CS 179: GPU Computing
|
|
|
- Edmund Wilcox
- 5 years ago
- Views:
Transcription
1 CS 179: GPU Computing LECTURE 2: INTRO TO THE SIMD LIFESTYLE AND GPU INTERNALS
2 Recap Can use GPU to solve highly parallelizable problems Straightforward extension to C++ Separate CUDA code into.cu and.cuh files and compile with nvcc to create object files (.o files) Looked at the a[] + b[] -> c[] example
3 Recap If you forgot everything, just make sure you understand that CUDA is simply an extension of other bits of code you write!!!! Evident in.cu/.cuh vs.cpp/.hpp distinction.cu/.cuh is compiled by nvcc to produce a.o file.cpp/.hpp is compiled by g++ and the.o file from the CUDA code is simply linked in using a "#include xxx.cuh" call No different from how you link in.o files from normal C++ code
4 .cu/.cuh vs.cpp/.hpp
5 .cu/.cuh vs.cpp/.hpp
6 .cu/.cuh vs.cpp/.hpp
7 .cu/.cuh vs.cpp/.hpp
 Grid - A group of one or more blocks.")
8 Thread Block Organization Keywords Keywords you MUST know to code in CUDA: Thread - Distributed by the CUDA runtime (threadidx) Block - A user defined group of 1 to ~512 threads (blockidx) Grid - A group of one or more blocks. A grid is created for each CUDA kernel function called
; // defines a grid of 256 x 1 x 1 blocks dim3 block(512, 512); // defines a block of 512 x 512 x 1 threads foo<<<grid,")
9 Block and Grid Dimensions You can use a struct (defined in vector_types.h) called dim3 to define your Grid and Block dimensions. dim3 grid(256); // defines a grid of 256 x 1 x 1 blocks dim3 block(512, 512); // defines a block of 512 x 512 x 1 threads foo<<<grid, block>>>(...);

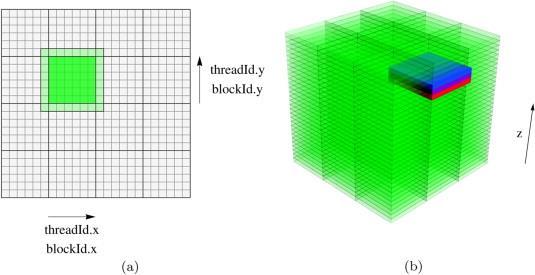
10 Grid/Block/Thread Visualized
11 Single Instruction, Multiple Data (SIMD) SIMD describes a class of instructions which perform the same operation on multiple registers simultaneously. Example: Add some scalar to 3 registers, storing the output for each addition in those registers. Used to increase the brightness of a pixel CPUs also have SIMD instructions and are very important for applications that need to do a lot of number crunching Video codecs like x264/x265 make extensive use of SIMD instructions to speed up video encoding and decoding.
12 SIMD continued Converting an algorithm to use SIMD is usually called Vectorizing Not every algorithm can benefit from this or even be vectorized at all, e.x. Parsing. Using SIMD instructions is not always beneficial though. Even using the SIMD hardware requires additional power, and thus waste heat. If the gains are small it probably isn t worth the additional complexity. Optimizing compilers like GCC and LLVM are still being trained to be able to vectorize code usefully, though there has been many exciting developments on this front in the last 2 years and is an active area of study.

13 Thread blocks and Warps visualized Copyright Games Workshop inc.
14 Keywords you MUST know to code WELL in CUDA Streaming Multiprocessor Each contains ~128 CUDA cores (which execute a thread) and their associated cache. Warp - A scheduling unit of up to 32 threads (all within the same block) Warp Divergence A condition where threads within a warp need to execute different instructions in order to continue executing their kernel. Causes threads to execute sequentially, in most cases ruining parallel performance As of the Kepler (2012) architecture each Warp can have at most 2 branches, starting with Volta (2017) this condition has been nearly eliminated. For this class assume your code must only branch at most twice as we are not yet allocating Volta GPUs to this class.

