Chapter 3. Pipelining. EE511 In-Cheol Park, KAIST
|
|
|
- Nathaniel Cummings
- 5 years ago
- Views:
Transcription



1 Chapter 3. Pipelining EE511 In-Cheol Park, KAIST
2 Terminology Pipeline stage Throughput Pipeline register Ideal speedup Assume The stages are perfectly balanced No overhead on pipeline registers Speedup = # of stages
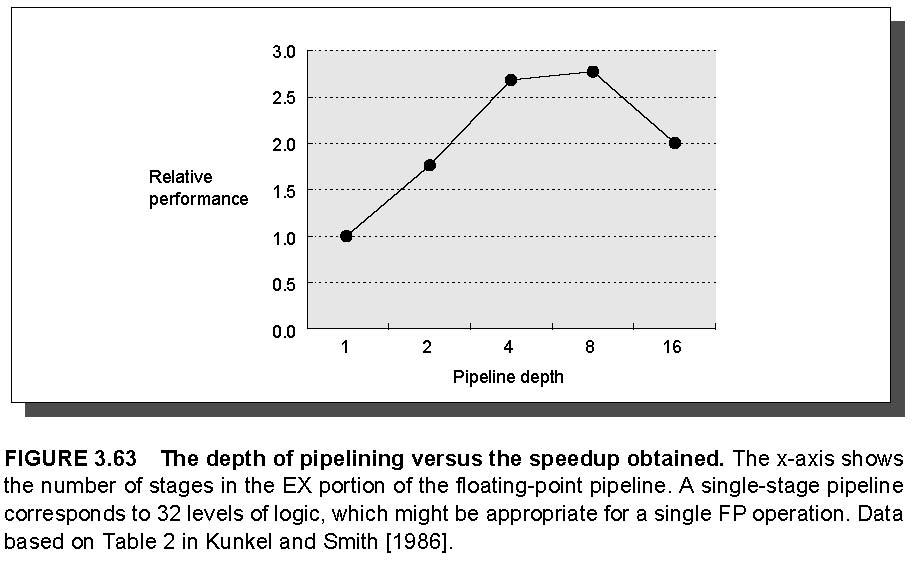
3
4 IF (Instruction fetch) ID (Instruction decode / Register fetch) EX (Execution / Effective address) MEM (Memory access / Branch completion) WB (Write-back) IF/ID ID/EX EX/MEM MEM/WB IF ID EX MEM WB
5

6
7
8
9 Hazards Prevent the next instruction from executing during its desired clock cycle pipeline stall Earlier instructions must continue, while later instructions are stalled Classes Structural Hazards Resource conflicts Data Hazards Data dependency Control Hazards Caused by instructions changing the PC such as branches
10 Functional unit conflict For example, not fully pipelined FU Memory access conflict For example, MEM and IF Solutions: Separate I$ and D$ Dual-port memory On-chip I$ Instruction queue Register file access conflict For example, ID and WB Solutions: Multi-port register file Time multiplexed R/W access
11
12
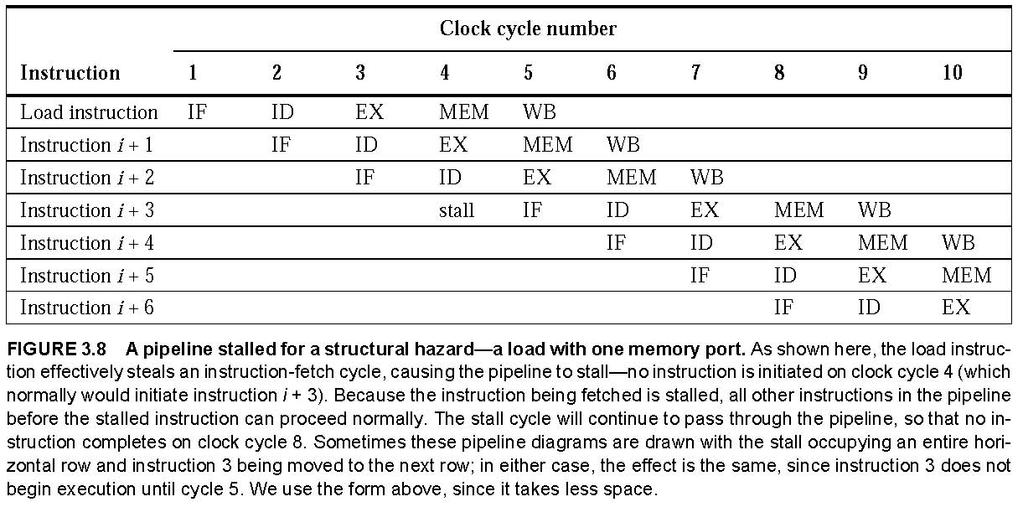
13
14 Data hazard classification RAW (True data dependency) Internal data forwarding To reduce forwarding logic, register file write is done before read Instruction scheduling Rearranges code sequence Delayed Load Insert a NOP if there is no proper instruction to be inserted into the delay slot WAR (Anti-dependency), WAW (Output dependency) Register renaming
15
16
17
18
19

20

21
22 Pipeline stalls until the new PC is available Branch delay Turns into a branch penalty Solutions Pipeline stalls when we find a branch instruction Fill with NOPs Rearrange code sequence Delayed branch To reduce the branch penalty Compute the branch instructions as early as possible Target, taken/not-taken Delayed branch / Squashed branch / Annulled branch Branch prediction
23
24

25

26

27
28
29

30
31
32
33 Static prediction at compile time Predict taken or predict not-taken as a whole Predict on the basis of branch direction Backward-going taken Forward-going not taken Profile-based prediction: Branch prediction for each individual branch instruction Individual branch instructions are highly biased Introduce a prediction bit in the instruction format Dynamic Prediction at run time
34

35
36 Exception / Interrupt Synchronous / Asynchronous User requested / Coerced User maskable / Nonmaskable Within / Between instructions Resume / Terminate Restartability almost all machines support Precise exception Restarting Execution 1. Force a trap instruction into the pipeline on the next IF 2. Turn off all writes for the faulting instructions and all following instructions in the pipeline, but not the preceding instructions 3. Save the PC of the faulting instruction
37
38
39 Initiation interval = repeat interval The number of cycles that must elapse between issuing two operations of a given type Latency The number of intervening cycles between an instruction that produces a result and an instruction that uses the result # of EX stages 1 Problems in longer latency pipelines Structural hazards Multiple register writes Stall before it issues Stall a conflicting instruction when it tries to enter the MEM stage
40

41
42
43
44 WAW hazards no longer reach WB in order Delay the issue of the later instruction Stamp out the result of the former instruction so that the instruction does not write its result Instructions can complete in an order different from that of issued (outof-order completion) Leads to imprecise exceptions RAW hazards are more frequent
45
46
47 Precise / Imprecise Precise exceptions Exception is checked at the WB stage Hardware posts all exceptions in a status vector which is carried along as the instruction goes down the pipeline Once an exception indication is set in the status vector, all writes are turned off
48 Ignore the problem and settle for imprecise exceptions Two operating modes Fast but imprecise / slower but precise Buffer the results of an instruction until all the instruction that were issued earlier are complete History file / future file Smith and Plezskun, Implementing precise interrupts in pipelined processors, IEEE Trans. Computes, 1988 Keep enough information so that the trap-handling routines can create a precise sequence for the exception Hwu and Patt, Check-point repair for out-of-order execution machines, ISCA 1987 Allows the instruction issue only if it is certain that all the instructions before the issuing instruction will complete without causing an exception
49
50
51 Variable instruction lengths and running times can lead to imbalance among pipeline stages Sometimes justify the added complexity cache Sophisticated addressing modes can complicate pipeline control and make it difficult to keep the pipeline flowing Writes into instruction space (self-modifying code) can cause trouble for pipelining Implicitly set condition codes increase the difficulty of finding when a branch has been decided and the difficulty of scheduling branch delays
52 Deeper integer pipeline 8 stages IF IS RF EX DF DS TC WB IF : First half of instruction fetch IS : Second half of instruction fetch, complete I$ access DF : First half of D$ access DS : Second half of data fetch, completion of D$ access TC : Tag check, determine whether the D$ access hit Two cycle load delay 3 cycle branch delay Single cycle delayed branch Predict-not-taken for the remaining two cycles If taken, two idle cycles
53
54
55
56
57
58 Pitfall: Unexpected execution sequences may cause unexpected hazards Pitfall: Extensive pipelining can impact other aspects of a design, leading to overall worse cost/performance Fallacy: Increasing the number of pipeline stages always increases performance Pitfall: Evaluating a compile-time scheduler on the basis of unoptimized code
Instruction Pipelining Review
 Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Instruction Pipelining Review Instruction pipelining is CPU implementation technique where multiple operations on a number of instructions are overlapped. An instruction execution pipeline involves a number
Minimizing Data hazard Stalls by Forwarding Data Hazard Classification Data Hazards Present in Current MIPS Pipeline
 Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Instruction Pipelining Review: MIPS In-Order Single-Issue Integer Pipeline Performance of Pipelines with Stalls Pipeline Hazards Structural hazards Data hazards Minimizing Data hazard Stalls by Forwarding
Predict Not Taken. Revisiting Branch Hazard Solutions. Filling the delay slot (e.g., in the compiler) Delayed Branch
 Delayed Branch") branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
branch taken Revisiting Branch Hazard Solutions Stall Predict Not Taken Predict Taken Branch Delay Slot Branch I+1 I+2 I+3 Predict Not Taken branch not taken Branch I+1 IF (bubble) (bubble) (bubble) (bubble)
ECE 486/586. Computer Architecture. Lecture # 12
 ECE 486/586 Computer Architecture Lecture # 12 Spring 2015 Portland State University Lecture Topics Pipelining Control Hazards Delayed branch Branch stall impact Implementing the pipeline Detecting hazards
ECE 486/586 Computer Architecture Lecture # 12 Spring 2015 Portland State University Lecture Topics Pipelining Control Hazards Delayed branch Branch stall impact Implementing the pipeline Detecting hazards
There are different characteristics for exceptions. They are as follows:
 e-pg PATHSHALA- Computer Science Computer Architecture Module 15 Exception handling and floating point pipelines The objectives of this module are to discuss about exceptions and look at how the MIPS architecture
e-pg PATHSHALA- Computer Science Computer Architecture Module 15 Exception handling and floating point pipelines The objectives of this module are to discuss about exceptions and look at how the MIPS architecture
CMCS Mohamed Younis CMCS 611, Advanced Computer Architecture 1
 CMCS 611-101 Advanced Computer Architecture Lecture 9 Pipeline Implementation Challenges October 5, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer Architecture
CMCS 611-101 Advanced Computer Architecture Lecture 9 Pipeline Implementation Challenges October 5, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer Architecture
LECTURE 10. Pipelining: Advanced ILP
 LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
LECTURE 10 Pipelining: Advanced ILP EXCEPTIONS An exception, or interrupt, is an event other than regular transfers of control (branches, jumps, calls, returns) that changes the normal flow of instruction
Appendix C: Pipelining: Basic and Intermediate Concepts
 Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
Appendix C: Pipelining: Basic and Intermediate Concepts Key ideas and simple pipeline (Section C.1) Hazards (Sections C.2 and C.3) Structural hazards Data hazards Control hazards Exceptions (Section C.4)
Instruction Level Parallelism. ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction
 Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
Instruction Level Parallelism ILP, Loop level Parallelism Dependences, Hazards Speculation, Branch prediction Basic Block A straight line code sequence with no branches in except to the entry and no branches
COSC4201 Pipelining. Prof. Mokhtar Aboelaze York University
 COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
COSC4201 Pipelining Prof. Mokhtar Aboelaze York University 1 Instructions: Fetch Every instruction could be executed in 5 cycles, these 5 cycles are (MIPS like machine). Instruction fetch IR Mem[PC] NPC
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3. Complications With Long Instructions
 CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study Complications With Long Instructions So far, all MIPS instructions take 5 cycles But haven't talked
Lecture 7: Pipelining Contd. More pipelining complications: Interrupts and Exceptions
 Lecture 7: Pipelining Contd. Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 More pipelining complications: Interrupts and Exceptions Hard to handle in pipelined
Lecture 7: Pipelining Contd. Kunle Olukotun Gates 302 kunle@ogun.stanford.edu http://www-leland.stanford.edu/class/ee282h/ 1 More pipelining complications: Interrupts and Exceptions Hard to handle in pipelined
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
Announcement. ECE475/ECE4420 Computer Architecture L4: Advanced Issues in Pipelining. Edward Suh Computer Systems Laboratory
 ECE475/ECE4420 Computer Architecture L4: Advanced Issues in Pipelining Edward Suh Computer Systems Laboratory suh@csl.cornell.edu Announcement Lab1 is released Start early we only have limited computing
ECE475/ECE4420 Computer Architecture L4: Advanced Issues in Pipelining Edward Suh Computer Systems Laboratory suh@csl.cornell.edu Announcement Lab1 is released Start early we only have limited computing
Pipeline Hazards. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Pipeline Hazards Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Hazards What are hazards? Situations that prevent starting the next instruction
Instr. execution impl. view
 Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Pipelining Sangyeun Cho Computer Science Department Instr. execution impl. view Single (long) cycle implementation Multi-cycle implementation Pipelined implementation Processing an instruction Fetch instruction
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard
 Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Data Hazards Compiler Scheduling Pipeline scheduling or instruction scheduling: Compiler generates code to eliminate hazard Consider: a = b + c; d = e - f; Assume loads have a latency of one clock cycle:
Anti-Inspiration. It s true hard work never killed anybody, but I figure, why take the chance? Ronald Reagan, US President
 Anti-Inspiration From pg. A-78 H&P It s true hard work never killed anybody, but I figure, why take the chance? Ronald Reagan, US President Hard work. Well, that s all right for people who don t know how
Anti-Inspiration From pg. A-78 H&P It s true hard work never killed anybody, but I figure, why take the chance? Ronald Reagan, US President Hard work. Well, that s all right for people who don t know how
Instruction Level Parallelism. Appendix C and Chapter 3, HP5e
 Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
Instruction Level Parallelism Appendix C and Chapter 3, HP5e Outline Pipelining, Hazards Branch prediction Static and Dynamic Scheduling Speculation Compiler techniques, VLIW Limits of ILP. Implementation
ECEC 355: Pipelining
 ECEC 355: Pipelining November 8, 2007 What is Pipelining Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. A pipeline is similar in concept to an assembly
ECEC 355: Pipelining November 8, 2007 What is Pipelining Pipelining is an implementation technique whereby multiple instructions are overlapped in execution. A pipeline is similar in concept to an assembly
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science Cases that affect instruction execution semantics
Midnight Laundry. IC220 Set #19: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life. Return to Chapter 4
 Life. Return to Chapter 4") IC220 Set #9: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Return to Chapter 4 Midnight Laundry Task order A B C D 6 PM 7 8 9 0 2 2 AM 2 Smarty Laundry Task order A B C D 6 PM
IC220 Set #9: Laundry, Co-dependency, and other Hazards of Modern (Architecture) Life Return to Chapter 4 Midnight Laundry Task order A B C D 6 PM 7 8 9 0 2 2 AM 2 Smarty Laundry Task order A B C D 6 PM
Pipelining. Principles of pipelining. Simple pipelining. Structural Hazards. Data Hazards. Control Hazards. Interrupts. Multicycle operations
 Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
Complications with long instructions. CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3. How slow is slow?
 Complications with long instructions CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study So far, all MIPS instructions take 5 cycles But haven't talked
Complications with long instructions CMSC 411 Computer Systems Architecture Lecture 6 Basic Pipelining 3 Long Instructions & MIPS Case Study So far, all MIPS instructions take 5 cycles But haven't talked
Basic Pipelining Concepts
 Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
Basic ipelining oncepts Appendix A (recommended reading, not everything will be covered today) Basic pipelining ipeline hazards Data hazards ontrol hazards Structural hazards Multicycle operations Execution
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Computer Architecture Spring 2016 Lecture 02: Introduction II Shuai Wang Department of Computer Science and Technology Nanjing University Pipeline Hazards Major hurdle to pipelining: hazards prevent the
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
Thoai Nam Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy & David a Patterson,
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Computer Architecture Instruction Level Parallelism Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson /
CMSC 611: Advanced Computer Architecture Instruction Level Parallelism Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson /
ECE 505 Computer Architecture
 ECE 505 Computer Architecture Pipelining 2 Berk Sunar and Thomas Eisenbarth Review 5 stages of RISC IF ID EX MEM WB Ideal speedup of pipelining = Pipeline depth (N) Practically Implementation problems
ECE 505 Computer Architecture Pipelining 2 Berk Sunar and Thomas Eisenbarth Review 5 stages of RISC IF ID EX MEM WB Ideal speedup of pipelining = Pipeline depth (N) Practically Implementation problems
ELE 655 Microprocessor System Design
 ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
ELE 655 Microprocessor System Design Section 2 Instruction Level Parallelism Class 1 Basic Pipeline Notes: Reg shows up two places but actually is the same register file Writes occur on the second half
(Basic) Processor Pipeline
 Processor Pipeline") (Basic) Processor Pipeline Nima Honarmand Generic Instruction Life Cycle Logical steps in processing an instruction: Instruction Fetch (IF_STEP) Instruction Decode (ID_STEP) Operand Fetch (OF_STEP) Might
(Basic) Processor Pipeline Nima Honarmand Generic Instruction Life Cycle Logical steps in processing an instruction: Instruction Fetch (IF_STEP) Instruction Decode (ID_STEP) Operand Fetch (OF_STEP) Might
CMCS Mohamed Younis CMCS 611, Advanced Computer Architecture 1
 CMCS 611-101 Advanced Computer Architecture Lecture 8 Control Hazards and Exception Handling September 30, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer
CMCS 611-101 Advanced Computer Architecture Lecture 8 Control Hazards and Exception Handling September 30, 2009 www.csee.umbc.edu/~younis/cmsc611/cmsc611.htm Mohamed Younis CMCS 611, Advanced Computer
1 Hazards COMP2611 Fall 2015 Pipelined Processor
 1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
1 Hazards Dependences in Programs 2 Data dependence Example: lw $1, 200($2) add $3, $4, $1 add can t do ID (i.e., read register $1) until lw updates $1 Control dependence Example: bne $1, $2, target add
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Appendix C. Instructor: Josep Torrellas CS433. Copyright Josep Torrellas 1999, 2001, 2002,
 Appendix C Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Pipelining Multiple instructions are overlapped in execution Each is in a different stage Each stage is called
Appendix C Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Pipelining Multiple instructions are overlapped in execution Each is in a different stage Each stage is called
Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome
 Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
Pipeline Thoai Nam Outline Pipelining concepts The DLX architecture A simple DLX pipeline Pipeline Hazards and Solution to overcome Reference: Computer Architecture: A Quantitative Approach, John L Hennessy
Lecture 4: Advanced Pipelines. Data hazards, control hazards, multi-cycle in-order pipelines (Appendix A.4-A.10)
") Lecture 4: Advanced Pipelines Data hazards, control hazards, multi-cycle in-order pipelines (Appendix A.4-A.10) 1 Hazards Structural hazards: different instructions in different stages (or the same stage)
Lecture 4: Advanced Pipelines Data hazards, control hazards, multi-cycle in-order pipelines (Appendix A.4-A.10) 1 Hazards Structural hazards: different instructions in different stages (or the same stage)
Advanced Parallel Architecture Lessons 5 and 6. Annalisa Massini /2017
 Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Advanced Parallel Architecture Lessons 5 and 6 Annalisa Massini - Pipelining Hennessy, Patterson Computer architecture A quantitive approach Appendix C Sections C.1, C.2 Pipelining Pipelining is an implementation
Lecture 9. Pipeline Hazards. Christos Kozyrakis Stanford University
 Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
Multi-cycle Instructions in the Pipeline (Floating Point)
") Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
Lecture 6 Multi-cycle Instructions in the Pipeline (Floating Point) Introduction to instruction level parallelism Recap: Support of multi-cycle instructions in a pipeline (App A.5) Recap: Superpipelining
COMP 4211 Seminar Presentation
 COMP Seminar Presentation Based On: Computer Architecture A Quantitative Approach by Hennessey and Patterson Presenter : Feri Danes Outline Exceptions Handling Floating Points Operations Case Study: MIPS
COMP Seminar Presentation Based On: Computer Architecture A Quantitative Approach by Hennessey and Patterson Presenter : Feri Danes Outline Exceptions Handling Floating Points Operations Case Study: MIPS
ECE154A Introduction to Computer Architecture. Homework 4 solution
 ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
ECE154A Introduction to Computer Architecture Homework 4 solution 4.16.1 According to Figure 4.65 on the textbook, each register located between two pipeline stages keeps data shown below. Register IF/ID
HY425 Lecture 05: Branch Prediction
 HY425 Lecture 05: Branch Prediction Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS October 19, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 05: Branch Prediction 1 / 45 Exploiting ILP in hardware
HY425 Lecture 05: Branch Prediction Dimitrios S. Nikolopoulos University of Crete and FORTH-ICS October 19, 2011 Dimitrios S. Nikolopoulos HY425 Lecture 05: Branch Prediction 1 / 45 Exploiting ILP in hardware
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Computer Architecture
 Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Lecture 3: Pipelining Iakovos Mavroidis Computer Science Department University of Crete 1 Previous Lecture Measurements and metrics : Performance, Cost, Dependability, Power Guidelines and principles in
Pipelining: Hazards Ver. Jan 14, 2014
 POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
POLITECNICO DI MILANO Parallelism in wonderland: are you ready to see how deep the rabbit hole goes? Pipelining: Hazards Ver. Jan 14, 2014 Marco D. Santambrogio: marco.santambrogio@polimi.it Simone Campanoni:
What is Pipelining? Time per instruction on unpipelined machine Number of pipe stages
 What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
What is Pipelining? Is a key implementation techniques used to make fast CPUs Is an implementation techniques whereby multiple instructions are overlapped in execution It takes advantage of parallelism
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESI
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count Determined by ISA and compiler
COSC 6385 Computer Architecture - Pipelining (II)
") COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
COSC 6385 Computer Architecture - Pipelining (II) Edgar Gabriel Spring 2018 Performance evaluation of pipelines (I) General Speedup Formula: Time Speedup Time IC IC ClockCycle ClockClycle CPI CPI For a
Chapter3 Pipelining: Basic Concepts
 Chapter3 Pipelining: Basic Concepts Part4 Extend 5-stage Pipeline To Multiple-cycle operations Exception in pipeline ComputerArchitecture Extending the MIPS pipeline to handle MultiCycle Operations Alternative
Chapter3 Pipelining: Basic Concepts Part4 Extend 5-stage Pipeline To Multiple-cycle operations Exception in pipeline ComputerArchitecture Extending the MIPS pipeline to handle MultiCycle Operations Alternative
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Lecture 9: Case Study MIPS R4000 and Introduction to Advanced Pipelining Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.SP96 1 Review: Evaluating Branch Alternatives Two part solution: Determine
Lecture Topics. Announcements. Today: Data and Control Hazards (P&H ) Next: continued. Exam #1 returned. Milestone #5 (due 2/27)
 Next: continued. Exam #1 returned. Milestone #5 (due 2/27)") Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Lecture Topics Today: Data and Control Hazards (P&H 4.7-4.8) Next: continued 1 Announcements Exam #1 returned Milestone #5 (due 2/27) Milestone #6 (due 3/13) 2 1 Review: Pipelined Implementations Pipelining
Instruction Pipelining
 Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Appendix A. Overview
 Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 1 Unpipelined
Appendix A Pipelining: Basic and Intermediate Concepts 1 Overview Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 2 1 Unpipelined
Overview. Appendix A. Pipelining: Its Natural! Sequential Laundry 6 PM Midnight. Pipelined Laundry: Start work ASAP
 Overview Appendix A Pipelining: Basic and Intermediate Concepts Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 1 2 Unpipelined
Overview Appendix A Pipelining: Basic and Intermediate Concepts Basics of Pipelining Pipeline Hazards Pipeline Implementation Pipelining + Exceptions Pipeline to handle Multicycle Operations 1 2 Unpipelined
zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture.
 zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture. We have already discussed in the previous module that true
zhandling Data Hazards The objectives of this module are to discuss how data hazards are handled in general and also in the MIPS architecture. We have already discussed in the previous module that true
ECE/CS 552: Pipeline Hazards
 ECE/CS 552: Pipeline Hazards Prof. Mikko Lipasti Lecture notes based in part on slides created by Mark Hill, David Wood, Guri Sohi, John Shen and Jim Smith Pipeline Hazards Forecast Program Dependences
ECE/CS 552: Pipeline Hazards Prof. Mikko Lipasti Lecture notes based in part on slides created by Mark Hill, David Wood, Guri Sohi, John Shen and Jim Smith Pipeline Hazards Forecast Program Dependences
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Pipelining, Instruction Level Parallelism and Memory in Processors. Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010
 Pipelining, Instruction Level Parallelism and Memory in Processors Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010 NOTE: The material for this lecture was taken from several
Pipelining, Instruction Level Parallelism and Memory in Processors Advanced Topics ICOM 4215 Computer Architecture and Organization Fall 2010 NOTE: The material for this lecture was taken from several
MIPS An ISA for Pipelining
 Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Pipelining: Basic and Intermediate Concepts Slides by: Muhamed Mudawar CS 282 KAUST Spring 2010 Outline: MIPS An ISA for Pipelining 5 stage pipelining i Structural Hazards Data Hazards & Forwarding Branch
Instruction Pipelining
 Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
Instruction Pipelining Simplest form is a 3-stage linear pipeline New instruction fetched each clock cycle Instruction finished each clock cycle Maximal speedup = 3 achieved if and only if all pipe stages
DLX Unpipelined Implementation
 LECTURE - 06 DLX Unpipelined Implementation Five cycles: IF, ID, EX, MEM, WB Branch and store instructions: 4 cycles only What is the CPI? F branch 0.12, F store 0.05 CPI0.1740.83550.174.83 Further reduction
LECTURE - 06 DLX Unpipelined Implementation Five cycles: IF, ID, EX, MEM, WB Branch and store instructions: 4 cycles only What is the CPI? F branch 0.12, F store 0.05 CPI0.1740.83550.174.83 Further reduction
Thomas Polzer Institut für Technische Informatik
 Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
Thomas Polzer tpolzer@ecs.tuwien.ac.at Institut für Technische Informatik Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =
EITF20: Computer Architecture Part2.2.1: Pipeline-1
 EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
EITF20: Computer Architecture Part2.2.1: Pipeline-1 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Pipelining Harzards Structural hazards Data hazards Control hazards Implementation issues Multi-cycle
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Modern Computer Architecture
 Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Modern Computer Architecture Lecture2 Pipelining: Basic and Intermediate Concepts Hongbin Sun 国家集成电路人才培养基地 Xi an Jiaotong University Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Lecture 6 MIPS R4000 and Instruction Level Parallelism. Computer Architectures S
 Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
Lecture 6 MIPS R4000 and Instruction Level Parallelism Computer Architectures 521480S Case Study: MIPS R4000 (200 MHz, 64-bit instructions, MIPS-3 instruction set) 8 Stage Pipeline: first half of fetching
CPE Computer Architecture. Appendix A: Pipelining: Basic and Intermediate Concepts
 CPE 110408443 Computer Architecture Appendix A: Pipelining: Basic and Intermediate Concepts Sa ed R. Abed [Computer Engineering Department, Hashemite University] Outline Basic concept of Pipelining The
CPE 110408443 Computer Architecture Appendix A: Pipelining: Basic and Intermediate Concepts Sa ed R. Abed [Computer Engineering Department, Hashemite University] Outline Basic concept of Pipelining The
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
Computer Systems Architecture I. CSE 560M Lecture 5 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 5 Prof. Patrick Crowley Plan for Today Note HW1 was assigned Monday Commentary was due today Questions Pipelining discussion II 2 Course Tip Question 1:
Computer Systems Architecture I CSE 560M Lecture 5 Prof. Patrick Crowley Plan for Today Note HW1 was assigned Monday Commentary was due today Questions Pipelining discussion II 2 Course Tip Question 1:
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
ECE 2300 Digital Logic & Computer Organization. More Caches Measuring Performance
 ECE 23 Digital Logic & Computer Organization Spring 28 More s Measuring Performance Announcements HW7 due tomorrow :59pm Prelab 5(c) due Saturday 3pm Lab 6 (last one) released HW8 (last one) to be released
ECE 23 Digital Logic & Computer Organization Spring 28 More s Measuring Performance Announcements HW7 due tomorrow :59pm Prelab 5(c) due Saturday 3pm Lab 6 (last one) released HW8 (last one) to be released
The Processor (3) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (3) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
CS 2506 Computer Organization II Test 2
 Instructions: Print your name in the space provided below. This examination is closed book and closed notes, aside from the permitted one-page formula sheet. No calculators or other computing devices may
Instructions: Print your name in the space provided below. This examination is closed book and closed notes, aside from the permitted one-page formula sheet. No calculators or other computing devices may
Slide Set 8. for ENCM 501 in Winter Steve Norman, PhD, PEng
 Slide Set 8 for ENCM 501 in Winter 2018 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary March 2018 ENCM 501 Winter 2018 Slide Set 8 slide
Slide Set 8 for ENCM 501 in Winter 2018 Steve Norman, PhD, PEng Electrical & Computer Engineering Schulich School of Engineering University of Calgary March 2018 ENCM 501 Winter 2018 Slide Set 8 slide
Instruction word R0 R1 R2 R3 R4 R5 R6 R8 R12 R31
 4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
Pipeline Overview. Dr. Jiang Li. Adapted from the slides provided by the authors. Jiang Li, Ph.D. Department of Computer Science
 Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
Pipeline Overview Dr. Jiang Li Adapted from the slides provided by the authors Outline MIPS An ISA for Pipelining 5 stage pipelining Structural and Data Hazards Forwarding Branch Schemes Exceptions and
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
ECE232: Hardware Organization and Design Lecture 17: Pipelining Wrapup Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Outline The textbook includes lots of information Focus on
COSC4201. Prof. Mokhtar Aboelaze York University
 COSC4201 Chapter 3 Multi Cycle Operations Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RTI) 1 Multicycle Operations More than one function unit, each
COSC4201 Chapter 3 Multi Cycle Operations Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RTI) 1 Multicycle Operations More than one function unit, each
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
ECE260: Fundamentals of Computer Engineering
 Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
Pipelining James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy What is Pipelining? Pipelining
Appendix C. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Appendix C Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure C.2 The pipeline can be thought of as a series of data paths shifted in time. This shows
Appendix C Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure C.2 The pipeline can be thought of as a series of data paths shifted in time. This shows
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Outline. A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception
 hazards Exception") Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Outline A pipelined datapath Pipelined control Data hazards and forwarding Data hazards and stalls Branch (control) hazards Exception 1 4 Which stage is the branch decision made? Case 1: 0 M u x 1 Add
Lecture 2: Pipelining Basics. Today: chapter 1 wrap-up, basic pipelining implementation (Sections A.1 - A.4)
") Lecture 2: Pipelining Basics Today: chapter 1 wrap-up, basic pipelining implementation (Sections A.1 - A.4) 1 Defining Fault, Error, and Failure A fault produces a latent error; it becomes effective when
Lecture 2: Pipelining Basics Today: chapter 1 wrap-up, basic pipelining implementation (Sections A.1 - A.4) 1 Defining Fault, Error, and Failure A fault produces a latent error; it becomes effective when
Floating Point/Multicycle Pipelining in DLX
 Floating Point/Multicycle Pipelining in DLX Completion of DLX EX stage floating point arithmetic operations in one or two cycles is impractical since it requires: A much longer CPU clock cycle, and/or
Floating Point/Multicycle Pipelining in DLX Completion of DLX EX stage floating point arithmetic operations in one or two cycles is impractical since it requires: A much longer CPU clock cycle, and/or
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards
 CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 6 - Hazards Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Lecture: Pipeline Wrap-Up and Static ILP
 Lecture: Pipeline Wrap-Up and Static ILP Topics: multi-cycle instructions, precise exceptions, deep pipelines, compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Multicycle
Lecture: Pipeline Wrap-Up and Static ILP Topics: multi-cycle instructions, precise exceptions, deep pipelines, compiler scheduling, loop unrolling, software pipelining (Sections C.5, 3.2) 1 Multicycle
Chapter 4 The Processor 1. Chapter 4B. The Processor
 Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Chapter 4 The Processor 1 Chapter 4B The Processor Chapter 4 The Processor 2 Control Hazards Branch determines flow of control Fetching next instruction depends on branch outcome Pipeline can t always
Advanced issues in pipelining
 Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Advanced issues in pipelining 1 Outline Handling exceptions Supporting multi-cycle operations Pipeline evolution Examples of real pipelines 2 Handling exceptions 3 Exceptions In pipelined execution, one
Pipelining. Principles of pipelining. Simple pipelining. Structural Hazards. Data Hazards. Control Hazards. Interrupts. Multicycle operations
 Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
Principles of pipelining Pipelining Simple pipelining Structural Hazards Data Hazards Control Hazards Interrupts Multicycle operations Pipeline clocking ECE D52 Lecture Notes: Chapter 3 1 Sequential Execution
Improve performance by increasing instruction throughput
 Improve performance by increasing instruction throughput Program execution order Time (in instructions) lw $1, 100($0) fetch 2 4 6 8 10 12 14 16 18 ALU Data access lw $2, 200($0) 8ns fetch ALU Data access
Improve performance by increasing instruction throughput Program execution order Time (in instructions) lw $1, 100($0) fetch 2 4 6 8 10 12 14 16 18 ALU Data access lw $2, 200($0) 8ns fetch ALU Data access