CS420/520 Computer Architecture I
|
|
|
- Johnathan Hancock
- 6 years ago
- Views:
Transcription
1 CS420/520 Computer Architecture I Instruction-Level Parallelism Dr. Xiaobo Zhou Department of Computer Science CS420/520 pipeline.1 Re: Pipeline Data Hazard Detection (Delay Load) Comparing the destination and sources of adjacent instructions CS420/520 pipeline.2
2 What is Instruction-level Parallelism (ILP) ILP: the potential overlap among instruction executions due to pipelining The instructions can be executed and evaluated in parallel How to exploit ILP Hardware stall Software NOP Hardware forwarding/bypassing Two MORE largely separable approaches to exploiting ILP Static/compiler pipeline scheduling by the compiler tries to minimize stalls by separating dependent instructions so that they will not lead to hazards Dynamic hardware scheduling tries to avoid stalls when dependences, which could generate hazards, are present. CS420/520 pipeline.3 Software (compiler) Static Scheduling / ILP Software scheduling: the goal is to exploit ILP by preserving program order only where it affects the outcome of the program Try producing fast code for a = b + c; d = e f; assuming a, b, c, d, e, and f in memory. Slow code: LW LW ADD SW LW LW SUB SW Rb,b Rc,c Ra,Rb,Rc a,ra Re,e Rf,f Rd,Re,Rf d,rd Fast code: LW LW LW ADD LW SW SUB SW Rb,b Rc,c Re,e Ra,Rb,RcRb Rc Rf,f a,ra Rd,Re,Rf d,rd CS420/520 pipeline.4
3 Compiler Avoiding Load Stalls: scheduled unscheduled gcc spice tex 14% 25% 31% 42% 54% 65% 0% 20% 40% 60% 80% % loads stalling pipeline CS420/520 pipeline.5 Data Dependences Data dependence Instruction i produces a result that may be used by instruction j Instruction j is data dependent on instruction k, and instruction k is data dependent on instruction i ( a chain of dependences) loop: LD F0, 0(R1) DADD F4, F0, F2 SD F4, 0(R1) DAADI R1, R1, -8 BNE R1, R2, Loop CS420/520 pipeline.6
4 Name Dependences Name dependence (not-true-data-hazard) Occurs when two instructions use the same register or memory location, called a name, but there is no flow of data between the instructions associating with that name Remember: do not be restricted to the 5-stage pipeline! p Anti-dependence (WAR) j writes a register or memory location that i reads: ADD $1, $2, $4 SUB $4, $5, $6 What if SUB does earlier than ADD? Is there a data flow? Output dependence (WAW) i and j write the same register or memory location SUB $4, $2, $7 SUBI $4, $5, 100 What if SUBI does earlier than SUB? Is there a data flow? How many ways for data to flow between instructions? CS420/520 pipeline.7 Data Hazards - RAW Data hazards may be classified, depending on the order of read and write accesses in the instructions RAR (read after read) is not a hazard, nor a name dependence RAW (read after write): j tries to read a source before i writes it, so j incorrectly gets the old value; most common type true data hazards Example? CS420/520 pipeline.8
5 Data Hazards - WAW WAW (write after write): Output dependence of name hazards: j tries to write an operand before it is written by i. Can you nominate an example? Short/long pipelines MULTF F4, F5, F6 LD F4, 0(F1) Is WAW possible in the MIPS classic five-stage integer pipelining? Why? CS420/520 pipeline.9 Data Hazards - WAR WAR (write after read): Anti-dependence of name hazards: j tries to write a destination before it is read by i, so i incorrectly gets the new value Example? 1) Due to re-ordering DIV $0, $2, $4 ADD $6, $0, $8 SUB $8, $10, $14 (add is stalled waiting DIV, if SUB is done before ADD, anti-dependence violated). 2) One writes early in the pipeline and some others read a source late in the pipeline Is WAR possible in the MIPS classic five-stage integer pipelining? CS420/520 pipeline.10
6 ILP and Dynamic Scheduling Dynamic scheduling: the goal is to exploit ILP by preserving program order only where it affects the outcome of the program Out-of-order execution DDIV F0, F2, F4 DADD F10, F0, F8 DSUB F12, F8, F14 // DSUB not dependent on // anything in the pipeline // can its order be exchanged // with DADD? Out-of-order execution may introduce WAR and WAW hazards DDIV F0, F2,F4F4 DADD F6, F0, F8 // anti-dependence between DADD DSUB F8, F10, F14 // and DSUB; if out-of-order, WAR DMUL F6, F10, F8 // register renaming helps! CS420/520 pipeline.11 Dynamic Scheduling Tomasulo Register Renaming Before: DDIV F0, F2, F4 DADD F6, F0, F8 SD F6, 0(R1) DSUB F8, F10, F14 DMUL F6, F10, F8 //anti-dependence DSUB F8, WAR //output dependence DMUL-F6, WAW // How many true data dependences? After: DDIV F0, F2, F4 DADD S, F0, F8 SD S, 0(R1) DSUB T, F10, F14 DMUL F6, F10, T What are dependencies there? What dependencies disappear? And what are still there? What to do with the subsequence use of F8? Finding the subsequent use of F8 requires compiler analysis or hardware support CS420/520 pipeline.12
7 Concurrency and Parallelism Concurrency in software is a way to manage the sharing of resources efficiently at the same time When multiple software threads of execution are running concurrently, the execution of the threads is interleaved onto a single hardware resource - Why not schedule another thread while one thread is on a cache miss or even page fault? - Time-sliced multi-threading increases concurrency, overlapping CPU time with I/O time - Pseudo-parallelism True parallelism requires multiple hardware resources Multiple software threads are running simultaneously on different hardware resources/processing elements One approach to addressing thread-level true parallelism is to increase the number of physical processors / execution elements in the computer CS420/520 pipeline.13 ILP and Super-Scalar Processors ILP: the potential overlap among instruction executions due to pipelining To increase the number of instructions that are executed by the processor on a single clock cycle A processor that is capable of executing multiple instructions in a single clock cycle is known as a super-scalar processor (a) A three-stage path (b) A superscalar CPU CS420/520 pipeline.14

8 Multi-Threading Process: for resource grouping and execution Thread: a finer-granularity entity for execution and parallelism Lightweight processes, multithreading Multi-threading: Operating system supports multiple threads of execution within a single process At hardware level, a thread is an execution path that remains independent of other hardware thread execution paths User-level Threads Used by applications and handled by user-level runtime Kernel-level level Threads Used and handled by OS kernel Hardware Threads Used by each processor Operation nal flow CS420/520 pipeline.15 Simultaneous Multi-threading (Hyper-Threading) Simultaneous multi-threading (SMT) Create multiple logical processors with a physical processor One logical processor for a thread, which requires an architecture state consisting of the GPRs and Interrupt logic Duplicate multiple architecture states (CPU state), and, let other CPU resources, such as caches, buses, execution units, branch prediction logic shared among architecture states Multi-threading at hardware level, instead of OS switching Intel s SMT implementation is called Hyper-Threading Technology (HT Technology) What is next? CS420/520 pipeline.16

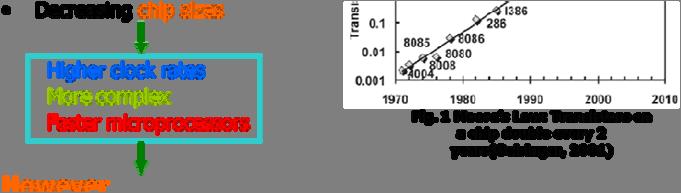









9 Multi-Core CS420/520 pipeline.17 Limitations of Sing-core Technology CS420/520 pipeline.18

10 Multi-Processor and Multi-Core multi-core processors use chip multi-processing (CMP) Cores are essentially two individual processors on a single die May or may not share on-chip cache True parallelism, instead of high concurrency CS420/520 pipeline.19 Stanford HYDRA Multi-core Structure CS420/520 pipeline.20
11 Multi-core Processors as a Solution a) Advantages and improvements Performance increase by means of parallel execution Power and Energy efficient cores (Dynamic power coordination) Minimized wire lengths and interconnect latencies Both ILP and thread level parallelism Reduced design time and complexity b) Task management and parceling Usually operating system distributes the application to the cores Can be done according to resource requirements c) Multicore examples AMD Opteron Enterprise, Athlon64 Intel Pentium Extreme edition, Pentium D IBM Power 4, Power 5 and Sun Niagara CS420/520 pipeline.21 Multi-core vs Superscalar vs SMT Multicore VS Superscalar VS SMT(Hammond, 1997) CS420/520 pipeline.22
12 Multi-core vs Superscalar Superscalar processors differ from multi-core processors in that the redundant functional units are not entire processors. A single superscalar processor is composed of finer-grained functional units such as the ALU, integer shifter, etc. There may be multiple versions of each functional unit to enable execution of many instructions in parallel. This differs from a multicore CPU that concurrently processes instructions from multiple threads, one thread per core. The various techniques are not mutually exclusive they can be (and frequently are) combined in a single processor. Thus a multicore CPU is possible where each core is an independent processor containing multiple parallel pipelines, each pipeline being superscalar. CS420/520 pipeline.23 Multi-Core and SMT multi-core processors can be combined with SMT technology CS420/520 pipeline.24
13 Pthreads Overview What are Pthreads? An IEEE standardized thread programming interface POSIX threads Defined as a set of C language g programming g types and procedure calls, implemented with a pthread.h header/include file and a thread library To software developer: a thread is a procedure that runs independently from its main program CS420/520 pipeline.25 The Pthreads API The API is defined in the ANSI/IEEE POSIX Naming conventions: all identifiers in the library begins with pthread_ Three major classes of subroutines - Thread management, mutexes, condition variables Routine Prefix pthread_ pthread_attr_ pthread_mutex_ pthread_mutexattr_ pthread_cond_ pthread_condattr_ pthread_key_ Functional Group Threads themselves and miscellaneous subroutines Thread attributes objects Mutexes Mutex attributes objects. Condition variables Condition attributes objects Thread-specific data keys CS420/520 pipeline.26
14 Multi-Thread Programming Reference Links Many examples and examples with bugs node/posix Threads.html GDB for debugging: DDD for debugging: CS420/520 pipeline.27 Where to get more information? CA4 2.1, 2.4 (pages 89 93) CA3: , 4.1 Multi-core programming, by Shameem Akhter and Jason Roberts, Intel Press (ISBN ) Internet Find out more about Multi-core technology, use your own words and write a summary report from both the hardware support and software programming viewpoints CS420/520 pipeline.28
15 Homework Pipeline homework; see course Web site. Reading assignment; see course Web site. CS420/520 pipeline.29 How to Improve Concurrency and Parallelism One approach to address the increasingly concurrent nature of modern software involves using a pre-emptive, or time-sliced, multitasking operating system Time-sliced multi-threading increases concurrency, overlapping CPU time with I/O time One approach to address thread-level true parallelism is to increase the number of physical processors / execution elements in the computer CS420/520 pipeline.30



16 Concurrency and Parallelism Concurrency in software is a way to manage the sharing of resources efficiently at the same time When multiple software threads of execution are running concurrently, the execution of the threads is interleaved onto a single hardware resource - Why not schedule another thread while one thread is on a cache miss or even page fault? - Pseudo-parallelism True parallelism requires multiple hardware resources Multiple software threads are running simultaneously on different hardware resources/processing elements CS420/520 pipeline.31 Superscalar and Superpipelining Superpipelining exploits the fact that many pipeline stages perform tasks that require less than half a clock cycle. Thus, a doubled internal clock speed allows the performance of two tasks in one external clock cycle [Stallings Com. O&A 7e] Superscalar [Shen & Lipasti, McGraw Hill] CS420/520 pipeline.32
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
Instruction Pipelining Review
 Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Lecture 4: Advanced Pipelines. Data hazards, control hazards, multi-cycle in-order pipelines (Appendix A.4-A.10)
") Lecture 4: Advanced Pipelines Data hazards, control hazards, multi-cycle in-order pipelines (Appendix A.4-A.10) 1 Hazards Structural hazards: different instructions in different stages (or the same stage)
Lecture 4: Advanced Pipelines Data hazards, control hazards, multi-cycle in-order pipelines (Appendix A.4-A.10) 1 Hazards Structural hazards: different instructions in different stages (or the same stage)
Instruction Level Parallelism. ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction
 Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Pipelining: Hazards Ver. Jan 14, 2014
 POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Overview. Appendix A. Pipelining: Its Natural! Sequential Laundry 6 PM Midnight. Pipelined Laundry: Start work ASAP
 Overview Appendix A Pipelining: Basic and Intermediate Concepts Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 1 2 Unpipelined
Overview Appendix A Pipelining: Basic and Intermediate Concepts Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 1 2 Unpipelined
Hyperthreading Technology
 Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
Hyperthreading Technology Aleksandar Milenkovic Electrical and Computer Engineering Department University of Alabama in Huntsville milenka@ece.uah.edu www.ece.uah.edu/~milenka/ Outline What is hyperthreading?
Instruction-Level Parallelism (ILP)
") Instruction Level Parallelism Instruction-Level Parallelism (ILP): overlap the execution of instructions to improve performance 2 approaches to exploit ILP: 1. Rely on hardware to help discover and exploit
Instruction Level Parallelism Instruction-Level Parallelism (ILP): overlap the execution of instructions to improve performance 2 approaches to exploit ILP: 1. Rely on hardware to help discover and exploit
Pipelining and Exploiting Instruction-Level Parallelism (ILP)
") Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Pipelining and Exploiting Instruction-Level Parallelism (ILP) Pipelining and Instruction-Level Parallelism (ILP). Definition of basic instruction block Increasing Instruction-Level Parallelism (ILP) &
Multi-core Programming Evolution
 Multi-core Programming Evolution Based on slides from Intel Software ollege and Multi-ore Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts, Evolution
Multi-core Programming Evolution Based on slides from Intel Software ollege and Multi-ore Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts, Evolution
ECE 571 Advanced Microprocessor-Based Design Lecture 4
 ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
ECE 571 Advanced Microprocessor-Based Design Lecture 4 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 January 2016 Homework #1 was due Announcements Homework #2 will be posted
TDT 4260 lecture 7 spring semester 2015
 1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
1 TDT 4260 lecture 7 spring semester 2015 Lasse Natvig, The CARD group Dept. of computer & information science NTNU 2 Lecture overview Repetition Superscalar processor (out-of-order) Dependencies/forwarding
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)
 Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)") Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
EECC551 - Shaaban. 1 GHz? to???? GHz CPI > (?)
") Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Exploiting ILP with SW Approaches. Aleksandar Milenković, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Lecture : Exploiting ILP with SW Approaches Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Basic Pipeline Scheduling and Loop
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Instruction Level Parallelism
 Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
In embedded systems there is a trade off between performance and power consumption. Using ILP saves power and leads to DECREASING clock frequency.
 Lesson 1 Course Notes Review of Computer Architecture Embedded Systems ideal: low power, low cost, high performance Overview of VLIW and ILP What is ILP? It can be seen in: Superscalar In Order Processors
Lesson 1 Course Notes Review of Computer Architecture Embedded Systems ideal: low power, low cost, high performance Overview of VLIW and ILP What is ILP? It can be seen in: Superscalar In Order Processors
Appendix A. Overview
 Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 1 Unpipelined
Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 1 Unpipelined
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism
 ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
ELEC 5200/6200 Computer Architecture and Design Fall 2016 Lecture 9: Instruction Level Parallelism Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University,
Computer Architecture
 Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Appendix C: Pipelining: Basic and Intermediate Concepts
 Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
EECC551 Review. Dynamic Hardware-Based Speculation
 EECC551 Review Recent Trends in Computer Design. Computer Performance Measures. Instruction Pipelining. Branch Prediction. Instruction-Level Parallelism (ILP). Loop-Level Parallelism (LLP). Dynamic Pipeline
EECC551 Review Recent Trends in Computer Design. Computer Performance Measures. Instruction Pipelining. Branch Prediction. Instruction-Level Parallelism (ILP). Loop-Level Parallelism (LLP). Dynamic Pipeline
Instruction Level Parallelism (ILP)
") 1 / 26 Instruction Level Parallelism (ILP) ILP: The simultaneous execution of multiple instructions from a program. While pipelining is a form of ILP, the general application of ILP goes much further into
1 / 26 Instruction Level Parallelism (ILP) ILP: The simultaneous execution of multiple instructions from a program. While pipelining is a form of ILP, the general application of ILP goes much further into
COSC4201 Pipelining. Prof. Mokhtar Aboelaze York University
 COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
EE 4683/5683: COMPUTER ARCHITECTURE
 EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
EE 4683/5683: COMPUTER ARCHITECTURE Lecture 4A: Instruction Level Parallelism - Static Scheduling Avinash Kodi, kodi@ohio.edu Agenda 2 Dependences RAW, WAR, WAW Static Scheduling Loop-carried Dependence
Pipeline Review. Review
 Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2018 Static Instruction Scheduling 1 Techniques to reduce stalls CPI = Ideal CPI + Structural stalls per instruction + RAW stalls per instruction + WAR stalls per
CS425 Computer Systems Architecture Fall 2018 Static Instruction Scheduling 1 Techniques to reduce stalls CPI = Ideal CPI + Structural stalls per instruction + RAW stalls per instruction + WAR stalls per
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Modern Computer Architecture
 Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
Chapter 06: Instruction Pipelining and Parallel Processing
 Chapter 06: Instruction Pipelining and Parallel Processing Lesson 09: Superscalar Processors and Parallel Computer Systems Objective To understand parallel pipelines and multiple execution units Instruction
Chapter 06: Instruction Pipelining and Parallel Processing Lesson 09: Superscalar Processors and Parallel Computer Systems Objective To understand parallel pipelines and multiple execution units Instruction
Processor: Superscalars Dynamic Scheduling
 Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
Processor: Superscalars Dynamic Scheduling Z. Jerry Shi Assistant Professor of Computer Science and Engineering University of Connecticut * Slides adapted from Blumrich&Gschwind/ELE475 03, Peh/ELE475 (Princeton),
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Advanced Processor Architecture. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Advanced Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Page # CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Michela Taufer
 Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Page 1. CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Pipeline CPI (II) Michela Taufer
 Pipeline CPI (II) Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards
 CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Advanced d Processor Architecture. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by:
 Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
Reduction of Data Hazards Stalls with Dynamic Scheduling So far we have dealt with data hazards in instruction pipelines by: Result forwarding (register bypassing) to reduce or eliminate stalls needed
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
CS425 Computer Systems Architecture Fall 2017 Multiple Issue: Superscalar and VLIW CS425 - Vassilis Papaefstathiou 1 Example: Dynamic Scheduling in PowerPC 604 and Pentium Pro In-order Issue, Out-of-order
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Chapter 3 & Appendix C Part B: ILP and Its Exploitation
 CS359: Computer Architecture Chapter 3 & Appendix C Part B: ILP and Its Exploitation Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 3.1 Concepts and
CS359: Computer Architecture Chapter 3 & Appendix C Part B: ILP and Its Exploitation Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 3.1 Concepts and
Pipeline Overview. Dr. Jiang Li. Adapted from the slides provided by the authors. Jiang Li, Ph.D. Department of Computer Science
 Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
What is ILP? Instruction Level Parallelism. Where do we find ILP? How do we expose ILP?
 What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
What is ILP? Instruction Level Parallelism or Declaration of Independence The characteristic of a program that certain instructions are, and can potentially be. Any mechanism that creates, identifies,
Lecture 3. Pipelining. Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1
 Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
Super Scalar. Kalyan Basu March 21,
 Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
Super Scalar Kalyan Basu basu@cse.uta.edu March 21, 2007 1 Super scalar Pipelines A pipeline that can complete more than 1 instruction per cycle is called a super scalar pipeline. We know how to build
Advanced Processor Architecture
 Advanced Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong
Advanced Processor Architecture Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE2030: Introduction to Computer Systems, Spring 2018, Jinkyu Jeong
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Computer Architecture Instruction Level Parallelism Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson /
CMSC 611: Advanced Computer Architecture Instruction Level Parallelism Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson /
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
Instruction-Level Parallelism. Instruction Level Parallelism (ILP)
") Instruction-Level Parallelism CS448 1 Pipelining Instruction Level Parallelism (ILP) Limited form of ILP Overlapping instructions, these instructions can be evaluated in parallel (to some degree) Pipeline
Instruction-Level Parallelism CS448 1 Pipelining Instruction Level Parallelism (ILP) Limited form of ILP Overlapping instructions, these instructions can be evaluated in parallel (to some degree) Pipeline
Metodologie di Progettazione Hardware-Software
 Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Metodologie di Progettazione Hardware-Software Advanced Pipelining and Instruction-Level Paralelism Metodologie di Progettazione Hardware/Software LS Ing. Informatica 1 ILP Instruction-level Parallelism
Chapter 7. Digital Design and Computer Architecture, 2 nd Edition. David Money Harris and Sarah L. Harris. Chapter 7 <1>
 Chapter 7 Digital Design and Computer Architecture, 2 nd Edition David Money Harris and Sarah L. Harris Chapter 7 Chapter 7 :: Topics Introduction (done) Performance Analysis (done) Single-Cycle Processor
Chapter 7 Digital Design and Computer Architecture, 2 nd Edition David Money Harris and Sarah L. Harris Chapter 7 Chapter 7 :: Topics Introduction (done) Performance Analysis (done) Single-Cycle Processor
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT-1
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS
 CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
CS6303 Computer Architecture Regulation 2013 BE-Computer Science and Engineering III semester 2 MARKS UNIT-I OVERVIEW & INSTRUCTIONS 1. What are the eight great ideas in computer architecture? The eight
Pipelining: Basic and Intermediate Concepts
 Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of fpipelining i Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 Unpipelined
Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of fpipelining i Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 Unpipelined
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Course on Advanced Computer Architectures
 Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
Surname (Cognome) Name (Nome) POLIMI ID Number Signature (Firma) SOLUTION Politecnico di Milano, July 9, 2018 Course on Advanced Computer Architectures Prof. D. Sciuto, Prof. C. Silvano EX1 EX2 EX3 Q1
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Multi-core Architectures Dr. Yingwu Zhu What is parallel computing? Using multiple processors in parallel to solve problems more quickly than with a single processor Examples of parallel computing A cluster
Lecture 7: Pipelining Contd. More pipelining complications: Interrupts and Exceptions
 Lecture 7: Pipelining Contd. Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 More pipelining complications: Interrupts and Exceptions Hard to handle in pipelined
Lecture 7: Pipelining Contd. Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 More pipelining complications: Interrupts and Exceptions Hard to handle in pipelined
EITF20: Computer Architecture Part3.2.1: Pipeline - 3
 EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
Midterm I March 21 st, 2007 CS252 Graduate Computer Architecture
 University of California, Berkeley College of Engineering Computer Science Division EECS Spring 2007 John Kubiatowicz Midterm I March 21 st, 2007 CS252 Graduate Computer Architecture Your Name: SID Number:
University of California, Berkeley College of Engineering Computer Science Division EECS Spring 2007 John Kubiatowicz Midterm I March 21 st, 2007 CS252 Graduate Computer Architecture Your Name: SID Number:
RECAP. B649 Parallel Architectures and Programming
 RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
Lecture: Pipeline Wrap-Up and Static ILP
 Lecture: Pipeline Wrap-Up and Static ILP Topics: multi-cycle instructions, precise exceptions, deep pipelines, compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Multicycle
Lecture: Pipeline Wrap-Up and Static ILP Topics: multi-cycle instructions, precise exceptions, deep pipelines, compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Multicycle
Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP)
 in the Stanford Hydra Chip Multiprocessor (CMP)") Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP) Hydra is a 4-core Chip Multiprocessor (CMP) based microarchitecture/compiler effort at Stanford that provides hardware/software
Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP) Hydra is a 4-core Chip Multiprocessor (CMP) based microarchitecture/compiler effort at Stanford that provides hardware/software
Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP)
 in the Stanford Hydra Chip Multiprocessor (CMP)") Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP) Hydra ia a 4-core Chip Multiprocessor (CMP) based microarchitecture/compiler effort at Stanford that provides hardware/software
Data/Thread Level Speculation (TLS) in the Stanford Hydra Chip Multiprocessor (CMP) Hydra ia a 4-core Chip Multiprocessor (CMP) based microarchitecture/compiler effort at Stanford that provides hardware/software
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
TDT 4260 TDT ILP Chap 2, App. C
 TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
TDT 4260 ILP Chap 2, App. C Intro Ian Bratt (ianbra@idi.ntnu.no) ntnu no) Instruction level parallelism (ILP) A program is sequence of instructions typically written to be executed one after the other
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Advanced Computer Architecture Pipelining
 Advanced Computer Architecture Pipelining Dr. Shadrokh Samavi Some slides are from the instructors resources which accompany the 6 th and previous editions of the textbook. Some slides are from David Patterson,
Advanced Computer Architecture Pipelining Dr. Shadrokh Samavi Some slides are from the instructors resources which accompany the 6 th and previous editions of the textbook. Some slides are from David Patterson,
Predict Not Taken. Revisiting Branch Hazard Solutions. Filling the delay slot (e.g., in the compiler) Delayed Branch
 Delayed Branch") branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design
 ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN1640: Design of Computing Systems Topic 06: Advanced Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
EEC 581 Computer Architecture. Lec 4 Instruction Level Parallelism
 EEC 581 Computer Architecture Lec 4 Instruction Level Parallelism Chansu Yu Electrical and Computer Engineering Cleveland State University Acknowledgement Part of class notes are from David Patterson Electrical
EEC 581 Computer Architecture Lec 4 Instruction Level Parallelism Chansu Yu Electrical and Computer Engineering Cleveland State University Acknowledgement Part of class notes are from David Patterson Electrical
UNIT I (Two Marks Questions & Answers)
") UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Multi-core Architectures. Dr. Yingwu Zhu
 Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to
Multi-core Architectures Dr. Yingwu Zhu Outline Parallel computing? Multi-core architectures Memory hierarchy Vs. SMT Cache coherence What is parallel computing? Using multiple processors in parallel to