Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
|
|
|
- Hilary Willis
- 5 years ago
- Views:
Transcription


1 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld XSEDE 12 July 16,
2 Agenda Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers 08:00 08:45 Stampede and MIC Overview 08:45 10:00 Vectorization 10:00 10:15 Break 10:15 11:15 OpenMP and Offloading 11:15 12:00 Lab (on a Sandy Bridge machine) 2
3 Stampede and MIC Overview The TACC Stampede System Overview of Intel s MIC ecosystem MIC: Many Integrated Cores Basic Design Roadmap Coprocessor vs. Accelerator Programming Models OpenMP, MPI MKL, TBB, and Cilk Plus Roadmap & Preparation MIC is pronounced Mike 3
4 Stampede A new NSF-funded XSEDE resource at TACC Funded two components of a new system: Two petaflop, 100,000+ core Xeon based Dell cluster to be the new workhorse of the NSF open science community (>3x Ranger) Eight additional petaflops of Intel Many-Integrated- Core (MIC) processors to provide a revolutionary innovative capability: a new generation of supercomputing. Change the power/performance curves of supercomputing without changing the programming model (terribly much).
5 Stampede - Headlines Up to 10PF Peak performance in initial system (Early 2013) 100,000+ conventional Intel processor cores Almost 500,000 total cores with Intel MIC Upgrade with Future Knight s in PB+ disk 272TB+ RAM 56Gb FDR InfiniBand interconnect Nearly 200 racks of compute hardware (10,000 sq ft) >SIX MEGAWATTS total power
6 The Stampede Project A Complete Advanced Computing Ecosystem: HPC Compute, storage, interconnect Visualization subsystem (144 high end GPUs Large memory support (16 1TB nodes) Integration with archive, and (coming soon) TACC global work filesystem and other data systems People, training, and documentation to support computational science Hosted at an expanded building in TACC; massive power upgrades 12MW new total datacenter power Thermal energy storage to reduce operating costs 6
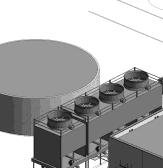

7 7

8 Stampede Datacenter February 20th

9 Stampede Datacenter March 22nd

10 Stampede Datacenter May 16th

11 Stampede Datacenter June 20th 11
 ~75 Miles of InfiniBand")
12 Facilities at TACC Stampede Footprint Stampede: 8000 ft 2 10 PF 6.5 MW Ranger: 3000 ft PF 3 MW Capabilities: 20x Footprint: 2x Stampede InfiniBand (fat-tree) ~75 Miles of InfiniBand Cables 12
13 Stampede and MIC Overview The TACC Stampede System Overview of Intel s MIC ecosystem MIC: Many Integrated Cores Basic Design Roadmap Coprocessor vs. Accelerator Programming Models OpenMP, MPI MKL, TBB, and Cilk Plus Roadmap & Preparation 13
14 An Inflection point (or two) in High Performance Computing Relatively boring, but rapidly improving architectures for the last 15 years. Performance rising much faster than Moore s Law But power rising faster And concurrency rising faster than that, with serial performance decreasing. Something had to give
15 Consider this Example Homogeneous v. Heterogeneous Acquisition costs and power consumption Homogeneous system: K computer in Japan 10 PF unaccelerated Rumored $1.2 billion acquisition costs Large power bill and foot print Heterogeneous system: Stampede at TACC Near 10PF (2 SNB + up to 8 MIC) Modest footprint: 8,000 ft 2, 6.5MW $27.5 million 15
16 Accelerated Computing for Exascale Exascale systems, predicted for 2018, would have required 500MW on the old curves. Something new was clearly needed. The accelerated computing movement was reborn (this happens periodically, starting with 387 math coprocessors).
17 Key aspects of acceleration We have lots of transistors Moore s law is holding; this isn t necessarily the problem. We don t really need lower power per transistor, we need lower power per *operation*. How to do this? nvidia GPU -AMD Fusion FPGA -ARM Cores
18 Intel s MIC approach Since the days of RISC vs. CISC, Intel has mastered the art of figuring out what is important about a new processing technology, and saying why can t we do this in x86? The Intel Many Integrated Core (MIC) architecture is about large die, simpler circuit, much more parallelism, in the x86 line.
