Early Experiences Writing Performance Portable OpenMP 4 Codes
|
|
|
- Susanna McKenzie
- 5 years ago
- Views:
Transcription






1 Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory

 CPU + discrete accelerator (NVIDIA GPU) Many users run on")
2 Problem statement APU FPGA neuromorphic quantum... All upcoming leadership-scale systems in the US are accelerated, of two different types: manycore self-hosted (Intel Phi) CPU + discrete accelerator (NVIDIA GPU) Many users run on both. How to program portably?


3 Performance portability requirements Based on the need, the US DOE has made it a priority that science applications be performance portable across multiple architectures This has led to several multi-lab meetings to discuss this issue, most recently the DOE Centers of Excellence workshop in Glendale, AZ, April 2016
4 Performance portability requirements Users at our center generally run their codes at other centers as well, on many different kinds of systems Furthermore, science application code bases are tending to become increasingly large and complex often with multiple physics, making it unwieldy to maintain alternative code branches for different systems Even within the same product family (e.g., Intel Phi Knights-X), architectures can be different enough to warrant different code tuning and possibly different code execution paths for performance The challenge is expected to increase as nodes become more complex with deepening memory hierarchies and complex NUMA domains
5 Performance portability approaches It is the belief of many that, at least for Fortran and C codes, the use of OpenMP compiler directives offers the most promising path forward for performance portability The broadly-supported OpenMP standard defines programming models to specify node-level parallelism Traditionally, OpenMP 3.1 directives can be used to specify parallelism for shared memory / self-hosted systems More recently, OpenMP 4.X directives provide data and computation offload syntax to support discrete accelerator devices
6 Performance portability approaches OpenMP thus offers (at least) two distinct programming models within the same standard: one that supports self-hosted devices, another supporting offload to discrete accelerators We want to address: How can an application developer use a single OpenMP-based programming style to support both architectures? In this study we examine how to use a single approach within the OpenMP standard to develop performance portable code across both broad classes of systems To test this approach, we use the Intel compiler for a representative Phi-based system (for Xeon multicore processor and for a Phi coprocessor) and also the Cray compiler for a GPU-based system
7 OpenMP 3.1 directives - review We are primarily focused on parallelizing loops in the following fashion:!$omp parallel!---parallel region!$omp do!---parallelize loop iterations do j=1,m... enddo...
8 OpenMP 4.X offload directives - review For OpenMP 4.X, we have more structure, including data and execution offload directives:!---specify data transfer to/from device!$omp target data map(...)!---execute on device!$omp target!---specify thread teams!---distribute loop iterations to teams,!---threads and SIMD units!$omp teams distribute parallel do simd do j=1,m... enddo This is more verbose, but potentially more helpful to the compiler because it specifies more information, e.g., data motion
9 Fundamental approach To achieve performance portability in a single programming model, we select the OpenMP 4 offload approach To run code on either a self-hosted processor or a discrete accelerator device, we use an offload to self strategy, which is supported by these compilers via compilation options Our fundamental question is whether compilers will generate code using this technique that is (nearly) as efficient as using the best approach (whether shared or offload), for each respective hardware choice Also want to observe how each of these cases compares to best performance attainable for the algorithm and hardware


10 Test case: Jacobi iteration kernel A commonly studied and well-understood kernel Jacobi iterative solver for 2-D structured finite difference discretization of the Poisson equation 5-point constant coefficient stencil with nearest-neighbor updates
