Coarse Grain Reconfigurable Arrays are Signal Processing Engines!
|
|
|
- Erik Weaver
- 6 years ago
- Views:
Transcription

1 Coarse Grain Reconfigurable Arrays are Signal Processing Engines! Advanced Topics in Telecommunications, Algorithms and Implementation Platforms for Wireless Communications, TLT-9707 Waqar Hussain Researcher Tampere University of Technology, Finland Electronic Products Multifunction devices are becoming popular besides their reliability and durability Example Mobile Phone The key selling features of a cell phone are size, weight, longer battery times, audio/video streaming and several games running onto it Adaptability to many communication standards Expectations for Real Time performance No Limits to Human Desire 2
2 Embedded Technology The embedded technology empowers a mobile phone to carry all these features. Intended for a specific use which consist of a hardware capable to perform a set of different tasks with the help of software Example Embedded System = RISC + Accelerator(s) 3 Why Coarse Grain Reconfigurable Arrays? Answer : Computationally Intensive Kernels (CIK) need to be accelerated in a Signal Processing System. Examples of CIKs 1. FIR Filtering 2. Encoding and Decoding a) Viterbi b) Reed-Solomon 3. Matrix-Vector Multiplication 4. Fast Fourier Transform 4
3 Why Coarse Grain Reconfigurable Arrays? Question: So why CGRA, why not traditional accelerators? Its more desirable to use devices that could accelerate multiple kernels than typical traditional accelerators that were designed to accelerate only a single kernel. Thanks to Reconfigurability! 5 Why CGRAs are Powerful Engines? Answer: Due to its structure! CGRAs offer high parallelism and throughput due to its arraybased structure. Algorithms containing parallelism are most suitable to be mapped on a CGRA. It can process large streams of data. Unit of Structure of a CGRA is an ALU, called Processing Elements (PE). Each PE is connected to other PEs using point-to-point or a Network on Chip (NoC). 6
4 CGRA in an Embedded System An Example of Embedded System is RISC + Accelerator(s) RISC = COFFEE Accelerator = BUTTER Both COFFEE and BUTTER were designed at the Department of Computer Systems, Tampere University of Technology, Finland BUTTER A general purpose Coarse Grain Reconfigurable Array (CGRA) which is a martix of processing elements (PEs). Each PE is capable to perform a set of different tasks and connected with each other using point to point interconnections. BUTTER was capable to process many computationally intensive kernels. 7 Problems with BUTTER! BUTTER s presence in the system was expensive if it is not used most of the time BUTTER occupies a large number of hardware resources A General Purpose CGRA requires a few million gates of FPGA 8






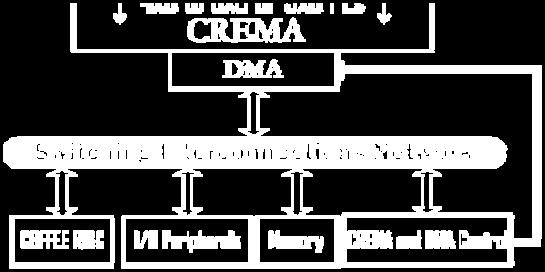
5 Solution CREMA A parameterized general purpose CGRA to generate special purpose accelerators. 9 Category of Interconnections




6 Processing Elements in CREMA Two Operand Registers Decoder for Operation Selection Supports Integer and Floating point operations Blocks with dashed border are scalable and selectable for instantiation LUT for logical operations Processing Element Template CREMA based System COFFEE for general purpose processing CREMA generated accelerator for CIK Network of Switched Interconnections ti for faster data transfer between modules 12
7 CGRAs to be made Scalable 13 Scalability in Software A fixed hardware can be used to process a variable length algorithm For example: A single FFT butterfly can be used to process 4, 8, 16, 64, 128, 256 and higher points of FFT In this case, the hardware (FFT Butterfly) is fixed but we can scale the software as required to process different lengths of FFTs Another example can be matrix-vector multiplication Arithmetic resources required by 4 th order matrix-vector multiplication can be used to process higher order matrix-vector multiplication. 14



8 Scalability in CGRA 15 Why to Scale Hardware? An Example Wireless LAN 16
9 How to Scale the Hardware? The resources required by a set of applications can give an idea about to scale the hardware In short, nature of applications has to drive the dimensioning in hardware For a small set of applications, it might be easier but for a large set of applications, it might be difficult A method needs to be defined??? 17 Case Study Applications Driving Dimensioning Matrix-Vector Multiplication Radix-4 FFT Processing Target Platform under Dimensioning CREMA, a Coarse-Grain Reconfigurable Array consisting of 4x8 processing elements Scaling Order 1. Matrix-Vector Multiplication From 4x8 to 6x8 and 4x16 PEs CGRA 2. Radix-4, FFT Processing From 4x8 to 9x8 and 4x16 PEs CGRA Scaling Influence on Design Strategies Rapid Prototyping and System Integration Global Optimum Implementation for Area and Speed 18
10 Applications Mapped on CREMA and BUTTER Integer and Floating-point Matrix-Vector Multiplication Execution Time Compared with RISC and DSP 2D-Low Pass Image Filtering based on Averaging Window FFT Satisfied Execution Time Constraints for SISO and MIMO OFDM Applications Resource utilization and execution time was compared with other state-of-the-art W-CDMA cell search Execution time compared with a RISC core In all of the above applications, CREMA as a templatebased device required lesser resources for its generated accelerator than BUTTER 19 Thank You *Questions**
All MSEE students are required to take the following two core courses: Linear systems Probability and Random Processes
 MSEE Curriculum All MSEE students are required to take the following two core courses: 3531-571 Linear systems 3531-507 Probability and Random Processes The course requirements for students majoring in
MSEE Curriculum All MSEE students are required to take the following two core courses: 3531-571 Linear systems 3531-507 Probability and Random Processes The course requirements for students majoring in
COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design
![COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design](/thumbs/80/81947289.jpg "COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design") COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design Lecture Objectives Background Need for Accelerator Accelerators and different type of parallelizm
COPROCESSOR APPROACH TO ACCELERATING MULTIMEDIA APPLICATION [CLAUDIO BRUNELLI, JARI NURMI ] Processor Design Lecture Objectives Background Need for Accelerator Accelerators and different type of parallelizm
Session: Configurable Systems. Tailored SoC building using reconfigurable IP blocks
 IP 08 Session: Configurable Systems Tailored SoC building using reconfigurable IP blocks Lodewijk T. Smit, Gerard K. Rauwerda, Jochem H. Rutgers, Maciej Portalski and Reinier Kuipers Recore Systems www.recoresystems.com
IP 08 Session: Configurable Systems Tailored SoC building using reconfigurable IP blocks Lodewijk T. Smit, Gerard K. Rauwerda, Jochem H. Rutgers, Maciej Portalski and Reinier Kuipers Recore Systems www.recoresystems.com
Design of Reusable Context Pipelining for Coarse Grained Reconfigurable Architecture
 Design of Reusable Context Pipelining for Coarse Grained Reconfigurable Architecture P. Murali 1 (M. Tech), Dr. S. Tamilselvan 2, S. Yazhinian (Research Scholar) 3 1, 2, 3 Dept of Electronics and Communication
Design of Reusable Context Pipelining for Coarse Grained Reconfigurable Architecture P. Murali 1 (M. Tech), Dr. S. Tamilselvan 2, S. Yazhinian (Research Scholar) 3 1, 2, 3 Dept of Electronics and Communication
Reconfigurable Computing. Introduction
 Reconfigurable Computing Tony Givargis and Nikil Dutt Introduction! Reconfigurable computing, a new paradigm for system design Post fabrication software personalization for hardware computation Traditionally
Reconfigurable Computing Tony Givargis and Nikil Dutt Introduction! Reconfigurable computing, a new paradigm for system design Post fabrication software personalization for hardware computation Traditionally
ENERGY EFFICIENCY EXPLORATION OF COARSE-GRAIN RECONFIGURABLE ARCHITECTURE WITH EMERGING NONVOLATILE MEMORY
 University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses Dissertations and Theses 2015 ENERGY EFFICIENCY EXPLORATION OF COARSE-GRAIN RECONFIGURABLE ARCHITECTURE WITH EMERGING NONVOLATILE
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses Dissertations and Theses 2015 ENERGY EFFICIENCY EXPLORATION OF COARSE-GRAIN RECONFIGURABLE ARCHITECTURE WITH EMERGING NONVOLATILE
Coarse Grained Reconfigurable Architecture
 Coarse Grained Reconfigurable Architecture Akeem Edwards July 29 2012 Abstract: This paper examines the challenges of mapping applications on to a Coarsegrained reconfigurable architecture (CGRA). Through
Coarse Grained Reconfigurable Architecture Akeem Edwards July 29 2012 Abstract: This paper examines the challenges of mapping applications on to a Coarsegrained reconfigurable architecture (CGRA). Through
The extreme Adaptive DSP Solution to Sensor Data Processing
 The extreme Adaptive DSP Solution to Sensor Data Processing Abstract Martin Vorbach PACT XPP Technologies Leo Mirkin Sky Computers, Inc. The new ISR mobile autonomous sensor platforms present a difficult
The extreme Adaptive DSP Solution to Sensor Data Processing Abstract Martin Vorbach PACT XPP Technologies Leo Mirkin Sky Computers, Inc. The new ISR mobile autonomous sensor platforms present a difficult
CONTACT: ,
 S.N0 Project Title Year of publication of IEEE base paper 1 Design of a high security Sha-3 keccak algorithm 2012 2 Error correcting unordered codes for asynchronous communication 2012 3 Low power multipliers
S.N0 Project Title Year of publication of IEEE base paper 1 Design of a high security Sha-3 keccak algorithm 2012 2 Error correcting unordered codes for asynchronous communication 2012 3 Low power multipliers
The S6000 Family of Processors
 The S6000 Family of Processors Today s Design Challenges The advent of software configurable processors In recent years, the widespread adoption of digital technologies has revolutionized the way in which
The S6000 Family of Processors Today s Design Challenges The advent of software configurable processors In recent years, the widespread adoption of digital technologies has revolutionized the way in which
Two-level Reconfigurable Architecture for High-Performance Signal Processing
 International Conference on Engineering of Reconfigurable Systems and Algorithms, ERSA 04, pp. 177 183, Las Vegas, Nevada, June 2004. Two-level Reconfigurable Architecture for High-Performance Signal Processing
International Conference on Engineering of Reconfigurable Systems and Algorithms, ERSA 04, pp. 177 183, Las Vegas, Nevada, June 2004. Two-level Reconfigurable Architecture for High-Performance Signal Processing
M.TECH VLSI IEEE TITLES
 2016 2017 M.TECH VLSI IEEE TITLES S.NO TITLES DOMAIN 1 A Fixed-Point Squaring Algorithm Using an Implicit Arbitrary Radix Number System 2 An Improved Design of a Reversible Fault Tolerant LUT-Based FPGA
2016 2017 M.TECH VLSI IEEE TITLES S.NO TITLES DOMAIN 1 A Fixed-Point Squaring Algorithm Using an Implicit Arbitrary Radix Number System 2 An Improved Design of a Reversible Fault Tolerant LUT-Based FPGA
Benchmarking Processors for DSP Applications
 Insight, Analysis, and Advice on Signal Processing Technology Benchmarking Processors for DSP Applications Berkeley Design Technology, Inc. 2107 Dwight Way, Second Floor Berkeley, California 94704 USA
Insight, Analysis, and Advice on Signal Processing Technology Benchmarking Processors for DSP Applications Berkeley Design Technology, Inc. 2107 Dwight Way, Second Floor Berkeley, California 94704 USA
Reconfigurable VLSI Communication Processor Architectures
 Reconfigurable VLSI Communication Processor Architectures Joseph R. Cavallaro Center for Multimedia Communication www.cmc.rice.edu Department of Electrical and Computer Engineering Rice University, Houston
Reconfigurable VLSI Communication Processor Architectures Joseph R. Cavallaro Center for Multimedia Communication www.cmc.rice.edu Department of Electrical and Computer Engineering Rice University, Houston
QUKU: A Fast Run Time Reconfigurable Platform for Image Edge Detection
 QUKU: A Fast Run Time Reconfigurable Platform for Image Edge Detection Sunil Shukla 1,2, Neil W. Bergmann 1, Jürgen Becker 2 1 ITEE, University of Queensland, Brisbane, QLD 4072, Australia {sunil, n.bergmann}@itee.uq.edu.au
QUKU: A Fast Run Time Reconfigurable Platform for Image Edge Detection Sunil Shukla 1,2, Neil W. Bergmann 1, Jürgen Becker 2 1 ITEE, University of Queensland, Brisbane, QLD 4072, Australia {sunil, n.bergmann}@itee.uq.edu.au
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA
 Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
Benchmarking Multithreaded, Multicore and Reconfigurable Processors
 Insight, Analysis, and Advice on Signal Processing Technology Benchmarking Multithreaded, Multicore and Reconfigurable Processors Berkeley Design Technology, Inc. 2107 Dwight Way, Second Floor Berkeley,
Insight, Analysis, and Advice on Signal Processing Technology Benchmarking Multithreaded, Multicore and Reconfigurable Processors Berkeley Design Technology, Inc. 2107 Dwight Way, Second Floor Berkeley,
HRL: Efficient and Flexible Reconfigurable Logic for Near-Data Processing
 HRL: Efficient and Flexible Reconfigurable Logic for Near-Data Processing Mingyu Gao and Christos Kozyrakis Stanford University http://mast.stanford.edu HPCA March 14, 2016 PIM is Coming Back End of Dennard
HRL: Efficient and Flexible Reconfigurable Logic for Near-Data Processing Mingyu Gao and Christos Kozyrakis Stanford University http://mast.stanford.edu HPCA March 14, 2016 PIM is Coming Back End of Dennard
RUN-TIME RECONFIGURABLE IMPLEMENTATION OF DSP ALGORITHMS USING DISTRIBUTED ARITHMETIC. Zoltan Baruch
 RUN-TIME RECONFIGURABLE IMPLEMENTATION OF DSP ALGORITHMS USING DISTRIBUTED ARITHMETIC Zoltan Baruch Computer Science Department, Technical University of Cluj-Napoca, 26-28, Bariţiu St., 3400 Cluj-Napoca,
RUN-TIME RECONFIGURABLE IMPLEMENTATION OF DSP ALGORITHMS USING DISTRIBUTED ARITHMETIC Zoltan Baruch Computer Science Department, Technical University of Cluj-Napoca, 26-28, Bariţiu St., 3400 Cluj-Napoca,
Memory-Aware Loop Mapping on Coarse-Grained Reconfigurable Architectures
 Memory-Aware Loop Mapping on Coarse-Grained Reconfigurable Architectures Abstract: The coarse-grained reconfigurable architectures (CGRAs) are a promising class of architectures with the advantages of
Memory-Aware Loop Mapping on Coarse-Grained Reconfigurable Architectures Abstract: The coarse-grained reconfigurable architectures (CGRAs) are a promising class of architectures with the advantages of
A Methodology for Energy Efficient FPGA Designs Using Malleable Algorithms
 A Methodology for Energy Efficient FPGA Designs Using Malleable Algorithms Jingzhao Ou and Viktor K. Prasanna Department of Electrical Engineering, University of Southern California Los Angeles, California,
A Methodology for Energy Efficient FPGA Designs Using Malleable Algorithms Jingzhao Ou and Viktor K. Prasanna Department of Electrical Engineering, University of Southern California Los Angeles, California,
An Ultra High Performance Scalable DSP Family for Multimedia. Hot Chips 17 August 2005 Stanford, CA Erik Machnicki
 An Ultra High Performance Scalable DSP Family for Multimedia Hot Chips 17 August 2005 Stanford, CA Erik Machnicki Media Processing Challenges Increasing performance requirements Need for flexibility &
An Ultra High Performance Scalable DSP Family for Multimedia Hot Chips 17 August 2005 Stanford, CA Erik Machnicki Media Processing Challenges Increasing performance requirements Need for flexibility &
MULTIPLIERLESS HIGH PERFORMANCE FFT COMPUTATION
 MULTIPLIERLESS HIGH PERFORMANCE FFT COMPUTATION Maheshwari.U 1, Josephine Sugan Priya. 2, 1 PG Student, Dept Of Communication Systems Engg, Idhaya Engg. College For Women, 2 Asst Prof, Dept Of Communication
MULTIPLIERLESS HIGH PERFORMANCE FFT COMPUTATION Maheshwari.U 1, Josephine Sugan Priya. 2, 1 PG Student, Dept Of Communication Systems Engg, Idhaya Engg. College For Women, 2 Asst Prof, Dept Of Communication
Design and Development from Single Core Reconfigurable Accelerators to a Heterogeneous Accelerator-Rich Platform
 Tampereen teknillinen yliopisto. Julkaisu 1263 Tampere University of Technology. Publication 1263 M. Waqar Hussain Design and Development from Single Core Reconfigurable Accelerators to a Heterogeneous
Tampereen teknillinen yliopisto. Julkaisu 1263 Tampere University of Technology. Publication 1263 M. Waqar Hussain Design and Development from Single Core Reconfigurable Accelerators to a Heterogeneous
Higher Level Programming Abstractions for FPGAs using OpenCL
 Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
Higher Level Programming Abstractions for FPGAs using OpenCL Desh Singh Supervising Principal Engineer Altera Corporation Toronto Technology Center ! Technology scaling favors programmability CPUs."#/0$*12'$-*
Reconfigurable Cell Array for DSP Applications
 Outline econfigurable Cell Array for DSP Applications Chenxin Zhang Department of Electrical and Information Technology Lund University, Sweden econfigurable computing Coarse-grained reconfigurable cell
Outline econfigurable Cell Array for DSP Applications Chenxin Zhang Department of Electrical and Information Technology Lund University, Sweden econfigurable computing Coarse-grained reconfigurable cell
Cut DSP Development Time Use C for High Performance, No Assembly Required
 Cut DSP Development Time Use C for High Performance, No Assembly Required Digital signal processing (DSP) IP is increasingly required to take on complex processing tasks in signal processing-intensive
Cut DSP Development Time Use C for High Performance, No Assembly Required Digital signal processing (DSP) IP is increasingly required to take on complex processing tasks in signal processing-intensive
Abstract A SCALABLE, PARALLEL, AND RECONFIGURABLE DATAPATH ARCHITECTURE
 A SCALABLE, PARALLEL, AND RECONFIGURABLE DATAPATH ARCHITECTURE Reiner W. Hartenstein, Rainer Kress, Helmut Reinig University of Kaiserslautern Erwin-Schrödinger-Straße, D-67663 Kaiserslautern, Germany
A SCALABLE, PARALLEL, AND RECONFIGURABLE DATAPATH ARCHITECTURE Reiner W. Hartenstein, Rainer Kress, Helmut Reinig University of Kaiserslautern Erwin-Schrödinger-Straße, D-67663 Kaiserslautern, Germany
General Purpose Signal Processors
 General Purpose Signal Processors First announced in 1978 (AMD) for peripheral computation such as in printers, matured in early 80 s (TMS320 series). General purpose vs. dedicated architectures: Pros:
General Purpose Signal Processors First announced in 1978 (AMD) for peripheral computation such as in printers, matured in early 80 s (TMS320 series). General purpose vs. dedicated architectures: Pros:
Core Facts. Documentation Design File Formats. Verification Instantiation Templates Reference Designs & Application Notes Additional Items
 (FFT_MIXED) November 26, 2008 Product Specification Dillon Engineering, Inc. 4974 Lincoln Drive Edina, MN USA, 55436 Phone: 952.836.2413 Fax: 952.927.6514 E mail: info@dilloneng.com URL: www.dilloneng.com
(FFT_MIXED) November 26, 2008 Product Specification Dillon Engineering, Inc. 4974 Lincoln Drive Edina, MN USA, 55436 Phone: 952.836.2413 Fax: 952.927.6514 E mail: info@dilloneng.com URL: www.dilloneng.com
MPSoC Design Space Exploration Framework
 MPSoC Design Space Exploration Framework Gerd Ascheid RWTH Aachen University, Germany Outline Motivation: MPSoC requirements in wireless and multimedia MPSoC design space exploration framework Summary
MPSoC Design Space Exploration Framework Gerd Ascheid RWTH Aachen University, Germany Outline Motivation: MPSoC requirements in wireless and multimedia MPSoC design space exploration framework Summary
System-on-Chip Architecture for Mobile Applications. Sabyasachi Dey
 System-on-Chip Architecture for Mobile Applications Sabyasachi Dey Email: sabyasachi.dey@gmail.com Agenda What is Mobile Application Platform Challenges Key Architecture Focus Areas Conclusion Mobile Revolution
System-on-Chip Architecture for Mobile Applications Sabyasachi Dey Email: sabyasachi.dey@gmail.com Agenda What is Mobile Application Platform Challenges Key Architecture Focus Areas Conclusion Mobile Revolution
Organic Computing. Dr. rer. nat. Christophe Bobda Prof. Dr. Rolf Wanka Department of Computer Science 12 Hardware-Software-Co-Design
 Dr. rer. nat. Christophe Bobda Prof. Dr. Rolf Wanka Department of Computer Science 12 Hardware-Software-Co-Design 1 Reconfigurable Computing Platforms 2 The Von Neumann Computer Principle In 1945, the
Dr. rer. nat. Christophe Bobda Prof. Dr. Rolf Wanka Department of Computer Science 12 Hardware-Software-Co-Design 1 Reconfigurable Computing Platforms 2 The Von Neumann Computer Principle In 1945, the
REAL TIME DIGITAL SIGNAL PROCESSING
 REAL TIME DIGITAL SIGNAL PROCESSING UTN - FRBA 2011 www.electron.frba.utn.edu.ar/dplab Introduction Why Digital? A brief comparison with analog. Advantages Flexibility. Easily modifiable and upgradeable.
REAL TIME DIGITAL SIGNAL PROCESSING UTN - FRBA 2011 www.electron.frba.utn.edu.ar/dplab Introduction Why Digital? A brief comparison with analog. Advantages Flexibility. Easily modifiable and upgradeable.
VLSI Design & Implementation of Bus Arbiter 2009 E09VL33 Circuitry
 1 CODE IEEE TRANSACTION ON VLSI YEAR E09VL32 VLSI Design & Implementation of Encryption & Decryption using VHDL E09VL01 Low-Power Programmable FPGA Routing VLSI Design & Implementation of Bus Arbiter E09VL33
1 CODE IEEE TRANSACTION ON VLSI YEAR E09VL32 VLSI Design & Implementation of Encryption & Decryption using VHDL E09VL01 Low-Power Programmable FPGA Routing VLSI Design & Implementation of Bus Arbiter E09VL33
Storage I/O Summary. Lecture 16: Multimedia and DSP Architectures
 Storage I/O Summary Storage devices Storage I/O Performance Measures» Throughput» Response time I/O Benchmarks» Scaling to track technological change» Throughput with restricted response time is normal
Storage I/O Summary Storage devices Storage I/O Performance Measures» Throughput» Response time I/O Benchmarks» Scaling to track technological change» Throughput with restricted response time is normal
Digital Integrated Circuits
 Digital Integrated Circuits Lecture 9 Jaeyong Chung Robust Systems Laboratory Incheon National University DIGITAL DESIGN FLOW Chung EPC6055 2 FPGA vs. ASIC FPGA (A programmable Logic Device) Faster time-to-market
Digital Integrated Circuits Lecture 9 Jaeyong Chung Robust Systems Laboratory Incheon National University DIGITAL DESIGN FLOW Chung EPC6055 2 FPGA vs. ASIC FPGA (A programmable Logic Device) Faster time-to-market
REAL TIME DIGITAL SIGNAL PROCESSING
 REAL TIME DIGITAL SIGNAL PROCESSING UTN-FRBA 2010 Introduction Why Digital? A brief comparison with analog. Advantages Flexibility. Easily modifiable and upgradeable. Reproducibility. Don t depend on components
REAL TIME DIGITAL SIGNAL PROCESSING UTN-FRBA 2010 Introduction Why Digital? A brief comparison with analog. Advantages Flexibility. Easily modifiable and upgradeable. Reproducibility. Don t depend on components
A New CDMA Encoding/Decoding Method for on- Chip Communication Network
 A New CDMA Encoding/Decoding Method for on- Chip Communication Network Abstract: As a high performance on-chip communication method, the code division multiple access (CDMA) technique has recently been
A New CDMA Encoding/Decoding Method for on- Chip Communication Network Abstract: As a high performance on-chip communication method, the code division multiple access (CDMA) technique has recently been
Flexible wireless communication architectures
 Flexible wireless communication architectures Sridhar Rajagopal Department of Electrical and Computer Engineering Rice University, Houston TX Faculty Candidate Seminar Southern Methodist University April
Flexible wireless communication architectures Sridhar Rajagopal Department of Electrical and Computer Engineering Rice University, Houston TX Faculty Candidate Seminar Southern Methodist University April
Core Facts. Documentation Design File Formats. Verification Instantiation Templates Reference Designs & Application Notes Additional Items
 (FFT_PIPE) Product Specification Dillon Engineering, Inc. 4974 Lincoln Drive Edina, MN USA, 55436 Phone: 952.836.2413 Fax: 952.927.6514 E mail: info@dilloneng.com URL: www.dilloneng.com Core Facts Documentation
(FFT_PIPE) Product Specification Dillon Engineering, Inc. 4974 Lincoln Drive Edina, MN USA, 55436 Phone: 952.836.2413 Fax: 952.927.6514 E mail: info@dilloneng.com URL: www.dilloneng.com Core Facts Documentation
Simplifying FPGA Design for SDR with a Network on Chip Architecture
 Simplifying FPGA Design for SDR with a Network on Chip Architecture Matt Ettus Ettus Research GRCon13 Outline 1 Introduction 2 RF NoC 3 Status and Conclusions USRP FPGA Capability Gen
Simplifying FPGA Design for SDR with a Network on Chip Architecture Matt Ettus Ettus Research GRCon13 Outline 1 Introduction 2 RF NoC 3 Status and Conclusions USRP FPGA Capability Gen
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System
 Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
The Nios II Family of Configurable Soft-core Processors
 The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
The Nios II Family of Configurable Soft-core Processors James Ball August 16, 2005 2005 Altera Corporation Agenda Nios II Introduction Configuring your CPU FPGA vs. ASIC CPU Design Instruction Set Architecture
A PROGRAMMABLE BASEBAND PLATFORM FOR SOFTWARE-DEFINED RADIO
 A PROGRAMMABLE BASEBAND PLATFORM FOR SOFTWARE-DEFINED RADIO Hans-Martin Bluethgen, Cyprian Grassmann, Wolfgang Raab, Ulrich Ramacher, Josef Hausner, Infineon Technologies AG, 81609 Munich, Germany, Hans-Martin.Bluethgen@infineon.com
A PROGRAMMABLE BASEBAND PLATFORM FOR SOFTWARE-DEFINED RADIO Hans-Martin Bluethgen, Cyprian Grassmann, Wolfgang Raab, Ulrich Ramacher, Josef Hausner, Infineon Technologies AG, 81609 Munich, Germany, Hans-Martin.Bluethgen@infineon.com
The Efficient Implementation of Numerical Integration for FPGA Platforms
 Website: www.ijeee.in (ISSN: 2348-4748, Volume 2, Issue 7, July 2015) The Efficient Implementation of Numerical Integration for FPGA Platforms Hemavathi H Department of Electronics and Communication Engineering
Website: www.ijeee.in (ISSN: 2348-4748, Volume 2, Issue 7, July 2015) The Efficient Implementation of Numerical Integration for FPGA Platforms Hemavathi H Department of Electronics and Communication Engineering
White Paper Using Cyclone III FPGAs for Emerging Wireless Applications
 White Paper Introduction Emerging wireless applications such as remote radio heads, pico/femto base stations, WiMAX customer premises equipment (CPE), and software defined radio (SDR) have stringent power
White Paper Introduction Emerging wireless applications such as remote radio heads, pico/femto base stations, WiMAX customer premises equipment (CPE), and software defined radio (SDR) have stringent power
Programmable Logic Devices UNIT II DIGITAL SYSTEM DESIGN
 Programmable Logic Devices UNIT II DIGITAL SYSTEM DESIGN 2 3 4 5 6 7 8 9 2 3 4 5 6 7 8 9 2 Implementation in Sequential Logic 2 PAL Logic Implementation Design Example: BCD to Gray Code Converter A B
Programmable Logic Devices UNIT II DIGITAL SYSTEM DESIGN 2 3 4 5 6 7 8 9 2 3 4 5 6 7 8 9 2 Implementation in Sequential Logic 2 PAL Logic Implementation Design Example: BCD to Gray Code Converter A B
Embedded Computation
 Embedded Computation What is an Embedded Processor? Any device that includes a programmable computer, but is not itself a general-purpose computer [W. Wolf, 2000]. Commonly found in cell phones, automobiles,
Embedded Computation What is an Embedded Processor? Any device that includes a programmable computer, but is not itself a general-purpose computer [W. Wolf, 2000]. Commonly found in cell phones, automobiles,
Mapping and Performance of DSP Benchmarks on a Medium-Grain Reconfigurable Architecture
 Mapping and Performance of DSP Benchmarks on a Medium-Grain Reconfigurable Architecture Mitchell J. Myjak, Jonathan K. Larson, and José G. Delgado-Frias School of Electrical Engineering and Computer Science
Mapping and Performance of DSP Benchmarks on a Medium-Grain Reconfigurable Architecture Mitchell J. Myjak, Jonathan K. Larson, and José G. Delgado-Frias School of Electrical Engineering and Computer Science
Coarse-Grained Reconfigurable Array Architectures
 Coarse-Grained Reconfigurable Array Architectures Bjorn De Sutter, Praveen Raghavan, Andy Lambrechts Abstract Coarse-Grained Reconfigurable Array (CGRA) architectures accelerate the same inner loops that
Coarse-Grained Reconfigurable Array Architectures Bjorn De Sutter, Praveen Raghavan, Andy Lambrechts Abstract Coarse-Grained Reconfigurable Array (CGRA) architectures accelerate the same inner loops that
IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 21, NO. 7, JULY
 SYSTEMS, VOL. 21, NO. 7, JULY") IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 21, NO. 7, JULY 2013 1285 BilRC: An Execution Triggered Coarse Grained Reconfigurable Architecture Oguzhan Atak and Abdullah Atalar,
IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. 21, NO. 7, JULY 2013 1285 BilRC: An Execution Triggered Coarse Grained Reconfigurable Architecture Oguzhan Atak and Abdullah Atalar,
Runtime Adaptation of Application Execution under Thermal and Power Constraints in Massively Parallel Processor Arrays
 Runtime Adaptation of Application Execution under Thermal and Power Constraints in Massively Parallel Processor Arrays Éricles Sousa 1, Frank Hannig 1, Jürgen Teich 1, Qingqing Chen 2, and Ulf Schlichtmann
Runtime Adaptation of Application Execution under Thermal and Power Constraints in Massively Parallel Processor Arrays Éricles Sousa 1, Frank Hannig 1, Jürgen Teich 1, Qingqing Chen 2, and Ulf Schlichtmann
Hardware Design with VHDL PLDs I ECE 443. FPGAs can be configured at least once, many are reprogrammable.
 PLDs, ASICs and FPGAs FPGA definition: Digital integrated circuit that contains configurable blocks of logic and configurable interconnects between these blocks. Key points: Manufacturer does NOT determine
PLDs, ASICs and FPGAs FPGA definition: Digital integrated circuit that contains configurable blocks of logic and configurable interconnects between these blocks. Key points: Manufacturer does NOT determine
Developing and Integrating FPGA Co-processors with the Tic6x Family of DSP Processors
 Developing and Integrating FPGA Co-processors with the Tic6x Family of DSP Processors Paul Ekas, DSP Engineering, Altera Corp. pekas@altera.com, Tel: (408) 544-8388, Fax: (408) 544-6424 Altera Corp., 101
Developing and Integrating FPGA Co-processors with the Tic6x Family of DSP Processors Paul Ekas, DSP Engineering, Altera Corp. pekas@altera.com, Tel: (408) 544-8388, Fax: (408) 544-6424 Altera Corp., 101
DSP Co-Processing in FPGAs: Embedding High-Performance, Low-Cost DSP Functions
 White Paper: Spartan-3 FPGAs WP212 (v1.0) March 18, 2004 DSP Co-Processing in FPGAs: Embedding High-Performance, Low-Cost DSP Functions By: Steve Zack, Signal Processing Engineer Suhel Dhanani, Senior
White Paper: Spartan-3 FPGAs WP212 (v1.0) March 18, 2004 DSP Co-Processing in FPGAs: Embedding High-Performance, Low-Cost DSP Functions By: Steve Zack, Signal Processing Engineer Suhel Dhanani, Senior
Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA
 Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA Yun R. Qu, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 90089
Scalable and Dynamically Updatable Lookup Engine for Decision-trees on FPGA Yun R. Qu, Viktor K. Prasanna Ming Hsieh Dept. of Electrical Engineering University of Southern California Los Angeles, CA 90089
A Survey on various Reconfigurable Architectures for Wireless communication Systems
 Volume 119 No. 12 2018, 1427-1434 ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu A Survey on various Reconfigurable Architectures for Wireless communication Systems Karthi S P 1, Kavitha
Volume 119 No. 12 2018, 1427-1434 ISSN: 1314-3395 (on-line version) url: http://www.ijpam.eu ijpam.eu A Survey on various Reconfigurable Architectures for Wireless communication Systems Karthi S P 1, Kavitha
FABRICATION TECHNOLOGIES
 FABRICATION TECHNOLOGIES DSP Processor Design Approaches Full custom Standard cell** higher performance lower energy (power) lower per-part cost Gate array* FPGA* Programmable DSP Programmable general
FABRICATION TECHNOLOGIES DSP Processor Design Approaches Full custom Standard cell** higher performance lower energy (power) lower per-part cost Gate array* FPGA* Programmable DSP Programmable general
Experiment 3. Getting Start with Simulink
 Experiment 3 Getting Start with Simulink Objectives : By the end of this experiment, the student should be able to: 1. Build and simulate simple system model using Simulink 2. Use Simulink test and measurement
Experiment 3 Getting Start with Simulink Objectives : By the end of this experiment, the student should be able to: 1. Build and simulate simple system model using Simulink 2. Use Simulink test and measurement
Low-Power Split-Radix FFT Processors Using Radix-2 Butterfly Units
 Low-Power Split-Radix FFT Processors Using Radix-2 Butterfly Units Abstract: Split-radix fast Fourier transform (SRFFT) is an ideal candidate for the implementation of a lowpower FFT processor, because
Low-Power Split-Radix FFT Processors Using Radix-2 Butterfly Units Abstract: Split-radix fast Fourier transform (SRFFT) is an ideal candidate for the implementation of a lowpower FFT processor, because
Vertex Shader Design I
 The following content is extracted from the paper shown in next page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This course used only
The following content is extracted from the paper shown in next page. If any wrong citation or reference missing, please contact ldvan@cs.nctu.edu.tw. I will correct the error asap. This course used only
Energy Optimizations for FPGA-based 2-D FFT Architecture
 Energy Optimizations for FPGA-based 2-D FFT Architecture Ren Chen and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Ganges.usc.edu/wiki/TAPAS Outline
Energy Optimizations for FPGA-based 2-D FFT Architecture Ren Chen and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California Ganges.usc.edu/wiki/TAPAS Outline
Floating-Point Butterfly Architecture Based on Binary Signed-Digit Representation
 Floating-Point Butterfly Architecture Based on Binary Signed-Digit Representation Abstract: Fast Fourier transform (FFT) coprocessor, having a significant impact on the performance of communication systems,
Floating-Point Butterfly Architecture Based on Binary Signed-Digit Representation Abstract: Fast Fourier transform (FFT) coprocessor, having a significant impact on the performance of communication systems,
INTRODUCTION TO FPGA ARCHITECTURE
 3/3/25 INTRODUCTION TO FPGA ARCHITECTURE DIGITAL LOGIC DESIGN (BASIC TECHNIQUES) a b a y 2input Black Box y b Functional Schematic a b y a b y a b y 2 Truth Table (AND) Truth Table (OR) Truth Table (XOR)
3/3/25 INTRODUCTION TO FPGA ARCHITECTURE DIGITAL LOGIC DESIGN (BASIC TECHNIQUES) a b a y 2input Black Box y b Functional Schematic a b y a b y a b y 2 Truth Table (AND) Truth Table (OR) Truth Table (XOR)
Improved Convolutional Coding and Decoding of IEEE802.11n Based on General Purpose Processors
 2013 th International Conference on Communications and Networking in China (CHINACOM) Improved Convolutional Coding and Decoding of IEEE02.11n Based on General Purpose Processors Yanuo Xu, Kai Niu, Zhiqiang
2013 th International Conference on Communications and Networking in China (CHINACOM) Improved Convolutional Coding and Decoding of IEEE02.11n Based on General Purpose Processors Yanuo Xu, Kai Niu, Zhiqiang
Choosing a Processor: Benchmarks and Beyond (S043)
") Insight, Analysis, and Advice on Signal Processing Technology Choosing a Processor: Benchmarks and Beyond (S043) Jeff Bier Berkeley Design Technology, Inc. Berkeley, California USA +1 (510) 665-1600 info@bdti.com
Insight, Analysis, and Advice on Signal Processing Technology Choosing a Processor: Benchmarks and Beyond (S043) Jeff Bier Berkeley Design Technology, Inc. Berkeley, California USA +1 (510) 665-1600 info@bdti.com
Enabling the design of multicore SoCs with ARM cores and programmable accelerators
 Enabling the design of multicore SoCs with ARM cores and programmable accelerators Target Compiler Technologies www.retarget.com Sol Bergen-Bartel China Business Development 03 Target Compiler Technologies
Enabling the design of multicore SoCs with ARM cores and programmable accelerators Target Compiler Technologies www.retarget.com Sol Bergen-Bartel China Business Development 03 Target Compiler Technologies
Massively Parallel Computing on Silicon: SIMD Implementations. V.M.. Brea Univ. of Santiago de Compostela Spain
 Massively Parallel Computing on Silicon: SIMD Implementations V.M.. Brea Univ. of Santiago de Compostela Spain GOAL Give an overview on the state-of of-the- art of Digital on-chip CMOS SIMD Solutions,
Massively Parallel Computing on Silicon: SIMD Implementations V.M.. Brea Univ. of Santiago de Compostela Spain GOAL Give an overview on the state-of of-the- art of Digital on-chip CMOS SIMD Solutions,
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Core Facts. Documentation Design File Formats. Verification Instantiation Templates Reference Designs & Application Notes Additional Items
 (ULFFT) November 3, 2008 Product Specification Dillon Engineering, Inc. 4974 Lincoln Drive Edina, MN USA, 55436 Phone: 952.836.2413 Fax: 952.927.6514 E-mail: info@dilloneng.com URL: www.dilloneng.com Core
(ULFFT) November 3, 2008 Product Specification Dillon Engineering, Inc. 4974 Lincoln Drive Edina, MN USA, 55436 Phone: 952.836.2413 Fax: 952.927.6514 E-mail: info@dilloneng.com URL: www.dilloneng.com Core
ERCBench An Open-Source Benchmark Suite for Embedded and Reconfigurable Computing
 ERCBench An Open-Source Benchmark Suite for Embedded and Reconfigurable Computing Daniel Chang Chris Jenkins, Philip Garcia, Syed Gilani, Paula Aguilera, Aishwarya Nagarajan, Michael Anderson, Matthew
ERCBench An Open-Source Benchmark Suite for Embedded and Reconfigurable Computing Daniel Chang Chris Jenkins, Philip Garcia, Syed Gilani, Paula Aguilera, Aishwarya Nagarajan, Michael Anderson, Matthew
Microprocessor Extensions for Wireless Communications
 Microprocessor Extensions for Wireless Communications Sridhar Rajagopal and Joseph R. Cavallaro DRAFT REPORT Rice University Center for Multimedia Communication Department of Electrical and Computer Engineering
Microprocessor Extensions for Wireless Communications Sridhar Rajagopal and Joseph R. Cavallaro DRAFT REPORT Rice University Center for Multimedia Communication Department of Electrical and Computer Engineering
Model-Based Design for effective HW/SW Co-Design Alexander Schreiber Senior Application Engineer MathWorks, Germany
 Model-Based Design for effective HW/SW Co-Design Alexander Schreiber Senior Application Engineer MathWorks, Germany 2013 The MathWorks, Inc. 1 Agenda Model-Based Design of embedded Systems Software Implementation
Model-Based Design for effective HW/SW Co-Design Alexander Schreiber Senior Application Engineer MathWorks, Germany 2013 The MathWorks, Inc. 1 Agenda Model-Based Design of embedded Systems Software Implementation
Algorithm-Architecture Co- Design for Efficient SDR Signal Processing
 Algorithm-Architecture Co- Design for Efficient SDR Signal Processing Min Li, limin@imec.be Wireless Research, IMEC Introduction SDR Baseband Platforms Today are Usually Based on ILP + DLP + MP Massive
Algorithm-Architecture Co- Design for Efficient SDR Signal Processing Min Li, limin@imec.be Wireless Research, IMEC Introduction SDR Baseband Platforms Today are Usually Based on ILP + DLP + MP Massive
Coarse-Grained Reconfigurable Computing for Power Aware Applications
 Coarse-Grained Reconfigurable Computing for Power Aware Applications Paul M. Heysters Recore Systems P.O. Box 217, 7500 AE, Enschede, The Netherlands paul.heysters@recoresystems.com Abstract Reconfigurable
Coarse-Grained Reconfigurable Computing for Power Aware Applications Paul M. Heysters Recore Systems P.O. Box 217, 7500 AE, Enschede, The Netherlands paul.heysters@recoresystems.com Abstract Reconfigurable
DESIGN METHODOLOGY. 5.1 General
 87 5 FFT DESIGN METHODOLOGY 5.1 General The fast Fourier transform is used to deliver a fast approach for the processing of data in the wireless transmission. The Fast Fourier Transform is one of the methods
87 5 FFT DESIGN METHODOLOGY 5.1 General The fast Fourier transform is used to deliver a fast approach for the processing of data in the wireless transmission. The Fast Fourier Transform is one of the methods
Independent DSP Benchmarks: Methodologies and Results. Outline
 Independent DSP Benchmarks: Methodologies and Results Berkeley Design Technology, Inc. 2107 Dwight Way, Second Floor Berkeley, California U.S.A. +1 (510) 665-1600 info@bdti.com http:// Copyright 1 Outline
Independent DSP Benchmarks: Methodologies and Results Berkeley Design Technology, Inc. 2107 Dwight Way, Second Floor Berkeley, California U.S.A. +1 (510) 665-1600 info@bdti.com http:// Copyright 1 Outline
Embedded Computing Platform. Architecture and Instruction Set
 Embedded Computing Platform Microprocessor: Architecture and Instruction Set Ingo Sander ingo@kth.se Microprocessor A central part of the embedded platform A platform is the basic hardware and software
Embedded Computing Platform Microprocessor: Architecture and Instruction Set Ingo Sander ingo@kth.se Microprocessor A central part of the embedded platform A platform is the basic hardware and software
Rapid Prototyping System for Teaching Real-Time Digital Signal Processing
 IEEE TRANSACTIONS ON EDUCATION, VOL. 43, NO. 1, FEBRUARY 2000 19 Rapid Prototyping System for Teaching Real-Time Digital Signal Processing Woon-Seng Gan, Member, IEEE, Yong-Kim Chong, Wilson Gong, and
IEEE TRANSACTIONS ON EDUCATION, VOL. 43, NO. 1, FEBRUARY 2000 19 Rapid Prototyping System for Teaching Real-Time Digital Signal Processing Woon-Seng Gan, Member, IEEE, Yong-Kim Chong, Wilson Gong, and
University of California, Davis Department of Electrical and Computer Engineering. EEC180B DIGITAL SYSTEMS Spring Quarter 2018
 University of California, Davis Department of Electrical and Computer Engineering EEC180B DIGITAL SYSTEMS Spring Quarter 2018 LAB 2: FPGA Synthesis and Combinational Logic Design Objective: This lab covers
University of California, Davis Department of Electrical and Computer Engineering EEC180B DIGITAL SYSTEMS Spring Quarter 2018 LAB 2: FPGA Synthesis and Combinational Logic Design Objective: This lab covers
Interfacing a High Speed Crypto Accelerator to an Embedded CPU
 Interfacing a High Speed Crypto Accelerator to an Embedded CPU Alireza Hodjat ahodjat @ee.ucla.edu Electrical Engineering Department University of California, Los Angeles Ingrid Verbauwhede ingrid @ee.ucla.edu
Interfacing a High Speed Crypto Accelerator to an Embedded CPU Alireza Hodjat ahodjat @ee.ucla.edu Electrical Engineering Department University of California, Los Angeles Ingrid Verbauwhede ingrid @ee.ucla.edu
An introduction to Digital Signal Processors (DSP) Using the C55xx family
 Using the C55xx family") An introduction to Digital Signal Processors (DSP) Using the C55xx family Group status (~2 minutes each) 5 groups stand up What processor(s) you are using Wireless? If so, what technologies/chips are you
An introduction to Digital Signal Processors (DSP) Using the C55xx family Group status (~2 minutes each) 5 groups stand up What processor(s) you are using Wireless? If so, what technologies/chips are you
Signal Processing Algorithms into Fixed Point FPGA Hardware Dennis Silage ECE Temple University
 Signal Processing Algorithms into Fixed Point FPGA Hardware Dennis Silage silage@temple.edu ECE Temple University www.temple.edu/scdl Signal Processing Algorithms into Fixed Point FPGA Hardware Motivation
Signal Processing Algorithms into Fixed Point FPGA Hardware Dennis Silage silage@temple.edu ECE Temple University www.temple.edu/scdl Signal Processing Algorithms into Fixed Point FPGA Hardware Motivation
White Paper Assessing FPGA DSP Benchmarks at 40 nm
 White Paper Assessing FPGA DSP Benchmarks at 40 nm Introduction Benchmarking the performance of algorithms, devices, and programming methodologies is a well-worn topic among developers and research of
White Paper Assessing FPGA DSP Benchmarks at 40 nm Introduction Benchmarking the performance of algorithms, devices, and programming methodologies is a well-worn topic among developers and research of
Development and synthesis of adaptive multi-grained i reconfigurable hardware architecture for dynamic functions patterns (AMURHA)
") Development and synthesis of adaptive multi-grained i reconfigurable hardware architecture for dynamic functions patterns (AMURHA) Alexander Thomas Institut für Technik der Informationsverarbeitung (ITIV)
Development and synthesis of adaptive multi-grained i reconfigurable hardware architecture for dynamic functions patterns (AMURHA) Alexander Thomas Institut für Technik der Informationsverarbeitung (ITIV)
90A John Muir Drive Buffalo, New York Tel: Fax:
 Reed Solomon Coding The VOCAL implementation of Reed Solomon (RS) Forward Error Correction (FEC) algorithms is available in several forms. The forms include pure software and software with varying levels
Reed Solomon Coding The VOCAL implementation of Reed Solomon (RS) Forward Error Correction (FEC) algorithms is available in several forms. The forms include pure software and software with varying levels
Chapter 5 Embedded Soft Core Processors
 Embedded Soft Core Processors Coarse Grained Architecture. The programmable gate array (PGA) has provided the opportunity for the design and implementation of a soft core processor in embedded design.
Embedded Soft Core Processors Coarse Grained Architecture. The programmable gate array (PGA) has provided the opportunity for the design and implementation of a soft core processor in embedded design.
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto
 FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
High performance, power-efficient DSPs based on the TI C64x
 High performance, power-efficient DSPs based on the TI C64x Sridhar Rajagopal, Joseph R. Cavallaro, Scott Rixner Rice University {sridhar,cavallar,rixner}@rice.edu RICE UNIVERSITY Recent (2003) Research
High performance, power-efficient DSPs based on the TI C64x Sridhar Rajagopal, Joseph R. Cavallaro, Scott Rixner Rice University {sridhar,cavallar,rixner}@rice.edu RICE UNIVERSITY Recent (2003) Research
Qsys and IP Core Integration
 Qsys and IP Core Integration Stephen A. Edwards (after David Lariviere) Columbia University Spring 2016 IP Cores Altera s IP Core Integration Tools Connecting IP Cores IP Cores Cyclone V SoC: A Mix of
Qsys and IP Core Integration Stephen A. Edwards (after David Lariviere) Columbia University Spring 2016 IP Cores Altera s IP Core Integration Tools Connecting IP Cores IP Cores Cyclone V SoC: A Mix of
ENERGY EFFICIENT PARAMETERIZED FFT ARCHITECTURE. Ren Chen, Hoang Le, and Viktor K. Prasanna
 ENERGY EFFICIENT PARAMETERIZED FFT ARCHITECTURE Ren Chen, Hoang Le, and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California, Los Angeles, USA 989 Email:
ENERGY EFFICIENT PARAMETERIZED FFT ARCHITECTURE Ren Chen, Hoang Le, and Viktor K. Prasanna Ming Hsieh Department of Electrical Engineering University of Southern California, Los Angeles, USA 989 Email:
Programmable Logic Design Grzegorz Budzyń Lecture. 15: Advanced hardware in FPGA structures
 Programmable Logic Design Grzegorz Budzyń Lecture 15: Advanced hardware in FPGA structures Plan Introduction PowerPC block RocketIO Introduction Introduction The larger the logical chip, the more additional
Programmable Logic Design Grzegorz Budzyń Lecture 15: Advanced hardware in FPGA structures Plan Introduction PowerPC block RocketIO Introduction Introduction The larger the logical chip, the more additional
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto
 FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
Modeling a 4G LTE System in MATLAB
 Modeling a 4G LTE System in MATLAB Part 3: Path to implementation (C and HDL) Houman Zarrinkoub PhD. Signal Processing Product Manager MathWorks houmanz@mathworks.com 2011 The MathWorks, Inc. 1 LTE Downlink
Modeling a 4G LTE System in MATLAB Part 3: Path to implementation (C and HDL) Houman Zarrinkoub PhD. Signal Processing Product Manager MathWorks houmanz@mathworks.com 2011 The MathWorks, Inc. 1 LTE Downlink
REAL TIME DIGITAL SIGNAL PROCESSING
 REAL TIME DIGITAL SIGNAL PROCESSING SASE 2010 Universidad Tecnológica Nacional - FRBA Introduction Why Digital? A brief comparison with analog. Advantages Flexibility. Easily modifiable and upgradeable.
REAL TIME DIGITAL SIGNAL PROCESSING SASE 2010 Universidad Tecnológica Nacional - FRBA Introduction Why Digital? A brief comparison with analog. Advantages Flexibility. Easily modifiable and upgradeable.
FPGAs: THE HIGH-END ALTERNATIVE FOR DSP APPLICATIONS. By Dr. Chris Dick
 THE HIGH-END ALTERNATIVE FOR D APPLICATIONS By Dr. Chris Dick Engineers have been using field programmable gate arrays (FPGAs) to build high performance D systems for several years. FPGAs are uniquely
THE HIGH-END ALTERNATIVE FOR D APPLICATIONS By Dr. Chris Dick Engineers have been using field programmable gate arrays (FPGAs) to build high performance D systems for several years. FPGAs are uniquely
Flexible Architecture Research Machine (FARM)
") Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
Flexible Architecture Research Machine (FARM) RAMP Retreat June 25, 2009 Jared Casper, Tayo Oguntebi, Sungpack Hong, Nathan Bronson Christos Kozyrakis, Kunle Olukotun Motivation Why CPUs + FPGAs make sense
PyGen: A MATLAB/Simulink Based Tool for Synthesizing Parameterized and Energy Efficient Designs Using FPGAs
 PyGen: A MATLAB/Simulink Based Tool for Synthesizing Parameterized and Energy Efficient Designs Using FPGAs Jingzhao Ou and Viktor K. Prasanna Department of Electrical Engineering, University of Southern
PyGen: A MATLAB/Simulink Based Tool for Synthesizing Parameterized and Energy Efficient Designs Using FPGAs Jingzhao Ou and Viktor K. Prasanna Department of Electrical Engineering, University of Southern
FPGAs: FAST TRACK TO DSP
 FPGAs: FAST TRACK TO DSP Revised February 2009 ABSRACT: Given the prevalence of digital signal processing in a variety of industry segments, several implementation solutions are available depending on
FPGAs: FAST TRACK TO DSP Revised February 2009 ABSRACT: Given the prevalence of digital signal processing in a variety of industry segments, several implementation solutions are available depending on