19 What is MIC? MIC is Intel s solution to try and change the power curves Stage 1: Knights Ferry (KNF) SDP: Software Development Platform Intel has granted early access to KNF to several dozen institutions Training has started TACC had access to KNF hardware since early March 2011 and is hosting a system since mid March 2011 TACC continues to evaluate the hardware and programming models Stage 2: Knights Corner (KNC) -- Now Xeon Phi Early silicon now at TACC for Stampede development First product expected early 2013 MIC Ancestors 80-core Terascale research program Larrabee many-core visual computing Single-chip Cloud Computer (SCC) 19
20 What is MIC? Basic Design Ideas Leverage x86 architecture (CPU with many cores) Leverage (Intel s) existing x86 programming models Dedicate much of the silicon to floating point ops., keep some cache(s) Keep cache-coherency protocol (was debated at the beginning) Increase floating-point throughput per core Implement as a separate device Pre-product Software Development Platform: Knights Ferry x86 cores that are simpler, but allow for more compute throughput Strip expensive features (out-of-order execution, branch prediction, etc.) Widen SIMD registers for more throughput Fast (GDDR5) memory on card GPU form factor: size, power, PCIe connection 20
 per core Slow operation in double precision Knights Corner (first product) 50+ cores Increased amount of RAM Details are under NDA")
21 MIC Architecture Many cores on the die L1 and L2 cache Bidirectional ring network Memory and PCIe connection MIC (KNF) architecture block diagram Knights Ferry SDP Up to 32 cores 1-2 GB of GDDR5 RAM 512-bit wide SIMD registers L1/L2 caches Multiple threads (up to 4) per core Slow operation in double precision Knights Corner (first product) 50+ cores Increased amount of RAM Details are under NDA Double precision half the speed of single precision (canonical ratio) 22 nm technology 21
22 MIC vs. Xeon Number of cores Clock Speed (GHz) SIMD width (bit) MIC (KNF) Xeon ~ Xeon chip designed to work well for all work loads MIC designed to work well for number crunching Single MIC core is slower than a Xeon core Number of cores on card is much higher What is Vectorization? Instruction set: Streaming SIMD Extensions (SSE) Single Instruction Multiple Data (SIMD) Multiple data elements are loaded into SSE registers One operation produces 2, 4, or 8 results in double precision Effective vectorization (by the compiler) crucial for performance 22
23 What we at TACC like about MIC Intel s MIC is based on x86 technology x86 cores w/ caches and cache coherency SIMD instruction set Programming for MIC is similar to programming for CPUs Familiar languages: C/C++ and Fortran Familiar parallel programming models: OpenMP & MPI MPI on host and on the coprocessor Any code can run on MIC, not just kernels Optimizing for MIC is similar to optimizing for CPUs Optimize once, run anywhere Our early MIC porting efforts for codes in the field are frequently doubling performance on Sandy Bridge.
24 Coprocessor vs. Accelerator GPUs are often called Accelerators Intel calls MIC a Coprocessor Similarities Large die device, all silicon dedicated to compute Fast GDDR5 memory Connected through PCIe bus, two physical address spaces Number of MIC cores similar to number of GPU Streaming Multiprocessors 24
25 Differences Coprocessor vs. Accelerator Architecture: x86 vs. streaming processors HPC Programming model: Threading/MPI: Programming details coherent caches vs. shared memory and caches extension to C++/C/Fortran vs. CUDA/OpenCL OpenCL support OpenMP and Multithreading vs. threads in hardware MPI on host and/or MIC vs. MPI on host only offloaded regions vs. kernels Support for any code: serial, scripting, etc. Yes vs. No Native mode: MIC-compiled code may be run as an independent process on the coprocessor. 25
26 The MIC Promise Competitive Performance: Peak and Sustained Familiar Programming Model HPC: C/C++, Fortran, and Intel s TBB Parallel Programming: OpenMP, MPI, Pthreads, Cilk Plus, OpenCL Intel s MKL library (later: third party libraries) Serial and Scripting, etc. (anything a CPU core can do) Easy transition for OpenMP code Pragmas/directives added to offload OMP parallel regions onto MIC See examples later Support for MPI MPI tasks on host, communication through offloading MPI tasks on MIC, communication through MPI 26
27 Stampede and MIC Overview The TACC Stampede System Overview of Intel s MIC ecosystem MIC: Many Integrated Cores Basic Design Roadmap Coprocessor vs. Accelerator Programming Models OpenMP, MPI MKL, TBB, and Cilk Plus Roadmap & Preparation 27
28 Adapting and Optimizing Code for MIC Hybrid Programming MPI + Threads (OpenMP, etc.) Optimize for higher thread performance Minimize serial sections and synchronization Test different execution models Symmetric vs. Offloaded Optimize for L1/L2 caches Test performance on MIC Optimize for specific architecture Start production Today Any resource Today/KNF/early KNC Stampede MIC 2013+
29 Levels of Parallel Execution Multi-core CPUs, Coprocessors (MIC), and Accelerators (GPUs) exploit hardware parallelism on 2 levels 1. Processing unit (CPU, MIC, GPU) with multiple functional units CPU/MIC: Cores GPU: Streaming Multiprocessor/SIMD Engine Functional units operate independently 2. Each functional units executes in lock-step (in parallel) CPU/MIC: Vector processing unit utilizes SIMD lanes GPU: Warp/Wavefront executes on CUDA or Stream cores 29
30 SIMD vs. CUDA/Stream Cores Each functional units executes in lock-step (in parallel) CPU/MIC: Vector processing unit utilizes SIMD lanes GPU: Warp/Wavefront executing on CUDA or Stream cores GPU programming model exposes low level parallelism All CUDA/Stream cores must be utilized for good performance; this is stating the obvious and it is transparent to the programmer Programmer is forced to manually setup blocks and grids of threads Steep learning curve at the beginning, but it leads naturally to the (data-parallel) utilization of all cores CPU programming model leaves vectorization to compiler Programmers may be unaware of parallel hardware Failing to write vectorizable code will lead to a significant performance penalty of 87.5% on MIC (50-75% on Xeon) 30
31 Early MIC Programming Experiences at TACC Codes port easily Minutes to days depending mostly on library dependencies Performance requires real work While the silicon continues to evolve Getting codes to run *at all* is almost too easy; really need to put in the effort to get what you expect Scalability is pretty good Multiple threads per core *really important* Getting your code to vectorize *really important*
32 Host-only Offload Symmetric Reverse Offload MIC Native Stampede Programming Five Possible Models


33 Programming Intel MIC-based Systems MPI+Offload MPI ranks on Intel Xeon processors (only) Offload All messages into/out of processors Offload models used to accelerate MPI ranks Intel Cilk TM Plus, OpenMP*, Intel Threading Building Blocks, Pthreads* within Intel MIC Network MPI Data Xeon Data Xeon MIC MIC Homogenous network of hybrid nodes: Data Xeon MIC Data Xeon MIC 11
34 Programming Intel MIC-based Systems Many-core Hosted MPI ranks on Intel MIC (only) All messages into/out of Intel MIC Intel Cilk TM Plus, OpenMP*, Intel Threading Building Blocks, Pthreads used directly within MPI processes Programmed as homogenous network of many-core CPUs: Network Xeon Xeon Data MIC Data MIC Data MPI Xeon MIC Data Xeon MIC 13


35 Programming Intel MIC-based Systems Symmetric MPI ranks on Intel MIC and Intel Xeon processors Messages to/from any core Data MPI Data Intel Cilk TM Plus, OpenMP*, Intel Threading Building Blocks, Pthreads* used directly within MPI processes MPI Xeon Data MIC Data MPI Network Xeon MIC Programmed as heterogeneous network of homogeneous nodes: Data Data Xeon MIC Data Data Xeon MIC 14
36 MIC Programming with OpenMP MIC specific pragma precedes OpenMP pragma Fortran:!dir$ omp offload target(mic) < > C: #pragma offload target(mic) < > All data transfer is handled by the compiler (optional keywords provide user control) Offload and OpenMP section will go over examples for: Automatic data management Manual data management I/O from within offloaded region Data can stream through the MIC; no need to leave MIC to fetch new data Also very helpful when debugging (print statements) Offloading a subroutine and using MKL 36
37 Programming Models Ready to use on day one! TBB s will be available to C++ programmers MKL will be available Automatic offloading by compiler for some MKL features (probably most transparent mode) Cilk Plus Useful for task-parallel programing (add-on to OpenMP) May become available for Fortran users as well OpenMP TACC expects that OpenMP will be the most interesting programming model for our HPC users 37
38 Stampede and MIC Overview The TACC Stampede System Overview of Intel s MIC ecosystem MIC: Many Integrated Cores Basic Design Roadmap Coprocessor vs. Accelerator Programming Models OpenMP, MPI MKL, TBB, and Cilk Plus Roadmap & Preparation 38
39 General expectation: Roadmap What comes next? How to get prepared? Many of the upcoming large systems will be accelerated Stampede s base Sandy Bridge cluster being constructed now Intel s MIC coprocessor is on track for 2013 Expect that (large) systems with MIC coprocessors will become available in 2013 at/after product launch MPI + OpenMP is the main HPC programming model If you are not using TBBs If you are not spending all your time in libraries (MKL, etc.) Early user access sometime after SC12 39
40 Roadmap What comes next? How to get prepared? Many HPC applications are pure-mpi codes Start thinking about upgrading to a hybrid scheme Adding OpenMP is a larger effort than adding MIC directives Special MIC/OpenMP considerations Many more threads will be needed: 50+ cores (Production KNC) 50+/100+/200+ threads Good OpenMP scaling will be (much) more important Vectorize, vectorize, vectorize There is no unified last-level cache (LLC): Cache shared among cores, several MB on CPUs Stay tuned The coming years will be exciting 40
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
Introduction to the Intel Xeon Phi on Stampede
 June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
The Era of Heterogeneous Computing
 The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
The Era of Heterogeneous Computing EU-US Summer School on High Performance Computing New York, NY, USA June 28, 2013 Lars Koesterke: Research Staff @ TACC Nomenclature Architecture Model -------------------------------------------------------
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Preparing for Highly Parallel, Heterogeneous Coprocessing
 Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
A Unified Approach to Heterogeneous Architectures Using the Uintah Framework
 DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
Trends in HPC (hardware complexity and software challenges)
") Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
Trends in HPC (hardware complexity and software challenges) Mike Giles Oxford e-research Centre Mathematical Institute MIT seminar March 13th, 2013 Mike Giles (Oxford) HPC Trends March 13th, 2013 1 / 18
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Many Integrated Core (MIC) Architecture
 Architecture") Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
Intel Many Integrated Core (MIC) Architecture Karl Solchenbach Director European Exascale Labs BMW2011, November 3, 2011 1 Notice and Disclaimers Notice: This document contains information on products
PORTING CP2K TO THE INTEL XEON PHI. ARCHER Technical Forum, Wed 30 th July Iain Bethune
 PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
PORTING CP2K TO THE INTEL XEON PHI ARCHER Technical Forum, Wed 30 th July Iain Bethune (ibethune@epcc.ed.ac.uk) Outline Xeon Phi Overview Porting CP2K to Xeon Phi Performance Results Lessons Learned Further
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Intel Xeon Phi Coprocessors
 Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Xeon Phi Coprocessors Reference: Parallel Programming and Optimization with Intel Xeon Phi Coprocessors, by A. Vladimirov and V. Karpusenko, 2013 Ring Bus on Intel Xeon Phi Example with 8 cores Xeon
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
HPC Hardware Overview
 HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Introduc)on to Xeon Phi MIC Training Event at TACC Lars Koesterke Xeon Phi MIC Xeon Phi = first product of Intel s Many Integrated Core (MIC) architecture Co- processor PCI Express card Stripped down Linux
Path to Exascale? Intel in Research and HPC 2012
 Path to Exascale? Intel in Research and HPC 2012 Intel s Investment in Manufacturing New Capacity for 14nm and Beyond D1X Oregon Development Fab Fab 42 Arizona High Volume Fab 22nm Fab Upgrades D1D Oregon
Path to Exascale? Intel in Research and HPC 2012 Intel s Investment in Manufacturing New Capacity for 14nm and Beyond D1X Oregon Development Fab Fab 42 Arizona High Volume Fab 22nm Fab Upgrades D1D Oregon
HPC. Accelerating. HPC Advisory Council Lugano, CH March 15 th, Herbert Cornelius Intel
 15.03.2012 1 Accelerating HPC HPC Advisory Council Lugano, CH March 15 th, 2012 Herbert Cornelius Intel Legal Disclaimer 15.03.2012 2 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
15.03.2012 1 Accelerating HPC HPC Advisory Council Lugano, CH March 15 th, 2012 Herbert Cornelius Intel Legal Disclaimer 15.03.2012 2 INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL PRODUCTS.
An Introduction to the Intel Xeon Phi. Si Liu Feb 6, 2015
 Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Achieving High Performance. Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013
 Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
Achieving High Performance Jim Cownie Principal Engineer SSG/DPD/TCAR Multicore Challenge 2013 Does Instruction Set Matter? We find that ARM and x86 processors are simply engineering design points optimized
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
John Hengeveld Director of Marketing, HPC Evangelist
 MIC, Intel and Rearchitecting for Exascale John Hengeveld Director of Marketing, HPC Evangelist Intel Data Center Group Dr. Jean-Laurent Philippe, PhD Technical Sales Manager & Exascale Technical Lead
MIC, Intel and Rearchitecting for Exascale John Hengeveld Director of Marketing, HPC Evangelist Intel Data Center Group Dr. Jean-Laurent Philippe, PhD Technical Sales Manager & Exascale Technical Lead
Introduction to the Xeon Phi programming model. Fabio AFFINITO, CINECA
 Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
Introduction to the Xeon Phi programming model Fabio AFFINITO, CINECA What is a Xeon Phi? MIC = Many Integrated Core architecture by Intel Other names: KNF, KNC, Xeon Phi... Not a CPU (but somewhat similar
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson a.jackson@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past,
Architecture, Programming and Performance of MIC Phi Coprocessor
 Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Architecture, Programming and Performance of MIC Phi Coprocessor JanuszKowalik, Piotr Arłukowicz Professor (ret), The Boeing Company, Washington, USA Assistant professor, Faculty of Mathematics, Physics
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012
 Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Vincent C. Betro, R. Glenn Brook, & Ryan C. Hulguin XSEDE Xtreme Scaling Workshop Chicago, IL July 15-16, 2012 Outline NICS and AACE Architecture Overview Resources Native Mode Boltzmann BGK Solver Native/Offload
Introduction to Intel Xeon Phi programming techniques. Fabio Affinito Vittorio Ruggiero
 Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Introduction to Intel Xeon Phi programming techniques Fabio Affinito Vittorio Ruggiero Outline High level overview of the Intel Xeon Phi hardware and software stack Intel Xeon Phi programming paradigms:
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ,
 Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Intel MIC Programming Workshop, Hardware Overview & Native Execution LRZ, 27.6.- 29.6.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi Products Programming models Native
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Intel MIC Programming Workshop, Hardware Overview & Native Execution. IT4Innovations, Ostrava,
 , Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
, Hardware Overview & Native Execution IT4Innovations, Ostrava, 3.2.- 4.2.2016 1 Agenda Intro @ accelerators on HPC Architecture overview of the Intel Xeon Phi (MIC) Programming models Native mode programming
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Building NVLink for Developers
 Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Building NVLink for Developers Unleashing programmatic, architectural and performance capabilities for accelerated computing Why NVLink TM? Simpler, Better and Faster Simplified Programming No specialized
Investigation of Intel MIC for implementation of Fast Fourier Transform
 Investigation of Intel MIC for implementation of Fast Fourier Transform Soren Goyal Department of Physics IIT Kanpur e-mail address: soren@iitk.ac.in The objective of the project was to run the code for
Investigation of Intel MIC for implementation of Fast Fourier Transform Soren Goyal Department of Physics IIT Kanpur e-mail address: soren@iitk.ac.in The objective of the project was to run the code for
OpenMP 4.0 (and now 5.0)
") OpenMP 4.0 (and now 5.0) John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Classic OpenMP OpenMP was designed to replace low-level and tedious solutions like POSIX
OpenMP 4.0 (and now 5.0) John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Classic OpenMP OpenMP was designed to replace low-level and tedious solutions like POSIX
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES
 COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
COMPUTING ELEMENT EVOLUTION AND ITS IMPACT ON SIMULATION CODES P(ND) 2-2 2014 Guillaume Colin de Verdière OCTOBER 14TH, 2014 P(ND)^2-2 PAGE 1 CEA, DAM, DIF, F-91297 Arpajon, France October 14th, 2014 Abstract:
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design
 L25: Modern Compiler Design") Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
High performance computing and numerical modeling
 High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
High performance computing and numerical modeling Volker Springel Plan for my lectures Lecture 1: Collisional and collisionless N-body dynamics Lecture 2: Gravitational force calculation Lecture 3: Basic
the Intel Xeon Phi coprocessor
 the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
the Intel Xeon Phi coprocessor 1 Introduction about the Intel Xeon Phi coprocessor comparing Phi with CUDA the Intel Many Integrated Core architecture 2 Programming the Intel Xeon Phi Coprocessor with
The Intel Xeon Phi Coprocessor. Dr-Ing. Michael Klemm Software and Services Group Intel Corporation
 The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
The Intel Xeon Phi Coprocessor Dr-Ing. Michael Klemm Software and Services Group Intel Corporation (michael.klemm@intel.com) Legal Disclaimer & Optimization Notice INFORMATION IN THIS DOCUMENT IS PROVIDED
Computer Architecture and Structured Parallel Programming James Reinders, Intel
 Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
Computer Architecture and Structured Parallel Programming James Reinders, Intel Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 17 Manycore Computing and GPUs Computer
GPU 101. Mike Bailey. Oregon State University. Oregon State University. Computer Graphics gpu101.pptx. mjb April 23, 2017
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA How Can You Gain Access to GPU Power? 3
GPU 101. Mike Bailey. Oregon State University
 1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
1 GPU 101 Mike Bailey mjb@cs.oregonstate.edu gpu101.pptx Why do we care about GPU Programming? A History of GPU Performance vs. CPU Performance 2 Source: NVIDIA 1 How Can You Gain Access to GPU Power?
Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package
 High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
High Performance Machine Learning Workshop Energy Efficient K-Means Clustering for an Intel Hybrid Multi-Chip Package Matheus Souza, Lucas Maciel, Pedro Penna, Henrique Freitas 24/09/2018 Agenda Introduction
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Heterogeneous SoCs. May 28, 2014 COMPUTER SYSTEM COLLOQUIUM 1
 COSCOⅣ Heterogeneous SoCs M5171111 HASEGAWA TORU M5171112 IDONUMA TOSHIICHI May 28, 2014 COMPUTER SYSTEM COLLOQUIUM 1 Contents Background Heterogeneous technology May 28, 2014 COMPUTER SYSTEM COLLOQUIUM
COSCOⅣ Heterogeneous SoCs M5171111 HASEGAWA TORU M5171112 IDONUMA TOSHIICHI May 28, 2014 COMPUTER SYSTEM COLLOQUIUM 1 Contents Background Heterogeneous technology May 28, 2014 COMPUTER SYSTEM COLLOQUIUM
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Scalasca support for Intel Xeon Phi. Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany
 Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Scalasca support for Intel Xeon Phi Brian Wylie & Wolfgang Frings Jülich Supercomputing Centre Forschungszentrum Jülich, Germany Overview Scalasca performance analysis toolset support for MPI & OpenMP
Thread and Data parallelism in CPUs - will GPUs become obsolete?
 Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Thread and Data parallelism in CPUs - will GPUs become obsolete? USP, Sao Paulo 25/03/11 Carsten Trinitis Carsten.Trinitis@tum.de Lehrstuhl für Rechnertechnik und Rechnerorganisation (LRR) Institut für
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
CPU-GPU Heterogeneous Computing
 CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
CPU-GPU Heterogeneous Computing Advanced Seminar "Computer Engineering Winter-Term 2015/16 Steffen Lammel 1 Content Introduction Motivation Characteristics of CPUs and GPUs Heterogeneous Computing Systems
The Mont-Blanc approach towards Exascale
 http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
http://www.montblanc-project.eu The Mont-Blanc approach towards Exascale Alex Ramirez Barcelona Supercomputing Center Disclaimer: Not only I speak for myself... All references to unavailable products are
Umeå University
 HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N HPC at a glance. HPC2N Abisko, Kebnekaise HPC Programming
HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N HPC at a glance. HPC2N Abisko, Kebnekaise HPC Programming
Accelerator Programming Lecture 1
 Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Accelerator Programming Lecture 1 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de January 11, 2016 Accelerator Programming
Umeå University
 HPC2N: Introduction to HPC2N and Kebnekaise, 2017-09-12 HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N
HPC2N: Introduction to HPC2N and Kebnekaise, 2017-09-12 HPC2N @ Umeå University Introduction to HPC2N and Kebnekaise Jerry Eriksson, Pedro Ojeda-May, and Birgitte Brydsö Outline Short presentation of HPC2N
8/28/12. CSE 820 Graduate Computer Architecture. Richard Enbody. Dr. Enbody. 1 st Day 2
 CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
CSE 820 Graduate Computer Architecture Richard Enbody Dr. Enbody 1 st Day 2 1 Why Computer Architecture? Improve coding. Knowledge to make architectural choices. Ability to understand articles about architecture.
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
HPC code modernization with Intel development tools
 HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor
HPC code modernization with Intel development tools Bayncore, Ltd. Intel HPC Software Workshop Series 2016 HPC Code Modernization for Intel Xeon and Xeon Phi February 17 th 2016, Barcelona Microprocessor
INF5063: Programming heterogeneous multi-core processors Introduction
 INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
INF5063: Programming heterogeneous multi-core processors Introduction Håkon Kvale Stensland August 19 th, 2012 INF5063 Overview Course topic and scope Background for the use and parallel processing using
Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor.
 on a single die. Also called a chip-multiprocessor.") CS 320 Ch. 18 Multicore Computers Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor. Definitions: Hyper-threading Intel's proprietary simultaneous
CS 320 Ch. 18 Multicore Computers Multicore computer: Combines two or more processors (cores) on a single die. Also called a chip-multiprocessor. Definitions: Hyper-threading Intel's proprietary simultaneous
Paving the Road to Exascale
 Paving the Road to Exascale Gilad Shainer August 2015, MVAPICH User Group (MUG) Meeting The Ever Growing Demand for Performance Performance Terascale Petascale Exascale 1 st Roadrunner 2000 2005 2010 2015
Paving the Road to Exascale Gilad Shainer August 2015, MVAPICH User Group (MUG) Meeting The Ever Growing Demand for Performance Performance Terascale Petascale Exascale 1 st Roadrunner 2000 2005 2010 2015
Intel Enterprise Processors Technology
 Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Enterprise Processors Technology Kosuke Hirano Enterprise Platforms Group March 20, 2002 1 Agenda Architecture in Enterprise Xeon Processor MP Next Generation Itanium Processor Interconnect Technology
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Intel Xeon Phi архитектура, модели программирования, оптимизация.
 Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
Нижний Новгород, 2017 Intel Xeon Phi архитектура, модели программирования, оптимизация. Дмитрий Прохоров, Дмитрий Рябцев, Intel Agenda What and Why Intel Xeon Phi Top 500 insights, roadmap, architecture
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors
 The Intel Larrabee, Intel Xeon Phi and IBM Cell processors") COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
COSC 6385 Computer Architecture - Data Level Parallelism (III) The Intel Larrabee, Intel Xeon Phi and IBM Cell processors Edgar Gabriel Fall 2018 References Intel Larrabee: [1] L. Seiler, D. Carmean, E.
Overview of research activities Toward portability of performance
 Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Intra-MIC MPI Communication using MVAPICH2: Early Experience
 Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
Intra-MIC MPI Communication using MVAPICH: Early Experience Sreeram Potluri, Karen Tomko, Devendar Bureddy, and Dhabaleswar K. Panda Department of Computer Science and Engineering Ohio State University
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
General introduction: GPUs and the realm of parallel architectures
 General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
General introduction: GPUs and the realm of parallel architectures GPU Computing Training August 17-19 th 2015 Jan Lemeire (jan.lemeire@vub.ac.be) Graduated as Engineer in 1994 at VUB Worked for 4 years
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Manycore Processors. Manycore Chip: A chip having many small CPUs, typically statically scheduled and 2-way superscalar or scalar.
 phi 1 Manycore Processors phi 1 Definition Manycore Chip: A chip having many small CPUs, typically statically scheduled and 2-way superscalar or scalar. Manycore Accelerator: [Definition only for this
phi 1 Manycore Processors phi 1 Definition Manycore Chip: A chip having many small CPUs, typically statically scheduled and 2-way superscalar or scalar. Manycore Accelerator: [Definition only for this
Accelerating Implicit LS-DYNA with GPU
 Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Accelerating Implicit LS-DYNA with GPU Yih-Yih Lin Hewlett-Packard Company Abstract A major hindrance to the widespread use of Implicit LS-DYNA is its high compute cost. This paper will show modern GPU,
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Preparing GPU-Accelerated Applications for the Summit Supercomputer
 Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
Preparing GPU-Accelerated Applications for the Summit Supercomputer Fernanda Foertter HPC User Assistance Group Training Lead foertterfs@ornl.gov This research used resources of the Oak Ridge Leadership
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP
 GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
GPU > CPU. FOR HIGH PERFORMANCE COMPUTING PRESENTATION BY - SADIQ PASHA CHETHANA DILIP INTRODUCTION or With the exponential increase in computational power of todays hardware, the complexity of the problem
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
PROGRAMOVÁNÍ V C++ CVIČENÍ. Michal Brabec
 PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
PROGRAMOVÁNÍ V C++ CVIČENÍ Michal Brabec PARALLELISM CATEGORIES CPU? SSE Multiprocessor SIMT - GPU 2 / 17 PARALLELISM V C++ Weak support in the language itself, powerful libraries Many different parallelization
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Intel Xeon Processor E7 v2 Family-Based Platforms
 Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Maximize Performance and Scalability of RADIOSS* Structural Analysis Software on Family-Based Platforms Executive Summary Complex simulations of structural and systems performance, such as car crash simulations,
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
Lecture 9: MIMD Architectures
 Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Lecture 9: MIMD Architectures Introduction and classification Symmetric multiprocessors NUMA architecture Clusters Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is connected
Parallel Programming on Larrabee. Tim Foley Intel Corp
 Parallel Programming on Larrabee Tim Foley Intel Corp Motivation This morning we talked about abstractions A mental model for GPU architectures Parallel programming models Particular tools and APIs This
Parallel Programming on Larrabee Tim Foley Intel Corp Motivation This morning we talked about abstractions A mental model for GPU architectures Parallel programming models Particular tools and APIs This
ECE 574 Cluster Computing Lecture 23
 ECE 574 Cluster Computing Lecture 23 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 December 2015 Announcements Project presentations next week There is a final. time. Maybe
ECE 574 Cluster Computing Lecture 23 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 December 2015 Announcements Project presentations next week There is a final. time. Maybe
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU