assembly code on the right are disassembled from cuda binary (cubin) using "decuda", link


99 If No Branch Divergence in a Warp If threads within a warp take the same path, the other path will not be executed.


100 Branch Divergence within a Warp If threads within a warp diverge, both paths have to be executed. Masks are set to filter out threads not executing on current path.




101 Dynamic Warp Formation Example: merge two divergent warps into a new warp if possible. Without dynamic warp formation With dynamic warp formation Create warp 3 from warp 0 and 1 Create warp 4 from warp 0 and 1 ref: Dynamic warp formation: Efficient MIMD control flow on SIMD graphics hardware.
102 Paulius Micikevicius Developer Technology, NVIDIA GPGPU Memory Hierarchy
103 Kepler Memory Hierarchy SM-0 Registers SM-1 Registers SM- N Registers L1 SME M Read only L1 SME M Read only L1 SME M Read only L2 Global Memory (DRAM) 1
104 Memory Hierarchy Review Registers o o Storage local to each threads Compiler-managed Shared memory / L1 o o o o 64 KB, program-configurable into shared:l1 Program-managed Accessible by all threads in the same threadblock Low latency, high bandwidth: ~2.5 TB/s Read-only cache o o o L2 o o Up to 48 KB per Kepler SM Hardware-managed (also used by texture units) Used for read-only GMEM accesses (not coherent with writes) 1.5 MB Hardware-managed: all accesses to global memory go through L2, including CPU and peer GPU Global memory o o o 6 GB, accessible by all threads, host (CPU), other GPUs in the same system Higher latency ( cycles) 250 GB/s 1
105 CUDA Device Memory Space Overview Each thread can: R/W per-thread registers R/W per-thread local memory R/W per-block shared memory R/W per-grid global memory Read only per-grid constant memory Read only per-grid texture memory The host can R/W global, constant, and texture memories Host (Device) Grid Block (0, 0) Registers Local Memory Global Memory Constant Memory Texture Memory Shared Memory Thread (0, 0) Registers Thread (1, 0) Local Memory Block (1, 0) Registers Local Memory Shared Memory Thread (0, 0) Registers Thread (1, 0) Local Memory University of Oslo INF5063, Pål Halvorsen, Carsten Griwodz, Håvard Espeland, Håkon Stensland
106 Global, Constant, and Texture Memories Global memory: Main means of communicating R/W Data between host and device Contents visible to all threads Texture and Constant Memories: Constants initialized by host Contents visible to all threads Host (Device) Grid Block (0, 0) Registers Local Memory Global Memory Constant Memory Texture Memory Shared Memory Thread (0, 0) Registers Thread (1, 0) Local Memory Block (1, 0) Registers Local Memory Shared Memory Thread (0, 0) Registers Thread (1, 0) Local Memory University of Oslo INF5063, Pål Halvorsen, Carsten Griwodz, Håvard Espeland, Håkon Stensland
107 Access Times Register Dedicated HW Single cycle Shared Memory Dedicated HW Single cycle Local Memory DRAM, no cache Slow Global Memory DRAM, no cache Slow Constant Memory DRAM, cached, 1 10s 100s of cycles, depending on cache locality Texture Memory DRAM, cached, 1 10s 100s of cycles, depending on cache locality University of Oslo INF5063, Pål Halvorsen, Carsten Griwodz, Håvard Espeland, Håkon Stensland
108 Memory Throughput Analysis Two perspectives on the throughput: o Application s point of view: count only bytes requested by application o HW point of view: count all bytes moved by hardware The two views can be different: o Memory is accessed at 32 byte granularity Scattered/offset pattern: application doesn t use all the hw transaction bytes o Broadcast: the same small transaction serves many threads in a warp Two aspects to inspect for performance impact: o Address pattern o Number of concurrent accesses in flight 1
109 Global Memory Operation Memory operations are executed per warp o 32 threads in a warp provide memory addresses o Hardware determines into which lines those addresses fall Memory transaction granularity is 32 bytes There are benefits to a warp accessing a contiguous aligned region of 128 or 256 bytes Access word size o Natively supported sizes (per thread): 1, 2, 4, 8, 16 bytes Assumes that each thread s address is aligned on the word size boundary o If you are accessing a data type that s of non-native size, compiler will generate several load or store instructions with native sizes 1
110 Scenario: o Warp requests 32 aligned, consecutive 4-byte words Addresses fall within 4 segments o Warp needs 128 bytes o 128 bytes move across the bus o Bus utilization: 100% addresses from a warp Memory addresses 1
111 Scenario: o Warp requests 32 aligned, permuted 4-byte words Addresses fall within 4 segments o Warp needs 128 bytes o 128 bytes move across the bus o Bus utilization: 100% addresses from a warp Memory addresses 1
112 Scenario: o Warp requests 32 misaligned, consecutive 4-byte words Addresses fall within at most 5 segments o Warp needs 128 bytes o At most 160 bytes move across the bus o Bus utilization: at least 80% Some misaligned patterns will fall within 4 segments, so 100% utilization... addresses from a warp Memory addresses 1
113 Scenario: o All threads in a warp request the same 4-byte word Addresses fall within a single segment o Warp needs 4 bytes o 32 bytes move across the bus o Bus utilization: 12.5% addresses from a warp Memory addresses 1
114 Scenario: o Warp requests 32 scattered 4-byte words Addresses fall within N segments o Warp needs 128 bytes o N*32 bytes move across the bus o Bus utilization: 128 / (N*32) addresses from a warp Memory addresses 1
115 Structure of Non-Native Size Say we are reading a 12-byte structure per thread struct Position { float x, y, z; };... global void kernel( Position *data,... ) { int idx = blockidx.x * blockdim.x + threadidx.x; Position temp = data[idx];... } 1
116 Structure of Non-Native Size Compiler converts temp = data[idx] into 3 loads: o Each loads 4 bytes o Can t do an 8 and a 4 byte load: 12 bytes per element means that every other element wouldn t align the 8- byte load on 8-byte boundary Addresses per warp for each of the loads: o Successive threads read 4 bytes at 12-byte stride 1
117 First Load Instruction addresses from a warp
118 Second Load Instruction addresses from a warp
119 Third Load Instruction addresses from a warp
120 Performance and Solutions Because of the address pattern, we end up moving 3x more bytes than application requests o We waste a lot of bandwidth, leaving performance on the table Potential solutions: o Change data layout from array of structures to structure of arrays In this case: 3 separate arrays of floats The most reliable approach (also ideal for both CPUs and GPUs) o Use loads via read-only cache As long as lines survive in the cache, performance will be nearly optimal o Stage loads via shared memory 1
121 Read-only Loads Go through the read-only cache o Not coherent with writes o Thus, addresses must not be written by the same kernel Two ways to enable: o Decorating pointer arguments as hints to compiler: Pointer of interest: const restrict All other pointer arguments: restrict Conveys to compiler that no aliasing will occur o Using ldg() intrinsic Requires no pointer decoration 1

 intrinsic output[idx] =.")
122 Read-only Loads Go through the read-only cache o Not coherent with writes o Thus, addresses must not be written by the same kernel Two ways to enable: global void kernel( int* restrict o Decorating pointer arguments output, as hints to compiler: Pointer of interest: restrict const const int* All other pointer restrict arguments: input restrict ) Conveys to compiler { that no aliasing will occur... o Using ldg() intrinsic output[idx] =... + input[idx]; Requires no pointer } decoration 1
 All other pointer { arguments: restrict Conveys to compiler... that no aliasing will occur output[idx] =.")
123 Read-only Loads Go through the read-only cache o Not coherent with writes o Thus, addresses must not be written by the same kernel Two ways to enable: o Decorating pointer arguments global void as hints kernel( to compiler: int *output, Pointer of interest: restrict constint *input ) All other pointer { arguments: restrict Conveys to compiler... that no aliasing will occur output[idx] =... + ldg( &input[idx] ); o Using ldg() intrinsic } Requires no pointer decoration 1
124 Having Sufficient Concurrent Accesses In order to saturate memory bandwidth, SM must issue enough independent memory requests 1
125 Elements per Thread and Performance Experiment: each warp has 2 concurrent requests (memcopy, one word per thread) o o o 4B word request: 1 line 8B word request: 2 lines 16B word request: 4 lines To achieve the same throughput at lower occupancy: Need more independent requests per warp To achieve the same throughput with smaller words: Need more independent requests per warp 125
126 Optimizing Access Concurrency Have enough concurrent accesses to saturate the bus o Little s law: need (mem_latency)x(bandwidth) bytes Ways to increase concurrent accesses: o Increase occupancy (run more warps concurrently) Adjust threadblock dimensions To maximize occupancy at given register and smem requirements If occupancy is limited by registers per thread: Reduce register count (-maxrregcount option, or launch_bounds ) o Modify code to process several elements per thread Doubling elements per thread doubles independent accesses per thread 1
127 Optimizations When Addresses Are Coalesced When looking for more performance and code: o Is memory bandwidth limited o Achieves high percentage of bandwidth theory o Addresses are coalesced Consider compression o GPUs provide instructions for converting between fp16, fp32, and fp64 representations: A single instruction, implemented in hw ( float2half(),...) o If data has few distinct values, consider lookup tables Store indices into the table Small enough tables will likely survive in caches if used often enough 1
128 L1 Sizing Shared memory and L1 use the same 64KB o Program-configurable split: Fermi: 48:16, 16:48 Kepler: 48:16, 16:48, 32:32 o CUDA API: cudadevicesetcacheconfig(), cudafuncsetcacheconfig() Large L1 can improve performance when: o Spilling registers (more lines in the cache -> fewer evictions) Large SMEM can improve performance when: o Occupancy is limited by SMEM 1
129 Summary: GMEM Optimization Strive for perfect address coalescing per warp o Align starting address (may require padding) o A warp will ideally access within a contiguous region o Avoid scattered address patterns or patterns with large strides between threads Analyze and optimize address patterns: o Use profiling tools (included with CUDA toolkit download) o Compare the transactions per request to the ideal ratio o Choose appropriate data layout (prefer SoA) o If needed, try read-only loads, staging accesses via SMEM Have enough concurrent accesses to saturate the bus o Launch enough threads to maximize throughput Latency is hidden by switching threads (warps) o If needed, process several elements per thread More concurrent loads/stores 1
130 SHARED MEMORY 1
131 Shared Memory On-chip (on each SM) memory Comparing SMEM to GMEM: o Order of magnitude (20-30x) lower latency o Order of magnitude (~10x) higher bandwidth o Accessed at bank-width granularity Kepler: 8 bytes For comparison: GMEM access granularity is either 32 or 128 bytes SMEM instruction operation: o 32 threads in a warp provide addresses o Determine into which 8-byte words addresses fall o Fetch the words, distribute the requested bytes among the threads Multi-cast capable Bank conflicts cause serialization 1


132 Shared Mem Contains Multiple Banks
133 Kepler Shared Memory Banking 32 banks, 8 bytes wide o Bandwidth: 8 bytes per bank per clock per SM (256 bytes per clk per SM) o 2x the bandwidth compared to Fermi Two modes: o 4-byte access (default): Maintains Fermi bank-conflict behavior exactly Provides 8-byte bandwidth for certain access patterns o 8-byte access: Some access patterns with Fermi-specific padding may incur bank conflicts Provides 8-byte bandwidth for all patterns (assuming 8-byte words) o Selected with cudadevicesetsharedmemconfig() function arguments: cudasharedmembanksizefourbyte cudasharedmembanksizeeightbyte 1
134 Kepler 8-byte Bank Mode Mapping addresses to banks: o Successive 8-byte words go to successive banks o Bank index: (8B word index) mod 32 (4B word index) mod (32*2) (byte address) mod (32*8) o Given the 8 least-significant address bits:...bbbbbxxx xxx selects the byte within an 8-byte word BBBBB selects the bank Higher bits select a column within a bank 1
135 Kepler 8-byte Bank Mode To visualize, let s pretend we have 4 banks, not 32 (easier to draw) Byte-address: Data: (or 4B-word index) Bank-0 Bank-1 Bank-2 Bank-3 1
136 Shared Memory Bank Conflicts A bank conflict occurs when: o 2 or more threads in a warp access different words in the same bank Think: 2 or more threads access different rows in the same bank o N-way bank conflict: N threads in a warp conflict Instruction gets issued N times: increases latency Note there is no bank conflict if: o Several threads access the same word o Several threads access different bytes of the same word 1
137 SMEM Access Examples Addresses from a warp: no bank conflicts One address access per bank Bank-0 Bank-1 Bank-2 Bank-3 Bank-31 1
138 SMEM Access Examples Addresses from a warp: no bank conflicts One address access per bank Bank-0 Bank-1 Bank-2 Bank-3 Bank-31 1
139 SMEM Access Examples Addresses from a warp: no bank conflicts Multiple addresses per bank, but within the same word Bank-0 Bank-1 Bank-2 Bank-3 Bank-31 1
140 SMEM Access Examples Addresses from a warp: 2-way bank conflict 2 accesses per bank, fall in two different words Bank-0 Bank-1 Bank-2 Bank-3 Bank-31 1
141 SMEM Access Examples Addresses from a warp: 3-way bank conflict 4 accesses per bank, fall in 3 different words Bank-0 Bank-1 Bank-2 Bank-3 Bank-31 1
142 Diagnosing Bank Conflicts Profiler counters: o Number of instructions executed, does not include replays: shared_load, shared_store o Number of replays (number of instruction issues due to bank conflicts) l1_shared_bank_conflict Analysis: o Number of replays per instruction l1_shared_bank_conflict / (shared_load + shared_store) o Replays are potentially a concern because: Replays add latency Compete for issue cycles with other SMEM and GMEM operations Except for read-only loads, which go to different hardware Remedy: o Usually padding SMEM data structures resolves/reduces bank conflicts 1
143 Summary: Shared Memory Shared memory is a tremendous resource o Very high bandwidth (terabytes per second) o 20-30x lower latency than accessing GMEM o Data is programmer-managed, no evictions by hardware Performance issues to look out for: o Bank conflicts add latency and reduce throughput o Many-way bank conflicts can be very expensive Replay latency adds up However, few code patterns have high conflicts, padding is a very simple and effective solution 1
144 CPU + GPGPU System Architecture Sharing Memory
145 Review- Typical Structure of a CUDA Program Global variables declaration Function prototypes global void kernelone( ) Main () allocate memory space on the device cudamalloc(&d_glblvarptr, bytes ) transfer data from host to device cudamemcpy(d_glblvarptr, h_gl ) execution configuration setup kernel call kernelone<<<execution configuration>>>( args ); repeat transfer results from device to host cudamemcpy(h_glblvarptr, ) optional: compare against golden (host computed) solution Kernel void kernelone(type args, ) variables declaration - local, shared automatic variables transparently assigned to registers or local memory syncthreads() as needed David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign
146 Bandwidth Gravity of Modern Computer Systems The Bandwidth between key components ultimately dictates system performance Especially true for massively parallel systems processing massive amount of data Tricks like buffering, reordering, caching can temporarily defy the rules in some cases Ultimately, the performance falls back to what the speeds and feeds dictate David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign


147 Bandwidth in a CPU-GPU system David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign

148 Classic PC architecture Northbridge connects 3 components that must be communicate at high speed CPU, DRAM, video Video also needs to have 1 st - class access to DRAM Previous NVIDIA cards are connected to AGP, up to 2 GB/s transfers Southbridge serves as a concentrator for slower I/O devices CPU David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign Core Logic Chipset
 Shared bus with arbitration Winner of arbitration becomes bus master and can connect to CPU or DRAM through the southbridge and northbridge David Kirk/NVIDIA")
149 (Original) PCI Bus Specification Connected to the southbridge Originally 33 MHz, 32-bit wide, 132 MB/second peak transfer rate More recently 66 MHz, 64-bit, 528 MB/second peak Upstream bandwidth remain slow for device (~256MB/s peak) Shared bus with arbitration Winner of arbitration becomes bus master and can connect to CPU or DRAM through the southbridge and northbridge David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign

150 PCI as Memory Mapped I/O PCI device registers are mapped into the CPU s physical address space Accessed through loads/ stores (kernel mode) Addresses are assigned to the PCI devices at boot time All devices listen for their addresses David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign

151 PCI Express (PCIe) Switched, point-to-point connection Each card has a dedicated link to the central switch, no bus arbitration. Packet switches messages form virtual channel Prioritized packets for QoS E.g., real-time video streaming David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign
 Upstream and downstream now simultaneous and symmetric Each Link can combine 1, 2, 4, 8, 12, 16 lanes- x1, x2, etc.")
152 PCIe 2 Links and Lanes Each link consists of one or more lanes Each lane is 1-bit wide (4 wires, each 2-wire pair can transmit 2.5Gb/s in one direction) Upstream and downstream now simultaneous and symmetric Each Link can combine 1, 2, 4, 8, 12, 16 lanes- x1, x2, etc. Each byte data is 8b/10b encoded into 10 bits with equal number of 1 s and 0 s; net data rate 2 Gb/s per lane each way. Thus, the net data rates are 250 MB/s (x1) 500 MB/s (x2), 1GB/s (x4), 2 GB/s (x8), 4 GB/s (x16), each way David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign
153 8/10 bit encoding Goal is to maintain DC balance while have sufficient state transition for clock recovery The difference of 1s and 0s in a 20-bit stream should be 2 There should be no more than 5 consecutive 1s or 0s in any stream , , bad , good Find 256 good patterns among 1024 total patterns of 10 bits to encode an 8-bit data An 20% overhead David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign

154 PCIe PC Architecture PCIe forms the interconnect backbone Northbridge/Southbridge are both PCIe switches Some Southbridge designs have built-in PCI-PCIe bridge to allow old PCI cards Some PCIe I/O cards are PCI cards with a PCI-PCIe bridge Source: Jon Stokes, PCI Express: An Overview s/paedia/hardware/pcie.ars David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign


155 GeForce 7800 GTX Board Details SLI Connector Single slot cooling svideo TV Out DVI x 2 16x PCI-Express David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign 256MB/256-bit DDR3 600 MHz 8 pieces of 8Mx32
156 PCIe 3 A total of 8 Giga Transfers per second in each direction No more 8/10 encoding but uses a polynomial transformation at the transmitter and its inverse at the receiver to achieve the same effect So the effective bandwidth is (almost) double of PCIe 2: 985MB/s per lane David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign
157 PCIe Data Transfer using DMA DMA (Direct Memory Access) is used to fully utilize the bandwidth of an I/O bus DMA uses physical address for source and destination Transfers a number of bytes requested by OS Needs pinned memory Main Memory (DRAM) CPU Global Memory DMA GPU card (or other I/O cards) David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign
158 Pinned Memory DMA uses physical addresses The OS could accidentally page out the data that is being read or written by a DMA and page in another virtual page into the same location Pinned memory cannot not be paged out David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign If a source or destination of a cudamemcpy() in the host memory is not pinned, it needs to be first copied to a pinned memory extra overhead cudamemcpy is much faster with pinned host memory source or destination
159 Allocate/Free Pinned Memory (a.k.a. Page Locked Memory) cudahostalloc() Three parameters Address of pointer to the allocated memory Size of the allocated memory in bytes Option use cudahostallocdefault for now cudafreehost() One parameter Pointer to the memory to be freed David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign
160 Using Pinned Memory Use the allocated memory and its pointer the same way those returned by malloc(); The only difference is that the allocated memory cannot be paged by the OS The cudamemcpy function should be about 2X faster with pinned memory Pinned memory is a limited resource whose over-subscription can have serious consequences David Kirk/NVIDIA and Wen-mei W. Hwu, ECE408/CS483, ECE 498AL, University of Illinois, Urbana-Champaign
, with the smallest unit of connectivity being a block. A block contains 8 lanes, each rated for 20Gbps, for a combined bandwidth of 20GB/sec. 20 vs.")
161 Next-gen technologies: NVLINK 16GB/sec (16-lanes) made available by PCI-Express 3.0 is hardly adequate vs. 250GB/sec+ of memory bandwidth available within a single card. NVLink uses differential signaling (like PCIe), with the smallest unit of connectivity being a block. A block contains 8 lanes, each rated for 20Gbps, for a combined bandwidth of 20GB/sec. 20 vs. 8GT/sec for PCIe 3.0 NVIDIA targets x5-x12 wrt PCIe

162 Moving towards Unified Memory
163 Backup Slides
164 Performance Modeling What is the bottleneck?


165 Roofline Model Identify performance bottleneck: computation bound v.s. bandwidth bound

166 Optimization Is Key for Attainable Gflops/s

167 Computation, Bandwidth, Latency Illustrating three bottlenecks in the Roofline model.
168 Program Optimization If I know the bottleneck, how to optimize? Optimization techniques for NVIDIA GPUs: "CUDA C Best Practices Guide"
169 Recap: What We have Learned GPU architecture (what is the difference?) GPU programming (why threads?) Performance analysis (bottlenecks)
170 Further Reading GPU architecture and programming: NVIDIA Tesla: A unified graphics and computing architecture, in IEEE Micro ( Scalable Parallel Programming with CUDA, in ACM Queue ( Understanding throughput-oriented architectures, in Communications of the ACM (
171 Recommended Reading Performance modeling: Roofline: an insightful visual performance model for multicore architectures, in Communications of the ACM ( Optional (if you are interested) How branches are executed in GPUs: Dynamic warp formation: Efficient MIMD control flow on SIMD graphics hardware, in ACM Transactions on Architecture and Code Optimization (
172 Common Optimization Techniques Optimizations on memory latency tolerance Reduce register pressure Reduce shared memory pressure Optimizations on memory bandwidth Global memory coalesce Avoid shared memory bank conflicts Grouping byte access Avoid Partition camping Optimizations on computation efficiency Mul/Add balancing Increase floating point proportion Optimizations on operational intensity Use tiled algorithm Tuning thread granularity
173 Common Optimization Techniques Optimizations on memory latency tolerance Reduce register pressure Reduce shared memory pressure Optimizations on memory bandwidth Global memory coalesce Avoid shared memory bank conflicts Grouping byte access Avoid Partition camping Optimizations on computation efficiency Mul/Add balancing Increase floating point proportion Optimizations on operational intensity Use tiled algorithm Tuning thread granularity
 R/W Shared No 1~3 R/W Constant Yes 1~3 Read-only Texture Yes ~100 Read-only")
174 Multiple Levels of Memory Hierarchy Name Cache? Latency (cycle) Read-only? Global L1/L2 200~400 (cache miss) R/W Shared No 1~3 R/W Constant Yes 1~3 Read-only Texture Yes ~100 Read-only Local L1/L2 200~400 (cache miss) R/W
CS/ECE 217. GPU Architecture and Parallel Programming. Lecture 16: GPU within a computing system
 CS/ECE 217 GPU Architecture and Parallel Programming Lecture 16: GPU within a computing system Objective To understand the major factors that dictate performance when using GPU as an compute co-processor
CS/ECE 217 GPU Architecture and Parallel Programming Lecture 16: GPU within a computing system Objective To understand the major factors that dictate performance when using GPU as an compute co-processor
Efficient Data Transfers
 Efficient Data fers Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2016 PCIE Review Typical Structure of a CUDA Program Global variables declaration Function prototypes global
Efficient Data fers Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2016 PCIE Review Typical Structure of a CUDA Program Global variables declaration Function prototypes global
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental Optimizations
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
Fundamental Optimizations Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access
GPU Accelerated Application Performance Tuning. Delivered by John Ashley, Slides by Cliff Woolley, NVIDIA Developer Technology Group
 GPU Accelerated Application Performance Tuning Delivered by John Ashley, Slides by Cliff Woolley, NVIDIA Developer Technology Group Main Requirements for GPU Performance Expose sufficient parallelism Use
GPU Accelerated Application Performance Tuning Delivered by John Ashley, Slides by Cliff Woolley, NVIDIA Developer Technology Group Main Requirements for GPU Performance Expose sufficient parallelism Use
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Advanced CUDA Programming. Dr. Timo Stich
 Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput
Advanced CUDA Programming Dr. Timo Stich (tstich@nvidia.com) Outline SIMT Architecture, Warps Kernel optimizations Global memory throughput Launch configuration Shared memory access Instruction throughput
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer
 CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
Performance Optimization: Programming Guidelines and GPU Architecture Reasons Behind Them
 Performance Optimization: Programming Guidelines and GPU Architecture Reasons Behind Them Paulius Micikevicius Developer Technology, NVIDIA Goals of this Talk Two-fold: Describe how hardware operates Show
Performance Optimization: Programming Guidelines and GPU Architecture Reasons Behind Them Paulius Micikevicius Developer Technology, NVIDIA Goals of this Talk Two-fold: Describe how hardware operates Show
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010
 Analysis-Driven Optimization Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Performance Optimization Process Use appropriate performance metric for each kernel For example,
Analysis-Driven Optimization Paulius Micikevicius NVIDIA Supercomputing, Tutorial S03 New Orleans, Nov 14, 2010 Performance Optimization Process Use appropriate performance metric for each kernel For example,
Performance Optimization Process
 Analysis-Driven Optimization (GTC 2010) Paulius Micikevicius NVIDIA Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for a bandwidth-bound
Analysis-Driven Optimization (GTC 2010) Paulius Micikevicius NVIDIA Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for a bandwidth-bound
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Advanced CUDA Optimizations. Umar Arshad ArrayFire
 Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Advanced CUDA Optimizations Umar Arshad (@arshad_umar) ArrayFire (@arrayfire) ArrayFire World s leading GPU experts In the industry since 2007 NVIDIA Partner Deep experience working with thousands of customers
Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011
 Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011 Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for
Identifying Performance Limiters Paulius Micikevicius NVIDIA August 23, 2011 Performance Optimization Process Use appropriate performance metric for each kernel For example, Gflops/s don t make sense for
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Maximizing Face Detection Performance
 Maximizing Face Detection Performance Paulius Micikevicius Developer Technology Engineer, NVIDIA GTC 2015 1 Outline Very brief review of cascaded-classifiers Parallelization choices Reducing the amount
Maximizing Face Detection Performance Paulius Micikevicius Developer Technology Engineer, NVIDIA GTC 2015 1 Outline Very brief review of cascaded-classifiers Parallelization choices Reducing the amount
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Preparing seismic codes for GPUs and other
 Preparing seismic codes for GPUs and other many-core architectures Paulius Micikevicius Developer Technology Engineer, NVIDIA 2010 SEG Post-convention Workshop (W-3) High Performance Implementations of
Preparing seismic codes for GPUs and other many-core architectures Paulius Micikevicius Developer Technology Engineer, NVIDIA 2010 SEG Post-convention Workshop (W-3) High Performance Implementations of
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, DRAM Bandwidth
 Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2016 DRAM Bandwidth MEMORY ACCESS PERFORMANCE Objective To learn that memory bandwidth is a first-order performance factor in
Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2016 DRAM Bandwidth MEMORY ACCESS PERFORMANCE Objective To learn that memory bandwidth is a first-order performance factor in
Programming in CUDA. Malik M Khan
 Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
Programming in CUDA October 21, 2010 Malik M Khan Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement
2/2/11. Administrative. L6: Memory Hierarchy Optimization IV, Bandwidth Optimization. Project Proposal (due 3/9) Faculty Project Suggestions
 Faculty Project Suggestions") Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES. Stephen Jones, GTC 2017
 CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES Stephen Jones, GTC 2017 The art of doing more with less 2 Performance RULE #1: DON T TRY TOO HARD Peak Performance Time 3 Unrealistic Effort/Reward Performance
CUDA OPTIMIZATION TIPS, TRICKS AND TECHNIQUES Stephen Jones, GTC 2017 The art of doing more with less 2 Performance RULE #1: DON T TRY TOO HARD Peak Performance Time 3 Unrealistic Effort/Reward Performance
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
Spring Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION. Julien Demouth, NVIDIA Cliff Woolley, NVIDIA
 CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION Julien Demouth, NVIDIA Cliff Woolley, NVIDIA WHAT WILL YOU LEARN? An iterative method to optimize your GPU code A way to conduct that method with NVIDIA
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
2/17/10. Administrative. L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies. Administrative, cont.
 Administrative L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies Next assignment on the website Description at end of class Due Wednesday, Feb. 17, 5PM Use handin program on
Administrative L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies Next assignment on the website Description at end of class Due Wednesday, Feb. 17, 5PM Use handin program on
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
Dense Linear Algebra. HPC - Algorithms and Applications
 Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Reductions and Low-Level Performance Considerations CME343 / ME May David Tarjan NVIDIA Research
 Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0. Julien Demouth, NVIDIA
 CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
CUDA Optimization with NVIDIA Nsight Visual Studio Edition 3.0 Julien Demouth, NVIDIA What Will You Learn? An iterative method to optimize your GPU code A way to conduct that method with Nsight VSE APOD
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
Profiling & Tuning Applications. CUDA Course István Reguly
 Profiling & Tuning Applications CUDA Course István Reguly Introduction Why is my application running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA, needs
Profiling & Tuning Applications CUDA Course István Reguly Introduction Why is my application running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA, needs
GPU Programming. Performance Considerations. Miaoqing Huang University of Arkansas Fall / 60
 1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
CUDA Experiences: Over-Optimization and Future HPC
 CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CSE 591: GPU Programming. Memories. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591: GPU Programming Memories Klaus Mueller Computer Science Department Stony Brook University Importance of Memory Access Efficiency Every loop iteration has two global memory accesses two floating
CSE 591: GPU Programming Memories Klaus Mueller Computer Science Department Stony Brook University Importance of Memory Access Efficiency Every loop iteration has two global memory accesses two floating
Memory. Lecture 2: different memory and variable types. Memory Hierarchy. CPU Memory Hierarchy. Main memory
 Memory Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Key challenge in modern computer architecture
Memory Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Key challenge in modern computer architecture
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Lecture 7. Overlap Using Shared Memory Performance programming the memory hierarchy
 Lecture 7 Overlap Using Shared Memory Performance programming the memory hierarchy Announcements Mac Mini lab (APM 2402) Starts Tuesday Every Tues and Fri for the next 2 weeks Project proposals due on
Lecture 7 Overlap Using Shared Memory Performance programming the memory hierarchy Announcements Mac Mini lab (APM 2402) Starts Tuesday Every Tues and Fri for the next 2 weeks Project proposals due on
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
Introduction to CUDA (1 of n*)
") Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION
 April 4-7, 2016 Silicon Valley CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION CHRISTOPH ANGERER, NVIDIA JAKOB PROGSCH, NVIDIA 1 WHAT YOU WILL LEARN An iterative method to optimize your GPU
April 4-7, 2016 Silicon Valley CUDA OPTIMIZATION WITH NVIDIA NSIGHT VISUAL STUDIO EDITION CHRISTOPH ANGERER, NVIDIA JAKOB PROGSCH, NVIDIA 1 WHAT YOU WILL LEARN An iterative method to optimize your GPU
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
Register File Organization
 Register File Organization Sudhakar Yalamanchili unless otherwise noted (1) To understand the organization of large register files used in GPUs Objective Identify the performance bottlenecks and opportunities
Register File Organization Sudhakar Yalamanchili unless otherwise noted (1) To understand the organization of large register files used in GPUs Objective Identify the performance bottlenecks and opportunities
VOLTA: PROGRAMMABILITY AND PERFORMANCE. Jack Choquette NVIDIA Hot Chips 2017
 VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Introduction to CUDA (1 of n*)
") Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
Lecture 2: different memory and variable types
 Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 2 p. 1 Memory Key challenge in modern
Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 2 p. 1 Memory Key challenge in modern
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
CSE 599 I Accelerated Computing - Programming GPUS. Memory performance
 CSE 599 I Accelerated Computing - Programming GPUS Memory performance GPU Teaching Kit Accelerated Computing Module 6.1 Memory Access Performance DRAM Bandwidth Objective To learn that memory bandwidth
CSE 599 I Accelerated Computing - Programming GPUS Memory performance GPU Teaching Kit Accelerated Computing Module 6.1 Memory Access Performance DRAM Bandwidth Objective To learn that memory bandwidth
Code Optimizations for High Performance GPU Computing
 Code Optimizations for High Performance GPU Computing Yi Yang and Huiyang Zhou Department of Electrical and Computer Engineering North Carolina State University 1 Question to answer Given a task to accelerate
Code Optimizations for High Performance GPU Computing Yi Yang and Huiyang Zhou Department of Electrical and Computer Engineering North Carolina State University 1 Question to answer Given a task to accelerate
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
 By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Spring 2009 Prof. Hyesoon Kim
 Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION
 CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION WHAT YOU WILL LEARN An iterative method to optimize your GPU code Some common bottlenecks to look out for Performance diagnostics with NVIDIA Nsight
CUDA OPTIMIZATION WITH NVIDIA NSIGHT ECLIPSE EDITION WHAT YOU WILL LEARN An iterative method to optimize your GPU code Some common bottlenecks to look out for Performance diagnostics with NVIDIA Nsight
Hands-on CUDA Optimization. CUDA Workshop
 Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Memory concept. Grid concept, Synchronization. GPU Programming. Szénási Sándor.
 Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
COSC 6339 Accelerators in Big Data
 COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
ME964 High Performance Computing for Engineering Applications
 ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
ME964 High Performance Computing for Engineering Applications Memory Issues in CUDA Execution Scheduling in CUDA February 23, 2012 Dan Negrut, 2012 ME964 UW-Madison Computers are useless. They can only
Performance optimization with CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide