Toward Scale-Invariance and Position-Sensitive Region Proposal Networks
|
|
|
- Shannon Long
- 5 years ago
- Views:
Transcription
1 Toward Scale-Invariance and Position-Sensitive Region Proposal Networks Hsueh-Fu Lu [ ], Xiaofei Du [ ], and Ping-Lin Chang [ ] Umbo Computer Vision {topper.lu, xiaofei.du, Abstract. Accurately localising object proposals is an important precondition for high detection rate for the state-of-the-art object detection frameworks. The accuracy of an object detection method has been shown highly related to the average recall (AR) of the proposals. In this work, we propose an advanced object proposal network in favour of translationinvariance for objectness classification, translation-variance for bounding box regression, large effective receptive fields for capturing global context and scale-invariance for dealing with a range of object sizes from extremely small to large. The design of the network architecture aims to be simple while being effective and with real-time performance. Without bells and whistles the proposed object proposal network significantly improves the AR at 1,000 proposals by 35% and 45% on PASCAL VOC and COCO dataset respectively and has a fast inference time of 44.8 ms for input image size of Empirical studies have also shown that the proposed method is class-agnostic to be generalised for general object proposal. Keywords: Object Detection Region Proposal Networks Position- Sensitive Anchors 1 Introduction Object detection has been a challenging task in computer vision [6,17]. Significant progress has been achieved in the last decade from traditional slidingwindow paradigms [7,28] to recent top-performance proposal-based [27] detection frameworks [9,10,11]. A proposal algorithm plays a crucial role in an object detection pipeline. On one hand, it speeds up the detection process by considerably reducing the search space for image regions to be subsequently classified. On the other hand, the average recall (AR) of the object proposal method has been shown notably correlating with the precision of final detection, in which AR essentially reveals how accurate the detected bounding boxes are localised comparing with the ground truth [13]. Instead of using low-level image features to heuristically generate the proposals [27,30], trendy methods extract high-level features by using deep convolutional neural networks (ConvNets) [12,26,29] to train a class-agnostic classifier
2 2 H.-F. Lu, X. Du and P.-L. Chang with a large number of annotated objects [15,21,23]. For general objectness detection, such supervised learning approaches make an important assumption that given enough number of different object categories, an objectness classifier can be sufficiently generalised to unseen categories. It has been shown that learningbased methods indeed tend to be unbiased to the dataset categories and learn the union of features in the annotated object regions [4,13,15,20]. Despite their good performance [5,12,23], there is still much room to improve the recall especially for small objects and accuracy for the bounding box localisation [2,14,16,20]. To tackle object detection using ConvNets at various scales and for more accurate localisation, prior works adopted an encoder-decoder architecture with skip-connections [24] for exploiting low-resolution strong semantic and highresolution weak semantic features [16], used position sensitive score maps for enhancing translation variance and invariance respectively for localisation and classification [5], and used a global convolutional network (GCN) component for enlarging valid receptive field (VRF) particularly for capturing larger image context [19]. In this paper, we devise an advanced object proposal network which is capable of handling a large range of object scales and accurately localising proposed bounding boxes. The proposed network architecture embraces fully convolutional networks (FCNs) [18] without using fully-connected and pooling layers to preserve spatial information as much as possible. The design takes simplicity into account, in which the features extracted by ConvNets are entirely shared with a light-weight network head as shown in Fig. 2. Ablation studies have been conducted to show the effectiveness of each designed component. We have empirically found that GCN and position-sensitivity structure can each individually improves the AR at 1,000 proposals. As shown in Table 2 and 3, evaluating the baseline model on PASCAL VOC and COCO dataset, GCN brings performance gains from 8 and 2 to 9 (22%) and to 4 (29%) respectively, and, the use of position-sensitivity to 1 (26%) and to 5 (6%) respectively. Using them together can furthermore boost the scores to 5 (35%) and to 1 (44%) respectively. Together the proposed framework achieves the state of the art and has a real-time performance. 2 Related works Traditional object proposal methods take low-level image features to heuristically propose regions containing objectness. Methods such as Selective Search[27], CPMC [3] and MCG [1] adopt grouping of multiple hierarchical segmentations to produce the final proposals. Edge boxes [30] on the other hand takes an assumption that objectness is supposed to have clearer contours. Hosang et al. [13] have comprehensively evaluated different proposal methods. Learningbased proposal approaches have gained more attentions recently. DeepBox [15] uses convolutional neural network to re-rank object proposals based on other bottom-up non-learning proposal methods. Faster R-CNN [23] trains a region proposal network (RPN) on a large number of annotated ground truth bounding

















 on this")



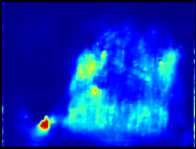


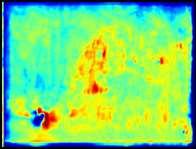
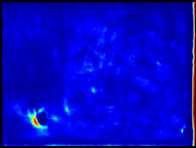



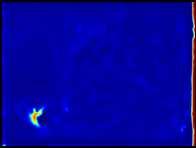











3 Toward Scale-Inv. and Pos.-Sens. Reg. Propos. Net. 3 s =4 s = 64 D 2 D 3 D 4 D 5 D 6 Fig. 1. The proposed method. Left: The position-sensitive score maps and windows with k 2 grids (k = 4) in yellow at D 2 and D 6 shown at the top and bottom respectively. One can see the D 2 activates on small objects while D 6 activates on extreme large ones. Note that D 6 is enlarged for visualisation, in which the window size is in fact identical to the one shown in D 2. Right: The windows are mapped into anchors in cyan in the input image with sizes of the multiple of layer stride s. Both: The bounding box in orange is the only labeled ground truth (in bike category) on this image from PASCAL VOC The large object on the right has no ground truth but the proposed classagnostic method can still be generalised to extract its objectness features as shown in the visualised D 6 feature maps. boxes to obtain high-quality box proposals for object detection. Region-based fully-convolutional network(r-fcn)[5] introduces position-sensitive score maps to improve localisation of the bounding boxes at detection stage. Feature pyramid network (FPN) [16] takes multi-scale feature maps into account to exploit scale-invariant features for both object proposal and detection stages. Instead of using feature pyramids and learning from ground truth bounding boxes, Deep- Mask [20] and SharpMask [21] use feed-forward ConvNets trained by ground truth masks and exploit multi-scale input images to perform mask proposals to achieve state-of-the-art performances. 3 Proposed method Inspired by FPN [16] and R-FCN [5], the proposed object proposal method is devised in favour of scale-invariance and position-sensitivity to retain both invariance and variance on translation for respectively classifying and localising objects. We also take VRF into account to learn objectness from a larger image
4 <latexit sha1_base64="gnkafes2zd0k6u13g2bphm4bmps=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leug9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bwx8mpn6bywzemaqujet+o6wv1bx1jfjmzwt7z3evun/wqjnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0m/vbt6g0t+sdgacyxhqgecqznvbyb3v5+arxrbl1dwaytlyc1kbas1f96vytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zctqzsj1gibeldzurvizzgwo/j0hbg1az1ojcv//m6mykug5zlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl5ejf1a/qnv357xgdzfggy7gge7bgwtowb00wqcghj7hfd4c6bw4787hvlxkfdoh8afo5w/zui5q</latexit> <latexit sha1_base64="gnkafes2zd0k6u13g2bphm4bmps=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leug9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bwx8mpn6bywzemaqujet+o6wv1bx1jfjmzwt7z3evun/wqjnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0m/vbt6g0t+sdgacyxhqgecqznvbyb3v5+arxrbl1dwaytlyc1kbas1f96vytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zctqzsj1gibeldzurvizzgwo/j0hbg1az1ojcv//m6mykug5zlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl5ejf1a/qnv357xgdzfggy7gge7bgwtowb00wqcghj7hfd4c6bw4787hvlxkfdoh8afo5w/zui5q</latexit> <latexit sha1_base64="gnkafes2zd0k6u13g2bphm4bmps=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leug9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bwx8mpn6bywzemaqujet+o6wv1bx1jfjmzwt7z3evun/wqjnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0m/vbt6g0t+sdgacyxhqgecqznvbyb3v5+arxrbl1dwaytlyc1kbas1f96vytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zctqzsj1gibeldzurvizzgwo/j0hbg1az1ojcv//m6mykug5zlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl5ejf1a/qnv357xgdzfggy7gge7bgwtowb00wqcghj7hfd4c6bw4787hvlxkfdoh8afo5w/zui5q</latexit> <latexit sha1_base64="gnkafes2zd0k6u13g2bphm4bmps=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leug9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bwx8mpn6bywzemaqujet+o6wv1bx1jfjmzwt7z3evun/wqjnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0m/vbt6g0t+sdgacyxhqgecqznvbyb3v5+arxrbl1dwaytlyc1kbas1f96vytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zctqzsj1gibeldzurvizzgwo/j0hbg1az1ojcv//m6mykug5zlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl5ejf1a/qnv357xgdzfggy7gge7bgwtowb00wqcghj7hfd4c6bw4787hvlxkfdoh8afo5w/zui5q</latexit> <latexit sha1_base64="izvhgbuc5lps3cd5cqbebnhys5q=">aaab63icbvbns8naej3ur1q/qh69lbbbu0luug9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bqw8ghu/nmdmvtaxxxnw/nnls8srqwnm9srg5tb1t3d170emmgposeylqh1sj4bj9w43adqqqxqhavji6nvqtr1saj/lejfmmyjqqpokmgiv5n738dnkr1ty6owp5s7yc1kbas1f97pytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zcjqzsj1gibeldzurpizzgwo/j0hbg1az1ojcv//m6mykugpzlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl/8s/6r+wffuzmqnqyknmhzairydb+fqgftogg8modzbc7w60nl23pz3ewvjkwb24recj2/yni5p</latexit> <latexit sha1_base64="izvhgbuc5lps3cd5cqbebnhys5q=">aaab63icbvbns8naej3ur1q/qh69lbbbu0luug9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bqw8ghu/nmdmvtaxxxnw/nnls8srqwnm9srg5tb1t3d170emmgposeylqh1sj4bj9w43adqqqxqhavji6nvqtr1saj/lejfmmyjqqpokmgiv5n738dnkr1ty6owp5s7yc1kbas1f97pytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zcjqzsj1gibeldzurpizzgwo/j0hbg1az1ojcv//m6mykugpzlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl/8s/6r+wffuzmqnqyknmhzairydb+fqgftogg8modzbc7w60nl23pz3ewvjkwb24recj2/yni5p</latexit> <latexit sha1_base64="izvhgbuc5lps3cd5cqbebnhys5q=">aaab63icbvbns8naej3ur1q/qh69lbbbu0luug9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bqw8ghu/nmdmvtaxxxnw/nnls8srqwnm9srg5tb1t3d170emmgposeylqh1sj4bj9w43adqqqxqhavji6nvqtr1saj/lejfmmyjqqpokmgiv5n738dnkr1ty6owp5s7yc1kbas1f97pytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zcjqzsj1gibeldzurpizzgwo/j0hbg1az1ojcv//m6mykugpzlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl/8s/6r+wffuzmqnqyknmhzairydb+fqgftogg8modzbc7w60nl23pz3ewvjkwb24recj2/yni5p</latexit> <latexit sha1_base64="izvhgbuc5lps3cd5cqbebnhys5q=">aaab63icbvbns8naej3ur1q/qh69lbbbu0luug9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bqw8ghu/nmdmvtaxxxnw/nnls8srqwnm9srg5tb1t3d170emmgposeylqh1sj4bj9w43adqqqxqhavji6nvqtr1saj/lejfmmyjqqpokmgiv5n738dnkr1ty6owp5s7yc1kbas1f97pytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zcjqzsj1gibeldzurpizzgwo/j0hbg1az1ojcv//m6mykugpzlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl/8s/6r+wffuzmqnqyknmhzairydb+fqgftogg8modzbc7w60nl23pz3ewvjkwb24recj2/yni5p</latexit> <latexit sha1_base64="x6hajygpmt4xfnhhc/zmeis3wvu=">aaab63icbvbns8naej34wetx1aoxxsj4kkkr1ftrbi8vjc20owy2k3bpzhn2n0ij/q1epkh49q9589+4bxpq1gcdj/dmmjkxpojr47rfzsrq2vrgzmmrvl2zu7dfoth81emmgposeylqh1sj4bj9w43adqqqxqhavji6mfqtj1saj/lbjfmmyjqqpokmgiv5t728pulvqm7nnyese68gvsjq7fw+uv2eztfkwwtvuuo5qqlyqgxnaiflbqyxpwxeb9ixvniydzdpjp2qu6v0szqow9kqmfp7iqex1um4tj0xnuo96e3f/7xozqlliocyzqxknl8uzykyhew/j32ukbkxtoqyxe2tha2poszyfmo2bg/x5wxi12txne/+vnq4ltiowtgcwbl4caenuimm+mcawzo8wpsjnrfn3fmyt644xcwr/ihz+qpwsi5o</latexit> <latexit sha1_base64="x6hajygpmt4xfnhhc/zmeis3wvu=">aaab63icbvbns8naej34wetx1aoxxsj4kkkr1ftrbi8vjc20owy2k3bpzhn2n0ij/q1epkh49q9589+4bxpq1gcdj/dmmjkxpojr47rfzsrq2vrgzmmrvl2zu7dfoth81emmgposeylqh1sj4bj9w43adqqqxqhavji6mfqtj1saj/lbjfmmyjqqpokmgiv5t728pulvqm7nnyese68gvsjq7fw+uv2eztfkwwtvuuo5qqlyqgxnaiflbqyxpwxeb9ixvniydzdpjp2qu6v0szqow9kqmfp7iqex1um4tj0xnuo96e3f/7xozqlliocyzqxknl8uzykyhew/j32ukbkxtoqyxe2tha2poszyfmo2bg/x5wxi12txne/+vnq4ltiowtgcwbl4caenuimm+mcawzo8wpsjnrfn3fmyt644xcwr/ihz+qpwsi5o</latexit> <latexit sha1_base64="x6hajygpmt4xfnhhc/zmeis3wvu=">aaab63icbvbns8naej34wetx1aoxxsj4kkkr1ftrbi8vjc20owy2k3bpzhn2n0ij/q1epkh49q9589+4bxpq1gcdj/dmmjkxpojr47rfzsrq2vrgzmmrvl2zu7dfoth81emmgposeylqh1sj4bj9w43adqqqxqhavji6mfqtj1saj/lbjfmmyjqqpokmgiv5t728pulvqm7nnyese68gvsjq7fw+uv2eztfkwwtvuuo5qqlyqgxnaiflbqyxpwxeb9ixvniydzdpjp2qu6v0szqow9kqmfp7iqex1um4tj0xnuo96e3f/7xozqlliocyzqxknl8uzykyhew/j32ukbkxtoqyxe2tha2poszyfmo2bg/x5wxi12txne/+vnq4ltiowtgcwbl4caenuimm+mcawzo8wpsjnrfn3fmyt644xcwr/ihz+qpwsi5o</latexit> <latexit sha1_base64="x6hajygpmt4xfnhhc/zmeis3wvu=">aaab63icbvbns8naej34wetx1aoxxsj4kkkr1ftrbi8vjc20owy2k3bpzhn2n0ij/q1epkh49q9589+4bxpq1gcdj/dmmjkxpojr47rfzsrq2vrgzmmrvl2zu7dfoth81emmgposeylqh1sj4bj9w43adqqqxqhavji6mfqtj1saj/lbjfmmyjqqpokmgiv5t728pulvqm7nnyese68gvsjq7fw+uv2eztfkwwtvuuo5qqlyqgxnaiflbqyxpwxeb9ixvniydzdpjp2qu6v0szqow9kqmfp7iqex1um4tj0xnuo96e3f/7xozqlliocyzqxknl8uzykyhew/j32ukbkxtoqyxe2tha2poszyfmo2bg/x5wxi12txne/+vnq4ltiowtgcwbl4caenuimm+mcawzo8wpsjnrfn3fmyt644xcwr/ihz+qpwsi5o</latexit> <latexit sha1_base64="ovpom5kixagxw+gtqcjufmo2cga=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leuw9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bqw8ghu/nmdmvtaxxxnw/nnls8srqwnm9srg5tb1t3d170emmgposeylqh1sj4bj9w43adqqqxqhavji6nvqtr1saj/lejfmmyjqqpokmgiv5n738bnkr1ty6owp5s7yc1kbas1f97pytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zcjqzsj1gibeldzurpizzgwo/j0hbg1az1ojcv//m6mykugpzlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl/8s/6r+wffutmunqyknmhzairydb+fqgftogg8modzbc7w60nl23pz3ewvjkwb24recj2/1pi5r</latexit> <latexit sha1_base64="ovpom5kixagxw+gtqcjufmo2cga=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leuw9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bqw8ghu/nmdmvtaxxxnw/nnls8srqwnm9srg5tb1t3d170emmgposeylqh1sj4bj9w43adqqqxqhavji6nvqtr1saj/lejfmmyjqqpokmgiv5n738bnkr1ty6owp5s7yc1kbas1f97pytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zcjqzsj1gibeldzurpizzgwo/j0hbg1az1ojcv//m6mykugpzlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl/8s/6r+wffutmunqyknmhzairydb+fqgftogg8modzbc7w60nl23pz3ewvjkwb24recj2/1pi5r</latexit> <latexit sha1_base64="ovpom5kixagxw+gtqcjufmo2cga=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leuw9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bqw8ghu/nmdmvtaxxxnw/nnls8srqwnm9srg5tb1t3d170emmgposeylqh1sj4bj9w43adqqqxqhavji6nvqtr1saj/lejfmmyjqqpokmgiv5n738bnkr1ty6owp5s7yc1kbas1f97pytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zcjqzsj1gibeldzurpizzgwo/j0hbg1az1ojcv//m6mykugpzlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl/8s/6r+wffutmunqyknmhzairydb+fqgftogg8modzbc7w60nl23pz3ewvjkwb24recj2/1pi5r</latexit> <latexit sha1_base64="ovpom5kixagxw+gtqcjufmo2cga=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leuw9fetxwmlbqhrlzttqlm03y3qgl9dd48adi1t/kzx/jts1bqw8ghu/nmdmvtaxxxnw/nnls8srqwnm9srg5tb1t3d170emmgposeylqh1sj4bj9w43adqqqxqhavji6nvqtr1saj/lejfmmyjqqpokmgiv5n738bnkr1ty6owp5s7yc1kbas1f97pytlsuodrnu647npibiqtkcczxuupngllirhwdhuklj1ee+o3zcjqzsj1gibeldzurpizzgwo/j0hbg1az1ojcv//m6mykugpzlndmo2xxrlaliejl9nps5qmbe2blkfle3ejakijjj86nyelzfl/8s/6r+wffutmunqyknmhzairydb+fqgftogg8modzbc7w60nl23pz3ewvjkwb24recj2/1pi5r</latexit> <latexit sha1_base64="0kznpbickmmo7nmdy1onzrk1b+i=">aaab63icbvbns8naej3ur1q/qh69lbbbu0le/lgv9ecxgrgfnptndtiu3wzc7kyoob/biwcvr/4hb/4bt20own0w8hhvhpl5ysq4nq775zswlldw18rrly3nre2d6u7eg04yxdbniuhuo6qabzfog24etlofna4ftslr9drvpalspjh3zpxienob5bfn1fjjv+nlz5netebw3rnix+ivpayfmr3qz7efscxgazigwnc8nzvbtpxhtock0s00ppsn6aa7lkoaow7y2betcmsvpokszusamln/tuq01noch7yzpmaof72p+j/xyux0eercpplbyealokwqk5dp56tpftijxpzqpri9lbahvzqzm0/fhuatvvyx+cf1y7p3d1prxbvploeadueypdihbtxce3xgwoejxudvkc6z8+a8z1tltjgzd7/gfhwd9tmouq==</latexit> <latexit sha1_base64="0kznpbickmmo7nmdy1onzrk1b+i=">aaab63icbvbns8naej3ur1q/qh69lbbbu0le/lgv9ecxgrgfnptndtiu3wzc7kyoob/biwcvr/4hb/4bt20own0w8hhvhpl5ysq4nq775zswlldw18rrly3nre2d6u7eg04yxdbniuhuo6qabzfog24etlofna4ftslr9drvpalspjh3zpxienob5bfn1fjjv+nlz5netebw3rnix+ivpayfmr3qz7efscxgazigwnc8nzvbtpxhtock0s00ppsn6aa7lkoaow7y2betcmsvpokszusamln/tuq01noch7yzpmaof72p+j/xyux0eercpplbyealokwqk5dp56tpftijxpzqpri9lbahvzqzm0/fhuatvvyx+cf1y7p3d1prxbvploeadueypdihbtxce3xgwoejxudvkc6z8+a8z1tltjgzd7/gfhwd9tmouq==</latexit> <latexit sha1_base64="0kznpbickmmo7nmdy1onzrk1b+i=">aaab63icbvbns8naej3ur1q/qh69lbbbu0le/lgv9ecxgrgfnptndtiu3wzc7kyoob/biwcvr/4hb/4bt20own0w8hhvhpl5ysq4nq775zswlldw18rrly3nre2d6u7eg04yxdbniuhuo6qabzfog24etlofna4ftslr9drvpalspjh3zpxienob5bfn1fjjv+nlz5netebw3rnix+ivpayfmr3qz7efscxgazigwnc8nzvbtpxhtock0s00ppsn6aa7lkoaow7y2betcmsvpokszusamln/tuq01noch7yzpmaof72p+j/xyux0eercpplbyealokwqk5dp56tpftijxpzqpri9lbahvzqzm0/fhuatvvyx+cf1y7p3d1prxbvploeadueypdihbtxce3xgwoejxudvkc6z8+a8z1tltjgzd7/gfhwd9tmouq==</latexit> <latexit sha1_base64="0kznpbickmmo7nmdy1onzrk1b+i=">aaab63icbvbns8naej3ur1q/qh69lbbbu0le/lgv9ecxgrgfnptndtiu3wzc7kyoob/biwcvr/4hb/4bt20own0w8hhvhpl5ysq4nq775zswlldw18rrly3nre2d6u7eg04yxdbniuhuo6qabzfog24etlofna4ftslr9drvpalspjh3zpxienob5bfn1fjjv+nlz5netebw3rnix+ivpayfmr3qz7efscxgazigwnc8nzvbtpxhtock0s00ppsn6aa7lkoaow7y2betcmsvpokszusamln/tuq01noch7yzpmaof72p+j/xyux0eercpplbyealokwqk5dp56tpftijxpzqpri9lbahvzqzm0/fhuatvvyx+cf1y7p3d1prxbvploeadueypdihbtxce3xgwoejxudvkc6z8+a8z1tltjgzd7/gfhwd9tmouq==</latexit> <latexit sha1_base64="dm6uivelahafxktkrj0jmbxeyi0=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leuw9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudvh8mpn6bywzemaqujet+oawl5zxvtfj6zwnza3unurv3ojnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0pfvbj6g0t+s9gacyxhqgecqznvbyb3r52arxrbl1dwbyl3gfqugbzq/62e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyehfmlt6je2zkgznsfezmntr7hoe2mqrnqrw8q/ud1mhndbdmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixill/8l/kn9su7dndyav0uaztiaqzggd86habfqbb8ychicf3h1pppsvdnv89asu8zswy84h9/zty5q</latexit> <latexit sha1_base64="dm6uivelahafxktkrj0jmbxeyi0=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leuw9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudvh8mpn6bywzemaqujet+oawl5zxvtfj6zwnza3unurv3ojnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0pfvbj6g0t+s9gacyxhqgecqznvbyb3r52arxrbl1dwbyl3gfqugbzq/62e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyehfmlt6je2zkgznsfezmntr7hoe2mqrnqrw8q/ud1mhndbdmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixill/8l/kn9su7dndyav0uaztiaqzggd86habfqbb8ychicf3h1pppsvdnv89asu8zswy84h9/zty5q</latexit> <latexit sha1_base64="dm6uivelahafxktkrj0jmbxeyi0=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leuw9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudvh8mpn6bywzemaqujet+oawl5zxvtfj6zwnza3unurv3ojnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0pfvbj6g0t+s9gacyxhqgecqznvbyb3r52arxrbl1dwbyl3gfqugbzq/62e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyehfmlt6je2zkgznsfezmntr7hoe2mqrnqrw8q/ud1mhndbdmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixill/8l/kn9su7dndyav0uaztiaqzggd86habfqbb8ychicf3h1pppsvdnv89asu8zswy84h9/zty5q</latexit> <latexit sha1_base64="dm6uivelahafxktkrj0jmbxeyi0=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leuw9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudvh8mpn6bywzemaqujet+oawl5zxvtfj6zwnza3unurv3ojnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0pfvbj6g0t+s9gacyxhqgecqznvbyb3r52arxrbl1dwbyl3gfqugbzq/62e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyehfmlt6je2zkgznsfezmntr7hoe2mqrnqrw8q/ud1mhndbdmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixill/8l/kn9su7dndyav0uaztiaqzggd86habfqbb8ychicf3h1pppsvdnv89asu8zswy84h9/zty5q</latexit> <latexit sha1_base64="upg9mxvrupsniztq8nwwdkjrlwg=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leug9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudtj4yelw3w8y8mbvcg9f9dkorq2vrg+xnytb2zu5edf/gusezyuizrcsqhvkngkv0dtcc26lcgoccw+hozuq3nlbpnsghm04xiola8ogzaqzk3/by80mvwnpr7gxkmxgfqugbzq/61e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyenfilt6je2zkgzntfezmntr7hoe2mqrnqrw8q/ud1mhndbjmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixilly8t/6x+vffuz2un6yknmhzbmzycbxfqgdtogg8modzdk7w50nlx3p2pewvjkwyo4q+czx/ymy5p</latexit> <latexit sha1_base64="upg9mxvrupsniztq8nwwdkjrlwg=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leug9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudtj4yelw3w8y8mbvcg9f9dkorq2vrg+xnytb2zu5edf/gusezyuizrcsqhvkngkv0dtcc26lcgoccw+hozuq3nlbpnsghm04xiola8ogzaqzk3/by80mvwnpr7gxkmxgfqugbzq/61e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyenfilt6je2zkgzntfezmntr7hoe2mqrnqrw8q/ud1mhndbjmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixilly8t/6x+vffuz2un6yknmhzbmzycbxfqgdtogg8modzdk7w50nlx3p2pewvjkwyo4q+czx/ymy5p</latexit> <latexit sha1_base64="upg9mxvrupsniztq8nwwdkjrlwg=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leug9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudtj4yelw3w8y8mbvcg9f9dkorq2vrg+xnytb2zu5edf/gusezyuizrcsqhvkngkv0dtcc26lcgoccw+hozuq3nlbpnsghm04xiola8ogzaqzk3/by80mvwnpr7gxkmxgfqugbzq/61e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyenfilt6je2zkgzntfezmntr7hoe2mqrnqrw8q/ud1mhndbjmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixilly8t/6x+vffuz2un6yknmhzbmzycbxfqgdtogg8modzdk7w50nlx3p2pewvjkwyo4q+czx/ymy5p</latexit> <latexit sha1_base64="upg9mxvrupsniztq8nwwdkjrlwg=">aaab63icbvbns8naej3ur1q/qh69lbbbu0leug9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudtj4yelw3w8y8mbvcg9f9dkorq2vrg+xnytb2zu5edf/gusezyuizrcsqhvkngkv0dtcc26lcgoccw+hozuq3nlbpnsghm04xiola8ogzaqzk3/by80mvwnpr7gxkmxgfqugbzq/61e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyenfilt6je2zkgzntfezmntr7hoe2mqrnqrw8q/ud1mhndbjmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixilly8t/6x+vffuz2un6yknmhzbmzycbxfqgdtogg8modzdk7w50nlx3p2pewvjkwyo4q+czx/ymy5p</latexit> <latexit sha1_base64="vwwarll58ijtlcy24js1nbautvc=">aaab63icbvbns8naej3ur1q/qh69lbbbu0luug9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudvh8mpn6bywzemaqujet+oawl5zxvtfj6zwnza3unurv3ojnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0pfvbj6g0t+s9gacyxhqgecqznvbyb3r56arxrbl1dwbyl3gfqugbzq/62e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyehfmlt6je2zkgznsfezmntr7hoe2mqrnqrw8q/ud1mhndbdmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixill/8l/kn9su7dnduav0uaztiaqzggd86habfqbb8ychicf3h1pppsvdnv89asu8zswy84h9/wry5o</latexit> <latexit sha1_base64="vwwarll58ijtlcy24js1nbautvc=">aaab63icbvbns8naej3ur1q/qh69lbbbu0luug9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudvh8mpn6bywzemaqujet+oawl5zxvtfj6zwnza3unurv3ojnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0pfvbj6g0t+s9gacyxhqgecqznvbyb3r56arxrbl1dwbyl3gfqugbzq/62e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyehfmlt6je2zkgznsfezmntr7hoe2mqrnqrw8q/ud1mhndbdmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixill/8l/kn9su7dnduav0uaztiaqzggd86habfqbb8ychicf3h1pppsvdnv89asu8zswy84h9/wry5o</latexit> <latexit sha1_base64="vwwarll58ijtlcy24js1nbautvc=">aaab63icbvbns8naej3ur1q/qh69lbbbu0luug9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudvh8mpn6bywzemaqujet+oawl5zxvtfj6zwnza3unurv3ojnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0pfvbj6g0t+s9gacyxhqgecqznvbyb3r56arxrbl1dwbyl3gfqugbzq/62e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyehfmlt6je2zkgznsfezmntr7hoe2mqrnqrw8q/ud1mhndbdmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixill/8l/kn9su7dnduav0uaztiaqzggd86habfqbb8ychicf3h1pppsvdnv89asu8zswy84h9/wry5o</latexit> <latexit sha1_base64="vwwarll58ijtlcy24js1nbautvc=">aaab63icbvbns8naej3ur1q/qh69lbbbu0luug9fpxisygyhdwwznbrln5uwuxfk6g/w4khfq3/im//gbzudvh8mpn6bywzemaqujet+oawl5zxvtfj6zwnza3unurv3ojnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0pfvbj6g0t+s9gacyxhqgecqznvbyb3r56arxrbl1dwbyl3gfqugbzq/62e0nlitrgiao1h3ptu2qu2u4ezipddonkwujoscopzlgqin8duyehfmlt6je2zkgznsfezmntr7hoe2mqrnqrw8q/ud1mhndbdmxawzqsvmikbpejgt6oelzhcyisswukw5vjwxifwxg5loxixill/8l/kn9su7dnduav0uaztiaqzggd86habfqbb8ychicf3h1pppsvdnv89asu8zswy84h9/wry5o</latexit> <latexit sha1_base64="+za7psnqi6qxevz+hspqvssftok=">aaab63icbvbns8naej34wetx1aoxxsj4kkkr1ftrdx4rgftoq9lsj+3szsbsboqs+hu8efdx6h/y5r9x2+agrq8ghu/nmdmvtaxxxnw/nzxvtfwnzdjwextnd2+/cnd4qjnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0m/vbt6g0t+sdgacyxhqgecqznvbyb3t5fdkrvn2aownzjl5bqlcg2at8dfsjy2kuhgmqdcdzuxpkvbnobe7k3uxjstmidrbjqaqx6icfhtshp1bpkyhrtqqhm/x3re5jrcdxadtjaoz60zuk/3mdzesxqc5lmhmubl4oygqxczl+tvpcitniballittbcrtsrzmx+zrtcn7iy8ver9euat79ebvxxarrgmm4gtpw4aiacadn8iebh2d4htdhoi/ou/mxb11xipkj+apn8wfvky5n</latexit> <latexit sha1_base64="+za7psnqi6qxevz+hspqvssftok=">aaab63icbvbns8naej34wetx1aoxxsj4kkkr1ftrdx4rgftoq9lsj+3szsbsboqs+hu8efdx6h/y5r9x2+agrq8ghu/nmdmvtaxxxnw/nzxvtfwnzdjwextnd2+/cnd4qjnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0m/vbt6g0t+sdgacyxhqgecqznvbyb3t5fdkrvn2aownzjl5bqlcg2at8dfsjy2kuhgmqdcdzuxpkvbnobe7k3uxjstmidrbjqaqx6icfhtshp1bpkyhrtqqhm/x3re5jrcdxadtjaoz60zuk/3mdzesxqc5lmhmubl4oygqxczl+tvpcitniballittbcrtsrzmx+zrtcn7iy8ver9euat79ebvxxarrgmm4gtpw4aiacadn8iebh2d4htdhoi/ou/mxb11xipkj+apn8wfvky5n</latexit> <latexit sha1_base64="+za7psnqi6qxevz+hspqvssftok=">aaab63icbvbns8naej34wetx1aoxxsj4kkkr1ftrdx4rgftoq9lsj+3szsbsboqs+hu8efdx6h/y5r9x2+agrq8ghu/nmdmvtaxxxnw/nzxvtfwnzdjwextnd2+/cnd4qjnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0m/vbt6g0t+sdgacyxhqgecqznvbyb3t5fdkrvn2aownzjl5bqlcg2at8dfsjy2kuhgmqdcdzuxpkvbnobe7k3uxjstmidrbjqaqx6icfhtshp1bpkyhrtqqhm/x3re5jrcdxadtjaoz60zuk/3mdzesxqc5lmhmubl4oygqxczl+tvpcitniballittbcrtsrzmx+zrtcn7iy8ver9euat79ebvxxarrgmm4gtpw4aiacadn8iebh2d4htdhoi/ou/mxb11xipkj+apn8wfvky5n</latexit> <latexit sha1_base64="+za7psnqi6qxevz+hspqvssftok=">aaab63icbvbns8naej34wetx1aoxxsj4kkkr1ftrdx4rgftoq9lsj+3szsbsboqs+hu8efdx6h/y5r9x2+agrq8ghu/nmdmvtaxxxnw/nzxvtfwnzdjwextnd2+/cnd4qjnmmfrzihlvdqlgwsx6hhub7vqhjuobrxb0m/vbt6g0t+sdgacyxhqgecqznvbyb3t5fdkrvn2aownzjl5bqlcg2at8dfsjy2kuhgmqdcdzuxpkvbnobe7k3uxjstmidrbjqaqx6icfhtshp1bpkyhrtqqhm/x3re5jrcdxadtjaoz60zuk/3mdzesxqc5lmhmubl4oygqxczl+tvpcitniballittbcrtsrzmx+zrtcn7iy8ver9euat79ebvxxarrgmm4gtpw4aiacadn8iebh2d4htdhoi/ou/mxb11xipkj+apn8wfvky5n</latexit> 4 H.-F. Lu, X. Du and P.-L. Chang D6 down conv5 E5 2048:256 up D5 Baseline E4 1024:256 Naïve conv4 D4 E3 512:256 up RPN Head GCN shared smoother (GCN-S) 256:64 C1x15 C15x1 C15x1 C1x15 BR 64:256 conv3 D3 Large kernel shared smoother (LK-S) up 256: :256 E2 GCN non-shared smoother (GCN-NS) conv2 conv1 D2 CB1 CB1 256:4k 2 256:k 2 256:64 C1x15 C15x1 C15x1 C1x15 Large kernel non-shared smoother (LK-NS) BR 64:256 Position-sensitive RoI / Global average pooling sigmoid 256: :256 Input image reg cls Fig.2. The overall proposed system architecture. Left: The ResNet together with the feature pyramid structure form the general backbone of RPN heads. Right: The structures of different RPN heads. Both: Rectangles are components with learnable parameters to train and ellipses are parameter-free operations. Dash arrow indicates that the RPN head is shared by all feature pyramid levels. spatial context [19]. In addition, instead of regressing and classifying a set of anchors using default profile (i.e., scale and aspect ratio) by a fixed (3 3) convolutional kernel in certain layers [16,23], we propose directly mapping anchors from sliding windows in each decoding layer together with sharing the positionsensitive score maps. The overall ConvNets takes an input image with arbitrary size to bottom-up encode and top-down decode features with skip connections to preserve object locality [24]. Scale-invariance as one of the important traits of the proposed method is thus achieved by extracting multi-scale features from the input image. These semantically weak to strong features are then feed into a series of decoding layers being shared by a RPN head. Anchors are generated by a dense sliding window fashion shared by a bank of position sensitive score maps. In the end, the network regresses the anchors to localise objects (reg for short) and classifies the objectness with scores (cls for short).
5 Toward Scale-Inv. and Pos.-Sens. Reg. Propos. Net Encoder The encoder is a feed-forward ConvNet as the backbone feature extractor, which scales down by a factor of 2 several times. Although the proposed method can be equipped with any popular ConvNet architectures [26,29] for the backbone, ResNet [12] is adopted particularly for its FCN structure being able to retain the local information as much as possible. ResNets are structured with residual blocks each consisting of a subset of ConvNets. We note the conv2, conv3, conv4 and conv5 blocks from the original paper [12] as {E 2,E 3,E 4,E 5 } with the corresponding dense sliding window strides s = {4,8,16,32} in regard to the input image. 3.2 Decoder The decoder recovers the feature resolution for the strongest semantic feature maps from low to high with skip connections in between the corresponding encoder and decoder layers. The skip connection is substantial for the accuracy of bounding box proposal as it propagates detail-preserving and position-accurate features from the encoding process to the decoded features which are later shared by the RPN head. Specifically with ResNet, the decoding process starts from E5 using 1 1 convolution and 256 output channels for feature selection followed by batch normalisation (BN) and rectified linear unit (ReLU) layers, which together we brief as CBR{ } where is the kernel size. Likewise, each skip connection at a layer takes a with 256 output channels. The bottom-up decoding process is therefore done by using bilinear upsampling followed by element-wise addition with the selected features from the encoding layers. A block is inserted in each decoding layer right after the addition for the purpose of de-aliasing. We note the decoding layers as {D 2,D 3,D 4,D 5 } corresponding to {E 2,E 3,E 4,E 5 } in the encoding layers. An extra D 6 is added by directly down sampling D 5 for gaining an even larger stride s = 64, which is in favor of extremely large objectness detection. 3.3 RPN heads A RPN head is in charge of learning features across a range of scales for reg and cls. The learnable parameters in the RPN head share all features in the decoding layers to capture different levels of semantics for various object sizes. We will show that the design of a RPN head has a significant impact on the final proposal accuracy in Sec. 4. We show a number of different RPN head designs in Fig. 2. Each head takes 256 channel feature map as input and outputs two sibling CB1 blocks for reg and cls with 4 k 2 and k 2 channels respectively, where k 2 is the number of regular grids for position-sensitive score maps described in Sec We regard the state-of-the-art RPN used in FPN [16] as a Baseline method, in which a block is adopted for fusing multi-scale features. Our
6 6 H.-F. Lu, X. Du and P.-L. Chang Baseline implementation, which is a bit different from [16], uses BN and ReLU which have been found helpful in converging the end-to-end training. Inspired by GCN within residual structure[19], we hypothesise that enlarging VRF to learn from larger image context can improve the overall object proposal performance. For the GCN shared smoother (GCN-S) and Large kernel shared smoother (LK-S), a larger convolution kernel (15 15) is inserted before the smoothing. Additionally their non-shared smoother counterpart (GCN- NS and LK-NS) are also compared. To study the effect of model capacity and the increased number of parameters, a Naïve head is taken into account, which is simply added with more blocks to approximately match the number of learnable parameters compared with other RPN heads. Table 1 lists the number of parameters of all RPN heads. Compared with the Baseline, the numbers of parameter ratio of the other models are within a 15 standard deviation. 3.4 Position-sensitive anchors We argue that using a default set of scales and aspect ratios to map anchors from a constant-size convolution kernel can potentially undermine the accuracy of reg and cls. This could be due to the mismatch of the receptive field of network and the mapped anchors. Prior works have used such strategy [5,16,23] with little exploration of other varieties. To improve the fidelity of relationship between features and anchors with respect to the receptive field of ConvNets, in the proposed method, at each layer, the size of an anchor is calculated by (w s) (h s) where w and h are the width and height of the sliding window. Since the anchor and the sliding window are now naturally mapped, positionsensitive score maps can be further exploited for improving the accuracy of localisation. Fig. 1 illustrates the stack of score maps for k 2 regular grids in the sliding window. Each grid in the window takes average of its coverage on the corresponding score map (i.e., average pooling). All k 2 grids then undergo a global average pooling to output 4-channel t and 1-channel o for the final reg and cls result respectively. We further feed o to an activation function sigmoid for evaluating the objectness score. Details of position-sensitive pooling can be found in [5]. In this paper we use k = 4 for illustration as well as for all experiments. 3.5 Implementation details In this paper, all the experiments were conducted with ResNet-50 with the removal of average pooling, fully-connected and softmax layers in the end of the original model. We do not use conv1 in the pyramid due to the high memory footage and too low-level features which contribute very little for semantically representing objectness. The architecture is illustrated in Fig. 2. A set of window sizes w : h = {8 : 8, 4 : 8, 8 : 4, 3 : 9, 9 : 3} are used for the dense sliding windows at each layer for generating anchors. At the most top D 6 and bottom D 2 layer, additional window sizes {12 : 12, 6 : 12, 12 : 6, 12 : 4, 4 : 12} and
7 Toward Scale-Inv. and Pos.-Sens. Reg. Propos. Net. 7 {4 : 4, 2 : 4, 4 : 2} are respectively used for discovering extremely large and small objectness. The proposed position-sensitive anchors mapped from the windows are all inside the input image, but the bounding boxes regressed from anchors can possibly exceed the image boundary. We simply discard those bounding boxes exceeding the image boundary. In addition, the number of total anchors depends on the size of input image and the used anchor profile. The effect of anchor number is discussed in the supplementary material. Training In each image, a large amount of anchors are generated across all decoding layers to be further assigned positive and negative labels. An anchor having intersection-over-union () with any ground truth bounding box greater thanisassignedapositivelabelpandlessthananegativelabeln.foreach ground truth bounding box, the anchor with the highest is also assigned to a positive label, only if the is greater than. This policy is similar to [23] but with the additional lower bound for avoiding distraction of outliers. N A anchors (half positive and half negative anchors) are selected for each training iteration. The model can be trained end-to-end with N B mini-batch images together with the sampled anchors using a defined loss: 1 N B L = N B N A i=1 ] [L reg (t p i,j,t i,j)+l cls (o p i,j ) N A ] + L cls (o n i,j), (1) [ NA j=1 where t is the regressed bounding box with t as its ground truth correspondent, and o is the objectness score. L reg is the smooth L 1 loss taking the difference between normalised bounding box coordinates with the ground truth as defined in [9], and L cls the cross-entropy loss. We use stochastic gradient descent (SGD) with momentum of, weight decay of 10 4 and exponential decay learning rate l e = l 0 b λe, in which the e is the epoch number and we set l 0 = and λ = for the base b = 10. j=1 4 Empirical studies We have conducted comprehensive experiments for comparing different RPN heads as well as ablation studies to show the impact of position-sensitive score maps. The experiment platform is equipped with an Intel(R) Xeon(R) CPU E5-2650v4@2.20GHzCPUandNvidiaTitanX(Pascal)GPUswith12GBmemory. Such hardware spec allowed us to train the models with batch size N B listed in Table 1. Note that we particularly focus on conducting ablation studies on different components. In all experiments we therefore did not exploit additional tricks for boosting the performance such as using multi-scale input images for training [11] and testing [12], iterative regression [8], hard example mining [25], etc.
8 8 H.-F. Lu, X. Du and P.-L. Chang Table 1. The number of parameters in the different models and the corresponding inference time T in ms averaged on the number of all testing images w/o position-sensitive w/ position-sensitive # params N B T 07test T minival # params N B T 07test T minival Baseline 26,858, ,875, Naïve 28,039, ,055, GCN-S 27,137, ,154, LK-S 27,81, ,830, GCN-NS 27,727, ,744, LK-NS 28,403, ,420, Baseline model The implementation of our Baseline model, with or without using position-sensitive score maps, differ from the original FPN [16] in the use of BN and ReLU in the RPN head, as well as the de-aliasing block in each layer. In addition, the evaluation in their paper was conducted with rescaling image short side to 800 pixels. The rest of setting such as anchor generation, the number of pyramid layers, etc. are remained the same. Note that such discrepancy do not affect the ablation studies here to compare the baseline architecture. The main purpose is to assess performance gains when adding other network components. Evaluation protocol All models are evaluated on PASCAL VOC [6] and COCO [17]. For Pascal VOC we used all train and validation dataset in 2007 and 2012 (denoted as 07+12), which has in total 16,551 images with 40,058 objects, and report test result on the 2007 test dataset (denoted as 07test) consisting of 4,952 images with 12,032 objects. For COCO we employed the union of train and a subset of validation set for in total 109,172 images and 654,212 objects (denoted as trainval35k), and report test results on the rest of validation set for 4,589 images and 27,436 objects (denoted as minival). Our evaluation is consistent with the official COCO evaluation protocol, in which areas marked as crowds are ignored and do not affect detector s scores [17]. In order to perform mini-batch training, we rescaled images in with the long side fixed and zero-pad along the rescaled short side to for batching, and for images in trainval35k, the short side were fixed to 768 with random crop along the rescaled long side to For testing, images in 07test and minival are padded to have width and height being the closest multiple of the maximum stride (i.e., s = 64), to avoid rounding errors. All models were trained for 40 epochs which roughly take 30 and 90 hours for PASCAL VOC and COCO trainval35k respectively. Following [4,13,17], we evaluated models at AR with different proposal numbers of 10, 100 and 1,000 {AR 10,AR 100,AR 1k } and the area under the curve
9 Toward Scale-Inv. and Pos.-Sens. Reg. Propos. Net Proposals w/o ps Naïve w/o ps LK-S w/o ps LK-NS w/ ps Naïve w/ ps LK-S w/ ps LK-NS Proposals 100 Proposals w/o ps Naïve w/o ps LK-S w/o ps LK-NS w/ ps Naïve w/ ps LK-S w/ ps LK-NS Proposals 1000 Proposals w/o ps Naïve w/o ps LK-S w/o ps LK-NS w/ ps Naïve w/ ps LK-S w/ ps LK-NS Proposals Average Average PASCAL VOC w/o ps Naïve w/o ps LK-S w/o ps LK-NS w/ ps Naïve w/ ps LK-S w/ ps LK-NS Number of Proposals COCO Proposals Proposals Proposals Average Number of Proposals Trained on PASCAL VOC and Tested on COCO Number of Proposals Fig.3. against with different proposal numbers of 10, 100 and 1,000 and average recall against the number of proposals of all models: The results of PASCAL VOC 07test using models trained on PASCAL VOC (Row 1). The results of COCO minival using models trained on COCO trainval35k (Row 2) and models trained on PASCAL VOC (Row 3). (AUC) of recall across all proposal numbers. Besides, we also evaluated models at AR for different object area a: small (a < 32 2 ), medium (32 2 < a < 96 2 ) and large (a > 96 2 ) with 1,000 proposals {AR 1k s,ar 1k m,ar 1k l }. It is worth noting that COCO has more complex scenes with diverse and many more small objects than PASCAL VOC does [17,22]. We therefore evaluated all models with PASCAL VOC while selected the top-performance GCN-S and GCN-NS models for COCO evaluation. In the tables, numbers with underline indicate the highest score of a metric among models with different RPN heads, and numbers in bold indicate the highest score of a metric among models with or without using position-sensitivity. 4.1 Impact of using GCN The results of Table 2 and 3 reveal that by adding GCN in the RPN head, the overall AR can be remarkably improved regardless the number of considered proposals or if the position-sensitivity is employed. This can be also observed in Fig. 3 in which GCN-S and GCN-NS curves are always on the top of others. AR 1k s in particular benefits from learning the global image context. One can observe that compared to Baseline model, the scores have been boosted by 85% from 54 to 71 on PASCAL VOC with GCN-S model, and by 37% from 08 to 22 on COCO with GCN-NS. Therefore, the AR 1k has been overall improved from 80 and 21 to 86 and 42, which are 22% and 29% respectively. Fig. 3 also shows that GCN-S and GCN-NS models have the highest recall scores across all thresholds with different proposal numbers.
10 10 H.-F. Lu, X. Du and P.-L. Chang Table 2. Object proposal results of all models trained on PASCAL VOC and evaluated on 07test w/o position-sensitive AR 10 AR 100 AR 1k AUC AR 1k s AR 1k m AR 1k l w/ position-sensitive AR 10 AR 100 AR 1k AUC AR 1k s AR 1k m AR 1k l Baseline Naïve GCN-S LK-S GCN-NS LK-NS Table 3. Object proposal results of all models trained on COCO trainval35k and evaluated on minival w/o position-sensitive AR 10 AR 100 AR 1k AUC AR 1k s AR 1k m AR 1k l w/ position-sensitive AR 10 AR 100 AR 1k AUC AR 1k s AR 1k m AR 1k l Baseline GCN-S GCN-NS One may argue that the improvement in GCN-S and GCN-NS models is due to the increased number of parameters. From Table 2, LK-S and LK-NS models have also shown some improvement but considering the extra number of parameters compared with Baseline model, they are not as effective as GCN-S and GCN-NS models. This shows that using separable convolution kernel matters, which aligns with the observation in [19]. Naïve model also exhibits similar results. 4.2 Impact of using position-sensitivity As shown in Table 2, on PASCAL VOC, among different proposal numbers and object sizes, models using position-sensitive components generally result in higher AR. Specifically, for AR 1k, Baseline model shows an improvement from 80 to 05 (26%) and GCN-NS from 86 to 53 (11%). As shown in Table 3, the experiment on COCO shows similar results, in which Baseline model has an improvement from 21 to 48 (6%) and GCN-NS model from 32 to 07 (14%). To investigate on the small object proposals, AR 1k s reveal that training on a large number of annotated small objects in COCO indeed helps in higher AR 1k s scores, compared with the results of PASCAL VOC counterpart. GCN-NS has achieved much higher AR 1k s (93) score, which is a 17% improvement compared to the counterpart. Fig. 4 visualises the distribution heatmap and hit-and-miss of top 1,000 proposals using GCN-NS models with and without taking position-sensitivity into account, in which the hits are with a threshold for the ground truth. One can qualitatively tell that by using the position-
11 Toward Scale-Inv. and Pos.-Sens. Reg. Propos. Net. 11 sensitivity, models can generate proposals closer to objects and thus result in more hits, especially for objects with extremely large or small sizes. 4.3 Inference time Introducing both GCN structure and position-sensitive score maps in the RPN head brings in more learnable parameters resulting in more computation. Beside the input image size which has a directly impact on the overall inference time, the number of anchors, the kernel size of GCN and the grid number k of position-sensitive score maps are also key factors. Table 1 lists the models inference times averaged on all input images in both 07test and minival, in which Baseline model shows a performance of 26.6/58.2 (denoted for 07test/minival) ms. Adding the position-sensitive score maps (with grid size k = 4) takes extra 9.1/21.3 ms, 9.8/19.8 ms and 8.9/2 ms for Baseline, GCN-S and GCN-NS model respectively, which show a comparable time difference. In contrast, introducing the GCN structure in the Baseline model adds 7.7/18.1 ms for GCN-S model while additional 9.3/25.3 ms for GCN-NS model. This reveals that using non-shared smoother generally takes more times than using shared smoother does. GCN-NS with position-sensitivity, as the best performance model, has a running time 44.8 ms ( 22 fps) for and ms ( 10 fps) for minival. 4.4 Model generalisation To evaluate the generalisation ability of the proposed method, the models trained on PASCAL VOC are used to evaluate on COCO minival. Note that compared to COCO (80 categories), PASCAL VOC is a much smaller dataset with limited object categories (20 categories) and almost all categories in PAS- CAL VOC are included in COCO. We separate the categories of COCO into two sets: common and non-common. Common categories are ones in PASCAL VOC, while non-common are unseen categories. In addition, image scenes in PASCAL VOC are relatively simple with less small objects annotations. It is therefore more challenging for a model learned from PASCAL VOC to performance object proposal on COCO images. The results are shown in Table 4 and Fig. 3 (Row 3). Surprisingly, the AR 1k of the best performance models, GCN-S and GCN-NS with position-sensitivity, trained with PASCAL VOC can still outperform Baseline model trained with COCO trainval35k (i.e., 38 vs. 21). It is expected that the model will not work well on small objects since PASCAL VOC does not contain many small objects, but nevertheless the model still shows decent performance on large objects in which the AR 1k l is up to 93 as shown in Table 4. The score is comparable to the other models trained on COCO trainval35k as shown in Table 3. Delving into the details, we show the breakdown results of the model generalisation experiment for common and noncommon categories are shown in Table 5. All models have better performance on common categories overall. However, compared to the Baseline model, the proposed components significantly improved the performance on both common and non-common categories. The per-category AUC performance in Fig. 5 shows
12 12 H.-F. Lu, X. Du and P.-L. Chang that non-common categories do not necessarily have worse performance than common categories (e.g., bear, zebra, and toilet). This indicates that the proposed object proposal networks are able to generalise proposals from a smaller to a larger and more complex dataset, from common to non-common categories, and that the proposed architecture can further improve the generalisation for all categories. Fig. 6 qualitatively demonstrates the generalisation ability of the proposed method. Although the model trained on PASCAL VOC fails at detecting small objectness, it still exhibits a certain degree of generalisation to unseen categories (e.g., elephant, teddy bear, or fire hydrant). Table 4. Object proposal results of all models trained on PASCAL VOC and evaluated on COCO minival w/o position-sensitive AR 10 AR 100 AR 1k AUC AR 1k s AR 1k m AR 1k l w/ position-sensitive AR 10 AR 100 AR 1k AUC AR 1k s AR 1k m AR 1k l Baseline GCN-S GCN-NS Table 5. Object proposal results of all models trained on PASCAL VOC and evaluated on COCO minival for common and non-common categories. Note that( non) denotes models evaluated on non-common categories w/o position-sensitive AR 10 AR 100 AR 1k AUC AR 1k s AR 1k m AR 1k l w/ position-sensitive AR 10 AR 100 AR 1k AUC AR 1k s AR 1k m AR 1k l Baseline Baseline (non) GCN-S GCN-S (non) GCN-NS GCN-NS (non) Conclusions In this paper, we have proposed object proposal networks based on the observation that accurate detection relies on translation-invariance for objectness classification, translation-variance for localisation as regression and scale-invariance for various object sizes. Thorough experiments on PASCAL VOC and COCO datasets have shown that the adoption of global convolutional network (GCN) and position-sensitivity components can significantly improve object proposal performance while keeping the network lightweight to achieve real-time performance.




 and COCO")









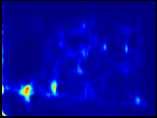
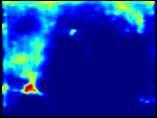
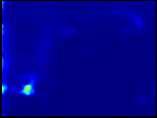
13 Toward Scale-Inv. and Pos.-Sens. Reg. Propos. Net. 13 Fig. 4. The impact of position-sensitivity: visualisation on the distribution heatmap and hit-and-miss of the top 1,000 proposals by GCN-NS models for a number of selected PASCAL VOC 07test (Row 1-2) and COCO minival (Row 3-5) images. For each pair of images, model without position-sensitivity is on the left and the one with position-sensitivity is on the right. Col 1-2: The heatmaps are plotted by stacking the proposal boxes. Col 3-4: The bounding boxes in orange are ground truth boxes with their corresponding hit proposals in cyan, in which the threshold is set to, and the bounding boxes in red are missed cases. Row 6-7: All models tend to fail in images with complex scenes and diverse object aspect ratios. Nonetheless, note that models with position-sensitivity generally have higher hit rate. Sec. 4.2 for detailed discussions.










14 14 H.-F. Lu, X. Du and P.-L. Chang airplane bicycle bird boat bottle bus car cat chair cow dining table dog horse motorcycle person book sheep couch train tv truck traffic light fire hydrant stop sign parking meter bench elephant bear zebra giraffe backpack umbrella handbag tie suitcase frisbee skis snowboard sports ball kite baseball bat baseball glove skateboard surfboard tennis racket wine glass cup fork knife spoon bowl banana apple sandwich orange broccoli carrot hot dog pizza donut cake potted plant bed toilet laptop mouse remote keyboard cell phone microwave oven toaster sink refrigerator clock vase scissors teddy bear hair drier toothbrush AUC Fig. 5. Per-category AUC performance of models trained on PASCAL VOC and evaluated on COCO minival. Common and non-common categories are split in the white and green region respectively. Fig. 6. The results of model generalisation experiments visualised in the distribution heatmap and hit-and-miss of the top 1,000 proposals by GCN-NS models for a number of selected COCO minival. For each pair of COCO minival images, result of model trained on PASCAL VOC is on the left and the one of model trained on COCO is on the right. See Sec. 4.4 for detailed discussions.
Mask R-CNN. presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma
 Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
Mask R-CNN presented by Jiageng Zhang, Jingyao Zhan, Yunhan Ma Mask R-CNN Background Related Work Architecture Experiment Mask R-CNN Background Related Work Architecture Experiment Background From left
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm
 CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
CIS680: Vision & Learning Assignment 2.b: RPN, Faster R-CNN and Mask R-CNN Due: Nov. 21, 2018 at 11:59 pm Instructions This is an individual assignment. Individual means each student must hand in their
Object Detection on Self-Driving Cars in China. Lingyun Li
 Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Object Detection on Self-Driving Cars in China Lingyun Li Introduction Motivation: Perception is the key of self-driving cars Data set: 10000 images with annotation 2000 images without annotation (not
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
3 Object Detection. BVM 2018 Tutorial: Advanced Deep Learning Methods. Paul F. Jaeger, Division of Medical Image Computing
 3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
3 Object Detection BVM 2018 Tutorial: Advanced Deep Learning Methods Paul F. Jaeger, of Medical Image Computing What is object detection? classification segmentation obj. detection (1 label per pixel)
Mask R-CNN. Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018
 Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Mask R-CNN Kaiming He, Georgia, Gkioxari, Piotr Dollar, Ross Girshick Presenters: Xiaokang Wang, Mengyao Shi Feb. 13, 2018 1 Common computer vision tasks Image Classification: one label is generated for
Mask R-CNN. By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi
 Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
Mask R-CNN By Kaiming He, Georgia Gkioxari, Piotr Dollar and Ross Girshick Presented By Aditya Sanghi Types of Computer Vision Tasks http://cs231n.stanford.edu/ Semantic vs Instance Segmentation Image
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL
 SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
SEMANTIC SEGMENTATION AVIRAM BAR HAIM & IRIS TAL IMAGE DESCRIPTIONS IN THE WILD (IDW-CNN) LARGE KERNEL MATTERS (GCN) DEEP LEARNING SEMINAR, TAU NOVEMBER 2017 TOPICS IDW-CNN: Improving Semantic Segmentation
SSD: Single Shot MultiBox Detector. Author: Wei Liu et al. Presenter: Siyu Jiang
 SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
SSD: Single Shot MultiBox Detector Author: Wei Liu et al. Presenter: Siyu Jiang Outline 1. Motivations 2. Contributions 3. Methodology 4. Experiments 5. Conclusions 6. Extensions Motivation Motivation
Spatial Localization and Detection. Lecture 8-1
 Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Lecture 8: Spatial Localization and Detection Lecture 8-1 Administrative - Project Proposals were due on Saturday Homework 2 due Friday 2/5 Homework 1 grades out this week Midterm will be in-class on Wednesday
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Learning to Segment Object Candidates
 Learning to Segment Object Candidates Pedro Pinheiro, Ronan Collobert and Piotr Dollar Presented by - Sivaraman, Kalpathy Sitaraman, M.S. in Computer Science, University of Virginia Facebook Artificial
Learning to Segment Object Candidates Pedro Pinheiro, Ronan Collobert and Piotr Dollar Presented by - Sivaraman, Kalpathy Sitaraman, M.S. in Computer Science, University of Virginia Facebook Artificial
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren Kaiming He Ross Girshick Jian Sun Present by: Yixin Yang Mingdong Wang 1 Object Detection 2 1 Applications Basic
Advanced Video Analysis & Imaging
 Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
Advanced Video Analysis & Imaging (5LSH0), Module 09B Machine Learning with Convolutional Neural Networks (CNNs) - Workout Farhad G. Zanjani, Clint Sebastian, Egor Bondarev, Peter H.N. de With ( p.h.n.de.with@tue.nl
Object detection using Region Proposals (RCNN) Ernest Cheung COMP Presentation
 Ernest Cheung COMP Presentation") Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
Object detection using Region Proposals (RCNN) Ernest Cheung COMP790-125 Presentation 1 2 Problem to solve Object detection Input: Image Output: Bounding box of the object 3 Object detection using CNN
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs
 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution and Fully Connected CRFs Zhipeng Yan, Moyuan Huang, Hao Jiang 5/1/2017 1 Outline Background semantic segmentation Objective,
Fully Convolutional Networks for Semantic Segmentation
 Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
Fully Convolutional Networks for Semantic Segmentation Jonathan Long* Evan Shelhamer* Trevor Darrell UC Berkeley Chaim Ginzburg for Deep Learning seminar 1 Semantic Segmentation Define a pixel-wise labeling
R-FCN: OBJECT DETECTION VIA REGION-BASED FULLY CONVOLUTIONAL NETWORKS
 R-FCN: OBJECT DETECTION VIA REGION-BASED FULLY CONVOLUTIONAL NETWORKS JIFENG DAI YI LI KAIMING HE JIAN SUN MICROSOFT RESEARCH TSINGHUA UNIVERSITY MICROSOFT RESEARCH MICROSOFT RESEARCH SPEED/ACCURACY TRADE-OFFS
R-FCN: OBJECT DETECTION VIA REGION-BASED FULLY CONVOLUTIONAL NETWORKS JIFENG DAI YI LI KAIMING HE JIAN SUN MICROSOFT RESEARCH TSINGHUA UNIVERSITY MICROSOFT RESEARCH MICROSOFT RESEARCH SPEED/ACCURACY TRADE-OFFS
Instance-aware Semantic Segmentation via Multi-task Network Cascades
 Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai, Kaiming He, Jian Sun Microsoft research 2016 Yotam Gil Amit Nativ Agenda Introduction Highlights Implementation Further
Instance-aware Semantic Segmentation via Multi-task Network Cascades Jifeng Dai, Kaiming He, Jian Sun Microsoft research 2016 Yotam Gil Amit Nativ Agenda Introduction Highlights Implementation Further
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
Machine Learning 13. week
 Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Machine Learning 13. week Deep Learning Convolutional Neural Network Recurrent Neural Network 1 Why Deep Learning is so Popular? 1. Increase in the amount of data Thanks to the Internet, huge amount of
Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. Presented by: Karen Lucknavalai and Alexandr Kuznetsov
 Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization Presented by: Karen Lucknavalai and Alexandr Kuznetsov Example Style Content Result Motivation Transforming content of an image
Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization Presented by: Karen Lucknavalai and Alexandr Kuznetsov Example Style Content Result Motivation Transforming content of an image
YOLO9000: Better, Faster, Stronger
 YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
YOLO9000: Better, Faster, Stronger Date: January 24, 2018 Prepared by Haris Khan (University of Toronto) Haris Khan CSC2548: Machine Learning in Computer Vision 1 Overview 1. Motivation for one-shot object
arxiv: v1 [cs.cv] 14 Jun 2016
![arxiv: v1 [cs.cv] 14 Jun 2016](/thumbs/72/67347331.jpg "arxiv: v1 [cs.cv] 14 Jun 2016") S. GIDARIS AND N. KOMODAKIS: ATTEND REFINE REPEAT 1 arxiv:1606.04446v1 [cs.cv] 14 Jun 2016 Attend Refine Repeat: Active Box Proposal Generation via In-Out Localization Spyros Gidaris spyros.gidaris@enpc.fr
S. GIDARIS AND N. KOMODAKIS: ATTEND REFINE REPEAT 1 arxiv:1606.04446v1 [cs.cv] 14 Jun 2016 Attend Refine Repeat: Active Box Proposal Generation via In-Out Localization Spyros Gidaris spyros.gidaris@enpc.fr
Yield Estimation using faster R-CNN
 Yield Estimation using faster R-CNN 1 Vidhya Sagar, 2 Sailesh J.Jain and 2 Arjun P. 1 Assistant Professor, 2 UG Scholar, Department of Computer Engineering and Science SRM Institute of Science and Technology,Chennai,
Yield Estimation using faster R-CNN 1 Vidhya Sagar, 2 Sailesh J.Jain and 2 Arjun P. 1 Assistant Professor, 2 UG Scholar, Department of Computer Engineering and Science SRM Institute of Science and Technology,Chennai,
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Inception and Residual Networks. Hantao Zhang. Deep Learning with Python.
 Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
Inception and Residual Networks Hantao Zhang Deep Learning with Python https://en.wikipedia.org/wiki/residual_neural_network Deep Neural Network Progress from Large Scale Visual Recognition Challenge (ILSVRC)
EE-559 Deep learning Networks for semantic segmentation
 EE-559 Deep learning 7.4. Networks for semantic segmentation François Fleuret https://fleuret.org/ee559/ Mon Feb 8 3:35:5 UTC 209 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The historical approach to image
EE-559 Deep learning 7.4. Networks for semantic segmentation François Fleuret https://fleuret.org/ee559/ Mon Feb 8 3:35:5 UTC 209 ÉCOLE POLYTECHNIQUE FÉDÉRALE DE LAUSANNE The historical approach to image
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK. Wenjie Guan, YueXian Zou*, Xiaoqun Zhou
 MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
MULTI-SCALE OBJECT DETECTION WITH FEATURE FUSION AND REGION OBJECTNESS NETWORK Wenjie Guan, YueXian Zou*, Xiaoqun Zhou ADSPLAB/Intelligent Lab, School of ECE, Peking University, Shenzhen,518055, China
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Deep Learning and Its Applications
 Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
Convolutional Neural Network and Its Application in Image Recognition Oct 28, 2016 Outline 1 A Motivating Example 2 The Convolutional Neural Network (CNN) Model 3 Training the CNN Model 4 Issues and Recent
WITH the recent advance [1] of deep convolutional neural
![WITH the recent advance [1] of deep convolutional neural](/thumbs/91/106774335.jpg "WITH the recent advance [1] of deep convolutional neural") 1 Action-Driven Object Detection with Top-Down Visual Attentions Donggeun Yoo, Student Member, IEEE, Sunggyun Park, Student Member, IEEE, Kyunghyun Paeng, Student Member, IEEE, Joon-Young Lee, Member,
1 Action-Driven Object Detection with Top-Down Visual Attentions Donggeun Yoo, Student Member, IEEE, Sunggyun Park, Student Member, IEEE, Kyunghyun Paeng, Student Member, IEEE, Joon-Young Lee, Member,
SAFE: Scale Aware Feature Encoder for Scene Text Recognition
 SAFE: Scale Aware Feature Encoder for Scene Text Recognition Wei Liu, Chaofeng Chen, and Kwan-Yee K. Wong Department of Computer Science, The University of Hong Kong {wliu, cfchen, kykwong}@cs.hku.hk arxiv:1901.05770v1
SAFE: Scale Aware Feature Encoder for Scene Text Recognition Wei Liu, Chaofeng Chen, and Kwan-Yee K. Wong Department of Computer Science, The University of Hong Kong {wliu, cfchen, kykwong}@cs.hku.hk arxiv:1901.05770v1
Inception Network Overview. David White CS793
 Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
Inception Network Overview David White CS793 So, Leonardo DiCaprio dreams about dreaming... https://m.media-amazon.com/images/m/mv5bmjaxmzy3njcxnf5bml5banbnxkftztcwnti5otm0mw@@._v1_sy1000_cr0,0,675,1 000_AL_.jpg
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials)
") ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
ActiveStereoNet: End-to-End Self-Supervised Learning for Active Stereo Systems (Supplementary Materials) Yinda Zhang 1,2, Sameh Khamis 1, Christoph Rhemann 1, Julien Valentin 1, Adarsh Kowdle 1, Vladimir
Deep Learning for Object detection & localization
 Deep Learning for Object detection & localization RCNN, Fast RCNN, Faster RCNN, YOLO, GAP, CAM, MSROI Aaditya Prakash Sep 25, 2018 Image classification Image classification Whole of image is classified
Deep Learning for Object detection & localization RCNN, Fast RCNN, Faster RCNN, YOLO, GAP, CAM, MSROI Aaditya Prakash Sep 25, 2018 Image classification Image classification Whole of image is classified
Object Proposal Generation with Fully Convolutional Networks
 This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI.9/TCSVT.26.2576759,
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI.9/TCSVT.26.2576759,
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
R-FCN: Object Detection with Really - Friggin Convolutional Networks
 R-FCN: Object Detection with Really - Friggin Convolutional Networks Jifeng Dai Microsoft Research Li Yi Tsinghua Univ. Kaiming He FAIR Jian Sun Microsoft Research NIPS, 2016 Or Region-based Fully Convolutional
R-FCN: Object Detection with Really - Friggin Convolutional Networks Jifeng Dai Microsoft Research Li Yi Tsinghua Univ. Kaiming He FAIR Jian Sun Microsoft Research NIPS, 2016 Or Region-based Fully Convolutional
Encoder-Decoder Networks for Semantic Segmentation. Sachin Mehta
 Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Encoder-Decoder Networks for Semantic Segmentation Sachin Mehta Outline > Overview of Semantic Segmentation > Encoder-Decoder Networks > Results What is Semantic Segmentation? Input: RGB Image Output:
Detection and Segmentation of Manufacturing Defects with Convolutional Neural Networks and Transfer Learning
 Detection and Segmentation of Manufacturing Defects with Convolutional Neural Networks and Transfer Learning Max Ferguson 1 Ronay Ak 2 Yung-Tsun Tina Lee 2 and Kincho. H. Law 1 Abstract Automatic detection
Detection and Segmentation of Manufacturing Defects with Convolutional Neural Networks and Transfer Learning Max Ferguson 1 Ronay Ak 2 Yung-Tsun Tina Lee 2 and Kincho. H. Law 1 Abstract Automatic detection
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Efficient Segmentation-Aided Text Detection For Intelligent Robots
 Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Efficient Segmentation-Aided Text Detection For Intelligent Robots Junting Zhang, Yuewei Na, Siyang Li, C.-C. Jay Kuo University of Southern California Outline Problem Definition and Motivation Related
Automatic detection of books based on Faster R-CNN
 Automatic detection of books based on Faster R-CNN Beibei Zhu, Xiaoyu Wu, Lei Yang, Yinghua Shen School of Information Engineering, Communication University of China Beijing, China e-mail: zhubeibei@cuc.edu.cn,
Automatic detection of books based on Faster R-CNN Beibei Zhu, Xiaoyu Wu, Lei Yang, Yinghua Shen School of Information Engineering, Communication University of China Beijing, China e-mail: zhubeibei@cuc.edu.cn,
TextBoxes++: A Single-Shot Oriented Scene Text Detector
 1 TextBoxes++: A Single-Shot Oriented Scene Text Detector Minghui Liao, Baoguang Shi, Xiang Bai, Senior Member, IEEE arxiv:1801.02765v3 [cs.cv] 27 Apr 2018 Abstract Scene text detection is an important
1 TextBoxes++: A Single-Shot Oriented Scene Text Detector Minghui Liao, Baoguang Shi, Xiang Bai, Senior Member, IEEE arxiv:1801.02765v3 [cs.cv] 27 Apr 2018 Abstract Scene text detection is an important
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
arxiv: v2 [cs.cv] 3 Sep 2018
![arxiv: v2 [cs.cv] 3 Sep 2018](/thumbs/93/113217497.jpg "arxiv: v2 [cs.cv] 3 Sep 2018") Detection and Segmentation of Manufacturing Defects with Convolutional Neural Networks and Transfer Learning Max Ferguson 1 Ronay Ak 2 Yung-Tsun Tina Lee 2 and Kincho. H. Law 1 arxiv:1808.02518v2 [cs.cv]
Detection and Segmentation of Manufacturing Defects with Convolutional Neural Networks and Transfer Learning Max Ferguson 1 Ronay Ak 2 Yung-Tsun Tina Lee 2 and Kincho. H. Law 1 arxiv:1808.02518v2 [cs.cv]
Perceptron: This is convolution!
 Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Perceptron: This is convolution! v v v Shared weights v Filter = local perceptron. Also called kernel. By pooling responses at different locations, we gain robustness to the exact spatial location of image
Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab.
 [ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
[ICIP 2017] Direct Multi-Scale Dual-Stream Network for Pedestrian Detection Sang-Il Jung and Ki-Sang Hong Image Information Processing Lab., POSTECH Pedestrian Detection Goal To draw bounding boxes that
Deep Face Recognition. Nathan Sun
 Deep Face Recognition Nathan Sun Why Facial Recognition? Picture ID or video tracking Higher Security for Facial Recognition Software Immensely useful to police in tracking suspects Your face will be an
Deep Face Recognition Nathan Sun Why Facial Recognition? Picture ID or video tracking Higher Security for Facial Recognition Software Immensely useful to police in tracking suspects Your face will be an
AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015)
") AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015) Donggeun Yoo, Sunggyun Park, Joon-Young Lee, Anthony Paek, In So Kweon. State-of-the-art frameworks for object
AttentionNet for Accurate Localization and Detection of Objects. (To appear in ICCV 2015) Donggeun Yoo, Sunggyun Park, Joon-Young Lee, Anthony Paek, In So Kweon. State-of-the-art frameworks for object
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Deep Learning. Visualizing and Understanding Convolutional Networks. Christopher Funk. Pennsylvania State University.
 Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Machine Learning. Deep Learning. Eric Xing (and Pengtao Xie) , Fall Lecture 8, October 6, Eric CMU,
 , Fall Lecture 8, October 6, Eric CMU,") Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Machine Learning 10-701, Fall 2015 Deep Learning Eric Xing (and Pengtao Xie) Lecture 8, October 6, 2015 Eric Xing @ CMU, 2015 1 A perennial challenge in computer vision: feature engineering SIFT Spin image
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Learning to Match. Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li
 Learning to Match Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li 1. Introduction The main tasks in many applications can be formalized as matching between heterogeneous objects, including search, recommendation,
Learning to Match Jun Xu, Zhengdong Lu, Tianqi Chen, Hang Li 1. Introduction The main tasks in many applications can be formalized as matching between heterogeneous objects, including search, recommendation,
FINE-GRAINED image classification aims to recognize. Fast Fine-grained Image Classification via Weakly Supervised Discriminative Localization
 1 Fast Fine-grained Image Classification via Weakly Supervised Discriminative Localization Xiangteng He, Yuxin Peng and Junjie Zhao arxiv:1710.01168v1 [cs.cv] 30 Sep 2017 Abstract Fine-grained image classification
1 Fast Fine-grained Image Classification via Weakly Supervised Discriminative Localization Xiangteng He, Yuxin Peng and Junjie Zhao arxiv:1710.01168v1 [cs.cv] 30 Sep 2017 Abstract Fine-grained image classification
Airport Detection Using End-to-End Convolutional Neural Network with Hard Example Mining
 remote sensing Article Airport Detection Using End-to-End Convolutional Neural Network with Hard Example Mining Bowen Cai 1,2, Zhiguo Jiang 1,2, Haopeng Zhang 1,2, * ID, Danpei Zhao 1,2 and Yuan Yao 1,2
remote sensing Article Airport Detection Using End-to-End Convolutional Neural Network with Hard Example Mining Bowen Cai 1,2, Zhiguo Jiang 1,2, Haopeng Zhang 1,2, * ID, Danpei Zhao 1,2 and Yuan Yao 1,2
CNN Basics. Chongruo Wu
 CNN Basics Chongruo Wu Overview 1. 2. 3. Forward: compute the output of each layer Back propagation: compute gradient Updating: update the parameters with computed gradient Agenda 1. Forward Conv, Fully
CNN Basics Chongruo Wu Overview 1. 2. 3. Forward: compute the output of each layer Back propagation: compute gradient Updating: update the parameters with computed gradient Agenda 1. Forward Conv, Fully
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains
 Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Supplementary Material for Zoom and Learn: Generalizing Deep Stereo Matching to Novel Domains Jiahao Pang 1 Wenxiu Sun 1 Chengxi Yang 1 Jimmy Ren 1 Ruichao Xiao 1 Jin Zeng 1 Liang Lin 1,2 1 SenseTime Research
Know your data - many types of networks
 Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
Architectures Know your data - many types of networks Fixed length representation Variable length representation Online video sequences, or samples of different sizes Images Specific architectures for
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors
![[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors](/thumbs/89/97941029.jpg "[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors") [Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
[Supplementary Material] Improving Occlusion and Hard Negative Handling for Single-Stage Pedestrian Detectors Junhyug Noh Soochan Lee Beomsu Kim Gunhee Kim Department of Computer Science and Engineering
COMP9444 Neural Networks and Deep Learning 7. Image Processing. COMP9444 c Alan Blair, 2017
 COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
COMP9444 Neural Networks and Deep Learning 7. Image Processing COMP9444 17s2 Image Processing 1 Outline Image Datasets and Tasks Convolution in Detail AlexNet Weight Initialization Batch Normalization
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs
 In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
In-Place Activated BatchNorm for Memory- Optimized Training of DNNs Samuel Rota Bulò, Lorenzo Porzi, Peter Kontschieder Mapillary Research Paper: https://arxiv.org/abs/1712.02616 Code: https://github.com/mapillary/inplace_abn
YOLO 9000 TAEWAN KIM
 YOLO 9000 TAEWAN KIM DNN-based Object Detection R-CNN MultiBox SPP-Net DeepID-Net NoC Fast R-CNN DeepBox MR-CNN 2013.11 Faster R-CNN YOLO AttentionNet DenseBox SSD Inside-OutsideNet(ION) G-CNN NIPS 15
YOLO 9000 TAEWAN KIM DNN-based Object Detection R-CNN MultiBox SPP-Net DeepID-Net NoC Fast R-CNN DeepBox MR-CNN 2013.11 Faster R-CNN YOLO AttentionNet DenseBox SSD Inside-OutsideNet(ION) G-CNN NIPS 15
Convolutional Networks in Scene Labelling
 Convolutional Networks in Scene Labelling Ashwin Paranjape Stanford ashwinpp@stanford.edu Ayesha Mudassir Stanford aysh@stanford.edu Abstract This project tries to address a well known problem of multi-class
Convolutional Networks in Scene Labelling Ashwin Paranjape Stanford ashwinpp@stanford.edu Ayesha Mudassir Stanford aysh@stanford.edu Abstract This project tries to address a well known problem of multi-class
Rich feature hierarchies for accurate object detection and semant
 Rich feature hierarchies for accurate object detection and semantic segmentation Speaker: Yucong Shen 4/5/2018 Develop of Object Detection 1 DPM (Deformable parts models) 2 R-CNN 3 Fast R-CNN 4 Faster
Rich feature hierarchies for accurate object detection and semantic segmentation Speaker: Yucong Shen 4/5/2018 Develop of Object Detection 1 DPM (Deformable parts models) 2 R-CNN 3 Fast R-CNN 4 Faster
CMU Lecture 18: Deep learning and Vision: Convolutional neural networks. Teacher: Gianni A. Di Caro
 CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
CMU 15-781 Lecture 18: Deep learning and Vision: Convolutional neural networks Teacher: Gianni A. Di Caro DEEP, SHALLOW, CONNECTED, SPARSE? Fully connected multi-layer feed-forward perceptrons: More powerful
Constrained Convolutional Neural Networks for Weakly Supervised Segmentation. Deepak Pathak, Philipp Krähenbühl and Trevor Darrell
 Constrained Convolutional Neural Networks for Weakly Supervised Segmentation Deepak Pathak, Philipp Krähenbühl and Trevor Darrell 1 Multi-class Image Segmentation Assign a class label to each pixel in
Constrained Convolutional Neural Networks for Weakly Supervised Segmentation Deepak Pathak, Philipp Krähenbühl and Trevor Darrell 1 Multi-class Image Segmentation Assign a class label to each pixel in
Facial Expression Classification with Random Filters Feature Extraction
 Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Facial Expression Classification with Random Filters Feature Extraction Mengye Ren Facial Monkey mren@cs.toronto.edu Zhi Hao Luo It s Me lzh@cs.toronto.edu I. ABSTRACT In our work, we attempted to tackle
Dynamic Routing Between Capsules
 Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Report Explainable Machine Learning Dynamic Routing Between Capsules Author: Michael Dorkenwald Supervisor: Dr. Ullrich Köthe 28. Juni 2018 Inhaltsverzeichnis 1 Introduction 2 2 Motivation 2 3 CapusleNet
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
DeepBIBX: Deep Learning for Image Based Bibliographic Data Extraction
 DeepBIBX: Deep Learning for Image Based Bibliographic Data Extraction Akansha Bhardwaj 1,2, Dominik Mercier 1, Sheraz Ahmed 1, Andreas Dengel 1 1 Smart Data and Services, DFKI Kaiserslautern, Germany firstname.lastname@dfki.de
DeepBIBX: Deep Learning for Image Based Bibliographic Data Extraction Akansha Bhardwaj 1,2, Dominik Mercier 1, Sheraz Ahmed 1, Andreas Dengel 1 1 Smart Data and Services, DFKI Kaiserslautern, Germany firstname.lastname@dfki.de
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Supplementary A. Overview. C. Time and Space Complexity. B. Shape Retrieval. D. Permutation Invariant SOM. B.1. Dataset
 Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Supplementary A. Overview This supplementary document provides more technical details and experimental results to the main paper. Shape retrieval experiments are demonstrated with ShapeNet Core55 dataset
Places Challenge 2017
 Places Challenge 2017 Scene Parsing Task CASIA_IVA_JD Jun Fu, Jing Liu, Longteng Guo, Haijie Tian, Fei Liu, Hanqing Lu Yong Li, Yongjun Bao, Weipeng Yan National Laboratory of Pattern Recognition, Institute
Places Challenge 2017 Scene Parsing Task CASIA_IVA_JD Jun Fu, Jing Liu, Longteng Guo, Haijie Tian, Fei Liu, Hanqing Lu Yong Li, Yongjun Bao, Weipeng Yan National Laboratory of Pattern Recognition, Institute
Deep Residual Learning
 Deep Residual Learning MSRA @ ILSVRC & COCO 2015 competitions Kaiming He with Xiangyu Zhang, Shaoqing Ren, Jifeng Dai, & Jian Sun Microsoft Research Asia (MSRA) MSRA @ ILSVRC & COCO 2015 Competitions 1st
Deep Residual Learning MSRA @ ILSVRC & COCO 2015 competitions Kaiming He with Xiangyu Zhang, Shaoqing Ren, Jifeng Dai, & Jian Sun Microsoft Research Asia (MSRA) MSRA @ ILSVRC & COCO 2015 Competitions 1st
OBJECT DETECTION HYUNG IL KOO
 OBJECT DETECTION HYUNG IL KOO INTRODUCTION Computer Vision Tasks Classification + Localization Classification: C-classes Input: image Output: class label Evaluation metric: accuracy Localization Input:
OBJECT DETECTION HYUNG IL KOO INTRODUCTION Computer Vision Tasks Classification + Localization Classification: C-classes Input: image Output: class label Evaluation metric: accuracy Localization Input:
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Martian lava field, NASA, Wikipedia
 Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
Martian lava field, NASA, Wikipedia Old Man of the Mountain, Franconia, New Hampshire Pareidolia http://smrt.ccel.ca/203/2/6/pareidolia/ Reddit for more : ) https://www.reddit.com/r/pareidolia/top/ Pareidolia
A Deep Learning Approach to Vehicle Speed Estimation
 A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
A Deep Learning Approach to Vehicle Speed Estimation Benjamin Penchas bpenchas@stanford.edu Tobin Bell tbell@stanford.edu Marco Monteiro marcorm@stanford.edu ABSTRACT Given car dashboard video footage,
Supplementary Materials for Learning to Parse Wireframes in Images of Man-Made Environments
 Supplementary Materials for Learning to Parse Wireframes in Images of Man-Made Environments Kun Huang, Yifan Wang, Zihan Zhou 2, Tianjiao Ding, Shenghua Gao, and Yi Ma 3 ShanghaiTech University {huangkun,
Supplementary Materials for Learning to Parse Wireframes in Images of Man-Made Environments Kun Huang, Yifan Wang, Zihan Zhou 2, Tianjiao Ding, Shenghua Gao, and Yi Ma 3 ShanghaiTech University {huangkun,
Deep Learning. Deep Learning provided breakthrough results in speech recognition and image classification. Why?
 Data Mining Deep Learning Deep Learning provided breakthrough results in speech recognition and image classification. Why? Because Speech recognition and image classification are two basic examples of
Data Mining Deep Learning Deep Learning provided breakthrough results in speech recognition and image classification. Why? Because Speech recognition and image classification are two basic examples of
Single-Shot Refinement Neural Network for Object Detection -Supplementary Material-
 Single-Shot Refinement Neural Network for Object Detection -Supplementary Material- Shifeng Zhang 1,2, Longyin Wen 3, Xiao Bian 3, Zhen Lei 1,2, Stan Z. Li 4,1,2 1 CBSR & NLPR, Institute of Automation,
Single-Shot Refinement Neural Network for Object Detection -Supplementary Material- Shifeng Zhang 1,2, Longyin Wen 3, Xiao Bian 3, Zhen Lei 1,2, Stan Z. Li 4,1,2 1 CBSR & NLPR, Institute of Automation,
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018
 Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset By Joa õ Carreira and Andrew Zisserman Presenter: Zhisheng Huang 03/02/2018 Outline: Introduction Action classification architectures
SEMANTIC segmentation has a wide array of applications
 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 39, NO. 12, DECEMBER 2017 2481 SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation Vijay Badrinarayanan,
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 39, NO. 12, DECEMBER 2017 2481 SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation Vijay Badrinarayanan,
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Mobile Human Detection Systems based on Sliding Windows Approach-A Review
 Mobile Human Detection Systems based on Sliding Windows Approach-A Review Seminar: Mobile Human detection systems Njieutcheu Tassi cedrique Rovile Department of Computer Engineering University of Heidelberg
Mobile Human Detection Systems based on Sliding Windows Approach-A Review Seminar: Mobile Human detection systems Njieutcheu Tassi cedrique Rovile Department of Computer Engineering University of Heidelberg
arxiv: v1 [cs.cv] 19 Mar 2018
![arxiv: v1 [cs.cv] 19 Mar 2018](/thumbs/78/77646221.jpg "arxiv: v1 [cs.cv] 19 Mar 2018") arxiv:1803.07066v1 [cs.cv] 19 Mar 2018 Learning Region Features for Object Detection Jiayuan Gu 1, Han Hu 2, Liwei Wang 1, Yichen Wei 2 and Jifeng Dai 2 1 Key Laboratory of Machine Perception, School of
arxiv:1803.07066v1 [cs.cv] 19 Mar 2018 Learning Region Features for Object Detection Jiayuan Gu 1, Han Hu 2, Liwei Wang 1, Yichen Wei 2 and Jifeng Dai 2 1 Key Laboratory of Machine Perception, School of
Flow-Based Video Recognition
 Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
Flow-Based Video Recognition Jifeng Dai Visual Computing Group, Microsoft Research Asia Joint work with Xizhou Zhu*, Yuwen Xiong*, Yujie Wang*, Lu Yuan and Yichen Wei (* interns) Talk pipeline Introduction
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation
 AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation Introduction Supplementary material In the supplementary material, we present additional qualitative results of the proposed AdaDepth
Human Pose Estimation with Deep Learning. Wei Yang
 Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Human Pose Estimation with Deep Learning Wei Yang Applications Understand Activities Family Robots American Heist (2014) - The Bank Robbery Scene 2 What do we need to know to recognize a crime scene? 3
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Residual Networks And Attention Models. cs273b Recitation 11/11/2016. Anna Shcherbina
 Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
Residual Networks And Attention Models cs273b Recitation 11/11/2016 Anna Shcherbina Introduction to ResNets Introduced in 2015 by Microsoft Research Deep Residual Learning for Image Recognition (He, Zhang,
Lecture 37: ConvNets (Cont d) and Training
 and Training") Lecture 37: ConvNets (Cont d) and Training CS 4670/5670 Sean Bell [http://bbabenko.tumblr.com/post/83319141207/convolutional-learnings-things-i-learned-by] (Unrelated) Dog vs Food [Karen Zack, @teenybiscuit]
Lecture 37: ConvNets (Cont d) and Training CS 4670/5670 Sean Bell [http://bbabenko.tumblr.com/post/83319141207/convolutional-learnings-things-i-learned-by] (Unrelated) Dog vs Food [Karen Zack, @teenybiscuit]
Return of the Devil in the Details: Delving Deep into Convolutional Nets
 Return of the Devil in the Details: Delving Deep into Convolutional Nets Ken Chatfield - Karen Simonyan - Andrea Vedaldi - Andrew Zisserman University of Oxford The Devil is still in the Details 2011 2014
Return of the Devil in the Details: Delving Deep into Convolutional Nets Ken Chatfield - Karen Simonyan - Andrea Vedaldi - Andrew Zisserman University of Oxford The Devil is still in the Details 2011 2014