Modern GPUs (Graphics Processing Units)
|
|
|
- Brent Cole
- 6 years ago
- Views:
Transcription

1 Modern GPUs (Graphics Processing Units) Powerful data parallel computation platform. High computation density, high memory bandwidth. Relatively low cost. NVIDIA GTX cores 1.6 Tera FLOPs 1.5 GB memory 200GB/s bandwidth $499 1

2 GPU for Scientific Computing [NVIDIA] 2

3 GPU based QUIC SVD Algorithm Department of Computer Science
4 Introduction Singular Value Decomposition (SVD) of large matrices. Low Rank Approximation. QUIC SVD: Fast SVD using cosine trees, by Michael Holmes, Alexander Gray and Charles Isbell, NIPS


5 QUIC SVD: Fast SVD using Cosine Trees [Holmes et al. 2008] 5
6 QUIC SVD: Fast SVD using Cosine Trees [Holmes et al. 2008] Start from a root node that owns the entire matrix. 6
7 QUIC SVD: Fast SVD using Cosine Trees [Holmes et al. 2008] Select pivot row based on length square distribution; Compute inner product of every row with the pivot row; 7
8 QUIC SVD: Fast SVD using Cosine Trees [Holmes et al. 2008] The inner product results determine how the rows are partitioned to 2 subsets, each represented by a child node. 8

![2008] Compute the row mean (centroid) of](/docs-images/80/80607660/images/9-3.jpg "each subset; add it to the current basis")
9 QUIC SVD: Fast SVD using Cosine Trees [Holmes et al. 2008] Compute the row mean (centroid) of each subset; add it to the current basis set (keep orthogonalized). 9

10 QUIC SVD: Fast SVD using Cosine Trees [Holmes et al. 2008] Repeat, until the estimated error is below a threshold. The final basis set then provides a good low rank approximation. 10
 Basis orthogonalization Key: find")
11 GPU based Implementation of QUIC SVD Most computation time is spent on splitting nodes. Computationally expensive steps: Computing vector inner products Computing row means (centroids) Basis orthogonalization Key: find enough computation to keep the GPU busy! 11
12 Parallelize Vector Inner Products and Row Means Compute all inner products and row means in parallel. There are enough row vectors to keep the GPU busy. 12
13 Parallelize Gram Schmidt Orthogonalization Classical Gram Schmidt: Assume vectors u are already orthgonalized, to 1, u2, u3... un orthogonalize a new vector v with respect to them: vu, vu, vu, n u k v u u... u u, u u, u u, u This is easy to parallelize (as each projection is independently calculated), but it has poor numerical stability due to rounding errors. n n n 13
14 Parallelize Gram Schmidt Orthogonalization Modified Gram Schmidt: v, u v, u v v u, v v u, v v u, (1) (2) (1) vu, 1 (2) (1) 2 (3) (2) u1, u1 u2, u2 u3, u3, u ( k 1) ( k 1) k uk 1 v uk uk, uk v This has good numerical stability, but is hard to parallelize, as the computation is sequential! 14
15 Parallelize Gram Schmidt Orthogonalization Our approach: Blocked Gram Schmidt vu, vu, vu, (1) 1 2 m v v u1 u2... um u1, u1 u2, u2 um, um v, u v, u v, u (1) (1) (1) (2) (1) m 1 m 2 2m v v um 1 um 2... u2m um 1, um 1 um 2, um 2 u2m, u2m v, u v, u v, u u v u u (2) (2) (2) (2) 2m 1 2m 2 k k 1 2m 1 m 2... u2m 1, u2m 1 u2m 2, u2m 2 uk, uk u k This hybrid approach proves to be both numerically stable, and GPU friendly. 15
16 Partitioned QUIC SVD As the advantage of exploiting the GPU is only obvious for large scale problems, we need to test our algorithm on large matrices (>10,000x10,000). For dense matrices, this will soon become an out of core problem. We modified our algorithm to use a matrix partitioning scheme, so that each partition can fit in GPU memory. 16

17 Partitioned QUIC SVD 17
18 Performance We generate test data by multiplying two randomly generated left and right matrices, resulting in a low rank matrix. We set the termination error in QUIC SVD to This forces the algorithm to produce accurate results. We compare 1) Matlab s svds; 2) CPU implementation of QUIC SVD; 3) GPU implementation of QUIC SVD. CPU version considerably optimized using Intel MKL and tested on an Intel Core i7 GPU version is tested on an NVIDIA 480 GTX 18
19 Performance 19
20 Performance 20
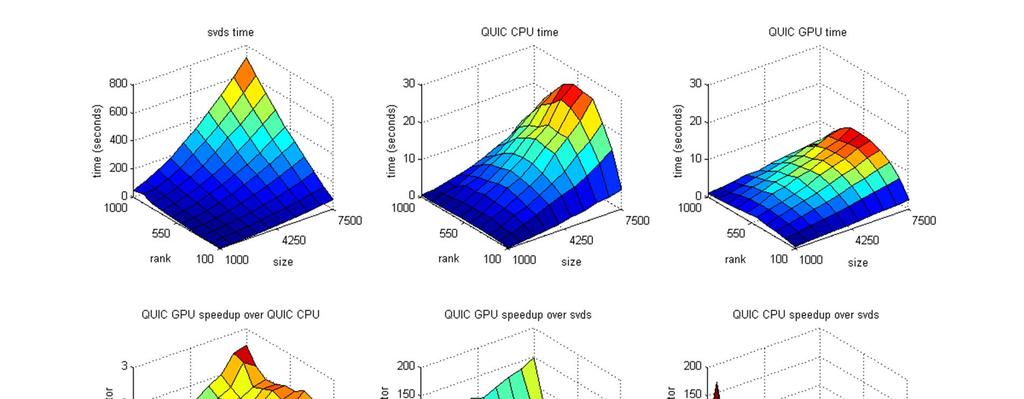

21 Performance 21
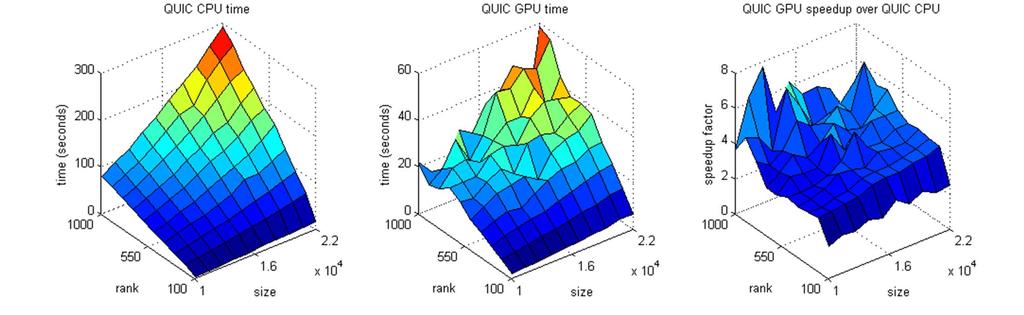
22 Performance 22

23 Integration with Manifold Alignment Framework 23
24 Conclusion and Future Work Our initial effort has shown that a GPU based implementation of QUIC SVD can achieve reasonable speedup. With additional optimizations, 10X speedup foreseeable. Handle sparse matrices. Components from this project can become fundamental building blocks for other algorithms: random projection trees, diffusion wavelets etc. Design new algorithms that are suitable for data parallel computation. 24
25 25

26 Programming on the GPU General Purpose GPU Programming Language CUDA, OpenCL, DirectCompute, BrookGPU [NVIDIA] 26
A GPU-based Approximate SVD Algorithm Blake Foster, Sridhar Mahadevan, Rui Wang
 A GPU-based Approximate SVD Algorithm Blake Foster, Sridhar Mahadevan, Rui Wang University of Massachusetts Amherst Introduction Singular Value Decomposition (SVD) A: m n matrix (m n) U, V: orthogonal
A GPU-based Approximate SVD Algorithm Blake Foster, Sridhar Mahadevan, Rui Wang University of Massachusetts Amherst Introduction Singular Value Decomposition (SVD) A: m n matrix (m n) U, V: orthogonal
QR Decomposition on GPUs
 QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 1: Course Overview; Matrix Multiplication Xiangmin Jiao Stony Brook University Xiangmin Jiao Numerical Analysis I 1 / 21 Outline 1 Course
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 1: Course Overview; Matrix Multiplication Xiangmin Jiao Stony Brook University Xiangmin Jiao Numerical Analysis I 1 / 21 Outline 1 Course
NEW ADVANCES IN GPU LINEAR ALGEBRA
 GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
GTC 2012: NEW ADVANCES IN GPU LINEAR ALGEBRA Kyle Spagnoli EM Photonics 5/16/2012 QUICK ABOUT US» HPC/GPU Consulting Firm» Specializations in:» Electromagnetics» Image Processing» Fluid Dynamics» Linear
Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors
 Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors Andrés Tomás 1, Zhaojun Bai 1, and Vicente Hernández 2 1 Department of Computer
Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors Andrés Tomás 1, Zhaojun Bai 1, and Vicente Hernández 2 1 Department of Computer
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
MAGMA. Matrix Algebra on GPU and Multicore Architectures
 MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
Parallelization of Shortest Path Graph Kernels on Multi-Core CPUs and GPU
 Parallelization of Shortest Path Graph Kernels on Multi-Core CPUs and GPU Lifan Xu Wei Wang Marco A. Alvarez John Cavazos Dongping Zhang Department of Computer and Information Science University of Delaware
Parallelization of Shortest Path Graph Kernels on Multi-Core CPUs and GPU Lifan Xu Wei Wang Marco A. Alvarez John Cavazos Dongping Zhang Department of Computer and Information Science University of Delaware
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms. Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli
 High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
Parallel FFT Program Optimizations on Heterogeneous Computers
 Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Parallel FFT Program Optimizations on Heterogeneous Computers Shuo Chen, Xiaoming Li Department of Electrical and Computer Engineering University of Delaware, Newark, DE 19716 Outline Part I: A Hybrid
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
A GPU Sparse Direct Solver for AX=B
 1 / 25 A GPU Sparse Direct Solver for AX=B Jonathan Hogg, Evgueni Ovtchinnikov, Jennifer Scott* STFC Rutherford Appleton Laboratory 26 March 2014 GPU Technology Conference San Jose, California * Thanks
1 / 25 A GPU Sparse Direct Solver for AX=B Jonathan Hogg, Evgueni Ovtchinnikov, Jennifer Scott* STFC Rutherford Appleton Laboratory 26 March 2014 GPU Technology Conference San Jose, California * Thanks
Accelerated Machine Learning Algorithms in Python
 Accelerated Machine Learning Algorithms in Python Patrick Reilly, Leiming Yu, David Kaeli reilly.pa@husky.neu.edu Northeastern University Computer Architecture Research Lab Outline Motivation and Goals
Accelerated Machine Learning Algorithms in Python Patrick Reilly, Leiming Yu, David Kaeli reilly.pa@husky.neu.edu Northeastern University Computer Architecture Research Lab Outline Motivation and Goals
Matrix algorithms: fast, stable, communication-optimizing random?!
 Matrix algorithms: fast, stable, communication-optimizing random?! Ioana Dumitriu Department of Mathematics University of Washington (Seattle) Joint work with Grey Ballard, James Demmel, Olga Holtz, Robert
Matrix algorithms: fast, stable, communication-optimizing random?! Ioana Dumitriu Department of Mathematics University of Washington (Seattle) Joint work with Grey Ballard, James Demmel, Olga Holtz, Robert
A MATLAB Interface to the GPU
 Introduction Results, conclusions and further work References Department of Informatics Faculty of Mathematics and Natural Sciences University of Oslo June 2007 Introduction Results, conclusions and further
Introduction Results, conclusions and further work References Department of Informatics Faculty of Mathematics and Natural Sciences University of Oslo June 2007 Introduction Results, conclusions and further
Exploiting GPU Caches in Sparse Matrix Vector Multiplication. Yusuke Nagasaka Tokyo Institute of Technology
 Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
MAGMA: a New Generation
 1.3 MAGMA: a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Jack Dongarra T. Dong, M. Gates, A. Haidar, S. Tomov, and I. Yamazaki University of Tennessee, Knoxville Release
1.3 MAGMA: a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Jack Dongarra T. Dong, M. Gates, A. Haidar, S. Tomov, and I. Yamazaki University of Tennessee, Knoxville Release
A MATLAB Interface to the GPU
 A MATLAB Interface to the GPU Second Winter School Geilo, Norway André Rigland Brodtkorb SINTEF ICT Department of Applied Mathematics 2007-01-24 Outline 1 Motivation and previous
A MATLAB Interface to the GPU Second Winter School Geilo, Norway André Rigland Brodtkorb SINTEF ICT Department of Applied Mathematics 2007-01-24 Outline 1 Motivation and previous
Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors
 Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors Andrés Tomás 1, Zhaojun Bai 1, and Vicente Hernández 2 1 Department of Computer
Parallelization of the QR Decomposition with Column Pivoting Using Column Cyclic Distribution on Multicore and GPU Processors Andrés Tomás 1, Zhaojun Bai 1, and Vicente Hernández 2 1 Department of Computer
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
A Multi-Tiered Optimization Framework for Heterogeneous Computing
 A Multi-Tiered Optimization Framework for Heterogeneous Computing IEEE HPEC 2014 Alan George Professor of ECE University of Florida Herman Lam Assoc. Professor of ECE University of Florida Andrew Milluzzi
A Multi-Tiered Optimization Framework for Heterogeneous Computing IEEE HPEC 2014 Alan George Professor of ECE University of Florida Herman Lam Assoc. Professor of ECE University of Florida Andrew Milluzzi
QUIC-SVD: Fast SVD Using Cosine Trees
 QUIC-SVD: Fast SVD Using Cosine Trees Michael P. Holmes, Alexander G. Gray and Charles Lee Isbell, Jr. College of Computing Georgia Tech Atlanta, GA 3327 {mph, agray, isbell}@cc.gatech.edu Abstract The
QUIC-SVD: Fast SVD Using Cosine Trees Michael P. Holmes, Alexander G. Gray and Charles Lee Isbell, Jr. College of Computing Georgia Tech Atlanta, GA 3327 {mph, agray, isbell}@cc.gatech.edu Abstract The
G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G
 Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Fast BVH Construction on GPUs
 Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Fast BVH Construction on GPUs Published in EUROGRAGHICS, (2009) C. Lauterbach, M. Garland, S. Sengupta, D. Luebke, D. Manocha University of North Carolina at Chapel Hill NVIDIA University of California
Sparse LU Factorization for Parallel Circuit Simulation on GPUs
 Department of Electronic Engineering, Tsinghua University Sparse LU Factorization for Parallel Circuit Simulation on GPUs Ling Ren, Xiaoming Chen, Yu Wang, Chenxi Zhang, Huazhong Yang Nano-scale Integrated
Department of Electronic Engineering, Tsinghua University Sparse LU Factorization for Parallel Circuit Simulation on GPUs Ling Ren, Xiaoming Chen, Yu Wang, Chenxi Zhang, Huazhong Yang Nano-scale Integrated
DEGENERACY AND THE FUNDAMENTAL THEOREM
 DEGENERACY AND THE FUNDAMENTAL THEOREM The Standard Simplex Method in Matrix Notation: we start with the standard form of the linear program in matrix notation: (SLP) m n we assume (SLP) is feasible, and
DEGENERACY AND THE FUNDAMENTAL THEOREM The Standard Simplex Method in Matrix Notation: we start with the standard form of the linear program in matrix notation: (SLP) m n we assume (SLP) is feasible, and
An Approximate Singular Value Decomposition of Large Matrices in Julia
 An Approximate Singular Value Decomposition of Large Matrices in Julia Alexander J. Turner 1, 1 Harvard University, School of Engineering and Applied Sciences, Cambridge, MA, USA. In this project, I implement
An Approximate Singular Value Decomposition of Large Matrices in Julia Alexander J. Turner 1, 1 Harvard University, School of Engineering and Applied Sciences, Cambridge, MA, USA. In this project, I implement
Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations
 Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations D. Zheltkov, N. Zamarashkin INM RAS September 24, 2018 Scalability of Lanczos method Notations Matrix order
Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations D. Zheltkov, N. Zamarashkin INM RAS September 24, 2018 Scalability of Lanczos method Notations Matrix order
AMS 148: Chapter 1: What is Parallelization
 AMS 148: Chapter 1: What is Parallelization 1 Introduction of Parallelism Traditional codes and algorithms, much of what you, the student, have experienced previously has been computation in a sequential
AMS 148: Chapter 1: What is Parallelization 1 Introduction of Parallelism Traditional codes and algorithms, much of what you, the student, have experienced previously has been computation in a sequential
GPU COMPUTING WITH MSC NASTRAN 2013
 SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
SESSION TITLE WILL BE COMPLETED BY MSC SOFTWARE GPU COMPUTING WITH MSC NASTRAN 2013 Srinivas Kodiyalam, NVIDIA, Santa Clara, USA THEME Accelerated computing with GPUs SUMMARY Current trends in HPC (High
Optimizing Data Locality for Iterative Matrix Solvers on CUDA
 Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs
 High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
8. Hardware-Aware Numerics. Approaching supercomputing...
 Approaching supercomputing... Numerisches Programmieren, Hans-Joachim Bungartz page 1 of 48 8.1. Hardware-Awareness Introduction Since numerical algorithms are ubiquitous, they have to run on a broad spectrum
Approaching supercomputing... Numerisches Programmieren, Hans-Joachim Bungartz page 1 of 48 8.1. Hardware-Awareness Introduction Since numerical algorithms are ubiquitous, they have to run on a broad spectrum
8. Hardware-Aware Numerics. Approaching supercomputing...
 Approaching supercomputing... Numerisches Programmieren, Hans-Joachim Bungartz page 1 of 22 8.1. Hardware-Awareness Introduction Since numerical algorithms are ubiquitous, they have to run on a broad spectrum
Approaching supercomputing... Numerisches Programmieren, Hans-Joachim Bungartz page 1 of 22 8.1. Hardware-Awareness Introduction Since numerical algorithms are ubiquitous, they have to run on a broad spectrum
FatMan vs. LittleBoy: Scaling up Linear Algebraic Operations in Scale-out Data Platforms
 FatMan vs. LittleBoy: Scaling up Linear Algebraic Operations in Scale-out Data Platforms Luna Xu (Virginia Tech) Seung-Hwan Lim (ORNL) Ali R. Butt (Virginia Tech) Sreenivas R. Sukumar (ORNL) Ramakrishnan
FatMan vs. LittleBoy: Scaling up Linear Algebraic Operations in Scale-out Data Platforms Luna Xu (Virginia Tech) Seung-Hwan Lim (ORNL) Ali R. Butt (Virginia Tech) Sreenivas R. Sukumar (ORNL) Ramakrishnan
Challenges Simulating Real Fuel Combustion Kinetics: The Role of GPUs
 Challenges Simulating Real Fuel Combustion Kinetics: The Role of GPUs M. J. McNenly and R. A. Whitesides GPU Technology Conference March 27, 2014 San Jose, CA LLNL-PRES-652254! This work performed under
Challenges Simulating Real Fuel Combustion Kinetics: The Role of GPUs M. J. McNenly and R. A. Whitesides GPU Technology Conference March 27, 2014 San Jose, CA LLNL-PRES-652254! This work performed under
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
Outline. Parallel Algorithms for Linear Algebra. Number of Processors and Problem Size. Speedup and Efficiency
 1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
Administrative Issues. L11: Sparse Linear Algebra on GPUs. Triangular Solve (STRSM) A Few Details 2/25/11. Next assignment, triangular solve
 A Few Details 2/25/11. Next assignment, triangular solve") Administrative Issues L11: Sparse Linear Algebra on GPUs Next assignment, triangular solve Due 5PM, Tuesday, March 15 handin cs6963 lab 3 Project proposals Due 5PM, Wednesday, March 7 (hard
Administrative Issues L11: Sparse Linear Algebra on GPUs Next assignment, triangular solve Due 5PM, Tuesday, March 15 handin cs6963 lab 3 Project proposals Due 5PM, Wednesday, March 7 (hard
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
PLB-HeC: A Profile-based Load-Balancing Algorithm for Heterogeneous CPU-GPU Clusters
 PLB-HeC: A Profile-based Load-Balancing Algorithm for Heterogeneous CPU-GPU Clusters IEEE CLUSTER 2015 Chicago, IL, USA Luis Sant Ana 1, Daniel Cordeiro 2, Raphael Camargo 1 1 Federal University of ABC,
PLB-HeC: A Profile-based Load-Balancing Algorithm for Heterogeneous CPU-GPU Clusters IEEE CLUSTER 2015 Chicago, IL, USA Luis Sant Ana 1, Daniel Cordeiro 2, Raphael Camargo 1 1 Federal University of ABC,
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
CALCULATING RANKS, NULL SPACES AND PSEUDOINVERSE SOLUTIONS FOR SPARSE MATRICES USING SPQR
 CALCULATING RANKS, NULL SPACES AND PSEUDOINVERSE SOLUTIONS FOR SPARSE MATRICES USING SPQR Leslie Foster Department of Mathematics, San Jose State University October 28, 2009, SIAM LA 09 DEPARTMENT OF MATHEMATICS,
CALCULATING RANKS, NULL SPACES AND PSEUDOINVERSE SOLUTIONS FOR SPARSE MATRICES USING SPQR Leslie Foster Department of Mathematics, San Jose State University October 28, 2009, SIAM LA 09 DEPARTMENT OF MATHEMATICS,
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design
 Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
Piz Daint: Application driven co-design of a supercomputer based on Cray s adaptive system design Sadaf Alam & Thomas Schulthess CSCS & ETHzürich CUG 2014 * Timelines & releases are not precise Top 500
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
DECOMPOSITION is one of the important subjects in
 Proceedings of the Federated Conference on Computer Science and Information Systems pp. 561 565 ISBN 978-83-60810-51-4 Analysis and Comparison of QR Decomposition Algorithm in Some Types of Matrix A. S.
Proceedings of the Federated Conference on Computer Science and Information Systems pp. 561 565 ISBN 978-83-60810-51-4 Analysis and Comparison of QR Decomposition Algorithm in Some Types of Matrix A. S.
Dense Matrix Algorithms
 Dense Matrix Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text Introduction to Parallel Computing, Addison Wesley, 2003. Topic Overview Matrix-Vector Multiplication
Dense Matrix Algorithms Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar To accompany the text Introduction to Parallel Computing, Addison Wesley, 2003. Topic Overview Matrix-Vector Multiplication
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER PROF. BRYANT PROF. KAYVON 15618: PARALLEL COMPUTER ARCHITECTURE
 HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
A Scalable, Numerically Stable, High- Performance Tridiagonal Solver for GPUs. Li-Wen Chang, Wen-mei Hwu University of Illinois
 A Scalable, Numerically Stable, High- Performance Tridiagonal Solver for GPUs Li-Wen Chang, Wen-mei Hwu University of Illinois A Scalable, Numerically Stable, High- How to Build a gtsv for Performance
A Scalable, Numerically Stable, High- Performance Tridiagonal Solver for GPUs Li-Wen Chang, Wen-mei Hwu University of Illinois A Scalable, Numerically Stable, High- How to Build a gtsv for Performance
HPC with Multicore and GPUs
 HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
HPC with Multicore and GPUs Stan Tomov Electrical Engineering and Computer Science Department University of Tennessee, Knoxville COSC 594 Lecture Notes March 22, 2017 1/20 Outline Introduction - Hardware
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Sparse Matrices in Image Compression
 Chapter 5 Sparse Matrices in Image Compression 5. INTRODUCTION With the increase in the use of digital image and multimedia data in day to day life, image compression techniques have become a major area
Chapter 5 Sparse Matrices in Image Compression 5. INTRODUCTION With the increase in the use of digital image and multimedia data in day to day life, image compression techniques have become a major area
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi
 Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
Evaluation and Exploration of Next Generation Systems for Applicability and Performance Volodymyr Kindratenko Guochun Shi National Center for Supercomputing Applications University of Illinois at Urbana-Champaign
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation
 Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Efficient Tridiagonal Solvers for ADI methods and Fluid Simulation Nikolai Sakharnykh - NVIDIA San Jose Convention Center, San Jose, CA September 21, 2010 Introduction Tridiagonal solvers very popular
Exploiting the Graphics Hardware to solve two compute intensive problems: Singular Value Decomposition and Ray Tracing Parametric Patches
 Exploiting the Graphics Hardware to solve two compute intensive problems: Singular Value Decomposition and Ray Tracing Parametric Patches Thesis submitted in partial fulfillment of the requirements for
Exploiting the Graphics Hardware to solve two compute intensive problems: Singular Value Decomposition and Ray Tracing Parametric Patches Thesis submitted in partial fulfillment of the requirements for
designing a GPU Computing Solution
 designing a GPU Computing Solution Patrick Van Reeth EMEA HPC Competency Center - GPU Computing Solutions Saturday, May the 29th, 2010 1 2010 Hewlett-Packard Development Company, L.P. The information contained
designing a GPU Computing Solution Patrick Van Reeth EMEA HPC Competency Center - GPU Computing Solutions Saturday, May the 29th, 2010 1 2010 Hewlett-Packard Development Company, L.P. The information contained
Maths for Signals and Systems Linear Algebra in Engineering. Some problems by Gilbert Strang
 Maths for Signals and Systems Linear Algebra in Engineering Some problems by Gilbert Strang Problems. Consider u, v, w to be non-zero vectors in R 7. These vectors span a vector space. What are the possible
Maths for Signals and Systems Linear Algebra in Engineering Some problems by Gilbert Strang Problems. Consider u, v, w to be non-zero vectors in R 7. These vectors span a vector space. What are the possible
Summer 2009 REU: Introduction to Some Advanced Topics in Computational Mathematics
 Summer 2009 REU: Introduction to Some Advanced Topics in Computational Mathematics Moysey Brio & Paul Dostert July 4, 2009 1 / 18 Sparse Matrices In many areas of applied mathematics and modeling, one
Summer 2009 REU: Introduction to Some Advanced Topics in Computational Mathematics Moysey Brio & Paul Dostert July 4, 2009 1 / 18 Sparse Matrices In many areas of applied mathematics and modeling, one
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
(Creating Arrays & Matrices) Applied Linear Algebra in Geoscience Using MATLAB
 Applied Linear Algebra in Geoscience Using MATLAB") Applied Linear Algebra in Geoscience Using MATLAB (Creating Arrays & Matrices) Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional
Applied Linear Algebra in Geoscience Using MATLAB (Creating Arrays & Matrices) Contents Getting Started Creating Arrays Mathematical Operations with Arrays Using Script Files and Managing Data Two-Dimensional
Haar Wavelet Image Compression
 Math 57 Haar Wavelet Image Compression. Preliminaries Haar wavelet compression is an efficient way to perform both lossless and lossy image compression. It relies on averaging and differencing the values
Math 57 Haar Wavelet Image Compression. Preliminaries Haar wavelet compression is an efficient way to perform both lossless and lossy image compression. It relies on averaging and differencing the values
Exploiting Parallelism to Support Scalable Hierarchical Clustering
 Exploiting Parallelism to Support Scalable Hierarchical Clustering Rebecca Cathey, Eric Jensen, Steven Beitzel, Ophir Frieder, David Grossman Information Retrieval Laboratory http://ir.iit.edu Background
Exploiting Parallelism to Support Scalable Hierarchical Clustering Rebecca Cathey, Eric Jensen, Steven Beitzel, Ophir Frieder, David Grossman Information Retrieval Laboratory http://ir.iit.edu Background
Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication. Steve Rennich Nvidia Developer Technology - Compute
 Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication Steve Rennich Nvidia Developer Technology - Compute Block Sparse Matrix Vector Multiplication Sparse Matrix-Vector Multiplication
Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication Steve Rennich Nvidia Developer Technology - Compute Block Sparse Matrix Vector Multiplication Sparse Matrix-Vector Multiplication
Parallel Reduction from Block Hessenberg to Hessenberg using MPI
 Parallel Reduction from Block Hessenberg to Hessenberg using MPI Viktor Jonsson May 24, 2013 Master s Thesis in Computing Science, 30 credits Supervisor at CS-UmU: Lars Karlsson Examiner: Fredrik Georgsson
Parallel Reduction from Block Hessenberg to Hessenberg using MPI Viktor Jonsson May 24, 2013 Master s Thesis in Computing Science, 30 credits Supervisor at CS-UmU: Lars Karlsson Examiner: Fredrik Georgsson
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Parallel Methods for Convex Optimization. A. Devarakonda, J. Demmel, K. Fountoulakis, M. Mahoney
 Parallel Methods for Convex Optimization A. Devarakonda, J. Demmel, K. Fountoulakis, M. Mahoney Problems minimize g(x)+f(x; A, b) Sparse regression g(x) =kxk 1 f(x) =kax bk 2 2 mx Sparse SVM g(x) =kxk
Parallel Methods for Convex Optimization A. Devarakonda, J. Demmel, K. Fountoulakis, M. Mahoney Problems minimize g(x)+f(x; A, b) Sparse regression g(x) =kxk 1 f(x) =kax bk 2 2 mx Sparse SVM g(x) =kxk
Novel implementations of recursive discrete wavelet transform for real time computation with multicore systems on chip (SOC)
") Science Journal of Circuits, Systems and Signal Processing 2013; 2(2) : 22-28 Published online April 2, 2013 (http://www.sciencepublishinggroup.com/j/cssp) doi: 10.11648/j.cssp.20130202.11 Novel implementations
Science Journal of Circuits, Systems and Signal Processing 2013; 2(2) : 22-28 Published online April 2, 2013 (http://www.sciencepublishinggroup.com/j/cssp) doi: 10.11648/j.cssp.20130202.11 Novel implementations
Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18
 Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
Accelerating PageRank using Partition-Centric Processing Kartik Lakhotia, Rajgopal Kannan, Viktor Prasanna USENIX ATC 18 Outline Introduction Partition-centric Processing Methodology Analytical Evaluation
Recognition, SVD, and PCA
 Recognition, SVD, and PCA Recognition Suppose you want to find a face in an image One possibility: look for something that looks sort of like a face (oval, dark band near top, dark band near bottom) Another
Recognition, SVD, and PCA Recognition Suppose you want to find a face in an image One possibility: look for something that looks sort of like a face (oval, dark band near top, dark band near bottom) Another
GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis
 GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis Abstract: Lower upper (LU) factorization for sparse matrices is the most important computing step for circuit simulation
GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis Abstract: Lower upper (LU) factorization for sparse matrices is the most important computing step for circuit simulation
Addition/Subtraction flops. ... k k + 1, n (n k)(n k) (n k)(n + 1 k) n 1 n, n (1)(1) (1)(2)
(n k) (n k)(n + 1 k) n 1 n, n (1)(1) (1)(2)") 1 CHAPTER 10 101 The flop counts for LU decomposition can be determined in a similar fashion as was done for Gauss elimination The major difference is that the elimination is only implemented for the left-hand
1 CHAPTER 10 101 The flop counts for LU decomposition can be determined in a similar fashion as was done for Gauss elimination The major difference is that the elimination is only implemented for the left-hand
State of Art and Project Proposals Intensive Computation
 State of Art and Project Proposals Intensive Computation Annalisa Massini - 2015/2016 Today s lecture Project proposals on the following topics: Sparse Matrix- Vector Multiplication Tridiagonal Solvers
State of Art and Project Proposals Intensive Computation Annalisa Massini - 2015/2016 Today s lecture Project proposals on the following topics: Sparse Matrix- Vector Multiplication Tridiagonal Solvers
Clustering and Dimensionality Reduction. Stony Brook University CSE545, Fall 2017
 Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
Clustering and Dimensionality Reduction Stony Brook University CSE545, Fall 2017 Goal: Generalize to new data Model New Data? Original Data Does the model accurately reflect new data? Supervised vs. Unsupervised
Lecture 17: Array Algorithms
 Lecture 17: Array Algorithms CS178: Programming Parallel and Distributed Systems April 4, 2001 Steven P. Reiss I. Overview A. We talking about constructing parallel programs 1. Last time we discussed sorting
Lecture 17: Array Algorithms CS178: Programming Parallel and Distributed Systems April 4, 2001 Steven P. Reiss I. Overview A. We talking about constructing parallel programs 1. Last time we discussed sorting
Memory Hierarchy. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Memory Hierarchy Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Time (ns) The CPU-Memory Gap The gap widens between DRAM, disk, and CPU speeds
Memory Hierarchy Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Time (ns) The CPU-Memory Gap The gap widens between DRAM, disk, and CPU speeds
International Journal of Computer Science and Network (IJCSN) Volume 1, Issue 4, August ISSN
 Volume 1, Issue 4, August ISSN") Accelerating MATLAB Applications on Parallel Hardware 1 Kavita Chauhan, 2 Javed Ashraf 1 NGFCET, M.D.University Palwal,Haryana,India Page 80 2 AFSET, M.D.University Dhauj,Haryana,India Abstract MATLAB
Accelerating MATLAB Applications on Parallel Hardware 1 Kavita Chauhan, 2 Javed Ashraf 1 NGFCET, M.D.University Palwal,Haryana,India Page 80 2 AFSET, M.D.University Dhauj,Haryana,India Abstract MATLAB
Linear Algebra libraries in Debian. DebConf 10 New York 05/08/2010 Sylvestre
 Linear Algebra libraries in Debian Who I am? Core developer of Scilab (daily job) Debian Developer Involved in Debian mainly in Science and Java aspects sylvestre.ledru@scilab.org / sylvestre@debian.org
Linear Algebra libraries in Debian Who I am? Core developer of Scilab (daily job) Debian Developer Involved in Debian mainly in Science and Java aspects sylvestre.ledru@scilab.org / sylvestre@debian.org
DCT SVD Based Hybrid Transform Coding for Image Compression
 DCT SVD Based Hybrid Coding for Image Compression Raghavendra.M.J 1, 1 Assistant Professor, Department of Telecommunication P.E.S. Institute of Technology Bangalore, India mjraghavendra@gmail.com Dr.Prasantha.H.S
DCT SVD Based Hybrid Coding for Image Compression Raghavendra.M.J 1, 1 Assistant Professor, Department of Telecommunication P.E.S. Institute of Technology Bangalore, India mjraghavendra@gmail.com Dr.Prasantha.H.S
Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, DRAM Bandwidth
 Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2016 DRAM Bandwidth MEMORY ACCESS PERFORMANCE Objective To learn that memory bandwidth is a first-order performance factor in
Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2016 DRAM Bandwidth MEMORY ACCESS PERFORMANCE Objective To learn that memory bandwidth is a first-order performance factor in
Scan Primitives for GPU Computing
 Scan Primitives for GPU Computing Shubho Sengupta, Mark Harris *, Yao Zhang, John Owens University of California Davis, *NVIDIA Corporation Motivation Raw compute power and bandwidth of GPUs increasing
Scan Primitives for GPU Computing Shubho Sengupta, Mark Harris *, Yao Zhang, John Owens University of California Davis, *NVIDIA Corporation Motivation Raw compute power and bandwidth of GPUs increasing
Determinant Computation on the GPU using the Condensation AMMCS Method / 1
 Determinant Computation on the GPU using the Condensation Method Sardar Anisul Haque Marc Moreno Maza Ontario Research Centre for Computer Algebra University of Western Ontario, London, Ontario AMMCS 20,
Determinant Computation on the GPU using the Condensation Method Sardar Anisul Haque Marc Moreno Maza Ontario Research Centre for Computer Algebra University of Western Ontario, London, Ontario AMMCS 20,
Communication-Avoiding QR Decomposition for GPUs
 Communication-Avoiding QR Decomposition for GPUs Michael Anderson, Grey Ballard, James Demmel and Kurt Keutzer UC Berkeley: Department of Electrical Engineering and Computer Science Berkeley, CA USA {mjanders,ballard,demmel,keutzer}@cs.berkeley.edu
Communication-Avoiding QR Decomposition for GPUs Michael Anderson, Grey Ballard, James Demmel and Kurt Keutzer UC Berkeley: Department of Electrical Engineering and Computer Science Berkeley, CA USA {mjanders,ballard,demmel,keutzer}@cs.berkeley.edu
CSE 599 I Accelerated Computing - Programming GPUS. Memory performance
 CSE 599 I Accelerated Computing - Programming GPUS Memory performance GPU Teaching Kit Accelerated Computing Module 6.1 Memory Access Performance DRAM Bandwidth Objective To learn that memory bandwidth
CSE 599 I Accelerated Computing - Programming GPUS Memory performance GPU Teaching Kit Accelerated Computing Module 6.1 Memory Access Performance DRAM Bandwidth Objective To learn that memory bandwidth
CafeGPI. Single-Sided Communication for Scalable Deep Learning
 CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
Realization of Hardware Architectures for Householder Transformation based QR Decomposition using Xilinx System Generator Block Sets
 IJSTE - International Journal of Science Technology & Engineering Volume 2 Issue 08 February 2016 ISSN (online): 2349-784X Realization of Hardware Architectures for Householder Transformation based QR
IJSTE - International Journal of Science Technology & Engineering Volume 2 Issue 08 February 2016 ISSN (online): 2349-784X Realization of Hardware Architectures for Householder Transformation based QR
Exploiting Locality in Sparse Matrix-Matrix Multiplication on the Many Integrated Core Architecture
 Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Exploiting Locality in Sparse Matrix-Matrix Multiplication on the Many Integrated Core Architecture K. Akbudak a, C.Aykanat
Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Exploiting Locality in Sparse Matrix-Matrix Multiplication on the Many Integrated Core Architecture K. Akbudak a, C.Aykanat
International Conference on Computational Science (ICCS 2017)
") International Conference on Computational Science (ICCS 2017) Exploiting Hybrid Parallelism in the Kinematic Analysis of Multibody Systems Based on Group Equations G. Bernabé, J. C. Cano, J. Cuenca, A.
International Conference on Computational Science (ICCS 2017) Exploiting Hybrid Parallelism in the Kinematic Analysis of Multibody Systems Based on Group Equations G. Bernabé, J. C. Cano, J. Cuenca, A.
CS 664 Structure and Motion. Daniel Huttenlocher
 CS 664 Structure and Motion Daniel Huttenlocher Determining 3D Structure Consider set of 3D points X j seen by set of cameras with projection matrices P i Given only image coordinates x ij of each point
CS 664 Structure and Motion Daniel Huttenlocher Determining 3D Structure Consider set of 3D points X j seen by set of cameras with projection matrices P i Given only image coordinates x ij of each point
Computational Methods in Statistics with Applications A Numerical Point of View. Large Data Sets. L. Eldén. March 2016
 Computational Methods in Statistics with Applications A Numerical Point of View L. Eldén SeSe March 2016 Large Data Sets IDA Machine Learning Seminars, September 17, 2014. Sequential Decision Making: Experiment
Computational Methods in Statistics with Applications A Numerical Point of View L. Eldén SeSe March 2016 Large Data Sets IDA Machine Learning Seminars, September 17, 2014. Sequential Decision Making: Experiment
Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU
 Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU The myth 10x-1000x speed up on GPU vs CPU Papers supporting the myth: Microsoft: N. K. Govindaraju, B. Lloyd, Y.
Debunking the 100X GPU vs CPU Myth: An Evaluation of Throughput Computing on CPU and GPU The myth 10x-1000x speed up on GPU vs CPU Papers supporting the myth: Microsoft: N. K. Govindaraju, B. Lloyd, Y.
Exploiting Multiple GPUs in Sparse QR: Regular Numerics with Irregular Data Movement
 Exploiting Multiple GPUs in Sparse QR: Regular Numerics with Irregular Data Movement Tim Davis (Texas A&M University) with Sanjay Ranka, Mohamed Gadou (University of Florida) Nuri Yeralan (Microsoft) NVIDIA
Exploiting Multiple GPUs in Sparse QR: Regular Numerics with Irregular Data Movement Tim Davis (Texas A&M University) with Sanjay Ranka, Mohamed Gadou (University of Florida) Nuri Yeralan (Microsoft) NVIDIA
Sampling Using GPU Accelerated Sparse Hierarchical Models
 Sampling Using GPU Accelerated Sparse Hierarchical Models Miroslav Stoyanov Oak Ridge National Laboratory supported by Exascale Computing Project (ECP) exascaleproject.org April 9, 28 Miroslav Stoyanov
Sampling Using GPU Accelerated Sparse Hierarchical Models Miroslav Stoyanov Oak Ridge National Laboratory supported by Exascale Computing Project (ECP) exascaleproject.org April 9, 28 Miroslav Stoyanov
GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU
 April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
April 4-7, 2016 Silicon Valley GPU ACCELERATION OF CHOLMOD: BATCHING, HYBRID AND MULTI-GPU Steve Rennich, Darko Stosic, Tim Davis, April 6, 2016 OBJECTIVE Direct sparse methods are among the most widely
Parallelizing The Matrix Multiplication. 6/10/2013 LONI Parallel Programming Workshop
 Parallelizing The Matrix Multiplication 6/10/2013 LONI Parallel Programming Workshop 2013 1 Serial version 6/10/2013 LONI Parallel Programming Workshop 2013 2 X = A md x B dn = C mn d c i,j = a i,k b k,j
Parallelizing The Matrix Multiplication 6/10/2013 LONI Parallel Programming Workshop 2013 1 Serial version 6/10/2013 LONI Parallel Programming Workshop 2013 2 X = A md x B dn = C mn d c i,j = a i,k b k,j
Block Lanczos-Montgomery method over large prime fields with GPU accelerated dense operations
 Block Lanczos-Montgomery method over large prime fields with GPU accelerated dense operations Nikolai Zamarashkin and Dmitry Zheltkov INM RAS, Gubkina 8, Moscow, Russia {nikolai.zamarashkin,dmitry.zheltkov}@gmail.com
Block Lanczos-Montgomery method over large prime fields with GPU accelerated dense operations Nikolai Zamarashkin and Dmitry Zheltkov INM RAS, Gubkina 8, Moscow, Russia {nikolai.zamarashkin,dmitry.zheltkov}@gmail.com
Implementing a Speech Recognition System on a GPU using CUDA. Presented by Omid Talakoub Astrid Yi
 Implementing a Speech Recognition System on a GPU using CUDA Presented by Omid Talakoub Astrid Yi Outline Background Motivation Speech recognition algorithm Implementation steps GPU implementation strategies
Implementing a Speech Recognition System on a GPU using CUDA Presented by Omid Talakoub Astrid Yi Outline Background Motivation Speech recognition algorithm Implementation steps GPU implementation strategies
Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures
 Photos placed in horizontal position with even amount of white space between photos and header Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures Christopher Forster,
Photos placed in horizontal position with even amount of white space between photos and header Portability and Scalability of Sparse Tensor Decompositions on CPU/MIC/GPU Architectures Christopher Forster,
Highly Efficient Compensationbased Parallelism for Wavefront Loops on GPUs
 Highly Efficient Compensationbased Parallelism for Wavefront Loops on GPUs Kaixi Hou, Hao Wang, Wu chun Feng {kaixihou, hwang121, wfeng}@vt.edu Jeffrey S. Vetter, Seyong Lee vetter@computer.org, lees2@ornl.gov
Highly Efficient Compensationbased Parallelism for Wavefront Loops on GPUs Kaixi Hou, Hao Wang, Wu chun Feng {kaixihou, hwang121, wfeng}@vt.edu Jeffrey S. Vetter, Seyong Lee vetter@computer.org, lees2@ornl.gov