CS 3410 Computer Science Cornell University
|
|
|
- Maurice Bradford
- 5 years ago
- Views:
Transcription
1 CS 3410 Computer Science Cornell University The slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, McKee, and Sirer. Also some slides from Amir Roth & Milo Martin in here. 1
2 C practice assignment Due Monday, April 23rd P4-Buffer Overflow is due tomorrow Due Wednesday, April 18th P5-Cache Collusion! Due Friday, April 27 th Pizza party & Tournament, Monday, May 7 th Prelim2 Thursday, May 3 rd, 7:30pm 185 Statler Hall
3
4
5 Why do I need four computing cores on my phone?!
6 Why do I need eight computing cores on my phone?!
7 Why do I need sixteen computing cores on my phone?!
8 Execution time after improvement = affected execution time amount of improvement + execution time unaffected T improved = T affected improvement factor + T unaffected
9 Improving an aspect of a computer and expecting a proportional improvement in overall performance T T improved = affected + T improvement factor unaffected Example: multiply accounts for 80s out of 100s Multiply can be parallelized How much improvement do we need in the multiply performance to get 5 overall improvement? (a) 2x (b) 10x (c) 100x (d) 1000x (e) not possible
10 Improving an aspect of a computer and expecting a proportional improvement in overall performance T T improved = affected + T improvement factor unaffected Example: multiply accounts for 80s out of 100s Multiply can be parallelized How much improvement do we need in the multiply performance to get 5 overall improvement? 20 = 80 nn + 20 Can t be done!
11 Workload: sum of 10 scalars, and matrix sum Speed up from 10 to 100 processors? Single processor: Time = ( ) t add 10 processors Time = 100/10 t add + 10 t add = 20 t add Speedup = 110/20 = processors Time = 100/100 t add + 10 t add = 11 t add Speedup = 110/11 = 10 Assumes load can be balanced across processors
12 Unfortunately, we cannot not obtain unlimited scaling (speedup) by adding unlimited parallel resources, eventual performance is dominated by a component needing to be executed sequentially. Amdahl's Law is a caution about this diminishing return
13 seconds instructions cycles seconds = x x program program instruction cycle 2 Classic Goals of Architects: Clock period ( Clock frequency) Cycles per Instruction ( IPC) 14
14 Darling of performance improvement for decades Why is this no longer the strategy? Hitting Limits: Pipeline depth Clock frequency Moore s Law & Technology Scaling Power 15
15 Exploiting Intra-instruction parallelism: Pipelining (decode A while fetching B) Exploiting Instruction Level Parallelism (ILP): Multiple issue pipeline (2-wide, 4-wide, etc.) Statically detected by compiler (VLIW) Dynamically detected by HW Dynamically Scheduled (OoO) 16
16 Pipelining: execute multiple instructions in parallel Q: How to get more instruction level parallelism? A: Deeper pipeline E.g. 250MHz 1-stage; 500Mhz 2-stage; 1GHz 4-stage; 4GHz 16-stage Pipeline depth limited by max clock speed (less work per stage shorter clock cycle) min unit of work dependencies, hazards / forwarding logic
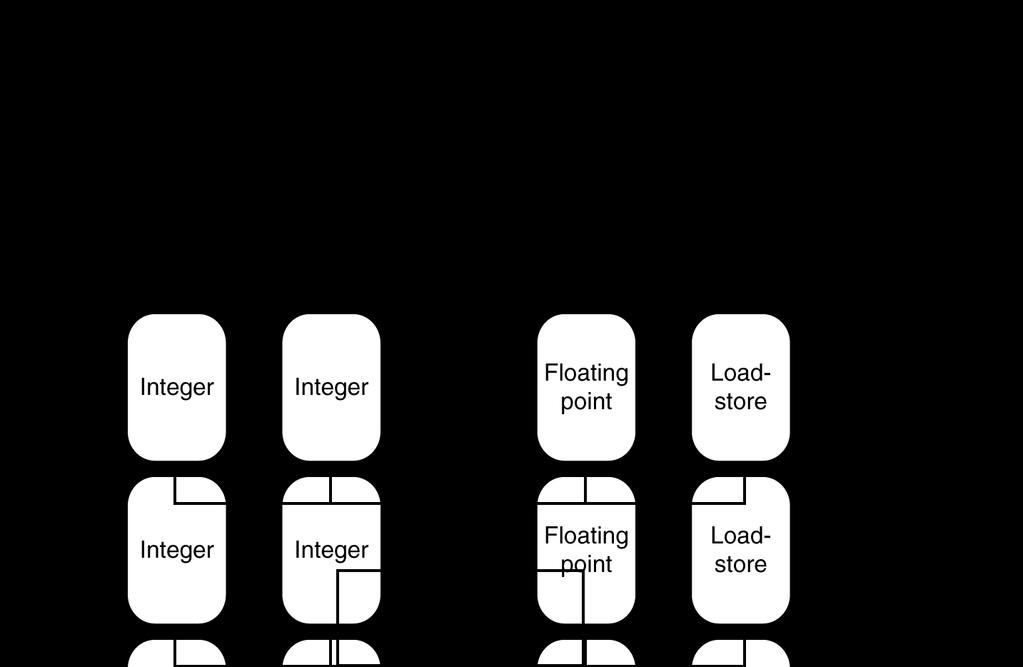
17 Pipelining: execute multiple instructions in parallel Q: How to get more instruction level parallelism? A: Multiple issue pipeline Start multiple instructions per clock cycle in duplicate stages ALU/Br LW/SW
18 a.k.a. Very Long Instruction Word (VLIW) Compiler groups instructions to be issued together Packages them into issue slots How does HW detect and resolve hazards? It doesn t. Compiler must avoid hazards Example: Static Dual-Issue 32-bit MIPS Instructions come in pairs (64-bit aligned) One ALU/branch instruction (or nop) One load/store instruction (or nop) 20
19 Two-issue packets One ALU/branch instruction One load/store instruction 64-bit aligned ALU/branch, then load/store Pad an unused instruction with nop Address Instruction type Pipeline Stages n ALU/branch IF ID EX MEM WB n + 4 Load/store IF ID EX MEM WB n + 8 ALU/branch IF ID EX MEM WB n + 12 Load/store IF ID EX MEM WB n + 16 ALU/branch IF ID EX MEM WB n + 20 Load/store IF ID EX MEM WB 21
20 Schedule this for dual-issue MIPS Loop: lw $t0, 0($s1) # $t0=array element addu $t0, $t0, $s2 # add scalar in $s2 sw $t0, 0($s1) # store result addi $s1, $s1, 4 # decrement pointer bne $s1, $zero, Loop # branch $s1!=0 ALU/branch Load/store cycle Loop: nop lw $t0, 0($s1) 1 addi $s1, $s1, 4 nop 2 addu $t0, $t0, $s2 nop 3 bne $s1, $zero, Loop sw $t0, 4($s1) 4 Clicker Question: What is the IPC of this machine? (A) 0.8 (B) 1.0 (C) 1.25 (D) 1.5 (E) 2.0
21 Schedule this for dual-issue MIPS Loop: lw $t0, 0($s1) # $t0=array element addu $t0, $t0, $s2 # add scalar in $s2 sw $t0, 0($s1) # store result addi $s1, $s1, 4 # decrement pointer bne $s1, $zero, Loop # branch $s1!=0 ALU/branch Load/store cycle Loop: nop lw $t0, 0($s1) 1 addi $s1, $s1, 4 nop 2 addu $t0, $t0, $s2 nop 3 bne $s1, $zero, Loop sw $t0, 4($s1) 4 5 instructions 4 cycles 4 cycles 5 instructions = IPC = 1.25 = CPI = 0.8
22 Goal: larger instruction windows (to play with) Predication Loop unrolling Function in-lining Basic block modifications (superblocks, etc.) Roadblocks Memory dependences (aliasing) Control dependences 24
23 Reorder instructions To fill the issue slot with useful work Complicated: exceptions may occur
24 Move instructions to fill in nops Need to track hazards and dependencies Loop unrolling
25 Compiler scheduling for dual-issue MIPS Loop: lw $t0, 0($s1) # $t0 = A[i] lw $t1, 4($s1) # $t1 = A[i+1] addu $t0, $t0, $s2 # add $s2 addu $t1, $t1, $s2 # add $s2 sw $t0, -8 0($s1) # store A[i] sw $t1, -4 4($s1) # store A[i+1] addi $s1, $s1, +8 # increment pointer bne $s1, $s3, Loop # continue if $s1!=end 8 cycles ALU/branch slot Load/store slot cycle Loop: nop delay slot lw $t0, 0($s1) 1 nop lw $t1, 4($s1) 2 addu $t0, $t0, $s2 nop 3 addu $t1, $t1, $s2 sw $t0, 0($s1) 4 addi $s1, $s1, +8 sw $t1, 4($s1) 5 bne $s1, $s3, Loop nop 6 6 cycles 6 cycles 8 instructions = CPI = 0.75
26 Compiler scheduling for dual-issue MIPS Loop: lw $t0, 0($s1) # $t0 = A[i] lw $t1, 4($s1) # $t1 = A[i+1] addu $t0, $t0, $s2 # add $s2 addu $t1, $t1, $s2 # add $s2 sw $t0, -8 0($s1) # store A[i] sw $t1, -4 4($s1) # store A[i+1] addi $s1, $s1, +8 # increment pointer bne $s1, $s3, Loop # continue if $s1!=end 8 cycles ALU/branch slot Load/store slot cycle Loop: nop lw $t0, 0($s1) 1 addi $s1, $s1, +8 lw $t1, 4($s1) 2 addu $t0, $t0, $s2 nop 3 addu $t1, $t1, $s2 sw $t0, -8($s1) 4 bne $s1, $s3, Loop sw $t1, -4($s1) 5 5 cycles 5 cycles 8 instructions = CPI = 0.625
27 Compiler scheduling for dual-issue MIPS lw $t0, 0($s1) # load A addi $t0, $t0, +1 # increment A sw $t0, 0($s1) # store A lw $t0, 0($s2) # load B addi $t0, $t0, +1 # increment B sw $t0, 0($s2) # store B ALU/branch slot Load/store slot cycle nop lw $t0, 0($s1) 1 nop nop 2 addi $t0, $t0, +1 nop 3 nop sw $t0, 0($s1) 4 nop lw $t0, 0($s2) 5 nop nop 6 addi $t0, $t0, +1 nop 7 nop sw $t0, 0($s2) 8
28 Compiler scheduling for dual-issue MIPS lw $t0, 0($s1) # load A addi $t0, $t0, +1 # increment A sw $t0, 0($s1) # store A lw $t1, 0($s2) # load B addi $t1, $t1, +1 # increment B sw $t1, 0($s2) # store B ALU/branch slot Load/store slot cycle nop lw $t0, 0($s1) 1 nop nop 2 addi $t0, $t0, +1 nop 3 nop sw $t0, 0($s1) 4 nop lw $t1, 0($s2) 5 nop nop 6 addi $t1, $t1, +1 nop 7 nop sw $t1, 0($s2) 8
29 Compiler scheduling for dual-issue MIPS lw $t0, 0($s1) # load A addi $t0, $t0, +1 # increment A sw $t0, 0($s1) # store A lw $t1, 0($s2) # load B addi $t1, $t1, +1 # increment B sw $t1, 0($s2) # store B ALU/branch slot Load/store slot cycle nop lw $t0, 0($s1) 1 nop lw $t1, 0($s2) 2 addi $t0, $t0, +1 nop 3 addi $t1, $t1, +1 sw $t0, 0($s1) 4 nop sw $t1, 0($s2) 5 Problem: What if $s1 and $s2 are equal (aliasing)? Won t work
30 Exploiting Intra-instruction parallelism: Pipelining (decode A while fetching B) Exploiting Instruction Level Parallelism (ILP): Multiple issue pipeline (2-wide, 4-wide, etc.) Statically detected by compiler (VLIW) Dynamically detected by HW Dynamically Scheduled (OoO) 32
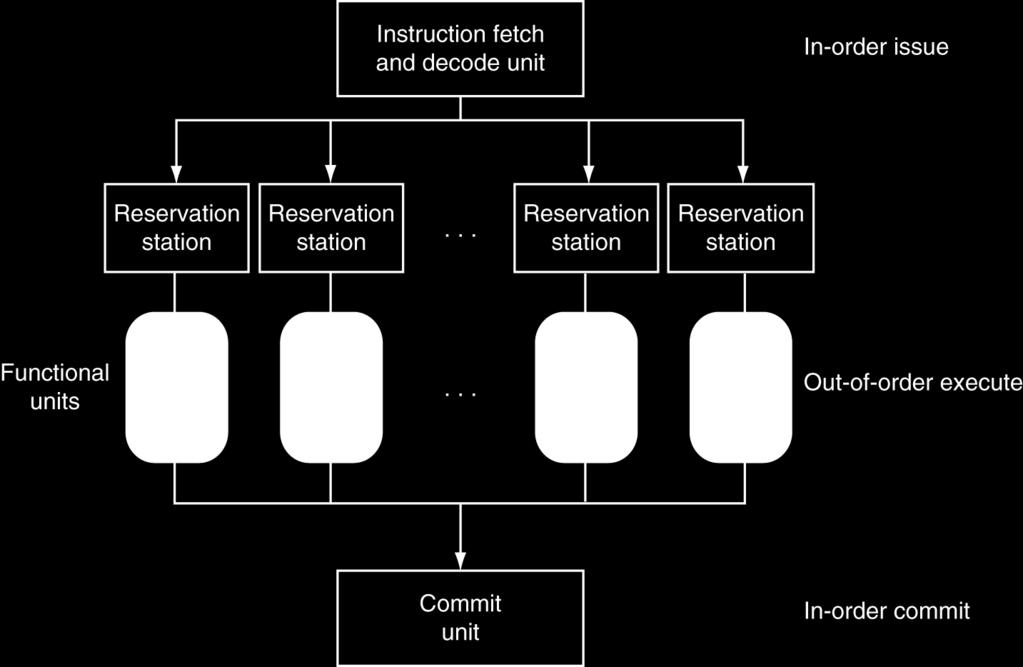
31 aka SuperScalar Processor (c.f. Intel) CPU chooses multiple instructions to issue each cycle Compiler can help, by reordering instructions. but CPU resolves hazards Even better: Speculation/Out-of-order Execution Execute instructions as early as possible Aggressive register renaming (indirection to the rescue!) Guess results of branches, loads, etc. Roll back if guesses were wrong Don t commit results until all previous insns committed 33
32
33 It was awesome, but then it stopped improving Limiting factors? Programs dependencies Memory dependence detection be conservative e.g. Pointer Aliasing: A[0] += 1; B[0] *= 2; Hard to expose parallelism Still limited by the fetch stream of the static program Structural limits Memory delays and limited bandwidth Hard to keep pipelines full, especially with branches 35
34 Exploiting Thread-Level parallelism Hardware multithreading to improve utilization: Multiplexing multiple threads on single CPU Sacrifices latency for throughput Single thread cannot fully utilize CPU? Try more! Three types: Course-grain (has preferred thread) Fine-grain (round robin between threads) Simultaneous (hyperthreading) 36

35 Process: multiple threads, code, data and OS state Threads: share code, data, files, not regs or stack 37
36 Time evolution of issue slots Color = thread, white = no instruction time 4-wide Superscalar CGMT FGMT SMT Switch to thread B on thread A L2 miss Switch threads every cycle Insns from multiple threads coexist 38
37 Q: Does multiple issue / ILP cost much? A: Yes. Dynamic issue and speculation requires power CPU Year Clock Rate Pipeline Stages Issue width Out-of-order/ Speculation Cores Power i MHz 5 1 No 1 5W Pentium MHz 5 2 No 1 10W Pentium Pro MHz 10 3 Yes 1 29W P4 Willamette MHz 22 3 Yes 1 75W UltraSparc III MHz 14 4 No 1 90W P4 Prescott MHz 31 3 Yes 1 103W Those simpler cores did something very right.
38 Dual-core Itanium 2 K10 Itanium 2 K8 P4 Atom Pentium
39 Moore s law A law about transistors Smaller means more transistors per die And smaller means faster too But: Power consumption growing too

40 Surface of Sun Rocket Nozzle Nuclear Reactor Hot Plate Xeon 180nm 32nm
41 Power = capacitance * voltage 2 * frequency In practice: Power ~ voltage 3 Reducing voltage helps (a lot)... so does reducing clock speed Better cooling helps The power wall We can t reduce voltage further We can t remove more heat Lower Frequency
42 Performance Power 1.2x 1.7x Single-Core Overclocked +20% Performance Power 1.0x 1.0x Single-Core Performance Power 0.8x 0.51x 1.02x 1.6x Single-Core Dual-Core Underclocked -20%
43 Q: Does multiple issue / ILP cost much? A: Yes. Dynamic issue and speculation requires power CPU Year Clock Rate Pipeline Stages Issue width Out-of-order/ Speculation Cores Power i MHz 5 1 No 1 5W Pentium MHz 5 2 No 1 10W Pentium Pro MHz 10 3 Yes 1 29W P4 Willamette MHz 22 3 Yes 1 75W UltraSparc III MHz 14 4 No 1 90W P4 Prescott MHz 31 3 Yes 1 103W Core MHz 14 4 Yes 2 75W Core i5 Nehal MHz 14 4 Yes 1 87W Core i5 Ivy Br MHz 14 4 Yes 8 77W UltraSparc T MHz 6 1 No 8 70W Those simpler cores did something very right.


44 AMD Barcelona Quad-Core: 4 processor cores


45 Intel Nehalem Hex-Core 4-wide pipeline

46 8 die (aka 8 sockets) 4 core per socket 2 HT per core Note: a socket is a processor, where each processor may have multiple processing cores, so this is an example of a multiprocessor multicore hyperthreaded system
47 Q: So lets just all use multicore from now on! A: Software must be written as parallel program Multicore difficulties Partitioning work Coordination & synchronization Communications overhead How do you write parallel programs?... without knowing exact underlying architecture? 50
48 Partition work so all cores have something to do
49 Load Balancing Need to partition so all cores are actually working
50 If tasks have a serial part and a parallel part Example: step 1: divide input data into n pieces step 2: do work on each piece step 3: combine all results Recall: Amdahl s Law As number of cores increases time to execute parallel part? goes to zero time to execute serial part? Remains the same Serial part eventually dominates
51
52 Necessity, not luxury Power wall Not easy to get performance out of Many solutions Pipelining Multi-issue Hyperthreading Multicore
53 Q: So lets just all use multicore from now on! A: Software must be written as parallel program Multicore difficulties Partitioning work Coordination & synchronization Communications overhead HW How do you write parallel programs? SW Your career... without knowing exact underlying architecture? 56
54 How do I take advantage of parallelism? How do I write (correct) parallel programs? What primitives do I need to implement correct parallel programs?
55 Cache Coherency Processors cache shared data they see different (incoherent) values for the same memory location Synchronizing parallel programs Atomic Instructions HW support for synchronization How to write parallel programs Threads and processes Critical sections, race conditions, and mutexes 58
56 Cache Coherency Problem: What happens when to two or more processors cache shared data?
57 Cache Coherency Problem: What happens when to two or more processors cache shared data? i.e. the view of memory held by two different processors is through their individual caches. As a result, processors can see different (incoherent) values to the same memory location.
58
59 Each processor core has its own L1 cache
60 Each processor core has its own L1 cache
61 Each processor core has its own L1 cache Core0 Core1 Core2 Core3 Cache Cache Cache Cache Interconnect Memory I/O
62 Shared Memory Multiprocessor (SMP) Typical (today): 2 4 processor dies, 2 8 cores each HW provides single physical address space for all processors Core0 Core1 Core2 Core3 Cache Cache Cache Cache Interconnect Memory I/O
63 Shared Memory Multiprocessor (SMP) Typical (today): 2 4 processor dies, 2 8 cores each HW provides single physical address space for all processors Core0 Cache Core1 Cache CoreN Cache Interconnect Memory I/O
64 Thread A (on Core0) Thread B (on Core1) for(int i = 0, i < 5; i++) { for(int j = 0; j < 5; j++) { x = x + 1; x = x + 1; } } What will the value of x be after both loops finish? Core0 Cache Core1 Cache CoreN Cache Interconnect Memory I/O 67
65 Thread A (on Core0) Thread B (on Core1) for(int i = 0, i < 5; i++) { for(int j = 0; j < 5; j++) { x = x + 1; x = x + 1; } } What will the value of x be after both loops finish? (x starts as 0) a) 6 b) 8 c) 10 d) Could be any of the above Clicker Question e) Couldn t be any of the above 68
66 Thread A (on Core0) Thread B (on Core1) for(int i = 0, i < 5; i++) { for(int j = 0; j < 5; j++) { x = x + 1; x = x + 1; } } What will the value of x be after both loops finish? (x starts as 0) a) 6 b) 8 c) 10 d) Could be any of the above Clicker Question e) Couldn t be any of the above 69
67 Thread A (on Core0) Thread B (on Core1) for(int i = 0, i < 5; i++) { for(int j = 0; j < 5; j++) { LW $t0, addr(x) $t0=0 LW $t0, addr(x) $t0=0 $t0=1 ADDIU $t0, $t0, 1 $t0=1 ADDIU $t0, $t0, 1 SW $t0, addr(x) } } x=1 Problem! x=1 SW $t0, addr(x) Core0 X 01 Cache X 01 Core1 Cache CoreN Cache Interconnect X 0 Memory I/O 70
68 Executing on a write-thru cache Time Event CPU A s CPU B s Memory step cache cache CPU A reads X CPU B reads X CPU A writes 1 to X Core0 Cache Core1 Cache CoreN Cache Interconnect Memory I/O
69 Coherence What values can be returned by a read Need a globally uniform (consistent) view of a single memory location Solution: Cache Coherence Protocols Consistency When a written value will be returned by a read Need a globally uniform (consistent) view of all memory locations relative to each other Solution: Memory Consistency Models 72
70 Informal: Reads return most recently written value Formal: For concurrent processes P 1 and P 2 P writes X before P reads X (with no intervening writes) read returns written value (preserve program order) P 1 writes X before P 2 reads X read returns written value (coherent memory view, can t read old value forever) P 1 writes X and P 2 writes X all processors see writes in the same order all see the same final value for X Aka write serialization (else P A can see P 2 s write before P 1 s and P B can see the opposite; their final understanding of state is wrong)
71 Operations performed by caches in multiprocessors to ensure coherence Migration of data to local caches Reduces bandwidth for shared memory Replication of read-shared data Reduces contention for access Snooping protocols Each cache monitors bus reads/writes
72 Snooping for Hardware Cache Coherence All caches monitor bus and all other caches Bus read: respond if you have dirty data Bus write: update/invalidate your copy of data Snoop Core0 Cache Snoop Core1 Cache Snoop CoreN Cache Interconnect Memory I/O
73 Cache gets exclusive access to a block when it is to be written Broadcasts an invalidate message on the bus Subsequent read in another cache misses Owning cache supplies updated value Time CPU activity Bus activity CPU A s CPU B s Memory Step cache cache CPU A reads X Cache miss for X CPU B reads X Cache miss for X CPU A writes 1 to X Invalidate for X CPU B read X Cache miss for X 1 1 1
74 Write-back policies for bandwidth Write-invalidate coherence policy First invalidate all other copies of data Then write it in cache line Anybody else can read it Permits one writer, multiple readers In reality: many coherence protocols Snooping doesn t scale Directory-based protocols Caches and memory record sharing status of blocks in a directory
75 Coherence introduces two new kinds of cache misses Upgrade miss On stores to read-only blocks Delay to acquire write permission to read-only block Coherence miss Miss to a block evicted by another processor s requests Making the cache larger Doesn t reduce these type of misses As cache grows large, these sorts of misses dominate False sharing Two or more processors sharing parts of the same block But not the same bytes within that block (no actual sharing) Creates pathological ping-pong behavior Careful data placement may help, but is difficult 84
76 Informally, Cache Coherency requires that reads return most recently written value Cache coherence hard problem Snooping protocols are one approach
77 Is cache coherency sufficient? i.e. Is cache coherency (what values are read) sufficient to maintain consistency (when a written value will be returned to a read). Both coherency and consistency are required to maintain consistency in shared memory programs.
78 Thread A lw t0, 0(r3) Thread B lw t0, 0(r3) ADDIU $t0,$t0,1 sw t0,0(x) CPU0 CPU1 Mem 0 S:0 0 S:0 S:0 0 I: M:1 0 ADDIU $t0,$t0,1 sw t0,0(x) M:1 I: 1 What just happened??? Is Cache Coherency Protocol Broken?? 88
79 The Previous example shows us that a) Caches can be incoherent even if there is a coherence protocol. b) Cache coherence protocols are not rich enough to support multi-threaded programs c) Coherent caches are not enough to guarantee expected program behavior. d) Multithreading is just a really bad idea. e) All of the above 90
80 The Previous example shows us that a) Caches can be incoherent even if there is a coherence protocol. b) Cache coherence protocols are not rich enough to support multi-threaded programs c) Coherent caches are not enough to guarantee expected program behavior. d) Multithreading is just a really bad idea. e) All of the above 91
81 Need it to exploit multiple processing units to parallelize for multicore to write servers that handle many clients Problem: hard even for experienced programmers Behavior can depend on subtle timing differences Bugs may be impossible to reproduce Needed: synchronization of threads
82 Within a thread: execution is sequential Between threads? No ordering or timing guarantees Might even run on different cores at the same time Problem: hard to program, hard to reason about Behavior can depend on subtle timing differences Bugs may be impossible to reproduce Cache coherency is not sufficient Need explicit synchronization to make sense of concurrency!
83 Concurrency poses challenges for: Correctness Threads accessing shared memory should not interfere with each other Liveness Threads should not get stuck, should make forward progress Efficiency Program should make good use of available computing resources (e.g., processors). Fairness Resources apportioned fairly between threads
84 Apache web server void main() { setup(); while (c = accept_connection()) { req = read_request(c); hits[req]++; send_response(c, req); } } cleanup();
85 Each client request handled by a separate thread (in parallel) Some shared state: hit counter,... Thread 52 read... hits addiu hits = hits + 1; write... hits (look familiar?) Timing-dependent failure race condition hard to reproduce hard to debug Thread 205 read... hits addiu hits = hits + 1; write... hits
86 Possible result: lost update! hits = 0 time T1 LW (0) ADDIU/SW: hits = hits = 1 LW (0) T2 ADDIU/SW: hits = Timing-dependent failure race condition Very hard to reproduce Difficult to debug
87 Timing-dependent error involving access to shared state Race conditions depend on how threads are scheduled i.e. who wins races to update state Challenges of Race Conditions Races are intermittent, may occur rarely Timing dependent = small changes can hide bug Program is correct only if all possible schedules are safe Number of possible schedules is huge Imagine adversary who switches contexts at worst possible time 98
88 What if we can designate parts of the execution as critical sections Rule: only one thread can be inside a critical section Thread 52 CSEnter() read hits addi write hits CSExit() Thread 205 CSEnter() read hits addi write hits CSExit()
89 To eliminate races: use critical sections that only one thread can be in Contending threads must wait to enter T1 T2 time CSEnter(); Critical section CSExit(); T1 CSEnter(); # wait # wait Critical section CSExit(); T2
90 Implement CSEnter and CSExit; ie. a critical section Only one thread can hold the lock at a time I have the lock Mutual Exclusion Lock (mutex) lock(m): wait till it becomes free, then lock it unlock(m): unlock it safe_increment() { pthread_mutex_lock(&m); hits = hits + 1; pthread_mutex_unlock(&m); }
91 Only one thread can hold a given mutex at a time Acquire (lock) mutex on entry to critical section Or block if another thread already holds it Release (unlock) mutex on exit Allow one waiting thread (if any) to acquire & proceed pthread_mutex_init(&m); pthread_mutex_lock(&m); pthread_mutex_lock(&m); # wait hits = hits+1; # wait pthread_mutex_unlock(&m); hits = hits+1; pthread_mutex_unlock(&m); T1 T2
92 How to implement mutex locks? What are the hardware primitives? Then, use these mutex locks to implement critical sections, and use critical sections to write parallel safe programs
93 Atomic read & write memory operation Between read & write: no writes to that address Many atomic hardware primitives test and set (x86) atomic increment (x86) bus lock prefix (x86) compare and exchange (x86, ARM deprecated) linked load / store conditional (pair of insns) (MIPS, ARM, PowerPC, DEC Alpha, ) 104
94 Load linked: LL rt, offset(rs) I want the value at address X. Also, start monitoring any writes to this address. Store conditional: SC rt, offset(rs) If no one has changed the value at address X since the LL, perform this store and tell me it worked. Data at location has not changed since the LL? SUCCESS: Performs the store Returns 1 in rt Data at location has changed since the LL? FAILURE: Does not perform the store Returns 0 in rt 105
95 Load linked: LL rt, offset(rs) Store conditional: SC rt, offset(rs) Succeeds if location not changed since the LL Returns 1 in rt Fails if location is changed Returns 0 in rt Any time a processor intervenes and modifies the value in memory between the LL and SC instruction, the SC returns 0 in $t0, causing the code to try again. i.e. use this value 0 in $t0 to try again.
96 Load linked: LL rt, offset(rs) Store conditional: SC rt, offset(rs) Succeeds if location not changed since the LL Returns 1 in rt Fails if location is changed Returns 0 in rt Example: atomic incrementor i++ LW $t0, 0($s0) ADDIU $t0, $t0, 1 SW $t0, 0($s0) try: atomic(i++) LL $t0, 0($s0) ADDIU $t0, $t0, 1 SC $t0, 0($s0) BEQZ $t0, try Value in memory changed between LL and SC? SC returns 0 in $t0 retry
97 Load linked: LL $t0, offset($s0) Store conditional: SC $t0, offset($s0) Time Thread A Thread B Thread A $t0 Thread B $t try: LL $t0, 0($s0) 2 try: LL $t0, 0($s0) 3 ADDIU $t0, $t0, 1 4 ADDIU $t0, $t0, 1 5 SC $t0, 0($s0) 6 BEQZ $t0, try 7 SC $t0, 0 ($s0) 8 BEQZ $t0, try Mem [$s0]
98 Load linked: LL $t0, offset($s0) Store conditional: SC $t0, offset($s0) Time Thread A Thread B Thread A $t0 Thread B $t try: LL $t0, 0($s0) try: LL $t0, 0($s0) ADDIU $t0, $t0, ADDIU $t0, $t0, SC $t0, 0($s0) BEQZ $t0, try SC $t0, 0 ($s0) BEQZ $t0, try Success! Mem [$s0] Failure! 109
99 Linked load / Store Conditional m = 0; // m=0 means lock is free; otherwise, if m=1, then lock locked mutex_lock(int *m) { while(test_and_set(m)){} } int test_and_set(int *m) { old = *m; *m = 1; LL SC Atomic return old; }
100 Linked load / Store Conditional m = 0; // m=0 means lock is free; otherwise, if m=1, then lock locked mutex_lock(int *m) { while(test_and_set(m)){} } int test_and_set(int *m) { try: } LI $t0, 1 LL $t1, 0($a0) SC $t0, 0($a0) MOVE $v0, $t1 BEQZ $t0, try
101 Linked load / Store Conditional m = 0; // m=0 means lock is free; otherwise, if m=1, then lock locked mutex_lock(int *m) { while(test_and_set(m)){} } int test_and_set(int *m) { try: LI $t0, 1 LL $t1, 0($a0) SC $t0, 0($a0) BEQZ $t0, try MOVE $v0, $t1
102 Linked load / Store Conditional m = 0; // m=0 means lock is free; otherwise, if m=1, then lock locked mutex_lock(int *m) { test_and_set: LI $t0, 1 LL $t1, 0($a0) BNEZ $t1, test_and_set SC $t0, 0($a0) BEQZ $t0, test_and_set } mutex_unlock(int *m) { *m = 0;
103 Linked load / Store Conditional m = 0; // m=0 means lock is free; otherwise, if m=1, then lock locked mutex_lock(int *m) { } test_and_set: LI $t0, 1 LL $t1, 0($a0) BNEZ $t1, test_and_set SC $t0, 0($a0) BEQZ $t0, test_and_set This is called a Spin lock Aka spin waiting mutex_unlock(int *m) { SW $zero, 0($a0)
104 Linked load / Store Conditional m = 0; // m=0 means lock is free; otherwise, if m=1, then lock locked mutex_lock(int *m) { Time Step Thread A Thread B Thread A $t0 Thread A $t1 Thread B $t0 Thread B $t1 Mem M[$a0] try: LI $t0, 1 try: LI $t0, 1 2 LL $t1, 0($a0) LL $t1, 0($a0) 3 BNEZ $t1, try BNEZ $t1, try 4 SC $t0, 0 ($a0) 5 SC $t0, 0($a0) 6 BEQZ $t0, try BEQZ $t0, try 7
105 Linked load / Store Conditional m = 0; // m=0 means lock is free; otherwise, if m=1, then lock locked mutex_lock(int *m) { Time Step Thread A Thread B Thread A $t0 Thread A $t1 Thread B $t0 Thread B $t1 Mem M[$a0] try: LI $t0, 1 try: LI $t0, LL $t1, 0($a0) LL $t1, 0($a0) BNEZ $t1, try BNEZ $t1, try SC $t0, 0 ($a0) SC $t0, 0($a0) BEQZ $t0, try BEQZ $t0, try
106 Linked load / Store Conditional m = 0; // m=0 means lock is free; otherwise, if m=1, then lock locked mutex_lock(int *m) { Time Step Thread A Thread B Thread A $t0 Thread A $t1 Thread B $t0 Thread B $t1 Mem M[$a0] try: LI $t0, 1 try: LI $t0, LL $t1, 0($a0) LL $t1, 0($a0) BNEZ $t1, try BNEZ $t1, try SC $t0, 0 ($a0) SC $t0, 0($a0) BEQZ $t0, try BEQZ $t0, try try: LI $t0, 1 Critical section Failed to get mutex lock try again Success grabbing mutex lock! Inside Critical section
107 Linked load / Store Conditional m = 0; // m=0 means lock is free; otherwise, if m=1, then lock locked mutex_lock(int *m) { } test_and_set: LI $t0, 1 LL $t1, 0($a0) BNEZ $t1, test_and_set SC $t0, 0($a0) BEQZ $t0, test_and_set This is called a Spin lock Aka spin waiting mutex_unlock(int *m) { SW $zero, 0($a0)
108 Linked load / Store Conditional m = 0; // m=0 means lock is free; otherwise, if m=1, then lock locked mutex_lock(int *m) { Time Step Thread A Thread B Thread A $t0 Thread A $t1 Thread B $t0 Thread B $t1 Mem M[$a0] try: LI $t0, 1 try: LI $t0,
109 Linked load / Store Conditional m = 0; // m=0 means lock is free; otherwise, if m=1, then lock locked mutex_lock(int *m) { Time Step Thread A Thread B Thread A $t0 Thread A $t1 Thread B $t0 Thread B $t1 Mem M[$a0] try: LI $t0, 1 try: LI $t0, LL $t1, 0($a0) LL $t1, 0($a0) BNEZ $t1, try BNEZ $t1, try try: LI $t0, 1 try: LI $t0, LL $t1, 0($a0) LL $t1, 0($a0) BNEZ $t1, try BNEZ $t1, try try: LI $t0, 1 try: LI $t0, LL $t1, 0($a0) LL $t1, 0($a0) BNEZ $t1, try BNEZ $t1, try
110 Thread A Thread B for(int i = 0, i < 5; i++) { for(int j = 0; j < 5; j++) { mutex_lock(m); mutex_lock(m); x = x + 1; x = x + 1; mutex_unlock(m); mutex_unlock(m); } }
111 Other atomic hardware primitives - test and set (x86) - atomic increment (x86) - bus lock prefix (x86) - compare and exchange (x86, ARM deprecated) - linked load / store conditional (MIPS, ARM, PowerPC, DEC Alpha, )
112 Synchronization techniques clever code must work despite adversarial scheduler/interrupts used by: hackers also: noobs disable interrupts used by: exception handler, scheduler, device drivers, disable preemption dangerous for user code, but okay for some kernel code mutual exclusion locks (mutex) general purpose, except for some interrupt-related cases
113 Need parallel abstractions, especially for multicore Writing correct programs is hard Need to prevent data races Need critical sections to prevent data races Mutex, mutual exclusion, implements critical section Mutex often implemented using a lock abstraction Hardware provides synchronization primitives such as LL and SC (load linked and store conditional) instructions to efficiently implement locks
114 How do we use synchronization primitives to build concurrency-safe data structure?
115 Access to shared data must be synchronized Goal: enforce datastructure invariants // invariant: // data is in A[h t-1] char A[100]; int h = 0, t = 0; // producer: add to list tail void put(char c) { } A[t] = c; t = (t+1)%n; head tail
116 Access to shared data must be synchronized Goal: enforce datastructure invariants // invariant: // data is in A[h t-1] char A[100]; int h = 0, t = 0; // producer: add to list tail void put(char c) { } A[t] = c; t = (t+1)%n; head // consumer: take from list head char get() { } while (h == t) { }; char c = A[h]; h = (h+1)%n; return c; tail
117 Access to shared data must be synchronized Goal: enforce datastructure invariants // invariant: // data is in A[h t-1] char A[100]; int h = 0, t = 0; // producer: add to list tail void put(char c) { } A[t] = c; t = (t+1)%n; What is wrong with code? a) Will lose update to t and/or h b) Invariant is not upheld c) Will produce if full d) Will consume if empty e) All of the above // consumer: take from list head char get() { } head while (h == t) { }; char c = A[h]; h = (h+1)%n; return c; tail
118 Access to shared data must be synchronized Goal: enforce datastructure invariants // invariant: // data is in A[h t-1] char A[100]; int h = 0, t = 0; // producer: add to list tail void put(char c) { } A[t] = c; t = (t+1)%n; head // consumer: take from list head char get() { while (h == t) { }; char c = A[h]; h = (h+1)%n; return c; What is wrong with the code? } Could miss an update to t or h Breaks invariant: only produce if not full and only consume if not empty Need to synchronize access to shared data tail
119 Access to shared data must be synchronized Goal: enforce datastructure invariants // invariant: // data is in A[h t-1] char A[100]; int h = 0, t = 0; // producer: add to list tail void put(char c) { } A[t] = c; t = (t+1)%n; acquire-lock() acquire-lock() // consumer: take from list head char get() { } head while (h == t) { }; char c = A[h]; h = (h+1)%n; return c; tail acquire-lock() acquire-lock() Rule of thumb: all access and updates that can affect invariant become critical sections
120 // invariant: (protected by mutex m) // data is in A[h t-1] pthread_mutex_t *m = pthread_mutex_create(); char A[100]; int h = 0, t = 0; Does this fix work? // producer: add to list tail void put(char c) { } pthread_mutex_lock(m); A[t] = c; t = (t+1)%n; pthread_mutex_unlock(m); // consumer: take from list head char get() { } pthread_mutex_lock(m); while(h == t) {} char c = A[h]; h = (h+1)%n; pthread_mutex_unlock(m); return c; Rule of thumb: all access and updates that can affect invariant become critical sections
121 // invariant: (protected by mutex m) // data is in A[h t-1] pthread_mutex_t *m = pthread_mutex_create(); char A[100]; int h = 0, t = 0; // producer: add to list tail void put(char c) { } pthread_mutex_lock(m); A[t] = c; t = (t+1)%n; pthread_mutex_unlock(m); // consumer: take from list head char get() { } pthread_mutex_lock(m); while(h == t) {} char c = A[h]; h = (h+1)%n; pthread_mutex_unlock(m); return c; Does this fix work? BUG: Can t wait while holding lock Rule of thumb: all access and updates that can affect invariant become critical sections
122 Insufficient locking can cause races Skimping on mutexes? Just say no! Poorly designed locking can cause deadlock P1: lock(m1); lock(m2); know why you are using mutexes! acquire locks in a consistent order to avoid cycles use lock/unlock like braces (match them lexically) lock(&m); ; unlock(&m) P2: lock(m2); lock(m1); watch out for return, goto, and function calls! watch out for exception/error conditions! Circular Wait
123 Writers must check for full buffer & Readers must check for empty buffer ideal: don t busy wait go to sleep instead char get() { while(empty) {} acquire(l); char c = A[h]; h = (h+1)%n; release(l); return c; } empty head last==head
124 Writers must check for full buffer & Readers must check for empty buffer ideal: don t busy wait go to sleep instead char char get() get() { acquire(l); while acquire(l); (h == t) { }; while acquire(l); char c (h = == A[h]; t) { }; char h = (h+1)%n; c = A[h]; h release(l); = (h+1)%n; release(l); return c; } return c; } Cannot check condition while Holding the lock, BUT, empty condition may no longer hold in critical section empty head last==head Dilemma: Have to check while holding lock,
125 Writers must check for full buffer & Readers must check for empty buffer ideal: don t busy wait go to sleep instead char char get() get() { acquire(l); acquire(l); while char c (h = == A[h]; t) { }; char h++; c = A[h]; h release(l); = (h+1)%n; release(l); return c; } return c; } Dilemma: Have to check while holding lock, but cannot wait while hold lock
126 Writers must check for full buffer & Readers must check for empty buffer ideal: don t busy wait go to sleep instead char get() { } do { acquire(l); empty = (h == t); if (!empty) { c = A[h]; h = (h+1)%n; } release(l); } while (empty); return c; Does this work? a) Yes b) no
127 Writers must check for full buffer & Readers must check for empty buffer ideal: don t busy wait go to sleep instead char get() { } do { acquire(l); empty = (h == t); if (!empty) { c = A[h]; h = (h+1)%n; } release(l); } while (empty); return c; It works. But, it is wasteful Due to the spinning
128 Language-level Synchronization
129 Use [Hoare] a condition variable to wait for a condition to become true (without holding lock!) wait(m, c) : atomically release m and sleep, waiting for condition c wake up holding m sometime after c was signaled signal(c) : wake up one thread waiting on c broadcast(c) : wake up all threads waiting on c POSIX (e.g., Linux): pthread_cond_wait, pthread_cond_signal, pthread_cond_broadcast
130 wait(m, c) : release m, sleep until c, wake up holding m signal(c) : wake up one thread waiting on c cond_t *not_full =...; cond_t *not_empty =...; mutex_t *m =...; void put(char c) { lock(m); while ((t-h) % n == 1) wait(m, not_full); A[t] = c; t = (t+1) % n; unlock(m); signal(not_empty); } char get() { lock(m); while (t == h) wait(m, not_empty); char c = A[h]; h = (h+1) % n; unlock(m); signal(not_full); return c; }
131 A Monitor is a concurrency-safe datastructure, with one mutex some condition variables some operations All operations on monitor acquire/release mutex one thread in the monitor at a time Ring buffer was a monitor Java, C#, etc., have built-in support for monitors
132 Java objects can be monitors synchronized keyword locks/releases the mutex Has one (!) builtin condition variable o.wait() = wait(o, o) o.notify() = signal(o) o.notifyall() = broadcast(o) Java wait() can be called even when mutex is not held. Mutex not held when awoken by signal(). Useful?
133 Lots of synchronization variations Reader/writer locks Any number of threads can hold a read lock Only one thread can hold the writer lock Semaphores N threads can hold lock at the same time Monitors Concurrency-safe data structure with 1 mutex All operations on monitor acquire/release mutex One thread in the monitor at a time Message-passing, sockets, queues, ring buffers, transfer data and synchronize 144
134 Hardware Primitives: test-and-set, LL/SC, barrier,... used to build Synchronization primitives: mutex, semaphore,... used to build Language Constructs: monitors, signals,...
Parallelism, Multicore, and Synchronization
 Parallelism, Multicore, and Synchronization Hakim Weatherspoon CS 3410 Computer Science Cornell University [Weatherspoon, Bala, Bracy, McKee, and Sirer, Roth, Martin] xkcd/619 3 Big Picture: Multicore
Parallelism, Multicore, and Synchronization Hakim Weatherspoon CS 3410 Computer Science Cornell University [Weatherspoon, Bala, Bracy, McKee, and Sirer, Roth, Martin] xkcd/619 3 Big Picture: Multicore
Anne Bracy CS 3410 Computer Science Cornell University
 Anne Bracy CS 3410 Computer Science Cornell University The slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, McKee, and Sirer. Also some slides from Amir
Anne Bracy CS 3410 Computer Science Cornell University The slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, McKee, and Sirer. Also some slides from Amir
CS 3410 Computer Science Cornell University. [K. Bala, A. Bracy, M. Martin, S. McKee, A. Roth E. Sirer, and H. Weatherspoon]
![CS 3410 Computer Science Cornell University. [K. Bala, A. Bracy, M. Martin, S. McKee, A. Roth E. Sirer, and H. Weatherspoon]](/thumbs/88/117744972.jpg "CS 3410 Computer Science Cornell University. [K. Bala, A. Bracy, M. Martin, S. McKee, A. Roth E. Sirer, and H. Weatherspoon]") CS 3410 Computer Science Cornell University [K. Bala, A. Bracy, M. Martin, S. McKee, A. Roth E. Sirer, and H. Weatherspoon] 1 Which of the following is trouble-free code? A C int *bubble() { int a; return
CS 3410 Computer Science Cornell University [K. Bala, A. Bracy, M. Martin, S. McKee, A. Roth E. Sirer, and H. Weatherspoon] 1 Which of the following is trouble-free code? A C int *bubble() { int a; return
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University. P & H Chapter 4.10, 1.7, 1.8, 5.10, 6
 Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
Prof. Hakim Weatherspoon CS 3410, Spring 2015 Computer Science Cornell University P & H Chapter 4.10, 1.7, 1.8, 5.10, 6 Why do I need four computing cores on my phone?! Why do I need eight computing
Multicore and Parallel Processing
 Multicore and Parallel Processing Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 4.10 11, 7.1 6 xkcd/619 2 Pitfall: Amdahl s Law Execution time after improvement
Multicore and Parallel Processing Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University P & H Chapter 4.10 11, 7.1 6 xkcd/619 2 Pitfall: Amdahl s Law Execution time after improvement
Atomic Instructions! Hakim Weatherspoon CS 3410, Spring 2011 Computer Science Cornell University. P&H Chapter 2.11
 Atomic Instructions! Hakim Weatherspoon CS 3410, Spring 2011 Computer Science Cornell University P&H Chapter 2.11 Announcements! PA4 due next, Friday, May 13 th Work in pairs Will not be able to use slip
Atomic Instructions! Hakim Weatherspoon CS 3410, Spring 2011 Computer Science Cornell University P&H Chapter 2.11 Announcements! PA4 due next, Friday, May 13 th Work in pairs Will not be able to use slip
Lec 25: Parallel Processors. Announcements
 Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Lec 25: Parallel Processors Kavita Bala CS 340, Fall 2008 Computer Science Cornell University PA 3 out Hack n Seek Announcements The goal is to have fun with it Recitations today will talk about it Pizza
Synchronization. P&H Chapter 2.11 and 5.8. Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University
 Synchronization P&H Chapter 2.11 and 5.8 Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University Big Picture: Parallelism and Synchronization How do I take advantage of multiple processors;
Synchronization P&H Chapter 2.11 and 5.8 Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University Big Picture: Parallelism and Synchronization How do I take advantage of multiple processors;
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced Instruction-Level Parallelism
 Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
Advanced Instruction-Level Parallelism Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
Real Processors. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
Homework 5. Start date: March 24 Due date: 11:59PM on April 10, Monday night. CSCI 402: Computer Architectures
 Homework 5 Start date: March 24 Due date: 11:59PM on April 10, Monday night 4.1.1, 4.1.2 4.3 4.8.1, 4.8.2 4.9.1-4.9.4 4.13.1 4.16.1, 4.16.2 1 CSCI 402: Computer Architectures The Processor (4) Fengguang
Homework 5 Start date: March 24 Due date: 11:59PM on April 10, Monday night 4.1.1, 4.1.2 4.3 4.8.1, 4.8.2 4.9.1-4.9.4 4.13.1 4.16.1, 4.16.2 1 CSCI 402: Computer Architectures The Processor (4) Fengguang
Synchronization. Han Wang CS 3410, Spring 2012 Computer Science Cornell University. P&H Chapter 2.11
 Synchronization Han Wang CS 3410, Spring 2012 Computer Science Cornell University P&H Chapter 2.11 Shared Memory Multiprocessor (SMP) Shared Memory Multiprocessors Typical (today): 2 4 processor dies,
Synchronization Han Wang CS 3410, Spring 2012 Computer Science Cornell University P&H Chapter 2.11 Shared Memory Multiprocessor (SMP) Shared Memory Multiprocessors Typical (today): 2 4 processor dies,
Lec 26: Parallel Processing. Announcements
 Lec 26: Parallel Processing Kavita Bala CS 341, Fall 28 Computer Science Cornell University Announcements Pizza party Tuesday Dec 2, 6:3-9: Location: TBA Final project (parallel ray tracer) out next week
Lec 26: Parallel Processing Kavita Bala CS 341, Fall 28 Computer Science Cornell University Announcements Pizza party Tuesday Dec 2, 6:3-9: Location: TBA Final project (parallel ray tracer) out next week
COMPUTER ORGANIZATION AND DESIGN. The Hardware/Software Interface. Chapter 4. The Processor: C Multiple Issue Based on P&H
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: C Multiple Issue Based on P&H Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: C Multiple Issue Based on P&H Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 32: Pipeline Parallelism 3
 Lecture 32: Pipeline Parallelism 3") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 32: Pipeline Parallelism 3 Instructor: Dan Garcia inst.eecs.berkeley.edu/~cs61c! Compu@ng in the News At a laboratory in São Paulo,
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 32: Pipeline Parallelism 3 Instructor: Dan Garcia inst.eecs.berkeley.edu/~cs61c! Compu@ng in the News At a laboratory in São Paulo,
Synchronization. Han Wang CS 3410, Spring 2012 Computer Science Cornell University. P&H Chapter 2.11
 Synchronization Han Wang CS 3410, Spring 2012 Computer Science Cornell University P&H Chapter 2.11 Shared Memory Multiprocessor (SMP) Shared Memory Multiprocessors Typical (today): 2 4 processor dies,
Synchronization Han Wang CS 3410, Spring 2012 Computer Science Cornell University P&H Chapter 2.11 Shared Memory Multiprocessor (SMP) Shared Memory Multiprocessors Typical (today): 2 4 processor dies,
Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]
![Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]](/thumbs/83/88761675.jpg "Adapted from instructor s. Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK]") Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
Review and Advanced d Concepts Adapted from instructor s supplementary material from Computer Organization and Design, 4th Edition, Patterson & Hennessy, 2008, MK] Pipelining Review PC IF/ID ID/EX EX/M
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Chapter 4 The Processor (Part 4)
") Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
Department of Electr rical Eng ineering, Chapter 4 The Processor (Part 4) 王振傑 (Chen-Chieh Wang) ccwang@mail.ee.ncku.edu.tw ncku edu Depar rtment of Electr rical Engineering, Feng-Chia Unive ersity Outline
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
CS 61C: Great Ideas in Computer Architecture. Multiple Instruction Issue, Virtual Memory Introduction
 CS 61C: Great Ideas in Computer Architecture Multiple Instruction Issue, Virtual Memory Introduction Instructor: Justin Hsia 7/26/2012 Summer 2012 Lecture #23 1 Parallel Requests Assigned to computer e.g.
CS 61C: Great Ideas in Computer Architecture Multiple Instruction Issue, Virtual Memory Introduction Instructor: Justin Hsia 7/26/2012 Summer 2012 Lecture #23 1 Parallel Requests Assigned to computer e.g.
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Computer Science 146. Computer Architecture
 Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. The Processor
 Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
CS 316: Multicore/GPUs-II
 CS 316: Multicore/GPUs-II Kavita Bala Fall 2007 Computer Science Cornell University Announcements PA 4 graded Corewars due next Tuesday: Nov 27 Corewars party next Friday: Nov 30 Prelim 2: Thursday Nov
CS 316: Multicore/GPUs-II Kavita Bala Fall 2007 Computer Science Cornell University Announcements PA 4 graded Corewars due next Tuesday: Nov 27 Corewars party next Friday: Nov 30 Prelim 2: Thursday Nov
Introduction. Coherency vs Consistency. Lec-11. Multi-Threading Concepts: Coherency, Consistency, and Synchronization
 Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
Lec-11 Multi-Threading Concepts: Coherency, Consistency, and Synchronization Coherency vs Consistency Memory coherency and consistency are major concerns in the design of shared-memory systems. Consistency
IF1/IF2. Dout2[31:0] Data Memory. Addr[31:0] Din[31:0] Zero. Res ALU << 2. CPU Registers. extension. sign. W_add[4:0] Din[31:0] Dout[31:0] PC+4
![IF1/IF2. Dout2[31:0] Data Memory. Addr[31:0] Din[31:0] Zero. Res ALU << 2. CPU Registers. extension. sign. W_add[4:0] Din[31:0] Dout[31:0] PC+4](/thumbs/74/71306691.jpg "IF1/IF2. Dout2[31:0] Data Memory. Addr[31:0] Din[31:0] Zero. Res ALU << 2. CPU Registers. extension. sign. W_add[4:0] Din[31:0] Dout[31:0] PC+4") 12 1 CMPE110 Fall 2006 A. Di Blas 110 Fall 2006 CMPE pipeline concepts Advanced ffl ILP ffl Deep pipeline ffl Static multiple issue ffl Loop unrolling ffl VLIW ffl Dynamic multiple issue Textbook Edition:
12 1 CMPE110 Fall 2006 A. Di Blas 110 Fall 2006 CMPE pipeline concepts Advanced ffl ILP ffl Deep pipeline ffl Static multiple issue ffl Loop unrolling ffl VLIW ffl Dynamic multiple issue Textbook Edition:
CS 31: Introduction to Computer Systems : Threads & Synchronization April 16-18, 2019
 CS 31: Introduction to Computer Systems 22-23: Threads & Synchronization April 16-18, 2019 Making Programs Run Faster We all like how fast computers are In the old days (1980 s - 2005): Algorithm too slow?
CS 31: Introduction to Computer Systems 22-23: Threads & Synchronization April 16-18, 2019 Making Programs Run Faster We all like how fast computers are In the old days (1980 s - 2005): Algorithm too slow?
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Other consistency models
 Last time: Symmetric multiprocessing (SMP) Lecture 25: Synchronization primitives Computer Architecture and Systems Programming (252-0061-00) CPU 0 CPU 1 CPU 2 CPU 3 Timothy Roscoe Herbstsemester 2012
Last time: Symmetric multiprocessing (SMP) Lecture 25: Synchronization primitives Computer Architecture and Systems Programming (252-0061-00) CPU 0 CPU 1 CPU 2 CPU 3 Timothy Roscoe Herbstsemester 2012
EIE/ENE 334 Microprocessors
 EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
Multiprocessor Synchronization
 Multiprocessor Synchronization Material in this lecture in Henessey and Patterson, Chapter 8 pgs. 694-708 Some material from David Patterson s slides for CS 252 at Berkeley 1 Multiprogramming and Multiprocessing
Multiprocessor Synchronization Material in this lecture in Henessey and Patterson, Chapter 8 pgs. 694-708 Some material from David Patterson s slides for CS 252 at Berkeley 1 Multiprogramming and Multiprocessing
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
Systems Group Department of Computer Science ETH Zürich Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Today Non-Uniform
EECS 470. Lecture 18. Simultaneous Multithreading. Fall 2018 Jon Beaumont
 Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
Lecture 18 Simultaneous Multithreading Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi,
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Today. SMP architecture. SMP architecture. Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming ( )
") Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
Lecture 26: Multiprocessing continued Computer Architecture and Systems Programming (252-0061-00) Timothy Roscoe Herbstsemester 2012 Systems Group Department of Computer Science ETH Zürich SMP architecture
Chapter 4. The Processor
 Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
Prelim 3 Review. Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University
 Prelim 3 Review Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University Administrivia Pizza party: PA3 Games Night Tomorrow, Friday, April 27 th, 5:00-7:00pm Location: Upson B17 Prelim
Prelim 3 Review Hakim Weatherspoon CS 3410, Spring 2012 Computer Science Cornell University Administrivia Pizza party: PA3 Games Night Tomorrow, Friday, April 27 th, 5:00-7:00pm Location: Upson B17 Prelim
Synchronization and Prelim 2 Review" Hakim Weatherspoon CS 3410, Spring 2011 Computer Science Cornell University
 Synchronization and Prelim 2 Review" Hakim Weatherspoon CS 3410, Spring 2011 Computer Science Cornell University Announcements" FarmVille pizza Party was fun! Winner: Team HakimPeterSpoon Joseph Mongeluzzi
Synchronization and Prelim 2 Review" Hakim Weatherspoon CS 3410, Spring 2011 Computer Science Cornell University Announcements" FarmVille pizza Party was fun! Winner: Team HakimPeterSpoon Joseph Mongeluzzi
In-order vs. Out-of-order Execution. In-order vs. Out-of-order Execution
 In-order vs. Out-of-order Execution In-order instruction execution instructions are fetched, executed & committed in compilergenerated order if one instruction stalls, all instructions behind it stall
In-order vs. Out-of-order Execution In-order instruction execution instructions are fetched, executed & committed in compilergenerated order if one instruction stalls, all instructions behind it stall
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Issues in Parallel Processing. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Issues in Parallel Processing Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Introduction Goal: connecting multiple computers to get higher performance
Instruction-Level Parallelism. Instruction Level Parallelism (ILP)
") Instruction-Level Parallelism CS448 1 Pipelining Instruction Level Parallelism (ILP) Limited form of ILP Overlapping instructions, these instructions can be evaluated in parallel (to some degree) Pipeline
Instruction-Level Parallelism CS448 1 Pipelining Instruction Level Parallelism (ILP) Limited form of ILP Overlapping instructions, these instructions can be evaluated in parallel (to some degree) Pipeline
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Multiprocessors and Locking
 Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
Parallelism Marco Serafini
 Parallelism Marco Serafini COMPSCI 590S Lecture 3 Announcements Reviews First paper posted on website Review due by this Wednesday 11 PM (hard deadline) Data Science Career Mixer (save the date!) November
Parallelism Marco Serafini COMPSCI 590S Lecture 3 Announcements Reviews First paper posted on website Review due by this Wednesday 11 PM (hard deadline) Data Science Career Mixer (save the date!) November
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
MULTIPROCESSORS AND THREAD LEVEL PARALLELISM
 UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
5 th Edition. The Processor We will examine two MIPS implementations A simplified version A more realistic pipelined version
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 5 th Edition Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined
Module 7: Synchronization Lecture 13: Introduction to Atomic Primitives. The Lecture Contains: Synchronization. Waiting Algorithms.
 The Lecture Contains: Synchronization Waiting Algorithms Implementation Hardwired Locks Software Locks Hardware Support Atomic Exchange Test & Set Fetch & op Compare & Swap Traffic of Test & Set Backoff
The Lecture Contains: Synchronization Waiting Algorithms Implementation Hardwired Locks Software Locks Hardware Support Atomic Exchange Test & Set Fetch & op Compare & Swap Traffic of Test & Set Backoff
Goldibear and the 3 Locks. Programming With Locks Is Tricky. More Lock Madness. And To Make It Worse. Transactional Memory: The Big Idea
 Programming With Locks s Tricky Multicore processors are the way of the foreseeable future thread-level parallelism anointed as parallelism model of choice Just one problem Writing lock-based multi-threaded
Programming With Locks s Tricky Multicore processors are the way of the foreseeable future thread-level parallelism anointed as parallelism model of choice Just one problem Writing lock-based multi-threaded
Cache Coherence and Atomic Operations in Hardware
 Cache Coherence and Atomic Operations in Hardware Previously, we introduced multi-core parallelism. Today we ll look at 2 things: 1. Cache coherence 2. Instruction support for synchronization. And some
Cache Coherence and Atomic Operations in Hardware Previously, we introduced multi-core parallelism. Today we ll look at 2 things: 1. Cache coherence 2. Instruction support for synchronization. And some
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
CS5460: Operating Systems
 CS5460: Operating Systems Lecture 9: Implementing Synchronization (Chapter 6) Multiprocessor Memory Models Uniprocessor memory is simple Every load from a location retrieves the last value stored to that
CS5460: Operating Systems Lecture 9: Implementing Synchronization (Chapter 6) Multiprocessor Memory Models Uniprocessor memory is simple Every load from a location retrieves the last value stored to that
EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors
 EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Prelim 3 Review. Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University
 Prelim 3 Review Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University Administrivia Pizza party: Project3 Games Night Cache Race Tomorrow, Friday, April 26 th, 5:00-7:00pm Location:
Prelim 3 Review Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University Administrivia Pizza party: Project3 Games Night Cache Race Tomorrow, Friday, April 26 th, 5:00-7:00pm Location:
c. What are the machine cycle times (in nanoseconds) of the non-pipelined and the pipelined implementations?
 of the non-pipelined and the pipelined implementations?") Brown University School of Engineering ENGN 164 Design of Computing Systems Professor Sherief Reda Homework 07. 140 points. Due Date: Monday May 12th in B&H 349 1. [30 points] Consider the non-pipelined
Brown University School of Engineering ENGN 164 Design of Computing Systems Professor Sherief Reda Homework 07. 140 points. Due Date: Monday May 12th in B&H 349 1. [30 points] Consider the non-pipelined
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Multiprocessors II: CC-NUMA DSM. CC-NUMA for Large Systems
 Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Multiple Issue ILP Processors. Summary of discussions
 Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
Summary of discussions Multiple Issue ILP Processors ILP processors - VLIW/EPIC, Superscalar Superscalar has hardware logic for extracting parallelism - Solutions for stalls etc. must be provided in hardware
Instruction-Level Parallelism Dynamic Branch Prediction. Reducing Branch Penalties
 Instruction-Level Parallelism Dynamic Branch Prediction CS448 1 Reducing Branch Penalties Last chapter static schemes Move branch calculation earlier in pipeline Static branch prediction Always taken,
Instruction-Level Parallelism Dynamic Branch Prediction CS448 1 Reducing Branch Penalties Last chapter static schemes Move branch calculation earlier in pipeline Static branch prediction Always taken,
Last lecture. Some misc. stuff An older real processor Class review/overview.
 Last lecture Some misc. stuff An older real processor Class review/overview. HW5 Misc. Status issues Answers posted Returned on Wednesday (next week) Project presentation signup at http://tinyurl.com/470w14talks
Last lecture Some misc. stuff An older real processor Class review/overview. HW5 Misc. Status issues Answers posted Returned on Wednesday (next week) Project presentation signup at http://tinyurl.com/470w14talks
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instruction Level Parallelism: Multiple Instruction Issue
 Instruction Level Parallelism: Multiple Instruction Issue") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instruction Level Parallelism: Multiple Instruction Issue Guest Lecturer: Justin Hsia You Are Here! Software Hardware Parallel Requests
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Instruction Level Parallelism: Multiple Instruction Issue Guest Lecturer: Justin Hsia You Are Here! Software Hardware Parallel Requests
Multi-threaded processors. Hung-Wei Tseng x Dean Tullsen
 Multi-threaded processors Hung-Wei Tseng x Dean Tullsen OoO SuperScalar Processor Fetch instructions in the instruction window Register renaming to eliminate false dependencies edule an instruction to
Multi-threaded processors Hung-Wei Tseng x Dean Tullsen OoO SuperScalar Processor Fetch instructions in the instruction window Register renaming to eliminate false dependencies edule an instruction to
ECE 571 Advanced Microprocessor-Based Design Lecture 4
 ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
Systèmes d Exploitation Avancés
 Systèmes d Exploitation Avancés Instructor: Pablo Oliveira ISTY Instructor: Pablo Oliveira (ISTY) Systèmes d Exploitation Avancés 1 / 32 Review : Thread package API tid thread create (void (*fn) (void
Systèmes d Exploitation Avancés Instructor: Pablo Oliveira ISTY Instructor: Pablo Oliveira (ISTY) Systèmes d Exploitation Avancés 1 / 32 Review : Thread package API tid thread create (void (*fn) (void
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
2 GHz = 500 picosec frequency. Vars declared outside of main() are in static. 2 # oset bits = block size Put starting arrow in FSM diagrams
 are in static. 2 # oset bits = block size Put starting arrow in FSM diagrams") CS 61C Fall 2011 Kenny Do Final cheat sheet Increment memory addresses by multiples of 4, since lw and sw are bytealigned When going from C to Mips, always use addu, addiu, and subu When saving stu into
CS 61C Fall 2011 Kenny Do Final cheat sheet Increment memory addresses by multiples of 4, since lw and sw are bytealigned When going from C to Mips, always use addu, addiu, and subu When saving stu into
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov
 ECE 154B Dmitri Strukov") Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Instruction-Level Parallelism and Its Exploitation (Part III) ECE 154B Dmitri Strukov Dealing With Control Hazards Simplest solution to stall pipeline until branch is resolved and target address is calculated
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
Control Hazards. Prediction
 Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Control Hazards The nub of the problem: In what pipeline stage does the processor fetch the next instruction? If that instruction is a conditional branch, when does the processor know whether the conditional
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
CMSC Computer Architecture Lecture 12: Multi-Core. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
administrivia final hour exam next Wednesday covers assembly language like hw and worksheets
 administrivia final hour exam next Wednesday covers assembly language like hw and worksheets today last worksheet start looking at more details on hardware not covered on ANY exam probably won t finish
administrivia final hour exam next Wednesday covers assembly language like hw and worksheets today last worksheet start looking at more details on hardware not covered on ANY exam probably won t finish
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Computer Architecture
 Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Static, multiple-issue (superscaler) pipelines
 pipelines") Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue
Static, multiple-issue (superscaler) pipelines Start more than one instruction in the same cycle Instruction Register file EX + MEM + WB PC Instruction Register file EX + MEM + WB 79 A static two-issue