Managing and Mining Billion Node Graphs. Haixun Wang Microsoft Research Asia
|
|
|
- Estella Washington
- 5 years ago
- Views:
Transcription
1 Managing and Mining Billion Node Graphs Haixun Wang Microsoft Research Asia
2 Outline Overview Storage Online query processing Offline graph analytics Advanced applications
3 Is it hard to manage graphs? Good systems for processing graphs: PBGL, Neo4j Good systems for processing large data: Map/Reduce, Hadoop Good systems for processing large graph data: Specialized systems for pagerank, etc.
4 This is hard. Graph System Big Data System General System
5 Existing Systems Native Graph* Online Query Index Transaction Support Parallel Graph Processing Topology in memory Distributed Neo4j YES YES Lucene YES NO NO NO HyperGraphDB NO YES Built-in YES NO NO NO InfiniteGraph NO YES Built-in + Lucene NO NO NO YES Pregel NO NO NO NO YES NO YES.
6 An Example: Online Query Processing in Graphs

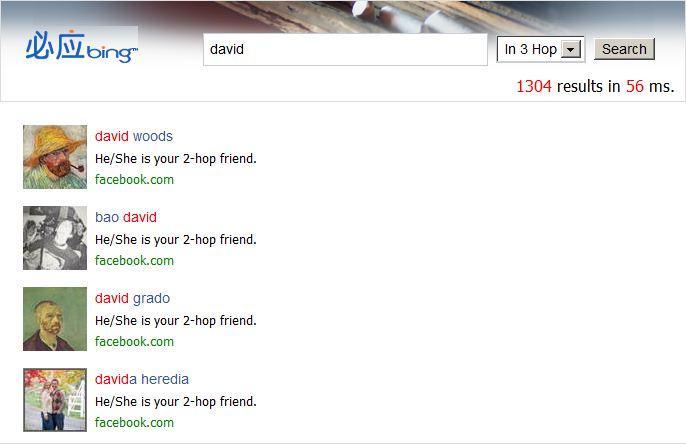
7 People Search Demo
8 Very efficient graph exploration Visiting 2.2 million nodes on 8 machines in 100ms Graph models Relational Matrix Native (Trinity) Relation/Matrix requires data join operations for graph exploration Costly and producing large intermediary results
9 Joins vs. Graph Exploration for subgraph matching Subgraph matching Index sub-structures Decompose a query into a set of sub-structures Query each sub-structure Join intermediary results Index size and construction time Super-linear for any non-trivial sub-structure Infeasible for billion node graphs Graph exploration No structural index is needed Very few join operations Small intermediary results

10 SPARQL Query On Satori Microsoft s Knowledge System One of the world s largest repository of knowledge Billion 5x 4 Billion 3x 12 Billion Jun Dec Jun (expected)
11 Compare with RDF-3x RDF3x is a state-of-the-art single node RDF engine Dataset Statistics LUBM-10240, a public benchmark for RDF Triple number: 1.36 billion Subject/Object number: 0.3 billion Queries are chosen from the benchmark queries published with LUBM Query ID Our System RDF-3x 39m2s
12 Subgraph matching on a billion node graph No feasible solution for billion node graphs Super-linear index is not feasible Desiderata: requiring no index
13 Subgraph Match Query
14 Scale to size One size fits all? Disk-based Key-value Store Column Store Document Store Typical RDBMS In-memory Key-value Store Graph DB SQL Comfort Zone Scale to complexity
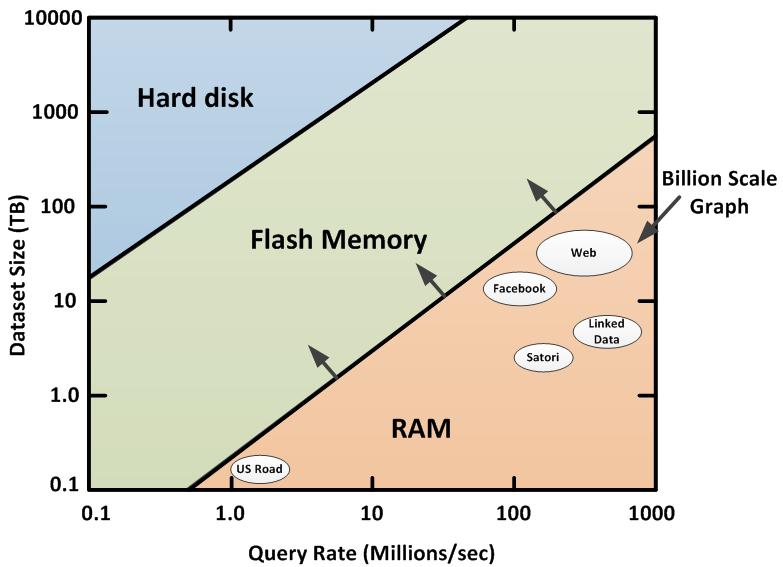
15 Memory-based Systems

16 Trinity A distributed, in-memory key/value store A graph database for online query processing A parallel platform for offline graph analytics
17 Graphs # of Edges 1 trillion the Web 104 billion Facebook 31 billion Linked Data 5.6 billion Satori 58 million US Road Map # of Nodes 24 million 504 million 800 million 1.4 billion 50 billion
18 # of Edges How many machines? 1 trillion the Web: 275 Trinity machines 104 billion Facebook: 25 Trinity machines 31 billion 5.6 billion Linked Data: 16 Trinity machines Satori: 4-10 Trinity machines 58 million US Road Map: 1 Trinity machine # of Nodes 24 million 504 million 800 million 1.4 billion 50 billion
19 Performance Highlight Graph DB (online query processing): visiting 2.2 million users (3 hop neighborhood) on Facebook: <= 100ms foundation for graph-based service, e.g., entity search Computing platform (offline graph analytics): one iteration on a 1 billion node graph: <= 60sec foundation for analytics, e.g., social analytics
20 Performance Highlight Typical Job State-of-the-Art Trinity N hop People Search 2 hop search 100 ms; 3 hop is not doable online 2 hop search in 10ms 3 hop search in 100ms Subgraph Matching For billion node graphs, indexing takes months to build No structural index required; response time 500 ms (Approximate) Shortest Distances/Paths No efficient solution for large graphs 10 ms for discovering shortest paths within 6-hops PageRank of Web Graph Cosmos/MapReduce: 2 days using thousands of machines 1 iteration on 1B graph 60sec using 10 machines Billion Node Graph Partitioning <22M nodes Billions of nodes Graph Generation For small graph only Generates 1 billion node graph of power law distribution in 15 minutes
21 Applications Algorithms Trinity Programming models Computation platform Query processing engine Storage infrastructures
22 Storage and Communication
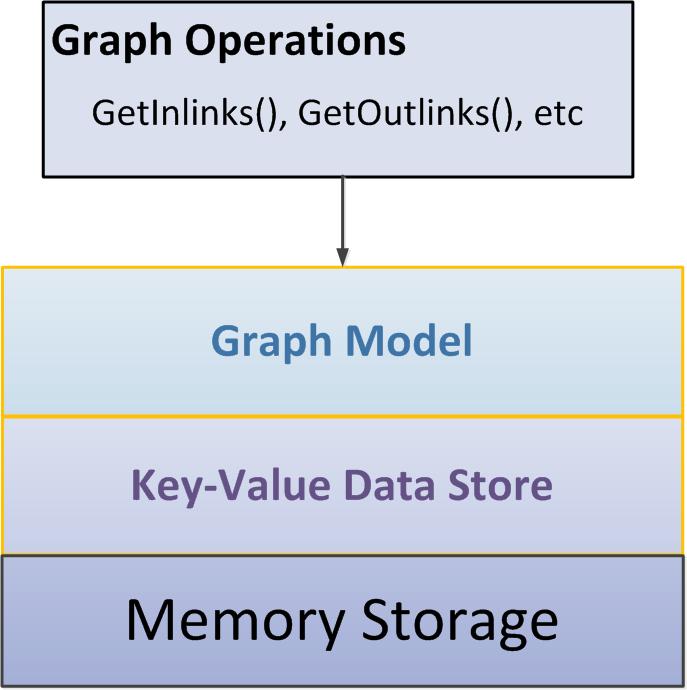
23
 Edge has rich info: an independent cell")
24 Modeling a graph Basic data structure: Cell A graph node is a Cell A graph edge may or may not be a Cell Edge has no info Edge has very simple info (e.g., label, weight) Edge has rich info: an independent cell
25 Cell Schema Example public class mycell: ISubgraphMatchCell, IVisualCellParser { public byte[] label; public List<long> inlinks; public List<long> outlinks; internal long cell_id; public unsafe byte[] ToBinary(); public unsafe ISubgraphMatchCell FromBinary(byte[] bytes); } public void VisualParseCell(long nodeid, byte[] cell_bytes, VisualizerCallbackToolkit toolkit); Subgraph Matching Cell

26 Cell Transformation and Cell Parsing
27 Cell Transformation SubgraphMatch Cell DFS Cell
28 Partitioning Default: random partitioning by hashing Customizing hashing function Re-partitioning a graph (as an analytical job)
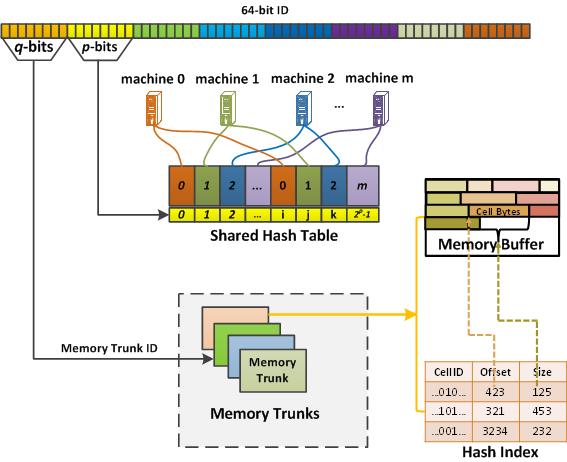
29 Cell Addressing
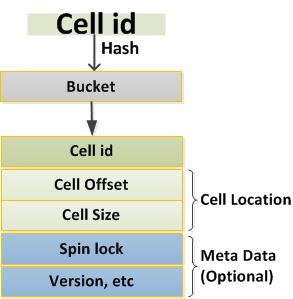
30 Cell Addressing

31 Big cell A warning to graph system builders: Lady Gaga has 40,000,000 fans. Her cell takes 320 Mb.


32 Cell as memory objects vs. blobs A memory object Runtime object on heap A Blob A binary stream Benefit: 50,000,000 cells, each of size 35 bytes CLR heap objects: 3,934 MB Flat memory streams: 1,668 MB Challenge: Parsing vs.

33 Data Model

34 In-place Blob Update The operations to a cell can be translated to memory manipulations to blob using a cell parser, e.g.
35 Cell Placements in Memory Cells are of different size Two types of applications: Mostly read-only, few cell-expansion operations (e.g., a knowledge taxonomy, a semantic network) Many cell-expansion operations (e.g., synthetic graph generation)
36 Cell Placements in Memory Sequential memory storage Cells are continuously stored in memory Compact. Sparse hash storage A cell may be stored as non-continuous blocks Dynamic. (streaming updates)
37 Concurrent Sequential Memory Allocation Concurrent Memory Allocation Request Atomically Incrementing Memory Pointer (A CAS-compare and swap-instruction) Concurrent write from allocated buffer header
38 Concurrent operations on a cell (using a Spin Cell Lock) while(cas(ref lockarray[index], 1, 0)!= 0); if(cas(ref spin_lock, 1, 0)!= 0) { While(true) { if(volatile_read(ref spin_lock) == 0 && CAS(ref lockarray[index], 1, 0) == 0) return; } } Optimized Version
39 Hash Storage The memory address space is a hash space. Use a hash function to allocate memory. Support lock-free streaming cell updates.
40 Hash Storage head id links -1 head id links -1 head id1 links jmp head id links -1 links jmp head id links -1 Chaining Links -1
41 Conflict Resolution in Hash Storage Conflicts Two node IDs are hashed to the same slot One node ID is hashed to the middle of the other Rehashing
42 Concurrency Control To lock: change HEAD flag to OCCUPY flag To unlock: change OCCUPY back to HEAD The Flag changing must be atomic (e.g. Interlocked CAS) HEAD id links -1 OCCUPY id links -1
43 Fast Billion Node Graph Generator Challenge: i) massive random access; ii) cell size change Existing graph generators Slow For small graphs only Trinity graph generator generate a 1 billion node graph of power law distribution in 15 minutes

44 Trinity Graph Generator parallel execution in the entire cluster edge #: 10 B node #: 1 B graph type
45 Offline Graph Analytics
46 Vertex-Based Graph Computation
47 Page Rank Script public class Cell : BaseCell { public int OutDegree; public Message message; Local Variables public override void Initialize() { OutDegree = outlinks.length; message.pagerankscore = 1.0f / GlobalNodeNumber; } public override void Computation() { float PageRankScore = 0; if (CurrentIterationRoundNumber > 100) VoteToStop(); foreach (long msg_id in inlinks) { Message msg = (Message)CacheManager.GetMessage(msg_id); PageRankScore += msg.pagerankscore; } message.pagerankscore = PageRankScore / OutDegree; } } Vertex-based Computation Fetch Message Generate New Message public struct Message { public float PageRankScore; }
48 Vertex-based Computation Take each graph vertex as a processor Synchronous communication model (BSP) Used in Pregel and its open source variants, such as Giraph and GoldenOrb
49 Restricted vertex-based computation In each super step, the sender and receiver set are known beforehand Messages can be categorized by their hotness Messages can be pre-fetched and cached
50 A bi-partite view Local Vertices Remote Vertices
51 A bi-partite view Local Vertices Remote Vertices
52 How many machines do we need? Facebook 800 million users, 130 friends per user 30 Trinity machines Web 25 billion pages, 40 links per page 150 Trinity machines 30 Trinity machines
53 Distribution-Aware Computing Support message sending by two APIs: Local message sending sending messages to neighboring nodes on the same machine Message sending sending messages to neighboring nodes
54 Distribution-Aware Computing Nodes are distributed on N machines (randomly) Each machine has 1/N nodes, and d/n edges Can we perform computation on 1 machine and estimate the results for the entire graph? Graph density estimation Can we perform computation on each machine locally, and aggregate their results as the final step? Finding connected components
55 Distributed betweenness Betweeness is the most effective guideline to select landmarks Exact betweenness costs O(nm) time, unacceptable on large graphs Approximate fast betweenness is expected Count shortest paths rooted at sampled vertices Count shortest path with limited depth On distributed platform We count the shortest paths within each machines approximation
56 How many machines do we need? Facebook 800 million users, 130 friends per user 30 Trinity machines 1 Trinity machine Web 25 billion pages, 40 links per page 150 Trinity machines 1 Trinity machine
57 Billion-node graph partitioning
58 Why partition? Divide a graph into k (almost) equal-size partitions, such that the number of edges between partitions is minimized. A better partition helps Load balance Reduce communication Example: BFS on the graph Best partitioning needs 3 communications Worst partitioning needs 17 e g f h a c b d i k j l
59 State-of-art method: Metis A multi-level framework Three phrases Coarsening by maximal match until the graph is small enough Partition the coarsest graph by KL algorithm [kl1972] Uncoarsening Ref: [Metis 1995]
60 Weakness of metis Not semantic aware: Coarsening is ineffective on real graphs Principle of coarsening An optimal partitioning on a coarser graph implies a good partitioning in the finer graph Coarsening by maximal match can guarantee this only when node degree is bounded, for example 2D, 3D meshes Real networks have skewed degree c, f e, g h, i distribution Inefficiency To support uncoarsening, many mappings and intermediate graphs need to be stored, leading to bad performance For example, a 4M graphs consumes 10G memory Not general enough Exclusive for partitioning a, d b, j k, l
61 Suggested solution : Multi-level Label Propagation Coarsening by label propagation Lightweight Can be easily implemented by message passing Semantic aware Can discover the inherent community structure of real graph Label propagation In each iteration, a vertex takes the label that is prevalent in its neighborhood as its own label. C 1 C 2 C 3
62 Handling Imbalance Imbalance: Too many small clusters Some extremely large clusters (monster clusters) Our approach First, we set size constraint on each label, to limit monster clusters Second, we use the following model to merge small cluster multiprocessor scheduling (MS) weighted graph partitioning (WGP)
63 Results - quality and performance Quality is comparable to Metis Performance is significantly better than Metis
64 Results- Scalability We use 8 machines, each of which has 48G memory. Our solution takes 4 hours on a graph with 512M node and 6.5G edges
65 Community search on large graphs
66 Distance Oracle
67 Why approximate distance oracle? What is your Erdos number? The shortest distance from you to mathematician Paul Erdos in the scientific collaboration network Shortest distance can also be used to compute centrality, betweenness Exact solutions Online computation Dijkstra-like algorithms, BFS At least linear complexity, computational prohibitive on large graphs Pre-computing all pairs of shortest path Of quadratic space complexity Approximate distance oracle Report approximate distance between any two vertices in a graph in constant time by pre-computation When graph is huge, approximation is acceptable, and precomputation is necessary
68 Current Solutions Two possible solutions Coordinate based Sketch based Problem solved Approximate distance in (almost) constant time by pre-computation. Currently for undirected, un-weighted graph only With potential consideration for dynamic graphs
69 Distributed betweenness Betweeness is the most effective guideline to select landmarks Exact betweenness costs O(nm) time, unacceptable on large graphs Approximate fast betweenness is expected Count shortest paths rooted at sampled vertices Count shortest path with limited depth On distributed platform We count the shortest paths within each machines approximation
70 Information about Trinity
71 Thanks!
72
73 Buffered Asynchronous Message Sender Lock free
modern database systems lecture 10 : large-scale graph processing
 modern database systems lecture 1 : large-scale graph processing Aristides Gionis spring 18 timeline today : homework is due march 6 : homework out april 5, 9-1 : final exam april : homework due graphs
modern database systems lecture 1 : large-scale graph processing Aristides Gionis spring 18 timeline today : homework is due march 6 : homework out april 5, 9-1 : final exam april : homework due graphs
Distributed Systems. 21. Graph Computing Frameworks. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 21. Graph Computing Frameworks Paul Krzyzanowski Rutgers University Fall 2016 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Can we make MapReduce easier? November 21, 2016 2014-2016
Distributed Systems 21. Graph Computing Frameworks Paul Krzyzanowski Rutgers University Fall 2016 November 21, 2016 2014-2016 Paul Krzyzanowski 1 Can we make MapReduce easier? November 21, 2016 2014-2016
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 60 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Pregel: A System for Large-Scale Graph Processing
ECE 60 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 3: Programming Models Pregel: A System for Large-Scale Graph Processing
Data-Intensive Computing with MapReduce
 Data-Intensive Computing with MapReduce Session 5: Graph Processing Jimmy Lin University of Maryland Thursday, February 21, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Computing with MapReduce Session 5: Graph Processing Jimmy Lin University of Maryland Thursday, February 21, 2013 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Link Analysis in the Cloud
 Cloud Computing Link Analysis in the Cloud Dell Zhang Birkbeck, University of London 2017/18 Graph Problems & Representations What is a Graph? G = (V,E), where V represents the set of vertices (nodes)
Cloud Computing Link Analysis in the Cloud Dell Zhang Birkbeck, University of London 2017/18 Graph Problems & Representations What is a Graph? G = (V,E), where V represents the set of vertices (nodes)
Apache Giraph. for applications in Machine Learning & Recommendation Systems. Maria Novartis
 Apache Giraph for applications in Machine Learning & Recommendation Systems Maria Stylianou @marsty5 Novartis Züri Machine Learning Meetup #5 June 16, 2014 Apache Giraph for applications in Machine Learning
Apache Giraph for applications in Machine Learning & Recommendation Systems Maria Stylianou @marsty5 Novartis Züri Machine Learning Meetup #5 June 16, 2014 Apache Giraph for applications in Machine Learning
One Trillion Edges. Graph processing at Facebook scale
 One Trillion Edges Graph processing at Facebook scale Introduction Platform improvements Compute model extensions Experimental results Operational experience How Facebook improved Apache Giraph Facebook's
One Trillion Edges Graph processing at Facebook scale Introduction Platform improvements Compute model extensions Experimental results Operational experience How Facebook improved Apache Giraph Facebook's
Large-Scale Graph Processing 1: Pregel & Apache Hama Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC
 CSIE, NDHU, Taiwan, ROC") Large-Scale Graph Processing 1: Pregel & Apache Hama Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei
Large-Scale Graph Processing 1: Pregel & Apache Hama Shiow-yang Wu ( 吳秀陽 ) CSIE, NDHU, Taiwan, ROC Lecture material is mostly home-grown, partly taken with permission and courtesy from Professor Shih-Wei
Graph Analytics in the Big Data Era
 Graph Analytics in the Big Data Era Yongming Luo, dr. George H.L. Fletcher Web Engineering Group What is really hot? 19-11-2013 PAGE 1 An old/new data model graph data Model entities and relations between
Graph Analytics in the Big Data Era Yongming Luo, dr. George H.L. Fletcher Web Engineering Group What is really hot? 19-11-2013 PAGE 1 An old/new data model graph data Model entities and relations between
G(B)enchmark GraphBench: Towards a Universal Graph Benchmark. Khaled Ammar M. Tamer Özsu
enchmark GraphBench: Towards a Universal Graph Benchmark. Khaled Ammar M. Tamer Özsu") G(B)enchmark GraphBench: Towards a Universal Graph Benchmark Khaled Ammar M. Tamer Özsu Bioinformatics Software Engineering Social Network Gene Co-expression Protein Structure Program Flow Big Graphs o
G(B)enchmark GraphBench: Towards a Universal Graph Benchmark Khaled Ammar M. Tamer Özsu Bioinformatics Software Engineering Social Network Gene Co-expression Protein Structure Program Flow Big Graphs o
E6885 Network Science Lecture 10: Graph Database (II)
") E 6885 Topics in Signal Processing -- Network Science E6885 Network Science Lecture 10: Graph Database (II) Ching-Yung Lin, Dept. of Electrical Engineering, Columbia University November 18th, 2013 Course
E 6885 Topics in Signal Processing -- Network Science E6885 Network Science Lecture 10: Graph Database (II) Ching-Yung Lin, Dept. of Electrical Engineering, Columbia University November 18th, 2013 Course
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Jure Leskovec Including joint work with Y. Perez, R. Sosič, A. Banarjee, M. Raison, R. Puttagunta, P. Shah
 Jure Leskovec (@jure) Including joint work with Y. Perez, R. Sosič, A. Banarjee, M. Raison, R. Puttagunta, P. Shah 2 My research group at Stanford: Mining and modeling large social and information networks
Jure Leskovec (@jure) Including joint work with Y. Perez, R. Sosič, A. Banarjee, M. Raison, R. Puttagunta, P. Shah 2 My research group at Stanford: Mining and modeling large social and information networks
Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing
 /34 Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat 1 Karim Awara 1 Amani Alonazi 1 Hani Jamjoom 2 Dan Williams 2 Panos Kalnis 1 1 King Abdullah University of
/34 Mizan: A System for Dynamic Load Balancing in Large-scale Graph Processing Zuhair Khayyat 1 Karim Awara 1 Amani Alonazi 1 Hani Jamjoom 2 Dan Williams 2 Panos Kalnis 1 1 King Abdullah University of
A New Parallel Algorithm for Connected Components in Dynamic Graphs. Robert McColl Oded Green David Bader
 A New Parallel Algorithm for Connected Components in Dynamic Graphs Robert McColl Oded Green David Bader Overview The Problem Target Datasets Prior Work Parent-Neighbor Subgraph Results Conclusions Problem
A New Parallel Algorithm for Connected Components in Dynamic Graphs Robert McColl Oded Green David Bader Overview The Problem Target Datasets Prior Work Parent-Neighbor Subgraph Results Conclusions Problem
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 10. Graph databases Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Graph Databases Basic
NDBI040 Big Data Management and NoSQL Databases Lecture 10. Graph databases Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Graph Databases Basic
Jordan Boyd-Graber University of Maryland. Thursday, March 3, 2011
 Data-Intensive Information Processing Applications! Session #5 Graph Algorithms Jordan Boyd-Graber University of Maryland Thursday, March 3, 2011 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Information Processing Applications! Session #5 Graph Algorithms Jordan Boyd-Graber University of Maryland Thursday, March 3, 2011 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Graph-Processing Systems. (focusing on GraphChi)
") Graph-Processing Systems (focusing on GraphChi) Recall: PageRank in MapReduce (Hadoop) Input: adjacency matrix H D F S (a,[c]) (b,[a]) (c,[a,b]) (c,pr(a) / out (a)), (a,[c]) (a,pr(b) / out (b)), (b,[a])
Graph-Processing Systems (focusing on GraphChi) Recall: PageRank in MapReduce (Hadoop) Input: adjacency matrix H D F S (a,[c]) (b,[a]) (c,[a,b]) (c,pr(a) / out (a)), (a,[c]) (a,pr(b) / out (b)), (b,[a])
On Smart Query Routing: For Distributed Graph Querying with Decoupled Storage
 On Smart Query Routing: For Distributed Graph Querying with Decoupled Storage Arijit Khan Nanyang Technological University (NTU), Singapore Gustavo Segovia ETH Zurich, Switzerland Donald Kossmann Microsoft
On Smart Query Routing: For Distributed Graph Querying with Decoupled Storage Arijit Khan Nanyang Technological University (NTU), Singapore Gustavo Segovia ETH Zurich, Switzerland Donald Kossmann Microsoft
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU
 Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Fall 2018: Introduction to Data Science GIRI NARASIMHAN, SCIS, FIU !2 MapReduce Overview! Sometimes a single computer cannot process data or takes too long traditional serial programming is not always
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Grid Computing Systems: A Survey and Taxonomy
 Grid Computing Systems: A Survey and Taxonomy Material for this lecture from: A Survey and Taxonomy of Resource Management Systems for Grid Computing Systems, K. Krauter, R. Buyya, M. Maheswaran, CS Technical
Grid Computing Systems: A Survey and Taxonomy Material for this lecture from: A Survey and Taxonomy of Resource Management Systems for Grid Computing Systems, K. Krauter, R. Buyya, M. Maheswaran, CS Technical
Graph Data Management
 Graph Data Management Analysis and Optimization of Graph Data Frameworks presented by Fynn Leitow Overview 1) Introduction a) Motivation b) Application for big data 2) Choice of algorithms 3) Choice of
Graph Data Management Analysis and Optimization of Graph Data Frameworks presented by Fynn Leitow Overview 1) Introduction a) Motivation b) Application for big data 2) Choice of algorithms 3) Choice of
Graphs (Part II) Shannon Quinn
 Shannon Quinn") Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
Graphs (Part II) Shannon Quinn (with thanks to William Cohen and Aapo Kyrola of CMU, and J. Leskovec, A. Rajaraman, and J. Ullman of Stanford University) Parallel Graph Computation Distributed computation
CS November 2017
 Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 18. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Automatic Scaling Iterative Computations. Aug. 7 th, 2012
 Automatic Scaling Iterative Computations Guozhang Wang Cornell University Aug. 7 th, 2012 1 What are Non-Iterative Computations? Non-iterative computation flow Directed Acyclic Examples Batch style analytics
Automatic Scaling Iterative Computations Guozhang Wang Cornell University Aug. 7 th, 2012 1 What are Non-Iterative Computations? Non-iterative computation flow Directed Acyclic Examples Batch style analytics
Sempala. Interactive SPARQL Query Processing on Hadoop
 Sempala Interactive SPARQL Query Processing on Hadoop Alexander Schätzle, Martin Przyjaciel-Zablocki, Antony Neu, Georg Lausen University of Freiburg, Germany ISWC 2014 - Riva del Garda, Italy Motivation
Sempala Interactive SPARQL Query Processing on Hadoop Alexander Schätzle, Martin Przyjaciel-Zablocki, Antony Neu, Georg Lausen University of Freiburg, Germany ISWC 2014 - Riva del Garda, Italy Motivation
Research challenges in data-intensive computing The Stratosphere Project Apache Flink
 Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
Research challenges in data-intensive computing The Stratosphere Project Apache Flink Seif Haridi KTH/SICS haridi@kth.se e2e-clouds.org Presented by: Seif Haridi May 2014 Research Areas Data-intensive
GPU Sparse Graph Traversal. Duane Merrill
 GPU Sparse Graph Traversal Duane Merrill Breadth-first search of graphs (BFS) 1. Pick a source node 2. Rank every vertex by the length of shortest path from source Or label every vertex by its predecessor
GPU Sparse Graph Traversal Duane Merrill Breadth-first search of graphs (BFS) 1. Pick a source node 2. Rank every vertex by the length of shortest path from source Or label every vertex by its predecessor
PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING
 PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING G. Malewicz, M. Austern, A. Bik, J. Dehnert, I. Horn, N. Leiser, G. Czajkowski Google, Inc. SIGMOD 2010 Presented by Ke Hong (some figures borrowed from
PREGEL: A SYSTEM FOR LARGE- SCALE GRAPH PROCESSING G. Malewicz, M. Austern, A. Bik, J. Dehnert, I. Horn, N. Leiser, G. Czajkowski Google, Inc. SIGMOD 2010 Presented by Ke Hong (some figures borrowed from
On Fast Parallel Detection of Strongly Connected Components (SCC) in Small-World Graphs
 in Small-World Graphs") On Fast Parallel Detection of Strongly Connected Components (SCC) in Small-World Graphs Sungpack Hong 2, Nicole C. Rodia 1, and Kunle Olukotun 1 1 Pervasive Parallelism Laboratory, Stanford University
On Fast Parallel Detection of Strongly Connected Components (SCC) in Small-World Graphs Sungpack Hong 2, Nicole C. Rodia 1, and Kunle Olukotun 1 1 Pervasive Parallelism Laboratory, Stanford University
GPU Sparse Graph Traversal
 GPU Sparse Graph Traversal Duane Merrill (NVIDIA) Michael Garland (NVIDIA) Andrew Grimshaw (Univ. of Virginia) UNIVERSITY of VIRGINIA Breadth-first search (BFS) 1. Pick a source node 2. Rank every vertex
GPU Sparse Graph Traversal Duane Merrill (NVIDIA) Michael Garland (NVIDIA) Andrew Grimshaw (Univ. of Virginia) UNIVERSITY of VIRGINIA Breadth-first search (BFS) 1. Pick a source node 2. Rank every vertex
Introduction to NoSQL by William McKnight
 Introduction to NoSQL by William McKnight All rights reserved. Reproduction in whole or part prohibited except by written permission. Product and company names mentioned herein may be trademarks of their
Introduction to NoSQL by William McKnight All rights reserved. Reproduction in whole or part prohibited except by written permission. Product and company names mentioned herein may be trademarks of their
CS November 2018
 Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Bigtable Highly available distributed storage Distributed Systems 19. Bigtable Built with semi-structured data in mind URLs: content, metadata, links, anchors, page rank User data: preferences, account
Pregel. Ali Shah
 Pregel Ali Shah s9alshah@stud.uni-saarland.de 2 Outline Introduction Model of Computation Fundamentals of Pregel Program Implementation Applications Experiments Issues with Pregel 3 Outline Costs of Computation
Pregel Ali Shah s9alshah@stud.uni-saarland.de 2 Outline Introduction Model of Computation Fundamentals of Pregel Program Implementation Applications Experiments Issues with Pregel 3 Outline Costs of Computation
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09. Presented by: Daniel Isaacs
 Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Locality. Christoph Koch. School of Computer & Communication Sciences, EPFL
 Locality Christoph Koch School of Computer & Communication Sciences, EPFL Locality Front view of instructor 2 Locality Locality relates (software) systems with the physical world. Front view of instructor
Locality Christoph Koch School of Computer & Communication Sciences, EPFL Locality Front view of instructor 2 Locality Locality relates (software) systems with the physical world. Front view of instructor
Module 4: Tree-Structured Indexing
 Module 4: Tree-Structured Indexing Module Outline 4.1 B + trees 4.2 Structure of B + trees 4.3 Operations on B + trees 4.4 Extensions 4.5 Generalized Access Path 4.6 ORACLE Clusters Web Forms Transaction
Module 4: Tree-Structured Indexing Module Outline 4.1 B + trees 4.2 Structure of B + trees 4.3 Operations on B + trees 4.4 Extensions 4.5 Generalized Access Path 4.6 ORACLE Clusters Web Forms Transaction
SociaLite: A Datalog-based Language for
 SociaLite: A Datalog-based Language for Large-Scale Graph Analysis Jiwon Seo M OBIS OCIAL RESEARCH GROUP Overview Overview! SociaLite: language for large-scale graph analysis! Extensions to Datalog! Compiler
SociaLite: A Datalog-based Language for Large-Scale Graph Analysis Jiwon Seo M OBIS OCIAL RESEARCH GROUP Overview Overview! SociaLite: language for large-scale graph analysis! Extensions to Datalog! Compiler
CS /21/2016. Paul Krzyzanowski 1. Can we make MapReduce easier? Distributed Systems. Apache Pig. Apache Pig. Pig: Loading Data.
 Distributed Systems 1. Graph Computing Frameworks Can we make MapReduce easier? Paul Krzyzanowski Rutgers University Fall 016 1 Apache Pig Apache Pig Why? Make it easy to use MapReduce via scripting instead
Distributed Systems 1. Graph Computing Frameworks Can we make MapReduce easier? Paul Krzyzanowski Rutgers University Fall 016 1 Apache Pig Apache Pig Why? Make it easy to use MapReduce via scripting instead
Distributed Graph Algorithms
 Distributed Graph Algorithms Alessio Guerrieri University of Trento, Italy 2016/04/26 This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. Contents 1 Introduction
Distributed Graph Algorithms Alessio Guerrieri University of Trento, Italy 2016/04/26 This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License. Contents 1 Introduction
Distributed Graph Storage. Veronika Molnár, UZH
 Distributed Graph Storage Veronika Molnár, UZH Overview Graphs and Social Networks Criteria for Graph Processing Systems Current Systems Storage Computation Large scale systems Comparison / Best systems
Distributed Graph Storage Veronika Molnár, UZH Overview Graphs and Social Networks Criteria for Graph Processing Systems Current Systems Storage Computation Large scale systems Comparison / Best systems
MapReduce: A Programming Model for Large-Scale Distributed Computation
 CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
CSC 258/458 MapReduce: A Programming Model for Large-Scale Distributed Computation University of Rochester Department of Computer Science Shantonu Hossain April 18, 2011 Outline Motivation MapReduce Overview
Graph Processing. Connor Gramazio Spiros Boosalis
 Graph Processing Connor Gramazio Spiros Boosalis Pregel why not MapReduce? semantics: awkward to write graph algorithms efficiency: mapreduces serializes state (e.g. all nodes and edges) while pregel keeps
Graph Processing Connor Gramazio Spiros Boosalis Pregel why not MapReduce? semantics: awkward to write graph algorithms efficiency: mapreduces serializes state (e.g. all nodes and edges) while pregel keeps
CS 5220: Parallel Graph Algorithms. David Bindel
 CS 5220: Parallel Graph Algorithms David Bindel 2017-11-14 1 Graphs Mathematically: G = (V, E) where E V V Convention: V = n and E = m May be directed or undirected May have weights w V : V R or w E :
CS 5220: Parallel Graph Algorithms David Bindel 2017-11-14 1 Graphs Mathematically: G = (V, E) where E V V Convention: V = n and E = m May be directed or undirected May have weights w V : V R or w E :
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Distributed computing: index building and use
 Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
Distributed computing: index building and use Distributed computing Goals Distributing computation across several machines to Do one computation faster - latency Do more computations in given time - throughput
TI2736-B Big Data Processing. Claudia Hauff
 TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Ctd. Graphs Pig Design Patterns Hadoop Ctd. Giraph Zoo Keeper Spark Spark Ctd. Learning objectives
TI2736-B Big Data Processing Claudia Hauff ti2736b-ewi@tudelft.nl Intro Streams Streams Map Reduce HDFS Pig Ctd. Graphs Pig Design Patterns Hadoop Ctd. Giraph Zoo Keeper Spark Spark Ctd. Learning objectives
Oracle Spatial and Graph: Benchmarking a Trillion Edges RDF Graph ORACLE WHITE PAPER NOVEMBER 2016
 Oracle Spatial and Graph: Benchmarking a Trillion Edges RDF Graph ORACLE WHITE PAPER NOVEMBER 2016 Introduction One trillion is a really big number. What could you store with one trillion facts?» 1000
Oracle Spatial and Graph: Benchmarking a Trillion Edges RDF Graph ORACLE WHITE PAPER NOVEMBER 2016 Introduction One trillion is a really big number. What could you store with one trillion facts?» 1000
Introduction to Parallel & Distributed Computing Parallel Graph Algorithms
 Introduction to Parallel & Distributed Computing Parallel Graph Algorithms Lecture 16, Spring 2014 Instructor: 罗国杰 gluo@pku.edu.cn In This Lecture Parallel formulations of some important and fundamental
Introduction to Parallel & Distributed Computing Parallel Graph Algorithms Lecture 16, Spring 2014 Instructor: 罗国杰 gluo@pku.edu.cn In This Lecture Parallel formulations of some important and fundamental
Billion-Node Graph Challenges
 Billion-Node Graph Challenges Yanghua Xiao, Bin Shao Fudan University, Micorosoft Research Asia shawyh@fudan.edu.cn, binshao@microsoft.com Abstract Graph is a universal model in big data era and finds
Billion-Node Graph Challenges Yanghua Xiao, Bin Shao Fudan University, Micorosoft Research Asia shawyh@fudan.edu.cn, binshao@microsoft.com Abstract Graph is a universal model in big data era and finds
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2014/15
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Lecture II: Indexing Part I of this course Indexing 3 Database File Organization and Indexing Remember: Database tables
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Lecture II: Indexing Part I of this course Indexing 3 Database File Organization and Indexing Remember: Database tables
Putting it together. Data-Parallel Computation. Ex: Word count using partial aggregation. Big Data Processing. COS 418: Distributed Systems Lecture 21
 Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Big Processing -Parallel Computation COS 418: Distributed Systems Lecture 21 Michael Freedman 2 Ex: Word count using partial aggregation Putting it together 1. Compute word counts from individual files
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Efficient, Scalable, and Provenance-Aware Management of Linked Data
 Efficient, Scalable, and Provenance-Aware Management of Linked Data Marcin Wylot 1 Motivation and objectives of the research The proliferation of heterogeneous Linked Data on the Web requires data management
Efficient, Scalable, and Provenance-Aware Management of Linked Data Marcin Wylot 1 Motivation and objectives of the research The proliferation of heterogeneous Linked Data on the Web requires data management
Graph Algorithms using Map-Reduce. Graphs are ubiquitous in modern society. Some examples: The hyperlink structure of the web
 Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some examples: The hyperlink structure of the web Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some
Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some examples: The hyperlink structure of the web Graph Algorithms using Map-Reduce Graphs are ubiquitous in modern society. Some
Accessing Arbitrary Hierarchical Data
 D.G.Muir February 2010 Accessing Arbitrary Hierarchical Data Accessing experimental data is relatively straightforward when data are regular and can be modelled using fixed size arrays of an atomic data
D.G.Muir February 2010 Accessing Arbitrary Hierarchical Data Accessing experimental data is relatively straightforward when data are regular and can be modelled using fixed size arrays of an atomic data
University of Maryland. Tuesday, March 2, 2010
 Data-Intensive Information Processing Applications Session #5 Graph Algorithms Jimmy Lin University of Maryland Tuesday, March 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Data-Intensive Information Processing Applications Session #5 Graph Algorithms Jimmy Lin University of Maryland Tuesday, March 2, 2010 This work is licensed under a Creative Commons Attribution-Noncommercial-Share
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Efficient graph computation on hybrid CPU and GPU systems
 J Supercomput (2015) 71:1563 1586 DOI 10.1007/s11227-015-1378-z Efficient graph computation on hybrid CPU and GPU systems Tao Zhang Jingjie Zhang Wei Shu Min-You Wu Xiaoyao Liang Published online: 21 January
J Supercomput (2015) 71:1563 1586 DOI 10.1007/s11227-015-1378-z Efficient graph computation on hybrid CPU and GPU systems Tao Zhang Jingjie Zhang Wei Shu Min-You Wu Xiaoyao Liang Published online: 21 January
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Rajiv GandhiCollegeof Engineering& Technology, Kirumampakkam.Page 1 of 10
 Rajiv GandhiCollegeof Engineering& Technology, Kirumampakkam.Page 1 of 10 RAJIV GANDHI COLLEGE OF ENGINEERING & TECHNOLOGY, KIRUMAMPAKKAM-607 402 DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING QUESTION BANK
Rajiv GandhiCollegeof Engineering& Technology, Kirumampakkam.Page 1 of 10 RAJIV GANDHI COLLEGE OF ENGINEERING & TECHNOLOGY, KIRUMAMPAKKAM-607 402 DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING QUESTION BANK
GPS: A Graph Processing System
 GPS: A Graph Processing System Semih Salihoglu and Jennifer Widom Stanford University {semih,widom}@cs.stanford.edu Abstract GPS (for Graph Processing System) is a complete open-source system we developed
GPS: A Graph Processing System Semih Salihoglu and Jennifer Widom Stanford University {semih,widom}@cs.stanford.edu Abstract GPS (for Graph Processing System) is a complete open-source system we developed
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Webinar Series TMIP VISION
 Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Webinar Series TMIP VISION TMIP provides technical support and promotes knowledge and information exchange in the transportation planning and modeling community. Today s Goals To Consider: Parallel Processing
Text transcript of show #280. August 18, Microsoft Research: Trinity is a Graph Database and a Distributed Parallel Platform for Graph Data
 Hanselminutes is a weekly audio talk show with noted web developer and technologist Scott Hanselman and hosted by Carl Franklin. Scott discusses utilities and tools, gives practical how-to advice, and
Hanselminutes is a weekly audio talk show with noted web developer and technologist Scott Hanselman and hosted by Carl Franklin. Scott discusses utilities and tools, gives practical how-to advice, and
Accelerating Irregular Computations with Hardware Transactional Memory and Active Messages
 MACIEJ BESTA, TORSTEN HOEFLER spcl.inf.ethz.ch Accelerating Irregular Computations with Hardware Transactional Memory and Active Messages LARGE-SCALE IRREGULAR GRAPH PROCESSING Becoming more important
MACIEJ BESTA, TORSTEN HOEFLER spcl.inf.ethz.ch Accelerating Irregular Computations with Hardware Transactional Memory and Active Messages LARGE-SCALE IRREGULAR GRAPH PROCESSING Becoming more important
CSE 544 Principles of Database Management Systems
 CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 5 - DBMS Architecture and Indexing 1 Announcements HW1 is due next Thursday How is it going? Projects: Proposals are due
CSE 544 Principles of Database Management Systems Alvin Cheung Fall 2015 Lecture 5 - DBMS Architecture and Indexing 1 Announcements HW1 is due next Thursday How is it going? Projects: Proposals are due
Efficient Aggregation for Graph Summarization
 Efficient Aggregation for Graph Summarization Yuanyuan Tian (University of Michigan) Richard A. Hankins (Nokia Research Center) Jignesh M. Patel (University of Michigan) Motivation Graphs are everywhere
Efficient Aggregation for Graph Summarization Yuanyuan Tian (University of Michigan) Richard A. Hankins (Nokia Research Center) Jignesh M. Patel (University of Michigan) Motivation Graphs are everywhere
PuLP: Scalable Multi-Objective Multi-Constraint Partitioning for Small-World Networks
 PuLP: Scalable Multi-Objective Multi-Constraint Partitioning for Small-World Networks George M. Slota 1,2 Kamesh Madduri 2 Sivasankaran Rajamanickam 1 1 Sandia National Laboratories, 2 The Pennsylvania
PuLP: Scalable Multi-Objective Multi-Constraint Partitioning for Small-World Networks George M. Slota 1,2 Kamesh Madduri 2 Sivasankaran Rajamanickam 1 1 Sandia National Laboratories, 2 The Pennsylvania
Giraph: Large-scale graph processing infrastructure on Hadoop. Qu Zhi
 Giraph: Large-scale graph processing infrastructure on Hadoop Qu Zhi Why scalable graph processing? Web and social graphs are at immense scale and continuing to grow In 2008, Google estimated the number
Giraph: Large-scale graph processing infrastructure on Hadoop Qu Zhi Why scalable graph processing? Web and social graphs are at immense scale and continuing to grow In 2008, Google estimated the number
1 Copyright 2011, Oracle and/or its affiliates. All rights reserved.
 1 Copyright 2011, Oracle and/or its affiliates. All rights reserved. Integrating Complex Financial Workflows in Oracle Database Xavier Lopez Seamus Hayes Oracle PolarLake, LTD 2 Copyright 2011, Oracle
1 Copyright 2011, Oracle and/or its affiliates. All rights reserved. Integrating Complex Financial Workflows in Oracle Database Xavier Lopez Seamus Hayes Oracle PolarLake, LTD 2 Copyright 2011, Oracle
Harp-DAAL for High Performance Big Data Computing
 Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark. by Nkemdirim Dockery
 Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark by Nkemdirim Dockery High Performance Computing Workloads Core-memory sized Floating point intensive Well-structured
Challenges in large-scale graph processing on HPC platforms and the Graph500 benchmark by Nkemdirim Dockery High Performance Computing Workloads Core-memory sized Floating point intensive Well-structured
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Fast and Concurrent RDF Queries with RDMA-Based Distributed Graph Exploration
 Fast and Concurrent RDF Queries with RDMA-Based Distributed Graph Exploration JIAXIN SHI, YOUYANG YAO, RONG CHEN, HAIBO CHEN, FEIFEI LI PRESENTED BY ANDREW XIA APRIL 25, 2018 Wukong Overview of Wukong
Fast and Concurrent RDF Queries with RDMA-Based Distributed Graph Exploration JIAXIN SHI, YOUYANG YAO, RONG CHEN, HAIBO CHEN, FEIFEI LI PRESENTED BY ANDREW XIA APRIL 25, 2018 Wukong Overview of Wukong
Voldemort. Smruti R. Sarangi. Department of Computer Science Indian Institute of Technology New Delhi, India. Overview Design Evaluation
 Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Voldemort Smruti R. Sarangi Department of Computer Science Indian Institute of Technology New Delhi, India Smruti R. Sarangi Leader Election 1/29 Outline 1 2 3 Smruti R. Sarangi Leader Election 2/29 Data
Pregel: A System for Large- Scale Graph Processing. Written by G. Malewicz et al. at SIGMOD 2010 Presented by Chris Bunch Tuesday, October 12, 2010
 Pregel: A System for Large- Scale Graph Processing Written by G. Malewicz et al. at SIGMOD 2010 Presented by Chris Bunch Tuesday, October 12, 2010 1 Graphs are hard Poor locality of memory access Very
Pregel: A System for Large- Scale Graph Processing Written by G. Malewicz et al. at SIGMOD 2010 Presented by Chris Bunch Tuesday, October 12, 2010 1 Graphs are hard Poor locality of memory access Very
Large Scale Complex Network Analysis using the Hybrid Combination of a MapReduce Cluster and a Highly Multithreaded System
 Large Scale Complex Network Analysis using the Hybrid Combination of a MapReduce Cluster and a Highly Multithreaded System Seunghwa Kang David A. Bader 1 A Challenge Problem Extracting a subgraph from
Large Scale Complex Network Analysis using the Hybrid Combination of a MapReduce Cluster and a Highly Multithreaded System Seunghwa Kang David A. Bader 1 A Challenge Problem Extracting a subgraph from
Graph Algorithms. Revised based on the slides by Ruoming Kent State
 Graph Algorithms Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Graph Algorithms Adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/
Analyzing a social network using Big Data Spatial and Graph Property Graph
 Analyzing a social network using Big Data Spatial and Graph Property Graph Oskar van Rest Principal Member of Technical Staff Gabriela Montiel-Moreno Principal Member of Technical Staff Safe Harbor Statement
Analyzing a social network using Big Data Spatial and Graph Property Graph Oskar van Rest Principal Member of Technical Staff Gabriela Montiel-Moreno Principal Member of Technical Staff Safe Harbor Statement
COSC 6339 Big Data Analytics. Graph Algorithms and Apache Giraph
 COSC 6339 Big Data Analytics Graph Algorithms and Apache Giraph Parts of this lecture are adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share
COSC 6339 Big Data Analytics Graph Algorithms and Apache Giraph Parts of this lecture are adapted from UMD Jimmy Lin s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share
CSE 530A. B+ Trees. Washington University Fall 2013
 CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
Graph-Parallel Problems. ML in the Context of Parallel Architectures
 Case Study 4: Collaborative Filtering Graph-Parallel Problems Synchronous v. Asynchronous Computation Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 20 th, 2014
Case Study 4: Collaborative Filtering Graph-Parallel Problems Synchronous v. Asynchronous Computation Machine Learning for Big Data CSE547/STAT548, University of Washington Emily Fox February 20 th, 2014
I ++ Mapreduce: Incremental Mapreduce for Mining the Big Data
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 3, Ver. IV (May-Jun. 2016), PP 125-129 www.iosrjournals.org I ++ Mapreduce: Incremental Mapreduce for
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 18, Issue 3, Ver. IV (May-Jun. 2016), PP 125-129 www.iosrjournals.org I ++ Mapreduce: Incremental Mapreduce for
Extreme Computing. NoSQL.
 Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
Extreme Computing NoSQL PREVIOUSLY: BATCH Query most/all data Results Eventually NOW: ON DEMAND Single Data Points Latency Matters One problem, three ideas We want to keep track of mutable state in a scalable
HANA Performance. Efficient Speed and Scale-out for Real-time BI
 HANA Performance Efficient Speed and Scale-out for Real-time BI 1 HANA Performance: Efficient Speed and Scale-out for Real-time BI Introduction SAP HANA enables organizations to optimize their business
HANA Performance Efficient Speed and Scale-out for Real-time BI 1 HANA Performance: Efficient Speed and Scale-out for Real-time BI Introduction SAP HANA enables organizations to optimize their business
Learn Well Technocraft
 Getting Started with ASP.NET This module explains how to build and configure a simple ASP.NET application. Introduction to ASP.NET Web Applications Features of ASP.NET Configuring ASP.NET Applications
Getting Started with ASP.NET This module explains how to build and configure a simple ASP.NET application. Introduction to ASP.NET Web Applications Features of ASP.NET Configuring ASP.NET Applications
Fusion iomemory PCIe Solutions from SanDisk and Sqrll make Accumulo Hypersonic
 WHITE PAPER Fusion iomemory PCIe Solutions from SanDisk and Sqrll make Accumulo Hypersonic Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Executive
WHITE PAPER Fusion iomemory PCIe Solutions from SanDisk and Sqrll make Accumulo Hypersonic Western Digital Technologies, Inc. 951 SanDisk Drive, Milpitas, CA 95035 www.sandisk.com Table of Contents Executive
King Abdullah University of Science and Technology. CS348: Cloud Computing. Large-Scale Graph Processing
 King Abdullah University of Science and Technology CS348: Cloud Computing Large-Scale Graph Processing Zuhair Khayyat 10/March/2013 The Importance of Graphs A graph is a mathematical structure that represents
King Abdullah University of Science and Technology CS348: Cloud Computing Large-Scale Graph Processing Zuhair Khayyat 10/March/2013 The Importance of Graphs A graph is a mathematical structure that represents
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 10: Mutable State (1/2) March 14, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
FlashGraph: Processing Billion-Node Graphs on an Array of Commodity SSDs
 FlashGraph: Processing Billion-Node Graphs on an Array of Commodity SSDs Da Zheng, Disa Mhembere, Randal Burns Department of Computer Science Johns Hopkins University Carey E. Priebe Department of Applied
FlashGraph: Processing Billion-Node Graphs on an Array of Commodity SSDs Da Zheng, Disa Mhembere, Randal Burns Department of Computer Science Johns Hopkins University Carey E. Priebe Department of Applied
DIVING IN: INSIDE THE DATA CENTER
 1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
1 DIVING IN: INSIDE THE DATA CENTER Anwar Alhenshiri Data centers 2 Once traffic reaches a data center it tunnels in First passes through a filter that blocks attacks Next, a router that directs it to
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI Presented by Xiang Gao
 Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Bigtable: A Distributed Storage System for Structured Data By Fay Chang, et al. OSDI 2006 Presented by Xiang Gao 2014-11-05 Outline Motivation Data Model APIs Building Blocks Implementation Refinement
Something to think about. Problems. Purpose. Vocabulary. Query Evaluation Techniques for large DB. Part 1. Fact:
 Query Evaluation Techniques for large DB Part 1 Fact: While data base management systems are standard tools in business data processing they are slowly being introduced to all the other emerging data base
Query Evaluation Techniques for large DB Part 1 Fact: While data base management systems are standard tools in business data processing they are slowly being introduced to all the other emerging data base
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017)
") Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 5: Analyzing Graphs (2/2) February 2, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Big Data Infrastructure CS 489/698 Big Data Infrastructure (Winter 2017) Week 5: Analyzing Graphs (2/2) February 2, 2017 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo These
Introduction to NoSQL Databases
 Introduction to NoSQL Databases Roman Kern KTI, TU Graz 2017-10-16 Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 1 / 31 Introduction Intro Why NoSQL? Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 2 / 31 Introduction
Introduction to NoSQL Databases Roman Kern KTI, TU Graz 2017-10-16 Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 1 / 31 Introduction Intro Why NoSQL? Roman Kern (KTI, TU Graz) Dbase2 2017-10-16 2 / 31 Introduction
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate