Hakam Zaidan Stephen Moore
|
|
|
- Sara Wood
- 5 years ago
- Views:
Transcription

1 Hakam Zaidan Stephen Moore
2 Outline Vector Architectures Properties Applications History Westinghouse Solomon ILLIAC IV CDC STAR 100 Cray 1 Other Cray Vector Machines Vector Machines Today

3 Introduction A Vector processor is a CPU that can run one instructiononanentire vector of data. The fetched number of instructions are small. They also achieve data parallelism in large scientific and multimedia applications.
4 Styles of Vector Architectures Based on how the operands are fetched, vector processors can be divided into two categories: Memory Memory Architecture. Vector Register Architecture.
: Usually 4 8 functional units: FP mult, FP add, and FP divide, in addition to the integer add and logical shift Vector Load Store Unit (LSUs).")
5 Vector Processor Elements Vector Register: Fixed length, single vector, ports for reading and writing. Usually 8 to 32 registers of length 64 or 128 bits. Vector Functional Units (FUs): Usually 4 8 functional units: FP mult, FP add, and FP divide, in addition to the integer add and logical shift Vector Load Store Unit (LSUs). Scalar registers. Cross bar.
6 Vector Processor Properties Results are independent. Known pattern for memory access by the vector instructions. In pipelines, branches and branch problems are reduced. Single vector instruction indicate huge amount of calculations (e.g. loops).
7 Disadvantages With scalar instructions: Relatively slow. Some difficulties in the implementation of the precise exceptions. High cost for on chip vector memory systems. Code complexity.
8 Applications Lossy compression. Lossless compression. Multimedia Processing. Standard benchmarking kernels. Handwriting recognition. Speech recognition. Cryptography. Operating system and networking. Databases. Support of language run time.
9 History In 1962, Illinois Automatic Computer series of super computers ILLIAC I, ILLIAC II, ILLIAC III, ILLIAC IV (with 64 ALUs Mflops). In 1973 TI s Advance Scientific Computer (ASC) Mflops. In 1975 the Cray 1 ( Mflops) was the first super computer to have vector registers instead of keeping data in memory. CRAY XMP, CRAY YMP, NEC SX/2, CRAY C 90, NEC SX/4, CRAY J 90, CRAY T 90, NEC SX/5. (from 1976 to 1999).
10 Westinghouse Solomon Project Used an array of processing elements (PE) Applied same instruction to all processors, different data per processor Research contract with US Air Force Prototype built in 1964 Development ended after contract expired

11
12 ILLIAC IV Parallel Machine One Control Unit (CU) controlled PEs One of predicted four CUs built 64 PEs available per CU Each PE had private memory unit Expected 1000 MFLOPS Achieved MFLOPS Fastest machine until 1981
13
14 CDC STAR 100 Designed to operate at 100 MFLOPS Long pipelines Long vector setup time Needed to have 50 elements to be faster than competitors Scalar performance was slow
15 Cray 1 Supercomputer built in MFLOPS, or 250 MFLOPS for bursts Fast Vector and Scalar computation Smaller than other computers

16
17 Architecture Uses registers to increase speed 8 24 bit address registers bit address save registers 8 64 bit scalar registers bit scalar save registers 8 64 word vector registers Chains together functional units Address, Scalar, Vector, and Floating Point




18
19 Other Cray Computers Cray X MP (1983) Used shared memory, faster clock, more memory bandwidth, 2 CPUs, MFLOPS Cray 2 (1985) New architecture, fast memory, 1.9 GFLOPS Cray Y MP (1988) 2, 4, or 8 vector processors, 2.67 GFLOPS Cray X1 (2003) Unification of multiple architectures, 12.8 GFLOPS Not financially successful
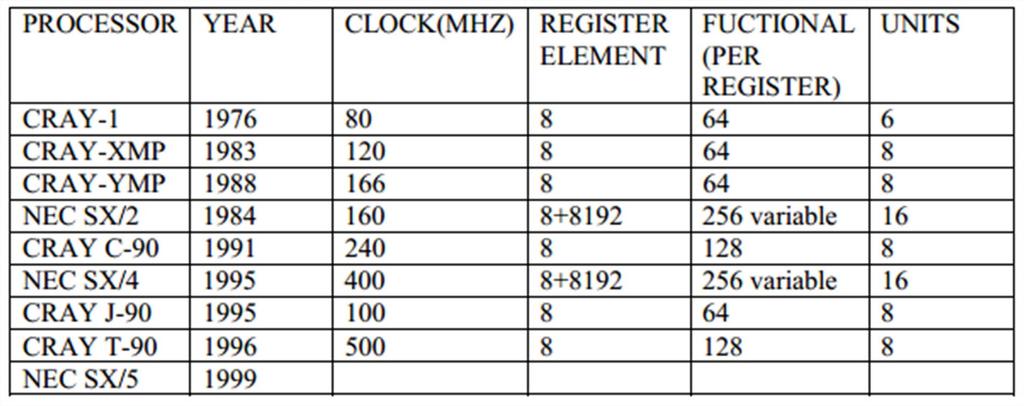
20 Vector Supercomputers
21 Vector Machines Today Very expensive to build Smaller speedup compared to using multiple processors Processors with many sequential cores are preferred Vector Machine concepts are still used IBM ViVA Virtual Vector machine Uses multiple functional units Acts as a vector processor
22 Vector Intelligent RAM (VIRAM) Architecture developed at UC Berkeley. Full vector microprocessor and DRAM on a single chip. Lower memory latency up to 5 10X lower, and bandwidth up to X higher. High bandwidth for I/O up to GB/sec. Improve energy efficiency 2X 4X, as there are no off chip bus. Adjustable memory size. Lower cost and power than traditional vector supercomputers.
23 Clustered Organization for Decoupled Execution (CODE) Developed at UC Berkeley. CODE is a proposed vector architecture to overcome the conventional vector processors disadvantages or limitations. CODE organizes the vector registers in clusters 4 8 registers in each cluster. CODE allows partial completion of an instruction in case of an exception. CODE supports precise exception using a history buffer. CODE can hide communication latency.
24 Conclusion Vector supercomputers are not practical due its high cost. To improve the cost performance, vector supercomputers are adapting commodity technology like SMT. Designs of superscalar microprocessors designs began to absorb some of the techniques made popular in earlier vector computer systems. (e.g. Intel MMX extension). Vector processors are useful for embedded and multimedia applications which require low power, small code size and high performance.
25 References C. Kozyrakis, D. Patterson, Overcoming the Limitations of Conventional Vector Processors, in ISCA, C. Kozyrakis, D. Patterson, Vector vs. Superscalar and VLIW Architectures for Embedded Multimedia Benchmarks, in MICRO, W. J. Bouknight, et al., The Illiac IV System, Proceedings of the IEEE Vol 60, No. 4, April R. M. Russell, The Cray 1 Computer System, Communications of the ACM Vol 21, No 1, Jan J Gebis, et al., Improving Memory Subsystem Performance using ViVA: Virtual Vector Architecture in ARCS '09 Proceedings of the 22nd International Conference on Architecture of Computing Systems, 2009, pp D. L. Slotnick, et al., The Solomon Computer, Westinghouse Electric Corporation, Baltimore, MD, 1962.
26 Questions?
CMPE 655 Multiple Processor Systems. SIMD/Vector Machines. Daniel Terrance Stephen Charles Rajkumar Ramadoss
 CMPE 655 Multiple Processor Systems SIMD/Vector Machines Daniel Terrance Stephen Charles Rajkumar Ramadoss SIMD Machines - Introduction Computers with an array of multiple processing elements (PE). Similar
CMPE 655 Multiple Processor Systems SIMD/Vector Machines Daniel Terrance Stephen Charles Rajkumar Ramadoss SIMD Machines - Introduction Computers with an array of multiple processing elements (PE). Similar
Advanced Topics in Computer Architecture
 Advanced Topics in Computer Architecture Lecture 7 Data Level Parallelism: Vector Processors Marenglen Biba Department of Computer Science University of New York Tirana Cray I m certainly not inventing
Advanced Topics in Computer Architecture Lecture 7 Data Level Parallelism: Vector Processors Marenglen Biba Department of Computer Science University of New York Tirana Cray I m certainly not inventing
Asanovic/Devadas Spring Vector Computers. Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology
 Vector Computers Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology Supercomputers Definition of a supercomputer: Fastest machine in world at given task Any machine costing
Vector Computers Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology Supercomputers Definition of a supercomputer: Fastest machine in world at given task Any machine costing
Vector Architectures Vs. Superscalar and VLIW for Embedded Media Benchmarks
 Vector Architectures Vs. Superscalar and VLIW for Embedded Media Benchmarks Christos Kozyrakis Stanford University David Patterson U.C. Berkeley http://csl.stanford.edu/~christos Motivation Ideal processor
Vector Architectures Vs. Superscalar and VLIW for Embedded Media Benchmarks Christos Kozyrakis Stanford University David Patterson U.C. Berkeley http://csl.stanford.edu/~christos Motivation Ideal processor
Memory Systems IRAM. Principle of IRAM
 Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
CPS104 Computer Organization and Programming Lecture 20: Superscalar processors, Multiprocessors. Robert Wagner
 CS104 Computer Organization and rogramming Lecture 20: Superscalar processors, Multiprocessors Robert Wagner Faster and faster rocessors So much to do, so little time... How can we make computers that
CS104 Computer Organization and rogramming Lecture 20: Superscalar processors, Multiprocessors Robert Wagner Faster and faster rocessors So much to do, so little time... How can we make computers that
Processors. Young W. Lim. May 12, 2016
 Processors Young W. Lim May 12, 2016 Copyright (c) 2016 Young W. Lim. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version
Processors Young W. Lim May 12, 2016 Copyright (c) 2016 Young W. Lim. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version
This Unit: Putting It All Together. CIS 501 Computer Architecture. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
CS 152 Computer Architecture and Engineering. Lecture 18: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 18: Multithreading Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
These slides do not give detailed coverage of the material. See class notes and solved problems (last page) for more information.
 for more information.") 11 1 This Set 11 1 These slides do not give detailed coverage of the material. See class notes and solved problems (last page) for more information. Text covers multiple-issue machines in Chapter 4, but
11 1 This Set 11 1 These slides do not give detailed coverage of the material. See class notes and solved problems (last page) for more information. Text covers multiple-issue machines in Chapter 4, but
Parallel computer architecture classification
 Parallel computer architecture classification Hardware Parallelism Computing: execute instructions that operate on data. Computer Instructions Data Flynn s taxonomy (Michael Flynn, 1967) classifies computer
Parallel computer architecture classification Hardware Parallelism Computing: execute instructions that operate on data. Computer Instructions Data Flynn s taxonomy (Michael Flynn, 1967) classifies computer
SIMD Parallel Computers
 CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) SIMD Computers Copyright 2003 J. E. Smith University of Wisconsin-Madison SIMD Parallel Computers BSP: Classic SIMD number
CS/ECE 757: Advanced Computer Architecture II (Parallel Computer Architecture) SIMD Computers Copyright 2003 J. E. Smith University of Wisconsin-Madison SIMD Parallel Computers BSP: Classic SIMD number
06-2 EE Lecture Transparency. Formatted 14:50, 4 December 1998 from lsli
 06-1 Vector Processors, Etc. 06-1 Some material from Appendix B of Hennessy and Patterson. Outline Memory Latency Hiding v. Reduction Program Characteristics Vector Processors Data Prefetch Processor /DRAM
06-1 Vector Processors, Etc. 06-1 Some material from Appendix B of Hennessy and Patterson. Outline Memory Latency Hiding v. Reduction Program Characteristics Vector Processors Data Prefetch Processor /DRAM
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
ASSEMBLY LANGUAGE MACHINE ORGANIZATION
 ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
Static Compiler Optimization Techniques
 Static Compiler Optimization Techniques We examined the following static ISA/compiler techniques aimed at improving pipelined CPU performance: Static pipeline scheduling. Loop unrolling. Static branch
Static Compiler Optimization Techniques We examined the following static ISA/compiler techniques aimed at improving pipelined CPU performance: Static pipeline scheduling. Loop unrolling. Static branch
NOW Handout Page 1 NO! Today s Goal: CS 258 Parallel Computer Architecture. What will you get out of CS258? Will it be worthwhile?
 Today s Goal: CS 258 Parallel Computer Architecture Introduce you to Parallel Computer Architecture Answer your questions about CS 258 Provide you a sense of the trends that shape the field CS 258, Spring
Today s Goal: CS 258 Parallel Computer Architecture Introduce you to Parallel Computer Architecture Answer your questions about CS 258 Provide you a sense of the trends that shape the field CS 258, Spring
Vector IRAM: A Microprocessor Architecture for Media Processing
 IRAM: A Microprocessor Architecture for Media Processing Christoforos E. Kozyrakis kozyraki@cs.berkeley.edu CS252 Graduate Computer Architecture February 10, 2000 Outline Motivation for IRAM technology
IRAM: A Microprocessor Architecture for Media Processing Christoforos E. Kozyrakis kozyraki@cs.berkeley.edu CS252 Graduate Computer Architecture February 10, 2000 Outline Motivation for IRAM technology
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Chapter 4 Data-Level Parallelism
 CS359: Computer Architecture Chapter 4 Data-Level Parallelism Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 4.1 Introduction 4.2 Vector Architecture
CS359: Computer Architecture Chapter 4 Data-Level Parallelism Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 4.1 Introduction 4.2 Vector Architecture
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13
 Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Using Intel Streaming SIMD Extensions for 3D Geometry Processing
 Using Intel Streaming SIMD Extensions for 3D Geometry Processing Wan-Chun Ma, Chia-Lin Yang Dept. of Computer Science and Information Engineering National Taiwan University firebird@cmlab.csie.ntu.edu.tw,
Using Intel Streaming SIMD Extensions for 3D Geometry Processing Wan-Chun Ma, Chia-Lin Yang Dept. of Computer Science and Information Engineering National Taiwan University firebird@cmlab.csie.ntu.edu.tw,
Quiz for Chapter 1 Computer Abstractions and Technology
 Date: Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
Date: Not all questions are of equal difficulty. Please review the entire quiz first and then budget your time carefully. Name: Course: Solutions in Red 1. [15 points] Consider two different implementations,
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Hardware/Compiler Codevelopment for an Embedded Media Processor
 Hardware/Compiler Codevelopment for an Embedded Media Processor CHRISTOFOROS KOZYRAKIS, STUDENT MEMBER, IEEE, DAVID JUDD, JOSEPH GEBIS, STUDENT MEMBER, IEEE, SAMUEL WILLIAMS, DAVID PATTERSON, FELLOW, IEEE,
Hardware/Compiler Codevelopment for an Embedded Media Processor CHRISTOFOROS KOZYRAKIS, STUDENT MEMBER, IEEE, DAVID JUDD, JOSEPH GEBIS, STUDENT MEMBER, IEEE, SAMUEL WILLIAMS, DAVID PATTERSON, FELLOW, IEEE,
General Purpose Signal Processors
 General Purpose Signal Processors First announced in 1978 (AMD) for peripheral computation such as in printers, matured in early 80 s (TMS320 series). General purpose vs. dedicated architectures: Pros:
General Purpose Signal Processors First announced in 1978 (AMD) for peripheral computation such as in printers, matured in early 80 s (TMS320 series). General purpose vs. dedicated architectures: Pros:
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Architectures & instruction sets R_B_T_C_. von Neumann architecture. Computer architecture taxonomy. Assembly language.
 Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Architectures & instruction sets Computer architecture taxonomy. Assembly language. R_B_T_C_ 1. E E C E 2. I E U W 3. I S O O 4. E P O I von Neumann architecture Memory holds data and instructions. Central
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Why Parallel Architecture
 Why Parallel Architecture and Programming? Todd C. Mowry 15-418 January 11, 2011 What is Parallel Programming? Software with multiple threads? Multiple threads for: convenience: concurrent programming
Why Parallel Architecture and Programming? Todd C. Mowry 15-418 January 11, 2011 What is Parallel Programming? Software with multiple threads? Multiple threads for: convenience: concurrent programming
Alternate definition: Instruction Set Architecture (ISA) What is Computer Architecture? Computer Organization. Computer structure: Von Neumann model
 What is Computer Architecture? Computer Organization. Computer structure: Von Neumann model") What is Computer Architecture? Structure: static arrangement of the parts Organization: dynamic interaction of the parts and their control Implementation: design of specific building blocks Performance:
What is Computer Architecture? Structure: static arrangement of the parts Organization: dynamic interaction of the parts and their control Implementation: design of specific building blocks Performance:
Processing Unit CS206T
 Processing Unit CS206T Microprocessors The density of elements on processor chips continued to rise More and more elements were placed on each chip so that fewer and fewer chips were needed to construct
Processing Unit CS206T Microprocessors The density of elements on processor chips continued to rise More and more elements were placed on each chip so that fewer and fewer chips were needed to construct
Parallelism. Execution Cycle. Dual Bus Simple CPU. Pipelining COMP375 1
 Pipelining COMP375 Computer Architecture and dorganization Parallelism The most common method of making computers faster is to increase parallelism. There are many levels of parallelism Macro Multiple
Pipelining COMP375 Computer Architecture and dorganization Parallelism The most common method of making computers faster is to increase parallelism. There are many levels of parallelism Macro Multiple
Data Parallel Architectures
 EE392C: Advanced Topics in Computer Architecture Lecture #2 Chip Multiprocessors and Polymorphic Processors Thursday, April 3 rd, 2003 Data Parallel Architectures Lecture #2: Thursday, April 3 rd, 2003
EE392C: Advanced Topics in Computer Architecture Lecture #2 Chip Multiprocessors and Polymorphic Processors Thursday, April 3 rd, 2003 Data Parallel Architectures Lecture #2: Thursday, April 3 rd, 2003
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 260 Introduction to Parallel Computation
 CSE 260 Introduction to Parallel Computation Larry Carter carter@cs.ucsd.edu Office Hours: AP&M 4101 MW 10:00-11 or by appointment 9/20/2001 Topics Instances Principles Theory Hardware specific machines
CSE 260 Introduction to Parallel Computation Larry Carter carter@cs.ucsd.edu Office Hours: AP&M 4101 MW 10:00-11 or by appointment 9/20/2001 Topics Instances Principles Theory Hardware specific machines
PERFORMANCE ANALYSIS OF AN H.263 VIDEO ENCODER FOR VIRAM
 PERFORMANCE ANALYSIS OF AN H.263 VIDEO ENCODER FOR VIRAM Thinh PQ Nguyen, Avideh Zakhor, and Kathy Yelick * Department of Electrical Engineering and Computer Sciences University of California at Berkeley,
PERFORMANCE ANALYSIS OF AN H.263 VIDEO ENCODER FOR VIRAM Thinh PQ Nguyen, Avideh Zakhor, and Kathy Yelick * Department of Electrical Engineering and Computer Sciences University of California at Berkeley,
What are Clusters? Why Clusters? - a Short History
 What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
15-740/ Computer Architecture Lecture 8: Issues in Out-of-order Execution. Prof. Onur Mutlu Carnegie Mellon University
 15-740/18-740 Computer Architecture Lecture 8: Issues in Out-of-order Execution Prof. Onur Mutlu Carnegie Mellon University Readings General introduction and basic concepts Smith and Sohi, The Microarchitecture
15-740/18-740 Computer Architecture Lecture 8: Issues in Out-of-order Execution Prof. Onur Mutlu Carnegie Mellon University Readings General introduction and basic concepts Smith and Sohi, The Microarchitecture
PREPARED BY S.RAVINDRAKUMAR, SENIOR ASSISTANT PROFESSOR/ECE,CHETTINAD COLLEGE OF ENGINEERING AND TECHNOLOGY Page 1
 TECHNOLOGY Page 1 Intel x86 Microcomputer CPU Characteristics 8086 16 bit Expansion Bus 16 bit External Bus 8 bit Internal Bus 20 bit Memory Address 2 20 = 1,048,576 = 1024 Kb Physical Memory Real Address
TECHNOLOGY Page 1 Intel x86 Microcomputer CPU Characteristics 8086 16 bit Expansion Bus 16 bit External Bus 8 bit Internal Bus 20 bit Memory Address 2 20 = 1,048,576 = 1024 Kb Physical Memory Real Address
Introducing Multi-core Computing / Hyperthreading
 Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Lecture 14: Multithreading
 CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
CS 152 Computer Architecture and Engineering Lecture 14: Multithreading John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~johnw
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CS 152 Computer Architecture and Engineering. Lecture 16: Vector Computers
 CS 152 Computer Architecture and Engineering Lecture 16: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
CS 152 Computer Architecture and Engineering Lecture 16: Vector Computers Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://www.eecs.berkeley.edu/~krste
A Data-Parallel Genealogy: The GPU Family Tree. John Owens University of California, Davis
 A Data-Parallel Genealogy: The GPU Family Tree John Owens University of California, Davis Outline Moore s Law brings opportunity Gains in performance and capabilities. What has 20+ years of development
A Data-Parallel Genealogy: The GPU Family Tree John Owens University of California, Davis Outline Moore s Law brings opportunity Gains in performance and capabilities. What has 20+ years of development
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Supercomputers. Alex Reid & James O'Donoghue
 Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Donn Morrison Department of Computer Science. TDT4255 Memory hierarchies
 TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
Next Generation Technology from Intel Intel Pentium 4 Processor
 Next Generation Technology from Intel Intel Pentium 4 Processor 1 The Intel Pentium 4 Processor Platform Intel s highest performance processor for desktop PCs Targeted at consumer enthusiasts and business
Next Generation Technology from Intel Intel Pentium 4 Processor 1 The Intel Pentium 4 Processor Platform Intel s highest performance processor for desktop PCs Targeted at consumer enthusiasts and business
Pipelining and Vector Processing
 Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Pipelining and Vector Processing Chapter 8 S. Dandamudi Outline Basic concepts Handling resource conflicts Data hazards Handling branches Performance enhancements Example implementations Pentium PowerPC
Multi-core Programming - Introduction
 Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Dynamic Scheduling. CSE471 Susan Eggers 1
 Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Vector Processors. Kavitha Chandrasekar Sreesudhan Ramkumar
 Vector Processors Kavitha Chandrasekar Sreesudhan Ramkumar Agenda Why Vector processors Basic Vector Architecture Vector Execution time Vector load - store units and Vector memory systems Vector length
Vector Processors Kavitha Chandrasekar Sreesudhan Ramkumar Agenda Why Vector processors Basic Vector Architecture Vector Execution time Vector load - store units and Vector memory systems Vector length
AR-SMT: A Microarchitectural Approach to Fault Tolerance in Microprocessors
 AR-SMT: A Microarchitectural Approach to Fault Tolerance in Microprocessors Computer Sciences Department University of Wisconsin Madison http://www.cs.wisc.edu/~ericro/ericro.html ericro@cs.wisc.edu High-Performance
AR-SMT: A Microarchitectural Approach to Fault Tolerance in Microprocessors Computer Sciences Department University of Wisconsin Madison http://www.cs.wisc.edu/~ericro/ericro.html ericro@cs.wisc.edu High-Performance
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Advanced cache optimizations. ECE 154B Dmitri Strukov
 Advanced cache optimizations ECE 154B Dmitri Strukov Advanced Cache Optimization 1) Way prediction 2) Victim cache 3) Critical word first and early restart 4) Merging write buffer 5) Nonblocking cache
Advanced cache optimizations ECE 154B Dmitri Strukov Advanced Cache Optimization 1) Way prediction 2) Victim cache 3) Critical word first and early restart 4) Merging write buffer 5) Nonblocking cache
Basic Computer Architecture
 Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I
Review: Moore s Law. EECS 252 Graduate Computer Architecture Lecture 2. Bell s Law new class per decade
 EECS 252 Graduate Computer Architecture Lecture 2 0 Review of Instruction Sets and Pipelines January 23 th, 202 Review: Moore s Law John Kubiatowicz Electrical Engineering and Computer Sciences University
EECS 252 Graduate Computer Architecture Lecture 2 0 Review of Instruction Sets and Pipelines January 23 th, 202 Review: Moore s Law John Kubiatowicz Electrical Engineering and Computer Sciences University
Design and Implementation of a Super Scalar DLX based Microprocessor
 Design and Implementation of a Super Scalar DLX based Microprocessor 2 DLX Architecture As mentioned above, the Kishon is based on the original DLX as studies in (Hennessy & Patterson, 1996). By: Amnon
Design and Implementation of a Super Scalar DLX based Microprocessor 2 DLX Architecture As mentioned above, the Kishon is based on the original DLX as studies in (Hennessy & Patterson, 1996). By: Amnon
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
EE282H: Computer Architecture and Organization. EE282H: Computer Architecture and Organization -- Course Overview
 : Computer Architecture and Organization Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ : Computer Architecture and Organization -- Course Overview Goals»
: Computer Architecture and Organization Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ : Computer Architecture and Organization -- Course Overview Goals»
A Key Theme of CIS 371: Parallelism. CIS 371 Computer Organization and Design. Readings. This Unit: (In-Order) Superscalar Pipelines
 Superscalar Pipelines") A Key Theme of CIS 371: arallelism CIS 371 Computer Organization and Design Unit 10: Superscalar ipelines reviously: pipeline-level parallelism Work on execute of one instruction in parallel with decode
A Key Theme of CIS 371: arallelism CIS 371 Computer Organization and Design Unit 10: Superscalar ipelines reviously: pipeline-level parallelism Work on execute of one instruction in parallel with decode
Digital Signal Processor Supercomputing
 Digital Signal Processor Supercomputing ENCM 515: Individual Report Prepared by Steven Rahn Submitted: November 29, 2013 Abstract: Analyzing the history of supercomputers: how the industry arrived to where
Digital Signal Processor Supercomputing ENCM 515: Individual Report Prepared by Steven Rahn Submitted: November 29, 2013 Abstract: Analyzing the history of supercomputers: how the industry arrived to where
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Parallel Systems I The GPU architecture. Jan Lemeire
 Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
Parallel Systems I The GPU architecture Jan Lemeire 2012-2013 Sequential program CPU pipeline Sequential pipelined execution Instruction-level parallelism (ILP): superscalar pipeline out-of-order execution
EE282 Computer Architecture. Lecture 1: What is Computer Architecture?
 EE282 Computer Architecture Lecture : What is Computer Architecture? September 27, 200 Marc Tremblay Computer Systems Laboratory Stanford University marctrem@csl.stanford.edu Goals Understand how computer
EE282 Computer Architecture Lecture : What is Computer Architecture? September 27, 200 Marc Tremblay Computer Systems Laboratory Stanford University marctrem@csl.stanford.edu Goals Understand how computer
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Simultaneous Multithreading (SMT)
") Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
Simultaneous Multithreading (SMT) An evolutionary processor architecture originally introduced in 1995 by Dean Tullsen at the University of Washington that aims at reducing resource waste in wide issue
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Evolution of ISAs. Instruction set architectures have changed over computer generations with changes in the
 Evolution of ISAs Instruction set architectures have changed over computer generations with changes in the cost of the hardware density of the hardware design philosophy potential performance gains One
Evolution of ISAs Instruction set architectures have changed over computer generations with changes in the cost of the hardware density of the hardware design philosophy potential performance gains One
Classification of Parallel Architecture Designs
 Classification of Parallel Architecture Designs Level of Parallelism Job level between jobs between phases of a job Program level between parts of a program within do-loops between different function invocations
Classification of Parallel Architecture Designs Level of Parallelism Job level between jobs between phases of a job Program level between parts of a program within do-loops between different function invocations
Ti Parallel Computing PIPELINING. Michał Roziecki, Tomáš Cipr
 Ti5317000 Parallel Computing PIPELINING Michał Roziecki, Tomáš Cipr 2005-2006 Introduction to pipelining What is this What is pipelining? Pipelining is an implementation technique in which multiple instructions
Ti5317000 Parallel Computing PIPELINING Michał Roziecki, Tomáš Cipr 2005-2006 Introduction to pipelining What is this What is pipelining? Pipelining is an implementation technique in which multiple instructions
PowerPC 620 Case Study
 Chapter 6: The PowerPC 60 Modern Processor Design: Fundamentals of Superscalar Processors PowerPC 60 Case Study First-generation out-of-order processor Developed as part of Apple-IBM-Motorola alliance
Chapter 6: The PowerPC 60 Modern Processor Design: Fundamentals of Superscalar Processors PowerPC 60 Case Study First-generation out-of-order processor Developed as part of Apple-IBM-Motorola alliance
Flynn s Classification
 Flynn s Classification Guang R. Gao ACM Fellow and IEEE Fellow Endowed Distinguished Professor Electrical & Computer Engineering University of Delaware ggao@capsl.udel.edu 652-14F-PXM-intro 1 Execution
Flynn s Classification Guang R. Gao ACM Fellow and IEEE Fellow Endowed Distinguished Professor Electrical & Computer Engineering University of Delaware ggao@capsl.udel.edu 652-14F-PXM-intro 1 Execution
Illiac IV History. Illiac IV. First massively parallel computer
 Illiac IV History Illiac IV First massively parallel computer SIMD (duplicate the PE, not the CU) First large system with semiconductorbased primary memory Three earlier designs (vacuum tubes and transistors)
Illiac IV History Illiac IV First massively parallel computer SIMD (duplicate the PE, not the CU) First large system with semiconductorbased primary memory Three earlier designs (vacuum tubes and transistors)
New Advances in Micro-Processors and computer architectures
 New Advances in Micro-Processors and computer architectures Prof. (Dr.) K.R. Chowdhary, Director SETG Email: kr.chowdhary@jietjodhpur.com Jodhpur Institute of Engineering and Technology, SETG August 27,
New Advances in Micro-Processors and computer architectures Prof. (Dr.) K.R. Chowdhary, Director SETG Email: kr.chowdhary@jietjodhpur.com Jodhpur Institute of Engineering and Technology, SETG August 27,
Lecture 8: RISC & Parallel Computers. Parallel computers
 Lecture 8: RISC & Parallel Computers RISC vs CISC computers Parallel computers Final remarks Zebo Peng, IDA, LiTH 1 Introduction Reduced Instruction Set Computer (RISC) is an important innovation in computer
Lecture 8: RISC & Parallel Computers RISC vs CISC computers Parallel computers Final remarks Zebo Peng, IDA, LiTH 1 Introduction Reduced Instruction Set Computer (RISC) is an important innovation in computer
Latches. IT 3123 Hardware and Software Concepts. Registers. The Little Man has Registers. Data Registers. Program Counter
 IT 3123 Hardware and Software Concepts Notice: This session is being recorded. CPU and Memory June 11 Copyright 2005 by Bob Brown Latches Can store one bit of data Can be ganged together to store more
IT 3123 Hardware and Software Concepts Notice: This session is being recorded. CPU and Memory June 11 Copyright 2005 by Bob Brown Latches Can store one bit of data Can be ganged together to store more
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Unit 8: Superscalar Pipelines
 A Key Theme: arallelism reviously: pipeline-level parallelism Work on execute of one instruction in parallel with decode of next CIS 501: Computer Architecture Unit 8: Superscalar ipelines Slides'developed'by'Milo'Mar0n'&'Amir'Roth'at'the'University'of'ennsylvania'
A Key Theme: arallelism reviously: pipeline-level parallelism Work on execute of one instruction in parallel with decode of next CIS 501: Computer Architecture Unit 8: Superscalar ipelines Slides'developed'by'Milo'Mar0n'&'Amir'Roth'at'the'University'of'ennsylvania'
Power 7. Dan Christiani Kyle Wieschowski
 Power 7 Dan Christiani Kyle Wieschowski History 1980-2000 1980 RISC Prototype 1990 POWER1 (Performance Optimization With Enhanced RISC) (1 um) 1993 IBM launches 66MHz POWER2 (.35 um) 1997 POWER2 Super
Power 7 Dan Christiani Kyle Wieschowski History 1980-2000 1980 RISC Prototype 1990 POWER1 (Performance Optimization With Enhanced RISC) (1 um) 1993 IBM launches 66MHz POWER2 (.35 um) 1997 POWER2 Super
EE382 Processor Design. Concurrent Processors
 EE382 Processor Design Winter 1998-99 Chapter 7 and Green Book Lectures Concurrent Processors, including SIMD and Vector Processors Slide 1 Concurrent Processors Vector processors SIMD and small clustered
EE382 Processor Design Winter 1998-99 Chapter 7 and Green Book Lectures Concurrent Processors, including SIMD and Vector Processors Slide 1 Concurrent Processors Vector processors SIMD and small clustered
CPE300: Digital System Architecture and Design
 CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Pipelining 11142011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review I/O Chapter 5 Overview Pipelining Pipelining
CPE300: Digital System Architecture and Design Fall 2011 MW 17:30-18:45 CBC C316 Pipelining 11142011 http://www.egr.unlv.edu/~b1morris/cpe300/ 2 Outline Review I/O Chapter 5 Overview Pipelining Pipelining
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
CSE502 Graduate Computer Architecture. Lec 22 Goodbye to Computer Architecture and Review
 CSE502 Graduate Computer Architecture Lec 22 Goodbye to Computer Architecture and Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE502 Graduate Computer Architecture Lec 22 Goodbye to Computer Architecture and Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
Exploring the Effects of Hyperthreading on Scientific Applications
 Exploring the Effects of Hyperthreading on Scientific Applications by Kent Milfeld milfeld@tacc.utexas.edu edu Kent Milfeld, Chona Guiang, Avijit Purkayastha, Jay Boisseau TEXAS ADVANCED COMPUTING CENTER
Exploring the Effects of Hyperthreading on Scientific Applications by Kent Milfeld milfeld@tacc.utexas.edu edu Kent Milfeld, Chona Guiang, Avijit Purkayastha, Jay Boisseau TEXAS ADVANCED COMPUTING CENTER
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
A Data-Parallel Genealogy: The GPU Family Tree
 A Data-Parallel Genealogy: The GPU Family Tree Department of Electrical and Computer Engineering Institute for Data Analysis and Visualization University of California, Davis Outline Moore s Law brings
A Data-Parallel Genealogy: The GPU Family Tree Department of Electrical and Computer Engineering Institute for Data Analysis and Visualization University of California, Davis Outline Moore s Law brings
Software Pipelining for Coarse-Grained Reconfigurable Instruction Set Processors
 Software Pipelining for Coarse-Grained Reconfigurable Instruction Set Processors Francisco Barat, Murali Jayapala, Pieter Op de Beeck and Geert Deconinck K.U.Leuven, Belgium. {f-barat, j4murali}@ieee.org,
Software Pipelining for Coarse-Grained Reconfigurable Instruction Set Processors Francisco Barat, Murali Jayapala, Pieter Op de Beeck and Geert Deconinck K.U.Leuven, Belgium. {f-barat, j4murali}@ieee.org,
Getting CPI under 1: Outline
 CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
Architectures of Flynn s taxonomy -- A Comparison of Methods
 Architectures of Flynn s taxonomy -- A Comparison of Methods Neha K. Shinde Student, Department of Electronic Engineering, J D College of Engineering and Management, RTM Nagpur University, Maharashtra,
Architectures of Flynn s taxonomy -- A Comparison of Methods Neha K. Shinde Student, Department of Electronic Engineering, J D College of Engineering and Management, RTM Nagpur University, Maharashtra,
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)