Pipelining: Basic and Intermediate Concepts
|
|
|
- Alice Hutchinson
- 6 years ago
- Views:
Transcription
1 Appendix A Pipelining: Basic and Intermediate Concepts 1
2 Overview Basics of fpipelining i Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2
3 Unpipelined pp Execution of 3 LD Instructions Assumed are the following delays: Memory access = 2 nsec, ALU operation = 2 nsec, Register file access = 1 nsec; P r o g r a m execution order Tim e (in in s tru c tio n s ) ld r 1, 100(r 4) In s tru ction fe tc h Reg ALU Data access Reg ld r 2, 200(r 5) 8 n s In s tru c tio n fe tc h Reg ALU Data access Reg ld r 3, 300(r 6) Assuming 2nsec clock cycle time (i.e. 500 MHz clock), every ld instruction needs 4 clock cycles (i.e. 8 nsec) to execute. The total time to execute this sequence is 12 clock cycles (i.e. 24 nsec). CPI = 12 cycles/3 instructions= s 4 cycles / instruction. 8 n s In s tru c tio n fe tc h 8 n s... 3
4 Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and dfold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder takes 20 minutes 4
5 T a s k O r d e r A B C D Sequential Laundry 6 PM Midnight Time Sequential laundry takes 6 hours for 4 loads If they learned pipelining, how long would laundry take? 5
6 Pipelined Laundry: Start work ASAP 6 PM Midnight Time T a s k O r d e r A B C D Pipelined laundry takes 3.5 hours for 4 loads 6
7 Key Definitions Pipelining is a key implementation technique used to build fast processors. It allows the execution of multiple instructions to overlap in time. A pipeline within a processor is similar to a car assembly line. Each assembly station is called a pipe stage or a pipe segment. The throughput of an instruction pipeline is the measure of how often an instruction exits the pipeline. 7
8 Pipeline Stages We can divide the execution of an instruction into the following 5 classic stages: IF: Instruction Fetch ID: Instruction Decode, register fetch EX: Execution MEM: Memory Access WB: Register write Back 8
9 Pipeline Throughput and Latency IF ID EX MEM WB 5 ns 4 ns 5 ns 10 ns 4 ns Consider the pipeline above with the indicated delays. We want to know what is the pipeline pp throughput and the pipeline latency. Pipeline throughput: instructions completed per second. Pipeline latency: how long does it take to execute a single instruction in the pipeline. 9
10 Pipeline Throughput and Latency IF ID EX MEM WB 5 ns 4 ns 5 ns 10 ns 4 ns Pipeline throughput: how often an instruction is completed. = 1instr / max lat( IF), lat( ID), lat( EX ), lat( MEM ), lat( WB) = 1 instr / max 5 = 1instr /10ns [ ] [ 5ns,4 ns,5 ns,10 ns,4 ns ] ( ignoring pipeline register overhead) Pipeline latency: how long does it take to execute an instruction in the pipeline. L = lat( IF) + lat( ID) + lat( EX ) + lat( MEM ) + lat( WB) = 5 ns + 4ns + 5ns + 10ns + 4ns = 28ns Is this right? 10
11 Pipeline Throughput and Latency I1 IF I2 IF ID EX MEM WB 5 ns 4 ns 5 ns 10 ns 4 ns Simply adding the latencies to compute the pipeline latency, only would work for an isolated instruction ID IF I3 EX MEM WB L(I1) = 28ns ID EX MEM WB L(I2) = 33ns IF ID EX MEM WB L(I3) = 38ns I4 IF ID EX MEM WB We are in trouble! The latency is not constant. L(I5) = 43ns This happens because this is an unbalanced pipeline. The solution is to make every state the same length as the longest one. 11
12 Pipelining Lessons T a s k O r d e r 6PM Pipelining i doesn t help latency of single task, it helps throughput of entire workload Time Pipeline rate limited by slowest pipeline stage Multiple tasks operating A simultaneously Potential speedup = B Number pipe stages Unbalanced lengths of C pipe stages reduces speedup D Time to fill pipeline and time to drain it reduces speedup 12
13 Other Definitions Pipe stage or pipe segment A decomposable unit of the fetch-decode-execute paradigm Pipeline depth Number of stages in a pipeline Machine cycle Clock cycle time Latch Per phase/stage local information storage unit 13
14 Design Issues Balance the length of each pipeline stage Problems Depth of the pipeline Throughput = Time per instruction on unpipelined machine Usually, stages are not balanced Pipelining overhead Hazards (conflicts) Performance (throughput CPU performance equation) Decrease of the CPI Decrease of cycle time 14
15 Basic Pipeline Instr # i i +1 i +2 i +3 i +4 Clock number IF ID EX MEM WB IF ID EX MEM WB IF ID EX MEM WB IF ID EX MEM WB IF ID EX MEM WB 15
16 Pipelined Datapath with Resources 16

17 Pipeline Registers 17
18 Physics of Clock Skew Basically caused because the clock edge reaches different parts of the chip at different times Capacitance-charge-discharge rates All wires, leads, transistors, etc. have capacitance Longer wire, larger capacitance Repeaters used dto drive current, handle fan-out problems C is inversely proportional to rate-of-change of V Time to charge/discharge adds to delay Dominant problem in old integration densities. For a fixed C, rate-of-change of V is proportional to I Problem with this approach is power requirements go up Power dissipation becomes a problem. Speed-of-light propagation p delays Dominates current integration densities as nowadays capacitances are much lower. But nowadays clock rates are much faster (even small delays will consume a large part of the clock cycle) Current day research asynchronous chip designs 18
19 Performance Issues Unpipelined processor 1.0 nsec clock cycle 4 cycles for ALU and branches 5 cycles for memory Frequencies ALU (40%), Branch (20%), and Memory (40%) Clock skew and setup adds 0.2ns overhead Speedup with pipelining? 19
20 Computing Pipeline Speedup p Speedup p= average instruction time unpipelined p average instruction time pipelined CPI pipelined = Ideal CPI pipelined + Pipeline stall clock cycles per instr Speedup = Ideal CPI x Pipeline depth Clock Cycle x unpipelined Ideal CPI + Pipeline stall per instr Clock Cycle pipelined Speedup = Pipeline depth Clock Cycle x unpipelined 1 + Pipeline stall CPI Clock Cycle pipelined Remember that average instruction time = CPI*Clock Cycle And ideal CPI for pipelined machine is 1. 20
21 Pipeline Hazards Limits to pipelining: Hazards prevent next instruction from executing during its designated clock cycle Structural hazards: HW cannot support this combination of instructions (single person to fold and put clothes away) Data hazards: Instruction depends on result of prior instruction still in the pipeline (missing sock) Control hazards: Pipelining of branches & other instructions that change the PC Common solution is to stall the pipeline until the hazard is resolved, inserting one or more bubbles in the pipeline 21
22 Structural Hazards Overlapped execution of instructions: Pipelining of functional units Duplication of resources Structural Hazard When the pipeline pp can not accommodate some combination of instructions Consequences Stall Increase of CPI from its ideal value (1) 22
23 Structural Hazard with 1 port per Memory 23
24 Pipelining of Functional Units Fully pipelined M1 M2 M3 M4 M5 IF ID FP Multiply l MEM WB EX Partially pipelined M1 M2 M3 M4 M5 IF ID FP Multiply MEM WB EX Not pipelined M1 M2 M3 M4 M5 IF ID FP Multiply py MEM WB EX 24
25 To pipeline or Not to pipeline Elements to consider Effects of pipelining and duplicating units Increased costs Higher latency (pipeline register overhead) Frequency of structural lhazard Example: unpipelined FP multiply unit in MIPS Lt Latency: 5 cycles Impact on mdljdp2 program? Frequency of FP instructions: 14% Depends on the distribution of FP multiplies Best case: uniform distribution Worst case: clustered, back-to-back b k multiplies li 25
26 Example: Dual-port vs. Single-port Machine A: Dual ported memory Machine B: Single ported memory, but its pipelined implementation has a 1.05 times faster clock rate Ideal CPI = 1 for both Loads are 40% of instructions executed SpeedUp A = Pipeline Depth/(1 + 0) x (clock unpipe /clock pipe ) = Pipeline Depth SpeedUp B = Pipeline Depth/( x 1) x (clock unpipe /(clock unpipe / 1.05) = (Pipeline Depth/1.4) x 1.05 = 0.75 x Pipeline Depth SpeedUp A / SpeedUp B = Pipeline Depth/(0.75 x Pipeline Depth) = 1.33 Machine A is 1.33 times faster
27 Data Hazards 27
28 Three Generic Data Hazards Instr I fll followed dby Instr J Read After Write (RAW) Instr J tries to read operand before Instr I writes it 28
29 Three Generic Data Hazards (Cont d) Instr I followed by Instr J Write After Read (WAR) Instr J tries to write operand before Instr I reads i Gets wrong operand Can t happen in MIPS 5 stage pipeline because: All instructions take 5 stages, and Reads are always in stage 2, and Writes are always in stage 5 29
30 Three Generic Data Hazards (Cont d) Instr I followed by Instr J Wit Write After Write Wit (WAW) Instr J tries to write operand before Instr I writes it Leaves wrong result ( Instr I not Instr J ) Can t happen in MIPS 5 stage pipeline because: All instructions take 5 stages, and Writes are always in stage 5 Will see WAR and WAW in later more complicated pipes 30
31 Examples in more complicated pipelines WAW - write after write LW R1, 0(R2) IF ID EX M1 M2 WB ADD R1, R2, R3 IF ID EX WB WAR - write after read SW 0(R1), R2 IF ID EX M1 M2 WB ADD R2, R3, R4 IF ID EX WB This is a problem if Register writes are during The first half of the cycle And reads during the 31 Second half
32 Avoiding Data Hazard with Forwarding 32
33 Forwarding of Operands by Stores 33
34 Stalls in spite of Forwarding 34
35 Software Scheduling to Avoid Load Hazards Try producing fast code for a = b + c; d = e f; assuming a, b, c, d,e, and f in memory. Slow code: Fast code: LW Rb,b LW Rb,b LW Rc,c LW Rc,c ADD Ra,Rb,Rc LW Re,e SW a,ra LW Re,e ADD Ra,Rb,RcRb Rc LW Rf,f LW Rf,f SUB Rd,Re,Rf SW a,ra SW d,rd SUB Rd,Re,Rf SW d,rd 35
36 Effect of Software Scheduling LW Rb,b IF ID EX MEM WB LW Rc,c IF ID EX MEM WB ADD Ra,Rb,Rc IF ID EX MEM WB SW a,ra IF ID EX MEM WB LW Re,e IF ID EX MEM WB LW Rf,f IF ID EX MEM WB SUB Rd,Re,Rf IF ID EX MEM WB SW d,rd IF ID EX MEM WB LW Rb,b IF ID EX MEM WB LW Rc,c IF ID EX MEM WB LW Re,e IF ID EX MEM WB ADD Ra,Rb,Rc IF ID EX MEM WB LW Rf,f IF ID EX MEM WB SW a,ra IF ID EX MEM WB SUB Rd,Re,Rf R Rf IF ID EX MEM WB SW d,rd IF ID EX MEM WB 36
37 Compiler Scheduling Eliminates load interlocks Demands more registers Simple scheduling Basic block (sequential segment of code) Good for simple pipelines Percentage of loads that result in a stall FP: 13% Int: 25% 37
38 Control (Branch) Hazards Branch IF ID EX MEM WB Branch successor IF stall stall IF ID EX MEM WB Branch successor+1 IF ID EX MEM WB Branch successor+2 IF ID EX MEM WB Branch successor+3 IF ID EX MEM Branch successor+4 IF ID EX Stall the pipeline until we reach MEM Easy, but expensive Three cycles for every branch To reduce the branch delay Find out branch is taken or not taken ASAP Compute the branch target ASAP 38
39 Impact of Branch Stall on Pipeline Speedup If CPI = 1, 30% branch, 39
40 Reduction of Branch Penalties Static, compile-time, branch prediction schemes 1 Stall llthe pipeline Simple in hardware and software 2 Treat every branch as not taken Continue execution as if branch were normal instruction If branch is taken, turn the fetched instruction i into a no-op 3 Treat every branch as taken Useless in MIPS. Why? 4 Delayed branch Sequential successors (in delay slots) are executed anyway No branches in the delay slots 40
41 Delayed Branch #4: Delayed Branch Define branch to take place AFTER a following instruction branch instruction sequential successor 1 sequential successor 2... sequential successor n branch target t if taken Branch delay of length n 1 slot delay allows proper decision and branch target address in 5 stage pipeline MIPS uses this 41
42 Predict-not-taken Scheme Untaken Branch IF ID EX MEM WB Instruction i+1 IF ID EX MEM WB Instruction i+1 IF ID EX MEM WB Instruction i+2 IF ID EX MEM WB Instruction i+3 IF ID EX MEM WB Taken Branch IF ID EX MEM WB Instruction i+1 IF stall stall stall stall (clear the IF/ID register) Branch target IF ID EX MEM WB Branch target+1 IF ID EX MEM WB Branch target+2 IF ID EX MEM WB Compiler organizes code so that the most frequent path is the not-taken one 42
43 Canceling Branch Instructions Canceling branch includes the predicted direction Incorrect prediction => delay-slot instruction becomes no-op Helps the compiler to fill branch delay slots (no requirements for. b and c) Behavior of a predicted-takentaken canceling branch Untaken Branch IF ID EX MEM WB Instruction i+1 IF stall stall stall stall (clear the IF/ID register) Instruction i+2 IF ID EX MEM WB Instruction i+3 IF ID EX MEM WB Instruction i+4 IF ID EX MEM WB Taken Branch IF ID EX MEM WB Instruction i+1 IF ID EX MEM WB Branch target IF ID EX MEM WB Branch target i+1 IF ID EX MEM WB Branch target i+2 IF ID EX MEM WB 43
44 Delayed ed Branch Where to get instructions to fill branch delay slot? Before branch instruction From the target address: only valuable when branch taken From fall through: only valuable when branch not taken Compiler effectiveness for single branch delay slot: Fills about 60% of branch delay slots About 80% of instructions executed in branch delay slots useful in computation About 50% (60% x 80%) of slots usefully filled Delayed Branch downside: 7-8 stage pipelines, multiple instructions issued per clock (superscalar) 44
45 Optimizations of the Branch Slot DADD R1,R2,R3 if R2=0 then From before if R2=0 then DADD R1,R2,R3 DSUB R4,R5,R6 DADD R1,R2,R3 if R1=0 then From target DSUB R4,R5,R6 DADD R1,R2,R3 if R1=0 then DSUB R4,R5,R6 DADD R1,R2,R3 if R1=0 then OR R7,R8,R9R8 R9 DSUB R4,R5,R6 From fall throughh DADD R1,R2,R3 if R1=0 then OR R7,R8,R9 DSUB R4,R5,R6 45
46 Branch Slot Requirements Strategy Requirements Improves performance a) )From before Branch must not tdepend d on delayed d Always instruction b) From target Must be OK to execute delayed When branch is taken instruction if branch is not taken c) From fall Must be OK to execute delayed When branch is not taken through instruction if branch is taken Limitations in delayed-branch scheduling Restrictions titi on instructions ti that thtare scheduled hdld Ability to predict branches at compile time 46
47 Some Working Examples 47
48 Branch Behavior in Programs Integer Forward conditional branches 13% 7% FP Backward conditional branches 3% 2% Unconditional i lbranches 4% 1% Branches taken 62% 70% Pipeline speedup = Pipeline depth 1 +Branch frequency Branch penalty Branch hpenalty for predict ttaken = 1 Branch Penalty for predict not taken = probability of branches taken Branch Penalty for delayed branches is function of how often delay Slot is usefully filled (not cancelled) always guaranteed to be as Good or better than the other approaches. 48
49 Static Branch Prediction for scheduling to avoid data hazards Correct predictions Reduce branch hazard penalty Help the scheduling of data hazards: LW R1, 0(R2) SUB R1, R1, R3 BEQZ R1, L OR R4, R5, R6 ADD R10, R4, R3 L: ADD R7, R8, R9 If branch is almost never taken Prediction methods Examination of program behavior (benchmarks) Use of profile information from previous runs If branch is almost always taken 49
50 How is Pipelining Implemented? MIPS Instruction Formats I opcode rs 1 rd immediate R opcode rs 1 rs 2 rd Shamt/function J opcode address Fixed-field decoding 50
51 1st and 2nd Instruction cycles Instruction fetch (IF) IR Mem[PC]; NPC PC + 4 Instruction decode & register fetch (ID) A Regs[IR ]; B Regs[IR ]; Imm ((IR 16 ) 16 # # IR ) 51
52 3rd Instruction cycle Execution & effective address (EX) Memory reference ALUOutput A + Imm Register - Register ALU instruction ALUOutput A func B Register - Immediate ALU instruction ALUOutput A op Imm Branch ALUOutput NPC + Imm; Cond (A op 0) 52
53 4th Instruction cycle Memory access & branch completion (MEM) Memory reference PC NPC LMD Mem[ALUOutput] (load) Mem[ALUOutput] B (store) Branch if (cond) PC ALUOutput; else PC NPC 53
54 5th Instruction cycle Write-back (WB) Register - register ALU instruction Regs[IR ] ALUOutput Register - immediate ALU instruction Regs[IR ] ALUOutput Load instruction Regs[IR ] LMD 54
55 5 Stages of MIPS Datapath 55
56 5 Stages of MIPS Datapath with Registers 56
57 Events on Every Pipe Stage 57
58 Implementing the Control for the MIPS Pipeline LD R1, 45 (R2) DADD R5, R6, R7 DSUB R8, R6, R7 OR R9, R6, R7 LD R1, 45 (R2) DADD R5, R1, R7 DSUB R8, R6, R7 OR R9, R6, R7 LD R1, 45 (R2) DADD R5, R6, R7 DSUB R8, R1, R7 OR R9, R6, R7 LD R1, 45 (R2) DADD R5, R6, R7 DSUB R8, R6, R7 OR R9,R1, R7 58
59 Pipeline Interlocks LW R1, 0(R2) IM Reg ALU DM Reg SUB R4, R1, R5 IM Reg ALU DM Reg AND R6, R1, R7 IM Reg ALU DM OR R8, R1, R9 IM Reg ALU LW R1, 0(R2) IF ID EX MEM WB SUB R4, R1, R5 IF ID stall EX MEM WB AND R6, R1, R7 IF stall ID EX MEM WB OR R8, R1, R9 stall IF ID EX MEM WB 59
60 Load Interlock Implementation RAW load interlock detection during ID Load instruction in EX Instruction that needs the load data in ID Logic to detect load interlock ID/EX.IR 0..5 IF/ID.IR 0..5 Comparison Load r-r ALU ID/EX.IR IR [RT] == IF/ID.IR IR [RS] Load r-r ALU ID/EX.IR [RT] == IF/ID.IR [RT] Load Load, Store, r-i ALU, branch ID/EX.IR [RT] == IF/ID.IR [RS] Action (insert the pipeline stall) ID/EX.IRIR 0..5 =0(noop) (no-op) Re-circulate contents of IF/ID 60
61 Forwarding Implementation Source: ALU or MEM output Destination: ALU, MEM or Zero? input(s) Compare (forwarding to ALU input): Important Please refer to Fig. A.22 in slide #63 61
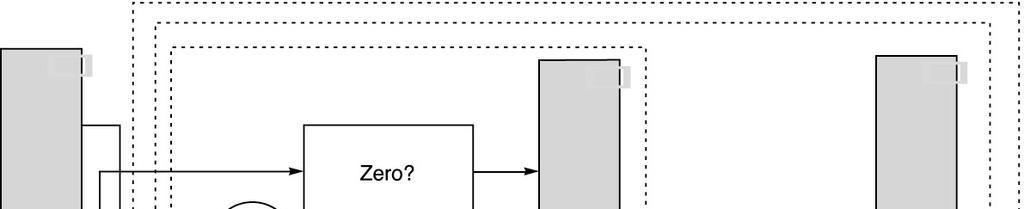
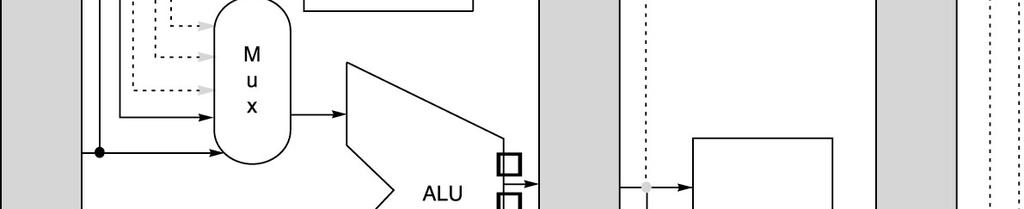
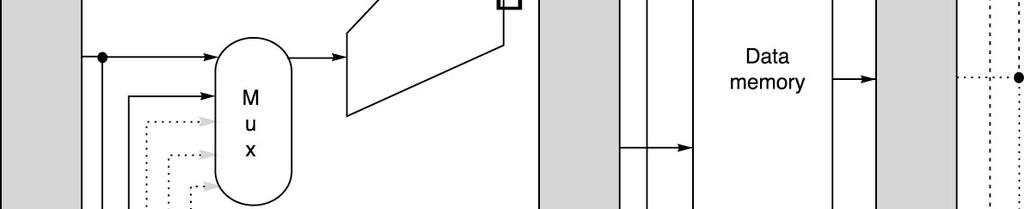
62 Forwarding Implementation (Cont d) 62
63 Forwarding Implementation - All Possible Forwarding 63
64 Handling Branch Hazards 64
65 Revised Pipeline Structure 65
66 Exceptions I/O device request Operating system call Tracing instruction execution Breakpoint Integer overflow FP arithmetic anomaly Page fault Misaligned memory access Memory protection violation Undefined instruction Hardware malfunctions Power failure 66
67 Exception Categories Synchronous vs. asynchronous User requested vs. coerced User maskable vs. nonmaskable Within vs. between instructions ti Resume vs. terminate Most difficult Occur in the middle of the instruction Must be able to restart Requires intervention of another program (OS) 67
68 Overview of Exceptions 68
69 Exception Handling CPU IF ID EX M WB Complete Cache IF ID EX M WB Memory IF ID EX M WB IF ID EX M WB Suspend Execution Disk Trap addr IF ID EX WB M Exception handling procedure IF ID EX M WB... RFE 69
70 Stopping and Restarting Execution TRAP, RFE(return-from-exception) instructions IAR register saves the PC of faulting instruction Safely save the state of the pipeline ForceaTRAPonthenextIF on next Until the TRAP is taken, turn off all writes for the faulting instruction and the following ones. Exception-handling routine saves the PC of the faulting instruction For dl delayed dbranches we need to save more PCs Precise Exceptions 70
71 Exceptions in MIPS Pipeline Stage Exceptions IF ID EX MEM WB Page fault, misaligned memory access, memory-protection violation Undefined opcode Arithmetic exception Page fault, misaligned memory access, memory-protection violation None 71
72 Exception Handling in MIPS LW IF ID EX M WB ADD IF ID EX M WB LW IF ID EX M WB ADD IF ID EX M WB M IF ID EX WB Exception Status Vector 72 Check exceptions here
73 ISA and Exceptions Instructions before complete, instructions after do not, exceptions handled in order Precise Exceptions Precise exceptions are simple in MIPS Only one result per instruction Result is written at the end of execution Problems Instructions change machine state in the middle of the execution Autoincrement addressing modes Multicycle operations Many machines have two modes Imprecise (efficient) Precise (relatively inefficient) 73
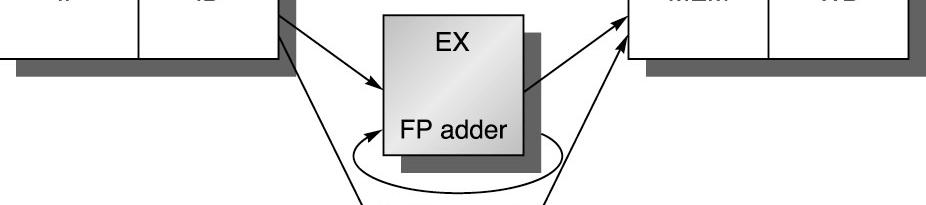
74 Handling Multicycle Operations 74
75 Handling Multicycle Operations (Cont d) 75
76 Latencies and Initiation Intervals Functional Unit Latency Initiation Interval It Integer ALU 0 1 Data Memory 1 1 FP adder 3 1 FP/int multiply 6 1 FP/int divider MULTD IF ID M1 M2 M3 M4 M5 M6 M7 Mem WB ADDD IF ID A1 A2 A3 A4 Mem WB LD IF ID EX Mem WB SD IF ID EX Mem WB 76
77 Hazards in FP pipelines Structural hazards in DIV unit Structural hazards in WB WAW hazards are possible (WAR not possible) Out-of-order completion Exception handling issues More frequent RAW hazards Longer pipelines LD F4, 0(R2) IF ID EX Mem WB MULTD F0, F4, F6 IF ID stall M1 M2 M3 M4 M5 M6 M7 Mem WB ADD F2, F0, F8 IF stall ID stall stall stall stall stall stall A1 A2 A3 A4 Mem WB 77
78 Hazards in FP pipelines (Cont d) 78
79 Hazard Detection Logic at ID Check for Structural Hazards Divide unit/make sure register write port is available when needed Check for RAW hazard Check source registers against destination registers in pipeline latches of instructions that are ahead in the pipeline. Similar to I-pipeline Check for WAW hazard ard Determine if any instruction in A1-A4, M1-M7 has same register destination as this instruction. 79
80 Handling Hazards Working Examples 80
Overview. Appendix A. Pipelining: Its Natural! Sequential Laundry 6 PM Midnight. Pipelined Laundry: Start work ASAP
 Overview Appendix A Pipelining: Basic and Intermediate Concepts Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 1 2 Unpipelined
Overview Appendix A Pipelining: Basic and Intermediate Concepts Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 1 2 Unpipelined
Appendix A. Overview
 Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 1 Unpipelined
Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 1 Unpipelined
Instruction Pipelining Review
 Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
COSC4201 Pipelining. Prof. Mokhtar Aboelaze York University
 COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
Pipelining. Maurizio Palesi
 * Pipelining * Adapted from David A. Patterson s CS252 lecture slides, http://www.cs.berkeley/~pattrsn/252s98/index.html Copyright 1998 UCB 1 References John L. Hennessy and David A. Patterson, Computer
* Pipelining * Adapted from David A. Patterson s CS252 lecture slides, http://www.cs.berkeley/~pattrsn/252s98/index.html Copyright 1998 UCB 1 References John L. Hennessy and David A. Patterson, Computer
Page 1. Pipelining: Its Natural! Chapter 3. Pipelining. Pipelined Laundry Start work ASAP. Sequential Laundry A B C D. 6 PM Midnight
 Pipelining: Its Natural! Chapter 3 Pipelining Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder
Pipelining: Its Natural! Chapter 3 Pipelining Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder
Lecture 3. Pipelining. Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1
 Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
Lecture 3 Pipelining Dr. Soner Onder CS 4431 Michigan Technological University 9/23/2009 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero, DP take pair)
Modern Computer Architecture
 Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
CPE Computer Architecture. Appendix A: Pipelining: Basic and Intermediate Concepts
 CPE 110408443 Computer Architecture Appendix A: Pipelining: Basic and Intermediate Concepts Sa ed R. Abed [Computer Engineering Department, Hashemite University] Outline Basic concept of Pipelining The
CPE 110408443 Computer Architecture Appendix A: Pipelining: Basic and Intermediate Concepts Sa ed R. Abed [Computer Engineering Department, Hashemite University] Outline Basic concept of Pipelining The
Instruction Level Parallelism. ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction
 Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Computer Architecture
 Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science 6 PM 7 8 9 10 11 Midnight Time 30 40 20 30 40 20
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science 6 PM 7 8 9 10 11 Midnight Time 30 40 20 30 40 20
Pipeline Overview. Dr. Jiang Li. Adapted from the slides provided by the authors. Jiang Li, Ph.D. Department of Computer Science
 Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
Appendix C: Pipelining: Basic and Intermediate Concepts
 Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Predict Not Taken. Revisiting Branch Hazard Solutions. Filling the delay slot (e.g., in the compiler) Delayed Branch
 Delayed Branch") branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
Pipeline Review. Review
 Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
Pipeline Review Review Covered in EECS2021 (was CSE2021) Just a reminder of pipeline and hazards If you need more details, review 2021 materials 1 The basic MIPS Processor Pipeline 2 Performance of pipelining
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards
 CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Appendix C. Instructor: Josep Torrellas CS433. Copyright Josep Torrellas 1999, 2001, 2002,
 Appendix C Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Pipelining Multiple instructions are overlapped in execution Each is in a different stage Each stage is called
Appendix C Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Pipelining Multiple instructions are overlapped in execution Each is in a different stage Each stage is called
CMCS Mohamed Younis CMCS 611, Advanced Computer Architecture 1
 CMCS 611-101 Advanced Computer Architecture Lecture 8 Control Hazards and Exception Handling September 30, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer
CMCS 611-101 Advanced Computer Architecture Lecture 8 Control Hazards and Exception Handling September 30, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer
What is Pipelining? Time per instruction on unpipelined machine Number of pipe stages
 What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Outline. Pipelining basics The Basic Pipeline for DLX & MIPS Pipeline hazards. Handling exceptions Multi-cycle operations
 Pipelining 1 Outline Pipelining basics The Basic Pipeline for DLX & MIPS Pipeline hazards Structural Hazards Data Hazards Control Hazards Handling exceptions Multi-cycle operations 2 Pipelining basics
Pipelining 1 Outline Pipelining basics The Basic Pipeline for DLX & MIPS Pipeline hazards Structural Hazards Data Hazards Control Hazards Handling exceptions Multi-cycle operations 2 Pipelining basics
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
The Big Picture Problem Focus S re r g X r eg A d, M lt2 Sub u, Shi h ft Mac2 M l u t l 1 Mac1 Mac Performance Focus Gate Source Drain BOX
 Appendix A - Pipelining 1 The Big Picture SPEC f2() { f3(s2, &j, &i); *s2->p = 10; i = *s2->q + i; } Requirements Algorithms Prog. Lang./OS ISA f1 f2 f5 f3 s q p fp j f3 f4 i1: ld r1, b i2: ld r2,
Appendix A - Pipelining 1 The Big Picture SPEC f2() { f3(s2, &j, &i); *s2->p = 10; i = *s2->q + i; } Requirements Algorithms Prog. Lang./OS ISA f1 f2 f5 f3 s q p fp j f3 f4 i1: ld r1, b i2: ld r2,
Lecture 05: Pipelining: Basic/ Intermediate Concepts and Implementation
 Lecture 05: Pipelining: Basic/ Intermediate Concepts and Implementation CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu www.secs.oakland.edu/~yan
Lecture 05: Pipelining: Basic/ Intermediate Concepts and Implementation CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu www.secs.oakland.edu/~yan
What is Pipelining? RISC remainder (our assumptions)
") What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
Pipelining: Hazards Ver. Jan 14, 2014
 POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
Advanced Computer Architecture Pipelining
 Advanced Computer Architecture Pipelining Dr. Shadrokh Samavi Some slides are from the instructors resources which accompany the 6 th and previous editions of the textbook. Some slides are from David Patterson,
Advanced Computer Architecture Pipelining Dr. Shadrokh Samavi Some slides are from the instructors resources which accompany the 6 th and previous editions of the textbook. Some slides are from David Patterson,
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
CS 110 Computer Architecture. Pipelining. Guest Lecture: Shu Yin. School of Information Science and Technology SIST
 CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
CS 110 Computer Architecture Pipelining Guest Lecture: Shu Yin http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on UC Berkley's CS61C
第三章 Instruction-Level Parallelism and Its Dynamic Exploitation. 陈文智 浙江大学计算机学院 2014 年 10 月
 第三章 Instruction-Level Parallelism and Its Dynamic Exploitation 陈文智 chenwz@zju.edu.cn 浙江大学计算机学院 2014 年 10 月 1 3.3 The Major Hurdle of Pipelining Pipeline Hazards 本科回顾 ------- Appendix A.2 3.3.1 Taxonomy
第三章 Instruction-Level Parallelism and Its Dynamic Exploitation 陈文智 chenwz@zju.edu.cn 浙江大学计算机学院 2014 年 10 月 1 3.3 The Major Hurdle of Pipelining Pipeline Hazards 本科回顾 ------- Appendix A.2 3.3.1 Taxonomy
Computer Architecture. Lecture 6.1: Fundamentals of
 CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
MIPS An ISA for Pipelining
 Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Execution/Effective address
 Pipelined RC 69 Pipelined RC Instruction Fetch IR mem[pc] NPC PC+4 Instruction Decode/Operands fetch A Regs[rs]; B regs[rt]; Imm sign extended immediate field Execution/Effective address Memory Ref ALUOutput
Pipelined RC 69 Pipelined RC Instruction Fetch IR mem[pc] NPC PC+4 Instruction Decode/Operands fetch A Regs[rs]; B regs[rt]; Imm sign extended immediate field Execution/Effective address Memory Ref ALUOutput
ECE 486/586. Computer Architecture. Lecture # 12
 ECE 486/586 Computer Architecture Lecture # 12 Spring 2015 Portland State University Lecture Topics Pipelining Control Hazards Delayed branch Branch stall impact Implementing the pipeline Detecting hazards
ECE 486/586 Computer Architecture Lecture # 12 Spring 2015 Portland State University Lecture Topics Pipelining Control Hazards Delayed branch Branch stall impact Implementing the pipeline Detecting hazards
There are different characteristics for exceptions. They are as follows:
 e-pg PATHSHALA- Computer Science Computer Architecture Module 15 Exception handling and floating point pipelines The objectives of this module are to discuss about exceptions and look at how the MIPS architecture
e-pg PATHSHALA- Computer Science Computer Architecture Module 15 Exception handling and floating point pipelines The objectives of this module are to discuss about exceptions and look at how the MIPS architecture
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
The Processor Pipeline. Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes.
 The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
The Processor Pipeline Chapter 4, Patterson and Hennessy, 4ed. Section 5.3, 5.4: J P Hayes. Pipeline A Basic MIPS Implementation Memory-reference instructions Load Word (lw) and Store Word (sw) ALU instructions
Pipelining. Each step does a small fraction of the job All steps ideally operate concurrently
 Pipelining Computational assembly line Each step does a small fraction of the job All steps ideally operate concurrently A form of vertical concurrency Stage/segment - responsible for 1 step 1 machine
Pipelining Computational assembly line Each step does a small fraction of the job All steps ideally operate concurrently A form of vertical concurrency Stage/segment - responsible for 1 step 1 machine
Appendix C. Abdullah Muzahid CS 5513
 Appendix C Abdullah Muzahid CS 5513 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero) Single address mode for load/store: base + displacement no indirection
Appendix C Abdullah Muzahid CS 5513 1 A "Typical" RISC ISA 32-bit fixed format instruction (3 formats) 32 32-bit GPR (R0 contains zero) Single address mode for load/store: base + displacement no indirection
Basic Pipelining Concepts
 Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
COEN-4710 Computer Hardware Lecture 4 Processor Part 2: Pipelining (Ch.4) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations from Mike
CPS104 Computer Organization and Programming Lecture 19: Pipelining. Robert Wagner
 CPS104 Computer Organization and Programming Lecture 19: Pipelining Robert Wagner cps 104 Pipelining..1 RW Fall 2000 Lecture Overview A Pipelined Processor : Introduction to the concept of pipelined processor.
CPS104 Computer Organization and Programming Lecture 19: Pipelining Robert Wagner cps 104 Pipelining..1 RW Fall 2000 Lecture Overview A Pipelined Processor : Introduction to the concept of pipelined processor.
Instruction Pipelining
 Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Complications with long instructions. CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3. How slow is slow?
 Complications with long instructions CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study So far, all MIPS instructions take 5 cycles But haven't talked
Complications with long instructions CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study So far, all MIPS instructions take 5 cycles But haven't talked
Instruction Pipelining
 Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3. Complications With Long Instructions
 CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
Pipelining, Instruction Level Parallelism and Memory in Processors. Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010
 Pipelining, Instruction Level Parallelism and Memory in Processors Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010 NOTE: The material for this lecture was taken from several
Pipelining, Instruction Level Parallelism and Memory in Processors Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010 NOTE: The material for this lecture was taken from several
Pipelining. Principles of pipelining. Simple pipelining. Structural Hazards. Data Hazards. Control Hazards. Interrupts. Multicycle operations
 Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
CS4617 Computer Architecture
 1/47 CS4617 Computer Architecture Lectures 21 22: Pipelining Reference: Appendix C, Hennessy & Patterson Dr J Vaughan November 2013 MIPS data path implementation (unpipelined) Figure C.21 The implementation
1/47 CS4617 Computer Architecture Lectures 21 22: Pipelining Reference: Appendix C, Hennessy & Patterson Dr J Vaughan November 2013 MIPS data path implementation (unpipelined) Figure C.21 The implementation
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
Computer System. Hiroaki Kobayashi 6/16/2010. Ver /16/2010 Computer Science 1
 Computer System Hiroaki Kobayashi 6/16/2010 6/16/2010 Computer Science 1 Ver. 1.1 Agenda Basic model of modern computer systems Von Neumann Model Stored-program instructions and data are stored on memory
Computer System Hiroaki Kobayashi 6/16/2010 6/16/2010 Computer Science 1 Ver. 1.1 Agenda Basic model of modern computer systems Von Neumann Model Stored-program instructions and data are stored on memory
Lecture 2: Processor and Pipelining 1
 The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
The Simple BIG Picture! Chapter 3 Additional Slides The Processor and Pipelining CENG 6332 2 Datapath vs Control Datapath signals Control Points Controller Datapath: Storage, FU, interconnect sufficient
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
CISC 662 Graduate Computer Architecture Lecture 7 - Multi-cycles
 CISC 662 Graduate Computer Architecture Lecture 7 - Multi-cycles Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 7 - Multi-cycles Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Computer System. Agenda
 Computer System Hiroaki Kobayashi 7/6/2011 Ver. 07062011 7/6/2011 Computer Science 1 Agenda Basic model of modern computer systems Von Neumann Model Stored-program instructions and data are stored on memory
Computer System Hiroaki Kobayashi 7/6/2011 Ver. 07062011 7/6/2011 Computer Science 1 Agenda Basic model of modern computer systems Von Neumann Model Stored-program instructions and data are stored on memory
Lecture 7: Pipelining Contd. More pipelining complications: Interrupts and Exceptions
 Lecture 7: Pipelining Contd. Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 More pipelining complications: Interrupts and Exceptions Hard to handle in pipelined
Lecture 7: Pipelining Contd. Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 More pipelining complications: Interrupts and Exceptions Hard to handle in pipelined
ELCT 501: Digital System Design
 ELCT 501: Digital System Lecture 8: Pipelining Dr. Mohamed Abd El Ghany, Pipelining: Its Natural! Laundry Example Ann, brian, cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes
ELCT 501: Digital System Lecture 8: Pipelining Dr. Mohamed Abd El Ghany, Pipelining: Its Natural! Laundry Example Ann, brian, cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes
CISC 662 Graduate Computer Architecture Lecture 7 - Multi-cycles. Interrupts and Exceptions. Device Interrupt (Say, arrival of network message)
") CISC 662 Graduate Computer Architecture Lecture 7 - Multi-cycles Michela Taufer Interrupts and Exceptions http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy
CISC 662 Graduate Computer Architecture Lecture 7 - Multi-cycles Michela Taufer Interrupts and Exceptions http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy
Chapter 5 (a) Overview
 Overview") Chapter 5 (a) Overview (a) The principles of pipelining (a) A pipelined design of SRC (b) Pipeline hazards (b) Instruction-level parallelism (ILP) Superscalar processors Very Long Instruction Word (VLIW)
Chapter 5 (a) Overview (a) The principles of pipelining (a) A pipelined design of SRC (b) Pipeline hazards (b) Instruction-level parallelism (ILP) Superscalar processors Very Long Instruction Word (VLIW)
CSE 533: Advanced Computer Architectures. Pipelining. Instructor: Gürhan Küçük. Yeditepe University
 CSE 533: Advanced Computer Architectures Pipelining Instructor: Gürhan Küçük Yeditepe University Lecture notes based on notes by Mark D. Hill and John P. Shen Updated by Mikko Lipasti Pipelining Forecast
CSE 533: Advanced Computer Architectures Pipelining Instructor: Gürhan Küçük Yeditepe University Lecture notes based on notes by Mark D. Hill and John P. Shen Updated by Mikko Lipasti Pipelining Forecast
Instr. execution impl. view
 Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
CMCS Mohamed Younis CMCS 611, Advanced Computer Architecture 1
 CMCS 611-101 Advanced Computer Architecture Lecture 9 Pipeline Implementation Challenges October 5, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer Architecture
CMCS 611-101 Advanced Computer Architecture Lecture 9 Pipeline Implementation Challenges October 5, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer Architecture
Pipeline: Introduction
 Pipeline: Introduction These slides are derived from: CSCE430/830 Computer Architecture course by Prof. Hong Jiang and Dave Patterson UCB Some figures and tables have been derived from : Computer System
Pipeline: Introduction These slides are derived from: CSCE430/830 Computer Architecture course by Prof. Hong Jiang and Dave Patterson UCB Some figures and tables have been derived from : Computer System
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
CSE 502 Graduate Computer Architecture. Lec 3-5 Performance + Instruction Pipelining Review
 CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
DLX Unpipelined Implementation
 LECTURE - 06 DLX Unpipelined Implementation Five cycles: IF, ID, EX, MEM, WB Branch and store instructions: 4 cycles only What is the CPI? F branch 0.12, F store 0.05 CPI0.1740.83550.174.83 Further reduction
LECTURE - 06 DLX Unpipelined Implementation Five cycles: IF, ID, EX, MEM, WB Branch and store instructions: 4 cycles only What is the CPI? F branch 0.12, F store 0.05 CPI0.1740.83550.174.83 Further reduction
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
C.1 Introduction. What Is Pipelining? C-2 Appendix C Pipelining: Basic and Intermediate Concepts
 C-2 Appendix C Pipelining: Basic and Intermediate Concepts C.1 Introduction Many readers of this text will have covered the basics of pipelining in another text (such as our more basic text Computer Organization
C-2 Appendix C Pipelining: Basic and Intermediate Concepts C.1 Introduction Many readers of this text will have covered the basics of pipelining in another text (such as our more basic text Computer Organization
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Pipelining. Principles of pipelining. Simple pipelining. Structural Hazards. Data Hazards. Control Hazards. Interrupts. Multicycle operations
 Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
Lecture 7 Pipelining. Peng Liu.
 Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Chapter 3. Pipelining. EE511 In-Cheol Park, KAIST
 Chapter 3. Pipelining EE511 In-Cheol Park, KAIST Terminology Pipeline stage Throughput Pipeline register Ideal speedup Assume The stages are perfectly balanced No overhead on pipeline registers Speedup
Chapter 3. Pipelining EE511 In-Cheol Park, KAIST Terminology Pipeline stage Throughput Pipeline register Ideal speedup Assume The stages are perfectly balanced No overhead on pipeline registers Speedup
Four Steps of Speculative Tomasulo cycle 0
 HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
HW support for More ILP Hardware Speculative Execution Speculation: allow an instruction to issue that is dependent on branch, without any consequences (including exceptions) if branch is predicted incorrectly
Advanced Computer Architecture
 ECE 563 Advanced Computer Architecture Fall 2010 Lecture 2: Review of Metrics and Pipelining 563 L02.1 Fall 2010 Review from Last Time Computer Architecture >> instruction sets Computer Architecture skill
ECE 563 Advanced Computer Architecture Fall 2010 Lecture 2: Review of Metrics and Pipelining 563 L02.1 Fall 2010 Review from Last Time Computer Architecture >> instruction sets Computer Architecture skill
Chapter 8. Pipelining
 Chapter 8. Pipelining Overview Pipelining is widely used in modern processors. Pipelining improves system performance in terms of throughput. Pipelined organization requires sophisticated compilation techniques.
Chapter 8. Pipelining Overview Pipelining is widely used in modern processors. Pipelining improves system performance in terms of throughput. Pipelined organization requires sophisticated compilation techniques.
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
Computer Systems Architecture I. CSE 560M Lecture 5 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 5 Prof. Patrick Crowley Plan for Today Note HW1 was assigned Monday Commentary was due today Questions Pipelining discussion II 2 Course Tip Question 1:
Computer Systems Architecture I CSE 560M Lecture 5 Prof. Patrick Crowley Plan for Today Note HW1 was assigned Monday Commentary was due today Questions Pipelining discussion II 2 Course Tip Question 1:
CS422 Computer Architecture
 CS422 Computer Architecture Spring 2004 Lecture 07, 08 Jan 2004 Bhaskaran Raman Department of CSE IIT Kanpur http://web.cse.iitk.ac.in/~cs422/index.html Recall: Data Hazards Have to be detected dynamically,
CS422 Computer Architecture Spring 2004 Lecture 07, 08 Jan 2004 Bhaskaran Raman Department of CSE IIT Kanpur http://web.cse.iitk.ac.in/~cs422/index.html Recall: Data Hazards Have to be detected dynamically,
COSC 6385 Computer Architecture - Pipelining (II)
") COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
CSE 502 Graduate Computer Architecture. Lec 3-5 Performance + Instruction Pipelining Review
 CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CSE 502 Graduate Computer Architecture Lec 3-5 Performance + Instruction Pipelining Review Larry Wittie Computer Science, StonyBrook University http://www.cs.sunysb.edu/~cse502 and ~lw Slides adapted from
CO Computer Architecture and Programming Languages CAPL. Lecture 18 & 19
 CO2-3224 Computer Architecture and Programming Languages CAPL Lecture 8 & 9 Dr. Kinga Lipskoch Fall 27 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be
CO2-3224 Computer Architecture and Programming Languages CAPL Lecture 8 & 9 Dr. Kinga Lipskoch Fall 27 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be
LECTURE 10. Pipelining: Advanced ILP
 LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
Updated Exercises by Diana Franklin
 C-82 Appendix C Pipelining: Basic and Intermediate Concepts Updated Exercises by Diana Franklin C.1 [15/15/15/15/25/10/15] Use the following code fragment: Loop: LD R1,0(R2) ;load R1 from address
C-82 Appendix C Pipelining: Basic and Intermediate Concepts Updated Exercises by Diana Franklin C.1 [15/15/15/15/25/10/15] Use the following code fragment: Loop: LD R1,0(R2) ;load R1 from address
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
mywbut.com Pipelining
 Pipelining 1 What Is Pipelining? Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. Today, pipelining is the key implementation technique used to make
Pipelining 1 What Is Pipelining? Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. Today, pipelining is the key implementation technique used to make
Computer Systems Architecture Spring 2016
 Computer Systems Architecture Spring 2016 Lecture 01: Introduction Shuai Wang Department of Computer Science and Technology Nanjing University [Adapted from Computer Architecture: A Quantitative Approach,
Computer Systems Architecture Spring 2016 Lecture 01: Introduction Shuai Wang Department of Computer Science and Technology Nanjing University [Adapted from Computer Architecture: A Quantitative Approach,
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified