Network Coding: Theory and Applica7ons
|
|
|
- Allyson Woods
- 5 years ago
- Views:
Transcription

, Daniel E.")
1 Network Coding: Theory and Applica7ons PhD Course Part IV Tuesday Muriel Médard (MIT), Frank H. P. Fitzek (AAU), Daniel E. Lucani (AAU), Morten V. Pedersen (AAU)
2 Plan Hello World! Intra flow network coding Intra flow Complexity Overhead Energy Analog Core Project Ass. Theory Mul7cast and Co Distributed Storage Wash Up Inter flow network coding KODO + Simulator KODO + Exercises Group Work Group Work Group Work
3 Recoding Packets Genera7ng a new linear network coded packet (CP) Coded data Coding Coeff. Header f 1 f 2 f 3 f 4 f 5 x x x x x C 11 x C 12 x Header d 1 d 1 d 1 d 1 d e 1 e 2 e 3 e 4 e 5 x x x x x d 2 d 2 d 2 d 2 d 2 d 1 d C 21 x C 22 x d 2 d 2 Header New Coded Data X 1 X 2 X 1 = d 1 C 11 + d 2 C 21 and X 2 = d 1 C 12 + d 2 C 22 Recall that: f = C 11 P 1 + C 12 P 2 and e = C 21 P 1 + C 22 P 2 Thus, d 1 f + d 2 e = d 1 C 11 P 1 + d 1 C 12 P 2 + d 2 C 21 P 1 + d 2 C 22 P 2 = X 1 P 1 + X 2 P 2 3
4 Systematic Coding: Complexity D Uncoded packets CP 1 1 P 1 CP 2 1 P 2 CP 3 CP 4 = a 41 a 42 1 a 43 a 44 a 45 a 46 P 3 P 4 CP 5 a 51 a 52 a 53 a 54 a 55 a 56 P 5 CP 6 a 61 a 62 a 63 a 64 a 65 a 66 P 6 M x M Opera7ons first elimina7on (Product): Gaussian elimina7on n x n matrix, n = M - D requires An 3 + Bn 2 + Cn opera7ons Distribu7on of D determines average # of opera7ons Linked to channel model Erasures IID Be(Pe):
5 Systematic Coding: Complexity CP 1 1 P 1 CP 2 1 P 2 CP 3 CP 4 = a 41 a 42 1 a 43 a 44 a 45 a 46 P 3 P 4 CP 5 a 51 a 52 a 53 a 54 a 55 a 56 P 5 CP 6 a 61 a 62 a 63 a 64 a 65 a 66 P 6 M x M Opera7ons first elimina7on (Product): Gaussian elimina7on n x n matrix, n = M - D requires An 3 + Bn 2 + Cn opera7ons Distribu7on of D determines average # of opera7ons Linked to channel model Erasures IID Be(Pe): D (M- D)
6 Systematic Coding: Complexity CP 1 CP 2 CP 3 CP 4 CP 5 CP 6 = Opera7ons first elimina7on (Product): D (M- D) Gaussian elimina7on n x n matrix, n = M - D requires An 3 + Bn 2 + Cn opera7ons Distribu7on of D determines average # of opera7ons Linked to channel model Erasures IID Be(Pe): a 44 a 54 a 64 a 45 a 55 a 65 a 46 a 56 a 66 M x M A(MPe) 3 + B (MPe) 2 + C (MPe) - - > O(M 3 Pe 3 ) P 1 P 2 P 3 P 4 P 5 P 6
7 S6 Implementa7on RLNC (27)



8 Network Coding GF(2)

")


9 Systema7c Network Coding GF(2)

10 Coding throughput on a laptop Lenovo T61p, 2.53 GHz Intel Core2Duo, 2 GB ram, Kubuntu bit
11 Coding throughput on Nokia N95 Nokia N95-8GB, ARM MHz CPU, 128 MB ram, Symbian OS 9.2
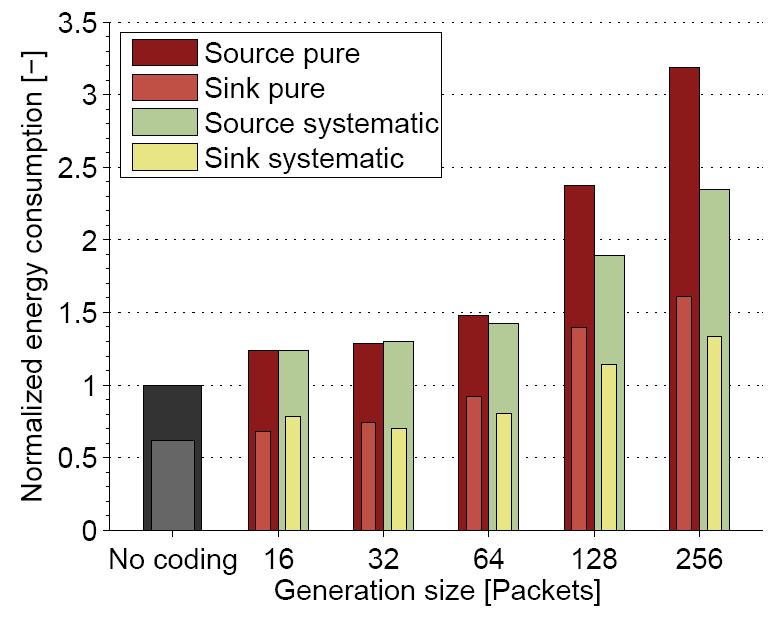
12 Energy Consump7on
![Current coding speeds in 212 Speed [MByte/s] 1 1 1 1 2 8 16 OPF 2 8 1 Field size 16](/docs-images/87/96819224/images/13-1.jpg "OPF 128 64 32 Genera7on size 16... and in 27 we had 2 kbyte/s for genera7on size of 5!")
13 Current coding speeds in 212 Speed [MByte/s] OPF Field size 16 OPF Genera7on size and in 27 we had 2 kbyte/s for genera7on size of 5!
14 Current coding speeds in 212 Speed [MByte/s] OPF Field size 16 OPF Genera7on size and in 27 we had 2 kbyte/s for genera7on size of 5!
15 IMPLEMENTATION OF RANDOM LINEAR NETWORK CODING ON OPENGL- ENABLED GRAPHICS CARDS
16 Main Mo7va7on Mobile devices have co- processor or accelerators for specific tasks Speed Energy consump7on Examples Voice codec Video Codec Gaming But no network coding support (yet)
17 Example: Video on N95 Spiderman3 Sopware approach DivX player 1.59 W Display.4 W Audio.1 W 88%.675 W Hardware accelerator Build- In player.94 W Display.4 W Audio.1 W 31%.35 W Accelerator.2 W
18 CPU implementa7on A simple C++ console applica7on with some customizable parameters: L: packet length N: genera7on size Object- oriented implementa7on: Encoder and Decoder classes Addi7on and subtrac7on over the Galois Field are simply XOR opera7ons on the CPU Galois mul7plica7on and division tables are pre- calculated and stored in arrays: both opera7ons can be performed by array lookups Gauss- Jordan elimina7on is used for decoding: on- the- fly version of the standard Gaussian elimina7on It is used as a reference implementa7on
19 Graphics card Originally designed for real- 7me rendering of 3D graphics The past: fixed- func7on pipeline They evolved into programmable parallel processors with enormous compu7ng power The present: programmable pipeline Now they can even perform general- purpose computa7ons with some restric7ons The future: General Purpose Graphics Processing Unit (GPGPU)


20 Plavorm of choice NVidia GeForce 96 GT NVidia GeForce 92M GS

21 OpenGL & CG implementa7on OpenGL is a standard cross- plavorm API for computer graphics It cannot be used on its own, a shader language is also necessary to implement custom algorithms A shader is a short program which is used to program certain stages of the rendering pipeline Chose NVIDIA s CG toolkit as a shader language The developer is forced to think with the tradi7onal concepts of 3D graphics (e.g. ver7ces, pixels, triangles, lines and points)
 line- by- line onto")
22 Encoder shader in CG A regular bitmap image serves as input data Coefficients and data packets are stored in textures (2D arrays of bytes in graphics memory that can be accessed efficiently) The XOR opera7on and Galois mul7plica7on are also implemented by texture look- ups: a 256x256- sized black&white texture is necessary for each The encoded packets are rendered (computed) line- by- line onto the screen and they are saved into a texture
23 Decoder shaders in CG The decoding algorithm is more complex It must be decomposed into 3 different shaders These shaders correspond to the 3 consecu7ve phases of the Gauss- Jordan elimina7on: 1. Forward elimina7on: reduce the new packet by the exis7ng rows 2. Finding the pivot element in the reduced packet 3. Backward subs7tute the reduced and normalized packet into the exis7ng rows
 model, meaning that a user-")
24 NVIDIA s CUDA toolkit Compute Unified Device Architecture (CUDA) Parallel compu7ng applica7ons in the C language Modern GPUs have many processor cores and they can launch thousands of threads with zero scheduling overhead Terminology: host = CPU device = GPU kernel = a func7on executed on the GPU A kernel is executed in the Single Program Mul7ple Data (SPMD) model, meaning that a user- specified number of threads execute the same program.
25 CUDA implementa7on A CUDA- capable device is required! NVIDIA GeForce 8 series at minimum This is a more na7ve approach, we have fewer restric7ons A large number of threads must be launched to achieve the GPU s peak performance All data structures are stored in CUDA arrays, which are bound to texture references if necessary Computa7ons are visualized using an OpenGL GUI
26 Encoder kernel in CUDA Encoding is a matrix mul7plica7on in the GF domain, and can be considered as a highly parallel computa7on problem We can achieve a very fine granularity by launching a thread for every single byte to be computed Galois mul7plica7on is implemented by array look- ups, but we have a na7ve XOR operator The encoder kernel is quite simple
27 Decoder kernels in CUDA Gauss- Jordan elimina7on means that the decoding of each coded packet can only start aper the decoding of the previous coded packets has finished => we have a sequen7al algorithm Paralleliza7on is only possible within the decoding of the current coded packet We need 2 separate kernels for forward and backward subs7tu7on A search for the first non- zero element must be performed on the CPU side, because synchroniza7on is not possible between all GPU threads => the CPU must assist the GPU
28 Random Coefficient Matrix Encoding OpenGL (A) Ongoing decoding OpenGL Final Decoding OpenGL Original Encoding CPU (B) Ongoing decoding CPU Final Decoding CPU
 Ongoing decoding CPU Final Decoding")
29 Random Coefficient Matrix Encoding OpenGL (A) Ongoing decoding OpenGL Final Decoding OpenGL Original Encoding CPU (B) Ongoing decoding CPU Final Decoding CPU
30 Performance evalua7on It is difficult to compare the actual performance of these implementa7ons A lot of factors have to be taken into considera7on: Shader/kernel execu7on 7mes Memory transfers between host and device memory Shader/kernel ini7aliza7on & parameter setup CPU- GPU synchroniza7on Measurement results are not uniform, because we cannot have exclusive control over the GPU: other applica7ons may have a nega7ve impact
31 CPU implementa7on
32 OpenGL & CG implementa7on
33 CUDA implementa7on
34 Sparse Code Structures What does sparsity mean? Large frac7on of the coefficients are zero Why use sparse structures? Efficient decoders (less complexity) What are we giving up? Performance: need to transmit more coded packets What are the challenges? Decoders Complexity performance trade- off Re- coding may destroy sparse structure
35 Sparse Code Structures Decoders: Forward pass of Gaussian elimina7on Dominant effect towards complexity It can introduce spurious coefficients in unprocessed coded packets: sparse structure is lost Re- coding: If not careful, can increase density P 1 + 2P 3 3P 5 + 5P 6 P 1 P 2 P 3 P 4 P 5 P 6 Start: 14 non- zero coeff. Aper some steps: 16 non- zero coeff. P 1 + 2P 3 + 3P 5 + 5P 6

36 Sparse Code Structures Decoders: Forward pass of Gaussian elimina7on Dominant effect towards complexity It can introduce spurious coefficients in unprocessed coded packets: sparse structure is lost Re- coding: If not careful, can increase density P 1 + 2P 3 3P 5 + 5P 6 P 1 P 2 P 3 P 4 P 5 P 6 Start: 14 non- zero coeff. Aper some steps: 16 non- zero coeff. P 1 + 2P 3 + 3P 5 + 5P 6
Implementation of Random Linear Network Coding using NVIDIA's CUDA toolkit
 Implementation of Random Linear Network Coding using NVIDIA's CUDA toolkit Péter Vingelmann* and Frank H. P. Fitzek * Budapest University of Technology and Economics Aalborg University, Department of Electronic
Implementation of Random Linear Network Coding using NVIDIA's CUDA toolkit Péter Vingelmann* and Frank H. P. Fitzek * Budapest University of Technology and Economics Aalborg University, Department of Electronic
Published in: IEEE International Conference on Communications Workshops, ICC Workshops 2009
 Aalborg Universitet Network Coding for Mobile Devices - Systematic Binary Random Rateless Codes Heide, Janus; Pedersen, Morten Videbæk; Fitzek, Frank Hanns Paul; Larsen, Torben Published in: IEEE International
Aalborg Universitet Network Coding for Mobile Devices - Systematic Binary Random Rateless Codes Heide, Janus; Pedersen, Morten Videbæk; Fitzek, Frank Hanns Paul; Larsen, Torben Published in: IEEE International
RouteBricks: Exploi2ng Parallelism to Scale So9ware Routers
 RouteBricks: Exploi2ng Parallelism to Scale So9ware Routers Mihai Dobrescu and etc. SOSP 2009 Presented by Shuyi Chen Mo2va2on Router design Performance Extensibility They are compe2ng goals Hardware approach
RouteBricks: Exploi2ng Parallelism to Scale So9ware Routers Mihai Dobrescu and etc. SOSP 2009 Presented by Shuyi Chen Mo2va2on Router design Performance Extensibility They are compe2ng goals Hardware approach
GPGPU. Peter Laurens 1st-year PhD Student, NSC
 GPGPU Peter Laurens 1st-year PhD Student, NSC Presentation Overview 1. What is it? 2. What can it do for me? 3. How can I get it to do that? 4. What s the catch? 5. What s the future? What is it? Introducing
GPGPU Peter Laurens 1st-year PhD Student, NSC Presentation Overview 1. What is it? 2. What can it do for me? 3. How can I get it to do that? 4. What s the catch? 5. What s the future? What is it? Introducing
GASPP: A GPU- Accelerated Stateful Packet Processing Framework
 GASPP: A GPU- Accelerated Stateful Packet Processing Framework Giorgos Vasiliadis, FORTH- ICS, Greece Lazaros Koromilas, FORTH- ICS, Greece Michalis Polychronakis, Columbia University, USA So5ris Ioannidis,
GASPP: A GPU- Accelerated Stateful Packet Processing Framework Giorgos Vasiliadis, FORTH- ICS, Greece Lazaros Koromilas, FORTH- ICS, Greece Michalis Polychronakis, Columbia University, USA So5ris Ioannidis,
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
Efficient Memory and Bandwidth Management for Industrial Strength Kirchhoff Migra<on
 Efficient Memory and Bandwidth Management for Industrial Strength Kirchhoff Migra
Efficient Memory and Bandwidth Management for Industrial Strength Kirchhoff Migra
Graphics Hardware. Graphics Processing Unit (GPU) is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics
 is a Subsidiary hardware. With massively multi-threaded many-core. Dedicated to 2D and 3D graphics") Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
Why GPU? Chapter 1 Graphics Hardware Graphics Processing Unit (GPU) is a Subsidiary hardware With massively multi-threaded many-core Dedicated to 2D and 3D graphics Special purpose low functionality, high
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
GPU Cluster Computing. Advanced Computing Center for Research and Education
 GPU Cluster Computing Advanced Computing Center for Research and Education 1 What is GPU Computing? Gaming industry and high- defini3on graphics drove the development of fast graphics processing Use of
GPU Cluster Computing Advanced Computing Center for Research and Education 1 What is GPU Computing? Gaming industry and high- defini3on graphics drove the development of fast graphics processing Use of
Graphics Hardware. Instructor Stephen J. Guy
 Instructor Stephen J. Guy Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability! Programming Examples Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability!
Instructor Stephen J. Guy Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability! Programming Examples Overview What is a GPU Evolution of GPU GPU Design Modern Features Programmability!
ECE 571 Advanced Microprocessor-Based Design Lecture 20
 ECE 571 Advanced Microprocessor-Based Design Lecture 20 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 12 April 2016 Project/HW Reminder Homework #9 was posted 1 Raspberry Pi
ECE 571 Advanced Microprocessor-Based Design Lecture 20 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 12 April 2016 Project/HW Reminder Homework #9 was posted 1 Raspberry Pi
hashfs Applying Hashing to Op2mize File Systems for Small File Reads
 hashfs Applying Hashing to Op2mize File Systems for Small File Reads Paul Lensing, Dirk Meister, André Brinkmann Paderborn Center for Parallel Compu2ng University of Paderborn Mo2va2on and Problem Design
hashfs Applying Hashing to Op2mize File Systems for Small File Reads Paul Lensing, Dirk Meister, André Brinkmann Paderborn Center for Parallel Compu2ng University of Paderborn Mo2va2on and Problem Design
Spring 2009 Prof. Hyesoon Kim
 Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2009 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
PictureViewer Pedersen, Morten Videbæk; Heide, Janus; Fitzek, Frank Hanns Paul; Larsen, Torben
 Aalborg Universitet PictureViewer Pedersen, Morten Videbæk; Heide, Janus; Fitzek, Frank Hanns Paul; Larsen, Torben Published in: European Wireless 29 DOI (link to publication from Publisher): 1.119/EW.29.5357968
Aalborg Universitet PictureViewer Pedersen, Morten Videbæk; Heide, Janus; Fitzek, Frank Hanns Paul; Larsen, Torben Published in: European Wireless 29 DOI (link to publication from Publisher): 1.119/EW.29.5357968
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
ECE 571 Advanced Microprocessor-Based Design Lecture 18
 ECE 571 Advanced Microprocessor-Based Design Lecture 18 Vince Weaver http://www.eece.maine.edu/ vweaver vincent.weaver@maine.edu 11 November 2014 Homework #4 comments Project/HW Reminder 1 Stuff from Last
ECE 571 Advanced Microprocessor-Based Design Lecture 18 Vince Weaver http://www.eece.maine.edu/ vweaver vincent.weaver@maine.edu 11 November 2014 Homework #4 comments Project/HW Reminder 1 Stuff from Last
SEDA An architecture for Well Condi6oned, scalable Internet Services
 SEDA An architecture for Well Condi6oned, scalable Internet Services Ma= Welsh, David Culler, and Eric Brewer University of California, Berkeley Symposium on Operating Systems Principles (SOSP), October
SEDA An architecture for Well Condi6oned, scalable Internet Services Ma= Welsh, David Culler, and Eric Brewer University of California, Berkeley Symposium on Operating Systems Principles (SOSP), October
A Distributed Data- Parallel Execu3on Framework in the Kepler Scien3fic Workflow System
 A Distributed Data- Parallel Execu3on Framework in the Kepler Scien3fic Workflow System Ilkay Al(ntas and Daniel Crawl San Diego Supercomputer Center UC San Diego Jianwu Wang UMBC WorDS.sdsc.edu Computa3onal
A Distributed Data- Parallel Execu3on Framework in the Kepler Scien3fic Workflow System Ilkay Al(ntas and Daniel Crawl San Diego Supercomputer Center UC San Diego Jianwu Wang UMBC WorDS.sdsc.edu Computa3onal
First: Shameless Adver2sing
 Agenda A Shameless self promo2on Introduc2on to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy The Cuda Memory Hierarchy Mapping Cuda to Nvidia GPUs As much of the OpenCL informa2on as I can
Agenda A Shameless self promo2on Introduc2on to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy The Cuda Memory Hierarchy Mapping Cuda to Nvidia GPUs As much of the OpenCL informa2on as I can
X. GPU Programming. Jacobs University Visualization and Computer Graphics Lab : Advanced Graphics - Chapter X 1
 X. GPU Programming 320491: Advanced Graphics - Chapter X 1 X.1 GPU Architecture 320491: Advanced Graphics - Chapter X 2 GPU Graphics Processing Unit Parallelized SIMD Architecture 112 processing cores
X. GPU Programming 320491: Advanced Graphics - Chapter X 1 X.1 GPU Architecture 320491: Advanced Graphics - Chapter X 2 GPU Graphics Processing Unit Parallelized SIMD Architecture 112 processing cores
NetSlices: Scalable Mul/- Core Packet Processing in User- Space
 NetSlices: Scalable Mul/- Core Packet Processing in - Space Tudor Marian, Ki Suh Lee, Hakim Weatherspoon Cornell University Presented by Ki Suh Lee Packet Processors Essen/al for evolving networks Sophis/cated
NetSlices: Scalable Mul/- Core Packet Processing in - Space Tudor Marian, Ki Suh Lee, Hakim Weatherspoon Cornell University Presented by Ki Suh Lee Packet Processors Essen/al for evolving networks Sophis/cated
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
CS179 GPU Programming Introduction to CUDA. Lecture originally by Luke Durant and Tamas Szalay
 Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
GPGPU on Mobile Devices
 GPGPU on Mobile Devices Introduction Addressing GPGPU for very mobile devices Tablets Smartphones Introduction Why dedicated GPUs in mobile devices? Gaming Physics simulation for realistic effects 3D-GUI
GPGPU on Mobile Devices Introduction Addressing GPGPU for very mobile devices Tablets Smartphones Introduction Why dedicated GPUs in mobile devices? Gaming Physics simulation for realistic effects 3D-GUI
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects?
 Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects? N. S. Islam, X. Lu, M. W. Rahman, and D. K. Panda Network- Based Compu2ng Laboratory Department of Computer
Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects? N. S. Islam, X. Lu, M. W. Rahman, and D. K. Panda Network- Based Compu2ng Laboratory Department of Computer
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
Spring 2011 Prof. Hyesoon Kim Application Geometry Rasterizer CPU Each stage cane be also pipelined The slowest of the pipeline stage determines the rendering speed. Frames per second (fps) Executes on
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Shadows for Many Lights sounds like it might mean something, but In fact it can mean very different things, that require very different solutions.
 1 2 Shadows for Many Lights sounds like it might mean something, but In fact it can mean very different things, that require very different solutions. 3 We aim for something like the numbers of lights
1 2 Shadows for Many Lights sounds like it might mean something, but In fact it can mean very different things, that require very different solutions. 3 We aim for something like the numbers of lights
Soft GPGPUs for Embedded FPGAS: An Architectural Evaluation
 Soft GPGPUs for Embedded FPGAS: An Architectural Evaluation 2nd International Workshop on Overlay Architectures for FPGAs (OLAF) 2016 Kevin Andryc, Tedy Thomas and Russell Tessier University of Massachusetts
Soft GPGPUs for Embedded FPGAS: An Architectural Evaluation 2nd International Workshop on Overlay Architectures for FPGAs (OLAF) 2016 Kevin Andryc, Tedy Thomas and Russell Tessier University of Massachusetts
A Script- Based Autotuning Compiler System to Generate High- Performance CUDA code
 A Script- Based Autotuning Compiler System to Generate High- Performance CUDA code Malik Khan, Protonu Basu, Gabe Rudy, Mary Hall, Chun Chen, Jacqueline Chame Mo:va:on Challenges to programming the GPU
A Script- Based Autotuning Compiler System to Generate High- Performance CUDA code Malik Khan, Protonu Basu, Gabe Rudy, Mary Hall, Chun Chen, Jacqueline Chame Mo:va:on Challenges to programming the GPU
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Multimedia in Mobile Phones. Architectures and Trends Lund
 Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
LOOP PARALLELIZATION!
 PROGRAMMING LANGUAGES LABORATORY! Universidade Federal de Minas Gerais - Department of Computer Science LOOP PARALLELIZATION! PROGRAM ANALYSIS AND OPTIMIZATION DCC888! Fernando Magno Quintão Pereira! fernando@dcc.ufmg.br
PROGRAMMING LANGUAGES LABORATORY! Universidade Federal de Minas Gerais - Department of Computer Science LOOP PARALLELIZATION! PROGRAM ANALYSIS AND OPTIMIZATION DCC888! Fernando Magno Quintão Pereira! fernando@dcc.ufmg.br
A Comparison of GPU Box- Plane Intersec8on Algorithms for Direct Volume Rendering. Chair of Computer Science Prof. Lang University of Cologne, Germany
 A Comparison of GPU Box- Plane Intersec8on Algorithms for Direct Volume Rendering Chair of Computer Science Prof. Lang, Germany Stefan Zellmann (zellmans@uni- koeln.de) Ulrich Lang (lang@uni- koeln.de)
A Comparison of GPU Box- Plane Intersec8on Algorithms for Direct Volume Rendering Chair of Computer Science Prof. Lang, Germany Stefan Zellmann (zellmans@uni- koeln.de) Ulrich Lang (lang@uni- koeln.de)
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Low Complexity Opportunistic Decoder for Network Coding
 Low Complexity Opportunistic Decoder for Network Coding Bei Yin, Michael Wu, Guohui Wang, and Joseph R. Cavallaro ECE Department, Rice University, 6100 Main St., Houston, TX 77005 Email: {by2, mbw2, wgh,
Low Complexity Opportunistic Decoder for Network Coding Bei Yin, Michael Wu, Guohui Wang, and Joseph R. Cavallaro ECE Department, Rice University, 6100 Main St., Houston, TX 77005 Email: {by2, mbw2, wgh,
Agenda. General Organiza/on and architecture Structural/func/onal view of a computer Evolu/on/brief history of computer.
 UNIT I: OVERVIEW Agenda General Organiza/on and architecture Structural/func/onal view of a computer Evolu/on/brief history of computer. Architecture & Organiza/on Computer Architecture is those abributes
UNIT I: OVERVIEW Agenda General Organiza/on and architecture Structural/func/onal view of a computer Evolu/on/brief history of computer. Architecture & Organiza/on Computer Architecture is those abributes
REDUCING BEAMFORMING CALCULATION TIME WITH GPU ACCELERATED ALGORITHMS
 BeBeC-2014-08 REDUCING BEAMFORMING CALCULATION TIME WITH GPU ACCELERATED ALGORITHMS Steffen Schmidt GFaI ev Volmerstraße 3, 12489, Berlin, Germany ABSTRACT Beamforming algorithms make high demands on the
BeBeC-2014-08 REDUCING BEAMFORMING CALCULATION TIME WITH GPU ACCELERATED ALGORITHMS Steffen Schmidt GFaI ev Volmerstraße 3, 12489, Berlin, Germany ABSTRACT Beamforming algorithms make high demands on the
Windowing System on a 3D Pipeline. February 2005
 Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
Windowing System on a 3D Pipeline February 2005 Agenda 1.Overview of the 3D pipeline 2.NVIDIA software overview 3.Strengths and challenges with using the 3D pipeline GeForce 6800 220M Transistors April
Implemen'ng IPv6 Segment Rou'ng in the Linux Kernel
 Implemen'ng IPv6 Segment Rou'ng in the Linux Kernel David Lebrun, Olivier Bonaventure ICTEAM, UCLouvain Work supported by ARC grant 12/18-054 (ARC-SDN) and a Cisco grant Agenda IPv6 Segment Rou'ng Implementa'on
Implemen'ng IPv6 Segment Rou'ng in the Linux Kernel David Lebrun, Olivier Bonaventure ICTEAM, UCLouvain Work supported by ARC grant 12/18-054 (ARC-SDN) and a Cisco grant Agenda IPv6 Segment Rou'ng Implementa'on
A Bandwidth Effective Rendering Scheme for 3D Texture-based Volume Visualization on GPU
 for 3D Texture-based Volume Visualization on GPU Won-Jong Lee, Tack-Don Han Media System Laboratory (http://msl.yonsei.ac.k) Dept. of Computer Science, Yonsei University, Seoul, Korea Contents Background
for 3D Texture-based Volume Visualization on GPU Won-Jong Lee, Tack-Don Han Media System Laboratory (http://msl.yonsei.ac.k) Dept. of Computer Science, Yonsei University, Seoul, Korea Contents Background
CSE 599 I Accelerated Computing - Programming GPUS. Memory performance
 CSE 599 I Accelerated Computing - Programming GPUS Memory performance GPU Teaching Kit Accelerated Computing Module 6.1 Memory Access Performance DRAM Bandwidth Objective To learn that memory bandwidth
CSE 599 I Accelerated Computing - Programming GPUS Memory performance GPU Teaching Kit Accelerated Computing Module 6.1 Memory Access Performance DRAM Bandwidth Objective To learn that memory bandwidth
Optimization solutions for the segmented sum algorithmic function
 Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Current Trends in Computer Graphics Hardware
 Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
Current Trends in Computer Graphics Hardware Dirk Reiners University of Louisiana Lafayette, LA Quick Introduction Assistant Professor in Computer Science at University of Louisiana, Lafayette (since 2006)
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
Performance Evaluation of a MongoDB and Hadoop Platform for Scientific Data Analysis
 Performance Evaluation of a MongoDB and Hadoop Platform for Scientific Data Analysis Elif Dede, Madhusudhan Govindaraju Lavanya Ramakrishnan, Dan Gunter, Shane Canon Department of Computer Science, Binghamton
Performance Evaluation of a MongoDB and Hadoop Platform for Scientific Data Analysis Elif Dede, Madhusudhan Govindaraju Lavanya Ramakrishnan, Dan Gunter, Shane Canon Department of Computer Science, Binghamton
E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices
 E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph
E6895 Advanced Big Data Analytics Lecture 8: GPU Examples and GPU on ios devices Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science IBM Chief Scientist, Graph
Overview. Videos are everywhere. But can take up large amounts of resources. Exploit redundancy to reduce file size
 Overview Videos are everywhere But can take up large amounts of resources Disk space Memory Network bandwidth Exploit redundancy to reduce file size Spatial Temporal General lossless compression Huffman
Overview Videos are everywhere But can take up large amounts of resources Disk space Memory Network bandwidth Exploit redundancy to reduce file size Spatial Temporal General lossless compression Huffman
CMPE 665:Multiple Processor Systems CUDA-AWARE MPI VIGNESH GOVINDARAJULU KOTHANDAPANI RANJITH MURUGESAN
 CMPE 665:Multiple Processor Systems CUDA-AWARE MPI VIGNESH GOVINDARAJULU KOTHANDAPANI RANJITH MURUGESAN Graphics Processing Unit Accelerate the creation of images in a frame buffer intended for the output
CMPE 665:Multiple Processor Systems CUDA-AWARE MPI VIGNESH GOVINDARAJULU KOTHANDAPANI RANJITH MURUGESAN Graphics Processing Unit Accelerate the creation of images in a frame buffer intended for the output
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Physis: An Implicitly Parallel Framework for Stencil Computa;ons
 Physis: An Implicitly Parallel Framework for Stencil Computa;ons Naoya Maruyama RIKEN AICS (Formerly at Tokyo Tech) GTC12, May 2012 1 è Good performance with low programmer produc;vity Mul;- GPU Applica;on
Physis: An Implicitly Parallel Framework for Stencil Computa;ons Naoya Maruyama RIKEN AICS (Formerly at Tokyo Tech) GTC12, May 2012 1 è Good performance with low programmer produc;vity Mul;- GPU Applica;on
Viral Loops for Mobile Clouds. Frank Fitzek Aalborg University
 Viral Loops for Mobile Clouds Frank Fitzek Aalborg University Stephan Hawking, A Brief History of Time (1988) SOMEONE TOLD ME THAT EACH EQUATION I INCLUDED IN THE BOOK WOULD HALVE THE SALES. I THEREFORE
Viral Loops for Mobile Clouds Frank Fitzek Aalborg University Stephan Hawking, A Brief History of Time (1988) SOMEONE TOLD ME THAT EACH EQUATION I INCLUDED IN THE BOOK WOULD HALVE THE SALES. I THEREFORE
Graphics Architectures and OpenCL. Michael Doggett Department of Computer Science Lund university
 Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview Parallelism Radeon 5870 Tiled Graphics Architectures Important when Memory and Bandwidth limited
Graphics Architectures and OpenCL Michael Doggett Department of Computer Science Lund university Overview Parallelism Radeon 5870 Tiled Graphics Architectures Important when Memory and Bandwidth limited
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Profiling & Tuning Applica1ons. CUDA Course July István Reguly
 Profiling & Tuning Applica1ons CUDA Course July 21-25 István Reguly Introduc1on Why is my applica1on running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA,
Profiling & Tuning Applica1ons CUDA Course July 21-25 István Reguly Introduc1on Why is my applica1on running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA,
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Real - Time Rendering. Graphics pipeline. Michal Červeňanský Juraj Starinský
 Real - Time Rendering Graphics pipeline Michal Červeňanský Juraj Starinský Overview History of Graphics HW Rendering pipeline Shaders Debugging 2 History of Graphics HW First generation Second generation
Real - Time Rendering Graphics pipeline Michal Červeňanský Juraj Starinský Overview History of Graphics HW Rendering pipeline Shaders Debugging 2 History of Graphics HW First generation Second generation
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Computer Graphics. 2D Transforma5ons. Review Vertex Transforma5ons 2/3/15. adjust the zoom. posi+on the camera. posi+on the model
 /3/5 Computer Graphics D Transforma5ons Review Verte Transforma5ons posi+on the model posi+on the camera adjust the zoom verte shader input verte shader output, transformed /3/5 From Object to World Space
/3/5 Computer Graphics D Transforma5ons Review Verte Transforma5ons posi+on the model posi+on the camera adjust the zoom verte shader input verte shader output, transformed /3/5 From Object to World Space
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Shaders. Slide credit to Prof. Zwicker
 Shaders Slide credit to Prof. Zwicker 2 Today Shader programming 3 Complete model Blinn model with several light sources i diffuse specular ambient How is this implemented on the graphics processor (GPU)?
Shaders Slide credit to Prof. Zwicker 2 Today Shader programming 3 Complete model Blinn model with several light sources i diffuse specular ambient How is this implemented on the graphics processor (GPU)?
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS
 GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
GPGPU, 1st Meeting Mordechai Butrashvily, CEO GASS Agenda Forming a GPGPU WG 1 st meeting Future meetings Activities Forming a GPGPU WG To raise needs and enhance information sharing A platform for knowledge
Next Generation OpenGL Neil Trevett Khronos President NVIDIA VP Mobile Copyright Khronos Group Page 1
 Next Generation OpenGL Neil Trevett Khronos President NVIDIA VP Mobile Ecosystem @neilt3d Copyright Khronos Group 2015 - Page 1 Copyright Khronos Group 2015 - Page 2 Khronos Connects Software to Silicon
Next Generation OpenGL Neil Trevett Khronos President NVIDIA VP Mobile Ecosystem @neilt3d Copyright Khronos Group 2015 - Page 1 Copyright Khronos Group 2015 - Page 2 Khronos Connects Software to Silicon
Turing Architecture and CUDA 10 New Features. Minseok Lee, Developer Technology Engineer, NVIDIA
 Turing Architecture and CUDA 10 New Features Minseok Lee, Developer Technology Engineer, NVIDIA Turing Architecture New SM Architecture Multi-Precision Tensor Core RT Core Turing MPS Inference Accelerated,
Turing Architecture and CUDA 10 New Features Minseok Lee, Developer Technology Engineer, NVIDIA Turing Architecture New SM Architecture Multi-Precision Tensor Core RT Core Turing MPS Inference Accelerated,
Comparison of CPU and GPGPU performance as applied to procedurally generating complex cave systems
 Comparison of CPU and GPGPU performance as applied to procedurally generating complex cave systems Subject: Comp6470 - Special Topics in Computing Student: Tony Oakden (U4750194) Supervisor: Dr Eric McCreath
Comparison of CPU and GPGPU performance as applied to procedurally generating complex cave systems Subject: Comp6470 - Special Topics in Computing Student: Tony Oakden (U4750194) Supervisor: Dr Eric McCreath
CS 220: Introduction to Parallel Computing. Introduction to CUDA. Lecture 28
 CS 220: Introduction to Parallel Computing Introduction to CUDA Lecture 28 Today s Schedule Project 4 Read-Write Locks Introduction to CUDA 5/2/18 CS 220: Parallel Computing 2 Today s Schedule Project
CS 220: Introduction to Parallel Computing Introduction to CUDA Lecture 28 Today s Schedule Project 4 Read-Write Locks Introduction to CUDA 5/2/18 CS 220: Parallel Computing 2 Today s Schedule Project
Performance improvements to peer-to-peer file transfers using network coding
 Performance improvements to peer-to-peer file transfers using network coding Aaron Kelley April 29, 2009 Mentor: Dr. David Sturgill Outline Introduction Network Coding Background Contributions Precomputation
Performance improvements to peer-to-peer file transfers using network coding Aaron Kelley April 29, 2009 Mentor: Dr. David Sturgill Outline Introduction Network Coding Background Contributions Precomputation
Optimizing Data Locality for Iterative Matrix Solvers on CUDA
 Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Optimizing Data Locality for Iterative Matrix Solvers on CUDA Raymond Flagg, Jason Monk, Yifeng Zhu PhD., Bruce Segee PhD. Department of Electrical and Computer Engineering, University of Maine, Orono,
Leveraging Hybrid Hardware in New Ways: The GPU Paging Cache
 Leveraging Hybrid Hardware in New Ways: The GPU Paging Cache Frank Feinbube, Peter Tröger, Johannes Henning, Andreas Polze Hasso Plattner Institute Operating Systems and Middleware Prof. Dr. Andreas Polze
Leveraging Hybrid Hardware in New Ways: The GPU Paging Cache Frank Feinbube, Peter Tröger, Johannes Henning, Andreas Polze Hasso Plattner Institute Operating Systems and Middleware Prof. Dr. Andreas Polze
GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS
 CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
Dave Shreiner, ARM March 2009
 4 th Annual Dave Shreiner, ARM March 2009 Copyright Khronos Group, 2009 - Page 1 Motivation - What s OpenGL ES, and what can it do for me? Overview - Lingo decoder - Overview of the OpenGL ES Pipeline
4 th Annual Dave Shreiner, ARM March 2009 Copyright Khronos Group, 2009 - Page 1 Motivation - What s OpenGL ES, and what can it do for me? Overview - Lingo decoder - Overview of the OpenGL ES Pipeline
Real-Time Ray Tracing Using Nvidia Optix Holger Ludvigsen & Anne C. Elster 2010
 1 Real-Time Ray Tracing Using Nvidia Optix Holger Ludvigsen & Anne C. Elster 2010 Presentation by Henrik H. Knutsen for TDT24, fall 2012 Om du ønsker, kan du sette inn navn, tittel på foredraget, o.l.
1 Real-Time Ray Tracing Using Nvidia Optix Holger Ludvigsen & Anne C. Elster 2010 Presentation by Henrik H. Knutsen for TDT24, fall 2012 Om du ønsker, kan du sette inn navn, tittel på foredraget, o.l.
Pushing the Envelope: Extreme Network Coding on the GPU
 Pushing the Envelope: Extreme Network Coding on the GPU Abstract While it is well known that network coding achieves optimal flow rates in multicast sessions, its potential for practical use has remained
Pushing the Envelope: Extreme Network Coding on the GPU Abstract While it is well known that network coding achieves optimal flow rates in multicast sessions, its potential for practical use has remained
Using Dynamic Voltage Frequency Scaling and CPU Pinning for Energy Efficiency in Cloud Compu1ng. Jakub Krzywda Umeå University
 Using Dynamic Voltage Frequency Scaling and CPU Pinning for Energy Efficiency in Cloud Compu1ng Jakub Krzywda Umeå University How to use DVFS and CPU Pinning to lower the power consump1on during periods
Using Dynamic Voltage Frequency Scaling and CPU Pinning for Energy Efficiency in Cloud Compu1ng Jakub Krzywda Umeå University How to use DVFS and CPU Pinning to lower the power consump1on during periods
GPGPU introduction and network applications. PacketShaders, SSLShader
 GPGPU introduction and network applications PacketShaders, SSLShader Agenda GPGPU Introduction Computer graphics background GPGPUs past, present and future PacketShader A GPU-Accelerated Software Router
GPGPU introduction and network applications PacketShaders, SSLShader Agenda GPGPU Introduction Computer graphics background GPGPUs past, present and future PacketShader A GPU-Accelerated Software Router
For example, could you make the XNA func8ons yourself?
 1 For example, could you make the XNA func8ons yourself? For the second assignment you need to know about the en8re process of using the graphics hardware. You will use shaders which play a vital role
1 For example, could you make the XNA func8ons yourself? For the second assignment you need to know about the en8re process of using the graphics hardware. You will use shaders which play a vital role
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
1. Introduction 2. Methods for I/O Operations 3. Buses 4. Liquid Crystal Displays 5. Other Types of Displays 6. Graphics Adapters 7.
 1. Introduction 2. Methods for I/O Operations 3. Buses 4. Liquid Crystal Displays 5. Other Types of Displays 6. Graphics Adapters 7. Optical Discs 1 Structure of a Graphics Adapter Video Memory Graphics
1. Introduction 2. Methods for I/O Operations 3. Buses 4. Liquid Crystal Displays 5. Other Types of Displays 6. Graphics Adapters 7. Optical Discs 1 Structure of a Graphics Adapter Video Memory Graphics
Motivation Hardware Overview Programming model. GPU computing. Part 1: General introduction. Ch. Hoelbling. Wuppertal University
 Part 1: General introduction Ch. Hoelbling Wuppertal University Lattice Practices 2011 Outline 1 Motivation 2 Hardware Overview History Present Capabilities 3 Programming model Past: OpenGL Present: CUDA
Part 1: General introduction Ch. Hoelbling Wuppertal University Lattice Practices 2011 Outline 1 Motivation 2 Hardware Overview History Present Capabilities 3 Programming model Past: OpenGL Present: CUDA
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Adding Advanced Shader Features and Handling Fragmentation
 Copyright Khronos Group, 2010 - Page 1 Adding Advanced Shader Features and Handling Fragmentation How to enable your application on a wide range of devices Imagination Technologies Copyright Khronos Group,
Copyright Khronos Group, 2010 - Page 1 Adding Advanced Shader Features and Handling Fragmentation How to enable your application on a wide range of devices Imagination Technologies Copyright Khronos Group,
Bifurcation Between CPU and GPU CPUs General purpose, serial GPUs Special purpose, parallel CPUs are becoming more parallel Dual and quad cores, roadm
 XMT-GPU A PRAM Architecture for Graphics Computation Tom DuBois, Bryant Lee, Yi Wang, Marc Olano and Uzi Vishkin Bifurcation Between CPU and GPU CPUs General purpose, serial GPUs Special purpose, parallel
XMT-GPU A PRAM Architecture for Graphics Computation Tom DuBois, Bryant Lee, Yi Wang, Marc Olano and Uzi Vishkin Bifurcation Between CPU and GPU CPUs General purpose, serial GPUs Special purpose, parallel
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Lecture 1 Introduc-on
 Lecture 1 Introduc-on What would you get out of this course? Structure of a Compiler Op9miza9on Example 15-745: Introduc9on 1 What Do Compilers Do? 1. Translate one language into another e.g., convert
Lecture 1 Introduc-on What would you get out of this course? Structure of a Compiler Op9miza9on Example 15-745: Introduc9on 1 What Do Compilers Do? 1. Translate one language into another e.g., convert
Hardware Accelerated Volume Visualization. Leonid I. Dimitrov & Milos Sramek GMI Austrian Academy of Sciences
 Hardware Accelerated Volume Visualization Leonid I. Dimitrov & Milos Sramek GMI Austrian Academy of Sciences A Real-Time VR System Real-Time: 25-30 frames per second 4D visualization: real time input of
Hardware Accelerated Volume Visualization Leonid I. Dimitrov & Milos Sramek GMI Austrian Academy of Sciences A Real-Time VR System Real-Time: 25-30 frames per second 4D visualization: real time input of
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Graphics Processing Unit (GPU) Acceleration of Machine Vision Software for Space Flight Applications
 Acceleration of Machine Vision Software for Space Flight Applications") Graphics Processing Unit (GPU) Acceleration of Machine Vision Software for Space Flight Applications Workshop on Space Flight Software November 6, 2009 Brent Tweddle Massachusetts Institute of Technology
Graphics Processing Unit (GPU) Acceleration of Machine Vision Software for Space Flight Applications Workshop on Space Flight Software November 6, 2009 Brent Tweddle Massachusetts Institute of Technology
GPGPU/CUDA/C Workshop 2012
 GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
Virtualization. Introduction. Why we interested? 11/28/15. Virtualiza5on provide an abstract environment to run applica5ons.
 Virtualization Yifu Rong Introduction Virtualiza5on provide an abstract environment to run applica5ons. Virtualiza5on technologies have a long trail in the history of computer science. Why we interested?
Virtualization Yifu Rong Introduction Virtualiza5on provide an abstract environment to run applica5ons. Virtualiza5on technologies have a long trail in the history of computer science. Why we interested?
Vision: Towards an Extensible App Ecosystem for Home Automa;on through Cloud- Offload
 Vision: Towards an Extensible App Ecosystem for Home Automa;on through Cloud- Offload Yuichi Igarashi Hitachi Ltd., Yokohama Research Laboratory Kaustubh Joshi MaL Hiltunen Richard Schlich;ng AT&T Shannon
Vision: Towards an Extensible App Ecosystem for Home Automa;on through Cloud- Offload Yuichi Igarashi Hitachi Ltd., Yokohama Research Laboratory Kaustubh Joshi MaL Hiltunen Richard Schlich;ng AT&T Shannon
AES Cryptosystem Acceleration Using Graphics Processing Units. Ethan Willoner Supervisors: Dr. Ramon Lawrence, Scott Fazackerley
 AES Cryptosystem Acceleration Using Graphics Processing Units Ethan Willoner Supervisors: Dr. Ramon Lawrence, Scott Fazackerley Overview Introduction Compute Unified Device Architecture (CUDA) Advanced
AES Cryptosystem Acceleration Using Graphics Processing Units Ethan Willoner Supervisors: Dr. Ramon Lawrence, Scott Fazackerley Overview Introduction Compute Unified Device Architecture (CUDA) Advanced
POWERVR MBX & SGX OpenVG Support and Resources
 POWERVR MBX & SGX OpenVG Support and Resources Kristof Beets 3 rd Party Relations Manager - Imagination Technologies kristof.beets@imgtec.com Copyright Khronos Group, 2006 - Page 1 Copyright Khronos Group,
POWERVR MBX & SGX OpenVG Support and Resources Kristof Beets 3 rd Party Relations Manager - Imagination Technologies kristof.beets@imgtec.com Copyright Khronos Group, 2006 - Page 1 Copyright Khronos Group,
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER PROF. BRYANT PROF. KAYVON 15618: PARALLEL COMPUTER ARCHITECTURE
 HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
HYPERDRIVE IMPLEMENTATION AND ANALYSIS OF A PARALLEL, CONJUGATE GRADIENT LINEAR SOLVER AVISHA DHISLE PRERIT RODNEY ADHISLE PRODNEY 15618: PARALLEL COMPUTER ARCHITECTURE PROF. BRYANT PROF. KAYVON LET S
High Quality DXT Compression using OpenCL for CUDA. Ignacio Castaño
 High Quality DXT Compression using OpenCL for CUDA Ignacio Castaño icastano@nvidia.com March 2009 Document Change History Version Date Responsible Reason for Change 0.1 02/01/2007 Ignacio Castaño First
High Quality DXT Compression using OpenCL for CUDA Ignacio Castaño icastano@nvidia.com March 2009 Document Change History Version Date Responsible Reason for Change 0.1 02/01/2007 Ignacio Castaño First