@h2oai presents. Sparkling Water Meetup
|
|
|
- Madeleine Gibbs
- 6 years ago
- Views:
Transcription


1 @h2oai presents Sparkling Water Meetup


2 User-friendly API for data transformation Large and active community Memory efficient Performance of computation Platform components - SQL Machine learning algorithms Multitenancy Parser, GUI, R-interface
3 Sparkling Water Spark H 2 O + RDD immutable world DataFrame mutable world
4 Sparkling Water Spark H 2 O RDD DataFrame
5 Sparkling Water Provides Transparent integration into Spark ecosystem Pure H2ORDD encapsulating H2O DataFrame Transparent use of H2O data structures and algorithms with Spark API Excels in Spark workflows requiring advanced Machine Learning algorithms


6 Sparkling Water Design? Sparkling Water Cluster implements Spark Worker JVM Spark Executor JVM H2O Sparkling App spark-submit Spark Master JVM Spark Worker JVM Spark Executor JVM H2O Spark Worker JVM Spark Executor JVM H2O Contains application and Sparkling Water classes
7 Data Distribution Sparkling Water Cluster Data Source (e.g. HDFS) Spark Executor JVM Spark RDD H2O H2O RDD H2O Spark Executor JVM H2O RDDs and DataFrames share same memory space Spark Executor JVM
8 Devel Internals Sparkling Water Assembly Sparkling Water Core H2O Core H2O Algos H2O Scala API H2O Flow + Application Code Spark Core Spark Platform Spark SQL Assembly is deployed to Spark cluster as regular Spark application
9 Hands-On #1 Sparkling Shell
10 Sparkling Water Requirements Linux or Mac OS X Oracle Java 1.7+ Spark 1.1.0

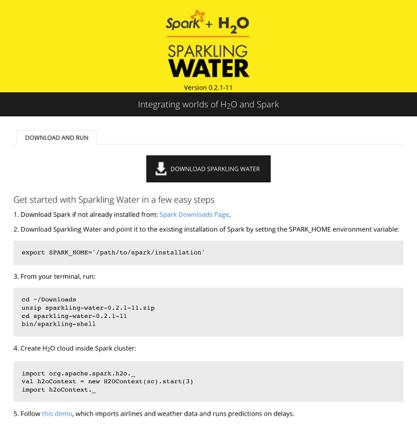
11 Download
12 Where is the code? blob/master/examples/scripts/
13 Flight delays prediction Build a model using weather and flight data to predict delays of flights arriving to Chicago O Hare International Airport
14 Example Outline Load & Parse CSV data from 2 data sources Use Spark API to filter data, do SQL query for join Create regression models Use models to predict delays Graph residual plot from R
15 Install and Launch Unpack zip file and Point SPARK_HOME to your Spark installation and Launch bin/sparkling-shell
16 What is Sparkling Shell? Standard spark-shell With additional Sparkling Water classes export MASTER= local-cluster[3,2,1024] Spark Master address spark-shell \ -jars sparkling-water.jar JAR containing Sparkling Water
17 Lets play with Sparkling shell
18 Create H2O Client Contains implicit utility functions Demo specific classes Size of demanded H2O cloud import org.apache.spark.h2o._ import org.apache.spark.examples.h2o._ val h2ocontext = new H2OContext(sc).start(3) import h2ocontext._ Regular Spark context provided by Spark shell

19 Is Spark Running? Go to
20 Is H2O running?
21 Load Data #1 Load weather data into RDD val weatherdatafile = examples/smalldata/weather.csv" val wrawdata = sc.textfile(weatherdatafile,3).cache() val weathertable = wrawdata.map(_.split(,")).map(row => WeatherParse(row)).filter(!_.isWrongRow()) Regular Spark API Ad-hoc Parser
22 Weather Data case class Weather( val Year : Option[Int], val Month : Option[Int], val Day : Option[Int], val TmaxF : Option[Int], // Max temperatur in F val TminF : Option[Int], // Min temperatur in F val TmeanF : Option[Float], // Mean temperatur in F val PrcpIn : Option[Float], // Precipitation (inches) val SnowIn : Option[Float], // Snow (inches) val CDD : Option[Float], // Cooling Degree Day val HDD : Option[Float], // Heating Degree Day val GDD : Option[Float]) // Growing Degree Day Simple POJO to hold one row of weather data
23 Load Data #2 Load flights data into H2O frame import java.io.file val datafile = examples/smalldata/year2005.csv.gz" val airlinesdata = new DataFrame(new File(dataFile)) Shortcut for data load and parse

24 Where is the data? Go to index.html
25 Use Spark API for Data Filtering Create a cheap wrapper around H2O DataFrame // Create RDD wrapper around DataFrame val airlinestable : RDD[Airlines] = asrdd[airlines](airlinesdata) // And use Spark RDD API directly val flightstoord = airlinestable.filter( f => f.dest == Some( ORD") ) Regular Spark RDD call
26 Use Spark SQL to Data Join import org.apache.spark.sql.sqlcontext // We need to create SQL context implicit val sqlcontext = new SQLContext(sc) import sqlcontext._ flightstoord.registertemptable("flightstoord") weathertable.registertemptable("weatherord") Make context implicit to share it with h2ocontext
27 Join Data based on Flight Date val joinedtable = sql( """SELECT f.year,f.month,f.dayofmonth, f.crsdeptime,f.crsarrtime,f.crselapsedtime, f.uniquecarrier,f.flightnum,f.tailnum, f.origin,f.distance, w.tmaxf,w.tminf,w.tmeanf, w.prcpin,w.snowin,w.cdd,w.hdd,w.gdd, f.arrdelay FROM FlightsToORD f JOIN WeatherORD w ON f.year=w.year AND f.month=w.month AND f.dayofmonth=w.day""".stripmargin)
28 Split data import hex.splitframe.splitframe import hex.splitframe.splitframemodel.splitframeparameters val sfparams = new SplitFrameParameters() sfparams._train = joinedtable sfparams._ratios = Array(0.7, 0.2) val sf = new SplitFrame(sfParams) val splits = sf.trainmodel().get._output._splits val traintable = splits(0) val validtable = splits(1) val testtable = splits(2) Result of SQL query is implicitly converted into H2O DataFrame
29 Launch H2O Algorithms import hex.deeplearning._ import hex.deeplearning.deeplearningmodel.deeplearningparameters // Setup deep learning parameters val dlparams = new DeepLearningParameters() dlparams._train = traintable dlparams._response_column = 'ArrDelay dlparams._valid = validtable dlparams._epochs = 100 dlparams._reproducible = true dlparams._force_load_balance = false // Create a new model builder val dl = new DeepLearning(dlParams) val dlmodel = dl.trainmodel.get Blocking call
30 Make a prediction // Use model to score data val dlpredicttable = dlmodel.score(testtable)( predict) // Collect predicted values via RDD API val predictionvalues = toshemardd(dlpredicttable).collect.map (row => if (row.isnullat(0)) Double.NaN else row(0)
31 Hands-On #2 Can I access results from R? YES!
32 Requirements R RStudio H2O R package


33 Install R package You can find R package on USB stick 1. Open RStudio 2. Click on Install Packages 3. Select h2o_ tar.gz file from USB
34 Generate R code In Sparkling Shell: import org.apache.spark.examples.h2o.demoutils.residualplotrcode residualplotrcode( predictionh2oframe, 'predict, testframe, 'ArrDelay) Utility generating R code to show residuals plot for predicted and actual values
35 Residuals Plot in R # Import H2O library and initialize H2O client library(h2o) h = h2o.init() References of data # Fetch prediction and actual data, use remembered keys pred = h2o.getframe(h, "dframe_b5f449d0c04ee75fda1b9bc865b14a69") act = h2o.getframe (h, "frame_rdd_14_b429e8b43d2d8c02899ccb61b72c4e57") # Select right columns preddelay = pred$predict actdelay = act$arrdelay # Make sure that number of rows is same nrow(actdelay) == nrow(preddelay) # Compute residuals residuals = preddelay - actdelay # Plot residuals compare = cbind( as.data.frame(actdelay$arrdelay), as.data.frame(residuals$predict)) residuals plot( compare[,1:2] )
36 Warning! If you are running R v3.1.0 you will see different plot: Why? Float number handling was changed in that version. Our recommendation is to upgrade your R to the newest version.
37 Try GBM Algo import hex.tree.gbm.gbm import hex.tree.gbm.gbmmodel.gbmparameters val gbmparams = new GBMParameters() gbmparams._train = traintable gbmparams._response_column = 'ArrDelay gbmparams._valid = validtable gbmparams._ntrees = 100 val gbm = new GBM(gbmParams) val gbmmodel = gbm.trainmodel.get // Print R code for residual plot val gbmpredicttable = gbmmodel.score(testtable)('predict) printf( residualplotrcode(gbmpredicttable, 'predict, testtable, 'ArrDelay) )
38 Residuals plot for GBM prediction residuals
39 Hands-On #3 How Can I Develop and Run Standalone App?
40 Requirements Idea or Eclipse Git
41 Use Sparkling Water Droplet Clone H2O Droplets repository git clone cd h2o-droplets/sparkling-water-droplet/
42 Generate IDE project For Idea./gradlew idea For Eclipse./gradlew eclipse add import project into your IDE
43 Create An Application object AirlinesWeatherAnalysis { /** Entry point */ def main(args: Array[String]) { // Configure this application val conf: SparkConf = new SparkConf().setAppName("Flights Water") conf.setifmissing("spark.master", sys.env.getorelse("spark.master", "local")) } } // Create SparkContext to execute application on Spark cluster val sc = new SparkContext(conf) // Start H2O cluster only new H2OContext(sc).start() // User code //... Create Spark Context Create H2O context and start H2O on top of Spark
44 Build the Application Build and test./gradlew build shadowjar Create an assembly which can be submitted to Spark cluster

45 Run code on Spark #!/usr/bin/env bash APP_CLASS=water.droplets.AirlineWeatherAnalysis FAT_JAR_FILE= build/libs/sparkling-water-droplet-app.jar MASTER=${MASTER:-"local-cluster[3,2,1024]"} DRIVER_MEMORY=2g $SPARK_HOME/bin/spark-submit \ --driver-memory $DRIVER_MEMORY \ --master $MASTER \ --class "$APP_CLASS" $FAT_JAR_FILE
46 It is Open Source! You can participate in H2O Scala API Sparkling Water testing Mesos, Yarn, workflows (PUBDEV-23,26,27,31-33) Spark integration MLLib Pipelines Check out our JIRA at

47 Come to Meetup




48 More info Checkout H2O.ai Training Books Checkout H2O.ai Blog for Sparkling Water tutorials Checkout H2O.ai Youtube Channel Checkout GitHub
49 Thank you! Learn more about H 2 O at h2o.ai or > for r in sparkling-water; do git clone git@github.com:h2oai/$r.git done Follow us

50 And the winner is
Machine Learning with Sparkling Water: H2O + Spark
 Machine Learning with Sparkling Water: H2O + Spark Michal Malohlava Nidhi Mehta Edited by: Brandon Hill & Vinod Iyengar http://h2o.ai/resources July 2016: First Edition Machine Learning with Sparkling
Machine Learning with Sparkling Water: H2O + Spark Michal Malohlava Nidhi Mehta Edited by: Brandon Hill & Vinod Iyengar http://h2o.ai/resources July 2016: First Edition Machine Learning with Sparkling
Sparkling Water. August 2015: First Edition
 Sparkling Water Michal Malohlava Alex Tellez Jessica Lanford http://h2o.gitbooks.io/sparkling-water-and-h2o/ August 2015: First Edition Sparkling Water by Michal Malohlava, Alex Tellez & Jessica Lanford
Sparkling Water Michal Malohlava Alex Tellez Jessica Lanford http://h2o.gitbooks.io/sparkling-water-and-h2o/ August 2015: First Edition Sparkling Water by Michal Malohlava, Alex Tellez & Jessica Lanford
Scalable Machine Learning in R. with H2O
 Scalable Machine Learning in R with H2O Erin LeDell @ledell DSC July 2016 Introduction Statistician & Machine Learning Scientist at H2O.ai in Mountain View, California, USA Ph.D. in Biostatistics with
Scalable Machine Learning in R with H2O Erin LeDell @ledell DSC July 2016 Introduction Statistician & Machine Learning Scientist at H2O.ai in Mountain View, California, USA Ph.D. in Biostatistics with
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Machine Learning with Sparkling Water: H2O + Spark
 Machine Learning with Sparkling Water: H2O + Spark Michal Malohlava Jakub Hava Nidhi Mehta Edited by: Vinod Iyengar & Angela Bartz http://h2o.ai/resources January 2018: Third Edition Machine Learning with
Machine Learning with Sparkling Water: H2O + Spark Michal Malohlava Jakub Hava Nidhi Mehta Edited by: Vinod Iyengar & Angela Bartz http://h2o.ai/resources January 2018: Third Edition Machine Learning with
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Beyond MapReduce: Apache Spark Antonino Virgillito
 Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team
 TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team What is TensorFlowOnSpark Why TensorFlowOnSpark at Yahoo? Major contributor to open-source
TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team What is TensorFlowOnSpark Why TensorFlowOnSpark at Yahoo? Major contributor to open-source
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
08/04/2018. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
2/26/2017. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
2/4/2019 Week 3- A Sangmi Lee Pallickara
 Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Week 3-A-0 2/4/2019 Colorado State University, Spring 2019 Week 3-A-1 CS535 BIG DATA FAQs PART A. BIG DATA TECHNOLOGY 3. DISTRIBUTED COMPUTING MODELS FOR SCALABLE BATCH COMPUTING SECTION 1: MAPREDUCE PA1
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
TDDE31/732A54 - Big Data Analytics Lab compendium
 TDDE31/732A54 - Big Data Analytics Lab compendium For relational databases lab, please refer to http://www.ida.liu.se/~732a54/lab/rdb/index.en.shtml. Description and Aim In the lab exercises you will work
TDDE31/732A54 - Big Data Analytics Lab compendium For relational databases lab, please refer to http://www.ida.liu.se/~732a54/lab/rdb/index.en.shtml. Description and Aim In the lab exercises you will work
Pyspark standalone code
 COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
L6: Introduction to Spark Spark
 L6: Introduction to Spark Spark Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revised on December 20, 2017 Today we are going to learn...
L6: Introduction to Spark Spark Feng Li feng.li@cufe.edu.cn School of Statistics and Mathematics Central University of Finance and Economics Revised on December 20, 2017 Today we are going to learn...
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Introduction to Apache Spark. Patrick Wendell - Databricks
 Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Spark Tutorial. General Instructions
 CS246: Mining Massive Datasets Winter 2018 Spark Tutorial Due Thursday January 25, 2018 at 11:59pm Pacific time General Instructions The purpose of this tutorial is (1) to get you started with Spark and
CS246: Mining Massive Datasets Winter 2018 Spark Tutorial Due Thursday January 25, 2018 at 11:59pm Pacific time General Instructions The purpose of this tutorial is (1) to get you started with Spark and
Apache Spark and Scala Certification Training
 About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
About Intellipaat Intellipaat is a fast-growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 600,000 in over
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Machine Learning With Spark
 Ons Dridi R&D Engineer 13 Novembre 2015 Centre d Excellence en Technologies de l Information et de la Communication CETIC Presentation - An applied research centre in the field of ICT - The knowledge developed
Ons Dridi R&D Engineer 13 Novembre 2015 Centre d Excellence en Technologies de l Information et de la Communication CETIC Presentation - An applied research centre in the field of ICT - The knowledge developed
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Using Apache Zeppelin
 3 Using Apache Zeppelin Date of Publish: 2018-04-01 http://docs.hortonworks.com Contents Introduction... 3 Launch Zeppelin... 3 Working with Zeppelin Notes... 5 Create and Run a Note...6 Import a Note...7
3 Using Apache Zeppelin Date of Publish: 2018-04-01 http://docs.hortonworks.com Contents Introduction... 3 Launch Zeppelin... 3 Working with Zeppelin Notes... 5 Create and Run a Note...6 Import a Note...7
Reactive App using Actor model & Apache Spark. Rahul Kumar Software
 Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Big Streaming Data Processing. How to Process Big Streaming Data 2016/10/11. Fraud detection in bank transactions. Anomalies in sensor data
 Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Big Data Big Streaming Data Big Streaming Data Processing Fraud detection in bank transactions Anomalies in sensor data Cat videos in tweets How to Process Big Streaming Data Raw Data Streams Distributed
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
732A54 - Big Data Analytics Lab compendium
 Description and Aim 732A54 - Big Data Analytics Lab compendium (Spark and Spark SQL) In the lab exercises you will work with the historical meteorological data from the Swedish Meteorological and Hydrological
Description and Aim 732A54 - Big Data Analytics Lab compendium (Spark and Spark SQL) In the lab exercises you will work with the historical meteorological data from the Swedish Meteorological and Hydrological
IoT with Apache ActiveMQ, Camel and Spark
 IoT with Apache ActiveMQ, Camel and Spark Burr Sutter - Red Hat Agenda Business & IT Architecture IoT Architecture IETF IoT Use Case Ingestion: Apache ActiveMQ, Apache Camel Analytics: Apache Spark Demos
IoT with Apache ActiveMQ, Camel and Spark Burr Sutter - Red Hat Agenda Business & IT Architecture IoT Architecture IETF IoT Use Case Ingestion: Apache ActiveMQ, Apache Camel Analytics: Apache Spark Demos
TUTORIAL: BIG DATA ANALYTICS USING APACHE SPARK
 TUTORIAL: BIG DATA ANALYTICS USING APACHE SPARK Sugimiyanto Suma Yasir Arfat Supervisor: Prof. Rashid Mehmood Outline 2 Big Data Big Data Analytics Problem Basics of Apache Spark Practice basic examples
TUTORIAL: BIG DATA ANALYTICS USING APACHE SPARK Sugimiyanto Suma Yasir Arfat Supervisor: Prof. Rashid Mehmood Outline 2 Big Data Big Data Analytics Problem Basics of Apache Spark Practice basic examples
A CD Framework For Data Pipelines. Yaniv
 A CD Framework For Data Pipelines Yaniv Rodenski @YRodenski yaniv@apache.org Archetypes of Data Pipelines Builders Data People (Data Scientist/ Analysts/BI Devs) Exploratory workloads Code centric Software
A CD Framework For Data Pipelines Yaniv Rodenski @YRodenski yaniv@apache.org Archetypes of Data Pipelines Builders Data People (Data Scientist/ Analysts/BI Devs) Exploratory workloads Code centric Software
Analyzing Flight Data
 IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
IBM Analytics Analyzing Flight Data Jeff Carlson Rich Tarro July 21, 2016 2016 IBM Corporation Agenda Spark Overview a quick review Introduction to Graph Processing and Spark GraphX GraphX Overview Demo
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
HPCC / Spark Integration. Boca Raton Documentation Team
 Boca Raton Documentation Team HPCC / Spark Integration Boca Raton Documentation Team Copyright 2018 HPCC Systems. All rights reserved We welcome your comments and feedback about this document via email
Boca Raton Documentation Team HPCC / Spark Integration Boca Raton Documentation Team Copyright 2018 HPCC Systems. All rights reserved We welcome your comments and feedback about this document via email
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Hadoop course content
 course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
Apache Spark 2.0. Matei
 Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Apache Spark 2.0 Matei Zaharia @matei_zaharia What is Apache Spark? Open source data processing engine for clusters Generalizes MapReduce model Rich set of APIs and libraries In Scala, Java, Python and
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Big Data Analytics with Hadoop and Spark at OSC
 Big Data Analytics with Hadoop and Spark at OSC 09/28/2017 SUG Shameema Oottikkal Data Application Engineer Ohio SuperComputer Center email:soottikkal@osc.edu 1 Data Analytics at OSC Introduction: Data
Big Data Analytics with Hadoop and Spark at OSC 09/28/2017 SUG Shameema Oottikkal Data Application Engineer Ohio SuperComputer Center email:soottikkal@osc.edu 1 Data Analytics at OSC Introduction: Data
Spark and Spark SQL. Amir H. Payberah. SICS Swedish ICT. Amir H. Payberah (SICS) Spark and Spark SQL June 29, / 71
 Spark and Spark SQL June 29, / 71") Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Spark and Spark SQL Amir H. Payberah amir@sics.se SICS Swedish ICT Amir H. Payberah (SICS) Spark and Spark SQL June 29, 2016 1 / 71 What is Big Data? Amir H. Payberah (SICS) Spark and Spark SQL June 29,
Apache Spark Internals
 Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
The detailed Spark programming guide is available at:
 Aims This exercise aims to get you to: Analyze data using Spark shell Monitor Spark tasks using Web UI Write self-contained Spark applications using Scala in Eclipse Background Spark is already installed
Aims This exercise aims to get you to: Analyze data using Spark shell Monitor Spark tasks using Web UI Write self-contained Spark applications using Scala in Eclipse Background Spark is already installed
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Big Data Analytics with Apache Spark. Nastaran Fatemi
 Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Data Science Bootcamp Curriculum. NYC Data Science Academy
 Data Science Bootcamp Curriculum NYC Data Science Academy 100+ hours free, self-paced online course. Access to part-time in-person courses hosted at NYC campus Machine Learning with R and Python Foundations
Data Science Bootcamp Curriculum NYC Data Science Academy 100+ hours free, self-paced online course. Access to part-time in-person courses hosted at NYC campus Machine Learning with R and Python Foundations
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Introduction to Apache Spark
 Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Introduction to Apache Spark Bu eğitim sunumları İstanbul Kalkınma Ajansı nın 2016 yılı Yenilikçi ve Yaratıcı İstanbul Mali Destek Programı kapsamında yürütülmekte olan TR10/16/YNY/0036 no lu İstanbul
Index. bfs() function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225
 function, 225 Big data characteristics, 2 variety, 3 velocity, 3 veracity, 3 volume, 2 Breadth-first search algorithm, 220, 225") Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Index A Anonymous function, 66 Apache Hadoop, 1 Apache HBase, 42 44 Apache Hive, 6 7, 230 Apache Kafka, 8, 178 Apache License, 7 Apache Mahout, 5 Apache Mesos, 38 42 Apache Pig, 7 Apache Spark, 9 Apache
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Matrix Computations and " Neural Networks in Spark
 Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS
 WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS Andrew Ray StampedeCon 2016 Silicon Valley Data Science is a boutique consulting firm focused on transforming your business through data science
WHAT S NEW IN SPARK 2.0: STRUCTURED STREAMING AND DATASETS Andrew Ray StampedeCon 2016 Silicon Valley Data Science is a boutique consulting firm focused on transforming your business through data science
RECORD LINKAGE, A REAL USE CASE WITH SPARK ML. Alexis Seigneurin
 RECORD LINKAGE, A REAL USE CASE WITH SPARK ML Alexis Seigneurin Who I am Software engineer for 15 years Consultant at Ippon USA, previously at Ippon France Favorite subjects: Spark, Machine Learning, Cassandra
RECORD LINKAGE, A REAL USE CASE WITH SPARK ML Alexis Seigneurin Who I am Software engineer for 15 years Consultant at Ippon USA, previously at Ippon France Favorite subjects: Spark, Machine Learning, Cassandra
An Overview of Apache Spark
 An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
An Overview of Apache Spark CIS 612 Sunnie Chung 2014 MapR Technologies 1 MapReduce Processing Model MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using
About the Tutorial. Audience. Prerequisites. Copyright and Disclaimer. PySpark
 About the Tutorial Apache Spark is written in Scala programming language. To support Python with Spark, Apache Spark community released a tool, PySpark. Using PySpark, you can work with RDDs in Python
About the Tutorial Apache Spark is written in Scala programming language. To support Python with Spark, Apache Spark community released a tool, PySpark. Using PySpark, you can work with RDDs in Python
Greenplum-Spark Connector Examples Documentation. kong-yew,chan
 Greenplum-Spark Connector Examples Documentation kong-yew,chan Dec 10, 2018 Contents 1 Overview 1 1.1 Pivotal Greenplum............................................ 1 1.2 Pivotal Greenplum-Spark Connector...................................
Greenplum-Spark Connector Examples Documentation kong-yew,chan Dec 10, 2018 Contents 1 Overview 1 1.1 Pivotal Greenplum............................................ 1 1.2 Pivotal Greenplum-Spark Connector...................................
Spark Streaming. Guido Salvaneschi
 Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
EPL660: Information Retrieval and Search Engines Lab 11
 EPL660: Information Retrieval and Search Engines Lab 11 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Introduction to Apache Spark Fast and general engine for
EPL660: Information Retrieval and Search Engines Lab 11 Παύλος Αντωνίου Γραφείο: B109, ΘΕΕ01 University of Cyprus Department of Computer Science Introduction to Apache Spark Fast and general engine for
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Scalable Data Science in R and Apache Spark 2.0. Felix Cheung, Principal Engineer, Microsoft
 Scalable Data Science in R and Apache Spark 2.0 Felix Cheung, Principal Engineer, Spark @ Microsoft About me Apache Spark Committer Apache Zeppelin PMC/Committer Contributing to Spark since 1.3 and Zeppelin
Scalable Data Science in R and Apache Spark 2.0 Felix Cheung, Principal Engineer, Spark @ Microsoft About me Apache Spark Committer Apache Zeppelin PMC/Committer Contributing to Spark since 1.3 and Zeppelin
THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION
 Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
MLeap: Release Spark ML Pipelines
 MLeap: Release Spark ML Pipelines Hollin Wilkins & Mikhail Semeniuk SATURDAY Web Dev @ Cornell Studied some General Biology Rails Consulting for TrueCar and other companies Implement ML model for ClearBook
MLeap: Release Spark ML Pipelines Hollin Wilkins & Mikhail Semeniuk SATURDAY Web Dev @ Cornell Studied some General Biology Rails Consulting for TrueCar and other companies Implement ML model for ClearBook
Franck Mercier. Technical Solution Professional Data + AI Azure Databricks
 Franck Mercier Technical Solution Professional Data + AI http://aka.ms/franck @FranmerMS Azure Databricks Thanks to our sponsors Global Gold Silver Bronze Microsoft JetBrains Rubrik Delphix Solution OMD
Franck Mercier Technical Solution Professional Data + AI http://aka.ms/franck @FranmerMS Azure Databricks Thanks to our sponsors Global Gold Silver Bronze Microsoft JetBrains Rubrik Delphix Solution OMD
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING
 RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
RESILIENT DISTRIBUTED DATASETS: A FAULT-TOLERANT ABSTRACTION FOR IN-MEMORY CLUSTER COMPUTING Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin,
Spark Streaming. Big Data Analysis with Scala and Spark Heather Miller
 Spark Streaming Big Data Analysis with Scala and Spark Heather Miller Where Spark Streaming fits in (1) Spark is focused on batching Processing large, already-collected batches of data. For example: Where
Spark Streaming Big Data Analysis with Scala and Spark Heather Miller Where Spark Streaming fits in (1) Spark is focused on batching Processing large, already-collected batches of data. For example: Where
Apache Spark. CS240A T Yang. Some of them are based on P. Wendell s Spark slides
 Apache Spark CS240A T Yang Some of them are based on P. Wendell s Spark slides Parallel Processing using Spark+Hadoop Hadoop: Distributed file system that connects machines. Mapreduce: parallel programming
Apache Spark CS240A T Yang Some of them are based on P. Wendell s Spark slides Parallel Processing using Spark+Hadoop Hadoop: Distributed file system that connects machines. Mapreduce: parallel programming
MLI - An API for Distributed Machine Learning. Sarang Dev
 MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Scaling Up & Out. Haidar Osman
 Scaling Up & Out Haidar Osman 1- Crash course in Scala - Classes - Objects 2- Actors - The Actor Model - Examples I, II, III, IV 3- Apache Spark - RDD & DAG - Word Count Example 2 1- Crash course in Scala
Scaling Up & Out Haidar Osman 1- Crash course in Scala - Classes - Objects 2- Actors - The Actor Model - Examples I, II, III, IV 3- Apache Spark - RDD & DAG - Word Count Example 2 1- Crash course in Scala
Going Big Data on Apache Spark. KNIME Italy Meetup
 Going Big Data on Apache Spark KNIME Italy Meetup Agenda Introduction Why Apache Spark? Section 1 Gathering Requirements Section 2 Tool Choice Section 3 Architecture Section 4 Devising New Nodes Section
Going Big Data on Apache Spark KNIME Italy Meetup Agenda Introduction Why Apache Spark? Section 1 Gathering Requirements Section 2 Tool Choice Section 3 Architecture Section 4 Devising New Nodes Section
Higher level data processing in Apache Spark
 Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Higher level data processing in Apache Spark Pelle Jakovits 12 October, 2016, Tartu Outline Recall Apache Spark Spark DataFrames Introduction Creating and storing DataFrames DataFrame API functions SQL
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Certification Study Guide. MapR Certified Spark Developer v1 Study Guide
 Certification Study Guide MapR Certified Spark Developer v1 Study Guide 1 CONTENTS About MapR Study Guides... 3 MapR Certified Spark Developer (MCSD)... 3 SECTION 1 WHAT S ON THE EXAM?... 5 1. Load and
Certification Study Guide MapR Certified Spark Developer v1 Study Guide 1 CONTENTS About MapR Study Guides... 3 MapR Certified Spark Developer (MCSD)... 3 SECTION 1 WHAT S ON THE EXAM?... 5 1. Load and
spark-testing-java Documentation Release latest
 spark-testing-java Documentation Release latest Nov 20, 2018 Contents 1 Input data preparation 3 2 Java 5 2.1 Context creation............................................. 5 2.2 Data preparation.............................................
spark-testing-java Documentation Release latest Nov 20, 2018 Contents 1 Input data preparation 3 2 Java 5 2.1 Context creation............................................. 5 2.2 Data preparation.............................................
About Intellipaat. About the Course. Why Take This Course?
 About Intellipaat Intellipaat is a fast growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 700,000 in over
About Intellipaat Intellipaat is a fast growing professional training provider that is offering training in over 150 most sought-after tools and technologies. We have a learner base of 700,000 in over
Lijuan Zhuge & Kailai Xu May 3, 2017 In this short article, we describe how to set up spark on clusters and the basic usage of pyspark.
 Lijuan Zhuge & Kailai Xu May 3, 2017 In this short article, we describe how to set up spark on clusters and the basic usage of pyspark. Set up spark The key to set up sparks is to make several machines
Lijuan Zhuge & Kailai Xu May 3, 2017 In this short article, we describe how to set up spark on clusters and the basic usage of pyspark. Set up spark The key to set up sparks is to make several machines
Integrating Solr & Spark
 Integrating Solr & Spark https://github.com/lucidworks/spark-solr/ Indexing from Spark Reading data from Solr Solr data as a Spark SQL DataFrame Interacting with Solr from the Spark shell Document Matching
Integrating Solr & Spark https://github.com/lucidworks/spark-solr/ Indexing from Spark Reading data from Solr Solr data as a Spark SQL DataFrame Interacting with Solr from the Spark shell Document Matching
Lambda Architecture with Apache Spark
 Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Lambda Architecture with Apache Spark Michael Hausenblas, Chief Data Engineer MapR First Galway Data Meetup, 2015-02-03 2015 MapR Technologies 2015 MapR Technologies 1 Polyglot Processing 2015 2014 MapR
Structured Streaming. Big Data Analysis with Scala and Spark Heather Miller
 Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
Structured Streaming Big Data Analysis with Scala and Spark Heather Miller Why Structured Streaming? DStreams were nice, but in the last session, aggregation operations like a simple word count quickly
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Index. Raul Estrada and Isaac Ruiz 2016 R. Estrada and I. Ruiz, Big Data SMACK, DOI /
 Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
Index A ACID, 251 Actor model Akka installation, 44 Akka logos, 41 OOP vs. actors, 42 43 thread-based concurrency, 42 Agents server, 140, 251 Aggregation techniques materialized views, 216 probabilistic
H2O: An open-source, in-memory prediction engine for data science
 H2O: An open-source, in-memory prediction engine for data science Some content is copyrighted from other sources, as noted. Dean Wampler Functional Programming for Java Developers Programming Hive Dean
H2O: An open-source, in-memory prediction engine for data science Some content is copyrighted from other sources, as noted. Dean Wampler Functional Programming for Java Developers Programming Hive Dean
Integrating Advanced Analytics with Big Data
 Integrating Advanced Analytics with Big Data Ian McKenna, Ph.D. Senior Financial Engineer 2017 The MathWorks, Inc. 1 The Goal SCALE! 2 The Solution tall 3 Agenda Introduction to tall data Case Study: Predicting
Integrating Advanced Analytics with Big Data Ian McKenna, Ph.D. Senior Financial Engineer 2017 The MathWorks, Inc. 1 The Goal SCALE! 2 The Solution tall 3 Agenda Introduction to tall data Case Study: Predicting
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals