Finding Clusters 1 / 60
|
|
|
- Claribel Wells
- 6 years ago
- Views:
Transcription
1 Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
2 Hierarchical Clustering 2 / 60
3 Hierarchical clustering 3 2 Iris virginica Iris versicolor Iris setosa In the two-dimensional MDS (Sammon mapping) representation of the Iris data set, two clusters can be identified. (The colours, indicating the species of the flowers, are ignored here.) 3 / 60
4 Hierarchical clustering Hierarchical clustering builds clusters step by step. 4 / 60
5 Hierarchical clustering Hierarchical clustering builds clusters step by step. Usually a bottom up strategy is applied by first considering each data object as a separate cluster and then step by step joining clusters together that are close to each other. This approach is called agglomerative hierarchical clustering. 4 / 60
6 Hierarchical clustering Hierarchical clustering builds clusters step by step. Usually a bottom up strategy is applied by first considering each data object as a separate cluster and then step by step joining clusters together that are close to each other. This approach is called agglomerative hierarchical clustering. In contrast to agglomerative hierarchical clustering, divisive hierarchical clustering starts with the whole data set as a single cluster and then divides clusters step by step into smaller clusters. 4 / 60
7 Hierarchical clustering Hierarchical clustering builds clusters step by step. Usually a bottom up strategy is applied by first considering each data object as a separate cluster and then step by step joining clusters together that are close to each other. This approach is called agglomerative hierarchical clustering. In contrast to agglomerative hierarchical clustering, divisive hierarchical clustering starts with the whole data set as a single cluster and then divides clusters step by step into smaller clusters. In order to decide which data objects should belong to the same cluster, a (dis-)similarity measure is needed. 4 / 60
8 Hierarchical clustering Hierarchical clustering builds clusters step by step. Usually a bottom up strategy is applied by first considering each data object as a separate cluster and then step by step joining clusters together that are close to each other. This approach is called agglomerative hierarchical clustering. In contrast to agglomerative hierarchical clustering, divisive hierarchical clustering starts with the whole data set as a single cluster and then divides clusters step by step into smaller clusters. In order to decide which data objects should belong to the same cluster, a (dis-)similarity measure is needed. Note: We do need to have access to features, all that is needed for hierarchical clustering is an n n-matrix [d i,j ], where d i,j is the (dis-)similarity of data objects i and j. (n is the number of data objects.) 4 / 60
9 Hierarchical clustering: Dissimilarity matrix The dissimilarity matrix [d i,j ] should at least satisfy the following conditions. d i,j 0, i.e. dissimilarity cannot be negative. d i,i = 0, i.e. each data object is completely similar to itself. d i,j = d j,i, i.e. data object i is (dis-)similar to data object j to the same degree as data object j is (dis-)similar to data object i. It is often useful if the dissimilarity is a (pseudo-)metric, satisfying also the triangle inequality d i,k d i,j + d j,k. 5 / 60
10 Agglomerative hierarchical clustering: Algorithm Input: n n dissimilarity matrix [d i,j ]. 1 Start with n clusters, each data objects forms a single cluster. 2 Reduce the number of clusters by joining those two clusters that are most similar (least dissimilar). 3 Repeat step 3 until there is only one cluster left containing all data objects. 6 / 60
11 Measuring dissimilarity between clusters The dissimilarity between two clusters containing only one data object each is simply the dissimilarity of the two data objects specified in the dissimilarity matrix [d i,j ]. 7 / 60
12 Measuring dissimilarity between clusters The dissimilarity between two clusters containing only one data object each is simply the dissimilarity of the two data objects specified in the dissimilarity matrix [d i,j ]. But how do we compute the dissimilarity between clusters that contain more than one data object? 7 / 60
13 Measuring dissimilarity between clusters 8 / 60
14 Measuring dissimilarity between clusters Centroid Distance between the centroids (mean value vectors) of the two clusters 1 1 Requires that we can compute the mean vector! 8 / 60
15 Measuring dissimilarity between clusters Centroid Distance between the centroids (mean value vectors) of the two clusters 1 Average Linkage Average dissimilarity between all pairs of points of the two clusters. 1 Requires that we can compute the mean vector! 8 / 60
16 Measuring dissimilarity between clusters Centroid Distance between the centroids (mean value vectors) of the two clusters 1 Average Linkage Average dissimilarity between all pairs of points of the two clusters. Single Linkage Dissimilarity between the two most similar data objects of the two clusters. 1 Requires that we can compute the mean vector! 8 / 60
17 Measuring dissimilarity between clusters Centroid Distance between the centroids (mean value vectors) of the two clusters 1 Average Linkage Average dissimilarity between all pairs of points of the two clusters. Single Linkage Dissimilarity between the two most similar data objects of the two clusters. Complete Linkage Dissimilarity between the two most dissimilar data objects of the two clusters. 1 Requires that we can compute the mean vector! 8 / 60
18 Measuring dissimilarity between clusters Centroid Distance between the centroids (mean value vectors) of the two clusters 1 Average Linkage Average dissimilarity between all pairs of points of the two clusters. Single Linkage Dissimilarity between the two most similar data objects of the two clusters. Complete Linkage Dissimilarity between the two most dissimilar data objects of the two clusters. 1 Requires that we can compute the mean vector! 8 / 60
19 Measuring dissimilarity between clusters Single linkage can follow chains in the data (may be desirable in certain applications). Complete linkage leads to very compact clusters. Average linkage also tends clearly towards compact clusters. 9 / 60
20 Measuring dissimilarity between clusters Single linkage Complete linkage 10 / 60
21 Measuring dissimilarity between clusters Ward s method another strategy for merging clusters In contrast to single, complete or average linkage, it takes the number of data objects in each cluster into account. 11 / 60
22 Measuring dissimilarity between clusters The updated dissimilarity between the newly formed cluster {C C } and the cluster C is computed in the follwing way. d ({C C }, C ) =... single linkage = min{d (C, C ), d (C, C )} complete linkage = max{d (C, C ), d (C, C )} average linkage = C d (C, C ) + C d (C, C ) C + C Ward = ( C + C )d (C, C ) + ( C + C )d (C, C ) C d (C, C ) C + C + C centroid 2 1 = d(x, y) C C C x C C y C 2 If metric, usually mean vector needs to be computed! 12 / 60
23 Dendrograms The cluster merging process arranges the data points in a binary tree. Draw the data tuples at the bottom or on the left (equally spaced if they are multi-dimensional). Draw a connection between clusters that are merged, with the distance to the data points representing the distance between the clusters. 13 / 60
24 Hierarchical clustering Example Clustering of the 1-dimensional data set {2, 12, 16, 25, 29, 45}. All three approaches to measure the distance between clusters lead to different dendrograms. 14 / 60
25 Hierarchical clustering Centroid Single linkage Complete linkage 15 / 60
26 Dendrograms 16 / 60
27 Dendrograms 17 / 60
28 Dendrograms 18 / 60
29 Choosing the right clusters Simplest Approach: Specify a minimum desired distance between clusters. Stop merging clusters if the closest two clusters are farther apart than this distance. Visual Approach: Merge clusters until all data points are combined into one cluster. Draw the dendrogram and find a good cut level. Advantage: Cut needs not be strictly horizontal. More Sophisticated Approaches: Analyze the sequence of distances in the merging process. Try to find a step in which the distance between the two clusters merged is considerably larger than the distance of the previous step. Several heuristic criteria exist for this step selection. 19 / 60
30 Heatmaps A heatmap combines a dendrogram resulting from clustering the data, a dendrogram resulting from clustering the attributes and colours to indicate the values of the attributes. 20 / 60
31 Example: Heatmap and dendrogram Count Value x y Color Key and Histogram 21 / 60
32 Example: Heatmap and dendrogram Color Key and Histogram Value Count / 60
33 Example: Heatmap and dendrogram Color Key and Histogram Value Count / 60
34 Iris Data: Heatmap and dendrogram Color Key and Histogram Value sw sl pl pw Count / 60
35 Divisive hierarchical clustering The top-down approach of divisive hierarchical clustering is rarely used. In agglomerative clustering the minimum of the pairwise dissimilarities has to be determined, leading to a quadratic complexity in each step (quadratic in the number of clusters still present in the corresponding step). In divisive clustering for each cluster all possible splits would have to be considered. In the first step, there are 2 n 1 1 possible splits, where n is the number of data objects. 25 / 60
36 What is Similarity? 26 / 60
37 How to cluster these objects? 27 / 60
38 How to cluster these objects? 28 / 60
39 How to cluster these objects? 29 / 60

40 Clustering example 30 / 60

41 Clustering example 31 / 60
42 Clustering example 32 / 60
43 Scaling The previous three slides show the same data set. In the second slide, the unit on the x-axis was changed to centi-units. In the third slide, the unit on the y-axis was changed to centi-units. 33 / 60
44 Scaling The previous three slides show the same data set. In the second slide, the unit on the x-axis was changed to centi-units. In the third slide, the unit on the y-axis was changed to centi-units. Clusters should not depend on the measurement unit! 33 / 60
45 Scaling The previous three slides show the same data set. In the second slide, the unit on the x-axis was changed to centi-units. In the third slide, the unit on the y-axis was changed to centi-units. Clusters should not depend on the measurement unit! Therefore, some kind of normalisation (see the chapter on data preparation) should be carried out before clustering. 33 / 60
46 Complex Similarities: An Example A few Adrenalin-like drug candidates: Adrenalin (D) (C) (B) (E) 34 / 60

47 Complex Similarities: An Example Similarity: Polarity 35 / 60

48 Complex Similarities: An Example Dissimilarity: Hydrophobic / Hydrophilic 36 / 60
49 Complex Similarities: An Example Similar to Adrenalin... Adrenalin Amphetamin Ephedrin Dopamin MDMA 37 / 60
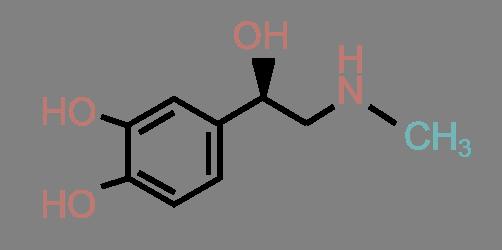
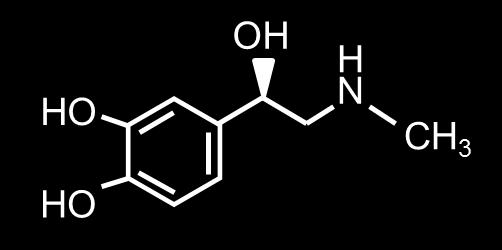
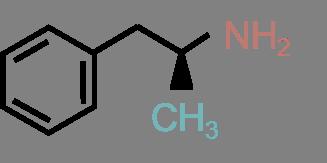
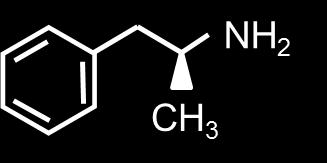
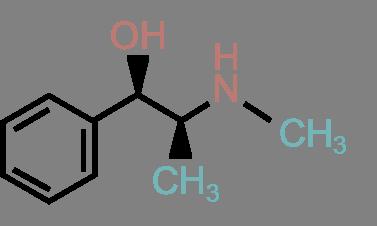
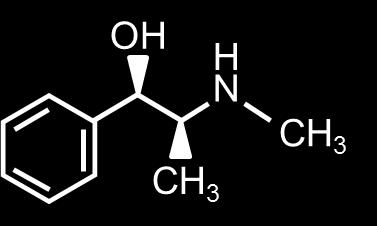
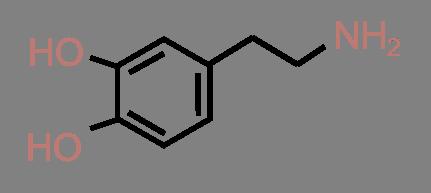
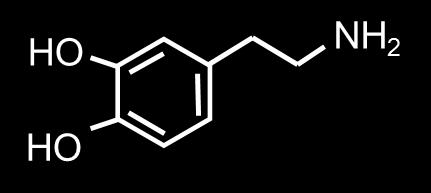
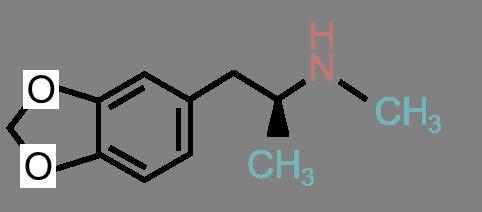
50 Complex Similarities: An Example Similar to Adrenalin...but some cross the blood-brain barrier Adrenalin Amphetamin (Speed) Ephedrin Dopamin MDMA (Ecstasy) 37 / 60
51 Similarity Measures 38 / 60
52 Notion of (dis-)similarity: Numerical attributes Various choices for dissimilarities between two numerical vectors: Pearson Manhatten Euclidean Tschebyschew Minkowksi L p d p (x, y) = p n i=1 x i y i p Euclidean L 2 d E (x, y) = (x 1 y 1 ) (x n y n ) 2 Manhattan L 1 d M (x, y) = x 1 y x n y n Tschebyschew L d (x, y) = max{ x 1 y 1,..., x n y n } Cosine d C (x, y) = 1 x y x y Tanimoto d T (x, y) = Pearson x y x 2 + y 2 x y Euclidean of z-score transformed x, y 39 / 60
53 Notion of (dis-)similarity: Binary attributes The two values (e.g. 0 and 1) of a binary attribute can be interpreted as some property being absent (0) or present (1). In this sense, a vector of binary attribute can be interpreted as a set of properties that the corresponding object has. Example The binary vector (0, 1, 1, 0, 1) corresponds to the set of properties {a 2, a 3, a 5 }. The binary vector (0, 0, 0, 0, 0) corresponds to the empty set. The binary vector (1, 1, 1, 1, 1) corresponds to the set {a 1, a 2, a 3, a 4, a 5 }. 40 / 60
54 Notion of (dis-)similarity: Binary attributes Dissimilarity measures for two vectors of binary attributes. Each data object is represent by the corresponding set of properties that are present. binary attributes sets of properties simple match d S = 1 b+n b+n+x Russel & Rao d R = 1 b b+n+x 1 X Y Ω Jaccard d J = 1 b b+x 1 X Y X Y Dice d D = 1 2b 2b+x 1 2 X Y X + Y no. of predicates that... b = n = x =...hold in both records...do not hold in both records...hold in only one of both records x y set X set Y b n x d M d R d J d D {a 1, a 3} {a 1, a 2, a 3} / 60
55 Notion of (dis-)similarity: Nominal attributes Nominal attributes may be transformed into a set of binary attributes, each of them indicating one particular feature of the attribute (1-of-n coding). 42 / 60
56 Notion of (dis-)similarity: Nominal attributes Nominal attributes may be transformed into a set of binary attributes, each of them indicating one particular feature of the attribute (1-of-n coding). Example Attribute Manufacturer with the values BMW, Chrysler, Dacia, Ford, Volkswagen. manufacturer... Volkswagen... Dacia... Ford... binary vector Then one of the dissimilarity measures for binary attribute can be applied. 42 / 60
57 Notion of (dis-)similarity: Nominal attributes Nominal attributes may be transformed into a set of binary attributes, each of them indicating one particular feature of the attribute (1-of-n coding). Example Attribute Manufacturer with the values BMW, Chrysler, Dacia, Ford, Volkswagen. manufacturer... Volkswagen... Dacia... Ford... binary vector Then one of the dissimilarity measures for binary attribute can be applied. Another way to measure similarity between two vectors of nominal attributes is to compute the proportion of attributes where both vectors have the same value, leading to the Russel & Rao dissimilarity measure. 42 / 60
58 Prototype Based Clustering 43 / 60
59 Prototype Based Clustering given: dataset of size n return: set of typical examples of size k << n. 44 / 60
60 k-means clustering Choose a number k of clusters to be found (user input). Initialize the cluster centres randomly (for instance, by randomly selecting k data points). Data point assignment: Assign each data point to the cluster centre that is closest to it (i.e. closer than any other cluster centre). Cluster centre update: Compute new cluster centres as the mean vectors of the assigned data points. (Intuitively: centre of gravity if each data point has unit weight.) 45 / 60
61 k-means clustering Repeat these two steps (data point assignment and cluster centre update) until the clusters centres do not change anymore. It can be shown that this scheme must converge, i.e., the update of the cluster centres cannot go on forever. 46 / 60
62 k-means clustering Aim: Minimize the objective function k n f = u ij d ij i=1 j=1 under the constraints u ij {0, 1} and k u ij = 1 for all j = 1,..., n. i=1 47 / 60
63 Alternating optimization Assuming the cluster centres to be fixed, u ij = 1 should be chosen for the cluster i to which data object x j has the smallest distance in order to minimize the objective function. Assuming the assignments to the clusters to be fixed, each cluster centre should be chosen as the mean vector of the data objects assigned to the cluster in order to minimize the objective function. 48 / 60
64 k-means clustering: Example 49 / 60
65 k-means clustering: Example 49 / 60
66 k-means clustering: Example 49 / 60
67 k-means clustering: Example 49 / 60
68 k-means clustering: Example 49 / 60
69 k-means clustering: Example 49 / 60
70 k-means clustering: Local minima Clustering is successful in this example: The clusters found are those that would have been formed intuitively. Convergence is achieved after only 5 steps. (This is typical: convergence is usually very fast.) However: The clustering result is fairly sensitive to the initial positions of the cluster centres. With a bad initialisation clustering may fail (the alternating update process gets stuck in a local minimum). 50 / 60
71 k-means clustering: Local minima 51 / 60
72 Gaussian Mixture Models 52 / 60
73 Gaussian mixture models EM clustering Assumption: Data was generated by sampling a set of normal distributions. (The probability density is a mixture of normal distributions.) Aim: Find the parameters for the normal distributions and how much each normal distribution contributes to the data. 53 / 60
74 Gaussian mixture models Two normal distributions / 60
75 Gaussian mixture models normal distrubutions contribute 50%) Two normal distributions Mixture model (both 54 / 60
76 Gaussian mixture models Two normal distributions Mixture model (both normal distrubutions contribute 50%) Mixture model (one normal distrubutions contributes 10%, the other 90%). 54 / 60
77 Gaussian mixture models 55 / 60
78 Gaussian mixture models EM clustering Assumption: Data were generated by sampling a set of normal distributions. (The probability density is a mixture of normal distributions.) Aim: Find the parameters for the normal distributions and how much each normal distribution contributes to the data. Algorithm: EM clustering (expectation maximisation). Alternating scheme in which the parameters of the normal distributions and the likelihoods of the data points to be generated by the corresponding normal distributions are estimated. 56 / 60
79 Density Based Clustering 57 / 60
80 Density-based clustering For numerical data, density-based clustering algorithm often yield the best results. Principle: A connected region with high data density corresponds to one cluster. DBScan is one of the most popular density-based clustering algorithms. 58 / 60
81 Density-based clustering: DBScan Principle idea of DBScan: 1 Find a data point where the data density is high, i.e. in whose ε-neighbourhood are at least l other points. (ε and l are parameters of the algorithm to be chosen by the user.) 2 All the points in the ε-neighbourhood are considered to belong to one cluster. 3 Expand this ε-neighbourhood (the cluster) as long as the high density criterion is satisfied. 4 Remove the cluster (all data points assigned to the cluster) from the data set and continue with 1. as long as data points with a high data density around them can be found. 59 / 60
82 Density-based clustering: DBScan grid cell grid cell neighbourhood cell with at least 3 hits neighbourhood cell with at least 3 hits 60 / 60
Cluster Analysis. Angela Montanari and Laura Anderlucci
 Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Cluster Analysis Angela Montanari and Laura Anderlucci 1 Introduction Clustering a set of n objects into k groups is usually moved by the aim of identifying internally homogenous groups according to a
Olmo S. Zavala Romero. Clustering Hierarchical Distance Group Dist. K-means. Center of Atmospheric Sciences, UNAM.
 Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Center of Atmospheric Sciences, UNAM November 16, 2016 Cluster Analisis Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster)
Hierarchical clustering
 Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hierarchical clustering Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Description Produces a set of nested clusters organized as a hierarchical tree. Can be visualized
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A
 MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
MultiDimensional Signal Processing Master Degree in Ingegneria delle Telecomunicazioni A.A. 205-206 Pietro Guccione, PhD DEI - DIPARTIMENTO DI INGEGNERIA ELETTRICA E DELL INFORMAZIONE POLITECNICO DI BARI
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Cluster Analysis. Ying Shen, SSE, Tongji University
 Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Cluster Analysis Ying Shen, SSE, Tongji University Cluster analysis Cluster analysis groups data objects based only on the attributes in the data. The main objective is that The objects within a group
Hierarchical Clustering
 What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
What is clustering Partitioning of a data set into subsets. A cluster is a group of relatively homogeneous cases or observations Hierarchical Clustering Mikhail Dozmorov Fall 2016 2/61 What is clustering
Hierarchical Clustering
 Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Hierarchical Clustering Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree-like diagram that records the sequences of merges
Cluster Analysis: Agglomerate Hierarchical Clustering
 Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Cluster Analysis: Agglomerate Hierarchical Clustering Yonghee Lee Department of Statistics, The University of Seoul Oct 29, 2015 Contents 1 Cluster Analysis Introduction Distance matrix Agglomerative Hierarchical
Stat 321: Transposable Data Clustering
 Stat 321: Transposable Data Clustering Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Clustering 1 / 27 Clustering Given n objects with d attributes, place them (the objects) into groups.
Stat 321: Transposable Data Clustering Art B. Owen Stanford Statistics Art B. Owen (Stanford Statistics) Clustering 1 / 27 Clustering Given n objects with d attributes, place them (the objects) into groups.
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
MSA220 - Statistical Learning for Big Data
 MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
MSA220 - Statistical Learning for Big Data Lecture 13 Rebecka Jörnsten Mathematical Sciences University of Gothenburg and Chalmers University of Technology Clustering Explorative analysis - finding groups
Hierarchical Clustering Lecture 9
 Hierarchical Clustering Lecture 9 Marina Santini Acknowledgements Slides borrowed and adapted from: Data Mining by I. H. Witten, E. Frank and M. A. Hall 1 Lecture 9: Required Reading Witten et al. (2011:
Hierarchical Clustering Lecture 9 Marina Santini Acknowledgements Slides borrowed and adapted from: Data Mining by I. H. Witten, E. Frank and M. A. Hall 1 Lecture 9: Required Reading Witten et al. (2011:
Multivariate Analysis
 Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Multivariate Analysis Cluster Analysis Prof. Dr. Anselmo E de Oliveira anselmo.quimica.ufg.br anselmo.disciplinas@gmail.com Unsupervised Learning Cluster Analysis Natural grouping Patterns in the data
Cluster Analysis. Mu-Chun Su. Department of Computer Science and Information Engineering National Central University 2003/3/11 1
 Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Cluster Analysis Mu-Chun Su Department of Computer Science and Information Engineering National Central University 2003/3/11 1 Introduction Cluster analysis is the formal study of algorithms and methods
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Mining. Clustering. Hamid Beigy. Sharif University of Technology. Fall 1394
 Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Data Mining Clustering Hamid Beigy Sharif University of Technology Fall 1394 Hamid Beigy (Sharif University of Technology) Data Mining Fall 1394 1 / 31 Table of contents 1 Introduction 2 Data matrix and
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Unsupervised Learning
 Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support, Fall 2005 Instructors: Professor Lucila Ohno-Machado and Professor Staal Vinterbo 6.873/HST.951 Medical Decision
Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision Support, Fall 2005 Instructors: Professor Lucila Ohno-Machado and Professor Staal Vinterbo 6.873/HST.951 Medical Decision
Understanding Clustering Supervising the unsupervised
 Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Understanding Clustering Supervising the unsupervised Janu Verma IBM T.J. Watson Research Center, New York http://jverma.github.io/ jverma@us.ibm.com @januverma Clustering Grouping together similar data
Lecture 10: Semantic Segmentation and Clustering
 Lecture 10: Semantic Segmentation and Clustering Vineet Kosaraju, Davy Ragland, Adrien Truong, Effie Nehoran, Maneekwan Toyungyernsub Department of Computer Science Stanford University Stanford, CA 94305
Lecture 10: Semantic Segmentation and Clustering Vineet Kosaraju, Davy Ragland, Adrien Truong, Effie Nehoran, Maneekwan Toyungyernsub Department of Computer Science Stanford University Stanford, CA 94305
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2008 CS 551, Spring 2008 c 2008, Selim Aksoy (Bilkent University)
Working with Unlabeled Data Clustering Analysis. Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan
 Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Working with Unlabeled Data Clustering Analysis Hsiao-Lung Chan Dept Electrical Engineering Chang Gung University, Taiwan chanhl@mail.cgu.edu.tw Unsupervised learning Finding centers of similarity using
Clustering and Dissimilarity Measures. Clustering. Dissimilarity Measures. Cluster Analysis. Perceptually-Inspired Measures
 Clustering and Dissimilarity Measures Clustering APR Course, Delft, The Netherlands Marco Loog May 19, 2008 1 What salient structures exist in the data? How many clusters? May 19, 2008 2 Cluster Analysis
Clustering and Dissimilarity Measures Clustering APR Course, Delft, The Netherlands Marco Loog May 19, 2008 1 What salient structures exist in the data? How many clusters? May 19, 2008 2 Cluster Analysis
Clustering. Chapter 10 in Introduction to statistical learning
 Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
Clustering Chapter 10 in Introduction to statistical learning 16 14 12 10 8 6 4 2 0 2 4 6 8 10 12 14 1 Clustering ² Clustering is the art of finding groups in data (Kaufman and Rousseeuw, 1990). ² What
SGN (4 cr) Chapter 11
 Chapter 11") SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
Clustering Part 3. Hierarchical Clustering
 Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Clustering Part Dr Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Hierarchical Clustering Two main types: Agglomerative Start with the points
Unsupervised Learning. Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team
 Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Unsupervised Learning Andrea G. B. Tettamanzi I3S Laboratory SPARKS Team Table of Contents 1)Clustering: Introduction and Basic Concepts 2)An Overview of Popular Clustering Methods 3)Other Unsupervised
Cluster Analysis. Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX April 2008 April 2010
 Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Cluster Analysis Prof. Thomas B. Fomby Department of Economics Southern Methodist University Dallas, TX 7575 April 008 April 010 Cluster Analysis, sometimes called data segmentation or customer segmentation,
Forestry Applied Multivariate Statistics. Cluster Analysis
 1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
1 Forestry 531 -- Applied Multivariate Statistics Cluster Analysis Purpose: To group similar entities together based on their attributes. Entities can be variables or observations. [illustration in Class]
Data Mining and Analysis: Fundamental Concepts and Algorithms
 Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki Wagner Meira Jr. Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA Department
Data Mining and Analysis: Fundamental Concepts and Algorithms dataminingbook.info Mohammed J. Zaki Wagner Meira Jr. Department of Computer Science Rensselaer Polytechnic Institute, Troy, NY, USA Department
STATS306B STATS306B. Clustering. Jonathan Taylor Department of Statistics Stanford University. June 3, 2010
 STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
STATS306B Jonathan Taylor Department of Statistics Stanford University June 3, 2010 Spring 2010 Outline K-means, K-medoids, EM algorithm choosing number of clusters: Gap test hierarchical clustering spectral
K-Means Clustering 3/3/17
 K-Means Clustering 3/3/17 Unsupervised Learning We have a collection of unlabeled data points. We want to find underlying structure in the data. Examples: Identify groups of similar data points. Clustering
K-Means Clustering 3/3/17 Unsupervised Learning We have a collection of unlabeled data points. We want to find underlying structure in the data. Examples: Identify groups of similar data points. Clustering
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
Clustering algorithms
 Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Clustering algorithms Machine Learning Hamid Beigy Sharif University of Technology Fall 1393 Hamid Beigy (Sharif University of Technology) Clustering algorithms Fall 1393 1 / 22 Table of contents 1 Supervised
Chapter DM:II. II. Cluster Analysis
 Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Hierarchical Clustering 4/5/17
 Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
Hierarchical Clustering 4/5/17 Hypothesis Space Continuous inputs Output is a binary tree with data points as leaves. Useful for explaining the training data. Not useful for making new predictions. Direction
MATH5745 Multivariate Methods Lecture 13
 MATH5745 Multivariate Methods Lecture 13 April 24, 2018 MATH5745 Multivariate Methods Lecture 13 April 24, 2018 1 / 33 Cluster analysis. Example: Fisher iris data Fisher (1936) 1 iris data consists of
MATH5745 Multivariate Methods Lecture 13 April 24, 2018 MATH5745 Multivariate Methods Lecture 13 April 24, 2018 1 / 33 Cluster analysis. Example: Fisher iris data Fisher (1936) 1 iris data consists of
Cluster Analysis. Jia Li Department of Statistics Penn State University. Summer School in Statistics for Astronomers IV June 9-14, 2008
 Cluster Analysis Jia Li Department of Statistics Penn State University Summer School in Statistics for Astronomers IV June 9-1, 8 1 Clustering A basic tool in data mining/pattern recognition: Divide a
Cluster Analysis Jia Li Department of Statistics Penn State University Summer School in Statistics for Astronomers IV June 9-1, 8 1 Clustering A basic tool in data mining/pattern recognition: Divide a
Clustering part II 1
 Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering part II 1 Clustering What is Cluster Analysis? Types of Data in Cluster Analysis A Categorization of Major Clustering Methods Partitioning Methods Hierarchical Methods 2 Partitioning Algorithms:
Clustering. SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic
 Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
Cluster Analysis. Summer School on Geocomputation. 27 June July 2011 Vysoké Pole
 Cluster Analysis Summer School on Geocomputation 27 June 2011 2 July 2011 Vysoké Pole Lecture delivered by: doc. Mgr. Radoslav Harman, PhD. Faculty of Mathematics, Physics and Informatics Comenius University,
Cluster Analysis Summer School on Geocomputation 27 June 2011 2 July 2011 Vysoké Pole Lecture delivered by: doc. Mgr. Radoslav Harman, PhD. Faculty of Mathematics, Physics and Informatics Comenius University,
Machine learning - HT Clustering
 Machine learning - HT 2016 10. Clustering Varun Kanade University of Oxford March 4, 2016 Announcements Practical Next Week - No submission Final Exam: Pick up on Monday Material covered next week is not
Machine learning - HT 2016 10. Clustering Varun Kanade University of Oxford March 4, 2016 Announcements Practical Next Week - No submission Final Exam: Pick up on Monday Material covered next week is not
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
Chapter 6: Cluster Analysis
 Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
Chapter 6: Cluster Analysis The major goal of cluster analysis is to separate individual observations, or items, into groups, or clusters, on the basis of the values for the q variables measured on each
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
DEIB - Politecnico di Milano Fall, 2017 Introduction Often, we have only a set of features x = x 1, x 2,, x n, but no associated response y. Therefore we are not interested in prediction nor classification,
Unsupervised: no target value to predict
 Clustering Unsupervised: no target value to predict Differences between models/algorithms: Exclusive vs. overlapping Deterministic vs. probabilistic Hierarchical vs. flat Incremental vs. batch learning
Clustering Unsupervised: no target value to predict Differences between models/algorithms: Exclusive vs. overlapping Deterministic vs. probabilistic Hierarchical vs. flat Incremental vs. batch learning
Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms
 Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms Padhraic Smyth Department of Computer Science Bren School of Information and Computer Sciences University of California,
Stats 170A: Project in Data Science Exploratory Data Analysis: Clustering Algorithms Padhraic Smyth Department of Computer Science Bren School of Information and Computer Sciences University of California,
Statistics 202: Data Mining. c Jonathan Taylor. Week 8 Based in part on slides from textbook, slides of Susan Holmes. December 2, / 1
 Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Week 8 Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Part I Clustering 2 / 1 Clustering Clustering Goal: Finding groups of objects such that the objects in a group
Introduction to Data Mining
 Introduction to Data Mining Lecture #14: Clustering Seoul National University 1 In This Lecture Learn the motivation, applications, and goal of clustering Understand the basic methods of clustering (bottom-up
Introduction to Data Mining Lecture #14: Clustering Seoul National University 1 In This Lecture Learn the motivation, applications, and goal of clustering Understand the basic methods of clustering (bottom-up
11/2/2017 MIST.6060 Business Intelligence and Data Mining 1. Clustering. Two widely used distance metrics to measure the distance between two records
 11/2/2017 MIST.6060 Business Intelligence and Data Mining 1 An Example Clustering X 2 X 1 Objective of Clustering The objective of clustering is to group the data into clusters such that the records within
11/2/2017 MIST.6060 Business Intelligence and Data Mining 1 An Example Clustering X 2 X 1 Objective of Clustering The objective of clustering is to group the data into clusters such that the records within
BBS654 Data Mining. Pinar Duygulu. Slides are adapted from Nazli Ikizler
 BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
BBS654 Data Mining Pinar Duygulu Slides are adapted from Nazli Ikizler 1 Classification Classification systems: Supervised learning Make a rational prediction given evidence There are several methods for
Clustering: K-means and Kernel K-means
 Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
Clustering: K-means and Kernel K-means Piyush Rai Machine Learning (CS771A) Aug 31, 2016 Machine Learning (CS771A) Clustering: K-means and Kernel K-means 1 Clustering Usually an unsupervised learning problem
k-means demo Administrative Machine learning: Unsupervised learning" Assignment 5 out
 Machine learning: Unsupervised learning" David Kauchak cs Spring 0 adapted from: http://www.stanford.edu/class/cs76/handouts/lecture7-clustering.ppt http://www.youtube.com/watch?v=or_-y-eilqo Administrative
Machine learning: Unsupervised learning" David Kauchak cs Spring 0 adapted from: http://www.stanford.edu/class/cs76/handouts/lecture7-clustering.ppt http://www.youtube.com/watch?v=or_-y-eilqo Administrative
Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic
 SEMANTIC COMPUTING Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 23 November 2018 Overview Unsupervised Machine Learning overview Association
SEMANTIC COMPUTING Lecture 6: Unsupervised Machine Learning Dagmar Gromann International Center For Computational Logic TU Dresden, 23 November 2018 Overview Unsupervised Machine Learning overview Association
University of Florida CISE department Gator Engineering. Clustering Part 2
 Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
Clustering Part 2 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Partitional Clustering Original Points A Partitional Clustering Hierarchical
 http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Slides From Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Data Mining Cluster Analysis: Basic Concepts and Algorithms Slides From Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
EECS730: Introduction to Bioinformatics
 EECS730: Introduction to Bioinformatics Lecture 15: Microarray clustering http://compbio.pbworks.com/f/wood2.gif Some slides were adapted from Dr. Shaojie Zhang (University of Central Florida) Microarray
EECS730: Introduction to Bioinformatics Lecture 15: Microarray clustering http://compbio.pbworks.com/f/wood2.gif Some slides were adapted from Dr. Shaojie Zhang (University of Central Florida) Microarray
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
Segmentation Computer Vision Spring 2018, Lecture 27
 Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Measure of Distance. We wish to define the distance between two objects Distance metric between points:
 Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
Measure of Distance We wish to define the distance between two objects Distance metric between points: Euclidean distance (EUC) Manhattan distance (MAN) Pearson sample correlation (COR) Angle distance
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Hierarchical Clustering
 Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Hierarchical Clustering Produces a set of nested clusters organized as a hierarchical tree Can be visualized as a dendrogram A tree like diagram that records the sequences of merges or splits 0 0 0 00
Objective of clustering
 Objective of clustering Discover structures and patterns in high-dimensional data. Group data with similar patterns together. This reduces the complexity and facilitates interpretation. Expression level
Objective of clustering Discover structures and patterns in high-dimensional data. Group data with similar patterns together. This reduces the complexity and facilitates interpretation. Expression level
ECLT 5810 Clustering
 ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
ECLT 5810 Clustering What is Cluster Analysis? Cluster: a collection of data objects Similar to one another within the same cluster Dissimilar to the objects in other clusters Cluster analysis Grouping
HW4 VINH NGUYEN. Q1 (6 points). Chapter 8 Exercise 20
. Chapter 8 Exercise 20") HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
HW4 VINH NGUYEN Q1 (6 points). Chapter 8 Exercise 20 a. For each figure, could you use single link to find the patterns represented by the nose, eyes and mouth? Explain? First, a single link is a MIN version
Unsupervised Learning
 Unsupervised Learning A review of clustering and other exploratory data analysis methods HST.951J: Medical Decision Support Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision
Unsupervised Learning A review of clustering and other exploratory data analysis methods HST.951J: Medical Decision Support Harvard-MIT Division of Health Sciences and Technology HST.951J: Medical Decision
An Introduction to Cluster Analysis. Zhaoxia Yu Department of Statistics Vice Chair of Undergraduate Affairs
 An Introduction to Cluster Analysis Zhaoxia Yu Department of Statistics Vice Chair of Undergraduate Affairs zhaoxia@ics.uci.edu 1 What can you say about the figure? signal C 0.0 0.5 1.0 1500 subjects Two
An Introduction to Cluster Analysis Zhaoxia Yu Department of Statistics Vice Chair of Undergraduate Affairs zhaoxia@ics.uci.edu 1 What can you say about the figure? signal C 0.0 0.5 1.0 1500 subjects Two
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC
 Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC Clustering Idea Given a set of data can we find a natural grouping? Essential R commands: D =rnorm(12,0,1)
Data Exploration with PCA and Unsupervised Learning with Clustering Paul Rodriguez, PhD PACE SDSC Clustering Idea Given a set of data can we find a natural grouping? Essential R commands: D =rnorm(12,0,1)
Machine Learning. B. Unsupervised Learning B.1 Cluster Analysis. Lars Schmidt-Thieme
 Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
PAM algorithm. Types of Data in Cluster Analysis. A Categorization of Major Clustering Methods. Partitioning i Methods. Hierarchical Methods
 Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Whatis Cluster Analysis? Clustering Types of Data in Cluster Analysis Clustering part II A Categorization of Major Clustering Methods Partitioning i Methods Hierarchical Methods Partitioning i i Algorithms:
Distances, Clustering! Rafael Irizarry!
 Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Distances, Clustering! Rafael Irizarry! Heatmaps! Distance! Clustering organizes things that are close into groups! What does it mean for two genes to be close?! What does it mean for two samples to
Data Mining Algorithms
 for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
for the original version: -JörgSander and Martin Ester - Jiawei Han and Micheline Kamber Data Management and Exploration Prof. Dr. Thomas Seidl Data Mining Algorithms Lecture Course with Tutorials Wintersemester
INF4820, Algorithms for AI and NLP: Hierarchical Clustering
 INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
INF4820, Algorithms for AI and NLP: Hierarchical Clustering Erik Velldal University of Oslo Sept. 25, 2012 Agenda Topics we covered last week Evaluating classifiers Accuracy, precision, recall and F-score
Clustering Lecture 3: Hierarchical Methods
 Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Clustering Lecture 3: Hierarchical Methods Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced
Unsupervised Learning: Clustering
 Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Machine Learning and Data Mining. Clustering (1): Basics. Kalev Kask
: Basics. Kalev Kask") Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
CLUSTERING IN BIOINFORMATICS
 CLUSTERING IN BIOINFORMATICS CSE/BIMM/BENG 8 MAY 4, 0 OVERVIEW Define the clustering problem Motivation: gene expression and microarrays Types of clustering Clustering algorithms Other applications of
CLUSTERING IN BIOINFORMATICS CSE/BIMM/BENG 8 MAY 4, 0 OVERVIEW Define the clustering problem Motivation: gene expression and microarrays Types of clustering Clustering algorithms Other applications of
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/28/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.