Leistungsanalyse von Rechnersystemen
|
|
|
- Tracey Dixon
- 5 years ago
- Views:
Transcription
 Matthias S.")
1 Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen 10. November 2010 Nöthnitzer Straße 46 Raum 1026 Tel Holger Brunst (holger.brunst@tu-dresden.de) Matthias S. Mueller (matthias.mueller@tu-dresden.de)
2 Center for Information Services and High Performance Computing (ZIH) Summary of Previous Lecture Nöthnitzer Straße 46 Raum 1026 Tel Holger Brunst (holger.brunst@tu-dresden.de) Matthias S. Mueller (matthias.mueller@tu-dresden.de)
3 Summary of Previous Lecture Different workloads: Test workload Real workload Synthetic workload Historical examples for test workloads: Addition instruction Instruction mixes Kernels Synthetic programs Application benchmarks Holger Brunst, Matthias Müller: Leistungsanalyse
4 Excursion on Speedup and Efficiency Metrics Comparison of sequential and parallel algorithms Speedup: n is the number of processors T 1 is the execution time of the sequential algorithm T n is the execution time of the parallel algorithm with n processors Efficiency: Its value estimates how well-utilized p processors solve a given problem Usually between zero and one. Exception: Super linear speedup (later) Holger Brunst, Matthias Müller: Leistungsanalyse
5 Amdahl s Law Find the maximum expected improvement to an overall system when only part of the system is improved Serial execution time = s+p Parallel execution time = s+p/n Normalizing with respect to serial time (s+p) = 1 results in: S n = 1/(s+p/n) Drops off rapidly as serial fraction increases Maximum speedup possible = 1/s, independent of n the number of processors! Bad news: If an application has only 1% serial work (s = 0.01) then you will never see a speedup greater than 100. So, why do we build system with more than 100 processors? What is wrong with this argument? Holger Brunst, Matthias Müller: Leistungsanalyse
6 Popilar and historic benchmarks Popular benchmarks: Eratosthenes sieve algorithm Ackermann s Function Whetstone LINPACK Dhrystone Lawrence Livermore Loops TPC-C SPEC Holger Brunst, Matthias Müller: Leistungsanalyse
7 Workload description Level of Detail of the workload description - Examples: Most frequent request (e.g. Addition) Frequency of request type (instruction mix) Time-stamped sequence of requests Average resource demand (e.g. 20 I/O requests per second) Distribution of resource demands (not only the average, but also probability distribution) Holger Brunst, Matthias Müller: Leistungsanalyse
8 Characterization of Benchmarks There are many metrics, each one has its purpose Computer Hardware Raw machine performance: Tflops Microbenchmarks: Stream Algorithmic benchmarks: Linpack Compact Apps/Kernels: NAS benchmarks Application Suites: SPEC User-specific applications: Custom benchmarks Applications Holger Brunst, Matthias Müller: Leistungsanalyse
9 Comparison of different benchmark classes coverage relevance Identify problems Time evolution Micro Algorithmic Kernels SPEC Apps Holger Brunst, Matthias Müller: Leistungsanalyse
10 SPEC Benchmarks: CPU 2006 Application Benchmarks Different metrics: Integer, floatingpoint Standard and rate Base, peak Run rules Holger Brunst, Matthias Müller: Leistungsanalyse
11 Center for Information Services and High Performance Computing (ZIH) Stream Nöthnitzer Straße 46 Raum 1026 Tel Holger Brunst (holger.brunst@tu-dresden.de) Matthias S. Mueller (matthias.mueller@tu-dresden.de)
12 Stream Benchmark Author: John McCalpin ( Mr Bandwidth ) John McCalpin Memory Bandwidth and Machine Balance in High Performance Computers, IEEE TCCA Newsletter, December STREAM: measure memory bandwidth with the operations: Copy: a(i) = b(i) Scale: a(i)=s*b(i) Add: a(i)=b(i)+c(i) Triad: a(i)=b(i)+s*c(i) STREAM2: measures memory hierarchy bandwidth with the operations: Fill: a(i)=0 Copy: a(i)=b(i) Daxpy: a(i) = a(i) +q*b(i) Sum: sum += a(i) Holger Brunst, Matthias Müller: Leistungsanalyse
13 Stream 2 properties Holger Brunst, Matthias Müller: Leistungsanalyse
14 Stream Results: TOP 10 STREAM Memory Bandwidth --- John D. McCalpin, Revised to Tue Jul 25 10:10:14 CST 2006 All results are in MB/s MB=10^6 B, *not* 2^20 B Machine ID ncpus COPY SCALE ADD TRIAD SGI_Altix_ SGI_Altix_ NEC_SX NEC_SX-5-16A NEC_SX HP_AlphaServer_GS Cray_T932_ E NEC_SX IBM_System_p5_ HP_Integrity_SuperDome Holger Brunst, Matthias Müller: Leistungsanalyse
15 Stream 2 Results Holger Brunst, Matthias Müller: Leistungsanalyse
16 Center for Information Services and High Performance Computing (ZIH) Linpack and TOP500 Slides courtesy Jack Dongarra Nöthnitzer Straße 46 Raum 1026 Tel Holger Brunst (holger.brunst@tu-dresden.de) Matthias S. Mueller (matthias.mueller@tu-dresden.de)
17 The Linpack Benchmark is a measure of a computer s floating-point rate of execution. It is determined by running a computer program that solves a dense system of linear equations. Over the years the characteristics of the benchmark has changed a bit. In fact, there are three benchmarks included in the Linpack Benchmark report. LINPACK Benchmark Dense linear system solve with LU factorization using partial pivoting Operation count is: 2/3 n 3 + O(n 2 ) Benchmark Measure: MFlop/s Original benchmark measures the execution rate for a Fortran program on a matrix of size 100x100.
18 When the Linpack Fortran n = 100 benchmark is run it produces the following kind of results: Please send the results of this run to: Jack J. Dongarra Computer Science Department University of Tennessee Knoxville, Tennessee Fax: Internet: dongarra@cs.utk.edu norm. resid resid machep x(1) x(n) E E E E E+00 times are reported for matrices of order 100 dgefa dgesl total mflops unit ratio times for array with leading dimension of E E E E E E E E E E E E E E E E E E E E E E E E-02 times for array with leading dimension of E E E E E E E E E E E E E E E E E E E E E E E E-02 Time Factor Time Solve Total Time Mflop/s rate
19 In the beginning there was the Linpack 100 Benchmark (1977) n=100 (80KB); size that would fit in all the machines Fortran; 64 bit floating point arithmetic No hand optimization (only compiler options)
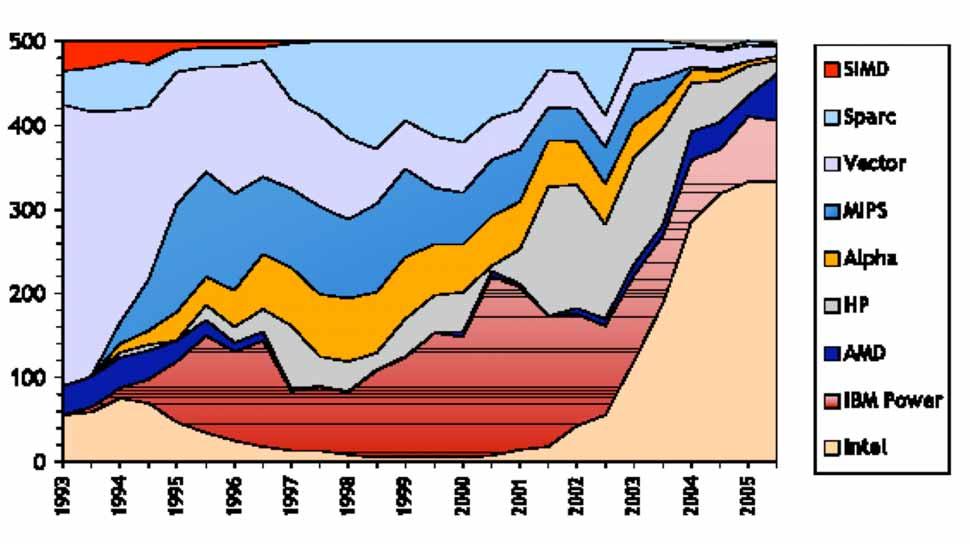
20 Year Computer Number of Processors Cycle time Mflop/s 2006 Intel Pentium Woodcrest (3 GHz) 1 3 GHz NEC SX-8/1 (1 proc) 1 2 GHz Intel Pentium Nocona (1 proc 3.6 GHz) GHz HP Integrity Server rx2600 (1 proc 1.5GHz) GHz Intel Pentium 4 (3.06 GHz) GHz Fujitsu VPP5000/ nsec Fujitsu VPP5000/ nsec CRAY T nsec CRAY T nsec CRAY C nsec CRAY C nsec CRAY C nsec CRAY C nsec CRAY Y-MP nsec CRAY Y-MP nsec CRAY Y-MP nsec ETA 10-E nsec NEC SX nsec NEC SX nsec CRAY X-MP nsec CRAY nsec CRAY nsec 3.4
21 In the beginning there was the Linpack 100 Benchmark (1977) n=100 (80KB); size that would fit in all the machines Fortran; 64 bit floating point arithmetic No hand optimization (only compiler options) Linpack 1000 (1986) n=1000 (8MB); wanted to see higher performance levels Any language; 64 bit floating point arithmetic Hand optimization OK Linpack TPP (1991) (Top500; 1993) Any size (n as large as you can; n=10 6 ; 8TB; ~6 hours); Any language; 64 bit floating point arithmetic Hand optimization OK Strassen s method not allowed (confuses the op count and rate) Reference implementation available In all cases results are verified by looking at: Operations count for factorization ; solve
22 R max Rate LINPACK NxN benchmark Size Solves system of linear equations by some method Allows the vendors to choose size of problem for benchmark Measures execution time for each size problem LINPACK NxN report N max the size of the chosen problem run on a machine R max the performance in Gflop/s for the chosen size problem run on the machine N 1/2 the size where half the R max execution rate is achieved R peak the theoretical peak performance Gflop/s for the machine LINPACK NxN is used to rank TOP500 fastest computers in the world N 1/2 N max
23 TPP performance Rate Size
24 (Entries for this table began in 1991.) Year Computer # of Procs Measured Gflop/s Size of Problem Size of 1/2 Perf Theoretical Peak Gflop/s IBM Blue Gene/L Earth Simulator Computer, NEC 2001 ASCI White-Pacific, IBM SP Power ASCI White-Pacific, IBM SP Power ASCI Red Intel Pentium II Xeon core 1998 ASCI Blue-Pacific SST, IBM SP 604E 1997 Intel ASCI Option Red (200 MHz Pentium Pro) Hitachi CP-PACS Intel Paragon XP/S MP Intel Paragon XP/S MP Fujitsu NWT NEC SX-3/ Fujitsu VP2600/
![Manufacturer Computer Rmax [TF/ s] Installation Site Country Year #Proc 1 IBM BlueGene/L eserver Blue Gene 280.6 DOE Lawrence Livermore Nat Lab USA 2005 custom 131072 2 IBM BGW eserver Blue Gene 91.](/docs-images/91/105028984/images/25-0.jpg "29 IBM Thomas Watson Research USA 2005 custom 40960 3 IBM ASC Purple Power5 p575 63.39 DOE Lawrence Livermore Nat Lab USA 2005 custom 10240 4 3 SGI Columbia Altix, Itanium/Infiniband 51.")

25 Manufacturer Computer Rmax [TF/ s] Installation Site Country Year #Proc 1 IBM BlueGene/L eserver Blue Gene DOE Lawrence Livermore Nat Lab USA 2005 custom IBM BGW eserver Blue Gene IBM Thomas Watson Research USA 2005 custom IBM ASC Purple Power5 p DOE Lawrence Livermore Nat Lab USA 2005 custom SGI Columbia Altix, Itanium/Infiniband NASA Ames USA 2004 hybrid Dell Thunderbird Pentium/Infiniband DOE Sandia Nat Lab USA 2005 commod Cray Red Storm Cray XT3 AMD DOE Sandia Nat Lab USA 2005 hybrid NEC Earth-Simulator SX Earth Simulator Center Japan 2002 custom IBM MareNostrum PPC 970/Myrinet Barcelona Supercomputer Center Spain 2005 commod IBM eserver Blue Gene ASTRON University Groningen Netherlands 2005 custom Cray Jaguar Cray XT3 AMD DOE Oak Ridge Nat Lab USA 2005 hybrid 5200


26 My Laptop

27 Cluster: Commodity processors & Commodity interconnect Constellation: # of procs/node nodes in the system
28

29
30
31 Center for Information Services and High Performance Computing (ZIH) HPCC Benchmark Slides courtesy Jack Dongara Matthias Müller
32 Linpack Benchmark Good One number Simple to define & easy to rank Allows problem size to change with machine and over time Bad Emphasizes only peak CPU speed and number of CPUs Does not stress local bandwidth Does not stress the network Does not test gather/scatter Ignores Amdahl s Law (Only does weak scaling) Ugly Benchmarketeering hype From Linpack Benchmark and Top500: no single number can reflect overall performance Clearly need something more than Linpack HPC Challenge Benchmark Test suite stresses not only the processors, but the memory system and the interconnect. The real utility of the HPCC benchmarks are that architectures can be described with a wider range of metrics than just Flop/s from Linpack.
33 Consists of basically 7 benchmarks; Think of it as a framework or harness for adding benchmarks of interest. 1. HPL (LINPACK) MPI Global (Ax = b) STREAM Local; single CPU *STREAM Embarrassingly parallel PTRANS (A A + B T ) MPI Global RandomAccess Local; single CPU *RandomAccess Embarrassingly parallel RandomAccess MPI Global BW and Latency MPI FFT - Global, single CPU, and EP 9. Matrix Multiply single CPU and EP
 HPC Challenge Memory Hierarchy Operands Registers Cache(s) Local Memory Remote Memory Disk Instructions Lines Blocks")

34 HPL: linear system solve Ax = b STREAM: vector operations A = B + s * C FFT: 1D Fast Fourier Transform Z = fft(x) RandomAccess: integer update T[i] = XOR( T[i], rand) HPC Challenge Memory Hierarchy Operands Registers Cache(s) Local Memory Remote Memory Disk Instructions Lines Blocks Messages Pages Performance Targets Tape HPCC was developed by HPCS to assist in testing new HEC systems Each benchmark focuses on a different part of the memory hierarchy HPCS performance targets attempt to Flatten the memory hierarchy Improve real application performance Make programming easier 34


35 Local - only a single processor is performing computations. Embarrassingly Parallel - each processor in the entire system is performing computations but they do no communicate with each other explicitly. Global - all processors in the system are performing computations and they explicitly communicate with each other.
36 CPU computational speed Computational resources Memory bandwidth Node Interconnect bandwidth
37 HPL Matrix Multiply CPU computational speed Computational resources STREAM Memory bandwidth Node Interconnect bandwidth Random & Natural Ring Bandwidth & Latency

38 Memory Access Patterns
39 Memory Access Patterns
40 TPP Linpack Benchmark Used for the Top500 ratings Solve Ax=b, dense problem, matrix is random Uses LU decomposition with partial pivoting Based on the ScaLAPACK routines but optimized The algorithm is scalable in the sense that the parallel efficiency is maintained constant with respect to the per processor memory usage In double precision (64-bit) arithmetic Run on all processors Problem size set by user These settings used for the other tests Requires An implementation of the MPI An implementation of the Basic Linear Algebra Subprograms (BLAS) Reports total TFlop/s achieved for set of processors Takes the most time Considering stopping the process after say 25% Rate TPP performance Size
41 The STREAM Benchmark is a standard benchmark for the measurement of computer memory bandwidth Measures bandwidth sustainable from standard operations -- not the theoretical "peak bandwidth" provided by most vendors name kernel bytes/iter FLOPS/iter COPY: a(i) = b(i) 16 0 SCALE: a(i) = q*b(i) 16 1 SUM: a(i) = b(i) + c(i) 24 1 TRIAD: a(i) = b(i) + q*c(i) Four operations COPY, SCALE ADD, TRIAD Measures: Machine Balance - relative cost of memory accesses vs arithmetic Vector lengths chosen to fill local memory Tested on a single processor Tested on all processors in the set in an embarrassingly parallel fashion Reports total GB/s achieved per processor
42 Implements parallel matrix transpose A = A + B T The matrices A and B are distributed across the processors Two-dimensional block-cyclic storage Same storage as for HPL Exercises the communications pattern where pairs of processors communicate with each other simultaneously. Large (out-of-cache) data transfers across the network Stresses the global bisection bandwidth Reports total GB/s achieved for set of processors
43 Integer Read-modify-write to random address No spatial or temporal locality Measures memory latency or the ability to hide memory latency Architecture stresses Latency to cache and main memory Architectures which can generate enough outstanding memory operations to tolerate the latency, change this into a main memory bandwidth constrained benchmark Three forms Tested on a single processor Tested on all processors in the set in an embarrassingly parallel fashion Tested with an MPI version across the set of processors Each processor caches updates then all processors perform MPI all-to-all communication to perform updates across processors Reports Gup/s (Giga updates per second) per processor
44 Ping-Pong test between pairs of processors Send a message from proc i to proc k then return message from proc k to proc i proc i MPI_Send() - proc k MPI_Recv() proc i MPI_Recv() - proc k MPI_Send() Other processors doing MPI_Waitall() time += MPI_Wtime() time /= 2 The test is performed between as many possible distinct pairs of processors. There is an upper bound on the time for the test Tries to find the weakest link amongst all pairs Minimum bandwidth Maximum latency Not necessarily the same link will be the worst for bandwidth and latency Message 8B used for latency test; take max time Message 2MB used for bandwidth test; take min GB/s
45 Two types of rings: Naturally ordered (use MPI_COMM_WORLD): 0,1,2,... P-1. Randomly ordered (30 rings tested) eg.: 7, 2, 5, 0, 3, 1, 4, 6 Each node posts two sends (to its left and right neighbor) and two receives (from its left and right neighbor). Two types of communication routines are used: combined send/receive and non-blocking send/receive. MPI_Sendrecv( TO: right_neighbor,from: left_neighbor) MPI_Irecv( left_neighbor )MPI_Irecv( right_neighbor ) and MPI_Isend( right_neighbor )MPI_Isend( left_neighbor ) The smaller (better) time for each is taken (which one is smaller depends on the MPI implementation). Message 8B used for latency test; Message 2MB used for bandwidth test;
46 Using FFTE software Daisuke Takahashi code from University of Tsukuba 64 bit complex 1-D FFT Uses 64 bit addressing Global transpose with MPI_Alltoall() Three transposes (data is never scrambled)
47 Single program to download and run Simple input file similar to HPL input Base Run and Optimization Run Base run must be made User supplies MPI and the BLAS Optimized run allowed to replace certain routines User specifies what was done Results upload via website html table and Excel spreadsheet generated with performance results Intentionally we are not providing a single figure of merit (no over all ranking) Goal: no more than 2 X the time to execute HPL.


