|
|
|
- Loraine Scott
- 5 years ago
- Views:
Transcription
1
2
3
4
5
6
7
8 ./pharo Pharo.image eval 3 + 4
9 ./pharo Pharo.image my_script.st
10 BioSequence newdna: atcggtcggctta.
11 BioSequence newambiguousdna: AAGTCAGTGTACTATTAGCATGCATGTGCAACACATTAGCTG. BioSequence newunambiguousdna: AAGTCAGTGTACTATTAGCATGCATGTGCAACACATTAGCTG. BioSequence newrna: auugccuacauaggc. BioSequence newprotein: AGFAVENDSA. abiosequence( sequence_size ) ([ letters_in_alphabet ] alphabet_class) [sequence_letters] ATGCTAGN assequence. a BioSequence(8) ([GATCN] IUPAC DNA) [ ATGCTAGN] RSWAFFGH assequence. IUPAC > Protein) [RSWAFFGH] a BioSequence(8) ([ACDEFGHIKLMNPQRSTVWY]
12 AGCUCGGCU assequence. a BioSequence(9) ([GAUCRYWSMKHBVDN] IUPAC > RNA > Ambiguous) [AGCUCGGCU] VPFSNATGVVRSPFEYPQYYLAE assequence a BioSequence(23) ([ACDEFGHIKLMNPQRSTVWY] IUPAC > Protein) [ VPFSNATGVVRSPFEYPQYYLAE]
13 (BioMutableSeq newrna: auugccuacauaggc ) at: 1 put: $g; yourself. a BioMutableSeq(15) ([GAUC] IUPAC > RNA > Unambiguous) [ guugccuacauaggc] (BioMutableSeq newunambiguousdna: ATGC ) seq: CGTA ; yourself.
14 ((BioSequence newdna: atcggtcggctta ) copyfrom: 3 to: 5) asstring. > cgg (BioSequence newunambiguousdna: AAGTCAGTGTACTATTAGCATGGCTG ) size. > 26 AGTACACTGGT assequence molecularweightnondegen > AGTACACTGGT assequence gc. (BioSequence newdna: AAGTCAGTGTACTATTAGCATGCATGTGCAACACATTAGCTG ) complement a BioSequence(42) ([GATCN] IUPAC DNA) [ TTCAGTCACATGATAATCGTACGTACACGTTGTGTAATCGAC]
15 (BioSequence newambiguousdna: AcTG C NH ) reversecomplement. a BioSequence(9) ([ACGTWSMKRYBDHVN] IUPAC DNA > Ambiguous) [DN G CAgT] (BioSequence newunambiguousdna: GGGGaaaaaaaatttatatat ) reversecomplement a BioSequence(21) ([GATCN] IUPAC DNA) [ATATATAAATTTTTTTTCCCC] (BioMutableSeq newdna: AAGTCAGTGTACTATTAGCATGCATGTGCAACACATTAGCTG ) reversecomplement a BioMutableSeq(42) ([GATCN] IUPAC DNA) [ CAGCTAATGTGTTGCACATGCATGCTAATAGTACACTGACTT] myseq myseq := BioSequence newdna: AAGTCAGTGTACTATTAGCATGCATGTGCAACACATTAGCTG. myseq alphabet = myseq reversecomplement alphabet
16 (BioSequence newrna: AUGGCCAUUGUAAUGGGCCGCUGAAAGGGUGCCCGAUAG ) translate. a BioSequence(13) ([ACDEFGHIKLMNPQRSTVWY] IUPAC > Protein) [MAIVMGR *KGAR*] (BioSequence newrna: AUGGCCAUUGUAAUGGGCCGCUGAAAGGGUGCCCGAUAG ) translatetostop a BioSequence(7) ([ACDEFGHIKLMNPQRSTVWY] IUPAC > Protein) [MAIVMGR] dna protein dna := BioSequence newdna: atcggtcggctta. protein := BioSequence newprotein: AGFAVENDSA. protein, dna translate. (BioSequence newrna: AUGGCCAUUGUAAUGGGCCGCUGAAAGGGUGCCCGAUAG ) translatewithtableid: 2. a BioSequence(13) ([ACDEFGHIKLMNPQRSTVWY] IUPAC > Protein) [ MAIVMGRWKGAR*]
17 BioCodonTables currentcodontable a BioCodonTable [2] a Dictionary( AAA > K AAC > N AAG > K AAU > N ACA > T ACC > T ACG > T ACU > T AGC > S AGU > S AUA > M AUC > I AUG > M AUU > I CAA > Q CAC > H CAG > Q CAU > H CCA > P CCC > P CCG > P CCU > P CGA > R CGC > R CGG > R CGU > R CUA > L CUC > L CUG > L CUU > L GAA > E GAC > D GAG > E GAU > D GCA > A GCC > A GCG > A GCU > A GGA > G GGC > G GGG > G GGU > G GUA > V GUC > V GUG > V GUU > V UAC > Y UAU > Y UCA > S UCC > S UCG > S UCU > S UGA > W UGC > C UGG > W UGU > C UUA > L UUC > F UUG > L UUU > F ) BioCodonTables currentcodontable: BioCodonTables defaultcodontable
18 GTCG BioIUPACAlphabet ambiguousalphabets. --> an OrderedCollection( BioIUPACAmbiguousRNA BioIUPACAmbiguousDNA) BioIUPACAmbiguousDNA codes --> ACGTWSMKRYBDHVN BioIUPACAmbiguousRNA codes --> GAUCRYWSMKHBVDN BioIUPACAmbiguousDNA ambiguitycodes --> WSMKRYBDHVN BioIUPACAmbiguousRNA ambiguitycodes --> RYWSMKHBVDN
19 BioIUPACUnambiguousDNA codes --> GATCN BioIUPACUnambiguousRNA codes --> GAUC BioIUPACDNAExtended codes --> GATCBDSW BioIUPACProtein codes --> ACDEFGHIKLMNPQRSTVWY BioIUPACProteinExtended codes --> ACDEFGHIKLMNPQRSTVWYBXZJUO BioNullAlphabet codes --> - - sequence sequence := atcggtcggctta assequence. sequence alphabet. sequence := gccuacau assequence. sequence alphabet.
20 sequence sequence := BioSequence newprotein: mdstnvrsgmksrkkkpkttvidddddcmtcsacqslkllndfas. (BioSeqRecord new: sequence) id: P ; name: P20994 ; description: Protein A19 ; dbxrefs: #( Pfam:PF05077 InterPro:IPR DIP:2186N ); annotationat: #note put: A simple note ; yourself.
21 seq_records.xml BioMicrosatelliteLocus name: BM1818 ; chrlocation: D23S21 ; besimplerepeat; yourself
22
23 #dnasequence asparser matches: TCGTACGA. --> true #dnasequence asparser matches: TCGTZZZACGA. --> false
24 #dnasequence asparser parse: TCGTACGA. --> TCGTACGA #dnasequence asparser parse: TCGTA3344CGA. --> end of input expected at 5 BioParser parseaccession: CAF > a BioAccession CAF (BioParser parseaccession: CAF ) isversioned --> true
25 (BioParser parseaccession: CAF ) version --> 1 XP_ asaccession version --> 2 BioParser parsemultifasta: (BioFASTAFile on: my_sequenceshm.fasta ) contents. BioParser tokenizefastaheader: >gi ref NC_ Acidithiobacillus ferrooxidans ATCC chromosome, complete genome. #( >gi ref NC_ Acidithiobacillus ferrooxidans ATCC chromosome, complete genome ) fastastring fastastring := >gi emb Z CIZ78533 C.irapeanum 5.8S rrna gene and ITS1 and ITS2 DNA CGTAACAAGGTTTCCGTAGGTGAACCTGCGGAAGGATCATTGATGAGACCGTGGAATAAACGATCGAGTG AATCCGGAGGACCGGTGTACTCAGCTCACCGGGGGCATTGCTCCCGTGGTGACCCTGATTTGTTGTTGGG CCGCCTCGGGAGCGTCCATGGCGGGTTTGAACCTCTAGCCCGGCGCAGTTTGGGCGCCAAGCCATATGAA AGCATCACCGGCGAATGGCATTGTCTTCCCCAAAACCCGGAGCGGCGGCGTGCTGTCGCGTGCCCAATGA ATTTTGATGACTCTCGCAAACGGGAATCTTGGCTCTTTGCATCGGATGGAAGGACGCAGCGAAATGCGAT
26 AAGTGGTGTGAATTGCAAGATCCCGTGAACCATCGAGTCTTTTGAACGCAAGTTGCGCCCGAGGCCATCA GGCTAAGGGCACGCCTGCTTGGGCGTCGCGCTTCGTCTCTCTCCTGCCAATGCTTGCCCGGCATACAGCC AGGCCGGCGTGGTGCGGATGTGAAAGATTGGCCCCTTGTGCCTAGGTGCGGCGGGTCCAAGAGCTGGTGT TTTGATGGCCCGGAACCCGGCAAGAGGTGGACGGATGCTGGCAGCAGCTGCCGTGCGAATCCCCCATGTT GTCGTGCTTGTCGGACAGGCAGGAGAACCCTTCCGAACCCCAATGGAGGGCGGTTGACCGCCATTCGGAT GTGACCCCAGGTCAGGCGGGGGCACCCGCTGAGTTTACGC >gi emb Z CCZ78532 C.californicum 5.8S rrna gene and ITS1 and ITS2 DNA CGTAACAAGGTTTCCGTAGGTGAACCTGCGGAAGGATCATTGTTGAGACAACAGAATATATGATCGAGTG AATCTGGAGGACCTGTGGTAACTCAGCTCGTCGTGGCACTGCTTTTGTCGTGACCCTGCTTTGTTGTTGG GCCTCCTCAAGAGCTTTCATGGCAGGTTTGAACTTTAGTACGGTGCAGTTTGCGCCAAGTCATATAAAGC ATCACTGATGAATGACATTATTGTCAGAAAAAATCAGAGGGGCAGTATGCTACTGAGCATGCCAGTGAAT TTTTATGACTCTCGCAACGGATATCTTGGCTCTAACATCGATGAAGAACGCAGCTAAATGCGATAAGTGG TGTGAATTGCAGAATCCCGTGAACCATCGAGTCTTTGAACGCAAGTTGCGCTCGAGGCCATCAGGCTAAG GGCACGCCTGCCTGGGCGTCGTGTGTTGCGTCTCTCCTACCAATGCTTGCTTGGCATATCGCTAAGCTGG CATTATACGGATGTGAATGATTGGCCCCTTGTGCCTAGGTGCGGTGGGTCTAAGGATTGTTGCTTTGATG GGTAGGAATGTGGCACGAGGTGGAGAATGCTAACAGTCATAAGGCTGCTATTTGAATCCCCCATGTTGTT GTATTTTTTCGAACCTACACAAGAACCTAATTGAACCCCAATGGAGCTAAAATAACCATTGGGCAGTTGA TTTCCATTCAGATGCGACCCCAGGTCAGGCGGGGCCACCCGCTGAGTTGAGGC. (BioParser parsemultifasta: fastastring) do: [ : seqrecord Transcript show: seqrecord name; cr; show: seqrecord size; cr; cr ]
27 align := BioAlignment new. align addsequence: ACTGCTAGCTAG ; addsequence: ACT CTAGCTAG ; addsequence: ACTGCTAGATAG ; addsequence: ACTGCTTGCTAG ; addsequence: ACTGCTTGATAG.
28 search search := BioNCBIWebBlastWrapper new nucleotide query: TCGAAATAACGCGTGTTCTCAACGCGGTCGCGCAGATGCCTTTGCTCATC AGATGCGACCGCAACCACGTCCGCCGCCTTGTTCGCCGTCCCCGTGCCTC AACCACCACCACGGTGTCGTCTTCCCCGAACGCGTCCCGGTCAGCCAGCC TCCACGCGCCGCGCGCGCGGAGTGCCCATTCGGGCCGCAGCTGCGACGGT GCCGCTCAGATTCTGTGTGGCAGGCGCGTGTTGGAGTCTAAA ; hitlistsize: 200; filterlowcomplexity; expectvalue: 10; blastn; formattypexml;
29 fetch. search outputtofile: blast, BioObject currentseconds,.xml.
30 mfasta fpath fpath := BioObject testfilesfulldirectoryname, Fasta_example_1.fa. mfasta := BioParser parsemultifasta: (BioFASTAFile on: fpath) contents. mfasta collect: #occurrencesofletters an OrderedCollection(a Dictionary($A->24 $C->18 $G->25 $T->23 ) a Dictionary($A->33 $C->30 $G->23 $T->34 ) a Dictionary($A->25 $C->30 $G->15 $T->39 ) a Dictionary($A->17 $C->9 $G->19 $T->15 ) a Dictionary($A->26 $C->17 $G->36 $T->41 ) a Dictionary($A->8 $C->4 $ G->11 $T->31 ) a Dictionary($A->31 $C->16 $G->17 $T->22 ) a Dictionary($A->16 $C->14 $G->15 $T->25 ) a Dictionary($A->14 $C->20 $G->11 $T->21 ) a Dictionary($A->20 $C->29 $G->25 $T->41 ) a Dictionary($A->12 $C->14 $G->8 $T->26 ) a Dictionary($A->26 $C->8 $ G->11 $T->24 ) a Dictionary($A->36 $C->37 $G->16 $T->36 ) a Dictionary($A->30 $C->30 $G->33 $T->27 ) a Dictionary($A->14 $C->11 $G->13 $T->20 ) a Dictionary($A->34 $C->31 $G->20 $T->27 ) a Dictionary($A->23 $C->31 $G->29 $T->37 ) a Dictionary($A->30 $C->42 $G->25 $T->31 ) a Dictionary($A->7 $C->23 $G->5 $T->18 ) a Dictionary($A->15 $C->28 $G->6 $T->18 ) a Dictionary($A->23 $C->44 $G->12 $T->37 ))
31 mfasta filepath filepath := BioObject testfilesfulldirectoryname, Fasta_example_1.fa. mfasta := BioParser parsemultifasta: (BioFASTAFile on: filepath) contents. BioCSVFormatter new exportfrom: (mfasta collect: #occurrencesofletters). A;24 G;25 C;18 T;23 A;33 G;23 C;30 T;34 A;25 G;15 C;30 T;39...
32 (BioEntrezClient new protein term: NP_ ; usewebenv; setfasta; fetch) outputtofile: NP_ fasta (BioEntrezClient new protein term: NP_ ; usewebenv; setseqid; fetch) outputtofile: NP_ seqid
33 (BioEntrezClient new nuccore uids: #( ); setgb; fetch) outputtofile: fetchnuccore3.gb result result := BioEntrezClient new pubmed uids: #( ); setmodexml; fetch. result outputtofile: efetch1.xml (BioEntrezClient new protein term: insulin AND homo ; search) outputtofile: insulin AND homo_protein.xml
34

35 BioPEDMAPFilesLoader open. C:\BioSmalltalk\BioSmalltalkTestFiles\pedmap\sample_ped.ped > C:\ BioSmalltalk\BioSmalltalkTestFiles\pedmap\sample_ped.map
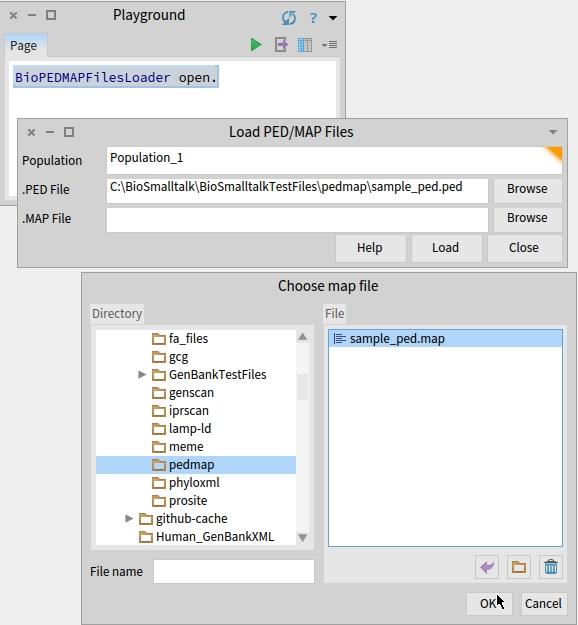
36
37 BioPEDMAPFilesLoader open actionblock: [ : pedfilename : mapfilename... ]
38 BioRTDotPlot x: BioSequence atrandom y: BioSequence atrandom; window: 3; threshold: 2;
39 open. BioRTDotPlot sequence: BioSequence atrandom; window: 3; threshold: 2; open. open. fastaseqs g ds seqrange Read and parse FASTA file with multiple sequences fastaseqs := (BioParser parsemultifastafile: BioObject testfilesdirectoryname asfilereference / ls_orchid.fasta ). Filter sequences seqrange := fastaseqs select: [ : fastarec fastarec size between: 750 and: 790 ]. Build diagram g := RTGrapher new extent: 200; yourself.
40 ds := RTStackedDataSet new. ds points: seqrange; x: #name; y: #size. ds barshape width: 10. ds histogramwithbartitle: [ : e (e sequencedescription first: 15),... ]. g add: ds. Configure axis settings g axisy title: Count ; nodecimal. g axisx nolabel; notick; title: Sequence length (bp). Open visualization in a new window g open.
41 BioChrSelector open. BioHMMERWrapper new help; execute.

42
43 samplesdir hmmfile stofile fastafile outputfile samplesdir := BioObject testfilesfulldirectoryname. hmmbuild globins4.hmm tutorial/globins4.sto hmmfile := samplesdir, globins4.hmm. stofile := samplesdir, globins4.sto. BioHMMERWrapper new addparameter: hmmfile; addparameter: stofile; runhmmbuild; execute. hmmsearch globins4.hmm uniprot sprot.fasta > globins4.out fastafile := samplesdir, globins45.fa. outputfile := samplesdir, globins4.out. BioHMMERWrapper new runhmmsearch; addparameter: hmmfile; addparameter: fastafile; addoption: o value: outputfile; execute.
44
45
46

47

48

49
50
51 mkdir /c/biosmalltalk cd /c/biosmalltalk wget -O- get.pharo.org/50+vm bash -./pharo Pharo.image config BioSmalltalk ConfigurationOfBioSmalltalk --printversion -- install=development mkdir /usr/local/src/biosmalltalk cd /usr/local/src/biosmalltalk wget -O- get.pharo.org/50+vm bash -./pharo Pharo.image config BioSmalltalk ConfigurationOfBioSmalltalk --printversion -- install=development
52 ./pharo Pharo.image & Gofer it smalltalkhubuser: hernan project: BioSmalltalk ; configurationof: BioSmalltalk ; loaddevelopment Metacello new smalltalkhubuser: hernan project: PhyloclassTalk ; configuration: PhyloclassTalk ; version: #development; load.

53

54
55 BioYourTestCase>>testFilesDirectoryName ^ super testfilesdirectoryname, BioObject filedirectoryclass slash, GenBankTestFiles
56 BioSerializationEngine serialize: anobject. (BioWebEngine for: anurl) httpget
57 BioSerializationEngine adapter #clientclass Answer a Symbol, the main external class name for this adapter #ispreferredadapter Private Answer <true> if the receiver is the best option for the current image and platform
58 ^ true
59
60
61 blastxmltree filter: [: hit hit name = Hit_def and: [ hit value = Homo sapiens ] ] blastxmltree hitdefinitionsequalto: Homo sapiens.
62 dbname See superimplementor s comment ^ sra
63 biosample Set and answer the receiver s working database ^ self database: (BioEntrezSample new client: self) self assert: (BioEntrezDatabase dbclassof: biosample ) = BioEntrezSample.
64 BioFileFormat isregistered: CSV. BioFileFormat fileextensionfor: FASTA. BioFileFormat registerformat: CSV extensions: #( csv ) description: General Comma Separated Values format rootclass: BioCSVFile
65
In Silico Modelling and Analysis of Ribosome Kinetics and aa-trna Competition
 In Silico Modelling and Analysis of Ribosome Kinetics and aa-trna Competition D. Bošnački 1, T.E. Pronk 2, and E.P. de Vink 3, 1 Dept. of Biomedical Engineering, Eindhoven University of Technology 2 Swammerdam
In Silico Modelling and Analysis of Ribosome Kinetics and aa-trna Competition D. Bošnački 1, T.E. Pronk 2, and E.P. de Vink 3, 1 Dept. of Biomedical Engineering, Eindhoven University of Technology 2 Swammerdam
Supplementary Materials:
 Supplementary Materials: Amino acid codo n Numb er Table S1. Codon usage in all the protein coding genes. RSC U Proportion (%) Amino acid codo n Numb er RSC U Proportion (%) Phe UUU 861 1.31 5.71 Ser UCU
Supplementary Materials: Amino acid codo n Numb er Table S1. Codon usage in all the protein coding genes. RSC U Proportion (%) Amino acid codo n Numb er RSC U Proportion (%) Phe UUU 861 1.31 5.71 Ser UCU
Appendix A. Example code output. Chapter 1. Chapter 3
 Appendix A Example code output This is a compilation of output from selected examples. Some of these examples requires exernal input from e.g. STDIN, for such examples the interaction with the program
Appendix A Example code output This is a compilation of output from selected examples. Some of these examples requires exernal input from e.g. STDIN, for such examples the interaction with the program
Genome Reconstruction: A Puzzle with a Billion Pieces Phillip E. C. Compeau and Pavel A. Pevzner
 Genome Reconstruction: A Puzzle with a Billion Pieces Phillip E. C. Compeau and Pavel A. Pevzner Outline I. Problem II. Two Historical Detours III.Example IV.The Mathematics of DNA Sequencing V.Complications
Genome Reconstruction: A Puzzle with a Billion Pieces Phillip E. C. Compeau and Pavel A. Pevzner Outline I. Problem II. Two Historical Detours III.Example IV.The Mathematics of DNA Sequencing V.Complications
by the Genevestigator program (www.genevestigator.com). Darker blue color indicates higher gene expression.
. Darker blue color indicates higher gene expression.") Figure S1. Tissue-specific expression profile of the genes that were screened through the RHEPatmatch and root-specific microarray filters. The gene expression profile (heat map) was drawn by the Genevestigator
Figure S1. Tissue-specific expression profile of the genes that were screened through the RHEPatmatch and root-specific microarray filters. The gene expression profile (heat map) was drawn by the Genevestigator
TCGR: A Novel DNA/RNA Visualization Technique
 TCGR: A Novel DNA/RNA Visualization Technique Donya Quick and Margaret H. Dunham Department of Computer Science and Engineering Southern Methodist University Dallas, Texas 75275 dquick@mail.smu.edu, mhd@engr.smu.edu
TCGR: A Novel DNA/RNA Visualization Technique Donya Quick and Margaret H. Dunham Department of Computer Science and Engineering Southern Methodist University Dallas, Texas 75275 dquick@mail.smu.edu, mhd@engr.smu.edu
Pyramidal and Chiral Groupings of Gold Nanocrystals Assembled Using DNA Scaffolds
 Pyramidal and Chiral Groupings of Gold Nanocrystals Assembled Using DNA Scaffolds February 27, 2009 Alexander Mastroianni, Shelley Claridge, A. Paul Alivisatos Department of Chemistry, University of California,
Pyramidal and Chiral Groupings of Gold Nanocrystals Assembled Using DNA Scaffolds February 27, 2009 Alexander Mastroianni, Shelley Claridge, A. Paul Alivisatos Department of Chemistry, University of California,
HP22.1 Roth Random Primer Kit A für die RAPD-PCR
 HP22.1 Roth Random Kit A für die RAPD-PCR Kit besteht aus 20 Einzelprimern, jeweils aufgeteilt auf 2 Reaktionsgefäße zu je 1,0 OD Achtung: Angaben beziehen sich jeweils auf ein Reaktionsgefäß! Sequenz
HP22.1 Roth Random Kit A für die RAPD-PCR Kit besteht aus 20 Einzelprimern, jeweils aufgeteilt auf 2 Reaktionsgefäße zu je 1,0 OD Achtung: Angaben beziehen sich jeweils auf ein Reaktionsgefäß! Sequenz
Genome 559 Intro to Statistical and Computational Genomics Lecture 18b: Biopython Larry Ruzzo (Thanks again to Mary Kuhner for many slides)
") Genome 559 Intro to Statistical and Computational Genomics 2009 Lecture 18b: Biopython Larry Ruzzo (Thanks again to Mary Kuhner for many slides) 1 1 Minute Responses Biopython is neat, makes me feel silly
Genome 559 Intro to Statistical and Computational Genomics 2009 Lecture 18b: Biopython Larry Ruzzo (Thanks again to Mary Kuhner for many slides) 1 1 Minute Responses Biopython is neat, makes me feel silly
Genome 559 Intro to Statistical and Computational Genomics. Lecture 17b: Biopython Larry Ruzzo
 Genome 559 Intro to Statistical and Computational Genomics Lecture 17b: Biopython Larry Ruzzo Biopython What is Biopython? How do I get it to run on my computer? What can it do? Biopython Biopython is
Genome 559 Intro to Statistical and Computational Genomics Lecture 17b: Biopython Larry Ruzzo Biopython What is Biopython? How do I get it to run on my computer? What can it do? Biopython Biopython is
Genome Reconstruction: A Puzzle with a Billion Pieces. Phillip Compeau Carnegie Mellon University Computational Biology Department
 http://cbd.cmu.edu Genome Reconstruction: A Puzzle with a Billion Pieces Phillip Compeau Carnegie Mellon University Computational Biology Department Eternity II: The Highest-Stakes Puzzle in History Courtesy:
http://cbd.cmu.edu Genome Reconstruction: A Puzzle with a Billion Pieces Phillip Compeau Carnegie Mellon University Computational Biology Department Eternity II: The Highest-Stakes Puzzle in History Courtesy:
6 Anhang. 6.1 Transgene Su(var)3-9-Linien. P{GS.ry + hs(su(var)3-9)egfp} 1 I,II,III,IV 3 2I 3 3 I,II,III 3 4 I,II,III 2 5 I,II,III,IV 3
3-9-Linien. P{GS.ry + hs(su(var)3-9)egfp} 1 I,II,III,IV 3 2I 3 3 I,II,III 3 4 I,II,III 2 5 I,II,III,IV 3") 6.1 Transgene Su(var)3-9-n P{GS.ry + hs(su(var)3-9)egfp} 1 I,II,III,IV 3 2I 3 3 I,II,III 3 4 I,II,II 5 I,II,III,IV 3 6 7 I,II,II 8 I,II,II 10 I,II 3 P{GS.ry + UAS(Su(var)3-9)EGFP} A AII 3 B P{GS.ry + (10.5kbSu(var)3-9EGFP)}
6.1 Transgene Su(var)3-9-n P{GS.ry + hs(su(var)3-9)egfp} 1 I,II,III,IV 3 2I 3 3 I,II,III 3 4 I,II,II 5 I,II,III,IV 3 6 7 I,II,II 8 I,II,II 10 I,II 3 P{GS.ry + UAS(Su(var)3-9)EGFP} A AII 3 B P{GS.ry + (10.5kbSu(var)3-9EGFP)}
Sequence Alignment. GBIO0002 Archana Bhardwaj University of Liege
 Sequence Alignment GBIO0002 Archana Bhardwaj University of Liege 1 What is Sequence Alignment? A sequence alignment is a way of arranging the sequences of DNA, RNA, or protein to identify regions of similarity.
Sequence Alignment GBIO0002 Archana Bhardwaj University of Liege 1 What is Sequence Alignment? A sequence alignment is a way of arranging the sequences of DNA, RNA, or protein to identify regions of similarity.
SUPPLEMENTARY INFORMATION. Systematic evaluation of CRISPR-Cas systems reveals design principles for genome editing in human cells
 SUPPLEMENTARY INFORMATION Systematic evaluation of CRISPR-Cas systems reveals design principles for genome editing in human cells Yuanming Wang 1,2,7, Kaiwen Ivy Liu 2,7, Norfala-Aliah Binte Sutrisnoh
SUPPLEMENTARY INFORMATION Systematic evaluation of CRISPR-Cas systems reveals design principles for genome editing in human cells Yuanming Wang 1,2,7, Kaiwen Ivy Liu 2,7, Norfala-Aliah Binte Sutrisnoh
Tutorial 4 BLAST Searching the CHO Genome
 Tutorial 4 BLAST Searching the CHO Genome Accessing the CHO Genome BLAST Tool The CHO BLAST server can be accessed by clicking on the BLAST button on the home page or by selecting BLAST from the menu bar
Tutorial 4 BLAST Searching the CHO Genome Accessing the CHO Genome BLAST Tool The CHO BLAST server can be accessed by clicking on the BLAST button on the home page or by selecting BLAST from the menu bar
How to Run NCBI BLAST on zcluster at GACRC
 How to Run NCBI BLAST on zcluster at GACRC BLAST: Basic Local Alignment Search Tool Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu 1 OVERVIEW What is BLAST?
How to Run NCBI BLAST on zcluster at GACRC BLAST: Basic Local Alignment Search Tool Georgia Advanced Computing Resource Center University of Georgia Suchitra Pakala pakala@uga.edu 1 OVERVIEW What is BLAST?
WSSP-10 Chapter 7 BLASTN: DNA vs DNA searches
 WSSP-10 Chapter 7 BLASTN: DNA vs DNA searches 4-3 DSAP: BLASTn Page p. 7-1 NCBI BLAST Home Page p. 7-1 NCBI BLASTN search page p. 7-2 Copy sequence from DSAP or wave form program p. 7-2 Choose a database
WSSP-10 Chapter 7 BLASTN: DNA vs DNA searches 4-3 DSAP: BLASTn Page p. 7-1 NCBI BLAST Home Page p. 7-1 NCBI BLASTN search page p. 7-2 Copy sequence from DSAP or wave form program p. 7-2 Choose a database
warm-up exercise Representing Data Digitally goals for today proteins example from nature
 Representing Data Digitally Anne Condon September 6, 007 warm-up exercise pick two examples of in your everyday life* in what media are the is represented? is the converted from one representation to another,
Representing Data Digitally Anne Condon September 6, 007 warm-up exercise pick two examples of in your everyday life* in what media are the is represented? is the converted from one representation to another,
Biopython. Karin Lagesen.
 Biopython Karin Lagesen karin.lagesen@bio.uio.no Object oriented programming Biopython is object-oriented Some knowledge helps understand how biopython works OOP is a way of organizing data and methods
Biopython Karin Lagesen karin.lagesen@bio.uio.no Object oriented programming Biopython is object-oriented Some knowledge helps understand how biopython works OOP is a way of organizing data and methods
Efficient Selection of Unique and Popular Oligos for Large EST Databases. Stefano Lonardi. University of California, Riverside
 Efficient Selection of Unique and Popular Oligos for Large EST Databases Stefano Lonardi University of California, Riverside joint work with Jie Zheng, Timothy Close, Tao Jiang University of California,
Efficient Selection of Unique and Popular Oligos for Large EST Databases Stefano Lonardi University of California, Riverside joint work with Jie Zheng, Timothy Close, Tao Jiang University of California,
Sequencing. Short Read Alignment. Sequencing. Paired-End Sequencing 6/10/2010. Tobias Rausch 7 th June 2010 WGS. ChIP-Seq. Applied Biosystems.
 Sequencing Short Alignment Tobias Rausch 7 th June 2010 WGS RNA-Seq Exon Capture ChIP-Seq Sequencing Paired-End Sequencing Target genome Fragments Roche GS FLX Titanium Illumina Applied Biosystems SOLiD
Sequencing Short Alignment Tobias Rausch 7 th June 2010 WGS RNA-Seq Exon Capture ChIP-Seq Sequencing Paired-End Sequencing Target genome Fragments Roche GS FLX Titanium Illumina Applied Biosystems SOLiD
(DNA#): Molecular Biology Computation Language Proposal
: Molecular Biology Computation Language Proposal") (DNA#): Molecular Biology Computation Language Proposal Aalhad Patankar, Min Fan, Nan Yu, Oriana Fuentes, Stan Peceny {ap3536, mf3084, ny2263, oif2102, skp2140} @columbia.edu Motivation Inspired by the
(DNA#): Molecular Biology Computation Language Proposal Aalhad Patankar, Min Fan, Nan Yu, Oriana Fuentes, Stan Peceny {ap3536, mf3084, ny2263, oif2102, skp2140} @columbia.edu Motivation Inspired by the
SEQUENCE MATCHING IN HOLOGRAPHICALLY STORED GENETIC STRINGS JOSEPH LEGARDE MERKLING, B.S., B.S. A THESIS ELECTRICAL ENGINEERING
 SEQUENCE MATCHING IN HOLOGRAPHICALLY STORED GENETIC STRINGS by JOSEPH LEGARDE MERKLING, B.S., B.S. A THESIS IN ELECTRICAL ENGINEERING Submitted to the Graduate Faculty of Texas Tech University in Partial
SEQUENCE MATCHING IN HOLOGRAPHICALLY STORED GENETIC STRINGS by JOSEPH LEGARDE MERKLING, B.S., B.S. A THESIS IN ELECTRICAL ENGINEERING Submitted to the Graduate Faculty of Texas Tech University in Partial
Genomic Perl. From Bioinformatics Basics to Working Code REX A. DWYER. Genomic Perl Consultancy, Inc.
 Genomic Perl From Bioinformatics Basics to Working Code REX A. DWYER Genomic Perl Consultancy, Inc. published by the press syndicate of the university of cambridge The Pitt Building, Trumpington Street,
Genomic Perl From Bioinformatics Basics to Working Code REX A. DWYER Genomic Perl Consultancy, Inc. published by the press syndicate of the university of cambridge The Pitt Building, Trumpington Street,
2. Take a few minutes to look around the site. The goal is to familiarize yourself with a few key components of the NCBI.
 2 Navigating the NCBI Instructions Aim: To become familiar with the resources available at the National Center for Bioinformatics (NCBI) and the search engine Entrez. Instructions: Write the answers to
2 Navigating the NCBI Instructions Aim: To become familiar with the resources available at the National Center for Bioinformatics (NCBI) and the search engine Entrez. Instructions: Write the answers to
PLAYING WITH PYTHON: DE-CODING DNA
 PLAYING WITH PYTHON: DE-CODING DNA A quick recap of the range function. The range you know: range with start/stop Range with variable steps print range(5) [0, 1, 2, 3, 4] print range(1,5) [1, 2, 3, 4]
PLAYING WITH PYTHON: DE-CODING DNA A quick recap of the range function. The range you know: range with start/stop Range with variable steps print range(5) [0, 1, 2, 3, 4] print range(1,5) [1, 2, 3, 4]
from scratch A primer for scientists working with Next-Generation- Sequencing data CHAPTER 8 biopython
 from scratch A primer for scientists working with Next-Generation- Sequencing data CHAPTER 8 biopython Chapter 8: Biopython Biopython is a collection of modules that implement common bioinformatical tasks
from scratch A primer for scientists working with Next-Generation- Sequencing data CHAPTER 8 biopython Chapter 8: Biopython Biopython is a collection of modules that implement common bioinformatical tasks
2) NCBI BLAST tutorial This is a users guide written by the education department at NCBI.
 NCBI BLAST tutorial This is a users guide written by the education department at NCBI.") Web resources -- Tour. page 1 of 8 This is a guided tour. Any homework is separate. In fact, this exercise is used for multiple classes and is publicly available to everyone. The entire tour will take
Web resources -- Tour. page 1 of 8 This is a guided tour. Any homework is separate. In fact, this exercise is used for multiple classes and is publicly available to everyone. The entire tour will take
Computational Theory MAT542 (Computational Methods in Genomics) - Part 2 & 3 -
 - Part 2 & 3 -") Computational Theory MAT542 (Computational Methods in Genomics) - Part 2 & 3 - Benjamin King Mount Desert Island Biological Laboratory bking@mdibl.org Overview of 4 Lectures Introduction to Computation
Computational Theory MAT542 (Computational Methods in Genomics) - Part 2 & 3 - Benjamin King Mount Desert Island Biological Laboratory bking@mdibl.org Overview of 4 Lectures Introduction to Computation
A relation between trinucleotide comma-free codes and trinucleotide circular codes
 Theoretical Computer Science 401 (2008) 17 26 www.elsevier.com/locate/tcs A relation between trinucleotide comma-free codes and trinucleotide circular codes Christian J. Michel a,, Giuseppe Pirillo b,c,
Theoretical Computer Science 401 (2008) 17 26 www.elsevier.com/locate/tcs A relation between trinucleotide comma-free codes and trinucleotide circular codes Christian J. Michel a,, Giuseppe Pirillo b,c,
BMMB 597D - Practical Data Analysis for Life Scientists. Week 12 -Lecture 23. István Albert Huck Institutes for the Life Sciences
 BMMB 597D - Practical Data Analysis for Life Scientists Week 12 -Lecture 23 István Albert Huck Institutes for the Life Sciences Tapping into data sources Entrez: Cross-Database Search System EntrezGlobal
BMMB 597D - Practical Data Analysis for Life Scientists Week 12 -Lecture 23 István Albert Huck Institutes for the Life Sciences Tapping into data sources Entrez: Cross-Database Search System EntrezGlobal
MetaPhyler Usage Manual
 MetaPhyler Usage Manual Bo Liu boliu@umiacs.umd.edu March 13, 2012 Contents 1 What is MetaPhyler 1 2 Installation 1 3 Quick Start 2 3.1 Taxonomic profiling for metagenomic sequences.............. 2 3.2
MetaPhyler Usage Manual Bo Liu boliu@umiacs.umd.edu March 13, 2012 Contents 1 What is MetaPhyler 1 2 Installation 1 3 Quick Start 2 3.1 Taxonomic profiling for metagenomic sequences.............. 2 3.2
Introduction to Biopython
 Introduction to Biopython Python libraries for computational molecular biology http://www.biopython.org Biopython functionality and tools Tools to parse bioinformatics files into Python data structures
Introduction to Biopython Python libraries for computational molecular biology http://www.biopython.org Biopython functionality and tools Tools to parse bioinformatics files into Python data structures
Python for Bioinformatics
 Python for Bioinformatics A look into the BioPython world... Christian Skjødt csh@cbs.dtu.dk Today s program 09-10: 10-12: 12-13: 13-13.30: 13.30-16: 16:00-17: Lecture: Introduction to BioPython Exercise:
Python for Bioinformatics A look into the BioPython world... Christian Skjødt csh@cbs.dtu.dk Today s program 09-10: 10-12: 12-13: 13-13.30: 13.30-16: 16:00-17: Lecture: Introduction to BioPython Exercise:
Due Thursday, July 18 at 11:00AM
 CS106B Summer 2013 Handout #10 July 10, 2013 Assignment 3: Recursion! Parts of this handout were written by Julie Zelenski, Jerry Cain, and Eric Roberts. This assignment consists of four recursive functions
CS106B Summer 2013 Handout #10 July 10, 2013 Assignment 3: Recursion! Parts of this handout were written by Julie Zelenski, Jerry Cain, and Eric Roberts. This assignment consists of four recursive functions
Sequence Assembly. BMI/CS 576 Mark Craven Some sequencing successes
 Sequence Assembly BMI/CS 576 www.biostat.wisc.edu/bmi576/ Mark Craven craven@biostat.wisc.edu Some sequencing successes Yersinia pestis Cannabis sativa The sequencing problem We want to determine the identity
Sequence Assembly BMI/CS 576 www.biostat.wisc.edu/bmi576/ Mark Craven craven@biostat.wisc.edu Some sequencing successes Yersinia pestis Cannabis sativa The sequencing problem We want to determine the identity
Figure 2.1: Simple model of a communication system
 Chapter 2 Codes In the previous chapter we examined the fundamental unit of information, the bit, and its various abstract representations: the mathematical bit, the control bit, the classical bit, and
Chapter 2 Codes In the previous chapter we examined the fundamental unit of information, the bit, and its various abstract representations: the mathematical bit, the control bit, the classical bit, and
Channel. Figure 2.1: Simple model of a communication system
 Chapter 2 Codes In the previous chapter we examined the fundamental unit of information, the bit, and its various abstract representations: the Boolean bit (with its associated Boolean algebra and realization
Chapter 2 Codes In the previous chapter we examined the fundamental unit of information, the bit, and its various abstract representations: the Boolean bit (with its associated Boolean algebra and realization
Digging into acceptor splice site prediction: an iterative feature selection approach
 Digging into acceptor splice site prediction: an iterative feature selection approach Yvan Saeys, Sven Degroeve, and Yves Van de Peer Department of Plant Systems Biology, Ghent University, Flanders Interuniversity
Digging into acceptor splice site prediction: an iterative feature selection approach Yvan Saeys, Sven Degroeve, and Yves Van de Peer Department of Plant Systems Biology, Ghent University, Flanders Interuniversity
Figure 2.1: Simple model of a communication system
 Chapter 2 Codes In the previous chapter we examined the fundamental unit of information, the bit, and its physical forms (the quantum bit and the classical bit), its classical mathematical model (the Boolean
Chapter 2 Codes In the previous chapter we examined the fundamental unit of information, the bit, and its physical forms (the quantum bit and the classical bit), its classical mathematical model (the Boolean
Machine Learning Classifiers
 Machine Learning Classifiers Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve Bayes Perceptrons, Multi-layer Neural Networks
Machine Learning Classifiers Outline Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve Bayes Perceptrons, Multi-layer Neural Networks
PERFORMANCE ANALYSIS OF DATAMINIG TECHNIQUE IN RBC, WBC and PLATELET CANCER DATASETS
 PERFORMANCE ANALYSIS OF DATAMINIG TECHNIQUE IN RBC, WBC and PLATELET CANCER DATASETS Mayilvaganan M 1 and Hemalatha 2 1 Associate Professor, Department of Computer Science, PSG College of arts and science,
PERFORMANCE ANALYSIS OF DATAMINIG TECHNIQUE IN RBC, WBC and PLATELET CANCER DATASETS Mayilvaganan M 1 and Hemalatha 2 1 Associate Professor, Department of Computer Science, PSG College of arts and science,
Crick s Hypothesis Revisited: The Existence of a Universal Coding Frame
 Crick s Hypothesis Revisited: The Existence of a Universal Coding Frame Jean-Louis Lassez*, Ryan A. Rossi Computer Science Department, Coastal Carolina University jlassez@coastal.edu, raross@coastal.edu
Crick s Hypothesis Revisited: The Existence of a Universal Coding Frame Jean-Louis Lassez*, Ryan A. Rossi Computer Science Department, Coastal Carolina University jlassez@coastal.edu, raross@coastal.edu
User's guide: Manual for V-Xtractor 2.0
 User's guide: Manual for V-Xtractor 2.0 This is a guide to install and use the software utility V-Xtractor. The software is reasonably platform-independent. The instructions below should work fine with
User's guide: Manual for V-Xtractor 2.0 This is a guide to install and use the software utility V-Xtractor. The software is reasonably platform-independent. The instructions below should work fine with
Assembly in the Clouds
 Assembly in the Clouds Michael Schatz October 13, 2010 Beyond the Genome Shredded Book Reconstruction Dickens accidentally shreds the first printing of A Tale of Two Cities Text printed on 5 long spools
Assembly in the Clouds Michael Schatz October 13, 2010 Beyond the Genome Shredded Book Reconstruction Dickens accidentally shreds the first printing of A Tale of Two Cities Text printed on 5 long spools
Supplementary Data. Image Processing Workflow Diagram A - Preprocessing. B - Hough Transform. C - Angle Histogram (Rose Plot)
") Supplementary Data Image Processing Workflow Diagram A - Preprocessing B - Hough Transform C - Angle Histogram (Rose Plot) D - Determination of holes Description of Image Processing Workflow The key steps
Supplementary Data Image Processing Workflow Diagram A - Preprocessing B - Hough Transform C - Angle Histogram (Rose Plot) D - Determination of holes Description of Image Processing Workflow The key steps
NOSEP: Non-Overlapping Sequence Pattern Mining with Gap Constraints
 1 NOSEP: Non-Overlapping Sequence Pattern Mining with Gap Constraints Youxi Wu, Yao Tong, Xingquan Zhu, Senior, IEEE, and Xindong Wu, Fellow, IEEE Abstract Sequence pattern mining aims to discover frequent
1 NOSEP: Non-Overlapping Sequence Pattern Mining with Gap Constraints Youxi Wu, Yao Tong, Xingquan Zhu, Senior, IEEE, and Xindong Wu, Fellow, IEEE Abstract Sequence pattern mining aims to discover frequent
INTRODUCTION TO BIOINFORMATICS
 Molecular Biology-2019 1 INTRODUCTION TO BIOINFORMATICS In this section, we want to provide a simple introduction to using the web site of the National Center for Biotechnology Information NCBI) to obtain
Molecular Biology-2019 1 INTRODUCTION TO BIOINFORMATICS In this section, we want to provide a simple introduction to using the web site of the National Center for Biotechnology Information NCBI) to obtain
BGGN 213 Foundations of Bioinformatics Barry Grant
 BGGN 213 Foundations of Bioinformatics Barry Grant http://thegrantlab.org/bggn213 Recap From Last Time: 25 Responses: https://tinyurl.com/bggn213-02-f17 Why ALIGNMENT FOUNDATIONS Why compare biological
BGGN 213 Foundations of Bioinformatics Barry Grant http://thegrantlab.org/bggn213 Recap From Last Time: 25 Responses: https://tinyurl.com/bggn213-02-f17 Why ALIGNMENT FOUNDATIONS Why compare biological
Notes for installing a local blast+ instance of NCBI BLAST F. J. Pineda 09/25/2017
 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 Notes for installing a local blast+ instance of NCBI BLAST F. J. Pineda 09/25/2017
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 Notes for installing a local blast+ instance of NCBI BLAST F. J. Pineda 09/25/2017
INTRODUCTION TO BIOINFORMATICS
 Molecular Biology-2017 1 INTRODUCTION TO BIOINFORMATICS In this section, we want to provide a simple introduction to using the web site of the National Center for Biotechnology Information NCBI) to obtain
Molecular Biology-2017 1 INTRODUCTION TO BIOINFORMATICS In this section, we want to provide a simple introduction to using the web site of the National Center for Biotechnology Information NCBI) to obtain
HymenopteraMine Documentation
 HymenopteraMine Documentation Release 1.0 Aditi Tayal, Deepak Unni, Colin Diesh, Chris Elsik, Darren Hagen Apr 06, 2017 Contents 1 Welcome to HymenopteraMine 3 1.1 Overview of HymenopteraMine.....................................
HymenopteraMine Documentation Release 1.0 Aditi Tayal, Deepak Unni, Colin Diesh, Chris Elsik, Darren Hagen Apr 06, 2017 Contents 1 Welcome to HymenopteraMine 3 1.1 Overview of HymenopteraMine.....................................
DNA Sequencing. Overview
 BINF 3350, Genomics and Bioinformatics DNA Sequencing Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Backgrounds Eulerian Cycles Problem Hamiltonian Cycles
BINF 3350, Genomics and Bioinformatics DNA Sequencing Young-Rae Cho Associate Professor Department of Computer Science Baylor University Overview Backgrounds Eulerian Cycles Problem Hamiltonian Cycles
Introduction to Unix/Linux INX_S17, Day 6,
 Introduction to Unix/Linux INX_S17, Day 6, 2017-04-17 Installing binaries, uname, hmmer and muscle, public data (wget and sftp) Learning Outcome(s): Install and run software from your home directory. Download
Introduction to Unix/Linux INX_S17, Day 6, 2017-04-17 Installing binaries, uname, hmmer and muscle, public data (wget and sftp) Learning Outcome(s): Install and run software from your home directory. Download
Exercises. Biological Data Analysis Using InterMine workshop exercises with answers
 Exercises Biological Data Analysis Using InterMine workshop exercises with answers Exercise1: Faceted Search Use HumanMine for this exercise 1. Search for one or more of the following using the keyword
Exercises Biological Data Analysis Using InterMine workshop exercises with answers Exercise1: Faceted Search Use HumanMine for this exercise 1. Search for one or more of the following using the keyword
Practical Course in Genome Bioinformatics
 Practical Course in Genome Bioinformatics 20/01/2017 Exercises - Day 1 http://ekhidna.biocenter.helsinki.fi/downloads/teaching/spring2017/ Answer questions Q1-Q3 below and include requested Figures 1-5
Practical Course in Genome Bioinformatics 20/01/2017 Exercises - Day 1 http://ekhidna.biocenter.helsinki.fi/downloads/teaching/spring2017/ Answer questions Q1-Q3 below and include requested Figures 1-5
Bioinformatics I, WS 09-10, D. Huson, February 10,
 Bioinformatics I, WS 09-10, D. Huson, February 10, 2010 189 12 More on Suffix Trees This week we study the following material: WOTD-algorithm MUMs finding repeats using suffix trees 12.1 The WOTD Algorithm
Bioinformatics I, WS 09-10, D. Huson, February 10, 2010 189 12 More on Suffix Trees This week we study the following material: WOTD-algorithm MUMs finding repeats using suffix trees 12.1 The WOTD Algorithm
Scalable Solutions for DNA Sequence Analysis
 Scalable Solutions for DNA Sequence Analysis Michael Schatz Dec 4, 2009 JHU/UMD Joint Sequencing Meeting The Evolution of DNA Sequencing Year Genome Technology Cost 2001 Venter et al. Sanger (ABI) $300,000,000
Scalable Solutions for DNA Sequence Analysis Michael Schatz Dec 4, 2009 JHU/UMD Joint Sequencing Meeting The Evolution of DNA Sequencing Year Genome Technology Cost 2001 Venter et al. Sanger (ABI) $300,000,000
Programming Languages and Uses in Bioinformatics
 Programming in Perl Programming Languages and Uses in Bioinformatics Perl, Python Pros: reformatting data files reading, writing and parsing files building web pages and database access building work flow
Programming in Perl Programming Languages and Uses in Bioinformatics Perl, Python Pros: reformatting data files reading, writing and parsing files building web pages and database access building work flow
Zero Configuration Scripts and Command-Line Handlers
 Zero Configuration Scripts and Command-Line Handlers Chapter 1 Zero Configuration Scripts and Command-Line Handlers with the participation of: Camillo Bruni (camillobruni@gmail.com) Weren t you fed up
Zero Configuration Scripts and Command-Line Handlers Chapter 1 Zero Configuration Scripts and Command-Line Handlers with the participation of: Camillo Bruni (camillobruni@gmail.com) Weren t you fed up
ICB Fall G4120: Introduction to Computational Biology. Oliver Jovanovic, Ph.D. Columbia University Department of Microbiology
 ICB Fall 2008 G4120: Computational Biology Oliver Jovanovic, Ph.D. Columbia University Department of Microbiology Copyright 2008 Oliver Jovanovic, All Rights Reserved. The Digital Language of Computers
ICB Fall 2008 G4120: Computational Biology Oliver Jovanovic, Ph.D. Columbia University Department of Microbiology Copyright 2008 Oliver Jovanovic, All Rights Reserved. The Digital Language of Computers
Data Mining for Bioinformatics
 Data Mining for Bioinformatics Sumeet Dua Pradeep Chowriappa Data Mining for Bioinformatics Data Mining for Bioinformatics Sumeet Dua Pradeep Chowriappa CRC Press Taylor & Francis Group 6000 Broken Sound
Data Mining for Bioinformatics Sumeet Dua Pradeep Chowriappa Data Mining for Bioinformatics Data Mining for Bioinformatics Sumeet Dua Pradeep Chowriappa CRC Press Taylor & Francis Group 6000 Broken Sound
Supplementary Table 1. Data collection and refinement statistics
 Supplementary Table 1. Data collection and refinement statistics APY-EphA4 APY-βAla8.am-EphA4 Crystal Space group P2 1 P2 1 Cell dimensions a, b, c (Å) 36.27, 127.7, 84.57 37.22, 127.2, 84.6 α, β, γ (
Supplementary Table 1. Data collection and refinement statistics APY-EphA4 APY-βAla8.am-EphA4 Crystal Space group P2 1 P2 1 Cell dimensions a, b, c (Å) 36.27, 127.7, 84.57 37.22, 127.2, 84.6 α, β, γ (
Essential Skills for Bioinformatics: Unix/Linux
 Essential Skills for Bioinformatics: Unix/Linux SHELL SCRIPTING Overview Bash, the shell we have used interactively in this course, is a full-fledged scripting language. Unlike Python, Bash is not a general-purpose
Essential Skills for Bioinformatics: Unix/Linux SHELL SCRIPTING Overview Bash, the shell we have used interactively in this course, is a full-fledged scripting language. Unlike Python, Bash is not a general-purpose
Purpose of sequence assembly
 Sequence Assembly Purpose of sequence assembly Reconstruct long DNA/RNA sequences from short sequence reads Genome sequencing RNA sequencing for gene discovery Amplicon sequencing But not for transcript
Sequence Assembly Purpose of sequence assembly Reconstruct long DNA/RNA sequences from short sequence reads Genome sequencing RNA sequencing for gene discovery Amplicon sequencing But not for transcript
Scientific Programming Practical 10
 Scientific Programming Practical 10 Introduction Luca Bianco - Academic Year 2017-18 luca.bianco@fmach.it Biopython FROM Biopython s website: The Biopython Project is an international association of developers
Scientific Programming Practical 10 Introduction Luca Bianco - Academic Year 2017-18 luca.bianco@fmach.it Biopython FROM Biopython s website: The Biopython Project is an international association of developers
Introduction to Matlab. Sasha Lukyanov, 2018 Xenopus Bioinformatics Workshop, MBL, Woods Hole
 Introduction to Matlab Sasha Lukyanov, 2018 Xenopus Bioinformatics Workshop, MBL, Woods Hole MATLAB Environment This image cannot currently be displayed. What do we use? Help? If you know the name of the
Introduction to Matlab Sasha Lukyanov, 2018 Xenopus Bioinformatics Workshop, MBL, Woods Hole MATLAB Environment This image cannot currently be displayed. What do we use? Help? If you know the name of the
LABORATORY STANDARD OPERATING PROCEDURE FOR PULSENET CODE: PNL28 MLVA OF SHIGA TOXIN-PRODUCING ESCHERICHIA COLI
 1. PURPOSE: to describe the standardized laboratory protocol for molecular subtyping of Shiga toxin-producing Escherichia coli O157 (STEC O157) and Salmonella enterica serotypes Typhimurium and Enteritidis.
1. PURPOSE: to describe the standardized laboratory protocol for molecular subtyping of Shiga toxin-producing Escherichia coli O157 (STEC O157) and Salmonella enterica serotypes Typhimurium and Enteritidis.
Combinatorial Pattern Matching
 Combinatorial Pattern Matching Outline Hash Tables Repeat Finding Exact Pattern Matching Keyword Trees Suffix Trees Heuristic Similarity Search Algorithms Approximate String Matching Filtration Comparing
Combinatorial Pattern Matching Outline Hash Tables Repeat Finding Exact Pattern Matching Keyword Trees Suffix Trees Heuristic Similarity Search Algorithms Approximate String Matching Filtration Comparing
Introduction to Biopython. Iddo Friedberg Associate Professor College of Veterinary Medicine (based on a slides by Stuart Brown, NYU)
") Introduction to Biopython Iddo Friedberg Associate Professor College of Veterinary Medicine (based on a slides by Stuart Brown, NYU) Learning Goals Biopython as a toolkit Seq objects and their methods
Introduction to Biopython Iddo Friedberg Associate Professor College of Veterinary Medicine (based on a slides by Stuart Brown, NYU) Learning Goals Biopython as a toolkit Seq objects and their methods
Computational Molecular Biology
 Computational Molecular Biology Erwin M. Bakker Lecture 3, mainly from material by R. Shamir [2] and H.J. Hoogeboom [4]. 1 Pairwise Sequence Alignment Biological Motivation Algorithmic Aspect Recursive
Computational Molecular Biology Erwin M. Bakker Lecture 3, mainly from material by R. Shamir [2] and H.J. Hoogeboom [4]. 1 Pairwise Sequence Alignment Biological Motivation Algorithmic Aspect Recursive
ChIP-seq (NGS) Data Formats
 Data Formats") ChIP-seq (NGS) Data Formats Biological samples Sequence reads SRA/SRF, FASTQ Quality control SAM/BAM/Pileup?? Mapping Assembly... DE Analysis Variant Detection Peak Calling...? Counts, RPKM VCF BED/narrowPeak/
ChIP-seq (NGS) Data Formats Biological samples Sequence reads SRA/SRF, FASTQ Quality control SAM/BAM/Pileup?? Mapping Assembly... DE Analysis Variant Detection Peak Calling...? Counts, RPKM VCF BED/narrowPeak/
Alignments BLAST, BLAT
 Alignments BLAST, BLAT Genome Genome Gene vs Built of DNA DNA Describes Organism Protein gene Stored as Circular/ linear Single molecule, or a few of them Both (depending on the species) Part of genome
Alignments BLAST, BLAT Genome Genome Gene vs Built of DNA DNA Describes Organism Protein gene Stored as Circular/ linear Single molecule, or a few of them Both (depending on the species) Part of genome
BLAST. Jon-Michael Deldin. Dept. of Computer Science University of Montana Mon
 BLAST Jon-Michael Deldin Dept. of Computer Science University of Montana jon-michael.deldin@mso.umt.edu 2011-09-19 Mon Jon-Michael Deldin (UM) BLAST 2011-09-19 Mon 1 / 23 Outline 1 Goals 2 Setting up your
BLAST Jon-Michael Deldin Dept. of Computer Science University of Montana jon-michael.deldin@mso.umt.edu 2011-09-19 Mon Jon-Michael Deldin (UM) BLAST 2011-09-19 Mon 1 / 23 Outline 1 Goals 2 Setting up your
CSCI2950-C Lecture 4 DNA Sequencing and Fragment Assembly
 CSCI2950-C Lecture 4 DNA Sequencing and Fragment Assembly Ben Raphael Sept. 22, 2009 http://cs.brown.edu/courses/csci2950-c/ l-mer composition Def: Given string s, the Spectrum ( s, l ) is unordered multiset
CSCI2950-C Lecture 4 DNA Sequencing and Fragment Assembly Ben Raphael Sept. 22, 2009 http://cs.brown.edu/courses/csci2950-c/ l-mer composition Def: Given string s, the Spectrum ( s, l ) is unordered multiset
Tutorial 1: Exploring the UCSC Genome Browser
 Last updated: May 12, 2011 Tutorial 1: Exploring the UCSC Genome Browser Open the homepage of the UCSC Genome Browser at: http://genome.ucsc.edu/ In the blue bar at the top, click on the Genomes link.
Last updated: May 12, 2011 Tutorial 1: Exploring the UCSC Genome Browser Open the homepage of the UCSC Genome Browser at: http://genome.ucsc.edu/ In the blue bar at the top, click on the Genomes link.
CSE : Computational Issues in Molecular Biology. Lecture 7. Spring 2004
 CSE 397-497: Computational Issues in Molecular Biology Lecture 7 Spring 2004-1 - CSE seminar on Monday Title: Redundancy Elimination Within Large Collections of Files Speaker: Dr. Fred Douglis (IBM T.J.
CSE 397-497: Computational Issues in Molecular Biology Lecture 7 Spring 2004-1 - CSE seminar on Monday Title: Redundancy Elimination Within Large Collections of Files Speaker: Dr. Fred Douglis (IBM T.J.
DNA Fragment Assembly
 SIGCSE 009 Algorithms in Bioinformatics Sami Khuri Department of Computer Science San José State University San José, California, USA khuri@cs.sjsu.edu www.cs.sjsu.edu/faculty/khuri DNA Fragment Assembly
SIGCSE 009 Algorithms in Bioinformatics Sami Khuri Department of Computer Science San José State University San José, California, USA khuri@cs.sjsu.edu www.cs.sjsu.edu/faculty/khuri DNA Fragment Assembly
Managing Your Biological Data with Python
 Chapman & Hall/CRC Mathematical and Computational Biology Series Managing Your Biological Data with Python Ailegra Via Kristian Rother Anna Tramontano CRC Press Taylor & Francis Group Boca Raton London
Chapman & Hall/CRC Mathematical and Computational Biology Series Managing Your Biological Data with Python Ailegra Via Kristian Rother Anna Tramontano CRC Press Taylor & Francis Group Boca Raton London
BioExtract Server User Manual
 BioExtract Server User Manual University of South Dakota About Us The BioExtract Server harnesses the power of online informatics tools for creating and customizing workflows. Users can query online sequence
BioExtract Server User Manual University of South Dakota About Us The BioExtract Server harnesses the power of online informatics tools for creating and customizing workflows. Users can query online sequence
B L A S T! BLAST: Basic local alignment search tool. Copyright notice. February 6, Pairwise alignment: key points. Outline of tonight s lecture
 February 6, 2008 BLAST: Basic local alignment search tool B L A S T! Jonathan Pevsner, Ph.D. Introduction to Bioinformatics pevsner@jhmi.edu 4.633.0 Copyright notice Many of the images in this powerpoint
February 6, 2008 BLAST: Basic local alignment search tool B L A S T! Jonathan Pevsner, Ph.D. Introduction to Bioinformatics pevsner@jhmi.edu 4.633.0 Copyright notice Many of the images in this powerpoint
Tutorial: chloroplast genomes
 Tutorial: chloroplast genomes Stacia Wyman Department of Computer Sciences Williams College Williamstown, MA 01267 March 10, 2005 ASSUMPTIONS: You are using Internet Explorer under OS X on the Mac. You
Tutorial: chloroplast genomes Stacia Wyman Department of Computer Sciences Williams College Williamstown, MA 01267 March 10, 2005 ASSUMPTIONS: You are using Internet Explorer under OS X on the Mac. You
Bioinformatics Database Worksheet
 Bioinformatics Database Worksheet (based on http://www.usm.maine.edu/~rhodes/goodies/matics.html) Where are the opsin genes in the human genome? Point your browser to the NCBI Map Viewer at http://www.ncbi.nlm.nih.gov/mapview/.
Bioinformatics Database Worksheet (based on http://www.usm.maine.edu/~rhodes/goodies/matics.html) Where are the opsin genes in the human genome? Point your browser to the NCBI Map Viewer at http://www.ncbi.nlm.nih.gov/mapview/.
Browser Exercises - I. Alignments and Comparative genomics
 Browser Exercises - I Alignments and Comparative genomics 1. Navigating to the Genome Browser (GBrowse) Note: For this exercise use http://www.tritrypdb.org a. Navigate to the Genome Browser (GBrowse)
Browser Exercises - I Alignments and Comparative genomics 1. Navigating to the Genome Browser (GBrowse) Note: For this exercise use http://www.tritrypdb.org a. Navigate to the Genome Browser (GBrowse)
Wilson Leung 01/03/2018 An Introduction to NCBI BLAST. Prerequisites: Detecting and Interpreting Genetic Homology: Lecture Notes on Alignment
 An Introduction to NCBI BLAST Prerequisites: Detecting and Interpreting Genetic Homology: Lecture Notes on Alignment Resources: The BLAST web server is available at https://blast.ncbi.nlm.nih.gov/blast.cgi
An Introduction to NCBI BLAST Prerequisites: Detecting and Interpreting Genetic Homology: Lecture Notes on Alignment Resources: The BLAST web server is available at https://blast.ncbi.nlm.nih.gov/blast.cgi
Installation and Use. The programs here are used to index and then search a database of nucleotides.
 August 28, 2018 Kevin C. O'Kane kc.okane@gmail.com https://threadsafebooks.com Installation and Use The programs here are used to index and then search a database of nucleotides. Sequence Database The
August 28, 2018 Kevin C. O'Kane kc.okane@gmail.com https://threadsafebooks.com Installation and Use The programs here are used to index and then search a database of nucleotides. Sequence Database The
VERY SHORT INTRODUCTION TO UNIX
 VERY SHORT INTRODUCTION TO UNIX Tore Samuelsson, Nov 2009. An operating system (OS) is an interface between hardware and user which is responsible for the management and coordination of activities and
VERY SHORT INTRODUCTION TO UNIX Tore Samuelsson, Nov 2009. An operating system (OS) is an interface between hardware and user which is responsible for the management and coordination of activities and
SUPPLEMENTARY INFORMATION
 doi:10.1038/nature25174 Sequences of DNA primers used in this study. Primer Primer sequence code 498 GTCCAGATCTTGATTAAGAAAAATGAAGAAA F pegfp 499 GTCCAGATCTTGGTTAAGAAAAATGAAGAAA F pegfp 500 GTCCCTGCAGCCTAGAGGGTTAGG
doi:10.1038/nature25174 Sequences of DNA primers used in this study. Primer Primer sequence code 498 GTCCAGATCTTGATTAAGAAAAATGAAGAAA F pegfp 499 GTCCAGATCTTGGTTAAGAAAAATGAAGAAA F pegfp 500 GTCCCTGCAGCCTAGAGGGTTAGG
DNA sequences obtained in section were assembled and edited using DNA
 Sequetyper DNA sequences obtained in section 4.4.1.3 were assembled and edited using DNA Baser Sequence Assembler v4 (www.dnabaser.com). The consensus sequences were used to interrogate the GenBank database
Sequetyper DNA sequences obtained in section 4.4.1.3 were assembled and edited using DNA Baser Sequence Assembler v4 (www.dnabaser.com). The consensus sequences were used to interrogate the GenBank database
DNA Fragment Assembly
 Algorithms in Bioinformatics Sami Khuri Department of Computer Science San José State University San José, California, USA khuri@cs.sjsu.edu www.cs.sjsu.edu/faculty/khuri DNA Fragment Assembly Overlap
Algorithms in Bioinformatics Sami Khuri Department of Computer Science San José State University San José, California, USA khuri@cs.sjsu.edu www.cs.sjsu.edu/faculty/khuri DNA Fragment Assembly Overlap
BovineMine Documentation
 BovineMine Documentation Release 1.0 Deepak Unni, Aditi Tayal, Colin Diesh, Christine Elsik, Darren Hag Oct 06, 2017 Contents 1 Tutorial 3 1.1 Overview.................................................
BovineMine Documentation Release 1.0 Deepak Unni, Aditi Tayal, Colin Diesh, Christine Elsik, Darren Hag Oct 06, 2017 Contents 1 Tutorial 3 1.1 Overview.................................................
ngaio.)' Thif. as you ore doubtless aware U the
' Thif. as you ore doubtless aware U the") c G c2 VV VV $60 c V X G Y Y 4 4 2 G F cg V c / g q c c c g c c c g c c g c c c cg VY gc c //Y 0 G!«> ] gc g 25 c Y g) g! c cg c c X c c 5 Y g g F g F g F «g c 3 x «(c X c! c c c g F VG ) g < c c c c g
c G c2 VV VV $60 c V X G Y Y 4 4 2 G F cg V c / g q c c c g c c c g c c g c c c cg VY gc c //Y 0 G!«> ] gc g 25 c Y g) g! c cg c c X c c 5 Y g g F g F g F «g c 3 x «(c X c! c c c g F VG ) g < c c c c g
Using many concepts related to bioinformatics, an application was created to
 Patrick Graves Bioinformatics Thursday, April 26, 2007 1 - ABSTRACT Using many concepts related to bioinformatics, an application was created to visually display EST s. Each EST was displayed in the correct
Patrick Graves Bioinformatics Thursday, April 26, 2007 1 - ABSTRACT Using many concepts related to bioinformatics, an application was created to visually display EST s. Each EST was displayed in the correct
24 Grundlagen der Bioinformatik, SS 10, D. Huson, April 26, This lecture is based on the following papers, which are all recommended reading:
 24 Grundlagen der Bioinformatik, SS 10, D. Huson, April 26, 2010 3 BLAST and FASTA This lecture is based on the following papers, which are all recommended reading: D.J. Lipman and W.R. Pearson, Rapid
24 Grundlagen der Bioinformatik, SS 10, D. Huson, April 26, 2010 3 BLAST and FASTA This lecture is based on the following papers, which are all recommended reading: D.J. Lipman and W.R. Pearson, Rapid
Example of repeats: ATGGTCTAGGTCCTAGTGGTC Motivation to find them: Genomic rearrangements are often associated with repeats Trace evolutionary
 Outline Hash Tables Repeat Finding Exact Pattern Matching Keyword Trees Suffix Trees Heuristic Similarity Search Algorithms Approximate String Matching Filtration Comparing a Sequence Against a Database
Outline Hash Tables Repeat Finding Exact Pattern Matching Keyword Trees Suffix Trees Heuristic Similarity Search Algorithms Approximate String Matching Filtration Comparing a Sequence Against a Database
Computational Methods for de novo Assembly of Next-Generation Genome Sequencing Data
 1/39 Computational Methods for de novo Assembly of Next-Generation Genome Sequencing Data Rayan Chikhi ENS Cachan Brittany / IRISA (Genscale team) Advisor : Dominique Lavenier 2/39 INTRODUCTION, YEAR 2000
1/39 Computational Methods for de novo Assembly of Next-Generation Genome Sequencing Data Rayan Chikhi ENS Cachan Brittany / IRISA (Genscale team) Advisor : Dominique Lavenier 2/39 INTRODUCTION, YEAR 2000
CLC Server. End User USER MANUAL
 CLC Server End User USER MANUAL Manual for CLC Server 10.0.1 Windows, macos and Linux March 8, 2018 This software is for research purposes only. QIAGEN Aarhus Silkeborgvej 2 Prismet DK-8000 Aarhus C Denmark
CLC Server End User USER MANUAL Manual for CLC Server 10.0.1 Windows, macos and Linux March 8, 2018 This software is for research purposes only. QIAGEN Aarhus Silkeborgvej 2 Prismet DK-8000 Aarhus C Denmark
CISC 636 Computational Biology & Bioinformatics (Fall 2016)
") CISC 636 Computational Biology & Bioinformatics (Fall 2016) Sequence pairwise alignment Score statistics: E-value and p-value Heuristic algorithms: BLAST and FASTA Database search: gene finding and annotations
CISC 636 Computational Biology & Bioinformatics (Fall 2016) Sequence pairwise alignment Score statistics: E-value and p-value Heuristic algorithms: BLAST and FASTA Database search: gene finding and annotations
Mapping Reads to Reference Genome
 Mapping Reads to Reference Genome DNA carries genetic information DNA is a double helix of two complementary strands formed by four nucleotides (bases): Adenine, Cytosine, Guanine and Thymine 2 of 31 Gene
Mapping Reads to Reference Genome DNA carries genetic information DNA is a double helix of two complementary strands formed by four nucleotides (bases): Adenine, Cytosine, Guanine and Thymine 2 of 31 Gene
A tuple can be created as a comma-separated list of values:
 Tuples A tuple is a sequence of values much like a list. The values stored in a tuple can be any type, and they are indexed by integers. The important difference is that tuples are immutable, and hence
Tuples A tuple is a sequence of values much like a list. The values stored in a tuple can be any type, and they are indexed by integers. The important difference is that tuples are immutable, and hence