Distributed systems: paradigms and models Motivations
|
|
|
- Chester Richard
- 6 years ago
- Views:
Transcription

 in Computer Science and")
1 Distributed systems: paradigms and models Motivations Prof. Marco Danelutto Dept. Computer Science University of Pisa Master Degree (Laurea Magistrale) in Computer Science and Networking Academic Year
2 Contents Hardware motivations CPU evolution HPC Clouds Software motivations innovative paradigms can be moved to different frameworks 2

3 Moore s law Moore's original statement can be found in his publication "Cramming more components onto integrated circuits", Electronics Magazine 19 April 1965: The complexity for minimum component costs has increased at a rate of roughly a factor of two per year... Certainly over the short term this rate can be expected to continue, if not to increase. Over the longer term, the rate of increase is a bit more uncertain, although there is no reason to believe it will not remain nearly constant for at least 10 years. That means by 1975, the number of components per integrated circuit for minimum cost will be 65,000. I believe that such a large circuit can be built on a single wafer. 3
4 Moore s law evolution Transistors/gates doubling every 2 years more and more powerful single processor systems Cores doubling every two years simpler cores more complex (?) memory hierarchy more complex interconnection structure 4
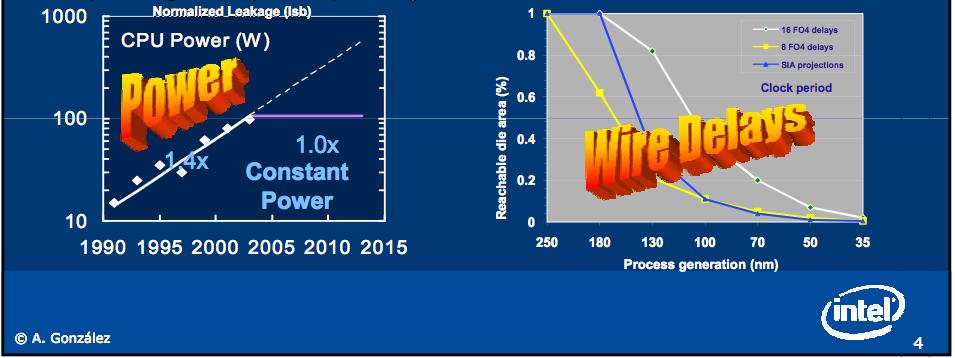
5 Why? doubling core exploits existing technology (and trends) keeping reasonable power consumption doubling the frequency of a single core chip costs much more than putting two simpler cores on the same chip Perf = Freq x IPC Power = DynamicCapacitance x Volt x Volt x Freq ( 5

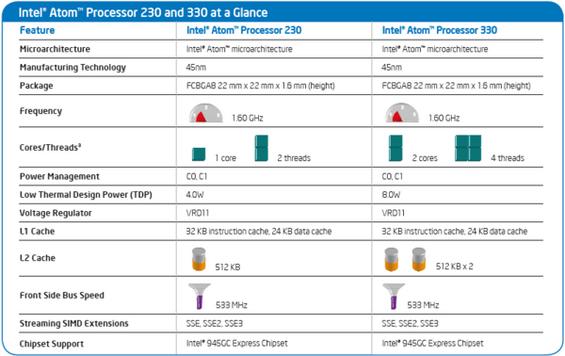
6 Commodity processors 6
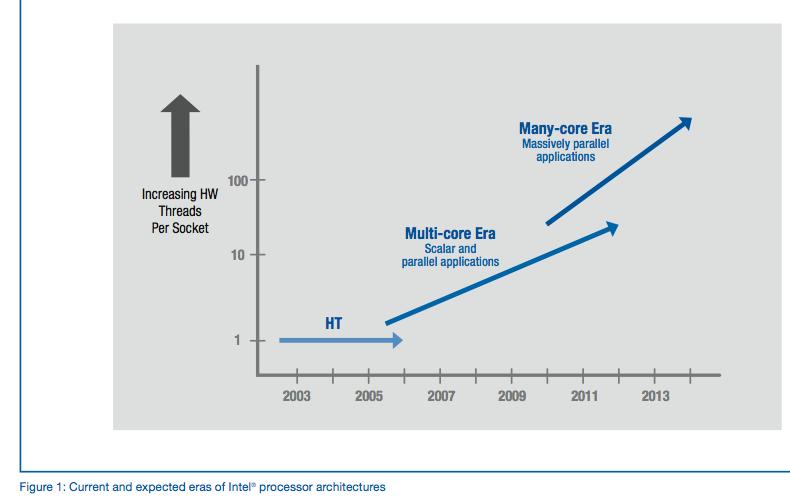
7 Intel perspective 7

8 Intel perspective (2) 8

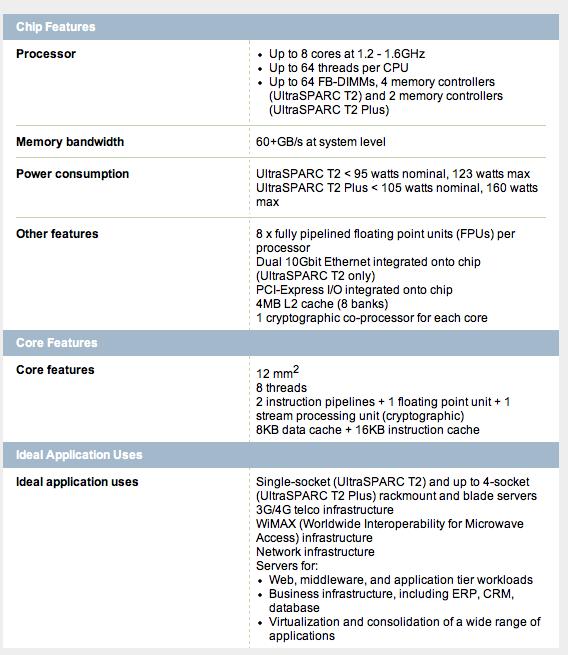
9 Commodity processors: non Intel 9


10 Commodity processors: niche products 10

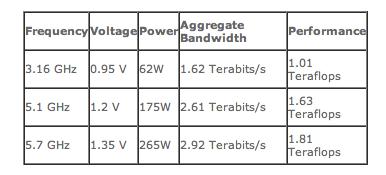

11 Research processors: Intel 80 cores 11
 10x8 core FP, 1,28 TFlops Tile: router: addesses each core on chip, implements the mesh VLIW processor (96 bit x instruction, up to 8 ops per")
12 More in detail... 4Ghz chip with mesh (logical and physical) 10x8 core FP, 1,28 TFlops Tile: router: addesses each core on chip, implements the mesh VLIW processor (96 bit x instruction, up to 8 ops per cycle), in-order-execution, 32 registers (6Read/4Write), 2K Data, 3K Instruction cache, 2 FPU (9 stages, 2FLOPs/cycle sustained), Cicli: FPU:9, Ld/St:2, Snd/ Rcv:2, Jmp/Br:1 12

