OpenMP for Heterogeneous Multicore Embedded Systems using MCA API standard interface
|
|
|
- Alan Lucas
- 5 years ago
- Views:
Transcription

 and")
1 OpenMP for Heterogeneous Multicore Embedded Systems using MCA API standard interface Sunita Chandrasekaran Peng Sun, Suyang zhu, Barbara Chapman HPCTools Group, University of Houston, USA in collaboration with freescale semiconductor (FSL) and Semiconductor Research Corporation (SRC) OpenMP SC14






2 Real- world applications using embedded systems FPGAS used to receive a number of acoustic pings form an image DSP, a device to interact with a user through the embedded processor within A self- piloted car powered by the NVIDIA Jetson TK1 11/18/14 2

3 Embedded programmers requirements Write once, reuse anywhere o Avoid rewriting from scratch o Provide incremental migration path essential for application codes o Exploit multiple levels of parallelism with familiar and/or commodity programming models o None are perfect, but industry adoption is critical 11/18/14 3
4 OpenMP widely adopted standard ( Industry standard for shared memory parallel programming o Supported by large # of vendors (TI, AMD, IBM, Intel, Cray, NVIDIA, HP..) o OpenMP 4.0 provides support for compute devices such as Xeon Phis, GPUs and others! High level directive-based solution o Compiler directives, library routines and envt. variables o Programming Model - Fork-Join parallelism o Threads communicate by sharing variables o Synchronizations to control race conditions o Structured programming to reduce likelihood of bugs Programming made easy! void main() { double Res[1000]; #pragma omp parallel fo for(int i=0;i<1000;i++) { do_huge_comp(res[i] } 11/18/14 4
5 OpenMP Solution Stack 5 OpenMP Parallel Computing Solution Stack User layer OpenMP Application Prog. layer OpenMP API Directives, Compiler OpenMP library Environment variables System layer Runtime library OS/system support for shared memory Core 1 Core 2 Core n 11/18/14 5

6 OpenMP for Embedded Systems " Programming embedded systems a challenge " Need high-level standards such as OpenMP " Runtime relies on lower level components OS, threading/hardware libraries, memory allocation, synchronization e.g. Linux, Pthreads o But embedded systems typically lack some of these features " OpenMP has shared-memory cache-coherent memory model But embedded platforms feature distributed, nonuniform memory, with no cache-coherency Vocabulary for heterogeneity is required in the embedded space OpenMP 4.0 is there!! 11/18/14 6
 - Basic synchronization - Shared/Distributed")
 -XML HW description from SW perspective")
7 Multicore Association Industry standard API (MCA) MCA Foundation APIs Communications (MCAPI) - Lightweight messaging Resource Management (MRAPI) - Basic synchronization - Shared/Distributed Memory - System Metadata Task Management (MTAPI) - Task lifecycle - Task placement - Task priority SW/HW Interface for Multicore/Manycore (SHIM) -XML HW description from SW perspective 11/18/14 7
8 Tasks in Heterogeneous Systems Domain Node Node Node Node MTAPI application MTAPI tasks MTAPI tasks tasks MTAPI tasks MTAPI runtime system (optionally MCAPI / MRAPI) sched. / lib. OS 1 OS 2 DSP CPU core CPU core CPU core CPU core GPU memory memory memory Tasks execute a job, implemented by an action function, on a local or remote node Task can be started individually or via queues (to influence the scheduling behavior) Arguments are copied to the remote node Results are copied back to the node that started the task Sven Brehmer, MCA Talk at the OpenMP Booth, SC13 11/18/14 8



9 Tasks, Jobs, Actions Node 1 task a Node 2 Task- based applicatio n task b job a job b action a action b task c task d job c Node 3 action a action c job d action d 11/18/14 9

10 Runtime Design and Optimizations Optimized Thread Creation, Waiting and Awakening o All threads in a team cannot be identical o Uses MRAPI meta data primitives o Avoid over-subscription o Distributed spin-waiting Synchronization Construct Memory Model o Uses MRAPI shared/remote memory primitives 10
11 Freescale s Communication processor with data path QorlQ P4080 processor 4-8 Power architecture e500mc cores Accelerators Encryption (SEC) Pattern Matching Engine (PME) Target applications: Aerospace and Defense Ethernet Switch, Router Pre-crash detection Forward Collision Warning hzp:// code=p4080&tid=redp /18/14 11



12 Portable OpenMP Implementation Translated OpenMP for MPSoCs Used Multicore Association (MCA) APIs as target for our OpenMP translation Developed MCA-based runtime: o Portable across MPSoCs o Light-weight o Supports non-cachecoherent systems o Performance comparable to customized vendorspecific implementations Applica-on'Layer' OpenMP' Programming' Layer' MCA'APIs'Layer' System'Layer' Hardware'Layer' Direc-ves' OpenMP'Applica-ons' Run-me' Library' Rou-nes' OpenMP'Run-me'Library' Environment' Variables' MRAPI' MCAPI' MTAPI' Opera-ng'Systems'(or'Virtualiza-on)' Mul-core'Embedded'Systems' 11/18/14 12





13 Compilation Process OpenUH as our frontend open source, optimizing compiler suite for C, C++ and Fortran, based on Open64 o Translates C+OpenMP source into C with OpenMP runtime function calls OpenMP source code Frontend source-tosource translation Bare C code with OpenMP runtime library calls app.c OpenUH Compiler app.w2c.c Power Architecture GCC Compiler OpenMP Runtime Library Power Architecture GCC Compiler libeomp MCA Libraries Power Architecture GCC Compiler libmca PowerPC-GCC as our backend to generate the object file and libraries Final executable file is generated by linking the object file, our OpenMP runtime library and the MCA runtime library. Object code app.w2c.o Power Architecture GCC Linker Dual-core power processor from Freescale Semiconductor app.out Executable image running on the board 11/18/14 13

14 Enhanced OpenMP runtime Vs proprietary runtime DIJKSTRA JACOBI Normalized Execution Time Number of Threads libgomp libeomp Normalized Time Number of Threads libgomp libeomp FFT LU Decomposition Normalized Execution Time Number of Threads libgomp libeomp Normalized Execution Time Number of Threads libgomp libeomp 11/18/14 14

15 OpenMP + MCA for heterogeneous systems QorlQ P4080 processor 4-8 Power architecture e500mc cores Accelerators Encryption (SEC) Pattern Matching Engine (PME) Target applications: Aerospace and Defense Ethernet Switch, Router Pre-crash detection Forward Collision Warning hzp:// code=p4080&tid=redp /18/14 15




16 Creating an MCA wrapper For communication between the power processor and PME MCA Wrapper DMA 11/18/14 16

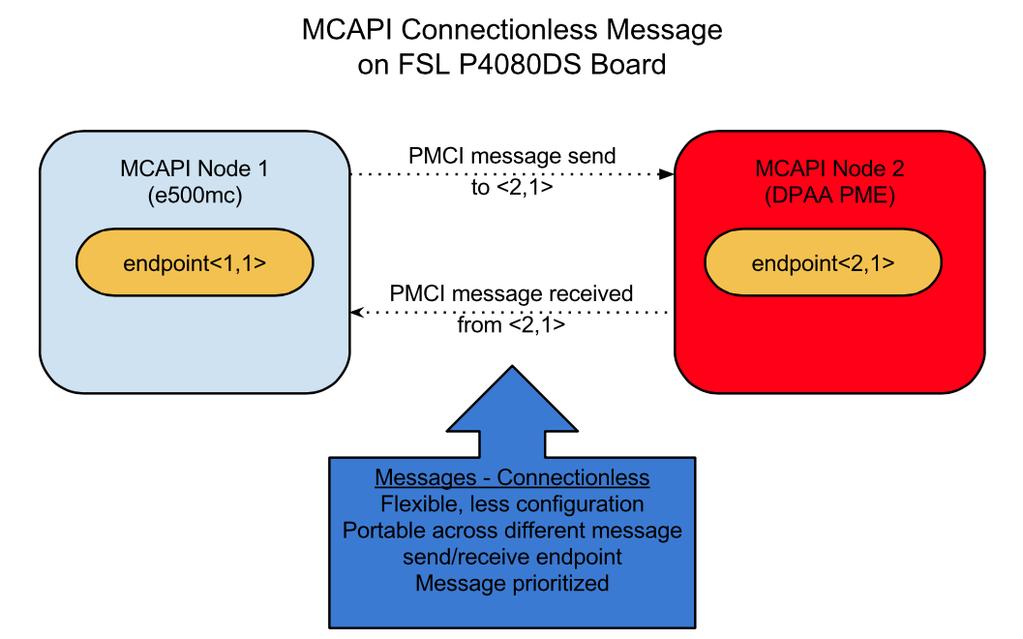
17 MCAPI Connectionless technique 11/18/14 17
18 MxAPI for accelerators lessons learned PME does not share memory with the main processor Data movement via a DMA channel Required thorough knowledge of low-level API very tightly tied to the hardware o Time consuming o Requires constant support from the vendor to understand the low-level API Created an MCA wrapper to abstract all lowlevel details o However the wrapper can be used for devices that relies on that same low-level API. 11/18/14 18

19 MTAPI Design and Implementation- Current Status On-going work: Implementing MTAPI features Writing small test cases to validate the MTAPI implementation Need to evaluate the MTAPI implementation on a heterogeneous multicore platform Preliminary results demonstrated overhead while communicating with a remote node through MCAPI 11/18/14 19

20 OpenMP and MCA API Applica-on'Layer' OpenMP'Applica-ons' OpenMP' Programming' Layer' Direc-ves' Run-me' Library' Rou-nes' OpenMP'Run-me'Library' Environment' Variables' MCA'APIs'Layer' MRAPI' MCAPI' MTAPI' System'Layer' No OS?? Opera-ng'Systems'(or'Virtualiza-on)' Hardware'Layer' Mul-core'Embedded'Systems' 11/18/14 20

21 Summary Extend OpenMP runtime library with MxAPI as the translation layer to target heterogeneous multicore SoCs o MTAPI prototype implementation UH SIEMENS : /10/31/siemens-produces-opensource-code-multicore-acceleration/ o Targeted a specialized accelerators 11/18/14 21







22 Accelerators are more than just GPUs 2013 onwards Before 2000 CPUs Intel Xeon Phi Intel Sandybridge Intel 2010 DSP Haswell + FPGAs Virtex 5 ARM FPGAs Virtex Convey Tilera Convey 7 AMD Berlin IBM Cyclops64 IBM Power AMD Warsaw Cell BE Xtreme 7 IBM Power DATA Blue Gene/Q 8 SGI RASC Nvidia Kepler Nvidia Maxwell Nvidia Nvidia Pascal Volta 11/18/14 22
23 MCAPI Communication API MCAPI Domain 1 MCAPI Node 1 endpoint <1,1,1> attributes port 1 endpoint <1,1,2> attributes port 2 Connectionless Message to <1,2,1> Messages: Connectionless - More flexible, less configuration - Blocking and non-blocking - Prioritized messages Connectionless Has More Flexibility MCAPI Node 2 endpoint <1,2,1> port 1 attributes Connectionless Message Connection- oriented Channels MCAPI Domain 1 MCAPI Node 1 endpoint <1,1,1> attributes port 1 Packets and Scalars: Connected - More efficient, more configuration - Blocking and non-blocking packets - Blocking scalars Connected Is More Efficient MCAPI Node 3 endpoint <1,1,2> attributes port 2 Packet Channel endpoint <1,3,1> port 1 attributes MCAPI Node 4 endpoint <1,4,1> attributes port 2 Scalar Channel endpoint <1,3,2> port 2 attributes 11/18/14 23
24 MRAPI Memory Concept LEGEND program data accesses data movement MRAPI API calls hardware/implementation specific MRAPI implementation activity local memory DMA Engine local memory local memory rmem buffer local buffer local buffer SW Cache native rd/wr MRAPI API rd/wr native rd/wr native rd/wr MRAPI API rd/wr ptr mrapi_rmem_handle mrapi_rmem_handle node0 node1 ptr ptr node2 core0 core1 core2 11/18/14 24
Exploring Task Parallelism for Heterogeneous Systems Using Multicore Task Management API
 EuroPAR 2016 ROME Workshop Exploring Task Parallelism for Heterogeneous Systems Using Multicore Task Management API Suyang Zhu 1, Sunita Chandrasekaran 2, Peng Sun 1, Barbara Chapman 1, Marcus Winter 3,
EuroPAR 2016 ROME Workshop Exploring Task Parallelism for Heterogeneous Systems Using Multicore Task Management API Suyang Zhu 1, Sunita Chandrasekaran 2, Peng Sun 1, Barbara Chapman 1, Marcus Winter 3,
Optimizing the performance and portability of multicore DSP platforms with a scalable programming model supporting the Multicore Association s MCAPI
 Texas Instruments, PolyCore Software, Inc. & The Multicore Association Optimizing the performance and portability of multicore DSP platforms with a scalable programming model supporting the Multicore Association
Texas Instruments, PolyCore Software, Inc. & The Multicore Association Optimizing the performance and portability of multicore DSP platforms with a scalable programming model supporting the Multicore Association
MTAPI: Parallel Programming for Embedded Multicore Systems
 MTAPI: Parallel Programming for Embedded Multicore Systems Urs Gleim Siemens AG, Corporate Technology http://www.ct.siemens.com/ urs.gleim@siemens.com Markus Levy The Multicore Association http://www.multicore-association.org/
MTAPI: Parallel Programming for Embedded Multicore Systems Urs Gleim Siemens AG, Corporate Technology http://www.ct.siemens.com/ urs.gleim@siemens.com Markus Levy The Multicore Association http://www.multicore-association.org/
HIGH-LEVEL PROGRAMMING MODEL FOR HETEROGENEOUS EMBEDDED SYSTEMS USING MULTICORE INDUSTRY STANDARD APIS
 HIGH-LEVEL PROGRAMMING MODEL FOR HETEROGENEOUS EMBEDDED SYSTEMS USING MULTICORE INDUSTRY STANDARD APIS A Dissertation Presented to the Faculty of the Department of Computer Science University of Houston
HIGH-LEVEL PROGRAMMING MODEL FOR HETEROGENEOUS EMBEDDED SYSTEMS USING MULTICORE INDUSTRY STANDARD APIS A Dissertation Presented to the Faculty of the Department of Computer Science University of Houston
Deploying OpenMP Task Parallelism on Multicore Embedded Systems with MCA Task APIs
 Deploying OpenMP Task Parallelism on Multicore Embedded Systems with MCA Task APIs Peng Sun, Sunita Chandrasekaran, Suyang Zhu and Barbara Chapman Department of Computer Science, University of Houston,
Deploying OpenMP Task Parallelism on Multicore Embedded Systems with MCA Task APIs Peng Sun, Sunita Chandrasekaran, Suyang Zhu and Barbara Chapman Department of Computer Science, University of Houston,
Embedded Multicore Building Blocks (EMB²)
") FOSDEM 16 Embedded Multicore Building Blocks (EMB²) Easy and Efficient Parallel Programming of Embedded Systems Tobias Schüle Siemens Corporate Technology Introduction The free lunch is over! 1995 2000
FOSDEM 16 Embedded Multicore Building Blocks (EMB²) Easy and Efficient Parallel Programming of Embedded Systems Tobias Schüle Siemens Corporate Technology Introduction The free lunch is over! 1995 2000
A unified multicore programming model
 A unified multicore programming model Simplifying multicore migration By Sven Brehmer Abstract There are a number of different multicore architectures and programming models available, making it challenging
A unified multicore programming model Simplifying multicore migration By Sven Brehmer Abstract There are a number of different multicore architectures and programming models available, making it challenging
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
Modeling and SW Synthesis for
 Modeling and SW Synthesis for Heterogeneous Embedded Systems in UML/MARTE Hector Posadas, Pablo Peñil, Alejandro Nicolás, Eugenio Villar University of Cantabria Spain Motivation Design productivity it
Modeling and SW Synthesis for Heterogeneous Embedded Systems in UML/MARTE Hector Posadas, Pablo Peñil, Alejandro Nicolás, Eugenio Villar University of Cantabria Spain Motivation Design productivity it
Industrial Multicore Software with EMB²
 Siemens Industrial Multicore Software with EMB² Dr. Tobias Schüle, Dr. Christian Kern Introduction In 2022, multicore will be everywhere. (IEEE CS) Parallel Patterns Library Apple s Grand Central Dispatch
Siemens Industrial Multicore Software with EMB² Dr. Tobias Schüle, Dr. Christian Kern Introduction In 2022, multicore will be everywhere. (IEEE CS) Parallel Patterns Library Apple s Grand Central Dispatch
OpenMP 3.0 Tasking Implementation in OpenUH
 Open64 Workshop @ CGO 09 OpenMP 3.0 Tasking Implementation in OpenUH Cody Addison Texas Instruments Lei Huang University of Houston James (Jim) LaGrone University of Houston Barbara Chapman University
Open64 Workshop @ CGO 09 OpenMP 3.0 Tasking Implementation in OpenUH Cody Addison Texas Instruments Lei Huang University of Houston James (Jim) LaGrone University of Houston Barbara Chapman University
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
Heterogeneous Processing Systems. Heterogeneous Multiset of Homogeneous Arrays (Multi-multi-core)
") Heterogeneous Processing Systems Heterogeneous Multiset of Homogeneous Arrays (Multi-multi-core) Processing Heterogeneity CPU (x86, SPARC, PowerPC) GPU (AMD/ATI, NVIDIA) DSP (TI, ADI) Vector processors
Heterogeneous Processing Systems Heterogeneous Multiset of Homogeneous Arrays (Multi-multi-core) Processing Heterogeneity CPU (x86, SPARC, PowerPC) GPU (AMD/ATI, NVIDIA) DSP (TI, ADI) Vector processors
1 of 6 Lecture 7: March 4. CISC 879 Software Support for Multicore Architectures Spring Lecture 7: March 4, 2008
 1 of 6 Lecture 7: March 4 CISC 879 Software Support for Multicore Architectures Spring 2008 Lecture 7: March 4, 2008 Lecturer: Lori Pollock Scribe: Navreet Virk Open MP Programming Topics covered 1. Introduction
1 of 6 Lecture 7: March 4 CISC 879 Software Support for Multicore Architectures Spring 2008 Lecture 7: March 4, 2008 Lecturer: Lori Pollock Scribe: Navreet Virk Open MP Programming Topics covered 1. Introduction
Introduction to OpenMP
 Introduction to OpenMP Lecture 2: OpenMP fundamentals Overview Basic Concepts in OpenMP History of OpenMP Compiling and running OpenMP programs 2 1 What is OpenMP? OpenMP is an API designed for programming
Introduction to OpenMP Lecture 2: OpenMP fundamentals Overview Basic Concepts in OpenMP History of OpenMP Compiling and running OpenMP programs 2 1 What is OpenMP? OpenMP is an API designed for programming
The Heterogeneous Programming Jungle. Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest
 The Heterogeneous Programming Jungle Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest June 19, 2012 Outline 1. Introduction 2. Heterogeneous System Zoo 3. Similarities 4. Programming
The Heterogeneous Programming Jungle Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest June 19, 2012 Outline 1. Introduction 2. Heterogeneous System Zoo 3. Similarities 4. Programming
S Comparing OpenACC 2.5 and OpenMP 4.5
 April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
Introduction to OpenMP. Lecture 2: OpenMP fundamentals
 Introduction to OpenMP Lecture 2: OpenMP fundamentals Overview 2 Basic Concepts in OpenMP History of OpenMP Compiling and running OpenMP programs What is OpenMP? 3 OpenMP is an API designed for programming
Introduction to OpenMP Lecture 2: OpenMP fundamentals Overview 2 Basic Concepts in OpenMP History of OpenMP Compiling and running OpenMP programs What is OpenMP? 3 OpenMP is an API designed for programming
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Overview: The OpenMP Programming Model
 Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
Cray XE6 Performance Workshop
 Cray XE6 Performance Workshop Multicore Programming Overview Shared memory systems Basic Concepts in OpenMP Brief history of OpenMP Compiling and running OpenMP programs 2 1 Shared memory systems OpenMP
Cray XE6 Performance Workshop Multicore Programming Overview Shared memory systems Basic Concepts in OpenMP Brief history of OpenMP Compiling and running OpenMP programs 2 1 Shared memory systems OpenMP
OpenCL TM & OpenMP Offload on Sitara TM AM57x Processors
 OpenCL TM & OpenMP Offload on Sitara TM AM57x Processors 1 Agenda OpenCL Overview of Platform, Execution and Memory models Mapping these models to AM57x Overview of OpenMP Offload Model Compare and contrast
OpenCL TM & OpenMP Offload on Sitara TM AM57x Processors 1 Agenda OpenCL Overview of Platform, Execution and Memory models Mapping these models to AM57x Overview of OpenMP Offload Model Compare and contrast
The Case for Heterogeneous HTAP
 The Case for Heterogeneous HTAP Raja Appuswamy, Manos Karpathiotakis, Danica Porobic, and Anastasia Ailamaki Data-Intensive Applications and Systems Lab EPFL 1 HTAP the contract with the hardware Hybrid
The Case for Heterogeneous HTAP Raja Appuswamy, Manos Karpathiotakis, Danica Porobic, and Anastasia Ailamaki Data-Intensive Applications and Systems Lab EPFL 1 HTAP the contract with the hardware Hybrid
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17
 Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
HSA Foundation! Advanced Topics on Heterogeneous System Architectures. Politecnico di Milano! Seminar Room (Bld 20)! 15 December, 2017!
! 15 December, 2017!") Advanced Topics on Heterogeneous System Architectures HSA Foundation! Politecnico di Milano! Seminar Room (Bld 20)! 15 December, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2
Advanced Topics on Heterogeneous System Architectures HSA Foundation! Politecnico di Milano! Seminar Room (Bld 20)! 15 December, 2017! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2
Chapter 4: Multi-Threaded Programming
 Chapter 4: Multi-Threaded Programming Chapter 4: Threads 4.1 Overview 4.2 Multicore Programming 4.3 Multithreading Models 4.4 Thread Libraries Pthreads Win32 Threads Java Threads 4.5 Implicit Threading
Chapter 4: Multi-Threaded Programming Chapter 4: Threads 4.1 Overview 4.2 Multicore Programming 4.3 Multithreading Models 4.4 Thread Libraries Pthreads Win32 Threads Java Threads 4.5 Implicit Threading
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
Mapping applications into MPSoC
 Mapping applications into MPSoC concurrency & communication Jos van Eijndhoven jos@vectorfabrics.com March 12, 2011 MPSoC mapping: exploiting concurrency 2 March 12, 2012 Computation on general purpose
Mapping applications into MPSoC concurrency & communication Jos van Eijndhoven jos@vectorfabrics.com March 12, 2011 MPSoC mapping: exploiting concurrency 2 March 12, 2012 Computation on general purpose
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
CUDA GPGPU Workshop 2012
 CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
OpenMP tasking model for Ada: safety and correctness
 www.bsc.es www.cister.isep.ipp.pt OpenMP tasking model for Ada: safety and correctness Sara Royuela, Xavier Martorell, Eduardo Quiñones and Luis Miguel Pinho Vienna (Austria) June 12-16, 2017 Parallel
www.bsc.es www.cister.isep.ipp.pt OpenMP tasking model for Ada: safety and correctness Sara Royuela, Xavier Martorell, Eduardo Quiñones and Luis Miguel Pinho Vienna (Austria) June 12-16, 2017 Parallel
OpenMP 4.0: A Significant Paradigm Shift in Parallelism
 OpenMP 4.0: A Significant Paradigm Shift in Parallelism Michael Wong OpenMP CEO michaelw@ca.ibm.com http://bit.ly/sc13-eval SC13 OpenMP 4.0 released 2 Agenda The OpenMP ARB History of OpenMP OpenMP 4.0
OpenMP 4.0: A Significant Paradigm Shift in Parallelism Michael Wong OpenMP CEO michaelw@ca.ibm.com http://bit.ly/sc13-eval SC13 OpenMP 4.0 released 2 Agenda The OpenMP ARB History of OpenMP OpenMP 4.0
Serial and Parallel Sobel Filtering for multimedia applications
 Serial and Parallel Sobel Filtering for multimedia applications Gunay Abdullayeva Institute of Computer Science University of Tartu Email: gunay@ut.ee Abstract GSteamer contains various plugins to apply
Serial and Parallel Sobel Filtering for multimedia applications Gunay Abdullayeva Institute of Computer Science University of Tartu Email: gunay@ut.ee Abstract GSteamer contains various plugins to apply
Concurrency, Thread. Dongkun Shin, SKKU
 Concurrency, Thread 1 Thread Classic view a single point of execution within a program a single PC where instructions are being fetched from and executed), Multi-threaded program Has more than one point
Concurrency, Thread 1 Thread Classic view a single point of execution within a program a single PC where instructions are being fetched from and executed), Multi-threaded program Has more than one point
Integrating DMA capabilities into BLIS for on-chip data movement. Devangi Parikh Ilya Polkovnichenko Francisco Igual Peña Murtaza Ali
 Integrating DMA capabilities into BLIS for on-chip data movement Devangi Parikh Ilya Polkovnichenko Francisco Igual Peña Murtaza Ali 5 Generations of TI Multicore Processors Keystone architecture Lowers
Integrating DMA capabilities into BLIS for on-chip data movement Devangi Parikh Ilya Polkovnichenko Francisco Igual Peña Murtaza Ali 5 Generations of TI Multicore Processors Keystone architecture Lowers
Unified Memory. Notes on GPU Data Transfers. Andreas Herten, Forschungszentrum Jülich, 24 April Member of the Helmholtz Association
 Unified Memory Notes on GPU Data Transfers Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Overview, Outline Overview Unified Memory enables easy access to GPU development But some
Unified Memory Notes on GPU Data Transfers Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Overview, Outline Overview Unified Memory enables easy access to GPU development But some
CellSs Making it easier to program the Cell Broadband Engine processor
 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Barbara Chapman, Gabriele Jost, Ruud van der Pas
 Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Support for Programming Reconfigurable Supercomputers
 Support for Programming Reconfigurable Supercomputers Miriam Leeser Nicholas Moore, Albert Conti Dept. of Electrical and Computer Engineering Northeastern University Boston, MA Laurie Smith King Dept.
Support for Programming Reconfigurable Supercomputers Miriam Leeser Nicholas Moore, Albert Conti Dept. of Electrical and Computer Engineering Northeastern University Boston, MA Laurie Smith King Dept.
A Uniform Programming Model for Petascale Computing
 A Uniform Programming Model for Petascale Computing Barbara Chapman University of Houston WPSE 2009, Tsukuba March 25, 2009 High Performance Computing and Tools Group http://www.cs.uh.edu/~hpctools Agenda
A Uniform Programming Model for Petascale Computing Barbara Chapman University of Houston WPSE 2009, Tsukuba March 25, 2009 High Performance Computing and Tools Group http://www.cs.uh.edu/~hpctools Agenda
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Professional Multicore Programming. Design and Implementation for C++ Developers
 Professional Multicore Programming Design and Implementation for C++ Developers Cameron Hughes Tracey Hughes WILEY Wiley Publishing, Inc. Introduction xxi Chapter 1: The New Architecture 1 What Is a Multicore?
Professional Multicore Programming Design and Implementation for C++ Developers Cameron Hughes Tracey Hughes WILEY Wiley Publishing, Inc. Introduction xxi Chapter 1: The New Architecture 1 What Is a Multicore?
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Module 10: Open Multi-Processing Lecture 19: What is Parallelization? The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program
 The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels
 National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Heterogeneous Software Architecture with OpenAMP
 Heterogeneous Software Architecture with OpenAMP Shaun Purvis, Xilinx Agenda Heterogeneous SoCs Linux and OpenAMP OpenAMP for HSA Heterogeneous SoCs A System-on-Chip that integrates multiple processor
Heterogeneous Software Architecture with OpenAMP Shaun Purvis, Xilinx Agenda Heterogeneous SoCs Linux and OpenAMP OpenAMP for HSA Heterogeneous SoCs A System-on-Chip that integrates multiple processor
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler
 GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
Shared Memory Parallel Programming. Shared Memory Systems Introduction to OpenMP
 Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Shared Memory Parallel Programming Shared Memory Systems Introduction to OpenMP Parallel Architectures Distributed Memory Machine (DMP) Shared Memory Machine (SMP) DMP Multicomputer Architecture SMP Multiprocessor
Introduction to Multicore Programming
 Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Synchronization 3 Automatic Parallelization and OpenMP 4 GPGPU 5 Q& A 2 Multithreaded
Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Synchronization 3 Automatic Parallelization and OpenMP 4 GPGPU 5 Q& A 2 Multithreaded
CSC573: TSHA Introduction to Accelerators
 CSC573: TSHA Introduction to Accelerators Sreepathi Pai September 5, 2017 URCS Outline Introduction to Accelerators GPU Architectures GPU Programming Models Outline Introduction to Accelerators GPU Architectures
CSC573: TSHA Introduction to Accelerators Sreepathi Pai September 5, 2017 URCS Outline Introduction to Accelerators GPU Architectures GPU Programming Models Outline Introduction to Accelerators GPU Architectures
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
Parallel and Distributed Computing
 Parallel and Distributed Computing NUMA; OpenCL; MapReduce José Monteiro MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer Science and Engineering
Parallel and Distributed Computing NUMA; OpenCL; MapReduce José Monteiro MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer Science and Engineering
PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
Applications to MPSoCs
 3 rd Workshop on Mapping of Applications to MPSoCs A Design Exploration Framework for Mapping and Scheduling onto Heterogeneous MPSoCs Christian Pilato, Fabrizio Ferrandi, Donatella Sciuto Dipartimento
3 rd Workshop on Mapping of Applications to MPSoCs A Design Exploration Framework for Mapping and Scheduling onto Heterogeneous MPSoCs Christian Pilato, Fabrizio Ferrandi, Donatella Sciuto Dipartimento
Shared Memory programming paradigm: openmp
 IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
6.1 Multiprocessor Computing Environment
 6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
Introduction to OpenMP. OpenMP basics OpenMP directives, clauses, and library routines
 Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
ADAPTIVE TASK SCHEDULING USING LOW-LEVEL RUNTIME APIs AND MACHINE LEARNING
 ADAPTIVE TASK SCHEDULING USING LOW-LEVEL RUNTIME APIs AND MACHINE LEARNING Keynote, ADVCOMP 2017 November, 2017, Barcelona, Spain Prepared by: Ahmad Qawasmeh Assistant Professor The Hashemite University,
ADAPTIVE TASK SCHEDULING USING LOW-LEVEL RUNTIME APIs AND MACHINE LEARNING Keynote, ADVCOMP 2017 November, 2017, Barcelona, Spain Prepared by: Ahmad Qawasmeh Assistant Professor The Hashemite University,
An Introduction to OpenMP
 An Introduction to OpenMP U N C L A S S I F I E D Slide 1 What Is OpenMP? OpenMP Is: An Application Program Interface (API) that may be used to explicitly direct multi-threaded, shared memory parallelism
An Introduction to OpenMP U N C L A S S I F I E D Slide 1 What Is OpenMP? OpenMP Is: An Application Program Interface (API) that may be used to explicitly direct multi-threaded, shared memory parallelism
trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell 05/12/2015 IWOCL 2015 SYCL Tutorial Khronos OpenCL SYCL committee
 trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell Khronos OpenCL SYCL committee 05/12/2015 IWOCL 2015 SYCL Tutorial OpenCL SYCL committee work... Weekly telephone meeting Define
trisycl Open Source C++17 & OpenMP-based OpenCL SYCL prototype Ronan Keryell Khronos OpenCL SYCL committee 05/12/2015 IWOCL 2015 SYCL Tutorial OpenCL SYCL committee work... Weekly telephone meeting Define
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Introduction to Multicore Programming
 Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Automatic Parallelization and OpenMP 3 GPGPU 2 Multithreaded Programming
Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Automatic Parallelization and OpenMP 3 GPGPU 2 Multithreaded Programming
Parallelization, OpenMP
 ~ Parallelization, OpenMP Scientific Computing Winter 2016/2017 Lecture 26 Jürgen Fuhrmann juergen.fuhrmann@wias-berlin.de made wit pandoc 1 / 18 Why parallelization? Computers became faster and faster
~ Parallelization, OpenMP Scientific Computing Winter 2016/2017 Lecture 26 Jürgen Fuhrmann juergen.fuhrmann@wias-berlin.de made wit pandoc 1 / 18 Why parallelization? Computers became faster and faster
THE FUTURE OF GPU DATA MANAGEMENT. Michael Wolfe, May 9, 2017
 THE FUTURE OF GPU DATA MANAGEMENT Michael Wolfe, May 9, 2017 CPU CACHE Hardware managed What data to cache? Where to store the cached data? What data to evict when the cache fills up? When to store data
THE FUTURE OF GPU DATA MANAGEMENT Michael Wolfe, May 9, 2017 CPU CACHE Hardware managed What data to cache? Where to store the cached data? What data to evict when the cache fills up? When to store data
Chapter 4: Threads. Operating System Concepts 9 th Edit9on
 Chapter 4: Threads Operating System Concepts 9 th Edit9on Silberschatz, Galvin and Gagne 2013 Chapter 4: Threads 1. Overview 2. Multicore Programming 3. Multithreading Models 4. Thread Libraries 5. Implicit
Chapter 4: Threads Operating System Concepts 9 th Edit9on Silberschatz, Galvin and Gagne 2013 Chapter 4: Threads 1. Overview 2. Multicore Programming 3. Multithreading Models 4. Thread Libraries 5. Implicit
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
OpenMP. António Abreu. Instituto Politécnico de Setúbal. 1 de Março de 2013
 OpenMP António Abreu Instituto Politécnico de Setúbal 1 de Março de 2013 António Abreu (Instituto Politécnico de Setúbal) OpenMP 1 de Março de 2013 1 / 37 openmp what? It s an Application Program Interface
OpenMP António Abreu Instituto Politécnico de Setúbal 1 de Março de 2013 António Abreu (Instituto Politécnico de Setúbal) OpenMP 1 de Março de 2013 1 / 37 openmp what? It s an Application Program Interface
JCudaMP: OpenMP/Java on CUDA
 JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
Chapter 3 Parallel Software
 Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Integrating ROS and ROS2 on mixed-critical robotic systems based on embedded heterogeneous platforms
 ROSCon 2018 Integrating ROS and ROS2 on mixed-critical robotic systems based on embedded heterogeneous platforms Fabio Federici, Giulio M. Mancuso This document contains no USA or EU export controlled
ROSCon 2018 Integrating ROS and ROS2 on mixed-critical robotic systems based on embedded heterogeneous platforms Fabio Federici, Giulio M. Mancuso This document contains no USA or EU export controlled
ECMWF Workshop on High Performance Computing in Meteorology. 3 rd November Dean Stewart
 ECMWF Workshop on High Performance Computing in Meteorology 3 rd November 2010 Dean Stewart Agenda Company Overview Rogue Wave Product Overview IMSL Fortran TotalView Debugger Acumem ThreadSpotter 1 Copyright
ECMWF Workshop on High Performance Computing in Meteorology 3 rd November 2010 Dean Stewart Agenda Company Overview Rogue Wave Product Overview IMSL Fortran TotalView Debugger Acumem ThreadSpotter 1 Copyright
Introduction. CS 2210 Compiler Design Wonsun Ahn
 Introduction CS 2210 Compiler Design Wonsun Ahn What is a Compiler? Compiler: A program that translates source code written in one language to a target code written in another language Source code: Input
Introduction CS 2210 Compiler Design Wonsun Ahn What is a Compiler? Compiler: A program that translates source code written in one language to a target code written in another language Source code: Input
On the Portability and Performance of Message-Passing Programs on Embedded Multicore Platforms
 On the Portability and Performance of Message-Passing Programs on Embedded Multicore Platforms Shih-Hao Hung, Po-Hsun Chiu, Chia-Heng Tu, Wei-Ting Chou and Wen-Long Yang Graduate Institute of Networking
On the Portability and Performance of Message-Passing Programs on Embedded Multicore Platforms Shih-Hao Hung, Po-Hsun Chiu, Chia-Heng Tu, Wei-Ting Chou and Wen-Long Yang Graduate Institute of Networking
Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Chapter 4: Threads. Chapter 4: Threads
 Chapter 4: Threads Silberschatz, Galvin and Gagne 2013 Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples
Chapter 4: Threads Silberschatz, Galvin and Gagne 2013 Chapter 4: Threads Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading Issues Operating System Examples
Alexei Katranov. IWOCL '16, April 21, 2016, Vienna, Austria
 Alexei Katranov IWOCL '16, April 21, 2016, Vienna, Austria Hardware: customization, integration, heterogeneity Intel Processor Graphics CPU CPU CPU CPU Multicore CPU + integrated units for graphics, media
Alexei Katranov IWOCL '16, April 21, 2016, Vienna, Austria Hardware: customization, integration, heterogeneity Intel Processor Graphics CPU CPU CPU CPU Multicore CPU + integrated units for graphics, media
Experiences Using Tegra K1 and X1 for Highly Energy Efficient Computing
 Experiences Using Tegra K1 and X1 for Highly Energy Efficient Computing Gaurav Mitra Andrew Haigh Luke Angove Anish Varghese Eric McCreath Alistair P. Rendell Research School of Computer Science Australian
Experiences Using Tegra K1 and X1 for Highly Energy Efficient Computing Gaurav Mitra Andrew Haigh Luke Angove Anish Varghese Eric McCreath Alistair P. Rendell Research School of Computer Science Australian
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
PRACE Autumn School Basic Programming Models
 PRACE Autumn School 2010 Basic Programming Models Basic Programming Models - Outline Introduction Key concepts Architectures Programming models Programming languages Compilers Operating system & libraries
PRACE Autumn School 2010 Basic Programming Models Basic Programming Models - Outline Introduction Key concepts Architectures Programming models Programming languages Compilers Operating system & libraries
Chapter 4: Multithreaded Programming
 Chapter 4: Multithreaded Programming Silberschatz, Galvin and Gagne 2013 Chapter 4: Multithreaded Programming Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading
Chapter 4: Multithreaded Programming Silberschatz, Galvin and Gagne 2013 Chapter 4: Multithreaded Programming Overview Multicore Programming Multithreading Models Thread Libraries Implicit Threading Threading
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries
 Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
HSA foundation! Advanced Topics on Heterogeneous System Architectures. Politecnico di Milano! Seminar Room A. Alario! 23 November, 2015!
 Advanced Topics on Heterogeneous System Architectures HSA foundation! Politecnico di Milano! Seminar Room A. Alario! 23 November, 2015! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2
Advanced Topics on Heterogeneous System Architectures HSA foundation! Politecnico di Milano! Seminar Room A. Alario! 23 November, 2015! Antonio R. Miele! Marco D. Santambrogio! Politecnico di Milano! 2
Questions from last time
 Questions from last time Pthreads vs regular thread? Pthreads are POSIX-standard threads (1995). There exist earlier and newer standards (C++11). Pthread is probably most common. Pthread API: about a 100
Questions from last time Pthreads vs regular thread? Pthreads are POSIX-standard threads (1995). There exist earlier and newer standards (C++11). Pthread is probably most common. Pthread API: about a 100
Introduction to OpenMP
 Introduction to OpenMP Le Yan Scientific computing consultant User services group High Performance Computing @ LSU Goals Acquaint users with the concept of shared memory parallelism Acquaint users with
Introduction to OpenMP Le Yan Scientific computing consultant User services group High Performance Computing @ LSU Goals Acquaint users with the concept of shared memory parallelism Acquaint users with
Achieving High Performance. Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013
 Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
When Will SystemC Replace gcc/g++? Bodo Parady, CTO Pentum Group Inc. Sunnyvale, CA
 When Will SystemC Replace gcc/g++? Bodo Parady, CTO Pentum Group Inc. Sunnyvale, CA 94087 bparady@pentum.com SystemC: The Next Programming Who Language Who will support future system development? What
When Will SystemC Replace gcc/g++? Bodo Parady, CTO Pentum Group Inc. Sunnyvale, CA 94087 bparady@pentum.com SystemC: The Next Programming Who Language Who will support future system development? What
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Early Experiences Writing Performance Portable OpenMP 4 Codes
 Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Lecture Topic: An Overview of OpenCL on Xeon Phi
 C-DAC Four Days Technology Workshop ON Hybrid Computing Coprocessors/Accelerators Power-Aware Computing Performance of Applications Kernels hypack-2013 (Mode-4 : GPUs) Lecture Topic: on Xeon Phi Venue
C-DAC Four Days Technology Workshop ON Hybrid Computing Coprocessors/Accelerators Power-Aware Computing Performance of Applications Kernels hypack-2013 (Mode-4 : GPUs) Lecture Topic: on Xeon Phi Venue
Little Motivation Outline Introduction OpenMP Architecture Working with OpenMP Future of OpenMP End. OpenMP. Amasis Brauch German University in Cairo
 OpenMP Amasis Brauch German University in Cairo May 4, 2010 Simple Algorithm 1 void i n c r e m e n t e r ( short a r r a y ) 2 { 3 long i ; 4 5 for ( i = 0 ; i < 1000000; i ++) 6 { 7 a r r a y [ i ]++;
OpenMP Amasis Brauch German University in Cairo May 4, 2010 Simple Algorithm 1 void i n c r e m e n t e r ( short a r r a y ) 2 { 3 long i ; 4 5 for ( i = 0 ; i < 1000000; i ++) 6 { 7 a r r a y [ i ]++;
Re-architecting Virtualization in Heterogeneous Multicore Systems
 Re-architecting Virtualization in Heterogeneous Multicore Systems Himanshu Raj, Sanjay Kumar, Vishakha Gupta, Gregory Diamos, Nawaf Alamoosa, Ada Gavrilovska, Karsten Schwan, Sudhakar Yalamanchili College
Re-architecting Virtualization in Heterogeneous Multicore Systems Himanshu Raj, Sanjay Kumar, Vishakha Gupta, Gregory Diamos, Nawaf Alamoosa, Ada Gavrilovska, Karsten Schwan, Sudhakar Yalamanchili College
Introduction to OpenMP.
 Introduction to OpenMP www.openmp.org Motivation Parallelize the following code using threads: for (i=0; i
Introduction to OpenMP www.openmp.org Motivation Parallelize the following code using threads: for (i=0; i
OpenACC (Open Accelerators - Introduced in 2012)
") OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015
 Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming