Hardware for Deep Learning
|
|
|
- Katherine Baker
- 6 years ago
- Views:
Transcription
1 Hardware for Deep Learning Bill Dally Stanford and NVIDIA Stanford Platform Lab Retreat June 3, 2016


2 HARDWARE AND DATA ENABLE DNNS 2
3 THE NEED FOR SPEED Larger data sets and models lead to better accuracy but also increase computation time. Therefore progress in deep neural networks is limited by how fast the networks can be computed. Likewise the application of convnets to low latency inference problems, such as pedestrian detection in self driving car video imagery, is limited by how fast a small set of images, possibly a single image, can be classified. More data è Bigger Models èmore Need for Compute But Moore s law is no longer providing more compute Lavin & Gray, Fast Algorithms for Convolutional Neural Networks,
4 Deep Neural Network What is frames/j and frames/s/mm 2 for training & inference? LeCun, Yann, et al. "Learning algorithms for classification: A comparison on handwritten digit recognition." Neural 4 networks: the statistical mechanics perspective 261 (1995): 276.
5 4 Distinct Sub-problems Training Inference Convolutional Train Conv Inference Conv B x S Weight Reuse Act Dominated Fully-Conn. Train FC Inference FC B Weight Reuse Weight Dominated 32b FP large batches Minimize Training Time Enables larger networks 8b Int small (unit) batches Meet real-time constraint 5
6 Inference 6
7 Precision Use the smallest representation that doesn t sacrifice accuracy (32FP -> 4-6 bits quantized) 7
8 Number Representation FP32 FP S E M S E M Range Accuracy % 6x x %* Int32 1 S 31 M 0 2x10 9 ½ Int S M 0 6x10 4 ½ Int8 1 7 S M ½ Binary 1 M 0-1 ½ 8

, ISSCC 2014 Area numbers are from synthesized")
9 Cost of Operations Operation: Energy (pj) 8b Add b Add b Add b FP Add b FP Add 0.9 8b Mult b Mult b FP Mult b FP Mult b SRAM Read (8KB) 5 32b DRAM Read 640 Area (µm 2 ) N/A N/A Energy numbers are from Mark Horowitz Computing s Energy Problem (and what we can do about it), ISSCC 2014 Area numbers are from synthesized result using Design Compiler under TSMC 45nm tech node. FP units used DesignWare Library. 9
10 The Importance of Staying Local LPDDR DRAM GB On-Chip SRAM MB Local SRAM KB 640pJ/word 50pJ/word 5pJ/word
11 Mixed Precision Store weights as 4b using Trained quantization, decode to 16b Store activations as 16b w ij x + bi a j 16b x 16b multiply round result to 16b accumulate 24b or 32b to avoid saturation Batch normalization important to center dynamic range
12 Trained Quantization Han et al. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization 12 and Huffman Coding, ICLR 2016 (Best Paper)




13 2-6 Bits/Weight Sufficient 13
14 Sparsity Don t do operations that don t matter (10x 30x) 14
15 Sparsity before pruning after pruning pruning synapses pruning neurons Han et al. Learning both Weights and Connections for Efficient Neural Networks, NIPS
16 Retrain To Recover Accuracy Train Connectivity Prune Connections Train Weights Accuracy Loss L2 regularization w/o retrain L1 regularization w/o retrain L1 regularization w/ retrain L2 regularization w/ retrain L2 regularization w/ iterative prune and retrain 0.5% 0.0% -0.5% -1.0% -1.5% -2.0% -2.5% -3.0% -3.5% -4.0% -4.5% 40% 50% 60% 70% 80% 90% 100% Parametes Pruned Pruned Away Han et al. Learning both Weights and Connections for Efficient Neural Networks, NIPS


17

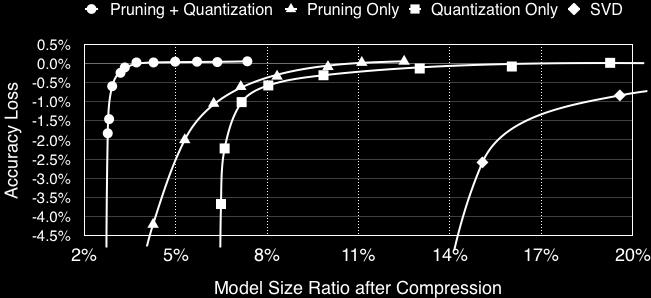
18 Pruning + Trained Quantization


19 Pruning Neural Talk And LSTM 19
20 Fixed-Function Hardware 20
2% Tn# input bi Memory#Interface# +' synapses *' NFU)1% NBin% x +' Instruc:ons# DMA# hidden layer Control#Processor#(CP)# Inst.")
 Registers 375,882 (12.43%) 86 (17.84%) Clock network 68,721 (2.27%) 132 (27.16%) Filler cell 811,632 (26.85%) SB 1,153,814 (38.17%) 105 (22.65%) NBin 427,992 (14.16%) 91 (19.")
.")
 177 (36.59%) Registers 375,882 (12.43%) 86 (17.84%) Clock network 68,721 (2.27%) 132 (27.16%) 8x8 16x16 32x32 32x4 64x8 128x16 Filler cell 811,632 (26.85%) SB 1,153,814 (38.17%) 105 (22.")
 neuron 846,563 to a neuron of the next 132 layer,(27.22%) and from one synapcp (5.69%)neuron.31 (6.39%) an execution tic latch141,809 to the associated For instance, AXIMUX time of 15ns 9,767 (0.")
21 Diannao (Electric Brain) Figure 15. Layout (65nm). DMA# *' weight' neuron output output layer Tn# synapse x ai table' Figure 9. Full hardware implementation of neural networks. DMA# NFU)3% Inst.# Inst.# NBout% Tn#x#Tn# neuron NFU)2% Tn# input bi Memory#Interface# +' synapses *' NFU)1% NBin% x +' Instruc:ons# DMA# hidden layer Control#Processor#(CP)# Inst.# SB% Component Area Power Critical or Block in µm2 (%) in mw (%) path in ns ACCELERATOR 3,023, Combinational 608,842 (20.14%) 89 (18.41%) Memory 1,158,000 (38.31%) 177 (36.59%) Registers 375,882 (12.43%) 86 (17.84%) Clock network 68,721 (2.27%) 132 (27.16%) Filler cell 811,632 (26.85%) SB 1,153,814 (38.17%) 105 (22.65%) NBin 427,992 (14.16%) 91 (19.76%) NBout 433,906 (14.35%) 92 (19.97%) NFU 846,563 (28.00%) 132 (27.22%) CP 141,809 (5.69%) 31 (6.39%) AXIMUX 9,767 (0.32%) 8 (2.65%) Other 9,226 (0.31%) 26 (5.36%) 5 Table 6. Characteristics of accelerator and breakdown by com4 FigureCritical 15.PathLayout (65nm). (ns) Area (mm^2) Energy (nj) Component Area Power Critical or Block in µm2 (%) in mw (%) path in ns ACCELERATOR 3,023, Combinational 608,842 (20.14%) 89 (18.41%) Memory 1,158,000 (38.31%) 177 (36.59%) Registers 375,882 (12.43%) 86 (17.84%) Clock network 68,721 (2.27%) 132 (27.16%) 8x8 16x16 32x32 32x4 64x8 128x16 Filler cell 811,632 (26.85%) SB 1,153,814 (38.17%) 105 (22.65%) Figure 10. Energy, critical path and area of full-hardware layers. NBin 427,992 (14.16%) 91 (19.76%) NBout 433,906 (14.35%) 92 (19.97%) NFU (28.00%) neuron 846,563 to a neuron of the next 132 layer,(27.22%) and from one synapcp (5.69%)neuron.31 (6.39%) an execution tic latch141,809 to the associated For instance, AXIMUX time of 15ns 9,767 (0.32%) 8 (2.65%) and an energy reduction of 974x over a core Other 9,226 (0.31%) 26 (5.36%)10 hidden, 10 has been reported for a (90 inputs, ponent type (first 5 lines), and functional block (last 7 lines). logic which is in charge of reading data out of NBin/NBout; such as the Intel ETANN [18] at the beginning of the 1990s, next Figure 16. Speedup of accelerator over SIMD, and of ideal ac-versions will focus on how to reduce or pipeline this not because neural networks were already large at the time, critical path. The total RAM capacity (NBin + NBout + SB celerator over accelerator. but because hardware resources (number of transistors) were + CP instructions) is 44KB (8KB for the CP RAM). The area naturally much more scarce. The principle was to timeand power are dominated by the buffers (NBin/NBout/SB) at share the physical neurons and use the on-chip RAM to respectively 56% and 60%, with the NFU being a close secstore synapses neurons values of hidden operations every cycle and (weintermediate naturally use 16-bit fixed-point layers. However, at that time, many neural networks were in the SIMD as well). As mentioned in Section 7.1,ond theat 28% and 27%. The percentage of the total cell power is 59.47%, but the routing network (included in the different small enough that all synapses and intermediate neurons accelerator performs bit operations every cycle for values could fit in the neural network RAM. Since this is no components of the table breakdown) accounts for a signif496 both classifier and convolutional layers, i.e., 62x more (icant 8 ) share of the total power at 38.77%. At 65nm, due to longer the case, one of the main challenges for large-scale than network the SIMD core. We empirically that on these neural accelerator design has become observe the interplay the high toggle rate of the accelerator, the leakage power is two types of layers, the is on average x between the computational and accelerator the memory hierarchy. almost negligible at 1.73%. faster than the SIMD core, so about 2x above the ratio Finally, we have also evaluated a design with Tn = 8, 5.of computational Accelerator foroperators Large Neural Networks and (62x). We measured that, forthus 64 multipliers in NFU-1. The total area for that design is 0.85 mm2, i.e., 3.59x smaller than for Tn = 16 Inclassifier this section, weconvolutional draw from the analysis Sections and performs and layers,ofthe SIMD3 core Diannao improved CNN computation efficiency by using dedicated functional units and memory buffers optimized for the CNN workload. Multiplier + adder tree + shifter + non-linear lookup orchestrated by instructions Weights in off-chip DRAM 452 GOP/s, 3.02 mm^2 and 485 mw 2 - Figure 11. Accelerator. Chen et al. Diannao: A small-footprint high-throughput accelerator for ubiquitous machine-learning, ASPLOS 2014 Fig cel eve in acc bot tha two fas of cla 2.0 upp to bin not cor hig CO the pre on we tha plo and ory tio of
 9.157 5.416 1.874 1.026 0.841 (59.15%) (20.46%) (11.20%) (9.18%) 0.112 1.807 4.955 1.162 1.122 (1.23%) (19.73%) (54.11%) (12.")
 (2.97%) (3.76%) Table 2: The implementation results of one PE in EIE and (CCU) the breakdown by component type (line 3-7), by module master Value (line 8-13).")
![Act The critical path of EIE is 1.15ns setting Act Queue Central Index library does [].](/docs-images/71/66151388/images/22-2.jpg "For the compressed dense layer, asnzero the Caffe the PEs sparse layer, we stored the sparse matrix in in CSR format, Act0,1,2,3 E can be Index for and used cusparse CSRMV kernel, which")


![From SW assumed s3 AC to DC conversion loss, 85%Pointer Act3 15% regulator efficiency and 15% power consumed by peripheral compocustom nents [26, 27] to report the AP+DRAM power for](/docs-images/71/66151388/images/22-5.jpg "Tegra K1.")
22 tch. activaake adon-zero h group nput acetection LNZD e result ould not he posieparate Efficient Inference Engine Total memory clock network register combinational filler cell Act_queue PtrRead SpmatRead ArithmUnit ActRW filler cell Power (mw) (59.15%) (20.46%) (11.20%) (9.18%) (1.23%) (19.73%) (54.11%) (12.68%) (12.25%) (%) Area µ (µ m 2 ) 638, , ,465 8,946 23, , ,412 3,110 18,934 23,961 (%) (93.22%) (0.14%) (1.48%) (1.40%) (3.76%) (0.12%) (19.10%) (73.57%) (0.49%) (2.97%) (3.76%) Table 2: The implementation results of one PE in EIE and (CCU) the breakdown by component type (line 3-7), by module master Value (line 8-13).Act The critical path of EIE is 1.15ns setting Act Queue Central Index library does []. For the compressed dense layer, asnzero the Caffe the PEs sparse layer, we stored the sparse matrix in in CSR format, Act0,1,2,3 E can be Index for and used cusparse CSRMV kernel, which isact optimized. In the multiplication on GPUs. From NE sparse s0 Act0matrix-vector sending 3) Mobile GPU. We use NVIDIA Tegra K1 that has 192 al order Ptr cublas SRAM Bank CUDA cores as our mobile GPU baseline.even We used From SE Leadingdense model and cusparse CSRMV Act1fors1the original t length GEMV Nzero structed for the compressed sparse model. Tegra K1 doesn t have Detect From NW software s2 Act2 interface Odd Ptr to report power consumption, so SRAM we mea-bank sured the total power consumption with a power-meter, then Read From SW assumed s3 AC to DC conversion loss, 85%Pointer Act3 15% regulator efficiency and 15% power consumed by peripheral compocustom nents [26, 27] to report the AP+DRAM power for Tegra K1. PE PE PE SpMat PE Act Value Act Queue Ptr_Even PE PE PE PE PE PE PE Arithm Act Index Even Ptr SRAM Bank PE PE PE Col Sparse Start/ Matrix End Addr SRAM SpMat Odd Ptr SRAM Bank PE Ptr_Odd PE Pointer Read Encoded Weight A Sparse Matrix Access Relative Index (a) (b) Act Value Act SRAM Encoded Weight Col Sparse Start/ Matrix End Addr SRAM D Regs Weight Decoder Regs Sparse Matrix Access Address Accum Relative Index (b) Bypass Dest Src Act Act Regs Regs Absolute Address Arithmetic Unit Act R/W Leading NZero Detect ReLU
23 Energy Efficiency CPU (Baseline) CPU Compressed x 120K 62K 35K 10000x GPU Compressed mgpu mgpu Compressed EIE 77K 15K 12K 9K 11K 1000x 24K 8K 100x 10x 1x Alex-6 CPU (Baseline) Alex-7 Alex-8 100x 248 VGG-6 CPU Compressed 1000x Speedup GPU GPU VGG-7 VGG-8 GPU Compressed NT-We mgpu NT-Wd NT-LSTM Geo Mean mgpu Compressed EIE x 1x 0.1x Alex-6 Alex-7 Alex-8 VGG-6 VGG-7 VGG-8 NT-We NT-Wd NT-LSTM Geo Mean
24 30 Energy/Inference (mj) Conv layers of VGG 16b arithmetic Activations Weights Math 0
25 Energy/Inference (mj) VGG16 FC Layers 16b Arithmetic Activations Weights Math
26 Inference Summary Prune 70-95% of static weights (3-20x reduction in size and ops) [3-20x] Exploit dynamic sparsity of activations (3x reduction in ops) [10-60x] Reduce precision to ~4 bits (8x size reduction) [80-480x] x smaller fits in smaller RAM (100x less power) [8,000-48,000x] Dedicated hardware to eliminate overhead Facilitates compression and sparsity Exploit locality Sparsity, Precision, Locality
27 Faster Training through Parallelism 27
28 Data Parallel Run Multiple Inputs In Parallel Doesn t affect latency for one input Requires P-fold larger batch size For training requires coordinated weight update 28

29 Parameter Update Parameter Server p = p + p p p Model! Workers Data! Shards Large Scale Distributed Deep Networks, Jeff Dean et al., 2013 Large scale distributed deep networks 29
30 Model-Parallel Convolution by output region (x,y) Kernels Multiple 3D K uvkj x 6D Loop Forall region XY For each output map j For each input map k For each pixel x,y in XY For each kernel element u,v B xyj += A (x-u)(y-v)k x K uvkj A ij A ij A xyk Input maps A xyk B B xyj B xyj xyj B xyj B B xyj xyj B B xyj B xyj xyj B xyj Output maps B xyj
31 Time (seconds) Parallel GPUs on Deep Speech (2560) 9-7 (1760) GPUs Baidu, Deep Speech 2: End-to-End Speech Recognition in English and Mandarin, 2015
32 4 Distinct Sub-problems Training Inference Convolutional 32b FP Batch Activation Storage GPUs ideal Comm for Parallelism Low-Precision Compressed Latency-Sensitive Fixed-Function HW Arithmetic Dominated B x S Weight Reuse Act Dominated Fully-Conn. 32b FP Batch Weight Storage GPUs ideal Comm. for Parallelism Low-Precision Compressed Latency-Sensitive No weight reuse Fixed-Function HW Storage dominated B Weight Reuse Weight Dominated 32b FP large batches Minimize Training Time Enables larger networks 8b Int small (unit) batches Meet real-time constraint 32
33 Summary Fixed-function hardware will dominate inference (100-10,000x gain) Sparse, low-precision, compressed (25-150x smaller) 3x dynamic sparsity All weights and activations from local memory (10-100x less energy) Flexible enough to track evolving algorithms GPUs will dominate training Only dynamic sparsity (3x activations, 2x dropout) Medium precision (FP16 for weights), stochastic rounding Large memory footprint (batch x retained activations) Communication BW scales with parallelism
High-Performance Hardware for Machine Learning
 High-Performance Hardware for Machine Learning Cadence ENN Summit 2/9/2016 Prof. William Dally Stanford University NVIDIA Corporation Hardware and Data enable DNNs The Need for Speed Larger data sets and
High-Performance Hardware for Machine Learning Cadence ENN Summit 2/9/2016 Prof. William Dally Stanford University NVIDIA Corporation Hardware and Data enable DNNs The Need for Speed Larger data sets and
Efficient Methods for Deep Learning
 Efficient Methods for Deep Learning Song Han Stanford University Sep 2016 Background: Deep Learning for Everything Source: Brody Huval et al., An Empirical Evaluation, arxiv:1504.01716 Source: leon A.
Efficient Methods for Deep Learning Song Han Stanford University Sep 2016 Background: Deep Learning for Everything Source: Brody Huval et al., An Empirical Evaluation, arxiv:1504.01716 Source: leon A.
arxiv: v2 [cs.cv] 3 May 2016
![arxiv: v2 [cs.cv] 3 May 2016](/thumbs/72/66717655.jpg "arxiv: v2 [cs.cv] 3 May 2016") EIE: Efficient Inference Engine on Compressed Deep Neural Network Song Han Xingyu Liu Huizi Mao Jing Pu Ardavan Pedram Mark A. Horowitz William J. Dally Stanford University, NVIDIA {songhan,xyl,huizi,jingpu,perdavan,horowitz,dally}@stanford.edu
EIE: Efficient Inference Engine on Compressed Deep Neural Network Song Han Xingyu Liu Huizi Mao Jing Pu Ardavan Pedram Mark A. Horowitz William J. Dally Stanford University, NVIDIA {songhan,xyl,huizi,jingpu,perdavan,horowitz,dally}@stanford.edu
Bandwidth-Efficient Deep Learning
 1 Bandwidth-Efficient Deep Learning from Compression to Acceleration Song Han Assistant Professor, EECS Massachusetts Institute of Technology 2 AI is Changing Our Lives Self-Driving Car Machine Translation
1 Bandwidth-Efficient Deep Learning from Compression to Acceleration Song Han Assistant Professor, EECS Massachusetts Institute of Technology 2 AI is Changing Our Lives Self-Driving Car Machine Translation
Revolutionizing the Datacenter
 Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
Power-Efficient Machine Learning using FPGAs on POWER Systems Ralph Wittig, Distinguished Engineer Office of the CTO, Xilinx Revolutionizing the Datacenter Join the Conversation #OpenPOWERSummit Top-5
Computer Architectures for Deep Learning. Ethan Dell and Daniyal Iqbal
 Computer Architectures for Deep Learning Ethan Dell and Daniyal Iqbal Agenda Introduction to Deep Learning Challenges Architectural Solutions Hardware Architectures CPUs GPUs Accelerators FPGAs SOCs ASICs
Computer Architectures for Deep Learning Ethan Dell and Daniyal Iqbal Agenda Introduction to Deep Learning Challenges Architectural Solutions Hardware Architectures CPUs GPUs Accelerators FPGAs SOCs ASICs
ESE: Efficient Speech Recognition Engine for Sparse LSTM on FPGA
 ESE: Efficient Speech Recognition Engine for Sparse LSTM on FPGA Song Han 1,2, Junlong Kang 2, Huizi Mao 1, Yiming Hu 3, Xin Li 2, Yubin Li 2, Dongliang Xie 2, Hong Luo 2, Song Yao 2, Yu Wang 2,3, Huazhong
ESE: Efficient Speech Recognition Engine for Sparse LSTM on FPGA Song Han 1,2, Junlong Kang 2, Huizi Mao 1, Yiming Hu 3, Xin Li 2, Yubin Li 2, Dongliang Xie 2, Hong Luo 2, Song Yao 2, Yu Wang 2,3, Huazhong
How to Estimate the Energy Consumption of Deep Neural Networks
 How to Estimate the Energy Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze MIT 1 Problem of DNNs Recognition Smart Drone AI Computation DNN 15k 300k OP/Px DPM 0.1k
How to Estimate the Energy Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze MIT 1 Problem of DNNs Recognition Smart Drone AI Computation DNN 15k 300k OP/Px DPM 0.1k
Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design
 Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design Song Yao 姚颂 Founder & CEO DeePhi Tech 深鉴科技 song.yao@deephi.tech Outline - About DeePhi Tech - Background - Bandwidth Matters
Bandwidth-Centric Deep Learning Processing through Software-Hardware Co-Design Song Yao 姚颂 Founder & CEO DeePhi Tech 深鉴科技 song.yao@deephi.tech Outline - About DeePhi Tech - Background - Bandwidth Matters
Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs
 Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs Ritchie Zhao 1, Weinan Song 2, Wentao Zhang 2, Tianwei Xing 3, Jeng-Hau Lin 4, Mani Srivastava 3, Rajesh Gupta 4, Zhiru
Accelerating Binarized Convolutional Neural Networks with Software-Programmable FPGAs Ritchie Zhao 1, Weinan Song 2, Wentao Zhang 2, Tianwei Xing 3, Jeng-Hau Lin 4, Mani Srivastava 3, Rajesh Gupta 4, Zhiru
TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory
 TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2017 Deep Neural
TETRIS: Scalable and Efficient Neural Network Acceleration with 3D Memory Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2017 Deep Neural
arxiv: v1 [cs.cv] 11 Feb 2018
![arxiv: v1 [cs.cv] 11 Feb 2018](/thumbs/79/79222664.jpg "arxiv: v1 [cs.cv] 11 Feb 2018") arxiv:8.8v [cs.cv] Feb 8 - Partitioning of Deep Neural Networks with Feature Space Encoding for Resource-Constrained Internet-of-Things Platforms ABSTRACT Jong Hwan Ko, Taesik Na, Mohammad Faisal Amir,
arxiv:8.8v [cs.cv] Feb 8 - Partitioning of Deep Neural Networks with Feature Space Encoding for Resource-Constrained Internet-of-Things Platforms ABSTRACT Jong Hwan Ko, Taesik Na, Mohammad Faisal Amir,
Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks
 Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks Yu-Hsin Chen 1, Joel Emer 1, 2, Vivienne Sze 1 1 MIT 2 NVIDIA 1 Contributions of This Work A novel energy-efficient
Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks Yu-Hsin Chen 1, Joel Emer 1, 2, Vivienne Sze 1 1 MIT 2 NVIDIA 1 Contributions of This Work A novel energy-efficient
Scalpel: Customizing DNN Pruning to the Underlying Hardware Parallelism
 Scalpel: Customizing DNN Pruning to the Underlying Hardware Parallelism Jiecao Yu 1, Andrew Lukefahr 1, David Palframan 2, Ganesh Dasika 2, Reetuparna Das 1, Scott Mahlke 1 1 University of Michigan 2 ARM
Scalpel: Customizing DNN Pruning to the Underlying Hardware Parallelism Jiecao Yu 1, Andrew Lukefahr 1, David Palframan 2, Ganesh Dasika 2, Reetuparna Das 1, Scott Mahlke 1 1 University of Michigan 2 ARM
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA
 Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School
Scalable and Modularized RTL Compilation of Convolutional Neural Networks onto FPGA Yufei Ma, Naveen Suda, Yu Cao, Jae-sun Seo, Sarma Vrudhula School of Electrical, Computer and Energy Engineering School
DNN Accelerator Architectures
 DNN Accelerator Architectures ISCA Tutorial (2017) Website: http://eyeriss.mit.edu/tutorial.html Joel Emer, Vivienne Sze, Yu-Hsin Chen 1 2 Highly-Parallel Compute Paradigms Temporal Architecture (SIMD/SIMT)
DNN Accelerator Architectures ISCA Tutorial (2017) Website: http://eyeriss.mit.edu/tutorial.html Joel Emer, Vivienne Sze, Yu-Hsin Chen 1 2 Highly-Parallel Compute Paradigms Temporal Architecture (SIMD/SIMT)
MIXED PRECISION TRAINING: THEORY AND PRACTICE Paulius Micikevicius
 MIXED PRECISION TRAINING: THEORY AND PRACTICE Paulius Micikevicius What is Mixed Precision Training? Reduced precision tensor math with FP32 accumulation, FP16 storage Successfully used to train a variety
MIXED PRECISION TRAINING: THEORY AND PRACTICE Paulius Micikevicius What is Mixed Precision Training? Reduced precision tensor math with FP32 accumulation, FP16 storage Successfully used to train a variety
Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture
 The 51st Annual IEEE/ACM International Symposium on Microarchitecture Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture Byungchul Hong Yeonju Ro John Kim FuriosaAI Samsung
The 51st Annual IEEE/ACM International Symposium on Microarchitecture Multi-dimensional Parallel Training of Winograd Layer on Memory-Centric Architecture Byungchul Hong Yeonju Ro John Kim FuriosaAI Samsung
Deep Learning Accelerators
 Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Deep Learning Accelerators Abhishek Srivastava (as29) Samarth Kulshreshtha (samarth5) University of Illinois, Urbana-Champaign Submitted as a requirement for CS 433 graduate student project Outline Introduction
Value-driven Synthesis for Neural Network ASICs
 Value-driven Synthesis for Neural Network ASICs Zhiyuan Yang University of Maryland, College Park zyyang@umd.edu ABSTRACT In order to enable low power and high performance evaluation of neural network
Value-driven Synthesis for Neural Network ASICs Zhiyuan Yang University of Maryland, College Park zyyang@umd.edu ABSTRACT In order to enable low power and high performance evaluation of neural network
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA
 Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
Towards a Uniform Template-based Architecture for Accelerating 2D and 3D CNNs on FPGA Junzhong Shen, You Huang, Zelong Wang, Yuran Qiao, Mei Wen, Chunyuan Zhang National University of Defense Technology,
SPARSE PERSISTENT RNN. Feiwen Zhu, 5/9/2017
 SPARSE PERSISTENT RNN Feiwen Zhu, 5/9/2017 Motivation Introduction Algorithm AGENDA Naïve Implementation Optimizations Experiments Conclusion 2 MOTIVATION Exploit sparsity for faster, larger networks Recurrent
SPARSE PERSISTENT RNN Feiwen Zhu, 5/9/2017 Motivation Introduction Algorithm AGENDA Naïve Implementation Optimizations Experiments Conclusion 2 MOTIVATION Exploit sparsity for faster, larger networks Recurrent
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks
 Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
Throughput-Optimized OpenCL-based FPGA Accelerator for Large-Scale Convolutional Neural Networks Naveen Suda, Vikas Chandra *, Ganesh Dasika *, Abinash Mohanty, Yufei Ma, Sarma Vrudhula, Jae-sun Seo, Yu
DNN ENGINE: A 16nm Sub-uJ DNN Inference Accelerator for the Embedded Masses
 DNN ENGINE: A 16nm Sub-uJ DNN Inference Accelerator for the Embedded Masses Paul N. Whatmough 1,2 S. K. Lee 2, N. Mulholland 2, P. Hansen 2, S. Kodali 3, D. Brooks 2, G.-Y. Wei 2 1 ARM Research, Boston,
DNN ENGINE: A 16nm Sub-uJ DNN Inference Accelerator for the Embedded Masses Paul N. Whatmough 1,2 S. K. Lee 2, N. Mulholland 2, P. Hansen 2, S. Kodali 3, D. Brooks 2, G.-Y. Wei 2 1 ARM Research, Boston,
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE. Dennis Lui August 2017
 DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
DEEP NEURAL NETWORKS CHANGING THE AUTONOMOUS VEHICLE LANDSCAPE Dennis Lui August 2017 THE RISE OF GPU COMPUTING APPLICATIONS 10 7 10 6 GPU-Computing perf 1.5X per year 1000X by 2025 ALGORITHMS 10 5 1.1X
High Performance Computing Hiroki Kanezashi Tokyo Institute of Technology Dept. of mathematical and computing sciences Matsuoka Lab.
 High Performance Computing 2015 Hiroki Kanezashi Tokyo Institute of Technology Dept. of mathematical and computing sciences Matsuoka Lab. 1 Reviewed Paper 1 DaDianNao: A Machine- Learning Supercomputer
High Performance Computing 2015 Hiroki Kanezashi Tokyo Institute of Technology Dept. of mathematical and computing sciences Matsuoka Lab. 1 Reviewed Paper 1 DaDianNao: A Machine- Learning Supercomputer
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.
 Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
Can FPGAs beat GPUs in accelerating next-generation Deep Neural Networks? Discussion of the FPGA 17 paper by Intel Corp. (Nurvitadhi et al.) Andreas Kurth 2017-12-05 1 In short: The situation Image credit:
Index. Springer Nature Switzerland AG 2019 B. Moons et al., Embedded Deep Learning,
 Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Index A Algorithmic noise tolerance (ANT), 93 94 Application specific instruction set processors (ASIPs), 115 116 Approximate computing application level, 95 circuits-levels, 93 94 DAS and DVAS, 107 110
Brainchip OCTOBER
 Brainchip OCTOBER 2017 1 Agenda Neuromorphic computing background Akida Neuromorphic System-on-Chip (NSoC) Brainchip OCTOBER 2017 2 Neuromorphic Computing Background Brainchip OCTOBER 2017 3 A Brief History
Brainchip OCTOBER 2017 1 Agenda Neuromorphic computing background Akida Neuromorphic System-on-Chip (NSoC) Brainchip OCTOBER 2017 2 Neuromorphic Computing Background Brainchip OCTOBER 2017 3 A Brief History
BHNN: a Memory-Efficient Accelerator for Compressing Deep Neural Network with Blocked Hashing Techniques
 BHNN: a Memory-Efficient Accelerator for Compressing Deep Neural Network with Blocked Hashing Techniques Jingyang Zhu 1, Zhiliang Qian 2*, and Chi-Ying Tsui 1 1 The Hong Kong University of Science and
BHNN: a Memory-Efficient Accelerator for Compressing Deep Neural Network with Blocked Hashing Techniques Jingyang Zhu 1, Zhiliang Qian 2*, and Chi-Ying Tsui 1 1 The Hong Kong University of Science and
The Explosion in Neural Network Hardware
 1 The Explosion in Neural Network Hardware USC Friday 19 th April Trevor Mudge Bredt Family Professor of Computer Science and Engineering The, Ann Arbor 1 What Just Happened? 2 For years the common wisdom
1 The Explosion in Neural Network Hardware USC Friday 19 th April Trevor Mudge Bredt Family Professor of Computer Science and Engineering The, Ann Arbor 1 What Just Happened? 2 For years the common wisdom
SOFTWARE HARDWARE CODESIGN ACCELERATION FOR EFFICIENT NEURAL NETWORK. ...Deep learning and neural
 ... SOFTWARE HARDWARE CODESIGN FOR EFFICIENT NEURAL NETWORK ACCELERATION... Kaiyuan Guo Tsinghua University and DeePhi Song Han Stanford University and DeePhi Song Yao DeePhi Yu Wang Tsinghua University
... SOFTWARE HARDWARE CODESIGN FOR EFFICIENT NEURAL NETWORK ACCELERATION... Kaiyuan Guo Tsinghua University and DeePhi Song Han Stanford University and DeePhi Song Yao DeePhi Yu Wang Tsinghua University
DEEP NEURAL NETWORKS AND GPUS. Julie Bernauer
 DEEP NEURAL NETWORKS AND GPUS Julie Bernauer GPU Computing GPU Computing Run Computations on GPUs x86 CUDA Framework to Program NVIDIA GPUs A simple sum of two vectors (arrays) in C void vector_add(int
DEEP NEURAL NETWORKS AND GPUS Julie Bernauer GPU Computing GPU Computing Run Computations on GPUs x86 CUDA Framework to Program NVIDIA GPUs A simple sum of two vectors (arrays) in C void vector_add(int
PERMDNN: Efficient Compressed DNN Architecture with Permuted Diagonal Matrices
 PERMDNN: Efficient Compressed DNN Architecture with Permuted Diagonal Matrices Chunhua Deng + City University of New York chunhua.deng@rutgers.edu Keshab K. Parhi University of Minnesota, Twin Cities parhi@umn.edu
PERMDNN: Efficient Compressed DNN Architecture with Permuted Diagonal Matrices Chunhua Deng + City University of New York chunhua.deng@rutgers.edu Keshab K. Parhi University of Minnesota, Twin Cities parhi@umn.edu
arxiv: v1 [cs.ne] 20 Nov 2017
![arxiv: v1 [cs.ne] 20 Nov 2017](/thumbs/83/87871407.jpg "arxiv: v1 [cs.ne] 20 Nov 2017") E-PUR: An Energy-Efficient Processing Unit for Recurrent Neural Networks arxiv:1711.748v1 [cs.ne] 2 Nov 217 ABSTRACT Franyell Silfa, Gem Dot, Jose-Maria Arnau, Antonio Gonzalez Computer Architecture Deparment,
E-PUR: An Energy-Efficient Processing Unit for Recurrent Neural Networks arxiv:1711.748v1 [cs.ne] 2 Nov 217 ABSTRACT Franyell Silfa, Gem Dot, Jose-Maria Arnau, Antonio Gonzalez Computer Architecture Deparment,
Unified Deep Learning with CPU, GPU, and FPGA Technologies
 Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
Unified Deep Learning with CPU, GPU, and FPGA Technologies Allen Rush 1, Ashish Sirasao 2, Mike Ignatowski 1 1: Advanced Micro Devices, Inc., 2: Xilinx, Inc. Abstract Deep learning and complex machine
The Explosion in Neural Network Hardware
 1 The Explosion in Neural Network Hardware Arm Summit, Cambridge, September 17 th, 2018 Trevor Mudge Bredt Family Professor of Computer Science and Engineering The, Ann Arbor 1 What Just Happened? 2 For
1 The Explosion in Neural Network Hardware Arm Summit, Cambridge, September 17 th, 2018 Trevor Mudge Bredt Family Professor of Computer Science and Engineering The, Ann Arbor 1 What Just Happened? 2 For
THE NVIDIA DEEP LEARNING ACCELERATOR
 THE NVIDIA DEEP LEARNING ACCELERATOR INTRODUCTION NVDLA NVIDIA Deep Learning Accelerator Developed as part of Xavier NVIDIA s SOC for autonomous driving applications Optimized for Convolutional Neural
THE NVIDIA DEEP LEARNING ACCELERATOR INTRODUCTION NVDLA NVIDIA Deep Learning Accelerator Developed as part of Xavier NVIDIA s SOC for autonomous driving applications Optimized for Convolutional Neural
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications
 Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications Jongsoo Park Facebook AI System SW/HW Co-design Team Sep-21 2018 Team Introduction
Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations, and Hardware Implications Jongsoo Park Facebook AI System SW/HW Co-design Team Sep-21 2018 Team Introduction
DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs
 IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
IBM Research AI Systems Day DNNBuilder: an Automated Tool for Building High-Performance DNN Hardware Accelerators for FPGAs Xiaofan Zhang 1, Junsong Wang 2, Chao Zhu 2, Yonghua Lin 2, Jinjun Xiong 3, Wen-mei
USING DATAFLOW TO OPTIMIZE ENERGY EFFICIENCY OF DEEP NEURAL NETWORK ACCELERATORS
 ... USING DATAFLOW TO OPTIMIZE ENERGY EFFICIENCY OF DEEP NEURAL NETWORK ACCELERATORS... Yu-Hsin Chen Massachusetts Institute of Technology Joel Emer Nvidia and Massachusetts Institute of Technology Vivienne
... USING DATAFLOW TO OPTIMIZE ENERGY EFFICIENCY OF DEEP NEURAL NETWORK ACCELERATORS... Yu-Hsin Chen Massachusetts Institute of Technology Joel Emer Nvidia and Massachusetts Institute of Technology Vivienne
In Live Computer Vision
 EVA 2 : Exploiting Temporal Redundancy In Live Computer Vision Mark Buckler, Philip Bedoukian, Suren Jayasuriya, Adrian Sampson International Symposium on Computer Architecture (ISCA) Tuesday June 5, 2018
EVA 2 : Exploiting Temporal Redundancy In Live Computer Vision Mark Buckler, Philip Bedoukian, Suren Jayasuriya, Adrian Sampson International Symposium on Computer Architecture (ISCA) Tuesday June 5, 2018
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System
 Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
Frequency Domain Acceleration of Convolutional Neural Networks on CPU-FPGA Shared Memory System Chi Zhang, Viktor K Prasanna University of Southern California {zhan527, prasanna}@usc.edu fpga.usc.edu ACM
A Method to Estimate the Energy Consumption of Deep Neural Networks
 A Method to Estimate the Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze Massachusetts Institute of Technology, Cambridge, MA, USA {tjy, yhchen, jsemer, sze}@mit.edu
A Method to Estimate the Consumption of Deep Neural Networks Tien-Ju Yang, Yu-Hsin Chen, Joel Emer, Vivienne Sze Massachusetts Institute of Technology, Cambridge, MA, USA {tjy, yhchen, jsemer, sze}@mit.edu
Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System
 Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System Xiaofan Zhang1, Mohamed El Hadedy1, Wen-mei Hwu1, Nam Sung Kim1, Jinjun Xiong2, Deming Chen1 1 University of Illinois Urbana-Champaign
Implementing Long-term Recurrent Convolutional Network Using HLS on POWER System Xiaofan Zhang1, Mohamed El Hadedy1, Wen-mei Hwu1, Nam Sung Kim1, Jinjun Xiong2, Deming Chen1 1 University of Illinois Urbana-Champaign
Deep Learning on Modern Architectures. Keren Zhou 4/17/2017
 Deep Learning on Modern Architectures Keren Zhou 4/17/2017 HPC Software Stack Application Algorithm Data Layout CPU GPU MIC Others HPC Software Stack Deep Learning Algorithm Data Layout CPU GPU MIC Others
Deep Learning on Modern Architectures Keren Zhou 4/17/2017 HPC Software Stack Application Algorithm Data Layout CPU GPU MIC Others HPC Software Stack Deep Learning Algorithm Data Layout CPU GPU MIC Others
Deep Learning on Arm Cortex-M Microcontrollers. Rod Crawford Director Software Technologies, Arm
 Deep Learning on Arm Cortex-M Microcontrollers Rod Crawford Director Software Technologies, Arm What is Machine Learning (ML)? Artificial Intelligence Machine Learning Deep Learning Neural Networks Additional
Deep Learning on Arm Cortex-M Microcontrollers Rod Crawford Director Software Technologies, Arm What is Machine Learning (ML)? Artificial Intelligence Machine Learning Deep Learning Neural Networks Additional
Recurrent Neural Networks. Deep neural networks have enabled major advances in machine learning and AI. Convolutional Neural Networks
 Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
Deep neural networks have enabled major advances in machine learning and AI Computer vision Language translation Speech recognition Question answering And more Problem: DNNs are challenging to serve and
Scaling Neural Network Acceleration using Coarse-Grained Parallelism
 Scaling Neural Network Acceleration using Coarse-Grained Parallelism Mingyu Gao, Xuan Yang, Jing Pu, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2018 Neural Networks (NNs)
Scaling Neural Network Acceleration using Coarse-Grained Parallelism Mingyu Gao, Xuan Yang, Jing Pu, Mark Horowitz, Christos Kozyrakis Stanford University Platform Lab Review Feb 2018 Neural Networks (NNs)
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in ReRAM-based Main Memory
 Scalable and Energy-Efficient Architecture Lab (SEAL) PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in -based Main Memory Ping Chi *, Shuangchen Li *, Tao Zhang, Cong
Scalable and Energy-Efficient Architecture Lab (SEAL) PRIME: A Novel Processing-in-memory Architecture for Neural Network Computation in -based Main Memory Ping Chi *, Shuangchen Li *, Tao Zhang, Cong
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, Yong Wang, Bo Yu, Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A dominant
Implementing Deep Learning for Video Analytics on Tegra X1.
 Implementing Deep Learning for Video Analytics on Tegra X1 research@hertasecurity.com Index Who we are, what we do Video analytics pipeline Video decoding Facial detection and preprocessing DNN: learning
Implementing Deep Learning for Video Analytics on Tegra X1 research@hertasecurity.com Index Who we are, what we do Video analytics pipeline Video decoding Facial detection and preprocessing DNN: learning
GPU-Accelerated Deep Learning
 GPU-Accelerated Deep Learning July 6 th, 2016. Greg Heinrich. Credits: Alison B. Lowndes, Julie Bernauer, Leo K. Tam. PRACTICAL DEEP LEARNING EXAMPLES Image Classification, Object Detection, Localization,
GPU-Accelerated Deep Learning July 6 th, 2016. Greg Heinrich. Credits: Alison B. Lowndes, Julie Bernauer, Leo K. Tam. PRACTICAL DEEP LEARNING EXAMPLES Image Classification, Object Detection, Localization,
Xilinx ML Suite Overview
 Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
Xilinx ML Suite Overview Yao Fu System Architect Data Center Acceleration Xilinx Accelerated Computing Workloads Machine Learning Inference Image classification and object detection Video Streaming Frame
Research Faculty Summit Systems Fueling future disruptions
 Research Faculty Summit 2018 Systems Fueling future disruptions Efficient Edge Computing for Deep Neural Networks and Beyond Vivienne Sze In collaboration with Yu-Hsin Chen, Joel Emer, Tien-Ju Yang, Sertac
Research Faculty Summit 2018 Systems Fueling future disruptions Efficient Edge Computing for Deep Neural Networks and Beyond Vivienne Sze In collaboration with Yu-Hsin Chen, Joel Emer, Tien-Ju Yang, Sertac
SDA: Software-Defined Accelerator for Large- Scale DNN Systems
 SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
SDA: Software-Defined Accelerator for Large- Scale DNN Systems Jian Ouyang, 1 Shiding Lin, 1 Wei Qi, 1 Yong Wang, 1 Bo Yu, 1 Song Jiang, 2 1 Baidu, Inc. 2 Wayne State University Introduction of Baidu A
NVIDIA FOR DEEP LEARNING. Bill Veenhuis
 NVIDIA FOR DEEP LEARNING Bill Veenhuis bveenhuis@nvidia.com Nvidia is the world s leading ai platform ONE ARCHITECTURE CUDA 2 GPU: Perfect Companion for Accelerating Apps & A.I. CPU GPU 3 Intro to AI AGENDA
NVIDIA FOR DEEP LEARNING Bill Veenhuis bveenhuis@nvidia.com Nvidia is the world s leading ai platform ONE ARCHITECTURE CUDA 2 GPU: Perfect Companion for Accelerating Apps & A.I. CPU GPU 3 Intro to AI AGENDA
Addressing the Memory Wall
 Lecture 26: Addressing the Memory Wall Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Cage the Elephant Back Against the Wall (Cage the Elephant) This song is for the
Lecture 26: Addressing the Memory Wall Parallel Computer Architecture and Programming CMU 15-418/15-618, Spring 2015 Tunes Cage the Elephant Back Against the Wall (Cage the Elephant) This song is for the
A Scalable Speech Recognizer with Deep-Neural-Network Acoustic Models
 A Scalable Speech Recognizer with Deep-Neural-Network Acoustic Models and Voice-Activated Power Gating Michael Price*, James Glass, Anantha Chandrakasan MIT, Cambridge, MA * now at Analog Devices, Cambridge,
A Scalable Speech Recognizer with Deep-Neural-Network Acoustic Models and Voice-Activated Power Gating Michael Price*, James Glass, Anantha Chandrakasan MIT, Cambridge, MA * now at Analog Devices, Cambridge,
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference
 FINN: A Framework for Fast, Scalable Binarized Neural Network Inference Yaman Umuroglu (XIR & NTNU), Nick Fraser (XIR & USydney), Giulio Gambardella (XIR), Michaela Blott (XIR), Philip Leong (USydney),
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference Yaman Umuroglu (XIR & NTNU), Nick Fraser (XIR & USydney), Giulio Gambardella (XIR), Michaela Blott (XIR), Philip Leong (USydney),
Lecture 12: Model Serving. CSE599W: Spring 2018
 Lecture 12: Model Serving CSE599W: Spring 2018 Deep Learning Applications That drink will get you to 2800 calories for today I last saw your keys in the store room Remind Tom of the party You re on page
Lecture 12: Model Serving CSE599W: Spring 2018 Deep Learning Applications That drink will get you to 2800 calories for today I last saw your keys in the store room Remind Tom of the party You re on page
Persistent RNNs. (stashing recurrent weights on-chip) Gregory Diamos. April 7, Baidu SVAIL
 Gregory Diamos. April 7, Baidu SVAIL") (stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
(stashing recurrent weights on-chip) Baidu SVAIL April 7, 2016 SVAIL Think hard AI. Goal Develop hard AI technologies that impact 100 million users. Deep Learning at SVAIL 100 GFLOP/s 1 laptop 6 TFLOP/s
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks
 Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks Charles Eckert Xiaowei Wang Jingcheng Wang Arun Subramaniyan Ravi Iyer Dennis Sylvester David Blaauw Reetuparna Das M-Bits Research
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks Charles Eckert Xiaowei Wang Jingcheng Wang Arun Subramaniyan Ravi Iyer Dennis Sylvester David Blaauw Reetuparna Das M-Bits Research
A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications
 A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications Ju-Ho Sohn, Jeong-Ho Woo, Min-Wuk Lee, Hye-Jung Kim, Ramchan Woo, Hoi-Jun Yoo Semiconductor System
A 50Mvertices/s Graphics Processor with Fixed-Point Programmable Vertex Shader for Mobile Applications Ju-Ho Sohn, Jeong-Ho Woo, Min-Wuk Lee, Hye-Jung Kim, Ramchan Woo, Hoi-Jun Yoo Semiconductor System
SparseNN: An Energy-Efficient Neural Network Accelerator Exploiting Input and Output Sparsity
 SparseNN: An Energy-Efficient Neural Network Accelerator Exploiting Input and Output Sparsity Jingyang Zhu 1, Jingbo Jiang 1, Xizi Chen 1 and Chi-Ying Tsui 2 Department of Electronic and Computer Engineering,
SparseNN: An Energy-Efficient Neural Network Accelerator Exploiting Input and Output Sparsity Jingyang Zhu 1, Jingbo Jiang 1, Xizi Chen 1 and Chi-Ying Tsui 2 Department of Electronic and Computer Engineering,
FPGA-based Accelerators of Deep Learning Networks for Learning and Classification: A Review
 Date of publication 2018 00, 0000, date of current version 2018 00, 0000. Digital Object Identifier 10.1109/ACCESS.2018.2890150.DOI arxiv:1901.00121v1 [cs.ne] 1 Jan 2019 FPGA-based Accelerators of Deep
Date of publication 2018 00, 0000, date of current version 2018 00, 0000. Digital Object Identifier 10.1109/ACCESS.2018.2890150.DOI arxiv:1901.00121v1 [cs.ne] 1 Jan 2019 FPGA-based Accelerators of Deep
Monolithic 3D IC Design for Deep Neural Networks
 Monolithic 3D IC Design for Deep Neural Networks 1 with Application on Low-power Speech Recognition Kyungwook Chang 1, Deepak Kadetotad 2, Yu (Kevin) Cao 2, Jae-sun Seo 2, and Sung Kyu Lim 1 1 School of
Monolithic 3D IC Design for Deep Neural Networks 1 with Application on Low-power Speech Recognition Kyungwook Chang 1, Deepak Kadetotad 2, Yu (Kevin) Cao 2, Jae-sun Seo 2, and Sung Kyu Lim 1 1 School of
ENVISION: A 0.26-to-10 TOPS/W Subword-Parallel Dynamic- Voltage-Accuracy-Frequency- Scalable CNN Processor in 28nm FDSOI
 ENVISION: A 0.26-to-10 TOPS/W Subword-Parallel Dynamic- Voltage-Accuracy-Frequency- Scalable CNN Processor in 28nm FDSOI Bert oons, Roel Uytterhoeven, Wim Dehaene, arian Verhelst ESAT/ICAS - KU Leuven
ENVISION: A 0.26-to-10 TOPS/W Subword-Parallel Dynamic- Voltage-Accuracy-Frequency- Scalable CNN Processor in 28nm FDSOI Bert oons, Roel Uytterhoeven, Wim Dehaene, arian Verhelst ESAT/ICAS - KU Leuven
High Performance Computing
 High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
High Performance Computing 9th Lecture 2016/10/28 YUKI ITO 1 Selected Paper: vdnn: Virtualized Deep Neural Networks for Scalable, MemoryEfficient Neural Network Design Minsoo Rhu, Natalia Gimelshein, Jason
Layer-wise Performance Bottleneck Analysis of Deep Neural Networks
 Layer-wise Performance Bottleneck Analysis of Deep Neural Networks Hengyu Zhao, Colin Weinshenker*, Mohamed Ibrahim*, Adwait Jog*, Jishen Zhao University of California, Santa Cruz, *The College of William
Layer-wise Performance Bottleneck Analysis of Deep Neural Networks Hengyu Zhao, Colin Weinshenker*, Mohamed Ibrahim*, Adwait Jog*, Jishen Zhao University of California, Santa Cruz, *The College of William
Implementation of Deep Convolutional Neural Net on a Digital Signal Processor
 Implementation of Deep Convolutional Neural Net on a Digital Signal Processor Elaina Chai December 12, 2014 1. Abstract In this paper I will discuss the feasibility of an implementation of an algorithm
Implementation of Deep Convolutional Neural Net on a Digital Signal Processor Elaina Chai December 12, 2014 1. Abstract In this paper I will discuss the feasibility of an implementation of an algorithm
Hello Edge: Keyword Spotting on Microcontrollers
 Hello Edge: Keyword Spotting on Microcontrollers Yundong Zhang, Naveen Suda, Liangzhen Lai and Vikas Chandra ARM Research, Stanford University arxiv.org, 2017 Presented by Mohammad Mofrad University of
Hello Edge: Keyword Spotting on Microcontrollers Yundong Zhang, Naveen Suda, Liangzhen Lai and Vikas Chandra ARM Research, Stanford University arxiv.org, 2017 Presented by Mohammad Mofrad University of
Low-Power Neural Processor for Embedded Human and Face detection
 Low-Power Neural Processor for Embedded Human and Face detection Olivier Brousse 1, Olivier Boisard 1, Michel Paindavoine 1,2, Jean-Marc Philippe, Alexandre Carbon (1) GlobalSensing Technologies (GST)
Low-Power Neural Processor for Embedded Human and Face detection Olivier Brousse 1, Olivier Boisard 1, Michel Paindavoine 1,2, Jean-Marc Philippe, Alexandre Carbon (1) GlobalSensing Technologies (GST)
Xilinx Machine Learning Strategies For Edge
 Xilinx Machine Learning Strategies For Edge Presented By Alvin Clark, Sr. FAE, Northwest The Hottest Research: AI / Machine Learning Nick s ML Model Nick s ML Framework copyright sources: Gospel Coalition
Xilinx Machine Learning Strategies For Edge Presented By Alvin Clark, Sr. FAE, Northwest The Hottest Research: AI / Machine Learning Nick s ML Model Nick s ML Framework copyright sources: Gospel Coalition
Efficiency and Programmability: Enablers for ExaScale. Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford
, EE&CS, Stanford") Efficiency and Programmability: Enablers for ExaScale Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford Scientific Discovery and Business Analytics Driving an Insatiable
Efficiency and Programmability: Enablers for ExaScale Bill Dally Chief Scientist and SVP, Research NVIDIA Professor (Research), EE&CS, Stanford Scientific Discovery and Business Analytics Driving an Insatiable
PULP: an open source hardware-software platform for near-sensor analytics. Luca Benini IIS-ETHZ & DEI-UNIBO
 PULP: an open source hardware-software platform for near-sensor analytics Luca Benini IIS-ETHZ & DEI-UNIBO An IoT System View Sense MEMS IMU MEMS Microphone ULP Imager Analyze µcontroller L2 Memory e.g.
PULP: an open source hardware-software platform for near-sensor analytics Luca Benini IIS-ETHZ & DEI-UNIBO An IoT System View Sense MEMS IMU MEMS Microphone ULP Imager Analyze µcontroller L2 Memory e.g.
direct hardware mapping of cnns on fpga-based smart cameras
 direct hardware mapping of cnns on fpga-based smart cameras Workshop on Architecture of Smart Cameras Kamel ABDELOUAHAB, Francois BERRY, Maxime PELCAT, Jocelyn SEROT, Jean-Charles QUINTON Cordoba, June
direct hardware mapping of cnns on fpga-based smart cameras Workshop on Architecture of Smart Cameras Kamel ABDELOUAHAB, Francois BERRY, Maxime PELCAT, Jocelyn SEROT, Jean-Charles QUINTON Cordoba, June
Arm s First-Generation Machine Learning Processor
 Arm s First-Generation Machine Learning Processor Ian Bratt 2018 Arm Limited Introducing the Arm Machine Learning (ML) Processor Optimized ground-up architecture for machine learning processing Massive
Arm s First-Generation Machine Learning Processor Ian Bratt 2018 Arm Limited Introducing the Arm Machine Learning (ML) Processor Optimized ground-up architecture for machine learning processing Massive
Versal: AI Engine & Programming Environment
 Engineering Director, Xilinx Silicon Architecture Group Versal: Engine & Programming Environment Presented By Ambrose Finnerty Xilinx DSP Technical Marketing Manager October 16, 2018 MEMORY MEMORY MEMORY
Engineering Director, Xilinx Silicon Architecture Group Versal: Engine & Programming Environment Presented By Ambrose Finnerty Xilinx DSP Technical Marketing Manager October 16, 2018 MEMORY MEMORY MEMORY
DaDianNao: A Machine-Learning Supercomputer
 2 7th Annual IEEE/ACM International Symposium on Microarchitecture DaDianNao: A Machine-Learning Supercomputer Yunji Chen, Tao Luo,3, Shaoli Liu, Shijin Zhang, Liqiang He 2,, Jia Wang, Ling Li, Tianshi
2 7th Annual IEEE/ACM International Symposium on Microarchitecture DaDianNao: A Machine-Learning Supercomputer Yunji Chen, Tao Luo,3, Shaoli Liu, Shijin Zhang, Liqiang He 2,, Jia Wang, Ling Li, Tianshi
Maximizing Server Efficiency from μarch to ML accelerators. Michael Ferdman
 Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency with ML accelerators Michael
Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency from μarch to ML accelerators Michael Ferdman Maximizing Server Efficiency with ML accelerators Michael
Scaling Convolutional Neural Networks on Reconfigurable Logic Michaela Blott, Principal Engineer, Xilinx Research
 Scaling Convolutional Neural Networks on Reconfigurable Logic Michaela Blott, Principal Engineer, Xilinx Research Nick Fraser (Xilinx & USydney) Yaman Umuroglu (Xilinx & NTNU) Giulio Gambardella (Xilinx)
Scaling Convolutional Neural Networks on Reconfigurable Logic Michaela Blott, Principal Engineer, Xilinx Research Nick Fraser (Xilinx & USydney) Yaman Umuroglu (Xilinx & NTNU) Giulio Gambardella (Xilinx)
GPU FOR DEEP LEARNING. 周国峰 Wuhan University 2017/10/13
 GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
GPU FOR DEEP LEARNING chandlerz@nvidia.com 周国峰 Wuhan University 2017/10/13 Why Deep Learning Boost Today? Nvidia SDK for Deep Learning? Agenda CUDA 8.0 cudnn TensorRT (GIE) NCCL DIGITS 2 Why Deep Learning
Real-time convolutional networks for sonar image classification in low-power embedded systems
 Real-time convolutional networks for sonar image classification in low-power embedded systems Matias Valdenegro-Toro Ocean Systems Laboratory - School of Engineering & Physical Sciences Heriot-Watt University,
Real-time convolutional networks for sonar image classification in low-power embedded systems Matias Valdenegro-Toro Ocean Systems Laboratory - School of Engineering & Physical Sciences Heriot-Watt University,
Nvidia Jetson TX2 and its Software Toolset. João Fernandes 2017/2018
 Nvidia Jetson TX2 and its Software Toolset João Fernandes 2017/2018 In this presentation Nvidia Jetson TX2: Hardware Nvidia Jetson TX2: Software Machine Learning: Neural Networks Convolutional Neural Networks
Nvidia Jetson TX2 and its Software Toolset João Fernandes 2017/2018 In this presentation Nvidia Jetson TX2: Hardware Nvidia Jetson TX2: Software Machine Learning: Neural Networks Convolutional Neural Networks
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference
 FINN: A Framework for Fast, Scalable Binarized Neural Network Inference Yaman Umuroglu (NTNU & Xilinx Research Labs Ireland) in collaboration with N Fraser, G Gambardella, M Blott, P Leong, M Jahre and
FINN: A Framework for Fast, Scalable Binarized Neural Network Inference Yaman Umuroglu (NTNU & Xilinx Research Labs Ireland) in collaboration with N Fraser, G Gambardella, M Blott, P Leong, M Jahre and
Making Sense of Artificial Intelligence: A Practical Guide
 Making Sense of Artificial Intelligence: A Practical Guide JEDEC Mobile & IOT Forum Copyright 2018 Young Paik, Samsung Senior Director Product Planning Disclaimer This presentation and/or accompanying
Making Sense of Artificial Intelligence: A Practical Guide JEDEC Mobile & IOT Forum Copyright 2018 Young Paik, Samsung Senior Director Product Planning Disclaimer This presentation and/or accompanying
Research Faculty Summit Systems Fueling future disruptions
 Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
Research Faculty Summit 2018 Systems Fueling future disruptions Wolong: A Back-end Optimizer for Deep Learning Computation Jilong Xue Researcher, Microsoft Research Asia System Challenge in Deep Learning
Software Defined Hardware
 Software Defined Hardware For data intensive computation Wade Shen DARPA I2O September 19, 2017 1 Goal Statement Build runtime reconfigurable hardware and software that enables near ASIC performance (within
Software Defined Hardware For data intensive computation Wade Shen DARPA I2O September 19, 2017 1 Goal Statement Build runtime reconfigurable hardware and software that enables near ASIC performance (within
Binary Convolutional Neural Network on RRAM
 Binary Convolutional Neural Network on RRAM Tianqi Tang, Lixue Xia, Boxun Li, Yu Wang, Huazhong Yang Dept. of E.E, Tsinghua National Laboratory for Information Science and Technology (TNList) Tsinghua
Binary Convolutional Neural Network on RRAM Tianqi Tang, Lixue Xia, Boxun Li, Yu Wang, Huazhong Yang Dept. of E.E, Tsinghua National Laboratory for Information Science and Technology (TNList) Tsinghua
ECE5775 High-Level Digital Design Automation, Fall 2018 School of Electrical Computer Engineering, Cornell University
 ECE5775 High-Level Digital Design Automation, Fall 2018 School of Electrical Computer Engineering, Cornell University Lab 4: Binarized Convolutional Neural Networks Due Wednesday, October 31, 2018, 11:59pm
ECE5775 High-Level Digital Design Automation, Fall 2018 School of Electrical Computer Engineering, Cornell University Lab 4: Binarized Convolutional Neural Networks Due Wednesday, October 31, 2018, 11:59pm
CapsAcc: An Efficient Hardware Accelerator for CapsuleNets with Data Reuse
 Accepted for publication at Design, Automation and Test in Europe (DATE 2019). Florence, Italy CapsAcc: An Efficient Hardware Accelerator for CapsuleNets with Reuse Alberto Marchisio, Muhammad Abdullah
Accepted for publication at Design, Automation and Test in Europe (DATE 2019). Florence, Italy CapsAcc: An Efficient Hardware Accelerator for CapsuleNets with Reuse Alberto Marchisio, Muhammad Abdullah
THE PATH TO EXASCALE COMPUTING. Bill Dally Chief Scientist and Senior Vice President of Research
 THE PATH TO EXASCALE COMPUTING Bill Dally Chief Scientist and Senior Vice President of Research The Goal: Sustained ExaFLOPs on problems of interest 2 Exascale Challenges Energy efficiency Programmability
THE PATH TO EXASCALE COMPUTING Bill Dally Chief Scientist and Senior Vice President of Research The Goal: Sustained ExaFLOPs on problems of interest 2 Exascale Challenges Energy efficiency Programmability
CafeGPI. Single-Sided Communication for Scalable Deep Learning
 CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
Inference Optimization Using TensorRT with Use Cases. Jack Han / 한재근 Solutions Architect NVIDIA
 Inference Optimization Using TensorRT with Use Cases Jack Han / 한재근 Solutions Architect NVIDIA Search Image NLP Maps TensorRT 4 Adoption Use Cases Speech Video AI Inference is exploding 1 Billion Videos
Inference Optimization Using TensorRT with Use Cases Jack Han / 한재근 Solutions Architect NVIDIA Search Image NLP Maps TensorRT 4 Adoption Use Cases Speech Video AI Inference is exploding 1 Billion Videos
Multicore SoC is coming. Scalable and Reconfigurable Stream Processor for Mobile Multimedia Systems. Source: 2007 ISSCC and IDF.
 Scalable and Reconfigurable Stream Processor for Mobile Multimedia Systems Liang-Gee Chen Distinguished Professor General Director, SOC Center National Taiwan University DSP/IC Design Lab, GIEE, NTU 1
Scalable and Reconfigurable Stream Processor for Mobile Multimedia Systems Liang-Gee Chen Distinguished Professor General Director, SOC Center National Taiwan University DSP/IC Design Lab, GIEE, NTU 1
Computer Architecture s Changing Definition
 Computer Architecture s Changing Definition 1950s Computer Architecture Computer Arithmetic 1960s Operating system support, especially memory management 1970s to mid 1980s Computer Architecture Instruction
Computer Architecture s Changing Definition 1950s Computer Architecture Computer Arithmetic 1960s Operating system support, especially memory management 1970s to mid 1980s Computer Architecture Instruction
ECE 2300 Digital Logic & Computer Organization. Caches
 ECE 23 Digital Logic & Computer Organization Spring 217 s Lecture 2: 1 Announcements HW7 will be posted tonight Lab sessions resume next week Lecture 2: 2 Course Content Binary numbers and logic gates
ECE 23 Digital Logic & Computer Organization Spring 217 s Lecture 2: 1 Announcements HW7 will be posted tonight Lab sessions resume next week Lecture 2: 2 Course Content Binary numbers and logic gates
Redundancy-reduced MobileNet Acceleration on Reconfigurable Logic For ImageNet Classification
 Redundancy-reduced MobileNet Acceleration on Reconfigurable Logic For ImageNet Classification Jiang Su, Julian Faraone, Junyi Liu, Yiren Zhao, David B. Thomas, Philip H. W. Leong, and Peter Y. K. Cheung
Redundancy-reduced MobileNet Acceleration on Reconfigurable Logic For ImageNet Classification Jiang Su, Julian Faraone, Junyi Liu, Yiren Zhao, David B. Thomas, Philip H. W. Leong, and Peter Y. K. Cheung