13 13
14 13
15 14


16 15


17 16

18 GPUs / FPGAs 17

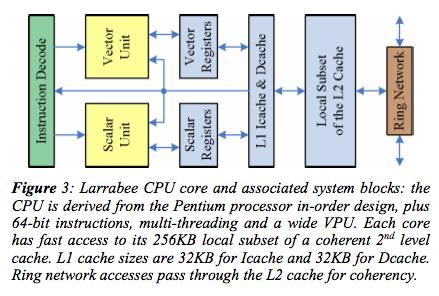
19 Intel Larrabee 18
20 Not only processors: FPGAs q1_embedded_xilinx.htm&usg= PXXvIQmng-24QwOWFUFfFuf1lS4=&h=380&w=650&sz=71&hl=en&start=6&um=1&tbnid=LaX1pZKYodDqSM:&tbnh=80&tbnw=137&prev=/images%3Fq%3Dprocessor %2Bevolution%26hl%3Den%26client%3Dsafari%26rls%3Den%26sa%3DN%26um%3D1 19


21 Not only processors: FPGAs q1_embedded_xilinx.htm&usg= PXXvIQmng-24QwOWFUFfFuf1lS4=&h=380&w=650&sz=71&hl=en&start=6&um=1&tbnid=LaX1pZKYodDqSM:&tbnh=80&tbnw=137&prev=/images%3Fq%3Dprocessor %2Bevolution%26hl%3Den%26client%3Dsafari%26rls%3Den%26sa%3DN%26um%3D1 19
22 Consequence: programming model Heterogeneous computing coming to the scene more and more adaptivity required in the code more and more special purpose solutions needed (transparent to the user) 20

23 Energy concerns/tradeoffs
24 Energy concerns/tradeoff 22
25 Consequence: programming model Faster single core systems faster dusty deck code Multi-many core require parallel / distributed code UMA NUMA 23
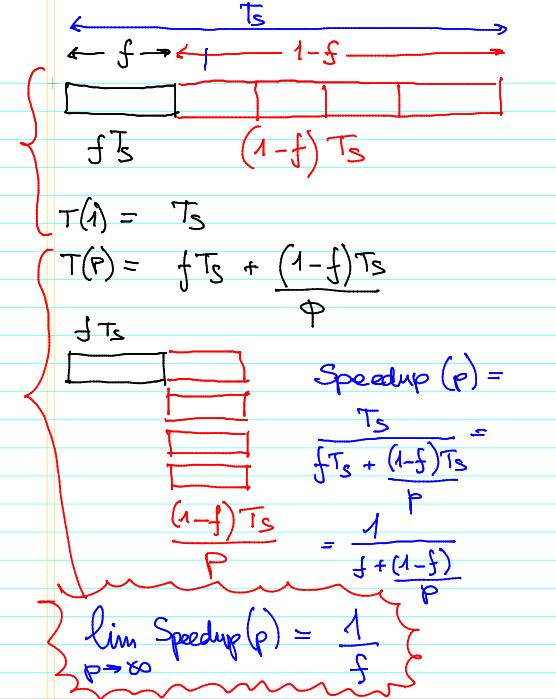
26 But... Amdhal law is still there serial fraction = f (% of code not parallelizable) p processors available to parallelize the non serial fraction (1-f) Speedup(p) = Ts / (f Ts + (1-f) (Ts / p)) = 1 / (f + (1-f)/p) asymptotically (when p increases): Speedup(p) = 1 / f 24
27 25
28 HPC evolution: Twice per year top 500 installations measured on standard benchmarks mostly installations from government, military, education, companies Significantly reflecting tendencies kind of Formula 1 in the parallel computing scenario e.g. interconnection networks scaled down to small COW/NOWs 26
29 Top 500: processor family 27
30 Top 500: processor family 27

31 Top 500: processor family 27
32 Top 500: operating system 28
33 Top 500: operating system 28

34 Top 500: operating system 28
35 Top 500: Interconnection network 29
36 Top 500: Interconnection network 29

37 Top 500: Interconnection network 29
38 Top 500: number of processors 30
39 Top 500: number of processors 30

40 Top 500: number of processors 30
41 Moore s law in HPC The Sourcebook of Parallel Computing, Dongarra, Foster, Fox, Gropp, Kennedy, Torczon, White editors,
42 Consequence: programming model Top parallel computing moving towards COW/NOW with smaller and smaller latencies and larger and larger bandwidth 32
43 Evolution in the user model Single processor standard superpipeline superscalar Multi processor ( 70 80) multi/many core ( 00) NOW COW ( 80 90) distributed architecture SSI GRID (late 90 00) meta computing grid (middleware) 33
44 Cloud 34
45 Cloud 35

46 Amazon cloud 36
47 Amazon cloud 37

48 Amazon cloud 37

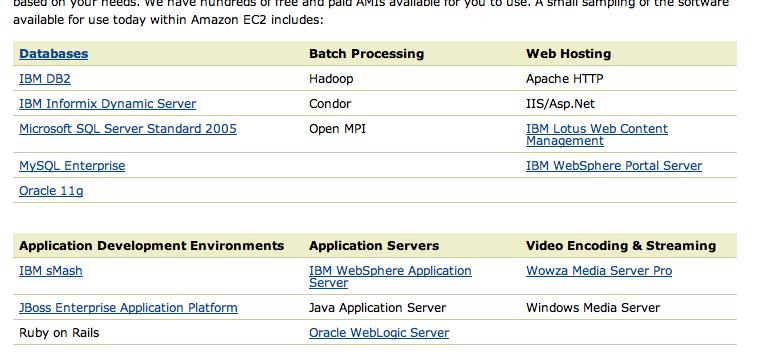
49 Amazon cloud 38
50 Consequences More and more general architecture virtualization (host, network, operating system,...) Need to adapt to the unknown heterogeneity in hw resources (computing, networking) 39
51 Software evolution Innovative concepts algorithmic skeletons, design patterns, coordination/ orchestration patterns/constructs all introduce efficiency/programmability/... at the price of limitations to programmer freedom software components extreme modular programming (interoperability, commodity and legacy code, portability (w.r.t. framework) services full decoupling usage and implementation 40
52 Software evolution: structured programming Skeletons mostly from HPC community Design patterns mostly from sw engineering community Different approaches language/library vs. programming methodology Different impact Successfully being moved to grids (clouds?) and distributed architectures in general 41
53 Software evolution: components and services Components mainly from sw engineering community (with HPC influences) Services mainly from the business/end user community Different approaches recently merged into a common framework (SCA by IBM et al.) Different impact SOA is everywhere (SaS SOA, IaaS clouds,...) 42
54 Parallel vs. distributed computing McDaniel, George, ed. IBM Dictionary of Computing. New York, NY: McGraw-Hill, Inc., Parallel computing a computer system in which interconnected processors perform concurrent or simultaneous execution of two or more processes Institute of Electrical and Electronics Engineers. IEEE Standard Computer Dictionary: A Compilation of IEEE Standard Computer Glossaries. New York, NY: 1990 Distributed computing a computer system in which several interconnected computers share the computing tasks assigned to the system Tanembaum Distributed systems: principles and paradigms, 2nd edition, 2006 Distributed system: a collection of independent computers presenting to the user a single, coherent system image 43

55 Distributed vs. parallel computing 44
56 Distributed vs. parallel computing 45
57 Distributed vs. parallel computing Distributed computing Parallel computing 45
58 Have a look at standard books indexes... Tanembaum, Van Steen Distributed systems: principles and paradigms, 2nd edition, 2006 Introduction, Architectures, Processes, Communications, Naming, Synchronization, Consistency & replicas, Fault tolerance, Security, OO distributed systems, Distributed file system, Web distributed systems, Coordination based systems Kshemkalyani, Singhal Distributed computing: Principles, algorithms and Systems, 2008 Introduction, A model of distributed computations, Logical time, Global state and snapshot recording algorithms, Terminology and basic algorithms, Message ordering and group communication, Termination detection, Reasoning with knowledge, Distributed mutual exclusion algorithms, Deadlock detection in distributed systems, Global predicate detection, Distributed shared memory, Checkpointing and rollback recovery, Consensus and agreement algorithms, Failure detectors, Authentication in distributed systems, Self-stabilization, Peer-to-peer computing and overlay graphs. 46
59 Have a look at standard books indexes... Tanembaum, Van Steen Distributed systems: principles and paradigms, 2nd edition, 2006 Introduction, Architectures, Processes, Communications, Naming, Synchronization, Consistency & replicas, Fault tolerance, Security, OO distributed systems, Distributed file system, Web distributed systems, Coordination based systems Kshemkalyani, Singhal Distributed computing: Principles, algorithms and Systems, 2008 Introduction, A model of distributed computations, Logical time, Global state and snapshot recording algorithms, Terminology and basic algorithms, Message ordering and group communication, Termination detection, Reasoning with knowledge, Distributed mutual exclusion algorithms, Deadlock detection in distributed systems, Global predicate detection, Distributed shared memory, Checkpointing and rollback recovery, Consensus and agreement algorithms, Failure detectors, Authentication in distributed systems, Self-stabilization, Peer-to-peer computing and overlay graphs. Distributed computing 46
60 books... Grama, Gupta, Karypis, Kumar Introduction to parallel computing, 2nd edition 2003 Introduction, Parallel programming platforms, Principles of Parallel Algorithmic design, Basic communication operations, Analytical models of Parallel Programs, Programming using Message passing paradigm, Programming shared address space platforms, Dense matrix algorithms, Sorting, Graph algorithms, Search algorithms for discrete optimization problems, Dynamic programming, Fast Fourier Transform, Appendix: Complexity functions and order analysis Wilkinson, Allen Parallel programming: technique and applications using networks workstations and parallel computers, 2nd edition, 2005 PART I: BASIC TECHNIQUES Parallel computers, Message passing computing, Embarrassingly parallel computations, Partitioning and divide-and--conquer strategies, Pipelined computations, Synchronous computations, Load balancing and termination detection, Programming with shared memory, Distributed shared memory systems and programming PART II: ALGORITHMS AND APPLICATIONS Sorting algorithms, Numerical algorithms, Image processing, Searching and optimization APPENDIXES: Basic MPI routines, Basic Pthread routines, OpenMP directives, library functions and environment variables 47
61 books... Grama, Gupta, Karypis, Kumar Introduction to parallel computing, 2nd edition 2003 Introduction, Parallel programming platforms, Principles of Parallel Algorithmic design, Basic communication operations, Analytical models of Parallel Programs, Programming using Message passing paradigm, Programming shared address space platforms, Dense matrix algorithms, Sorting, Graph algorithms, Search algorithms for discrete optimization problems, Dynamic programming, Fast Fourier Transform, Appendix: Complexity functions and order analysis Wilkinson, Allen Parallel programming: technique and applications using networks workstations and parallel computers, 2nd edition, 2005 PART I: BASIC TECHNIQUES Parallel computers, Message passing computing, Embarrassingly parallel computations, Partitioning and divide-and--conquer strategies, Pipelined computations, Synchronous computations, Load balancing and termination detection, Programming with shared memory, Distributed shared memory systems and programming PART II: ALGORITHMS AND APPLICATIONS Sorting algorithms, Numerical algorithms, Image processing, Searching and optimization APPENDIXES: Basic MPI routines, Basic Pthread routines, OpenMP directives, library functions and environment variables Parallel computing 47
62 Distributed systems: paradigms and models Distributed as a kind of summary word for distributed & parallel Systems systems as a whole : hardware + software Paradigms sample paradigms proven successful to exploit parallel & distributed systems Models programming models to exploit parallel & distributed systems 48
63 Methodology Analysis look for possibilities to apply known techniques/patterns figure out performances Implementation pick up proper tools/mechanisms/models if needed build your own ad-hoc tools Debugging/Tuning rely on application structure Porting rely on tools 49
Distributed systems: paradigms and models Motivations
 Distributed systems: paradigms and models Motivations Prof. Marco Danelutto Dept. Computer Science University of Pisa Master Degree (Laurea Magistrale) in Computer Science and Networking Academic Year
Distributed systems: paradigms and models Motivations Prof. Marco Danelutto Dept. Computer Science University of Pisa Master Degree (Laurea Magistrale) in Computer Science and Networking Academic Year
High Performance Computing. Introduction to Parallel Computing
 High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
High Performance Computing Introduction to Parallel Computing Acknowledgements Content of the following presentation is borrowed from The Lawrence Livermore National Laboratory https://hpc.llnl.gov/training/tutorials
Introduction to Parallel Computing
 Introduction to Parallel Computing Chieh-Sen (Jason) Huang Department of Applied Mathematics National Sun Yat-sen University Thank Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar for providing
Introduction to Parallel Computing Chieh-Sen (Jason) Huang Department of Applied Mathematics National Sun Yat-sen University Thank Ananth Grama, Anshul Gupta, George Karypis, and Vipin Kumar for providing
Parallel Algorithms on Clusters of Multicores: Comparing Message Passing vs Hybrid Programming
 Parallel Algorithms on Clusters of Multicores: Comparing Message Passing vs Hybrid Programming Fabiana Leibovich, Laura De Giusti, and Marcelo Naiouf Instituto de Investigación en Informática LIDI (III-LIDI),
Parallel Algorithms on Clusters of Multicores: Comparing Message Passing vs Hybrid Programming Fabiana Leibovich, Laura De Giusti, and Marcelo Naiouf Instituto de Investigación en Informática LIDI (III-LIDI),
SMP and ccnuma Multiprocessor Systems. Sharing of Resources in Parallel and Distributed Computing Systems
 Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
Reference Papers on SMP/NUMA Systems: EE 657, Lecture 5 September 14, 2007 SMP and ccnuma Multiprocessor Systems Professor Kai Hwang USC Internet and Grid Computing Laboratory Email: kaihwang@usc.edu [1]
Marco Danelutto. May 2011, Pisa
 Marco Danelutto Dept. of Computer Science, University of Pisa, Italy May 2011, Pisa Contents 1 2 3 4 5 6 7 Parallel computing The problem Solve a problem using n w processing resources Obtaining a (close
Marco Danelutto Dept. of Computer Science, University of Pisa, Italy May 2011, Pisa Contents 1 2 3 4 5 6 7 Parallel computing The problem Solve a problem using n w processing resources Obtaining a (close
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
Lecture 1: Course Introduction and Overview Prof. Randy H. Katz Computer Science 252 Spring 1996
 Lecture 1: Course Introduction and Overview Prof. Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Computer Architecture Is the attributes of a [computing] system as seen by the programmer, i.e.,
Lecture 1: Course Introduction and Overview Prof. Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Computer Architecture Is the attributes of a [computing] system as seen by the programmer, i.e.,
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Multi-core Programming - Introduction
 Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Multi-core Programming - Introduction Based on slides from Intel Software College and Multi-Core Programming increasing performance through software multi-threading by Shameem Akhter and Jason Roberts,
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core. Prof. Onur Mutlu Carnegie Mellon University
 18-742 Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core Prof. Onur Mutlu Carnegie Mellon University Research Project Project proposal due: Jan 31 Project topics Does everyone have a topic?
18-742 Spring 2011 Parallel Computer Architecture Lecture 4: Multi-core Prof. Onur Mutlu Carnegie Mellon University Research Project Project proposal due: Jan 31 Project topics Does everyone have a topic?
Introduction to Parallel and Distributed Computing. Linh B. Ngo CPSC 3620
 Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
Introduction to Parallel and Distributed Computing Linh B. Ngo CPSC 3620 Overview: What is Parallel Computing To be run using multiple processors A problem is broken into discrete parts that can be solved
CS 194 Parallel Programming. Why Program for Parallelism?
 CS 194 Parallel Programming Why Program for Parallelism? Katherine Yelick yelick@cs.berkeley.edu http://www.cs.berkeley.edu/~yelick/cs194f07 8/29/2007 CS194 Lecure 1 What is Parallel Computing? Parallel
CS 194 Parallel Programming Why Program for Parallelism? Katherine Yelick yelick@cs.berkeley.edu http://www.cs.berkeley.edu/~yelick/cs194f07 8/29/2007 CS194 Lecure 1 What is Parallel Computing? Parallel
Introduction to Parallel Programming
 Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Introduction to Parallel Programming January 14, 2015 www.cac.cornell.edu What is Parallel Programming? Theoretically a very simple concept Use more than one processor to complete a task Operationally
Lecture 1. Introduction Course Overview
 Lecture 1 Introduction Course Overview Welcome to CSE 260! Your instructor is Scott Baden baden@ucsd.edu Office: room 3244 in EBU3B Office hours Week 1: Today (after class), Tuesday (after class) Remainder
Lecture 1 Introduction Course Overview Welcome to CSE 260! Your instructor is Scott Baden baden@ucsd.edu Office: room 3244 in EBU3B Office hours Week 1: Today (after class), Tuesday (after class) Remainder
Contents. Preface xvii Acknowledgments. CHAPTER 1 Introduction to Parallel Computing 1. CHAPTER 2 Parallel Programming Platforms 11
 Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Preface xvii Acknowledgments xix CHAPTER 1 Introduction to Parallel Computing 1 1.1 Motivating Parallelism 2 1.1.1 The Computational Power Argument from Transistors to FLOPS 2 1.1.2 The Memory/Disk Speed
Parallel and Distributed Systems. Programming Models. Why Parallel or Distributed Computing? What is a parallel computer?
 Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Computer Architecture Lecture 27: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015
 18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
CMSC Computer Architecture Lecture 12: Multi-Core. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
CMSC 22200 Computer Architecture Lecture 12: Multi-Core Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 4 " Due: 11:49pm, Saturday " Two late days with penalty! Exam I " Grades out on
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448. The Greed for Speed
 Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Multiprocessors and Thread Level Parallelism Chapter 4, Appendix H CS448 1 The Greed for Speed Two general approaches to making computers faster Faster uniprocessor All the techniques we ve been looking
Fundamentals of Computers Design
 Computer Architecture J. Daniel Garcia Computer Architecture Group. Universidad Carlos III de Madrid Last update: September 8, 2014 Computer Architecture ARCOS Group. 1/45 Introduction 1 Introduction 2
Computer Architecture J. Daniel Garcia Computer Architecture Group. Universidad Carlos III de Madrid Last update: September 8, 2014 Computer Architecture ARCOS Group. 1/45 Introduction 1 Introduction 2
Multi MicroBlaze System for Parallel Computing
 Multi MicroBlaze System for Parallel Computing P.HUERTA, J.CASTILLO, J.I.MÁRTINEZ, V.LÓPEZ HW/SW Codesign Group Universidad Rey Juan Carlos 28933 Móstoles, Madrid SPAIN Abstract: - Embedded systems need
Multi MicroBlaze System for Parallel Computing P.HUERTA, J.CASTILLO, J.I.MÁRTINEZ, V.LÓPEZ HW/SW Codesign Group Universidad Rey Juan Carlos 28933 Móstoles, Madrid SPAIN Abstract: - Embedded systems need
Moore s Law. Computer architect goal Software developer assumption
 Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer
Moore s Law The number of transistors that can be placed inexpensively on an integrated circuit will double approximately every 18 months. Self-fulfilling prophecy Computer architect goal Software developer
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13
 Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Computer Architecture: Multi-Core Processors: Why? Onur Mutlu & Seth Copen Goldstein Carnegie Mellon University 9/11/13 Moore s Law Moore, Cramming more components onto integrated circuits, Electronics,
Parallel and Distributed Computing
 Parallel and Distributed Computing NUMA; OpenCL; MapReduce José Monteiro MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer Science and Engineering
Parallel and Distributed Computing NUMA; OpenCL; MapReduce José Monteiro MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer Science and Engineering
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University
 Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
Computer Architecture: Multi-Core Processors: Why? Prof. Onur Mutlu Carnegie Mellon University Moore s Law Moore, Cramming more components onto integrated circuits, Electronics, 1965. 2 3 Multi-Core Idea:
6.1 Multiprocessor Computing Environment
 6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
6 Parallel Computing 6.1 Multiprocessor Computing Environment The high-performance computing environment used in this book for optimization of very large building structures is the Origin 2000 multiprocessor,
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
Introduction to Parallel Computing
 Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Portland State University ECE 588/688 Introduction to Parallel Computing Reference: Lawrence Livermore National Lab Tutorial https://computing.llnl.gov/tutorials/parallel_comp/ Copyright by Alaa Alameldeen
Write a technical report Present your results Write a workshop/conference paper (optional) Could be a real system, simulation and/or theoretical
 Could be a real system, simulation and/or theoretical") Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
Identify a problem Review approaches to the problem Propose a novel approach to the problem Define, design, prototype an implementation to evaluate your approach Could be a real system, simulation and/or
GPU for HPC. October 2010
 GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
GPU for HPC Simone Melchionna Jonas Latt Francis Lapique October 2010 EPFL/ EDMX EPFL/EDMX EPFL/DIT simone.melchionna@epfl.ch jonas.latt@epfl.ch francis.lapique@epfl.ch 1 Moore s law: in the old days,
Multicore Hardware and Parallelism
 Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico February 29, 2016 CPD
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico February 29, 2016 CPD
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico September 26, 2011 CPD
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico September 26, 2011 CPD
Organizational issues (I)
") COSC 6374 Parallel Computation Introduction and Organizational Issues Spring 2008 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, F 154 Wednesday, 1.00pm 2.30pm, F 154 Evaluation 2 quizzes 1
COSC 6374 Parallel Computation Introduction and Organizational Issues Spring 2008 Organizational issues (I) Classes: Monday, 1.00pm 2.30pm, F 154 Wednesday, 1.00pm 2.30pm, F 154 Evaluation 2 quizzes 1
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
A Study of High Performance Computing and the Cray SV1 Supercomputer. Michael Sullivan TJHSST Class of 2004
 A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
A Study of High Performance Computing and the Cray SV1 Supercomputer Michael Sullivan TJHSST Class of 2004 June 2004 0.1 Introduction A supercomputer is a device for turning compute-bound problems into
The MPI Message-passing Standard Practical use and implementation (I) SPD Course 2/03/2010 Massimo Coppola
 SPD Course 2/03/2010 Massimo Coppola") The MPI Message-passing Standard Practical use and implementation (I) SPD Course 2/03/2010 Massimo Coppola What is MPI MPI: Message Passing Interface a standard defining a communication library that allows
The MPI Message-passing Standard Practical use and implementation (I) SPD Course 2/03/2010 Massimo Coppola What is MPI MPI: Message Passing Interface a standard defining a communication library that allows
Parallel Computing Concepts. CSInParallel Project
 Parallel Computing Concepts CSInParallel Project July 26, 2012 CONTENTS 1 Introduction 1 1.1 Motivation................................................ 1 1.2 Some pairs of terms...........................................
Parallel Computing Concepts CSInParallel Project July 26, 2012 CONTENTS 1 Introduction 1 1.1 Motivation................................................ 1 1.2 Some pairs of terms...........................................
Overview: Shared Memory Hardware. Shared Address Space Systems. Shared Address Space and Shared Memory Computers. Shared Memory Hardware
 Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware Shared Address Space Systems overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and
Overview: Shared Memory Hardware
 Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
Overview: Shared Memory Hardware overview of shared address space systems example: cache hierarchy of the Intel Core i7 cache coherency protocols: basic ideas, invalidate and update protocols false sharing
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
Fundamentals of Computer Design
 Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Fundamentals of Computer Design Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Introduction. HPC Fall 2007 Prof. Robert van Engelen
 Introduction HPC Fall 2007 Prof. Robert van Engelen Syllabus Title: High Performance Computing (ISC5935-1 and CIS5930-13) Classes: Tuesday and Thursday 2:00PM to 3:15PM in 152 DSL Evaluation: projects
Introduction HPC Fall 2007 Prof. Robert van Engelen Syllabus Title: High Performance Computing (ISC5935-1 and CIS5930-13) Classes: Tuesday and Thursday 2:00PM to 3:15PM in 152 DSL Evaluation: projects
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers
 Architecture and Multicomputers") Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer
Non-Uniform Memory Access (NUMA) Architecture and Multicomputers Parallel and Distributed Computing MSc in Information Systems and Computer Engineering DEA in Computational Engineering Department of Computer
Dr Tay Seng Chuan Tel: Office: S16-02, Dean s s Office at Level 2 URL:
 Self Introduction Dr Tay Seng Chuan Tel: Email: scitaysc@nus.edu.sg Office: S-0, Dean s s Office at Level URL: http://www.physics.nus.edu.sg/~phytaysc I have been working in NUS since 0, and I teach mainly
Self Introduction Dr Tay Seng Chuan Tel: Email: scitaysc@nus.edu.sg Office: S-0, Dean s s Office at Level URL: http://www.physics.nus.edu.sg/~phytaysc I have been working in NUS since 0, and I teach mainly
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Real Parallel Computers
 Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Real Parallel Computers Modular data centers Overview Short history of parallel machines Cluster computing Blue Gene supercomputer Performance development, top-500 DAS: Distributed supercomputing Short
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Parallel and Distributed Systems. Hardware Trends. Why Parallel or Distributed Computing? What is a parallel computer?
 Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
Parallel and Distributed Systems Instructor: Sandhya Dwarkadas Department of Computer Science University of Rochester What is a parallel computer? A collection of processing elements that communicate and
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction)
") EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Topic 08: Parallel Processor Design (introduction) Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
COSC 6374 Parallel Computation. Organizational issues (I)
") COSC 6374 Parallel Computation Spring 2007 Organizational issues (I) Classes: Monday, 4.00pm 5.30pm, SEC 204 Wednesday, 4.00pm 5.30pm, SEC 204 Evaluation 2 homeworks, 25% each 2 quizzes, 25% each In case
COSC 6374 Parallel Computation Spring 2007 Organizational issues (I) Classes: Monday, 4.00pm 5.30pm, SEC 204 Wednesday, 4.00pm 5.30pm, SEC 204 Evaluation 2 homeworks, 25% each 2 quizzes, 25% each In case
Parallelism in Hardware
 Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Parallelism in Hardware Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3 Moore s Law
Introduction to Parallel Computing
 Introduction to Parallel Computing This document consists of two parts. The first part introduces basic concepts and issues that apply generally in discussions of parallel computing. The second part consists
Introduction to Parallel Computing This document consists of two parts. The first part introduces basic concepts and issues that apply generally in discussions of parallel computing. The second part consists
Chapter 1: Distributed Systems: What is a distributed system? Fall 2013
 Chapter 1: Distributed Systems: What is a distributed system? Fall 2013 Course Goals and Content n Distributed systems and their: n Basic concepts n Main issues, problems, and solutions n Structured and
Chapter 1: Distributed Systems: What is a distributed system? Fall 2013 Course Goals and Content n Distributed systems and their: n Basic concepts n Main issues, problems, and solutions n Structured and
Parallel Programming Platforms
 arallel rogramming latforms Ananth Grama Computing Research Institute and Department of Computer Sciences, urdue University ayg@cspurdueedu http://wwwcspurdueedu/people/ayg Reference: Introduction to arallel
arallel rogramming latforms Ananth Grama Computing Research Institute and Department of Computer Sciences, urdue University ayg@cspurdueedu http://wwwcspurdueedu/people/ayg Reference: Introduction to arallel
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Parallel Algorithm Design. CS595, Fall 2010
 Parallel Algorithm Design CS595, Fall 2010 1 Programming Models The programming model o determines the basic concepts of the parallel implementation and o abstracts from the hardware as well as from the
Parallel Algorithm Design CS595, Fall 2010 1 Programming Models The programming model o determines the basic concepts of the parallel implementation and o abstracts from the hardware as well as from the
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
4. Shared Memory Parallel Architectures
 Master rogram (Laurea Magistrale) in Computer cience and Networking High erformance Computing ystems and Enabling latforms Marco Vanneschi 4. hared Memory arallel Architectures 4.4. Multicore Architectures
Master rogram (Laurea Magistrale) in Computer cience and Networking High erformance Computing ystems and Enabling latforms Marco Vanneschi 4. hared Memory arallel Architectures 4.4. Multicore Architectures
Master Program (Laurea Magistrale) in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.
 in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.") Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
Consultation for CZ4102
 Self Introduction Dr Tay Seng Chuan Tel: Email: scitaysc@nus.edu.sg Office: S-0, Dean s s Office at Level URL: http://www.physics.nus.edu.sg/~phytaysc I was a programmer from to. I have been working in
Self Introduction Dr Tay Seng Chuan Tel: Email: scitaysc@nus.edu.sg Office: S-0, Dean s s Office at Level URL: http://www.physics.nus.edu.sg/~phytaysc I was a programmer from to. I have been working in
Introduction to High-Performance Computing
 Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
Introduction to High-Performance Computing Simon D. Levy BIOL 274 17 November 2010 Chapter 12 12.1: Concurrent Processing High-Performance Computing A fancy term for computers significantly faster than
Efficient Smith-Waterman on multi-core with FastFlow
 BioBITs Euromicro PDP 2010 - Pisa Italy - 17th Feb 2010 Efficient Smith-Waterman on multi-core with FastFlow Marco Aldinucci Computer Science Dept. - University of Torino - Italy Massimo Torquati Computer
BioBITs Euromicro PDP 2010 - Pisa Italy - 17th Feb 2010 Efficient Smith-Waterman on multi-core with FastFlow Marco Aldinucci Computer Science Dept. - University of Torino - Italy Massimo Torquati Computer
THE IMPACT OF E-COMMERCE ON DEVELOPING A COURSE IN OPERATING SYSTEMS: AN INTERPRETIVE STUDY
 THE IMPACT OF E-COMMERCE ON DEVELOPING A COURSE IN OPERATING SYSTEMS: AN INTERPRETIVE STUDY Reggie Davidrajuh, Stavanger University College, Norway, reggie.davidrajuh@tn.his.no ABSTRACT This paper presents
THE IMPACT OF E-COMMERCE ON DEVELOPING A COURSE IN OPERATING SYSTEMS: AN INTERPRETIVE STUDY Reggie Davidrajuh, Stavanger University College, Norway, reggie.davidrajuh@tn.his.no ABSTRACT This paper presents
CS550. TA: TBA Office: xxx Office hours: TBA. Blackboard:
 CS550 Advanced Operating Systems (Distributed Operating Systems) Instructor: Xian-He Sun Email: sun@iit.edu, Phone: (312) 567-5260 Office hours: 1:30pm-2:30pm Tuesday, Thursday at SB229C, or by appointment
CS550 Advanced Operating Systems (Distributed Operating Systems) Instructor: Xian-He Sun Email: sun@iit.edu, Phone: (312) 567-5260 Office hours: 1:30pm-2:30pm Tuesday, Thursday at SB229C, or by appointment
DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN. Chapter 1. Introduction
 DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN Chapter 1 Introduction Modified by: Dr. Ramzi Saifan Definition of a Distributed System (1) A distributed
DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN Chapter 1 Introduction Modified by: Dr. Ramzi Saifan Definition of a Distributed System (1) A distributed
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Client Server & Distributed System. A Basic Introduction
 Client Server & Distributed System A Basic Introduction 1 Client Server Architecture A network architecture in which each computer or process on the network is either a client or a server. Source: http://webopedia.lycos.com
Client Server & Distributed System A Basic Introduction 1 Client Server Architecture A network architecture in which each computer or process on the network is either a client or a server. Source: http://webopedia.lycos.com
Networks for Multi-core Chips A A Contrarian View. Shekhar Borkar Aug 27, 2007 Intel Corp.
 Networks for Multi-core hips A A ontrarian View Shekhar Borkar Aug 27, 2007 Intel orp. 1 Outline Multi-core system outlook On die network challenges A simple contrarian proposal Benefits Summary 2 A Sample
Networks for Multi-core hips A A ontrarian View Shekhar Borkar Aug 27, 2007 Intel orp. 1 Outline Multi-core system outlook On die network challenges A simple contrarian proposal Benefits Summary 2 A Sample
Administration. Course material. Prerequisites. CS 395T: Topics in Multicore Programming. Instructors: TA: Course in computer architecture
 CS 395T: Topics in Multicore Programming Administration Instructors: Keshav Pingali (CS,ICES) 4.26A ACES Email: pingali@cs.utexas.edu TA: Xin Sui Email: xin@cs.utexas.edu University of Texas, Austin Fall
CS 395T: Topics in Multicore Programming Administration Instructors: Keshav Pingali (CS,ICES) 4.26A ACES Email: pingali@cs.utexas.edu TA: Xin Sui Email: xin@cs.utexas.edu University of Texas, Austin Fall
Computer Architecture Crash course
 Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping
Computer Architecture Crash course Frédéric Haziza Department of Computer Systems Uppsala University Summer 2008 Conclusions The multicore era is already here cost of parallelism is dropping
Parallel Computer Architecture II
 Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Parallel Computer Architecture II Stefan Lang Interdisciplinary Center for Scientific Computing (IWR) University of Heidelberg INF 368, Room 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors
 EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
EN164: Design of Computing Systems Lecture 34: Misc Multi-cores and Multi-processors Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering
Computer Architecture
 Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Computer Architecture Chapter 7 Parallel Processing 1 Parallelism Instruction-level parallelism (Ch.6) pipeline superscalar latency issues hazards Processor-level parallelism (Ch.7) array/vector of processors
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Data-Centric Architecture for Space Systems
 Data-Centric Architecture for Space Systems 3 rd Annual Workshop on Flight Software, Nov 5, 2009 The Real-Time Middleware Experts Rajive Joshi, Ph.D. Real-Time Innovations Our goals are the same but not
Data-Centric Architecture for Space Systems 3 rd Annual Workshop on Flight Software, Nov 5, 2009 The Real-Time Middleware Experts Rajive Joshi, Ph.D. Real-Time Innovations Our goals are the same but not
TDP3471 Distributed and Parallel Computing
 TDP3471 Distributed and Parallel Computing Lecture 1 Dr. Ian Chai ianchai@mmu.edu.my FIT Building: Room BR1024 Office : 03-8312-5379 Schedule for Dr. Ian (including consultation hours) available at http://pesona.mmu.edu.my/~ianchai/schedule.pdf
TDP3471 Distributed and Parallel Computing Lecture 1 Dr. Ian Chai ianchai@mmu.edu.my FIT Building: Room BR1024 Office : 03-8312-5379 Schedule for Dr. Ian (including consultation hours) available at http://pesona.mmu.edu.my/~ianchai/schedule.pdf
Efficient streaming applications on multi-core with FastFlow: the biosequence alignment test-bed
 Efficient streaming applications on multi-core with FastFlow: the biosequence alignment test-bed Marco Aldinucci Computer Science Dept. - University of Torino - Italy Marco Danelutto, Massimiliano Meneghin,
Efficient streaming applications on multi-core with FastFlow: the biosequence alignment test-bed Marco Aldinucci Computer Science Dept. - University of Torino - Italy Marco Danelutto, Massimiliano Meneghin,
Parallel Combinatorial Search on Computer Cluster: Sam Loyd s Puzzle
 Parallel Combinatorial Search on Computer Cluster: Sam Loyd s Puzzle Plamenka Borovska Abstract: The paper investigates the efficiency of parallel branch-and-bound search on multicomputer cluster for the
Parallel Combinatorial Search on Computer Cluster: Sam Loyd s Puzzle Plamenka Borovska Abstract: The paper investigates the efficiency of parallel branch-and-bound search on multicomputer cluster for the
Introduction to Parallel Computing
 Introduction to Parallel Computing Chris Kauffman CS 499: Spring 2016 GMU Goals Motivate: Parallel Programming Overview concepts a bit Discuss course mechanics Moore s Law Smaller transistors closer together
Introduction to Parallel Computing Chris Kauffman CS 499: Spring 2016 GMU Goals Motivate: Parallel Programming Overview concepts a bit Discuss course mechanics Moore s Law Smaller transistors closer together
Administration. Prerequisites. CS 395T: Topics in Multicore Programming. Why study parallel programming? Instructors: TA:
 CS 395T: Topics in Multicore Programming Administration Instructors: Keshav Pingali (CS,ICES) 4.126A ACES Email: pingali@cs.utexas.edu TA: Aditya Rawal Email: 83.aditya.rawal@gmail.com University of Texas,
CS 395T: Topics in Multicore Programming Administration Instructors: Keshav Pingali (CS,ICES) 4.126A ACES Email: pingali@cs.utexas.edu TA: Aditya Rawal Email: 83.aditya.rawal@gmail.com University of Texas,
Efficient Hardware Acceleration on SoC- FPGA using OpenCL
 Efficient Hardware Acceleration on SoC- FPGA using OpenCL Advisor : Dr. Benjamin Carrion Schafer Susmitha Gogineni 30 th August 17 Presentation Overview 1.Objective & Motivation 2.Configurable SoC -FPGA
Efficient Hardware Acceleration on SoC- FPGA using OpenCL Advisor : Dr. Benjamin Carrion Schafer Susmitha Gogineni 30 th August 17 Presentation Overview 1.Objective & Motivation 2.Configurable SoC -FPGA
Distributed Operating Systems Fall Prashant Shenoy UMass Computer Science. CS677: Distributed OS
 Distributed Operating Systems Fall 2009 Prashant Shenoy UMass http://lass.cs.umass.edu/~shenoy/courses/677 1 Course Syllabus CMPSCI 677: Distributed Operating Systems Instructor: Prashant Shenoy Email:
Distributed Operating Systems Fall 2009 Prashant Shenoy UMass http://lass.cs.umass.edu/~shenoy/courses/677 1 Course Syllabus CMPSCI 677: Distributed Operating Systems Instructor: Prashant Shenoy Email:
Using peer to peer. Marco Danelutto Dept. Computer Science University of Pisa
 Using peer to peer Marco Danelutto Dept. Computer Science University of Pisa Master Degree (Laurea Magistrale) in Computer Science and Networking Academic Year 2009-2010 Rationale Two common paradigms
Using peer to peer Marco Danelutto Dept. Computer Science University of Pisa Master Degree (Laurea Magistrale) in Computer Science and Networking Academic Year 2009-2010 Rationale Two common paradigms
Ian Foster, CS554: Data-Intensive Computing
 The advent of computation can be compared, in terms of the breadth and depth of its impact on research and scholarship, to the invention of writing and the development of modern mathematics. Ian Foster,
The advent of computation can be compared, in terms of the breadth and depth of its impact on research and scholarship, to the invention of writing and the development of modern mathematics. Ian Foster,
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Support for resource sharing Openness Concurrency Scalability Fault tolerance (reliability) Transparence. CS550: Advanced Operating Systems 2
 Transparence. CS550: Advanced Operating Systems 2") Support for resource sharing Openness Concurrency Scalability Fault tolerance (reliability) Transparence CS550: Advanced Operating Systems 2 Share hardware,software,data and information Hardware devices
Support for resource sharing Openness Concurrency Scalability Fault tolerance (reliability) Transparence CS550: Advanced Operating Systems 2 Share hardware,software,data and information Hardware devices
Distributed and Operating Systems Spring Prashant Shenoy UMass Computer Science.
 Distributed and Operating Systems Spring 2019 Prashant Shenoy UMass http://lass.cs.umass.edu/~shenoy/courses/677!1 Course Syllabus COMPSCI 677: Distributed and Operating Systems Course web page: http://lass.cs.umass.edu/~shenoy/courses/677
Distributed and Operating Systems Spring 2019 Prashant Shenoy UMass http://lass.cs.umass.edu/~shenoy/courses/677!1 Course Syllabus COMPSCI 677: Distributed and Operating Systems Course web page: http://lass.cs.umass.edu/~shenoy/courses/677
High Performance Computing on GPUs using NVIDIA CUDA
 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: http://www.gpgpu.org/s2007 1 Outline Motivation Stream programming Simplified HW and
Multimedia in Mobile Phones. Architectures and Trends Lund
 Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
Multimedia in Mobile Phones Architectures and Trends Lund 091124 Presentation Henrik Ohlsson Contact: henrik.h.ohlsson@stericsson.com Working with multimedia hardware (graphics and displays) at ST- Ericsson
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
The Use of Cloud Computing Resources in an HPC Environment
 The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
The Use of Cloud Computing Resources in an HPC Environment Bill, Labate, UCLA Office of Information Technology Prakashan Korambath, UCLA Institute for Digital Research & Education Cloud computing becomes
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Computer Science 146. Computer Architecture
 Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
The IBM Blue Gene/Q: Application performance, scalability and optimisation
 The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
The IBM Blue Gene/Q: Application performance, scalability and optimisation Mike Ashworth, Andrew Porter Scientific Computing Department & STFC Hartree Centre Manish Modani IBM STFC Daresbury Laboratory,
Performance Tools for Technical Computing
 Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology
Christian Terboven terboven@rz.rwth-aachen.de Center for Computing and Communication RWTH Aachen University Intel Software Conference 2010 April 13th, Barcelona, Spain Agenda o Motivation and Methodology