11 Jacobi kernel: serial case
12 Jacobi kernel: OpenMP 3.1 directives
13 Jacobi kernel: OpenMP 4.X directives
14 Jacobi kernel: OpenMP target

15 Execution modes: CPU + GPU system

16 Execution modes: Knights Corner system
17 Systems used ORNL Chester system Cray XK7 system with AMD Series 6200 Interlagos processors and NVIDIA K20X GPUs, architecturally identical to Titan but with slightly newer software stack Cray compiler, CCE Offload to host enabled by module load craype-accel-host UTK Beacon system Cray CS-300-AC Linux cluster with Intel Xeon E processors and Phi 5110P coprocessors Intel compiler, (XE compiler suite ) Offload to host enabled by ifort -qopenmp-offload=host
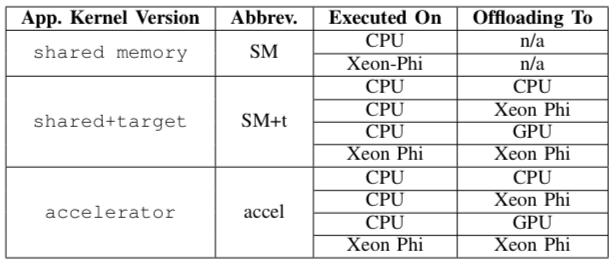
18 Experiment set
19 Computational results Codes are run on a single node of Beacon or Chester Fixed iteration count of 100 iterations Run across different problem sizes, to the maximum size that fits in memory Compare different execution modes Note that the Jacobi kernel performance is fundamentally memory-bound Thus, we will report performance in terms of GB/sec of memory bandwidth attained
20 Beacon results Intel Phi Compare to peak bandwidth: GB/s (CPUs), 330 GB/s (Phi) accel/phi/offload=phi and SM+t/phi/offload=phi perform similarly to SM/phi accel/cpu/offload=cpu and SM+t/CPU/offload=CPU perform similarly to SM/CPU accel/cpu/offload=phi and SM+t/CPU/offload=phi perform similarly
21 Chester results - GPU Compare to peak bandwidth: 51.2 GB/s (CPU), 250 GB/s (GPU) SM/CPU and accel/cpu/offload=gpu are high-performing accel/cpu/offload=cpu performs poorly compiler warns single-threaded code SM+t/CPU/* performs poorly
22 Summary The Intel compiler on Beacon, a Knights Corner system, gave performance as we had hoped, providing good performance using the self-offload approach that was nearly as effective as native OpenMP 3.1. Thus is an existence proof that this approach to performance portability can in principle work. The Cray compiler on Chester, a GPU-based system, generated good code using standard approaches but did not perform well using self-offload. The craype-accel-host option is not a widely documented feature and appears to be primarily intended for testing rather than production. Making this feature performant would help to enable this approach as a generally usable technique for performance portability
23 Discussion The end objective of this work is to seek a way to provide users with a means to express parallelism and data motion in their codes in a way that compilers can understand and use to generate performant code To satisfy portability, a standards-based approach seems most reasonable. OpenMP s directives-based approach is one of only a small number of current candidates This work shows how OpenMP can, at least in principle, enable true performance portability across the two major architectural classes of modern HPC systems, as well as standard multicore CPUs As OpenMP 4-capable compilers become mature, vendor support of this approach will help make this a viable strategy for performance portability
24 Future work This is a small study of very restricted scope. We would like to explore how well this approach applies to other kinds of code constructs prevalent in user codes Also, through our contact with code teams preparing for future systems, e.g., Summit, we wish to evaluate the effectiveness of this approach for those codes As OpenMP 4 support is improved for other compilers, we intend to evaluate those also Examine how to achieve performance portability with regard to other issues, e.g., memory hierarchies, NUMA issues and resilience

25 Questions? Wayne Joubert, This research used resources of the Oak Ridge Leadership Computing Facility at Oak Ridge National Laboratory, which is supported by the Office of Science of the U.S. Department of Energy under Contract No. DE-AC05-00OR This material is in part based upon work supported by the National Science Foundation under Grant Number and by the University of Tennessee through the Beacon Project. Any opinions, findings, conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation or the University of Tennessee.
