HPC Libraries. Hartmut Kaiser PhD. High Performance Computing: Concepts, Methods & Means
|
|
|
- Anis Porter
- 6 years ago
- Views:
Transcription

1 High Performance Computing: Concepts, Methods & Means HPC Libraries Hartmut Kaiser PhD Center for Computation & Technology Louisiana State University April 19 th, 2007
2 Outline Introduction to High Performance Libraries Linear Algebra Libraries (BLAS, LAPACK) PDE Solvers (PETSc) Mesh manipulation and load balancing (METIS/ParMETIS, JOSTLE) Special purpose libraries (FFTW) General purpose libraries (C++: Boost) Summary Materials for test 2
3 Outline Introduction to High Performance Libraries Linear Algebra Libraries (BLAS, LAPACK) PDE Solvers (PETSc) Mesh manipulation and load balancing (METIS/ParMETIS, JOSTLE) Special purpose libraries (FFTW) General purpose libraries (C++: Boost) Summary Materials for test 3
4 Puzzle of the Day #include <stdio.h> int main() { int a = 10; switch(a) { case '1': printf("one\n"); break; case '2': printf("two\n"); break; } defa1ut: printf("none\n"); } return 0; If you expect the output of the above program to be NONE, I would request you to check it out! 4
5 Application domains Linear algebra BLAS, ATLAS, LAPACK, ScaLAPACK, Slatec, pim Ordinary and partial Differential Equations PETSc Mesh manipulation and Load Balancing METIS, ParMETIS, CHACO, JOSTLE, PARTY Graph manipulation Boost.Graph library Vector/Signal/Image processing VSIPL, PSSL. General parallelization MPI, pthreads Other domain specific libraries NAMD, NWChem, Fluent, Gaussian, LS-DYNA 5
6 Application Domain Overview Linear Algebra Libraries Provide optimized methods for constructing sets of linear equations, performing operations on them (matrix-matrix products, matrix-vector products) and solving them (factoring, forward & backward substitution. Commonly used libraries include BLAS, ATLAS, LAPACK, ScaLAPACK, PaLAPACK PDE Solvers: Developing general-porpose, parallel numerical PDE libraries Usual toolsets include manipulation of sparse data structures, iterative linear system solvers, preconditioners, nonlinear solvers and time-stepping methods. Commonly used libraries for solving PDEs include SAMRAI, PETSc, PARASOL, Overture, among others. 6
7 Application Domain Overview Mesh manipulation and Load Balancing These libraries help in partitioning meshes in roughly equal sizes across processors, thereby balancing the workload while minimizing size of separators and communication costs. Commonly used libraries for this purpose include METIS, ParMetis, Chaco, JOSTLE among others. Other packages: FFTW: features highly optimized Fourier transform package including both real and complex multidimensional transforms in sequential, multithreaded, and parallel versions. NAMD: molecular dynamics library available for Unix/Linux, Windows, OS X Fluent: computational fluid dynamics package, used for such applications as environment control systems, propulsion, reactor modeling etc. 7
8 Outline Introduction to High Performance Libraries Linear Algebra Libraries (BLAS, LAPACK) PDE Solvers (PETSc) Mesh manipulation and load balancing (METIS/ParMETIS, JOSTLE) Special purpose libraries (FFTW) General purpose libraries (C++: Boost) Summary Materials for test 8
9 BLAS (Updated set of) Basic Linear Algebra Subprograms The BLAS functionality is divided into three levels: Level 1: contains vector operations of the form: as well as scalar dot products and vector norms Level 2: contains matrix-vector operations of the form as well as Tx = y solving for x with T being triangular Level 3: contains matrix-matrix operations of the form as well as solving for triangular matrices T. This level contains the widely used General Matrix Multiply operation. 9
10 BLAS Several implementations for different languages exist Reference implementation (F77 and C) ATLAS, highly optimized for particular processor architectures A generic C++ template class library providing BLAS functionality: ublas Several vendors provide libraries optimized for their architecture (AMD, HP, IBM, Intel, NEC, NViDIA, Sun) 10
11 BLAS: F77 naming conventions 11
12 BLAS: C naming conventions F77 routine name is changed to lowercase and prefixed with cblas_ All routines which accept two dimensional arrays have a new additional first parameter specifying the matrix memory layout (row major or column major) Character parameters are replaced by corresponding enum values Input arguments are declared const Non-complex scalar input parameters are passed by value Complex scalar input argiments are passed using a void* Arrays are passed by address Output scalar arguments are passed by address Complex functions become subroutines which return the result via an additional last parameter (void*), appending _sub to the name 12
13 BLAS Level 1 routines Vector operations (xrot, xswap, xcopy etc.) Scalar dot products (xdot etc.) Vector norms (IxAMX etc.) 13
14 BLAS Level 2 routines Matrix-vector operations (xgemv, xgbmv, xhemv, xhbmv etc.) Solving Tx = y for x, where T is triangular (xger, xher etc.) 14
 Solving for triangular matrices (xtrmm) Widely used matrix-matrix")
15 BLAS Level 3 routines Matrix-matrix operations (xgemm etc.) Solving for triangular matrices (xtrmm) Widely used matrix-matrix multiply (xsymm, xgemm) 15
16 Demo 1 Shows solving a matrix multiplication problem using BLAS expressed in FORTRAN, C, and C++ Shows genericity of ublas, by comparing generic and banded matrix versions Shows newmat, a C++ matrix library which uses operator overloading 16
17 Outline Introduction to High Performance Libraries Linear Algebra Libraries (BLAS, LAPACK) PDE Solvers (PETSc) Mesh manipulation and load balancing (METIS/ParMETIS, JOSTLE) Special purpose libraries (FFTW) General purpose libraries (C++: Boost) Summary Materials for test 17
18 LAPACK Linear Algebra PACKage Written in F77 Provides routines for Solving systems of simultaneous linear equations, Least-squares solutions of linear systems of equations, Eigenvalue problems, Householder transformation to implement QR decomposition on a matrix and Singular value problems Was initially designed to run efficiently on shared memory vector machines Depends on BLAS Has been extended for distributed (SIMD) systems (ScaPACK and PLAPACK) 18

19 LAPACK (Architecture) 19
20 LAPACK naming conventions 20
21 Demo 2 Shows how using a library might speed up the computation considerably 21
22 Outline Introduction to High Performance Libraries Linear Algebra Libraries (BLAS, LAPACK) PDE Solvers (PETSc) Mesh manipulation and load balancing (METIS/ParMETIS, JOSTLE) Special purpose libraries (FFTW) General purpose libraries (C++: Boost) Summary Materials for test 22
23 PETSc (pronounced PET-see) Portable, Extensible Toolkit for Scientific Computation ( Suite of data structures and routines for the scalable (parallel) solution of scientific applications modeled by partial differential equations (PDEs) Employs the MPI standard for all message-passing communication Intended for use in large-scale application projects Includes a large suite of parallel linear and nonlinear equation solvers Easily used in application codes written in C, C++, Fortran and Python Good introduction: 23
24 PETSc (general features) Features include: Parallel vectors Scatters (handles communicating ghost point information) Gathers Parallel matrices Several sparse storage formats Easy, efficient assembly. Scalable parallel preconditioners Krylov subspace methods Parallel Newton-based nonlinear solvers Parallel time stepping (ODE) solvers 24

25 PETSc (Architecture) PETSc: Module architecture and layers of abstraction 25
26 PETSc: Component details Vector operations (Vec): Provides the vector operations required for setting up and solving large-scale linear and nonlinear problems. Includes easy-to-use parallel scatter and gather operations, as well as special-purpose code for handling ghost points for regular data structures. Matrix operations (Mat): A large suite of data structures and code for the manipulation of parallel sparse matrices. Includes four different parallel matrix data structures, each appropriate for a different class of problems. Preconditioners (PC): A collection of sequential and parallel preconditioners, including (sequential) ILU(k) (incomplete factorization), LU (lower/upper decomposition), both sequential and parallel block Jacobi, overlapping additive Schwarz methods Time stepping ODE solvers (TS): Code for the time evolution of solutions of PDEs. In addition, provides pseudo-transient continuation techniques for computing steady-state solutions. 26
27 PETSc: Component details Krylov subspace solvers (KSP): Parallel implementations of many popular Krylov subspace iterative methods, including GMRES (Generalized Minimal Residual method), CG (Conjugate Gradient), CGS (Conjugate Gradient Squared), Bi-CG-Stab (BiConjugate Gradient Squared), two variants of TFQMR (transpose free QMR), CR (Conjugate Residuals), LSQR (Least Square Root). All are coded so that they are immediately usable with any preconditioners and any matrix data structures, including matrix-free methods. Non-linear solvers (SNES): Data-structure-neutral implementations of Newton-like methods for nonlinear systems. Includes both line search and trust region techniques with a single interface. Employs by default the above data structures and linear solvers. Users can set custom monitoring routines, convergence criteria, etc. 27
28 Outline Introduction to High Performance Libraries Linear Algebra Libraries (BLAS, LAPACK) PDE Solvers (PETSc) Mesh manipulation and load balancing (METIS/ParMETIS, JOSTLE) Special purpose libraries (FFTW) General purpose libraries (C++: Boost) Summary Materials for test 28
29 Mesh libraries Introduction Structured/unstructured meshes Examples Mesh decomposition 29
30 Introduction to Meshes and Grids Mesh/Grid : 2D or 3D representation of the computational domain. Common 2D meshes are composed of triangular or quadrilateral elements Common 3D meshes are composed of hexahedral, tetrahedral or pyramidal elements Quadrilateral Triangle 2D Mesh elements Hexahedron Prism Tetrahedron 3D Mesh elements 30


31 Structured/Unstructured Meshes Structured Grids (Meshes) Cartesian grids, logically rectangular grids Mesh info accessed implicitly using grid point indices Efficient in both computation and storage Typically use finite difference discretization Unstructured Meshes Mesh connectivity information must be stored Incurs additional memory and computational cost Handles complex geometries and grid adaptivity Typically use finite volume or finite element discretization Mesh quality becomes a concern 31


32 Mesh examples 32

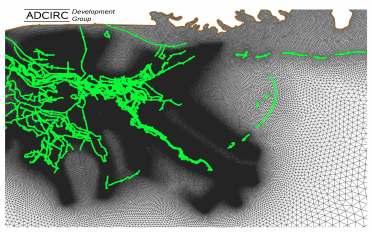
33 Meshes are used for Computation 33
34 Mesh Decomposition Goal is to maximize interior while minimizing connections between subdomains. That is, minimize communication. Such decomposition problems have been studied in load balancing for parallel computation. Lots of choices: METIS, ParMETIS -- University of Minnesota. PARTI -- University of Maryland, CHACO -- Sandia National Laboratories, JOSTLE -- University of Greenwich, PARTY -- University of Paderborn, SCOTCH -- Université Bordeaux, TOP/DOMDEC -- NAS at NASA Ames Research Center. 34
35 Mesh Decomposition Load balancing Distribute elements evenly across processors. Each processor should have equal share of work. Communication costs should be minimized. Minimize sub-domain boundary elements. Minimize number of neighboring domains. Distribution should reflect machine architecture. Communication versus calculation. Bandwidth versus latency. Note that optimizing load balance and communication cost simultaneously is an NP-hard problem. 35

36 Mesh decomposition
37 Static and Dynamic Meshes Static Grids (Meshes) Decomposition need only be carried out once Static decomposition may therefore be carried out as a preprocessing step, often done in serial Dynamic Meshes Decomposition must be adapted as underlying mesh or processor load changes. Dynamic decomposition therefore becomes part of the calculation itself and cannot be carried out solely as a pre-processing step. 37
38 HP J CPU Solve Time: 13:26 Baseline Time src : Amy Apon, 38
39 Linux Cluster 2 CPU s Solve Time: 5:20 Speed-Up: 2.5X src : Amy Apon, 39

40 Linux Cluster 4 CPU s Solve Time: 3:07 Speed-Up: 4.3X src : Amy Apon, 40
41 Linux Cluster 8 CPU s Solve Time: 1:51 Speed-Up: 7.3X src : Amy Apon, 41
42 Linux Cluster 16 CPU s Solve Time: 1:03 Speed-Up: 12.8X src : Amy Apon, 42
43 Speedup due to decomposition # CPUs Run-times (s)

44 Jostle and Metis

45 Jostle
46 Jostle

47 Jostle
48 Metis
49 ParMetis

50 Metis (serial)
51 Comparison
52 Outline Introduction to High Performance Libraries Linear Algebra Libraries (BLAS, LAPACK) PDE Solvers (PETSc) Mesh manipulation and load balancing (METIS/ParMETIS, JOSTLE) Special purpose libraries (FFTW) General purpose libraries (C++: Boost) Summary Materials for test 52
53 FFTW Fastest Fourier Transform in the West Portable C subroutine library for computing discrete cosine/sine transform (DCT/DST) Computes arbitrary size discrete Fourier and Hartley transforms on real or complex data, in one or more dimensions Optimized for speed through application of special-purpose compiler genfft (codelet generator), originally written in OCaml; performance comparable even with vendor optimized libraries Free software, distributed under GPL; also available under commercial MIT license Developed at MIT by Matteo Frigo and Steven G. Johnson Won J. H. Wilkinson Prize for Numerical Software in 1999 Most recent stable version is ( 53
54 Main FFTW Features C and FORTRAN interfaces, C++ wrappers available Speed, including support for SSE, SSE2, 3dNow! and Altivec Arbitrary size transforms with complexity of O(n log(n)) (sizes which can be factored to 2, 3, 5 and 7 are most efficient by default, but a custom code can be also generated for other sizes if required) Even/odd data (DCT/DST), types I-IV Can produce pure real output, or process pure real input data Efficient handling of multiple, strided transforms (e.g. transformation of multiple arrays at once; one dimension of multi-dimensional array; one field of multi-component array) Parallel code supporting Cilk, SMP platforms with threads, or MPI Ability to save and restore plans optimized for a given platform (through wisdom mechanism) Portable to any platform with a working C compiler 54
55 FFTW Sample Code Computing 1-D complex DFT #include <fftw3.h>... { fftw_complex *in, *out; fftw_plan p;... in = (fftw_complex*) fftw_malloc(sizeof(fftw_complex) * N); out = (fftw_complex*) fftw_malloc(sizeof(fftw_complex) * N); /* populate in[] with input data */ p = fftw_plan_dft_1d(n, in, out, FFTW_FORWARD, FFTW_ESTIMATE);... fftw_execute(p); /* repeat as needed */ /* transform now available in out[] */... fftw_destroy_plan(p); fftw_free(in); fftw_free(out); } Source: 55
56 Outline Introduction to High Performance Libraries Linear Algebra Libraries (BLAS, LAPACK) PDE Solvers (PETSc) Mesh manipulation and load balancing (METIS/ParMETIS, JOSTLE) Special purpose libraries (FFTW) General purpose libraries (C++: Boost) Summary Materials for test 56
57 The Boost Libraries What s Boost What s important Other stuff 57
58 What is Boost? Data Structures, Containers, Iterators, and Algorithms String and Text Processing Function Objects and Higher-Order Programming Generic Programming and Template Metaprogramming Math and Numerics Input/Output Miscellaneous Mostly header only 58
59 What s important OS abstraction Thread: OS independent kernel level thread interface Asio: asynchronous input output Filesystem: file system operations as file copy, delete, directory create, file path handling System: OS error code abstraction and handling Program options: handling of command line arguments and parameters Streams: build your own C++ streams DateTime: Handling of dates, times and time periods Timer: simple timer object 59
60 What s important Data types, Container types, all extending STL Pointer containers: allow for pointers in STL containers: vector<char *> ptr_vector<char> Multi index: data structures with multiple indicies Constant sized arrays: array<char, 10>, acts like vector or plain C array Any: can hold values of any type (if you need polymorphism) Variant: can hold values of any of the types specified at compile time ( C equivalent is discriminated union) Optional: can hold a value or nothing Tuple: like a vector or array, but every element may have a different type (similar to plain struct) Graph library: very sophisticated collection of graph releated data structures and algorithms Parallel version exists (using MPI) 60
61 What s important Helper classes Smart pointers: working with pointers without having to worry about memory management Memory pools: specialized memory allocation for containers Iterator library: write your own iterator classes with ease (non trivial otherwise) 61
62 Other stuff in Boost String and Text processing Regex, parsing, format, conversion etc. Alorithms String algos, FOR_EACH, minmax etc. Math and numerics Conversion, interval, random, octonion, quarternion, special functions, rational, ublas Functional and higher order prgramming Bind, lambda, function, ref, signals etc. Generic and template metaprogramming Proto, mpl, fusion, phoenix, enable_if etc. Testing Unit tests, concept checks, static_assert 62
63 Conclusion Look at Boost first if you need something not available in Standard library Even if it s not in Boost look around, there are a lot of libraries in preparation for Boost (Boost Sandbox, File Vault) 63
64 Links Boost, current release V Web: CVS: Boost Sandbox CVS: File Vault: Boost mailing lists 64
65 Outlook Elliptic PDE discretized by Finite Volume Functional specification with a Domain Specific Embedded Language (DSEL) equation = sum<vertex_edge> [ sumf<edge_vertex>(0.0, _e) [ pot * orient(_e, _1) ] * A / d * eps ] - V * rho References: [1] 65
66 References 1. Rene Heinzl, Modern Application Design using Modern Programming Paradigms and a Library-Centric Software Approach, OOPSLA 2006, Workshop on Library Centric Software Design, Portland, Oregon, October
67 Outline Introduction to High Performance Libraries Linear Algebra Libraries (BLAS, LAPACK) PDE Solvers (PETSc) Mesh manipulation and load balancing (METIS/ParMETIS, JOSTLE) Special purpose libraries (FFTW) General purpose libraries (C++: Boost) Summary Materials for test 67
68 Summary Material for the Test High performance libraries 5,6,7 Linear algebra libraries: BLAS: 9, 11, 12 Linear algebra libraries: LinPACK: 18 PDE Solvers: 23, 24, 26, 27 Mesh decomposition & load balancing: 30, 31, 34, 35, 37, 44, 45, 46, 48, 49 FFTW: 53, 54 Boost: 58, 59, 60, 61, 62



69
Dense matrix algebra and libraries (and dealing with Fortran)
") Dense matrix algebra and libraries (and dealing with Fortran) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Dense matrix algebra and libraries (and dealing with Fortran)
Dense matrix algebra and libraries (and dealing with Fortran) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Dense matrix algebra and libraries (and dealing with Fortran)
A Few Numerical Libraries for HPC
 A Few Numerical Libraries for HPC CPS343 Parallel and High Performance Computing Spring 2016 CPS343 (Parallel and HPC) A Few Numerical Libraries for HPC Spring 2016 1 / 37 Outline 1 HPC == numerical linear
A Few Numerical Libraries for HPC CPS343 Parallel and High Performance Computing Spring 2016 CPS343 (Parallel and HPC) A Few Numerical Libraries for HPC Spring 2016 1 / 37 Outline 1 HPC == numerical linear
Scientific Computing. Some slides from James Lambers, Stanford
 Scientific Computing Some slides from James Lambers, Stanford Dense Linear Algebra Scaling and sums Transpose Rank-one updates Rotations Matrix vector products Matrix Matrix products BLAS Designing Numerical
Scientific Computing Some slides from James Lambers, Stanford Dense Linear Algebra Scaling and sums Transpose Rank-one updates Rotations Matrix vector products Matrix Matrix products BLAS Designing Numerical
PETSc Satish Balay, Kris Buschelman, Bill Gropp, Dinesh Kaushik, Lois McInnes, Barry Smith
 PETSc http://www.mcs.anl.gov/petsc Satish Balay, Kris Buschelman, Bill Gropp, Dinesh Kaushik, Lois McInnes, Barry Smith PDE Application Codes PETSc PDE Application Codes! ODE Integrators! Nonlinear Solvers,!
PETSc http://www.mcs.anl.gov/petsc Satish Balay, Kris Buschelman, Bill Gropp, Dinesh Kaushik, Lois McInnes, Barry Smith PDE Application Codes PETSc PDE Application Codes! ODE Integrators! Nonlinear Solvers,!
Introduction to Parallel Computing
 Introduction to Parallel Computing W. P. Petersen Seminar for Applied Mathematics Department of Mathematics, ETHZ, Zurich wpp@math. ethz.ch P. Arbenz Institute for Scientific Computing Department Informatik,
Introduction to Parallel Computing W. P. Petersen Seminar for Applied Mathematics Department of Mathematics, ETHZ, Zurich wpp@math. ethz.ch P. Arbenz Institute for Scientific Computing Department Informatik,
MPI Related Software
 1 MPI Related Software Profiling Libraries and Tools Visualizing Program Behavior Timing Performance Measurement and Tuning High Level Libraries Profiling Libraries MPI provides mechanism to intercept
1 MPI Related Software Profiling Libraries and Tools Visualizing Program Behavior Timing Performance Measurement and Tuning High Level Libraries Profiling Libraries MPI provides mechanism to intercept
Mathematical Libraries and Application Software on JUQUEEN and JURECA
 Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUQUEEN and JURECA JSC Training Course May 2017 I.Gutheil Outline General Informations Sequential Libraries Parallel
Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUQUEEN and JURECA JSC Training Course May 2017 I.Gutheil Outline General Informations Sequential Libraries Parallel
High-Performance Libraries and Tools. HPC Fall 2012 Prof. Robert van Engelen
 High-Performance Libraries and Tools HPC Fall 2012 Prof. Robert van Engelen Overview Dense matrix BLAS (serial) ATLAS (serial/threaded) LAPACK (serial) Vendor-tuned LAPACK (shared memory parallel) ScaLAPACK/PLAPACK
High-Performance Libraries and Tools HPC Fall 2012 Prof. Robert van Engelen Overview Dense matrix BLAS (serial) ATLAS (serial/threaded) LAPACK (serial) Vendor-tuned LAPACK (shared memory parallel) ScaLAPACK/PLAPACK
Mathematical Libraries and Application Software on JUROPA, JUGENE, and JUQUEEN. JSC Training Course
 Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUROPA, JUGENE, and JUQUEEN JSC Training Course May 22, 2012 Outline General Informations Sequential Libraries Parallel
Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUROPA, JUGENE, and JUQUEEN JSC Training Course May 22, 2012 Outline General Informations Sequential Libraries Parallel
Mathematical Libraries and Application Software on JUQUEEN and JURECA
 Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUQUEEN and JURECA JSC Training Course November 2015 I.Gutheil Outline General Informations Sequential Libraries Parallel
Mitglied der Helmholtz-Gemeinschaft Mathematical Libraries and Application Software on JUQUEEN and JURECA JSC Training Course November 2015 I.Gutheil Outline General Informations Sequential Libraries Parallel
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS. Kyle Spagnoli. Research EM Photonics 3/20/2013
 GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
MPI Related Software. Profiling Libraries. Performance Visualization with Jumpshot
 1 MPI Related Software Profiling Libraries and Tools Visualizing Program Behavior Timing Performance Measurement and Tuning High Level Libraries Performance Visualization with Jumpshot For detailed analysis
1 MPI Related Software Profiling Libraries and Tools Visualizing Program Behavior Timing Performance Measurement and Tuning High Level Libraries Performance Visualization with Jumpshot For detailed analysis
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 20: Sparse Linear Systems; Direct Methods vs. Iterative Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 26
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 20: Sparse Linear Systems; Direct Methods vs. Iterative Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 26
Dynamic Selection of Auto-tuned Kernels to the Numerical Libraries in the DOE ACTS Collection
 Numerical Libraries in the DOE ACTS Collection The DOE ACTS Collection SIAM Parallel Processing for Scientific Computing, Savannah, Georgia Feb 15, 2012 Tony Drummond Computational Research Division Lawrence
Numerical Libraries in the DOE ACTS Collection The DOE ACTS Collection SIAM Parallel Processing for Scientific Computing, Savannah, Georgia Feb 15, 2012 Tony Drummond Computational Research Division Lawrence
HPC Numerical Libraries. Nicola Spallanzani SuperComputing Applications and Innovation Department
 HPC Numerical Libraries Nicola Spallanzani n.spallanzani@cineca.it SuperComputing Applications and Innovation Department Algorithms and Libraries Many numerical algorithms are well known and largely available.
HPC Numerical Libraries Nicola Spallanzani n.spallanzani@cineca.it SuperComputing Applications and Innovation Department Algorithms and Libraries Many numerical algorithms are well known and largely available.
Linear Algebra libraries in Debian. DebConf 10 New York 05/08/2010 Sylvestre
 Linear Algebra libraries in Debian Who I am? Core developer of Scilab (daily job) Debian Developer Involved in Debian mainly in Science and Java aspects sylvestre.ledru@scilab.org / sylvestre@debian.org
Linear Algebra libraries in Debian Who I am? Core developer of Scilab (daily job) Debian Developer Involved in Debian mainly in Science and Java aspects sylvestre.ledru@scilab.org / sylvestre@debian.org
Introduction to Numerical Libraries for HPC. Bilel Hadri. Computational Scientist KAUST Supercomputing Lab.
 Introduction to Numerical Libraries for HPC Bilel Hadri bilel.hadri@kaust.edu.sa Computational Scientist KAUST Supercomputing Lab Bilel Hadri 1 Numerical Libraries Application Areas Most used libraries/software
Introduction to Numerical Libraries for HPC Bilel Hadri bilel.hadri@kaust.edu.sa Computational Scientist KAUST Supercomputing Lab Bilel Hadri 1 Numerical Libraries Application Areas Most used libraries/software
Intel Performance Libraries
 Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
Intel Math Kernel Library
 Intel Math Kernel Library Release 7.0 March 2005 Intel MKL Purpose Performance, performance, performance! Intel s scientific and engineering floating point math library Initially only basic linear algebra
Intel Math Kernel Library Release 7.0 March 2005 Intel MKL Purpose Performance, performance, performance! Intel s scientific and engineering floating point math library Initially only basic linear algebra
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA. NVIDIA Corporation
 Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
ESPRESO ExaScale PaRallel FETI Solver. Hybrid FETI Solver Report
 ESPRESO ExaScale PaRallel FETI Solver Hybrid FETI Solver Report Lubomir Riha, Tomas Brzobohaty IT4Innovations Outline HFETI theory from FETI to HFETI communication hiding and avoiding techniques our new
ESPRESO ExaScale PaRallel FETI Solver Hybrid FETI Solver Report Lubomir Riha, Tomas Brzobohaty IT4Innovations Outline HFETI theory from FETI to HFETI communication hiding and avoiding techniques our new
Mathematical libraries at the CHPC
 Presentation Mathematical libraries at the CHPC Martin Cuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu October 19, 2006 http://www.chpc.utah.edu Overview What and what
Presentation Mathematical libraries at the CHPC Martin Cuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu October 19, 2006 http://www.chpc.utah.edu Overview What and what
Contents. I The Basic Framework for Stationary Problems 1
 page v Preface xiii I The Basic Framework for Stationary Problems 1 1 Some model PDEs 3 1.1 Laplace s equation; elliptic BVPs... 3 1.1.1 Physical experiments modeled by Laplace s equation... 5 1.2 Other
page v Preface xiii I The Basic Framework for Stationary Problems 1 1 Some model PDEs 3 1.1 Laplace s equation; elliptic BVPs... 3 1.1.1 Physical experiments modeled by Laplace s equation... 5 1.2 Other
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
BDDCML. solver library based on Multi-Level Balancing Domain Decomposition by Constraints copyright (C) Jakub Šístek version 1.
 Jakub Šístek version 1.") BDDCML solver library based on Multi-Level Balancing Domain Decomposition by Constraints copyright (C) 2010-2012 Jakub Šístek version 1.3 Jakub Šístek i Table of Contents 1 Introduction.....................................
BDDCML solver library based on Multi-Level Balancing Domain Decomposition by Constraints copyright (C) 2010-2012 Jakub Šístek version 1.3 Jakub Šístek i Table of Contents 1 Introduction.....................................
Anna Morajko.
 Performance analysis and tuning of parallel/distributed applications Anna Morajko Anna.Morajko@uab.es 26 05 2008 Introduction Main research projects Develop techniques and tools for application performance
Performance analysis and tuning of parallel/distributed applications Anna Morajko Anna.Morajko@uab.es 26 05 2008 Introduction Main research projects Develop techniques and tools for application performance
Introduction to PETSc KSP, PC. CS595, Fall 2010
 Introduction to PETSc KSP, PC CS595, Fall 2010 1 Linear Solution Main Routine PETSc Solve Ax = b Linear Solvers (KSP) PC Application Initialization Evaluation of A and b Post- Processing User code PETSc
Introduction to PETSc KSP, PC CS595, Fall 2010 1 Linear Solution Main Routine PETSc Solve Ax = b Linear Solvers (KSP) PC Application Initialization Evaluation of A and b Post- Processing User code PETSc
Parallel Libraries And ToolBoxes for PDEs Luca Heltai
 The 2nd Workshop on High Performance Computing Parallel Libraries And ToolBoxes for PDEs Luca Heltai SISSA/eLAB - Trieste Shahid Beheshti University, Institute for Studies in Theoretical Physics and Mathematics
The 2nd Workshop on High Performance Computing Parallel Libraries And ToolBoxes for PDEs Luca Heltai SISSA/eLAB - Trieste Shahid Beheshti University, Institute for Studies in Theoretical Physics and Mathematics
Performance of Multicore LUP Decomposition
 Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
Performance of Multicore LUP Decomposition Nathan Beckmann Silas Boyd-Wickizer May 3, 00 ABSTRACT This paper evaluates the performance of four parallel LUP decomposition implementations. The implementations
Preface... 1 The Boost C++ Libraries Overview... 5 Math Toolkit: Special Functions Math Toolkit: Orthogonal Functions... 29
 Preface... 1 Goals of this Book... 1 Structure of the Book... 1 For whom is this Book?... 1 Using the Boost Libraries... 2 Practical Hints and Guidelines... 2 What s Next?... 2 1 The Boost C++ Libraries
Preface... 1 Goals of this Book... 1 Structure of the Book... 1 For whom is this Book?... 1 Using the Boost Libraries... 2 Practical Hints and Guidelines... 2 What s Next?... 2 1 The Boost C++ Libraries
Optimization and Scalability
 Optimization and Scalability Drew Dolgert CAC 29 May 2009 Intro to Parallel Computing 5/29/2009 www.cac.cornell.edu 1 Great Little Program What happens when I run it on the cluster? How can I make it faster?
Optimization and Scalability Drew Dolgert CAC 29 May 2009 Intro to Parallel Computing 5/29/2009 www.cac.cornell.edu 1 Great Little Program What happens when I run it on the cluster? How can I make it faster?
Resources for parallel computing
 Resources for parallel computing BLAS Basic linear algebra subprograms. Originally published in ACM Toms (1979) (Linpack Blas + Lapack). Implement matrix operations upto matrix-matrix multiplication and
Resources for parallel computing BLAS Basic linear algebra subprograms. Originally published in ACM Toms (1979) (Linpack Blas + Lapack). Implement matrix operations upto matrix-matrix multiplication and
Performance Strategies for Parallel Mathematical Libraries Based on Historical Knowledgebase
 Performance Strategies for Parallel Mathematical Libraries Based on Historical Knowledgebase CScADS workshop 29 Eduardo Cesar, Anna Morajko, Ihab Salawdeh Universitat Autònoma de Barcelona Objective Mathematical
Performance Strategies for Parallel Mathematical Libraries Based on Historical Knowledgebase CScADS workshop 29 Eduardo Cesar, Anna Morajko, Ihab Salawdeh Universitat Autònoma de Barcelona Objective Mathematical
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
SCALABLE ALGORITHMS for solving large sparse linear systems of equations
 SCALABLE ALGORITHMS for solving large sparse linear systems of equations CONTENTS Sparse direct solvers (multifrontal) Substructuring methods (hybrid solvers) Jacko Koster, Bergen Center for Computational
SCALABLE ALGORITHMS for solving large sparse linear systems of equations CONTENTS Sparse direct solvers (multifrontal) Substructuring methods (hybrid solvers) Jacko Koster, Bergen Center for Computational
Lecture 15: More Iterative Ideas
 Lecture 15: More Iterative Ideas David Bindel 15 Mar 2010 Logistics HW 2 due! Some notes on HW 2. Where we are / where we re going More iterative ideas. Intro to HW 3. More HW 2 notes See solution code!
Lecture 15: More Iterative Ideas David Bindel 15 Mar 2010 Logistics HW 2 due! Some notes on HW 2. Where we are / where we re going More iterative ideas. Intro to HW 3. More HW 2 notes See solution code!
Parallelism V. HPC Profiling. John Cavazos. Dept of Computer & Information Sciences University of Delaware
 Parallelism V HPC Profiling John Cavazos Dept of Computer & Information Sciences University of Delaware Lecture Overview Performance Counters Profiling PAPI TAU HPCToolkit PerfExpert Performance Counters
Parallelism V HPC Profiling John Cavazos Dept of Computer & Information Sciences University of Delaware Lecture Overview Performance Counters Profiling PAPI TAU HPCToolkit PerfExpert Performance Counters
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015
 AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
EFFICIENT SOLVER FOR LINEAR ALGEBRAIC EQUATIONS ON PARALLEL ARCHITECTURE USING MPI
 EFFICIENT SOLVER FOR LINEAR ALGEBRAIC EQUATIONS ON PARALLEL ARCHITECTURE USING MPI 1 Akshay N. Panajwar, 2 Prof.M.A.Shah Department of Computer Science and Engineering, Walchand College of Engineering,
EFFICIENT SOLVER FOR LINEAR ALGEBRAIC EQUATIONS ON PARALLEL ARCHITECTURE USING MPI 1 Akshay N. Panajwar, 2 Prof.M.A.Shah Department of Computer Science and Engineering, Walchand College of Engineering,
Parallel Implementations of Gaussian Elimination
 s of Western Michigan University vasilije.perovic@wmich.edu January 27, 2012 CS 6260: in Parallel Linear systems of equations General form of a linear system of equations is given by a 11 x 1 + + a 1n
s of Western Michigan University vasilije.perovic@wmich.edu January 27, 2012 CS 6260: in Parallel Linear systems of equations General form of a linear system of equations is given by a 11 x 1 + + a 1n
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation
 Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
NEW ADVANCES IN GPU LINEAR ALGEBRA
 GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
Parallel Computing. Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides)
, A Grama book (chapter 3 slides)") Parallel Computing 2012 Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides) Parallel Algorithm Design Outline Computational Model Design Methodology Partitioning Communication
Parallel Computing 2012 Slides credit: M. Quinn book (chapter 3 slides), A Grama book (chapter 3 slides) Parallel Algorithm Design Outline Computational Model Design Methodology Partitioning Communication
A Local-View Array Library for Partitioned Global Address Space C++ Programs
 Lawrence Berkeley National Laboratory A Local-View Array Library for Partitioned Global Address Space C++ Programs Amir Kamil, Yili Zheng, and Katherine Yelick Lawrence Berkeley Lab Berkeley, CA, USA June
Lawrence Berkeley National Laboratory A Local-View Array Library for Partitioned Global Address Space C++ Programs Amir Kamil, Yili Zheng, and Katherine Yelick Lawrence Berkeley Lab Berkeley, CA, USA June
PetIGA. A Framework for High Performance Isogeometric Analysis. Santa Fe, Argentina. Knoxville, United States. Thuwal, Saudi Arabia
 PetIGA A Framework for High Performance Isogeometric Analysis Lisandro Dalcin 1,3, Nathaniel Collier 2, Adriano Côrtes 3, Victor M. Calo 3 1 Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET)
PetIGA A Framework for High Performance Isogeometric Analysis Lisandro Dalcin 1,3, Nathaniel Collier 2, Adriano Côrtes 3, Victor M. Calo 3 1 Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET)
FFTSS Library Version 3.0 User s Guide
 Last Modified: 31/10/07 FFTSS Library Version 3.0 User s Guide Copyright (C) 2002-2007 The Scalable Software Infrastructure Project, is supported by the Development of Software Infrastructure for Large
Last Modified: 31/10/07 FFTSS Library Version 3.0 User s Guide Copyright (C) 2002-2007 The Scalable Software Infrastructure Project, is supported by the Development of Software Infrastructure for Large
Intel Math Kernel Library 10.3
 Intel Math Kernel Library 10.3 Product Brief Intel Math Kernel Library 10.3 The Flagship High Performance Computing Math Library for Windows*, Linux*, and Mac OS* X Intel Math Kernel Library (Intel MKL)
Intel Math Kernel Library 10.3 Product Brief Intel Math Kernel Library 10.3 The Flagship High Performance Computing Math Library for Windows*, Linux*, and Mac OS* X Intel Math Kernel Library (Intel MKL)
High Performance Computing: Tools and Applications
 High Performance Computing: Tools and Applications Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Lecture 15 Numerically solve a 2D boundary value problem Example:
High Performance Computing: Tools and Applications Edmond Chow School of Computational Science and Engineering Georgia Institute of Technology Lecture 15 Numerically solve a 2D boundary value problem Example:
In 1986, I had degrees in math and engineering and found I wanted to compute things. What I ve mostly found is that:
 Parallel Computing and Data Locality Gary Howell In 1986, I had degrees in math and engineering and found I wanted to compute things. What I ve mostly found is that: Real estate and efficient computation
Parallel Computing and Data Locality Gary Howell In 1986, I had degrees in math and engineering and found I wanted to compute things. What I ve mostly found is that: Real estate and efficient computation
Numerical Implementation of Overlapping Balancing Domain Decomposition Methods on Unstructured Meshes
 Numerical Implementation of Overlapping Balancing Domain Decomposition Methods on Unstructured Meshes Jung-Han Kimn 1 and Blaise Bourdin 2 1 Department of Mathematics and The Center for Computation and
Numerical Implementation of Overlapping Balancing Domain Decomposition Methods on Unstructured Meshes Jung-Han Kimn 1 and Blaise Bourdin 2 1 Department of Mathematics and The Center for Computation and
APPLICATION OF PARALLEL ARRAYS FOR SEMIAUTOMATIC PARALLELIZATION OF FLOW IN POROUS MEDIA PROBLEM SOLVER
 Mathematical Modelling and Analysis 2005. Pages 171 177 Proceedings of the 10 th International Conference MMA2005&CMAM2, Trakai c 2005 Technika ISBN 9986-05-924-0 APPLICATION OF PARALLEL ARRAYS FOR SEMIAUTOMATIC
Mathematical Modelling and Analysis 2005. Pages 171 177 Proceedings of the 10 th International Conference MMA2005&CMAM2, Trakai c 2005 Technika ISBN 9986-05-924-0 APPLICATION OF PARALLEL ARRAYS FOR SEMIAUTOMATIC
PARDISO Version Reference Sheet Fortran
 PARDISO Version 5.0.0 1 Reference Sheet Fortran CALL PARDISO(PT, MAXFCT, MNUM, MTYPE, PHASE, N, A, IA, JA, 1 PERM, NRHS, IPARM, MSGLVL, B, X, ERROR, DPARM) 1 Please note that this version differs significantly
PARDISO Version 5.0.0 1 Reference Sheet Fortran CALL PARDISO(PT, MAXFCT, MNUM, MTYPE, PHASE, N, A, IA, JA, 1 PERM, NRHS, IPARM, MSGLVL, B, X, ERROR, DPARM) 1 Please note that this version differs significantly
1.2 Numerical Solutions of Flow Problems
 1.2 Numerical Solutions of Flow Problems DIFFERENTIAL EQUATIONS OF MOTION FOR A SIMPLIFIED FLOW PROBLEM Continuity equation for incompressible flow: 0 Momentum (Navier-Stokes) equations for a Newtonian
1.2 Numerical Solutions of Flow Problems DIFFERENTIAL EQUATIONS OF MOTION FOR A SIMPLIFIED FLOW PROBLEM Continuity equation for incompressible flow: 0 Momentum (Navier-Stokes) equations for a Newtonian
Partitioning and Partitioning Tools. Tim Barth NASA Ames Research Center Moffett Field, California USA
 Partitioning and Partitioning Tools Tim Barth NASA Ames Research Center Moffett Field, California 94035-00 USA 1 Graph/Mesh Partitioning Why do it? The graph bisection problem What are the standard heuristic
Partitioning and Partitioning Tools Tim Barth NASA Ames Research Center Moffett Field, California 94035-00 USA 1 Graph/Mesh Partitioning Why do it? The graph bisection problem What are the standard heuristic
Outline. Parallel Algorithms for Linear Algebra. Number of Processors and Problem Size. Speedup and Efficiency
 1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
LAPACK. Linear Algebra PACKage. Janice Giudice David Knezevic 1
 LAPACK Linear Algebra PACKage 1 Janice Giudice David Knezevic 1 Motivating Question Recalling from last week... Level 1 BLAS: vectors ops Level 2 BLAS: matrix-vectors ops 2 2 O( n ) flops on O( n ) data
LAPACK Linear Algebra PACKage 1 Janice Giudice David Knezevic 1 Motivating Question Recalling from last week... Level 1 BLAS: vectors ops Level 2 BLAS: matrix-vectors ops 2 2 O( n ) flops on O( n ) data
Modelling and implementation of algorithms in applied mathematics using MPI
 Modelling and implementation of algorithms in applied mathematics using MPI Lecture 1: Basics of Parallel Computing G. Rapin Brazil March 2011 Outline 1 Structure of Lecture 2 Introduction 3 Parallel Performance
Modelling and implementation of algorithms in applied mathematics using MPI Lecture 1: Basics of Parallel Computing G. Rapin Brazil March 2011 Outline 1 Structure of Lecture 2 Introduction 3 Parallel Performance
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop
: Automatic Performance Tuning Workshop") Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop http://cscads.rice.edu/ Discussion and Feedback CScADS Autotuning 07 Top Priority Questions for Discussion
Center for Scalable Application Development Software (CScADS): Automatic Performance Tuning Workshop http://cscads.rice.edu/ Discussion and Feedback CScADS Autotuning 07 Top Priority Questions for Discussion
CS 470 Spring Other Architectures. Mike Lam, Professor. (with an aside on linear algebra)
") CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
High-Performance Computational Electromagnetic Modeling Using Low-Cost Parallel Computers
 High-Performance Computational Electromagnetic Modeling Using Low-Cost Parallel Computers July 14, 1997 J Daniel S. Katz (Daniel.S.Katz@jpl.nasa.gov) Jet Propulsion Laboratory California Institute of Technology
High-Performance Computational Electromagnetic Modeling Using Low-Cost Parallel Computers July 14, 1997 J Daniel S. Katz (Daniel.S.Katz@jpl.nasa.gov) Jet Propulsion Laboratory California Institute of Technology
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER PROF. BRYANT PROF. KAYVON 15618: PARALLEL COMPUTER ARCHITECTURE
 HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
HPC Algorithms and Applications
 HPC Algorithms and Applications Dwarf #5 Structured Grids Michael Bader Winter 2012/2013 Dwarf #5 Structured Grids, Winter 2012/2013 1 Dwarf #5 Structured Grids 1. dense linear algebra 2. sparse linear
HPC Algorithms and Applications Dwarf #5 Structured Grids Michael Bader Winter 2012/2013 Dwarf #5 Structured Grids, Winter 2012/2013 1 Dwarf #5 Structured Grids 1. dense linear algebra 2. sparse linear
CUDA Accelerated Compute Libraries. M. Naumov
 CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
CUDA Accelerated Compute Libraries M. Naumov Outline Motivation Why should you use libraries? CUDA Toolkit Libraries Overview of performance CUDA Proprietary Libraries Address specific markets Third Party
Optimizing Data Locality for Iterative Matrix Solvers on CUDA
 Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
OpenFOAM + GPGPU. İbrahim Özküçük
 OpenFOAM + GPGPU İbrahim Özküçük Outline GPGPU vs CPU GPGPU plugins for OpenFOAM Overview of Discretization CUDA for FOAM Link (cufflink) Cusp & Thrust Libraries How Cufflink Works Performance data of
OpenFOAM + GPGPU İbrahim Özküçük Outline GPGPU vs CPU GPGPU plugins for OpenFOAM Overview of Discretization CUDA for FOAM Link (cufflink) Cusp & Thrust Libraries How Cufflink Works Performance data of
Advanced Numerical Techniques for Cluster Computing
 Advanced Numerical Techniques for Cluster Computing Presented by Piotr Luszczek http://icl.cs.utk.edu/iter-ref/ Presentation Outline Motivation hardware Dense matrix calculations Sparse direct solvers
Advanced Numerical Techniques for Cluster Computing Presented by Piotr Luszczek http://icl.cs.utk.edu/iter-ref/ Presentation Outline Motivation hardware Dense matrix calculations Sparse direct solvers
Application of GPU-Based Computing to Large Scale Finite Element Analysis of Three-Dimensional Structures
 Paper 6 Civil-Comp Press, 2012 Proceedings of the Eighth International Conference on Engineering Computational Technology, B.H.V. Topping, (Editor), Civil-Comp Press, Stirlingshire, Scotland Application
Paper 6 Civil-Comp Press, 2012 Proceedings of the Eighth International Conference on Engineering Computational Technology, B.H.V. Topping, (Editor), Civil-Comp Press, Stirlingshire, Scotland Application
A User Friendly Toolbox for Parallel PDE-Solvers
 A User Friendly Toolbox for Parallel PDE-Solvers Manfred Liebmann Institute for Analysis and Computational Mathematics Johannes Kepler University Linz manfred.liebmann@uni-graz.at April 4, 6 Abstract The
A User Friendly Toolbox for Parallel PDE-Solvers Manfred Liebmann Institute for Analysis and Computational Mathematics Johannes Kepler University Linz manfred.liebmann@uni-graz.at April 4, 6 Abstract The
Parallel solution for finite element linear systems of. equations on workstation cluster *
 Aug. 2009, Volume 6, No.8 (Serial No.57) Journal of Communication and Computer, ISSN 1548-7709, USA Parallel solution for finite element linear systems of equations on workstation cluster * FU Chao-jiang
Aug. 2009, Volume 6, No.8 (Serial No.57) Journal of Communication and Computer, ISSN 1548-7709, USA Parallel solution for finite element linear systems of equations on workstation cluster * FU Chao-jiang
BLAS. Christoph Ortner Stef Salvini
 BLAS Christoph Ortner Stef Salvini The BLASics Basic Linear Algebra Subroutines Building blocks for more complex computations Very widely used Level means number of operations Level 1: vector-vector operations
BLAS Christoph Ortner Stef Salvini The BLASics Basic Linear Algebra Subroutines Building blocks for more complex computations Very widely used Level means number of operations Level 1: vector-vector operations
Performance Evaluation of Multiple and Mixed Precision Iterative Refinement Method and its Application to High-Order Implicit Runge-Kutta Method
 Performance Evaluation of Multiple and Mixed Precision Iterative Refinement Method and its Application to High-Order Implicit Runge-Kutta Method Tomonori Kouya Shizuoa Institute of Science and Technology,
Performance Evaluation of Multiple and Mixed Precision Iterative Refinement Method and its Application to High-Order Implicit Runge-Kutta Method Tomonori Kouya Shizuoa Institute of Science and Technology,
Self Adapting Numerical Software (SANS-Effort)
") Self Adapting Numerical Software (SANS-Effort) Jack Dongarra Innovative Computing Laboratory University of Tennessee and Oak Ridge National Laboratory 1 Work on Self Adapting Software 1. Lapack For Clusters
Self Adapting Numerical Software (SANS-Effort) Jack Dongarra Innovative Computing Laboratory University of Tennessee and Oak Ridge National Laboratory 1 Work on Self Adapting Software 1. Lapack For Clusters
Intel Math Kernel Library (Intel MKL) BLAS. Victor Kostin Intel MKL Dense Solvers team manager
 BLAS. Victor Kostin Intel MKL Dense Solvers team manager") Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
Journal of Engineering Research and Studies E-ISSN
 Journal of Engineering Research and Studies E-ISS 0976-79 Research Article SPECTRAL SOLUTIO OF STEADY STATE CODUCTIO I ARBITRARY QUADRILATERAL DOMAIS Alavani Chitra R 1*, Joshi Pallavi A 1, S Pavitran
Journal of Engineering Research and Studies E-ISS 0976-79 Research Article SPECTRAL SOLUTIO OF STEADY STATE CODUCTIO I ARBITRARY QUADRILATERAL DOMAIS Alavani Chitra R 1*, Joshi Pallavi A 1, S Pavitran
ECE 697NA MATH 697NA Numerical Algorithms
 ECE 697NA MATH 697NA Numerical Algorithms Introduction Prof. Eric Polizzi Department of Electrical and Computer Engineering, Department of Mathematics and Statitstics, University of Massachusetts, Amherst,
ECE 697NA MATH 697NA Numerical Algorithms Introduction Prof. Eric Polizzi Department of Electrical and Computer Engineering, Department of Mathematics and Statitstics, University of Massachusetts, Amherst,
FFTW. for version 3.3.7, 29 October Matteo Frigo Steven G. Johnson
 FFTW for version 3.3.7, 29 October 2017 Matteo Frigo Steven G. Johnson This manual is for FFTW (version 3.3.7, 29 October 2017). Copyright c 2003 Matteo Frigo. Copyright c 2003 Massachusetts Institute
FFTW for version 3.3.7, 29 October 2017 Matteo Frigo Steven G. Johnson This manual is for FFTW (version 3.3.7, 29 October 2017). Copyright c 2003 Matteo Frigo. Copyright c 2003 Massachusetts Institute
New Challenges In Dynamic Load Balancing
 New Challenges In Dynamic Load Balancing Karen D. Devine, et al. Presentation by Nam Ma & J. Anthony Toghia What is load balancing? Assignment of work to processors Goal: maximize parallel performance
New Challenges In Dynamic Load Balancing Karen D. Devine, et al. Presentation by Nam Ma & J. Anthony Toghia What is load balancing? Assignment of work to processors Goal: maximize parallel performance
A parallel direct/iterative solver based on a Schur complement approach
 A parallel direct/iterative solver based on a Schur complement approach Gene around the world at CERFACS Jérémie Gaidamour LaBRI and INRIA Bordeaux - Sud-Ouest (ScAlApplix project) February 29th, 2008
A parallel direct/iterative solver based on a Schur complement approach Gene around the world at CERFACS Jérémie Gaidamour LaBRI and INRIA Bordeaux - Sud-Ouest (ScAlApplix project) February 29th, 2008
Contents. Preface xvii Acknowledgments. CHAPTER 1 Introduction to Parallel Computing 1. CHAPTER 2 Parallel Programming Platforms 11
 Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Contents. F10: Parallel Sparse Matrix Computations. Parallel algorithms for sparse systems Ax = b. Discretized domain a metal sheet
 Contents 2 F10: Parallel Sparse Matrix Computations Figures mainly from Kumar et. al. Introduction to Parallel Computing, 1st ed Chap. 11 Bo Kågström et al (RG, EE, MR) 2011-05-10 Sparse matrices and storage
Contents 2 F10: Parallel Sparse Matrix Computations Figures mainly from Kumar et. al. Introduction to Parallel Computing, 1st ed Chap. 11 Bo Kågström et al (RG, EE, MR) 2011-05-10 Sparse matrices and storage
Numerical Linear Algebra
 Numerical Linear Algebra Probably the simplest kind of problem. Occurs in many contexts, often as part of larger problem. Symbolic manipulation packages can do linear algebra "analytically" (e.g. Mathematica,
Numerical Linear Algebra Probably the simplest kind of problem. Occurs in many contexts, often as part of larger problem. Symbolic manipulation packages can do linear algebra "analytically" (e.g. Mathematica,
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok
 Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND
 Student Submission for the 5 th OpenFOAM User Conference 2017, Wiesbaden - Germany: SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND TESSA UROIĆ Faculty of Mechanical Engineering and Naval Architecture, Ivana
Student Submission for the 5 th OpenFOAM User Conference 2017, Wiesbaden - Germany: SELECTIVE ALGEBRAIC MULTIGRID IN FOAM-EXTEND TESSA UROIĆ Faculty of Mechanical Engineering and Naval Architecture, Ivana
Matrix Multiplication
 Matrix Multiplication CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Matrix Multiplication Spring 2013 1 / 32 Outline 1 Matrix operations Importance Dense and sparse
Matrix Multiplication CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Matrix Multiplication Spring 2013 1 / 32 Outline 1 Matrix operations Importance Dense and sparse
THE application of advanced computer architecture and
 544 IEEE TRANSACTIONS ON ANTENNAS AND PROPAGATION, VOL. 45, NO. 3, MARCH 1997 Scalable Solutions to Integral-Equation and Finite-Element Simulations Tom Cwik, Senior Member, IEEE, Daniel S. Katz, Member,
544 IEEE TRANSACTIONS ON ANTENNAS AND PROPAGATION, VOL. 45, NO. 3, MARCH 1997 Scalable Solutions to Integral-Equation and Finite-Element Simulations Tom Cwik, Senior Member, IEEE, Daniel S. Katz, Member,
Review of previous examinations TMA4280 Introduction to Supercomputing
 Review of previous examinations TMA4280 Introduction to Supercomputing NTNU, IMF April 24. 2017 1 Examination The examination is usually comprised of: one problem related to linear algebra operations with
Review of previous examinations TMA4280 Introduction to Supercomputing NTNU, IMF April 24. 2017 1 Examination The examination is usually comprised of: one problem related to linear algebra operations with
A Test Suite for High-Performance Parallel Java
 page 1 A Test Suite for High-Performance Parallel Java Jochem Häuser, Thorsten Ludewig, Roy D. Williams, Ralf Winkelmann, Torsten Gollnick, Sharon Brunett, Jean Muylaert presented at 5th National Symposium
page 1 A Test Suite for High-Performance Parallel Java Jochem Häuser, Thorsten Ludewig, Roy D. Williams, Ralf Winkelmann, Torsten Gollnick, Sharon Brunett, Jean Muylaert presented at 5th National Symposium
THE DEVELOPMENT OF THE POTENTIAL AND ACADMIC PROGRAMMES OF WROCLAW UNIVERISTY OF TECH- NOLOGY ITERATIVE LINEAR SOLVERS
 ITERATIVE LIEAR SOLVERS. Objectives The goals of the laboratory workshop are as follows: to learn basic properties of iterative methods for solving linear least squares problems, to study the properties
ITERATIVE LIEAR SOLVERS. Objectives The goals of the laboratory workshop are as follows: to learn basic properties of iterative methods for solving linear least squares problems, to study the properties
Parallel resolution of sparse linear systems by mixing direct and iterative methods
 Parallel resolution of sparse linear systems by mixing direct and iterative methods Phyleas Meeting, Bordeaux J. Gaidamour, P. Hénon, J. Roman, Y. Saad LaBRI and INRIA Bordeaux - Sud-Ouest (ScAlApplix
Parallel resolution of sparse linear systems by mixing direct and iterative methods Phyleas Meeting, Bordeaux J. Gaidamour, P. Hénon, J. Roman, Y. Saad LaBRI and INRIA Bordeaux - Sud-Ouest (ScAlApplix
Faster Code for Free: Linear Algebra Libraries. Advanced Research Compu;ng 22 Feb 2017
 Faster Code for Free: Linear Algebra Libraries Advanced Research Compu;ng 22 Feb 2017 Outline Introduc;on Implementa;ons Using them Use on ARC systems Hands on session Conclusions Introduc;on 3 BLAS Level
Faster Code for Free: Linear Algebra Libraries Advanced Research Compu;ng 22 Feb 2017 Outline Introduc;on Implementa;ons Using them Use on ARC systems Hands on session Conclusions Introduc;on 3 BLAS Level
Asynchronous OpenCL/MPI numerical simulations of conservation laws
 Asynchronous OpenCL/MPI numerical simulations of conservation laws Philippe HELLUY 1,3, Thomas STRUB 2. 1 IRMA, Université de Strasbourg, 2 AxesSim, 3 Inria Tonus, France IWOCL 2015, Stanford Conservation
Asynchronous OpenCL/MPI numerical simulations of conservation laws Philippe HELLUY 1,3, Thomas STRUB 2. 1 IRMA, Université de Strasbourg, 2 AxesSim, 3 Inria Tonus, France IWOCL 2015, Stanford Conservation
A Scalable Parallel LSQR Algorithm for Solving Large-Scale Linear System for Seismic Tomography
 1 A Scalable Parallel LSQR Algorithm for Solving Large-Scale Linear System for Seismic Tomography He Huang, Liqiang Wang, Po Chen(University of Wyoming) John Dennis (NCAR) 2 LSQR in Seismic Tomography
1 A Scalable Parallel LSQR Algorithm for Solving Large-Scale Linear System for Seismic Tomography He Huang, Liqiang Wang, Po Chen(University of Wyoming) John Dennis (NCAR) 2 LSQR in Seismic Tomography
Achieve Better Performance with PEAK on XSEDE Resources
 Achieve Better Performance with PEAK on XSEDE Resources Haihang You, Bilel Hadri, Shirley Moore XSEDE 12 July 18 th 2012 Motivations FACTS ALTD ( Automatic Tracking Library Database ) ref Fahey, Jones,
Achieve Better Performance with PEAK on XSEDE Resources Haihang You, Bilel Hadri, Shirley Moore XSEDE 12 July 18 th 2012 Motivations FACTS ALTD ( Automatic Tracking Library Database ) ref Fahey, Jones,
Performance Comparison between Blocking and Non-Blocking Communications for a Three-Dimensional Poisson Problem
 Performance Comparison between Blocking and Non-Blocking Communications for a Three-Dimensional Poisson Problem Guan Wang and Matthias K. Gobbert Department of Mathematics and Statistics, University of
Performance Comparison between Blocking and Non-Blocking Communications for a Three-Dimensional Poisson Problem Guan Wang and Matthias K. Gobbert Department of Mathematics and Statistics, University of
Using Existing Numerical Libraries on Spark
 Using Existing Numerical Libraries on Spark Brian Spector Chicago Spark Users Meetup June 24 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm
Using Existing Numerical Libraries on Spark Brian Spector Chicago Spark Users Meetup June 24 th, 2015 Experts in numerical algorithms and HPC services How to use existing libraries on Spark Call algorithm
FOR P3: A monolithic multigrid FEM solver for fluid structure interaction
 FOR 493 - P3: A monolithic multigrid FEM solver for fluid structure interaction Stefan Turek 1 Jaroslav Hron 1,2 Hilmar Wobker 1 Mudassar Razzaq 1 1 Institute of Applied Mathematics, TU Dortmund, Germany
FOR 493 - P3: A monolithic multigrid FEM solver for fluid structure interaction Stefan Turek 1 Jaroslav Hron 1,2 Hilmar Wobker 1 Mudassar Razzaq 1 1 Institute of Applied Mathematics, TU Dortmund, Germany