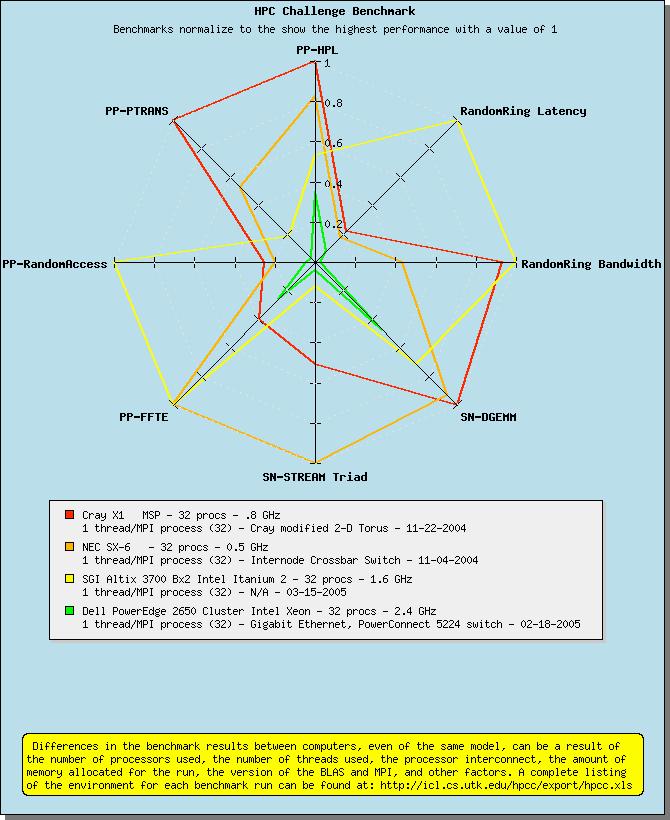
48 1. Download 2. Install 3. Run 4. Upload results 5. Confirm via 6. Tune 7. Run 8. Upload results 9. Confirm via Optional Prequesites: C compiler BLAS MPI Provide detailed installation and execution environment Only some routines can be replaced Data layout needs to be preserved Multiple languages can be used Results are immediately available on the web site: Interactive HTML XML MS Excel Kiviat charts (radar plots) 48

49

50

51

52

53

54
55
56
Presentations: Jack Dongarra, University of Tennessee & ORNL. The HPL Benchmark: Past, Present & Future. Mike Heroux, Sandia National Laboratories
 HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
HPC Benchmarking Presentations: Jack Dongarra, University of Tennessee & ORNL The HPL Benchmark: Past, Present & Future Mike Heroux, Sandia National Laboratories The HPCG Benchmark: Challenges It Presents
Benchmark Results. 2006/10/03
 Benchmark Results cychou@nchc.org.tw 2006/10/03 Outline Motivation HPC Challenge Benchmark Suite Software Installation guide Fine Tune Results Analysis Summary 2 Motivation Evaluate, Compare, Characterize
Benchmark Results cychou@nchc.org.tw 2006/10/03 Outline Motivation HPC Challenge Benchmark Suite Software Installation guide Fine Tune Results Analysis Summary 2 Motivation Evaluate, Compare, Characterize
HPCC Results. Nathan Wichmann Benchmark Engineer
 HPCC Results Nathan Wichmann Benchmark Engineer Outline What is HPCC? Results Comparing current machines Conclusions May 04 2 HPCChallenge Project Goals To examine the performance of HPC architectures
HPCC Results Nathan Wichmann Benchmark Engineer Outline What is HPCC? Results Comparing current machines Conclusions May 04 2 HPCChallenge Project Goals To examine the performance of HPC architectures
The STREAM Benchmark. John D. McCalpin, Ph.D. IBM eserver Performance ^ Performance
 The STREAM Benchmark John D. McCalpin, Ph.D. IBM eserver Performance 2005-01-27 History Scientific computing was largely based on the vector paradigm from the late 1970 s through the 1980 s E.g., the classic
The STREAM Benchmark John D. McCalpin, Ph.D. IBM eserver Performance 2005-01-27 History Scientific computing was largely based on the vector paradigm from the late 1970 s through the 1980 s E.g., the classic
Composite Metrics for System Throughput in HPC
 Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
Composite Metrics for System Throughput in HPC John D. McCalpin, Ph.D. IBM Corporation Austin, TX SuperComputing 2003 Phoenix, AZ November 18, 2003 Overview The HPC Challenge Benchmark was announced last
Computer Comparisons Using HPCC. Nathan Wichmann Benchmark Engineer
 Computer Comparisons Using HPCC Nathan Wichmann Benchmark Engineer Outline Comparisons using HPCC HPCC test used Methods used to compare machines using HPCC Normalize scores Weighted averages Comparing
Computer Comparisons Using HPCC Nathan Wichmann Benchmark Engineer Outline Comparisons using HPCC HPCC test used Methods used to compare machines using HPCC Normalize scores Weighted averages Comparing
An Overview of High Performance Computing
 IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
IFIP Working Group 10.3 on Concurrent Systems An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 1/3/2006 1 Overview Look at fastest computers
HPCS HPCchallenge Benchmark Suite
 HPCS HPCchallenge Benchmark Suite David Koester, Ph.D. () Jack Dongarra (UTK) Piotr Luszczek () 28 September 2004 Slide-1 Outline Brief DARPA HPCS Overview Architecture/Application Characterization Preliminary
HPCS HPCchallenge Benchmark Suite David Koester, Ph.D. () Jack Dongarra (UTK) Piotr Luszczek () 28 September 2004 Slide-1 Outline Brief DARPA HPCS Overview Architecture/Application Characterization Preliminary
Leistungsanalyse von Rechnersystemen
 Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen Monitoring Techniques Nöthnitzer Straße 46 Raum 1026 Tel. +49 351-463 - 35048 Holger Brunst (holger.brunst@tu-dresden.de)
Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen Monitoring Techniques Nöthnitzer Straße 46 Raum 1026 Tel. +49 351-463 - 35048 Holger Brunst (holger.brunst@tu-dresden.de)
Balance of HPC Systems Based on HPCC Benchmark Results
 Proceedings, Cray Users Group Conference, CUG 2005, May 16-19, Albuquerque, NM USA. Extended version of the paper R. Rabenseifner et al., Network Bandwidth Measurements and Ratio Analysis with the HPC
Proceedings, Cray Users Group Conference, CUG 2005, May 16-19, Albuquerque, NM USA. Extended version of the paper R. Rabenseifner et al., Network Bandwidth Measurements and Ratio Analysis with the HPC
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Performance Evaluation with the HPCC Benchmarks as a Guide on the Way to Peta Scale Systems
 Performance Evaluation with the HPCC Benchmarks as a Guide on the Way to Peta Scale Systems Rolf Rabenseifner, Michael M. Resch, Sunil Tiyyagura, Panagiotis Adamidis rabenseifner@hlrs.de resch@hlrs.de
Performance Evaluation with the HPCC Benchmarks as a Guide on the Way to Peta Scale Systems Rolf Rabenseifner, Michael M. Resch, Sunil Tiyyagura, Panagiotis Adamidis rabenseifner@hlrs.de resch@hlrs.de
What have we learned from the TOP500 lists?
 What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
What have we learned from the TOP500 lists? Hans Werner Meuer University of Mannheim and Prometeus GmbH Sun HPC Consortium Meeting Heidelberg, Germany June 19-20, 2001 Outlook TOP500 Approach Snapshots
Presentation of the 16th List
 Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Presentation of the 16th List Hans- Werner Meuer, University of Mannheim Erich Strohmaier, University of Tennessee Jack J. Dongarra, University of Tennesse Horst D. Simon, NERSC/LBNL SC2000, Dallas, TX,
Confessions of an Accidental Benchmarker
 Confessions of an Accidental Benchmarker http://bit.ly/hpcg-benchmark 1 Appendix B of the Linpack Users Guide Designed to help users extrapolate execution Linpack software package First benchmark report
Confessions of an Accidental Benchmarker http://bit.ly/hpcg-benchmark 1 Appendix B of the Linpack Users Guide Designed to help users extrapolate execution Linpack software package First benchmark report
CSE5351: Parallel Processing Part III
 CSE5351: Parallel Processing Part III -1- Performance Metrics and Benchmarks How should one characterize the performance of applications and systems? What are user s requirements in performance and cost?
CSE5351: Parallel Processing Part III -1- Performance Metrics and Benchmarks How should one characterize the performance of applications and systems? What are user s requirements in performance and cost?
Benchmarking CPU Performance. Benchmarking CPU Performance
 Cluster Computing Benchmarking CPU Performance Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance,
Cluster Computing Benchmarking CPU Performance Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance,
HPCS HPCchallenge Benchmark Suite
 HPCS HPCchallenge Benchmark Suite David Koester The Corporation Email Address: dkoester@mitre.org Jack Dongarra and Piotr Luszczek ICL/UT Email Addresses: {dongarra, luszczek}@cs.utk.edu Abstract The Defense
HPCS HPCchallenge Benchmark Suite David Koester The Corporation Email Address: dkoester@mitre.org Jack Dongarra and Piotr Luszczek ICL/UT Email Addresses: {dongarra, luszczek}@cs.utk.edu Abstract The Defense
HPCC Optimizations and Results for the Cray X1 Nathan Wichmann Cray Inc. May 14, 2004
 HPCC Optimizations and Results for the Cray X1 Nathan Wichmann Cray Inc. May 14, 2004 ABSTRACT: A new benchmark call HPCC has recently been proposed to evaluate High Performance systems. This paper discusses
HPCC Optimizations and Results for the Cray X1 Nathan Wichmann Cray Inc. May 14, 2004 ABSTRACT: A new benchmark call HPCC has recently been proposed to evaluate High Performance systems. This paper discusses
An Overview of High Performance Computing. Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/2005 1
 An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/ 1 Overview Look at fastest computers From the Top5 Some of the changes that face
An Overview of High Performance Computing Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 11/29/ 1 Overview Look at fastest computers From the Top5 Some of the changes that face
Cluster Computing Paul A. Farrell 9/15/2011. Dept of Computer Science Kent State University 1. Benchmarking CPU Performance
 Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance, since it is designed to defeat any effort to
Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance, since it is designed to defeat any effort to
High Performance Computing in Europe and USA: A Comparison
 High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
High Performance Computing in Europe and USA: A Comparison Hans Werner Meuer University of Mannheim and Prometeus GmbH 2nd European Stochastic Experts Forum Baden-Baden, June 28-29, 2001 Outlook Introduction
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology
 TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
TOP500 List s Twice-Yearly Snapshots of World s Fastest Supercomputers Develop Into Big Picture of Changing Technology BY ERICH STROHMAIER COMPUTER SCIENTIST, FUTURE TECHNOLOGIES GROUP, LAWRENCE BERKELEY
Overview of the HPC Challenge Benchmark Suite
 Overview of the HPC Challenge Benchmark Suite Jack J. Dongarra Oak Ridge National Laboratory and University of Tennessee Knoxville Piotr Luszczek University of Tennessee Knoxville Abstract The HPC Challenge
Overview of the HPC Challenge Benchmark Suite Jack J. Dongarra Oak Ridge National Laboratory and University of Tennessee Knoxville Piotr Luszczek University of Tennessee Knoxville Abstract The HPC Challenge
Making a Case for a Green500 List
 Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
Making a Case for a Green500 List S. Sharma, C. Hsu, and W. Feng Los Alamos National Laboratory Virginia Tech Outline Introduction What Is Performance? Motivation: The Need for a Green500 List Challenges
Benchmarking CPU Performance
 Benchmarking CPU Performance Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance, since it is designed
Benchmarking CPU Performance Many benchmarks available MHz (cycle speed of processor) MIPS (million instructions per second) Peak FLOPS Whetstone Stresses unoptimized scalar performance, since it is designed
Outline. Execution Environments for Parallel Applications. Supercomputers. Supercomputers
 Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
Outline Execution Environments for Parallel Applications Master CANS 2007/2008 Departament d Arquitectura de Computadors Universitat Politècnica de Catalunya Supercomputers OS abstractions Extended OS
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Performance of computer systems
 Performance of computer systems Many different factors among which: Technology Raw speed of the circuits (clock, switching time) Process technology (how many transistors on a chip) Organization What type
Performance of computer systems Many different factors among which: Technology Raw speed of the circuits (clock, switching time) Process technology (how many transistors on a chip) Organization What type
Optimizing Cache Performance in Matrix Multiplication. UCSB CS240A, 2017 Modified from Demmel/Yelick s slides
 Optimizing Cache Performance in Matrix Multiplication UCSB CS240A, 2017 Modified from Demmel/Yelick s slides 1 Case Study with Matrix Multiplication An important kernel in many problems Optimization ideas
Optimizing Cache Performance in Matrix Multiplication UCSB CS240A, 2017 Modified from Demmel/Yelick s slides 1 Case Study with Matrix Multiplication An important kernel in many problems Optimization ideas
The Architecture and the Application Performance of the Earth Simulator
 The Architecture and the Application Performance of the Earth Simulator Ken ichi Itakura (JAMSTEC) http://www.jamstec.go.jp 15 Dec., 2011 ICTS-TIFR Discussion Meeting-2011 1 Location of Earth Simulator
The Architecture and the Application Performance of the Earth Simulator Ken ichi Itakura (JAMSTEC) http://www.jamstec.go.jp 15 Dec., 2011 ICTS-TIFR Discussion Meeting-2011 1 Location of Earth Simulator
Leistungsanalyse von Rechnersystemen
 Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen Capacity Planning Zellescher Weg 12 Raum WIL A113 Tel. +49 351-463 - 39835 Matthias Müller (matthias.mueller@tu-dresden.de)
Center for Information Services and High Performance Computing (ZIH) Leistungsanalyse von Rechnersystemen Capacity Planning Zellescher Weg 12 Raum WIL A113 Tel. +49 351-463 - 39835 Matthias Müller (matthias.mueller@tu-dresden.de)
represent parallel computers, so distributed systems such as Does not consider storage or I/O issues
 Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Top500 Supercomputer list represent parallel computers, so distributed systems such as SETI@Home are not considered Does not consider storage or I/O issues Both custom designed machines and commodity machines
Performance I: Benchmarking
 High Performance Computing: Concepts, Methods & Means Performance I: Benchmarking Prof. Thomas Sterling Department of Computer Science Louisiana State University January 23 rd, 2007 Topics Definitions,
High Performance Computing: Concepts, Methods & Means Performance I: Benchmarking Prof. Thomas Sterling Department of Computer Science Louisiana State University January 23 rd, 2007 Topics Definitions,
Fabio AFFINITO.
 Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Introduction to High Performance Computing Fabio AFFINITO What is the meaning of High Performance Computing? What does HIGH PERFORMANCE mean??? 1976... Cray-1 supercomputer First commercial successful
Algorithms and Architecture. William D. Gropp Mathematics and Computer Science
 Algorithms and Architecture William D. Gropp Mathematics and Computer Science www.mcs.anl.gov/~gropp Algorithms What is an algorithm? A set of instructions to perform a task How do we evaluate an algorithm?
Algorithms and Architecture William D. Gropp Mathematics and Computer Science www.mcs.anl.gov/~gropp Algorithms What is an algorithm? A set of instructions to perform a task How do we evaluate an algorithm?
The TOP500 Project of the Universities Mannheim and Tennessee
 The TOP500 Project of the Universities Mannheim and Tennessee Hans Werner Meuer University of Mannheim EURO-PAR 2000 29. August - 01. September 2000 Munich/Germany Outline TOP500 Approach HPC-Market as
The TOP500 Project of the Universities Mannheim and Tennessee Hans Werner Meuer University of Mannheim EURO-PAR 2000 29. August - 01. September 2000 Munich/Germany Outline TOP500 Approach HPC-Market as
Supercomputers. Alex Reid & James O'Donoghue
 Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Supercomputers Alex Reid & James O'Donoghue The Need for Supercomputers Supercomputers allow large amounts of processing to be dedicated to calculation-heavy problems Supercomputers are centralized in
Performance of HPC Applications over InfiniBand, 10 Gb and 1 Gb Ethernet. Swamy N. Kandadai and Xinghong He and
 Performance of HPC Applications over InfiniBand, 10 Gb and 1 Gb Ethernet Swamy N. Kandadai and Xinghong He swamy@us.ibm.com and xinghong@us.ibm.com ABSTRACT: We compare the performance of several applications
Performance of HPC Applications over InfiniBand, 10 Gb and 1 Gb Ethernet Swamy N. Kandadai and Xinghong He swamy@us.ibm.com and xinghong@us.ibm.com ABSTRACT: We compare the performance of several applications
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Chapter 5b: top500. Top 500 Blades Google PC cluster. Computer Architecture Summer b.1
 Chapter 5b: top500 Top 500 Blades Google PC cluster Computer Architecture Summer 2005 5b.1 top500: top 10 Rank Site Country/Year Computer / Processors Manufacturer Computer Family Model Inst. type Installation
Chapter 5b: top500 Top 500 Blades Google PC cluster Computer Architecture Summer 2005 5b.1 top500: top 10 Rank Site Country/Year Computer / Processors Manufacturer Computer Family Model Inst. type Installation
LINPACK Benchmark. on the Fujitsu AP The LINPACK Benchmark. Assumptions. A popular benchmark for floating-point performance. Richard P.
 1 2 The LINPACK Benchmark on the Fujitsu AP 1000 Richard P. Brent Computer Sciences Laboratory The LINPACK Benchmark A popular benchmark for floating-point performance. Involves the solution of a nonsingular
1 2 The LINPACK Benchmark on the Fujitsu AP 1000 Richard P. Brent Computer Sciences Laboratory The LINPACK Benchmark A popular benchmark for floating-point performance. Involves the solution of a nonsingular
Measuring Performance. Speed-up, Amdahl s Law, Gustafson s Law, efficiency, benchmarks
 Measuring Performance Speed-up, Amdahl s Law, Gustafson s Law, efficiency, benchmarks Why Measure Performance? Performance tells you how you are doing and whether things can be improved appreciably When
Measuring Performance Speed-up, Amdahl s Law, Gustafson s Law, efficiency, benchmarks Why Measure Performance? Performance tells you how you are doing and whether things can be improved appreciably When
Cray events. ! Cray User Group (CUG): ! Cray Technical Workshop Europe:
: ! Cray Technical Workshop Europe:") Cray events! Cray User Group (CUG):! When: May 16-19, 2005! Where: Albuquerque, New Mexico - USA! Registration: reserved to CUG members! Web site: http://www.cug.org! Cray Technical Workshop Europe:! When:
Cray events! Cray User Group (CUG):! When: May 16-19, 2005! Where: Albuquerque, New Mexico - USA! Registration: reserved to CUG members! Web site: http://www.cug.org! Cray Technical Workshop Europe:! When:
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Parallel Computing Platforms. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Elements of a Parallel Computer Hardware Multiple processors Multiple
CUDA Accelerated Linpack on Clusters. E. Phillips, NVIDIA Corporation
 CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
CUDA Accelerated Linpack on Clusters E. Phillips, NVIDIA Corporation Outline Linpack benchmark CUDA Acceleration Strategy Fermi DGEMM Optimization / Performance Linpack Results Conclusions LINPACK Benchmark
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
Real Parallel Computers
 Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Stockholm Brain Institute Blue Gene/L
 Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Stockholm Brain Institute Blue Gene/L 1 Stockholm Brain Institute Blue Gene/L 2 IBM Systems & Technology Group and IBM Research IBM Blue Gene /P - An Overview of a Petaflop Capable System Carl G. Tengwall
Comparison of Parallel Processing Systems. Motivation
 Comparison of Parallel Processing Systems Ash Dean Katie Willis CS 67 George Mason University Motivation Increasingly, corporate and academic projects require more computing power than a typical PC can
Comparison of Parallel Processing Systems Ash Dean Katie Willis CS 67 George Mason University Motivation Increasingly, corporate and academic projects require more computing power than a typical PC can
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
Jack Dongarra University of Tennessee Oak Ridge National Laboratory
 Jack Dongarra University of Tennessee Oak Ridge National Laboratory 3/9/11 1 TPP performance Rate Size 2 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 100 Tflop/s 100000 10 Tflop/s 10000
Jack Dongarra University of Tennessee Oak Ridge National Laboratory 3/9/11 1 TPP performance Rate Size 2 100 Pflop/s 100000000 10 Pflop/s 10000000 1 Pflop/s 1000000 100 Tflop/s 100000 10 Tflop/s 10000
What is Good Performance. Benchmark at Home and Office. Benchmark at Home and Office. Program with 2 threads Home program.
 Performance COMP375 Computer Architecture and dorganization What is Good Performance Which is the best performing jet? Airplane Passengers Range (mi) Speed (mph) Boeing 737-100 101 630 598 Boeing 747 470
Performance COMP375 Computer Architecture and dorganization What is Good Performance Which is the best performing jet? Airplane Passengers Range (mi) Speed (mph) Boeing 737-100 101 630 598 Boeing 747 470
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Altix Usage and Application Programming
 Center for Information Services and High Performance Computing (ZIH) Altix Usage and Application Programming Discussion And Important Information For Users Zellescher Weg 12 Willers-Bau A113 Tel. +49 351-463
Center for Information Services and High Performance Computing (ZIH) Altix Usage and Application Programming Discussion And Important Information For Users Zellescher Weg 12 Willers-Bau A113 Tel. +49 351-463
COMP Parallel Computing. SMM (1) Memory Hierarchies and Shared Memory
 Memory Hierarchies and Shared Memory") COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
HPC Challenge Awards 2010 Class2 XcalableMP Submission
 HPC Challenge Awards 2010 Class2 XcalableMP Submission Jinpil Lee, Masahiro Nakao, Mitsuhisa Sato University of Tsukuba Submission Overview XcalableMP Language and model, proposed by XMP spec WG Fortran
HPC Challenge Awards 2010 Class2 XcalableMP Submission Jinpil Lee, Masahiro Nakao, Mitsuhisa Sato University of Tsukuba Submission Overview XcalableMP Language and model, proposed by XMP spec WG Fortran
Commodity Cluster Computing
 Commodity Cluster Computing Ralf Gruber, EPFL-SIC/CAPA/Swiss-Tx, Lausanne http://capawww.epfl.ch Commodity Cluster Computing 1. Introduction 2. Characterisation of nodes, parallel machines,applications
Commodity Cluster Computing Ralf Gruber, EPFL-SIC/CAPA/Swiss-Tx, Lausanne http://capawww.epfl.ch Commodity Cluster Computing 1. Introduction 2. Characterisation of nodes, parallel machines,applications
David Cronk University of Tennessee, Knoxville, TN
 Penvelope: A New Approach to Rapidly Predicting the Performance of Computationally Intensive Scientific Applications on Parallel Computer Architectures Daniel M. Pressel US Army Research Laboratory (ARL),
Penvelope: A New Approach to Rapidly Predicting the Performance of Computationally Intensive Scientific Applications on Parallel Computer Architectures Daniel M. Pressel US Army Research Laboratory (ARL),
Thinking Outside of the Tera-Scale Box. Piotr Luszczek
 Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
Thinking Outside of the Tera-Scale Box Piotr Luszczek Brief History of Tera-flop: 1997 1997 ASCI Red Brief History of Tera-flop: 2007 Intel Polaris 2007 1997 ASCI Red Brief History of Tera-flop: GPGPU
Organizational issues (I)
") COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2007 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, PGH 232 Wednesday, 1.00pm 2.30pm, PGH 232 Evaluation 25% homework
COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2007 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, PGH 232 Wednesday, 1.00pm 2.30pm, PGH 232 Evaluation 25% homework
TOP500 Listen und industrielle/kommerzielle Anwendungen
 TOP500 Listen und industrielle/kommerzielle Anwendungen Hans Werner Meuer Universität Mannheim Gesprächsrunde Nichtnumerische Anwendungen im Bereich des Höchstleistungsrechnens des BMBF Berlin, 16./ 17.
TOP500 Listen und industrielle/kommerzielle Anwendungen Hans Werner Meuer Universität Mannheim Gesprächsrunde Nichtnumerische Anwendungen im Bereich des Höchstleistungsrechnens des BMBF Berlin, 16./ 17.
EE 4683/5683: COMPUTER ARCHITECTURE
 3/3/205 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 8: Interconnection Networks Avinash Kodi, kodi@ohio.edu Agenda 2 Interconnection Networks Performance Metrics Topology 3/3/205 IN Performance Metrics
3/3/205 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 8: Interconnection Networks Avinash Kodi, kodi@ohio.edu Agenda 2 Interconnection Networks Performance Metrics Topology 3/3/205 IN Performance Metrics
Instructor Information
 CS 203A Advanced Computer Architecture Lecture 1 1 Instructor Information Rajiv Gupta Office: Engg.II Room 408 E-mail: gupta@cs.ucr.edu Tel: (951) 827-2558 Office Times: T, Th 1-2 pm 2 1 Course Syllabus
CS 203A Advanced Computer Architecture Lecture 1 1 Instructor Information Rajiv Gupta Office: Engg.II Room 408 E-mail: gupta@cs.ucr.edu Tel: (951) 827-2558 Office Times: T, Th 1-2 pm 2 1 Course Syllabus
Fujitsu s Approach to Application Centric Petascale Computing
 Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Fujitsu s Approach to Application Centric Petascale Computing 2 nd Nov. 2010 Motoi Okuda Fujitsu Ltd. Agenda Japanese Next-Generation Supercomputer, K Computer Project Overview Design Targets System Overview
Lecture 3 Notes Topic: Benchmarks
 Lecture 3 Notes Topic: Benchmarks What do you want in a benchmark? o benchmarks must be representative of actual workloads o first few computers were benchmarked based on how fast they could add/multiply
Lecture 3 Notes Topic: Benchmarks What do you want in a benchmark? o benchmarks must be representative of actual workloads o first few computers were benchmarked based on how fast they could add/multiply
Code Performance Analysis
 Code Performance Analysis Massimiliano Fatica ASCI TST Review May 8 2003 Performance Theoretical peak performance of the ASCI machines are in the Teraflops range, but sustained performance with real applications
Code Performance Analysis Massimiliano Fatica ASCI TST Review May 8 2003 Performance Theoretical peak performance of the ASCI machines are in the Teraflops range, but sustained performance with real applications
Lecture 3: Intro to parallel machines and models
 Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
European energy efficient supercomputer project
 http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
http://www.montblanc-project.eu European energy efficient supercomputer project Simon McIntosh-Smith University of Bristol (Based on slides from Alex Ramirez, BSC) Disclaimer: Speaking for myself... All
Computer Systems Performance Analysis and Benchmarking (37-235)
") Computer Systems Performance Analysis and Benchmarking (37-235) Analytic Modelling Simulation Measurements / Benchmarking Lecture/Assignments/Projects: Dipl. Inf. Ing. Christian Kurmann Textbook: Raj Jain,
Computer Systems Performance Analysis and Benchmarking (37-235) Analytic Modelling Simulation Measurements / Benchmarking Lecture/Assignments/Projects: Dipl. Inf. Ing. Christian Kurmann Textbook: Raj Jain,
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Computer Architecture Performance Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science
CMSC 611: Advanced Computer Architecture Performance Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science
Parallel computer architecture classification
 Parallel computer architecture classification Hardware Parallelism Computing: execute instructions that operate on data. Computer Instructions Data Flynn s taxonomy (Michael Flynn, 1967) classifies computer
Parallel computer architecture classification Hardware Parallelism Computing: execute instructions that operate on data. Computer Instructions Data Flynn s taxonomy (Michael Flynn, 1967) classifies computer
Early Evaluation of the Cray X1 at Oak Ridge National Laboratory
 Early Evaluation of the Cray X1 at Oak Ridge National Laboratory Patrick H. Worley Thomas H. Dunigan, Jr. Oak Ridge National Laboratory 45th Cray User Group Conference May 13, 2003 Hyatt on Capital Square
Early Evaluation of the Cray X1 at Oak Ridge National Laboratory Patrick H. Worley Thomas H. Dunigan, Jr. Oak Ridge National Laboratory 45th Cray User Group Conference May 13, 2003 Hyatt on Capital Square
High Performance MPI on IBM 12x InfiniBand Architecture
 High Performance MPI on IBM 12x InfiniBand Architecture Abhinav Vishnu, Brad Benton 1 and Dhabaleswar K. Panda {vishnu, panda} @ cse.ohio-state.edu {brad.benton}@us.ibm.com 1 1 Presentation Road-Map Introduction
High Performance MPI on IBM 12x InfiniBand Architecture Abhinav Vishnu, Brad Benton 1 and Dhabaleswar K. Panda {vishnu, panda} @ cse.ohio-state.edu {brad.benton}@us.ibm.com 1 1 Presentation Road-Map Introduction
Convergence of Parallel Architecture
 Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
Parallel Computing Convergence of Parallel Architecture Hwansoo Han History Parallel architectures tied closely to programming models Divergent architectures, with no predictable pattern of growth Uncertainty
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
What are Clusters? Why Clusters? - a Short History
 What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
What are Clusters? Our definition : A parallel machine built of commodity components and running commodity software Cluster consists of nodes with one or more processors (CPUs), memory that is shared by
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
ECE 574 Cluster Computing Lecture 2
 ECE 574 Cluster Computing Lecture 2 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 24 January 2019 Announcements Put your name on HW#1 before turning in! 1 Top500 List November
ECE 574 Cluster Computing Lecture 2 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 24 January 2019 Announcements Put your name on HW#1 before turning in! 1 Top500 List November
Outline. Parallel Algorithms for Linear Algebra. Number of Processors and Problem Size. Speedup and Efficiency
 1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
Lecture 2: Single processor architecture and memory
 Lecture 2: Single processor architecture and memory David Bindel 30 Aug 2011 Teaser What will this plot look like? for n = 100:10:1000 tic; A = []; for i = 1:n A(i,i) = 1; end times(n) = toc; end ns =
Lecture 2: Single processor architecture and memory David Bindel 30 Aug 2011 Teaser What will this plot look like? for n = 100:10:1000 tic; A = []; for i = 1:n A(i,i) = 1; end times(n) = toc; end ns =
The TOP500 list. Hans-Werner Meuer University of Mannheim. SPEC Workshop, University of Wuppertal, Germany September 13, 1999
 The TOP500 list Hans-Werner Meuer University of Mannheim SPEC Workshop, University of Wuppertal, Germany September 13, 1999 Outline TOP500 Approach HPC-Market as of 6/99 Market Trends, Architecture Trends,
The TOP500 list Hans-Werner Meuer University of Mannheim SPEC Workshop, University of Wuppertal, Germany September 13, 1999 Outline TOP500 Approach HPC-Market as of 6/99 Market Trends, Architecture Trends,
Outline. Overview Theoretical background Parallel computing systems Parallel programming models MPI/OpenMP examples
 Outline Overview Theoretical background Parallel computing systems Parallel programming models MPI/OpenMP examples OVERVIEW y What is Parallel Computing? Parallel computing: use of multiple processors
Outline Overview Theoretical background Parallel computing systems Parallel programming models MPI/OpenMP examples OVERVIEW y What is Parallel Computing? Parallel computing: use of multiple processors
Slides compliment of Yong Chen and Xian-He Sun From paper Reevaluating Amdahl's Law in the Multicore Era. 11/16/2011 Many-Core Computing 2
 Slides compliment of Yong Chen and Xian-He Sun From paper Reevaluating Amdahl's Law in the Multicore Era 11/16/2011 Many-Core Computing 2 Gene M. Amdahl, Validity of the Single-Processor Approach to Achieving
Slides compliment of Yong Chen and Xian-He Sun From paper Reevaluating Amdahl's Law in the Multicore Era 11/16/2011 Many-Core Computing 2 Gene M. Amdahl, Validity of the Single-Processor Approach to Achieving
FUJITSU HPC and the Development of the Post-K Supercomputer
 FUJITSU HPC and the Development of the Post-K Supercomputer Toshiyuki Shimizu Vice President, System Development Division, Next Generation Technical Computing Unit 0 November 16 th, 2016 Post-K is currently
FUJITSU HPC and the Development of the Post-K Supercomputer Toshiyuki Shimizu Vice President, System Development Division, Next Generation Technical Computing Unit 0 November 16 th, 2016 Post-K is currently
Review of previous examinations TMA4280 Introduction to Supercomputing
 Review of previous examinations TMA4280 Introduction to Supercomputing NTNU, IMF April 24. 2017 1 Examination The examination is usually comprised of: one problem related to linear algebra operations with
Review of previous examinations TMA4280 Introduction to Supercomputing NTNU, IMF April 24. 2017 1 Examination The examination is usually comprised of: one problem related to linear algebra operations with
Parallel Processing. Parallel Processing. 4 Optimization Techniques WS 2018/19
 Parallel Processing WS 2018/19 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: September 7, 2018 Betriebssysteme / verteilte Systeme Parallel Processing
Parallel Processing WS 2018/19 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: September 7, 2018 Betriebssysteme / verteilte Systeme Parallel Processing
Advanced Numerical Techniques for Cluster Computing
 Advanced Numerical Techniques for Cluster Computing Presented by Piotr Luszczek http://icl.cs.utk.edu/iter-ref/ Presentation Outline Motivation hardware Dense matrix calculations Sparse direct solvers
Advanced Numerical Techniques for Cluster Computing Presented by Piotr Luszczek http://icl.cs.utk.edu/iter-ref/ Presentation Outline Motivation hardware Dense matrix calculations Sparse direct solvers
Self Adapting Numerical Software (SANS-Effort)
") Self Adapting Numerical Software (SANS-Effort) Jack Dongarra Innovative Computing Laboratory University of Tennessee and Oak Ridge National Laboratory 1 Work on Self Adapting Software 1. Lapack For Clusters
Self Adapting Numerical Software (SANS-Effort) Jack Dongarra Innovative Computing Laboratory University of Tennessee and Oak Ridge National Laboratory 1 Work on Self Adapting Software 1. Lapack For Clusters
Self Adapting Numerical Software. Self Adapting Numerical Software (SANS) Effort and Fault Tolerance in Linear Algebra Algorithms
 Effort and Fault Tolerance in Linear Algebra Algorithms") Self Adapting Numerical Software (SANS) Effort and Fault Tolerance in Linear Algebra Algorithms Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 9/19/2005 1 Overview Quick look at
Self Adapting Numerical Software (SANS) Effort and Fault Tolerance in Linear Algebra Algorithms Jack Dongarra University of Tennessee and Oak Ridge National Laboratory 9/19/2005 1 Overview Quick look at
High Performance Computing - Benchmarks. Prof Matt Probert
 High Performance Computing - Benchmarks Prof Matt Probert http://www-users.york.ac.uk/~mijp1 Overview Why Benchmark? LINPACK HPC Challenge STREAMS SPEC Custom Benchmarks Why Benchmark? How do you know
High Performance Computing - Benchmarks Prof Matt Probert http://www-users.york.ac.uk/~mijp1 Overview Why Benchmark? LINPACK HPC Challenge STREAMS SPEC Custom Benchmarks Why Benchmark? How do you know
Unit 9 : Fundamentals of Parallel Processing
 Unit 9 : Fundamentals of Parallel Processing Lesson 1 : Types of Parallel Processing 1.1. Learning Objectives On completion of this lesson you will be able to : classify different types of parallel processing
Unit 9 : Fundamentals of Parallel Processing Lesson 1 : Types of Parallel Processing 1.1. Learning Objectives On completion of this lesson you will be able to : classify different types of parallel processing
Organizational issues (I)
") COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2009 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, SEC 202 Wednesday, 1.00pm 2.30pm, SEC 202 Evaluation 25% homework
COSC 6385 Computer Architecture Introduction and Organizational Issues Fall 2009 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, SEC 202 Wednesday, 1.00pm 2.30pm, SEC 202 Evaluation 25% homework
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks
 An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract
An evaluation of the Performance and Scalability of a Yellowstone Test-System in 5 Benchmarks WRF Model NASA Parallel Benchmark Intel MPI Bench My own personal benchmark HPC Challenge Benchmark Abstract
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
Analyzing Cache Bandwidth on the Intel Core 2 Architecture
 John von Neumann Institute for Computing Analyzing Cache Bandwidth on the Intel Core 2 Architecture Robert Schöne, Wolfgang E. Nagel, Stefan Pflüger published in Parallel Computing: Architectures, Algorithms
John von Neumann Institute for Computing Analyzing Cache Bandwidth on the Intel Core 2 Architecture Robert Schöne, Wolfgang E. Nagel, Stefan Pflüger published in Parallel Computing: Architectures, Algorithms
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC?
 Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA
Supercomputing with Commodity CPUs: Are Mobile SoCs Ready for HPC? Nikola Rajovic, Paul M. Carpenter, Isaac Gelado, Nikola Puzovic, Alex Ramirez, Mateo Valero SC 13, November 19 th 2013, Denver, CO, USA