Spark Programming with RDD
|
|
|
- Eric Hunt
- 5 years ago
- Views:
Transcription

1 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत DS256:Jan17 (3:1) Department of Computational and Data Sciences Spark Programming with RDD Yogesh Simmhan 21 M a r, e/spark/api/java/javardd.html e/spark/api/java/javapairrdd.html Yogesh Simmhan & Partha Talukdar, 2016 This work is licensed under a Creative Commons Attribution 4.0 International License Copyright for external content used with attribution is retained by their original authors
2 Spark Language Much more flexible than MapReduce Compose complex dataflows Data (RDD) centric ~object oriented 2
3 Creating RDD Load external data from distributed storage Create logical RDD on which you can operate Support for different input formats HDFS files, Cassandra, Java serialized, directory, gzipped Can control the number of partitions in loaded RDD Default depends on external DFS, e.g. 128MB on HDFS 3
4 RDD Operations Transformations From one RDD to one or more RDDs Lazy evaluation use with care Executed in a distributed manner Actions Perform aggregations on RDD items Return single (or distributed) results to driver code RDD.collect() brings RDD partitions to single driver machine 4


5 Anonymous Classes Data-centric model allows functions to be passed Functions applied to items in the RDD Typically, on individual partitions in data-parallel Anonymous class implements interface 5

6 Anonymous Classes & Lambda Expressions Or Java 8 functions are short-forms for simple code fragments to iterate over collections Caution: Cannot pass local driver variables to lambda expressions/anonymous classes.only final Will fail when distributed 6

7 RDD and PairRDD RDD is logically a collection of items with a generic type PairRDD is like a Map, where each item in collection is a <key,value> pair, each a generic type Transformation functions use RDD or PairRDD as input/output E.g. Map-Reduce 7
8 Transformations JavaRDD<R> map(function<t,r> f) : 1:1 mapping from input to output. Can be different types. JavaRDD<T> filter(function<t,boolean> f) : 1:0/1 from input to output, same type. JavaRDD<U> flatmap(flatmapfunction<t,u> f) : 1:N mapping from input to output, different types. 8
9 Transformations Earlier Map and Filter operate on one item at a time. No state across calls! JavaRDD<U> mappartitions(flatmapfunc<iterator<t>,u> f) mappartitions has access to iterator of values in entire partition, jot just a single item at a time. 9
10 Transformations JavaRDD<T> sample(boolean withreplacement, double fraction): fraction between [0,1] without replacement, >0 with replacement JavaRDD<T> union(javardd<t> other): Items in other RDD added to this RDD. Same type. Can have duplicate items (i.e. not a set union). 10
11 Transformations JavaRDD<T> intersection(javardd<t> other): Does a set intersection of the RDDs. Output will not have duplicates, even if inputs did. JavaRDD<T> distinct(): Returns a new RDD with unique elements, eliminating duplicates. 11
12 Transformations: PairRDD JavaPairRDD<K,Iterable<V>> groupbykey(): Groups values for each key into a single iterable. JavaPairRDD<K,V> reducebykey(function2<v,v,v> func) : Merge the values for each key into a single value using an associative and commutative reduce function. Output value is of same type as input. For aggregate that returns a different type? numpartitions can be used to generate output RDD with different number of partitions than input RDD. 12
13 Transformations JavaPairRDD<K,U> aggregatebykey(u zerovalue, Function2<U,V,U> seqfunc, Function2<U,U,U> combfunc) : Aggregate the values of each key, using given combine functions and a neutral zero value. SeqOp for merging a V into a U within a partition CombOp for merging two U's, within/across partitions JavaPairRDD<K,V> sortbykey(comparator<k> comp): Global sort of the RDD by key Each partition contains a sorted range, i.e., output RDD is rangepartitioned. Calling collect will return an ordered list of records 13
14 Transformations JavaPairRDD<K, Tuple2<V,W>> join(javapairrdd<k,w> other, int numparts): Matches keys in this and other. Each output pair is (k, (v1, v2)). Performs a hash join across the cluster. JavaPairRDD<T,U> cartesian(javarddlike<u,?> other): Cross product of values in each RDD as a pair 14
15 Actions 15
16 RDD Persistence & Caching RDDs can be reused in a dataflow Branch, iteration But it will be re-evaluated each time it is reused! Explicitly persist RDD to reuse output of a dataflow path multiple times Multiple storage levels for persistence Disk or memory Serialized or object form in memory Partial spill-to-disk possible Cache indicates persist to memory 16
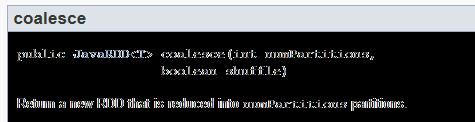
17 RePartitioning 17

18 From DAG to RDD lineage 18
L3: Spark & RDD. CDS Department of Computational and Data Sciences. Department of Computational and Data Sciences
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences L3: Spark & RDD Department of Computational and Data Science, IISc, 2016 This
L10: Dictionary & Skip List
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-09-14 L10: Dictionary & Skip List Yogesh Simmhan s i m m h a n
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-09-14 L10: Dictionary & Skip List Yogesh Simmhan s i m m h a n
CAP Theorem, BASE & DynamoDB
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत DS256:Jan18 (3:1) Department of Computational and Data Sciences CAP Theorem, BASE & DynamoDB Yogesh Simmhan Yogesh Simmhan
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत DS256:Jan18 (3:1) Department of Computational and Data Sciences CAP Theorem, BASE & DynamoDB Yogesh Simmhan Yogesh Simmhan
Tutorial: Apache Storm
 Indian Institute of Science Bangalore, India भ रत य वज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan17 (3:1) Tutorial: Apache Storm Anshu Shukla 16 Feb, 2017 Yogesh Simmhan
Indian Institute of Science Bangalore, India भ रत य वज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan17 (3:1) Tutorial: Apache Storm Anshu Shukla 16 Feb, 2017 Yogesh Simmhan
L20-21: Graph Data Structure
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS86 06-0-6,8 L0-: Graph Data Structure Yogesh Simmhan s immhan@cds.iisc.ac.in
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS86 06-0-6,8 L0-: Graph Data Structure Yogesh Simmhan s immhan@cds.iisc.ac.in
L5-6:Runtime Platforms Hadoop and HDFS
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L5-6:Runtime Platforms Hadoop and HDFS Yogesh Simmhan 03/
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L5-6:Runtime Platforms Hadoop and HDFS Yogesh Simmhan 03/
Introduction to Spark
 Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
Introduction to Spark Outlines A brief history of Spark Programming with RDDs Transformations Actions A brief history Limitations of MapReduce MapReduce use cases showed two major limitations: Difficulty
DS ,21. L11-12: Hashmap
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-09-16,21 L11-12: Hashmap Yogesh Simmhan s i m m h a n @ c d s.
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-09-16,21 L11-12: Hashmap Yogesh Simmhan s i m m h a n @ c d s.
L6,7: Time & Space Complexity
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-08-31,09-02 L6,7: Time & Space Complexity Yogesh Simmhan s i m
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-08-31,09-02 L6,7: Time & Space Complexity Yogesh Simmhan s i m
Data Structures, Algorithms & Data Science Platforms
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS221 19 Sep 19 Oct, 2017 Data Structures, Algorithms & Data Science Platforms
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS221 19 Sep 19 Oct, 2017 Data Structures, Algorithms & Data Science Platforms
DS L9: Queues
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-09-09 L9: Queues Yogesh Simmhan s i m m h a n @ c d s. i i s c.
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-09-09 L9: Queues Yogesh Simmhan s i m m h a n @ c d s. i i s c.
L22-23: Graph Algorithms
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS 0--0,0 L-: Graph Algorithms Yogesh Simmhan simmhan@cds.iisc.ac.in Slides
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS 0--0,0 L-: Graph Algorithms Yogesh Simmhan simmhan@cds.iisc.ac.in Slides
DS & 26. L4: Linear Lists
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-08-24 & 26 L4: Linear Lists Yogesh Simmhan s i m m h a n @ c d
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS286 2016-08-24 & 26 L4: Linear Lists Yogesh Simmhan s i m m h a n @ c d
Shared Memory Parallelism using OpenMP
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत SE 292: High Performance Computing [3:0][Aug:2014] Shared Memory Parallelism using OpenMP Yogesh Simmhan Adapted from: o
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत SE 292: High Performance Computing [3:0][Aug:2014] Shared Memory Parallelism using OpenMP Yogesh Simmhan Adapted from: o
L1:Google File System Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung ACM SOSP, 2003
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan18 (3:1) L1:Google File System Sanjay Ghemawat, Howard Gobioff, and
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan18 (3:1) L1:Google File System Sanjay Ghemawat, Howard Gobioff, and
Analytics in Spark. Yanlei Diao Tim Hunter. Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig
 Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
Analytics in Spark Yanlei Diao Tim Hunter Slides Courtesy of Ion Stoica, Matei Zaharia and Brooke Wenig Outline 1. A brief history of Big Data and Spark 2. Technical summary of Spark 3. Unified analytics
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION
 Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Memory Organization Redux
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत SE 292: High Performance Computing [3:0][Aug:2014] Memory Organization Redux Yogesh Simmhan Adapted from Memory Organization
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत SE 292: High Performance Computing [3:0][Aug:2014] Memory Organization Redux Yogesh Simmhan Adapted from Memory Organization
Data Structures, Algorithms & Data Science Platforms
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS221 19 Sep 19 Oct, 2017 Data Structures, Algorithms & Data Science Platforms
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS221 19 Sep 19 Oct, 2017 Data Structures, Algorithms & Data Science Platforms
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Data Structures, Algorithms & Data Science Platforms
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS221 19 Sep 19 Oct, 2017 Data Structures, Algorithms & Data Science Platforms
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS221 19 Sep 19 Oct, 2017 Data Structures, Algorithms & Data Science Platforms
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/85/91873103.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Frequently asked questions from the previous class survey 48-bit bookending in Bzip2: does the number have to be special? Spark seems to have too many
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Frequently asked questions from the previous class survey 48-bit bookending in Bzip2: does the number have to be special? Spark seems to have too many
12/04/2018. Spark supports also RDDs of key-value pairs. Many applications are based on pair RDDs Pair RDDs allow
 Spark supports also RDDs of key-value pairs They are called pair RDDs Pair RDDs are characterized by specific operations reducebykey(), join, etc. Obviously, pair RDDs are characterized also by the operations
Spark supports also RDDs of key-value pairs They are called pair RDDs Pair RDDs are characterized by specific operations reducebykey(), join, etc. Obviously, pair RDDs are characterized also by the operations
L2,3:Programming for Large Datasets MapReduce
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan17 (3:1) L2,3:Programming for Large Datasets MapReduce Yogesh Simmhan
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences DS256:Jan17 (3:1) L2,3:Programming for Large Datasets MapReduce Yogesh Simmhan
Spark supports also RDDs of key-value pairs
 1 Spark supports also RDDs of key-value pairs They are called pair RDDs Pair RDDs are characterized by specific operations reducebykey(), join, etc. Obviously, pair RDDs are characterized also by the operations
1 Spark supports also RDDs of key-value pairs They are called pair RDDs Pair RDDs are characterized by specific operations reducebykey(), join, etc. Obviously, pair RDDs are characterized also by the operations
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
11/04/2018. In the following, the following syntax is used. The Spark s actions can
 The Spark s actions can Return the content of the RDD and store it in a local Java variable of the Driver program Pay attention to the size of the returned value Or store the content of an RDD in an output
The Spark s actions can Return the content of the RDD and store it in a local Java variable of the Driver program Pay attention to the size of the returned value Or store the content of an RDD in an output
Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks
 COMP 322: Fundamentals of Parallel Programming Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks Mack Joyner and Zoran Budimlić {mjoyner, zoran}@rice.edu http://comp322.rice.edu COMP
COMP 322: Fundamentals of Parallel Programming Lecture 30: Distributed Map-Reduce using Hadoop and Spark Frameworks Mack Joyner and Zoran Budimlić {mjoyner, zoran}@rice.edu http://comp322.rice.edu COMP
10/04/2019. Spark supports also RDDs of key-value pairs. Many applications are based on pair RDDs Pair RDDs allow
 Spark supports also RDDs of key-value pairs They are called pair RDDs Pair RDDs are characterized by specific operations reducebykey(), join(), etc. Obviously, pair RDDs are characterized also by the operations
Spark supports also RDDs of key-value pairs They are called pair RDDs Pair RDDs are characterized by specific operations reducebykey(), join(), etc. Obviously, pair RDDs are characterized also by the operations
Big Data Analytics with Apache Spark. Nastaran Fatemi
 Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Apache Spark Internals
 Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Concurrent Programming
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत SE 292: High Performance Computing [3:0][Aug:2014] Concurrent Programming Yogesh Simmhan Adapted from Intro to Concurrent
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत SE 292: High Performance Computing [3:0][Aug:2014] Concurrent Programming Yogesh Simmhan Adapted from Intro to Concurrent
SPARK PAIR RDD JOINING ZIPPING, SORTING AND GROUPING
 SPARK PAIR RDD JOINING ZIPPING, SORTING AND GROUPING By www.hadoopexam.com Note: These instructions should be used with the HadoopExam Apache Spark: Professional Trainings. Where it is executed and you
SPARK PAIR RDD JOINING ZIPPING, SORTING AND GROUPING By www.hadoopexam.com Note: These instructions should be used with the HadoopExam Apache Spark: Professional Trainings. Where it is executed and you
COMP 322: Fundamentals of Parallel Programming. Lecture 37: Distributed Computing, Apache Spark
 COMP 322: Fundamentals of Parallel Programming Lecture 37: Distributed Computing, Apache Spark Vivek Sarkar, Shams Imam Department of Computer Science, Rice University vsarkar@rice.edu, shams@rice.edu
COMP 322: Fundamentals of Parallel Programming Lecture 37: Distributed Computing, Apache Spark Vivek Sarkar, Shams Imam Department of Computer Science, Rice University vsarkar@rice.edu, shams@rice.edu
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University
![CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University](/thumbs/83/87457744.jpg "CS555: Distributed Systems [Fall 2017] Dept. Of Computer Science, Colorado State University") CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey If an RDD is read once, transformed will Spark
CS 555: DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey If an RDD is read once, transformed will Spark
An Introduction to Apache Spark Big Data Madison: 29 July William Red Hat, Inc.
 An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
An Introduction to Apache Spark Big Data Madison: 29 July 2014 William Benton @willb Red Hat, Inc. About me At Red Hat for almost 6 years, working on distributed computing Currently contributing to Spark,
Comparative Study of Apache Hadoop vs Spark
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 7 ISSN : 2456-3307 Comparative Study of Apache Hadoop vs Spark Varsha
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 7 ISSN : 2456-3307 Comparative Study of Apache Hadoop vs Spark Varsha
Evolution From Shark To Spark SQL:
 Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
Evolution From Shark To Spark SQL: Preliminary Analysis and Qualitative Evaluation Xinhui Tian and Xiexuan Zhou Institute of Computing Technology, Chinese Academy of Sciences and University of Chinese
It is an entirely new way of typing and hence please go through the instructions to experience the best usability.
 Panini Keypad allows you to write in all languages of India on the phone, fast and easily without the need of printed characters on the keypad. It is based on a patented invention of statistical predictive
Panini Keypad allows you to write in all languages of India on the phone, fast and easily without the need of printed characters on the keypad. It is based on a patented invention of statistical predictive
A very short introduction
 A very short introduction General purpose compute engine for clusters batch / interactive / streaming used by and many others History developed in 2009 @ UC Berkeley joined the Apache foundation in 2013
A very short introduction General purpose compute engine for clusters batch / interactive / streaming used by and many others History developed in 2009 @ UC Berkeley joined the Apache foundation in 2013
6.830 Lecture Spark 11/15/2017
 6.830 Lecture 19 -- Spark 11/15/2017 Recap / finish dynamo Sloppy Quorum (healthy N) Dynamo authors don't think quorums are sufficient, for 2 reasons: - Decreased durability (want to write all data at
6.830 Lecture 19 -- Spark 11/15/2017 Recap / finish dynamo Sloppy Quorum (healthy N) Dynamo authors don't think quorums are sufficient, for 2 reasons: - Decreased durability (want to write all data at
Spark. Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica.
 Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Spark Cluster Computing with Working Sets Matei Zaharia, Mosharaf Chowdhury, Michael Franklin, Scott Shenker, Ion Stoica UC Berkeley Background MapReduce and Dryad raised level of abstraction in cluster
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/24/2018 Week 10-B Sangmi Lee Pallickara
 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B00 CS435 Introduction to Big Data 10/24/2018 CS435 Introduction to Big Data - FALL 2018 W10B1 FAQs Programming Assignment 3 has been posted Recitations
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
CSE 414: Section 7 Parallel Databases. November 8th, 2018
 CSE 414: Section 7 Parallel Databases November 8th, 2018 Agenda for Today This section: Quick touch up on parallel databases Distributed Query Processing In this class, only shared-nothing architecture
CSE 414: Section 7 Parallel Databases November 8th, 2018 Agenda for Today This section: Quick touch up on parallel databases Distributed Query Processing In this class, only shared-nothing architecture
Evaluation of Relational Operations: Other Techniques
 Evaluation of Relational Operations: Other Techniques Chapter 14, Part B Database Management Systems 3ed, R. Ramakrishnan and Johannes Gehrke 1 Using an Index for Selections Cost depends on #qualifying
Evaluation of Relational Operations: Other Techniques Chapter 14, Part B Database Management Systems 3ed, R. Ramakrishnan and Johannes Gehrke 1 Using an Index for Selections Cost depends on #qualifying
Apache Spark. CS240A T Yang. Some of them are based on P. Wendell s Spark slides
 Apache Spark CS240A T Yang Some of them are based on P. Wendell s Spark slides Parallel Processing using Spark+Hadoop Hadoop: Distributed file system that connects machines. Mapreduce: parallel programming
Apache Spark CS240A T Yang Some of them are based on P. Wendell s Spark slides Parallel Processing using Spark+Hadoop Hadoop: Distributed file system that connects machines. Mapreduce: parallel programming
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
CompSci 516: Database Systems
 CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
CompSci 516 Database Systems Lecture 12 Map-Reduce and Spark Instructor: Sudeepa Roy Duke CS, Fall 2017 CompSci 516: Database Systems 1 Announcements Practice midterm posted on sakai First prepare and
Installing Apache Zeppelin
 3 Installing Date of Publish: 2018-04-01 http://docs.hortonworks.com Contents Install Using Ambari...3 Enabling HDFS and Configuration Storage for Zeppelin Notebooks in HDP-2.6.3+...4 Overview... 4 Enable
3 Installing Date of Publish: 2018-04-01 http://docs.hortonworks.com Contents Install Using Ambari...3 Enabling HDFS and Configuration Storage for Zeppelin Notebooks in HDP-2.6.3+...4 Overview... 4 Enable
Data Intensive Computing Handout 9 Spark
 Data Intensive Computing Handout 9 Spark According to homepage: Apache Spark is a fast and general engine for large-scale data processing. Spark is available either in Scala (and therefore in Java) or
Data Intensive Computing Handout 9 Spark According to homepage: Apache Spark is a fast and general engine for large-scale data processing. Spark is available either in Scala (and therefore in Java) or
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/83/87457683.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Return type for collect()? Can
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Return type for collect()? Can
Lecture 09. Spark for batch and streaming processing FREDERICK AYALA-GÓMEZ. CS-E4610 Modern Database Systems
 CS-E4610 Modern Database Systems 05.01.2018-05.04.2018 Lecture 09 Spark for batch and streaming processing FREDERICK AYALA-GÓMEZ PHD STUDENT I N COMPUTER SCIENCE, ELT E UNIVERSITY VISITING R ESEA RCHER,
CS-E4610 Modern Database Systems 05.01.2018-05.04.2018 Lecture 09 Spark for batch and streaming processing FREDERICK AYALA-GÓMEZ PHD STUDENT I N COMPUTER SCIENCE, ELT E UNIVERSITY VISITING R ESEA RCHER,
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
Introduction to Apache Spark
 1 Introduction to Apache Spark Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of this lectures is inspired by: The lecture notes of Yann Vernaz. The lecture notes of Vincent
1 Introduction to Apache Spark Thomas Ropars thomas.ropars@univ-grenoble-alpes.fr 2017 2 References The content of this lectures is inspired by: The lecture notes of Yann Vernaz. The lecture notes of Vincent
Pig on Spark project proposes to add Spark as an execution engine option for Pig, similar to current options of MapReduce and Tez.
 Pig on Spark Mohit Sabharwal and Xuefu Zhang, 06/30/2015 Objective The initial patch of Pig on Spark feature was delivered by Sigmoid Analytics in September 2014. Since then, there has been effort by a
Pig on Spark Mohit Sabharwal and Xuefu Zhang, 06/30/2015 Objective The initial patch of Pig on Spark feature was delivered by Sigmoid Analytics in September 2014. Since then, there has been effort by a
Today s content. Resilient Distributed Datasets(RDDs) Spark and its data model
 Spark and its data model") Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Today s content Resilient Distributed Datasets(RDDs) ------ Spark and its data model Resilient Distributed Datasets: A Fault- Tolerant Abstraction for In-Memory Cluster Computing -- Spark By Matei Zaharia,
Spark and Spark SQL. Amir H. Payberah. SICS Swedish ICT. Amir H. Payberah (SICS) Spark and Spark SQL June 29, / 71
 Spark and Spark SQL June 29, / 71") Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Data Platforms and Pattern Mining
 Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Morteza Zihayat Data Platforms and Pattern Mining IBM Corporation About Myself IBM Software Group Big Data Scientist 4Platform Computing, IBM (2014 Now) PhD Candidate (2011 Now) 4Lassonde School of Engineering,
Spark: A Brief History. https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf
 Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Spark: A Brief History https://stanford.edu/~rezab/sparkclass/slides/itas_workshop.pdf A Brief History: 2004 MapReduce paper 2010 Spark paper 2002 2004 2006 2008 2010 2012 2014 2002 MapReduce @ Google
Parallel Processing - MapReduce and FlumeJava. Amir H. Payberah 14/09/2018
 Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
Parallel Processing - MapReduce and FlumeJava Amir H. Payberah payberah@kth.se 14/09/2018 The Course Web Page https://id2221kth.github.io 1 / 83 Where Are We? 2 / 83 What do we do when there is too much
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Shuffling, Partitioning, and Closures. Parallel Programming and Data Analysis Heather Miller
 Shuffling, Partitioning, and Closures Parallel Programming and Data Analysis Heather Miller What we ve learned so far We extended data parallel programming to the distributed case. We saw that Apache Spark
Shuffling, Partitioning, and Closures Parallel Programming and Data Analysis Heather Miller What we ve learned so far We extended data parallel programming to the distributed case. We saw that Apache Spark
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기
 MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
MapReduce: Simplified Data Processing on Large Clusters 유연일민철기 Introduction MapReduce is a programming model and an associated implementation for processing and generating large data set with parallel,
We consider the general additive objective function that we saw in previous lectures: n F (w; x i, y i ) i=1
 i=1") CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
CME 323: Distributed Algorithms and Optimization, Spring 2015 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 13, 5/9/2016. Scribed by Alfredo Láinez, Luke de Oliveira.
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite. Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017
 Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
Accelerate MySQL for Demanding OLAP and OLTP Use Cases with Apache Ignite Peter Zaitsev, Denis Magda Santa Clara, California April 25th, 2017 About the Presentation Problems Existing Solutions Denis Magda
Address Change Process Related Documents
 Address Change Process Documents Back ground and Requirement of Policy-: RKCL is running its operations through its ITGKs. These ITGKs are working on certain premises, some of them in rented premise and
Address Change Process Documents Back ground and Requirement of Policy-: RKCL is running its operations through its ITGKs. These ITGKs are working on certain premises, some of them in rented premise and
L2-4:Programming for Large Datasets MapReduce
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L2-4:Programming for Large Datasets MapReduce Yogesh Simmhan
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत Department of Computational and Data Sciences SE256:Jan16 (2:1) L2-4:Programming for Large Datasets MapReduce Yogesh Simmhan
SciSpark 201. Searching for MCCs
 SciSpark 201 Searching for MCCs Agenda for 201: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project What is Spark? SciSpark Extensions scitensor: N-dimensional arrays
SciSpark 201 Searching for MCCs Agenda for 201: Access your SciSpark & Notebook VM (personal sandbox) Quick recap. of SciSpark Project What is Spark? SciSpark Extensions scitensor: N-dimensional arrays
CS435 Introduction to Big Data FALL 2018 Colorado State University. 10/22/2018 Week 10-A Sangmi Lee Pallickara. FAQs.
 10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
10/22/2018 - FALL 2018 W10.A.0.0 10/22/2018 - FALL 2018 W10.A.1 FAQs Term project: Proposal 5:00PM October 23, 2018 PART 1. LARGE SCALE DATA ANALYTICS IN-MEMORY CLUSTER COMPUTING Computer Science, Colorado
MapReduce. Stony Brook University CSE545, Fall 2016
 MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
MapReduce Stony Brook University CSE545, Fall 2016 Classical Data Mining CPU Memory Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining CPU Memory (64 GB) Disk Classical Data Mining
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Resilient Distributed Datasets
 Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
Resilient Distributed Datasets A Fault- Tolerant Abstraction for In- Memory Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin,
CS Spark. Slides from Matei Zaharia and Databricks
 CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
CS 5450 Spark Slides from Matei Zaharia and Databricks Goals uextend the MapReduce model to better support two common classes of analytics apps Iterative algorithms (machine learning, graphs) Interactive
Evaluation of Relational Operations: Other Techniques
 Evaluation of Relational Operations: Other Techniques [R&G] Chapter 14, Part B CS4320 1 Using an Index for Selections Cost depends on #qualifying tuples, and clustering. Cost of finding qualifying data
Evaluation of Relational Operations: Other Techniques [R&G] Chapter 14, Part B CS4320 1 Using an Index for Selections Cost depends on #qualifying tuples, and clustering. Cost of finding qualifying data
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Spark supports several storage levels
 1 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the
1 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the
15/04/2018. Spark supports several storage levels. The storage level is used to specify if the content of the RDD is stored
 Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the RDD,
Spark computes the content of an RDD each time an action is invoked on it If the same RDD is used multiple times in an application, Spark recomputes its content every time an action is invoked on the RDD,
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source
 Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Apache Ignite TM - In- Memory Data Fabric Fast Data Meets Open Source DMITRIY SETRAKYAN Founder, PPMC https://ignite.apache.org @apacheignite @dsetrakyan Agenda About In- Memory Computing Apache Ignite
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU
 Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Dept. Of Computer Science, Colorado State University
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK STREAMING] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Can Spark repartition
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [SPARK STREAMING] Shrideep Pallickara Computer Science Colorado State University Frequently asked questions from the previous class survey Can Spark repartition