Intel PSG (Altera) Enabling the SKA Community. Lance Brown Sr. Strategic & Technical Marketing Mgr.
|
|
|
- Rosemary Gilmore
- 6 years ago
- Views:
Transcription
1 Intel PSG (Altera) Enabling the SKA Community Lance Brown Sr. Strategic & Technical Marketing Mgr
2 Agenda Intel Programmable Solutions Group (Altera) PSG s COTS Strategy for PowerMX High Bandwidth Memory (HBM2), Lower Power Case Study CNN FPGA vs GPU Power Density Stratix 10 Current Status, HLS, OpenCL NRAO Efforts 2
3 3 Altera == Intel Programmable Solutions Group

4 Intel Completes Altera Acquisition December 28, 2015 STRATEGIC RATIONALE Accelerated FPGA innovation from combined R&D scale Improved FPGA power and performance via early access and greater optimization of process node advancements New, breakthrough Data Center and IoT products harnessing combined FPGA + CPU expertise POST-MERGER STRUCTURE Altera operates as a new Intel business unit called Programmable Solutions Group (PSG) with intact and dedicated sales and support Dan McNamara appointed Corporate VP and General Manager leading PSG, reports directly to Intel CEO 4
5 Intel Programmable Solutions Group (PSG) (Altera) Altera GM Promoted to Intel VP to run PSG Intel is adding resources to PSG On 14nm, 10nm & 7nm roadmap with larger Intel Enhancing High Performance Computing teams for OpenCL, OpenMP and Virtualization Access to Intel Labs Research Projects Huge Will Continue ARM based System-on-Chip Arria and Stratix Product Lines 5
6 Proposed PowerMX COTS Model NRC + CEI + Intel PSG (Altera) Moving PowerMX to Broader Industries
 Backplane PowerMX Module (Existing) S10 PowerMX Module with HMC (New) S10 SiP PowerMX Module")

7 Proposed PowerMX COTS Business Model Approaching Top COTS Providers PowerMX CEI COTS Products A10 PowerMX Module with HMC (Existing) Backplane PowerMX Module (Existing) S10 PowerMX Module with HMC (New) S10 SiP PowerMX Module (New) RFQs Quotes Orders Shipments Support SKA Consortium Members Australia Canada China India Italy New Zealand South Africa Sweden The Netherlands United Kingdom Identifying & Working with Standards Bodies for Broader Adoption 8
8 High Bandwidth Memory 10X Improvement, Lower Power 9



9 Memory Bandwidth Need for Memory Bandwidth Is Critical HPC Growing Memory Bandwidth Gap Financial RADAR Networking 8K Video Evolution of Applications Over Time 10



10 Key Challenges to Meeting Memory Bandwidth 1. End of the DDR roadmap 2. Memory bandwidth is IO limited 3. Flat system level power budgets 4. Limits to monolithic memory integration Innovation Needed to Meet High End Memory Bandwidth Requirements 11






11 Package Far Memory with Discrete DRAM Discrete Near Memory with DRAM SiP System-In Package DRAM E M I B FPGA E M I B DRAM Lower bandwidth Higher power Largest footprint Highest bandwidth Lowest power Smallest footprint Cannot meet requirements of next-generation applications Meets the memory bandwidth needs of next-generation applications 12



12 Adoption of SiP Extends Beyond FPGAs GPU CPU MCDRAM AMD Radeon GPU +Memory AMD Fiji GPU 4 SK Hynix HBM1 Intel Xeon CPU + Memory MCDRAM 16GB RAM NVIDIA Volta GPU +Memory 4 HBM1 Planned for


13 Stratix 10 Industry s Only FPGA-based DRAM SiP 10X bandwidth versus discrete DRAM 256 GBytes/second per DRAM Not possible with conventional solutions Multiple system-level advantages Lower system power Smaller form factor Ease of use Intel EMIB technology Solves the Memory Bandwidth Challenge 14

 2 HMC Memories (HMC: 31 mmx31 mm) 1 DRAM SiP (DRAM SiP: 52.5 mm x 52.")
14 Radar Data Processor Application Required Bandwidth: 400+ GB/s FPGA + DDR FPGA + Hybrid Memory Cube 30G VSR Stratix 10 DRAM SiP PCB SiP PCB 5 FPGAs (FPGA: 42.5 mmx42.5 mm, 680 IO, 48 Transceiver) 20 DDR4 DIMMs 1 FPGA (FPGA: 52.5 mmx52.5 mm, 480 IO, 144 Transceiver) 2 HMC Memories (HMC: 31 mmx31 mm) 1 DRAM SiP (DRAM SiP: 52.5 mm x 52.5mm ) Memory: 0 (Included) 21 GB/s BW / DDR4 DIMM 320 GB/s BW /HMC GB/s BW 17 Drawings are NOT drawn to scale
15 234mm 234mm High Performance Computing PCIe Acceleration Card Application Required Bandwidth: 1000 GB/s FPGA + Hybrid Memory Cube 30G VSR Stratix 10 DRAM SiP 107mm 107mm Hybrid Memory Cube 64 XCVR 64 XCVR Hybrid Memory Cube SiP Hybrid Memory Cube 64 XCVR 64 XCVR Hybrid Memory Cube 18 2 FPGAs, 4 HMC Memories (FPGA: 52.5 mmx52.5 mm, 480 IO, 144 Transceiver HMC: 31 mm X 31 mm) 320 GB/s BW /HMC Drawings are NOT drawn to scale 1 DRAM SiP, GB/s (DRAM SiP: 52.5 mm X 52.5 mm) Memory: 0 (Included)
16 Ultra HD 8K Viewer (8KP120) Application Required Bandwidth: GB/s FPGA + Hybrid Memory Cube 30G VSR PCB Stratix 10 DRAM SiP PCB Hybrid Memory Cube 64 XCVR 64 XCVR Hybrid Memory Cube SiP 1 FPGA (FPGA: 52.5 mmx52.5 mm, 480 IO, 144 Transceiver) 2 HMC Memories (HMC: 31 mmx31 mm) 320 GB/s BW / HMC 1 DRAM SiP (DRAM SiP: 52.5 mm x 52.5 mm) Memory: 0 (Included) GB/s BW 19 Drawings are NOT drawn to scale
 1 HMC Memory (HMC: 31 mmx31 mm) 320 GB/s BW Drawings are NOT drawn to scale 1 DRAM SiP (DRAM SiP: 52.")
17 Ultra HD 8K High End Camera Application Required Bandwidth: 172 GB/s Form factor critical application Hybrid Memory Cube 30G VSR PCB NHK 8K camera in 10cm housing Stratix 10 DRAM SiP PCB Hybrid Memory Cube 64 XCVR channels SiP 20 1 FPGA (FPGA: 52.5 mmx52.5 mm, 480 IO, 144 Transceiver) 1 HMC Memory (HMC: 31 mmx31 mm) 320 GB/s BW Drawings are NOT drawn to scale 1 DRAM SiP (DRAM SiP: 52.5 mm x 52.5 mm) Memory: 0 (Included) GB/s BW ~50%+ Board space savings
18 Summary Stratix 10 DRAM SiP Solves the memory bandwidth challenge Provides 10X memory bandwidth versus discrete solutions Enabled by innovative 3D SiP, EMIB and next-generation Stratix 10 FPGA technologies Enables key applications including wireline, broadcast, military, HPC, test, and more 21
19 CNN Case Study FPGA vs GPU Performance & Power 22



20 Deep Learning: Convolutional Neural Network (CNN) Convolutional Neural Network Feed forward artificial neural network Inspired by biological processes Applications Classification & Detection Image recognition/tagging Big Data pattern detection Datastreaming Analytics Targeted ads Fraud & face detection Gaming 23

21 ImageNet ImageNet is a yearly competition held since 2010 Large Scale Visual Recognition Challenge. 1.2 million images for training, 50,000 for validation, 100,000 for testing different image classes Winner: AlexNet, top-5 error rate of 15.3%, 5 convolution layers 2014 Winner: GoogleNet, top-5 error rate of 6.67%, 22 layers in total 2015 Winner: Microsoft with 4.94% (Baidu was 4.8%, but was disqualified) Top-5 Error Rate: How often is the correct answer not in the top-5 results? Trained human result: 5.1% Top-5 Error Rate, at 1 minute per image 24
22 AlexNet Competitive Analysis Classification System Throughput Est. Power Throughput / Watt Arria img/s ~60W 10 img/s/w 2 x Arria img/s ~90W 13.3 img/s/w Caffe on NVIDIA TitanX with CUDA 1000 img/s ~250W 4 img/s/w FPGA competitive with GPUs on raw AlexNet throughput Dominates in throughput per watt, for similar node GPU Expect similar ratios for Stratix 10 vs. NVIDIA 14nm Pascal 25
23 26 Stratix 10 Updates
24 Schedule Near the front of the line with direct Intel mfg support Next Update on Feb 17 th S10 Common Element (S10CE) is meant to help with early S10 work Early Power Estimator (EPE) updates frequently Certify Partners in all GEOs on HyperFlex 2 Week Course 27
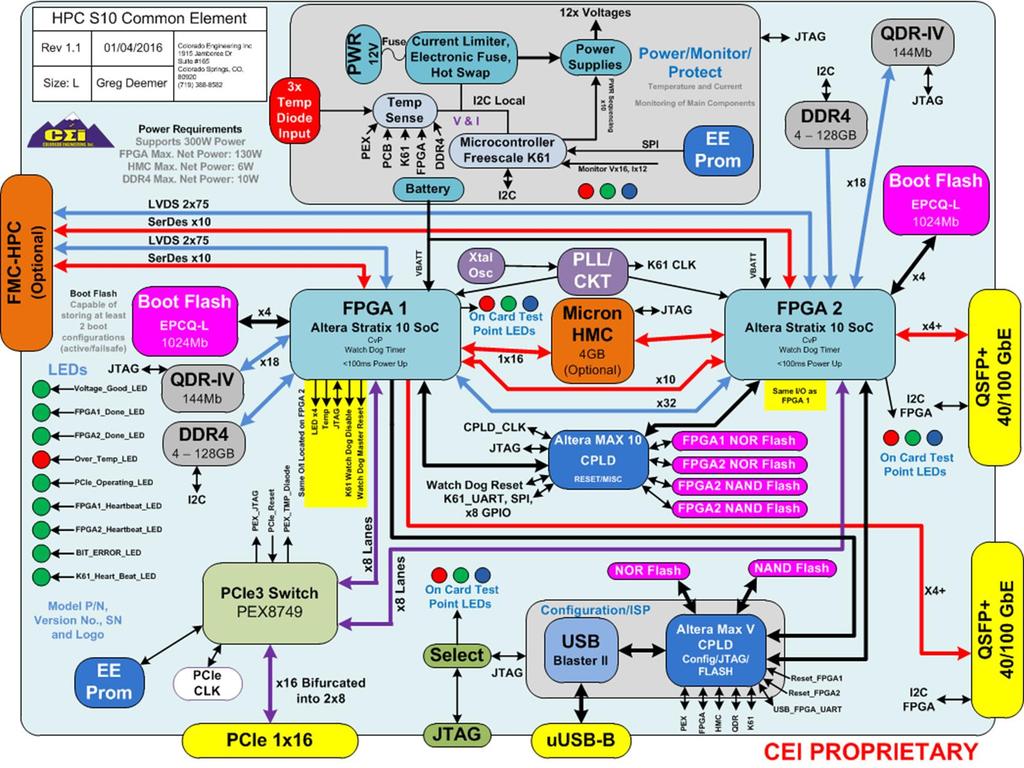
25 28 S10CE - Preliminary










26 Up to 70% Reduction in Power Consumption 1024-bits 390 MHz 400G 400G 50% Reduction 512-bits 781 MHz Customer Designs Wired Network Wireless Network Data Center Server Enterprise Storage Power Savings Stratix V vs. Stratix 10 40% Less 52% Less 63% Less 70% Less 29




27 Enables Higher FPGA Adoption in the Data Center 120W vs. 44W Five Stratix V FPGAs PCIe Gen2 x8 DDR3 800 MHz FPGA performance 250 MHz One Stratix 10 FPGA PCIe Gen3 x8 DDR3 1.2 GHz FPGA performance 500 MHz HyperFlex Delivers 2X core performance of FPGA 63% power reduction 30


28 OpenCL vs a++ Compiler Summary Targets CPU, GPU and FPGAs Target user is HW or SW Implements FPGA in software development flow Performance is determined by resources allocated Builds the entire FPGA system Host Required Targets FPGAs Target user is HW Implements FPGA in traditional FPGA development flow Performance is defined and amount of resource to achieve is reported Builds an IP block Host is optional 31
29 Altera Efforts for NRAO: Gridding + Image Deconvolution Updates



30 Project Potential Gridding and Image Deconvolutions are the current bottlenecks in post processing Single Image Data: 100GB-400TB (Double Precision FP) CPUs take 1 day to process data. 1 CPU takes 10 days. Final Image Resolution: ~1k*1k 15k*15k pixels All processing done offline in batch Potentially scalable solutions using Altera FPGA for algorithm acceleration in conjunction to NRAO SW toolkit CASA Higher data processing needs are a reality


31 Technical Overview How do we analyze the data? Sampled Data Dirty Image Too slow Gridding Put data on regular spaced grid FFT -1 34
")
32 Technical Overview How can we make the data look better? Dirty Beam True Sky Image Dirty Image = (u,v Coordinates) 35
33 Project Scope Implementations of Gridding algorithms using OpenCL should provide 10x-20x performance boost Altera working with partner ImpulseAccelerated for benchmarking source code Need to test on ReFLEX Arria10 Dev kit Testing planned on Arria10 or Stratix10 (due to Floating Point DSPs) Deploy and Test implementation within NRAO s development environment Develop and implement parallel algorithm for Image Deconvolution 36


34 Multithreaded gridding algorithms tested Kumar s Romein s 37
35 Implementations/Progress Single-Threaded Ran on S5, integrated with CASA. Slow- no parallelization Multi-Threaded (Kumar Golap - NRAO) Load balancing soln. partitioning, W-only projection Ported from FORTRAN to C & integrated with CASA Multi-Threaded (John Romein - ASTRON) Sorts input data on host to increase locality Trying to figure out if IDG is based off Romein s alg IDG (Bram Veenboer ASTRON) Standalone (not sure if practical solution) OpenCL implementation exists (from ImpulseAccelerated) Still need results on A10 board All Not double-precision floating point numbers 38
36 Next Steps/Learnings Need to target multithreaded solutions Figure out which implementation is best-suited for FPGAs Simplify CASA integration by creating a more standalone application this will allow faster development Implement the best (or more) implementations on AOCL using standalone app Requires data re-organization if using Romein/IDG Profile timing and resources used Impulseaccelerated benchmarking projections: 39
37 Thank You
World s most advanced data center accelerator for PCIe-based servers
 NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
NVIDIA TESLA P100 GPU ACCELERATOR World s most advanced data center accelerator for PCIe-based servers HPC data centers need to support the ever-growing demands of scientists and researchers while staying
Welcome. Altera Technology Roadshow 2013
 Welcome Altera Technology Roadshow 2013 Altera at a Glance Founded in Silicon Valley, California in 1983 Industry s first reprogrammable logic semiconductors $1.78 billion in 2012 sales Over 2,900 employees
Welcome Altera Technology Roadshow 2013 Altera at a Glance Founded in Silicon Valley, California in 1983 Industry s first reprogrammable logic semiconductors $1.78 billion in 2012 sales Over 2,900 employees
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks
 Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
Altera SDK for OpenCL
 Altera SDK for OpenCL A novel SDK that opens up the world of FPGAs to today s developers Altera Technology Roadshow 2013 Today s News Altera today announces its SDK for OpenCL Altera Joins Khronos Group
Altera SDK for OpenCL A novel SDK that opens up the world of FPGAs to today s developers Altera Technology Roadshow 2013 Today s News Altera today announces its SDK for OpenCL Altera Joins Khronos Group
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.
 Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
GPUS FOR NGVLA. M Clark, April 2015
 S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
S FOR NGVLA M Clark, April 2015 GAMING DESIGN ENTERPRISE VIRTUALIZATION HPC & CLOUD SERVICE PROVIDERS AUTONOMOUS MACHINES PC DATA CENTER MOBILE The World Leader in Visual Computing 2 What is a? Tesla K40
Intel Stratix 10 MX Devices Solve the Memory Bandwidth Challenge
 white paper Intel Stratix 10 MX Devices Solve the Memory Bandwidth Challenge The Intel Stratix 10 MX family helps customers efficiently meet their most demanding memory bandwidth requirements. Authors
white paper Intel Stratix 10 MX Devices Solve the Memory Bandwidth Challenge The Intel Stratix 10 MX family helps customers efficiently meet their most demanding memory bandwidth requirements. Authors
Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package
 High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Small is the New Big: Data Analytics on the Edge
 Small is the New Big: Data Analytics on the Edge An overview of processors and algorithms for deep learning techniques on the edge Dr. Abhay Samant VP Engineering, Hiller Measurements Adjunct Faculty,
Small is the New Big: Data Analytics on the Edge An overview of processors and algorithms for deep learning techniques on the edge Dr. Abhay Samant VP Engineering, Hiller Measurements Adjunct Faculty,
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
Fast Hardware For AI
 Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
Fast Hardware For AI Karl Freund karl@moorinsightsstrategy.com Sr. Analyst, AI and HPC Moor Insights & Strategy Follow my blogs covering Machine Learning Hardware on Forbes: http://www.forbes.com/sites/moorinsights
OpenPOWER Performance
 OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
OpenPOWER Performance Alex Mericas Chief Engineer, OpenPOWER Performance IBM Delivering the Linux ecosystem for Power SOLUTIONS OpenPOWER IBM SOFTWARE LINUX ECOSYSTEM OPEN SOURCE Solutions with full stack
Cloud Acceleration with FPGA s. Mike Strickland, Director, Computer & Storage BU, Altera
 Cloud Acceleration with FPGA s Mike Strickland, Director, Computer & Storage BU, Altera Agenda Mission Alignment & Data Center Trends OpenCL and Algorithm Acceleration Networking Acceleration Data Access
Cloud Acceleration with FPGA s Mike Strickland, Director, Computer & Storage BU, Altera Agenda Mission Alignment & Data Center Trends OpenCL and Algorithm Acceleration Networking Acceleration Data Access
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Xilinx ML Suite Overview
 Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
Big Data Systems on Future Hardware. Bingsheng He NUS Computing
 Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
Big Data Systems on Future Hardware Bingsheng He NUS Computing http://www.comp.nus.edu.sg/~hebs/ 1 Outline Challenges for Big Data Systems Why Hardware Matters? Open Challenges Summary 2 3 ANYs in Big
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
An introduction to Machine Learning silicon
 An introduction to Machine Learning silicon November 28 2017 Insight for Technology Investors AI/ML terminology Artificial Intelligence Machine Learning Deep Learning Algorithms: CNNs, RNNs, etc. Additional
An introduction to Machine Learning silicon November 28 2017 Insight for Technology Investors AI/ML terminology Artificial Intelligence Machine Learning Deep Learning Algorithms: CNNs, RNNs, etc. Additional
The Path to Embedded Vision & AI using a Low Power Vision DSP. Yair Siegel, Director of Segment Marketing Hotchips August 2016
 The Path to Embedded Vision & AI using a Low Power Vision DSP Yair Siegel, Director of Segment Marketing Hotchips August 2016 Presentation Outline Introduction The Need for Embedded Vision & AI Vision
The Path to Embedded Vision & AI using a Low Power Vision DSP Yair Siegel, Director of Segment Marketing Hotchips August 2016 Presentation Outline Introduction The Need for Embedded Vision & AI Vision
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
ATS-GPU Real Time Signal Processing Software
 Transfer A/D data to at high speed Up to 4 GB/s transfer rate for PCIe Gen 3 digitizer boards Supports CUDA compute capability 2.0+ Designed to work with AlazarTech PCI Express waveform digitizers Optional
Transfer A/D data to at high speed Up to 4 GB/s transfer rate for PCIe Gen 3 digitizer boards Supports CUDA compute capability 2.0+ Designed to work with AlazarTech PCI Express waveform digitizers Optional
Emerging IC Packaging Platforms for ICT Systems - MEPTEC, IMAPS and SEMI Bay Area Luncheon Presentation
 Emerging IC Packaging Platforms for ICT Systems - MEPTEC, IMAPS and SEMI Bay Area Luncheon Presentation Dr. Li Li Distinguished Engineer June 28, 2016 Outline Evolution of Internet The Promise of Internet
Emerging IC Packaging Platforms for ICT Systems - MEPTEC, IMAPS and SEMI Bay Area Luncheon Presentation Dr. Li Li Distinguished Engineer June 28, 2016 Outline Evolution of Internet The Promise of Internet
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
Accelerating Business Analytics with Flash Storage and FPGAs
 Accelerating Business Analytics with Flash Storage and FPGAs Satoru Watanabe Center for Technology Innovation - Information and Telecommunications Hitachi, Ltd., Research and Development Group Aug.10 2016
Accelerating Business Analytics with Flash Storage and FPGAs Satoru Watanabe Center for Technology Innovation - Information and Telecommunications Hitachi, Ltd., Research and Development Group Aug.10 2016
ACCELERATED COMPUTING: THE PATH FORWARD. Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015
 ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
ACCELERATED COMPUTING: THE PATH FORWARD Jen-Hsun Huang, Co-Founder and CEO, NVIDIA SC15 Nov. 16, 2015 COMMODITY DISRUPTS CUSTOM SOURCE: Top500 ACCELERATED COMPUTING: THE PATH FORWARD It s time to start
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems
 S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
TESLA V100 PERFORMANCE GUIDE. Life Sciences Applications
 TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
TESLA V100 PERFORMANCE GUIDE Life Sciences Applications NOVEMBER 2017 TESLA V100 PERFORMANCE GUIDE Modern high performance computing (HPC) data centers are key to solving some of the world s most important
Enabling the A.I. Era: From Materials to Systems
 Enabling the A.I. Era: From Materials to Systems Sundeep Bajikar Head of Market Intelligence, Applied Materials New Street Research Conference May 30, 2018 External Use Key Message PART 1 PART 2 A.I. *
Enabling the A.I. Era: From Materials to Systems Sundeep Bajikar Head of Market Intelligence, Applied Materials New Street Research Conference May 30, 2018 External Use Key Message PART 1 PART 2 A.I. *
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
Catapult: A Reconfigurable Fabric for Petaflop Computing in the Cloud
 Catapult: A Reconfigurable Fabric for Petaflop Computing in the Cloud Doug Burger Director, Hardware, Devices, & Experiences MSR NExT November 15, 2015 The Cloud is a Growing Disruptor for HPC Moore s
Catapult: A Reconfigurable Fabric for Petaflop Computing in the Cloud Doug Burger Director, Hardware, Devices, & Experiences MSR NExT November 15, 2015 The Cloud is a Growing Disruptor for HPC Moore s
IBM Deep Learning Solutions
 IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
Maximizing Server Efficiency from μarch to ML accelerators. Michael Ferdman
 Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency with ML accelerators Michael
Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency with ML accelerators Michael
IBM Power Advanced Compute (AC) AC922 Server
 AC922 Server") IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
Low-Power Neural Processor for Embedded Human and Face detection
 Low-Power Neural Processor for Embedded Human and Face detection Olivier Brousse 1, Olivier Boisard 1, Michel Paindavoine 1,2, Jean-Marc Philippe, Alexandre Carbon (1) GlobalSensing Technologies (GST)
Low-Power Neural Processor for Embedded Human and Face detection Olivier Brousse 1, Olivier Boisard 1, Michel Paindavoine 1,2, Jean-Marc Philippe, Alexandre Carbon (1) GlobalSensing Technologies (GST)
Brainchip OCTOBER
 Brainchip OCTOBER 2017 1 Agenda Neuromorphic computing background Akida Neuromorphic System-on-Chip (NSoC) Brainchip OCTOBER 2017 2 Neuromorphic Computing Background Brainchip OCTOBER 2017 3 A Brief History
Brainchip OCTOBER 2017 1 Agenda Neuromorphic computing background Akida Neuromorphic System-on-Chip (NSoC) Brainchip OCTOBER 2017 2 Neuromorphic Computing Background Brainchip OCTOBER 2017 3 A Brief History
System Design of Kepler Based HPC Solutions. Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering.
 System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
Characterization and Benchmarking of Deep Learning. Natalia Vassilieva, PhD Sr. Research Manager
 Characterization and Benchmarking of Deep Learning Natalia Vassilieva, PhD Sr. Research Manager Deep learning applications Vision Speech Text Other Search & information extraction Security/Video surveillance
Characterization and Benchmarking of Deep Learning Natalia Vassilieva, PhD Sr. Research Manager Deep learning applications Vision Speech Text Other Search & information extraction Security/Video surveillance
Data center: The center of possibility
 Data center: The center of possibility Diane bryant Executive vice president & general manager Data center group, intel corporation Data center: The center of possibility The future is Thousands of Clouds
Data center: The center of possibility Diane bryant Executive vice president & general manager Data center group, intel corporation Data center: The center of possibility The future is Thousands of Clouds
Accelerating Real-Time Big Data. Breaking the limitations of captive NVMe storage
 Accelerating Real-Time Big Data Breaking the limitations of captive NVMe storage 18M IOPs in 2u Agenda Everything related to storage is changing! The 3rd Platform NVM Express architected for solid state
Accelerating Real-Time Big Data Breaking the limitations of captive NVMe storage 18M IOPs in 2u Agenda Everything related to storage is changing! The 3rd Platform NVM Express architected for solid state
High Performance Memory in FPGAs
 High Performance Memory in FPGAs Industry Trends and Customer Challenges Packet Processing & Transport > 400G OTN Software Defined Networks Video Over IP Network Function Virtualization Wireless LTE Advanced
High Performance Memory in FPGAs Industry Trends and Customer Challenges Packet Processing & Transport > 400G OTN Software Defined Networks Video Over IP Network Function Virtualization Wireless LTE Advanced
24th MONDAY. Overview 2018
 24th MONDAY Overview 2018 Imagination: your route to success At Imagination, we create and license market-leading processor solutions for graphics, vision & AI processing, and multi-standard communications.
24th MONDAY Overview 2018 Imagination: your route to success At Imagination, we create and license market-leading processor solutions for graphics, vision & AI processing, and multi-standard communications.
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA
 Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
Emergence of the Memory Centric Architectures
 Emergence of the Memory Centric Architectures Balint Fleischer Chief Scientist AI is Everywhere Business Consumer Advising the CEO External Sensing: Market trends, Competitive environment, Customer sentiment,
Emergence of the Memory Centric Architectures Balint Fleischer Chief Scientist AI is Everywhere Business Consumer Advising the CEO External Sensing: Market trends, Competitive environment, Customer sentiment,
Accelerating Data Center Workloads with FPGAs
 Accelerating Data Center Workloads with FPGAs Enno Lübbers NorCAS 2017, Linköping, Sweden Intel technologies features and benefits depend on system configuration and may require enabled hardware, software
Accelerating Data Center Workloads with FPGAs Enno Lübbers NorCAS 2017, Linköping, Sweden Intel technologies features and benefits depend on system configuration and may require enabled hardware, software
DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs
 IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Deep Learning with Intel DAAL
 Deep Learning with Intel DAAL on Knights Landing Processor David Ojika dave.n.ojika@cern.ch March 22, 2017 Outline Introduction and Motivation Intel Knights Landing Processor Intel Data Analytics and Acceleration
Deep Learning with Intel DAAL on Knights Landing Processor David Ojika dave.n.ojika@cern.ch March 22, 2017 Outline Introduction and Motivation Intel Knights Landing Processor Intel Data Analytics and Acceleration
Deep Learning Requirements for Autonomous Vehicles
 Deep Learning Requirements for Autonomous Vehicles Pierre Paulin, Director of R&D Synopsys Inc. Chipex, 1 May 2018 1 Agenda Deep Learning and Convolutional Neural Networks for Embedded Vision Automotive
Deep Learning Requirements for Autonomous Vehicles Pierre Paulin, Director of R&D Synopsys Inc. Chipex, 1 May 2018 1 Agenda Deep Learning and Convolutional Neural Networks for Embedded Vision Automotive
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI
 NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
OCP Engineering Workshop - Telco
 OCP Engineering Workshop - Telco Low Latency Mobile Edge Computing Trevor Hiatt Product Management, IDT IDT Company Overview Founded 1980 Workforce Approximately 1,800 employees Headquarters San Jose,
OCP Engineering Workshop - Telco Low Latency Mobile Edge Computing Trevor Hiatt Product Management, IDT IDT Company Overview Founded 1980 Workforce Approximately 1,800 employees Headquarters San Jose,
RECENT TRENDS IN GPU ARCHITECTURES. Perspectives of GPU computing in Science, 26 th Sept 2016
 RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
RECENT TRENDS IN GPU ARCHITECTURES Perspectives of GPU computing in Science, 26 th Sept 2016 NVIDIA THE AI COMPUTING COMPANY GPU Computing Computer Graphics Artificial Intelligence 2 NVIDIA POWERS WORLD
There s STILL plenty of room at the bottom! Andreas Olofsson
 There s STILL plenty of room at the bottom! Andreas Olofsson 1 Richard Feynman s Lecture (1959) There's Plenty of Room at the Bottom An Invitation to Enter a New Field of Physics Why cannot we write the
There s STILL plenty of room at the bottom! Andreas Olofsson 1 Richard Feynman s Lecture (1959) There's Plenty of Room at the Bottom An Invitation to Enter a New Field of Physics Why cannot we write the
Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters
 Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters *Argonne National Lab +BU & USTC Presented by Martin Herbordt Work by Ahmed
Two FPGA-DNN Projects: 1. Low Latency Multi-Layer Perceptrons using FPGAs 2. Acceleration of CNN Training on FPGA-based Clusters *Argonne National Lab +BU & USTC Presented by Martin Herbordt Work by Ahmed
Experts in Application Acceleration Synective Labs AB
 Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
SDACCEL DEVELOPMENT ENVIRONMENT. The Xilinx SDAccel Development Environment. Bringing The Best Performance/Watt to the Data Center
 SDAccel Environment The Xilinx SDAccel Development Environment Bringing The Best Performance/Watt to the Data Center Introduction Data center operators constantly seek more server performance. Currently
SDAccel Environment The Xilinx SDAccel Development Environment Bringing The Best Performance/Watt to the Data Center Introduction Data center operators constantly seek more server performance. Currently
Bringing Intelligence to Enterprise Storage Drives
 Bringing Intelligence to Enterprise Storage Drives Neil Werdmuller Director Storage Solutions Arm Santa Clara, CA 1 Who am I? 28 years experience in embedded Lead the storage solutions team Work closely
Bringing Intelligence to Enterprise Storage Drives Neil Werdmuller Director Storage Solutions Arm Santa Clara, CA 1 Who am I? 28 years experience in embedded Lead the storage solutions team Work closely
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
TR An Overview of NVIDIA Tegra K1 Architecture. Ang Li, Radu Serban, Dan Negrut
 TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
High Performance Computing
 High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Renderscript Accelerated Advanced Image and Video Processing on ARM Mali T-600 GPUs. Lihua Zhang, Ph.D. MulticoreWare Inc.
 Renderscript Accelerated Advanced Image and Video Processing on ARM Mali T-600 GPUs Lihua Zhang, Ph.D. MulticoreWare Inc. lihua@multicorewareinc.com Overview More & more mobile apps are beginning to require
Renderscript Accelerated Advanced Image and Video Processing on ARM Mali T-600 GPUs Lihua Zhang, Ph.D. MulticoreWare Inc. lihua@multicorewareinc.com Overview More & more mobile apps are beginning to require
John W. Romein. Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands
 Dwingeloo, the Netherlands") Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Signal Conversion in a Modular Open Standard Form Factor. CASPER Workshop August 2017 Saeed Karamooz, VadaTech
 Signal Conversion in a Modular Open Standard Form Factor CASPER Workshop August 2017 Saeed Karamooz, VadaTech At VadaTech we are technology leaders First-to-market silicon Continuous innovation Open systems
Signal Conversion in a Modular Open Standard Form Factor CASPER Workshop August 2017 Saeed Karamooz, VadaTech At VadaTech we are technology leaders First-to-market silicon Continuous innovation Open systems
Machine Learning on VMware vsphere with NVIDIA GPUs
 Machine Learning on VMware vsphere with NVIDIA GPUs Uday Kurkure, Hari Sivaraman, Lan Vu GPU Technology Conference 2017 2016 VMware Inc. All rights reserved. Gartner Hype Cycle for Emerging Technology
Machine Learning on VMware vsphere with NVIDIA GPUs Uday Kurkure, Hari Sivaraman, Lan Vu GPU Technology Conference 2017 2016 VMware Inc. All rights reserved. Gartner Hype Cycle for Emerging Technology
Stacked Silicon Interconnect Technology (SSIT)
") Stacked Silicon Interconnect Technology (SSIT) Suresh Ramalingam Xilinx Inc. MEPTEC, January 12, 2011 Agenda Background and Motivation Stacked Silicon Interconnect Technology Summary Background and Motivation
Stacked Silicon Interconnect Technology (SSIT) Suresh Ramalingam Xilinx Inc. MEPTEC, January 12, 2011 Agenda Background and Motivation Stacked Silicon Interconnect Technology Summary Background and Motivation
GPU COMPUTING AND THE FUTURE OF HPC. Timothy Lanfear, NVIDIA
 GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
GPU COMPUTING AND THE FUTURE OF HPC Timothy Lanfear, NVIDIA ~1 W ~3 W ~100 W ~30 W 1 kw 100 kw 20 MW Power-constrained Computers 2 EXASCALE COMPUTING WILL ENABLE TRANSFORMATIONAL SCIENCE RESULTS First-principles
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER. Markus Weber and Haiduong Vo
 DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER Markus Weber and Haiduong Vo NVIDIA DGX SYSTEMS Agenda NVIDIA DGX-1 NVIDIA DGX STATION 2 ONE YEAR LATER NVIDIA DGX-1 Barriers Toppled, the Unsolvable
DGX SYSTEMS: DEEP LEARNING FROM DESK TO DATA CENTER Markus Weber and Haiduong Vo NVIDIA DGX SYSTEMS Agenda NVIDIA DGX-1 NVIDIA DGX STATION 2 ONE YEAR LATER NVIDIA DGX-1 Barriers Toppled, the Unsolvable
Cisco UCS C480 ML M5 Rack Server Performance Characterization
 White Paper Cisco UCS C480 ML M5 Rack Server Performance Characterization The Cisco UCS C480 ML M5 Rack Server platform is designed for artificial intelligence and machine-learning workloads. 2018 Cisco
White Paper Cisco UCS C480 ML M5 Rack Server Performance Characterization The Cisco UCS C480 ML M5 Rack Server platform is designed for artificial intelligence and machine-learning workloads. 2018 Cisco
NVIDIA Update and Directions on GPU Acceleration for Earth System Models
 NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
NVIDIA Update and Directions on GPU Acceleration for Earth System Models Stan Posey, HPC Program Manager, ESM and CFD, NVIDIA, Santa Clara, CA, USA Carl Ponder, PhD, Applications Software Engineer, NVIDIA,
Using Graphics Chips for General Purpose Computation
 White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
White Paper Using Graphics Chips for General Purpose Computation Document Version 0.1 May 12, 2010 442 Northlake Blvd. Altamonte Springs, FL 32701 (407) 262-7100 TABLE OF CONTENTS 1. INTRODUCTION....1
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE. Dennis Lui August 2017
 DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
Expand In-Memory Capacity at a Fraction of the Cost of DRAM: AMD EPYCTM and Ultrastar
 White Paper March, 2019 Expand In-Memory Capacity at a Fraction of the Cost of DRAM: AMD EPYCTM and Ultrastar Massive Memory for AMD EPYC-based Servers at a Fraction of the Cost of DRAM The ever-expanding
White Paper March, 2019 Expand In-Memory Capacity at a Fraction of the Cost of DRAM: AMD EPYCTM and Ultrastar Massive Memory for AMD EPYC-based Servers at a Fraction of the Cost of DRAM The ever-expanding
High Capacity and High Performance 20nm FPGAs. Steve Young, Dinesh Gaitonde August Copyright 2014 Xilinx
 High Capacity and High Performance 20nm FPGAs Steve Young, Dinesh Gaitonde August 2014 Not a Complete Product Overview Page 2 Outline Page 3 Petabytes per month Increasing Bandwidth Global IP Traffic Growth
High Capacity and High Performance 20nm FPGAs Steve Young, Dinesh Gaitonde August 2014 Not a Complete Product Overview Page 2 Outline Page 3 Petabytes per month Increasing Bandwidth Global IP Traffic Growth
Adrian Proctor Vice President, Marketing Viking Technology
 Storage PRESENTATION in the TITLE DIMM GOES HERE Socket Adrian Proctor Vice President, Marketing Viking Technology SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless
Storage PRESENTATION in the TITLE DIMM GOES HERE Socket Adrian Proctor Vice President, Marketing Viking Technology SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless
Deep Learning mit PowerAI - Ein Überblick
 Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
SUPERCHARGE DEEP LEARNING WITH DGX-1. Markus Weber SC16 - November 2016
 SUPERCHARGE DEEP LEARNING WITH DGX-1 Markus Weber SC16 - November 2016 NVIDIA Pioneered GPU Computing Founded 1993 $7B 9,500 Employees 100M NVIDIA GeForce Gamers The world s largest gaming platform Pioneering
SUPERCHARGE DEEP LEARNING WITH DGX-1 Markus Weber SC16 - November 2016 NVIDIA Pioneered GPU Computing Founded 1993 $7B 9,500 Employees 100M NVIDIA GeForce Gamers The world s largest gaming platform Pioneering
Arm Processor Technology Update and Roadmap
 Arm Processor Technology Update and Roadmap ARM Processor Technology Update and Roadmap Cavium: Giri Chukkapalli is a Distinguished Engineer in the Data Center Group (DCG) Introduction to ARM Architecture
Arm Processor Technology Update and Roadmap ARM Processor Technology Update and Roadmap Cavium: Giri Chukkapalli is a Distinguished Engineer in the Data Center Group (DCG) Introduction to ARM Architecture
Machine Learning on FPGAs
 Machine Learning on FPGAs Jason Cong Chancellor s Professor, UCLA Director, Center for Domain-Specific Computing cong@cs.ucla.edu http://cadlab.cs.ucla.edu/~cong 1 Impacts of deep learning for many applications
Machine Learning on FPGAs Jason Cong Chancellor s Professor, UCLA Director, Center for Domain-Specific Computing cong@cs.ucla.edu http://cadlab.cs.ucla.edu/~cong 1 Impacts of deep learning for many applications
Unified Deep Learning with CPU, GPU, and FPGA Technologies
 Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Data-Centric Innovation Summit DAN MCNAMARA SENIOR VICE PRESIDENT GENERAL MANAGER, PROGRAMMABLE SOLUTIONS GROUP
 Data-Centric Innovation Summit DAN MCNAMARA SENIOR VICE PRESIDENT GENERAL MANAGER, PROGRAMMABLE SOLUTIONS GROUP Devices / edge network Cloud/data center Removing data Bottlenecks with Fpga acceleration
Data-Centric Innovation Summit DAN MCNAMARA SENIOR VICE PRESIDENT GENERAL MANAGER, PROGRAMMABLE SOLUTIONS GROUP Devices / edge network Cloud/data center Removing data Bottlenecks with Fpga acceleration
Revolutionizing the Datacenter
 Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA
 Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School
7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT
 7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT Draft Printed for SECO Murex S.A.S 2012 all rights reserved Murex Analytics Only global vendor of trading, risk management and processing systems focusing also
7 DAYS AND 8 NIGHTS WITH THE CARMA DEV KIT Draft Printed for SECO Murex S.A.S 2012 all rights reserved Murex Analytics Only global vendor of trading, risk management and processing systems focusing also
Implementation of Deep Convolutional Neural Net on a Digital Signal Processor
 Implementation of Deep Convolutional Neural Net on a Digital Signal Processor Elaina Chai December 12, 2014 1. Abstract In this paper I will discuss the feasibility of an implementation of an algorithm
Implementation of Deep Convolutional Neural Net on a Digital Signal Processor Elaina Chai December 12, 2014 1. Abstract In this paper I will discuss the feasibility of an implementation of an algorithm
Agenda. Sun s x Sun s x86 Strategy. 2. Sun s x86 Product Portfolio. 3. Virtualization < 1 >
 Agenda Sun s x86 1. Sun s x86 Strategy 2. Sun s x86 Product Portfolio 3. Virtualization < 1 > 1. SUN s x86 Strategy Customer Challenges Power and cooling constraints are very real issues Energy costs are
Agenda Sun s x86 1. Sun s x86 Strategy 2. Sun s x86 Product Portfolio 3. Virtualization < 1 > 1. SUN s x86 Strategy Customer Challenges Power and cooling constraints are very real issues Energy costs are
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Predicting Service Outage Using Machine Learning Techniques. HPE Innovation Center
 Predicting Service Outage Using Machine Learning Techniques HPE Innovation Center HPE Innovation Center - Our AI Expertise Sense Learn Comprehend Act Computer Vision Machine Learning Natural Language Processing
Predicting Service Outage Using Machine Learning Techniques HPE Innovation Center HPE Innovation Center - Our AI Expertise Sense Learn Comprehend Act Computer Vision Machine Learning Natural Language Processing
SoftFlash: Programmable Storage in Future Data Centers Jae Do Researcher, Microsoft Research
 SoftFlash: Programmable Storage in Future Data Centers Jae Do Researcher, Microsoft Research 1 The world s most valuable resource Data is everywhere! May. 2017 Values from Data! Need infrastructures for
SoftFlash: Programmable Storage in Future Data Centers Jae Do Researcher, Microsoft Research 1 The world s most valuable resource Data is everywhere! May. 2017 Values from Data! Need infrastructures for
What s P. Thierry
 What s new@intel P. Thierry Principal Engineer, Intel Corp philippe.thierry@intel.com CPU trend Memory update Software Characterization in 30 mn 10 000 feet view CPU : Range of few TF/s and
What s new@intel P. Thierry Principal Engineer, Intel Corp philippe.thierry@intel.com CPU trend Memory update Software Characterization in 30 mn 10 000 feet view CPU : Range of few TF/s and