Soft GPGPUs for Embedded FPGAS: An Architectural Evaluation
|
|
|
- Milton Bradley
- 6 years ago
- Views:
Transcription
 2016 Kevin Andryc, Tedy Thomas and Russell Tessier University of")
1 Soft GPGPUs for Embedded FPGAS: An Architectural Evaluation 2nd International Workshop on Overlay Architectures for FPGAs (OLAF) 2016 Kevin Andryc, Tedy Thomas and Russell Tessier University of Massachusetts
2 Outline Mo+va+on Background FlexGrip: So6 GPGPU Op:miza:ons Experimental Results Summary 2


3 Mo+va+on Compiling FPGA designs is :me consuming Requires resynthesizing design for each change Synthesize to create netlist Implement Not every system has a GPGPU available GPGPUs not prac:cal for systems that require minimal power and heat Inflexible compared to FPGAs Translate Map Place & Route Create BIT File 3
4 FlexGrip SoA GPGPU FlexGrip: FLEXible GRaphIcs Processor Fully CUDA binary-compa:ble integer so6 GPGPU Run mul:ple applica:ons without the need to recompile the hardware Support for highly mul:threaded applica:ons and complex condi:onal execu:on Architectural Customiza:ons Trade power versus performance Add processing, memory, and custom resources Choose between bitstreams, each with different architectural features Reconfigure (perhaps on-the-fly) for specific applica:ons 4
5 Outline Mo:va:on Background FlexGrip: So6 GPGPU Op:miza:ons Experimental Results Summary 5
 SFU Special func:on unit (Used for transcendental func:ons like sine, cosine, log")
6 Introduc+on to the GPGPU Hardware Array of streaming mul-processors (SMs) Architecture Each SM consists of a set of 32-bit scalar processors (SPs) Single Instruc:on Mul:ple Data (SIMD) execu:on Mul:processor executes same instruc:ons on different scalar processors at each clock cycle SP Scalar Processor (core) SFU Special func:on unit (Used for transcendental func:ons like sine, cosine, log etc.) Image courtesy: S. Collange, M. Daumas, D. Defour, and D. Parello, Barra: A Parallel Func:onal Simulator for GPGPU, IEEE Interna-onal Symposium on Modeling, Analysis & Simula-on of Computer and Telecommunica-on Systems (MASCOTS), Aug
")
7 SoAware to Hardware Mapping Compute Unified Device Architecture Block scheduler: Assigns thread blocks to mul:processors Thread Block: collec:on of opera:ons which can be performed in parallel Threads are scheduled in the form of warps Warp: Subset of opera:ons performed in parallel; some:mes condi:onally Fine grained scheduling: SM architected as single instruc:on, mul:ple thread (SIMT) processor Each scalar processor (SP) executes one thread maintaining its own PC Performs same opera:on on different set of data; some:mes condi:onally 7 Image courtesy: S. Collange, M. Daumas, D. Defour, and D. Parello, Barra: A Parallel Func:onal Simulator for GPGPU, IEEE Interna-onal Symposium on Modeling, Analysis & Simula-on of Computer and Telecommunica-on Systems (MASCOTS), Aug 2010
8 Outline Mo:va:on Background FlexGrip: SoA GPGPU Op:miza:ons Experimental Results Summary 8
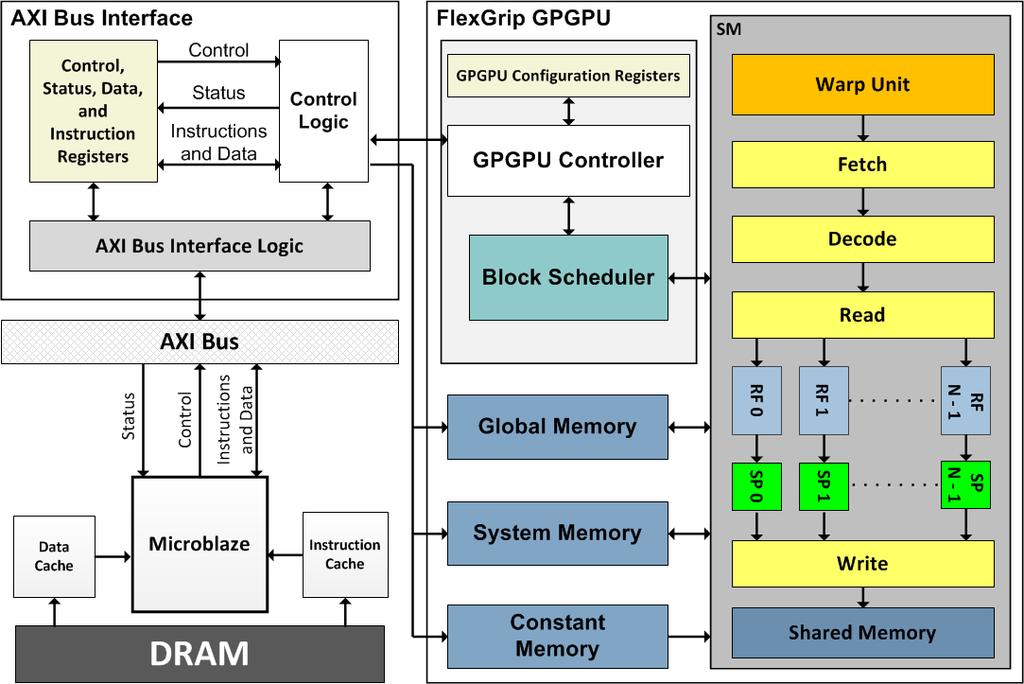
9 System Architecture 9

10 FlexGrip Streaming Mul+processor 10
11 Branch Divergence Branch divergence occurs when threads inside a warp branch to different execu:on paths Example: Instruc:ons inside ELSE statement are masked (i.e.: not executed) Once IF statement complete, use the complement of mask to execute ELSE statement Branch Path A Path B Thread 11
12 Outline Mo:va:on Background FlexGrip: So6 GPGPU Op+miza+ons Experimental Results Summary 12
13 Condi+onal Branch Op+miza+ons Each of the 24 warps within an SM contains it s own Warp Stack Each warp stack has entry for each thread (32) Each entry: 32-bit ac:ve thread mask, 2-bit type, 32- bit address Instruction Condition Thread Mask Instruction Mask Selected Predicate Reg Predicate Lookup Table 4x32 Predicate Registers P0 P1 P2 P3 Instruction ID Warp Identifier Thread 31 0 Control Flow Unit Active Thread Mask FSM Warp Stack Control Target Address RPC RPC Mask[1:N] Type Token Addr RPC RPC RPC Mask[1:N] Type Token Addr RPC RPC RPC Mask[1:N] Token RPC Type Addr RPC RPC Mask[1:N] Type Token Addr RPC Prior to execu:ng taken path -- instruc:on address and ac:ve thread mask are pushed on the stack Upon comple:on of the taken path -- stack is read, the ac:ve mask inverted, and processing con:nues Worst case: Require nes:ng for all 32 threads (~50KB of memory!) Op:miza:on: Profile applica:ons for op:mal depth 13 To write back Next PC
14 Source Operand Op+miza+ons Read Controller SRC 3 Addr SRC 2 Addr Read Operand Controller Calculate Address Read Source 3 Operand Control 3 Addr 3 Memory (Global, Shared, Constant) Execute Stage Data From Decode Stage SRC 1 Addr Read Operand Controller Calculate Address Read Source 2 Operand Control 2 Addr 2 Memory and Register Controller Op 3 Op 2 Op 1 Multiplier Read Stage Read Operand Controller Calculate Address Read Source 1 Operand Control 1 Addr 1 Registers (Vector, Predicate, Address) + Data to write stage 14

15 Mul+ple Streaming Mul+processors Maximum of 256 threads in a thread block At the start of execu:on, the max number of thread blocks that can be scheduled is calculated HOST: CUDA Software DEVICE: FlexGrip Hardware Grid Thread Block 0 Thread Block 1 Streaming Multiprocessor 0 Warp Scheduling Unit Kernel Block Scheduler Thread Block N-1 Streaming Multiprocessor N - 1 Warp Scheduling Unit Vector Register File SP SP SP SP..... Vector Register File SP SP SP SP SP SP SP SP SP SP SP SP SIMD Execution Shared Memory SIMD Execution Shared Memory Memory Interconnect Threads scheduled in a roundrobin fashion Global / System / Constant Memory 15
16 Outline Mo:va:on Background FlexGrip: So6 GPGPU Op:miza:ons Experimental Results Summary 16
17 Design Environment and Benchmarks Design Environment Synthesis and Design: Xilinx ISE 14.2 Simula:on: Modelsim SE 10.1 Total of Five CUDA Applica:ons Evaluated Benchmarks from University of Wisconsin 1 and NVIDIA Programmers Guide 2 Mix of data parallel and control-flow intensive Benchmark Autocorr Bitonic MatrixMul Reduc:on Transpose Descrip+on Autocorrela:on of 1D array High performance sor:ng network Mul:plica:on of square matrices Parallel reduc:on of 1D array Matrix transpose Autocorr Bitonic MatMult Reduction Transpose 100% 80% 60% 40% 20% 0% 1 D. Chang, C. Jenkins, P. Garcia, S. Gilani, P. Aguilera, A. Nagarajan,M. Anderson, M. Kenny, S. Bauer, M. Schulte, and K. Compton, ERCBench: An open-source benchmark suite for embedded and reconfigurable compu:ng, in Interna:onal Conference on Field Programmable Logic and Applica:ons, Aug. 2010, pp Nvidia CUDA programming guide, version
18 Benchmarking vs. MicroBlaze MicroBlaze so6 processor Implemented on Xilinx ML605 development board (Virtex-6 VLX240T FPGA) So6ware :mer used for execu:on :me FlexGrip: So6 GPGPU Implemented on ML605 for 1 SM and 8 SPs ModelSim 10.1 for benchmarking 1 SM with 16 and 32 SPs and 2 SM 8, 16, and 32 SP designs All five benchmarks ran successfully with same bitstream Compile :mes < 1 second All designs were evaluated at 100 MHz 18

19 Architecture Scalability 1 SM Varying SPs in Single SM Average speedups: 8 cores 12x 16 cores 18x 32 cores 22x Largest Speedups: Reduc+on: Array size mul:ple of 32, fully u:lizing warps MatrixMult: High arithme:c density Bitonic: Divergence cost amor:zed by more swapping in parallel Memory bandwidth limita:on Speedup vs. MicroBlaze for variable scalar processors and input data size 256 for 1 SM 19
 8 SP 16 SP 32 SP Autocorr 1.94 1.94 1.94 Bitonic 1.82 1.83 1.85 MatrixMul 1.98 1.")
20 Architecture Scalability 2 SM Varying SPs in 2 SM Design Peak Speedup over 40x for 4 of 5 benchmarks 1 SM vs. 2 SM Speedup ranged from 1.77x (Reduc:on) to 1.98x (Transpose, MatrixMul) Speedup vs. MicroBlaze for variable scalar processors and input data size 256 for 2 SM Speedup of 2 SM vs. 1 SM (256 data size) 8 SP 16 SP 32 SP Autocorr Bitonic MatrixMul Reduc:on Transpose

21 Es:mated using Xilinx s XPower Tool Dynamic power used to generate efficiency Sta:c power largely func:on of device size Energy = Power x Execu:on Time Energy Efficiency MicroBlaze requires an average of 80% more energy than FlexGrip for 1 SM, 8 SP configura:on 21
22 Architectural Customiza+ons Num. Of Oper. Warp Depth Slice LUTs Flip Flops Block RAM DSP % Area Red. % Dyn. Red. Baseline , , Autocorr ,121 82, % 3% Mat. Mult ,536 60, % 9% Reduc:on ,536 60, % 9% Transpose ,536 60, % 9% Bitonic ,189 57, % 15% Bitonic ,136 27, % 38% Removing mul:plier/third operand and reduced warp depth achieves 23% energy reduc:on for any benchmark Depending on applica:on space, one could vary parameters to op:mize system 22
23 Outline Mo:va:on Background FlexGrip: So6 GPGPU Op:miza:ons Experimental Results Summary 23
24 Summary Implemented a fully-func:onal so6 GPGPU for FPGAs Executes CUDA code on FPGA very quickly; no need to resynthesize Can be used in systems that do not have GPGPUs Scalable and flexible design Control the number of processing cores and mul:processors Customize hardware to op:mize system Swap so6 GPGPU into FPGA as needed Significant benefits vs. MicroBlaze Up to 55x for highly parallel benchmarks with 2 SM design On average 80% dynamic energy reduc:on versus MicroBlaze Addi:onal benefits architectural op:miza:ons Addi:onal dynamic energy savings of up to 14% Reduced LUT area by 33% on average 24

25 Thank you! Acknowledgements: My parents, family and friends My advisor, Prof. Russell Tessier L-3 KEO Xilinx 25
FlexGrip: A Soft GPGPU for FPGAs
 FlexGrip: A Soft GPGPU for FPGAs Kevin Andryc, Murtaza Merchant, and Russell Tessier Department of Electrical and Computer Engineering University of Massachusetts, Amherst, MA, USA Abstract Over the past
FlexGrip: A Soft GPGPU for FPGAs Kevin Andryc, Murtaza Merchant, and Russell Tessier Department of Electrical and Computer Engineering University of Massachusetts, Amherst, MA, USA Abstract Over the past
ERCBench An Open-Source Benchmark Suite for Embedded and Reconfigurable Computing
 ERCBench An Open-Source Benchmark Suite for Embedded and Reconfigurable Computing Daniel Chang Chris Jenkins, Philip Garcia, Syed Gilani, Paula Aguilera, Aishwarya Nagarajan, Michael Anderson, Matthew
ERCBench An Open-Source Benchmark Suite for Embedded and Reconfigurable Computing Daniel Chang Chris Jenkins, Philip Garcia, Syed Gilani, Paula Aguilera, Aishwarya Nagarajan, Michael Anderson, Matthew
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
First: Shameless Adver2sing
 Agenda A Shameless self promo2on Introduc2on to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy The Cuda Memory Hierarchy Mapping Cuda to Nvidia GPUs As much of the OpenCL informa2on as I can
Agenda A Shameless self promo2on Introduc2on to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy The Cuda Memory Hierarchy Mapping Cuda to Nvidia GPUs As much of the OpenCL informa2on as I can
FPGAs as Streaming MIMD Machines for Data Analy9cs. James Thomas, Matei Zaharia, Pat Hanrahan
 FPGAs as Streaming MIMD Machines for Data Analy9cs James Thomas, Matei Zaharia, Pat Hanrahan CPU/GPU Control Flow Divergence For peak performance, CPUs and GPUs require groups of threads to have iden9cal
FPGAs as Streaming MIMD Machines for Data Analy9cs James Thomas, Matei Zaharia, Pat Hanrahan CPU/GPU Control Flow Divergence For peak performance, CPUs and GPUs require groups of threads to have iden9cal
Profiling & Tuning Applica1ons. CUDA Course July István Reguly
 Profiling & Tuning Applica1ons CUDA Course July 21-25 István Reguly Introduc1on Why is my applica1on running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA,
Profiling & Tuning Applica1ons CUDA Course July 21-25 István Reguly Introduc1on Why is my applica1on running slow? Work it out on paper Instrument code Profile it NVIDIA Visual Profiler Works with CUDA,
Testing and Validation of a Prototype Gpgpu Design for FPGAs
 University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 Dissertations and Theses 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 Dissertations and Theses 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant
Lecture 1 Introduc-on
 Lecture 1 Introduc-on What would you get out of this course? Structure of a Compiler Op9miza9on Example 15-745: Introduc9on 1 What Do Compilers Do? 1. Translate one language into another e.g., convert
Lecture 1 Introduc-on What would you get out of this course? Structure of a Compiler Op9miza9on Example 15-745: Introduc9on 1 What Do Compilers Do? 1. Translate one language into another e.g., convert
CDA 4253 FPGA System Design Op7miza7on Techniques. Hao Zheng Comp S ci & Eng Univ of South Florida
 CDA 4253 FPGA System Design Op7miza7on Techniques Hao Zheng Comp S ci & Eng Univ of South Florida 1 Extracted from Advanced FPGA Design by Steve Kilts 2 Op7miza7on for Performance 3 Performance Defini7ons
CDA 4253 FPGA System Design Op7miza7on Techniques Hao Zheng Comp S ci & Eng Univ of South Florida 1 Extracted from Advanced FPGA Design by Steve Kilts 2 Op7miza7on for Performance 3 Performance Defini7ons
BLAS. Basic Linear Algebra Subprograms
 BLAS Basic opera+ons with vectors and matrices dominates scien+fic compu+ng programs To achieve high efficiency and clean computer programs an effort has been made in the last few decades to standardize
BLAS Basic opera+ons with vectors and matrices dominates scien+fic compu+ng programs To achieve high efficiency and clean computer programs an effort has been made in the last few decades to standardize
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto
 FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
: Advanced Compiler Design. 8.0 Instruc?on scheduling
 6-80: Advanced Compiler Design 8.0 Instruc?on scheduling Thomas R. Gross Computer Science Department ETH Zurich, Switzerland Overview 8. Instruc?on scheduling basics 8. Scheduling for ILP processors 8.
6-80: Advanced Compiler Design 8.0 Instruc?on scheduling Thomas R. Gross Computer Science Department ETH Zurich, Switzerland Overview 8. Instruc?on scheduling basics 8. Scheduling for ILP processors 8.
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto
 FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
FCUDA: Enabling Efficient Compilation of CUDA Kernels onto FPGAs October 13, 2009 Overview Presenting: Alex Papakonstantinou, Karthik Gururaj, John Stratton, Jason Cong, Deming Chen, Wen-mei Hwu. FCUDA:
Implementation and Experimental Evaluation of a CUDA Core under Single Event Effects. Werner Nedel, Fernanda Kastensmidt, José.
 Implementation and Experimental Evaluation of a CUDA Core under Single Event Effects Werner Nedel, Fernanda Kastensmidt, José Universidade Federal do Rio Grande do Sul (UFRGS) Rodrigo Azambuja Instituto
Implementation and Experimental Evaluation of a CUDA Core under Single Event Effects Werner Nedel, Fernanda Kastensmidt, José Universidade Federal do Rio Grande do Sul (UFRGS) Rodrigo Azambuja Instituto
Register Alloca.on Deconstructed. David Ryan Koes Seth Copen Goldstein
 Register Alloca.on Deconstructed David Ryan Koes Seth Copen Goldstein 12th Interna+onal Workshop on So3ware and Compilers for Embedded Systems April 24, 12009 Register Alloca:on Problem unbounded number
Register Alloca.on Deconstructed David Ryan Koes Seth Copen Goldstein 12th Interna+onal Workshop on So3ware and Compilers for Embedded Systems April 24, 12009 Register Alloca:on Problem unbounded number
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Handout 3. HSAIL and A SIMT GPU Simulator
 Handout 3 HSAIL and A SIMT GPU Simulator 1 Outline Heterogeneous System Introduction of HSA Intermediate Language (HSAIL) A SIMT GPU Simulator Summary 2 Heterogeneous System CPU & GPU CPU GPU CPU wants
Handout 3 HSAIL and A SIMT GPU Simulator 1 Outline Heterogeneous System Introduction of HSA Intermediate Language (HSAIL) A SIMT GPU Simulator Summary 2 Heterogeneous System CPU & GPU CPU GPU CPU wants
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 32: Pipeline Parallelism 3
 Lecture 32: Pipeline Parallelism 3") CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 32: Pipeline Parallelism 3 Instructor: Dan Garcia inst.eecs.berkeley.edu/~cs61c! Compu@ng in the News At a laboratory in São Paulo,
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 32: Pipeline Parallelism 3 Instructor: Dan Garcia inst.eecs.berkeley.edu/~cs61c! Compu@ng in the News At a laboratory in São Paulo,
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
PhD in Computer And Control Engineering XXVII cycle. Torino February 27th, 2015.
 PhD in Computer And Control Engineering XXVII cycle Torino February 27th, 2015. Parallel and reconfigurable systems are more and more used in a wide number of applica7ons and environments, ranging from
PhD in Computer And Control Engineering XXVII cycle Torino February 27th, 2015. Parallel and reconfigurable systems are more and more used in a wide number of applica7ons and environments, ranging from
Por$ng Monte Carlo Algorithms to the GPU. Ryan Bergmann UC Berkeley Serpent Users Group Mee$ng 9/20/2012 Madrid, Spain
 Por$ng Monte Carlo Algorithms to the GPU Ryan Bergmann UC Berkeley Serpent Users Group Mee$ng 9/20/2012 Madrid, Spain 1 Outline Introduc$on to GPUs Why they are interes$ng How they operate Pros and cons
Por$ng Monte Carlo Algorithms to the GPU Ryan Bergmann UC Berkeley Serpent Users Group Mee$ng 9/20/2012 Madrid, Spain 1 Outline Introduc$on to GPUs Why they are interes$ng How they operate Pros and cons
Introduc)on to GPU Programming
on to GPU Programming") Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
Introduc)on to GPU Programming Mubashir Adnan Qureshi h3p://www.ncsa.illinois.edu/people/kindr/projects/hpca/files/singapore_p1.pdf h3p://developer.download.nvidia.com/cuda/training/nvidia_gpu_compu)ng_webinars_cuda_memory_op)miza)on.pdf
ECSE 425 Lecture 25: Mul1- threading
 ECSE 425 Lecture 25: Mul1- threading H&P Chapter 3 Last Time Theore1cal and prac1cal limits of ILP Instruc1on window Branch predic1on Register renaming 2 Today Mul1- threading Chapter 3.5 Summary of ILP:
ECSE 425 Lecture 25: Mul1- threading H&P Chapter 3 Last Time Theore1cal and prac1cal limits of ILP Instruc1on window Branch predic1on Register renaming 2 Today Mul1- threading Chapter 3.5 Summary of ILP:
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
RISC Architecture: Multi-Cycle Implementation
 RISC Architecture: Multi-Cycle Implementation Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay
RISC Architecture: Multi-Cycle Implementation Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay
Instructor: Randy H. Katz hap://inst.eecs.berkeley.edu/~cs61c/fa13. Fall Lecture #7. Warehouse Scale Computer
 CS 61C: Great Ideas in Computer Architecture Everything is a Number Instructor: Randy H. Katz hap://inst.eecs.berkeley.edu/~cs61c/fa13 9/19/13 Fall 2013 - - Lecture #7 1 New- School Machine Structures
CS 61C: Great Ideas in Computer Architecture Everything is a Number Instructor: Randy H. Katz hap://inst.eecs.berkeley.edu/~cs61c/fa13 9/19/13 Fall 2013 - - Lecture #7 1 New- School Machine Structures
FPGA architecture and design technology
 CE 435 Embedded Systems Spring 2017 FPGA architecture and design technology Nikos Bellas Computer and Communications Engineering Department University of Thessaly 1 FPGA fabric A generic island-style FPGA
CE 435 Embedded Systems Spring 2017 FPGA architecture and design technology Nikos Bellas Computer and Communications Engineering Department University of Thessaly 1 FPGA fabric A generic island-style FPGA
Instructor: Randy H. Katz hbp://inst.eecs.berkeley.edu/~cs61c/fa13. Fall Lecture #13. Warehouse Scale Computer
 CS 61C: Great Ideas in Computer Architecture Cache Performance and Parallelism Instructor: Randy H. Katz hbp://inst.eecs.berkeley.edu/~cs61c/fa13 10/8/13 Fall 2013 - - Lecture #13 1 New- School Machine
CS 61C: Great Ideas in Computer Architecture Cache Performance and Parallelism Instructor: Randy H. Katz hbp://inst.eecs.berkeley.edu/~cs61c/fa13 10/8/13 Fall 2013 - - Lecture #13 1 New- School Machine
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
ECE 636. Reconfigurable Computing. Lecture 2. Field Programmable Gate Arrays I
 ECE 636 Reconfigurable Computing Lecture 2 Field Programmable Gate Arrays I Overview Anti-fuse and EEPROM-based devices Contemporary SRAM devices - Wiring - Embedded New trends - Single-driver wiring -
ECE 636 Reconfigurable Computing Lecture 2 Field Programmable Gate Arrays I Overview Anti-fuse and EEPROM-based devices Contemporary SRAM devices - Wiring - Embedded New trends - Single-driver wiring -
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Task 8: Extending the DLX Pipeline to Decrease Execution Time
 FB Elektrotechnik und Informationstechnik AG Entwurf mikroelektronischer Systeme Prof. Dr.-Ing. N. Wehn Vertieferlabor Mikroelektronik Modelling the DLX RISC Architecture in VHDL Task 8: Extending the
FB Elektrotechnik und Informationstechnik AG Entwurf mikroelektronischer Systeme Prof. Dr.-Ing. N. Wehn Vertieferlabor Mikroelektronik Modelling the DLX RISC Architecture in VHDL Task 8: Extending the
Network Coding: Theory and Applica7ons
 Network Coding: Theory and Applica7ons PhD Course Part IV Tuesday 9.15-12.15 18.6.213 Muriel Médard (MIT), Frank H. P. Fitzek (AAU), Daniel E. Lucani (AAU), Morten V. Pedersen (AAU) Plan Hello World! Intra
Network Coding: Theory and Applica7ons PhD Course Part IV Tuesday 9.15-12.15 18.6.213 Muriel Médard (MIT), Frank H. P. Fitzek (AAU), Daniel E. Lucani (AAU), Morten V. Pedersen (AAU) Plan Hello World! Intra
Simultaneous Branch and Warp Interweaving for Sustained GPU Performance
 Simultaneous Branch and Warp Interweaving for Sustained GPU Performance Nicolas Brunie Sylvain Collange Gregory Diamos by Ravi Godavarthi Outline Introduc)on ISCA'39 (Interna'onal Society for Computers
Simultaneous Branch and Warp Interweaving for Sustained GPU Performance Nicolas Brunie Sylvain Collange Gregory Diamos by Ravi Godavarthi Outline Introduc)on ISCA'39 (Interna'onal Society for Computers
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
A Configurable Multi-Ported Register File Architecture for Soft Processor Cores
 A Configurable Multi-Ported Register File Architecture for Soft Processor Cores Mazen A. R. Saghir and Rawan Naous Department of Electrical and Computer Engineering American University of Beirut P.O. Box
A Configurable Multi-Ported Register File Architecture for Soft Processor Cores Mazen A. R. Saghir and Rawan Naous Department of Electrical and Computer Engineering American University of Beirut P.O. Box
Utility Reduced Logic (v1.00a)
") DS482 December 2, 2009 Introduction The Utility Reduced Logic core applies a logic reduction function over an input vector to generate a single bit result. The core is intended as glue logic between peripherals.
DS482 December 2, 2009 Introduction The Utility Reduced Logic core applies a logic reduction function over an input vector to generate a single bit result. The core is intended as glue logic between peripherals.
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Op#miza#on of CUDA- based Monte Carlo Simula#on for Radia#on Therapy. GTC 2014 N. Henderson & K. Murakami
 Op#miza#on of CUDA- based Monte Carlo Simula#on for Radia#on Therapy GTC 2014 N. Henderson & K. Murakami The collabora#on Geant4 @ Special thanks to the CUDA Center of Excellence Program Makoto Asai, SLAC
Op#miza#on of CUDA- based Monte Carlo Simula#on for Radia#on Therapy GTC 2014 N. Henderson & K. Murakami The collabora#on Geant4 @ Special thanks to the CUDA Center of Excellence Program Makoto Asai, SLAC
Parallelizing FPGA Technology Mapping using GPUs. Doris Chen Deshanand Singh Aug 31 st, 2010
 Parallelizing FPGA Technology Mapping using GPUs Doris Chen Deshanand Singh Aug 31 st, 2010 Motivation: Compile Time In last 12 years: 110x increase in FPGA Logic, 23x increase in CPU speed, 4.8x gap Question:
Parallelizing FPGA Technology Mapping using GPUs Doris Chen Deshanand Singh Aug 31 st, 2010 Motivation: Compile Time In last 12 years: 110x increase in FPGA Logic, 23x increase in CPU speed, 4.8x gap Question:
FPGA: What? Why? Marco D. Santambrogio
 FPGA: What? Why? Marco D. Santambrogio marco.santambrogio@polimi.it 2 Reconfigurable Hardware Reconfigurable computing is intended to fill the gap between hardware and software, achieving potentially much
FPGA: What? Why? Marco D. Santambrogio marco.santambrogio@polimi.it 2 Reconfigurable Hardware Reconfigurable computing is intended to fill the gap between hardware and software, achieving potentially much
Instruc=on Set Architecture
 ECPE 170 Jeff Shafer University of the Pacific Instruc=on Set Architecture 2 Schedule Today Closer look at instruc=on sets Thursday Brief discussion of real ISAs Quiz 4 (over Chapter 5, i.e. HW #10 and
ECPE 170 Jeff Shafer University of the Pacific Instruc=on Set Architecture 2 Schedule Today Closer look at instruc=on sets Thursday Brief discussion of real ISAs Quiz 4 (over Chapter 5, i.e. HW #10 and
EITF35: Introduction to Structured VLSI Design
 EITF35: Introduction to Structured VLSI Design Introduction to FPGA design Rakesh Gangarajaiah Rakesh.gangarajaiah@eit.lth.se Slides from Chenxin Zhang and Steffan Malkowsky WWW.FPGA What is FPGA? Field
EITF35: Introduction to Structured VLSI Design Introduction to FPGA design Rakesh Gangarajaiah Rakesh.gangarajaiah@eit.lth.se Slides from Chenxin Zhang and Steffan Malkowsky WWW.FPGA What is FPGA? Field
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
Reconfigurable Hardware Implementation of Mesh Routing in the Number Field Sieve Factorization
 Reconfigurable Hardware Implementation of Mesh Routing in the Number Field Sieve Factorization Sashisu Bajracharya, Deapesh Misra, Kris Gaj George Mason University Tarek El-Ghazawi The George Washington
Reconfigurable Hardware Implementation of Mesh Routing in the Number Field Sieve Factorization Sashisu Bajracharya, Deapesh Misra, Kris Gaj George Mason University Tarek El-Ghazawi The George Washington
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
asoc: : A Scalable On-Chip Communication Architecture
 asoc: : A Scalable On-Chip Communication Architecture Russell Tessier, Jian Liang,, Andrew Laffely,, and Wayne Burleson University of Massachusetts, Amherst Reconfigurable Computing Group Supported by
asoc: : A Scalable On-Chip Communication Architecture Russell Tessier, Jian Liang,, Andrew Laffely,, and Wayne Burleson University of Massachusetts, Amherst Reconfigurable Computing Group Supported by
Exploring GPU Architecture for N2P Image Processing Algorithms
 Exploring GPU Architecture for N2P Image Processing Algorithms Xuyuan Jin(0729183) x.jin@student.tue.nl 1. Introduction It is a trend that computer manufacturers provide multithreaded hardware that strongly
Exploring GPU Architecture for N2P Image Processing Algorithms Xuyuan Jin(0729183) x.jin@student.tue.nl 1. Introduction It is a trend that computer manufacturers provide multithreaded hardware that strongly
INTRODUCTION TO FPGA ARCHITECTURE
 3/3/25 INTRODUCTION TO FPGA ARCHITECTURE DIGITAL LOGIC DESIGN (BASIC TECHNIQUES) a b a y 2input Black Box y b Functional Schematic a b y a b y a b y 2 Truth Table (AND) Truth Table (OR) Truth Table (XOR)
3/3/25 INTRODUCTION TO FPGA ARCHITECTURE DIGITAL LOGIC DESIGN (BASIC TECHNIQUES) a b a y 2input Black Box y b Functional Schematic a b y a b y a b y 2 Truth Table (AND) Truth Table (OR) Truth Table (XOR)
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
High-Level Synthesis Creating Custom Circuits from High-Level Code
 High-Level Synthesis Creating Custom Circuits from High-Level Code Hao Zheng Comp Sci & Eng University of South Florida Exis%ng Design Flow Register-transfer (RT) synthesis - Specify RT structure (muxes,
High-Level Synthesis Creating Custom Circuits from High-Level Code Hao Zheng Comp Sci & Eng University of South Florida Exis%ng Design Flow Register-transfer (RT) synthesis - Specify RT structure (muxes,
UNIT V: CENTRAL PROCESSING UNIT
 UNIT V: CENTRAL PROCESSING UNIT Agenda Basic Instruc1on Cycle & Sets Addressing Instruc1on Format Processor Organiza1on Register Organiza1on Pipeline Processors Instruc1on Pipelining Co-Processors RISC
UNIT V: CENTRAL PROCESSING UNIT Agenda Basic Instruc1on Cycle & Sets Addressing Instruc1on Format Processor Organiza1on Register Organiza1on Pipeline Processors Instruc1on Pipelining Co-Processors RISC
Compiler: Control Flow Optimization
 Compiler: Control Flow Optimization Virendra Singh Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay http://www.ee.iitb.ac.in/~viren/
Compiler: Control Flow Optimization Virendra Singh Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay http://www.ee.iitb.ac.in/~viren/
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
"On the Capability and Achievable Performance of FPGAs for HPC Applications"
 "On the Capability and Achievable Performance of FPGAs for HPC Applications" Wim Vanderbauwhede School of Computing Science, University of Glasgow, UK Or in other words "How Fast Can Those FPGA Thingies
"On the Capability and Achievable Performance of FPGAs for HPC Applications" Wim Vanderbauwhede School of Computing Science, University of Glasgow, UK Or in other words "How Fast Can Those FPGA Thingies
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
COL 380: Introduc1on to Parallel & Distributed Programming. Lecture 1 Course Overview + Introduc1on to Concurrency. Subodh Sharma
 COL 380: Introduc1on to Parallel & Distributed Programming Lecture 1 Course Overview + Introduc1on to Concurrency Subodh Sharma Indian Ins1tute of Technology Delhi Credits Material derived from Peter Pacheco:
COL 380: Introduc1on to Parallel & Distributed Programming Lecture 1 Course Overview + Introduc1on to Concurrency Subodh Sharma Indian Ins1tute of Technology Delhi Credits Material derived from Peter Pacheco:
FPGA for Dummies. Introduc)on to Programmable Logic
on to Programmable Logic") FPGA for Dummies Introduc)on to Programmable Logic FPGA for Dummies Historical introduc)on, where we come from; FPGA Architecture: Ø basic blocks (Logic, FFs, wires and IOs); Ø addi)onal elements; FPGA
FPGA for Dummies Introduc)on to Programmable Logic FPGA for Dummies Historical introduc)on, where we come from; FPGA Architecture: Ø basic blocks (Logic, FFs, wires and IOs); Ø addi)onal elements; FPGA
Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include
 3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
3.1 Overview Accelerator cards are typically PCIx cards that supplement a host processor, which they require to operate Today, the most common accelerators include GPUs (Graphics Processing Units) AMD/ATI
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
RISC Architecture: Multi-Cycle Implementation
 RISC Architecture: Multi-Cycle Implementation Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay
RISC Architecture: Multi-Cycle Implementation Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay
L17: CUDA, cont. 11/3/10. Final Project Purpose: October 28, Next Wednesday, November 3. Example Projects
 L17: CUDA, cont. October 28, 2010 Final Project Purpose: - A chance to dig in deeper into a parallel programming model and explore concepts. - Present results to work on communication of technical ideas
L17: CUDA, cont. October 28, 2010 Final Project Purpose: - A chance to dig in deeper into a parallel programming model and explore concepts. - Present results to work on communication of technical ideas
FPGA for Complex System Implementation. National Chiao Tung University Chun-Jen Tsai 04/14/2011
 FPGA for Complex System Implementation National Chiao Tung University Chun-Jen Tsai 04/14/2011 About FPGA FPGA was invented by Ross Freeman in 1989 SRAM-based FPGA properties Standard parts Allowing multi-level
FPGA for Complex System Implementation National Chiao Tung University Chun-Jen Tsai 04/14/2011 About FPGA FPGA was invented by Ross Freeman in 1989 SRAM-based FPGA properties Standard parts Allowing multi-level
DESIGN AND IMPLEMENTATION OF 32-BIT CONTROLLER FOR INTERACTIVE INTERFACING WITH RECONFIGURABLE COMPUTING SYSTEMS
 DESIGN AND IMPLEMENTATION OF 32-BIT CONTROLLER FOR INTERACTIVE INTERFACING WITH RECONFIGURABLE COMPUTING SYSTEMS Ashutosh Gupta and Kota Solomon Raju Digital System Group, Central Electronics Engineering
DESIGN AND IMPLEMENTATION OF 32-BIT CONTROLLER FOR INTERACTIVE INTERFACING WITH RECONFIGURABLE COMPUTING SYSTEMS Ashutosh Gupta and Kota Solomon Raju Digital System Group, Central Electronics Engineering
CSSE232 Computer Architecture I. Datapath
 CSSE232 Computer Architecture I Datapath Class Status Reading Sec;ons 4.1-3 Project Project group milestone assigned Indicate who you want to work with Indicate who you don t want to work with Due next
CSSE232 Computer Architecture I Datapath Class Status Reading Sec;ons 4.1-3 Project Project group milestone assigned Indicate who you want to work with Indicate who you don t want to work with Due next
Computer Architecture 计算机体系结构. Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
Computer Architecture 计算机体系结构 Lecture 10. Data-Level Parallelism and GPGPU 第十讲 数据级并行化与 GPGPU Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2017 Review Thread, Multithreading, SMT CMP and multicore Benefits of
Compiler Optimization Intermediate Representation
 Compiler Optimization Intermediate Representation Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology
Compiler Optimization Intermediate Representation Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
GPU Cluster Computing. Advanced Computing Center for Research and Education
 GPU Cluster Computing Advanced Computing Center for Research and Education 1 What is GPU Computing? Gaming industry and high- defini3on graphics drove the development of fast graphics processing Use of
GPU Cluster Computing Advanced Computing Center for Research and Education 1 What is GPU Computing? Gaming industry and high- defini3on graphics drove the development of fast graphics processing Use of
Programmer's View of Execution Teminology Summary
 CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 28: GP-GPU Programming GPUs Hardware specialized for graphics calculations Originally developed to facilitate the use of CAD programs
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 28: GP-GPU Programming GPUs Hardware specialized for graphics calculations Originally developed to facilitate the use of CAD programs
A Study of the Speedups and Competitiveness of FPGA Soft Processor Cores using Dynamic Hardware/Software Partitioning
 A Study of the Speedups and Competitiveness of FPGA Soft Processor Cores using Dynamic Hardware/Software Partitioning By: Roman Lysecky and Frank Vahid Presented By: Anton Kiriwas Disclaimer This specific
A Study of the Speedups and Competitiveness of FPGA Soft Processor Cores using Dynamic Hardware/Software Partitioning By: Roman Lysecky and Frank Vahid Presented By: Anton Kiriwas Disclaimer This specific
CS 61C: Great Ideas in Computer Architecture Compilers and Floa-ng Point. Today s. Lecture
 CS 61C: Great Ideas in Computer Architecture s and Floa-ng Point Instructors: Krste Asanovic, Randy H. Katz hdp://inst.eecs.berkeley.edu/~cs61c/fa12 Fall 2012 - - Lecture #13 1 New- School Machine Structures
CS 61C: Great Ideas in Computer Architecture s and Floa-ng Point Instructors: Krste Asanovic, Randy H. Katz hdp://inst.eecs.berkeley.edu/~cs61c/fa12 Fall 2012 - - Lecture #13 1 New- School Machine Structures
GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis
 GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis Abstract: Lower upper (LU) factorization for sparse matrices is the most important computing step for circuit simulation
GPU-Accelerated Parallel Sparse LU Factorization Method for Fast Circuit Analysis Abstract: Lower upper (LU) factorization for sparse matrices is the most important computing step for circuit simulation
Is There A Tradeoff Between Programmability and Performance?
 Is There A Tradeoff Between Programmability and Performance? Robert Halstead Jason Villarreal Jacquard Computing, Inc. Roger Moussalli Walid Najjar Abstract While the computational power of Field Programmable
Is There A Tradeoff Between Programmability and Performance? Robert Halstead Jason Villarreal Jacquard Computing, Inc. Roger Moussalli Walid Najjar Abstract While the computational power of Field Programmable
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.
 Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
Introduction to Partial Reconfiguration Methodology
 Methodology This material exempt per Department of Commerce license exception TSU Objectives After completing this module, you will be able to: Define Partial Reconfiguration technology List common applications
Methodology This material exempt per Department of Commerce license exception TSU Objectives After completing this module, you will be able to: Define Partial Reconfiguration technology List common applications
OS History and OS Structures
 OS History and OS Structures Karthik Dantu CSE 421/521: Opera>ng Systems Slides adopted from CS162 class at Berkeley, CSE 451 at U-Washington and CSE 421 by Prof Kosar at UB Join Piazza Ac>on Items From
OS History and OS Structures Karthik Dantu CSE 421/521: Opera>ng Systems Slides adopted from CS162 class at Berkeley, CSE 451 at U-Washington and CSE 421 by Prof Kosar at UB Join Piazza Ac>on Items From
FPGA IMPLEMENTATION FOR REAL TIME SOBEL EDGE DETECTOR BLOCK USING 3-LINE BUFFERS
 FPGA IMPLEMENTATION FOR REAL TIME SOBEL EDGE DETECTOR BLOCK USING 3-LINE BUFFERS 1 RONNIE O. SERFA JUAN, 2 CHAN SU PARK, 3 HI SEOK KIM, 4 HYEONG WOO CHA 1,2,3,4 CheongJu University E-maul: 1 engr_serfs@yahoo.com,
FPGA IMPLEMENTATION FOR REAL TIME SOBEL EDGE DETECTOR BLOCK USING 3-LINE BUFFERS 1 RONNIE O. SERFA JUAN, 2 CHAN SU PARK, 3 HI SEOK KIM, 4 HYEONG WOO CHA 1,2,3,4 CheongJu University E-maul: 1 engr_serfs@yahoo.com,
CS 61C: Great Ideas in Computer Architecture Func%ons and Numbers
 CS 61C: Great Ideas in Computer Architecture Func%ons and Numbers 9/11/12 Instructor: Krste Asanovic, Randy H. Katz hcp://inst.eecs.berkeley.edu/~cs61c/sp12 Fall 2012 - - Lecture #8 1 New- School Machine
CS 61C: Great Ideas in Computer Architecture Func%ons and Numbers 9/11/12 Instructor: Krste Asanovic, Randy H. Katz hcp://inst.eecs.berkeley.edu/~cs61c/sp12 Fall 2012 - - Lecture #8 1 New- School Machine
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Code Genera*on for Control Flow Constructs
 Code Genera*on for Control Flow Constructs 1 Roadmap Last *me: Got the basics of MIPS CodeGen for some AST node types This *me: Do the rest of the AST nodes Introduce control flow graphs Scanner Parser
Code Genera*on for Control Flow Constructs 1 Roadmap Last *me: Got the basics of MIPS CodeGen for some AST node types This *me: Do the rest of the AST nodes Introduce control flow graphs Scanner Parser
CSE Opera,ng System Principles
 CSE 30341 Opera,ng System Principles Lecture 5 Processes / Threads Recap Processes What is a process? What is in a process control bloc? Contrast stac, heap, data, text. What are process states? Which
CSE 30341 Opera,ng System Principles Lecture 5 Processes / Threads Recap Processes What is a process? What is in a process control bloc? Contrast stac, heap, data, text. What are process states? Which
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
Macro Assembler. Defini3on from h6p://www.computeruser.com
 The Macro Assembler Macro Assembler Defini3on from h6p://www.computeruser.com A program that translates assembly language instruc3ons into machine code and which the programmer can use to define macro
The Macro Assembler Macro Assembler Defini3on from h6p://www.computeruser.com A program that translates assembly language instruc3ons into machine code and which the programmer can use to define macro
Supporting Multithreading in Configurable Soft Processor Cores
 Supporting Multithreading in Configurable Soft Processor Cores Roger Moussali, Nabil Ghanem, and Mazen A. R. Saghir Department of Electrical and Computer Engineering American University of Beirut P.O.
Supporting Multithreading in Configurable Soft Processor Cores Roger Moussali, Nabil Ghanem, and Mazen A. R. Saghir Department of Electrical and Computer Engineering American University of Beirut P.O.
DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2)
") 1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
1 DATA-LEVEL PARALLELISM IN VECTOR, SIMD ANDGPU ARCHITECTURES(PART 2) Chapter 4 Appendix A (Computer Organization and Design Book) OUTLINE SIMD Instruction Set Extensions for Multimedia (4.3) Graphical
International IEEE Symposium on Field-Programmable Custom Computing Machines
 - International IEEE Symposium on ield-programmable Custom Computing Machines Scalable Streaming-Array of Simple Soft-Processors for Stencil Computations with Constant Bandwidth Kentaro Sano Yoshiaki Hatsuda
- International IEEE Symposium on ield-programmable Custom Computing Machines Scalable Streaming-Array of Simple Soft-Processors for Stencil Computations with Constant Bandwidth Kentaro Sano Yoshiaki Hatsuda
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
CS252 Graduate Computer Architecture Spring 2014 Lecture 13: Mul>threading
 CS252 Graduate Computer Architecture Spring 2014 Lecture 13: Mul>threading Krste Asanovic krste@eecs.berkeley.edu http://inst.eecs.berkeley.edu/~cs252/sp14 Last Time in Lecture 12 Synchroniza?on and Memory
CS252 Graduate Computer Architecture Spring 2014 Lecture 13: Mul>threading Krste Asanovic krste@eecs.berkeley.edu http://inst.eecs.berkeley.edu/~cs252/sp14 Last Time in Lecture 12 Synchroniza?on and Memory
A Prototype Multithreaded Associative SIMD Processor
 A Prototype Multithreaded Associative SIMD Processor Kevin Schaffer and Robert A. Walker Department of Computer Science Kent State University Kent, Ohio 44242 {kschaffe, walker}@cs.kent.edu Abstract The
A Prototype Multithreaded Associative SIMD Processor Kevin Schaffer and Robert A. Walker Department of Computer Science Kent State University Kent, Ohio 44242 {kschaffe, walker}@cs.kent.edu Abstract The
Ways to implement a language
 Interpreters Implemen+ng PLs Most of the course is learning fundamental concepts for using PLs Syntax vs. seman+cs vs. idioms Powerful constructs like closures, first- class objects, iterators (streams),
Interpreters Implemen+ng PLs Most of the course is learning fundamental concepts for using PLs Syntax vs. seman+cs vs. idioms Powerful constructs like closures, first- class objects, iterators (streams),
Implementation of GP-GPU with SIMT Architecture in the Embedded Environment
 , pp.221-226 http://dx.doi.org/10.14257/ijmue.2014.9.4.23 Implementation of GP-GPU with SIMT Architecture in the Embedded Environment Kwang-yeob Lee and Jae-chang Kwak 1 * Dept. of Computer Engineering,
, pp.221-226 http://dx.doi.org/10.14257/ijmue.2014.9.4.23 Implementation of GP-GPU with SIMT Architecture in the Embedded Environment Kwang-yeob Lee and Jae-chang Kwak 1 * Dept. of Computer Engineering,
Fusion PIC Code Performance Analysis on the Cori KNL System. T. Koskela*, J. Deslippe*,! K. Raman**, B. Friesen*! *NERSC! ** Intel!
 Fusion PIC Code Performance Analysis on the Cori KNL System T. Koskela*, J. Deslippe*,! K. Raman**, B. Friesen*! *NERSC! ** Intel! tkoskela@lbl.gov May 18, 2017-1- Outline Introduc3on to magne3c fusion
Fusion PIC Code Performance Analysis on the Cori KNL System T. Koskela*, J. Deslippe*,! K. Raman**, B. Friesen*! *NERSC! ** Intel! tkoskela@lbl.gov May 18, 2017-1- Outline Introduc3on to magne3c fusion