Beyond relational databases. Daniele Apiletti
|
|
|
- Brent Boyd
- 5 years ago
- Views:
Transcription

1 Beyond relational databases Daniele Apiletti



2 «NoSQL» birth In 1998 Carlo Strozzi s lightweight, open-source relational database that did not expose the standard SQL interface In 2009 Johan Oskarsson s (Last.fm) organizes an event to discuss recent advances on non-relational databases. A new, unique, short hashtag to promote the event on Twitter was needed: #NoSQL

3 NoSQL main features no joins schema-less (no tables, implicit schema) Exam Student ID Name Surname Course Course number Name Professor Course number Student ID Mark Student Student ID Name Surname S Mario Rossi horizontal scalability
4 Comparison Relational databases Table-based, each record is a structured row Predefined schema for each table, changes allowed but usually blocking (expensive in distributed and live environments) Vertically scalable, i.e., typically scaled by increasing the power of the hardware Use SQL (Structured Query Language) for defining and manipulating the data, very powerful Non-Relational databases Specialized storage solutions, e.g, document-based, key-value pairs, graph databases, columnar storage Schema-less, schema-free, schema change is dynamic for each document, suitable for semi-structured or un-structured data Horizontally scalable, NoSQL databases are scaled by increasing the databases servers in the pool of resources to reduce the load Custom query languages, focused on collection of documents, graphs, and other specialized data structures
5 Comparison Relational databases Suitable for complex queries, based on data joins Suitable for flat and structured data storage Examples: MySql, Oracle, Sqlite, Postgres and Microsoft SQL Server Non-Relational databases No standard interfaces to perform complex queries, no joins Suitable for complex (e.g., hierarchical) data, similar to JSON and XML Examples: MongoDB, BigTable, Redis, Cassandra, Hbase and CouchDB
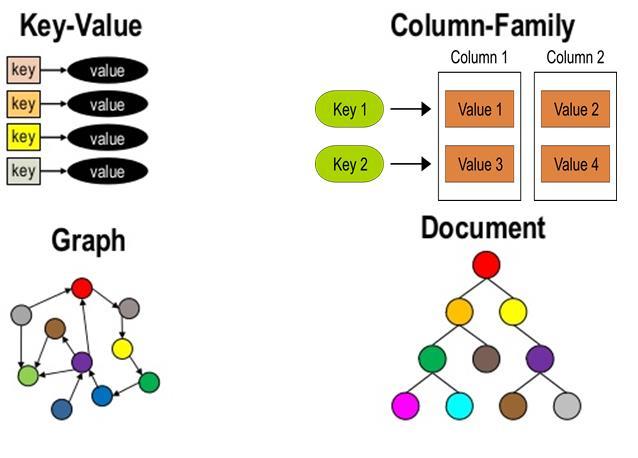
6 Types of NoSQL databases

7 Key-values databases Simplest NoSQL data stores Match keys with values No structure Great performance Easily scaled Very fast Examples: Redis, Riak, Memcached
 Rows can be constructed from column values Column stores can produce row output (tables) Completely transparent")
8 Column-oriented databases Store data in columnar format Name = Daniele :row1,row3; Marco :row2,row4; Surname = Apiletti :row1,row5; Rossi :row2,row6,row7 A column is a (possibly-complex) attribute Key-value pairs stored and retrieved on key in a parallel system (similar to indexes) Rows can be constructed from column values Column stores can produce row output (tables) Completely transparent to application Examples: Cassandra, Hbase, Hypertable, Amazon DynamoDB

9 Graph databases Based on graph theory Made up by Vertex and Edges Used to store information about networks Good fit for several real world applications Examples: Neo4J, Infinite Graph, OrientDB

10 Document databases Database stores and retrieves documents Keys are mapped to documents Documents are self-describing (attribute=value) Has hierarchical-tree nested data structures (e.g., maps, lists, datetime, ) Heterogeneous nature of documents Examples: MongoDB, CouchDB, RavenDB.

11 a notable NoSQL example CouchDB Cluster Of Unreliable Commodity Hardware
12 CouchDB original home page Document-oriented database can be queried and indexed in a MapReduce fashion Offers incremental replication with bidirectional conflict detection and resolution Written in Erlang, a robust functional programming language ideal for building concurrent distributed systems. Erlang allows for a flexible design that is easily scalable and readily extensible Provides a RESTful JSON API than can be accessed from any enviroment that allows HTTP requests




13 CouchDB original home page Document-oriented database can be queried and indexed in a MapReduce fashion Offers incremental replication with bidirectional conflict detection and resolution Written in Erlang, a robust functional programming language ideal for building concurrent distributed systems. Erlang allows for a flexible design that is easily scalable and readily extensible Provides a RESTful JSON API than can be accessed from any enviroment that allows HTTP requests

14 a scalable distributed programming model to process Big Data MapReduce
15 MapReduce Published in 2004 by Google J. Dean and S. Ghemawat, MapReduce: Simplified Data Processing on Large Clusters, OSDI'04: Sixth Symposium on Operating System Design and Implementation, San Francisco, CA, December, 2004 used to rewrite the production indexing system with 24 MapReduce operations (in August 2004 alone, 3288 TeraBytes read, 80k machine-days used, jobs of 10 avg) Distributed programming model Process large data sets with parallel algorithms on a cluster of common machines, e.g., PCs Great for parallel jobs requiring pieces of computations to be executed on all data records Move the computation (algorithm) to the data (remote node, PC, disk) Inspired by the map and reduce functions used in functional programming In functional code, the output value of a function depends only on the arguments that are passed to the function, so calling a function f twice with the same value for an argument x produces the same result f(x) each time; this is in contrast to procedures depending on a local or global state, which may produce different results at different times when called with the same arguments but a different program state.
16 MapReduce: working principles Consists of two functions, a Map and a Reduce The Reduce is optional Map function Process each record (document) INPUT Return a list of key-value pairs OUTPUT Reduce function for each key, reduces the list of its values, returned by the map, to a single value Returned value can be a complex piece of data, e.g., a list, tuple, etc.
17 Map Map functions are called once for each document: function(doc) { emit(key 1, value 1 ); // key 1 = f k1 (doc); value 1 = f v1 (doc) emit(key 2, value 2 ); // key 2 = f k2 (doc); value 2 = f v2 (doc) } The map function can choose to skip the document altogether or emit one or more key/value pairs Map function may not depend on any information outside the document. This independence is what allows CouchDB views to be generated incrementally and in parallel
18 Map example Example database, a collection of docs describing university exam records Id: 1 Exam: Database Student: s AYear: Date: Mark=29 CFU=8 Id: 2 Exam: Computer architectures Student: s AYear: Date: Mark=24 CFU=10 Id: 3 Exam: Computer architectures Student: s AYear: Date: Mark=27 CFU=10 Id: 4 Exam: Database Student: s AYear: Date: Mark=26 CFU=8 Id: 5 Exam: Software engineering Student: s AYear: Date: Mark=21 CFU=8 Id: 6 Exam: Bioinformatics Student: s AYear: Date: Mark=30 CFU=6 Id: 7 Exam: Software engineering Student: s AYear: Date: Mark=18 CFU=8 Id: 8 Exam: Database Student: s AYear: Date: Mark=25 CFU=8
19 Map example (1) List of exams and corresponding marks Function(doc){ emit(doc.exam, doc.mark); } Key Value Result: Id: 2 Exam: Computer architectures Student: s AYear: Date: Mark=24 CFU=10 Id: 1 Exam: Database Student: s AYear: Date: Mark=29 CFU=8 Id: 8 Exam: Database Student: s AYear: Date: Mark=25 CFU=8 Id: 3 Exam: Computer architectures Student: s AYear: Date: Mark=27 CFU=10 Id: 7 Exam: Software engineering Student: s AYear: Date: Mark=18 CFU=8 Id: 4 Exam: Database Student: s AYear: Date: Mark=26 CFU=8 Id: 5 Exam: Software engineering Student: s AYear: Date: Mark=21 CFU=8 Id: 6 Exam: Bioinformatics Student: s AYear: Date: Mark=30 CFU=6 doc.id Key Value 6 Bioinformatics 30 2 Computer architectures 24 3 Computer architectures 27 1 Database 29 4 Database 26 8 Database 25 5 Software engineering 21 7 Software engineering 18
20 Map example (2) Ordered list of exams, academic year, and date, and select their mark Function(doc) { key = [doc.exam, doc.ayear] Result: } Id: 2 Exam: Computer architectures Student: s AYear: Date: Mark=24 CFU=10 Id: 1 Exam: Database Student: s AYear: Date: Mark=29 CFU=8 Id: 8 Exam: Database Student: s AYear: Date: Mark=25 CFU=8 value = doc.mark emit(key, value); Id: 3 Exam: Computer architectures Student: s AYear: Date: Mark=27 CFU=10 Id: 7 Exam: Software engineering Student: s AYear: Date: Mark=18 CFU=8 Id: 4 Exam: Database Student: s AYear: Date: Mark=26 CFU=8 Id: 5 Exam: Software engineering Student: s AYear: Date: Mark=21 CFU=8 Id: 6 Exam: Bioinformatics Student: s AYear: Date: Mark=30 CFU=6 doc.id Key Value 6 [Bioinformatics, ] 30 2 [Computer architectures, ] 24 3 [Computer architectures, ] 27 4 [Database, ] 26 8 [Database, ] 25 1 [Database, ] 29 5 [Software engineering, ] 21 7 [Software engineering, ] 18
21 Map example (3) Ordered list of students, with mark and CFU for each exam Function(doc) { key = doc.student value = [doc.mark, doc.cfu] emit(key, value); Result: Id: 2 Exam: Computer architectures Student: s AYear: Date: Mark=24 CFU=10 Id: 1 Exam: Database Student: s AYear: Date: Mark=29 CFU=8 Id: 8 Exam: Database Student: s AYear: Date: Mark=25 CFU=8 } Id: 3 Exam: Computer architectures Student: s AYear: Date: Mark=27 CFU=10 Id: 7 Exam: Software engineering Student: s AYear: Date: Mark=18 CFU=8 Id: 4 Exam: Database Student: s AYear: Date: Mark=26 CFU=8 Id: 5 Exam: Software engineering Student: s AYear: Date: Mark=21 CFU=8 Id: 6 Exam: Bioinformatics Student: s AYear: Date: Mark=30 CFU=6 doc.id Key Value 1 S [29, 8] 2 S [24, 10] 5 S [21, 8] 6 S [30, 6] 3 S [27, 10] 4 S [26, 8] 7 S [18, 8] 8 s [25, 8]
22 Reduce Documents (key-value pairs) emitted by the map function are sorted by key some platforms (e.g. Hadoop) allow you to specifically define a shuffle phase to manage the distribution of map results to reducers spread over different nodes, thus providing a fine-grained control over communication costs Reduce inputs are the map outputs: a list of key-value documents Each execution of the reduce function returns one key-value document The most simple SQL-equivalent operations performed by means of reducers are «group by» aggregations, but reducers are very flexible functions that can execute even complex operations Re-reduce: reduce functions can be called on their own results in CouchDB
23 MapReduce example (1) Map - List of exams and corresponding mark Function(doc){ emit(doc.exam, doc.mark); } id: 1 DOC Exam: Database Student: s AYear: Date: Mark=29 CFU=8 Map The reduce function receives: key=bioinformatics, values=[30] key=database, values=[29,26,25] Reduce doc.id Key Value Key Value Reduce - Compute the average mark for each exam Function(key, values){ S = sum(values); N = len(values); AVG = S/N; return AVG; } 6 Bioinformatics 30 2 Computer architectures 24 3 Computer architectures 27 1 Database 29 4 Database 26 8 Database 25 5 Software engineering 21 7 Software engineering 18 Bioinformatics 30 Computer architectures 25.5 Database Software engineering 19.5
24 MapReduce example (2) Map - List of exams and corresponding mark Function(doc){ emit( [doc.exam, doc.ayear], doc.mark ); } Reduce - Compute the average mark for each exam and academic year Function(key, values){ S = sum(values); N = len(values); AVG = S/N; return AVG; } Reduce is the same as before id: 1 DOC Exam: Database Student: s AYear: Date: Mark=29 CFU=8 Map doc.id Key Value 6 Bioinformatics, Computer architectures, Computer architectures, Database, Database, Database, Software engineering, Software engineering, The reduce function receives: key=[database, ], values=[26,25] key=[database, ], values=[29] Reduce Key Value [Bioinformatics, ] 30 [Computer architectures, ] 25.5 [Database, ] 25.5 [Database, ] 29 [Software engineering, ] 21 [Software engineering, ] 18
25 Rereduce in CouchDB Average mark the for each exam (group level=1) same Reduce as before DB Map Reduce Rereduce Id: 1 Exam: Database Student: s AYear: Date: Mark=29 CFU=8 Id: 8 Exam: Database Student: s AYear: Date: Mark=25 CFU=8 doc.id Key Value 6 Bioinformatics, Key Value [Bioinformatics, ] 30 Key Value Bioinformatics 30 Id: 6 Exam: Bioinformatics Student: s AYear: Date: Mark=30 CFU=6 Id: 5 Exam: Software engineering Student: s AYear: Date: Mark=21 CFU=8 Id: 3 Exam: Computer architectures Student: s AYear: Date: Mark=27 CFU=10 Id: 4 Exam: Database Student: s AYear: Date: Mark=26 CFU=8 Id: 7 Exam: Software engineering Student: s AYear: Date: Mark=18 CFU=8 Id: 2 Exam: Computer architectures Student: s AYear: Date: Mark=24 CFU= Computer architectures, Computer architectures, Database, Database, Database, Software engineering, Software engineering, [Computer architectures, ] 25.5 [Database, ] 25.5 [Database, ] 29 [Software engineering, ] 21 [Software engineering, ] 18 Computer architectures 25.5 Database Software engineering 19.5
26 MapReduce example (3a) Average CFU-weighted mark for each student id: 1 DOC Exam: Database Student: s AYear: Date: Mark=29 CFU=8 MapFunction(doc) { key = doc.student The reduce function receives: value = [doc.mark, doc.cfu] key= values= emit(key, value); } key= values= Map doc.id Key Value Reduce Key Value Reduce Function(key, values){ S = sum([ X*Y for X,Y in values ]); values= N = sum([ Y for X,Y in values ]); AVG = S/N; return AVG; } The reduce function results: key= key= values=
27 MapReduce example (3a) Map - Ordered list of students, with mark and CFU for each exam Function(doc) { key = doc.student value = [doc.mark, doc.cfu] emit(key, value); } Map doc.id Key Value The reduce function receives: key=s123456, values=[(29,8), (24,10), (21,8) ] key=s987654, values=[(25,8)] Reduce Key Value Reduce - Average CFU-weighted mark for each student Function(key, values){ S = sum([ X*Y for X,Y in values ]); N = sum([ Y for X,Y in values ]); AVG = S/N; } return AVG; key = S123456, values = [(29,8), (24,10), (21,8) ] X = 29, 24, 21, mark Y = 8, 10, 8, CFU 1 S [29, 8] 2 S [24, 10] 5 S [21, 8] 6 S [30, 6] 3 S [27, 10] 4 S [26, 8] 7 S [18, 8] 8 s [25, 8] S S s
28 MapReduce example (3b) Compute the number of exams for each student Technological view of data distribution among different nodes DB Map doc.id Key Value Key Reduce Value Rereduce Key Value Id: 1 Exam: Database Student: s AYear: Date: Mark=29 CFU=8 1 S [29, 1] Id: 2 Exam: Computer architectures Student: s AYear: Date: Mark=24 CFU=10 Id: 5 Exam: Software engineering Student: s AYear: Date: Mark=21 CFU=8 2 S [24, 1] 5 S [21, 1] S S Id: 6 Exam: Bioinformatics Student: s AYear: Date: Mark=30 CFU=6 6 S [30, 1] S Id: 3 Exam: Computer architectures Student: s AYear: Date: Mark=27 CFU=10 3 S [27, 1] Id: 4 Exam: Database Student: s AYear: Date: Mark=26 CFU=8 4 S [26, 1] S S Id: 7 Exam: Software engineering Student: s AYear: Date: Mark=18 CFU=8 7 S [18, 1] Id: 8 Exam: Database Student: s AYear: Date: Mark=25 CFU=8 8 s [25, 1] s s
29 Views (indexes) The only way to query CouchDB is to build a view on the data A view is produced by a MapReduce The predefined view for each database has the document ID as key, the whole document as value no Reduce CouchDB views are materialized as values sorted by key allows the same DB to have multiple primary indexes When writing CouchDB map functions, your primary goal is to build an index that stores related data under nearby keys
")
30 Same data in different places (content and schema) Replication
31 Replication Same data portions of the whole dataset (chunks) in different places local and/or remote servers, clusters, data centers Goals Redundancy helps surviving failures (availability) Better performance Approaches Master-Slave replication A-Synchronous replication
32 Master-Slave replication Master-Slave A master server takes all the writes, updates, inserts One or more Slave servers take all the reads (they can t write) Only read scalability The master is a single point of failure CouchDB supports Master-Master replication Read-write operations Master Slave Slave Slave Slave Only read operations
33 Synchronous replication Before committing a transaction, the Master waits for (all) the Slaves to commit Similar in concept to the 2-Phase Commit in relational databases Performance killer, in particular for replication in the cloud Trade-off: wait for a subset of Slaves to commit, e.g., the majority of them It s ready to commit new transaction Master Wait for all slaves Replicate Slave Slave Slave Slave
34 Asynchronous replication The Master commits locally, it does not wait for any Slave Each Slave independently fetches updates from Master, which may fail IF no Slave has replicated, then you ve lost the data committed to the Master IF some Slaves have replicated and some haven t, then you have to reconcile Faster and unreliable Can commit other transactions Master Replicate Slave Slave Slave Slave

35 Different autonomous machines, working together to manage the same dataset Distributed databases
36 Key features of distributed databases There are 3 typical problems in distributed databases: Consistency All the distributed databases provide the same data to the application Availability Database failures (e.g., master node) do not prevent survivors from continuing to operate Partition tolerance The system continues to operate despite arbitrary message loss, when connectivity failures cause network partitions
37 CAP Theorem The CAP theorem, also known as Brewer's theorem, states that it is impossible for a distributed system to simultaneously provide all three of the previous guarantees The theorem began as a conjecture made by University of California in Armando Fox and Eric Brewer, Harvest, Yield and Scalable Tolerant Systems, Proc. 7th Workshop Hot Topics in Operating Systems (HotOS 99), IEEE CS, 1999, pg In 2002 a formal proof was published, establishing it as a theorem Seth Gilbert and Nancy Lynch, Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services, ACM SIGACT News, Volume 33 Issue 2 (2002), pg In 2012, a follow-up by Eric Brewer, CAP twelve years later: How the "rules" have changed IEEE Explore, Volume 45, Issue 2 (2012), pg

38 CAP Theorem The easiest way to understand CAP is to think of two nodes on opposite sides of a partition. Allowing at least one node to update state will cause the nodes to become inconsistent, thus forfeiting C. If the choice is to preserve consistency, one side of the partition must act as if it is unavailable, thus forfeiting A. Only when no network partition exists, is it possible to preserve both consistency and availability, thereby forfeiting P. The general belief is that for wide-area systems, designers cannot forfeit P and therefore have a difficult choice between C and A.
39 CAP Theorem
40 CA without P (local consistency) Partitioning (communication breakdown) causes a failure. We can still have Consistency and Availability of the data shared by agents within each Partition, by ignoring other partitions. Local rather than global consistency / availability Local consistency for a partial system, 100% availability for the partial system, and no partitioning does not exclude several partitions from existing with their own internal CA. So partitioning means having multiple independent systems with 100% CA that do not need to interact.
41 CP without A (transaction locking) A system is allowed to not answer requests at all (turn off A ). We claim to tolerate partitioning/faults, because we simply block all responses if a partition occurs, assuming that we cannot continue to function correctly without the data on the other side of a partition. Once the partition is healed and consistency can once again be verified, we can restore availability and leave this mode. In this configuration there are global consistency, and global correct behaviour in partitioning is to block access to replica sets that are not in synch. In order to tolerate P at any time, we must sacrifice A at any time for global consistency. This is basically the transaction lock.
42 AP without C (best effort) If we don't care about global consistency (i.e. simultaneity), then every part of the system can make available what it knows. Each part might be able to answer someone, even though the system as a whole has been broken up into incommunicable regions (partitions). In this configuration without consistency means without the assurance of global consistency at all times.
43 A consequence of CAP Each node in a system should be able to make decisions purely based on local state. If you need to do something under high load with failures occurring and you need to reach agreement, you re lost. If you re concerned about scalability, any algorithm that forces you to run agreement will eventually become your bottleneck. Take that as a given. Werner Vogels, Amazon CTO and Vice President
44 Beyond CAP The "2 of 3" view is misleading on several fronts. First, because partitions are rare, there is little reason to forfeit C or A when the system is not partitioned. Second, the choice between C and A can occur many times within the same system at very fine granularity; not only can subsystems make different choices, but the choice can change according to the operation or even the specific data or user involved. Finally, all three properties are more continuous than binary. Availability is obviously continuous from 0 to 100 percent, but there are also many levels of consistency, and even partitions have nuances, including disagreement within the system about whether a partition exists.
45 ACID versus BASE ACID and BASE represent two design philosophies at opposite ends of the consistency-availability spectrum ACID properties focus on consistency and are the traditional approach of databases BASE properties focus on high availability and to make explicit both the choice and the spectrum BASE: Basically Available, Soft state, Eventually consistent, work well in the presence of partitions and thus promote availability
46 ACID The four ACID properties are: Atomicity (A) All systems benefit from atomic operations, the database transaction must completely succeed or fail, partial success is not allowed Consistency (C) During the database transaction, the database progresses from a valid state to another. In ACID, the C means that a transaction preserves all the database rules, such as unique keys. In contrast, the C in CAP refers only to single copy consistency. Isolation (I) Isolation is at the core of the CAP theorem: if the system requires ACID isolation, it can operate on at most one side during a partition, because a client s transaction must be isolated from other client s transaction Durability (D) The results of applying a transaction are permanent, it must persist after the transaction completes, even in the presence of failures.
47 BASE Basically Available: the system provides availability, in terms of the CAP theorem Soft state: indicates that the state of the system may change over time, even without input, because of the eventual consistency model. Eventual consistency: indicates that the system will become consistent over time, given that the system doesn't receive input during that time Example: DNS Domain Name Servers DNS is not multi-master
48 Conflict resolution problem There are two customers, A and B A books a hotel room, the last available room B does the same, on a different node of the system, which was not consistent
49 Conflict resolution problem The hotel room document is affected by two conflicting updates Applications should solve the conflict with custom logic (it s a business decision) The database can Detect the conflict Provide a local solution, e.g., latest version is saved as the winning version
50 Conflict CouchDB guarantees that each instance that sees the same conflict comes up with the same winning and losing revisions. It does so by running a deterministic algorithm to pick the winner. The revision with the longest revision history list becomes the winning revision. If they are the same, the _rev values are compared in ASCII sort order, and the highest wins.

51 HTTP API a «web» database, no ad-hoc client required
52 HTTP RESTful API How to get a document? Use your browser and write its URL Any application and language can access web data GET /somedatabase/some_doc_id HTTP/1.0 HEAD /somedatabase/some_doc_id HTTP/1.0 HTTP/ OK Write a document by means of PUT HTTP request (specify revision to avoid conflicts) PUT /somedatabase/some_doc_id HTTP/1.0 HTTP/ Created HTTP/ Conflict

53 The leading NoSQL database currently on the market MongoDB

54 MongoDB - intro Full of features, beyond NoSQL High performance and natively scalable Open source 311$ millions in funding 500+ employees customers

55 MongoDB - why


56 MongoDB Document Data Design High-level, business-ready representation of the data Flexible and rich, adapting to most use cases Mapping into developer-language objects year, month, day, timestamp, lists, sub-documents, etc. BUT Relations among documents / records are inefficient, and leads to de-normalization Object(ID) reference, with no native join Temptation to go too much schema-free / nonrelational even with structured relational data
 search you might have to implement ElasticSearch for")
57 «So, which database should I choose?» If you're building an app today, then there might be a need for using two or more databases at the same time If your app does (text) search you might have to implement ElasticSearch for non-relational data-storage, MongoDB works the best if you're building an IoT which has sensors pumping out a ton of data, shoot it into Cassandra Implementing multiple databases to build one app is called "Polyglot Persistence"

58 The de facto standard Big Data platform Hadoop

59 Hadoop, a Big-Data-everything platform 2003: Google File System 2004: MapReduce by Google (Jeff Dean) 2005: Hadoop, funded by Yahoo, to power a search engine project 2006: Hadoop migrated to Apache Software Foundation 2006: Google BigTable 2008: Hadoop wins the Terabyte Sort Benchmark, sorted 1 Terabyte of data in 209 seconds, previous record was 297 seconds 2009: additional components and subprojects started to be added to the Hadoop platform
60 Hadoop, platform overview
61 Hadoop, platform overview
62 Hadoop, platform overview

63 Hadoop, platform overview
64 Apache Hadoop, core components Hadoop Common: The common utilities that support the other Hadoop modules. Hadoop Distributed File System (HDFS ): A distributed file system that provides high-throughput access to application data. Hadoop YARN: A framework for job scheduling and cluster resource management. Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
65 Hadoop-related projects at Apache Ambari : A web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. Ambari also provides a dashboard for viewing cluster health such as heatmaps and ability to view MapReduce, Pig and Hive applications visually alongwith features to diagnose their performance characteristics in a user-friendly manner. Avro : A data serialization system. Cassandra : A scalable multi-master database with no single points of failure. Chukwa : A data collection system for managing large distributed systems. HBase : A scalable, distributed database that supports structured data storage for large tables. Hive : A data warehouse infrastructure that provides data summarization and ad hoc querying. Mahout : A Scalable machine learning and data mining library. Pig : A high-level data-flow language and execution framework for parallel computation. Spark : A fast and general compute engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation. Tez : A generalized data-flow programming framework, built on Hadoop YARN, which provides a powerful and flexible engine to execute an arbitrary DAG of tasks to process data for both batch and interactive use-cases. Tez is being adopted by Hive, Pig and other frameworks in the Hadoop ecosystem, and also by other commercial software (e.g. ETL tools), to replace Hadoop MapReduce as the underlying execution engine. ZooKeeper : A high-performance coordination service for distributed applications.




66 Apache Spark A fast and general engine for large-scale data processing Speed Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. Apache Spark has an advanced DAG execution engine that supports acyclic data flow and in-memory computing. Ease of Use Write applications quickly in Java, Scala, Python, R. Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python and R shells. Generality Combine SQL, streaming, and complex analytics. Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application. Runs Everywhere Spark runs on Hadoop, Mesos, standalone, or in the cloud. It can access diverse data sources including HDFS, Cassandra, HBase, and S3.

, batch and")


67 Hadoop - why Storage distributed, fault-tolerant, heterogenous, Huge-data storage engine. Processing Flexible (multi-purpose), parallel and scalable, high-level programming (Java, Python, Scala, R), batch and real-time, historical and streaming data processing, complex modeling and basic KPI analytics. High availability Handle failures of nodes by design. High scalability Grow by adding low-cost nodes, not by replacement with higherpowered computers. Low cost. Lots of commodity-hardware nodes instead of expensive super-power computers.
68 A design recipe A notable example of NoSQL design


69 Design recipe: banking account Banks are serious business They need serious databases to store serious transactions and serious account information They can t lose or create money A bank must be in balance all the time
70 Design recipe: banking example Say you want to give $100 to your cousin Paul for Christmas. You need to: decrease your account balance by 100$ increase Paul s account balance by 100$ { { _id: "account_123456", _id: "account_654321", account:"bank_account_001", account:"bank_account_002", balance: 900, balance: 1100, timestamp: ,45, timestamp: ,46, categories: ["banktransfer" ], categories: ["banktransfer" ], } }
71 Design recipe: banking example What if some kind of failure occurs between the two separate updates to the two accounts? decrease your account balance by 100$ Bank Send increase Paul s account balance by 100$
72 Design recipe: banking example What if some kind of failure occurs between the two separate updates to the two accounts? decrease your account balance by 100$ Bank Send increase Paul s account balance by 100$ Message lost during transmission
73 Design recipe: banking example What if some kind of failure occurs between the two separate updates to the two accounts? decrease your account balance by 100$ Bank Send increase Paul s account balance by 100$ Message lost during transmission CouchDB cannot guarantee the bank balance. A different strategy (design) must be adopted.
74 Banking recipe solution What if some kind of failure occurs between the two separate updates to the two accounts? CouchDB cannot guarantee the bank balance. A different strategy (design) must be adopted. id: transaction001 from: "bank_account_001", to: "bank_account_002", qty: 100, when: ,
75 Design recipe: banking example How do we read the current account balance? Map function(transaction){ emit(transaction.from, transaction.amount*-1); emit(transaction.to, transaction.amount); } Reduce function(key, values){ return sum(values); } Result {rows: [ {key: "bank_account_001", value: 900} ] {rows: [ {key: "bank_account_002", value: 1100} ] The reduce function receives: key= bank_account_001, values=[1000, -100] key= bank_account_002, values=[1000, 100]


76 Beyond relational databases Daniele Apiletti Data Base and Data Mining group Politecnico di Torino
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CIB Session 12th NoSQL Databases Structures
 CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
CIB Session 12th NoSQL Databases Structures By: Shahab Safaee & Morteza Zahedi Software Engineering PhD Email: safaee.shx@gmail.com, morteza.zahedi.a@gmail.com cibtrc.ir cibtrc cibtrc 2 Agenda What is
Webinar Series TMIP VISION
 Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Introduction Aggregate data model Distribution Models Consistency Map-Reduce Types of NoSQL Databases
 Introduction Aggregate data model Distribution Models Consistency Map-Reduce Types of NoSQL Databases Key-Value Document Column Family Graph John Edgar 2 Relational databases are the prevalent solution
Introduction Aggregate data model Distribution Models Consistency Map-Reduce Types of NoSQL Databases Key-Value Document Column Family Graph John Edgar 2 Relational databases are the prevalent solution
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Introduction to NoSQL Databases
 Introduction to NoSQL Databases Roman Kern KTI, TU Graz 2017-10-16 Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 1 / 31 Introduction Intro Why NoSQL? Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 2 / 31 Introduction
Introduction to NoSQL Databases Roman Kern KTI, TU Graz 2017-10-16 Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 1 / 31 Introduction Intro Why NoSQL? Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 2 / 31 Introduction
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Stages of Data Processing
 Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Data processing can be understood as the conversion of raw data into a meaningful and desired form. Basically, producing information that can be understood by the end user. So then, the question arises,
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Introduction to Big Data. NoSQL Databases. Instituto Politécnico de Tomar. Ricardo Campos
 Instituto Politécnico de Tomar Introduction to Big Data NoSQL Databases Ricardo Campos Mestrado EI-IC Análise e Processamento de Grandes Volumes de Dados Tomar, Portugal, 2016 Part of the slides used in
Instituto Politécnico de Tomar Introduction to Big Data NoSQL Databases Ricardo Campos Mestrado EI-IC Análise e Processamento de Grandes Volumes de Dados Tomar, Portugal, 2016 Part of the slides used in
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
COSC 416 NoSQL Databases. NoSQL Databases Overview. Dr. Ramon Lawrence University of British Columbia Okanagan
 COSC 416 NoSQL Databases NoSQL Databases Overview Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca Databases Brought Back to Life!!! Image copyright: www.dragoart.com Image
COSC 416 NoSQL Databases NoSQL Databases Overview Dr. Ramon Lawrence University of British Columbia Okanagan ramon.lawrence@ubc.ca Databases Brought Back to Life!!! Image copyright: www.dragoart.com Image
CompSci 516 Database Systems
 CompSci 516 Database Systems Lecture 20 NoSQL and Column Store Instructor: Sudeepa Roy Duke CS, Fall 2018 CompSci 516: Database Systems 1 Reading Material NOSQL: Scalable SQL and NoSQL Data Stores Rick
CompSci 516 Database Systems Lecture 20 NoSQL and Column Store Instructor: Sudeepa Roy Duke CS, Fall 2018 CompSci 516: Database Systems 1 Reading Material NOSQL: Scalable SQL and NoSQL Data Stores Rick
Databases : Lecture 1 2: Beyond ACID/Relational databases Timothy G. Griffin Lent Term Apologies to Martin Fowler ( NoSQL Distilled )
") Databases : Lecture 1 2: Beyond ACID/Relational databases Timothy G. Griffin Lent Term 2016 Rise of Web and cluster-based computing NoSQL Movement Relationships vs. Aggregates Key-value store XML or JSON
Databases : Lecture 1 2: Beyond ACID/Relational databases Timothy G. Griffin Lent Term 2016 Rise of Web and cluster-based computing NoSQL Movement Relationships vs. Aggregates Key-value store XML or JSON
NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY
 NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY WHAT IS NOSQL? Stands for No-SQL or Not Only SQL. Class of non-relational data storage systems E.g.
NOSQL EGCO321 DATABASE SYSTEMS KANAT POOLSAWASD DEPARTMENT OF COMPUTER ENGINEERING MAHIDOL UNIVERSITY WHAT IS NOSQL? Stands for No-SQL or Not Only SQL. Class of non-relational data storage systems E.g.
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Goal of the presentation is to give an introduction of NoSQL databases, why they are there.
 1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
1 Goal of the presentation is to give an introduction of NoSQL databases, why they are there. We want to present "Why?" first to explain the need of something like "NoSQL" and then in "What?" we go in
Understanding NoSQL Database Implementations
 Understanding NoSQL Database Implementations Sadalage and Fowler, Chapters 7 11 Class 07: Understanding NoSQL Database Implementations 1 Foreword NoSQL is a broad and diverse collection of technologies.
Understanding NoSQL Database Implementations Sadalage and Fowler, Chapters 7 11 Class 07: Understanding NoSQL Database Implementations 1 Foreword NoSQL is a broad and diverse collection of technologies.
Non-Relational Databases. Pelle Jakovits
 Non-Relational Databases Pelle Jakovits 25 October 2017 Outline Background Relational model Database scaling The NoSQL Movement CAP Theorem Non-relational data models Key-value Document-oriented Column
Non-Relational Databases Pelle Jakovits 25 October 2017 Outline Background Relational model Database scaling The NoSQL Movement CAP Theorem Non-relational data models Key-value Document-oriented Column
Jargons, Concepts, Scope and Systems. Key Value Stores, Document Stores, Extensible Record Stores. Overview of different scalable relational systems
 Jargons, Concepts, Scope and Systems Key Value Stores, Document Stores, Extensible Record Stores Overview of different scalable relational systems Examples of different Data stores Predictions, Comparisons
Jargons, Concepts, Scope and Systems Key Value Stores, Document Stores, Extensible Record Stores Overview of different scalable relational systems Examples of different Data stores Predictions, Comparisons
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem. Zohar Elkayam
 Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Things Every Oracle DBA Needs to Know about the Hadoop Ecosystem Zohar Elkayam www.realdbamagic.com Twitter: @realmgic Who am I? Zohar Elkayam, CTO at Brillix Programmer, DBA, team leader, database trainer,
Introduction to Computer Science. William Hsu Department of Computer Science and Engineering National Taiwan Ocean University
 Introduction to Computer Science William Hsu Department of Computer Science and Engineering National Taiwan Ocean University Chapter 9: Database Systems supplementary - nosql You can have data without
Introduction to Computer Science William Hsu Department of Computer Science and Engineering National Taiwan Ocean University Chapter 9: Database Systems supplementary - nosql You can have data without
Overview. * Some History. * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL. * NoSQL Taxonomy. *TowardsNewSQL
 * Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy * Towards NewSQL Overview * Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy *TowardsNewSQL NoSQL
* Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy * Towards NewSQL Overview * Some History * What is NoSQL? * Why NoSQL? * RDBMS vs NoSQL * NoSQL Taxonomy *TowardsNewSQL NoSQL
SCALABLE CONSISTENCY AND TRANSACTION MODELS
 Data Management in the Cloud SCALABLE CONSISTENCY AND TRANSACTION MODELS 69 Brewer s Conjecture Three properties that are desirable and expected from realworld shared-data systems C: data consistency A:
Data Management in the Cloud SCALABLE CONSISTENCY AND TRANSACTION MODELS 69 Brewer s Conjecture Three properties that are desirable and expected from realworld shared-data systems C: data consistency A:
NoSQL Databases. Amir H. Payberah. Swedish Institute of Computer Science. April 10, 2014
 NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
NoSQL Databases Amir H. Payberah Swedish Institute of Computer Science amir@sics.se April 10, 2014 Amir H. Payberah (SICS) NoSQL Databases April 10, 2014 1 / 67 Database and Database Management System
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Distributed Data Store
 Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
Distributed Data Store Large-Scale Distributed le system Q: What if we have too much data to store in a single machine? Q: How can we create one big filesystem over a cluster of machines, whose data is
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Advanced Database Technologies NoSQL: Not only SQL
 Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
Advanced Database Technologies NoSQL: Not only SQL Christian Grün Database & Information Systems Group NoSQL Introduction 30, 40 years history of well-established database technology all in vain? Not at
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 11. Advanced Aspects of Big Data Management Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/
NDBI040 Big Data Management and NoSQL Databases Lecture 11. Advanced Aspects of Big Data Management Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/
CISC 7610 Lecture 5 Distributed multimedia databases. Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL
 CISC 7610 Lecture 5 Distributed multimedia databases Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL Motivation YouTube receives 400 hours of video per minute That is 200M hours
CISC 7610 Lecture 5 Distributed multimedia databases Topics: Scaling up vs out Replication Partitioning CAP Theorem NoSQL NewSQL Motivation YouTube receives 400 hours of video per minute That is 200M hours
NoSQL systems: sharding, replication and consistency. Riccardo Torlone Università Roma Tre
 NoSQL systems: sharding, replication and consistency Riccardo Torlone Università Roma Tre Data distribution NoSQL systems: data distributed over large clusters Aggregate is a natural unit to use for data
NoSQL systems: sharding, replication and consistency Riccardo Torlone Università Roma Tre Data distribution NoSQL systems: data distributed over large clusters Aggregate is a natural unit to use for data
CSE 530A. Non-Relational Databases. Washington University Fall 2013
 CSE 530A Non-Relational Databases Washington University Fall 2013 NoSQL "NoSQL" was originally the name of a specific RDBMS project that did not use a SQL interface Was co-opted years later to refer to
CSE 530A Non-Relational Databases Washington University Fall 2013 NoSQL "NoSQL" was originally the name of a specific RDBMS project that did not use a SQL interface Was co-opted years later to refer to
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
A Study of NoSQL Database
 A Study of NoSQL Database International Journal of Engineering Research & Technology (IJERT) Biswajeet Sethi 1, Samaresh Mishra 2, Prasant ku. Patnaik 3 1,2,3 School of Computer Engineering, KIIT University
A Study of NoSQL Database International Journal of Engineering Research & Technology (IJERT) Biswajeet Sethi 1, Samaresh Mishra 2, Prasant ku. Patnaik 3 1,2,3 School of Computer Engineering, KIIT University
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Databases and Big Data Today. CS634 Class 22
 Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
Databases and Big Data Today CS634 Class 22 Current types of Databases SQL using relational tables: still very important! NoSQL, i.e., not using relational tables: term NoSQL popular since about 2007.
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS
 MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
MODERN BIG DATA DESIGN PATTERNS CASE DRIVEN DESINGS SUJEE MANIYAM FOUNDER / PRINCIPAL @ ELEPHANT SCALE www.elephantscale.com sujee@elephantscale.com HI, I M SUJEE MANIYAM Founder / Principal @ ElephantScale
Big Data Analytics. Rasoul Karimi
 Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
Big Data Analytics Rasoul Karimi Information Systems and Machine Learning Lab (ISMLL) Institute of Computer Science University of Hildesheim, Germany Big Data Analytics Big Data Analytics 1 / 1 Outline
NoSQL Databases MongoDB vs Cassandra. Kenny Huynh, Andre Chik, Kevin Vu
 NoSQL Databases MongoDB vs Cassandra Kenny Huynh, Andre Chik, Kevin Vu Introduction - Relational database model - Concept developed in 1970 - Inefficient - NoSQL - Concept introduced in 1980 - Related
NoSQL Databases MongoDB vs Cassandra Kenny Huynh, Andre Chik, Kevin Vu Introduction - Relational database model - Concept developed in 1970 - Inefficient - NoSQL - Concept introduced in 1980 - Related
Distributed Computation Models
 Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
Distributed Computation Models SWE 622, Spring 2017 Distributed Software Engineering Some slides ack: Jeff Dean HW4 Recap https://b.socrative.com/ Class: SWE622 2 Review Replicating state machines Case
CMU SCS CMU SCS Who: What: When: Where: Why: CMU SCS
 Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB s C. Faloutsos A. Pavlo Lecture#23: Distributed Database Systems (R&G ch. 22) Administrivia Final Exam Who: You What: R&G Chapters 15-22
Carnegie Mellon Univ. Dept. of Computer Science 15-415/615 - DB s C. Faloutsos A. Pavlo Lecture#23: Distributed Database Systems (R&G ch. 22) Administrivia Final Exam Who: You What: R&G Chapters 15-22
PROFESSIONAL. NoSQL. Shashank Tiwari WILEY. John Wiley & Sons, Inc.
 PROFESSIONAL NoSQL Shashank Tiwari WILEY John Wiley & Sons, Inc. Examining CONTENTS INTRODUCTION xvil CHAPTER 1: NOSQL: WHAT IT IS AND WHY YOU NEED IT 3 Definition and Introduction 4 Context and a Bit
PROFESSIONAL NoSQL Shashank Tiwari WILEY John Wiley & Sons, Inc. Examining CONTENTS INTRODUCTION xvil CHAPTER 1: NOSQL: WHAT IT IS AND WHY YOU NEED IT 3 Definition and Introduction 4 Context and a Bit
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Relational databases
 COSC 6397 Big Data Analytics NoSQL databases Edgar Gabriel Spring 2017 Relational databases Long lasting industry standard to store data persistently Key points concurrency control, transactions, standard
COSC 6397 Big Data Analytics NoSQL databases Edgar Gabriel Spring 2017 Relational databases Long lasting industry standard to store data persistently Key points concurrency control, transactions, standard
Architekturen für die Cloud
 Architekturen für die Cloud Eberhard Wolff Architecture & Technology Manager adesso AG 08.06.11 What is Cloud? National Institute for Standards and Technology (NIST) Definition On-demand self-service >
Architekturen für die Cloud Eberhard Wolff Architecture & Technology Manager adesso AG 08.06.11 What is Cloud? National Institute for Standards and Technology (NIST) Definition On-demand self-service >
Chapter 24 NOSQL Databases and Big Data Storage Systems
 Chapter 24 NOSQL Databases and Big Data Storage Systems - Large amounts of data such as social media, Web links, user profiles, marketing and sales, posts and tweets, road maps, spatial data, email - NOSQL
Chapter 24 NOSQL Databases and Big Data Storage Systems - Large amounts of data such as social media, Web links, user profiles, marketing and sales, posts and tweets, road maps, spatial data, email - NOSQL
Databases : Lectures 11 and 12: Beyond ACID/Relational databases Timothy G. Griffin Lent Term 2013
 Databases : Lectures 11 and 12: Beyond ACID/Relational databases Timothy G. Griffin Lent Term 2013 Rise of Web and cluster-based computing NoSQL Movement Relationships vs. Aggregates Key-value store XML
Databases : Lectures 11 and 12: Beyond ACID/Relational databases Timothy G. Griffin Lent Term 2013 Rise of Web and cluster-based computing NoSQL Movement Relationships vs. Aggregates Key-value store XML
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
Introduction to NoSQL
 Introduction to NoSQL Agenda History What is NoSQL Types of NoSQL The CAP theorem History - RDBMS Relational DataBase Management Systems were invented in the 1970s. E. F. Codd, "Relational Model of Data
Introduction to NoSQL Agenda History What is NoSQL Types of NoSQL The CAP theorem History - RDBMS Relational DataBase Management Systems were invented in the 1970s. E. F. Codd, "Relational Model of Data
CSE 544 Principles of Database Management Systems. Magdalena Balazinska Winter 2015 Lecture 14 NoSQL
 CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2015 Lecture 14 NoSQL References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No.
CSE 544 Principles of Database Management Systems Magdalena Balazinska Winter 2015 Lecture 14 NoSQL References Scalable SQL and NoSQL Data Stores, Rick Cattell, SIGMOD Record, December 2010 (Vol. 39, No.
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Modern Database Concepts
 Modern Database Concepts Basic Principles Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz NoSQL Overview Main objective: to implement a distributed state Different objects stored on different
Modern Database Concepts Basic Principles Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz NoSQL Overview Main objective: to implement a distributed state Different objects stored on different
CAP Theorem. March 26, Thanks to Arvind K., Dong W., and Mihir N. for slides.
 C A CAP Theorem P March 26, 2018 Thanks to Arvind K., Dong W., and Mihir N. for slides. CAP Theorem It is impossible for a web service to provide these three guarantees at the same time (pick 2 of 3):
C A CAP Theorem P March 26, 2018 Thanks to Arvind K., Dong W., and Mihir N. for slides. CAP Theorem It is impossible for a web service to provide these three guarantees at the same time (pick 2 of 3):
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES
 1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
1 THE ATLAS DISTRIBUTED DATA MANAGEMENT SYSTEM & DATABASES Vincent Garonne, Mario Lassnig, Martin Barisits, Thomas Beermann, Ralph Vigne, Cedric Serfon Vincent.Garonne@cern.ch ph-adp-ddm-lab@cern.ch XLDB
Comparing SQL and NOSQL databases
 COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
COSC 6397 Big Data Analytics Data Formats (II) HBase Edgar Gabriel Spring 2014 Comparing SQL and NOSQL databases Types Development History Data Storage Model SQL One type (SQL database) with minor variations
Motivation Overview of NoSQL space Comparing technologies used Getting hands dirty tutorial section
 NOSQL 1 GOAL Motivation Overview of NoSQL space Comparing technologies used Getting hands dirty tutorial section 2 MOTIVATION Assume we have a product that becomes popular 3. 1 TYPICAL WEBSERVER ARCHITECTURE
NOSQL 1 GOAL Motivation Overview of NoSQL space Comparing technologies used Getting hands dirty tutorial section 2 MOTIVATION Assume we have a product that becomes popular 3. 1 TYPICAL WEBSERVER ARCHITECTURE
MapR Enterprise Hadoop
 2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Database Architectures
 Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 4/15/15 Agenda Check-in Parallelism and Distributed Databases Technology Research Project Introduction to NoSQL
Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 4/15/15 Agenda Check-in Parallelism and Distributed Databases Technology Research Project Introduction to NoSQL
Integrity in Distributed Databases
 Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Extreme Computing. NoSQL.
 Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Perspectives on NoSQL
 Perspectives on NoSQL PGCon 2010 Gavin M. Roy What is NoSQL? NoSQL is a movement promoting a loosely defined class of nonrelational data stores that break with a long history of relational
Perspectives on NoSQL PGCon 2010 Gavin M. Roy What is NoSQL? NoSQL is a movement promoting a loosely defined class of nonrelational data stores that break with a long history of relational
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
CS 655 Advanced Topics in Distributed Systems
 Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
Presented by : Walid Budgaga CS 655 Advanced Topics in Distributed Systems Computer Science Department Colorado State University 1 Outline Problem Solution Approaches Comparison Conclusion 2 Problem 3
NoSQL systems. Lecture 21 (optional) Instructor: Sudeepa Roy. CompSci 516 Data Intensive Computing Systems
 Instructor: Sudeepa Roy. CompSci 516 Data Intensive Computing Systems") CompSci 516 Data Intensive Computing Systems Lecture 21 (optional) NoSQL systems Instructor: Sudeepa Roy Duke CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Key- Value Stores Duke CS,
CompSci 516 Data Intensive Computing Systems Lecture 21 (optional) NoSQL systems Instructor: Sudeepa Roy Duke CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Key- Value Stores Duke CS,
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Distributed Non-Relational Databases. Pelle Jakovits
 Distributed Non-Relational Databases Pelle Jakovits Tartu, 7 December 2018 Outline Relational model NoSQL Movement Non-relational data models Key-value Document-oriented Column family Graph Non-relational
Distributed Non-Relational Databases Pelle Jakovits Tartu, 7 December 2018 Outline Relational model NoSQL Movement Non-relational data models Key-value Document-oriented Column family Graph Non-relational
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
New Approaches to Big Data Processing and Analytics
 New Approaches to Big Data Processing and Analytics Contributing authors: David Floyer, David Vellante Original publication date: February 12, 2013 There are number of approaches to processing and analyzing
New Approaches to Big Data Processing and Analytics Contributing authors: David Floyer, David Vellante Original publication date: February 12, 2013 There are number of approaches to processing and analyzing
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Advances in Data Management - NoSQL, NewSQL and Big Data A.Poulovassilis
 Advances in Data Management - NoSQL, NewSQL and Big Data A.Poulovassilis 1 NoSQL So-called NoSQL systems offer reduced functionalities compared to traditional Relational DBMS, with the aim of achieving
Advances in Data Management - NoSQL, NewSQL and Big Data A.Poulovassilis 1 NoSQL So-called NoSQL systems offer reduced functionalities compared to traditional Relational DBMS, with the aim of achieving
DEMYSTIFYING BIG DATA WITH RIAK USE CASES. Martin Schneider Basho Technologies!
 DEMYSTIFYING BIG DATA WITH RIAK USE CASES Martin Schneider Basho Technologies! Agenda Defining Big Data in Regards to Riak A Series of Trade-Offs Use Cases Q & A About Basho & Riak Basho Technologies is
DEMYSTIFYING BIG DATA WITH RIAK USE CASES Martin Schneider Basho Technologies! Agenda Defining Big Data in Regards to Riak A Series of Trade-Offs Use Cases Q & A About Basho & Riak Basho Technologies is
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Cassandra- A Distributed Database
 Cassandra- A Distributed Database Tulika Gupta Department of Information Technology Poornima Institute of Engineering and Technology Jaipur, Rajasthan, India Abstract- A relational database is a traditional
Cassandra- A Distributed Database Tulika Gupta Department of Information Technology Poornima Institute of Engineering and Technology Jaipur, Rajasthan, India Abstract- A relational database is a traditional
Chase Wu New Jersey Institute of Technology
 CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
CS 644: Introduction to Big Data Chapter 4. Big Data Analytics Platforms Chase Wu New Jersey Institute of Technology Some of the slides were provided through the courtesy of Dr. Ching-Yung Lin at Columbia
Big Data Fundamentals
 Big Data Fundamentals. Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides and audio/video recordings of this class lecture are at: 18-1 Overview 1. Why
Big Data Fundamentals. Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu These slides and audio/video recordings of this class lecture are at: 18-1 Overview 1. Why
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
4/9/2018 Week 13-A Sangmi Lee Pallickara. CS435 Introduction to Big Data Spring 2018 Colorado State University. FAQs. Architecture of GFS
 W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
W13.A.0.0 CS435 Introduction to Big Data W13.A.1 FAQs Programming Assignment 3 has been posted PART 2. LARGE SCALE DATA STORAGE SYSTEMS DISTRIBUTED FILE SYSTEMS Recitations Apache Spark tutorial 1 and
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
NoSQL systems: introduction and data models. Riccardo Torlone Università Roma Tre
 NoSQL systems: introduction and data models Riccardo Torlone Università Roma Tre Leveraging the NoSQL boom 2 Why NoSQL? In the last fourty years relational databases have been the default choice for serious
NoSQL systems: introduction and data models Riccardo Torlone Università Roma Tre Leveraging the NoSQL boom 2 Why NoSQL? In the last fourty years relational databases have been the default choice for serious