Advanced Parallel Programming. Is there life beyond MPI?
|
|
|
- Johnathan Clark
- 6 years ago
- Views:
Transcription
1 Advanced Parallel Programming Is there life beyond MPI?
2 Outline MPI vs. High Level Languages Declarative Languages Map Reduce and Hadoop Shared Global Address Space Languages Charm++ ChaNGa ChaNGa on GPUs
3 Parallel Programming in MPI Good performance Highly portable: de facto standard Poor match to some architectures Active Messages, Shared Memory New machines are hybrid architectures Multicore, Vector, RDMA, Cell Parallel Assembly?
4 Parallel Programming in High Level Languages Abstraction allows easy expression of new algorithms Low level architecture is hidden (or abstracted) Integrated debugging/performance tools Sometimes a poor mapping of algorithm onto the language Steep learning curve
5 Parallel Programming Hierarchy Decomposition of computation into parallel components Parallelizing compiler, Chapel Mapping of components to processors Charm++ Scheduling of components OpenMP, HPF Expressing the above in data movement and thread execution MPI
6 Language Requirements General Purpose Expressive for application domain Including matching representations: *(a + i) vs a[i] High Level Efficiency/obvious cost model Modularity and Reusability Context independent libraries Similar to/interoperable with existing languages
7 Declarative Languages SQL example: SELECT SUM(L_Bol) FROM stars WHERE tform > 12.0 Performance through abstraction Limited expressivity, otherwise Complicated Slow (UDF)
8 Map Reduce & Hadoop Map: function produces (key, value) pairs Reduce: collects Map output Pig: SQL-like query language Effective data reduction framework Not suitable for HPC
9 Array Languages, e.g., CAF Arrays distributed across images Each processor can access data on other processors via co-array syntax call sync_all(/up, down/) new_a(1:ncol) = new_a(1:ncol) +A(1:ncol)[up] + A(1:ncol)[down] call sync_all(/up, down/) Easy expression of array model Cost transparent
10 Programmer: [Over] decomposition into virtual processors Runtime: Assigns VPs to processors Enables adaptive runtime strategies Charm++: Migratable Objects System implementation Benefits Software engineering Number of virtual processors can be independently controlled Separate VPs for different modules Message driven execution Adaptive overlap of communication Dynamic mapping Heterogeneous clusters Vacate, adjust to speed, share Automatic checkpointing Change set of processors used Automatic dynamic load balancing Communication optimization User View
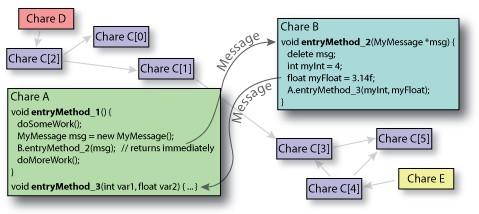
11 User view

12 System View
13 Gravity Implementations Standard Tree-code Send : distribute particles to tree nodes as the walk proceeds. Naturally expressed in Charm++ Extremely communication intensive Cache : request treenodes from off processor as they are needed. More complicated programming Cache is now part of the language
14 ChaNGa Features Tree-based gravity solver High order multipole expansion Periodic boundaries (if needed) SPH: (Gasoline compatible) Individual multiple timesteps Dynamic load balancing with choice of strategies Checkpointing (via migration to disk) Visualization
15 Cosmological Comparisons: Mass Function Heitmann, et al. 2005

16 Overall structure 08/06/10 Parallel Programming UIUC 16
17 Remote/local latency hiding Clustered data on 1,024 BlueGene/L processors Remote data work Local data work 08/06/10 Parallel Programming UIUC s

18 Load balancing with GreedyLB Zoom In 5M on 1,024 BlueGene/L processors 5.6s 6.1s 4x messages 08/06/10 Parallel Programming UIUC 18
19 Load balancing with OrbRefineLB Zoom in 5M on 1,024 BlueGene/L processors 5.6s 5.0s 08/06/10 Parallel Programming UIUC 19
20 Scaling with load balancing Number of Processors x Execution Time per Iteration (s) 08/06/10 Parallel Programming UIUC 20
21 Cosmo Loadbalancer Use Charm++ measurement based load balancer Modification: provide LB database with information about timestepping. Large timestep : balance based on previous Large step Small step balance based on previous small step



22 Results on 3 rung example 613s 429s 228s
23 Multistep Scaling
24 SPH Scaling
25 ChaNGa on GPU clusters Immense computational power Feeding the monster is a problem Charm++ GPU Manager User submits work requests with callback System transfers memory, executes, returns via callback GPU operates asynchronously Pipelined execution
26 Execution of Work Requests
27 GPU Scaling
28 GPU optimization
