Vampir and Lustre. Understanding Boundaries in I/O Intensive Applications
|
|
|
- Asher Ball
- 5 years ago
- Views:
Transcription
 - HRSK 151 Tel. +49 351-463 - 39871 (guido.")
1 Center for Information Services and High Performance Computing (ZIH) Vampir and Lustre Understanding Boundaries in I/O Intensive Applications Zellescher Weg 14 Treffz-Bau (HRSK-Anbau) - HRSK 151 Tel (guido.juckeland@tu-dresden.de)
2 Agenda Vampir The Tool for Understanding Application Behavior ZIH Focusing Resources around the Users Data Tracing I/O First Results and Further Steps Slide 2
3 Vampir The Tool for Understanding Application Behavior Slide 3

4 Vampir Server Architecture Parallel Program Monitor System File System Analysis Server Merged Traces Trace 1 Trace 2 Trace 3 Trace N Worker 1 Classic Analysis: Worker 2 Master Worker m Event Streams Process Visualization Client Parallel I/O Timeline with 16 Traces visible Message Passing Interne t Segment Indicator 768 Processes Thumbnail View Slide 4
5 Requires: Source Code Instrumentation int foo(void* arg){ int foo(void* arg){ enter(7); if (cond){ if (cond){ leave(7); return 1; return 1; } } leave(7); return 0; } return 0; } manually or automatically Slide 5
6 What You Get: Parallel Trace (Open Trace Format (OTF)) DEF TIMERRES P 1 ENTER 5 DEF PROCESS 1 `Master` P 1 ENTER 6 DEF PROCESS 1 `Slave` P 1 ENTER P 1 SEND TO 3 LEN P 1 LEAVE P 2 ENTER 5 DEF FUNCTION 5 `main` DEF FUNCTION 6 `foo` P 1 LEAVE P 2 ENTER 6 DEF FUNCTION 9 `bar` P 1 ENTER P 2 ENTER 13 DEF FUNCTION 12 `MPI_Send` P 1 LEAVE 9 DEF FUNCTION 13 `MPI_Recv` P 2 RECV FROM 3 LEN P 2 LEAVE P 2 LEAVE P 2 ENTER P 2 LEAVE 9... Slide 6
7 Common Event Types enter/leave of function/routine/region time stamp, process/thread, function ID send/receive of P2P message (MPI) time stamp, sender, receiver, length, tag, communicator collective communication (MPI) time stamp, process, root, communicator, # bytes hardware performance counter values time stamp, process, counter ID, value etc. Slide 7

8 Vampir: Global Timeline Slide 8
9 Vampir: Global Timeline Slide 9


10 Vampir: Global Timeline Slide 10


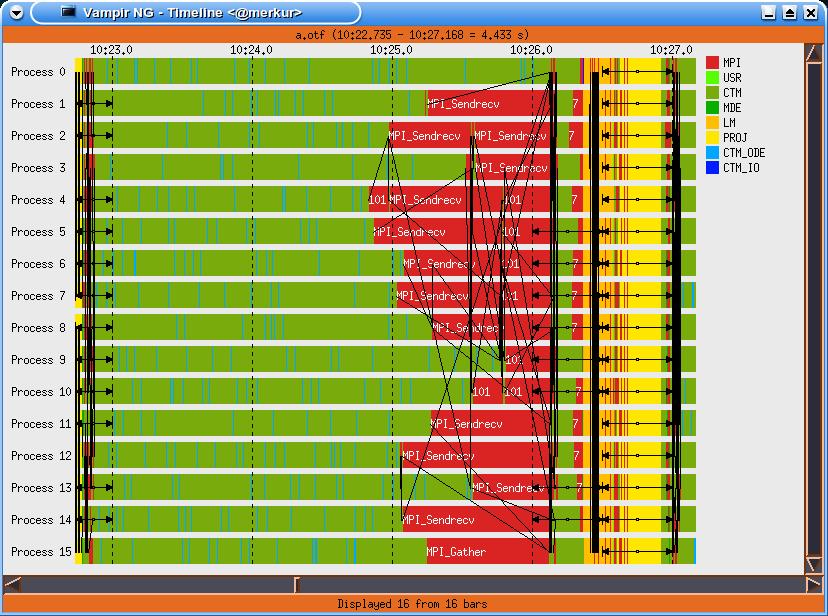
11 Vampir: Global Timeline Slide 11

12 Vampir: Process Timeline Slide 12


13 Vampir: Process Timeline Slide 13


14 Vampir: Process Timeline Slide 14






15 Vampir: Process Timeline Slide 15

16 Vampir: Summary Chart Slide 16

17 Vampir: Summary Timeline Slide 17



18 Vampir: Process Profile Slide 18
19 ZIH Focusing Resources around the Users Data Slide 19

 LNXI PC-Farm 8 GiB/s 4 GiB/s HPC SAN 4 GiB/s PC SAN")

20 Realization of the Concept for Data Intensive Computing HPC Component Memory PC Farm 6,5 TiByte SGI Altix x Sockets mit Itanium2 Montecito Dual-Core CPUs (1.6 GHz/9MB L3 Cache) LNXI PC-Farm 8 GiB/s 4 GiB/s HPC SAN 4 GiB/s PC SAN Capacity Capacity 68 TiByte 51TiByte 1,8 GiB/s PetaByte Tape Archive Capacity 1 PiByte Slide 20 AMD Opteron X85 Dual Core Chip mit 2,6 GHz 384x Single CPU Nodes 232x Dual CPU Nodes 112x Quad CPU Nodes
21 Lustre Relevant Components HPC Component Memory PC Farm 6,5 TiByte SGI Altix x Sockets mit Itanium2 Montecito Dual-Core CPUs (1.6 GHz/9MB L3 Cache) LNXI PC-Farm 8 GiB/s 4 GiB/s HPC SAN 4 GiB/s PC SAN Capacity Capacity 68 TiByte 51TiByte 1,8 GiB/s PetaByte Tape Archive Capacity 1 PiByte Slide 21 AMD Opteron X85 Dual Core Chip mit 2,6 GHz 384x Single CPU Nodes 232x Dual CPU Nodes 112x Quad CPU Nodes
22 Lustre Setup 1TB oss001 16TB oss002 mds001 SGI TP9300 mds002 oss003 oss004 16TB oss005 I/O Infiniband oss006 core switch oss TB oss008 oss009 SGI InfiniteStorage 6700 Serving two file systems: /work and /fastfs Slide 22

23 User profile: Image Analysis in Biology (MPI-CBG) Quantitative image analysis Identify cells and cell components in images Derive statistical information about the cell components Functional genomics assays High resolution images of large number of cells Live cell imaging Low resolution images in time series Slide 23


24 Image Analysis Workflow 1 Preparing Plates 2 Acquiring Images 3 Preprocessing Images 4 Adjusting Parameters 5 Structure Identification 6 Calculating Statistics Pa es ra m et Im ag er Plates 384 well plate Images Image Packages 384 image packages ~ 3000 image files ~18 GiB s 1 parameter file Slide 24 Structure Information ~ 3000 image files ~3 GiB Results ~ 50 global statistics
25 Tracing I/O First results and further steps Slide 25

26 Getting Data from the DDN-RAIDs Own QT-GUI Uses DDN-API for live-data every 0.1s Needs network access to DDN controllers Slide 26
27 Getting Data from the Application Catching all I/O calls from the application Adding them to the trace as performance counter data Include filenames, offsets, and request sizes as OTF comments Currently done with LD_PRELOAD library Data needs to be merged with application OTF trace Captured data: open (filename, filedescriptor), read/write (filedescriptor, size), close/dup (filedescriptor), seek (filedescriptor, position) Tracing I/O requests within the kernel To follow the path of the request to the devices Slide 27
")
28 Vampir I/O Stats per Process (work in progress) Slide 28
")
29 Vampir I/O Stats per Process (work in progress) Slide 29
 Slide")
30 Including DDN Statistics (work in progress) Slide 30
31 Restraints and Requirements I/O Tracing cannot modify kernel (site requirements) DDN data is sampling data DDN data is global data Kernel data is global data Therefore: Need existing FS (e.g. Lustre) to include on demand trace hooks Device mappings need to be known as well Slide 31
32 Conclusions and Further Work Data intensive computing produces new bottlenecks New HPC user groups (e.g. biologists) produce new problems Vampir platform is/was extended to help indentify I/O bottlenecks DDN data needs to be correlated with application trace Should work with any device and any FS (Lustre very good starting point) Could include file object information Need to follow I/O request form application to device Slide 32
 Holger Brunst (holger.brunst@tu-dresden.de) ZIH System Setup Dr. Matthias Müller (matthias.")
 Holger Mickler (holger.mickler@zih.tu-dresden.de) Visit us at www.tu-dresden.de/zih and www.")
33 Thanks and Contacts Vampir/OTF Introduction Andreas Knüpfer Holger Brunst ZIH System Setup Dr. Matthias Müller I/O Tracing Facilities Michael Kluge Holger Mickler Visit us at and Slide 33
Introducing OTF / Vampir / VampirTrace
 Center for Information Services and High Performance Computing (ZIH) Introducing OTF / Vampir / VampirTrace Zellescher Weg 12 Willers-Bau A115 Tel. +49 351-463 - 34049 (Robert.Henschel@zih.tu-dresden.de)
Center for Information Services and High Performance Computing (ZIH) Introducing OTF / Vampir / VampirTrace Zellescher Weg 12 Willers-Bau A115 Tel. +49 351-463 - 34049 (Robert.Henschel@zih.tu-dresden.de)
Comprehensive Lustre I/O Tracing with Vampir
 Comprehensive Lustre I/O Tracing with Vampir Lustre User Group 2010 Zellescher Weg 12 WIL A 208 Tel. +49 351-463 34217 ( michael.kluge@tu-dresden.de ) Michael Kluge Content! Vampir Introduction! VampirTrace
Comprehensive Lustre I/O Tracing with Vampir Lustre User Group 2010 Zellescher Weg 12 WIL A 208 Tel. +49 351-463 34217 ( michael.kluge@tu-dresden.de ) Michael Kluge Content! Vampir Introduction! VampirTrace
VAMPIR & VAMPIRTRACE INTRODUCTION AND OVERVIEW
 VAMPIR & VAMPIRTRACE INTRODUCTION AND OVERVIEW 8th VI-HPS Tuning Workshop at RWTH Aachen September, 2011 Tobias Hilbrich and Joachim Protze Slides by: Andreas Knüpfer, Jens Doleschal, ZIH, Technische Universität
VAMPIR & VAMPIRTRACE INTRODUCTION AND OVERVIEW 8th VI-HPS Tuning Workshop at RWTH Aachen September, 2011 Tobias Hilbrich and Joachim Protze Slides by: Andreas Knüpfer, Jens Doleschal, ZIH, Technische Universität
Altix Usage and Application Programming
 Center for Information Services and High Performance Computing (ZIH) Altix Usage and Application Programming Discussion And Important Information For Users Zellescher Weg 12 Willers-Bau A113 Tel. +49 351-463
Center for Information Services and High Performance Computing (ZIH) Altix Usage and Application Programming Discussion And Important Information For Users Zellescher Weg 12 Willers-Bau A113 Tel. +49 351-463
Interactive Performance Analysis with Vampir UCAR Software Engineering Assembly in Boulder/CO,
 Interactive Performance Analysis with Vampir UCAR Software Engineering Assembly in Boulder/CO, 2013-04-03 Andreas Knüpfer, Thomas William TU Dresden, Germany Overview Introduction Vampir displays GPGPU
Interactive Performance Analysis with Vampir UCAR Software Engineering Assembly in Boulder/CO, 2013-04-03 Andreas Knüpfer, Thomas William TU Dresden, Germany Overview Introduction Vampir displays GPGPU
Introduction to High Performance Computing at ZIH
 Center for Information Services and High Performance Computing (ZIH) Introduction to High Performance Computing at ZIH Architecture of the PC Farm (Deimos) Zellescher Weg 12 Trefftz-Bau/HRSK 151 Phone
Center for Information Services and High Performance Computing (ZIH) Introduction to High Performance Computing at ZIH Architecture of the PC Farm (Deimos) Zellescher Weg 12 Trefftz-Bau/HRSK 151 Phone
Score-P. SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1
 Score-P SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1 Score-P Functionality Score-P is a joint instrumentation and measurement system for a number of PA tools. Provide
Score-P SC 14: Hands-on Practical Hybrid Parallel Application Performance Engineering 1 Score-P Functionality Score-P is a joint instrumentation and measurement system for a number of PA tools. Provide
I/O at the Center for Information Services and High Performance Computing
 Mich ael Kluge, ZIH I/O at the Center for Information Services and High Performance Computing HPC-I/O in the Data Center Workshop @ ISC 2015 Zellescher Weg 12 Willers-Bau A 208 Tel. +49 351-463 34217 Michael
Mich ael Kluge, ZIH I/O at the Center for Information Services and High Performance Computing HPC-I/O in the Data Center Workshop @ ISC 2015 Zellescher Weg 12 Willers-Bau A 208 Tel. +49 351-463 34217 Michael
Analyzing I/O Performance on a NEXTGenIO Class System
 Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
Analyzing I/O Performance on a NEXTGenIO Class System holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden LUG17, Indiana University, June 2 nd 2017 NEXTGenIO Fact Sheet Project Research & Innovation
Performance Analysis with Vampir
 Performance Analysis with Vampir Ronald Geisler, Holger Brunst, Bert Wesarg, Matthias Weber, Hartmut Mix, Ronny Tschüter, Robert Dietrich, and Andreas Knüpfer Technische Universität Dresden Outline Part
Performance Analysis with Vampir Ronald Geisler, Holger Brunst, Bert Wesarg, Matthias Weber, Hartmut Mix, Ronny Tschüter, Robert Dietrich, and Andreas Knüpfer Technische Universität Dresden Outline Part
NEXTGenIO Performance Tools for In-Memory I/O
 NEXTGenIO Performance Tools for In- I/O holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden 22 nd -23 rd March 2017 Credits Intro slides by Adrian Jackson (EPCC) A new hierarchy New non-volatile
NEXTGenIO Performance Tools for In- I/O holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden 22 nd -23 rd March 2017 Credits Intro slides by Adrian Jackson (EPCC) A new hierarchy New non-volatile
DDN s Vision for the Future of Lustre LUG2015 Robert Triendl
 DDN s Vision for the Future of Lustre LUG2015 Robert Triendl 3 Topics 1. The Changing Markets for Lustre 2. A Vision for Lustre that isn t Exascale 3. Building Lustre for the Future 4. Peak vs. Operational
DDN s Vision for the Future of Lustre LUG2015 Robert Triendl 3 Topics 1. The Changing Markets for Lustre 2. A Vision for Lustre that isn t Exascale 3. Building Lustre for the Future 4. Peak vs. Operational
Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks
 Center for Information Services and High Performance Computing (ZIH) Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks EnA-HPC, Sept 16 th 2010, Robert Schöne, Daniel Molka,
Center for Information Services and High Performance Computing (ZIH) Quantifying power consumption variations of HPC systems using SPEC MPI benchmarks EnA-HPC, Sept 16 th 2010, Robert Schöne, Daniel Molka,
HPC Capabilities at Research Intensive Universities
 HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
( ZIH ) Center for Information Services and High Performance Computing. Event Tracing and Visualization for Cell Broadband Engine Systems
 Center for Information Services and High Performance Computing. Event Tracing and Visualization for Cell Broadband Engine Systems") ( ZIH ) Center for Information Services and High Performance Computing Event Tracing and Visualization for Cell Broadband Engine Systems ( daniel.hackenberg@zih.tu-dresden.de ) Daniel Hackenberg Cell Broadband
( ZIH ) Center for Information Services and High Performance Computing Event Tracing and Visualization for Cell Broadband Engine Systems ( daniel.hackenberg@zih.tu-dresden.de ) Daniel Hackenberg Cell Broadband
Performance analysis with Periscope
 Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität petkovve@in.tum.de March 2010 Outline Motivation Periscope (PSC) Periscope performance analysis
Performance analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität petkovve@in.tum.de March 2010 Outline Motivation Periscope (PSC) Periscope performance analysis
An Overview of Fujitsu s Lustre Based File System
 An Overview of Fujitsu s Lustre Based File System Shinji Sumimoto Fujitsu Limited Apr.12 2011 For Maximizing CPU Utilization by Minimizing File IO Overhead Outline Target System Overview Goals of Fujitsu
An Overview of Fujitsu s Lustre Based File System Shinji Sumimoto Fujitsu Limited Apr.12 2011 For Maximizing CPU Utilization by Minimizing File IO Overhead Outline Target System Overview Goals of Fujitsu
Performance Analysis with Vampir. Joseph Schuchart ZIH, Technische Universität Dresden
 Performance Analysis with Vampir Joseph Schuchart ZIH, Technische Universität Dresden 1 Mission Visualization of dynamics of complex parallel processes Full details for arbitrary temporal and spatial levels
Performance Analysis with Vampir Joseph Schuchart ZIH, Technische Universität Dresden 1 Mission Visualization of dynamics of complex parallel processes Full details for arbitrary temporal and spatial levels
EZTrace upcoming features
 EZTrace 1.0 + upcoming features François Trahay francois.trahay@telecom-sudparis.eu 2015-01-08 Context Hardware is more and more complex NUMA, hierarchical caches, GPU,... Software is more and more complex
EZTrace 1.0 + upcoming features François Trahay francois.trahay@telecom-sudparis.eu 2015-01-08 Context Hardware is more and more complex NUMA, hierarchical caches, GPU,... Software is more and more complex
ISC 09 Poster Abstract : I/O Performance Analysis for the Petascale Simulation Code FLASH
 ISC 09 Poster Abstract : I/O Performance Analysis for the Petascale Simulation Code FLASH Heike Jagode, Shirley Moore, Dan Terpstra, Jack Dongarra The University of Tennessee, USA [jagode shirley terpstra
ISC 09 Poster Abstract : I/O Performance Analysis for the Petascale Simulation Code FLASH Heike Jagode, Shirley Moore, Dan Terpstra, Jack Dongarra The University of Tennessee, USA [jagode shirley terpstra
Performance Analysis of Large-Scale OpenMP and Hybrid MPI/OpenMP Applications with Vampir NG
 Performance Analysis of Large-Scale OpenMP and Hybrid MPI/OpenMP Applications with Vampir NG Holger Brunst Center for High Performance Computing Dresden University, Germany June 1st, 2005 Overview Overview
Performance Analysis of Large-Scale OpenMP and Hybrid MPI/OpenMP Applications with Vampir NG Holger Brunst Center for High Performance Computing Dresden University, Germany June 1st, 2005 Overview Overview
VAMPIR & VAMPIRTRACE Hands On
 VAMPIR & VAMPIRTRACE Hands On PRACE Spring School 2012 in Krakow May, 2012 Holger Brunst Slides by: Andreas Knüpfer, Jens Doleschal, ZIH, Technische Universität Dresden Hands-on: NPB Build Copy NPB sources
VAMPIR & VAMPIRTRACE Hands On PRACE Spring School 2012 in Krakow May, 2012 Holger Brunst Slides by: Andreas Knüpfer, Jens Doleschal, ZIH, Technische Universität Dresden Hands-on: NPB Build Copy NPB sources
SGI Overview. HPC User Forum Dearborn, Michigan September 17 th, 2012
 SGI Overview HPC User Forum Dearborn, Michigan September 17 th, 2012 SGI Market Strategy HPC Commercial Scientific Modeling & Simulation Big Data Hadoop In-memory Analytics Archive Cloud Public Private
SGI Overview HPC User Forum Dearborn, Michigan September 17 th, 2012 SGI Market Strategy HPC Commercial Scientific Modeling & Simulation Big Data Hadoop In-memory Analytics Archive Cloud Public Private
Advanced Software for the Supercomputer PRIMEHPC FX10. Copyright 2011 FUJITSU LIMITED
 Advanced Software for the Supercomputer PRIMEHPC FX10 System Configuration of PRIMEHPC FX10 nodes Login Compilation Job submission 6D mesh/torus Interconnect Local file system (Temporary area occupied
