Behavioral Data Mining. Lecture 18 Clustering
|
|
|
- Preston Green
- 5 years ago
- Views:
Transcription
1 Behavioral Data Mining Lecture 18 Clustering
2 Outline Why? Cluster quality K-means Spectral clustering Generative Models
3 Rationale Given a set {X i } for i = 1,,n, a clustering is a partition of the X i into subsets C 1,, C k. Clustering has one or more goals: Segment a large set of cases into small (even-sized) subsets that can be treated similarly - segmentation Model the variation in a large dataset using a smaller number of samples - condensation Generate a more compact description of a dataset - compression Model an underlying process that generates the data as a mixture of different, localized processes representation
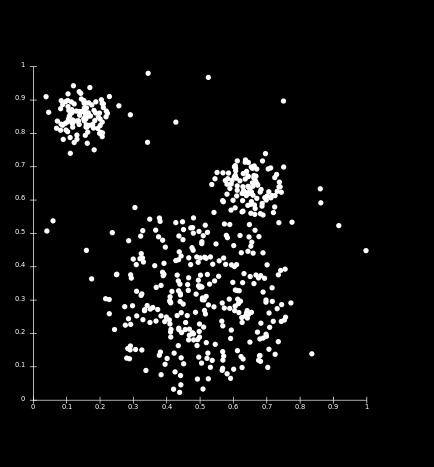
4 Stereotypical Clustering
5 Model-based Clustering
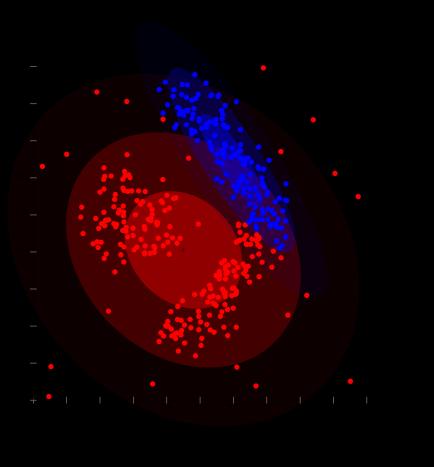
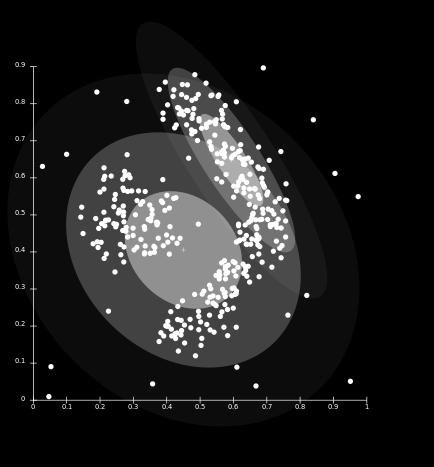
6 Model-based Clustering
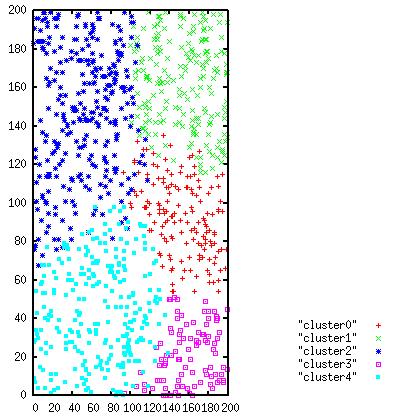
7 Clustering for Segmentation
8 Condensation/Compression



9 Cognitive Bias Human beings conceptualize the world through categories represented as examplars (Rosch 73, Estes 94). We tend to see cluster structure whether it is there or not.

10 Cognitive Bias
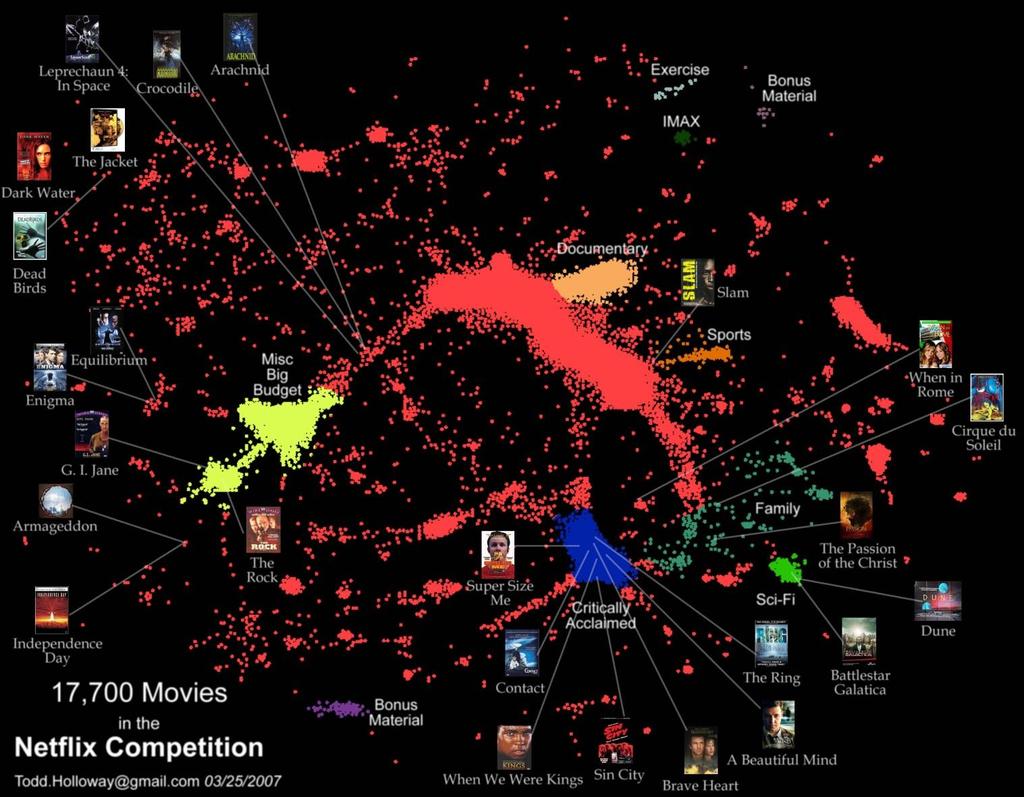
11 Netflix
12 Outline Why? Cluster quality K-means Spectral clustering Generative Models
13 Terminology Hierarchical clustering: clusters form a hierarchy. Can be computed bottom-up or top-down. Flat clustering: no inter-cluster structure. Hard clustering: items assigned to a unique cluster. Soft clustering: cluster membership is a real-valued function, distributed across several clusters.
14 Clustering Basics We need at a minimum a similarity measure for items. From the similarity measure, we can specify a clustering quality measure Q (objective function), which increases with intracluster similarity, and decreases with inter-cluster similarity. Choose an algorithm to (approximately) optimize the measure Q: Greedy assignment/cluster update (e.g. k-means) Expectation maximization Greedy merging (HAC clustering) Partitioning (spectral clustering) Cluster management: Splitting, merging, shattering clusters of low quality.
15 Normalized Cut measure Quality measure based on weight of cuts (total similarity weight of edges across a cut). Ncut miminizes:
16 Outline Why? Cluster quality K-means Spectral clustering
17 K-means clustering The standard k-means algorithm is based on Euclidean inner products (kernels) <u,v>. The cluster quality measure is an intra-cluster measure only, equivalent to the sum of item-to-centroid kernels. A simple greedy algorithm locally optimizes this measure: Find the best cluster (best item-centroid kernel) for each item Recompute the cluster centroid for the newly-assigned items in the cluster. Item vectors are normally scaled to unit magnitude. Otherwise large vectors will attract too many neighbors.
18 K-means clustering
19 K-means clustering
20 K-means properties Very simple convergence proofs. Performance is O(ntk) per iteration, not bad and can be heuristically improved. n = num docs, t = non-zeros per doc, k = num clusters Many generalizations, e.g. Simple generalization to m-best soft clustering As a local clustering method, it works well for data condensation/compression.
21 K-means properties No inter-cluster measure: Splitting clusters always improves the clustering Merging and shattering always worsen it Optimal clustering of N points is pathological Greedy algorithm fortunately fails to find it! Greedy algorithm cannot increase number of clusters
22 Choosing clustering dimension AIC or Akaike Information Criterion: K=dimension, L(K) is the likelihood (could be RSS) and q(k) is a measure of model complexity (cluster description complexity). AIC favors more compact (fewer clusters) clusterings. For sparse data, AIC will incorporate the number of nonzeros in the cluster spec. Lower is better.
23 Outline Why? Cluster quality K-means Spectral clustering Generative Models
24 Spectral Clustering Spectral clustering methods derive from graph partitioning. They are able to simultaneous find partitions with approximately increase affinity within a cluster while decreasing it between clusters. We look for the second-largest eigenvalue/vector of this matrix: Where W is the original affinity matrix, D a diagonal matrix of total weights for each node. The largest eigenvalue is 1, with eigenvector all 1 s.
25 Spectral Clustering Standard spectral clustering uses only the second eigenvector, sorts the nodes by the coefficients of this vector and then chooses the cut which minimizes In practice, enumeration of the cut values dominates the running time, so a reduced-resolution graph of the cut values can be used. This generates only a single binary split of the data. To complete the clustering, the to parts are recursively clustered.
26 Spectral Clustering with k-means
27 Results
28 Results
29 Spectral, Kernel, k-means Defines an objective function equivalent to normalized cut which can be directly minimized with k-means.
30 Spectral, Kernel, k-means Euclidean distance from (a) to center m j is Where (x) is the non-linear, kernel component function. Similar to Jordan et al., but allows general kernels, performs final k-means in original space.
31 Spectral, Kernel, k-means Triangle inequality estimation: uses cluster-cluster distances to bound new point scores.
32 Spectral, Kernel, k-means
33 Outline Why? Cluster quality K-means Spectral clustering Generative Models
34 Generative Clustering Generative or probabilistic clustering includes a probabilistic model which generates samples of the observed data. Each model assigns a likelihood to an actual dataset. We replace the item-item similarity measure with a likelihood of membership in cluster i. Each cluster may be represented by a center c i, and the (log) likelihood that d j is in cluster i by <c i, d j > for some <,> Generative models add a prior probability on the cluster parameters, on one or both sides.
35 Clustering Meta-Formula We can write our observed data A as A W U where A is typically sparse discrete data (e.g. A ij = count of word i in document j or event i by user j), possibly scaled (by tf-idf); W are word-cluster weights (e.g. cluster center weights); U are user(or document)-cluster weights;
36 Clustering Meta-Formula Key choices: A W U Metric: The likelihood of A given WU, i.e. what means. Multinomial for LDA, Poisson for GAP, (roughly KL-divergence) L 2 for k-means, NMF, spectral methods, LSA (SVD) Von Mises-Fisher distribution Laplacian approximation Sign of W: Are coefficients signed or non-negative? Signed: LSA, k-means* (depends on data) Non-negative: LDA, GAP, NMF
37 Clustering Meta-Formula Range of U: Signed: LSA Non-negative: k-means (soft), LDA, GAP, NMF {0,1}: k-means (hard) Prior: Whether there is a prior on W or U: K-means: No, or (sometimes) linear smoothing of center coefficients LDA: Dirichlet on U, in Monte-Carlo versions: Dirichlet on W GAP: Gamma prior on U NMF: No
38 Performance Comparison Cai et al. paper. TREC AP corpus. Scoring: Cluster docs into k clusters (oblivious to the actual doc. N category labels) and then compute the best k n matching. Accuracy and mutual information measurements are based on this matching.
39 Performance Comparison Algorithms: K-means LDA, Latent Dirichlet Allocation PLSI, probabilistic Latent Semantic Indexing (Hoffmann) AA: Average Association (spectral) NC: Normalized cut NMF: Normalized Matrix Factorization LapPLSI: Laplacian PLSI
40 Performance Comparison
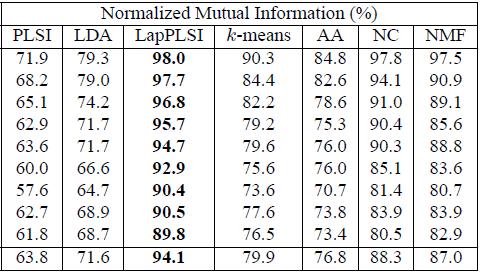
41 Performance Comparison
42 Performance Comparison
43 Performance Comparison
44 vmf distributions A d-dimensional unit random vector x is said to have a von Mises-Fisher (vmf) distribution if its pdf is given by: where is the mean direction, is the concentration parameter. vmf distributions generalize gaussian distributions to the unit sphere.
45 Spherical Admixture (SAM) 1. Draw a set of T topics on the unit hypersphere; 2. For each document d, draw topic weights d from a Dirichlet with hyperparameter 3. Draw a document vector v d from a vmf with mean d = Avg(, d ) and concentration The model is:

46 SAM performance
47 Spherical Admixture (SAM) 1. Draw a set of T topics on the unit hypersphere; 2. For each document d, draw topic weights d from a Dirichlet with hyperparameter 3. Draw a document vector v d from a vmf with mean d = Avg(, d ) and concentration The model is:
48 Google TouchGraph
49 Summary Why? Cluster quality K-means Spectral clustering Generative Models
Introduction to Data Science Lecture 8 Unsupervised Learning. CS 194 Fall 2015 John Canny
 Introduction to Data Science Lecture 8 Unsupervised Learning CS 194 Fall 2015 John Canny Outline Unsupervised Learning K-Means clustering DBSCAN Matrix Factorization Performance Machine Learning Supervised:
Introduction to Data Science Lecture 8 Unsupervised Learning CS 194 Fall 2015 John Canny Outline Unsupervised Learning K-Means clustering DBSCAN Matrix Factorization Performance Machine Learning Supervised:
SGN (4 cr) Chapter 11
 Chapter 11") SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
SGN-41006 (4 cr) Chapter 11 Clustering Jussi Tohka & Jari Niemi Department of Signal Processing Tampere University of Technology February 25, 2014 J. Tohka & J. Niemi (TUT-SGN) SGN-41006 (4 cr) Chapter
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Visual Representations for Machine Learning
 Visual Representations for Machine Learning Spectral Clustering and Channel Representations Lecture 1 Spectral Clustering: introduction and confusion Michael Felsberg Klas Nordberg The Spectral Clustering
Visual Representations for Machine Learning Spectral Clustering and Channel Representations Lecture 1 Spectral Clustering: introduction and confusion Michael Felsberg Klas Nordberg The Spectral Clustering
Clustering. Informal goal. General types of clustering. Applications: Clustering in information search and analysis. Example applications in search
 Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
Informal goal Clustering Given set of objects and measure of similarity between them, group similar objects together What mean by similar? What is good grouping? Computation time / quality tradeoff 1 2
( ) =cov X Y = W PRINCIPAL COMPONENT ANALYSIS. Eigenvectors of the covariance matrix are the principal components
 =cov X Y = W PRINCIPAL COMPONENT ANALYSIS. Eigenvectors of the covariance matrix are the principal components") Review Lecture 14 ! PRINCIPAL COMPONENT ANALYSIS Eigenvectors of the covariance matrix are the principal components 1. =cov X Top K principal components are the eigenvectors with K largest eigenvalues
Review Lecture 14 ! PRINCIPAL COMPONENT ANALYSIS Eigenvectors of the covariance matrix are the principal components 1. =cov X Top K principal components are the eigenvectors with K largest eigenvalues
Clustering Algorithms for general similarity measures
 Types of general clustering methods Clustering Algorithms for general similarity measures general similarity measure: specified by object X object similarity matrix 1 constructive algorithms agglomerative
Types of general clustering methods Clustering Algorithms for general similarity measures general similarity measure: specified by object X object similarity matrix 1 constructive algorithms agglomerative
Types of general clustering methods. Clustering Algorithms for general similarity measures. Similarity between clusters
 Types of general clustering methods Clustering Algorithms for general similarity measures agglomerative versus divisive algorithms agglomerative = bottom-up build up clusters from single objects divisive
Types of general clustering methods Clustering Algorithms for general similarity measures agglomerative versus divisive algorithms agglomerative = bottom-up build up clusters from single objects divisive
Unsupervised Learning
 Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Unsupervised Learning Unsupervised learning Until now, we have assumed our training samples are labeled by their category membership. Methods that use labeled samples are said to be supervised. However,
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Machine Learning (BSMC-GA 4439) Wenke Liu 01-25-2018 Outline Background Defining proximity Clustering methods Determining number of clusters Other approaches Cluster analysis as unsupervised Learning Unsupervised
Methods for Intelligent Systems
 Methods for Intelligent Systems Lecture Notes on Clustering (II) Davide Eynard eynard@elet.polimi.it Department of Electronics and Information Politecnico di Milano Davide Eynard - Lecture Notes on Clustering
Methods for Intelligent Systems Lecture Notes on Clustering (II) Davide Eynard eynard@elet.polimi.it Department of Electronics and Information Politecnico di Milano Davide Eynard - Lecture Notes on Clustering
Data Mining Cluster Analysis: Basic Concepts and Algorithms. Lecture Notes for Chapter 8. Introduction to Data Mining
 Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
Data Mining Cluster Analysis: Basic Concepts and Algorithms Lecture Notes for Chapter 8 Introduction to Data Mining by Tan, Steinbach, Kumar Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CHAPTER 4: CLUSTER ANALYSIS
 CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
CHAPTER 4: CLUSTER ANALYSIS WHAT IS CLUSTER ANALYSIS? A cluster is a collection of data-objects similar to one another within the same group & dissimilar to the objects in other groups. Cluster analysis
Machine Learning (BSMC-GA 4439) Wenke Liu
 Wenke Liu") Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Machine Learning (BSMC-GA 4439) Wenke Liu 01-31-017 Outline Background Defining proximity Clustering methods Determining number of clusters Comparing two solutions Cluster analysis as unsupervised Learning
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines Lecture 7: Document Clustering December 4th, 2014 Wolf-Tilo Balke and José Pinto Institut für Informationssysteme Technische Universität Braunschweig The Cluster
Information Retrieval and Web Search Engines
 Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Information Retrieval and Web Search Engines Lecture 7: Document Clustering May 25, 2011 Wolf-Tilo Balke and Joachim Selke Institut für Informationssysteme Technische Universität Braunschweig Homework
Clustering Lecture 5: Mixture Model
 Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
CS490W. Text Clustering. Luo Si. Department of Computer Science Purdue University
 CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
CS490W Text Clustering Luo Si Department of Computer Science Purdue University [Borrows slides from Chris Manning, Ray Mooney and Soumen Chakrabarti] Clustering Document clustering Motivations Document
Clustering CS 550: Machine Learning
 Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
Clustering CS 550: Machine Learning This slide set mainly uses the slides given in the following links: http://www-users.cs.umn.edu/~kumar/dmbook/ch8.pdf http://www-users.cs.umn.edu/~kumar/dmbook/dmslides/chap8_basic_cluster_analysis.pdf
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
My favorite application using eigenvalues: partitioning and community detection in social networks
 My favorite application using eigenvalues: partitioning and community detection in social networks Will Hobbs February 17, 2013 Abstract Social networks are often organized into families, friendship groups,
My favorite application using eigenvalues: partitioning and community detection in social networks Will Hobbs February 17, 2013 Abstract Social networks are often organized into families, friendship groups,
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University 09/25/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10.
INF4820. Clustering. Erik Velldal. Nov. 17, University of Oslo. Erik Velldal INF / 22
 INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
INF4820 Clustering Erik Velldal University of Oslo Nov. 17, 2009 Erik Velldal INF4820 1 / 22 Topics for Today More on unsupervised machine learning for data-driven categorization: clustering. The task
Clustering K-means. Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, Carlos Guestrin
 Clustering K-means Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, 2014 Carlos Guestrin 2005-2014 1 Clustering images Set of Images [Goldberger et al.] Carlos Guestrin 2005-2014
Clustering K-means Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, 2014 Carlos Guestrin 2005-2014 1 Clustering images Set of Images [Goldberger et al.] Carlos Guestrin 2005-2014
CSE 494 Project C. Garrett Wolf
 CSE 494 Project C Garrett Wolf Introduction The main purpose of this project task was for us to implement the simple k-means and buckshot clustering algorithms. Once implemented, we were asked to vary
CSE 494 Project C Garrett Wolf Introduction The main purpose of this project task was for us to implement the simple k-means and buckshot clustering algorithms. Once implemented, we were asked to vary
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Automatic Cluster Number Selection using a Split and Merge K-Means Approach
 Automatic Cluster Number Selection using a Split and Merge K-Means Approach Markus Muhr and Michael Granitzer 31st August 2009 The Know-Center is partner of Austria's Competence Center Program COMET. Agenda
Automatic Cluster Number Selection using a Split and Merge K-Means Approach Markus Muhr and Michael Granitzer 31st August 2009 The Know-Center is partner of Austria's Competence Center Program COMET. Agenda
CS 229 Midterm Review
 CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
CS 229 Midterm Review Course Staff Fall 2018 11/2/2018 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask
Lesson 3. Prof. Enza Messina
 Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Lesson 3 Prof. Enza Messina Clustering techniques are generally classified into these classes: PARTITIONING ALGORITHMS Directly divides data points into some prespecified number of clusters without a hierarchical
Favorites-Based Search Result Ordering
 Favorites-Based Search Result Ordering Ben Flamm and Georey Schiebinger CS 229 Fall 2009 1 Introduction Search engine rankings can often benet from knowledge of users' interests. The query jaguar, for
Favorites-Based Search Result Ordering Ben Flamm and Georey Schiebinger CS 229 Fall 2009 1 Introduction Search engine rankings can often benet from knowledge of users' interests. The query jaguar, for
Chapter 9. Classification and Clustering
 Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Chapter 9 Classification and Clustering Classification and Clustering Classification and clustering are classical pattern recognition and machine learning problems Classification, also referred to as categorization
Clustering. SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic
 Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
Clustering SC4/SM4 Data Mining and Machine Learning, Hilary Term 2017 Dino Sejdinovic Clustering is one of the fundamental and ubiquitous tasks in exploratory data analysis a first intuition about the
Clustering. Bruno Martins. 1 st Semester 2012/2013
 Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 Motivation Basic Concepts
Departamento de Engenharia Informática Instituto Superior Técnico 1 st Semester 2012/2013 Slides baseados nos slides oficiais do livro Mining the Web c Soumen Chakrabarti. Outline 1 Motivation Basic Concepts
Based on Raymond J. Mooney s slides
 Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
Instance Based Learning Based on Raymond J. Mooney s slides University of Texas at Austin 1 Example 2 Instance-Based Learning Unlike other learning algorithms, does not involve construction of an explicit
SYDE Winter 2011 Introduction to Pattern Recognition. Clustering
 SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
SYDE 372 - Winter 2011 Introduction to Pattern Recognition Clustering Alexander Wong Department of Systems Design Engineering University of Waterloo Outline 1 2 3 4 5 All the approaches we have learned
CS 664 Slides #11 Image Segmentation. Prof. Dan Huttenlocher Fall 2003
 CS 664 Slides #11 Image Segmentation Prof. Dan Huttenlocher Fall 2003 Image Segmentation Find regions of image that are coherent Dual of edge detection Regions vs. boundaries Related to clustering problems
CS 664 Slides #11 Image Segmentation Prof. Dan Huttenlocher Fall 2003 Image Segmentation Find regions of image that are coherent Dual of edge detection Regions vs. boundaries Related to clustering problems
Unsupervised Learning
 Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Outline Unsupervised Learning Basic concepts K-means algorithm Representation of clusters Hierarchical clustering Distance functions Which clustering algorithm to use? NN Supervised learning vs. unsupervised
Introduction to Mobile Robotics
 Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Introduction to Mobile Robotics Clustering Wolfram Burgard Cyrill Stachniss Giorgio Grisetti Maren Bennewitz Christian Plagemann Clustering (1) Common technique for statistical data analysis (machine learning,
Lecture 7: Segmentation. Thursday, Sept 20
 Lecture 7: Segmentation Thursday, Sept 20 Outline Why segmentation? Gestalt properties, fun illusions and/or revealing examples Clustering Hierarchical K-means Mean Shift Graph-theoretic Normalized cuts
Lecture 7: Segmentation Thursday, Sept 20 Outline Why segmentation? Gestalt properties, fun illusions and/or revealing examples Clustering Hierarchical K-means Mean Shift Graph-theoretic Normalized cuts
CSE 6242 A / CS 4803 DVA. Feb 12, Dimension Reduction. Guest Lecturer: Jaegul Choo
 CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo Data is Too Big To Do Something..
CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo CSE 6242 A / CS 4803 DVA Feb 12, 2013 Dimension Reduction Guest Lecturer: Jaegul Choo Data is Too Big To Do Something..
Segmentation and Grouping
 Segmentation and Grouping How and what do we see? Fundamental Problems ' Focus of attention, or grouping ' What subsets of pixels do we consider as possible objects? ' All connected subsets? ' Representation
Segmentation and Grouping How and what do we see? Fundamental Problems ' Focus of attention, or grouping ' What subsets of pixels do we consider as possible objects? ' All connected subsets? ' Representation
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Hard clustering. Each object is assigned to one and only one cluster. Hierarchical clustering is usually hard. Soft (fuzzy) clustering
 clustering") An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
An unsupervised machine learning problem Grouping a set of objects in such a way that objects in the same group (a cluster) are more similar (in some sense or another) to each other than to those in other
Clustering: Overview and K-means algorithm
 Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
Clustering: Overview and K-means algorithm Informal goal Given set of objects and measure of similarity between them, group similar objects together K-Means illustrations thanks to 2006 student Martin
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
CSE 5243 INTRO. TO DATA MINING Cluster Analysis: Basic Concepts and Methods Huan Sun, CSE@The Ohio State University Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han 2 Chapter 10. Cluster
Clustering Lecture 8. David Sontag New York University. Slides adapted from Luke Zettlemoyer, Vibhav Gogate, Carlos Guestrin, Andrew Moore, Dan Klein
 Clustering Lecture 8 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, Carlos Guestrin, Andrew Moore, Dan Klein Clustering: Unsupervised learning Clustering Requires
Clustering Lecture 8 David Sontag New York University Slides adapted from Luke Zettlemoyer, Vibhav Gogate, Carlos Guestrin, Andrew Moore, Dan Klein Clustering: Unsupervised learning Clustering Requires
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering
 INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
INF4820, Algorithms for AI and NLP: Evaluating Classifiers Clustering Erik Velldal University of Oslo Sept. 18, 2012 Topics for today 2 Classification Recap Evaluating classifiers Accuracy, precision,
Cluster Analysis (b) Lijun Zhang
 Lijun Zhang") Cluster Analysis (b) Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Grid-Based and Density-Based Algorithms Graph-Based Algorithms Non-negative Matrix Factorization Cluster Validation Summary
Cluster Analysis (b) Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Grid-Based and Density-Based Algorithms Graph-Based Algorithms Non-negative Matrix Factorization Cluster Validation Summary
Spectral Methods for Network Community Detection and Graph Partitioning
 Spectral Methods for Network Community Detection and Graph Partitioning M. E. J. Newman Department of Physics, University of Michigan Presenters: Yunqi Guo Xueyin Yu Yuanqi Li 1 Outline: Community Detection
Spectral Methods for Network Community Detection and Graph Partitioning M. E. J. Newman Department of Physics, University of Michigan Presenters: Yunqi Guo Xueyin Yu Yuanqi Li 1 Outline: Community Detection
Text Documents clustering using K Means Algorithm
 Text Documents clustering using K Means Algorithm Mrs Sanjivani Tushar Deokar Assistant professor sanjivanideokar@gmail.com Abstract: With the advancement of technology and reduced storage costs, individuals
Text Documents clustering using K Means Algorithm Mrs Sanjivani Tushar Deokar Assistant professor sanjivanideokar@gmail.com Abstract: With the advancement of technology and reduced storage costs, individuals
Unsupervised Learning. Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi
 Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Unsupervised Learning Presenter: Anil Sharma, PhD Scholar, IIIT-Delhi Content Motivation Introduction Applications Types of clustering Clustering criterion functions Distance functions Normalization Which
Text Modeling with the Trace Norm
 Text Modeling with the Trace Norm Jason D. M. Rennie jrennie@gmail.com April 14, 2006 1 Introduction We have two goals: (1) to find a low-dimensional representation of text that allows generalization to
Text Modeling with the Trace Norm Jason D. M. Rennie jrennie@gmail.com April 14, 2006 1 Introduction We have two goals: (1) to find a low-dimensional representation of text that allows generalization to
Unsupervised Learning and Clustering
 Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Unsupervised Learning and Clustering Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2009 CS 551, Spring 2009 c 2009, Selim Aksoy (Bilkent University)
Lecture 13 Segmentation and Scene Understanding Chris Choy, Ph.D. candidate Stanford Vision and Learning Lab (SVL)
") Lecture 13 Segmentation and Scene Understanding Chris Choy, Ph.D. candidate Stanford Vision and Learning Lab (SVL) http://chrischoy.org Stanford CS231A 1 Understanding a Scene Objects Chairs, Cups, Tables,
Lecture 13 Segmentation and Scene Understanding Chris Choy, Ph.D. candidate Stanford Vision and Learning Lab (SVL) http://chrischoy.org Stanford CS231A 1 Understanding a Scene Objects Chairs, Cups, Tables,
Machine Learning for OR & FE
 Machine Learning for OR & FE Unsupervised Learning: Clustering Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com (Some material
Machine Learning for OR & FE Unsupervised Learning: Clustering Martin Haugh Department of Industrial Engineering and Operations Research Columbia University Email: martin.b.haugh@gmail.com (Some material
6.801/866. Segmentation and Line Fitting. T. Darrell
 6.801/866 Segmentation and Line Fitting T. Darrell Segmentation and Line Fitting Gestalt grouping Background subtraction K-Means Graph cuts Hough transform Iterative fitting (Next time: Probabilistic segmentation)
6.801/866 Segmentation and Line Fitting T. Darrell Segmentation and Line Fitting Gestalt grouping Background subtraction K-Means Graph cuts Hough transform Iterative fitting (Next time: Probabilistic segmentation)
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Erik Velldal & Stephan Oepen Language Technology Group (LTG) September 23, 2015 Agenda Last week Supervised vs unsupervised learning.
INF4820 Algorithms for AI and NLP. Evaluating Classifiers Clustering
 INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
INF4820 Algorithms for AI and NLP Evaluating Classifiers Clustering Murhaf Fares & Stephan Oepen Language Technology Group (LTG) September 27, 2017 Today 2 Recap Evaluation of classifiers Unsupervised
Clustering. CE-717: Machine Learning Sharif University of Technology Spring Soleymani
 Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Clustering CE-717: Machine Learning Sharif University of Technology Spring 2016 Soleymani Outline Clustering Definition Clustering main approaches Partitional (flat) Hierarchical Clustering validation
Machine Learning. B. Unsupervised Learning B.1 Cluster Analysis. Lars Schmidt-Thieme
 Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
Machine Learning B. Unsupervised Learning B.1 Cluster Analysis Lars Schmidt-Thieme Information Systems and Machine Learning Lab (ISMLL) Institute for Computer Science University of Hildesheim, Germany
General Instructions. Questions
 CS246: Mining Massive Data Sets Winter 2018 Problem Set 2 Due 11:59pm February 8, 2018 Only one late period is allowed for this homework (11:59pm 2/13). General Instructions Submission instructions: These
CS246: Mining Massive Data Sets Winter 2018 Problem Set 2 Due 11:59pm February 8, 2018 Only one late period is allowed for this homework (11:59pm 2/13). General Instructions Submission instructions: These
Clustering and Visualisation of Data
 Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Clustering and Visualisation of Data Hiroshi Shimodaira January-March 28 Cluster analysis aims to partition a data set into meaningful or useful groups, based on distances between data points. In some
Applications. Foreground / background segmentation Finding skin-colored regions. Finding the moving objects. Intelligent scissors
 Segmentation I Goal Separate image into coherent regions Berkeley segmentation database: http://www.eecs.berkeley.edu/research/projects/cs/vision/grouping/segbench/ Slide by L. Lazebnik Applications Intelligent
Segmentation I Goal Separate image into coherent regions Berkeley segmentation database: http://www.eecs.berkeley.edu/research/projects/cs/vision/grouping/segbench/ Slide by L. Lazebnik Applications Intelligent
ECS 234: Data Analysis: Clustering ECS 234
 : Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
: Data Analysis: Clustering What is Clustering? Given n objects, assign them to groups (clusters) based on their similarity Unsupervised Machine Learning Class Discovery Difficult, and maybe ill-posed
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Machine Learning and Data Mining. Clustering (1): Basics. Kalev Kask
: Basics. Kalev Kask") Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
Machine Learning and Data Mining Clustering (1): Basics Kalev Kask Unsupervised learning Supervised learning Predict target value ( y ) given features ( x ) Unsupervised learning Understand patterns of
9.1. K-means Clustering
 424 9. MIXTURE MODELS AND EM Section 9.2 Section 9.3 Section 9.4 view of mixture distributions in which the discrete latent variables can be interpreted as defining assignments of data points to specific
424 9. MIXTURE MODELS AND EM Section 9.2 Section 9.3 Section 9.4 view of mixture distributions in which the discrete latent variables can be interpreted as defining assignments of data points to specific
DOCUMENT CLUSTERING USING HIERARCHICAL METHODS. 1. Dr.R.V.Krishnaiah 2. Katta Sharath Kumar. 3. P.Praveen Kumar. achieved.
 DOCUMENT CLUSTERING USING HIERARCHICAL METHODS 1. Dr.R.V.Krishnaiah 2. Katta Sharath Kumar 3. P.Praveen Kumar ABSTRACT: Cluster is a term used regularly in our life is nothing but a group. In the view
DOCUMENT CLUSTERING USING HIERARCHICAL METHODS 1. Dr.R.V.Krishnaiah 2. Katta Sharath Kumar 3. P.Praveen Kumar ABSTRACT: Cluster is a term used regularly in our life is nothing but a group. In the view
Spectral Clustering. Presented by Eldad Rubinstein Based on a Tutorial by Ulrike von Luxburg TAU Big Data Processing Seminar December 14, 2014
 Spectral Clustering Presented by Eldad Rubinstein Based on a Tutorial by Ulrike von Luxburg TAU Big Data Processing Seminar December 14, 2014 What are we going to talk about? Introduction Clustering and
Spectral Clustering Presented by Eldad Rubinstein Based on a Tutorial by Ulrike von Luxburg TAU Big Data Processing Seminar December 14, 2014 What are we going to talk about? Introduction Clustering and
K-Means Clustering 3/3/17
 K-Means Clustering 3/3/17 Unsupervised Learning We have a collection of unlabeled data points. We want to find underlying structure in the data. Examples: Identify groups of similar data points. Clustering
K-Means Clustering 3/3/17 Unsupervised Learning We have a collection of unlabeled data points. We want to find underlying structure in the data. Examples: Identify groups of similar data points. Clustering
4. Ad-hoc I: Hierarchical clustering
 4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
4. Ad-hoc I: Hierarchical clustering Hierarchical versus Flat Flat methods generate a single partition into k clusters. The number k of clusters has to be determined by the user ahead of time. Hierarchical
DATA MINING LECTURE 7. Hierarchical Clustering, DBSCAN The EM Algorithm
 DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
DATA MINING LECTURE 7 Hierarchical Clustering, DBSCAN The EM Algorithm CLUSTERING What is a Clustering? In general a grouping of objects such that the objects in a group (cluster) are similar (or related)
CSE 255 Lecture 6. Data Mining and Predictive Analytics. Community Detection
 CSE 255 Lecture 6 Data Mining and Predictive Analytics Community Detection Dimensionality reduction Goal: take high-dimensional data, and describe it compactly using a small number of dimensions Assumption:
CSE 255 Lecture 6 Data Mining and Predictive Analytics Community Detection Dimensionality reduction Goal: take high-dimensional data, and describe it compactly using a small number of dimensions Assumption:
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Unsupervised Learning : Clustering
 Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Unsupervised Learning : Clustering Things to be Addressed Traditional Learning Models. Cluster Analysis K-means Clustering Algorithm Drawbacks of traditional clustering algorithms. Clustering as a complex
Clustering: Classic Methods and Modern Views
 Clustering: Classic Methods and Modern Views Marina Meilă University of Washington mmp@stat.washington.edu June 22, 2015 Lorentz Center Workshop on Clusters, Games and Axioms Outline Paradigms for clustering
Clustering: Classic Methods and Modern Views Marina Meilă University of Washington mmp@stat.washington.edu June 22, 2015 Lorentz Center Workshop on Clusters, Games and Axioms Outline Paradigms for clustering
Effective Latent Space Graph-based Re-ranking Model with Global Consistency
 Effective Latent Space Graph-based Re-ranking Model with Global Consistency Feb. 12, 2009 1 Outline Introduction Related work Methodology Graph-based re-ranking model Learning a latent space graph A case
Effective Latent Space Graph-based Re-ranking Model with Global Consistency Feb. 12, 2009 1 Outline Introduction Related work Methodology Graph-based re-ranking model Learning a latent space graph A case
 http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
http://www.xkcd.com/233/ Text Clustering David Kauchak cs160 Fall 2009 adapted from: http://www.stanford.edu/class/cs276/handouts/lecture17-clustering.ppt Administrative 2 nd status reports Paper review
Segmentation Computer Vision Spring 2018, Lecture 27
 Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Segmentation http://www.cs.cmu.edu/~16385/ 16-385 Computer Vision Spring 218, Lecture 27 Course announcements Homework 7 is due on Sunday 6 th. - Any questions about homework 7? - How many of you have
Finding Clusters 1 / 60
 Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Finding Clusters Types of Clustering Approaches: Linkage Based, e.g. Hierarchical Clustering Clustering by Partitioning, e.g. k-means Density Based Clustering, e.g. DBScan Grid Based Clustering 1 / 60
Object Classification Problem
 HIERARCHICAL OBJECT CATEGORIZATION" Gregory Griffin and Pietro Perona. Learning and Using Taxonomies For Fast Visual Categorization. CVPR 2008 Marcin Marszalek and Cordelia Schmid. Constructing Category
HIERARCHICAL OBJECT CATEGORIZATION" Gregory Griffin and Pietro Perona. Learning and Using Taxonomies For Fast Visual Categorization. CVPR 2008 Marcin Marszalek and Cordelia Schmid. Constructing Category
Density estimation. In density estimation problems, we are given a random from an unknown density. Our objective is to estimate
 Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Data Clustering. Danushka Bollegala
 Data Clustering Danushka Bollegala Outline Why cluster data? Clustering as unsupervised learning Clustering algorithms k-means, k-medoids agglomerative clustering Brown s clustering Spectral clustering
Data Clustering Danushka Bollegala Outline Why cluster data? Clustering as unsupervised learning Clustering algorithms k-means, k-medoids agglomerative clustering Brown s clustering Spectral clustering
Chapter DM:II. II. Cluster Analysis
 Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Chapter DM:II II. Cluster Analysis Cluster Analysis Basics Hierarchical Cluster Analysis Iterative Cluster Analysis Density-Based Cluster Analysis Cluster Evaluation Constrained Cluster Analysis DM:II-1
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University
 Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Data Mining Chapter 9: Descriptive Modeling Fall 2011 Ming Li Department of Computer Science and Technology Nanjing University Descriptive model A descriptive model presents the main features of the data
Unsupervised Learning. Clustering and the EM Algorithm. Unsupervised Learning is Model Learning
 Unsupervised Learning Clustering and the EM Algorithm Susanna Ricco Supervised Learning Given data in the form < x, y >, y is the target to learn. Good news: Easy to tell if our algorithm is giving the
Unsupervised Learning Clustering and the EM Algorithm Susanna Ricco Supervised Learning Given data in the form < x, y >, y is the target to learn. Good news: Easy to tell if our algorithm is giving the
Segmentation. Bottom Up Segmentation
 Segmentation Bottom up Segmentation Semantic Segmentation Bottom Up Segmentation 1 Segmentation as clustering Depending on what we choose as the feature space, we can group pixels in different ways. Grouping
Segmentation Bottom up Segmentation Semantic Segmentation Bottom Up Segmentation 1 Segmentation as clustering Depending on what we choose as the feature space, we can group pixels in different ways. Grouping
Clustering K-means. Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, Carlos Guestrin
 Clustering K-means Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, 2014 Carlos Guestrin 2005-2014 1 Clustering images Set of Images [Goldberger et al.] Carlos Guestrin 2005-2014
Clustering K-means Machine Learning CSEP546 Carlos Guestrin University of Washington February 18, 2014 Carlos Guestrin 2005-2014 1 Clustering images Set of Images [Goldberger et al.] Carlos Guestrin 2005-2014
Normalized cuts and image segmentation
 Normalized cuts and image segmentation Department of EE University of Washington Yeping Su Xiaodan Song Normalized Cuts and Image Segmentation, IEEE Trans. PAMI, August 2000 5/20/2003 1 Outline 1. Image
Normalized cuts and image segmentation Department of EE University of Washington Yeping Su Xiaodan Song Normalized Cuts and Image Segmentation, IEEE Trans. PAMI, August 2000 5/20/2003 1 Outline 1. Image
Lecture 11: E-M and MeanShift. CAP 5415 Fall 2007
 Lecture 11: E-M and MeanShift CAP 5415 Fall 2007 Review on Segmentation by Clustering Each Pixel Data Vector Example (From Comanciu and Meer) Review of k-means Let's find three clusters in this data These
Lecture 11: E-M and MeanShift CAP 5415 Fall 2007 Review on Segmentation by Clustering Each Pixel Data Vector Example (From Comanciu and Meer) Review of k-means Let's find three clusters in this data These
Cluster Analysis. Jia Li Department of Statistics Penn State University. Summer School in Statistics for Astronomers IV June 9-14, 2008
 Cluster Analysis Jia Li Department of Statistics Penn State University Summer School in Statistics for Astronomers IV June 9-1, 8 1 Clustering A basic tool in data mining/pattern recognition: Divide a
Cluster Analysis Jia Li Department of Statistics Penn State University Summer School in Statistics for Astronomers IV June 9-1, 8 1 Clustering A basic tool in data mining/pattern recognition: Divide a
What is Clustering? Clustering. Characterizing Cluster Methods. Clusters. Cluster Validity. Basic Clustering Methodology
 Clustering Unsupervised learning Generating classes Distance/similarity measures Agglomerative methods Divisive methods Data Clustering 1 What is Clustering? Form o unsupervised learning - no inormation
Clustering Unsupervised learning Generating classes Distance/similarity measures Agglomerative methods Divisive methods Data Clustering 1 What is Clustering? Form o unsupervised learning - no inormation
Machine learning - HT Clustering
 Machine learning - HT 2016 10. Clustering Varun Kanade University of Oxford March 4, 2016 Announcements Practical Next Week - No submission Final Exam: Pick up on Monday Material covered next week is not
Machine learning - HT 2016 10. Clustering Varun Kanade University of Oxford March 4, 2016 Announcements Practical Next Week - No submission Final Exam: Pick up on Monday Material covered next week is not
Information Retrieval and Organisation
 Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Information Retrieval and Organisation Chapter 16 Flat Clustering Dell Zhang Birkbeck, University of London What Is Text Clustering? Text Clustering = Grouping a set of documents into classes of similar
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Unsupervised Learning
 Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Summary: A Tutorial on Learning With Bayesian Networks
 Summary: A Tutorial on Learning With Bayesian Networks Markus Kalisch May 5, 2006 We primarily summarize [4]. When we think that it is appropriate, we comment on additional facts and more recent developments.
Summary: A Tutorial on Learning With Bayesian Networks Markus Kalisch May 5, 2006 We primarily summarize [4]. When we think that it is appropriate, we comment on additional facts and more recent developments.
Feature Selection for fmri Classification
 Feature Selection for fmri Classification Chuang Wu Program of Computational Biology Carnegie Mellon University Pittsburgh, PA 15213 chuangw@andrew.cmu.edu Abstract The functional Magnetic Resonance Imaging
Feature Selection for fmri Classification Chuang Wu Program of Computational Biology Carnegie Mellon University Pittsburgh, PA 15213 chuangw@andrew.cmu.edu Abstract The functional Magnetic Resonance Imaging