Graphical Processing Units : Can we really entrust the compiler to reach the raw performance? Emmanuel Quemener IR CBP
|
|
|
- Brent Lester
- 5 years ago
- Views:
Transcription

1 Graphical Processing Units : Can we really entrust the compiler to reach the raw performance? IR CBP
2 Starting with a tiny joke! How do you call people speak 3 languages? How do you call people speak 2 languages? Trilingual people! Bilingual people! How do you call people speak 1 language? French people! I'm french : if I twist your eardrums, I apologize... 2/28
3 Plan of talk... What s Blaise Pascal Center? Where are we (now)? Raw processing power is NOT longer inside the CPU Where do we want to go (tomorrow)? What are the facilities provided for developing, learning, exploring in IT? What can we expect at most to reduce the Elapsed time... How can we go? Compiler? High level librairies? Hybrid approach? 3/28
4 What s Blaise Pascal Center? Director : Pr Ralf Everaers Centre Blaise Pascal: «maison de la modélisation» Hotel for projects, conferences, trainings on all IT services Hotel for projects: Technical benchs in an experimental platform for everybody Digital laboratory benchs for laboratories for specific purposes Hotel for trainings: ATOSIM (Erasmus Mundus) Continuing educations for searchers, teachers & engineers Advanced education : M1, M2 in physics, chemistry, geology, biology, Test center : to reuse, to divert, to explore in HPC & HPDA 4/28


5 Multinodes TechBenchs : 9 clusters 116 nodes, 4 IB speeds 2 nodes Sun V20Z with AMD physical Interconnection Infiniband SDR 10 Gb/s 2 nodes Sun X2200 with AMD 2218HE 8 physical Interconnection Infiniband DDR 20 Gb/s 8 nodes Sun X4150 with Xeon E physical Interconnection Infiniband DDR 20 Gb/s 64 nodes Dell R410 with Xeon X physical cores Interconnection Infiniband QDR 40 Gb/s 4 nodes Dell C6100 with Xeon X physical cores Interconnection Infiniband QDR 40 Gb/s + C410X with 4 GPGPU 16 nodes Dell C6100 with Xeon X physical cores Interconnection Infiniband QDR 40 Gb/s 8 nodes HP SL230 with Xeon E physical cores Interconnection Infiniband FDR 56 Gb/s 8 nodes Dell R410 with Xeon X physical cores Interconnection Infiniband DDR 20 Gb/s 4 nodes Sun X4500 with AMD physical Interconnection Infiniband SDR 10 Gb/s 5/28

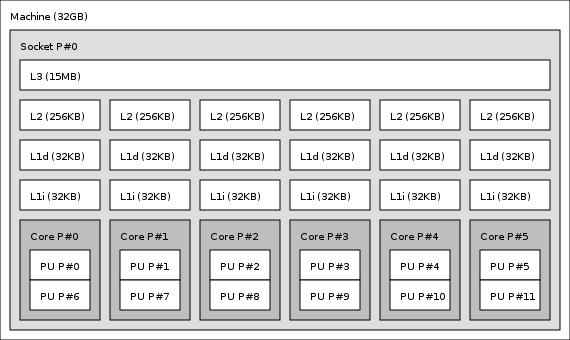


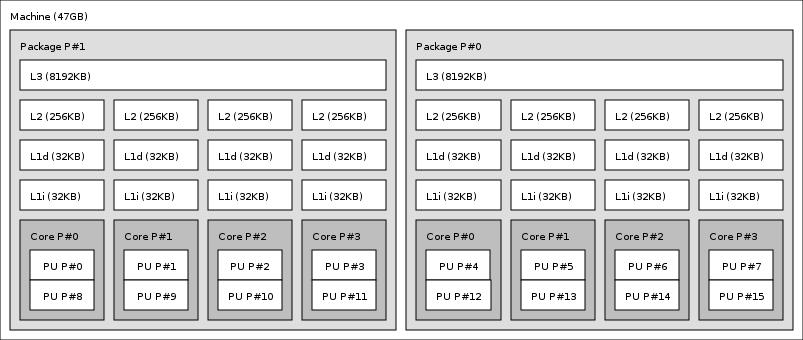
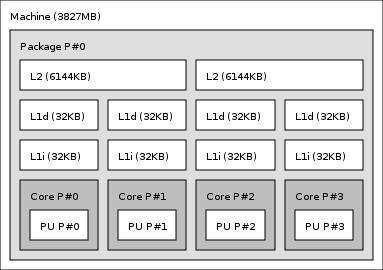
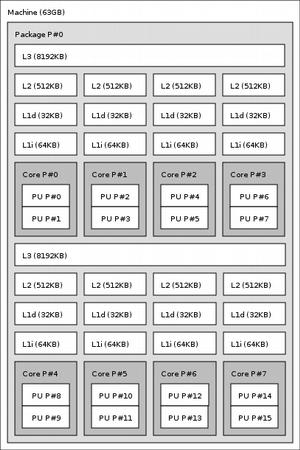

6 Multicores TechBenchs From 2 to 28 cores: examples... 6/28




7 Multishaders TechBenchs (GP)GPU 72 different models... GPU Gamer : 18 Nvidia GTX 560 Ti Nvidia GTX 680 Nvidia GTX 690 Nvidia GTX Titan Nvidia GTX 780 Nvidia GTX 780 Ti Nvidia GTX 750 Nvidia GTX 750 Ti Nvidia GTX 960 Nvidia GTX 970 Nvidia GTX 980 Nvidia GTX 980 Ti Nvidia GTX 1050 Ti Nvidia GTX 1060 Nvidia GTX 1070 Nvidia GTX 1080 Nvidia GTX 1080 Ti Nvidia RTX 2080 Ti GPU desktop & pro : 27 GPGPU : 9 Nvidia Tesla C1060 Nvidia Tesla M2050 Nvidia Tesla M2070 Nvidia Tesla M2090 Nvidia Tesla K20m Nvidia Tesla K40c Nvidia Tesla K40m Nvidia Tesla K80 Nvidia Tesla P100 NVS 290 Nvidia FX 4800 NVS 310 NVS 315 Nvidia Quadro 600 Nvidia Quadro 2000 Nvidia Quadro 4000 Nvidia Quadro K2000 Nvidia Quadro K4000 Nvidia Quadro K420 Nvidia Quadro P600 Nvidia 8400 GS Nvidia 8500 GT Nvidia 8800 GT Nvidia 9500 GT Nvidia GT 220 Nvidia GT 320 Nvidia GT 430 Nvidia GT 620 Nvidia GT 640 Nvidia GT 710 Nvidia GT 730 Nvidia GT 1030 Nvidia Quadro 2000M Nvidia Quadro K4000M Nvidia Quadro M2200 Nvidia MX150 7/28 GPU AMD Gamer & al : 18 HD 4350 HD 4890 HD 5850 HD 5870 HD 6450 HD 6670 Fusion E GPU HD 7970 FirePro V5900 FirePro W5000 Kaveri A K GPU R7 240 R9 290 R9 295X2 Nano Fury R9 Fury R9 380 RX Vega64
8 How to represent these testbenchs? Question of frequencies, cores,... (GP)GPUs CPUs 8/28










9 On TechBenchs in CBP: SIDUS Never installed, just started! What? Why? To perform unicity of configurations To Limit the footage of systems on drives For who? Deploying a system simply on a set of machines Researchers, teachers, students, engineers,... When & Where? Centre Blaise Pascal : since 2010, near from 200 machines PSMN : since 2011, more than 500 nodes (their proper instance) Laboratories : UMPA, LBMC, IGFL, CRAL,... How? To use a network share folder To divert a hack used in livecd since decades 9/28
10 Where are we? TOP 500 & the accelerators Where : on Top 500 When : Jun, 2018 How much : ~1/4 with accelerators : MIC (Intel & copied ones) GPGPU (Nvidia, AMD) 7/10 in Top 10 10/28


11 Where are we? What to expect? On a laptop, CPU & GPU benchs CPU CPU CPU A «Pi Dart Dash» In C/OpenCL In Python OpenCL A naive «N-Body» 11/28
12 12/28 Cluster 64n8c 2 GPUs per board! Cluster 8n16c 2x Intel Gold 6142 CPUs 1x Intel i7-6700k 2x Intel 2680v4 14c 2x Intel 2687v3 10c 2x Intel 2609v2 4c AMD 1x Intel c GTX for Gamers 2x Intel X5550 4c 2x AMD Epyc c AMD Ryzen c 1.00E+11 AMD FX c MIC Phi 7120P RX Vega64 Nano Fury R9 295X2 HD 7970 Tesla for Pros HD 5850 RTX 2080Ti GTX 1080Ti GTX 980Ti 4.00E+11 GTX 780Ti 5.00E+11 GTX 560Ti Tesla P E+11 Tesla K E+11 Tesla M2090 Tesla C1060 Raw performances on generations... A «Pi Dart Dash» in OpenCL 6.00E+11 FP32 FP64 AMD/ATI Intel 0.00E+00
13 13/28 Cluster 64n8c Cluster 8n16c 2x Intel Gold c CPUs 1x Intel i7-6700k 4c 2x Intel E5-2680v4 14c 2x Intel E5-2687v3 10c 2x Intel E5-2609v2 4c 1x Intel E c AMD 2x Intel X5550 4c 2x AMD Epyc c AMD Ryzen c GTX for Gamers AMD FX c MIC Phi 7120P RX Vega64 Nano Fury R9 295X2 HD E+11 HD 5850 RTX 2080Ti GTX 1080Ti GTX 980Ti GTX 780Ti 5.00E+10 GTX 560Ti Tesla P100 Tesla K80 Tesla M E+11 Tesla C1060 Raw performances in FP64 The same «Pi Dart Dash» 2.00E+11 FP64 Tesla for Pros AMD/ATI Intel 0.00E+00



14 For a more «physical» code Nbody.py in OpenCL/OpenGL Statistics Execution Deliberately simple Euler implicit implementation particules How many distances computed each step? 14/28
15 15/28 2x Intel Gold c 1x Intel i7-6700k 4c AMD 2x Intel E5-2680v4 14c GTX for Gamers 2x Intel E5-2640v3 10c 2x Intel E5-2637v2 4c 2x Intel E c 6E+10 2x Intel X5550 4c 2x AMD Epyc c 4E+10 AMD Ryzen c AMD FX c MIC Phi 7120P RX Vega64 Nano Fury R9-295X #1 Tesla For Pros HD7970 RTX 2080Ti GTX 1080Ti 2E+11 GTX 980Ti 2E+11 GTX 780Ti 2E+11 GTX 560Ti Tesla P100 1E+11 Tesla K80 1E+11 Tesla M2090 Tesla C1060 For a more «physical» code «N-Body» newtonian code D²/T_FP32 D²/T_FP64 1E+11 AMD/ATI 8E+10 CPUs Intel 2E+10 0E+00
16 16/28 2x Intel Gold c 1x Intel i7-6700k 4c AMD 2x Intel E5-2680v4 14c 2x Intel E5-2640v3 10c 2x Intel E5-2637v2 4c 2x Intel E c 2x Intel X5550 4c 2x AMD Epyc c AMD Ryzen c 1.00E+10 AMD FX c MIC Phi 7120P RX Vega64 Nano Fury R9-295X #1 GTX for Gamers HD7970 RTX 2080Ti GTX 1080Ti GTX 980Ti 5.00E+09 GTX 780Ti GTX 560Ti Tesla P100 Tesla K20m 1.50E+10 Tesla M2090 Tesla C1060 In double precision, another lecture GPGPU, the Best. CPU not so bad! 2.00E+10 D²/T_FP64 Tesla For Pros CPUs Intel AMD/ATI 0.00E+00
17 Xeon Phi is mentioned A stillborn, but instructive 3 ways of programming Intel compiler, cross-compiling, execution on embedded micro-system Intel compiler, OpenMP in «offload» mode, transparent execution Intel Implementation of OpenCL for MIC What is offload in OpenMP? Offload call on Xeon Phi MIC Classical OpenMP on independant tasks #pragma omp parallel for for (int i=0 ; i<process; i++) { inside[i]=mainloopglobal(iterations /process,seed_w+i,seed_z+i); } #pragma omp target device(0) #pragma omp teams num_teams(60) thread_limit(4) #pragma omp distribute for (int i=0 ; i<process; i++) { inside[i]=mainloopglobal(iterations/process,seed_w+i,seed_z+i); } 17/28
18 And in C/OpenCL implementation No Really simple But wait! Select the platform & device err = clgetplatformids(0, NULL, &platformcount); platforms = (cl_platform_id*) malloc(sizeof(cl_platform_id) * platformcount); err = clgetplatformids(platformcount, platforms, NULL); err = clgetdeviceids(platforms[myplatform], CL_DEVICE_TYPE_ALL, 0, NULL, &devicecount); Set attributes to OpenCL kernel devices = (cl_device_id*) malloc(sizeof(cl_device_id) * devicecount); err = clgetdeviceids(platforms[myplatform], CL_DEVICE_TYPE_ALL, devicecount, devices, NULL); cl_context GPUContext = clcreatecontext(props, 1, &devices[mydevice], NULL, NULL, &err); cl_command_queue cqcommandqueue = clcreatecommandqueue(gpucontext,devices[mydevice], 0, &err); cl_mem GPUInside = clcreatebuffer(gpucontext, CL_MEM_WRITE_ONLY, sizeof(uint64_t) * ParallelRate, NULL, NULL); cl_program OpenCLProgram = clcreateprogramwithsource(gpucontext, 130,OpenCLSource,NULL,NULL); clbuildprogram(openclprogram, 0, NULL, NULL, NULL, NULL); cl_kernel OpenCLMainLoopGlobal = clcreatekernel(openclprogram, "MainLoopGlobal", NULL); clsetkernelarg(openclmainloopglobal, 0, sizeof(cl_mem),&gpuinside); clsetkernelarg(openclmainloopglobal, 1, sizeof(uint64_t),&iterationseach); clsetkernelarg(openclmainloopglobal, 2, sizeof(uint32_t),&seed_w); clsetkernelarg(openclmainloopglobal, 3, sizeof(uint32_t),&seed_z); clsetkernelarg(openclmainloopglobal, 4, sizeof(uint32_t),&mytype); size_t WorkSize[1] = {ParallelRate}; // one dimensional Range clenqueuendrangekernel(cqcommandqueue, OpenCLMainLoopGlobal, 1, NULL, WorkSize, NULL, 0, NULL, NULL); clenqueuereadbuffer(cqcommandqueue, GPUInside, CL_TRUE, 0, ParallelRate * sizeof(uint64_t), HostInside, 0, NULL, NULL); 18/28
19 And what about the performances on the Xeon Phi with 60 cores Performance in itops from 60 to 7680, step 60 OpenMP Offload : Parallel Rate better for 32x the number of Cores, optimum at PR=7680 OpenCL : better than OpenMP, only when PR=4x the number of cores, optimum at PR= E+10 OMP FP32 OMP FP E+10 OCL FP32 OCL FP E E E E E /
20 Performances for Xeon Phi Ratio OpenCL/OpenMP Speed-up OpenCL > 2.5 for multiples of 240 as PR Speed-down OpenCL for all other numbers of PR 4.50 Ratio Ratio /
21 Performances around local max A period of 16 on Parallel Rate between max performances in OpenCL A performance divided by 40 between max and min as Parallel Rate for OpenCL A stability of performance for OpenMP 3.00E+10 OMP FP32 OMP FP E+10 OCL FP32 OCL FP E E E E E /
22 What OpenACC promises? The same thing as Intel promised in OpenMP offload? From presentation : Parallel Construct Data Constructs #pragma acc data [clause [[,] clause]...] new-line Loop Constructs #pragma acc parallel [clause [[,] clause]...] new-line #pragma acc loop [clause [[,] clause]...]new-line Why not... But can we test it? Yes! From Portland, a complete implementation of OpenACC on Nvidia 22/28
23 OpenACC on «Pi Dart Dash» Very simple implementation... Previous core routine : #pragma acc routine LENGTH MainLoopGlobal(LENGTH iterations,unsigned int seed_w,unsigned int seed_z) Previous distribution loop #pragma omp parallel for shared(parallelrate,inside) #pragma acc kernels loop for (int i=0 ; i<parallelrate; i++) { inside[i]=mainloopglobal(iterationseach,seed_w+i,seed_z+i); } 23/28
24 Open ACC/MP in «Pi Dart Dash» Mitigated results 6.00E+11 1E+12 OpenCL 32 OpenCL 64 OpenACC 32 OpenACC 64 OpenMP 32 OpenMP 64 Good! 5.00E E+11 Ugly? OpenCL 32 OpenCL 64 OpenACC 32 OpenACC 64 OpenMP 32 OpenMP 64 1E E+11 Bad :-( 2.00E+11 1E E+11 1E E+00 Tesla P100 RTX 2080 Ti E5-2637v4 2x4 E5-2640v4 2x10 Tesla P100 RTX 2080 Ti 24/28 E5-2637v4 2x4 E5-2640v4 2x10
 -cqs 0 : to perform a CPU only simulations 25/28")
25 Performance of a GPUfied code PKDGRAV3 Small hydrid code : MPI OpenMP CUDA (with kernels) Compilation : Classical cmake operations BUT old compiler required Execution : 256³ particules default : to use GPU (be careful in case of multigpu machine) -cqs 0 : to perform a CPU only simulations 25/28
26 PKDGRAV3 vs PiDartDash in FP64 Comparison between CPU & GPU 2.5E E+11 CPU Only x2 x15 FP64 Recent CPU sets 1/Elapsed 2.0E E+11 x3 1.5E E E-03 x4 5.0E E c c G ol d Ep yc G TX 26/28 2x 2x Te sl G ol d 2x 2x Ep yc Lots of work to do... 2x Ti RT X 20 2x 80 E5 Ti v 4 4c Ti G TX 10 2x 80 E5 Ti v 4 4c RT X a P1 E v 4 10 c Te sl 2x a P1 E v 4 10 c 0.0E E+00
27 How do we go? You have seen : Hybrid approach with primitives : OpenMP, OpenACC The more : easy to use, keeping code legacy The less : licence of compiler & continuity, jailed with Nvidia Kokkos, SyCL approach : The more & the less : C++ & continuity, mostly jailed with Nvidia But there is an alternative, the «thinking device» : Using Python as skeleton for calling small & efficient kernels Using OpenCL (or CUDA) for CPU, GPU, GPGPU for kernels Providing «matrix» codes as «inpiring» codes for grain, scalability, etc «Thinking device» demands to fit the parallel rate to device 27/28
28 Conclusion... In all cases : 3 questions to have in mind Do you need FP64 only sometimes but not all the time? Do your use case compatible with myriad of parallel rate? Use case : code + data Myriad : number of 10 thousands (optimum around 16 times number of ALU) Do you need less than 16GB of RAM for the core? If yes : (GP)GPU is a solution The Gamer GTX could be much more cheaper! 28/28
From modelisation house To test center. Emmanuel Quémener
 Presentation of IT resources provided by Blaise Pascal Center From modelisation house To test center Emmanuel Quémener Blaise Pascal Center «House of Modelisation» &... Conferences Trainings Projects Hotel
Presentation of IT resources provided by Blaise Pascal Center From modelisation house To test center Emmanuel Quémener Blaise Pascal Center «House of Modelisation» &... Conferences Trainings Projects Hotel
Videocard Benchmarks Over 800,000 Video Cards Benchmarked
 Home Software Hardware Benchmarks Services Store Support Forums About Us Home» Video Card Benchmarks» High End Video Cards CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android
Home Software Hardware Benchmarks Services Store Support Forums About Us Home» Video Card Benchmarks» High End Video Cards CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android
Houches 2016 : 6th School. Computational Physics. GPU : the disruptive technology of 21th century. Little comparison between CPU, MIC, GPU
 Houches 2016 : 6th School Computational Physics GPU : the disruptive technology of 21th century Little comparison between CPU, MIC, GPU Emmanuel Quémener A (human) generation before... A serial B film
Houches 2016 : 6th School Computational Physics GPU : the disruptive technology of 21th century Little comparison between CPU, MIC, GPU Emmanuel Quémener A (human) generation before... A serial B film
Videocard Benchmarks Over 800,000 Video Cards Benchmarked
 Page 1 of 9 Hom e Software Hardware Benchm arks Services Store Support Forum s AboutUs Home» Video Card Benchmarks» High End Video Cards CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC
Page 1 of 9 Hom e Software Hardware Benchm arks Services Store Support Forum s AboutUs Home» Video Card Benchmarks» High End Video Cards CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
SIDUS Extreme Deduplication & Reproducibility
 SIDUS Extreme Deduplication & Reproducibility Single Instance Distributing Universal System A Swiss Knife for Scientific Computing and elsewhere 1/46 Starting with a tiny joke... How do you call people
SIDUS Extreme Deduplication & Reproducibility Single Instance Distributing Universal System A Swiss Knife for Scientific Computing and elsewhere 1/46 Starting with a tiny joke... How do you call people
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Towards Transparent and Efficient GPU Communication on InfiniBand Clusters. Sadaf Alam Jeffrey Poznanovic Kristopher Howard Hussein Nasser El-Harake
 Towards Transparent and Efficient GPU Communication on InfiniBand Clusters Sadaf Alam Jeffrey Poznanovic Kristopher Howard Hussein Nasser El-Harake MPI and I/O from GPU vs. CPU Traditional CPU point-of-view
Towards Transparent and Efficient GPU Communication on InfiniBand Clusters Sadaf Alam Jeffrey Poznanovic Kristopher Howard Hussein Nasser El-Harake MPI and I/O from GPU vs. CPU Traditional CPU point-of-view
Astrosim Les «Houches» the 7th ;-) GPU : the disruptive technology of 21th century. Little comparison between CPU, MIC, GPU.
 GPU : the disruptive technology of 21th century. Little comparison between CPU, MIC, GPU.") Astrosim 217 Les «Houches» the 7th ;-) PU : the disruptive technology of 21th century Little comparison between CPU, MIC, PU Emmanuel Quémener A (human) generation before... A serial B film in 1984 1984
Astrosim 217 Les «Houches» the 7th ;-) PU : the disruptive technology of 21th century Little comparison between CPU, MIC, PU Emmanuel Quémener A (human) generation before... A serial B film in 1984 1984
GPU GPU CPU. Raymond Namyst 3 Samuel Thibault 3 Olivier Aumage 3
 /CPU,a),2,2 2,2 Raymond Namyst 3 Samuel Thibault 3 Olivier Aumage 3 XMP XMP-dev CPU XMP-dev/StarPU XMP-dev XMP CPU StarPU CPU /CPU XMP-dev/StarPU N /CPU CPU. Graphics Processing Unit GP General-Purpose
/CPU,a),2,2 2,2 Raymond Namyst 3 Samuel Thibault 3 Olivier Aumage 3 XMP XMP-dev CPU XMP-dev/StarPU XMP-dev XMP CPU StarPU CPU /CPU XMP-dev/StarPU N /CPU CPU. Graphics Processing Unit GP General-Purpose
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Exploiting Task-Parallelism on GPU Clusters via OmpSs and rcuda Virtualization
 Exploiting Task-Parallelism on Clusters via Adrián Castelló, Rafael Mayo, Judit Planas, Enrique S. Quintana-Ortí RePara 2015, August Helsinki, Finland Exploiting Task-Parallelism on Clusters via Power/energy/utilization
Exploiting Task-Parallelism on Clusters via Adrián Castelló, Rafael Mayo, Judit Planas, Enrique S. Quintana-Ortí RePara 2015, August Helsinki, Finland Exploiting Task-Parallelism on Clusters via Power/energy/utilization
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
PERFORMANCE PORTABILITY WITH OPENACC. Jeff Larkin, NVIDIA, November 2015
 PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
PERFORMANCE PORTABILITY WITH OPENACC Jeff Larkin, NVIDIA, November 2015 TWO TYPES OF PORTABILITY FUNCTIONAL PORTABILITY PERFORMANCE PORTABILITY The ability for a single code to run anywhere. The ability
HPC Current Development in Indonesia. Dr. Bens Pardamean Bina Nusantara University Indonesia
 HPC Current Development in Indonesia Dr. Bens Pardamean Bina Nusantara University Indonesia HPC Facilities Educational & Research Institutions in Indonesia CIBINONG SITE Basic Nodes: 80 node 2 processors
HPC Current Development in Indonesia Dr. Bens Pardamean Bina Nusantara University Indonesia HPC Facilities Educational & Research Institutions in Indonesia CIBINONG SITE Basic Nodes: 80 node 2 processors
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
GPU acceleration on IB clusters. Sadaf Alam Jeffrey Poznanovic Kristopher Howard Hussein Nasser El-Harake
 GPU acceleration on IB clusters Sadaf Alam Jeffrey Poznanovic Kristopher Howard Hussein Nasser El-Harake HPC Advisory Council European Workshop 2011 Why it matters? (Single node GPU acceleration) Control
GPU acceleration on IB clusters Sadaf Alam Jeffrey Poznanovic Kristopher Howard Hussein Nasser El-Harake HPC Advisory Council European Workshop 2011 Why it matters? (Single node GPU acceleration) Control
An Extension of XcalableMP PGAS Lanaguage for Multi-node GPU Clusters
 An Extension of XcalableMP PGAS Lanaguage for Multi-node Clusters Jinpil Lee, Minh Tuan Tran, Tetsuya Odajima, Taisuke Boku and Mitsuhisa Sato University of Tsukuba 1 Presentation Overview l Introduction
An Extension of XcalableMP PGAS Lanaguage for Multi-node Clusters Jinpil Lee, Minh Tuan Tran, Tetsuya Odajima, Taisuke Boku and Mitsuhisa Sato University of Tsukuba 1 Presentation Overview l Introduction
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler
 GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Architectures for Scalable Media Object Search
 Architectures for Scalable Media Object Search Dennis Sng Deputy Director & Principal Scientist NVIDIA GPU Technology Workshop 10 July 2014 ROSE LAB OVERVIEW 2 Large Database of Media Objects Next- Generation
Architectures for Scalable Media Object Search Dennis Sng Deputy Director & Principal Scientist NVIDIA GPU Technology Workshop 10 July 2014 ROSE LAB OVERVIEW 2 Large Database of Media Objects Next- Generation
Videocard Benchmarks Over 800,000 Video Cards Benchmarked
 Page 1 of 9 Hom e Software Hardware Benchm arks Services Store Support Forum s AboutUs Home» Video Card Benchmarks» Mid to High Range Video Cards CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks
Page 1 of 9 Hom e Software Hardware Benchm arks Services Store Support Forum s AboutUs Home» Video Card Benchmarks» Mid to High Range Video Cards CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Pedraforca: a First ARM + GPU Cluster for HPC
 www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
www.bsc.es Pedraforca: a First ARM + GPU Cluster for HPC Nikola Puzovic, Alex Ramirez We ve hit the power wall ALL computers are limited by power consumption Energy-efficient approaches Multi-core Fujitsu
Laptop Requirement: Technical Specifications and Guidelines. Frequently Asked Questions
 Laptop Requirement: Technical Specifications and Guidelines As artists and designers, you will be working in an increasingly digital landscape. The Parsons curriculum addresses this by making digital literacy
Laptop Requirement: Technical Specifications and Guidelines As artists and designers, you will be working in an increasingly digital landscape. The Parsons curriculum addresses this by making digital literacy
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
OpenACC. Part I. Ned Nedialkov. McMaster University Canada. October 2016
 OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
OpenACC. Part I Ned Nedialkov McMaster University Canada October 2016 Outline Introduction Execution model Memory model Compiling pgaccelinfo Example Speedups Profiling c 2016 Ned Nedialkov 2/23 Why accelerators
Heterogeneous Computing
 OpenCL Hwansoo Han Heterogeneous Computing Multiple, but heterogeneous multicores Use all available computing resources in system [AMD APU (Fusion)] Single core CPU, multicore CPU GPUs, DSPs Parallel programming
OpenCL Hwansoo Han Heterogeneous Computing Multiple, but heterogeneous multicores Use all available computing resources in system [AMD APU (Fusion)] Single core CPU, multicore CPU GPUs, DSPs Parallel programming
Home Software Hardware Benchmarks Services Store Support Forums About Us
 1 of 11 10/16/2018, 9:16 AM Home Software Hardware Benchmarks Services Store Support Forums About Us Home» Video Card Benchmarks» Mid to High Range Video Cards CPU Benchmarks Video Card Benchmarks Hard
1 of 11 10/16/2018, 9:16 AM Home Software Hardware Benchmarks Services Store Support Forums About Us Home» Video Card Benchmarks» Mid to High Range Video Cards CPU Benchmarks Video Card Benchmarks Hard
Directive-based Programming for Highly-scalable Nodes
 Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
Accelerating Financial Applications on the GPU
 Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
ECE 574 Cluster Computing Lecture 17
 ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 6 April 2017 HW#8 will be posted Announcements HW#7 Power outage Pi Cluster Runaway jobs (tried
ECE 574 Cluster Computing Lecture 17 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 6 April 2017 HW#8 will be posted Announcements HW#7 Power outage Pi Cluster Runaway jobs (tried
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation
 ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
ANSYS Improvements to Engineering Productivity with HPC and GPU-Accelerated Simulation Ray Browell nvidia Technology Theater SC12 1 2012 ANSYS, Inc. nvidia Technology Theater SC12 HPC Revolution Recent
Preparing for Highly Parallel, Heterogeneous Coprocessing
 Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Flexible modelling from point data
 Leapfrog Geo 3.1 Flexible modelling from point data Leapfrog Geo 3.1 introduces new workflows for modelling using point data. A 3D selection tool allows simple, fast in-scene categorisation of millions
Leapfrog Geo 3.1 Flexible modelling from point data Leapfrog Geo 3.1 introduces new workflows for modelling using point data. A 3D selection tool allows simple, fast in-scene categorisation of millions
Parallel Programming. Libraries and implementations
 Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Starting with a tiny joke!
 Starting with a tiny joke! How do you call people speak 3 languages? How do you call people speak 2 languages? Trilingual people! Bilingual people! How do you call people speak 1 language? French people!
Starting with a tiny joke! How do you call people speak 3 languages? How do you call people speak 2 languages? Trilingual people! Bilingual people! How do you call people speak 1 language? French people!
Titan - Early Experience with the Titan System at Oak Ridge National Laboratory
 Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
Office of Science Titan - Early Experience with the Titan System at Oak Ridge National Laboratory Buddy Bland Project Director Oak Ridge Leadership Computing Facility November 13, 2012 ORNL s Titan Hybrid
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
AMath 483/583, Lecture 24, May 20, Notes: Notes: What s a GPU? Notes: Some GPU application areas
 AMath 483/583 Lecture 24 May 20, 2011 Today: The Graphical Processing Unit (GPU) GPU Programming Today s lecture developed and presented by Grady Lemoine References: Andreas Kloeckner s High Performance
AMath 483/583 Lecture 24 May 20, 2011 Today: The Graphical Processing Unit (GPU) GPU Programming Today s lecture developed and presented by Grady Lemoine References: Andreas Kloeckner s High Performance
OpenACC (Open Accelerators - Introduced in 2012)
") OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators
 Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
CUDA. Matthew Joyner, Jeremy Williams
 CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
CUDA Matthew Joyner, Jeremy Williams Agenda What is CUDA? CUDA GPU Architecture CPU/GPU Communication Coding in CUDA Use cases of CUDA Comparison to OpenCL What is CUDA? What is CUDA? CUDA is a parallel
A Comprehensive Study on the Performance of Implicit LS-DYNA
 12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
12 th International LS-DYNA Users Conference Computing Technologies(4) A Comprehensive Study on the Performance of Implicit LS-DYNA Yih-Yih Lin Hewlett-Packard Company Abstract This work addresses four
OP2 FOR MANY-CORE ARCHITECTURES
 OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
OP2 FOR MANY-CORE ARCHITECTURES G.R. Mudalige, M.B. Giles, Oxford e-research Centre, University of Oxford gihan.mudalige@oerc.ox.ac.uk 27 th Jan 2012 1 AGENDA OP2 Current Progress Future work for OP2 EPSRC
CURRENT STATUS OF THE PROJECT TO ENABLE GAUSSIAN 09 ON GPGPUS
 CURRENT STATUS OF THE PROJECT TO ENABLE GAUSSIAN 09 ON GPGPUS Roberto Gomperts (NVIDIA, Corp.) Michael Frisch (Gaussian, Inc.) Giovanni Scalmani (Gaussian, Inc.) Brent Leback (PGI) TOPICS Gaussian Design
CURRENT STATUS OF THE PROJECT TO ENABLE GAUSSIAN 09 ON GPGPUS Roberto Gomperts (NVIDIA, Corp.) Michael Frisch (Gaussian, Inc.) Giovanni Scalmani (Gaussian, Inc.) Brent Leback (PGI) TOPICS Gaussian Design
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
Minnesota Supercomputing Institute Regents of the University of Minnesota. All rights reserved.
 Minnesota Supercomputing Institute Introduction to MSI for Physical Scientists Michael Milligan MSI Scientific Computing Consultant Goals Introduction to MSI resources Show you how to access our systems
Minnesota Supercomputing Institute Introduction to MSI for Physical Scientists Michael Milligan MSI Scientific Computing Consultant Goals Introduction to MSI resources Show you how to access our systems
University at Buffalo Center for Computational Research
 University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
CSC573: TSHA Introduction to Accelerators
 CSC573: TSHA Introduction to Accelerators Sreepathi Pai September 5, 2017 URCS Outline Introduction to Accelerators GPU Architectures GPU Programming Models Outline Introduction to Accelerators GPU Architectures
CSC573: TSHA Introduction to Accelerators Sreepathi Pai September 5, 2017 URCS Outline Introduction to Accelerators GPU Architectures GPU Programming Models Outline Introduction to Accelerators GPU Architectures
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices
 Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
Evaluation of Asynchronous Offloading Capabilities of Accelerator Programming Models for Multiple Devices Jonas Hahnfeld 1, Christian Terboven 1, James Price 2, Hans Joachim Pflug 1, Matthias S. Müller
GPU ARCHITECTURE Chris Schultz, June 2017
 GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
GPU ARCHITECTURE Chris Schultz, June 2017 MISC All of the opinions expressed in this presentation are my own and do not reflect any held by NVIDIA 2 OUTLINE CPU versus GPU Why are they different? CUDA
Deploying remote GPU virtualization with rcuda. Federico Silla Technical University of Valencia Spain
 Deploying remote virtualization with rcuda Federico Silla Technical University of Valencia Spain st Outline What is remote virtualization? HPC ADMINTECH 2016 2/53 It deals with s, obviously! HPC ADMINTECH
Deploying remote virtualization with rcuda Federico Silla Technical University of Valencia Spain st Outline What is remote virtualization? HPC ADMINTECH 2016 2/53 It deals with s, obviously! HPC ADMINTECH
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
JCudaMP: OpenMP/Java on CUDA
 JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
JCudaMP: OpenMP/Java on CUDA Georg Dotzler, Ronald Veldema, Michael Klemm Programming Systems Group Martensstraße 3 91058 Erlangen Motivation Write once, run anywhere - Java Slogan created by Sun Microsystems
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
GPGPU IGAD 2014/2015. Lecture 1. Jacco Bikker
 GPGPU IGAD 2014/2015 Lecture 1 Jacco Bikker Today: Course introduction GPGPU background Getting started Assignment Introduction GPU History History 3DO-FZ1 console 1991 History NVidia NV-1 (Diamond Edge
GPGPU IGAD 2014/2015 Lecture 1 Jacco Bikker Today: Course introduction GPGPU background Getting started Assignment Introduction GPU History History 3DO-FZ1 console 1991 History NVidia NV-1 (Diamond Edge
Overview of research activities Toward portability of performance
 Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Serial and Parallel Sobel Filtering for multimedia applications
 Serial and Parallel Sobel Filtering for multimedia applications Gunay Abdullayeva Institute of Computer Science University of Tartu Email: gunay@ut.ee Abstract GSteamer contains various plugins to apply
Serial and Parallel Sobel Filtering for multimedia applications Gunay Abdullayeva Institute of Computer Science University of Tartu Email: gunay@ut.ee Abstract GSteamer contains various plugins to apply
Maya , MotionBuilder & Mudbox 2018.x August 2018
 MICROSOFT WINDOWS Windows 7 SP1 Pro & Windows 10 Pro NVIDIA CERTIFIED Graphics Cards Viewport 2.0 Modes Quadro GV100 391.89 Quadro GP100 391.89 Quadro P6000 391.89 Quadro P5000 391.89 Quadro P4000 391.89
MICROSOFT WINDOWS Windows 7 SP1 Pro & Windows 10 Pro NVIDIA CERTIFIED Graphics Cards Viewport 2.0 Modes Quadro GV100 391.89 Quadro GP100 391.89 Quadro P6000 391.89 Quadro P5000 391.89 Quadro P4000 391.89
CPMD Performance Benchmark and Profiling. February 2014
 CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain)
") Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Carlos Reaño, Javier Prades and Federico Silla Technical University of Valencia (Spain) 4th IEEE International Workshop of High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB
Improved Event Generation at NLO and NNLO. or Extending MCFM to include NNLO processes
 Improved Event Generation at NLO and NNLO or Extending MCFM to include NNLO processes W. Giele, RadCor 2015 NNLO in MCFM: Jettiness approach: Using already well tested NLO MCFM as the double real and virtual-real
Improved Event Generation at NLO and NNLO or Extending MCFM to include NNLO processes W. Giele, RadCor 2015 NNLO in MCFM: Jettiness approach: Using already well tested NLO MCFM as the double real and virtual-real
LAMMPS-KOKKOS Performance Benchmark and Profiling. September 2015
 LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
COMP528: Multi-core and Multi-Processor Computing
 COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures
 MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
MAGMA a New Generation of Linear Algebra Libraries for GPU and Multicore Architectures Stan Tomov Innovative Computing Laboratory University of Tennessee, Knoxville OLCF Seminar Series, ORNL June 16, 2010
CUDA. GPU Computing. K. Cooper 1. 1 Department of Mathematics. Washington State University
 GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
GPU Computing K. Cooper 1 1 Department of Mathematics Washington State University 2014 Review of Parallel Paradigms MIMD Computing Multiple Instruction Multiple Data Several separate program streams, each
Parallel Systems. Project topics
 Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
Parallel Systems Project topics 2016-2017 1. Scheduling Scheduling is a common problem which however is NP-complete, so that we are never sure about the optimality of the solution. Parallelisation is a
CS 470 Spring Other Architectures. Mike Lam, Professor. (with an aside on linear algebra)
") CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
CS 470 Spring 2016 Mike Lam, Professor Other Architectures (with an aside on linear algebra) Parallel Systems Shared memory (uniform global address space) Primary story: make faster computers Programming
The Rise of Open Programming Frameworks. JC BARATAULT IWOCL May 2015
 The Rise of Open Programming Frameworks JC BARATAULT IWOCL May 2015 1,000+ OpenCL projects SourceForge GitHub Google Code BitBucket 2 TUM.3D Virtual Wind Tunnel 10K C++ lines of code, 30 GPU kernels CUDA
The Rise of Open Programming Frameworks JC BARATAULT IWOCL May 2015 1,000+ OpenCL projects SourceForge GitHub Google Code BitBucket 2 TUM.3D Virtual Wind Tunnel 10K C++ lines of code, 30 GPU kernels CUDA
Rock em Graphic Cards
 Rock em Graphic Cards Agnes Meyder 27.12.2013, 16:00 1 / 61 Layout Motivation Parallelism Old Standards OpenMPI OpenMP Accelerator Cards CUDA OpenCL OpenACC Hardware C++AMP The End 2 / 61 Layout Motivation
Rock em Graphic Cards Agnes Meyder 27.12.2013, 16:00 1 / 61 Layout Motivation Parallelism Old Standards OpenMPI OpenMP Accelerator Cards CUDA OpenCL OpenACC Hardware C++AMP The End 2 / 61 Layout Motivation
Martin Kruliš, v
 Martin Kruliš 1 GPGPU History Current GPU Architecture OpenCL Framework Example Optimizing Previous Example Alternative Architectures 2 1996: 3Dfx Voodoo 1 First graphical (3D) accelerator for desktop
Martin Kruliš 1 GPGPU History Current GPU Architecture OpenCL Framework Example Optimizing Previous Example Alternative Architectures 2 1996: 3Dfx Voodoo 1 First graphical (3D) accelerator for desktop
MILC Performance Benchmark and Profiling. April 2013
 MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
Qualified Apple Mac Systems for Media Composer 7.0
 Qualified Apple Mac Systems for Media Composer 7.0 System Mac Desktops Mac Pro 3.5 Ghz 6- core, 3.0 Ghz 8-core, or 2.7 Ghz 12-core Ivy Bridge CPU Mac Pro dual 6-Core 2.66 GHz "Westmere" Dual AMD FirePro
Qualified Apple Mac Systems for Media Composer 7.0 System Mac Desktops Mac Pro 3.5 Ghz 6- core, 3.0 Ghz 8-core, or 2.7 Ghz 12-core Ivy Bridge CPU Mac Pro dual 6-Core 2.66 GHz "Westmere" Dual AMD FirePro
Evaluating OpenMP s Effectiveness in the Many-Core Era
 Evaluating OpenMP s Effectiveness in the Many-Core Era Prof Simon McIntosh-Smith HPC Research Group simonm@cs.bris.ac.uk 1 Bristol, UK 10 th largest city in UK Aero, finance, chip design HQ for Cray EMEA
Evaluating OpenMP s Effectiveness in the Many-Core Era Prof Simon McIntosh-Smith HPC Research Group simonm@cs.bris.ac.uk 1 Bristol, UK 10 th largest city in UK Aero, finance, chip design HQ for Cray EMEA
HPC trends (Myths about) accelerator cards & more. June 24, Martin Schreiber,
 accelerator cards & more. June 24, Martin Schreiber,") HPC trends (Myths about) accelerator cards & more June 24, 2015 - Martin Schreiber, M.Schreiber@exeter.ac.uk Outline HPC & current architectures Performance: Programming models: OpenCL & OpenMP Some applications:
HPC trends (Myths about) accelerator cards & more June 24, 2015 - Martin Schreiber, M.Schreiber@exeter.ac.uk Outline HPC & current architectures Performance: Programming models: OpenCL & OpenMP Some applications:
Running the FIM and NIM Weather Models on GPUs
 Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Running the FIM and NIM Weather Models on GPUs Mark Govett Tom Henderson, Jacques Middlecoff, Jim Rosinski, Paul Madden NOAA Earth System Research Laboratory Global Models 0 to 14 days 10 to 30 KM resolution
Scalability of Processing on GPUs
 Scalability of Processing on GPUs Keith Kelley, CS6260 Final Project Report April 7, 2009 Research description: I wanted to figure out how useful General Purpose GPU computing (GPGPU) is for speeding up
Scalability of Processing on GPUs Keith Kelley, CS6260 Final Project Report April 7, 2009 Research description: I wanted to figure out how useful General Purpose GPU computing (GPGPU) is for speeding up
The rcuda technology: an inexpensive way to improve the performance of GPU-based clusters Federico Silla
 The rcuda technology: an inexpensive way to improve the performance of -based clusters Federico Silla Technical University of Valencia Spain The scope of this talk Delft, April 2015 2/47 More flexible
The rcuda technology: an inexpensive way to improve the performance of -based clusters Federico Silla Technical University of Valencia Spain The scope of this talk Delft, April 2015 2/47 More flexible
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
ANSYS Fluent 14 Performance Benchmark and Profiling. October 2012
 ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
HPC with GPU and its applications from Inspur. Haibo Xie, Ph.D
 HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance
HPC with GPU and its applications from Inspur Haibo Xie, Ph.D xiehb@inspur.com 2 Agenda I. HPC with GPU II. YITIAN solution and application 3 New Moore s Law 4 HPC? HPC stands for High Heterogeneous Performance