Advanced Software for the Supercomputer PRIMEHPC FX10 System Configuration of PRIMEHPC FX10 nodes Login Compilation Job submission 6D mesh/torus Interconnect Local file system (Temporary area occupied
I/O Profiling Towards the Exascale
 I/O Profiling Towards the Exascale holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden NEXTGenIO & SAGE: Working towards Exascale I/O Barcelona, NEXTGenIO facts Project Research & Innovation
I/O Profiling Towards the Exascale holger.brunst@tu-dresden.de ZIH, Technische Universität Dresden NEXTGenIO & SAGE: Working towards Exascale I/O Barcelona, NEXTGenIO facts Project Research & Innovation
Performance Analysis with Periscope
 Performance Analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München periscope@lrr.in.tum.de October 2010 Outline Motivation Periscope overview Periscope performance
Performance Analysis with Periscope M. Gerndt, V. Petkov, Y. Oleynik, S. Benedict Technische Universität München periscope@lrr.in.tum.de October 2010 Outline Motivation Periscope overview Periscope performance
Cache Profiling with Callgrind
 Center for Information Services and High Performance Computing (ZIH) Cache Profiling with Callgrind Linux/x86 Performance Practical, 17.06.2009 Zellescher Weg 12 Willers-Bau A106 Tel. +49 351-463 - 31945
Center for Information Services and High Performance Computing (ZIH) Cache Profiling with Callgrind Linux/x86 Performance Practical, 17.06.2009 Zellescher Weg 12 Willers-Bau A106 Tel. +49 351-463 - 31945
Performance Analysis with Vampir
 Performance Analysis with Vampir Johannes Ziegenbalg Technische Universität Dresden Outline Part I: Welcome to the Vampir Tool Suite Event Trace Visualization The Vampir Displays Vampir & VampirServer
Performance Analysis with Vampir Johannes Ziegenbalg Technische Universität Dresden Outline Part I: Welcome to the Vampir Tool Suite Event Trace Visualization The Vampir Displays Vampir & VampirServer
High Performance Storage Solutions
 November 2006 High Performance Storage Solutions Toine Beckers tbeckers@datadirectnet.com www.datadirectnet.com DataDirect Leadership Established 1988 Technology Company (ASICs, FPGA, Firmware, Software)
November 2006 High Performance Storage Solutions Toine Beckers tbeckers@datadirectnet.com www.datadirectnet.com DataDirect Leadership Established 1988 Technology Company (ASICs, FPGA, Firmware, Software)
Data Movement & Storage Using the Data Capacitor Filesystem
 Data Movement & Storage Using the Data Capacitor Filesystem Justin Miller jupmille@indiana.edu http://pti.iu.edu/dc Big Data for Science Workshop July 2010 Challenges for DISC Keynote by Alex Szalay identified
Data Movement & Storage Using the Data Capacitor Filesystem Justin Miller jupmille@indiana.edu http://pti.iu.edu/dc Big Data for Science Workshop July 2010 Challenges for DISC Keynote by Alex Szalay identified
Coordinating Parallel HSM in Object-based Cluster Filesystems
 Coordinating Parallel HSM in Object-based Cluster Filesystems Dingshan He, Xianbo Zhang, David Du University of Minnesota Gary Grider Los Alamos National Lab Agenda Motivations Parallel archiving/retrieving
Coordinating Parallel HSM in Object-based Cluster Filesystems Dingshan He, Xianbo Zhang, David Du University of Minnesota Gary Grider Los Alamos National Lab Agenda Motivations Parallel archiving/retrieving
Practical Scientific Computing
 Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Practical Scientific Computing Performance-optimized Programming Preliminary discussion: July 11, 2008 Dr. Ralf-Peter Mundani, mundani@tum.de Dipl.-Ing. Ioan Lucian Muntean, muntean@in.tum.de MSc. Csaba
Scalable Critical Path Analysis for Hybrid MPI-CUDA Applications
 Center for Information Services and High Performance Computing (ZIH) Scalable Critical Path Analysis for Hybrid MPI-CUDA Applications The Fourth International Workshop on Accelerators and Hybrid Exascale
Center for Information Services and High Performance Computing (ZIH) Scalable Critical Path Analysis for Hybrid MPI-CUDA Applications The Fourth International Workshop on Accelerators and Hybrid Exascale
Automatic trace analysis with the Scalasca Trace Tools
 Automatic trace analysis with the Scalasca Trace Tools Ilya Zhukov Jülich Supercomputing Centre Property Automatic trace analysis Idea Automatic search for patterns of inefficient behaviour Classification
Automatic trace analysis with the Scalasca Trace Tools Ilya Zhukov Jülich Supercomputing Centre Property Automatic trace analysis Idea Automatic search for patterns of inefficient behaviour Classification
Welcome. HRSK Practical on Debugging, Zellescher Weg 12 Willers-Bau A106 Tel
 Center for Information Services and High Performance Computing (ZIH) Welcome HRSK Practical on Debugging, 03.04.2009 Zellescher Weg 12 Willers-Bau A106 Tel. +49 351-463 - 31945 Matthias Lieber (matthias.lieber@tu-dresden.de)
Center for Information Services and High Performance Computing (ZIH) Welcome HRSK Practical on Debugging, 03.04.2009 Zellescher Weg 12 Willers-Bau A106 Tel. +49 351-463 - 31945 Matthias Lieber (matthias.lieber@tu-dresden.de)
Leistungsanalyse von Rechnersystemen
 Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen Capacity Planning Zellescher Weg 12 Raum WIL A113 Tel. +49 351-463 - 39835 Matthias Müller (matthias.mueller@tu-dresden.de)
Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen Capacity Planning Zellescher Weg 12 Raum WIL A113 Tel. +49 351-463 - 39835 Matthias Müller (matthias.mueller@tu-dresden.de)
LUG 2012 From Lustre 2.1 to Lustre HSM IFERC (Rokkasho, Japan)
") LUG 2012 From Lustre 2.1 to Lustre HSM Lustre @ IFERC (Rokkasho, Japan) Diego.Moreno@bull.net From Lustre-2.1 to Lustre-HSM - Outline About Bull HELIOS @ IFERC (Rokkasho, Japan) Lustre-HSM - Basis of Lustre-HSM
LUG 2012 From Lustre 2.1 to Lustre HSM Lustre @ IFERC (Rokkasho, Japan) Diego.Moreno@bull.net From Lustre-2.1 to Lustre-HSM - Outline About Bull HELIOS @ IFERC (Rokkasho, Japan) Lustre-HSM - Basis of Lustre-HSM
Leistungsanalyse von Rechnersystemen
 Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen Monitoring Techniques Nöthnitzer Straße 46 Raum 1026 Tel. +49 351-463 - 35048 Holger Brunst (holger.brunst@tu-dresden.de)
Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen Monitoring Techniques Nöthnitzer Straße 46 Raum 1026 Tel. +49 351-463 - 35048 Holger Brunst (holger.brunst@tu-dresden.de)
Tracing the Cache Behavior of Data Structures in Fortran Applications
 John von Neumann Institute for Computing Tracing the Cache Behavior of Data Structures in Fortran Applications L. Barabas, R. Müller-Pfefferkorn, W.E. Nagel, R. Neumann published in Parallel Computing:
John von Neumann Institute for Computing Tracing the Cache Behavior of Data Structures in Fortran Applications L. Barabas, R. Müller-Pfefferkorn, W.E. Nagel, R. Neumann published in Parallel Computing:
Parallel File Systems Compared
 Parallel File Systems Compared Computing Centre (SSCK) University of Karlsruhe, Germany Laifer@rz.uni-karlsruhe.de page 1 Outline» Parallel file systems (PFS) Design and typical usage Important features
Parallel File Systems Compared Computing Centre (SSCK) University of Karlsruhe, Germany Laifer@rz.uni-karlsruhe.de page 1 Outline» Parallel file systems (PFS) Design and typical usage Important features
Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters
 Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters Matthew Koop 1 Miao Luo D. K. Panda matthew.koop@nasa.gov {luom, panda}@cse.ohio-state.edu 1 NASA Center for Computational
Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters Matthew Koop 1 Miao Luo D. K. Panda matthew.koop@nasa.gov {luom, panda}@cse.ohio-state.edu 1 NASA Center for Computational
Performance Optimization: Simulation and Real Measurement
 Performance Optimization: Simulation and Real Measurement KDE Developer Conference, Introduction Agenda Performance Analysis Profiling Tools: Examples & Demo KCachegrind: Visualizing Results What s to
Performance Optimization: Simulation and Real Measurement KDE Developer Conference, Introduction Agenda Performance Analysis Profiling Tools: Examples & Demo KCachegrind: Visualizing Results What s to
Performance Analysis with Vampir
 Performance Analysis with Vampir Ronny Brendel Technische Universität Dresden Outline Part I: Welcome to the Vampir Tool Suite Mission Event Trace Visualization Vampir & VampirServer The Vampir Displays
Performance Analysis with Vampir Ronny Brendel Technische Universität Dresden Outline Part I: Welcome to the Vampir Tool Suite Mission Event Trace Visualization Vampir & VampirServer The Vampir Displays
ClearSpeed Visual Profiler
 ClearSpeed Visual Profiler Copyright 2007 ClearSpeed Technology plc. All rights reserved. 12 November 2007 www.clearspeed.com 1 Profiling Application Code Why use a profiler? Program analysis tools are
ClearSpeed Visual Profiler Copyright 2007 ClearSpeed Technology plc. All rights reserved. 12 November 2007 www.clearspeed.com 1 Profiling Application Code Why use a profiler? Program analysis tools are
HPC Solution. Technology for a New Era in Computing
 HPC Solution Technology for a New Era in Computing TEL IN HPC & Storage.. 20 years of changing with Technology Complete Solution Integrators for Select Verticals Mechanical Design & Engineering High Performance
HPC Solution Technology for a New Era in Computing TEL IN HPC & Storage.. 20 years of changing with Technology Complete Solution Integrators for Select Verticals Mechanical Design & Engineering High Performance
Technical Computing Suite supporting the hybrid system
 Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
Emerging Technologies for HPC Storage
 Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
Performance analysis basics
 Performance analysis basics Christian Iwainsky Iwainsky@rz.rwth-aachen.de 25.3.2010 1 Overview 1. Motivation 2. Performance analysis basics 3. Measurement Techniques 2 Why bother with performance analysis
Performance analysis basics Christian Iwainsky Iwainsky@rz.rwth-aachen.de 25.3.2010 1 Overview 1. Motivation 2. Performance analysis basics 3. Measurement Techniques 2 Why bother with performance analysis
VAMPIR & VAMPIRTRACE Hands On
 VAMPIR & VAMPIRTRACE Hands On 8th VI-HPS Tuning Workshop at RWTH Aachen September, 2011 Tobias Hilbrich and Joachim Protze Slides by: Andreas Knüpfer, Jens Doleschal, ZIH, Technische Universität Dresden
VAMPIR & VAMPIRTRACE Hands On 8th VI-HPS Tuning Workshop at RWTH Aachen September, 2011 Tobias Hilbrich and Joachim Protze Slides by: Andreas Knüpfer, Jens Doleschal, ZIH, Technische Universität Dresden
Developing Scalable Applications with Vampir, VampirServer and VampirTrace
 John von Neumann Institute for Computing Developing Scalable Applications with Vampir, VampirServer and VampirTrace Matthias S. Müller, Andreas Knüpfer, Matthias Jurenz, Matthias Lieber, Holger Brunst,
John von Neumann Institute for Computing Developing Scalable Applications with Vampir, VampirServer and VampirTrace Matthias S. Müller, Andreas Knüpfer, Matthias Jurenz, Matthias Lieber, Holger Brunst,
Performance Optimization for the Trinity RNA-Seq Assembler
 Performance Optimization for the Trinity RNA-Seq Assembler Michael Wagner, Ben Fulton, and Robert Henschel Abstract Utilizing the enormous computing resources of high performance computing systems is anything
Performance Optimization for the Trinity RNA-Seq Assembler Michael Wagner, Ben Fulton, and Robert Henschel Abstract Utilizing the enormous computing resources of high performance computing systems is anything
Shared Object-Based Storage and the HPC Data Center
 Shared Object-Based Storage and the HPC Data Center Jim Glidewell High Performance Computing BOEING is a trademark of Boeing Management Company. Computing Environment Cray X1 2 Chassis, 128 MSPs, 1TB memory
Shared Object-Based Storage and the HPC Data Center Jim Glidewell High Performance Computing BOEING is a trademark of Boeing Management Company. Computing Environment Cray X1 2 Chassis, 128 MSPs, 1TB memory
Sami Saarinen Peter Towers. 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1
 Acknowledgements: Petra Kogel Sami Saarinen Peter Towers 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1 Motivation Opteron and P690+ clusters MPI communications IFS Forecast Model IFS 4D-Var
Acknowledgements: Petra Kogel Sami Saarinen Peter Towers 11th ECMWF Workshop on the Use of HPC in Meteorology Slide 1 Motivation Opteron and P690+ clusters MPI communications IFS Forecast Model IFS 4D-Var
PCAP Assignment I. 1. A. Why is there a large performance gap between many-core GPUs and generalpurpose multicore CPUs. Discuss in detail.
 PCAP Assignment I 1. A. Why is there a large performance gap between many-core GPUs and generalpurpose multicore CPUs. Discuss in detail. The multicore CPUs are designed to maximize the execution speed
PCAP Assignment I 1. A. Why is there a large performance gap between many-core GPUs and generalpurpose multicore CPUs. Discuss in detail. The multicore CPUs are designed to maximize the execution speed
Parallel File Systems for HPC
 Introduction to Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 The Need for 2 The File System 3 Cluster & A typical
Introduction to Scuola Internazionale Superiore di Studi Avanzati Trieste November 2008 Advanced School in High Performance and Grid Computing Outline 1 The Need for 2 The File System 3 Cluster & A typical
Memory Performance and Cache Coherency Effects on an Intel Nehalem Multiprocessor System
 Center for Information ervices and High Performance Computing (ZIH) Memory Performance and Cache Coherency Effects on an Intel Nehalem Multiprocessor ystem Parallel Architectures and Compiler Technologies
Center for Information ervices and High Performance Computing (ZIH) Memory Performance and Cache Coherency Effects on an Intel Nehalem Multiprocessor ystem Parallel Architectures and Compiler Technologies
Performance Analysis of MPI Programs with Vampir and Vampirtrace Bernd Mohr
 Performance Analysis of MPI Programs with Vampir and Vampirtrace Bernd Mohr Research Centre Juelich (FZJ) John von Neumann Institute of Computing (NIC) Central Institute for Applied Mathematics (ZAM) 52425
Performance Analysis of MPI Programs with Vampir and Vampirtrace Bernd Mohr Research Centre Juelich (FZJ) John von Neumann Institute of Computing (NIC) Central Institute for Applied Mathematics (ZAM) 52425
Profiling: Understand Your Application
 Profiling: Understand Your Application Michal Merta michal.merta@vsb.cz 1st of March 2018 Agenda Hardware events based sampling Some fundamental bottlenecks Overview of profiling tools perf tools Intel
Profiling: Understand Your Application Michal Merta michal.merta@vsb.cz 1st of March 2018 Agenda Hardware events based sampling Some fundamental bottlenecks Overview of profiling tools perf tools Intel
The Last Bottleneck: How Parallel I/O can improve application performance
 The Last Bottleneck: How Parallel I/O can improve application performance HPC ADVISORY COUNCIL STANFORD WORKSHOP; DECEMBER 6 TH 2011 REX TANAKIT DIRECTOR OF INDUSTRY SOLUTIONS AGENDA Panasas Overview Who
The Last Bottleneck: How Parallel I/O can improve application performance HPC ADVISORY COUNCIL STANFORD WORKSHOP; DECEMBER 6 TH 2011 REX TANAKIT DIRECTOR OF INDUSTRY SOLUTIONS AGENDA Panasas Overview Who
High-Performance Lustre with Maximum Data Assurance
 High-Performance Lustre with Maximum Data Assurance Silicon Graphics International Corp. 900 North McCarthy Blvd. Milpitas, CA 95035 Disclaimer and Copyright Notice The information presented here is meant
High-Performance Lustre with Maximum Data Assurance Silicon Graphics International Corp. 900 North McCarthy Blvd. Milpitas, CA 95035 Disclaimer and Copyright Notice The information presented here is meant
Leistungsanalyse von Rechnersystemen
 Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen 10. November 2010 Nöthnitzer Straße 46 Raum 1026 Tel. +49 351-463 - 35048 Holger Brunst (holger.brunst@tu-dresden.de)
Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen 10. November 2010 Nöthnitzer Straße 46 Raum 1026 Tel. +49 351-463 - 35048 Holger Brunst (holger.brunst@tu-dresden.de)
ABySS Performance Benchmark and Profiling. May 2010
 ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
TGCC OVERVIEW. 13 février 2014 CEA 10 AVRIL 2012 PAGE 1
 STORAGE @ TGCC OVERVIEW CEA 10 AVRIL 2012 PAGE 1 CONTEXT Data-Centric Architecture Centralized storage, accessible from every TGCC s compute machines Make cross-platform data sharing possible Mutualized
STORAGE @ TGCC OVERVIEW CEA 10 AVRIL 2012 PAGE 1 CONTEXT Data-Centric Architecture Centralized storage, accessible from every TGCC s compute machines Make cross-platform data sharing possible Mutualized
MAHA. - Supercomputing System for Bioinformatics
 MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
Cray events. ! Cray User Group (CUG): ! Cray Technical Workshop Europe:
: ! Cray Technical Workshop Europe:") Cray events! Cray User Group (CUG):! When: May 16-19, 2005! Where: Albuquerque, New Mexico - USA! Registration: reserved to CUG members! Web site: http://www.cug.org! Cray Technical Workshop Europe:! When:
Cray events! Cray User Group (CUG):! When: May 16-19, 2005! Where: Albuquerque, New Mexico - USA! Registration: reserved to CUG members! Web site: http://www.cug.org! Cray Technical Workshop Europe:! When:
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments
 Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
Potentials and Limitations for Energy Efficiency Auto-Tuning
 Center for Information Services and High Performance Computing (ZIH) Potentials and Limitations for Energy Efficiency Auto-Tuning Parco Symposium Application Autotuning for HPC (Architectures) Robert Schöne
Center for Information Services and High Performance Computing (ZIH) Potentials and Limitations for Energy Efficiency Auto-Tuning Parco Symposium Application Autotuning for HPC (Architectures) Robert Schöne
Experiences with HP SFS / Lustre in HPC Production
 Experiences with HP SFS / Lustre in HPC Production Computing Centre (SSCK) University of Karlsruhe Laifer@rz.uni-karlsruhe.de page 1 Outline» What is HP StorageWorks Scalable File Share (HP SFS)? A Lustre
Experiences with HP SFS / Lustre in HPC Production Computing Centre (SSCK) University of Karlsruhe Laifer@rz.uni-karlsruhe.de page 1 Outline» What is HP StorageWorks Scalable File Share (HP SFS)? A Lustre
Multi-Application Online Profiling Tool
 Multi-Application Online Profiling Tool Vi-HPS Julien ADAM, Antoine CAPRA 1 About MALP MALP is a tool originally developed in CEA and in the University of Versailles (UVSQ) It generates rich HTML views
Multi-Application Online Profiling Tool Vi-HPS Julien ADAM, Antoine CAPRA 1 About MALP MALP is a tool originally developed in CEA and in the University of Versailles (UVSQ) It generates rich HTML views
Accelerating Spectrum Scale with a Intelligent IO Manager
 Accelerating Spectrum Scale with a Intelligent IO Manager Ray Coetzee Pre-Sales Architect Seagate Systems Group, HPC 2017 Seagate, Inc. All Rights Reserved. 1 ClusterStor: Lustre, Spectrum Scale and Object
Accelerating Spectrum Scale with a Intelligent IO Manager Ray Coetzee Pre-Sales Architect Seagate Systems Group, HPC 2017 Seagate, Inc. All Rights Reserved. 1 ClusterStor: Lustre, Spectrum Scale and Object
The Role of InfiniBand Technologies in High Performance Computing. 1 Managed by UT-Battelle for the Department of Energy
 The Role of InfiniBand Technologies in High Performance Computing 1 Managed by UT-Battelle Contributors Gil Bloch Noam Bloch Hillel Chapman Manjunath Gorentla- Venkata Richard Graham Michael Kagan Vasily
The Role of InfiniBand Technologies in High Performance Computing 1 Managed by UT-Battelle Contributors Gil Bloch Noam Bloch Hillel Chapman Manjunath Gorentla- Venkata Richard Graham Michael Kagan Vasily
Analyzing the High Performance Parallel I/O on LRZ HPC systems. Sandra Méndez. HPC Group, LRZ. June 23, 2016
 Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Analyzing the High Performance Parallel I/O on LRZ HPC systems Sandra Méndez. HPC Group, LRZ. June 23, 2016 Outline SuperMUC supercomputer User Projects Monitoring Tool I/O Software Stack I/O Analysis
Programming for Fujitsu Supercomputers
 Programming for Fujitsu Supercomputers Koh Hotta The Next Generation Technical Computing Fujitsu Limited To Programmers who are busy on their own research, Fujitsu provides environments for Parallel Programming
Programming for Fujitsu Supercomputers Koh Hotta The Next Generation Technical Computing Fujitsu Limited To Programmers who are busy on their own research, Fujitsu provides environments for Parallel Programming
The HiCFD Project A joint initiative from DLR, T-Systems SfR and TU Dresden with Airbus, MTU and IBM as associated partners
 The HiCFD Project A joint initiative from DLR, T-Systems SfR and TU Dresden with Airbus, MTU and IBM as associated partners Thomas Alrutz, Christian Simmendinger T-Systems Solutions for Research GmbH 02.06.2009
The HiCFD Project A joint initiative from DLR, T-Systems SfR and TU Dresden with Airbus, MTU and IBM as associated partners Thomas Alrutz, Christian Simmendinger T-Systems Solutions for Research GmbH 02.06.2009
The Optimal CPU and Interconnect for an HPC Cluster
 5. LS-DYNA Anwenderforum, Ulm 2006 Cluster / High Performance Computing I The Optimal CPU and Interconnect for an HPC Cluster Andreas Koch Transtec AG, Tübingen, Deutschland F - I - 15 Cluster / High Performance
5. LS-DYNA Anwenderforum, Ulm 2006 Cluster / High Performance Computing I The Optimal CPU and Interconnect for an HPC Cluster Andreas Koch Transtec AG, Tübingen, Deutschland F - I - 15 Cluster / High Performance
Scalasca performance properties The metrics tour
 Scalasca performance properties The metrics tour Markus Geimer m.geimer@fz-juelich.de Scalasca analysis result Generic metrics Generic metrics Time Total CPU allocation time Execution Overhead Visits Hardware
Scalasca performance properties The metrics tour Markus Geimer m.geimer@fz-juelich.de Scalasca analysis result Generic metrics Generic metrics Time Total CPU allocation time Execution Overhead Visits Hardware
Initial Performance Evaluation of the Cray SeaStar Interconnect
 Initial Performance Evaluation of the Cray SeaStar Interconnect Ron Brightwell Kevin Pedretti Keith Underwood Sandia National Laboratories Scalable Computing Systems Department 13 th IEEE Symposium on
Initial Performance Evaluation of the Cray SeaStar Interconnect Ron Brightwell Kevin Pedretti Keith Underwood Sandia National Laboratories Scalable Computing Systems Department 13 th IEEE Symposium on
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
ParaMEDIC: Parallel Metadata Environment for Distributed I/O and Computing
 ParaMEDIC: Parallel Metadata Environment for Distributed I/O and Computing Prof. Wu FENG Department of Computer Science Virginia Tech Work smarter not harder Overview Grand Challenge A large-scale biological
ParaMEDIC: Parallel Metadata Environment for Distributed I/O and Computing Prof. Wu FENG Department of Computer Science Virginia Tech Work smarter not harder Overview Grand Challenge A large-scale biological
Multiple Usage of KNIME in a Screening Laboratory Environment
 Multiple Usage of KNIME in a Screening Laboratory Environment KNIME UGM Zürich, 02.02.2012 Marc Bickle HT-TDS, MPI-CBG Outline Presentation of TDS Our problem: large complex datasets KNIME as data mining
Multiple Usage of KNIME in a Screening Laboratory Environment KNIME UGM Zürich, 02.02.2012 Marc Bickle HT-TDS, MPI-CBG Outline Presentation of TDS Our problem: large complex datasets KNIME as data mining
SCALASCA parallel performance analyses of SPEC MPI2007 applications
 Mitglied der Helmholtz-Gemeinschaft SCALASCA parallel performance analyses of SPEC MPI2007 applications 2008-05-22 Zoltán Szebenyi Jülich Supercomputing Centre, Forschungszentrum Jülich Aachen Institute
Mitglied der Helmholtz-Gemeinschaft SCALASCA parallel performance analyses of SPEC MPI2007 applications 2008-05-22 Zoltán Szebenyi Jülich Supercomputing Centre, Forschungszentrum Jülich Aachen Institute
MPI Application Development with MARMOT
 MPI Application Development with MARMOT Bettina Krammer University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Matthias Müller University of Dresden Centre for Information
MPI Application Development with MARMOT Bettina Krammer University of Stuttgart High-Performance Computing-Center Stuttgart (HLRS) www.hlrs.de Matthias Müller University of Dresden Centre for Information
Intel profiling tools and roofline model. Dr. Luigi Iapichino
 Intel profiling tools and roofline model Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimization (and to the next hour) We will focus on tools developed
Intel profiling tools and roofline model Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimization (and to the next hour) We will focus on tools developed
Scalable Performance Analysis of Parallel Systems: Concepts and Experiences
 1 Scalable Performance Analysis of Parallel Systems: Concepts and Experiences Holger Brunst ab and Wolfgang E. Nagel a a Center for High Performance Computing, Dresden University of Technology, 01062 Dresden,
1 Scalable Performance Analysis of Parallel Systems: Concepts and Experiences Holger Brunst ab and Wolfgang E. Nagel a a Center for High Performance Computing, Dresden University of Technology, 01062 Dresden,
Online Monitoring of I/O
 Introduction On-line Monitoring Framework Evaluation Summary References Research Group German Climate Computing Center 23-03-2017 Introduction On-line Monitoring Framework Evaluation Summary References
Introduction On-line Monitoring Framework Evaluation Summary References Research Group German Climate Computing Center 23-03-2017 Introduction On-line Monitoring Framework Evaluation Summary References
Fakultät Informatik, Institut für Technische Informatik, Professur Rechnerarchitektur. BenchIT. Project Overview
 Fakultät Informatik, Institut für Technische Informatik, Professur Rechnerarchitektur BenchIT Project Overview Nöthnitzer Straße 46 Raum INF 1041 Tel. +49 351-463 - 38458 (stefan.pflueger@tu-dresden.de)
Fakultät Informatik, Institut für Technische Informatik, Professur Rechnerarchitektur BenchIT Project Overview Nöthnitzer Straße 46 Raum INF 1041 Tel. +49 351-463 - 38458 (stefan.pflueger@tu-dresden.de)
Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage
![Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage](/thumbs/92/109196544.jpg "Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage") Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage Evaluation of Lustre File System software enhancements for improved Metadata performance Wojciech Turek, Paul Calleja,John
Intel Enterprise Edition Lustre (IEEL-2.3) [DNE-1 enabled] on Dell MD Storage Evaluation of Lustre File System software enhancements for improved Metadata performance Wojciech Turek, Paul Calleja,John
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
The Last Bottleneck: How Parallel I/O can attenuate Amdahl's Law
 The Last Bottleneck: How Parallel I/O can attenuate Amdahl's Law ERESEARCH AUSTRALASIA, NOVEMBER 2011 REX TANAKIT DIRECTOR OF INDUSTRY SOLUTIONS AGENDA Parallel System Parallel processing goes mainstream
The Last Bottleneck: How Parallel I/O can attenuate Amdahl's Law ERESEARCH AUSTRALASIA, NOVEMBER 2011 REX TANAKIT DIRECTOR OF INDUSTRY SOLUTIONS AGENDA Parallel System Parallel processing goes mainstream
Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge
 Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge Ryan Hulguin Applications Engineer ryan.hulguin@arm.com Agenda Introduction Overview of Allinea Products
Developing, Debugging, and Optimizing GPU Codes for High Performance Computing with Allinea Forge Ryan Hulguin Applications Engineer ryan.hulguin@arm.com Agenda Introduction Overview of Allinea Products
designed. engineered. results. Parallel DMF
 designed. engineered. results. Parallel DMF Agenda Monolithic DMF Parallel DMF Parallel configuration considerations Monolithic DMF Monolithic DMF DMF Databases DMF Central Server DMF Data File server
designed. engineered. results. Parallel DMF Agenda Monolithic DMF Parallel DMF Parallel configuration considerations Monolithic DMF Monolithic DMF DMF Databases DMF Central Server DMF Data File server
International Journal of High Performance Computing Applications. Trace-based Performance Analysis for the Petascale Simulation Code FLASH
 Trace-based Performance Analysis for the Petascale Simulation Code FLASH Journal: International Journal of High Performance Computing Manuscript ID: hpc-0-0 Manuscript Type: Full Length Article Date Submitted
Trace-based Performance Analysis for the Petascale Simulation Code FLASH Journal: International Journal of High Performance Computing Manuscript ID: hpc-0-0 Manuscript Type: Full Length Article Date Submitted
Multi-Rail LNet for Lustre
 Multi-Rail LNet for Lustre Rob Mollard September 2016 The SGI logos and SGI product names used or referenced herein are either registered trademarks or trademarks of Silicon Graphics International Corp.
Multi-Rail LNet for Lustre Rob Mollard September 2016 The SGI logos and SGI product names used or referenced herein are either registered trademarks or trademarks of Silicon Graphics International Corp.
KNL tools. Dr. Fabio Baruffa
 KNL tools Dr. Fabio Baruffa fabio.baruffa@lrz.de 2 Which tool do I use? A roadmap to optimization We will focus on tools developed by Intel, available to users of the LRZ systems. Again, we will skip the
KNL tools Dr. Fabio Baruffa fabio.baruffa@lrz.de 2 Which tool do I use? A roadmap to optimization We will focus on tools developed by Intel, available to users of the LRZ systems. Again, we will skip the
CSCI 402: Computer Architectures. Fengguang Song Department of Computer & Information Science IUPUI. Recall
 CSCI 402: Computer Architectures Memory Hierarchy (2) Fengguang Song Department of Computer & Information Science IUPUI Recall What is memory hierarchy? Where each level is located? Each level s speed,
CSCI 402: Computer Architectures Memory Hierarchy (2) Fengguang Song Department of Computer & Information Science IUPUI Recall What is memory hierarchy? Where each level is located? Each level s speed,
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Demonstration Milestone for Parallel Directory Operations
 Demonstration Milestone for Parallel Directory Operations This milestone was submitted to the PAC for review on 2012-03-23. This document was signed off on 2012-04-06. Overview This document describes
Demonstration Milestone for Parallel Directory Operations This milestone was submitted to the PAC for review on 2012-03-23. This document was signed off on 2012-04-06. Overview This document describes
HPC In The Cloud? Michael Kleber. July 2, Department of Computer Sciences University of Salzburg, Austria
 HPC In The Cloud? Michael Kleber Department of Computer Sciences University of Salzburg, Austria July 2, 2012 Content 1 2 3 MUSCLE NASA 4 5 Motivation wide spread availability of cloud services easy access
HPC In The Cloud? Michael Kleber Department of Computer Sciences University of Salzburg, Austria July 2, 2012 Content 1 2 3 MUSCLE NASA 4 5 Motivation wide spread availability of cloud services easy access
Prof. Konstantinos Krampis Office: Rm. 467F Belfer Research Building Phone: (212) Fax: (212)
 Fax: (212)") Director: Prof. Konstantinos Krampis agbiotec@gmail.com Office: Rm. 467F Belfer Research Building Phone: (212) 396-6930 Fax: (212) 650 3565 Facility Consultant:Carlos Lijeron 1/8 carlos@carotech.com Office:
Director: Prof. Konstantinos Krampis agbiotec@gmail.com Office: Rm. 467F Belfer Research Building Phone: (212) 396-6930 Fax: (212) 650 3565 Facility Consultant:Carlos Lijeron 1/8 carlos@carotech.com Office:
Optimizing Local File Accesses for FUSE-Based Distributed Storage
 Optimizing Local File Accesses for FUSE-Based Distributed Storage Shun Ishiguro 1, Jun Murakami 1, Yoshihiro Oyama 1,3, Osamu Tatebe 2,3 1. The University of Electro-Communications, Japan 2. University
Optimizing Local File Accesses for FUSE-Based Distributed Storage Shun Ishiguro 1, Jun Murakami 1, Yoshihiro Oyama 1,3, Osamu Tatebe 2,3 1. The University of Electro-Communications, Japan 2. University