29 Summary Successfully created highly scalable code in HLL Computation/communication overlap Object migration for LB and Checkpoints Method prioritization GPU Manager framework HLL not a silver bullet Communication needs to be considered Productivity unclear Real Programmers write Fortran in any language


30 Thomas Quinn Graeme Lufkin Joachim Stadel James Wadsley Laxmikant Kale Filippo Gioachin Pritish Jetley Celso Mendes Amit Sharma Lukasz Wesolowski Edgar Solomonik
31 Availability Charm++: ChaNGa download: Release information: Mailing list:
A Scalable Adaptive Mesh Refinement Framework For Parallel Astrophysics Applications
 A Scalable Adaptive Mesh Refinement Framework For Parallel Astrophysics Applications James Bordner, Michael L. Norman San Diego Supercomputer Center University of California, San Diego 15th SIAM Conference
A Scalable Adaptive Mesh Refinement Framework For Parallel Astrophysics Applications James Bordner, Michael L. Norman San Diego Supercomputer Center University of California, San Diego 15th SIAM Conference
HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY
 HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY Presenters: Harshitha Menon, Seonmyeong Bak PPL Group Phil Miller, Sam White, Nitin Bhat, Tom Quinn, Jim Phillips, Laxmikant Kale MOTIVATION INTEGRATED
HANDLING LOAD IMBALANCE IN DISTRIBUTED & SHARED MEMORY Presenters: Harshitha Menon, Seonmyeong Bak PPL Group Phil Miller, Sam White, Nitin Bhat, Tom Quinn, Jim Phillips, Laxmikant Kale MOTIVATION INTEGRATED
Scalable Fault Tolerance Schemes using Adaptive Runtime Support
 Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Scalable Interaction with Parallel Applications
 Scalable Interaction with Parallel Applications Filippo Gioachin Chee Wai Lee Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign Outline Overview Case Studies Charm++
Scalable Interaction with Parallel Applications Filippo Gioachin Chee Wai Lee Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana-Champaign Outline Overview Case Studies Charm++
Programming Models for Supercomputing in the Era of Multicore
 Programming Models for Supercomputing in the Era of Multicore Marc Snir MULTI-CORE CHALLENGES 1 Moore s Law Reinterpreted Number of cores per chip doubles every two years, while clock speed decreases Need
Programming Models for Supercomputing in the Era of Multicore Marc Snir MULTI-CORE CHALLENGES 1 Moore s Law Reinterpreted Number of cores per chip doubles every two years, while clock speed decreases Need
Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs
 Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs Laércio Lima Pilla llpilla@inf.ufrgs.br LIG Laboratory INRIA Grenoble University Grenoble, France Institute of Informatics
Load Balancing for Parallel Multi-core Machines with Non-Uniform Communication Costs Laércio Lima Pilla llpilla@inf.ufrgs.br LIG Laboratory INRIA Grenoble University Grenoble, France Institute of Informatics
Histogram sort with Sampling (HSS) Vipul Harsh, Laxmikant Kale
 Vipul Harsh, Laxmikant Kale") Histogram sort with Sampling (HSS) Vipul Harsh, Laxmikant Kale Parallel sorting in the age of Exascale Charm N-body GrAvity solver Massive Cosmological N-body simulations Parallel sorting in every iteration
Histogram sort with Sampling (HSS) Vipul Harsh, Laxmikant Kale Parallel sorting in the age of Exascale Charm N-body GrAvity solver Massive Cosmological N-body simulations Parallel sorting in every iteration
Dynamic Load Balancing for Weather Models via AMPI
 Dynamic Load Balancing for Eduardo R. Rodrigues IBM Research Brazil edrodri@br.ibm.com Celso L. Mendes University of Illinois USA cmendes@ncsa.illinois.edu Laxmikant Kale University of Illinois USA kale@cs.illinois.edu
Dynamic Load Balancing for Eduardo R. Rodrigues IBM Research Brazil edrodri@br.ibm.com Celso L. Mendes University of Illinois USA cmendes@ncsa.illinois.edu Laxmikant Kale University of Illinois USA kale@cs.illinois.edu
Welcome to the 2017 Charm++ Workshop!
 Welcome to the 2017 Charm++ Workshop! Laxmikant (Sanjay) Kale http://charm.cs.illinois.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at Urbana Champaign 2017
Welcome to the 2017 Charm++ Workshop! Laxmikant (Sanjay) Kale http://charm.cs.illinois.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at Urbana Champaign 2017
CHRONO::HPC DISTRIBUTED MEMORY FLUID-SOLID INTERACTION SIMULATIONS. Felipe Gutierrez, Arman Pazouki, and Dan Negrut University of Wisconsin Madison
 CHRONO::HPC DISTRIBUTED MEMORY FLUID-SOLID INTERACTION SIMULATIONS Felipe Gutierrez, Arman Pazouki, and Dan Negrut University of Wisconsin Madison Support: Rapid Innovation Fund, U.S. Army TARDEC ASME
CHRONO::HPC DISTRIBUTED MEMORY FLUID-SOLID INTERACTION SIMULATIONS Felipe Gutierrez, Arman Pazouki, and Dan Negrut University of Wisconsin Madison Support: Rapid Innovation Fund, U.S. Army TARDEC ASME
Adaptive Runtime Support
 Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Scalable Fault Tolerance Schemes using Adaptive Runtime Support Laxmikant (Sanjay) Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University of Illinois at
Microsoft Windows HPC Server 2008 R2 for the Cluster Developer
 50291B - Version: 1 02 May 2018 Microsoft Windows HPC Server 2008 R2 for the Cluster Developer Microsoft Windows HPC Server 2008 R2 for the Cluster Developer 50291B - Version: 1 5 days Course Description:
50291B - Version: 1 02 May 2018 Microsoft Windows HPC Server 2008 R2 for the Cluster Developer Microsoft Windows HPC Server 2008 R2 for the Cluster Developer 50291B - Version: 1 5 days Course Description:
Charm++ for Productivity and Performance
 Charm++ for Productivity and Performance A Submission to the 2011 HPC Class II Challenge Laxmikant V. Kale Anshu Arya Abhinav Bhatele Abhishek Gupta Nikhil Jain Pritish Jetley Jonathan Lifflander Phil
Charm++ for Productivity and Performance A Submission to the 2011 HPC Class II Challenge Laxmikant V. Kale Anshu Arya Abhinav Bhatele Abhishek Gupta Nikhil Jain Pritish Jetley Jonathan Lifflander Phil
PICS - a Performance-analysis-based Introspective Control System to Steer Parallel Applications
 PICS - a Performance-analysis-based Introspective Control System to Steer Parallel Applications Yanhua Sun, Laxmikant V. Kalé University of Illinois at Urbana-Champaign sun51@illinois.edu November 26,
PICS - a Performance-analysis-based Introspective Control System to Steer Parallel Applications Yanhua Sun, Laxmikant V. Kalé University of Illinois at Urbana-Champaign sun51@illinois.edu November 26,
NUMA Support for Charm++
 NUMA Support for Charm++ Christiane Pousa Ribeiro (INRIA) Filippo Gioachin (UIUC) Chao Mei (UIUC) Jean-François Méhaut (INRIA) Gengbin Zheng(UIUC) Laxmikant Kalé (UIUC) Outline Introduction Motivation
NUMA Support for Charm++ Christiane Pousa Ribeiro (INRIA) Filippo Gioachin (UIUC) Chao Mei (UIUC) Jean-François Méhaut (INRIA) Gengbin Zheng(UIUC) Laxmikant Kalé (UIUC) Outline Introduction Motivation
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
Introducing Overdecomposition to Existing Applications: PlasComCM and AMPI
 Introducing Overdecomposition to Existing Applications: PlasComCM and AMPI Sam White Parallel Programming Lab UIUC 1 Introduction How to enable Overdecomposition, Asynchrony, and Migratability in existing
Introducing Overdecomposition to Existing Applications: PlasComCM and AMPI Sam White Parallel Programming Lab UIUC 1 Introduction How to enable Overdecomposition, Asynchrony, and Migratability in existing
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede
 Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
Preliminary Experiences with the Uintah Framework on on Intel Xeon Phi and Stampede Qingyu Meng, Alan Humphrey, John Schmidt, Martin Berzins Thanks to: TACC Team for early access to Stampede J. Davison
CUDA GPGPU Workshop 2012
 CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
CUDA GPGPU Workshop 2012 Parallel Programming: C thread, Open MP, and Open MPI Presenter: Nasrin Sultana Wichita State University 07/10/2012 Parallel Programming: Open MP, MPI, Open MPI & CUDA Outline
Parallel Languages: Past, Present and Future
 Parallel Languages: Past, Present and Future Katherine Yelick U.C. Berkeley and Lawrence Berkeley National Lab 1 Kathy Yelick Internal Outline Two components: control and data (communication/sharing) One
Parallel Languages: Past, Present and Future Katherine Yelick U.C. Berkeley and Lawrence Berkeley National Lab 1 Kathy Yelick Internal Outline Two components: control and data (communication/sharing) One
Fast Multipole, GPUs and Memory Crushing: The 2 Trillion Particle Euclid Flagship Simulation. Joachim Stadel Doug Potter See [Potter+ 17]
![Fast Multipole, GPUs and Memory Crushing: The 2 Trillion Particle Euclid Flagship Simulation. Joachim Stadel Doug Potter See [Potter+ 17]](/thumbs/89/97666172.jpg "Fast Multipole, GPUs and Memory Crushing: The 2 Trillion Particle Euclid Flagship Simulation. Joachim Stadel Doug Potter See [Potter+ 17]") Fast Multipole, GPUs and Memory Crushing: The 2 Trillion Particle Euclid Flagship Simulation Joachim Stadel Doug Potter See [Potter+ 17] Outline Predictability The Euclid Flagship Light-cone and Mock Pkdgrav3:
Fast Multipole, GPUs and Memory Crushing: The 2 Trillion Particle Euclid Flagship Simulation Joachim Stadel Doug Potter See [Potter+ 17] Outline Predictability The Euclid Flagship Light-cone and Mock Pkdgrav3:
Load Balancing Techniques for Asynchronous Spacetime Discontinuous Galerkin Methods
 Load Balancing Techniques for Asynchronous Spacetime Discontinuous Galerkin Methods Aaron K. Becker (abecker3@illinois.edu) Robert B. Haber Laxmikant V. Kalé University of Illinois, Urbana-Champaign Parallel
Load Balancing Techniques for Asynchronous Spacetime Discontinuous Galerkin Methods Aaron K. Becker (abecker3@illinois.edu) Robert B. Haber Laxmikant V. Kalé University of Illinois, Urbana-Champaign Parallel
High performance computing and numerical modeling
 High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
A Parallel-Object Programming Model for PetaFLOPS Machines and BlueGene/Cyclops Gengbin Zheng, Arun Singla, Joshua Unger, Laxmikant Kalé
 A Parallel-Object Programming Model for PetaFLOPS Machines and BlueGene/Cyclops Gengbin Zheng, Arun Singla, Joshua Unger, Laxmikant Kalé Parallel Programming Laboratory Department of Computer Science University
A Parallel-Object Programming Model for PetaFLOPS Machines and BlueGene/Cyclops Gengbin Zheng, Arun Singla, Joshua Unger, Laxmikant Kalé Parallel Programming Laboratory Department of Computer Science University
Recent Advances in Heterogeneous Computing using Charm++
 Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
Recent Advances in Heterogeneous Computing using Charm++ Jaemin Choi, Michael Robson Parallel Programming Laboratory University of Illinois Urbana-Champaign April 12, 2018 1 / 24 Heterogeneous Computing
Charm++: An Asynchronous Parallel Programming Model with an Intelligent Adaptive Runtime System
 Charm++: An Asynchronous Parallel Programming Model with an Intelligent Adaptive Runtime System Laxmikant (Sanjay) Kale http://charm.cs.illinois.edu Parallel Programming Laboratory Department of Computer
Charm++: An Asynchronous Parallel Programming Model with an Intelligent Adaptive Runtime System Laxmikant (Sanjay) Kale http://charm.cs.illinois.edu Parallel Programming Laboratory Department of Computer
Scalable In-memory Checkpoint with Automatic Restart on Failures
 Scalable In-memory Checkpoint with Automatic Restart on Failures Xiang Ni, Esteban Meneses, Laxmikant V. Kalé Parallel Programming Laboratory University of Illinois at Urbana-Champaign November, 2012 8th
Scalable In-memory Checkpoint with Automatic Restart on Failures Xiang Ni, Esteban Meneses, Laxmikant V. Kalé Parallel Programming Laboratory University of Illinois at Urbana-Champaign November, 2012 8th
Charm++ Workshop 2010
 Charm++ Workshop 2010 Eduardo R. Rodrigues Institute of Informatics Federal University of Rio Grande do Sul - Brazil ( visiting scholar at CS-UIUC ) errodrigues@inf.ufrgs.br Supported by Brazilian Ministry
Charm++ Workshop 2010 Eduardo R. Rodrigues Institute of Informatics Federal University of Rio Grande do Sul - Brazil ( visiting scholar at CS-UIUC ) errodrigues@inf.ufrgs.br Supported by Brazilian Ministry
Enzo-P / Cello. Scalable Adaptive Mesh Refinement for Astrophysics and Cosmology. San Diego Supercomputer Center. Department of Physics and Astronomy
 Enzo-P / Cello Scalable Adaptive Mesh Refinement for Astrophysics and Cosmology James Bordner 1 Michael L. Norman 1 Brian O Shea 2 1 University of California, San Diego San Diego Supercomputer Center 2
Enzo-P / Cello Scalable Adaptive Mesh Refinement for Astrophysics and Cosmology James Bordner 1 Michael L. Norman 1 Brian O Shea 2 1 University of California, San Diego San Diego Supercomputer Center 2
Detecting and Using Critical Paths at Runtime in Message Driven Parallel Programs
 Detecting and Using Critical Paths at Runtime in Message Driven Parallel Programs Isaac Dooley, Laxmikant V. Kale Department of Computer Science University of Illinois idooley2@illinois.edu kale@illinois.edu
Detecting and Using Critical Paths at Runtime in Message Driven Parallel Programs Isaac Dooley, Laxmikant V. Kale Department of Computer Science University of Illinois idooley2@illinois.edu kale@illinois.edu
Scalable Dynamic Adaptive Simulations with ParFUM
 Scalable Dynamic Adaptive Simulations with ParFUM Terry L. Wilmarth Center for Simulation of Advanced Rockets and Parallel Programming Laboratory University of Illinois at Urbana-Champaign The Big Picture
Scalable Dynamic Adaptive Simulations with ParFUM Terry L. Wilmarth Center for Simulation of Advanced Rockets and Parallel Programming Laboratory University of Illinois at Urbana-Champaign The Big Picture
Towards a codelet-based runtime for exascale computing. Chris Lauderdale ET International, Inc.
 Towards a codelet-based runtime for exascale computing Chris Lauderdale ET International, Inc. What will be covered Slide 2 of 24 Problems & motivation Codelet runtime overview Codelets & complexes Dealing
Towards a codelet-based runtime for exascale computing Chris Lauderdale ET International, Inc. What will be covered Slide 2 of 24 Problems & motivation Codelet runtime overview Codelets & complexes Dealing
Parallel Programming Models. Parallel Programming Models. Threads Model. Implementations 3/24/2014. Shared Memory Model (without threads)
") Parallel Programming Models Parallel Programming Models Shared Memory (without threads) Threads Distributed Memory / Message Passing Data Parallel Hybrid Single Program Multiple Data (SPMD) Multiple Program
Parallel Programming Models Parallel Programming Models Shared Memory (without threads) Threads Distributed Memory / Message Passing Data Parallel Hybrid Single Program Multiple Data (SPMD) Multiple Program
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Scaling Hierarchical N-body Simulations on GPU Clusters
 Scaling Hierarchical N-body Simulations on GPU Clusters Pritish Jetley, Lukasz Wesolowski, Filippo Gioachin, Laxmikant V. Kalé and Thomas R. Quinn Department of Computer Science Department of Astronomy
Scaling Hierarchical N-body Simulations on GPU Clusters Pritish Jetley, Lukasz Wesolowski, Filippo Gioachin, Laxmikant V. Kalé and Thomas R. Quinn Department of Computer Science Department of Astronomy
Communication and Topology-aware Load Balancing in Charm++ with TreeMatch
 Communication and Topology-aware Load Balancing in Charm++ with TreeMatch Joint lab 10th workshop (IEEE Cluster 2013, Indianapolis, IN) Emmanuel Jeannot Esteban Meneses-Rojas Guillaume Mercier François
Communication and Topology-aware Load Balancing in Charm++ with TreeMatch Joint lab 10th workshop (IEEE Cluster 2013, Indianapolis, IN) Emmanuel Jeannot Esteban Meneses-Rojas Guillaume Mercier François
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures
 Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Communication and Optimization Aspects of Parallel Programming Models on Hybrid Architectures Rolf Rabenseifner rabenseifner@hlrs.de Gerhard Wellein gerhard.wellein@rrze.uni-erlangen.de University of Stuttgart
Large-Scale GPU programming
 Large-Scale GPU programming Tim Kaldewey Research Staff Member Database Technologies IBM Almaden Research Center tkaldew@us.ibm.com Assistant Adjunct Professor Computer and Information Science Dept. University
Large-Scale GPU programming Tim Kaldewey Research Staff Member Database Technologies IBM Almaden Research Center tkaldew@us.ibm.com Assistant Adjunct Professor Computer and Information Science Dept. University
Memory Tagging in Charm++
 Memory Tagging in Charm++ Filippo Gioachin Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana Champaign Outline Overview Memory tagging Charm++ RTS CharmDebug Charm++ memory
Memory Tagging in Charm++ Filippo Gioachin Laxmikant V. Kalé Department of Computer Science University of Illinois at Urbana Champaign Outline Overview Memory tagging Charm++ RTS CharmDebug Charm++ memory
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
ClearSpeed Visual Profiler
 ClearSpeed Visual Profiler Copyright 2007 ClearSpeed Technology plc. All rights reserved. 12 November 2007 www.clearspeed.com 1 Profiling Application Code Why use a profiler? Program analysis tools are
ClearSpeed Visual Profiler Copyright 2007 ClearSpeed Technology plc. All rights reserved. 12 November 2007 www.clearspeed.com 1 Profiling Application Code Why use a profiler? Program analysis tools are
Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures
 Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures Dirk Ribbrock, Markus Geveler, Dominik Göddeke, Stefan Turek Angewandte Mathematik, Technische Universität Dortmund
Performance and Accuracy of Lattice-Boltzmann Kernels on Multi- and Manycore Architectures Dirk Ribbrock, Markus Geveler, Dominik Göddeke, Stefan Turek Angewandte Mathematik, Technische Universität Dortmund
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters
 Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Enabling Efficient Use of UPC and OpenSHMEM PGAS models on GPU Clusters Presentation at GTC 2014 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Introduction to parallel Computing
 Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Introduction to parallel Computing VI-SEEM Training Paschalis Paschalis Korosoglou Korosoglou (pkoro@.gr) (pkoro@.gr) Outline Serial vs Parallel programming Hardware trends Why HPC matters HPC Concepts
Acknowledgments. Amdahl s Law. Contents. Programming with MPI Parallel programming. 1 speedup = (1 P )+ P N. Type to enter text
+ P N. Type to enter text") Acknowledgments Programming with MPI Parallel ming Jan Thorbecke Type to enter text This course is partly based on the MPI courses developed by Rolf Rabenseifner at the High-Performance Computing-Center
Acknowledgments Programming with MPI Parallel ming Jan Thorbecke Type to enter text This course is partly based on the MPI courses developed by Rolf Rabenseifner at the High-Performance Computing-Center
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Designing Parallel Programs. This review was developed from Introduction to Parallel Computing
 Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Designing Parallel Programs This review was developed from Introduction to Parallel Computing Author: Blaise Barney, Lawrence Livermore National Laboratory references: https://computing.llnl.gov/tutorials/parallel_comp/#whatis
Scientific Computing at Million-way Parallelism - Blue Gene/Q Early Science Program
 Scientific Computing at Million-way Parallelism - Blue Gene/Q Early Science Program Implementing Hybrid Parallelism in FLASH Christopher Daley 1 2 Vitali Morozov 1 Dongwook Lee 2 Anshu Dubey 1 2 Jonathon
Scientific Computing at Million-way Parallelism - Blue Gene/Q Early Science Program Implementing Hybrid Parallelism in FLASH Christopher Daley 1 2 Vitali Morozov 1 Dongwook Lee 2 Anshu Dubey 1 2 Jonathon
"Charting the Course to Your Success!" MOC A Developing High-performance Applications using Microsoft Windows HPC Server 2008
 Description Course Summary This course provides students with the knowledge and skills to develop high-performance computing (HPC) applications for Microsoft. Students learn about the product Microsoft,
Description Course Summary This course provides students with the knowledge and skills to develop high-performance computing (HPC) applications for Microsoft. Students learn about the product Microsoft,
Scalability of Uintah Past Present and Future
 DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps, INCITE, XSEDE Scalability of Uintah Past Present and Future Martin Berzins Qingyu Meng John Schmidt,
DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps, INCITE, XSEDE Scalability of Uintah Past Present and Future Martin Berzins Qingyu Meng John Schmidt,
Introduction to Parallel Programming for Multicore/Manycore Clusters Part II-3: Parallel FVM using MPI
 Introduction to Parallel Programming for Multi/Many Clusters Part II-3: Parallel FVM using MPI Kengo Nakajima Information Technology Center The University of Tokyo 2 Overview Introduction Local Data Structure
Introduction to Parallel Programming for Multi/Many Clusters Part II-3: Parallel FVM using MPI Kengo Nakajima Information Technology Center The University of Tokyo 2 Overview Introduction Local Data Structure
Data-Intensive Applications on Numerically-Intensive Supercomputers
 Data-Intensive Applications on Numerically-Intensive Supercomputers David Daniel / James Ahrens Los Alamos National Laboratory July 2009 Interactive visualization of a billion-cell plasma physics simulation
Data-Intensive Applications on Numerically-Intensive Supercomputers David Daniel / James Ahrens Los Alamos National Laboratory July 2009 Interactive visualization of a billion-cell plasma physics simulation
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Introduction to Parallel Computing. CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014
 Introduction to Parallel Computing CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014 1 Definition of Parallel Computing Simultaneous use of multiple compute resources to solve a computational
Introduction to Parallel Computing CPS 5401 Fall 2014 Shirley Moore, Instructor October 13, 2014 1 Definition of Parallel Computing Simultaneous use of multiple compute resources to solve a computational
Fault tolerant issues in large scale applications
 Fault tolerant issues in large scale applications Romain Teyssier George Lake, Ben Moore, Joachim Stadel and the other members of the project «Cosmology at the petascale» SPEEDUP 2010 1 Outline Computational
Fault tolerant issues in large scale applications Romain Teyssier George Lake, Ben Moore, Joachim Stadel and the other members of the project «Cosmology at the petascale» SPEEDUP 2010 1 Outline Computational
 5 th Annual Workshop on Charm++ and Applications Welcome and Introduction State of Charm++ Laxmikant Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University
5 th Annual Workshop on Charm++ and Applications Welcome and Introduction State of Charm++ Laxmikant Kale http://charm.cs.uiuc.edu Parallel Programming Laboratory Department of Computer Science University
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
RAMSES on the GPU: An OpenACC-Based Approach
 RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
CUDA Experiences: Over-Optimization and Future HPC
 CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
Parallel Applications on Distributed Memory Systems. Le Yan HPC User LSU
 Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Parallel Applications on Distributed Memory Systems Le Yan HPC User Services @ LSU Outline Distributed memory systems Message Passing Interface (MPI) Parallel applications 6/3/2015 LONI Parallel Programming
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit
 Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Analyzing the Performance of IWAVE on a Cluster using HPCToolkit John Mellor-Crummey and Laksono Adhianto Department of Computer Science Rice University {johnmc,laksono}@rice.edu TRIP Meeting March 30,
Portable Heterogeneous High-Performance Computing via Domain-Specific Virtualization. Dmitry I. Lyakh.
 Portable Heterogeneous High-Performance Computing via Domain-Specific Virtualization Dmitry I. Lyakh liakhdi@ornl.gov This research used resources of the Oak Ridge Leadership Computing Facility at the
Portable Heterogeneous High-Performance Computing via Domain-Specific Virtualization Dmitry I. Lyakh liakhdi@ornl.gov This research used resources of the Oak Ridge Leadership Computing Facility at the
Perspectives form US Department of Energy work on parallel programming models for performance portability
 Perspectives form US Department of Energy work on parallel programming models for performance portability Jeremiah J. Wilke Sandia National Labs Livermore, CA IMPACT workshop at HiPEAC Sandia National
Perspectives form US Department of Energy work on parallel programming models for performance portability Jeremiah J. Wilke Sandia National Labs Livermore, CA IMPACT workshop at HiPEAC Sandia National
Objective. We will study software systems that permit applications programs to exploit the power of modern high-performance computers.
 CS 612 Software Design for High-performance Architectures 1 computers. CS 412 is desirable but not high-performance essential. Course Organization Lecturer:Paul Stodghill, stodghil@cs.cornell.edu, Rhodes
CS 612 Software Design for High-performance Architectures 1 computers. CS 412 is desirable but not high-performance essential. Course Organization Lecturer:Paul Stodghill, stodghil@cs.cornell.edu, Rhodes
Scalability issues : HPC Applications & Performance Tools
 High Performance Computing Systems and Technology Group Scalability issues : HPC Applications & Performance Tools Chiranjib Sur HPC @ India Systems and Technology Lab chiranjib.sur@in.ibm.com Top 500 :
High Performance Computing Systems and Technology Group Scalability issues : HPC Applications & Performance Tools Chiranjib Sur HPC @ India Systems and Technology Lab chiranjib.sur@in.ibm.com Top 500 :
OpenACC 2.6 Proposed Features
 OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
Flexible Hardware Mapping for Finite Element Simulations on Hybrid CPU/GPU Clusters
 Flexible Hardware Mapping for Finite Element Simulations on Hybrid /GPU Clusters Aaron Becker (abecker3@illinois.edu) Isaac Dooley Laxmikant Kale SAAHPC, July 30 2009 Champaign-Urbana, IL Target Application
Flexible Hardware Mapping for Finite Element Simulations on Hybrid /GPU Clusters Aaron Becker (abecker3@illinois.edu) Isaac Dooley Laxmikant Kale SAAHPC, July 30 2009 Champaign-Urbana, IL Target Application
PoS(eIeS2013)008. From Large Scale to Cloud Computing. Speaker. Pooyan Dadvand 1. Sònia Sagristà. Eugenio Oñate
008. From Large Scale to Cloud Computing. Speaker. Pooyan Dadvand 1. Sònia Sagristà. Eugenio Oñate") 1 International Center for Numerical Methods in Engineering (CIMNE) Edificio C1, Campus Norte UPC, Gran Capitán s/n, 08034 Barcelona, Spain E-mail: pooyan@cimne.upc.edu Sònia Sagristà International Center
1 International Center for Numerical Methods in Engineering (CIMNE) Edificio C1, Campus Norte UPC, Gran Capitán s/n, 08034 Barcelona, Spain E-mail: pooyan@cimne.upc.edu Sònia Sagristà International Center
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Enzo-P / Cello. Formation of the First Galaxies. San Diego Supercomputer Center. Department of Physics and Astronomy
 Enzo-P / Cello Formation of the First Galaxies James Bordner 1 Michael L. Norman 1 Brian O Shea 2 1 University of California, San Diego San Diego Supercomputer Center 2 Michigan State University Department
Enzo-P / Cello Formation of the First Galaxies James Bordner 1 Michael L. Norman 1 Brian O Shea 2 1 University of California, San Diego San Diego Supercomputer Center 2 Michigan State University Department
Barbara Chapman, Gabriele Jost, Ruud van der Pas
 Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Parallel Computing Using OpenMP/MPI. Presented by - Jyotsna 29/01/2008
 Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
From the latency to the throughput age. Prof. Jesús Labarta Director Computer Science Dept (BSC) UPC
 UPC") From the latency to the throughput age Prof. Jesús Labarta Director Computer Science Dept (BSC) UPC ETP4HPC Post-H2020 HPC Vision Frankfurt, June 24 th 2018 To exascale... and beyond 2 Vision The multicore
From the latency to the throughput age Prof. Jesús Labarta Director Computer Science Dept (BSC) UPC ETP4HPC Post-H2020 HPC Vision Frankfurt, June 24 th 2018 To exascale... and beyond 2 Vision The multicore
Experiences with Achieving Portability across Heterogeneous Architectures
 Experiences with Achieving Portability across Heterogeneous Architectures Lukasz G. Szafaryn +, Todd Gamblin ++, Bronis R. de Supinski ++ and Kevin Skadron + + University of Virginia ++ Lawrence Livermore
Experiences with Achieving Portability across Heterogeneous Architectures Lukasz G. Szafaryn +, Todd Gamblin ++, Bronis R. de Supinski ++ and Kevin Skadron + + University of Virginia ++ Lawrence Livermore
Introduction to OpenMP. OpenMP basics OpenMP directives, clauses, and library routines
 Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Parallel Programming Environments. Presented By: Anand Saoji Yogesh Patel
 Parallel Programming Environments Presented By: Anand Saoji Yogesh Patel Outline Introduction How? Parallel Architectures Parallel Programming Models Conclusion References Introduction Recent advancements
Parallel Programming Environments Presented By: Anand Saoji Yogesh Patel Outline Introduction How? Parallel Architectures Parallel Programming Models Conclusion References Introduction Recent advancements
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
End-to-end optimization potentials in HPC applications for NWP and Climate Research
 End-to-end optimization potentials in HPC applications for NWP and Climate Research Luis Kornblueh and Many Colleagues and DKRZ MAX-PLANCK-GESELLSCHAFT ... or a guided tour through the jungle... MAX-PLANCK-GESELLSCHAFT
End-to-end optimization potentials in HPC applications for NWP and Climate Research Luis Kornblueh and Many Colleagues and DKRZ MAX-PLANCK-GESELLSCHAFT ... or a guided tour through the jungle... MAX-PLANCK-GESELLSCHAFT
An Efficient CUDA Implementation of a Tree-Based N-Body Algorithm. Martin Burtscher Department of Computer Science Texas State University-San Marcos
 An Efficient CUDA Implementation of a Tree-Based N-Body Algorithm Martin Burtscher Department of Computer Science Texas State University-San Marcos Mapping Regular Code to GPUs Regular codes Operate on
An Efficient CUDA Implementation of a Tree-Based N-Body Algorithm Martin Burtscher Department of Computer Science Texas State University-San Marcos Mapping Regular Code to GPUs Regular codes Operate on
6.1 Multiprocessor Computing Environment
 6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC
 DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
DLR.de Chart 1 Porting a parallel rotor wake simulation to GPGPU accelerators using OpenACC Melven Röhrig-Zöllner DLR, Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU)
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Automatic MPI to AMPI Program Transformation using Photran
 Automatic MPI to AMPI Program Transformation using Photran Stas Negara 1, Gengbin Zheng 1, Kuo-Chuan Pan 2, Natasha Negara 3, Ralph E. Johnson 1, Laxmikant V. Kalé 1, and Paul M. Ricker 2 1 Department
Automatic MPI to AMPI Program Transformation using Photran Stas Negara 1, Gengbin Zheng 1, Kuo-Chuan Pan 2, Natasha Negara 3, Ralph E. Johnson 1, Laxmikant V. Kalé 1, and Paul M. Ricker 2 1 Department
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics
 Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics
Scalable Software Components for Ultrascale Visualization Applications
 Scalable Software Components for Ultrascale Visualization Applications Wes Kendall, Tom Peterka, Jian Huang SC Ultrascale Visualization Workshop 2010 11-15-2010 Primary Collaborators Jian Huang Tom Peterka
Scalable Software Components for Ultrascale Visualization Applications Wes Kendall, Tom Peterka, Jian Huang SC Ultrascale Visualization Workshop 2010 11-15-2010 Primary Collaborators Jian Huang Tom Peterka
Intermediate Parallel Programming & Cluster Computing
 High Performance Computing Modernization Program (HPCMP) Summer 2011 Puerto Rico Workshop on Intermediate Parallel Programming & Cluster Computing in conjunction with the National Computational Science
High Performance Computing Modernization Program (HPCMP) Summer 2011 Puerto Rico Workshop on Intermediate Parallel Programming & Cluster Computing in conjunction with the National Computational Science
IBM High Performance Computing Toolkit
 IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
IBM High Performance Computing Toolkit Pidad D'Souza (pidsouza@in.ibm.com) IBM, India Software Labs Top 500 : Application areas (November 2011) Systems Performance Source : http://www.top500.org/charts/list/34/apparea
High performance Computing and O&G Challenges
 High performance Computing and O&G Challenges 2 Seismic exploration challenges High Performance Computing and O&G challenges Worldwide Context Seismic,sub-surface imaging Computing Power needs Accelerating
High performance Computing and O&G Challenges 2 Seismic exploration challenges High Performance Computing and O&G challenges Worldwide Context Seismic,sub-surface imaging Computing Power needs Accelerating
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
Intro to Parallel Computing
 Outline Intro to Parallel Computing Remi Lehe Lawrence Berkeley National Laboratory Modern parallel architectures Parallelization between nodes: MPI Parallelization within one node: OpenMP Why use parallel
Outline Intro to Parallel Computing Remi Lehe Lawrence Berkeley National Laboratory Modern parallel architectures Parallelization between nodes: MPI Parallelization within one node: OpenMP Why use parallel
Ultra Large-Scale FFT Processing on Graphics Processor Arrays. Author: J.B. Glenn-Anderson, PhD, CTO enparallel, Inc.
 Abstract Ultra Large-Scale FFT Processing on Graphics Processor Arrays Author: J.B. Glenn-Anderson, PhD, CTO enparallel, Inc. Graphics Processor Unit (GPU) technology has been shown well-suited to efficient
Abstract Ultra Large-Scale FFT Processing on Graphics Processor Arrays Author: J.B. Glenn-Anderson, PhD, CTO enparallel, Inc. Graphics Processor Unit (GPU) technology has been shown well-suited to efficient
Speedup Altair RADIOSS Solvers Using NVIDIA GPU
 Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Innovation Intelligence Speedup Altair RADIOSS Solvers Using NVIDIA GPU Eric LEQUINIOU, HPC Director Hongwei Zhou, Senior Software Developer May 16, 2012 Innovation Intelligence ALTAIR OVERVIEW Altair
Workloads Programmierung Paralleler und Verteilter Systeme (PPV)
") Workloads Programmierung Paralleler und Verteilter Systeme (PPV) Sommer 2015 Frank Feinbube, M.Sc., Felix Eberhardt, M.Sc., Prof. Dr. Andreas Polze Workloads 2 Hardware / software execution environment
Workloads Programmierung Paralleler und Verteilter Systeme (PPV) Sommer 2015 Frank Feinbube, M.Sc., Felix Eberhardt, M.Sc., Prof. Dr. Andreas Polze Workloads 2 Hardware / software execution environment
Improving Uintah s Scalability Through the Use of Portable
 Improving Uintah s Scalability Through the Use of Portable Kokkos-Based Data Parallel Tasks John Holmen1, Alan Humphrey1, Daniel Sunderland2, Martin Berzins1 University of Utah1 Sandia National Laboratories2
Improving Uintah s Scalability Through the Use of Portable Kokkos-Based Data Parallel Tasks John Holmen1, Alan Humphrey1, Daniel Sunderland2, Martin Berzins1 University of Utah1 Sandia National Laboratories2
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Peta-Scale Simulations with the HPC Software Framework walberla:
 Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,
Peta-Scale Simulations with the HPC Software Framework walberla: Massively Parallel AMR for the Lattice Boltzmann Method SIAM PP 2016, Paris April 15, 2016 Florian Schornbaum, Christian Godenschwager,