15 What a modern GPU looks like
16 Inside a GPU The black Xs are just crossing out things you don t have to think about just yet. You'll learn about them later
17 Inside a GPU Think of Device Memory (we will also refer to it as Global Memory) as a RAM for your GPU Faster than getting memory from the actual RAM but still can be faster Will come back to this in future lectures GPUs have many Streaming Multiprocessors (SMs) Each SM has multiple processors but only one instruction unit Groups of processors must run the exact same set of instructions at any given time with in a single SM
18 Inside a GPU When a kernel (the thing you define in.cu files) is called, the task is divided up into threads Each thread handles a small portion of the given task The threads are divided into a Grid of Blocks Both Grids and Blocks are 3 dimensional e.g. dim3 dimblock(8, 8, 8); dim3 dimgrid(100, 100, 1); Kernel<<<dimGrid, dimblock>>>( ); However, we'll often only work with 1 dimensional grids and blocks e.g. Kernel<<<block_count, block_size>>>( );
19 Inside a GPU Maximum number of threads per block count is usually 512 or 1024 depending on the machine Maximum number of blocks per grid is usually If you go over either of these numbers your GPU will just give up or output garbage data Much of GPU programming is dealing with this kind of hardware limitations! Get used to it This limitation also means that your Kernel must compensate for the fact that you may not have enough threads to individually allocate to your data points Will show how to do this later (this lecture)
20 Inside a GPU Each block is assigned to an SM Inside the SM, the block is divided into Warps of threads Warps consist of 32 threads All 32 threads MUST run the exact same set of instructions at the same time Due to the fact that there is only one instruction unit Warps are run concurrently in an SM If your Kernel tries to have threads do different things in a single warp (using if statements for example), the two tasks will be run sequentially Called Warp Divergence (NOT GOOD)
21 Inside a GPU (fun hardware info) In Fermi Architecture (i.e. GPUs with Compute Capability 2.x), each SM has 32 cores, later architectures have more. e.g. GTX 400, 500 series 32 cores is not what makes each warp have 32 threads. Previous architecture also had 32 threads per warp but had less than 32 cores per SM Some early Pascal (2016) GPUs (GP100) had 64 cores per SM, but later chips in that generation (GP104) had 128 core model.

22 Streaming Multiprocessor Shown here is a Pascal GP104 GPU Streaming Multiprocessor that can be found in a GTX1080 graphics card. The exact amount of Cache and Shared Memory differ between GPU models, and even more so between different architectures. Whitepapers with exact information can be gotten from Nvidia (use Google) L.pdf nvidia kepler whitepaper
23 A[] + B[] -> C[] (again)
24 A[] + B[] -> C[] (again)
25 A[] + B[] -> C[] (again)
26 Questions so far?

27 Stuff that will be useful later
28 Stuff that will be useful later
29 Stuff that will be useful later
30 Next Time... Global Memory access is not that fast Tends to be the bottleneck in many GPU programs Especially true if done stupidly We'll look at what "stupidly" means Optimize memory access by utilizing hardware specific memory access patterns Optimize memory access by utilizing different caches that come with the GPU
What is GPU? CS 590: High Performance Computing. GPU Architectures and CUDA Concepts/Terms
 CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CS 590: High Performance Computing GPU Architectures and CUDA Concepts/Terms Fengguang Song Department of Computer & Information Science IUPUI What is GPU? Conventional GPUs are used to generate 2D, 3D
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179 Lecture 4. GPU Compute Architecture
 CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
CS 179 Lecture 4 GPU Compute Architecture 1 This is my first lecture ever Tell me if I m not speaking loud enough, going too fast/slow, etc. Also feel free to give me lecture feedback over email or at
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Optimizing CUDA for GPU Architecture. CSInParallel Project
 Optimizing CUDA for GPU Architecture CSInParallel Project August 13, 2014 CONTENTS 1 CUDA Architecture 2 1.1 Physical Architecture........................................... 2 1.2 Virtual Architecture...........................................
Optimizing CUDA for GPU Architecture CSInParallel Project August 13, 2014 CONTENTS 1 CUDA Architecture 2 1.1 Physical Architecture........................................... 2 1.2 Virtual Architecture...........................................
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 28 March 2019 HW#8 (CUDA) posted. Project topics due. Announcements 1 CUDA installing On Linux
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
INTRODUCTION TO GPU COMPUTING WITH CUDA. Topi Siro
 INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
INTRODUCTION TO GPU COMPUTING WITH CUDA Topi Siro 19.10.2015 OUTLINE PART I - Tue 20.10 10-12 What is GPU computing? What is CUDA? Running GPU jobs on Triton PART II - Thu 22.10 10-12 Using libraries Different
Overview. Lecture 1: an introduction to CUDA. Hardware view. Hardware view. hardware view software view CUDA programming
 Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Overview Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk hardware view software view Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Lecture 1 p.
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU 101. Mike Bailey. Oregon State University. Oregon State University. Computer Graphics gpu101.pptx. mjb April 23, 2017
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
GPU 101. Mike Bailey. Oregon State University
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
An Introduction to GPU Architecture and CUDA C/C++ Programming. Bin Chen April 4, 2018 Research Computing Center
 An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
An Introduction to GPU Architecture and CUDA C/C++ Programming Bin Chen April 4, 2018 Research Computing Center Outline Introduction to GPU architecture Introduction to CUDA programming model Using the
CSE 591: GPU Programming. Programmer Interface. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591: GPU Programming Programmer Interface Klaus Mueller Computer Science Department Stony Brook University Compute Levels Encodes the hardware capability of a GPU card newer cards have higher compute
CSE 591: GPU Programming Programmer Interface Klaus Mueller Computer Science Department Stony Brook University Compute Levels Encodes the hardware capability of a GPU card newer cards have higher compute
CUDA PROGRAMMING MODEL. Carlo Nardone Sr. Solution Architect, NVIDIA EMEA
 CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
CUDA PROGRAMMING MODEL Carlo Nardone Sr. Solution Architect, NVIDIA EMEA CUDA: COMMON UNIFIED DEVICE ARCHITECTURE Parallel computing architecture and programming model GPU Computing Application Includes
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
CS6963: Parallel Programming for GPUs Midterm Exam March 25, 2009
 1 CS6963: Parallel Programming for GPUs Midterm Exam March 25, 2009 Instructions: This is an in class, open note exam. Please use the paper provided to submit your responses. You can include additional
1 CS6963: Parallel Programming for GPUs Midterm Exam March 25, 2009 Instructions: This is an in class, open note exam. Please use the paper provided to submit your responses. You can include additional
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Introduction to CUDA! Jonathan Baca!
 Introduction to CUDA! Jonathan Baca! Installing CUDA! CUDA-Ready System! Make sure you have the right Linux! Make sure that gcc is installed! Download the software! Install the drivers (NVIDIA)! Install
Introduction to CUDA! Jonathan Baca! Installing CUDA! CUDA-Ready System! Make sure you have the right Linux! Make sure that gcc is installed! Download the software! Install the drivers (NVIDIA)! Install
Introduction to CUDA CME343 / ME May James Balfour [ NVIDIA Research
 Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
Introduction to CUDA CME343 / ME339 18 May 2011 James Balfour [ jbalfour@nvidia.com] NVIDIA Research CUDA Programing system for machines with GPUs Programming Language Compilers Runtime Environments Drivers
University of Bielefeld
 Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Geistes-, Natur-, Sozial- und Technikwissenschaften gemeinsam unter einem Dach Introduction to GPU Programming using CUDA Olaf Kaczmarek University of Bielefeld STRONGnet Summerschool 2011 ZIF Bielefeld
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
CUDA. GPU Computing. K. Cooper 1. 1 Department of Mathematics. Washington State University
 GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
Supporting Data Parallelism in Matcloud: Final Report
 Supporting Data Parallelism in Matcloud: Final Report Yongpeng Zhang, Xing Wu 1 Overview Matcloud is an on-line service to run Matlab-like script on client s web browser. Internally it is accelerated by
Supporting Data Parallelism in Matcloud: Final Report Yongpeng Zhang, Xing Wu 1 Overview Matcloud is an on-line service to run Matlab-like script on client s web browser. Internally it is accelerated by
Lecture 1: an introduction to CUDA
 Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
Lecture 1: an introduction to CUDA Mike Giles mike.giles@maths.ox.ac.uk Oxford University Mathematical Institute Oxford e-research Centre Lecture 1 p. 1 Overview hardware view software view CUDA programming
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
COSC 6385 Computer Architecture. - Data Level Parallelism (II)
") COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
COSC 6385 Computer Architecture - Data Level Parallelism (II) Fall 2013 SIMD Instructions Originally developed for Multimedia applications Same operation executed for multiple data items Uses a fixed length
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
GPU Profiling and Optimization. Scott Grauer-Gray
 GPU Profiling and Optimization Scott Grauer-Gray Benefits of GPU Programming "Free" speedup with new architectures More cores in new architecture Improved features such as L1 and L2 cache Increased shared/local
GPU Profiling and Optimization Scott Grauer-Gray Benefits of GPU Programming "Free" speedup with new architectures More cores in new architecture Improved features such as L1 and L2 cache Increased shared/local
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
CUDA Parallelism Model
 GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
GPU Teaching Kit Accelerated Computing CUDA Parallelism Model Kernel-Based SPMD Parallel Programming Multidimensional Kernel Configuration Color-to-Grayscale Image Processing Example Image Blur Example
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
Scientific discovery, analysis and prediction made possible through high performance computing.
 Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Scientific discovery, analysis and prediction made possible through high performance computing. An Introduction to GPGPU Programming Bob Torgerson Arctic Region Supercomputing Center November 21 st, 2013
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
Improving Performance of Machine Learning Workloads
 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
CS377P Programming for Performance GPU Programming - II
 CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
CUDA Kenjiro Taura 1 / 36
 CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
CUDA Kenjiro Taura 1 / 36 Contents 1 Overview 2 CUDA Basics 3 Kernels 4 Threads and thread blocks 5 Moving data between host and device 6 Data sharing among threads in the device 2 / 36 Contents 1 Overview
GPU Computing: Introduction to CUDA. Dr Paul Richmond
 GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU Computing: Introduction to CUDA Dr Paul Richmond http://paulrichmond.shef.ac.uk This lecture CUDA Programming Model CUDA Device Code CUDA Host Code and Memory Management CUDA Compilation Programming
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
Lecture 11: GPU programming
 Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
Lecture 11: GPU programming David Bindel 4 Oct 2011 Logistics Matrix multiply results are ready Summary on assignments page My version (and writeup) on CMS HW 2 due Thursday Still working on project 2!
NVIDIA GPU CODING & COMPUTING
 NVIDIA GPU CODING & COMPUTING WHY GPU S? ARCHITECTURE & PROGRAM MODEL CPU v. GPU Multiprocessor Model Memory Model Memory Model: Thread Level Programing Model: Logical Mapping of Threads Programing Model:
NVIDIA GPU CODING & COMPUTING WHY GPU S? ARCHITECTURE & PROGRAM MODEL CPU v. GPU Multiprocessor Model Memory Model Memory Model: Thread Level Programing Model: Logical Mapping of Threads Programing Model:
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Reductions and Low-Level Performance Considerations CME343 / ME May David Tarjan NVIDIA Research
 Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
CS179 GPU Programming Introduction to CUDA. Lecture originally by Luke Durant and Tamas Szalay
 Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
Introduction to CUDA Lecture originally by Luke Durant and Tamas Szalay Today CUDA - Why CUDA? - Overview of CUDA architecture - Dense matrix multiplication with CUDA 2 Shader GPGPU - Before current generation,
GPU Programming Using CUDA. Samuli Laine NVIDIA Research
 GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
GPU Programming Using CUDA Samuli Laine NVIDIA Research Today GPU vs CPU Different architecture, different workloads Basics of CUDA Executing code on GPU Managing memory between CPU and GPU CUDA API Quick
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Tuning CUDA Applications for Fermi. Version 1.2
 Tuning CUDA Applications for Fermi Version 1.2 7/21/2010 Next-Generation CUDA Compute Architecture Fermi is NVIDIA s next-generation CUDA compute architecture. The Fermi whitepaper [1] gives a detailed
Tuning CUDA Applications for Fermi Version 1.2 7/21/2010 Next-Generation CUDA Compute Architecture Fermi is NVIDIA s next-generation CUDA compute architecture. The Fermi whitepaper [1] gives a detailed
CS 179: GPU Programming LECTURE 5: GPU COMPUTE ARCHITECTURE FOR THE LAST TIME
 CS 179: GPU Programming LECTURE 5: GPU COMPUTE ARCHITECTURE FOR THE LAST TIME 1 Last time... GPU Memory System Different kinds of memory pools, caches, etc Different optimization techniques 2 Warp Schedulers
CS 179: GPU Programming LECTURE 5: GPU COMPUTE ARCHITECTURE FOR THE LAST TIME 1 Last time... GPU Memory System Different kinds of memory pools, caches, etc Different optimization techniques 2 Warp Schedulers
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
NVidia s GPU Microarchitectures. By Stephen Lucas and Gerald Kotas
 NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
CS 220: Introduction to Parallel Computing. Introduction to CUDA. Lecture 28
 CS 220: Introduction to Parallel Computing Introduction to CUDA Lecture 28 Today s Schedule Project 4 Read-Write Locks Introduction to CUDA 5/2/18 CS 220: Parallel Computing 2 Today s Schedule Project
CS 220: Introduction to Parallel Computing Introduction to CUDA Lecture 28 Today s Schedule Project 4 Read-Write Locks Introduction to CUDA 5/2/18 CS 220: Parallel Computing 2 Today s Schedule Project
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes.
 HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
HiPANQ Overview of NVIDIA GPU Architecture and Introduction to CUDA/OpenCL Programming, and Parallelization of LDPC codes Ian Glendinning Outline NVIDIA GPU cards CUDA & OpenCL Parallel Implementation
GPGPU/CUDA/C Workshop 2012
 GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
GPGPU/CUDA/C Workshop 2012 Day-2: Intro to CUDA/C Programming Presenter(s): Abu Asaduzzaman Chok Yip Wichita State University July 11, 2012 GPGPU/CUDA/C Workshop 2012 Outline Review: Day-1 Brief history
Flynn s Classification (1966)
") COEN-4730 Computer Architecture Lecture 9 Intro to Graphics Processing Units (GPUs) Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
COEN-4730 Computer Architecture Lecture 9 Intro to Graphics Processing Units (GPUs) Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
CUDA Programming. Aiichiro Nakano
 CUDA Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
CUDA Programming Aiichiro Nakano Collaboratory for Advanced Computing & Simulations Department of Computer Science Department of Physics & Astronomy Department of Chemical Engineering & Materials Science
CS 179: GPU Computing. Lecture 2: The Basics
 CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
CS 179: GPU Computing Lecture 2: The Basics Recap Can use GPU to solve highly parallelizable problems Performance benefits vs. CPU Straightforward extension to C language Disclaimer Goal for Week 1: Fast-paced
Parallelising Pipelined Wavefront Computations on the GPU
 Parallelising Pipelined Wavefront Computations on the GPU S.J. Pennycook G.R. Mudalige, S.D. Hammond, and S.A. Jarvis. High Performance Systems Group Department of Computer Science University of Warwick
Parallelising Pipelined Wavefront Computations on the GPU S.J. Pennycook G.R. Mudalige, S.D. Hammond, and S.A. Jarvis. High Performance Systems Group Department of Computer Science University of Warwick
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
GPU. Ben de Waal Summer 2008
 GPU Ben de Waal Summer 2008 Agenda Quick Roadmap A few observations And a few positions 2 GPUs are Great at Graphics Crysis 2006 Crytek / Electronic Arts Hellgate: London 2005-2006 Flagship 3 Studios,
GPU Ben de Waal Summer 2008 Agenda Quick Roadmap A few observations And a few positions 2 GPUs are Great at Graphics Crysis 2006 Crytek / Electronic Arts Hellgate: London 2005-2006 Flagship 3 Studios,
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Register file. A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks.
 is partitioned among the threads of the dispatched blocks.") Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
Sharing the resources of an SM Warp 0 Warp 1 Warp 47 Register file A single large register file (ex. 16K registers) is partitioned among the threads of the dispatched blocks Shared A single SRAM (ex. 16KB)
CUDA Threads. Origins. ! The CPU processing core 5/4/11
 5/4/11 CUDA Threads James Gain, Michelle Kuttel, Sebastian Wyngaard, Simon Perkins and Jason Brownbridge { jgain mkuttel sperkins jbrownbr}@cs.uct.ac.za swyngaard@csir.co.za 3-6 May 2011! The CPU processing
5/4/11 CUDA Threads James Gain, Michelle Kuttel, Sebastian Wyngaard, Simon Perkins and Jason Brownbridge { jgain mkuttel sperkins jbrownbr}@cs.uct.ac.za swyngaard@csir.co.za 3-6 May 2011! The CPU processing
General Purpose GPU programming (GP-GPU) with Nvidia CUDA. Libby Shoop
 with Nvidia CUDA. Libby Shoop") General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
Graph Partitioning. Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM.
 Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
Graph Partitioning Standard problem in parallelization, partitioning sparse matrix in nearly independent blocks or discretization grids in FEM. Partition given graph G=(V,E) in k subgraphs of nearly equal
Programmer's View of Execution Teminology Summary
 CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 28: GP-GPU Programming GPUs Hardware specialized for graphics calculations Originally developed to facilitate the use of CAD programs
CS 61C: Great Ideas in Computer Architecture (Machine Structures) Lecture 28: GP-GPU Programming GPUs Hardware specialized for graphics calculations Originally developed to facilitate the use of CAD programs
Lecture 10!! Introduction to CUDA!
 1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
1(50) Lecture 10 Introduction to CUDA Ingemar Ragnemalm Information Coding, ISY 1(50) Laborations Some revisions may happen while making final adjustments for Linux Mint. Last minute changes may occur.
Generic Polyphase Filterbanks with CUDA
 Generic Polyphase Filterbanks with CUDA Jan Krämer German Aerospace Center Communication and Navigation Satellite Networks Weßling 04.02.2017 Knowledge for Tomorrow www.dlr.de Slide 1 of 27 > Generic Polyphase
Generic Polyphase Filterbanks with CUDA Jan Krämer German Aerospace Center Communication and Navigation Satellite Networks Weßling 04.02.2017 Knowledge for Tomorrow www.dlr.de Slide 1 of 27 > Generic Polyphase
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
GPU CUDA Programming
 GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications
GPU CUDA Programming 이정근 (Jeong-Gun Lee) 한림대학교컴퓨터공학과, 임베디드 SoC 연구실 www.onchip.net Email: Jeonggun.Lee@hallym.ac.kr ALTERA JOINT LAB Introduction 차례 Multicore/Manycore and GPU GPU on Medical Applications