EA-Based Generation of Compiler Heuristics for Polymorphous Computing Architectures
|
|
|
- Dorothy Ferguson
- 5 years ago
- Views:
Transcription

1 EA-Based Generation of Compiler Heuristics for Polymorphous Computing Architectures Laurence D. Merkle, Michael C. McClurg, Matt G. Ellis, Tyler G. Hicks-Wright Department of Computer Science and Software Engineering Rose-Hulman Institute of Technology 5500 Wabash Ave, CM-103, Terre Haute, IN This work was supported by the Advanced Computing Architectures Branch, Information Directorate, Air Force Research Laboratory, Air Force Materiel Command, USAF, under grant FA MSAEC July 8, 2006 Seattle, WA
2 Outline Research Objective PCA Background DARPA PCA Program MIT RAW Project UT Austin TRIPS Project Technical Progress Parallel EAs for PCAs Taxonomy of EAs in Compilers EA-Generation of TRIPS Compiler Heuristics Future Directions
3 Research Objective Enhance Raw and TRIPS compilers to produce more efficient executable code Approach: Adopt optimization view of compilation Hybridize EC techniques with existing algorithms
 3. Portability/Evolvability PCA Objectives GOAL Four Classes 1. Signal/Data Processing 2. Information 3.")

4 Processing Diversity 1. Breadth of processing 2. Uniform performance Mission Agility 1. In mission (retargetable) 2. Mission to - mission 3. New threat scenario Architectural Flexibility 1. High efficiency selectable virtual machines 2. Mission Adaptation (Constraints e.g. energy) 3. Portability/Evolvability PCA Objectives GOAL Four Classes 1. Signal/Data Processing 2. Information 3. Knowledge 4. Intelligence Competitive with best-in-class msec Days Months Two+ Major Morph States N Minor Morph States Two Layer Morphware Specialized Class Selectable Virtual Machines DSP Class PCA technology supports agile processing as as a function of of dynamic mission objectives and constraints P e r f o r m a n c e PCA Morph Space Architecture Space PPC Class Breadth Of PCA Server Class
5 Tile-based Architectures Context: Ongoing improvements in manufacturing technology Wire delays becoming more significant relative to gate delays Leading PCA efforts achieve dynamic responsiveness and scalability through use of tile-based architectures







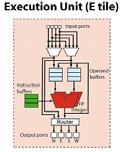
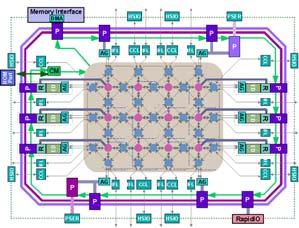
6 PCA Hardware Overview ISI/Raytheon/Mercury: MONARCH/MCHIP MIT: RAW (Early Prototype) Stanford: Smart Memories MIT/LL: Early Testbed University of Texas/IBM: TRIPS Prototype Production
7 RAW Architecture (Agarwal, et al.) Raw Architecture Workstation (RAW) fully exposes low-level details of architecture to compiler Allows compiler or software to optimize resource allocation for each application Compiler generates traditional machine instructions and switch instructions for each tile Two orders of magnitude better performance than traditional processors in simulations of certain applications



8 Presented at PCA PI Meeting, 18 Aug 04, Monterey, CA The Raw Architecture 8 Static Router Fetch Unit Divide the silicon into an array of identical, programmable tiles A signal can get through a small amount of logic and to the next tile in one cycle Compute Processor Fetch Unit Tiles connected by software-exposed on-chip interconnect Scalar Operand Network [HPCA 03] Compute Processor Data Cache
9 TRIPS Architecture (Burger, et al.) Grid Processor Architectures Composed of tightly coupled array of ALUs connected by thin network Producer instruction outputs delivered directly as consumer instruction inputs Example of Explicit Data Graph Execution (EDGE) Architecture Tera-op Reliable and Intelligently Adaptive Processing System (TRIPS) One or more grid processors working in parallel Sensor network monitors application behavior, feeds back to runtime system, application, and compiler

10 Presented at PCA PI Meeting, 18 Aug 04, Monterey, CA TRIPS Chip Floorplan TRIPS/PCA review August 18,
11 Compiling for the TRIPS Architecture (Burger, et al.) Difficult multicriteria optimization problem. Compiler must be able to Identify basic blocks Partition basic blocks into hyperblocks Map hyperblocks to tiles Map each operation to an execution unit Spatial scheduling affects both concurrency and communications delays Compiler currently employs a greedy approximation algorithm
12 Technical Progress: Parallel EAs for PCAs Enabling steps Toolchains obtained from developers Correct installations verified Parallel evolutionary algorithms Island-model implementations designed and implemented for both architectures Empirical evaluations in progress
13 Technical Progress: Taxonomy of EAs in Compilers Identified and described opportunities for additional compiler optimizations General classification of methods for application of EC to compilation Raw no automatic scheduling to optimize Programmer must partition source code EC no more and no less applicable to Raw than to any MIPS compiler TRIPS compiler partitions instructions into hyperblocks
14 Classification of Methods for Application of EC to Compilation Compiler Algorithms Effectiveness Application execution time Unconstrained search for best overall compiler Efficiency Compiler execution time Can be explicitly considered as an objective function Reproducibility (w/o controlling random number generator) Compilation Compiler Parameters Regular and nearly unconstrained search space Can be explicitly considered as an objective function Compilation Compile Time Unconstrained search for fastest executable Too slow for use in development environment Execution Schedule Time Dynamic search for fastest execution Essentially unchanged None
15 Technical Progress: EA-Generation of TRIPS Compiler Optimization Heuristics EA-based generation of more effective TRIPS compiler heuristics through integration of Finch Meta-Optimization Framework TRIPS C compiler Metrics Hyperblock count Instructions per hyperblock Ratio of hyperblocks to instructions per hyperblock Static vs. dynamic SPEC2000 Benchmarks PCA Community Benchmarks
16 Finch Meta-optimization Framework (Stephenson, et al.) Compiler heuristic to be optimized replaced by indirect invocation of EAprovided heuristic EA searches space of heuristics that have the required signature Candidate heuristics are evaluated by invoking compiler, then using objective function to evaluate compiler output EA executes on master processor, compiler and objective function execute on slave processors Benchmarks (e.g. GMTI) Finch (Evolutionary Algorithm) Objective function (e.g. instructions per hyperblock) Compiler flags (e.g. -inl 10) Compiler (e.g. Scale) Compiler component (e.g. in-lining priority function) Compiler output (e.g. assembly code)
17 TRIPS C Compiler Scalable Compiler for Analytical Experiments (Scale) Developed by Department of Computer Science, University of Massachusetts, Amherst Implemented by shell script wrappers around Scale compiler Modular compiler, easily modified for different output platforms Emphasis on hyperblock formation for TRIPS and other platforms
18 Scale Compiler Data Flow Diagram
19 Example Code int main(int argc, char** argv) { printf("hello world\n"); return 0; }.app-file "test.tcc.c".data.align 8 _V2:.ascii "Hello world\n\000".text.global main.bbegin main read $t0, $g1 read $t1, $g2 addi $t2, $t0, -96 sd -88($t0), $t1 S[0] entera $t3, _V2 enterb $t4, main$1 callo printf addi $t2, $t0, -96 sd -88($t0), $t1 S[0] entera $t3, _V2 enterb $t4, main$1. callo printf addi $t2, $t0, -96 sd -88($t0), $t1 S[0] entera $t3, _V2 enterb $t4, main$1 callo printf write $g1, $t2 write $g2, $t4 write $g3, $t3.bend.bbegin main$1 read $t0, $g1 movi $t1, 0 ld $t2, 8($t0) L[0] addi $t3, $t0, 96 ret $t2 write $g1, $t3 write $g2, $t2 write $g3, $t1.bend
20 Application of Finch to Scale Ported Scale to Finch environment Converted Finch to MPI-based communication Identified candidate heuristic functions (Re-)construction of abstract syntax tree Construction of control flow graph Standard posttranslation optimizations Benchmarks (e.g. GMTI) Finch (Evolutionary Algorithm) Objective function (e.g. instructions per hyperblock) Compiler flags (e.g. -inl 10) Compiler (e.g. Scale) Compiler component (e.g. in-lining priority function) Compiler output (e.g. assembly code)
21 In-Lining Technique Results: GMTI Benchmark Instructions per hyperblock ln(max code bloat)
22 References Agarwal, A. Raw Computation. Scientific American, August, Burger, D., S. Keckler, K. McKinley, M. Dahlin, L. John, C. Lin, C. Moore, J. Burrill, R. McDonald, W. Yoder, and the TRIPS Team. Scaling to the End of Silicon with EDGE Architectures. IEEE Computer, July 2004, pp Goldberg, D. The Design of Innovation. Kluwer Academic Publishers, Boston, Stephenson, et al. Meta Optimization: Improving Compiler Heuristics with Machine Learning. MIT. Scale project website ( Scale Compiler Group, Department of Computer Science, University of Massachusetts, Amherst. Taylor, M., J. Kim, J. Miller, D. Wentzlaff, F. Ghodrat, B. Greenwald, H. Hoffmann, P. Johnson, J.-W. Lee, W. Lee, A. Ma, A. Saraf, M. Seneski, N. Shnidman, V. Strumpen M. Frank, S. Amarasinghe and A. Agarwal. The Raw Microprocessor: A Computational Fabric for Software Circuits and General Purpose Programs. IEEE Micro, Mar/Apr 2002.
Creating a Scalable Microprocessor:
 Creating a Scalable Microprocessor: A 16-issue Multiple-Program-Counter Microprocessor With Point-to-Point Scalar Operand Network Michael Bedford Taylor J. Kim, J. Miller, D. Wentzlaff, F. Ghodrat, B.
Creating a Scalable Microprocessor: A 16-issue Multiple-Program-Counter Microprocessor With Point-to-Point Scalar Operand Network Michael Bedford Taylor J. Kim, J. Miller, D. Wentzlaff, F. Ghodrat, B.
MIT Laboratory for Computer Science
 The Raw Processor A Scalable 32 bit Fabric for General Purpose and Embedded Computing Michael Taylor, Jason Kim, Jason Miller, Fae Ghodrat, Ben Greenwald, Paul Johnson,Walter Lee, Albert Ma, Nathan Shnidman,
The Raw Processor A Scalable 32 bit Fabric for General Purpose and Embedded Computing Michael Taylor, Jason Kim, Jason Miller, Fae Ghodrat, Ben Greenwald, Paul Johnson,Walter Lee, Albert Ma, Nathan Shnidman,
MIT Laboratory for Computer Science
 The Raw Processor A Scalable 32 bit Fabric for General Purpose and Embedded Computing Michael Taylor, Jason Kim, Jason Miller, Fae Ghodrat, Ben Greenwald, Paul Johnson,Walter Lee, Albert Ma, Nathan Shnidman,
The Raw Processor A Scalable 32 bit Fabric for General Purpose and Embedded Computing Michael Taylor, Jason Kim, Jason Miller, Fae Ghodrat, Ben Greenwald, Paul Johnson,Walter Lee, Albert Ma, Nathan Shnidman,
StreamIt on Fleet. Amir Kamil Computer Science Division, University of California, Berkeley UCB-AK06.
 StreamIt on Fleet Amir Kamil Computer Science Division, University of California, Berkeley kamil@cs.berkeley.edu UCB-AK06 July 16, 2008 1 Introduction StreamIt [1] is a high-level programming language
StreamIt on Fleet Amir Kamil Computer Science Division, University of California, Berkeley kamil@cs.berkeley.edu UCB-AK06 July 16, 2008 1 Introduction StreamIt [1] is a high-level programming language
Processor Architectures At A Glance: M.I.T. Raw vs. UC Davis AsAP
 Processor Architectures At A Glance: M.I.T. Raw vs. UC Davis AsAP Presenter: Course: EEC 289Q: Reconfigurable Computing Course Instructor: Professor Soheil Ghiasi Outline Overview of M.I.T. Raw processor
Processor Architectures At A Glance: M.I.T. Raw vs. UC Davis AsAP Presenter: Course: EEC 289Q: Reconfigurable Computing Course Instructor: Professor Soheil Ghiasi Outline Overview of M.I.T. Raw processor
Exploiting ILP, TLP, and DLP with the Polymorphous TRIPS Architecture
 Exploiting ILP, TLP, and DLP with the Polymorphous TRIPS Architecture Ramadass Nagarajan Karthikeyan Sankaralingam Haiming Liu Changkyu Kim Jaehyuk Huh Doug Burger Stephen W. Keckler Charles R. Moore Computer
Exploiting ILP, TLP, and DLP with the Polymorphous TRIPS Architecture Ramadass Nagarajan Karthikeyan Sankaralingam Haiming Liu Changkyu Kim Jaehyuk Huh Doug Burger Stephen W. Keckler Charles R. Moore Computer
TRIPS: Extending the Range of Programmable Processors
 TRIPS: Extending the Range of Programmable Processors Stephen W. Keckler Doug Burger and Chuck oore Computer Architecture and Technology Laboratory Department of Computer Sciences www.cs.utexas.edu/users/cart
TRIPS: Extending the Range of Programmable Processors Stephen W. Keckler Doug Burger and Chuck oore Computer Architecture and Technology Laboratory Department of Computer Sciences www.cs.utexas.edu/users/cart
Computer Architecture s Changing Definition
 Computer Architecture s Changing Definition 1950s Computer Architecture Computer Arithmetic 1960s Operating system support, especially memory management 1970s to mid 1980s Computer Architecture Instruction
Computer Architecture s Changing Definition 1950s Computer Architecture Computer Arithmetic 1960s Operating system support, especially memory management 1970s to mid 1980s Computer Architecture Instruction
The Nios II Family of Configurable Soft-core Processors
 The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
Versatile Tiled-Processor Architectures: The Raw Approach
 Versatile Tiled-Processor Architectures: The Raw Approach Rodric M. Rabbah, Ian Bratt, and Anant Agarwal Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
Versatile Tiled-Processor Architectures: The Raw Approach Rodric M. Rabbah, Ian Bratt, and Anant Agarwal Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
Portland State University ECE 588/688. Dataflow Architectures
 Portland State University ECE 588/688 Dataflow Architectures Copyright by Alaa Alameldeen and Haitham Akkary 2018 Hazards in von Neumann Architectures Pipeline hazards limit performance Structural hazards
Portland State University ECE 588/688 Dataflow Architectures Copyright by Alaa Alameldeen and Haitham Akkary 2018 Hazards in von Neumann Architectures Pipeline hazards limit performance Structural hazards
30 Nov Dec Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy
 Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy Why serial is not enough Computing architectures Parallel paradigms Message Passing Interface How
Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy Why serial is not enough Computing architectures Parallel paradigms Message Passing Interface How
A Characterization of High Performance DSP Kernels on the TRIPS Architecture
 Technical Report #TR-06-62, Department of Computer Sciences, University of Texas A Characterization of High Performance DSP Kernels on the TRIPS Architecture Kevin B. Bush Mark Gebhart Doug Burger Stephen
Technical Report #TR-06-62, Department of Computer Sciences, University of Texas A Characterization of High Performance DSP Kernels on the TRIPS Architecture Kevin B. Bush Mark Gebhart Doug Burger Stephen
Master of Engineering Preliminary Thesis Proposal For Prototyping Research Results. December 5, 2002
 Master of Engineering Preliminary Thesis Proposal For 6.191 Prototyping Research Results December 5, 2002 Cemal Akcaba Massachusetts Institute of Technology Cambridge, MA 02139. Thesis Advisor: Prof. Agarwal
Master of Engineering Preliminary Thesis Proposal For 6.191 Prototyping Research Results December 5, 2002 Cemal Akcaba Massachusetts Institute of Technology Cambridge, MA 02139. Thesis Advisor: Prof. Agarwal
Extending Course-Grained Reconfigurable Arrays with Multi-Kernel Dataflow
 Extending Course-Grained Reconfigurable Arrays with Multi-Kernel Dataflow Robin Panda *, Aaron Wood *, Nathaniel McVicar *,Carl Ebeling, Scott Hauck * * Dept. of Electrical Engineering and Dept. of Computer
Extending Course-Grained Reconfigurable Arrays with Multi-Kernel Dataflow Robin Panda *, Aaron Wood *, Nathaniel McVicar *,Carl Ebeling, Scott Hauck * * Dept. of Electrical Engineering and Dept. of Computer
Architecture. Karthikeyan Sankaralingam Ramadass Nagarajan Haiming Liu Changkyu Kim Jaehyuk Huh Doug Burger Stephen W. Keckler Charles R.
 Exploiting ILP, TLP, and DLP with the Polymorphous TRIPS Architecture Karthikeyan Sankaralingam Ramadass Nagarajan Haiming Liu Changkyu Kim Jaehyuk Huh Doug Burger Stephen W. Keckler Charles R. Moore The
Exploiting ILP, TLP, and DLP with the Polymorphous TRIPS Architecture Karthikeyan Sankaralingam Ramadass Nagarajan Haiming Liu Changkyu Kim Jaehyuk Huh Doug Burger Stephen W. Keckler Charles R. Moore The
Networks-on-Chip Power Reduction by Encoding Scheme
 International Journal of Emerging Engineering Research and Technology Volume 2, Issue 4, July 2014, PP 349-359 ISSN 2349-4395 (Print) & ISSN 2349-4409 (Online) Networks-on-Chip Power Reduction by Encoding
International Journal of Emerging Engineering Research and Technology Volume 2, Issue 4, July 2014, PP 349-359 ISSN 2349-4395 (Print) & ISSN 2349-4409 (Online) Networks-on-Chip Power Reduction by Encoding
Kernel Benchmarks and Metrics for Polymorphous Computer Architectures James Lebak Hank Hoffmann Janice McMahon MIT Lincoln Laboratory
 Kernel Benchmarks and Metrics for Polymorphous Computer Architectures James Lebak Hank Hoffmann Janice McMahon Polymorphous computer architectures (PCA) are new computer architectures being developed under
Kernel Benchmarks and Metrics for Polymorphous Computer Architectures James Lebak Hank Hoffmann Janice McMahon Polymorphous computer architectures (PCA) are new computer architectures being developed under
Lecture 4: RISC Computers
 Lecture 4: RISC Computers Introduction Program execution features RISC characteristics RISC vs. CICS Zebo Peng, IDA, LiTH 1 Introduction Reduced Instruction Set Computer (RISC) is an important innovation
Lecture 4: RISC Computers Introduction Program execution features RISC characteristics RISC vs. CICS Zebo Peng, IDA, LiTH 1 Introduction Reduced Instruction Set Computer (RISC) is an important innovation
A Streaming Virtual Machine for GPUs
 A Streaming Virtual Machine for GPUs Kenneth Mackenzie (Reservoir L, Inc) Dan Campbell (Georgia Tech Research Institute) Peter Szilagyi (Reservoir L, Inc) Copyright 2005 Government Purpose Rights, All
A Streaming Virtual Machine for GPUs Kenneth Mackenzie (Reservoir L, Inc) Dan Campbell (Georgia Tech Research Institute) Peter Szilagyi (Reservoir L, Inc) Copyright 2005 Government Purpose Rights, All
Constructing Virtual Architectures on Tiled Processors. David Wentzlaff Anant Agarwal MIT
 Constructing Virtual Architectures on Tiled Processors David Wentzlaff Anant Agarwal MIT 1 Emulators and JITs for Multi-Core David Wentzlaff Anant Agarwal MIT 2 Why Multi-Core? 3 Why Multi-Core? Future
Constructing Virtual Architectures on Tiled Processors David Wentzlaff Anant Agarwal MIT 1 Emulators and JITs for Multi-Core David Wentzlaff Anant Agarwal MIT 2 Why Multi-Core? 3 Why Multi-Core? Future
Analysis of the TRIPS Architecture. Dipak Chand Boyed
 Analysis of the TRIPS Architecture by Dipak Chand Boyed Undergraduate Honors Thesis Supervised by Prof. Stephen W. Keckler Department of Computer Science The University of Texas at Austin Spring 2004 Table
Analysis of the TRIPS Architecture by Dipak Chand Boyed Undergraduate Honors Thesis Supervised by Prof. Stephen W. Keckler Department of Computer Science The University of Texas at Austin Spring 2004 Table
ARSITEKTUR SISTEM KOMPUTER. Wayan Suparta, PhD 17 April 2018
 ARSITEKTUR SISTEM KOMPUTER Wayan Suparta, PhD https://wayansuparta.wordpress.com/ 17 April 2018 Reduced Instruction Set Computers (RISC) CISC Complex Instruction Set Computer RISC Reduced Instruction Set
ARSITEKTUR SISTEM KOMPUTER Wayan Suparta, PhD https://wayansuparta.wordpress.com/ 17 April 2018 Reduced Instruction Set Computers (RISC) CISC Complex Instruction Set Computer RISC Reduced Instruction Set
A Stream Compiler for Communication-Exposed Architectures
 A Stream Compiler for Communication-Exposed Architectures Michael Gordon, William Thies, Michal Karczmarek, Jasper Lin, Ali Meli, Andrew Lamb, Chris Leger, Jeremy Wong, Henry Hoffmann, David Maze, Saman
A Stream Compiler for Communication-Exposed Architectures Michael Gordon, William Thies, Michal Karczmarek, Jasper Lin, Ali Meli, Andrew Lamb, Chris Leger, Jeremy Wong, Henry Hoffmann, David Maze, Saman
Register Organization and Raw Hardware. 1 Register Organization for Media Processing
 EE482C: Advanced Computer Organization Lecture #7 Stream Processor Architecture Stanford University Thursday, 25 April 2002 Register Organization and Raw Hardware Lecture #7: Thursday, 25 April 2002 Lecturer:
EE482C: Advanced Computer Organization Lecture #7 Stream Processor Architecture Stanford University Thursday, 25 April 2002 Register Organization and Raw Hardware Lecture #7: Thursday, 25 April 2002 Lecturer:
A Data-Parallel Genealogy: The GPU Family Tree. John Owens University of California, Davis
 A Data-Parallel Genealogy: The GPU Family Tree John Owens University of California, Davis Outline Moore s Law brings opportunity Gains in performance and capabilities. What has 20+ years of development
A Data-Parallel Genealogy: The GPU Family Tree John Owens University of California, Davis Outline Moore s Law brings opportunity Gains in performance and capabilities. What has 20+ years of development
Evaluation of Stream Virtual Machine on Raw Processor
 Evaluation of Stream Virtual Machine on Raw Processor Jinwoo Suh, Stephen P. Crago, Janice O. McMahon, Dong-In Kang University of Southern California Information Sciences Institute Richard Lethin Reservoir
Evaluation of Stream Virtual Machine on Raw Processor Jinwoo Suh, Stephen P. Crago, Janice O. McMahon, Dong-In Kang University of Southern California Information Sciences Institute Richard Lethin Reservoir
Hardware Design Environments. Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University
 Hardware Design Environments Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University Outline Welcome to COE 405 Digital System Design Design Domains and Levels of Abstractions Synthesis
Hardware Design Environments Dr. Mahdi Abbasi Computer Engineering Department Bu-Ali Sina University Outline Welcome to COE 405 Digital System Design Design Domains and Levels of Abstractions Synthesis
Intel: Driving the Future of IT Technologies. Kevin C. Kahn Senior Fellow, Intel Labs Intel Corporation
 Research @ Intel: Driving the Future of IT Technologies Kevin C. Kahn Senior Fellow, Intel Labs Intel Corporation kp Intel Labs Mission To fuel Intel s growth, we deliver breakthrough technologies that
Research @ Intel: Driving the Future of IT Technologies Kevin C. Kahn Senior Fellow, Intel Labs Intel Corporation kp Intel Labs Mission To fuel Intel s growth, we deliver breakthrough technologies that
CSE 548 Computer Architecture. Clock Rate vs IPC. V. Agarwal, M. S. Hrishikesh, S. W. Kechler. D. Burger. Presented by: Ning Chen
 CSE 548 Computer Architecture Clock Rate vs IPC V. Agarwal, M. S. Hrishikesh, S. W. Kechler. D. Burger Presented by: Ning Chen Transistor Changes Development of silicon fabrication technology caused transistor
CSE 548 Computer Architecture Clock Rate vs IPC V. Agarwal, M. S. Hrishikesh, S. W. Kechler. D. Burger Presented by: Ning Chen Transistor Changes Development of silicon fabrication technology caused transistor
Performance Improvement by N-Chance Clustered Caching in NoC based Chip Multi-Processors
 Performance Improvement by N-Chance Clustered Caching in NoC based Chip Multi-Processors Rakesh Yarlagadda, Sanmukh R Kuppannagari, and Hemangee K Kapoor Department of Computer Science and Engineering
Performance Improvement by N-Chance Clustered Caching in NoC based Chip Multi-Processors Rakesh Yarlagadda, Sanmukh R Kuppannagari, and Hemangee K Kapoor Department of Computer Science and Engineering
Computational Interdisciplinary Modelling High Performance Parallel & Distributed Computing Our Research
 Insieme Insieme-an Optimization System for OpenMP, MPI and OpenCLPrograms Institute of Computer Science University of Innsbruck Thomas Fahringer, Ivan Grasso, Klaus Kofler, Herbert Jordan, Hans Moritsch,
Insieme Insieme-an Optimization System for OpenMP, MPI and OpenCLPrograms Institute of Computer Science University of Innsbruck Thomas Fahringer, Ivan Grasso, Klaus Kofler, Herbert Jordan, Hans Moritsch,
Early Transition for Fully Adaptive Routing Algorithms in On-Chip Interconnection Networks
 Technical Report #2012-2-1, Department of Computer Science and Engineering, Texas A&M University Early Transition for Fully Adaptive Routing Algorithms in On-Chip Interconnection Networks Minseon Ahn,
Technical Report #2012-2-1, Department of Computer Science and Engineering, Texas A&M University Early Transition for Fully Adaptive Routing Algorithms in On-Chip Interconnection Networks Minseon Ahn,
System-on-Chip Architecture for Mobile Applications. Sabyasachi Dey
 System-on-Chip Architecture for Mobile Applications Sabyasachi Dey Email: sabyasachi.dey@gmail.com Agenda What is Mobile Application Platform Challenges Key Architecture Focus Areas Conclusion Mobile Revolution
System-on-Chip Architecture for Mobile Applications Sabyasachi Dey Email: sabyasachi.dey@gmail.com Agenda What is Mobile Application Platform Challenges Key Architecture Focus Areas Conclusion Mobile Revolution
A Data-Parallel Genealogy: The GPU Family Tree
 A Data-Parallel Genealogy: The GPU Family Tree Department of Electrical and Computer Engineering Institute for Data Analysis and Visualization University of California, Davis Outline Moore s Law brings
A Data-Parallel Genealogy: The GPU Family Tree Department of Electrical and Computer Engineering Institute for Data Analysis and Visualization University of California, Davis Outline Moore s Law brings
CMPT 379 Compilers. Anoop Sarkar.
 CMPT 379 Compilers Anoop Sarkar http://www.cs.sfu.ca/~anoop! Program Compiler Machine Code Input Runtime Output 2012-11- 01 2 main(){char *c="main(){char *c=%c%s%c;printf(c,34,c,34);}";printf(c,34,c,34);}!
CMPT 379 Compilers Anoop Sarkar http://www.cs.sfu.ca/~anoop! Program Compiler Machine Code Input Runtime Output 2012-11- 01 2 main(){char *c="main(){char *c=%c%s%c;printf(c,34,c,34);}";printf(c,34,c,34);}!
A Reconfigurable Architecture for Load-Balanced Rendering
 A Reconfigurable Architecture for Load-Balanced Rendering Jiawen Chen Michael I. Gordon William Thies Matthias Zwicker Kari Pulli Frédo Durand Graphics Hardware July 31, 2005, Los Angeles, CA The Load
A Reconfigurable Architecture for Load-Balanced Rendering Jiawen Chen Michael I. Gordon William Thies Matthias Zwicker Kari Pulli Frédo Durand Graphics Hardware July 31, 2005, Los Angeles, CA The Load
STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip
 STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip Codesign for Tiled Manycore Systems Mingyu Wang and Zhaolin Li Institute of Microelectronics, Tsinghua University, Beijing 100084,
STLAC: A Spatial and Temporal Locality-Aware Cache and Networkon-Chip Codesign for Tiled Manycore Systems Mingyu Wang and Zhaolin Li Institute of Microelectronics, Tsinghua University, Beijing 100084,
Multiprocessing and Scalability. A.R. Hurson Computer Science and Engineering The Pennsylvania State University
 A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
Cisco APIC Enterprise Module Simplifies Network Operations
 Cisco APIC Enterprise Module Simplifies Network Operations October 2015 Prepared by: Zeus Kerravala Cisco APIC Enterprise Module Simplifies Network Operations by Zeus Kerravala October 2015 º º º º º º
Cisco APIC Enterprise Module Simplifies Network Operations October 2015 Prepared by: Zeus Kerravala Cisco APIC Enterprise Module Simplifies Network Operations by Zeus Kerravala October 2015 º º º º º º
Chapter 7 The Potential of Special-Purpose Hardware
 Chapter 7 The Potential of Special-Purpose Hardware The preceding chapters have described various implementation methods and performance data for TIGRE. This chapter uses those data points to propose architecture
Chapter 7 The Potential of Special-Purpose Hardware The preceding chapters have described various implementation methods and performance data for TIGRE. This chapter uses those data points to propose architecture
CS 475: Parallel Programming Introduction
 CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
CS 475: Parallel Programming Introduction Wim Bohm, Sanjay Rajopadhye Colorado State University Fall 2014 Course Organization n Let s make a tour of the course website. n Main pages Home, front page. Syllabus.
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Efficiency and Programmability: Enablers for ExaScale. Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford
, EE&CS, Stanford") Efficiency and Programmability: Enablers for ExaScale Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford Scientific Discovery and Business Analytics Driving an Insatiable
Efficiency and Programmability: Enablers for ExaScale Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford Scientific Discovery and Business Analytics Driving an Insatiable
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
GreenDroid: An Architecture for the Dark Silicon Age
 GreenDroid: An Architecture for the Dark Silicon Age Nathan Goulding-Hotta, Jack Sampson, Qiaoshi Zheng, Vikram Bhatt, Joe Auricchio, Steven Swanson, Michael Bedford Taylor University of California, San
GreenDroid: An Architecture for the Dark Silicon Age Nathan Goulding-Hotta, Jack Sampson, Qiaoshi Zheng, Vikram Bhatt, Joe Auricchio, Steven Swanson, Michael Bedford Taylor University of California, San
1.3 Data processing; data storage; data movement; and control.
 CHAPTER 1 OVERVIEW ANSWERS TO QUESTIONS 1.1 Computer architecture refers to those attributes of a system visible to a programmer or, put another way, those attributes that have a direct impact on the logical
CHAPTER 1 OVERVIEW ANSWERS TO QUESTIONS 1.1 Computer architecture refers to those attributes of a system visible to a programmer or, put another way, those attributes that have a direct impact on the logical
ReFLEX: Block Atomic Execution on Conventional ISA Cores
 Author manuscript, published in "espma 2010 - Workshop on arallel Execution of Sequential rograms on Multi-core Architecture (2010)" ReFLEX: Block Atomic Execution on Conventional ISA Cores Mark Gebhart
Author manuscript, published in "espma 2010 - Workshop on arallel Execution of Sequential rograms on Multi-core Architecture (2010)" ReFLEX: Block Atomic Execution on Conventional ISA Cores Mark Gebhart
Adaptive Scientific Software Libraries
 Adaptive Scientific Software Libraries Lennart Johnsson Advanced Computing Research Laboratory Department of Computer Science University of Houston Challenges Diversity of execution environments Growing
Adaptive Scientific Software Libraries Lennart Johnsson Advanced Computing Research Laboratory Department of Computer Science University of Houston Challenges Diversity of execution environments Growing
Practical Malware Analysis
 Practical Malware Analysis Ch 4: A Crash Course in x86 Disassembly Revised 1-16-7 Basic Techniques Basic static analysis Looks at malware from the outside Basic dynamic analysis Only shows you how the
Practical Malware Analysis Ch 4: A Crash Course in x86 Disassembly Revised 1-16-7 Basic Techniques Basic static analysis Looks at malware from the outside Basic dynamic analysis Only shows you how the
Implementation and Evaluation of a Dynamically Routed Processor Operand Network
 Appears in The 1st ACM/IEEE International Symposium on Networks-on-Chip 2007. IEEE copyright restrictions apply. Implementation and Evaluation of a Dynamically Routed Processor Operand Network Paul Gratz,
Appears in The 1st ACM/IEEE International Symposium on Networks-on-Chip 2007. IEEE copyright restrictions apply. Implementation and Evaluation of a Dynamically Routed Processor Operand Network Paul Gratz,
TRIPS: A Distributed Explicit Data Graph Execution (EDGE) Microprocessor
 Microprocessor") TRIPS: A Distributed Explicit Data Graph Execution (EDGE) Microprocessor Madhu Saravana Sibi Govindan, Doug Burger, Steve Keckler, and the TRIPS Team Hot Chips 19, August 2007 Computer Architecture and
TRIPS: A Distributed Explicit Data Graph Execution (EDGE) Microprocessor Madhu Saravana Sibi Govindan, Doug Burger, Steve Keckler, and the TRIPS Team Hot Chips 19, August 2007 Computer Architecture and
2D-VLIW: An Architecture Based on the Geometry of Computation
 2D-VLIW: An Architecture Based on the Geometry of Computation Ricardo Santos,2 2 Dom Bosco Catholic University Computer Engineering Department Campo Grande, MS, Brazil Rodolfo Azevedo Guido Araujo State
2D-VLIW: An Architecture Based on the Geometry of Computation Ricardo Santos,2 2 Dom Bosco Catholic University Computer Engineering Department Campo Grande, MS, Brazil Rodolfo Azevedo Guido Araujo State
Lecture 4: RISC Computers
 Lecture 4: RISC Computers Introduction Program execution features RISC characteristics RISC vs. CICS Zebo Peng, IDA, LiTH 1 Introduction Reduced Instruction Set Computer (RISC) represents an important
Lecture 4: RISC Computers Introduction Program execution features RISC characteristics RISC vs. CICS Zebo Peng, IDA, LiTH 1 Introduction Reduced Instruction Set Computer (RISC) represents an important
Ibex: A Space Situational Awareness Data Fusion Program
 Ibex: A Space Situational Awareness Data Fusion Program Lt Col Travis Blake, PhD, USAF Program Manager DARPA/TTO - Space Systems Maj Christopher Gustin, USAF Deputy Program Manager SMC/SYFA - Space C2
Ibex: A Space Situational Awareness Data Fusion Program Lt Col Travis Blake, PhD, USAF Program Manager DARPA/TTO - Space Systems Maj Christopher Gustin, USAF Deputy Program Manager SMC/SYFA - Space C2
Simone Campanoni Loop transformations
 Simone Campanoni simonec@eecs.northwestern.edu Loop transformations Outline Simple loop transformations Loop invariants Induction variables Complex loop transformations Simple loop transformations Simple
Simone Campanoni simonec@eecs.northwestern.edu Loop transformations Outline Simple loop transformations Loop invariants Induction variables Complex loop transformations Simple loop transformations Simple
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction A set of general purpose processors is connected together.
DHANALAKSHMI SRINIVASAN INSTITUTE OF RESEARCH AND TECHNOLOGY. Department of Computer science and engineering
 DHANALAKSHMI SRINIVASAN INSTITUTE OF RESEARCH AND TECHNOLOGY Department of Computer science and engineering Year :II year CS6303 COMPUTER ARCHITECTURE Question Bank UNIT-1OVERVIEW AND INSTRUCTIONS PART-B
DHANALAKSHMI SRINIVASAN INSTITUTE OF RESEARCH AND TECHNOLOGY Department of Computer science and engineering Year :II year CS6303 COMPUTER ARCHITECTURE Question Bank UNIT-1OVERVIEW AND INSTRUCTIONS PART-B
RISC & Superscalar. COMP 212 Computer Organization & Architecture. COMP 212 Fall Lecture 12. Instruction Pipeline no hazard.
 COMP 212 Computer Organization & Architecture Pipeline Re-Cap Pipeline is ILP -Instruction Level Parallelism COMP 212 Fall 2008 Lecture 12 RISC & Superscalar Divide instruction cycles into stages, overlapped
COMP 212 Computer Organization & Architecture Pipeline Re-Cap Pipeline is ILP -Instruction Level Parallelism COMP 212 Fall 2008 Lecture 12 RISC & Superscalar Divide instruction cycles into stages, overlapped
The CPU Design Kit: An Instructional Prototyping Platform. for Teaching Processor Design. Anujan Varma, Lampros Kalampoukas
 The CPU Design Kit: An Instructional Prototyping Platform for Teaching Processor Design Anujan Varma, Lampros Kalampoukas Dimitrios Stiliadis, and Quinn Jacobson Computer Engineering Department University
The CPU Design Kit: An Instructional Prototyping Platform for Teaching Processor Design Anujan Varma, Lampros Kalampoukas Dimitrios Stiliadis, and Quinn Jacobson Computer Engineering Department University
Fundamentals of Quantitative Design and Analysis
 Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
Fundamentals of Quantitative Design and Analysis Dr. Jiang Li Adapted from the slides provided by the authors Computer Technology Performance improvements: Improvements in semiconductor technology Feature
The Raw Microprocessor: A Computational Fabric for Software Circuits and General Purpose Programs
 The Raw Microprocessor: A Computational Fabric for Software Circuits and General Purpose Programs Michael Bedford Taylor, Jason Kim, Jason Miller, David Wentzlaff, Fae Ghodrat, Ben Greenwald, Henry Hoffman,
The Raw Microprocessor: A Computational Fabric for Software Circuits and General Purpose Programs Michael Bedford Taylor, Jason Kim, Jason Miller, David Wentzlaff, Fae Ghodrat, Ben Greenwald, Henry Hoffman,
EECS4201 Computer Architecture
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis These slides are based on the slides provided by the publisher. The slides will be
Multiple Choice Type Questions
 Techno India Batanagar Computer Science and Engineering Model Questions Subject Name: Computer Architecture Subject Code: CS 403 Multiple Choice Type Questions 1. SIMD represents an organization that.
Techno India Batanagar Computer Science and Engineering Model Questions Subject Name: Computer Architecture Subject Code: CS 403 Multiple Choice Type Questions 1. SIMD represents an organization that.
CS Programming In C
 CS 24000 - Programming In C Week 16: Review Zhiyuan Li Department of Computer Science Purdue University, USA This has been quite a journey Congratulation to all students who have worked hard in honest
CS 24000 - Programming In C Week 16: Review Zhiyuan Li Department of Computer Science Purdue University, USA This has been quite a journey Congratulation to all students who have worked hard in honest
From CISC to RISC. CISC Creates the Anti CISC Revolution. RISC "Philosophy" CISC Limitations
 1 CISC Creates the Anti CISC Revolution Digital Equipment Company (DEC) introduces VAX (1977) Commercially successful 32-bit CISC minicomputer From CISC to RISC In 1970s and 1980s CISC minicomputers became
1 CISC Creates the Anti CISC Revolution Digital Equipment Company (DEC) introduces VAX (1977) Commercially successful 32-bit CISC minicomputer From CISC to RISC In 1970s and 1980s CISC minicomputers became
Two s Complement Review. Two s Complement Review. Agenda. Agenda 6/21/2011
 Two s Complement Review CS 61C: Great Ideas in Computer Architecture (Machine Structures) Introduction to C (Part I) Instructor: Michael Greenbaum http://inst.eecs.berkeley.edu/~cs61c/su11 Suppose we had
Two s Complement Review CS 61C: Great Ideas in Computer Architecture (Machine Structures) Introduction to C (Part I) Instructor: Michael Greenbaum http://inst.eecs.berkeley.edu/~cs61c/su11 Suppose we had
Embedded Computing Platform. Architecture and Instruction Set
 Embedded Computing Platform Microprocessor: Architecture and Instruction Set Ingo Sander ingo@kth.se Microprocessor A central part of the embedded platform A platform is the basic hardware and software
Embedded Computing Platform Microprocessor: Architecture and Instruction Set Ingo Sander ingo@kth.se Microprocessor A central part of the embedded platform A platform is the basic hardware and software
Memory Prefetching for the GreenDroid Microprocessor. David Curran December 10, 2012
 Memory Prefetching for the GreenDroid Microprocessor David Curran December 10, 2012 Outline Memory Prefetchers Overview GreenDroid Overview Problem Description Design Placement Prediction Logic Simulation
Memory Prefetching for the GreenDroid Microprocessor David Curran December 10, 2012 Outline Memory Prefetchers Overview GreenDroid Overview Problem Description Design Placement Prediction Logic Simulation
Evaluating Inter-cluster Communication in Clustered VLIW Architectures
 Evaluating Inter-cluster Communication in Clustered VLIW Architectures Anup Gangwar Embedded Systems Group, Department of Computer Science and Engineering, Indian Institute of Technology Delhi September
Evaluating Inter-cluster Communication in Clustered VLIW Architectures Anup Gangwar Embedded Systems Group, Department of Computer Science and Engineering, Indian Institute of Technology Delhi September
Compilers and Compiler-based Tools for HPC
 Compilers and Compiler-based Tools for HPC John Mellor-Crummey Department of Computer Science Rice University http://lacsi.rice.edu/review/2004/slides/compilers-tools.pdf High Performance Computing Algorithms
Compilers and Compiler-based Tools for HPC John Mellor-Crummey Department of Computer Science Rice University http://lacsi.rice.edu/review/2004/slides/compilers-tools.pdf High Performance Computing Algorithms
Energy Efficient Computing Systems (EECS) Magnus Jahre Coordinator, EECS
 Magnus Jahre Coordinator, EECS") Energy Efficient Computing Systems (EECS) Magnus Jahre Coordinator, EECS Who am I? Education Master of Technology, NTNU, 2007 PhD, NTNU, 2010. Title: «Managing Shared Resources in Chip Multiprocessor Memory
Energy Efficient Computing Systems (EECS) Magnus Jahre Coordinator, EECS Who am I? Education Master of Technology, NTNU, 2007 PhD, NTNU, 2010. Title: «Managing Shared Resources in Chip Multiprocessor Memory
ECE 261: Full Custom VLSI Design
 ECE 261: Full Custom VLSI Design Prof. James Morizio Dept. Electrical and Computer Engineering Hudson Hall Ph: 201-7759 E-mail: jmorizio@ee.duke.edu URL: http://www.ee.duke.edu/~jmorizio Course URL: http://www.ee.duke.edu/~jmorizio/ece261/261.html
ECE 261: Full Custom VLSI Design Prof. James Morizio Dept. Electrical and Computer Engineering Hudson Hall Ph: 201-7759 E-mail: jmorizio@ee.duke.edu URL: http://www.ee.duke.edu/~jmorizio Course URL: http://www.ee.duke.edu/~jmorizio/ece261/261.html
Special Course on Computer Architecture
 Special Course on Computer Architecture #9 Simulation of Multi-Processors Hiroki Matsutani and Hideharu Amano Outline: Simulation of Multi-Processors Background [10min] Recent multi-core and many-core
Special Course on Computer Architecture #9 Simulation of Multi-Processors Hiroki Matsutani and Hideharu Amano Outline: Simulation of Multi-Processors Background [10min] Recent multi-core and many-core
Next Generation Verification Process for Automotive and Mobile Designs with MIPI CSI-2 SM Interface
 Thierry Berdah, Yafit Snir Next Generation Verification Process for Automotive and Mobile Designs with MIPI CSI-2 SM Interface Agenda Typical Verification Challenges of MIPI CSI-2 SM designs IP, Sub System
Thierry Berdah, Yafit Snir Next Generation Verification Process for Automotive and Mobile Designs with MIPI CSI-2 SM Interface Agenda Typical Verification Challenges of MIPI CSI-2 SM designs IP, Sub System
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
Hardware/Software Co-design
 Hardware/Software Co-design Zebo Peng, Department of Computer and Information Science (IDA) Linköping University Course page: http://www.ida.liu.se/~petel/codesign/ 1 of 52 Lecture 1/2: Outline : an Introduction
Hardware/Software Co-design Zebo Peng, Department of Computer and Information Science (IDA) Linköping University Course page: http://www.ida.liu.se/~petel/codesign/ 1 of 52 Lecture 1/2: Outline : an Introduction
Lecture 4: Instruction Set Design/Pipelining
 Lecture 4: Instruction Set Design/Pipelining Instruction set design (Sections 2.9-2.12) control instructions instruction encoding Basic pipelining implementation (Section A.1) 1 Control Transfer Instructions
Lecture 4: Instruction Set Design/Pipelining Instruction set design (Sections 2.9-2.12) control instructions instruction encoding Basic pipelining implementation (Section A.1) 1 Control Transfer Instructions
Unit 9 : Fundamentals of Parallel Processing
 Unit 9 : Fundamentals of Parallel Processing Lesson 1 : Types of Parallel Processing 1.1. Learning Objectives On completion of this lesson you will be able to : classify different types of parallel processing
Unit 9 : Fundamentals of Parallel Processing Lesson 1 : Types of Parallel Processing 1.1. Learning Objectives On completion of this lesson you will be able to : classify different types of parallel processing
Topics in Object-Oriented Design Patterns
 Software design Topics in Object-Oriented Design Patterns Material mainly from the book Design Patterns by Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides; slides originally by Spiros Mancoridis;
Software design Topics in Object-Oriented Design Patterns Material mainly from the book Design Patterns by Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides; slides originally by Spiros Mancoridis;
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Intel Enterprise Processors Technology
 Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Kernel Benchmarks and Metrics for Polymorphous Computer Architectures
 PCAKernels-1 Kernel Benchmarks and Metrics for Polymorphous Computer Architectures Hank Hoffmann James Lebak (Presenter) Janice McMahon Seventh Annual High-Performance Embedded Computing Workshop (HPEC)
PCAKernels-1 Kernel Benchmarks and Metrics for Polymorphous Computer Architectures Hank Hoffmann James Lebak (Presenter) Janice McMahon Seventh Annual High-Performance Embedded Computing Workshop (HPEC)
New Advances in Micro-Processors and computer architectures
 New Advances in Micro-Processors and computer architectures Prof. (Dr.) K.R. Chowdhary, Director SETG Email: kr.chowdhary@jietjodhpur.com Jodhpur Institute of Engineering and Technology, SETG August 27,
New Advances in Micro-Processors and computer architectures Prof. (Dr.) K.R. Chowdhary, Director SETG Email: kr.chowdhary@jietjodhpur.com Jodhpur Institute of Engineering and Technology, SETG August 27,
PACE: Power-Aware Computing Engines
 PACE: Power-Aware Computing Engines Krste Asanovic Saman Amarasinghe Martin Rinard Computer Architecture Group MIT Laboratory for Computer Science http://www.cag.lcs.mit.edu/ PACE Approach Energy- Conscious
PACE: Power-Aware Computing Engines Krste Asanovic Saman Amarasinghe Martin Rinard Computer Architecture Group MIT Laboratory for Computer Science http://www.cag.lcs.mit.edu/ PACE Approach Energy- Conscious
Decoupling Dynamic Information Flow Tracking with a Dedicated Coprocessor
 Decoupling Dynamic Information Flow Tracking with a Dedicated Coprocessor Hari Kannan, Michael Dalton, Christos Kozyrakis Computer Systems Laboratory Stanford University Motivation Dynamic analysis help
Decoupling Dynamic Information Flow Tracking with a Dedicated Coprocessor Hari Kannan, Michael Dalton, Christos Kozyrakis Computer Systems Laboratory Stanford University Motivation Dynamic analysis help
ECE 669 Parallel Computer Architecture
 ECE 669 Parallel Computer Architecture Lecture 23 Parallel Compilation Parallel Compilation Two approaches to compilation Parallelize a program manually Sequential code converted to parallel code Develop
ECE 669 Parallel Computer Architecture Lecture 23 Parallel Compilation Parallel Compilation Two approaches to compilation Parallelize a program manually Sequential code converted to parallel code Develop
TrajStore: an Adaptive Storage System for Very Large Trajectory Data Sets
 TrajStore: an Adaptive Storage System for Very Large Trajectory Data Sets Philippe Cudré-Mauroux Eugene Wu Samuel Madden Computer Science and Artificial Intelligence Laboratory Massachusetts Institute
TrajStore: an Adaptive Storage System for Very Large Trajectory Data Sets Philippe Cudré-Mauroux Eugene Wu Samuel Madden Computer Science and Artificial Intelligence Laboratory Massachusetts Institute
EE282 Computer Architecture. Lecture 1: What is Computer Architecture?
 EE282 Computer Architecture Lecture : What is Computer Architecture? September 27, 200 Marc Tremblay Computer Systems Laboratory Stanford University marctrem@csl.stanford.edu Goals Understand how computer
EE282 Computer Architecture Lecture : What is Computer Architecture? September 27, 200 Marc Tremblay Computer Systems Laboratory Stanford University marctrem@csl.stanford.edu Goals Understand how computer
Alternate definition: Instruction Set Architecture (ISA) What is Computer Architecture? Computer Organization. Computer structure: Von Neumann model
 What is Computer Architecture? Computer Organization. Computer structure: Von Neumann model") What is Computer Architecture? Structure: static arrangement of the parts Organization: dynamic interaction of the parts and their control Implementation: design of specific building blocks Performance:
What is Computer Architecture? Structure: static arrangement of the parts Organization: dynamic interaction of the parts and their control Implementation: design of specific building blocks Performance:
The Two-dimensional Superscalar GAP Processor Architecture
 The Two-dimensional Superscalar GAP Processor Architecture 71 Sascha Uhrig, Basher Shehan, Ralf Jahr, Theo Ungerer Department of Computer Science University of Augsburg 86159 Augsburg, Germany {uhrig,
The Two-dimensional Superscalar GAP Processor Architecture 71 Sascha Uhrig, Basher Shehan, Ralf Jahr, Theo Ungerer Department of Computer Science University of Augsburg 86159 Augsburg, Germany {uhrig,
Cache Justification for Digital Signal Processors
 Cache Justification for Digital Signal Processors by Michael J. Lee December 3, 1999 Cache Justification for Digital Signal Processors By Michael J. Lee Abstract Caches are commonly used on general-purpose
Cache Justification for Digital Signal Processors by Michael J. Lee December 3, 1999 Cache Justification for Digital Signal Processors By Michael J. Lee Abstract Caches are commonly used on general-purpose
Micro-programmed Control Ch 15
 Micro-programmed Control Ch 15 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics 1 Hardwired Control (4) Complex Fast Difficult to design Difficult to modify Lots of
Micro-programmed Control Ch 15 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics 1 Hardwired Control (4) Complex Fast Difficult to design Difficult to modify Lots of
Programs. Function main. C Refresher. CSCI 4061 Introduction to Operating Systems
 Programs CSCI 4061 Introduction to Operating Systems C Program Structure Libraries and header files Compiling and building programs Executing and debugging Instructor: Abhishek Chandra Assume familiarity
Programs CSCI 4061 Introduction to Operating Systems C Program Structure Libraries and header files Compiling and building programs Executing and debugging Instructor: Abhishek Chandra Assume familiarity
Programming with MPI. Pedro Velho
 Programming with MPI Pedro Velho Science Research Challenges Some applications require tremendous computing power - Stress the limits of computing power and storage - Who might be interested in those applications?
Programming with MPI Pedro Velho Science Research Challenges Some applications require tremendous computing power - Stress the limits of computing power and storage - Who might be interested in those applications?
Machine Instructions vs. Micro-instructions. Micro-programmed Control Ch 15. Machine Instructions vs. Micro-instructions (2) Hardwired Control (4)
 Hardwired Control (4)") Micro-programmed Control Ch 15 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics 1 Machine Instructions vs. Micro-instructions Memory execution unit CPU control memory
Micro-programmed Control Ch 15 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics 1 Machine Instructions vs. Micro-instructions Memory execution unit CPU control memory
Micro-programmed Control Ch 15
 Micro-programmed Control Ch 15 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics 1 Hardwired Control (4) Complex Fast Difficult to design Difficult to modify Lots of
Micro-programmed Control Ch 15 Micro-instructions Micro-programmed Control Unit Sequencing Execution Characteristics 1 Hardwired Control (4) Complex Fast Difficult to design Difficult to modify Lots of
Advances in Compilers
 Advances in Compilers Prof. (Dr.) K.R. Chowdhary, Director COE Email: kr.chowdhary@jietjodhpur.ac.in webpage: http://www.krchowdhary.com JIET College of Engineering August 4, 2017 kr chowdhary Compilers
Advances in Compilers Prof. (Dr.) K.R. Chowdhary, Director COE Email: kr.chowdhary@jietjodhpur.ac.in webpage: http://www.krchowdhary.com JIET College of Engineering August 4, 2017 kr chowdhary Compilers
Parallel Programming Concepts. Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04. Parallel Background. Why Bother?
 Parallel Programming Concepts Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04 Parallel Background Why Bother? 1 What is Parallel Programming? Simultaneous use of multiple
Parallel Programming Concepts Tom Logan Parallel Software Specialist Arctic Region Supercomputing Center 2/18/04 Parallel Background Why Bother? 1 What is Parallel Programming? Simultaneous use of multiple