CS 179: GPU Computing. Lecture 2: The Basics
|
|
|
- Andra Merritt
- 6 years ago
- Views:
Transcription
1 CS 179: GPU Computing Lecture 2: The Basics
2 Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language
3 Disclaimer Goal for Week 1: Fast-paced introduction Know enough to be dangerous We will fill in details later!
4 Our original problem Add two arrays A[] + B[] -> C[] Goal: Understand what s going on
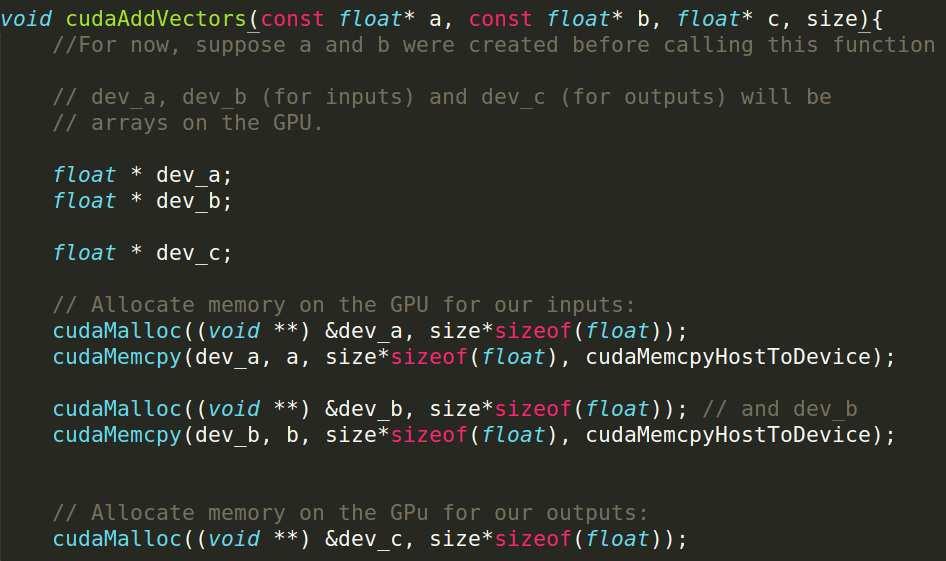
5 CUDA code (first part)
6 Basic formula Setup inputs on the host (CPU-accessible memory) Allocate memory for inputs on the GPU Copy inputs from host to GPU Allocate memory for outputs on the host Allocate memory for outputs on the GPU Start GPU kernel Copy output from GPU to host
7
8 Classic Memory Hierarchy
9 The GPU
10 Global memory The GPU
11
12 Pointers Difference between CPU and GPU pointers?
13 Pointers Difference between CPU and GPU pointers? None pointers are just addresses!
14 Pointers Difference between CPU and GPU pointers? None pointers are just addresses! Up to the programmer to keep track!
15 Pointers Good practice: Special naming conventions, e.g. dev_ prefix
16
17
18 Memory allocational With the CPU (host memory) float *c = malloc(n * sizeof(float)); Attempts to allocate #bytes in argument
19 Memory allocation On the GPU (global memory): float *dev_c; cudamalloc(&dev_c, N * sizeof(float)); Signature: cudaerror_t cudamalloc (void ** devptr, size_t size) Attempts to allocate #bytes in arg2 arg1 is the pointerto the pointer in GPU memory! Passed into function for modification Result after successful call: Memory allocated in location given by dev_con GPU Return value is error code, can be checked
20
21
22 Memory copying With the CPU (host memory) // pointers source,destination to memory regions memcpy(destination, source, N); Signature: void * memcpy (void * destination, const void * source, size_t num); Copies numbytes from (area pointed to by) source to (area pointed to by) destination
23 Memory copying Versatile cudamemcpy() equivalent CPU -> GPU GPU -> CPU GPU -> GPU CPU -> CPU
24 Memory copying Signature: cudaerror_t cudamemcpy(void *destination, void *src, size_t count, enum cudamemcpykind kind) f
25 Memory copying Signature: cudaerror_t cudamemcpy(void *destination, void *src, size_t count, enum cudamemcpykind kind) Values: cudamemcpyhosttohost cudamemcpyhosttodevice cudamemcpydevicetohost cudamemcpydevicetodevice F
26 Memory copying Signature: cudaerror_t cudamemcpy(void *destination, void *src, size_t count, enum cudamemcpykind kind) Values: cudamemcpyhosttohost cudamemcpyhosttodevice cudamemcpydevicetohost cudamemcpydevicetodevice Determines treatment of dst. and src. as CPU or GPU addresses F
27
28 Summary of memory CPU vs. GPU pointers cudamalloc() cudamemcpy()
29
30 Part 2
31 Recall GPUs Have lots of cores Are suited toward parallel problems
32 GPU internals
33 GPU internals
34 GPU internals
35 CPU internals
36 GPU internals One instruction unit for multiple cores!
37 Warps Groups of threads simultaneously execute same instructions! Called a warp (32 threads in a warp under current standards)

38 GPU internals
39 Blocks Group of threads scheduled to a multiprocessor Contain multiple warps Has a max. number (varies by GPU, e.g. 512 or 1024)

40 Multiprocessor execution timeline
41 Thread groups A grid (all the threads started ): contains blocks <- assigned to multiprocessors Each block contains warps <- executed simultaneously Each warp contains individual threads
42 Part 2
43 Moral 1: (from Lecture 1) Start lots of threads! Recall: Low context switch penalty Hide latency Start enough blocks! Occupy SMs e.g. Don t call: Call: kernel<<<1,1>>>(); // 1 block, 1 thread per block kernel<<<50,512>>>();// 50 blocks, 512 threads per block
44 Moral 2: Multiprocessors execute warps (of 32 threads) Block sizes of 32*n (integer n) are best e.g. Don t call: Call: kernel<<<50,97>>>(); // 50 blocks, 97 threads per block kernel<<<50,128>>>();// 50 blocks, 128 threads per block
45 Summary (processor internals) Key parameters on kernel call: Threads per block Number of blocks Choose carefully!
46
47 Kernel argument passing Similar to arg-passing in C functions Some rules: Don t pass host-memory pointers Small variables (e.g. individual ints) are fine No pass-by-reference
48 Kernel function Executed by many threads Threads have unique ID mechanism: Thread index within block Block index
49 Out of bounds issue: If index > (#elements), illegal access!
50 Out of bounds issue: If index > (#elements), illegal access!

51 #Threads issue: Cannot start e.g. 1e9 threads! Threads should handle arbitrary # of elements
52 #Threads issue: Cannot start e.g. 1e9 threads! Threads should handle arbitrary # of elements
53 #Threads issue: Cannot start e.g. 1e9 threads! Threads should handle arbitrary # of elements Total number of blocks
54 GPU -> CPU Host memory pointer (copy to here) Device memory pointer (copy from here)
55
56 cudafree() Equivalent to host memory s free() function (As on host) Free memory after completion!
57 Summary GPU global memory: Pointers (CPU vs GPU) cudamalloc() and cudamemcpy() GPU processor details: Thread group hierarchy Launch parameters Threads in kernel
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
COMP 322: Fundamentals of Parallel Programming. Flynn s Taxonomy for Parallel Computers
 COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: General-Purpose GPU (GPGPU) Computing Max Grossman, Vivek Sarkar Department of Computer Science, Rice University max.grossman@rice.edu, vsarkar@rice.edu
04. CUDA Data Transfer
 04. CUDA Data Transfer Fall Semester, 2015 COMP427 Parallel Programming School of Computer Sci. and Eng. Kyungpook National University 2013-5 N Baek 1 CUDA Compute Unified Device Architecture General purpose
04. CUDA Data Transfer Fall Semester, 2015 COMP427 Parallel Programming School of Computer Sci. and Eng. Kyungpook National University 2013-5 N Baek 1 CUDA Compute Unified Device Architecture General purpose
Memory concept. Grid concept, Synchronization. GPU Programming. Szénási Sándor.
 Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
Memory concept Grid concept, Synchronization GPU Programming http://cuda.nik.uni-obuda.hu Szénási Sándor szenasi.sandor@nik.uni-obuda.hu GPU Education Center of Óbuda University MEMORY CONCEPT Off-chip
CUDA Basics. July 6, 2016
 Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching
Mitglied der Helmholtz-Gemeinschaft CUDA Basics July 6, 2016 CUDA Kernels Parallel portion of application: execute as a kernel Entire GPU executes kernel, many threads CUDA threads: Lightweight Fast switching
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
EEM528 GPU COMPUTING
 EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
Stanford University. NVIDIA Tesla M2090. NVIDIA GeForce GTX 690
 Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
Stanford University NVIDIA Tesla M2090 NVIDIA GeForce GTX 690 Moore s Law 2 Clock Speed 10000 Pentium 4 Prescott Core 2 Nehalem Sandy Bridge 1000 Pentium 4 Williamette Clock Speed (MHz) 100 80486 Pentium
GPU Programming Using CUDA. Samuli Laine NVIDIA Research
 GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
Outline 2011/10/8. Memory Management. Kernels. Matrix multiplication. CIS 565 Fall 2011 Qing Sun
 Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Outline Memory Management CIS 565 Fall 2011 Qing Sun sunqing@seas.upenn.edu Kernels Matrix multiplication Managing Memory CPU and GPU have separate memory spaces Host (CPU) code manages device (GPU) memory
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
COMP 322: Fundamentals of Parallel Programming
 COMP 322: Fundamentals of Parallel Programming Lecture 38: General-Purpose GPU (GPGPU) Computing Guest Lecturer: Max Grossman Instructors: Vivek Sarkar, Mack Joyner Department of Computer Science, Rice
COMP 322: Fundamentals of Parallel Programming Lecture 38: General-Purpose GPU (GPGPU) Computing Guest Lecturer: Max Grossman Instructors: Vivek Sarkar, Mack Joyner Department of Computer Science, Rice
Massively Parallel Algorithms
 Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
Massively Parallel Algorithms Introduction to CUDA & Many Fundamental Concepts of Parallel Programming G. Zachmann University of Bremen, Germany cgvr.cs.uni-bremen.de Hybrid/Heterogeneous Computation/Architecture
CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci
 Ezio Bartocci") TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
GPU Programming Using CUDA. Samuli Laine NVIDIA Research
 GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
Programming with CUDA, WS09
 Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Lecture 3 Thursday, 29 Nov, 2009 Recap Motivational videos Example kernel Thread IDs Memory overhead CUDA hardware and programming
CUDA Workshop. High Performance GPU computing EXEBIT Karthikeyan
 CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
CUDA Workshop High Performance GPU computing EXEBIT- 2014 Karthikeyan CPU vs GPU CPU Very fast, serial, Low Latency GPU Slow, massively parallel, High Throughput Play Demonstration Compute Unified Device
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CS179 GPU Programming Recitation 4: CUDA Particles
 Recitation 4: CUDA Particles Lab 4 CUDA Particle systems Two parts Simple repeat of Lab 3 Interacting Flocking simulation 2 Setup Two folders given particles_simple, particles_interact Must install NVIDIA_CUDA_SDK
Recitation 4: CUDA Particles Lab 4 CUDA Particle systems Two parts Simple repeat of Lab 3 Interacting Flocking simulation 2 Setup Two folders given particles_simple, particles_interact Must install NVIDIA_CUDA_SDK
NVIDIA CUDA Compute Unified Device Architecture
 NVIDIA CUDA Compute Unified Device Architecture Programming Guide Version 0.8 2/12/2007 ii CUDA Programming Guide Version 0.8 Table of Contents Chapter 1. Introduction to CUDA... 1 1.1 The Graphics Processor
NVIDIA CUDA Compute Unified Device Architecture Programming Guide Version 0.8 2/12/2007 ii CUDA Programming Guide Version 0.8 Table of Contents Chapter 1. Introduction to CUDA... 1 1.1 The Graphics Processor
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
GPU Computing Workshop CSU Getting Started. Garland Durham Quantos Analytics
 1 GPU Computing Workshop CSU 2013 Getting Started Garland Durham Quantos Analytics nvidia-smi 2 At command line, run command nvidia-smi to get/set GPU properties. nvidia-smi Options: -q query -L list attached
1 GPU Computing Workshop CSU 2013 Getting Started Garland Durham Quantos Analytics nvidia-smi 2 At command line, run command nvidia-smi to get/set GPU properties. nvidia-smi Options: -q query -L list attached
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team
 Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
Tutorial: Parallel programming technologies on hybrid architectures HybriLIT Team Laboratory of Information Technologies Joint Institute for Nuclear Research The Helmholtz International Summer School Lattice
COSC 6385 Computer Architecture. - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors
 The Intel Larrabee, Nvidia GT200 and Fermi processors") COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
Review. Lecture 10. Today s Outline. Review. 03b.cu. 03?.cu CUDA (II) Matrix addition CUDA-C API
 Matrix addition CUDA-C API") Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Review Lecture 10 CUDA (II) host device CUDA many core processor threads thread blocks grid # threads >> # of cores to be efficient Threads within blocks can cooperate Threads between thread blocks cannot
Introduc)on to GPU Programming
on to GPU Programming") Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
COSC 6339 Accelerators in Big Data
 COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
HPCSE II. GPU programming and CUDA
 HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Introduction to memory spaces and memory access Shared memory Matrix multiplication example Lecture
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Lecture 2: Introduction to CUDA C
 CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CUDA Kenjiro Taura 1 / 36
 CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
High Performance Linear Algebra on Data Parallel Co-Processors I
 926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
926535897932384626433832795028841971693993754918980183 592653589793238462643383279502884197169399375491898018 415926535897932384626433832795028841971693993754918980 592653589793238462643383279502884197169399375491898018
Introduction to GPGPUs and to CUDA programming model
 Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
Introduction to GPGPUs and to CUDA programming model www.cineca.it Marzia Rivi m.rivi@cineca.it GPGPU architecture CUDA programming model CUDA efficient programming Debugging & profiling tools CUDA libraries
GPGPU in Film Production. Laurence Emms Pixar Animation Studios
 GPGPU in Film Production Laurence Emms Pixar Animation Studios Outline GPU computing at Pixar Demo overview Simulation on the GPU Future work GPU Computing at Pixar GPUs have been used for real-time preview
GPGPU in Film Production Laurence Emms Pixar Animation Studios Outline GPU computing at Pixar Demo overview Simulation on the GPU Future work GPU Computing at Pixar GPUs have been used for real-time preview
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
CUDA BASICS Matt Heavner -- 10/21/2010
 CUDA BASICS Matt Heavner -- mheavner@buffalo.edu 10/21/2010 Why CUDA? Image From: http://developer.download.nvidia.com/compute/cuda/3_1/toolkit/docs/nvidia_cuda_c_programmingguide_3.1.pdf CUDA: Where does
CUDA BASICS Matt Heavner -- mheavner@buffalo.edu 10/21/2010 Why CUDA? Image From: http://developer.download.nvidia.com/compute/cuda/3_1/toolkit/docs/nvidia_cuda_c_programmingguide_3.1.pdf CUDA: Where does
GPU Computing: Introduction to CUDA. Dr Paul Richmond
 GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs CUDA Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University CUDA - Compute Unified Device
Master Educational Program Information technology in applications Mathematical computations with GPUs CUDA Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University CUDA - Compute Unified Device
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
Parallel Computing. Lecture 19: CUDA - I
 CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
CSCI-UA.0480-003 Parallel Computing Lecture 19: CUDA - I Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com GPU w/ local DRAM (device) Behind CUDA CPU (host) Source: http://hothardware.com/reviews/intel-core-i5-and-i7-processors-and-p55-chipset/?page=4
Today s Content. Lecture 7. Trends. Factors contributed to the growth of Beowulf class computers. Introduction. CUDA Programming CUDA (I)
") Today s Content Lecture 7 CUDA (I) Introduction Trends in HPC GPGPU CUDA Programming 1 Trends Trends in High-Performance Computing HPC is never a commodity until 199 In 1990 s Performances of PCs are getting
Today s Content Lecture 7 CUDA (I) Introduction Trends in HPC GPGPU CUDA Programming 1 Trends Trends in High-Performance Computing HPC is never a commodity until 199 In 1990 s Performances of PCs are getting
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
CUDA Advanced Techniques 2 Mohamed Zahran (aka Z)
") CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming CUDA Advanced Techniques 2 Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Alignment Memory Alignment Memory
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming CUDA Advanced Techniques 2 Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Alignment Memory Alignment Memory
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CS 179: GPU Programming. Lecture 7
 CS 179: GPU Programming Lecture 7 Week 3 Goals: More involved GPU-accelerable algorithms Relevant hardware quirks CUDA libraries Outline GPU-accelerated: Reduction Prefix sum Stream compaction Sorting(quicksort)
CS 179: GPU Programming Lecture 7 Week 3 Goals: More involved GPU-accelerable algorithms Relevant hardware quirks CUDA libraries Outline GPU-accelerated: Reduction Prefix sum Stream compaction Sorting(quicksort)
CUDA. Sathish Vadhiyar High Performance Computing
 CUDA Sathish Vadhiyar High Performance Computing Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single
CUDA Sathish Vadhiyar High Performance Computing Hierarchical Parallelism Parallel computations arranged as grids One grid executes after another Grid consists of blocks Blocks assigned to SM. A single
Basic CUDA workshop. Outlines. Setting Up Your Machine Architecture Getting Started Programming CUDA. Fine-Tuning. Penporn Koanantakool
 Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine
Basic CUDA workshop Penporn Koanantakool twitter: @kaewgb e-mail: kaewgb@gmail.com Outlines Setting Up Your Machine Architecture Getting Started Programming CUDA Debugging Fine-Tuning Setting Up Your Machine
Introduction to CUDA C
 Introduction to CUDA C What will you learn today? Start from Hello, World! Write and launch CUDA C kernels Manage GPU memory Run parallel kernels in CUDA C Parallel communication and synchronization Race
Introduction to CUDA C What will you learn today? Start from Hello, World! Write and launch CUDA C kernels Manage GPU memory Run parallel kernels in CUDA C Parallel communication and synchronization Race
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation
 Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
Introduction to GPU Computing Junjie Lai, NVIDIA Corporation Outline Evolution of GPU Computing Heterogeneous Computing CUDA Execution Model & Walkthrough of Hello World Walkthrough : 1D Stencil Once upon
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
Introduction to CUDA C
 NVIDIA GPU Technology Introduction to CUDA C Samuel Gateau Seoul December 16, 2010 Who should you thank for this talk? Jason Sanders Senior Software Engineer, NVIDIA Co-author of CUDA by Example What is
NVIDIA GPU Technology Introduction to CUDA C Samuel Gateau Seoul December 16, 2010 Who should you thank for this talk? Jason Sanders Senior Software Engineer, NVIDIA Co-author of CUDA by Example What is
Hands-on CUDA Optimization. CUDA Workshop
 Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
Hands-on CUDA Optimization CUDA Workshop Exercise Today we have a progressive exercise The exercise is broken into 5 steps If you get lost you can always catch up by grabbing the corresponding directory
COSC 6385 Computer Architecture. - Data Level Parallelism (II)
") COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
GPU computing Simulating spin models on GPU Lecture 1: GPU architecture and CUDA programming. GPU computing. GPU computing.
 GPU computing Simulating spin models on GPU Lecture 1: GPU architecture and CUDA programming Martin Weigel Applied Mathematics Research Centre, Coventry University, Coventry, United Kingdom and Institut
GPU computing Simulating spin models on GPU Lecture 1: GPU architecture and CUDA programming Martin Weigel Applied Mathematics Research Centre, Coventry University, Coventry, United Kingdom and Institut
Lecture 3: Introduction to CUDA
 CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 3: Introduction to CUDA Some slides here are adopted from: NVIDIA teaching kit Mohamed Zahran (aka Z) mzahran@cs.nyu.edu
Module 2: Introduction to CUDA C
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
COSC 462 Parallel Programming
 November 22, 2017 1/12 COSC 462 Parallel Programming CUDA Beyond Basics Piotr Luszczek Mixing Blocks and Threads int N = 100, SN = N * sizeof(double); global void sum(double *a, double *b, double *c) {
November 22, 2017 1/12 COSC 462 Parallel Programming CUDA Beyond Basics Piotr Luszczek Mixing Blocks and Threads int N = 100, SN = N * sizeof(double); global void sum(double *a, double *b, double *c) {
Computation to Core Mapping Lessons learned from a simple application
 Lessons learned from a simple application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core Mapping Block schedule, Occupancy, and thread
Lessons learned from a simple application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core Mapping Block schedule, Occupancy, and thread
Lessons learned from a simple application
 Computation to Core Mapping Lessons learned from a simple application A Simple Application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core
Computation to Core Mapping Lessons learned from a simple application A Simple Application Matrix Multiplication Used as an example throughout the course Goal for today: Show the concept of Computation-to-Core
CUDA Memory Hierarchy
 CUDA Memory Hierarchy Piotr Danilewski October 2012 Saarland University Memory GTX 690 GTX 690 Memory host memory main GPU memory (global memory) shared memory caches registers Memory host memory GPU global
CUDA Memory Hierarchy Piotr Danilewski October 2012 Saarland University Memory GTX 690 GTX 690 Memory host memory main GPU memory (global memory) shared memory caches registers Memory host memory GPU global
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Information Coding / Computer Graphics, ISY, LiTH. Introduction to CUDA. Ingemar Ragnemalm Information Coding, ISY
 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY This lecture: Programming model and language Memory spaces and memory access Shared memory Examples Lecture questions: 1. Suggest two significant
CUDA Memories. Introduction 5/4/11
 5/4/11 CUDA Memories James Gain, Michelle Kuttel, Sebastian Wyngaard, Simon Perkins and Jason Brownbridge { jgain mkuttel sperkins jbrownbr}@cs.uct.ac.za swyngaard@csir.co.za 3-6 May 2011 Introduction
5/4/11 CUDA Memories James Gain, Michelle Kuttel, Sebastian Wyngaard, Simon Perkins and Jason Brownbridge { jgain mkuttel sperkins jbrownbr}@cs.uct.ac.za swyngaard@csir.co.za 3-6 May 2011 Introduction
CS : Many-core Computing with CUDA
 CS4402-9535: Many-core Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 (Moreno Maza) CS4402-9535: Many-core Computing with CUDA UWO-CS4402-CS9535
CS4402-9535: Many-core Computing with CUDA Marc Moreno Maza University of Western Ontario, London, Ontario (Canada) UWO-CS4402-CS9535 (Moreno Maza) CS4402-9535: Many-core Computing with CUDA UWO-CS4402-CS9535
Advanced Topics in CUDA C
 Advanced Topics in CUDA C S. Sundar and M. Panchatcharam August 9, 2014 S. Sundar and M. Panchatcharam ( IIT Madras, ) Advanced CUDA August 9, 2014 1 / 36 Outline 1 Julia Set 2 Julia GPU 3 Compilation
Advanced Topics in CUDA C S. Sundar and M. Panchatcharam August 9, 2014 S. Sundar and M. Panchatcharam ( IIT Madras, ) Advanced CUDA August 9, 2014 1 / 36 Outline 1 Julia Set 2 Julia GPU 3 Compilation
Parallel Programming and Debugging with CUDA C. Geoff Gerfin Sr. System Software Engineer
 Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
Memory. Lecture 2: different memory and variable types. Memory Hierarchy. CPU Memory Hierarchy. Main memory
 Memory Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Key challenge in modern computer architecture
Memory Lecture 2: different memory and variable types Prof. Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Key challenge in modern computer architecture
CS/CoE 1541 Final exam (Fall 2017). This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4
. This is the cumulative final exam given in the Fall of Question 1 (12 points): was on Chapter 4") CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
CS/CoE 1541 Final exam (Fall 2017). Name: This is the cumulative final exam given in the Fall of 2017. Question 1 (12 points): was on Chapter 4 Question 2 (13 points): was on Chapter 4 For Exam 2, you
Vector Addition on the Device: main()
") Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
An Introduction to GPU Computing and CUDA Architecture
 An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
Writing and compiling a CUDA code
 Writing and compiling a CUDA code Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) Writing CUDA code 1 / 65 The CUDA language If we want fast code, we (unfortunately)
Writing and compiling a CUDA code Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) Writing CUDA code 1 / 65 The CUDA language If we want fast code, we (unfortunately)
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
GPU Programming. Maciej Halber
 GPU Programming Maciej Halber Aim Give basic introduction to CUDA C How to write kernels Memory transfer Talk about general parallel computing concepts Memory communication patterns Talk about efficiency
GPU Programming Maciej Halber Aim Give basic introduction to CUDA C How to write kernels Memory transfer Talk about general parallel computing concepts Memory communication patterns Talk about efficiency
CS179 GPU Programming: CUDA Memory. Lecture originally by Luke Durant and Tamas Szalay
 : CUDA Memory Lecture originally by Luke Durant and Tamas Szalay CUDA Memory Review of Memory Spaces Memory syntax Constant Memory Allocation Issues Global Memory Gotchas Shared Memory Gotchas Texture
: CUDA Memory Lecture originally by Luke Durant and Tamas Szalay CUDA Memory Review of Memory Spaces Memory syntax Constant Memory Allocation Issues Global Memory Gotchas Shared Memory Gotchas Texture