Depth-aware CNN for RGB-D Segmentation
|
|
|
- Clinton Benson
- 5 years ago
- Views:
Transcription
1 Depth-aware CNN for RGB-D Segmentation Weiyue Wang [ ] and Ulrich Neumann University of Southern California, Los Angeles, California Abstract. Convolutional neural networks(cnn) are limited by the lack of capability to handle geometric information due to the fixed grid kernel structure. The availability of depth data enables progress in RGB-D semantic segmentation with CNNs. State-of-the-art methods either use depth as additional images or process spatial information in 3D volumes or point clouds. These methods suffer from high computation and memory cost. To address these issues, we present Depth-aware CNN by introducing two intuitive, flexible and effective operations: depth-aware convolution and depth-aware average pooling. By leveraging depth similarity between pixels in the process of information propagation, geometry is seamlessly incorporated into CNN. Without introducing any additional parameters, both operators can be easily integrated into existing CNNs. Extensive experiments and ablation studies on challenging RGB-D semantic segmentation benchmarks validate the effectiveness and flexibility of our approach. Keywords: Geometry in CNN, RGB-D Semantic Segmentation 1 Introduction Recent advances [29,37,4] in CNN have achieved significant success in scene understanding. With the help of range sensors (such as Kinect, LiDAR etc.), depth images are applicable along with RGB images. Taking advantages of the two complementary modalities with CNN is able to improve the performance of scene understanding. However, CNN is limited to model geometric variance due to the fixed grid computation structure. Incorporating the geometric information from depth images into CNN is important yet challenging. Extensive studies [27,5,17,22,28,6,35] have been carried out on this task. FCN [29] and its successors treat depth as another input image and construct two CNNs to process RGB and depth separately. This doubles the number of network parameters and computation cost. In addition, the two-stream network architecture still suffers from the fixed geometric structures of CNN. Even if the geometric relations of two pixels are given, this relation cannot be used in information propagation of CNN. An alternative is to leverage 3D networks [27,32,34] to handle geometry. Nevertheless, both volumetric CNNs[32] and 3D point cloud graph networks [27] are computationally more expensive than 2D CNN. Despite the encouraging results of these progresses, we need to seek a more flexible and efficient way to exploit 3D geometric information in 2D CNN.

, for RGB-D segmentation.")


2 2 Wang and Neumann Depth-Aware Convolution RGB A B C Ground Truth A B C Depth Depth-aware CNN Fig.1. Illustration of Depth-aware CNN. A and C are labeled as table and B is labeled as chair. They all have similar visual features in the RGB image, while they are separable in depth. Depth-aware CNN incorporate the geometric relations of pixels in both convolution and pooling. When A is the center of the receptive field, C then has more contribution to the output unit than B. Figures in the rightmost column shows the RGB-D semantic segmentation result of Depth-aware CNN. To address the aforementioned problems, in this paper, we present an end-toend network, Depth-aware CNN (D-CNN), for RGB-D segmentation. Two new operators are introduced: depth-aware convolution and depth-aware average pooling. Depth-aware convolution augments the standard convolution with a depth similarity term. We force pixels with similar depths with the center of the kernel to have more contribution to the output than others. This simple depth similarity term efficiently incorporates geometry in a convolution kernel and helps build a depth-aware receptive field, where convolution is not constrained to the fixed grid geometric structure. The second introduced operator is depth-ware average pooling. Similarly, when a filter is applied on a local region of the feature map, the pairwise relations in depth between neighboring pixels are considered in computing mean of the local region. Visual features are able to propagate along with the geometric structure given in depth images. Such geometry-aware operation enables the localization of object boundaries with depth images. Both operators are based on the intuition that pixels with the same semantic label and similar depths should have more impact on each other. We observe that two pixels with the same semantic labels have similar depths. As illustrated in Figure 1, pixel A and pixel C should be more correlated with each other than pixel A and pixel B. This correlation difference is obvious in depth image while it is not captured in RGB image. By encoding the depth correlation in CNN, pixel C has more contribution to the output unit than pixel B in the process of information propagation. The main advantages of depth-aware CNN are summarized as follows: By exploiting the nature of CNN kernel handling spatial information, geometry in depth image is able to be integrated into CNN seamlessly.
3 Depth-aware CNN for RGB-D Segmentation 3 Depth-aware CNN does not introduce any parameters and computation complexity to the conventional CNN. Both depth-aware convolution and depth-ware average pooling can replace their standard counterparts in conventional CNNs with minimal cost. Depth-aware CNN is a general framework that bonds 2D CNN and 3D geometry. Comparison with the state-of-the-art methods and extensive ablation studies on RGB-D semantic segmentation illustrate the flexibility, efficiency and effectiveness of our approach. 2 Related Works 2.1 RGB-D Semantic Segmentation With the help of CNNs, semantic segmentation on 2D images have achieved promising results [29,37,4,14]. These advances in 2D CNN and the availability of depth sensors enables progresses in RGB-D segmentation. Compared to the RGB settings, RGB-D segmentation is able to integrate geometry into scene understanding. In[8,21,10,33], depth is simply treated as additional channels and directly fed into CNN. Several works[29,10,9,18,24] encode depth to HHA image, which has three channels: horizontal disparity, height above ground, and norm angle. RGB image and HHA image are fed into two separate networks, and the two predictions are summed up in the last layer. The two-stream network doubles the number of parameters and forward time compared to the conventional 2D network. Moreover, CNNs per se are limited in their ability to model geometric transformations due to their fixed grid computation. Cheng et al. [5] propose a locality-sensitive deconvolution network with gated fusion. They build a feature affinity matrix to perform weighted average pooling and unpooling. Lin et al.[19] discretize depth and build different branches for different discrete depth value. He et al. [12] use spatio-temporal correspondences across frames to aggregate information over space and time. This requires heavy pre and post-processing such as optical flow and superpixel computation. Alternatively, many works [32,31] attempt to solve the problem with 3D CNNs. However, the volumetric representation prevents scaling up due to high memory and computation cost. Recently, deep learning frameworks[27,25,26,36,13] on point cloud are introduced to address the limitations of 3D volume. Qi et al. [27] built a 3D k-nearest neighbor (knn) graph neural network on a point cloud with extracted features from a CNN and achieved the state-of-the-art on RGB-D segmentation. Although their method is more efficient than 3D CNNs, the knn operation suffers from high computation complexity and lack of flexibility. Instead of using 3D representations, we use the raw depth input and integrate 3D geometry into 2D CNN in a more efficient and flexible fashion. 2.2 Spatial Transformations in CNN Standard CNNs are limited to model geometric transformations due to the fixed structure of convolution kernels. Recently, many works are focused on dealing with this issue. Dilated convolutions [37,4] increases the receptive field size with
4 4 Wang and Neumann keeping the same complexity in parameters. This operator achieves better performance on vision tasks such as semantic segmentation. Spatial transform networks [15] warps feature maps with a learned global spatial transformation. Deformable CNN [7] learns kernel offsets to augment the spatial sampling locations. These methods have shown geometric transformations enable performance boost on different vision tasks. With the advances in 3D sensors, depth is applicable at low cost. The geometric information that resides in depth is highly correlated with the spatial transformation in CNN. Bilateral filters [3,2] is widely used in computer graphics for image smoothness with edge preserving. They use a Gaussian term to weight neighboring pixels. Similarly as bilateral filter, our method integrates the geometric relation of pixels into basic operations of CNN, i.e. convolution and pooling, where we use a weighted kernel and force every neuron to have different contributions to the output. This weighted kernel is defined by depth and is able to incorporate geometric relationships without introducing any parameter. 3 Depth-aware CNN In this section, we introduce two depth-aware operations: depth-aware convolution and depth-aware average pooling. They are both simple and intuitive. Both operations require two inputs: the input feature map x R ci h w and the depth image D R h w, where c i is the number of input feature channels, h is the height and w is the width. The output feature map is denoted as y R co h w, where c o is the number of output feature channels. Although x and y are both 3D tensors, the operations are explained in 2D spatial domain for notation clarity and they remain the same across different channels. Depth Depth Similarity Depth Depth Similarity Input Feature * Conv Kernel Input Feature (a) Depth-aware Convolution (b) Depth-aware Average Pooling Fig. 2. Illustration of information propagation in Depth-aware CNN. Without loss of generality, we only show one filter window with kernel size 3 3. In depth similarity shown in figure, darker color indicates higher similarity while lighter color represents that two pixels are less similar in depth. In (a), the output activation of depth-aware convolution is the multiplication of depth similarity window and the convolved window on input feature map. Similarly in (b), the output of depth-aware average pooling is the average value of the input window weighted by the depth similarity. 3.1 Depth-aware Convolution A standard 2D convolution operation is the weighted sum of a local grid. For each pixel location p 0 on y, the output of standard 2D convolution is
5 Depth-aware CNN for RGB-D Segmentation 5 y(p 0 ) = p n R w(p n ) x(p 0 +p n ), (1) where R is the local grid around p 0 in x and w is the convolution kernel. R can be a regular grid defined by kernel size and dilation [37], and it can also be a non-regular grid [7]. As is shown in Figure 1, pixel A and pixel B have different semantic labels and different depths while they are not separable in RGB space. On the other hand, pixel A and pixel C have the same labels and similar depths. To exploit the depth correlation between pixels, depth-aware convolution simply adds a depth similarity term, resulting in two sets of weights in convolution: 1) the learnable convolution kernel w; 2) depth similarity F D between two pixels. Consequently, Equ. 1 becomes y(p 0 ) = p n R And F D (p i,p j ) is defined as w(p n ) F D (p 0,p 0 +p n ) x(p 0 +p n ). (2) F D (p i,p j ) = exp( α D(p i ) D(p j ) ), (3) where α is a constant. The selection of F D is based on the intuition that pixels with similar depths should have more impact on each other. We will study the effect of different α and different F D in Section 4.2. The gradients for x and w are simply multiplied by F D. Note that the F D part does not require gradient during back-propagation, therefore, Equ. 2 does not integrate any parameters by the depth similarity term. Figure 2(a) illustrates this process. Pixels which have similar depths with the convolving center will have more impact on the output during convolution. 3.2 Depth-aware Average Pooling The conventional average pooling computes the mean of a grid R over x. It is defined as y(p 0 ) = 1 R p n R x(p 0 +p n ). (4) It treats every pixel equally and will make the object boundary blurry. Geometric information is useful to address this issue. Similar to as in depth-aware convolution, we take advantage of the depth similarity F D to force pixels with more consistent geometry to make more contribution on the corresponding output. For each pixel location p 0, the depth-aware average pooling operation then becomes 1 y(p 0 ) = p F F D (p 0,p 0 +p n ) x(p 0 +p n ). (5) n R D(p 0,p 0 +p n ) p n R
6 6 Wang and Neumann F The gradient should be multiplied by D pn R F D(p 0,p 0+p n) during back propagation. As illustrated in Figure 2(b), this operation prevent suffering from the fixed geometric structure of standard pooling. 3.3 Understanding Depth-aware CNN A major advantage of CNN is its capability of using GPU to perform parallel computing and accelerate the computation. This acceleration mainly stems from unrolling convolution operation with the grid computation structure. However, this limits the ability of CNN to model geometric variations. Researchers in 3D deep learning have focused on modeling geometry in deep neural networks in the last few years. As the volumetric representation [32,31] is of high memory and computation cost, point clouds are considered as a more proper representation. However, deep learning frameworks [26,27] on point cloud are based on building knn. This not only suffers from high computation complexity, but also breaks the pixel-wise correspondence between RGB and depth, which makes the framework is not able to leverage the efficiency of CNN s grid computation structure. Instead of operating on 3D data, we exploit the raw depth input. By augmenting the convolution kernel with a depth similarity term, depth-aware CNN captures geometry with transformable receptive field. Wall Floor Bed Chair Table All Variance Table 1. Mean depth variance of different categories on NYUv2 dataset. All denotes the mean variance of all categories. For every image, pixelwise variance of depth for each category is calculated. Averaged variance is then computed over all images. For All, all pixels in a image are considered to calculate the depth variance. Mean variance over all images is further computed. Many works have studied spatial transformable receptive field of CNN. Dilated convolution [4,37] has demonstrated that increasing receptive field boost the performance of networks. In deformable CNN [7], Dai et al. demonstrate that learning receptive field adaptively can help CNN achieve better results. They also show that pixels within the same object in a receptive field contribute more to the output unit than pixels with different labels. We observe that semantic labels and depths have high correlations. Table 1 reports the statistics of pixel depth variance within the same class and across different classes on NYUv2 [23] dataset. Even the pixel depth variances of large objects such as wall and floor are much smaller than the variance of a whole scene. This indicates that pixels with the same semantic labels tend to have similar depths. This pattern is integrated in Equ. 2 and Equ. 5 with F D. Without introducing any parameter, depth-aware convolution and depthaware average pooling are able to enhance the localization ability of CNN. We evaluate the impact on performance of different depth similarity functions F D in Section 4.2. To get a better understanding of how depth-aware CNN captures geometry with depth, Figure 3 shows the effective receptive field of the given input neuron. In conventional CNN, the receptive fields and sampling locations are fixed across feature map. With the depth-aware term incorporated, they are ad-
, the green point is labeled as chair and the effective receptive field of the green point are essentially chair points.")
 is the input RGB images. (b), (c) and (d) are depth images.")
. 3.4 Depth-aware CNN for RGB-D Semantic Segmentation In this paper, we focus on RGB-D semantic segmentation with depth-aware CNN.")

7 Depth-aware CNN for RGB-D Segmentation 7 justed by the geometric variance. For example, in the second row of Figure 3(d), the green point is labeled as chair and the effective receptive field of the green point are essentially chair points. This indicates that the effective receptive field mostly have the same semantic label as the center. This pattern increases CNN s performance on semantic segmentation. (a) (b) (c) (d) Fig. 3. Illustration of effective receptive field of Depth-aware CNN. (a) is the input RGB images. (b), (c) and (d) are depth images. For (b), (c) and (d), we show the sampling locations (red dots) in three levels of 3 3 depth-aware convolutions for the activation unit (green dot). 3.4 Depth-aware CNN for RGB-D Semantic Segmentation In this paper, we focus on RGB-D semantic segmentation with depth-aware CNN. Given an RGB image along with depth, our goal is to produce a semantic mask indicating the label of each pixel. Both depth-aware convolution and average pooling easily replace their counterpart in standard CNN. layer name conv1 x conv2 x conv3 x conv4 x conv5 x conv6 & conv7 C C C C C C Baseline C C C C C C DeepLab maxpool maxpool C C C globalpool+concat maxpool maxpool avgpool DC DC DC DC DC DC C C C C C C D-CNN maxpool maxpool C C C globalpool+concat maxpool maxpool Davgpool Table 2. Network architecture. DeepLab is our baseline with a modified version of VGG-16 as the encoder. The convolution layer parameters are denoted as C[kernel size]-[number of channels]-[dilation]. DC and Davgpool represent depth-aware convolution and depth-aware average pooling respectively. DeepLab[4] is a state-of-the-art method for semantic segmentation. We adopt DeepLab as our baseline for semantic segmentation and a modified VGG-16 network is used as the encoder. We replace layers in this network with depthaware operations. The network configurations of the baseline and depth-aware CNN are outlined in Table 2. Suppose conv7 has C channels. Following [27], global pooling is used to compute a C-dim vector from conv7. This vector is
8 8 Wang and Neumann then appended to all spatial positions and results in a 2C-channel feature map. This feature map is followed by a 1 1 conv layer and produce the segmentation probability map. 4 Experiments Evaluation is performed on three popular RGB-D datasets: NYUv2 [23]: NYUv2 contains of 1, 449 RGB-D images with pixel-wise labels. We follow the 40-class settings and the standard split with 795 training images and 654 testing images. SUN-RGBD [30,16]: This dataset have 37 categories of objects and consists of 10,335 RGB-D images, with 5,285 as training and 5050 as testing. Stanford Indoor Dataset (SID) [1]: SID contains 70, 496 RGB-D images with 13 object categories. We use Area 1,2,3,4 and 6 as training, and Area 5 as testing. Four common metrics are used for evaluation: pixel accuracy (Acc), mean pixel accuracy of different categories (macc), mean Intersection-over-Union of different categories (miou), and frequency-weighted IoU (fwiou). Suppose n ij is the number of pixels with ground truth class i and predicted as class j, n C is the number of classes and s i is the number of pixels with ground truth class i, the total number of all pixels is s = i s i. The four metrics are defined as follows: Acc = i = 1 s i s n ii is i+ nji nii. j n ii s, macc = 1 n C i n ii s i, miou = 1 n C i n ii s i+ j nji nii, fwiou Implementation Details For most experiments, DeepLab with a modified VGG-16 encoder (c.f. Table 2) is the baseline. Depth-aware CNN based on DeepLab outlined in Table 2 is evaluated to validate the effectiveness of our approach and this is referred as D-CNN in the paper. We also conduct experiments with combining HHA encoding [9]. Following [29,27,8], two baseline networks consume RGB and HHA images separately and the predictions of both networks are summed up in the last layer. This two-stream network is dubbed as HHA. To make fair comparison, we also build depth-aware CNN with this two-stream fashion and denote this as D-CNN+HHA. In ablation study, we further replace VGG-16 with ResNet-50 [11] as the encoder to have a better understanding of the functionality of depth-aware operations. We use SGD optimizer with initial learning rate 0.001, momentum 0.9 and batch size 1. The learning rate is multiplied by (1 iter max iter )0.9 for every 10 iterarions. α is set to 8.3. (The impact of α is studied in Section 4.2.) The dataset is augmented by randomly scaling, cropping, and color jittering. We use PyTorch deep learning framework. Both depth-aware convolution and depthaware average pooling operators are implemented with CUDA acceleration. Code is available at github.com/laughtervv/depthawarecnn. 4.1 Main Results Depth-aware CNN is compared with both its baseline and the state-of-the-art methods on NYUv2 and SUN-RGBD dataset. It is also compared with the baseline on SID dataset.










































9 Depth-aware CNN for RGB-D Segmentation 9 RGB Depth GT Baseline HHA D-CNN DCNN+HHA Fig. 4. Segmentation results on NYUv2 test dataset. GT denotes ground truth. The white regions in GT are the ignoring category. Networks are trained from pre-trained models. NYUv2 Table 3 shows quantitative comparison results between D-CNNs and baseline models. Since D-CNN and its baseline are in different function space, all networks are trained from scratch to make fair comparison in this experiment. Without introducing any parameters, D-CNN outperforms the baseline by incorporating geometric information in convolution operation. Moreover, the performance of D-CNN also exceeds HHA network by using only half of its parameters. This effectively validate the superior capability of D-CNN on handling geometry over HHA. We also compare our results with the state-ofthe-art methods. Table 4 illustrates the good performance of D-CNN. In this experiment, the networks are initialized with the pre-trained parameters in [4]. Long et al. [29] and Eigen et al. [8] both use the two-stream network with HHA/depth encoding. Yang et al. [12] compute optical flows and superpixels to augment the performance with spatial-temporal information. D-CNN with only one VGG network is superior to their methods. Qi et al. [27] built a 3D graph on the top of VGG encoder and use RNN to update the graph, which
10 10 Wang and Neumann Baseline HHA D-CNN D-CNN+HHA Acc (%) macc (%) miou (%) fwiou (%) Table 3. Comparison with baseline CNNs on NYUv2 test set. Networks are trained from scratch. [29] [8] [12] [27] HHA D-CNN D-CNN+HHA DM-CNN+HHA [20] D-ResNet-152 macc (%) miou (%) Table 4. Comparison with the state-of-the-arts on NYUv2 test set. Networks are trained from pre-trained models. introduces more network parameters and higher computation complexity. By replacing max-pooling layers in Conv1, Conv2, Conv3 as depth-aware max-pooling (defined as y(p 0 ) = max pn RF D (p 0,p 0 +p n ) x(p 0 +p n )), we can get further performance improvement, and this experiment is referred as DM-CNN-HHA in Table 4. We also replace the baseline VGG with ResNet-152 (pre-trained with [20]) and compare with its baseline [20] in Table 4. As is shown in Table 4, D-CNN is already comparable with these state-of-the-art methods. By incorporating HHA encoding, our method achieves the state-of-the-art on this dataset. Figure 4 visualizes qualitative comparison results on NYUv2 test set.. SUN-RGBD The comparison results between D-CNN and its baseline are listed in Table 5. The networks in this table are trained from scratch. D-CNN outperforms baseline by a large margin. Substituting the baseline with the twostream HHA network is able to further improve the performance. By comparing with the state-of-the-art methods in Table 6, we can further see the effectiveness of D-CNN. Similarly as in NYUv2, the networks are initialized with pre-trained model in this experiment. Figure 5 illustrates the qualitative comparison results on SUN-RGBD test set. Our network achieves comparable performance with the state-of-the-art method [27], while their method is more time-consuming. We will further compare the runtime and numbers of model parameters in Section 4.3. Baseline HHA D-CNN D-CNN+HHA Acc (%) macc (%) miou (%) fwiou (%) Table 5. Comparison with baseline CNNs on SUN-RGBD test set. Networks are trained from scratch.
11 Depth-aware CNN for RGB-D Segmentation 11 [18] [27] HHA D-CNN D-CNN+HHA macc (%) miou (%) Table 6. Comparison with the state-of-the-arts on SUN-RGBD test set. Networks are trained from pre-trained models. SID The comparison results on SID between D-CNN with its baseline are reported in Table 7. Networks are trained from scratch. Using depth images, D-CNN is able to achieve 4% IoU over CNN while preserving the same number of parameters and computation complexity. 4.2 Ablation Study Baseline D-CNN Acc (%) macc (%) miou (%) fwiou (%) Table 7. Comparison with baseline CNNs on SID Area 5. Networks are trained from scratch. In this section, we conduct ablation studies on NYUv2 dataset to validate efficiency and efficacy of our approach. Testing results on NYUv2 test set are reported. Depth-aware CNN To verify the functionality of both depth-aware convolution and depth-aware average pooling, the following experiments are conducted. VGG-1:Conv1 1,Conv2 1,Conv3 1,Conv4 1,Conv5 1andConv6inVGG-16 are replaced with depth-aware convolution. This is the same as in Table 2. VGG-2: Conv4 1, Conv5 1 and Conv6 in VGG-16 are replaced with depthaware convolution. Other layers remain the same as in Table 2. VGG-3: The depth-aware average pooling layer listed in Table 2 is replaced with regular pooling. Other layers remain the same as in Table 2. VGG-4: Only Conv1 1, Conv2 1, Conv3 1 are replaced with depth-aware convolution. Results are shown in Table 8. Compared to VGG-2, VGG-1 adds depth-aware convolution in bottom layers. This helps the network propagate more fine-grained features with geometric relationships and increase segmentation performance by 6% in IoU. VGG-1 also outperforms VGG-4. Top layers conv4, 5 have more contextual information, and applying D-CNN on these layers still benefits the prediction. As is shown in [25], not all contextual information is useful. D-CNN helps to capture more effective contextual information. The depth-aware average pooling operation is able to further promote the accuracy. We also replace VGG-16 to ResNet as the encoder. We test depth-aware operations on ResNet. The Conv3 1, Conv4 1, and Conv5 1 in ResNet-50 are replaced with depth-aware convolution. ResNet-50 is initialized with parameters pre-trained on ADE20K [38]. Detailed architecture and training details for ResNet can be found in Supplementary Materials. Results are listed in Table 9.













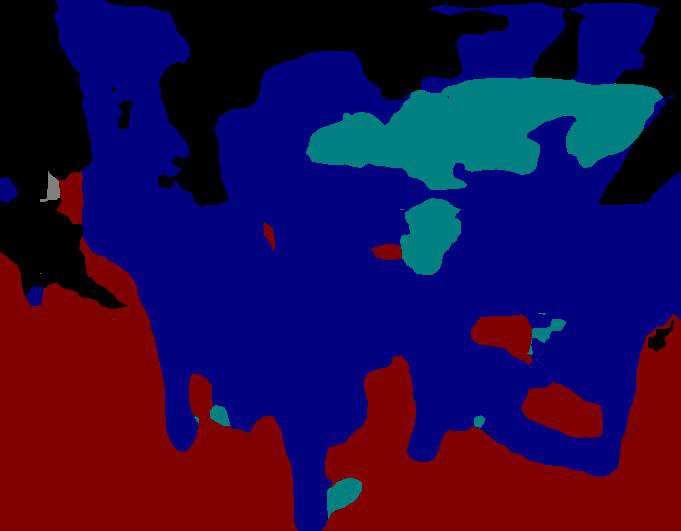



























12 12 Wang and Neumann RGB Depth GT Baseline HHA D-CNN DCNN+HHA Fig. 5. Segmentation results on SUN-RGBD test dataset. GT denotes ground truth. The white regions in GT are the ignoring category. Networks are trained from pretrained models. Depth Similarity Function WemodifyαandF D tofurthervalidatetheeffect of different choices of depth similarity function on performance. We conduct the following experiments: α 8.3 : α is set to 8.3. The network architecture is the same as Table 2. α 20 : α is set to 20. The network architecture is the same as Table 2. α 2.5 : α is set to 2.5. The network architecture is the same as Table 2. clipf D : The network architecture is the same as Table 2. F D is defined as { 0, D(p i ) D(p j ) 1 F D (p i,p j ) = (6) 1, otherwise Table 10 reports the test performances with different depth similarity functions. Though the performance varies with different α, they are all superior to baseline and even HHA. The result of clipf D is also comparable with HHA. This validate that the effectiveness of using a depth-sensitive term to weight the contributions of neurons.
 34.2 43.0 44.9 40.2 44.0 43.8 Table 8. Results of using depth-aware operations in different layers. Experiments are conducted on NYUv2 test set. Networks are trained from scratch.")
13 Depth-aware CNN for RGB-D Segmentation 13 Baseline HHA VGG-1 VGG-2 VGG-3 VGG-4 Acc (%) macc (%) miou (%) fwiou (%) Table 8. Results of using depth-aware operations in different layers. Experiments are conducted on NYUv2 test set. Networks are trained from scratch. VGG-1 ResNet-50 D-ResNet-50 Acc (%) macc (%) miou (%) fwiou (%) Table 9. Results of using depthaware operations in ResNet-50. Networks are trained from pretrained models. Baseline HHA α 8.3 α 20 α 2.5 clipf D Acc (%) macc (%) miou (%) fwiou (%) Table 10. Results of using different α and F D. Experiments are conducted on NYUv2 test set. Networks are trained from scratch. Performance Analysis To have a better understanding of how depth-aware CNN outperforms the baseline, we visualize the improvement of IoU for each semantic class in Figure 6(a). The statics shows that D-CNN outperform baseline on most object categories, especially these large objects such as ceilings and curtain. Moreover, we observe depth-aware CNN has a faster convergence than baseline, especially trained from scratch. Figure 6(b) shows the training loss evolution with respect to training steps. Our network gains lower loss values than baseline. Depth similarity helps preserving edge details, however, when depth values vary in a single object, depth-aware CNN may lose contextual information. Some failure cases can be found in supplemental material. (a) Fig. 6. Performance Analysis. (a) Per-class IoU improvement of D-CNN over baseline on NYUv2 test dataset. (b) Evolution of training loss on NYUv2 train dataset. Networks are trained from scratch. 4.3 Model Complexity and Runtime Analysis Table 11 reports the model complexity and runtime of D-CNN and the stateof-the-art method [27]. In their method, knn takes O(kN) runtime at least, (b)
14 14 Wang and Neumann where N is the number of pixels. We leverage the grid structure of raw depth input. As is shown in Table 11, depth-aware operations do not incorporate any new parameters. The network forward time is only slightly greater than its baseline. Without increasing any model parameters, D-CNN is able to incorporate geometric information in CNN efficiently. Baseline HHA [27] D-CNN D-CNN-HHA net. forward (ms) # of params 47.0M 92.0M 47.25M 47.0M 92.0M Table 11. Model complexity and runtime comparison. Runtime is tested on Nvidia 1080Ti, with input image size Conclusion We present a novel depth-aware CNN by introducing two operations: depthaware convolution and depth-aware average pooling. Depth-aware CNN augments conventional CNN with a depth similarity term and encode geometric variance into basic convolution and pooling operations. By adapting effective receptive field, these depth-aware operations are able to incorporate geometry into CNN while preserving CNN s efficiency. Without introducing any parameters and computational complexity, this method is able to improve the performance on RGB-D segmentation over baseline by a large margin. Moreover, depth-aware CNN is flexible and easily replaces its plain counterpart in standard CNNs. Comparison with the state-of-the-art methods and extensive ablation studies on RGB-D semantic segmentation demonstrate the effectiveness and efficiency of depth-aware CNN. Depth-aware CNN provides a general framework for vision tasks with RGB- D input. Moreover, depth-aware CNN takes the raw depth image as input and bridges the gap between 2D CNN and 3D geometry. In future works, we will apply depth-aware CNN on various tasks such as 3D detection, instance segmentation and we will perform depth-aware CNN on more challenging dataset. Apart from depth input, we will exploit more geometric input such as normal map. Acknowledgements We thank Ronald Yu, Yi Zhou and Qiangui Huang for the discussion and proofread. This research is supported by the Intelligence Advanced Research Projects Activity (IARPA) via Department of Interior/ Interior Business Center (DOI/IBC) contract number D17PC The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes notwithstanding any copyright annotation thereon. Disclaimer: The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies or endorsements, either expressed or implied, of IARPA, DOI/IBC, or the U.S. Government.
