Elements of CPU performance
|
|
|
- Merilyn Tucker
- 5 years ago
- Views:
Transcription
1 Elements of CPU performance Cycle time. CPU pipeline. Superscalar design. Memory system. Texec = instructions ( )( program cycles instruction seconds )( ) cycle

2 ARM7TDM CPU Core
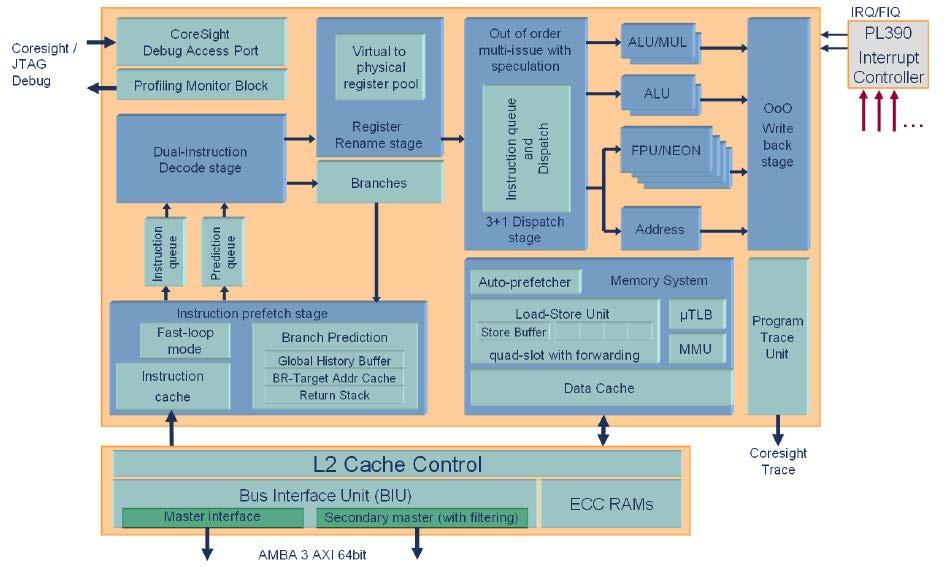
3 ARM Cortex A-9 Microarchitecture
4 Pipelining Several instructions are executed simultaneously at different stages of completion. I1 Fetch Decode Execute Write I2 Fetch Decode Execute Write I3 Fetch Decode Execute Write I4 Fetch Decode Execute Write Various conditions can cause pipeline bubbles that reduce utilization: branches; memory system delays; etc. I5 Fetch Decode Execute Write
5 ARM pipeline execution ARM7 has 3-stage pipes: fetch instruction from memory; decode opcode and operands; execute. fetch decode execute add r0,r1,#5 sub r2,r3,r6 fetch decode execute cmp r2,#3 fetch decode execute time

6 Pipeline changes for ARM9TDMI

7 ARM10 and ARM11 pipelines (superscalar design)
8 Performance measures Latency: time it takes for an instruction to get through the pipeline. Throughput: number of instructions executed per time period. Pipelining increases throughput without reducing latency. Assume a program with N, K-stage instructions Without pipeline: Texec = N*K With K-stage pipeline: Texec = K + (N-1) K cycles for 1 st instruction Speedup = For large N SSSSSSSSSSSSSS KK 1 cycle to complete each additional instruction NN KK KK+(NN 1) This assumes no pipeline stalls.
9 Pipeline stalls If every step cannot be completed in the same amount of time, pipeline stalls. Bubbles introduced by stall increase latency, reduce throughput.
10 ARM multi-cycle LDMIA instruction ldmia r0,{r2,r3} sub r2,r3,r6 fetch decodeex ld r2 fetch decode ex ld r3 Wait for new r3 value ex sub cmp r2,#3 fetch decodeex cmp time
11 Control stalls Branches often introduce stalls (branch penalty). Stall time may depend on whether branch is taken. May have to squash instructions that already started executing. Don t know what to fetch until condition is evaluated.
12 ARM pipelined branch bne foo fetch decode ex bne ex bne ex bne sub r2,r3,r6 foo add r0,r1,r2 fetch decode Branch taken Discontinue this instruction fetch decode ex add time
13 Delayed branch To increase pipeline efficiency, delayed branch mechanism requires n instructions after branch always executed whether branch is executed or not. SHARC supports delayed and non-delayed branches. Specified by bit in branch instruction. 2 instruction branch delay slot.
