Debugging CUDA Applications with Allinea DDT. Ian Lumb Sr. Systems Engineer, Allinea Software Inc.
|
|
|
- Duane Walton
- 5 years ago
- Views:
Transcription
1 Debugging CUDA Applications with Allinea DDT Ian Lumb Sr. Systems Engineer, Allinea Software Inc. GTC 2013, San Jose, March 20, 2013

2

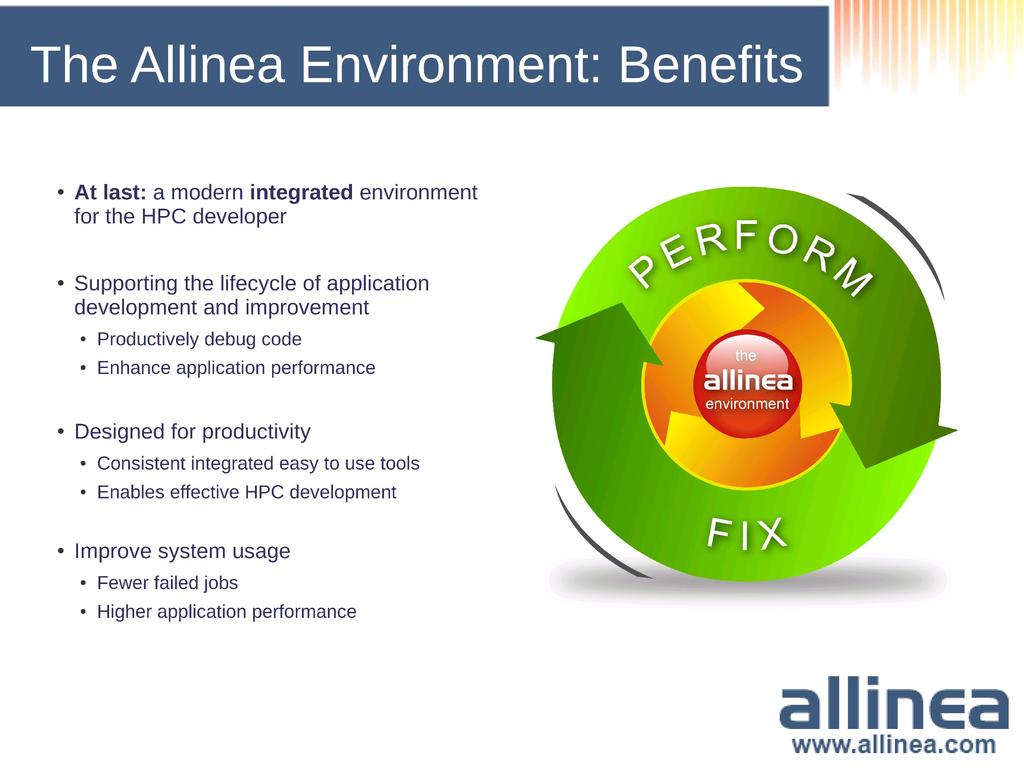
3 Embracing GPUs GPUs a rival to traditional processors New languages, compilers, standards Great price/performance ratios CUDA, OpenACC, OpenCL,... HPC developers need to consider Data transfer Multiple memory levels Grid/block layout and thread scheduling Synchronization Bugs are inevitable Processing flow
4
5

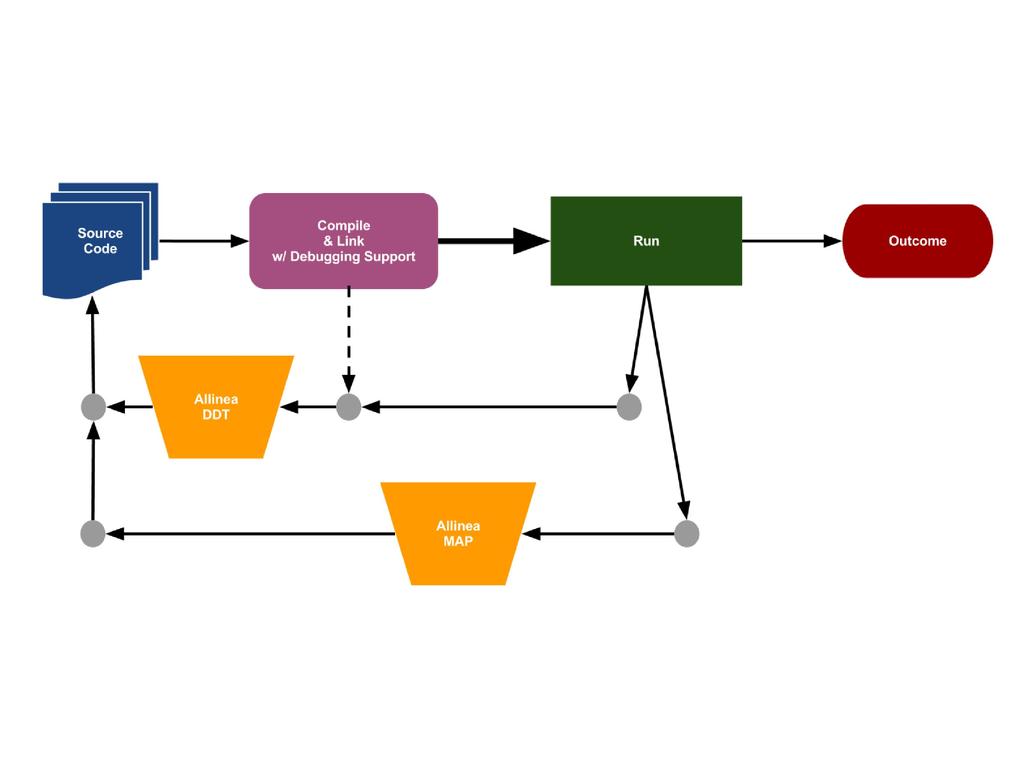
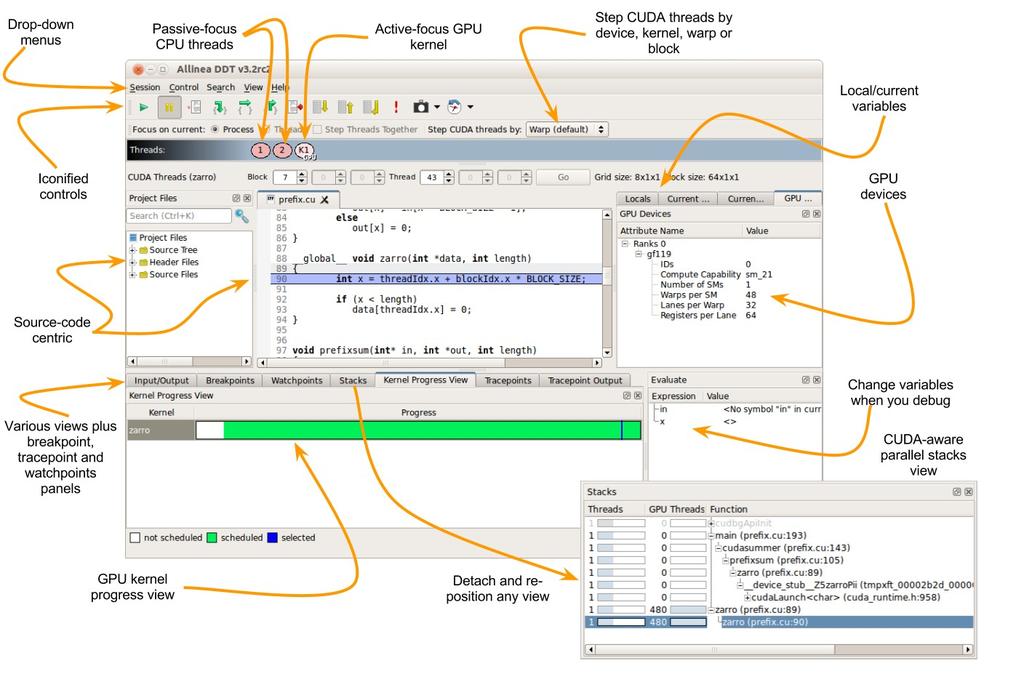
6 Full-scale parallel debugging Full CUDA 5 support OpenMP + OpenACC Mixed MPI / OpenMP / CUDA Debug the real device World-class Parallel Debugging
7 Allinea DDT Demo: CUDA Debugging Essentials
8
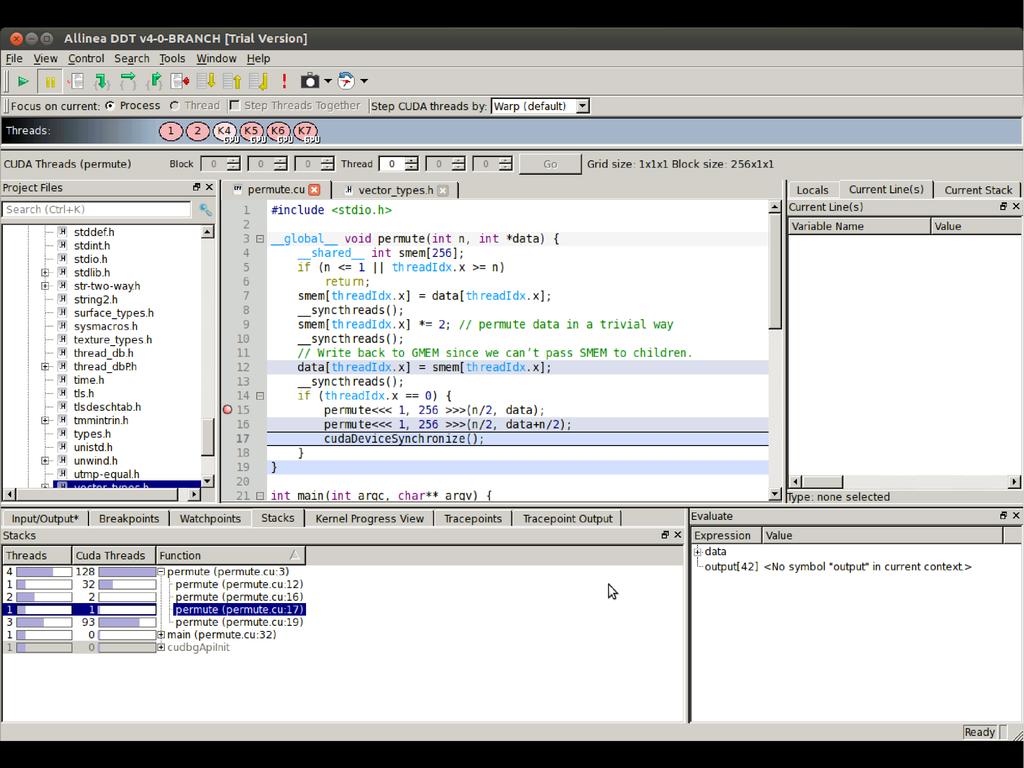
9 Debugging Dynamic Parallelism
10
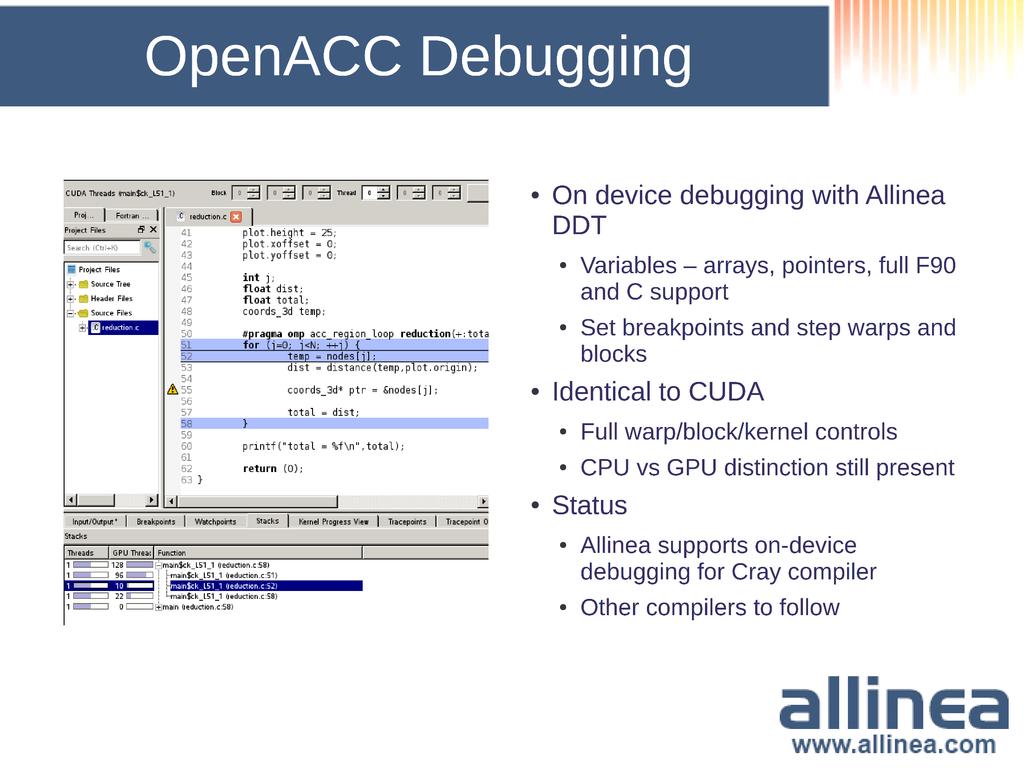
11

12 Full-scale parallel profiling Just 5% runtime overhead No need to instrument code MPI, memory and CPU See the slowest lines of code World-class Parallel Profiling
13 Use of Allinea DDT at SciNet Productively debug parallel CUDA code Completely understand parallel CUDA code Interact with data, algorithms, codes, programs and applications in real time Develop parallel CUDA code from scratch Port parallel algorithms, codes, programs and applications to CUDA Scale CUDA algorithms, codes, programs and applications

14 Petascale Debugging Cray XK* systems ORNL Titan MPI debugging proven at 220,000 CPU cores in 2010 ~300,000 CPU cores in 2012 MPI-OpenACC hybrid codes expected to scale similarly NCSA Blue Waters ~700,000 CPU cores
15 Allinea at GTC 2013 Please visit our booth!!! Live demonstrations Further information Call to action: Evaluate Allinea tools!

16
17

18 Allinea DDT: Fixing bugs made easy A tool that allows you to solve your problems faster Control threads and processes en-masse Syntax-highlighting source browser Parallel stacks and variable views that highlight divergence Supports the latest in MPI, OpenMP, CUDA and more CUDA 5.0 and Kepler K20 Intel Xeon Phi coprocessor


19 Allinea DDT: Proven to the extreme Scalability by design User interface that scales High performance tree architecture Proven performance at Petascale Measured in milliseconds Routine use at 100,000+ cores

20 Allinea DDT: More than debugger Integrated automated detection of bugs Static analysis Memory leaks and errors Open plugin architecture MPI checking tools Offline mode - debug in batch mode
21
22 Allinea DDT (10/2012) CUDA 5.0 support Intel Xeon Phi support MPMD support MPICH 2 Intel MPI IBM BlueGene /Q port
23 Allinea Tools 4.0 (3/2013) GA introduction of Allinea MAP Observe and improve the performance of your MPI application Improved syntax highlighting and code folding in code viewer Remote client Native client for Linux, Windows and Mac Redesigned welcome page Thread viewer Shows OpenMP thread ID for supported implementations
24 Allinea Tools 4.0 (2) Support for MPICH 3 Cray-specific Attach to GPU codes (Cray XK7) Memory Debugging Library preloading C/Fortran (no threads/threads) now supported (Cray XK6/7) C++ (no threads/threads) not supported
25
26

27
28 Allinea MAP: The profiler you'll want to use Works first time, every time From one process to tens of thousands 5% slowdown No instrumentation and no huge data files No need to recompile
29 Allinea MAP: Refreshing simple See where time is spent in your source code. Visualize the entire run Zoom in to explore iterations, functions and loops.
30 Allinea MAP: Surprisingly deep A wide range of metrics for deep insights into performance: CPU: Time spent in FPU, vector (SSE/AVX) and memory operations MPI: Time spent and bytes transferred in P2P / collective operations Visual display of distribution over ranks, min / max ranks labelled Export data via XML or CSV for deeper analysis and reports
31 Allinea MAP: Built on strength World-class scalability Shares Allinea DDT tree architecture proven beyond Petascale Data is merged on the cluster: no huge files.
Allinea Unified Environment
 Allinea Unified Environment Allinea s unified tools for debugging and profiling HPC Codes Beau Paisley Allinea Software bpaisley@allinea.com 720.583.0380 Today s Challenge Q: What is the impact of current
Allinea Unified Environment Allinea s unified tools for debugging and profiling HPC Codes Beau Paisley Allinea Software bpaisley@allinea.com 720.583.0380 Today s Challenge Q: What is the impact of current
Understanding Dynamic Parallelism
 Understanding Dynamic Parallelism Know your code and know yourself Presenter: Mark O Connor, VP Product Management Agenda Introduction and Background Fixing a Dynamic Parallelism Bug Understanding Dynamic
Understanding Dynamic Parallelism Know your code and know yourself Presenter: Mark O Connor, VP Product Management Agenda Introduction and Background Fixing a Dynamic Parallelism Bug Understanding Dynamic
Tools and Methodology for Ensuring HPC Programs Correctness and Performance. Beau Paisley
 Tools and Methodology for Ensuring HPC Programs Correctness and Performance Beau Paisley bpaisley@allinea.com About Allinea Over 15 years of business focused on parallel programming development tools Strong
Tools and Methodology for Ensuring HPC Programs Correctness and Performance Beau Paisley bpaisley@allinea.com About Allinea Over 15 years of business focused on parallel programming development tools Strong
GPU Debugging Made Easy. David Lecomber CTO, Allinea Software
 GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
GPU Debugging Made Easy David Lecomber CTO, Allinea Software david@allinea.com Allinea Software HPC development tools company Leading in HPC software tools market Wide customer base Blue-chip engineering,
Debugging HPC Applications. David Lecomber CTO, Allinea Software
 Debugging HPC Applications David Lecomber CTO, Allinea Software david@allinea.com Agenda Bugs and Debugging Debugging parallel applications Debugging OpenACC and other hybrid codes Debugging for Petascale
Debugging HPC Applications David Lecomber CTO, Allinea Software david@allinea.com Agenda Bugs and Debugging Debugging parallel applications Debugging OpenACC and other hybrid codes Debugging for Petascale
Debugging for the hybrid-multicore age (A HPC Perspective) David Lecomber CTO, Allinea Software
 David Lecomber CTO, Allinea Software") Debugging for the hybrid-multicore age (A HPC Perspective) David Lecomber CTO, Allinea Software david@allinea.com Agenda What is HPC? How is scale affecting HPC? Achieving tool scalability Scale in practice
Debugging for the hybrid-multicore age (A HPC Perspective) David Lecomber CTO, Allinea Software david@allinea.com Agenda What is HPC? How is scale affecting HPC? Achieving tool scalability Scale in practice
Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge
 Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge Ryan Hulguin Applications Engineer ryan.hulguin@arm.com Agenda Introduction Overview of Allinea Products
Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge Ryan Hulguin Applications Engineer ryan.hulguin@arm.com Agenda Introduction Overview of Allinea Products
Debugging at Scale Lindon Locks
 Debugging at Scale Lindon Locks llocks@allinea.com Debugging at Scale At scale debugging - from 100 cores to 250,000 Problems faced by developers on real systems Alternative approaches to debugging and
Debugging at Scale Lindon Locks llocks@allinea.com Debugging at Scale At scale debugging - from 100 cores to 250,000 Problems faced by developers on real systems Alternative approaches to debugging and
IBM High Performance Computing Toolkit
 IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Welcomes PRACE/LinkSCEEM 2011 Winter School Jacques Philouze Vice President Sales & Marketing
 Welcomes PRACE/LinkSCEEM 2011 Winter School Jacques Philouze jacques@allinea.com Vice President Sales & Marketing Content Company Background Products in more depth Allinea OPT (Optimization and Profiling
Welcomes PRACE/LinkSCEEM 2011 Winter School Jacques Philouze jacques@allinea.com Vice President Sales & Marketing Content Company Background Products in more depth Allinea OPT (Optimization and Profiling
AutoTune Workshop. Michael Gerndt Technische Universität München
 AutoTune Workshop Michael Gerndt Technische Universität München AutoTune Project Automatic Online Tuning of HPC Applications High PERFORMANCE Computing HPC application developers Compute centers: Energy
AutoTune Workshop Michael Gerndt Technische Universität München AutoTune Project Automatic Online Tuning of HPC Applications High PERFORMANCE Computing HPC application developers Compute centers: Energy
The Eclipse Parallel Tools Platform
 May 1, 2012 Toward an Integrated Development Environment for Improved Software Engineering on Crays Agenda 1. What is the Eclipse Parallel Tools Platform (PTP) 2. Tour of features available in Eclipse/PTP
May 1, 2012 Toward an Integrated Development Environment for Improved Software Engineering on Crays Agenda 1. What is the Eclipse Parallel Tools Platform (PTP) 2. Tour of features available in Eclipse/PTP
The Titan Tools Experience
 The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
The Titan Tools Experience Michael J. Brim, Ph.D. Computer Science Research, CSMD/NCCS Petascale Tools Workshop 213 Madison, WI July 15, 213 Overview of Titan Cray XK7 18,688+ compute nodes 16-core AMD
An Introduction to OpenACC
 An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
An Introduction to OpenACC Alistair Hart Cray Exascale Research Initiative Europe 3 Timetable Day 1: Wednesday 29th August 2012 13:00 Welcome and overview 13:15 Session 1: An Introduction to OpenACC 13:15
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Portable and Productive Performance with OpenACC Compilers and Tools. Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
Portable and Productive Performance with OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 Cray: Leadership in Computational Research Earth Sciences
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy.! Thomas C.
 The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
The challenges of new, efficient computer architectures, and how they can be met with a scalable software development strategy! Thomas C. Schulthess ENES HPC Workshop, Hamburg, March 17, 2014 T. Schulthess!1
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Development Tools for Parallel Computing. David Lecomber CTO, Allinea Software
 Development Tools for Parallel Computing David Lecomber CTO, Allinea Software david@allinea.com Agenda Introduction What is HPC Bugs and Debugging Debugging parallel applications Challenges for the future
Development Tools for Parallel Computing David Lecomber CTO, Allinea Software david@allinea.com Agenda Introduction What is HPC Bugs and Debugging Debugging parallel applications Challenges for the future
Development tools to enable Multicore
 Development tools to enable Multicore From the desktop to the extreme A perspective on multicore looking in from HPC David Lecomber CTO, Allinea Software david@allinea.com Introduction The Multicore Challenge
Development tools to enable Multicore From the desktop to the extreme A perspective on multicore looking in from HPC David Lecomber CTO, Allinea Software david@allinea.com Introduction The Multicore Challenge
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
ECMWF Workshop on High Performance Computing in Meteorology. 3 rd November Dean Stewart
 ECMWF Workshop on High Performance Computing in Meteorology 3 rd November 2010 Dean Stewart Agenda Company Overview Rogue Wave Product Overview IMSL Fortran TotalView Debugger Acumem ThreadSpotter 1 Copyright
ECMWF Workshop on High Performance Computing in Meteorology 3 rd November 2010 Dean Stewart Agenda Company Overview Rogue Wave Product Overview IMSL Fortran TotalView Debugger Acumem ThreadSpotter 1 Copyright
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Debugging Programs Accelerated with Intel Xeon Phi Coprocessors
 Debugging Programs Accelerated with Intel Xeon Phi Coprocessors A White Paper by Rogue Wave Software. Rogue Wave Software 5500 Flatiron Parkway, Suite 200 Boulder, CO 80301, USA www.roguewave.com Debugging
Debugging Programs Accelerated with Intel Xeon Phi Coprocessors A White Paper by Rogue Wave Software. Rogue Wave Software 5500 Flatiron Parkway, Suite 200 Boulder, CO 80301, USA www.roguewave.com Debugging
An Introduction to the SPEC High Performance Group and their Benchmark Suites
 An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
An Introduction to the SPEC High Performance Group and their Benchmark Suites Robert Henschel Manager, Scientific Applications and Performance Tuning Secretary, SPEC High Performance Group Research Technologies
OpenACC 2.6 Proposed Features
 OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2. (Mouse over to the left to see thumbnails of all of the slides)
") STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2 (Mouse over to the left to see thumbnails of all of the slides) ALLINEA DDT Allinea DDT is a powerful, easy-to-use graphical debugger capable of debugging a
STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2 (Mouse over to the left to see thumbnails of all of the slides) ALLINEA DDT Allinea DDT is a powerful, easy-to-use graphical debugger capable of debugging a
Large Scale Debugging
 Large Scale Debugging Project Meeting Report - December 2015 Didier Nadeau Under the supervision of Michel Dagenais Distributed Open Reliable Systems Analysis Lab École Polytechnique de Montréal Table
Large Scale Debugging Project Meeting Report - December 2015 Didier Nadeau Under the supervision of Michel Dagenais Distributed Open Reliable Systems Analysis Lab École Polytechnique de Montréal Table
GPU Technology Conference Three Ways to Debug Parallel CUDA Applications: Interactive, Batch, and Corefile
 GPU Technology Conference 2015 Three Ways to Debug Parallel CUDA Applications: Interactive, Batch, and Corefile Three Ways to Debug Parallel CUDA Applications: Interactive, Batch, and Corefile What do
GPU Technology Conference 2015 Three Ways to Debug Parallel CUDA Applications: Interactive, Batch, and Corefile Three Ways to Debug Parallel CUDA Applications: Interactive, Batch, and Corefile What do
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors
 Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors Chris Gottbrath Rogue Wave Software Boulder, CO Chris.Gottbrath@roguewave.com Abstract Intel Xeon Phi coprocessors present
Debugging and Optimizing Programs Accelerated with Intel Xeon Phi Coprocessors Chris Gottbrath Rogue Wave Software Boulder, CO Chris.Gottbrath@roguewave.com Abstract Intel Xeon Phi coprocessors present
The Cray Programming Environment. An Introduction
 The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
The Cray Programming Environment An Introduction Vision Cray systems are designed to be High Productivity as well as High Performance Computers The Cray Programming Environment (PE) provides a simple consistent
Debugging on Blue Waters
 Debugging on Blue Waters Debugging tools and techniques for Blue Waters are described here with example sessions, output, and pointers to small test codes. For tutorial purposes, this material will work
Debugging on Blue Waters Debugging tools and techniques for Blue Waters are described here with example sessions, output, and pointers to small test codes. For tutorial purposes, this material will work
Accelerate HPC Development with Allinea Performance Tools
 Accelerate HPC Development with Allinea Performance Tools 19 April 2016 VI-HPS, LRZ Florent Lebeau / Ryan Hulguin flebeau@allinea.com / rhulguin@allinea.com Agenda 09:00 09:15 Introduction 09:15 09:45
Accelerate HPC Development with Allinea Performance Tools 19 April 2016 VI-HPS, LRZ Florent Lebeau / Ryan Hulguin flebeau@allinea.com / rhulguin@allinea.com Agenda 09:00 09:15 Introduction 09:15 09:45
Programming for the Intel Many Integrated Core Architecture By James Reinders. The Architecture for Discovery. PowerPoint Title
 Programming for the Intel Many Integrated Core Architecture By James Reinders The Architecture for Discovery PowerPoint Title Intel Xeon Phi coprocessor 1. Designed for Highly Parallel workloads 2. and
Programming for the Intel Many Integrated Core Architecture By James Reinders The Architecture for Discovery PowerPoint Title Intel Xeon Phi coprocessor 1. Designed for Highly Parallel workloads 2. and
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
Debugging Intel Xeon Phi KNC Tutorial
 Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Debugging Intel Xeon Phi KNC Tutorial Last revised on: 10/7/16 07:37 Overview: The Intel Xeon Phi Coprocessor 2 Debug Library Requirements 2 Debugging Host-Side Applications that Use the Intel Offload
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc.
 Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
Portable and Productive Performance on Hybrid Systems with libsci_acc Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 What is Cray Libsci_acc? Provide basic scientific
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
HPC-BLAST Scalable Sequence Analysis for the Intel Many Integrated Core Future
 HPC-BLAST Scalable Sequence Analysis for the Intel Many Integrated Core Future Dr. R. Glenn Brook & Shane Sawyer Joint Institute For Computational Sciences University of Tennessee, Knoxville Dr. Bhanu
HPC-BLAST Scalable Sequence Analysis for the Intel Many Integrated Core Future Dr. R. Glenn Brook & Shane Sawyer Joint Institute For Computational Sciences University of Tennessee, Knoxville Dr. Bhanu
Hybrid Implementation of 3D Kirchhoff Migration
 Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
Hybrid Implementation of 3D Kirchhoff Migration Max Grossman, Mauricio Araya-Polo, Gladys Gonzalez GTC, San Jose March 19, 2013 Agenda 1. Motivation 2. The Problem at Hand 3. Solution Strategy 4. GPU Implementation
CUDA Development Using NVIDIA Nsight, Eclipse Edition. David Goodwin
 CUDA Development Using NVIDIA Nsight, Eclipse Edition David Goodwin NVIDIA Nsight Eclipse Edition CUDA Integrated Development Environment Project Management Edit Build Debug Profile SC'12 2 Powered By
CUDA Development Using NVIDIA Nsight, Eclipse Edition David Goodwin NVIDIA Nsight Eclipse Edition CUDA Integrated Development Environment Project Management Edit Build Debug Profile SC'12 2 Powered By
[Scalasca] Tool Integrations
![[Scalasca] Tool Integrations](/thumbs/95/125562042.jpg "[Scalasca] Tool Integrations") Mitglied der Helmholtz-Gemeinschaft [Scalasca] Tool Integrations Aug 2011 Bernd Mohr CScADS Performance Tools Workshop Lake Tahoe Contents Current integration of various direct measurement tools Paraver
Mitglied der Helmholtz-Gemeinschaft [Scalasca] Tool Integrations Aug 2011 Bernd Mohr CScADS Performance Tools Workshop Lake Tahoe Contents Current integration of various direct measurement tools Paraver
Scalability Improvements in the TAU Performance System for Extreme Scale
 Scalability Improvements in the TAU Performance System for Extreme Scale Sameer Shende Director, Performance Research Laboratory, University of Oregon TGCC, CEA / DAM Île de France Bruyères- le- Châtel,
Scalability Improvements in the TAU Performance System for Extreme Scale Sameer Shende Director, Performance Research Laboratory, University of Oregon TGCC, CEA / DAM Île de France Bruyères- le- Châtel,
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
ARCHER Single Node Optimisation
 ARCHER Single Node Optimisation Profiling Slides contributed by Cray and EPCC What is profiling? Analysing your code to find out the proportion of execution time spent in different routines. Essential
ARCHER Single Node Optimisation Profiling Slides contributed by Cray and EPCC What is profiling? Analysing your code to find out the proportion of execution time spent in different routines. Essential
GPU Computing with NVIDIA s new Kepler Architecture
 GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
GPU Computing with NVIDIA s new Kepler Architecture Axel Koehler Sr. Solution Architect HPC HPC Advisory Council Meeting, March 13-15 2013, Lugano 1 NVIDIA: Parallel Computing Company GPUs: GeForce, Quadro,
Debugging and profiling of MPI programs
 Debugging and profiling of MPI programs The code examples: http://syam.sharcnet.ca/mpi_debugging.tgz Sergey Mashchenko (SHARCNET / Compute Ontario / Compute Canada) Outline Introduction MPI debugging MPI
Debugging and profiling of MPI programs The code examples: http://syam.sharcnet.ca/mpi_debugging.tgz Sergey Mashchenko (SHARCNET / Compute Ontario / Compute Canada) Outline Introduction MPI debugging MPI
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Early Experiences Writing Performance Portable OpenMP 4 Codes
 Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Early Experiences Writing Performance Portable OpenMP 4 Codes Verónica G. Vergara Larrea Wayne Joubert M. Graham Lopez Oscar Hernandez Oak Ridge National Laboratory Problem statement APU FPGA neuromorphic
Parallel Programming and Debugging with CUDA C. Geoff Gerfin Sr. System Software Engineer
 Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Parallel Programming and Debugging with CUDA C Geoff Gerfin Sr. System Software Engineer CUDA - NVIDIA s Architecture for GPU Computing Broad Adoption Over 250M installed CUDA-enabled GPUs GPU Computing
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
Towards a Reconfigurable HPC Component Model
 C2S@EXA Meeting July 10, 2014 Towards a Reconfigurable HPC Component Model Vincent Lanore1, Christian Pérez2 1 ENS de Lyon, LIP 2 Inria, LIP Avalon team 1 Context 1/4 Adaptive Mesh Refinement 2 Context
C2S@EXA Meeting July 10, 2014 Towards a Reconfigurable HPC Component Model Vincent Lanore1, Christian Pérez2 1 ENS de Lyon, LIP 2 Inria, LIP Avalon team 1 Context 1/4 Adaptive Mesh Refinement 2 Context
Illinois Proposal Considerations Greg Bauer
 - 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
- 2016 Greg Bauer Support model Blue Waters provides traditional Partner Consulting as part of its User Services. Standard service requests for assistance with porting, debugging, allocation issues, and
Improved Event Generation at NLO and NNLO. or Extending MCFM to include NNLO processes
 Improved Event Generation at NLO and NNLO or Extending MCFM to include NNLO processes W. Giele, RadCor 2015 NNLO in MCFM: Jettiness approach: Using already well tested NLO MCFM as the double real and virtual-real
Improved Event Generation at NLO and NNLO or Extending MCFM to include NNLO processes W. Giele, RadCor 2015 NNLO in MCFM: Jettiness approach: Using already well tested NLO MCFM as the double real and virtual-real
Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010
 Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010 Chris Gottbrath Principal Product Manager Rogue Wave Major Product Offerings 2 TotalView Technologies Family
Improving the Productivity of Scalable Application Development with TotalView May 18th, 2010 Chris Gottbrath Principal Product Manager Rogue Wave Major Product Offerings 2 TotalView Technologies Family
Reusing this material
 XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
XEON PHI BASICS Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Debugging with GDB and DDT
 Debugging with GDB and DDT Ramses van Zon SciNet HPC Consortium University of Toronto June 13, 2014 1/41 Ontario HPC Summerschool 2014 Central Edition: Toronto Outline Debugging Basics Debugging with the
Debugging with GDB and DDT Ramses van Zon SciNet HPC Consortium University of Toronto June 13, 2014 1/41 Ontario HPC Summerschool 2014 Central Edition: Toronto Outline Debugging Basics Debugging with the
Parallel Programming. Libraries and implementations
 Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
LS-DYNA Scalability Analysis on Cray Supercomputers
 13 th International LS-DYNA Users Conference Session: Computing Technology LS-DYNA Scalability Analysis on Cray Supercomputers Ting-Ting Zhu Cray Inc. Jason Wang LSTC Abstract For the automotive industry,
13 th International LS-DYNA Users Conference Session: Computing Technology LS-DYNA Scalability Analysis on Cray Supercomputers Ting-Ting Zhu Cray Inc. Jason Wang LSTC Abstract For the automotive industry,
Accelerating HPL on Heterogeneous GPU Clusters
 Accelerating HPL on Heterogeneous GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline
Accelerating HPL on Heterogeneous GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda Outline
Running the FIM and NIM Weather Models on GPUs
 Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
COMP528: Multi-core and Multi-Processor Computing
 COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
Guillimin HPC Users Meeting July 14, 2016
 Guillimin HPC Users Meeting July 14, 2016 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Outline Compute Canada News System Status Software Updates Training
Guillimin HPC Users Meeting July 14, 2016 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Outline Compute Canada News System Status Software Updates Training
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Debugging, benchmarking, tuning i.e. software development tools. Martin Čuma Center for High Performance Computing University of Utah
 Debugging, benchmarking, tuning i.e. software development tools Martin Čuma Center for High Performance Computing University of Utah m.cuma@utah.edu SW development tools Development environments Compilers
Debugging, benchmarking, tuning i.e. software development tools Martin Čuma Center for High Performance Computing University of Utah m.cuma@utah.edu SW development tools Development environments Compilers
Operational Robustness of Accelerator Aware MPI
 Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
Oracle Developer Studio Performance Analyzer
 Oracle Developer Studio Performance Analyzer The Oracle Developer Studio Performance Analyzer provides unparalleled insight into the behavior of your application, allowing you to identify bottlenecks and
Oracle Developer Studio Performance Analyzer The Oracle Developer Studio Performance Analyzer provides unparalleled insight into the behavior of your application, allowing you to identify bottlenecks and
Bright Cluster Manager Advanced HPC cluster management made easy. Martijn de Vries CTO Bright Computing
 Bright Cluster Manager Advanced HPC cluster management made easy Martijn de Vries CTO Bright Computing About Bright Computing Bright Computing 1. Develops and supports Bright Cluster Manager for HPC systems
Bright Cluster Manager Advanced HPC cluster management made easy Martijn de Vries CTO Bright Computing About Bright Computing Bright Computing 1. Develops and supports Bright Cluster Manager for HPC systems
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Sami Saarinen Peter Towers. 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1
 Acknowledgements: Petra Kogel Sami Saarinen Peter Towers 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1 Motivation Opteron and P690+ clusters MPI communications IFS Forecast Model IFS 4D-Var
Acknowledgements: Petra Kogel Sami Saarinen Peter Towers 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1 Motivation Opteron and P690+ clusters MPI communications IFS Forecast Model IFS 4D-Var
Bei Wang, Dmitry Prohorov and Carlos Rosales
 Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Bei Wang, Dmitry Prohorov and Carlos Rosales Aspects of Application Performance What are the Aspects of Performance Intel Hardware Features Omni-Path Architecture MCDRAM 3D XPoint Many-core Xeon Phi AVX-512
Damaris. In-Situ Data Analysis and Visualization for Large-Scale HPC Simulations. KerData Team. Inria Rennes,
 Damaris In-Situ Data Analysis and Visualization for Large-Scale HPC Simulations KerData Team Inria Rennes, http://damaris.gforge.inria.fr Outline 1. From I/O to in-situ visualization 2. Damaris approach
Damaris In-Situ Data Analysis and Visualization for Large-Scale HPC Simulations KerData Team Inria Rennes, http://damaris.gforge.inria.fr Outline 1. From I/O to in-situ visualization 2. Damaris approach
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Нижний Новгород, 2016 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture How Programming
Peta-Scale Simulations with the HPC Software Framework walberla:
 Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Agenda
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Agenda 1 Agenda-Day 1 HPC Overview What is a cluster? Shared v.s. Distributed Parallel v.s. Massively Parallel Interconnects
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Agenda 1 Agenda-Day 1 HPC Overview What is a cluster? Shared v.s. Distributed Parallel v.s. Massively Parallel Interconnects
Heidi Poxon Cray Inc.
 Heidi Poxon Topics GPU support in the Cray performance tools CUDA proxy MPI support for GPUs (GPU-to-GPU) 2 3 Programming Models Supported for the GPU Goal is to provide whole program analysis for programs
Heidi Poxon Topics GPU support in the Cray performance tools CUDA proxy MPI support for GPUs (GPU-to-GPU) 2 3 Programming Models Supported for the GPU Goal is to provide whole program analysis for programs
Using Intel VTune Amplifier XE for High Performance Computing
 Using Intel VTune Amplifier XE for High Performance Computing Vladimir Tsymbal Performance, Analysis and Threading Lab 1 The Majority of all HPC-Systems are Clusters Interconnect I/O I/O... I/O I/O Message
Using Intel VTune Amplifier XE for High Performance Computing Vladimir Tsymbal Performance, Analysis and Threading Lab 1 The Majority of all HPC-Systems are Clusters Interconnect I/O I/O... I/O I/O Message
LDetector: A low overhead data race detector for GPU programs
 LDetector: A low overhead data race detector for GPU programs 1 PENGCHENG LI CHEN DING XIAOYU HU TOLGA SOYATA UNIVERSITY OF ROCHESTER 1 Data races in GPU Introduction & Contribution Impact correctness
LDetector: A low overhead data race detector for GPU programs 1 PENGCHENG LI CHEN DING XIAOYU HU TOLGA SOYATA UNIVERSITY OF ROCHESTER 1 Data races in GPU Introduction & Contribution Impact correctness
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
MPI RUNTIMES AT JSC, NOW AND IN THE FUTURE
 , NOW AND IN THE FUTURE Which, why and how do they compare in our systems? 08.07.2018 I MUG 18, COLUMBUS (OH) I DAMIAN ALVAREZ Outline FZJ mission JSC s role JSC s vision for Exascale-era computing JSC
, NOW AND IN THE FUTURE Which, why and how do they compare in our systems? 08.07.2018 I MUG 18, COLUMBUS (OH) I DAMIAN ALVAREZ Outline FZJ mission JSC s role JSC s vision for Exascale-era computing JSC
User Training Cray XC40 IITM, Pune
 User Training Cray XC40 IITM, Pune Sudhakar Yerneni, Raviteja K, Nachiket Manapragada, etc. 1 Cray XC40 Architecture & Packaging 3 Cray XC Series Building Blocks XC40 System Compute Blade 4 Compute Nodes
User Training Cray XC40 IITM, Pune Sudhakar Yerneni, Raviteja K, Nachiket Manapragada, etc. 1 Cray XC40 Architecture & Packaging 3 Cray XC Series Building Blocks XC40 System Compute Blade 4 Compute Nodes
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
Intel VTune Amplifier XE. Dr. Michael Klemm Software and Services Group Developer Relations Division
 Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
Intel VTune Amplifier XE Dr. Michael Klemm Software and Services Group Developer Relations Division Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED AS IS. NO LICENSE, EXPRESS
Automatic Tuning of HPC Applications with Periscope. Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München
 Automatic Tuning of HPC Applications with Periscope Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München Agenda 15:00 15:30 Introduction to the Periscope Tuning Framework (PTF)
Automatic Tuning of HPC Applications with Periscope Michael Gerndt, Michael Firbach, Isaias Compres Technische Universität München Agenda 15:00 15:30 Introduction to the Periscope Tuning Framework (PTF)
DDT Debugging Techniques
 DDT Debugging Techniques Carlos Rosales carlos@tacc.utexas.edu Scaling to Petascale 2010 July 7, 2010 Debugging Parallel Programs Usual problems Memory access issues Special cases not accounted for in
DDT Debugging Techniques Carlos Rosales carlos@tacc.utexas.edu Scaling to Petascale 2010 July 7, 2010 Debugging Parallel Programs Usual problems Memory access issues Special cases not accounted for in
Introduction to debugging. Martin Čuma Center for High Performance Computing University of Utah
 Introduction to debugging Martin Čuma Center for High Performance Computing University of Utah m.cuma@utah.edu Overview Program errors Simple debugging Graphical debugging DDT and Totalview Intel tools
Introduction to debugging Martin Čuma Center for High Performance Computing University of Utah m.cuma@utah.edu Overview Program errors Simple debugging Graphical debugging DDT and Totalview Intel tools
Parallel Systems. Project topics
 Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
CSCS Proposal writing webinar Technical review. 12th April 2015 CSCS
 CSCS Proposal writing webinar Technical review 12th April 2015 CSCS Agenda Tips for new applicants CSCS overview Allocation process Guidelines Basic concepts Performance tools Demo Q&A open discussion
CSCS Proposal writing webinar Technical review 12th April 2015 CSCS Agenda Tips for new applicants CSCS overview Allocation process Guidelines Basic concepts Performance tools Demo Q&A open discussion
Improving Applica/on Performance Using the TAU Performance System
 Improving Applica/on Performance Using the TAU Performance System Sameer Shende, John C. Linford {sameer, jlinford}@paratools.com ParaTools, Inc and University of Oregon. April 4-5, 2013, CG1, NCAR, UCAR
Improving Applica/on Performance Using the TAU Performance System Sameer Shende, John C. Linford {sameer, jlinford}@paratools.com ParaTools, Inc and University of Oregon. April 4-5, 2013, CG1, NCAR, UCAR
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
Automatic trace analysis with the Scalasca Trace Tools
 Automatic trace analysis with the Scalasca Trace Tools Ilya Zhukov Jülich Supercomputing Centre Property Automatic trace analysis Idea Automatic search for patterns of inefficient behaviour Classification
Automatic trace analysis with the Scalasca Trace Tools Ilya Zhukov Jülich Supercomputing Centre Property Automatic trace analysis Idea Automatic search for patterns of inefficient behaviour Classification