Parallel Accelerators
|
|
|
- Regina Palmer
- 5 years ago
- Views:
Transcription
1 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1
2 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon Phi 2


3 Graphical Processing Units 3

4 GPU Nvidia - Roadmap 4
5 GPU - Use GPU is especially well-suited to address problems that can be expressed as data-parallel computations. The same program is executed on many data elements in parallel - with high arithmetic intensity. Applications that process large data sets can use a data-parallel programming model to speed up the computations (3D rendering, image processing, video encoding, ) Many algorithms outside the field of image rendering and processing are accelerated by data-parallel processing too (machine learning, general signal processing, physics simulation, finance, ). 5
6 GPU - Overview CPU code runs on the host, GPU code runs on the device. A kernel consists of multiple threads. Threads execute in 32-thread groups called warps. Threads are grouped into blocks. A collection of blocks is called a grid. 6
7 GPU - Hardware Organization Overview GPU chip consists of one or more streaming multiprocessors (SM). A multiprocessor consists of 1 (CC 1.x), 2 (CC 2.x), or 4 (CC 3.x, 5.x, 6.x, 7.x) warp schedulers. (CC = CUDA Capability) Each warp scheduler can issue to 2 (CC 5 and 6) or 1 (CC 7) dispatch units. A multiprocessor consists of functional units of several types. 7
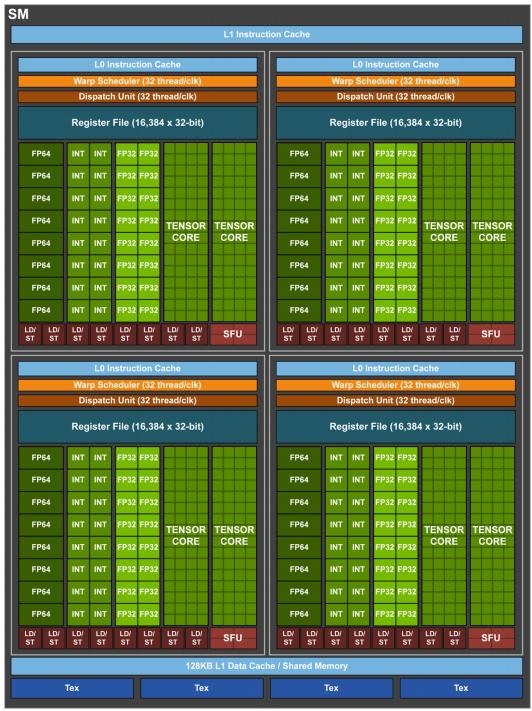
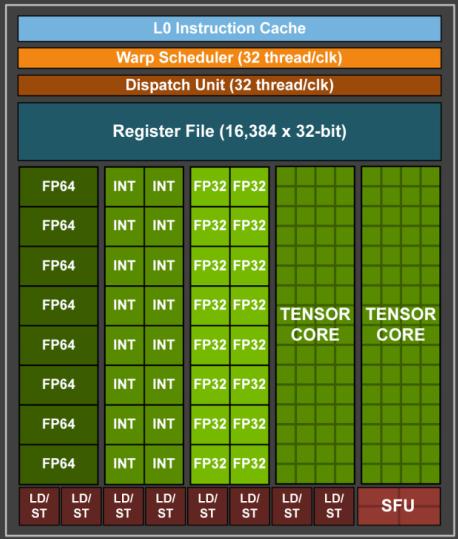
8 Streaming Multiprocessor (SM) - Volta 8
9 GPU - Functional Units INT, FP32 (CUDA Core) - functional units that executes most types of instructions, including most integer and single precision floating point instructions. FP64 (Double Precision) - executes double-precision floating point instructions. SFU (Special Functional Unit) - executes reciprocal and transcendental instructions such as sine, cosine, and reciprocal square root. LD/ST (Load/Store Unit) handles load and store instructions. TENSOR CORE for deep learning matrix arithmetic. 9
 operations per clock.")
10 GPU - Tensor Core V100 GPU contains 640 Tensor Cores: eight (8) per SM. Tensor Core performs 64 floating point FMA (fused multiply add) operations per clock. Matrix-Matrix multiplication (GEMM) operations are at the core of neural network training and inferencing. Each Tensor Core operates on a 4x4 matrices. 10
11 Streaming Multiprocessor (SM) Each SM has a set of temporary registers split amongst threads. Instructions can access high-speed shared memory. Instructions can access a cache-backed constant space. Instructions can access local memory. Instructions can access global space. (very slow in general) 11

12 GPU Architecture - Volta 12
13 GPU Architectures Tesla Product Tesla K40 Tesla M40 Tesla P100 Tesla V100 Manufacturing Process 28nm 28nm 16nm 12nm Transistors 7.1 Billion 8.0 Billion 15.3 Billion 21.1 Billion SMs / GPU F32 Cores / SM F32 Cores / GPU Peak FP32 TFLOPS Peak FP64 TFLOPS , GPU Boost Clock 810/870 MHz 1114 MHz 1480 MHz 1530 MHz TDP 235 W 250 W 300 W 300 W Memory Interface 384-bit GDDR5 384-bit GDDR bit HBM bit HBM2 Maximum TDP 244W 250W 250W 300W 13
14 Single-Instruction, Multiple-Thread SIMT is an execution model where single instruction, multiple data (SIMD) is combined with multithreading. The SM creates, manages, schedules, and executes threads in groups of 32 parallel threads called warps. A warp start together at the same program address, but they have their own instruction address counter and register state and are therefore free to branch and execute independently. 14
15 CUDA The NVIDIA GPU architecture is built around a scalable array of multithreaded Streaming Multiprocessors (SMs). CUDA (Compute Unified Device Architecture) provides a way how a CUDA program can be executed on any number of SMs. A multithreaded program is partitioned into blocks of threads that execute independently from each other. A GPU with more multiprocessors will automatically execute the program in less time than a GPU with fewer multiprocessors. 15
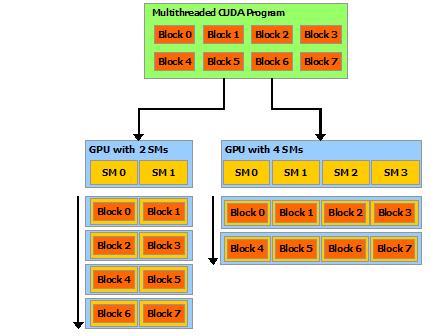
16 CUDA 16

17 Grid/Block/Thread threads can be identified using a 1-D, 2-D, or 3-D thread index, forming a 1-D, 2-D, or 3-D block of threads, called a thread block. Blocks are organized into a 1-D, 2-D, or 3-D grid of thread blocks. 2-D grid with 2-D thread blocks 17
18 Kernel CUDA C extends C by allowing the programmer to define C functions, called kernels. // Kernel definition global void VecAdd(float* A, float* B, float* C) { int i = threadidx.x; C[i] = A[i] + B[i]; } int main() {... } // Kernel invocation with N threads inside 1 thread block VecAdd<<<1, N>>>(A, B, C); threadidx is a 3-component vector, so that threads can be identified using a 1-D, 2-D, or 3-D thread index. 18

19 Memory Hierarchy Each thread has private set of registers and local memory. Each thread block has shared memory visible to all threads of the block. All threads have access to the same global memory. There are also two additional read-only memory spaces accessible by all threads (constant and texture memory). 19
20 GPU Programming - Example Element by element vector addition [1] NVIDIA Corporation, CUDA Toolkit Documentation v ,
21 Element by element vector addition /* Host main routine */ int main(void) { int numelements = 50000; size_t size = numelements * sizeof(float); // Allocate the host input vectors A and B and output vector C float *h_a = (float *)malloc(size); float *h_b = (float *)malloc(size); float *h_c = (float *)malloc(size); // Initialize the host input vectors for (int i = 0; i < numelements; ++i) { } h_a[i] = rand()/(float)rand_max; h_b[i] = rand()/(float)rand_max; 21
22 Element by element vector addition // Allocate the device input vectors A and B and output vector C float *d_a = NULL; cudamalloc((void **)&d_a, size); float *d_b = NULL; cudamalloc((void **)&d_b, size); float *d_c = NULL; cudamalloc((void **)&d_c, size); // Copy the host input vectors A and B in host memory to the device // input vectors in device memory cudamemcpy(d_a, h_a, size, cudamemcpyhosttodevice); cudamemcpy(d_b, h_b, size, cudamemcpyhosttodevice); 22
23 Element by element vector addition // Launch the Vector Add CUDA Kernel int threadsperblock = 256; int blockspergrid = (numelements + threadsperblock - 1) / threadsperblock; vectoradd<<<blockspergrid, threadsperblock>>>(d_a, d_b, d_c, numelements); // Copy the device result vector in device memory to the host result vector // in host memory. cudamemcpy(h_c, d_c, size, cudamemcpydevicetohost); 23
24 Element by element vector addition // Free device global memory err = cudafree(d_a); err = cudafree(d_b); err = cudafree(d_c); // Free host memory free(h_a); free(h_b); free(h_c); return 0; } 24
25 Element by element vector addition /** * CUDA Kernel Device code * * Computes the vector addition of A and B into C. The 3 vectors have the same * number of elements numelements. */ global void vectoradd(float *A, float *B, float *C, int numelements) { int i = blockdim.x * blockidx.x + threadidx.x; } if (i < numelements) { C[i] = A[i] + B[i]; } 25


26 Intel Xeon Phi 26

27 Intel Xeon Phi - Roadmap 27
28 Intel Xeon Phi Intel Xeon Phi coprocessors are designed to extend the reach of applications that have demonstrated the ability to fully utilize the scaling capabilities of Intel Xeon processor-based systems. Code compiled for Xeon processors can be run on an Xeon Phi (Knights Landing). For successful parallelization it requires a program with lots of threads and operations with vectors. 28

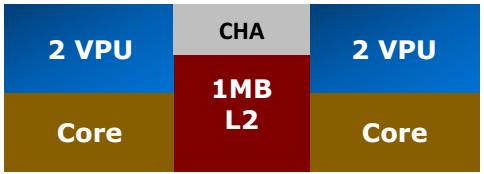
29 Knights Landing Architecture 29
30 Knights Landing Architecture The chip is constituted by 36 tiles interconnected by 2D mesh. The tile has two Cores (Atom Silvermont architecture), two vector processing units (VPU) and 1M L2 cache. A tile can execute concurrently 4 threads. The tiles are interconnected a cache-coherent 2D mesh; which provides a higher bandwidth and lower latency compare to the 1D ring interconnect on Knights corner. The mesh enforces XY routing rule. 30
31 Knights Landing Architecture Xeon Phi has 2 types of memory: (i) MCDRAM (Multichannel DRAM) and (ii) DDR. MCDRAM is a high-bandwidth memory integrated on the package. There are 8 of them 2 GB each. MCDRAM can be configured at boot time into one of three modes: Cache mode MCDRAM is a cache for DDR, Flat mode MCDRAM is a standard memory in the same address space as DDR, Hybrid a combination DDR is a high-capacity memory which is external to the Knight Landing package. 31
32 Vectorization Each tile has two VPUs (Vector Processing Unit). It is the heard of computation. It processes all floating point computations using SSE, AVX, AVX2,, AVX-512. Thus each tile can execute two 512-bit vector multiple-add instructions per cycle, i.e. compute 32 double precision resp. 64 single precision floating point operation in each cycle. 33
33 Knights Corner vs. Knights Landing Product Name Code Name Intel Xeon Phi Coprocessor 7120X Knights Corner Intel Xeon Phi Processor 7290F Knights Landing Lithography Recommended Customer Price # of Cores Processor Base Frequency Cache TDP Max Memory Size (dependent on memory type) Max Memory Bandwidth 22 nm 14 nm N/A $ GHz 1.50 GHz 30.5 MB L2 36 MB L2 300 W 260 W 16 GB 384 GB 352 GB/s 490 GB/s 34
34 Offloading Choose highly-parallel sections of code to run on the coprocessor. Serial code offloaded to the coprocessor will run much slower than on the CPU. Intel provides a set of directives to the compiler named LEO : Language Extension for Offload. These directives manage the transfer and execution of portions of code to the device. #include <omp.h> #pragma offload target(mic:0) { //a highly-parallel section } 35
35 Offloading A host and device don't have a shared memory, therefore variables must be copied in an explicit or in an implicit way. Implicit copy is assumed for scalar variables and static arrays. Explicit copy must be managed by the programmer using clauses defined in the LEO. Programmer clauses for explicit copy: in, out, inout, nocopy #pragma offload target(mic) in(data:length(size)) 36
36 Offloading void f() { } int x = 55; int y[10] = { 0,1,2,3,4,5,6,7,8,9}; // x, y sent from CPU // To use values computed into y by this offload in next offload, // y is brought back to the CPU #pragma offload target(mic:0) in(x,y) inout(y) { y[5] = 66; } // The assignment to x on the CPU // is independent of the value of x on the coprocessor x = 30; // Reuse of x from previous offload is possible using nocopy // However, array y needs to be sent again from CPU #pragma offload target(mic:0) nocopy(x) in(y) { = y[5]; // Has value 66 } = x; // x has value 55 from first offload 37
37 Xeon Phi Programming - Demo Simple matrix equation (A = a*a + B). [2] James Jeffers and James Reinders, Intel Xeon Phi Coprocessor High-Performance Programming, Morgan Kaufmann,
38 Simple matrix equation int main(int argc, char* argv[]) { high_resolution_clock::time_point start = high_resolution_clock::now(); uint64_t numthreads = 1; #pragma offload target(mic: 0) { init(); numthreads = omp_get_max_threads(); #pragma omp parallel { } kernel(); } double totalduration = duration_cast<duration<double>> return 0; (high_resolution_clock::now()-start).count(); } 39
39 Simple matrix equation #define IMCI_ALIGNMENT 64 #define ARR_SIZE (1024*1024) #define ITERS_PER_LOOP 128 #define LOOP_COUNT (64*1024*1024) #pragma omp declare target float a; float fa[arr_size] attribute ((aligned(imci_alignment))); float fb[arr_size] attribute ((aligned(imci_alignment))); inline void init() { } a = 1.1f; #pragma omp simd aligned(fa, fb: IMCI_ALIGNMENT) for (uint64_t i = 0; i < ARR_SIZE; ++i) { } fa[i] = ((float) i) + 0.1f; fb[i] = ((float) i) + 0.2f; 40
40 Simple matrix equation inline void kernel() { } uint64_t offset = omp_get_thread_num()*iters_per_loop; for (uint64_t j = 0; j < LOOP_COUNT; ++j) { } #pragma omp simd aligned(fa,fb: IMCI_ALIGNMENT) for (uint64_t k = 0; k < ITERS_PER_LOOP; ++k) fa[k+offset] = a*fa[k+offset]+fb[k+offset]; #pragma omp end declare target 41
41 References [1] David M. Koppelman, GPU Microarchitecture Lecture notes, Louisiana State University, [2] James Jeffers and James Reinders, Intel Xeon Phi Coprocessor High-Performance Programming, Morgan Kaufmann, [3] NVIDIA, CUDA Toolkit Documentation v10.0, ( [4] Avinash Sodani, Knights Landing (KNL): 2nd Generation Intel Xeon Phi Processor, Intel, [5] James Jeffers and James Reinders and Avinash Sodani, Intel Xeon Phi Processor High Performance Programming, 2nd Edition, Morgan Kaufmann,
42 References [6] Kevin, D: Effective Use of the Intel Compiler's Offload Features, [7] Fabio AFFINITO CINECA, Introduction to Intel Xeon Phi programming, CINECA,
Parallel Accelerators
 Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Parallel Accelerators Přemysl Šůcha ``Parallel algorithms'', 2017/2018 CTU/FEL 1 Topic Overview Graphical Processing Units (GPU) and CUDA Vector addition on CUDA Intel Xeon Phi Matrix equations on Xeon
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Lecture 8: GPU Programming. CSE599G1: Spring 2017
 Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
Lecture 8: GPU Programming CSE599G1: Spring 2017 Announcements Project proposal due on Thursday (4/28) 5pm. Assignment 2 will be out today, due in two weeks. Implement GPU kernels and use cublas library
High Performance Computing and GPU Programming
 High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
High Performance Computing and GPU Programming Lecture 1: Introduction Objectives C++/CPU Review GPU Intro Programming Model Objectives Objectives Before we begin a little motivation Intel Xeon 2.67GHz
COSC 6339 Accelerators in Big Data
 COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6339 Accelerators in Big Data Edgar Gabriel Fall 2018 Motivation Programming models such as MapReduce and Spark provide a high-level view of parallelism not easy for all problems, e.g. recursive algorithms,
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
CUDA Programming. Week 1. Basic Programming Concepts Materials are copied from the reference list
 CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
CUDA Programming Week 1. Basic Programming Concepts Materials are copied from the reference list G80/G92 Device SP: Streaming Processor (Thread Processors) SM: Streaming Multiprocessor 128 SP grouped into
GPU Computing: Introduction to CUDA. Dr Paul Richmond
 GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
GPU Computing with CUDA
 GPU Computing with CUDA Hands-on: CUDA Profiling, Thrust Dan Melanz & Dan Negrut Simulation-Based Engineering Lab Wisconsin Applied Computing Center Department of Mechanical Engineering University of Wisconsin-Madison
GPU Computing with CUDA Hands-on: CUDA Profiling, Thrust Dan Melanz & Dan Negrut Simulation-Based Engineering Lab Wisconsin Applied Computing Center Department of Mechanical Engineering University of Wisconsin-Madison
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
COSC 6385 Computer Architecture. - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors
 The Intel Larrabee, Nvidia GT200 and Fermi processors") COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
COSC 6385 Computer Architecture - Multi-Processors (V) The Intel Larrabee, Nvidia GT200 and Fermi processors Fall 2012 References Intel Larrabee: [1] L. Seiler, D. Carmean, E. Sprangle, T. Forsyth, M.
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
Basics of CADA Programming - CUDA 4.0 and newer
 Basics of CADA Programming - CUDA 4.0 and newer Feb 19, 2013 Outline CUDA basics Extension of C Single GPU programming Single node multi-gpus programing A brief introduction on the tools Jacket CUDA FORTRAN
Basics of CADA Programming - CUDA 4.0 and newer Feb 19, 2013 Outline CUDA basics Extension of C Single GPU programming Single node multi-gpus programing A brief introduction on the tools Jacket CUDA FORTRAN
COSC 6385 Computer Architecture. - Data Level Parallelism (II)
") COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
Introduc)on to GPU Programming
on to GPU Programming") Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca March 13, 2014 Outline 1 Heterogeneous Computing 2 GPGPU - Overview Hardware Software
Introduction to GPU Computing Using CUDA. Spring 2014 Westgid Seminar Series
 Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Introduction to GPU Computing Using CUDA Spring 2014 Westgid Seminar Series Scott Northrup SciNet www.scinethpc.ca (Slides http://support.scinet.utoronto.ca/ northrup/westgrid CUDA.pdf) March 12, 2014
Using a GPU in InSAR processing to improve performance
 Using a GPU in InSAR processing to improve performance Rob Mellors, ALOS PI 152 San Diego State University David Sandwell University of California, San Diego What is a GPU? (Graphic Processor Unit) A graphics
Using a GPU in InSAR processing to improve performance Rob Mellors, ALOS PI 152 San Diego State University David Sandwell University of California, San Diego What is a GPU? (Graphic Processor Unit) A graphics
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
Parallel Numerical Algorithms
 Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Parallel Numerical Algorithms http://sudalab.is.s.u-tokyo.ac.jp/~reiji/pna14/ [ 10 ] GPU and CUDA Parallel Numerical Algorithms / IST / UTokyo 1 PNA16 Lecture Plan General Topics 1. Architecture and Performance
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
CUDA C Programming Mark Harris NVIDIA Corporation
 CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CUDA C Programming Mark Harris NVIDIA Corporation Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction to Tesla CUDA Architecture Programming & Memory Models Programming Environment
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of
GPU programming: CUDA basics. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
GPU programming: CUDA basics Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline
VOLTA: PROGRAMMABILITY AND PERFORMANCE. Jack Choquette NVIDIA Hot Chips 2017
 VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
VOLTA: PROGRAMMABILITY AND PERFORMANCE Jack Choquette NVIDIA Hot Chips 2017 1 TESLA V100 21B transistors 815 mm 2 80 SM 5120 CUDA Cores 640 Tensor Cores 16 GB HBM2 900 GB/s HBM2 300 GB/s NVLink *full GV100
 By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
By: Tomer Morad Based on: Erik Lindholm, John Nickolls, Stuart Oberman, John Montrym. NVIDIA TESLA: A UNIFIED GRAPHICS AND COMPUTING ARCHITECTURE In IEEE Micro 28(2), 2008 } } Erik Lindholm, John Nickolls,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
Introduction to Intel Xeon Phi programming techniques. Fabio Affinito Vittorio Ruggiero
 Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
GPU 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
GPU 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
Accelerator Programming Lecture 1
 Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Lecture 6 CSE 260 Parallel Computation (Fall 2015) Scott B. Baden. Computing with Graphical Processing Units CUDA Programming Matrix multiplication
 Scott B. Baden. Computing with Graphical Processing Units CUDA Programming Matrix multiplication") Lecture 6 CSE 260 Parallel Computation (Fall 2015) Scott B. Baden Computing with Graphical Processing Units CUDA Programming Matrix multiplication Announcements A2 has been released: Matrix multiplication
Lecture 6 CSE 260 Parallel Computation (Fall 2015) Scott B. Baden Computing with Graphical Processing Units CUDA Programming Matrix multiplication Announcements A2 has been released: Matrix multiplication
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
Advanced OpenMP Features
 Christian Terboven, Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group {terboven,schmidl@itc.rwth-aachen.de IT Center der RWTH Aachen University Vectorization 2 Vectorization SIMD =
Christian Terboven, Dirk Schmidl IT Center, RWTH Aachen University Member of the HPC Group {terboven,schmidl@itc.rwth-aachen.de IT Center der RWTH Aachen University Vectorization 2 Vectorization SIMD =
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
GPU Architecture and Programming. Andrei Doncescu inspired by NVIDIA
 GPU Architecture and Programming Andrei Doncescu inspired by NVIDIA Traditional Computing Von Neumann architecture: instructions are sent from memory to the CPU Serial execution: Instructions are executed
GPU Architecture and Programming Andrei Doncescu inspired by NVIDIA Traditional Computing Von Neumann architecture: instructions are sent from memory to the CPU Serial execution: Instructions are executed
GPU Programming Using CUDA
 GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
GPU Programming Using CUDA Michael J. Schnieders Depts. of Biomedical Engineering & Biochemistry The University of Iowa & Gregory G. Howes Department of Physics and Astronomy The University of Iowa Iowa
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
High-Performance Computing Using GPUs
 High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
High-Performance Computing Using GPUs Luca Caucci caucci@email.arizona.edu Center for Gamma-Ray Imaging November 7, 2012 Outline Slide 1 of 27 Why GPUs? What is CUDA? The CUDA programming model Anatomy
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Cartoon parallel architectures; CPUs and GPUs
 Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
Cartoon parallel architectures; CPUs and GPUs CSE 6230, Fall 2014 Th Sep 11! Thanks to Jee Choi (a senior PhD student) for a big assist 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ~ socket 14 ~ core 14 ~ HWMT+SIMD
NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU
 NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU WP-08608-001_v1.1 August 2017 WP-08608-001_v1.1 TABLE OF CONTENTS Introduction to the NVIDIA Tesla V100 GPU Architecture...
NVIDIA TESLA V100 GPU ARCHITECTURE THE WORLD S MOST ADVANCED DATA CENTER GPU WP-08608-001_v1.1 August 2017 WP-08608-001_v1.1 TABLE OF CONTENTS Introduction to the NVIDIA Tesla V100 GPU Architecture...
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Don t reinvent the wheel. BLAS LAPACK Intel Math Kernel Library
 Libraries Don t reinvent the wheel. Specialized math libraries are likely faster. BLAS: Basic Linear Algebra Subprograms LAPACK: Linear Algebra Package (uses BLAS) http://www.netlib.org/lapack/ to download
Libraries Don t reinvent the wheel. Specialized math libraries are likely faster. BLAS: Basic Linear Algebra Subprograms LAPACK: Linear Algebra Package (uses BLAS) http://www.netlib.org/lapack/ to download
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
CSE 599 I Accelerated Computing Programming GPUS. Intro to CUDA C
 CSE 599 I Accelerated Computing Programming GPUS Intro to CUDA C GPU Teaching Kit Accelerated Computing Lecture 2.1 - Introduction to CUDA C CUDA C vs. Thrust vs. CUDA Libraries Objective To learn the
CSE 599 I Accelerated Computing Programming GPUS Intro to CUDA C GPU Teaching Kit Accelerated Computing Lecture 2.1 - Introduction to CUDA C CUDA C vs. Thrust vs. CUDA Libraries Objective To learn the
GPU programming: CUDA. Sylvain Collange Inria Rennes Bretagne Atlantique
 GPU programming: CUDA Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline GPU
GPU programming: CUDA Sylvain Collange Inria Rennes Bretagne Atlantique sylvain.collange@inria.fr This lecture: CUDA programming We have seen some GPU architecture Now how to program it? 2 Outline GPU
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
GPU COMPUTING. Ana Lucia Varbanescu (UvA)
") GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
GPU COMPUTING Ana Lucia Varbanescu (UvA) 2 Graphics in 1980 3 Graphics in 2000 4 Graphics in 2015 GPUs in movies 5 From Ariel in Little Mermaid to Brave So 6 GPUs are a steady market Gaming CAD-like activities
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
NVidia s GPU Microarchitectures. By Stephen Lucas and Gerald Kotas
 NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ,
 Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Improving Performance of Machine Learning Workloads
 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci
 Ezio Bartocci") TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
TECHNISCHE UNIVERSITÄT WIEN Fakultät für Informatik Cyber-Physical Systems Group CUDA Programming (Basics, Cuda Threads, Atomics) Ezio Bartocci Outline of CUDA Basics Basic Kernels and Execution on GPU
CUDA C/C++ BASICS. NVIDIA Corporation
 CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
CUDA C/C++ BASICS NVIDIA Corporation What is CUDA? CUDA Architecture Expose GPU parallelism for general-purpose computing Retain performance CUDA C/C++ Based on industry-standard C/C++ Small set of extensions
An Introduction to GPU Computing and CUDA Architecture
 An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
An Introduction to GPU Computing and CUDA Architecture Sarah Tariq, NVIDIA Corporation GPU Computing GPU: Graphics Processing Unit Traditionally used for real-time rendering High computational density
GPU Programming with CUDA. Pedro Velho
 GPU Programming with CUDA Pedro Velho Meeting the audience! How many of you used concurrent programming before? How many threads? How many already used CUDA? Introduction from games to science 1 2 Architecture
GPU Programming with CUDA Pedro Velho Meeting the audience! How many of you used concurrent programming before? How many threads? How many already used CUDA? Introduction from games to science 1 2 Architecture
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Learn CUDA in an Afternoon. Alan Gray EPCC The University of Edinburgh
 Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
Learn CUDA in an Afternoon Alan Gray EPCC The University of Edinburgh Overview Introduction to CUDA Practical Exercise 1: Getting started with CUDA GPU Optimisation Practical Exercise 2: Optimising a CUDA
EEM528 GPU COMPUTING
 EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
EEM528 CS 193G GPU COMPUTING Lecture 2: GPU History & CUDA Programming Basics Slides Credit: Jared Hoberock & David Tarjan CS 193G History of GPUs Graphics in a Nutshell Make great images intricate shapes
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
HPCSE II. GPU programming and CUDA
 HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
HPCSE II GPU programming and CUDA What is a GPU? Specialized for compute-intensive, highly-parallel computation, i.e. graphic output Evolution pushed by gaming industry CPU: large die area for control
Introduction to OpenACC. 16 May 2013
 Introduction to OpenACC 16 May 2013 GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance Rendering Data Analytics
Introduction to OpenACC 16 May 2013 GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance Rendering Data Analytics
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
Lecture 9. Outline. CUDA : a General-Purpose Parallel Computing Architecture. CUDA Device and Threads CUDA. CUDA Architecture CUDA (I)
") Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
Lecture 9 CUDA CUDA (I) Compute Unified Device Architecture 1 2 Outline CUDA Architecture CUDA Architecture CUDA programming model CUDA-C 3 4 CUDA : a General-Purpose Parallel Computing Architecture CUDA
HPC trends (Myths about) accelerator cards & more. June 24, Martin Schreiber,
 accelerator cards & more. June 24, Martin Schreiber,") HPC trends (Myths about) accelerator cards & more June 24, 2015 - Martin Schreiber, M.Schreiber@exeter.ac.uk Outline HPC & current architectures Performance: Programming models: OpenCL & OpenMP Some applications:
HPC trends (Myths about) accelerator cards & more June 24, 2015 - Martin Schreiber, M.Schreiber@exeter.ac.uk Outline HPC & current architectures Performance: Programming models: OpenCL & OpenMP Some applications:
CUDA GPGPU Workshop CUDA/GPGPU Arch&Prog
 CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
CUDA GPGPU Workshop 2012 CUDA/GPGPU Arch&Prog Yip Wichita State University 7/11/2012 GPU-Hardware perspective GPU as PCI device Original PCI PCIe Inside GPU architecture GPU as PCI device Traditional PC
Intel MIC Programming Workshop, Hardware Overview & Native Execution. IT4Innovations, Ostrava,
 , Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
, Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
Vector Addition on the Device: main()
") Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Vector Addition on the Device: main() #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space
Lecture 5. Performance Programming with CUDA
 Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Parallelism Model
 GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA
 EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
EARLY EVALUATION OF THE CRAY XC40 SYSTEM THETA SUDHEER CHUNDURI, SCOTT PARKER, KEVIN HARMS, VITALI MOROZOV, CHRIS KNIGHT, KALYAN KUMARAN Performance Engineering Group Argonne Leadership Computing Facility
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Introduction to GPU Programming
 Introduction to GPU Programming Volodymyr (Vlad) Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) Tutorial Goals Become familiar with
Introduction to GPU Programming Volodymyr (Vlad) Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) Tutorial Goals Become familiar with
Basic Elements of CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Basic Elements of CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA. Part 1: Hardware design and programming model
 Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel
Introduction to Numerical General Purpose GPU Computing with NVIDIA CUDA Part 1: Hardware design and programming model Dirk Ribbrock Faculty of Mathematics, TU dortmund 2016 Table of Contents Why parallel