14 Example: ARM execution time Determine execution time of FIR filter: for (i=0; i<n; i++) f = f + c[i]*x[i]; Only branch in loop test may take more than one cycle. BLT loop takes 1 cycle best case, 3 worst case.
15 FIR filter ARM code ; loop initiation code MOV r0,#0 ; use r0 for i, set to 0 MOV r8,#0 ; use a separate index for arrays ADR r2,n ; get address for N LDR r1,[r2] ; get value of N MOV r2,#0 ; use r2 for f, set to 0 ADR r3,c ; load r3 with address of base of c ADR r5,x ; load r5 with address of base of x ; loop body loop LDR r4,[r3,r8] ; get value of c[i] LDR r6,[r5,r8] ; get value of x[i] MUL r4,r4,r6 ; compute c[i]*x[i] ADD r2,r2,r4 ; add into running sum ; update loop counter and array index ADD r8,r8,#4 ; add one to array index ADD r0,r0,#1 ; add 1 to i ; test for exit CMP r0,r1 BLT loop ; if i < N, continue loop loopend... Overheads for Computers as Components 2 nd ed Wayne Wolf
16 FIR filter performance by block Block Variable # instructions # cycles Initialization t init 7 7 Body t body 4 4 Update t update 2 2 Test t test 2 [2,4] t loop = t init + N(t body + t update ) + (N-1) t test,worst + t test,best Loop test succeeds is worst case Loop test fails is best case Overheads for Computers as Components 2000 Morgan Kaufman
17 FIR performance on ARM t loop = t + N( t + t ) + ( N 1) t + t init body update test, worst test, best N = # times loop executed t loop = 5 + ( N 10) cycles Overheads for Computers as Components 2000 Morgan Kaufman
18 Superscalar execution Superscalar processor can execute several instructions per cycle. Uses multiple pipelined data paths. Programs execute faster, but it is harder to determine how much faster. Multicore module has multiple processors, each executing separate program threads
19 Data dependencies Execution time depends on operands, not just opcode. Superscalar CPU checks data dependencies dynamically: data dependency add r2,r0,r1 add r3,r2,r5 r0 r2 r1 r5 r3
20 C55x pipeline C55x has 7-stage pipe: fetch; decode; address: computes data/branch addresses; access 1: reads data; access 2: finishes data read; Read stage: puts operands on internal busses; execute.
21 C55x organization 3 data read busses D C, B bus D busses 3 data read address busses program address bus program read bus Instruction Writes Single Dual-multiply Data operand read fetch coefficient read from memory 32 Instruction unit Program flow unit Address unit Data unit 2 data write busses 2 data write address busses 16 24
22 C55x pipeline hazards Processor structure: Three computation units. 14 operators. Can perform two operations per instruction. Some combinations of operators are not legal.
23 C55x hazards A-unit ALU/A-unit ALU. A-unit swap/a-unit swap. D-unit ALU,shifter,MAC/D-unit ALU,shifter,MAC D-unit shifter/d-unit shift, store D-unit shift, store/d-unit shift, store D-unit swap/d-unit swap P-unit control/p-unit control
Memory management units
 Memory management units Memory management unit (MMU) translates addresses: CPU logical address memory management unit physical address main memory Computers as Components 1 Access time comparison Media
Memory management units Memory management unit (MMU) translates addresses: CPU logical address memory management unit physical address main memory Computers as Components 1 Access time comparison Media
CPUs. Caching: The Basic Idea. Cache : MainMemory :: Window : Caches. Memory management. CPU performance. 1. Door 2. Bigger Door 3. The Great Outdoors
 CPUs Caches. Memory management. CPU performance. Cache : MainMemory :: Window : 1. Door 2. Bigger Door 3. The Great Outdoors 4. Horizontal Blinds 18% 9% 64% 9% Door Bigger Door The Great Outdoors Horizontal
CPUs Caches. Memory management. CPU performance. Cache : MainMemory :: Window : 1. Door 2. Bigger Door 3. The Great Outdoors 4. Horizontal Blinds 18% 9% 64% 9% Door Bigger Door The Great Outdoors Horizontal
CS 310 Embedded Computer Systems CPUS. Seungryoul Maeng
 1 EMBEDDED SYSTEM HW CPUS Seungryoul Maeng 2 CPUs Types of Processors CPU Performance Instruction Sets Processors used in ES 3 Processors Single Purpose ( Hardware ) General Purpose ( Software ) Application
1 EMBEDDED SYSTEM HW CPUS Seungryoul Maeng 2 CPUs Types of Processors CPU Performance Instruction Sets Processors used in ES 3 Processors Single Purpose ( Hardware ) General Purpose ( Software ) Application