15 References Depth-aware CNN for RGB-D Segmentation Armeni, I., Sax, A., Zamir, A.R., Savarese, S.: Joint 2D-3D-Semantic Data for Indoor Scene Understanding. ArXiv e-prints (2017) 2. Barron, J.T., Poole, B.: The fast bilateral solver. In: ECCV (2016) 3. Chen, J., Paris, S., Durand, F.: Real-time edge-aware image processing with the bilateral grid. In: ACM Transactions on Graphics (TOG) (2007) 4. Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation with deep convolutional nets and fully connected crfs. In: ICLR (2015) 5. Cheng, Y., Cai, R., Li, Z., Zhao, X., Huang, K.: Locality-sensitive deconvolution networks with gated fusion for rgb-d indoor semantic segmentation. In: CVPR (2017) 6. Couprie, C., Farabet, C., Najman, L., Lecun, Y.: Indoor semantic segmentation using depth information. In: ICLR (2013) 7. Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., Wei, Y.: Deformable convolutional networks. In: ICCV (2017) 8. Eigen, D., Fergus, R.: Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In: ICCV (2015) 9. Gupta, S., Girshick, R., Arbelaez, P., Malik, J.: Learning rich features from RGB-D images for object detection and segmentation. In: ECCV (2014) 10. Hazirbas, C., Ma, L., Domokos, C., Cremers, D.: Fusenet: incorporating depth into semantic segmentation via fusion-based cnn architecture. In: ACCV (2016) 11. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016) 12. He, Y., Chiu, W.C., Keuper, M., Fritz, M.: Std2p: Rgbd semantic segmentation using spatio-temporal data-driven pooling. In: CVPR (2017) 13. Huang, Q., Wang, W., Neumann, U.: Recurrent slice networks for 3d segmentation on point clouds. CVPR (2018) 14. Huang, Q., Wang, W., Zhou, K., You, S., Neumann, U.: Scene labeling using gated recurrent units with explicit long range conditioning. arxiv preprint arxiv: (2016) 15. Jaderberg, M., Simonyan, K., Zisserman, A., kavukcuoglu, k.: Spatial transformer networks. In: NIPS (2015) 16. Janoch, A., Karayev, S., Jia, Y., Barron, J.T., Fritz, M., Saenko, K., Darrell, T.: A category-level 3-d object dataset: Putting the kinect to work. In: ICCV workshop (2011) 17. Khan, S.H., Bennamoun, M., Sohel, F., Togneri, R.: Geometry driven semantic labeling of indoor scenes. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV (2014) 18. Li, Z., Gan, Y., Liang, X., Yu, Y., Cheng, H., Lin, L.: Lstm-cf: Unifying context modeling and fusion with lstms for rgb-d scene labeling. In: ECCV (2016) 19. Lin, D., Chen, G., Cohen-Or, D., Heng, P.A., Huang, H.: Cascaded feature network for semantic segmentation of rgb-d images. In: ICCV (2017) 20. Lin, G., Milan, A., Shen, C., Reid, I.: RefineNet: Multi-path refinement networks for high-resolution semantic segmentation. In: CVPR (2017) 21. Ma, L., Stueckler, J., Kerl, C., Cremers, D.: Multi-view deep learning for consistent semantic mapping with rgb-d cameras. In: IROS (2017) 22. Nathan Silberman, Derek Hoiem, P.K., Fergus, R.: Indoor segmentation and support inference from rgbd images. In: ECCV (2012)
16 16 Wang and Neumann 23. Nathan Silberman, Derek Hoiem, P.K., Fergus, R.: Indoor segmentation and support inference from rgbd images. In: ECCV (2012) 24. Park, S.J., Hong, K.S., Lee, S.: Rdfnet: Rgb-d multi-level residual feature fusion for indoor semantic segmentation. In: ICCV (2017) 25. Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: CVPR (2017) 26. Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In: NIPS (2017) 27. Qi, X., Liao, R., Jia, J., Fidler, S., Urtasun, R.: 3d graph neural networks for rgbd semantic segmentation. In: ICCV (2017) 28. Ren, X., Bo, L., Fox, D.: Rgb-(d) scene labeling: Features and algorithms. In: CVPR (2012) 29. Shelhamer, E., Long, J., Darrell, T.: Fully convolutional networks for semantic segmentation. PAMI (2016) 30. Song, S., Lichtenberg, S.P., Xiao, J.: Sun rgb-d: A rgb-d scene understanding benchmark suite. In: CVPR (2015) 31. Song, S., Xiao, J.: Deep Sliding Shapes for amodal 3D object detection in RGB-D images. In: CVPR (2016) 32. Song, S., Yu, F., Zeng, A., Chang, A.X., Savva, M., Funkhouser, T.: Semantic scene completion from a single depth image. In: CVPR (2017) 33. Wang, J., Wang, Z., Tao, D., See, S., Wang, G.: Learning common and specific features for RGB-D semantic segmentation with deconvolutional networks. In: ECCV (2016) 34. Wang, W., Huang, Q., You, S., Yang, C., Neumann, U.: Shape inpainting using 3d generative adversarial network and recurrent convolutional networks. In: ICCV (2017) 35. Wang, W., Wang, N., Wu, X., You, S., Yang, C., Neumann, U.: Self-paced crossmodality transfer learning for efficient road segmentation. In: ICRA (2017) 36. Wang, W., Yu, R., Huang, Q., Neumann, U.: Sgpn: Similarity group proposal network for 3d point cloud instance segmentation. CVPR (2018) 37. Yu, F., Koltun, V.: Multi-scale context aggregation by dilated convolutions. In: ICLR (2016) 38. Zhou, B., Zhao, H., Puig, X., Fidler, S., Barriuso, A., Torralba, A.: Scene parsing through ade20k dataset. In: CVPR (2017)
RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation
 RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation Seong-Jin Park POSTECH Ki-Sang Hong POSTECH {windray,hongks,leesy}@postech.ac.kr Seungyong Lee POSTECH Abstract In multi-class
RDFNet: RGB-D Multi-level Residual Feature Fusion for Indoor Semantic Segmentation Seong-Jin Park POSTECH Ki-Sang Hong POSTECH {windray,hongks,leesy}@postech.ac.kr Seungyong Lee POSTECH Abstract In multi-class
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Fully Convolutional Network for Depth Estimation and Semantic Segmentation
 Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
Fully Convolutional Network for Depth Estimation and Semantic Segmentation Yokila Arora ICME Stanford University yarora@stanford.edu Ishan Patil Department of Electrical Engineering Stanford University
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
Deep learning for dense per-pixel prediction. Chunhua Shen The University of Adelaide, Australia
 Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Deep learning for dense per-pixel prediction Chunhua Shen The University of Adelaide, Australia Image understanding Classification error Convolution Neural Networks 0.3 0.2 0.1 Image Classification [Krizhevsky
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
 : Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1,2, Anton Milan 1, Chunhua Shen 1,2, Ian Reid 1,2 1 The University of Adelaide, 2 Australian Centre for Robotic
: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1,2, Anton Milan 1, Chunhua Shen 1,2, Ian Reid 1,2 1 The University of Adelaide, 2 Australian Centre for Robotic
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
RSRN: Rich Side-output Residual Network for Medial Axis Detection
 RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
RSRN: Rich Side-output Residual Network for Medial Axis Detection Chang Liu, Wei Ke, Jianbin Jiao, and Qixiang Ye University of Chinese Academy of Sciences, Beijing, China {liuchang615, kewei11}@mails.ucas.ac.cn,
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS. Zhao Chen Machine Learning Intern, NVIDIA
 JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
JOINT DETECTION AND SEGMENTATION WITH DEEP HIERARCHICAL NETWORKS Zhao Chen Machine Learning Intern, NVIDIA ABOUT ME 5th year PhD student in physics @ Stanford by day, deep learning computer vision scientist
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Depth Estimation from a Single Image Using a Deep Neural Network Milestone Report
 Figure 1: The architecture of the convolutional network. Input: a single view image; Output: a depth map. 3 Related Work In [4] they used depth maps of indoor scenes produced by a Microsoft Kinect to successfully
Figure 1: The architecture of the convolutional network. Input: a single view image; Output: a depth map. 3 Related Work In [4] they used depth maps of indoor scenes produced by a Microsoft Kinect to successfully
3D Graph Neural Networks for RGBD Semantic Segmentation
 3D Graph Neural Networks for RGBD Semantic Segmentation Xiaojuan Qi Renjie Liao, Jiaya Jia, Sanja Fidler Raquel Urtasun, The Chinese University of Hong Kong University of Toronto Uber Advanced Technologies
3D Graph Neural Networks for RGBD Semantic Segmentation Xiaojuan Qi Renjie Liao, Jiaya Jia, Sanja Fidler Raquel Urtasun, The Chinese University of Hong Kong University of Toronto Uber Advanced Technologies
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
 Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Learning with Side Information through Modality Hallucination
 Master Seminar Report for Recent Trends in 3D Computer Vision Learning with Side Information through Modality Hallucination Judy Hoffman, Saurabh Gupta, Trevor Darrell. CVPR 2016 Nan Yang Supervisor: Benjamin
Master Seminar Report for Recent Trends in 3D Computer Vision Learning with Side Information through Modality Hallucination Judy Hoffman, Saurabh Gupta, Trevor Darrell. CVPR 2016 Nan Yang Supervisor: Benjamin
Three-Dimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients
 ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
ThreeDimensional Object Detection and Layout Prediction using Clouds of Oriented Gradients Authors: Zhile Ren, Erik B. Sudderth Presented by: Shannon Kao, Max Wang October 19, 2016 Introduction Given an
Separating Objects and Clutter in Indoor Scenes
 Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
 : Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1 Anton Milan 2 Chunhua Shen 2,3 Ian Reid 2,3 1 Nanyang Technological University 2 University of Adelaide 3 Australian
: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation Guosheng Lin 1 Anton Milan 2 Chunhua Shen 2,3 Ian Reid 2,3 1 Nanyang Technological University 2 University of Adelaide 3 Australian
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
3D Scene Understanding from RGB-D Images. Thomas Funkhouser
 3D Scene Understanding from RGB-D Images Thomas Funkhouser Recent Ph.D. Student Current Postdocs Current Ph.D. Students Disclaimer: I am talking about the work of these people Shuran Song Yinda Zhang Andy
3D Scene Understanding from RGB-D Images Thomas Funkhouser Recent Ph.D. Student Current Postdocs Current Ph.D. Students Disclaimer: I am talking about the work of these people Shuran Song Yinda Zhang Andy
arxiv: v1 [cs.cv] 24 Nov 2016
![arxiv: v1 [cs.cv] 24 Nov 2016](/thumbs/75/72258621.jpg "arxiv: v1 [cs.cv] 24 Nov 2016") Recalling Holistic Information for Semantic Segmentation arxiv:1611.08061v1 [cs.cv] 24 Nov 2016 Hexiang Hu UCLA Los Angeles, CA hexiang.frank.hu@gmail.com Abstract Fei Sha UCLA Los Angeles, CA feisha@cs.ucla.edu
Recalling Holistic Information for Semantic Segmentation arxiv:1611.08061v1 [cs.cv] 24 Nov 2016 Hexiang Hu UCLA Los Angeles, CA hexiang.frank.hu@gmail.com Abstract Fei Sha UCLA Los Angeles, CA feisha@cs.ucla.edu
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
ECCV Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016
 ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
ECCV 2016 Presented by: Boris Ivanovic and Yolanda Wang CS 331B - November 16, 2016 Fundamental Question What is a good vector representation of an object? Something that can be easily predicted from 2D
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image. Supplementary Material
 Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
Holistic 3D Scene Parsing and Reconstruction from a Single RGB Image Supplementary Material Siyuan Huang 1,2, Siyuan Qi 1,2, Yixin Zhu 1,2, Yinxue Xiao 1, Yuanlu Xu 1,2, and Song-Chun Zhu 1,2 1 University
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION
 HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
HIERARCHICAL JOINT-GUIDED NETWORKS FOR SEMANTIC IMAGE SEGMENTATION Chien-Yao Wang, Jyun-Hong Li, Seksan Mathulaprangsan, Chin-Chin Chiang, and Jia-Ching Wang Department of Computer Science and Information
arxiv: v1 [cs.cv] 13 Feb 2018
![arxiv: v1 [cs.cv] 13 Feb 2018](/thumbs/85/92549074.jpg "arxiv: v1 [cs.cv] 13 Feb 2018") Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
Recurrent Slice Networks for 3D Segmentation on Point Clouds Qiangui Huang Weiyue Wang Ulrich Neumann University of Southern California Los Angeles, California {qianguih,weiyuewa,uneumann}@uscedu arxiv:180204402v1
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
arxiv: v2 [cs.cv] 14 May 2018
![arxiv: v2 [cs.cv] 14 May 2018](/thumbs/79/79495201.jpg "arxiv: v2 [cs.cv] 14 May 2018") ContextVP: Fully Context-Aware Video Prediction Wonmin Byeon 1234, Qin Wang 1, Rupesh Kumar Srivastava 3, and Petros Koumoutsakos 1 arxiv:1710.08518v2 [cs.cv] 14 May 2018 Abstract Video prediction models
ContextVP: Fully Context-Aware Video Prediction Wonmin Byeon 1234, Qin Wang 1, Rupesh Kumar Srivastava 3, and Petros Koumoutsakos 1 arxiv:1710.08518v2 [cs.cv] 14 May 2018 Abstract Video prediction models
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas
 PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation Charles R. Qi* Hao Su* Kaichun Mo Leonidas J. Guibas Big Data + Deep Representation Learning Robot Perception Augmented Reality
Label Propagation in RGB-D Video
 Label Propagation in RGB-D Video Md. Alimoor Reza, Hui Zheng, Georgios Georgakis, Jana Košecká Abstract We propose a new method for the propagation of semantic labels in RGB-D video of indoor scenes given
Label Propagation in RGB-D Video Md. Alimoor Reza, Hui Zheng, Georgios Georgakis, Jana Košecká Abstract We propose a new method for the propagation of semantic labels in RGB-D video of indoor scenes given
Semantic Segmentation
 Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Semantic Segmentation UCLA:https://goo.gl/images/I0VTi2 OUTLINE Semantic Segmentation Why? Paper to talk about: Fully Convolutional Networks for Semantic Segmentation. J. Long, E. Shelhamer, and T. Darrell,
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos
 Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
Supplementary Material: Unsupervised Domain Adaptation for Face Recognition in Unlabeled Videos Kihyuk Sohn 1 Sifei Liu 2 Guangyu Zhong 3 Xiang Yu 1 Ming-Hsuan Yang 2 Manmohan Chandraker 1,4 1 NEC Labs
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv: v1 [cs.cv] 29 Sep 2016
![arxiv: v1 [cs.cv] 29 Sep 2016](/thumbs/76/73787064.jpg "arxiv: v1 [cs.cv] 29 Sep 2016") arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
arxiv:1609.09545v1 [cs.cv] 29 Sep 2016 Two-stage Convolutional Part Heatmap Regression for the 1st 3D Face Alignment in the Wild (3DFAW) Challenge Adrian Bulat and Georgios Tzimiropoulos Computer Vision
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models
 One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
One Network to Solve Them All Solving Linear Inverse Problems using Deep Projection Models [Supplemental Materials] 1. Network Architecture b ref b ref +1 We now describe the architecture of the networks
Scene Parsing with Global Context Embedding
 Scene Parsing with Global Context Embedding Wei-Chih Hung 1, Yi-Hsuan Tsai 1,2, Xiaohui Shen 3, Zhe Lin 3, Kalyan Sunkavalli 3, Xin Lu 3, Ming-Hsuan Yang 1 1 University of California, Merced 2 NEC Laboratories
Scene Parsing with Global Context Embedding Wei-Chih Hung 1, Yi-Hsuan Tsai 1,2, Xiaohui Shen 3, Zhe Lin 3, Kalyan Sunkavalli 3, Xin Lu 3, Ming-Hsuan Yang 1 1 University of California, Merced 2 NEC Laboratories
LEARNING BOUNDARIES WITH COLOR AND DEPTH. Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen
 LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
LEARNING BOUNDARIES WITH COLOR AND DEPTH Zhaoyin Jia, Andrew Gallagher, Tsuhan Chen School of Electrical and Computer Engineering, Cornell University ABSTRACT To enable high-level understanding of a scene,
Fast Semantic Segmentation of RGB-D Scenes with GPU-Accelerated Deep Neural Networks
 Fast Semantic Segmentation of RGB-D Scenes with GPU-Accelerated Deep Neural Networks Nico Höft, Hannes Schulz, and Sven Behnke Rheinische Friedrich-Wilhelms-Universität Bonn Institut für Informatik VI,
Fast Semantic Segmentation of RGB-D Scenes with GPU-Accelerated Deep Neural Networks Nico Höft, Hannes Schulz, and Sven Behnke Rheinische Friedrich-Wilhelms-Universität Bonn Institut für Informatik VI,
Learning Fully Dense Neural Networks for Image Semantic Segmentation
 Learning Fully Dense Neural Networks for Image Semantic Segmentation Mingmin Zhen 1, Jinglu Wang 2, Lei Zhou 1, Tian Fang 3, Long Quan 1 1 Hong Kong University of Science and Technology, 2 Microsoft Research
Learning Fully Dense Neural Networks for Image Semantic Segmentation Mingmin Zhen 1, Jinglu Wang 2, Lei Zhou 1, Tian Fang 3, Long Quan 1 1 Hong Kong University of Science and Technology, 2 Microsoft Research
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
RGBd Image Semantic Labelling for Urban Driving Scenes via a DCNN
 RGBd Image Semantic Labelling for Urban Driving Scenes via a DCNN Jason Bolito, Research School of Computer Science, ANU Supervisors: Yiran Zhong & Hongdong Li 2 Outline 1. Motivation and Background 2.
RGBd Image Semantic Labelling for Urban Driving Scenes via a DCNN Jason Bolito, Research School of Computer Science, ANU Supervisors: Yiran Zhong & Hongdong Li 2 Outline 1. Motivation and Background 2.
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Multi-View 3D Object Detection Network for Autonomous Driving
 Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION
 A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION Wenkai Zhang a, b, Hai Huang c, *, Matthias Schmitz c, Xian Sun a, Hongqi Wang a, Helmut Mayer c a Key Laboratory
A MULTI-RESOLUTION FUSION MODEL INCORPORATING COLOR AND ELEVATION FOR SEMANTIC SEGMENTATION Wenkai Zhang a, b, Hai Huang c, *, Matthias Schmitz c, Xian Sun a, Hongqi Wang a, Helmut Mayer c a Key Laboratory
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials)
") ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
arxiv: v1 [cs.cv] 23 Nov 2017
![arxiv: v1 [cs.cv] 23 Nov 2017](/thumbs/82/86007822.jpg "arxiv: v1 [cs.cv] 23 Nov 2017") SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation arxiv:1711.08588v1 [cs.cv] 23 Nov 2017 Weiyue Wang 1 Ronald Yu 2 Qiangui Huang 1 Ulrich Neumann 1 1 University of Southern
SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation arxiv:1711.08588v1 [cs.cv] 23 Nov 2017 Weiyue Wang 1 Ronald Yu 2 Qiangui Huang 1 Ulrich Neumann 1 1 University of Southern
Feature-Fused SSD: Fast Detection for Small Objects
 Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
Feature-Fused SSD: Fast Detection for Small Objects Guimei Cao, Xuemei Xie, Wenzhe Yang, Quan Liao, Guangming Shi, Jinjian Wu School of Electronic Engineering, Xidian University, China xmxie@mail.xidian.edu.cn
In Defense of Fully Connected Layers in Visual Representation Transfer
 In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
SURGE: Surface Regularized Geometry Estimation from a Single Image
 SURGE: Surface Regularized Geometry Estimation from a Single Image Peng Wang 1 Xiaohui Shen 2 Bryan Russell 2 Scott Cohen 2 Brian Price 2 Alan Yuille 3 1 University of California, Los Angeles 2 Adobe Research
SURGE: Surface Regularized Geometry Estimation from a Single Image Peng Wang 1 Xiaohui Shen 2 Bryan Russell 2 Scott Cohen 2 Brian Price 2 Alan Yuille 3 1 University of California, Los Angeles 2 Adobe Research
Amodal and Panoptic Segmentation. Stephanie Liu, Andrew Zhou
 Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
Amodal and Panoptic Segmentation Stephanie Liu, Andrew Zhou This lecture: 1. 2. 3. 4. Semantic Amodal Segmentation Cityscapes Dataset ADE20K Dataset Panoptic Segmentation Semantic Amodal Segmentation Yan
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
TEXT SEGMENTATION ON PHOTOREALISTIC IMAGES
 TEXT SEGMENTATION ON PHOTOREALISTIC IMAGES Valery Grishkin a, Alexander Ebral b, Nikolai Stepenko c, Jean Sene d Saint Petersburg State University, 7 9 Universitetskaya nab., Saint Petersburg, 199034,
TEXT SEGMENTATION ON PHOTOREALISTIC IMAGES Valery Grishkin a, Alexander Ebral b, Nikolai Stepenko c, Jean Sene d Saint Petersburg State University, 7 9 Universitetskaya nab., Saint Petersburg, 199034,
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform. Xintao Wang Ke Yu Chao Dong Chen Change Loy
 Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Xintao Wang Ke Yu Chao Dong Chen Change Loy Problem enlarge 4 times Low-resolution image High-resolution image Previous
Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform Xintao Wang Ke Yu Chao Dong Chen Change Loy Problem enlarge 4 times Low-resolution image High-resolution image Previous
Cascade Region Regression for Robust Object Detection
 Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Cascade Region Regression for Robust Object Detection Jiankang Deng, Shaoli Huang, Jing Yang, Hui Shuai, Zhengbo Yu, Zongguang Lu, Qiang Ma, Yali
Convolutional Networks in Scene Labelling
 Convolutional Networks in Scene Labelling Ashwin Paranjape Stanford ashwinpp@stanford.edu Ayesha Mudassir Stanford aysh@stanford.edu Abstract This project tries to address a well known problem of multi-class
Convolutional Networks in Scene Labelling Ashwin Paranjape Stanford ashwinpp@stanford.edu Ayesha Mudassir Stanford aysh@stanford.edu Abstract This project tries to address a well known problem of multi-class
Team G-RMI: Google Research & Machine Intelligence
 Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Team G-RMI: Google Research & Machine Intelligence Alireza Fathi (alirezafathi@google.com) Nori Kanazawa, Kai Yang, George Papandreou, Tyler Zhu, Jonathan Huang, Vivek Rathod, Chen Sun, Kevin Murphy, et
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
Depth from Stereo. Dominic Cheng February 7, 2018
 Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
Depth from Stereo Dominic Cheng February 7, 2018 Agenda 1. Introduction to stereo 2. Efficient Deep Learning for Stereo Matching (W. Luo, A. Schwing, and R. Urtasun. In CVPR 2016.) 3. Cascade Residual
arxiv: v2 [cs.cv] 19 Nov 2018
![arxiv: v2 [cs.cv] 19 Nov 2018](/thumbs/90/103457332.jpg "arxiv: v2 [cs.cv] 19 Nov 2018") OCNet: Object Context Network for Scene Parsing Yuhui Yuan Jingdong Wang Microsoft Research {yuyua,jingdw}@microsoft.com arxiv:1809.00916v2 [cs.cv] 19 Nov 2018 Abstract In this paper, we address the problem
OCNet: Object Context Network for Scene Parsing Yuhui Yuan Jingdong Wang Microsoft Research {yuyua,jingdw}@microsoft.com arxiv:1809.00916v2 [cs.cv] 19 Nov 2018 Abstract In this paper, we address the problem
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network
 Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network Liwen Zheng, Canmiao Fu, Yong Zhao * School of Electronic and Computer Engineering, Shenzhen Graduate School of
Presentation Outline. Semantic Segmentation. Overview. Presentation Outline CNN. Learning Deconvolution Network for Semantic Segmentation 6/6/16
 6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
6/6/16 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo Noh, Seunghoon Hong,Bohyung Han Department of Computer Science and Engineering, POSTECH, Korea Shai Rozenberg 6/6/2016 1 2 Semantic
Depth Estimation from Single Image Using CNN-Residual Network
 Depth Estimation from Single Image Using CNN-Residual Network Xiaobai Ma maxiaoba@stanford.edu Zhenglin Geng zhenglin@stanford.edu Zhi Bie zhib@stanford.edu Abstract In this project, we tackle the problem
Depth Estimation from Single Image Using CNN-Residual Network Xiaobai Ma maxiaoba@stanford.edu Zhenglin Geng zhenglin@stanford.edu Zhi Bie zhib@stanford.edu Abstract In this project, we tackle the problem
Improving Face Recognition by Exploring Local Features with Visual Attention
 Improving Face Recognition by Exploring Local Features with Visual Attention Yichun Shi and Anil K. Jain Michigan State University Difficulties of Face Recognition Large variations in unconstrained face
Improving Face Recognition by Exploring Local Features with Visual Attention Yichun Shi and Anil K. Jain Michigan State University Difficulties of Face Recognition Large variations in unconstrained face
R-FCN: Object Detection with Really - Friggin Convolutional Networks
 R-FCN: Object Detection with Really - Friggin Convolutional Networks Jifeng Dai Microsoft Research Li Yi Tsinghua Univ. Kaiming He FAIR Jian Sun Microsoft Research NIPS, 2016 Or Region-based Fully Convolutional
R-FCN: Object Detection with Really - Friggin Convolutional Networks Jifeng Dai Microsoft Research Li Yi Tsinghua Univ. Kaiming He FAIR Jian Sun Microsoft Research NIPS, 2016 Or Region-based Fully Convolutional
arxiv: v4 [cs.cv] 6 Jul 2016
![arxiv: v4 [cs.cv] 6 Jul 2016](/thumbs/93/112985717.jpg "arxiv: v4 [cs.cv] 6 Jul 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
arxiv: v1 [cs.cv] 28 Nov 2017
![arxiv: v1 [cs.cv] 28 Nov 2017](/thumbs/81/83356256.jpg "arxiv: v1 [cs.cv] 28 Nov 2017") 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks arxiv:1711.10275v1 [cs.cv] 28 Nov 2017 Abstract Benjamin Graham, Martin Engelcke, Laurens van der Maaten Convolutional networks are
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks arxiv:1711.10275v1 [cs.cv] 28 Nov 2017 Abstract Benjamin Graham, Martin Engelcke, Laurens van der Maaten Convolutional networks are
Martian lava field, NASA, Wikipedia
 Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Bidirectional Recurrent Convolutional Networks for Video Super-Resolution
 Bidirectional Recurrent Convolutional Networks for Video Super-Resolution Qi Zhang & Yan Huang Center for Research on Intelligent Perception and Computing (CRIPAC) National Laboratory of Pattern Recognition
Bidirectional Recurrent Convolutional Networks for Video Super-Resolution Qi Zhang & Yan Huang Center for Research on Intelligent Perception and Computing (CRIPAC) National Laboratory of Pattern Recognition
Learning Deep Structured Models for Semantic Segmentation. Guosheng Lin
 Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
Learning Deep Structured Models for Semantic Segmentation Guosheng Lin Semantic Segmentation Outline Exploring Context with Deep Structured Models Guosheng Lin, Chunhua Shen, Ian Reid, Anton van dan Hengel;
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material
 Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing Supplementary Material Chi Li, M. Zeeshan Zia 2, Quoc-Huy Tran 2, Xiang Yu 2, Gregory D. Hager, and Manmohan Chandraker 2 Johns
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting
 Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting Yaguang Li Joint work with Rose Yu, Cyrus Shahabi, Yan Liu Page 1 Introduction Traffic congesting is wasteful of time,
Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting Yaguang Li Joint work with Rose Yu, Cyrus Shahabi, Yan Liu Page 1 Introduction Traffic congesting is wasteful of time,
Dense Image Labeling Using Deep Convolutional Neural Networks
 Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
Dense Image Labeling Using Deep Convolutional Neural Networks Md Amirul Islam, Neil Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, MB {amirul, bruce, ywang}@cs.umanitoba.ca
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks
 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks Benjamin Graham Facebook AI Research benjamingraham@fb.com Martin Engelcke University of Oxford martin@robots.ox.ac.uk Laurens van
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks Benjamin Graham Facebook AI Research benjamingraham@fb.com Martin Engelcke University of Oxford martin@robots.ox.ac.uk Laurens van
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018
 Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
arxiv: v1 [cs.cv] 24 May 2016
![arxiv: v1 [cs.cv] 24 May 2016](/thumbs/80/80473828.jpg "arxiv: v1 [cs.cv] 24 May 2016") Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
arxiv: v1 [cs.cv] 14 Jul 2017
![arxiv: v1 [cs.cv] 14 Jul 2017](/thumbs/74/70463879.jpg "arxiv: v1 [cs.cv] 14 Jul 2017") Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Supplementary Material for Ensemble Diffusion for Retrieval
 Supplementary Material for Ensemble Diffusion for Retrieval Song Bai 1, Zhichao Zhou 1, Jingdong Wang, Xiang Bai 1, Longin Jan Latecki 3, Qi Tian 4 1 Huazhong University of Science and Technology, Microsoft
Supplementary Material for Ensemble Diffusion for Retrieval Song Bai 1, Zhichao Zhou 1, Jingdong Wang, Xiang Bai 1, Longin Jan Latecki 3, Qi Tian 4 1 Huazhong University of Science and Technology, Microsoft
3D Deep Learning on Geometric Forms. Hao Su
 3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation
3D Deep Learning on Geometric Forms Hao Su Many 3D representations are available Candidates: multi-view images depth map volumetric polygonal mesh point cloud primitive-based CAD models 3D representation