High Quality Real Time Image Processing Framework on Mobile Platforms using Tegra K1. Eyal Hirsch
|
|
|
- Adela Douglas
- 6 years ago
- Views:
Transcription
1 High Quality Real Time Image Processing Framework on Mobile Platforms using Tegra K1 Eyal Hirsch
2 Established in 2009 and headquartered in Israel SagivTech Snapshot Core domain expertise: GPU Computing and Computer Vision What we do: - Technology - Solutions - Projects - EU Research - Training GPU expertise: - Hard core optimizations - Efficient streaming for single or multiple GPU systems - Mobile GPUs


3 The new era of mobile Mobile is everywhere
4 As mobile devices get smarter In the beginning: I can talk from anywhere! A bit later: My phone can take pictures! Now: Advanced camera More compute power Fast device cloud communication What can be done with those advancements?

5 Project Tango Mission: Running a depth sensing technology on a mobile platform Challenge: First time on NVIDIA s Tegra K1 Extreme optimizations on a CPU-GPU platform to allow the device to handle other tasks in parallel Expertise: Mantis Vision the algorithms NVIDIA the Tegra K1 platform SagivTech the GPU computing expertise Bottom line: Depth sensing running in real time in parallel to other compute intensive applications!

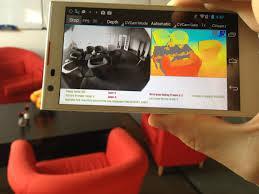
6 Project Tango Credits:

7 Mobile Crowdsourcing Video Scene Reconstruction If you ve been to a concert recently, you ve probably seen how many people take videos of the event with mobile phone cameras Each user has only one video taken from one angle and location and of only moderate quality
8 The Idea behind SceneNet Leverage the power of multiple mobile phone cameras Create a high-quality 3D video experience that is sharable via social networks



9 Creation of the 3D Video Sequence TIME The scene is photographed by several people using their cell phone camera The video data is transmitted via the cellular network to a High Performance Computing server. Following time synchronization, resolution normalization and spatial registration, the several videos are merged into a 3-D video cube.
10 Algorithms implemented on the TK1 Enabling the 3D reconstruction for SceneNet required various algorithms to run on the TK1 GPU FREAK: Fast Retina Key point BRISK: Binary Robust Invariant Scalable Key points DoG: Difference of Gaussians Algorithms had to run in real-time Algorithms are image processing building blocks for various image processing tasks
11 DoG: Input: 480 x 640 RGB Image Output: ~32K key points Freak: Freak &DoG performance on the TK1 Input: ~32K key points, Image Output: Descriptor per key point Majority of the code on the GPU Off loading to the GPU allows for real time processing, not possible on the CPU
12 DoG performance on the TK1 DoG flow: Gaussian DiffImage Find Key points Total: ms Kernel Misc Gaussian: Conv2D Gaussian: DownSampleBilinear DiffImage FindKeyPoints Total DoG Avg. time (ms)
13 FREAK performance on the TK1 FREAK flow: IntegralImage Extract descriptors Total: 2.4 ms Kernel IntegralImage GetDescriptors Total FREAK Avg. time (ms) Total DoG + FREAK: ms
14 Freak &DoG performance on the TK1 13 ms means real time processing on Ardbeg development board!!! Room for more tasks to run in the background Opens up possibilities for many mobile applications Having real time performance is not enough Need to evaluate power consumption as well

15 Performance is also GFlops/WATT
16 CUDA NVIDIA Programming the TK1 GPU OpenCL Khronos RenderScript Developed by Google
17 Programming the TK1 - CUDA Most rules and methods that apply to discrete cards, apply to the TK1 GPU Code and libraries (such as cufft, cublas, cusparse, CUB, Thrust, etc) should work out of the box for the TK1 Develop on Windows/Linux with discrete card and then migrate to the TK1 Use the profiler
18 Programming the TK1 - OpenCL Most of the tips for CUDA applies to OpenCL Runs nicely and shows nice performance Migrated the in-house Bilateral filter from CUDA to OpenCL in less than a day 2D separable convolution yield nice performance gains (compared to an optimized Neon implementation)
19 2D separable convolution on the TK1 Used 4 tests configuration to evaluate performance Highly optimized reference library utilizing the NEON (CPU) SagivTech s in-house Neon implementation (CPU) SagivTech s in-house OpenCL implementation (GPU) Test configuration Reference library ST single core NEON ST 4 cores NEON ST OpenCL 1K x 1K K x 2K
20 Programming the TK1 RenderScript - 1 Google s way of doing Compute on a mobile platform Quick CUDA to RenderScript acronym translation: User manages allocations (a.k.a buffers) User manages data transfer/copies to/from allocations User sets runtime parameters (a.k.a kernel params) User launches kernels much like OpenCL/CUDA Code ran on the GPU and yielded impressive performance boost (still lags behind CUDA) CUDA to RS migration fairly easy
21 Programming the TK1 RenderScript - 2 Google does NOT mandate which SoC component will run the RS code Developer has no control where RS code will run Depends on specific hardware, vendors, code, etc To test RS on TK1, locked GPU clocks in different configurations and run RS sparse matrix vector multiplication benchmark Performance of the RS code under different clocks, would reveal which component ran RS code
22 Programming the TK1 RenderScript - 3 Sparse matrix vector multiplication using Render script Used 3 test configurations Naive C++ CPU code SagivTech RS NVIDIA s cusparse RS running on GPU RS shows nice performance GPU: Full clocks Chart Title GPU: Half clocks GPU: Quarter clocks Naive C++ SagivTech RS NVIDIA cusparse
23 Programming the TK1 Optimization tips Only one SMX We ve seen cases where different optimizations behave differently on the TK1 than on equivalent discrete card (such as ldg etc) Try various optimizations, in some cases we got better performance when using atomics rather than shared memory Always optimize on the TK1 and not on discrete used for the development phase
24 The future Real time image processing of even complex algorithms is achievable on the TK1 Easy migration from mature discrete GPU code to new and exiting field of mobile compute Maxwell is already planed for next mobile generation, bringing more power efficiency and performance It works!!

25 T h a n k Yo u F o r m o r e i n f o r m a t i o n p l e a s e c o n t a c t E y a l H i r s c h e y a s a g i v t e c h. c o m
26 Programming the TK1 General tips TK1 hardware CC is 3.2 Tools and compilation chain is quite different. Need some time to get started Strive to do the CUDA and managing app/code in Windows/Linux using a discrete card and then migrate to Android Always have a reference code in naive, single thread C++ to compare the results of the parallel algorithm
27 Computational Photography: examples Background subtitution


28 FREAK Fast Retina Keypoint Binary feature descriptor Hamming distance matcher Sampling pattern Overlapping receptive fields Exponential change in size Rotation invariant

29 BRISK Binary Robust Invariant Scalable Key points Binary feature descriptor Hamming distance matcher Sampling pattern Equally spaced in circles Gaussian kernel size relative to distance from feature
30 DoG Difference of Gaussians Feature detector Local minima/maxima of the image convolved with difference of gaussians Acts as a 2D band-pass filter over the image Enhances corners
Computer Vision on Tegra K1. Chen Sagiv SagivTech Ltd.
 Computer Vision on Tegra K1 Chen Sagiv SagivTech Ltd. Established in 2009 and headquartered in Israel Core domain expertise: GPU Computing and Computer Vision What we do: - Technology - Solutions - Projects
Computer Vision on Tegra K1 Chen Sagiv SagivTech Ltd. Established in 2009 and headquartered in Israel Core domain expertise: GPU Computing and Computer Vision What we do: - Technology - Solutions - Projects
Maximizing GPU Power for Vision and Depth Sensor Processing. From NVIDIA's Tegra K1 to GPUs on the Cloud. Chen Sagiv Eri Rubin SagivTech Ltd.
 Maximizing GPU Power for Vision and Depth Sensor Processing From NVIDIA's Tegra K1 to GPUs on the Cloud Chen Sagiv Eri Rubin SagivTech Ltd. Today s Talk Mobile Revolution Mobile Cloud Concept 3D Imaging
Maximizing GPU Power for Vision and Depth Sensor Processing From NVIDIA's Tegra K1 to GPUs on the Cloud Chen Sagiv Eri Rubin SagivTech Ltd. Today s Talk Mobile Revolution Mobile Cloud Concept 3D Imaging
SceneNet: 3D Reconstruction of Videos Taken by the Crowd on GPU. Chen Sagiv SagivTech Ltd. GTC 2015 San Jose
 SceneNet: 3D Reconstruction of Videos Taken by the Crowd on GPU Chen Sagiv SagivTech Ltd. GTC 2015 San Jose Established in 2009 and headquartered in Israel Core domain expertise: GPU Computing and Computer
SceneNet: 3D Reconstruction of Videos Taken by the Crowd on GPU Chen Sagiv SagivTech Ltd. GTC 2015 San Jose Established in 2009 and headquartered in Israel Core domain expertise: GPU Computing and Computer
Renderscript Accelerated Advanced Image and Video Processing on ARM Mali T-600 GPUs. Lihua Zhang, Ph.D. MulticoreWare Inc.
 Renderscript Accelerated Advanced Image and Video Processing on ARM Mali T-600 GPUs Lihua Zhang, Ph.D. MulticoreWare Inc. lihua@multicorewareinc.com Overview More & more mobile apps are beginning to require
Renderscript Accelerated Advanced Image and Video Processing on ARM Mali T-600 GPUs Lihua Zhang, Ph.D. MulticoreWare Inc. lihua@multicorewareinc.com Overview More & more mobile apps are beginning to require
Lecture 4.1 Feature descriptors. Trym Vegard Haavardsholm
 Lecture 4.1 Feature descriptors Trym Vegard Haavardsholm Feature descriptors Histogram of Gradients (HoG) descriptors Binary descriptors 2 Histogram of Gradients (HOG) descriptors Scale Invariant Feature
Lecture 4.1 Feature descriptors Trym Vegard Haavardsholm Feature descriptors Histogram of Gradients (HoG) descriptors Binary descriptors 2 Histogram of Gradients (HOG) descriptors Scale Invariant Feature
Hardware Acceleration of Feature Detection and Description Algorithms on Low Power Embedded Platforms
 Hardware Acceleration of Feature Detection and Description Algorithms on LowPower Embedded Platforms Onur Ulusel, Christopher Picardo, Christopher Harris, Sherief Reda, R. Iris Bahar, School of Engineering,
Hardware Acceleration of Feature Detection and Description Algorithms on LowPower Embedded Platforms Onur Ulusel, Christopher Picardo, Christopher Harris, Sherief Reda, R. Iris Bahar, School of Engineering,
A System of Image Matching and 3D Reconstruction
 A System of Image Matching and 3D Reconstruction CS231A Project Report 1. Introduction Xianfeng Rui Given thousands of unordered images of photos with a variety of scenes in your gallery, you will find
A System of Image Matching and 3D Reconstruction CS231A Project Report 1. Introduction Xianfeng Rui Given thousands of unordered images of photos with a variety of scenes in your gallery, you will find
Image Features: Detection, Description, and Matching and their Applications
 Image Features: Detection, Description, and Matching and their Applications Image Representation: Global Versus Local Features Features/ keypoints/ interset points are interesting locations in the image.
Image Features: Detection, Description, and Matching and their Applications Image Representation: Global Versus Local Features Features/ keypoints/ interset points are interesting locations in the image.
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
A Systems View of Large- Scale 3D Reconstruction
 Lecture 23: A Systems View of Large- Scale 3D Reconstruction Visual Computing Systems Goals and motivation Construct a detailed 3D model of the world from unstructured photographs (e.g., Flickr, Facebook)
Lecture 23: A Systems View of Large- Scale 3D Reconstruction Visual Computing Systems Goals and motivation Construct a detailed 3D model of the world from unstructured photographs (e.g., Flickr, Facebook)
A Keypoint Descriptor Inspired by Retinal Computation
 A Keypoint Descriptor Inspired by Retinal Computation Bongsoo Suh, Sungjoon Choi, Han Lee Stanford University {bssuh,sungjoonchoi,hanlee}@stanford.edu Abstract. The main goal of our project is to implement
A Keypoint Descriptor Inspired by Retinal Computation Bongsoo Suh, Sungjoon Choi, Han Lee Stanford University {bssuh,sungjoonchoi,hanlee}@stanford.edu Abstract. The main goal of our project is to implement
To 3D or not to 3D? Why GPUs Are Critical for 3D Mass Spectrometry Imaging Eri Rubin SagivTech Ltd.
 To 3D or not to 3D? Why GPUs Are Critical for 3D Mass Spectrometry Imaging Eri Rubin SagivTech Ltd. Established in 2009 and headquartered in Israel Core domain expertise: GPU Computing and Computer Vision
To 3D or not to 3D? Why GPUs Are Critical for 3D Mass Spectrometry Imaging Eri Rubin SagivTech Ltd. Established in 2009 and headquartered in Israel Core domain expertise: GPU Computing and Computer Vision
Exploiting Depth Camera for 3D Spatial Relationship Interpretation
 Exploiting Depth Camera for 3D Spatial Relationship Interpretation Jun Ye Kien A. Hua Data Systems Group, University of Central Florida Mar 1, 2013 Jun Ye and Kien A. Hua (UCF) 3D directional spatial relationships
Exploiting Depth Camera for 3D Spatial Relationship Interpretation Jun Ye Kien A. Hua Data Systems Group, University of Central Florida Mar 1, 2013 Jun Ye and Kien A. Hua (UCF) 3D directional spatial relationships
EECS150 - Digital Design Lecture 14 FIFO 2 and SIFT. Recap and Outline
 EECS150 - Digital Design Lecture 14 FIFO 2 and SIFT Oct. 15, 2013 Prof. Ronald Fearing Electrical Engineering and Computer Sciences University of California, Berkeley (slides courtesy of Prof. John Wawrzynek)
EECS150 - Digital Design Lecture 14 FIFO 2 and SIFT Oct. 15, 2013 Prof. Ronald Fearing Electrical Engineering and Computer Sciences University of California, Berkeley (slides courtesy of Prof. John Wawrzynek)
The OpenVX Computer Vision and Neural Network Inference
 The OpenVX Computer and Neural Network Inference Standard for Portable, Efficient Code Radhakrishna Giduthuri Editor, OpenVX Khronos Group radha.giduthuri@amd.com @RadhaGiduthuri Copyright 2018 Khronos
The OpenVX Computer and Neural Network Inference Standard for Portable, Efficient Code Radhakrishna Giduthuri Editor, OpenVX Khronos Group radha.giduthuri@amd.com @RadhaGiduthuri Copyright 2018 Khronos
Next Generation Visual Computing
 Next Generation Visual Computing (Making GPU Computing a Reality with Mali ) Taipei, 18 June 2013 Roberto Mijat ARM Addressing Computational Challenges Trends Growing display sizes and resolutions Increasing
Next Generation Visual Computing (Making GPU Computing a Reality with Mali ) Taipei, 18 June 2013 Roberto Mijat ARM Addressing Computational Challenges Trends Growing display sizes and resolutions Increasing
John W. Romein. Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands
 Dwingeloo, the Netherlands") Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
Signal Processing on GPUs for Radio Telescopes John W. Romein Netherlands Institute for Radio Astronomy (ASTRON) Dwingeloo, the Netherlands 1 Overview radio telescopes six radio telescope algorithms on
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
Panoramic Image Stitching
 Mcgill University Panoramic Image Stitching by Kai Wang Pengbo Li A report submitted in fulfillment for the COMP 558 Final project in the Faculty of Computer Science April 2013 Mcgill University Abstract
Mcgill University Panoramic Image Stitching by Kai Wang Pengbo Li A report submitted in fulfillment for the COMP 558 Final project in the Faculty of Computer Science April 2013 Mcgill University Abstract
TR An Overview of NVIDIA Tegra K1 Architecture. Ang Li, Radu Serban, Dan Negrut
 TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
TR-2014-17 An Overview of NVIDIA Tegra K1 Architecture Ang Li, Radu Serban, Dan Negrut November 20, 2014 Abstract This paperwork gives an overview of NVIDIA s Jetson TK1 Development Kit and its Tegra K1
From Structure-from-Motion Point Clouds to Fast Location Recognition
 From Structure-from-Motion Point Clouds to Fast Location Recognition Arnold Irschara1;2, Christopher Zach2, Jan-Michael Frahm2, Horst Bischof1 1Graz University of Technology firschara, bischofg@icg.tugraz.at
From Structure-from-Motion Point Clouds to Fast Location Recognition Arnold Irschara1;2, Christopher Zach2, Jan-Michael Frahm2, Horst Bischof1 1Graz University of Technology firschara, bischofg@icg.tugraz.at
Cluster-based 3D Reconstruction of Aerial Video
 Cluster-based 3D Reconstruction of Aerial Video Scott Sawyer (scott.sawyer@ll.mit.edu) MIT Lincoln Laboratory HPEC 12 12 September 2012 This work is sponsored by the Assistant Secretary of Defense for
Cluster-based 3D Reconstruction of Aerial Video Scott Sawyer (scott.sawyer@ll.mit.edu) MIT Lincoln Laboratory HPEC 12 12 September 2012 This work is sponsored by the Assistant Secretary of Defense for
Advanced CUDA Optimization 1. Introduction
 Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Advanced CUDA Optimization 1. Introduction Thomas Bradley Agenda CUDA Review Review of CUDA Architecture Programming & Memory Models Programming Environment Execution Performance Optimization Guidelines
Midterm Examination CS 534: Computational Photography
 Midterm Examination CS 534: Computational Photography November 3, 2016 NAME: Problem Score Max Score 1 6 2 8 3 9 4 12 5 4 6 13 7 7 8 6 9 9 10 6 11 14 12 6 Total 100 1 of 8 1. [6] (a) [3] What camera setting(s)
Midterm Examination CS 534: Computational Photography November 3, 2016 NAME: Problem Score Max Score 1 6 2 8 3 9 4 12 5 4 6 13 7 7 8 6 9 9 10 6 11 14 12 6 Total 100 1 of 8 1. [6] (a) [3] What camera setting(s)
High-Performance Data Loading and Augmentation for Deep Neural Network Training
 High-Performance Data Loading and Augmentation for Deep Neural Network Training Trevor Gale tgale@ece.neu.edu Steven Eliuk steven.eliuk@gmail.com Cameron Upright c.upright@samsung.com Roadmap 1. The General-Purpose
High-Performance Data Loading and Augmentation for Deep Neural Network Training Trevor Gale tgale@ece.neu.edu Steven Eliuk steven.eliuk@gmail.com Cameron Upright c.upright@samsung.com Roadmap 1. The General-Purpose
Yudistira Pictures; Universitas Brawijaya
 Evaluation of Feature Detector-Descriptor for Real Object Matching under Various Conditions of Ilumination and Affine Transformation Novanto Yudistira1, Achmad Ridok2, Moch Ali Fauzi3 1) Yudistira Pictures;
Evaluation of Feature Detector-Descriptor for Real Object Matching under Various Conditions of Ilumination and Affine Transformation Novanto Yudistira1, Achmad Ridok2, Moch Ali Fauzi3 1) Yudistira Pictures;
SIFT Descriptor Extraction on the GPU for Large-Scale Video Analysis. Hannes Fassold, Jakub Rosner
 SIFT Descriptor Extraction on the GPU for Large-Scale Video Analysis Hannes Fassold, Jakub Rosner 2014-03-26 2 Overview GPU-activities @ AVM research group SIFT descriptor extraction Algorithm GPU implementation
SIFT Descriptor Extraction on the GPU for Large-Scale Video Analysis Hannes Fassold, Jakub Rosner 2014-03-26 2 Overview GPU-activities @ AVM research group SIFT descriptor extraction Algorithm GPU implementation
Parallel SIFT-detector implementation for images matching
 Parallel SIFT-detector implementation for images matching Anton I. Vasilyev, Andrey A. Boguslavskiy, Sergey M. Sokolov Keldysh Institute of Applied Mathematics of Russian Academy of Sciences, Moscow, Russia
Parallel SIFT-detector implementation for images matching Anton I. Vasilyev, Andrey A. Boguslavskiy, Sergey M. Sokolov Keldysh Institute of Applied Mathematics of Russian Academy of Sciences, Moscow, Russia
Embedded real-time stereo estimation via Semi-Global Matching on the GPU
 Embedded real-time stereo estimation via Semi-Global Matching on the GPU Daniel Hernández Juárez, Alejandro Chacón, Antonio Espinosa, David Vázquez, Juan Carlos Moure and Antonio M. López Computer Architecture
Embedded real-time stereo estimation via Semi-Global Matching on the GPU Daniel Hernández Juárez, Alejandro Chacón, Antonio Espinosa, David Vázquez, Juan Carlos Moure and Antonio M. López Computer Architecture
Real-Time Scene Reconstruction. Remington Gong Benjamin Harris Iuri Prilepov
 Real-Time Scene Reconstruction Remington Gong Benjamin Harris Iuri Prilepov June 10, 2010 Abstract This report discusses the implementation of a real-time system for scene reconstruction. Algorithms for
Real-Time Scene Reconstruction Remington Gong Benjamin Harris Iuri Prilepov June 10, 2010 Abstract This report discusses the implementation of a real-time system for scene reconstruction. Algorithms for
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
NumbaPro CUDA Python. Square matrix multiplication
 NumbaPro Enables parallel programming in Python Support various entry points: Low-level (CUDA-C like) programming language High-level array oriented interface CUDA library bindings Also support multicore
NumbaPro Enables parallel programming in Python Support various entry points: Low-level (CUDA-C like) programming language High-level array oriented interface CUDA library bindings Also support multicore
GETTING STARTED WITH CUDA SDK SAMPLES
 GETTING STARTED WITH CUDA SDK SAMPLES DA-05723-001_v01 January 2012 Application Note TABLE OF CONTENTS Getting Started with CUDA SDK Samples... 1 Before You Begin... 2 Getting Started With SDK Samples...
GETTING STARTED WITH CUDA SDK SAMPLES DA-05723-001_v01 January 2012 Application Note TABLE OF CONTENTS Getting Started with CUDA SDK Samples... 1 Before You Begin... 2 Getting Started With SDK Samples...
A Hybrid Feature Extractor using Fast Hessian Detector and SIFT
 Technologies 2015, 3, 103-110; doi:10.3390/technologies3020103 OPEN ACCESS technologies ISSN 2227-7080 www.mdpi.com/journal/technologies Article A Hybrid Feature Extractor using Fast Hessian Detector and
Technologies 2015, 3, 103-110; doi:10.3390/technologies3020103 OPEN ACCESS technologies ISSN 2227-7080 www.mdpi.com/journal/technologies Article A Hybrid Feature Extractor using Fast Hessian Detector and
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
GPGPU on ARM. Tom Gall, Gil Pitney, 30 th Oct 2013
 GPGPU on ARM Tom Gall, Gil Pitney, 30 th Oct 2013 Session Description This session will discuss the current state of the art of GPGPU technologies on ARM SoC systems. What standards are there? Where are
GPGPU on ARM Tom Gall, Gil Pitney, 30 th Oct 2013 Session Description This session will discuss the current state of the art of GPGPU technologies on ARM SoC systems. What standards are there? Where are
A Code Merging Optimization Technique for GPU. Ryan Taylor Xiaoming Li University of Delaware
 A Code Merging Optimization Technique for GPU Ryan Taylor Xiaoming Li University of Delaware FREE RIDE MAIN FINDING A GPU program can use the spare resources of another GPU program without hurting its
A Code Merging Optimization Technique for GPU Ryan Taylor Xiaoming Li University of Delaware FREE RIDE MAIN FINDING A GPU program can use the spare resources of another GPU program without hurting its
Integrating CPU and GPU, The ARM Methodology. Edvard Sørgård, Senior Principal Graphics Architect, ARM Ian Rickards, Senior Product Manager, ARM
 Integrating CPU and GPU, The ARM Methodology Edvard Sørgård, Senior Principal Graphics Architect, ARM Ian Rickards, Senior Product Manager, ARM The ARM Business Model Global leader in the development of
Integrating CPU and GPU, The ARM Methodology Edvard Sørgård, Senior Principal Graphics Architect, ARM Ian Rickards, Senior Product Manager, ARM The ARM Business Model Global leader in the development of
Outline 7/2/201011/6/
 Outline Pattern recognition in computer vision Background on the development of SIFT SIFT algorithm and some of its variations Computational considerations (SURF) Potential improvement Summary 01 2 Pattern
Outline Pattern recognition in computer vision Background on the development of SIFT SIFT algorithm and some of its variations Computational considerations (SURF) Potential improvement Summary 01 2 Pattern
Navigating the Vision API Jungle: Which API Should You Use and Why? Embedded Vision Summit, May 2015
 Copyright Khronos Group 2015 - Page 1 Navigating the Vision API Jungle: Which API Should You Use and Why? Embedded Vision Summit, May 2015 Neil Trevett Khronos President NVIDIA Vice President Mobile Ecosystem
Copyright Khronos Group 2015 - Page 1 Navigating the Vision API Jungle: Which API Should You Use and Why? Embedded Vision Summit, May 2015 Neil Trevett Khronos President NVIDIA Vice President Mobile Ecosystem
School of Computing University of Utah
 School of Computing University of Utah Presentation Outline 1 2 3 4 Main paper to be discussed David G. Lowe, Distinctive Image Features from Scale-Invariant Keypoints, IJCV, 2004. How to find useful keypoints?
School of Computing University of Utah Presentation Outline 1 2 3 4 Main paper to be discussed David G. Lowe, Distinctive Image Features from Scale-Invariant Keypoints, IJCV, 2004. How to find useful keypoints?
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
FPGA-Based Feature Detection
 FPGA-Based Feature Detection Wennie Tabib School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 wtabib@andrew.cmu.edu Abstract Fast, accurate, autonomous robot navigation is essential
FPGA-Based Feature Detection Wennie Tabib School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 wtabib@andrew.cmu.edu Abstract Fast, accurate, autonomous robot navigation is essential
SIGGRAPH Briefing August 2014
 Copyright Khronos Group 2014 - Page 1 SIGGRAPH Briefing August 2014 Neil Trevett VP Mobile Ecosystem, NVIDIA President, Khronos Copyright Khronos Group 2014 - Page 2 Significant Khronos API Ecosystem Advances
Copyright Khronos Group 2014 - Page 1 SIGGRAPH Briefing August 2014 Neil Trevett VP Mobile Ecosystem, NVIDIA President, Khronos Copyright Khronos Group 2014 - Page 2 Significant Khronos API Ecosystem Advances
MultiAR Project Michael Pekel, Ofir Elmakias [GIP] [234329]
![MultiAR Project Michael Pekel, Ofir Elmakias [GIP] [234329]](/thumbs/80/81451525.jpg "MultiAR Project Michael Pekel, Ofir Elmakias [GIP] [234329]") MultiAR Project Michael Pekel, Ofir Elmakias [GIP] [234329] Supervisors Dr. Matan Sela Mr. Yaron Honen Assistants Alexander Porotskiy Summary MultiAR is a multiplayer quest (Outdoor Real Time Multiplayer
MultiAR Project Michael Pekel, Ofir Elmakias [GIP] [234329] Supervisors Dr. Matan Sela Mr. Yaron Honen Assistants Alexander Porotskiy Summary MultiAR is a multiplayer quest (Outdoor Real Time Multiplayer
Lecture 6: Input Compaction and Further Studies
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 6: Input Compaction and Further Studies 1 Objective To learn the key techniques for compacting input data for reduced consumption of
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 6: Input Compaction and Further Studies 1 Objective To learn the key techniques for compacting input data for reduced consumption of
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
The Benefits of GPU Compute on ARM Mali GPUs
 The Benefits of GPU Compute on ARM Mali GPUs Tim Hartley 1 SEMICON Europa 2014 ARM Introduction World leading semiconductor IP Founded in 1990 1060 processor licenses sold to more than 350 companies >
The Benefits of GPU Compute on ARM Mali GPUs Tim Hartley 1 SEMICON Europa 2014 ARM Introduction World leading semiconductor IP Founded in 1990 1060 processor licenses sold to more than 350 companies >
SIMD Exploitation in (JIT) Compilers
 Compilers") SIMD Exploitation in (JIT) Compilers Hiroshi Inoue, IBM Research - Tokyo 1 What s SIMD? Single Instruction Multiple Data Same operations applied for multiple elements in a vector register input 1 A0 input
SIMD Exploitation in (JIT) Compilers Hiroshi Inoue, IBM Research - Tokyo 1 What s SIMD? Single Instruction Multiple Data Same operations applied for multiple elements in a vector register input 1 A0 input
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
PROGRAMMING NVIDIA GPUS WITH CUDANATIVE.JL
 DEPARTMENT ELECTRONICS AND INFORMATION SYSTEMS COMPUTER SYSTEMS LAB PROGRAMMING NVIDIA GPUS WITH CUDANATIVE.JL Tim Besard 2017-06-21 TABLE OF CONTENTS 1. GPU programming: what, why, how 2. CUDAnative.jl
DEPARTMENT ELECTRONICS AND INFORMATION SYSTEMS COMPUTER SYSTEMS LAB PROGRAMMING NVIDIA GPUS WITH CUDANATIVE.JL Tim Besard 2017-06-21 TABLE OF CONTENTS 1. GPU programming: what, why, how 2. CUDAnative.jl
Thrust ++ : Portable, Abstract Library for Medical Imaging Applications
 Siemens Corporate Technology March, 2015 Thrust ++ : Portable, Abstract Library for Medical Imaging Applications Siemens AG 2015. All rights reserved Agenda Parallel Computing Challenges and Solutions
Siemens Corporate Technology March, 2015 Thrust ++ : Portable, Abstract Library for Medical Imaging Applications Siemens AG 2015. All rights reserved Agenda Parallel Computing Challenges and Solutions
Photo Tourism: Exploring Photo Collections in 3D
 Click! Click! Oooo!! Click! Zoom click! Click! Some other camera noise!! Photo Tourism: Exploring Photo Collections in 3D Click! Click! Ahhh! Click! Click! Overview of Research at Microsoft, 2007 Jeremy
Click! Click! Oooo!! Click! Zoom click! Click! Some other camera noise!! Photo Tourism: Exploring Photo Collections in 3D Click! Click! Ahhh! Click! Click! Overview of Research at Microsoft, 2007 Jeremy
BSB663 Image Processing Pinar Duygulu. Slides are adapted from Selim Aksoy
 BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
Profiling and Debugging OpenCL Applications with ARM Development Tools. October 2014
 Profiling and Debugging OpenCL Applications with ARM Development Tools October 2014 1 Agenda 1. Introduction to GPU Compute 2. ARM Development Solutions 3. Mali GPU Architecture 4. Using ARM DS-5 Streamline
Profiling and Debugging OpenCL Applications with ARM Development Tools October 2014 1 Agenda 1. Introduction to GPU Compute 2. ARM Development Solutions 3. Mali GPU Architecture 4. Using ARM DS-5 Streamline
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Advanced Imaging Applications on Smart-phones Convergence of General-purpose computing, Graphics acceleration, and Sensors
 Advanced Imaging Applications on Smart-phones Convergence of General-purpose computing, Graphics acceleration, and Sensors Sriram Sethuraman Technologist & DMTS, Ittiam 1 Overview Imaging on Smart-phones
Advanced Imaging Applications on Smart-phones Convergence of General-purpose computing, Graphics acceleration, and Sensors Sriram Sethuraman Technologist & DMTS, Ittiam 1 Overview Imaging on Smart-phones
CS 220: Introduction to Parallel Computing. Introduction to CUDA. Lecture 28
 CS 220: Introduction to Parallel Computing Introduction to CUDA Lecture 28 Today s Schedule Project 4 Read-Write Locks Introduction to CUDA 5/2/18 CS 220: Parallel Computing 2 Today s Schedule Project
CS 220: Introduction to Parallel Computing Introduction to CUDA Lecture 28 Today s Schedule Project 4 Read-Write Locks Introduction to CUDA 5/2/18 CS 220: Parallel Computing 2 Today s Schedule Project
Interactive Non-Linear Image Operations on Gigapixel Images
 Interactive Non-Linear Image Operations on Gigapixel Images Markus Hadwiger, Ronell Sicat, Johanna Beyer King Abdullah University of Science and Technology Display-Aware Image Operations goal: perform
Interactive Non-Linear Image Operations on Gigapixel Images Markus Hadwiger, Ronell Sicat, Johanna Beyer King Abdullah University of Science and Technology Display-Aware Image Operations goal: perform
and Parallel Algorithms Programming with CUDA, WS09 Waqar Saleem, Jens Müller
 Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Organization People Waqar Saleem, waqar.saleem@uni-jena.de Jens Mueller, jkm@informatik.uni-jena.de Room 3335, Ernst-Abbe-Platz 2
Programming with CUDA and Parallel Algorithms Waqar Saleem Jens Müller Organization People Waqar Saleem, waqar.saleem@uni-jena.de Jens Mueller, jkm@informatik.uni-jena.de Room 3335, Ernst-Abbe-Platz 2
Parallel Tracking. Henry Spang Ethan Peters
 Parallel Tracking Henry Spang Ethan Peters Contents Introduction HAAR Cascades Viola Jones Descriptors FREAK Descriptor Parallel Tracking GPU Detection Conclusions Questions Introduction Tracking is a
Parallel Tracking Henry Spang Ethan Peters Contents Introduction HAAR Cascades Viola Jones Descriptors FREAK Descriptor Parallel Tracking GPU Detection Conclusions Questions Introduction Tracking is a
Combining NVIDIA Docker and databases to enhance agile development and optimize resource allocation
 Combining NVIDIA Docker and databases to enhance agile development and optimize resource allocation Chris Davis, Sophie Voisin, Devin White, Andrew Hardin Scalable and High Performance Geocomputation Team
Combining NVIDIA Docker and databases to enhance agile development and optimize resource allocation Chris Davis, Sophie Voisin, Devin White, Andrew Hardin Scalable and High Performance Geocomputation Team
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
HISTOGRAMS OF ORIENTATIO N GRADIENTS
 HISTOGRAMS OF ORIENTATIO N GRADIENTS Histograms of Orientation Gradients Objective: object recognition Basic idea Local shape information often well described by the distribution of intensity gradients
HISTOGRAMS OF ORIENTATIO N GRADIENTS Histograms of Orientation Gradients Objective: object recognition Basic idea Local shape information often well described by the distribution of intensity gradients
Building a Panorama. Matching features. Matching with Features. How do we build a panorama? Computational Photography, 6.882
 Matching features Building a Panorama Computational Photography, 6.88 Prof. Bill Freeman April 11, 006 Image and shape descriptors: Harris corner detectors and SIFT features. Suggested readings: Mikolajczyk
Matching features Building a Panorama Computational Photography, 6.88 Prof. Bill Freeman April 11, 006 Image and shape descriptors: Harris corner detectors and SIFT features. Suggested readings: Mikolajczyk
Implementing a Speech Recognition System on a GPU using CUDA. Presented by Omid Talakoub Astrid Yi
 Implementing a Speech Recognition System on a GPU using CUDA Presented by Omid Talakoub Astrid Yi Outline Background Motivation Speech recognition algorithm Implementation steps GPU implementation strategies
Implementing a Speech Recognition System on a GPU using CUDA Presented by Omid Talakoub Astrid Yi Outline Background Motivation Speech recognition algorithm Implementation steps GPU implementation strategies
OpenCV on Zynq: Accelerating 4k60 Dense Optical Flow and Stereo Vision. Kamran Khan, Product Manager, Software Acceleration and Libraries July 2017
 OpenCV on Zynq: Accelerating 4k60 Dense Optical Flow and Stereo Vision Kamran Khan, Product Manager, Software Acceleration and Libraries July 2017 Agenda Why Zynq SoCs for Traditional Computer Vision Automated
OpenCV on Zynq: Accelerating 4k60 Dense Optical Flow and Stereo Vision Kamran Khan, Product Manager, Software Acceleration and Libraries July 2017 Agenda Why Zynq SoCs for Traditional Computer Vision Automated
3D Reconstruction From Multiple Views Based on Scale-Invariant Feature Transform. Wenqi Zhu
 3D Reconstruction From Multiple Views Based on Scale-Invariant Feature Transform Wenqi Zhu wenqizhu@buffalo.edu Problem Statement! 3D reconstruction 3D reconstruction is a problem of recovering depth information
3D Reconstruction From Multiple Views Based on Scale-Invariant Feature Transform Wenqi Zhu wenqizhu@buffalo.edu Problem Statement! 3D reconstruction 3D reconstruction is a problem of recovering depth information
An Evaluation of Unified Memory Technology on NVIDIA GPUs
 An Evaluation of Unified Memory Technology on NVIDIA GPUs Wenqiang Li 1, Guanghao Jin 2, Xuewen Cui 1, Simon See 1,3 Center for High Performance Computing, Shanghai Jiao Tong University, China 1 Tokyo
An Evaluation of Unified Memory Technology on NVIDIA GPUs Wenqiang Li 1, Guanghao Jin 2, Xuewen Cui 1, Simon See 1,3 Center for High Performance Computing, Shanghai Jiao Tong University, China 1 Tokyo
MAPPING VIDEO CODECS TO HETEROGENEOUS ARCHITECTURES. Mauricio Alvarez-Mesa Techische Universität Berlin - Spin Digital MULTIPROG 2015
 MAPPING VIDEO CODECS TO HETEROGENEOUS ARCHITECTURES Mauricio Alvarez-Mesa Techische Universität Berlin - Spin Digital MULTIPROG 2015 Video Codecs 70% of internet traffic will be video in 2018 [CISCO] Video
MAPPING VIDEO CODECS TO HETEROGENEOUS ARCHITECTURES Mauricio Alvarez-Mesa Techische Universität Berlin - Spin Digital MULTIPROG 2015 Video Codecs 70% of internet traffic will be video in 2018 [CISCO] Video
rcuda: an approach to provide remote access to GPU computational power
 rcuda: an approach to provide remote access to computational power Rafael Mayo Gual Universitat Jaume I Spain (1 of 60) HPC Advisory Council Workshop Outline computing Cost of a node rcuda goals rcuda
rcuda: an approach to provide remote access to computational power Rafael Mayo Gual Universitat Jaume I Spain (1 of 60) HPC Advisory Council Workshop Outline computing Cost of a node rcuda goals rcuda
A Method to Eliminate Wrongly Matched Points for Image Matching
 2017 2nd International Seminar on Applied Physics, Optoelectronics and Photonics (APOP 2017) ISBN: 978-1-60595-522-3 A Method to Eliminate Wrongly Matched Points for Image Matching Xiao-fei AI * ABSTRACT
2017 2nd International Seminar on Applied Physics, Optoelectronics and Photonics (APOP 2017) ISBN: 978-1-60595-522-3 A Method to Eliminate Wrongly Matched Points for Image Matching Xiao-fei AI * ABSTRACT
Performance Analysis of Sobel Edge Detection Filter on GPU using CUDA & OpenGL
 Performance Analysis of Sobel Edge Detection Filter on GPU using CUDA & OpenGL Ms. Khyati Shah Assistant Professor, Computer Engineering Department VIER-kotambi, INDIA khyati30@gmail.com Abstract: CUDA(Compute
Performance Analysis of Sobel Edge Detection Filter on GPU using CUDA & OpenGL Ms. Khyati Shah Assistant Professor, Computer Engineering Department VIER-kotambi, INDIA khyati30@gmail.com Abstract: CUDA(Compute
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
Unified Memory. Notes on GPU Data Transfers. Andreas Herten, Forschungszentrum Jülich, 24 April Member of the Helmholtz Association
 Unified Memory Notes on GPU Data Transfers Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Overview, Outline Overview Unified Memory enables easy access to GPU development But some
Unified Memory Notes on GPU Data Transfers Andreas Herten, Forschungszentrum Jülich, 24 April 2017 Handout Version Overview, Outline Overview Unified Memory enables easy access to GPU development But some
Computer Vision Algorithm Acceleration Using GPGPU and the Tegra Processor's Unified Memory
 Engineering, Operations & Technology Boeing Research & Technology Computer Vision Algorithm Acceleration Using GPGPU and the Tegra Processor's Unified Memory Aaron Mosher Boeing Research & Technology Avionics
Engineering, Operations & Technology Boeing Research & Technology Computer Vision Algorithm Acceleration Using GPGPU and the Tegra Processor's Unified Memory Aaron Mosher Boeing Research & Technology Avionics
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
Computational Graphics: Lecture 15 SpMSpM and SpMV, or, who cares about complexity when we have a thousand processors?
 Computational Graphics: Lecture 15 SpMSpM and SpMV, or, who cares about complexity when we have a thousand processors? The CVDLab Team Francesco Furiani Tue, April 3, 2014 ROMA TRE UNIVERSITÀ DEGLI STUDI
Computational Graphics: Lecture 15 SpMSpM and SpMV, or, who cares about complexity when we have a thousand processors? The CVDLab Team Francesco Furiani Tue, April 3, 2014 ROMA TRE UNIVERSITÀ DEGLI STUDI
GpuWrapper: A Portable API for Heterogeneous Programming at CGG
 GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
GpuWrapper: A Portable API for Heterogeneous Programming at CGG Victor Arslan, Jean-Yves Blanc, Gina Sitaraman, Marc Tchiboukdjian, Guillaume Thomas-Collignon March 2 nd, 2016 GpuWrapper: Objectives &
Shadows for Many Lights sounds like it might mean something, but In fact it can mean very different things, that require very different solutions.
 1 2 Shadows for Many Lights sounds like it might mean something, but In fact it can mean very different things, that require very different solutions. 3 We aim for something like the numbers of lights
1 2 Shadows for Many Lights sounds like it might mean something, but In fact it can mean very different things, that require very different solutions. 3 We aim for something like the numbers of lights
Scale Invariant Feature Transform
 Scale Invariant Feature Transform Why do we care about matching features? Camera calibration Stereo Tracking/SFM Image moiaicing Object/activity Recognition Objection representation and recognition Image
Scale Invariant Feature Transform Why do we care about matching features? Camera calibration Stereo Tracking/SFM Image moiaicing Object/activity Recognition Objection representation and recognition Image
GTC Interaction Simplified. Gesture Recognition Everywhere: Gesture Solutions on Tegra
 GTC 2013 Interaction Simplified Gesture Recognition Everywhere: Gesture Solutions on Tegra eyesight at a Glance Touch-free technology providing an enhanced user experience. Easy and intuitive control
GTC 2013 Interaction Simplified Gesture Recognition Everywhere: Gesture Solutions on Tegra eyesight at a Glance Touch-free technology providing an enhanced user experience. Easy and intuitive control
Local features and image matching. Prof. Xin Yang HUST
 Local features and image matching Prof. Xin Yang HUST Last time RANSAC for robust geometric transformation estimation Translation, Affine, Homography Image warping Given a 2D transformation T and a source
Local features and image matching Prof. Xin Yang HUST Last time RANSAC for robust geometric transformation estimation Translation, Affine, Homography Image warping Given a 2D transformation T and a source
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CS 223B Computer Vision Problem Set 3
 CS 223B Computer Vision Problem Set 3 Due: Feb. 22 nd, 2011 1 Probabilistic Recursion for Tracking In this problem you will derive a method for tracking a point of interest through a sequence of images.
CS 223B Computer Vision Problem Set 3 Due: Feb. 22 nd, 2011 1 Probabilistic Recursion for Tracking In this problem you will derive a method for tracking a point of interest through a sequence of images.
CS 378: Autonomous Intelligent Robotics. Instructor: Jivko Sinapov
 CS 378: Autonomous Intelligent Robotics Instructor: Jivko Sinapov http://www.cs.utexas.edu/~jsinapov/teaching/cs378/ Visual Registration and Recognition Announcements Homework 6 is out, due 4/5 4/7 Installing
CS 378: Autonomous Intelligent Robotics Instructor: Jivko Sinapov http://www.cs.utexas.edu/~jsinapov/teaching/cs378/ Visual Registration and Recognition Announcements Homework 6 is out, due 4/5 4/7 Installing
Martin Dubois, ing. Contents
 Martin Dubois, ing Contents Without OpenNet vs With OpenNet Technical information Possible applications Artificial Intelligence Deep Packet Inspection Image and Video processing Network equipment development
Martin Dubois, ing Contents Without OpenNet vs With OpenNet Technical information Possible applications Artificial Intelligence Deep Packet Inspection Image and Video processing Network equipment development
CUDA on ARM Update. Developing Accelerated Applications on ARM. Bas Aarts and Donald Becker
 CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
CUDA on ARM Update Developing Accelerated Applications on ARM Bas Aarts and Donald Becker CUDA on ARM: a forward-looking development platform for high performance, energy efficient hybrid computing It
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Local invariant features
 Local invariant features Tuesday, Oct 28 Kristen Grauman UT-Austin Today Some more Pset 2 results Pset 2 returned, pick up solutions Pset 3 is posted, due 11/11 Local invariant features Detection of interest
Local invariant features Tuesday, Oct 28 Kristen Grauman UT-Austin Today Some more Pset 2 results Pset 2 returned, pick up solutions Pset 3 is posted, due 11/11 Local invariant features Detection of interest
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
April 4-7, 2016 Silicon Valley VISIONWORKS A CUDA ACCELERATED COMPUTER VISION LIBRARY S6783. Elif Albuz, April 4, 2016
 April 4-7, 2016 Silicon Valley VISIONWORKS A CUDA ACCELERATED COMPUTER VISION LIBRARY S6783 Elif Albuz, April 4, 2016 Motivation Introduction to VisionWorks AGENDA VisionWorks Software Stack VisionWorks
April 4-7, 2016 Silicon Valley VISIONWORKS A CUDA ACCELERATED COMPUTER VISION LIBRARY S6783 Elif Albuz, April 4, 2016 Motivation Introduction to VisionWorks AGENDA VisionWorks Software Stack VisionWorks
Anno accademico 2006/2007. Davide Migliore
 Robotica Anno accademico 6/7 Davide Migliore migliore@elet.polimi.it Today What is a feature? Some useful information The world of features: Detectors Edges detection Corners/Points detection Descriptors?!?!?
Robotica Anno accademico 6/7 Davide Migliore migliore@elet.polimi.it Today What is a feature? Some useful information The world of features: Detectors Edges detection Corners/Points detection Descriptors?!?!?
Pop Quiz 1 [10 mins]
![Pop Quiz 1 [10 mins]](/thumbs/77/76612064.jpg "Pop Quiz 1 [10 mins]") Pop Quiz 1 [10 mins] 1. An audio signal makes 250 cycles in its span (or has a frequency of 250Hz). How many samples do you need, at a minimum, to sample it correctly? [1] 2. If the number of bits is reduced,
Pop Quiz 1 [10 mins] 1. An audio signal makes 250 cycles in its span (or has a frequency of 250Hz). How many samples do you need, at a minimum, to sample it correctly? [1] 2. If the number of bits is reduced,
WHAT S NEW IN CUDA 8. Siddharth Sharma, Oct 2016
 WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
WHAT S NEW IN CUDA 8 Siddharth Sharma, Oct 2016 WHAT S NEW IN CUDA 8 Why Should You Care >2X Run Computations Faster* Solve Larger Problems** Critical Path Analysis * HOOMD Blue v1.3.3 Lennard-Jones liquid
Cuda Compilation Utilizing the NVIDIA GPU Oct 19, 2017
 Cuda Compilation Utilizing the NVIDIA GPU Oct 19, 2017 This document will essentially provide the reader with the understanding on how to use the CUDA 7.0 environment within the Electrical and Computer
Cuda Compilation Utilizing the NVIDIA GPU Oct 19, 2017 This document will essentially provide the reader with the understanding on how to use the CUDA 7.0 environment within the Electrical and Computer