Photo David Wright STEVEN R. BAGLEY PIPELINES AND ILP
 Photo David Wright https://www.flickr.com/photos/dhwright/3312563248 STEVEN R. BAGLEY PIPELINES AND ILP INTRODUCTION Been considering what makes the CPU run at a particular speed Spent the last two weeks
Photo David Wright https://www.flickr.com/photos/dhwright/3312563248 STEVEN R. BAGLEY PIPELINES AND ILP INTRODUCTION Been considering what makes the CPU run at a particular speed Spent the last two weeks
Chapter 2 Instructions Sets. Hsung-Pin Chang Department of Computer Science National ChungHsing University
 Chapter 2 Instructions Sets Hsung-Pin Chang Department of Computer Science National ChungHsing University Outline Instruction Preliminaries ARM Processor SHARC Processor 2.1 Instructions Instructions sets
Chapter 2 Instructions Sets Hsung-Pin Chang Department of Computer Science National ChungHsing University Outline Instruction Preliminaries ARM Processor SHARC Processor 2.1 Instructions Instructions sets
Basic Computer Architecture
 Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I
Pipeline Hazards. Midterm #2 on 11/29 5th and final problem set on 11/22 9th and final lab on 12/1. https://goo.gl/forms/hkuvwlhvuyzvdat42
 Pipeline Hazards https://goo.gl/forms/hkuvwlhvuyzvdat42 Midterm #2 on 11/29 5th and final problem set on 11/22 9th and final lab on 12/1 1 ARM 3-stage pipeline Fetch,, and Execute Stages Instructions are
Pipeline Hazards https://goo.gl/forms/hkuvwlhvuyzvdat42 Midterm #2 on 11/29 5th and final problem set on 11/22 9th and final lab on 12/1 1 ARM 3-stage pipeline Fetch,, and Execute Stages Instructions are
ARM Cortex-M4 Programming Model Flow Control Instructions
 ARM Cortex-M4 Programming Model Flow Control Instructions Textbook: Chapter 4, Section 4.9 (CMP, TEQ,TST) Chapter 6 ARM Cortex-M Users Manual, Chapter 3 1 CPU instruction types Data movement operations
ARM Cortex-M4 Programming Model Flow Control Instructions Textbook: Chapter 4, Section 4.9 (CMP, TEQ,TST) Chapter 6 ARM Cortex-M Users Manual, Chapter 3 1 CPU instruction types Data movement operations
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
EC 413 Computer Organization - Fall 2017 Problem Set 3 Problem Set 3 Solution
 EC 413 Computer Organization - Fall 2017 Problem Set 3 Problem Set 3 Solution Important guidelines: Always state your assumptions and clearly explain your answers. Please upload your solution document
EC 413 Computer Organization - Fall 2017 Problem Set 3 Problem Set 3 Solution Important guidelines: Always state your assumptions and clearly explain your answers. Please upload your solution document
VE7104/INTRODUCTION TO EMBEDDED CONTROLLERS UNIT III ARM BASED MICROCONTROLLERS
 VE7104/INTRODUCTION TO EMBEDDED CONTROLLERS UNIT III ARM BASED MICROCONTROLLERS Introduction to 32 bit Processors, ARM Architecture, ARM cortex M3, 32 bit ARM Instruction set, Thumb Instruction set, Exception
VE7104/INTRODUCTION TO EMBEDDED CONTROLLERS UNIT III ARM BASED MICROCONTROLLERS Introduction to 32 bit Processors, ARM Architecture, ARM cortex M3, 32 bit ARM Instruction set, Thumb Instruction set, Exception
Static, multiple-issue (superscaler) pipelines
 pipelines") Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
What is Pipelining? RISC remainder (our assumptions)
") What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Time per instruction on unpipelined machine Number of pipe stages
 What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
Architectures & instruction sets R_B_T_C_. von Neumann architecture. Computer architecture taxonomy. Assembly language.
 Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Chapter 5 (a) Overview
 Overview") Chapter 5 (a) Overview (a) The principles of pipelining (a) A pipelined design of SRC (b) Pipeline hazards (b) Instruction-level parallelism (ILP) Superscalar processors Very Long Instruction Word (VLIW)
Chapter 5 (a) Overview (a) The principles of pipelining (a) A pipelined design of SRC (b) Pipeline hazards (b) Instruction-level parallelism (ILP) Superscalar processors Very Long Instruction Word (VLIW)
The Processor Pipeline. Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes.
 The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
CSE 490/590 Computer Architecture Homework 2
 CSE 490/590 Computer Architecture Homework 2 1. Suppose that you have the following out-of-order datapath with 1-cycle ALU, 2-cycle Mem, 3-cycle Fadd, 5-cycle Fmul, no branch prediction, and in-order fetch
CSE 490/590 Computer Architecture Homework 2 1. Suppose that you have the following out-of-order datapath with 1-cycle ALU, 2-cycle Mem, 3-cycle Fadd, 5-cycle Fmul, no branch prediction, and in-order fetch
ARM Shift Operations. Shift Type 00 - logical left 01 - logical right 10 - arithmetic right 11 - rotate right. Shift Amount 0-31 bits
 ARM Shift Operations A novel feature of ARM is that all data-processing instructions can include an optional shift, whereas most other architectures have separate shift instructions. This is actually very
ARM Shift Operations A novel feature of ARM is that all data-processing instructions can include an optional shift, whereas most other architectures have separate shift instructions. This is actually very
CS433 Midterm. Prof Josep Torrellas. October 16, Time: 1 hour + 15 minutes
 CS433 Midterm Prof Josep Torrellas October 16, 2014 Time: 1 hour + 15 minutes Name: Alias: Instructions: 1. This is a closed-book, closed-notes examination. 2. The Exam has 4 Questions. Please budget your
CS433 Midterm Prof Josep Torrellas October 16, 2014 Time: 1 hour + 15 minutes Name: Alias: Instructions: 1. This is a closed-book, closed-notes examination. 2. The Exam has 4 Questions. Please budget your
Pipelining and Exploiting Instruction-Level Parallelism (ILP)
") Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
ECE 571 Advanced Microprocessor-Based Design Lecture 4
 ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
Structure of Computer Systems
 288 between this new matrix and the initial collision matrix M A, because the original forbidden latencies for functional unit A still have to be considered in later initiations. Figure 5.37. State diagram
288 between this new matrix and the initial collision matrix M A, because the original forbidden latencies for functional unit A still have to be considered in later initiations. Figure 5.37. State diagram
ARM Instruction Set Architecture. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 ARM Instruction Set Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Condition Field (1) Most ARM instructions can be conditionally
ARM Instruction Set Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Condition Field (1) Most ARM instructions can be conditionally
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Embedded Systems Ch 15 ARM Organization and Implementation
 Embedded Systems Ch 15 ARM Organization and Implementation Byung Kook Kim Dept of EECS Korea Advanced Institute of Science and Technology Summary ARM architecture Very little change From the first 3-micron
Embedded Systems Ch 15 ARM Organization and Implementation Byung Kook Kim Dept of EECS Korea Advanced Institute of Science and Technology Summary ARM architecture Very little change From the first 3-micron
CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture. VLIW, Vector, and Multithreaded Machines
 CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture VLIW, Vector, and Multithreaded Machines Assigned 3/24/2019 Problem Set #4 Due 4/5/2019 http://inst.eecs.berkeley.edu/~cs152/sp19
CS152 Computer Architecture and Engineering CS252 Graduate Computer Architecture VLIW, Vector, and Multithreaded Machines Assigned 3/24/2019 Problem Set #4 Due 4/5/2019 http://inst.eecs.berkeley.edu/~cs152/sp19
Assuming ideal conditions (perfect pipelining and no hazards), how much time would it take to execute the same program in: b) A 5-stage pipeline?
, how much time would it take to execute the same program in: b) A 5-stage pipeline?") 1. Imagine we have a non-pipelined processor running at 1MHz and want to run a program with 1000 instructions. a) How much time would it take to execute the program? 1 instruction per cycle. 1MHz clock
1. Imagine we have a non-pipelined processor running at 1MHz and want to run a program with 1000 instructions. a) How much time would it take to execute the program? 1 instruction per cycle. 1MHz clock
Chapter 9. Pipelining Design Techniques
 Chapter 9 Pipelining Design Techniques 9.1 General Concepts Pipelining refers to the technique in which a given task is divided into a number of subtasks that need to be performed in sequence. Each subtask
Chapter 9 Pipelining Design Techniques 9.1 General Concepts Pipelining refers to the technique in which a given task is divided into a number of subtasks that need to be performed in sequence. Each subtask
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Comparison InstruCtions
 Status Flags Now it is time to discuss what status flags are available. These five status flags are kept in a special register called the Program Status Register (PSR). The PSR also contains other important
Status Flags Now it is time to discuss what status flags are available. These five status flags are kept in a special register called the Program Status Register (PSR). The PSR also contains other important
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
ECEC 355: Pipelining
 ECEC 355: Pipelining November 8, 2007 What is Pipelining Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. A pipeline is similar in concept to an assembly
ECEC 355: Pipelining November 8, 2007 What is Pipelining Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. A pipeline is similar in concept to an assembly
HPC VT Machine-dependent Optimization
 HPC VT 2013 Machine-dependent Optimization Last time Choose good data structures Reduce number of operations Use cheap operations strength reduction Avoid too many small function calls inlining Use compiler
HPC VT 2013 Machine-dependent Optimization Last time Choose good data structures Reduce number of operations Use cheap operations strength reduction Avoid too many small function calls inlining Use compiler
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Insider Insights on the ARM11 s Signal-Processing Capabilities
 Insight, Analysis, and Advice on Signal Processing Technology Insider Insights on the 11 s Signal-Processing Capabilities Kenton Williston Berkeley Design Technology, Inc. Berkeley, California USA +1 (510)
Insight, Analysis, and Advice on Signal Processing Technology Insider Insights on the 11 s Signal-Processing Capabilities Kenton Williston Berkeley Design Technology, Inc. Berkeley, California USA +1 (510)
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
Instruction Level Parallelism. ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction
 Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Parallelism. Execution Cycle. Dual Bus Simple CPU. Pipelining COMP375 1
 Pipelining COMP375 Computer Architecture and dorganization Parallelism The most common method of making computers faster is to increase parallelism. There are many levels of parallelism Macro Multiple
Pipelining COMP375 Computer Architecture and dorganization Parallelism The most common method of making computers faster is to increase parallelism. There are many levels of parallelism Macro Multiple
Pipeline Processors David Rye :: MTRX3700 Pipelining :: Slide 1 of 15
 Pipeline Processors Pipelining :: Slide 1 of 15 Pipeline Processors A common feature of modern processors Works like a series production line An operation is divided into k decoupled (independent) elementary
Pipeline Processors Pipelining :: Slide 1 of 15 Pipeline Processors A common feature of modern processors Works like a series production line An operation is divided into k decoupled (independent) elementary
5 th Edition. The Processor We will examine two MIPS implementations A simplified version A more realistic pipelined version
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
CPE300: Digital System Architecture and Design
 CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Pipelining 11142011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review I/O Chapter 5 Overview Pipelining Pipelining
CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Pipelining 11142011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review I/O Chapter 5 Overview Pipelining Pipelining
Pipeline issues. Pipeline hazard: RaW. Pipeline hazard: RaW. Calcolatori Elettronici e Sistemi Operativi. Hazards. Data hazard.
 Calcolatori Elettronici e Sistemi Operativi Pipeline issues Hazards Pipeline issues Data hazard Control hazard Structural hazard Pipeline hazard: RaW Pipeline hazard: RaW 5 6 7 8 9 5 6 7 8 9 : add R,R,R
Calcolatori Elettronici e Sistemi Operativi Pipeline issues Hazards Pipeline issues Data hazard Control hazard Structural hazard Pipeline hazard: RaW Pipeline hazard: RaW 5 6 7 8 9 5 6 7 8 9 : add R,R,R
ARM Instruction Set. Computer Organization and Assembly Languages Yung-Yu Chuang. with slides by Peng-Sheng Chen
 ARM Instruction Set Computer Organization and Assembly Languages g Yung-Yu Chuang with slides by Peng-Sheng Chen Introduction The ARM processor is easy to program at the assembly level. (It is a RISC)
ARM Instruction Set Computer Organization and Assembly Languages g Yung-Yu Chuang with slides by Peng-Sheng Chen Introduction The ARM processor is easy to program at the assembly level. (It is a RISC)
Instr. execution impl. view
 Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
structural RTL for mov ra, rb Answer:- (Page 164) Virtualians Social Network Prepared by: Irfan Khan
 Virtualians Social Network Prepared by: Irfan Khan") Solved Subjective Midterm Papers For Preparation of Midterm Exam Two approaches for control unit. Answer:- (Page 150) Additionally, there are two different approaches to the control unit design; it can
Solved Subjective Midterm Papers For Preparation of Midterm Exam Two approaches for control unit. Answer:- (Page 150) Additionally, there are two different approaches to the control unit design; it can
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Module 4c: Pipelining
 Module 4c: Pipelining R E F E R E N C E S : S T A L L I N G S, C O M P U T E R O R G A N I Z A T I O N A N D A R C H I T E C T U R E M O R R I S M A N O, C O M P U T E R O R G A N I Z A T I O N A N D A
Module 4c: Pipelining R E F E R E N C E S : S T A L L I N G S, C O M P U T E R O R G A N I Z A T I O N A N D A R C H I T E C T U R E M O R R I S M A N O, C O M P U T E R O R G A N I Z A T I O N A N D A
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Two hours UNIVERSITY OF MANCHESTER SCHOOL OF COMPUTER SCIENCE
 Two hours UNIVERSITY OF MANCHESTER SCHOOL OF COMPUTER SCIENCE System Architecture Date: Tuesday 26th May 2015 Time: 14:00-16:00 Please answer any THREE Questions from the FOUR questions provided Use a
Two hours UNIVERSITY OF MANCHESTER SCHOOL OF COMPUTER SCIENCE System Architecture Date: Tuesday 26th May 2015 Time: 14:00-16:00 Please answer any THREE Questions from the FOUR questions provided Use a
Hi Hsiao-Lung Chan, Ph.D. Dept Electrical Engineering Chang Gung University, Taiwan
 Processors Hi Hsiao-Lung Chan, Ph.D. Dept Electrical Engineering Chang Gung University, Taiwan chanhl@maili.cgu.edu.twcgu General-purpose p processor Control unit Controllerr Control/ status Datapath ALU
Processors Hi Hsiao-Lung Chan, Ph.D. Dept Electrical Engineering Chang Gung University, Taiwan chanhl@maili.cgu.edu.twcgu General-purpose p processor Control unit Controllerr Control/ status Datapath ALU
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Chapter 8. Pipelining
 Chapter 8. Pipelining Overview Pipelining is widely used in modern processors. Pipelining improves system performance in terms of throughput. Pipelined organization requires sophisticated compilation techniques.
Chapter 8. Pipelining Overview Pipelining is widely used in modern processors. Pipelining improves system performance in terms of throughput. Pipelined organization requires sophisticated compilation techniques.
8.1. ( ) The operation performed in each step and the operands involved are as given in the figure below. Clock cycle Instruction
 The operation performed in each step and the operands involved are as given in the figure below. Clock cycle Instruction") Chapter 8 Pipelining 8.1. ( ) The operation performed in each step and the operands involved are as given in the figure below. I 1 : 20, 2000 R1 2020 I 2 : Mul 3, 50 Mul R3 150 I 3 : And $3A, 50 And R4
Chapter 8 Pipelining 8.1. ( ) The operation performed in each step and the operands involved are as given in the figure below. I 1 : 20, 2000 R1 2020 I 2 : Mul 3, 50 Mul R3 150 I 3 : And $3A, 50 And R4
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
Lecture 6 MIPS R4000 and Instruction Level Parallelism. Computer Architectures S
 Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
MIPS ISA AND PIPELINING OVERVIEW Appendix A and C
 1 MIPS ISA AND PIPELINING OVERVIEW Appendix A and C OUTLINE Review of MIPS ISA Review on Pipelining 2 READING ASSIGNMENT ReadAppendixA ReadAppendixC 3 THEMIPS ISA (A.9) First MIPS in 1985 General-purpose
1 MIPS ISA AND PIPELINING OVERVIEW Appendix A and C OUTLINE Review of MIPS ISA Review on Pipelining 2 READING ASSIGNMENT ReadAppendixA ReadAppendixC 3 THEMIPS ISA (A.9) First MIPS in 1985 General-purpose
Lecture: Pipeline Wrap-Up and Static ILP
 Lecture: Pipeline Wrap-Up and Static ILP Topics: multi-cycle instructions, precise exceptions, deep pipelines, compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Multicycle
Lecture: Pipeline Wrap-Up and Static ILP Topics: multi-cycle instructions, precise exceptions, deep pipelines, compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Multicycle
Please state clearly any assumptions you make in solving the following problems.
 Computer Architecture Homework 3 2012-2013 Please state clearly any assumptions you make in solving the following problems. 1 Processors Write a short report on at least five processors from at least three
Computer Architecture Homework 3 2012-2013 Please state clearly any assumptions you make in solving the following problems. 1 Processors Write a short report on at least five processors from at least three
CENG 3531 Computer Architecture Spring a. T / F A processor can have different CPIs for different programs.
 Exam 2 April 12, 2012 You have 80 minutes to complete the exam. Please write your answers clearly and legibly on this exam paper. GRADE: Name. Class ID. 1. (22 pts) Circle the selected answer for T/F and
Exam 2 April 12, 2012 You have 80 minutes to complete the exam. Please write your answers clearly and legibly on this exam paper. GRADE: Name. Class ID. 1. (22 pts) Circle the selected answer for T/F and
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Pipeline Review. Review
 Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 05
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 05
Architectural Performance. Superscalar Processing. 740 October 31, i486 Pipeline. Pipeline Stage Details. Page 1
 Superscalar Processing 740 October 31, 2012 Evolution of Intel Processor Pipelines 486, Pentium, Pentium Pro Superscalar Processor Design Speculative Execution Register Renaming Branch Prediction Architectural
Superscalar Processing 740 October 31, 2012 Evolution of Intel Processor Pipelines 486, Pentium, Pentium Pro Superscalar Processor Design Speculative Execution Register Renaming Branch Prediction Architectural
HW 2 is out! Due 9/25!
 HW 2 is out! Due 9/25! CS 6290 Static Exploitation of ILP Data-Dependence Stalls w/o OOO Single-Issue Pipeline When no bypassing exists Load-to-use Long-latency instructions Multiple-Issue (Superscalar),
HW 2 is out! Due 9/25! CS 6290 Static Exploitation of ILP Data-Dependence Stalls w/o OOO Single-Issue Pipeline When no bypassing exists Load-to-use Long-latency instructions Multiple-Issue (Superscalar),
Short Answer: [3] What is the primary difference between Tomasulo s algorithm and Scoreboarding?
![Short Answer: [3] What is the primary difference between Tomasulo s algorithm and Scoreboarding?](/thumbs/83/88057083.jpg "Short Answer: [3] What is the primary difference between Tomasulo s algorithm and Scoreboarding?") Short Answer: [] What is the primary difference between Tomasulo s algorithm and Scoreboarding? [] Which data hazard occurs when instructions are allowed to complete out of order? Which one occurs when
Short Answer: [] What is the primary difference between Tomasulo s algorithm and Scoreboarding? [] Which data hazard occurs when instructions are allowed to complete out of order? Which one occurs when
Updated Exercises by Diana Franklin
 C-82 Appendix C Pipelining: Basic and Intermediate Concepts Updated Exercises by Diana Franklin C.1 [15/15/15/15/25/10/15] Use the following code fragment: Loop: LD R1,0(R2) ;load R1 from address
C-82 Appendix C Pipelining: Basic and Intermediate Concepts Updated Exercises by Diana Franklin C.1 [15/15/15/15/25/10/15] Use the following code fragment: Loop: LD R1,0(R2) ;load R1 from address
Page 1. CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Pipeline CPI (II) Michela Taufer
 Pipeline CPI (II) Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
Dynamic Control Hazard Avoidance
 Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
Dynamic Control Hazard Avoidance Consider Effects of Increasing the ILP Control dependencies rapidly become the limiting factor they tend to not get optimized by the compiler more instructions/sec ==>
ECE 3056: Architecture, Concurrency, and Energy of Computation. Sample Problem Sets: Pipelining
 ECE 3056: Architecture, Concurrency, and Energy of Computation Sample Problem Sets: Pipelining 1. Consider the following code sequence used often in block copies. This produces a special form of the load
ECE 3056: Architecture, Concurrency, and Energy of Computation Sample Problem Sets: Pipelining 1. Consider the following code sequence used often in block copies. This produces a special form of the load
What is ILP? Instruction Level Parallelism. Where do we find ILP? How do we expose ILP?
 What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
ARM Instruction Set. Introduction. Memory system. ARM programmer model. The ARM processor is easy to program at the
 Introduction ARM Instruction Set The ARM processor is easy to program at the assembly level. (It is a RISC) We will learn ARM assembly programming at the user level l and run it on a GBA emulator. Computer
Introduction ARM Instruction Set The ARM processor is easy to program at the assembly level. (It is a RISC) We will learn ARM assembly programming at the user level l and run it on a GBA emulator. Computer
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards
 CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
CS 61C: Great Ideas in Computer Architecture Pipelining and Hazards Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Pipelined Execution Representation Time
COMPUTER ORGANIZATION AND DESIGN. The Hardware/Software Interface. Chapter 4. The Processor: C Multiple Issue Based on P&H
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: C Multiple Issue Based on P&H Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: C Multiple Issue Based on P&H Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in
Page # CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Michela Taufer
 Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Boolean Unit (The obvious way)
") oolean Unit (The obvious way) It is simple to build up a oolean unit using primitive gates and a mux to select the function. Since there is no interconnection between bits, this unit can be simply replicated
oolean Unit (The obvious way) It is simple to build up a oolean unit using primitive gates and a mux to select the function. Since there is no interconnection between bits, this unit can be simply replicated
Branch Instructions. R type: Cond
 Branch Instructions Standard branch instructions, B and BL, change the PC based on the PCR. The next instruction s address is found by adding a 24-bit signed 2 s complement immediate value
Branch Instructions Standard branch instructions, B and BL, change the PC based on the PCR. The next instruction s address is found by adding a 24-bit signed 2 s complement immediate value
Computer Organization & Assembly Language Programming (CSE 2312)
") Computer Organization & Assembly Language Programming (CSE 2312) Lecture 16: Processor Pipeline Introduction and Debugging with GDB Taylor Johnson Announcements and Outline Homework 5 due today Know how
Computer Organization & Assembly Language Programming (CSE 2312) Lecture 16: Processor Pipeline Introduction and Debugging with GDB Taylor Johnson Announcements and Outline Homework 5 due today Know how
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Good luck and have fun!
 Midterm Exam October 13, 2014 Name: Problem 1 2 3 4 total Points Exam rules: Time: 90 minutes. Individual test: No team work! Open book, open notes. No electronic devices, except an unprogrammed calculator.
Midterm Exam October 13, 2014 Name: Problem 1 2 3 4 total Points Exam rules: Time: 90 minutes. Individual test: No team work! Open book, open notes. No electronic devices, except an unprogrammed calculator.
For all questions, please show your step-by-step solution to get full-credits.
 For all questions, please show your step-by-step solution to get full-credits. Question 1: Assume a 5 stages microprocessor, calculate the number of cycles of below instructions for 1) no pipeline system
For all questions, please show your step-by-step solution to get full-credits. Question 1: Assume a 5 stages microprocessor, calculate the number of cycles of below instructions for 1) no pipeline system
A Bit of History. Program Mem Data Memory. CPU (Central Processing Unit) I/O (Input/Output) Von Neumann Architecture. CPU (Central Processing Unit)
 I/O (Input/Output) Von Neumann Architecture. CPU (Central Processing Unit)") Memory COncepts Address Contents Memory is divided into addressable units, each with an address (like an array with indices) Addressable units are usually larger than a bit, typically 8, 16, 32, or 64
Memory COncepts Address Contents Memory is divided into addressable units, each with an address (like an array with indices) Addressable units are usually larger than a bit, typically 8, 16, 32, or 64
The ARM Instruction Set Architecture
 The ARM Instruction Set Architecture Mark McDermott With help from our good friends at ARM Fall 008 Main features of the ARM Instruction Set All instructions are 3 bits long. Most instructions execute
The ARM Instruction Set Architecture Mark McDermott With help from our good friends at ARM Fall 008 Main features of the ARM Instruction Set All instructions are 3 bits long. Most instructions execute
Hi Hsiao-Lung Chan, Ph.D. Dept Electrical Engineering Chang Gung University, Taiwan
 ARM Programmers Model Hi Hsiao-Lung Chan, Ph.D. Dept Electrical Engineering Chang Gung University, Taiwan chanhl@maili.cgu.edu.twcgu Current program status register (CPSR) Prog Model 2 Data processing
ARM Programmers Model Hi Hsiao-Lung Chan, Ph.D. Dept Electrical Engineering Chang Gung University, Taiwan chanhl@maili.cgu.edu.twcgu Current program status register (CPSR) Prog Model 2 Data processing
DYNAMIC SPECULATIVE EXECUTION
 DYNAMIC SPECULATIVE EXECUTION Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
DYNAMIC SPECULATIVE EXECUTION Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 3, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 17 Advanced Processors I 2005-10-27 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/
CS 152 Computer Architecture and Engineering Lecture 17 Advanced Processors I 2005-10-27 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: David Marquardt and Udam Saini www-inst.eecs.berkeley.edu/~cs152/