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012
 Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
HPC future trends from a science perspective
 HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
HPC future trends from a science perspective Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Business as usual? We've all got used to new machines being relatively
Parallel Systems. Project topics
 Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Evaluation of Directive-based Performance Portable Programming Models. Azzam Haidar, Stanimire Tomov, and Jack Dongarra
 Int. J. Signal and Imaging Systems Engineering, Vol. x, No. x, 2017 1 Evaluation of Directive-based Performance Portable Programming Models M. Graham Lopez, Wayne Joubert, Verónica G. Vergara Larrea, Oscar
Int. J. Signal and Imaging Systems Engineering, Vol. x, No. x, 2017 1 Evaluation of Directive-based Performance Portable Programming Models M. Graham Lopez, Wayne Joubert, Verónica G. Vergara Larrea, Oscar
An Auto-Tuning Framework for Parallel Multicore Stencil Computations
 Software Engineering Seminar Sebastian Hafen An Auto-Tuning Framework for Parallel Multicore Stencil Computations Shoaib Kamil, Cy Chan, Leonid Oliker, John Shalf, Samuel Williams 1 Stencils What is a
Software Engineering Seminar Sebastian Hafen An Auto-Tuning Framework for Parallel Multicore Stencil Computations Shoaib Kamil, Cy Chan, Leonid Oliker, John Shalf, Samuel Williams 1 Stencils What is a
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17
 Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Performance of Variant Memory Configurations for Cray XT Systems
 Performance of Variant Memory Configurations for Cray XT Systems Wayne Joubert, Oak Ridge National Laboratory ABSTRACT: In late 29 NICS will upgrade its 832 socket Cray XT from Barcelona (4 cores/socket)
Performance of Variant Memory Configurations for Cray XT Systems Wayne Joubert, Oak Ridge National Laboratory ABSTRACT: In late 29 NICS will upgrade its 832 socket Cray XT from Barcelona (4 cores/socket)
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Intel Performance Libraries
 Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
Intel Performance Libraries Powerful Mathematical Library Intel Math Kernel Library (Intel MKL) Energy Science & Research Engineering Design Financial Analytics Signal Processing Digital Content Creation
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels
 National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
National Aeronautics and Space Administration Is OpenMP 4.5 Target Off-load Ready for Real Life? A Case Study of Three Benchmark Kernels Jose M. Monsalve Diaz (UDEL), Gabriele Jost (NASA), Sunita Chandrasekaran
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Optimising the Mantevo benchmark suite for multi- and many-core architectures
 Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
Optimising the Mantevo benchmark suite for multi- and many-core architectures Simon McIntosh-Smith Department of Computer Science University of Bristol 1 Bristol's rich heritage in HPC The University of
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
An Introduction to the SPEC High Performance Group and their Benchmark Suites
 An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Oak Ridge National Laboratory Computing and Computational Sciences
 Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Oak Ridge National Laboratory Computing and Computational Sciences OFA Update by ORNL Presented by: Pavel Shamis (Pasha) OFA Workshop Mar 17, 2015 Acknowledgments Bernholdt David E. Hill Jason J. Leverman
Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. ilumb@allinea.com GTC 2013, San Jose, March 20, 2013 Embracing GPUs GPUs a rival to traditional processors
A More Realistic Way of Stressing the End-to-end I/O System
 A More Realistic Way of Stressing the End-to-end I/O System Verónica G. Vergara Larrea Sarp Oral Dustin Leverman Hai Ah Nam Feiyi Wang James Simmons CUG 2015 April 29, 2015 Chicago, IL ORNL is managed
A More Realistic Way of Stressing the End-to-end I/O System Verónica G. Vergara Larrea Sarp Oral Dustin Leverman Hai Ah Nam Feiyi Wang James Simmons CUG 2015 April 29, 2015 Chicago, IL ORNL is managed
EXPOSING PARTICLE PARALLELISM IN THE XGC PIC CODE BY EXPLOITING GPU MEMORY HIERARCHY. Stephen Abbott, March
 EXPOSING PARTICLE PARALLELISM IN THE XGC PIC CODE BY EXPLOITING GPU MEMORY HIERARCHY Stephen Abbott, March 26 2018 ACKNOWLEDGEMENTS Collaborators: Oak Ridge Nation Laboratory- Ed D Azevedo NVIDIA - Peng
EXPOSING PARTICLE PARALLELISM IN THE XGC PIC CODE BY EXPLOITING GPU MEMORY HIERARCHY Stephen Abbott, March 26 2018 ACKNOWLEDGEMENTS Collaborators: Oak Ridge Nation Laboratory- Ed D Azevedo NVIDIA - Peng
S Comparing OpenACC 2.5 and OpenMP 4.5
 April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Achieving High Performance. Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013
 Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Intel Math Kernel Library 10.3
 Intel Math Kernel Library 10.3 Product Brief Intel Math Kernel Library 10.3 The Flagship High Performance Computing Math Library for Windows*, Linux*, and Mac OS* X Intel Math Kernel Library (Intel MKL)
Intel Math Kernel Library 10.3 Product Brief Intel Math Kernel Library 10.3 The Flagship High Performance Computing Math Library for Windows*, Linux*, and Mac OS* X Intel Math Kernel Library (Intel MKL)
Performance of deal.ii on a node
 Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
Performance of deal.ii on a node Bruno Turcksin Texas A&M University, Dept. of Mathematics Bruno Turcksin Deal.II on a node 1/37 Outline 1 Introduction 2 Architecture 3 Paralution 4 Other Libraries 5 Conclusions
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015
 AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
AmgX 2.0: Scaling toward CORAL Joe Eaton, November 19, 2015 Agenda Introduction to AmgX Current Capabilities Scaling V2.0 Roadmap for the future 2 AmgX Fast, scalable linear solvers, emphasis on iterative
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
Christopher Sewell Katrin Heitmann Li-ta Lo Salman Habib James Ahrens
 LA-UR- 14-25437 Approved for public release; distribution is unlimited. Title: Portable Parallel Halo and Center Finders for HACC Author(s): Christopher Sewell Katrin Heitmann Li-ta Lo Salman Habib James
LA-UR- 14-25437 Approved for public release; distribution is unlimited. Title: Portable Parallel Halo and Center Finders for HACC Author(s): Christopher Sewell Katrin Heitmann Li-ta Lo Salman Habib James
Optimizing Data Locality for Iterative Matrix Solvers on CUDA
 Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
HPC Saudi Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences. Presented to: March 14, 2017
 Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Creating an Exascale Ecosystem for Science Presented to: HPC Saudi 2017 Jeffrey A. Nichols Associate Laboratory Director Computing and Computational Sciences March 14, 2017 ORNL is managed by UT-Battelle
Programming for the Intel Many Integrated Core Architecture By James Reinders. The Architecture for Discovery. PowerPoint Title
 Programming for the Intel Many Integrated Core Architecture By James Reinders The Architecture for Discovery PowerPoint Title Intel Xeon Phi coprocessor 1. Designed for Highly Parallel workloads 2. and
Programming for the Intel Many Integrated Core Architecture By James Reinders The Architecture for Discovery PowerPoint Title Intel Xeon Phi coprocessor 1. Designed for Highly Parallel workloads 2. and
Using Intel VTune Amplifier XE for High Performance Computing
 Using Intel VTune Amplifier XE for High Performance Computing Vladimir Tsymbal Performance, Analysis and Threading Lab 1 The Majority of all HPC-Systems are Clusters Interconnect I/O I/O... I/O I/O Message
Using Intel VTune Amplifier XE for High Performance Computing Vladimir Tsymbal Performance, Analysis and Threading Lab 1 The Majority of all HPC-Systems are Clusters Interconnect I/O I/O... I/O I/O Message
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015
 Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
Development of Intel MIC Codes in NWChem. Edoardo Aprà Pacific Northwest National Laboratory
 Development of Intel MIC Codes in NWChem Edoardo Aprà Pacific Northwest National Laboratory Acknowledgements! Karol Kowalski (PNNL)! Michael Klemm (Intel)! Kiran Bhaskaran-Nair (LSU)! Wenjing Ma (Chinese
Development of Intel MIC Codes in NWChem Edoardo Aprà Pacific Northwest National Laboratory Acknowledgements! Karol Kowalski (PNNL)! Michael Klemm (Intel)! Kiran Bhaskaran-Nair (LSU)! Wenjing Ma (Chinese
Directive-based Programming for Highly-scalable Nodes
 Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
Introduction to Multicore Programming
 Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Automatic Parallelization and OpenMP 3 GPGPU 2 Multithreaded Programming
Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Automatic Parallelization and OpenMP 3 GPGPU 2 Multithreaded Programming
HTCondor on Titan. Wisconsin IceCube Particle Astrophysics Center. Vladimir Brik. HTCondor Week May 2018
 HTCondor on Titan Wisconsin IceCube Particle Astrophysics Center Vladimir Brik HTCondor Week May 2018 Overview of Titan Cray XK7 Supercomputer at Oak Ridge Leadership Computing Facility Ranked #5 by TOP500
HTCondor on Titan Wisconsin IceCube Particle Astrophysics Center Vladimir Brik HTCondor Week May 2018 Overview of Titan Cray XK7 Supercomputer at Oak Ridge Leadership Computing Facility Ranked #5 by TOP500
EE 7722 GPU Microarchitecture. Offered by: Prerequisites By Topic: Text EE 7722 GPU Microarchitecture. URL:
 00 1 EE 7722 GPU Microarchitecture 00 1 EE 7722 GPU Microarchitecture URL: http://www.ece.lsu.edu/gp/. Offered by: David M. Koppelman 345 ERAD, 578-5482, koppel@ece.lsu.edu, http://www.ece.lsu.edu/koppel
00 1 EE 7722 GPU Microarchitecture 00 1 EE 7722 GPU Microarchitecture URL: http://www.ece.lsu.edu/gp/. Offered by: David M. Koppelman 345 ERAD, 578-5482, koppel@ece.lsu.edu, http://www.ece.lsu.edu/koppel
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
COMP Parallel Computing. Programming Accelerators using Directives
 COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures
 Photos placed in horizontal position with even amount of white space between photos and header Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures Christopher Forster,
Photos placed in horizontal position with even amount of white space between photos and header Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures Christopher Forster,
Lecture 20: Distributed Memory Parallelism. William Gropp
 Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
Lecture 20: Distributed Parallelism William Gropp www.cs.illinois.edu/~wgropp A Very Short, Very Introductory Introduction We start with a short introduction to parallel computing from scratch in order
OpenACC Fundamentals. Steve Abbott November 13, 2016
 OpenACC Fundamentals Steve Abbott , November 13, 2016 Who Am I? 2005 B.S. Physics Beloit College 2007 M.S. Physics University of Florida 2015 Ph.D. Physics University of New Hampshire
OpenACC Fundamentals Steve Abbott , November 13, 2016 Who Am I? 2005 B.S. Physics Beloit College 2007 M.S. Physics University of Florida 2015 Ph.D. Physics University of New Hampshire
FPGA-based Supercomputing: New Opportunities and Challenges
 FPGA-based Supercomputing: New Opportunities and Challenges Naoya Maruyama (RIKEN AICS)* 5 th ADAC Workshop Feb 15, 2018 * Current Main affiliation is Lawrence Livermore National Laboratory SIAM PP18:
FPGA-based Supercomputing: New Opportunities and Challenges Naoya Maruyama (RIKEN AICS)* 5 th ADAC Workshop Feb 15, 2018 * Current Main affiliation is Lawrence Livermore National Laboratory SIAM PP18:
Experiences with ENZO on the Intel Many Integrated Core Architecture
 Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
Experiences with ENZO on the Intel Many Integrated Core Architecture Dr. Robert Harkness National Institute for Computational Sciences April 10th, 2012 Overview ENZO applications at petascale ENZO and
Interconnect Your Future
 Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Performance of Variant Memory Configurations for Cray XT Systems
 Performance of Variant Memory Configurations for Cray XT Systems presented by Wayne Joubert Motivation Design trends are leading to non-power of 2 core counts for multicore processors, due to layout constraints
Performance of Variant Memory Configurations for Cray XT Systems presented by Wayne Joubert Motivation Design trends are leading to non-power of 2 core counts for multicore processors, due to layout constraints
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Open Compute Stack (OpenCS) Overview. D.D. Nikolić Updated: 20 August 2018 DAE Tools Project,
 Overview. D.D. Nikolić Updated: 20 August 2018 DAE Tools Project,") Open Compute Stack (OpenCS) Overview D.D. Nikolić Updated: 20 August 2018 DAE Tools Project, http://www.daetools.com/opencs What is OpenCS? A framework for: Platform-independent model specification 1.
Open Compute Stack (OpenCS) Overview D.D. Nikolić Updated: 20 August 2018 DAE Tools Project, http://www.daetools.com/opencs What is OpenCS? A framework for: Platform-independent model specification 1.
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
ADAC Federated Testbed Creating a Blueprint for Portable Ecosystems
 ADAC Federated Testbed Creating a Blueprint for Portable Ecosystems Sadaf Alam, Jeffrey Vetter, Mark Klein, Maxime Martinasso, ExCL team @ ORNL,... ADAC Workshop February 15, 2018 January, 2016 June, 2016
ADAC Federated Testbed Creating a Blueprint for Portable Ecosystems Sadaf Alam, Jeffrey Vetter, Mark Klein, Maxime Martinasso, ExCL team @ ORNL,... ADAC Workshop February 15, 2018 January, 2016 June, 2016
NERSC Site Update. National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory. Richard Gerber
 NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
NERSC Site Update National Energy Research Scientific Computing Center Lawrence Berkeley National Laboratory Richard Gerber NERSC Senior Science Advisor High Performance Computing Department Head Cori
G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G
 Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Parallel and High Performance Computing CSE 745
 Parallel and High Performance Computing CSE 745 1 Outline Introduction to HPC computing Overview Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel
Parallel and High Performance Computing CSE 745 1 Outline Introduction to HPC computing Overview Parallel Computer Memory Architectures Parallel Programming Models Designing Parallel Programs Parallel
Architecture, Programming and Performance of MIC Phi Coprocessor
 Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
It's the end of the world as we know it
 It's the end of the world as we know it Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Background Graduated as Valedictorian in Computer Science from Cardiff University
It's the end of the world as we know it Simon McIntosh-Smith University of Bristol HPC Research Group simonm@cs.bris.ac.uk 1 Background Graduated as Valedictorian in Computer Science from Cardiff University
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
Intel Parallel Studio XE 2015 Composer Edition for Linux* Installation Guide and Release Notes
 Intel Parallel Studio XE 2015 Composer Edition for Linux* Installation Guide and Release Notes 23 October 2014 Table of Contents 1 Introduction... 1 1.1 Product Contents... 2 1.2 Intel Debugger (IDB) is
Intel Parallel Studio XE 2015 Composer Edition for Linux* Installation Guide and Release Notes 23 October 2014 Table of Contents 1 Introduction... 1 1.1 Product Contents... 2 1.2 Intel Debugger (IDB) is
The Constellation Project. Andrew W. Nash 14 November 2016
 The Constellation Project Andrew W. Nash 14 November 2016 The Constellation Project: Representing a High Performance File System as a Graph for Analysis The Titan supercomputer utilizes high performance
The Constellation Project Andrew W. Nash 14 November 2016 The Constellation Project: Representing a High Performance File System as a Graph for Analysis The Titan supercomputer utilizes high performance
OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017
 OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
OpenFOAM Scaling on Cray Supercomputers Dr. Stephen Sachs GOFUN 2017 Safe Harbor Statement This presentation may contain forward-looking statements that are based on our current expectations. Forward looking
Outline. Motivation Parallel k-means Clustering Intel Computing Architectures Baseline Performance Performance Optimizations Future Trends
 Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Collaborators: Richard T. Mills, Argonne National Laboratory Sarat Sreepathi, Oak Ridge National Laboratory Forrest M. Hoffman, Oak Ridge National Laboratory Jitendra Kumar, Oak Ridge National Laboratory
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package
 High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Porting the parallel Nek5000 application to GPU accelerators with OpenMP4.5. Alistair Hart (Cray UK Ltd.)
") Porting the parallel Nek5000 application to GPU accelerators with OpenMP4.5 Alistair Hart (Cray UK Ltd.) Safe Harbor Statement This presentation may contain forward-looking statements that are based on
Porting the parallel Nek5000 application to GPU accelerators with OpenMP4.5 Alistair Hart (Cray UK Ltd.) Safe Harbor Statement This presentation may contain forward-looking statements that are based on
Parallel Programming. Libraries and implementations
 Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Expressing Heterogeneous Parallelism in C++ with Intel Threading Building Blocks A full-day tutorial proposal for SC17
 Expressing Heterogeneous Parallelism in C++ with Intel Threading Building Blocks A full-day tutorial proposal for SC17 Tutorial Instructors [James Reinders, Michael J. Voss, Pablo Reble, Rafael Asenjo]
Expressing Heterogeneous Parallelism in C++ with Intel Threading Building Blocks A full-day tutorial proposal for SC17 Tutorial Instructors [James Reinders, Michael J. Voss, Pablo Reble, Rafael Asenjo]
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Evaluating OpenMP s Effectiveness in the Many-Core Era
 Evaluating OpenMP s Effectiveness in the Many-Core Era Prof Simon McIntosh-Smith HPC Research Group simonm@cs.bris.ac.uk 1 Bristol, UK 10 th largest city in UK Aero, finance, chip design HQ for Cray EMEA
Evaluating OpenMP s Effectiveness in the Many-Core Era Prof Simon McIntosh-Smith HPC Research Group simonm@cs.bris.ac.uk 1 Bristol, UK 10 th largest city in UK Aero, finance, chip design HQ for Cray EMEA
Identifying Working Data Set of Particular Loop Iterations for Dynamic Performance Tuning
 Identifying Working Data Set of Particular Loop Iterations for Dynamic Performance Tuning Yukinori Sato (JAIST / JST CREST) Hiroko Midorikawa (Seikei Univ. / JST CREST) Toshio Endo (TITECH / JST CREST)
Identifying Working Data Set of Particular Loop Iterations for Dynamic Performance Tuning Yukinori Sato (JAIST / JST CREST) Hiroko Midorikawa (Seikei Univ. / JST CREST) Toshio Endo (TITECH / JST CREST)
High Performance Computing. Leopold Grinberg T. J. Watson IBM Research Center, USA
 High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
High Performance Computing Leopold Grinberg T. J. Watson IBM Research Center, USA High Performance Computing Why do we need HPC? High Performance Computing Amazon can ship products within hours would it
The Heterogeneous Programming Jungle. Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest
 The Heterogeneous Programming Jungle Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest June 19, 2012 Outline 1. Introduction 2. Heterogeneous System Zoo 3. Similarities 4. Programming
The Heterogeneous Programming Jungle Service d Expérimentation et de développement Centre Inria Bordeaux Sud-Ouest June 19, 2012 Outline 1. Introduction 2. Heterogeneous System Zoo 3. Similarities 4. Programming
Some notes on efficient computing and high performance computing environments
 Some notes on efficient computing and high performance computing environments Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public
Some notes on efficient computing and high performance computing environments Abhi Datta 1, Sudipto Banerjee 2 and Andrew O. Finley 3 July 31, 2017 1 Department of Biostatistics, Bloomberg School of Public
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
Debugging Intel Xeon Phi KNC Tutorial
 Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Using R for HPC Data Science. Session: Parallel Programming Paradigms. George Ostrouchov
 Using R for HPC Data Science Session: Parallel Programming Paradigms George Ostrouchov Oak Ridge National Laboratory and University of Tennessee and pbdr Core Team Course at IT4Innovations, Ostrava, October
Using R for HPC Data Science Session: Parallel Programming Paradigms George Ostrouchov Oak Ridge National Laboratory and University of Tennessee and pbdr Core Team Course at IT4Innovations, Ostrava, October
The Titan Tools Experience
 The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
Electronic structure calculations on Thousands of CPU's and GPU's
 Electronic structure calculations on Thousands of CPU's and GPU's Emil Briggs, North Carolina State University 1. Outline of real-space Multigrid (RMG) 2. Trends in high performance computing 3. Scalability
Electronic structure calculations on Thousands of CPU's and GPU's Emil Briggs, North Carolina State University 1. Outline of real-space Multigrid (RMG) 2. Trends in high performance computing 3. Scalability
Intra-MIC MPI Communication using MVAPICH2: Early Experience
 Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
HPC code modernization with Intel development tools
 HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor
HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications